Teola: Towards End-to-End Optimization of LLM-based Applications
Abstract.
Large language model (LLM)-based applications consist of both LLM and non-LLM components, each contributing to the end-to-end latency. Despite great efforts to optimize LLM inference, end-to-end workflow optimization has been overlooked. Existing frameworks employ coarse-grained orchestration with task modules, which confines optimizations to within each module and yields suboptimal scheduling decisions.
We propose fine-grained end-to-end orchestration, which utilizes task primitives as the basic units and represents each query’s workflow as a primitive-level dataflow graph. This explicitly exposes a much larger design space, enables optimizations in parallelization and pipelining across primitives of different modules, and enhances scheduling to improve application-level performance. We build Teola, a novel orchestration framework for LLM-based applications that implements this scheme. Comprehensive experiments show that Teola can achieve up to 2.09x speedup over existing systems across various popular LLM applications.
1. Introduction
Large language models (LLMs) and their multi-modal variants have revolutionized user query understanding and content generation. This breakthrough has transformed many traditional and emerging applications. For instance, some search engines have integrated LLMs into their query processing pipelines, enhancing user experiences (perplexity, ; bing, ). Additionally, AI agents, a new paradigm for human-machine interaction, have led to new applications such as emotional companionship (characterai, ) and personalized assistants (privatellm, ).
Despite being the most intelligent component in the applications, LLMs by themselves often cannot satisfy the diverse and complicated user requirements. Examples include knowledge timeliness and long context understanding, for which LLMs cannot perform well due to their design. If not properly handled, these problems can easily cause the well-known hallucination issue (huang2023Hallucination, ). To mitigate such problems, many techniques have been proposed, including RAG (Retrieval Augmented Generation) (lewis2020retrieval, ; liu2024iterativere, ), external function calls (kim2023llmcompiler, ; openaifunc, ; huang2024tool, ) and even multiple LLM interactions. Popular frameworks such as Langchain (langchain, ) and LlamaIndex (llamaindex, ) support integrating various modules and building the end-to-end pipelines mentioned above.






While significant efforts have been made to optimize LLM inference across various aspects (kwon2023vllm, ; yu2022orca, ; zhong2024distserve, ; agrawal2023sarathi, ; dao2022flashattention, ), little attention has been paid to the end-to-end performance of LLM-based applications composed of diverse modules. Figure 1 illustrates the execution time breakdown of several popular LLM-based applications with Llamaindex (llamaindex, ). The non-LLM modules account for a significant portion of the end-to-end latency, and in some cases (Document question answering with RAG) even more than 50%. Optimizing end-to-end performance, however, faces more difficulties than one would expect in current orchestration frameworks (llamaindex, ; langchain, ; pairag, ; azurerag, ). They organize the workflow as a simple module-based chain pipeline (see Figure 3), where each module independently and sequentially handles a high-level task using its own execution engines (e.g. vLLM (kwon2023vllm, ) for LLM inference). Despite its ease of use, this coarse-grained chaining scheme significantly limits the potential for workflow-level joint optimization across modules, as they treat each module as a black-box (2.2). Additionally, the decoupling of frontend orchestration and backend execution implies that request scheduling cannot optimize for the application’s overall performance, forcing it to instead optimizing per-request performance, which may actually degrade the overall efficiency (2.3).
In this paper, we argue for a finer-grained exposition and orchestration of LLM-based applications, which can be the bedrock of end-to-end optimization. Rather than using the module-based chaining, we orchestrate with a primitive-level dataflow graph, where the task primitive serves as the basic unit. Each primitive is a symbolic node in the graph responsible for a specific primitive operation, and has a metadata profile to store its key attributes (2.2). This primitive-level graph allows us to exploit each primitive’s properties and their interactions to optimize the graph, identifying an execution plan with the best end-to-end latency (2.2). Furthermore, the graph captures request correlations and dependencies among different primitives as well as their topological depths, which enables application-aware scheduling and batching with better end-to-end performance (2.3).
Following this insight, we build Teola, a primitive-based orchestration framework for serving LLM-based application. Teola features two main components: 1) Graph Optimizer: It parses each user query into a specific primitive-level dataflow graph, incorporating the query’s input data and configurations along with the developer’s pre-defined coarse-grained workflow. Subsequently, targeted optimization passes are applied to the primitive graph to generate an efficient execution graph for runtime execution. 2) Runtime Scheduler: Utilizing a two-tier scheduling mechanism, the upper tier schedules each query’s execution graph, while the lower tier is managed by individual engine schedulers. The lower tier batches and processes primitives from queries’ execution graphs that request the same engine, taking into account the relationships between requests from each primitive to achieve application-aware scheduling.
We implement Teola’s prototype primarily using Ray (moritz2018ray, ) for distributed scheduling and execution, along with various libraries for the execution engines. We evaluate Teola using diverse datasets and applications, including search engine-empowered generation, document question answering using both naive and advanced RAG, and a newly released production workflow from Anthropic (contextual-retrieval, ). Comprehensive testbed experiments demonstrate that Teola can achieve up to a 2.09x speedup in end-to-end latency compared to existing schemes. These schemes include our distributed implementation of Llamaindex (llamaindex, ) with Ray and its advanced version that incorporates module parallelization and enhanced LLM execution, as well as another agentic framework, AutoGen (wu2023autogen, ).
Our contributions are summarized as follows:
-
•
We identify the limitations of current LLM-based orchestration frameworks, i.e. coarse-grained module-based orchestration that restricts optimization potential, and mismatch between request-level scheduling and end-to-end application performance.
-
•
We propose a fine-grained orchestration that represents query workflows as primitive-based dataflow graphs, enabling larger design space for end-to-end optimization including graph optimization (i.e., parallelization and pipelining) and application-aware scheduling.
-
•
We design and implement Teola to show the feasibility and benefit of our approach. Experiments using popular LLM applications demonstrate Teola’s superior performance over current systems.
2. Background and Motivation
2.1. LLM-based Applications
A primer on LLM. Current LLMs are built upon transformers, which rely on the attention mechanism to effectively capture the long context in natural languages (attention, ). LLM inference, which this paper focuses on, is autoregressive: in each forward pass the model produces a single new token—the basic unit of language modeling, which the becomes part of the context and is used as input for the subsequent iterations. To avoid redundant attention computation of preceding tokens in this process, a key-value (KV) cache is used which becomes a critical source of memory pressure (yu2022orca, ; kwon2023vllm, ).
LLM inference involves two phases: prefilling and decoding. Prefilling produces the very first output token by processing all input tokens (instruction, context, etc.), and is clearly compute-bound. After prefilling, the decoding phase iteratively generates the rest of the output based on the KV cache, and is memory-bound as in each iteration only the new token from the previous iteration needs to be processed.
LLM apps are more than just LLM. Despite their great generation capabilities, LLMs are not a panacea. Their training datasets are inevitably not up-to-date, leading to knowledge gaps and hallucination issues (azurerag, ; lewis2020retrieval, ). They also lack abilities to interact directly with the environment, that is they are not directly capable of sending an email though it can draft one (wu2023autogen, ; hong2023metagpt, ; shen2023hugginggpt, ). Thus real-world applications often need to integrate additional tools with LLMs to be practically usable.
Figure 2 illustrates five LLM-based application workflows, four of which are widely used in enterprise-production and open-source projects, and one recently released production workflow from Anthropic. Figure 2(a) demonstrates a search engine-empowered generation app, where the LLM utilizes the search engine to answer questions that are beyond its knowledge scope (bing, ; jeong2024adaptiverag, ; tan2024small, ). It employs a proxy and a judge model to determine if the search engine needs to be called. Figure 2(b) illustrates a generic LLM agent, where the LLM interacts with various tool APIs to execute the formulated plan (e.g. draft and send emails using the user’s account credentials) (hong2023metagpt, ; wu2023autogen, ). Figures 2(c) and 2(d) showcase document question answering (QA) with naive and advanced RAG, respectively. RAG is arguably the most popular technique to enhance LLM apps with many production uses (pairag, ; azurerag, ). Here the documents uploaded by users are ingested as chunks into the vector database as the domain knowledge base (lewis2020retrieval, ; pairag, ; azurerag, ), after processed by the embedding models. This step is known as indexing. The LLM uses the relevant chunks retrieved from the vector database to generate answers. The advanced version (Figure 2(d)) leverages LLM-based query expansion to refine and broaden new queries (jagerman2023queryexpansion, ; gao2023retrievalsurvey, ), thereby enhancing search accuracy, and subsequently reranks all retrieved chunks for the expanded queries to synthesize a precise final answer. Lastly, Figure 2(e) presents Anthropic’s contextual retrieval workflow (contextual-retrieval, ). The LLM generates contextual summaries for each document chunk using additional content from the document. These summaries are prepended to the chunks, ensuring that each fragment maintains coherence with the original document when processed independently.
| Workflow | Count | Proportion |
|---|---|---|
| SE generation | 16 | 53.33% |
| LLM agent | 13 | 43.33% |
| Doc QA w/ naive RAG | 26 | 86.67% |
| Doc QA w/ advanced RAG | 23 | 76.67% |

We also conduct a small case study to validate the prevalence of the first four workflows by searching GitHub for open-source projects using the keyword “LLM applications.” We select 30 best-matched projects with more than 1,000 stars, including notable ones such as Haystack (haystack, ), AutoGen (wu2023autogen, ), and Langchain (langchain, ). We manually check these projects to see if the four workflows or their similarities were present; it is common for them to contain multiple workflows. The results, presented in Table 1, illustrate the popularity of these LLM-based workflows. We observe that most workflows occur in more than half of the sampled projects, with RAG-based QA being the most popular in current open-source projects.
With the increasing adoption of such workflows, it is evident that the LLM may not be the sole performance bottleneck in complex application pipelines, as discussed earlier in 1. Therefore, carefully orchestrating the various components of the workflow is critical.
2.2. Fine-grained Orchestration of LLM Apps
Several frameworks, such as LlamaIndex (llamaindex, ), Langchain (langchain, ), and enterprise solutions like PAI-RAG (pairag, ) and Azure-RAG (azurerag, ), have emerged to facilitate the creation and orchestration of LLM applications. They naturally adopt module-level orchestration, where each app is defined and executed as a simple chain of modules, as depicted in Figure 3. Each module is executed independently on their backend engines. While coarse-grained module-level chaining is easy to implement and use, it is inherently limited in optimizing complex workflows for performance. It overlooks the larger design space of jointly optimizing the modules, particularly by exploiting the intricate dependencies among the internal operations of the individual modules. Moreover, several agentic-like frameworks (wu2023autogen, ; autogpt, ) feature a more compact and coarse-grained pattern, in which multiple agents with distinct roles working on distinct sub-tasks are connected with a predefined workflow to complete a complex task. These frameworks have not explored opportunities of end-to-end optimization across agents or sub-tasks either.
The central thesis of this paper is to advocate for fine-grained exposition and orchestration of LLM apps in order to improve end-to-end performance. Consider an alternative representation of the same app workflow (Figure 3) shown in Figure 3. Instead of working with modules, we decompose each module into fine-grained primitives as the basic unit of orchestration (i.e. nodes in the graph). The indexing module, for example, is decomposed into embedding creation and data ingestion primitives, and query expansion is decomposed into prefilling and decoding primitives just like the LLM synthesizing module.
Moreover, the dependency among these primitives are explicitly captured in this dataflow graph, enabling the exploration of more sophisticated joint optimizations across primitives and modules. As a simple example, it is apparent that the embedding creation and data ingestion primitives can be executed in parallel with prefilling and decoding primitives for query expansion in Figure 3, since their inputs are independent. Each primitive’s input/output relationship, along with other key information (see 2.3 for some examples), is encoded as node attributes in the graph.
We can then optimize this primitive-level dataflow graph to identify the best execution plan of the entire workflow with the lowest end-to-end latency. Figure 3 shows the optimized execution graph corresponding to the dataflow graph in Figure 3. Specifically, given that query expansion creates multiple new queries, the corresponding decoding primitive can run in a pipeline fashion with multiple partial decoding primitives, each generating a new query and sending it to the subsequent primitive (embedding creation) right away without waiting for all queries to come out. By the same token, the prefilling primitive of LLM synthesizing can be divided into a partial prefilling first that operates on the system instruction and user query, which can run in parallel with indexing before search and reranking.
Thus, primitive-level dataflow graph allows us to explore various parallelization and pipelining opportunities across primitives that are not visible in existing module-based orchestration. The gain is significant: in our example (Figure 3), the overall execution time is reduced from 4.1s to 2.4s.
2.3. Application-Aware Scheduling and Execution

Another limitation of current LLM application orchestration is the request-level optimization of the backend execution engines, which is a mismatch with the application-level performance that the user perceives. Suppose that Triton (tritonserver, ), a popular serving engine, is used to serve the embedding model for the indexing module. The Triton engine treats each request uniformly with a fixed batch size of 4 as shown in Figure 4. Without any application-level information, we can only optimize for the per-request latency with reasonable but sub-optimal GPU utilization.
Now given that these embedding requests come from the same module, it is obvious that the execution engine should optimize for the total completion time instead of per-batch latency. Therefore, a better strategy is to use a larger batch size of say 16 to fully utilize the GPU. With 48 requests in total (for 48 document chunks), the total completion time is reduced from 1.8s to 1.35s, a 1.3x speedup as seen in Figure 4, even though the per-batch latency is slightly higher.
The above toy example utilizes request correlation of an individual primitive. Another type of information we can exploit is request dependency across primitives. Consider the LLM synthesizing module, which makes a series of LLM calls in a tree-based synthesis mode in Figure 4. These requests are executed with a batch size of 2 in conventional request-level scheduling, again to optimize per-request latency. In contrast, given that they form a dependency tree of depth of 2, the LLM execution engine can process requests at the same depth with varying batch sizes, leading to a 1.4x speedup overall albeit longer per-batch latency.
To sum up, fine-grained orchestration also bridges the gap from the execution engine’s request-level optimization and enables application-aware scheduling, by using request correlation and dependency information from the primitive dataflow graph (as node attributes) to further optimize end-to-end performance.
3. Design Overview

3.1. Architecture
Teola is a novel orchestration framework to optimize the execution of LLM-based applications with primitive operations as the basic unit.
Figure 5 depicts Teola’s architecture. In the offline stage ①, developers register execution engines for an app, such as those for embedding models, LLMs, and database operations, along with their latency profiles for various input sizes (e.g., batch size and sequence length). They also provide a workflow template that outlines the app’s components (e.g., query expansion and LLM generation) and their execution sequence, similar to tasks modules in current frameworks (llamaindex, ; langchain, ). Optionally, developers may specify optimization strategies for certain primitive operations. Once the app is configured and deployed, the system is ready for online serving.
In the online stage, upon receiving a query with specific input data and workflow configurations, Teola creates a primitive-based dataflow graph (p-graph) ②, applies relevant optimizations to generate the execution graph (e-graph), and submits the e-graph to the runtime ③. The runtime accurately tracks and efficiently schedules the execution of the e-graph’s primitives on the appropriate backends. Finally, the results are returned to the frontend upon completion ④.
3.2. APIs
Listing LABEL:lst:code presents a simplified usage example of Teola, highlighting its main components as described below.
Execution engines. Execution engines handle requests for models or operations from workflow components (line 5). They can be model-free or model-based. Model-free engines, such as databases, are primarily CPU-based and do not involve DNN models. On the other hand, model-based engines can deploy various DNN models, including BERT-family models (devlin2018bert, ) for embedding and LLMs for generation. A single engine can serve multiple components with different purposes, such as the shared LLM engine for query expansion and LLM synthesizing in Figure 2(d).
Workflow definition. While Teola abstracts away the complexity of graph optimization and scheduling, developers must first define a high-level workflow template with runtime-rendered placeholders as input for each application, similar to existing frameworks (langchain, ; llamaindex, ; promptflow, ; wu2023autogen, ). Using Teola’s APIs (lines 8-20), developers specify essential components with their required engines, roles, and input-output configurations. These components can be annotated with optimization hints, such as batchable (for independent inputs) and splittable (for divisible outputs). The operator establishes execution sequences across components to ensure dataflow correctness. This workflow template serves as the foundation for constructing and optimizing detailed execution graphs that adapt to various query configurations.
Graph optimization. For each query, a finer-grained p-graph with primitive nodes is constructed based on the query-specific data, configuration, and predefined workflow template (line 22). Teola then utilizes built-in optimization passes for primitive operations and patterns to identify an optimized execution plan and generate an e-graph (4) for execution. Developers can also register custom optimizations through a provided interface (line 7).
Declarative query. A declarative interface is offered for submitting queries to a deployed app. Beyond specifying queries (i.e., question and context), users can customize the workflow (Figure 5), allowing for parameter tuning of components (e.g., document chunk size for indexing, LLM prompt template and LLM synthesis mode) to meet performance expectations.
4. Graph Optimizer
Graph optimizer generates a fine-grained, per-query representation (p-graph) by combining query information and workflow template. This p-graph, composed of symbolic primitive nodes, enables optimization strategies to produce an efficient e-graph for execution.
4.1. p-Graph
Primitives. Relying solely on high-level components, as discussed in 2.2, can oversimplify the intricate relationships between operations and expose limited information and flexibility. To address this, we introduce a refined abstraction: the task primitive (primitive for short). Akin to the operation nodes in TensorFlow (tensorflow, ), symbolic primitives at the workflow level enhance granularity in representation and provide valuable information for optimization prior to execution.
Specifically, as shown in Table 2, a primitive can correspond to the functionality of a standard operation within a registered execution engine (e.g., embedding creation in embedding engines or context ranking in reranking engines) or represent a fine-grained decomposed operation. For instance, LLM inference is decomposed into Prefilling and Decoding, with Partial Prefilling and Full Prefilling constituting LLM prefilling, and Partial Decoding managing different parts of full decoding. Additionally, primitives can be control flow operations such as aggregation or conditional branching (i.e., Aggregate and Condition). Each primitive includes a metadata profile detailing its inputs, outputs, parent nodes, and child nodes, forming the basis for graph construction. This profile also contains key attributes such as batch size for DNNs or prompts for LLMs, as well as the target execution engine.
| Type | Description | ||
|---|---|---|---|
| Reranking |
|
||
| Ingestion | Store embedding vectors into vector database | ||
| Searching | Perform vector searching in the database | ||
| Embedding | Create embedding vectors for docs or questions | ||
| Prefilling | The prefilling part of LLM inference | ||
| Decoding | The decoding part of LLM inference | ||
| Partial Prefilling |
|
||
| Full Prefilling | Prefilling for rest part of a prompt after a partial prefilling | ||
| Partial Decoding | Part of full decoding for partial output | ||
| Condition | Decide the conditional branch | ||
| Aggregate | Aggregate the results from multiple primitives |
p-Graph construction. The optimizer converts the original workflow template with query-specific configuration into a more granular p-graph as outlined in Algorithm 1, where represents components, dependencies, and user configurations. The process decomposes each template component into explicit symbolic primitives based on the configuration, creating a sub-primitive-level graph with well-defined dependencies. For instance, the LLM synthesizing module in refine mode with 3 context chunks is transformed into a sub-graph where 3 pairs of Prefilling and Decoding primitives are chained and configured with corresponding metadata. The final resulting p-graph preserves the original workflow dependencies while providing a more detailed view of the workflow’s inner workings.

4.2. Optimization
As mentioned in 2.2, Teola focuses on maximizing parallelism in distributed execution rather than single-point optimization or acceleration (orthogonal and discussed in 9). Specifically, the optimizer identifies opportunities for primitive parallelism (parallelization) and pipeline parallelism (pipelining), employing a set of static, rule-based optimizations.
Exploitable opportunities. Firstly, the original dependencies inherited from the workflow template, which only depict a high-level sequence of components, may introduce redundancy in the fine-grained p-graph. To maximize parallelization, it is essential to analyze and prune unnecessary dependencies, thereby freeing independent primitives and creating parallel dataflow branches (Pass 1). Additionally, compute-intensive primitives can be broken down into multiple pipelining stages, where feasible, enabling them to be executed concurrently with subsequent primitives (Pass 2).
Furthermore, we have observed that the core of the workflow, the LLM, has exploitable special attributes. Specifically, two key attributes can be leveraged: (1) causal prefilling: This allows the LLM’s prefilling to be split into dependent parts, enabling parallelization of partial prefilling with preceding primitives (Pass 3), and (2) streaming decoding output: The auto-regressive and partial output of specific LLM decoding can be pre-communicated as input to the downstream primitives, creating additional pipelining opportunities (Pass 4).
Optimization passes. Based on the above analysis, the following optimization passes are integrated and can be applied to the p-graph to optimize end-to-end workflow execution:
-
Pass 1: Dependency pruning. To increase parallelization potential, we eliminate unnecessary dependencies and identify independent dataflow branches for concurrent execution by examining each task primitive’s inputs with its current upstream primitives. Redundant edges are pruned, ensuring that remaining edges represent only data dependencies, which may detach certain task primitives from the original dependency structure. For example, primitives in query expansion and embedding modules are detached to form a new branch in Figure 3.
-
Pass 2: Stage decomposition. For batchable primitives that process data exceeding the engine’s maximum efficient batch size (i.e., the size beyond which throughput does not increase), they are decomposed into multiple stages, each handling a sub-micro-batch and pipelining with downstream batchable primitives. While more aggressive division may increase pipelining degree, finding the optimal split size is time-consuming. Moreover, adjacent batchable primitives lead to an exponential search space, which is impractical for latency-sensitive scenario. To balance resource utilization and execution efficiency, we only explicitly segment a primitive into multiple stages when its input size reaches the maximum efficient batch size. An Aggregate primitive is added at the end of pipelines to explicitly synchronize and aggregate the results if necessary.
-
Pass 3: LLM prefilling split. In LLM prefilling, a full prompt consists of components such as system/user instructions, questions, and context. Within a workflow, some prompt parts may be available in advance (e.g., user instructions or questions), while others may not be (e.g., retrieved context from database in RAG). Instead of waiting for all components, available components of a prompt can be opportunistically pre-computed as they become ready, while respecting the causal attribute of attention computation, thus enabling partial prefilling parallelization.
-
Pass 4: LLM decoding pipeling. During the decoding process of LLM, tokens are generated incrementally. Once a coherent output (e.g., a new rewritten sentence in query expansion) is available, it can be promptly forwarded to downstream batchable primitives, avoiding delays associated with waiting for full decoding. To enable this optimization, the LLM call must be annotated as splittable, indicating that its outputs can be semantically divided into distinct parts. The corresponding parser monitors the progressive, structured output (e.g., JSON) of the decoding process, extracting and forwarding complete pieces of a partial decoding to successors as soon as they become available.
Optimization procedure. The optimizer iteratively traverses the p-graph, matching primitive nodes to the pattern of each optimization pass. When a match is found, the corresponding pass is applied, and the relevant primitives are modified accordingly, as outlined in Algorithm 1. This process continues until no further optimizations are possible. To reduce overhead, a cache can be employed to store and reuse the results of optimized subgraphs.
An example. Figure 6 presents an optimized e-graph for the app example shown in Figure 2(d). In this optimized e-graph, query expansion module generates three new queries to enhance searching process, and the top three retrieved chunks are fed into the LLM synthesizing module. The LLM synthesizing module operates in refine mode, first generating an initial answer using the top chunk with a QA-style prompt template. It then refines the candidate answer twice using the remaining two chunks with a refine-style prompt template. The different passes applied by the optimizer are annotated in the figure for clarity.
5. Runtime Scheduling
Teola utilizes a two-tier scheduling mechanism at runtime. The upper-tier graph scheduler dispatches primitive nodes of each query’s optimized e-graph. The lower tier consists of engine schedulers that manage engine instances and fuse primitive requests from queries for efficient execution. Separating graph scheduling and operation execution enhances scalability and extensibility for Teola.
5.1. Graph Scheduler
The graph scheduler closely tracks the status of each query’s e-graph and issues primitive nodes as their dependencies are met. It evaluates node in-degrees and dispatches nodes to the appropriate engine scheduler when in-degrees reach zero. Note that the graph scheduler dispatches the node itself rather than its associated requests, ensuring that the lower scheduler can identify requests originating from a primitive, instead of treating them independently like in existing frameworks (see 2.3). Upon completion of a primitive’s execution, the scheduling thread is notified via RPC calls, and the output is transferred. The thread then decrements the in-degrees of downstream primitives, preparing them for execution.
Additionally, a dedicated per-query object store manages intermediate outputs. This store acts as both an input repository for pending primitives and offers a degree of fault tolerance, safeguarding against operation failures.


5.2. Engine Scheduler
Execution engine instances are managed by dedicated engine schedulers, enabling independent execution of primitive nodes mapped to different engine types. The main challenge is efficiently fusing primitives that request the same engine. With an optimized e-graph, a query may dispatch multiple primitive nodes simultaneously to an engine scheduler or have several pending primitive nodes in the queue, especially when components share the same engine, such as the proxy and judge modules in Figure 2(a) or the query expansion and LLM synthesizing modules in Figure 2(d) using the same LLM.
Strawman solution and limitation: blind batching. A naive approach to handling diverse primitive nodes is to treat them uniformly. A engine scheduler dynamically batches associated primitive requests from the pending queue using a FIFO policy, reaching a predefined maximum batch size or upon timeout, similar to existing systems (crankshaw2017clipper, ; tritonserver, ). The batch is then dispatched to an engine instance. However, this simplistic method overlooks that not all primitive nodes from the same query equally contribute to graph progression.
As illustrated in Figure 7, for query 1, primitive A and B requesting the LLM engine enter the queue along with primitive G and H from query 2. Blind batching would batch A and B, leaving G and H to wait. However, executing primitive B at this point yields little benefit since B’s child E cannot be issued later due to E’s other untriggered parent D. In contrast, batching A and H advances both queries’ graph execution, with B’s delay not bottlenecking query 1.
Our solution: topology-aware batching. The example highlights the limitations of blind batching, which ignores the unique contributions of each primitive to the query’s graph progression. Primitive nodes in a graph vary in topological depth; delaying lower-depth nodes can reserve resources for more contributive ones, enhancing overall execution. Besides, it is essential to consider the correlation and dependency between requests, unlike the approach taken by existing orchestration (as discussed in 2.3). Combining these insights, we propose topology-aware batching, a heuristic solution that leverages the depth of primitive nodes and their relationships to intelligently guide batch formation.
Concretely, the approach offers two primary benefits. First, for an individual query, depth information naturally captures the dependency among different primitives, enabling straightforward adjustments to the scheduling preferences with the inherent request correlation in each primitive (see 2.3). For example, primitives at the same depth can be executed at the maximum efficient batch size to optimize throughput and advance the graph. Second, while depth information may not pinpoint the exact critical path due to unpredictable latency in real execution, it guides primitive prioritization for a query (see Figure 7), facilitating efficient resource utilization across multiple queries.
Algorithm 2 shows the procedure for topology-aware batching. After obtaining a query’s e-graph, primitive nodes are reverse topologically sorted and their depths recorded, with the output node having the smallest depth (Event 1). When scheduling, primitives from the same query in the engine scheduler’s queue are grouped into buckets. Within each bucket, primitives are sorted by depth, prioritizing those with higher depths. The buckets are then sorted based on the earliest arrival time within each bucket. Given a slot number, which represents the pre-determined maximum batch size (or maximum token size for LLM) that ensures optimal throughput efficiency, the scheduler iterates through each bucket. For each bucket, it examines the highest-priority primitive nodes and, if free slots are available, moves the associated requests from a primitive into the candidates (Event 2).
5.3. Co-located Applications
Teola is designed to optimize individual app workflows. When applications are co-located in the same infrastructure (zhang2023shepherd, ; gujarati2020clockwork, ), they are orchestrated by Teola independently. That is, the e-graphs of different applications containing different or identical primitives with distinct app-level and query-level metadata, are treated by Teola in the same manner as in single-app scenarios. This leaves out the potential for further optimization when for example some co-located applications share the LLM engines and the model so advanced techniques like KV cache sharing across different applications may further improve throughput. We plan to explore these opportunities in future work. For completeness, we evaluate Teola’s capability to handle queries in co-located app scenarios with a discussion in 7.2.
6. Implementation
We implement the prototype of Teola with ~5,300 lines of code in Python. Specifically, we leverage several existing libraries: (1) Ray (moritz2018ray, ) for distributed scheduling and execution; (2) LlamaIndex (llamaindex, ) for pre-processing tasks, such as text chunking and HTML/PDF parsing; (3) postgresql (postgresql, ) as the default database; (4) pgvector (pgvector, ) as the vector search engine; (5) Google custom search (googlesearch, ) as the search engine, supporting both single and batched requests; and (6) vLLM (kwon2023vllm, ) as the LLM serving engine, which we additionally modify to support Partial Prefilling and Full Prefilling in Table 2.
For the frontend, we provide user interfaces via FastAPI (Fastapi, ) for submitting queries and user configurations. For the backend, the graph scheduler maintains a thread pool to allocate a dedicated thread for each new query, in order to construct, optimize and dispatch the e-graph. Beyond the discussion in 5, each engine scheduler also manages load balancing across different instances based on various load metrics – primarily the number of executed requests for general engines and the occupied KV cache slots for LLMs.
Mitigating communication overhead. To reduce communication overhead in a central scheduler, we use a dependent pre-scheduling mechanism for adjacent primitives with large data interactions or the same execution engine. This allows simultaneous issuance of two dependent primitives, namely A and B, with B waiting for the output of A. Along with sending A’s result to the scheduler, an RPC call also sends the output of A directly to the execution engine of B. This avoids relaying results through the scheduler before issuing B, and hence can reduce the communication overhead.
7. Evaluation

Testbed setup. We allocate model-based engines (e.g., LLMs) and model-free engines with GPUs and CPU-only resources, respectively. Each engine instance used for embeddings or other non-LLM models are each hosted on a single NVIDIA 3090 24GB GPU. For LLMs, each instance of gemma-2-2B, llama-2-7B, and llama-2-13B (touvron2023llama2model, ) is deployed on 1, 1, and 2 NVIDIA 3090 GPUs, respectively. Each instance of llama-30B (touvron2023llamamodel, ) is deployed on 2 NVIDIA A800 80GB GPUs. The network bandwidth between any physical servers is 100 Gbps.
Baseline. To our knowledge, few studies have specifically focused on optimizing LLM-based workflows execution in distributed settings. Therefore, we compare Teola with the following popular frameworks and their variants:
-
•
LlamaDist: a Ray-based distributed implementation of LlamaIndex (a popular framework with over 36k GitHub stars) that defines a chain of task modules to construct an application pipeline. Each task module invokes requests to different distributed backend engines. This implementation integrates Ray with LlamaIndex’s orchestration approach, utilizing the same engines as Teola but differing in the granularity of orchestration.
-
•
LlamaDistPC (parallel & cache-reuse): an advanced LlamaDist variant that examines the predefined pipeline and manually parallelizes independent modules for concurrent execution. It also incorporates prefix caching for LLM to avoid recomputation for partial instructions in the prompt, as proposed in some previous works (zheng2023sglang, ; liu2024optimizingquery, ; gim2023promptcache, ; lin2024parrot, ).
-
•
AutoGen: a popular framework for LLM applications with over 32k stars on GitHub. It constructs various agents for an application, with each agent managing several system modules (e.g., a retrieval agent handling indexing, query embedding, and searching) and communicating with each other following a pre-defined graph.
For the request scheduling of deployed engines, we compare two approaches:
-
•
Per-Invocation oriented (PO): We slightly modify the invocation from the orchestration side and make requests in an invocation as a bundle (essentially adding extra correlation information that is exploited in Teola to enhance baselines). The engines schedule each bundle at a time, prioritizing latency preferences for each invocation.
-
•
Throughput oriented (TO): We pre-tune a maximum batch/token size for each engine (i.e., increasing the batch size for DNNs or token size for LLMs by powers of 2 until no further throughput gain is observed) and employ dynamic batching strategy (tritonserver, ; crankshaw2017clipper, ; kwon2023vllm, ). This maximizes the overall throughput but ignores any relationships among requests.
Applications, models and workloads. Our experiments cover three applications:
-
•
Search engine-empowered generation (Figure 2(a)): A search engine assists a core LLM in generating answers. A smaller LLM (llama-2-7B) acts as a proxy and judge, formulating a heuristic answer and determining if a search is needed. Any search results (top 4 entities) are fed into the core LLM to synthesize the final answer. Workload requests are generated using a Poisson distribution-based synthesis of web_question (webquestion, ) and HotpotQA (yang2018hotpotqa, ) datasets.
-
•
Document QA with naive RAG (Figure 2(c)): Users input documents or webpages along with the question. The app segments the documents into chunks (default size: 256, overlap:30), embeds them with the bge-large-en-v1.5 model (xiao2023bgeembedding, ), and stores them in a vector database (postgresql & pgvector). It retrieves the most relevant chunks (default: top 3) to generate a response with a tree-based mode. The workload (i.e. question and documents/webpage) is synthesized from Finqabench (Finqabench, ) and TruthfulQA (lin2021truthfulqa, ) datasets using a Poisson distribution.
-
•
Document QA with advanced RAG (Figure 2(d)): Extending the second app, a query expansion is used (core LLM) to rewrite and expand the original query into multiple new queries (default: 3), improving retrieval accuracy. A reranker (bge-reranker-large (xiao2023bgeembedding, )) evaluates the similarity between retrieved chunks, with each query searching for 16 chunks and determining the top 3 overall. These top chunks are fed into the core LLM for generation in a refine mode as mentioned in 4.2.
-
•
Contextual retrieval (Figure 2(e)): Extending the naive RAG, this workflow incorporates contextualization using a lightweight LLM, gemma-2-2B (team2024gemma, ), to process each chunk before indexing. To optimize time and cost, each chunk is contextualized with its four neighboring chunks, generating a concise context to prepend to each chunk. A reranker, identical to the one in the advanced RAG, reranks the 32 fetched chunks. The top 3 chunks are then input into the core LLM for one-shot generation.
Unless otherwise specified, the above default configurations are applied. All models are deployed in half precision, and different core LLMs (7B, 13B and 30B) are experimented.
7.1. End-to-end Performance
We evaluate the performance with different schemes for various apps, all under the same resource allocation. Each non-LLM engine is provisioned with a single instance, while each LLM is provisioned with two instances.
Search engine-empowered generation. Figure 8 (1st row) shows Teola outperforming the other six schemes by up to 1.79x. Teola’s efficiency is attributed to parallelizable partial prefilling for instructions and questions for both the judge and core LLM, and effective batching coordination for different engines. In contrast, LlamaDist executes modules sequentially and struggles with request scheduling for multiple queries. PO’s focus on per-invocation latency results in longer queue times under high request rates, while TO generally performs better in these scenarios. LlamaDistPC fails to benefit from parallelization due to the lack of explicit parallelization across modules. Its prefix caching for partial instructions (typically around 60 tokens) provides limited benefit, as prefix caching is most advantageous when prefixes are significantly longer (promptflow, ; zheng2023sglang, ). AutoGen defines agents for the proxy model, judge model, search engine, and LLM synthesizer in this case, resulting in a structure similar to LlamaDist and therefore causing similar performance.
Document QA with naive RAG. Figure 8 (2rd row) demonstrates that Teola outperforms the other six schemes by up to 1.62x at low request rates and 1.67x at high rates. LlamaDist executes modules sequentially without specific optimizations, while LlamaDistPC enables limited parallelization (indexing and query embedding modules) and partial instruction KV cache reuse, performing slightly better than LlamaDist. While AutoGen’s workflow, consisting of a retrieval agent and synthesizer agent, performs adequately at low request volumes, its simplified orchestration architecture results in extended queuing delays when handling high request loads. Regarding scheduling, PO outperforms TO at low request rates due to its focus on per-invocation latency, but its performance suffers at high rates. Furthermore, the app introduces intricate request relationships, with both the indexing and query embedding modules utilizing the embedding model, and the LLM synthesizing module making three initial requests followed by a subsequent request to construct the tree synthesis. If overlooked, these relationships can cause batching inefficiencies and reduced goodput, similar to TO. In contrast, Teola leverages the e-graph, incorporating pipelining to split compute-heavy tasks like large embeddings for document chunks, while also exploring more parallelization opportunities, such as four partial prefilling. Additionally, Teola’s topology-aware batching captures dependencies and correlations among requests linked to different primitives, facilitating effective batching for each engine.
Document QA with advanced RAG. This app is the most complex in our settings, yet it provides ample opportunities to demonstrate the effectiveness of Teola. It leverages aggressive optimization techniques such as parallelization at different levels (e.g., independent dataflow branches and partial prefilling for different LLM calls) and pipelining (e.g., breaking large embeddings into smaller ones and splitting the decoding process in query expansion into three partial decodes), as shown in Figure 6. In contrast, LlamaDist runs sequentially with a simple run-to-completion paradigm, missing opportunities to reduce end-to-end latency. LlamaDistPC improves parallelization across the indexing and query expansion modules and reuses partial KV cache but still fails to explore the full optimization potential like Teola. For AutoGen, it would define four agents for retrieval, reranking, query expansion, and LLM synthesizer in this workflow, but it suffers from high request load due to its inability to pipeline and parallelize operations effectively. Additionally, similar to naive RAG, all other baselines struggle to efficiently coordinate requests whether in PO or TO, whereas Teola performs well. Overall, Teola outperforms others by up to 2.09x at low request rates and 2.03x at high request rates, as shown in Figure 8 (3rd row).
Contextual retrieval. This workflow mainly adds contextualization with a lightweight LLM for chunks before indexing and a reranking step after searching, compared to naive RAG. However, due to the massive volume of chunks to process, the contextualization occupies a significant portion of time for all schemes. Although little graph-level optimization could be applied to the contextualization part, Teola’s application-aware scheduling and graph optimization on other components still help it achieve 1.06x-1.59x speedup compared to other baselines, as shown in Figure 8 (4th row), which further validates the applicability of Teola.
7.2. Co-located Applications

Beyond evaluating Teola’s performance in single-application scenarios, we also assess its capability to handle concurrent queries across multiple applications. To demonstrate this, we present a scenario where two document QA applications—a naive RAG-based one and an advanced RAG-based one—operate simultaneously on the same underlying infrastructure. These apps share similar backend engines but differ in their calling semantics, with the advanced RAG-based QA requiring an additional reranking engine.
We compare the average latency of Teola against the stronger baseline, LlamaDistPC, at a request rate of 3 requests per second per application. Figure 9 illustrates the average latency for queries from both applications, revealing that Teola maintains a performance advantage over LlamaDistPC in multi-app co-location scenarios. Teola achieves a 1.2x to 1.55x latency speedup across the two apps, highlighting the consistency of its capabilities in handling multiple application queries. This can be attributed to Teola’s app-agnostic graph optimization and app-aware scheduling techniques.
Furthermore, in real-world deployments, applications could have varying priorities. For example, LLM chat services prioritize shorter latency to enhance user experience, while document summarization services may tolerate longer latencies. These differing priorities can influence the order of request processing within the infrastructure. The varying objectives among applications can be encoded as metadata within their generated primitives and used to facilitate priority-based scheduling or resource-constrained scheduling in each engine scheduler. However, a detailed exploration of this aspect is beyond the scope of this paper.
7.3. Ablation Study
We show the effectiveness of Teola’s main components from graph optimization and runtime scheduling perspectives.
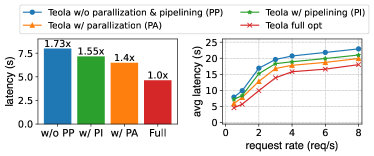
Graph optimization. As shown in Figure 10, we compare the performance of Teola under different scenarios, i.e., with or without parallelization (Pass 1 & 3) and pipelining (Pass 2 & 4) optimization as in 4. The left figure shows the average latency of a single query and explicitly demonstrates that both parallelization and pipelining effectively capture optimization opportunities and reduce latency. This holds true as well in a request trace with different request rates.
Runtime scheduling. Figure 12 illustrates the performance impact of enabling and disabling topology-aware batching as discussed in 5.2. The left figure demonstrates its effectiveness in capturing the varying depths of different primitives for the same engine and scheduling them with the informed correlation and dependency information to better meet the application-level performance. This results in an average 1.15x speedup for single query execution. In multi-query scenarios, topology-aware batching remains beneficial. Beyond single-query efficiency, it effectively fuses contributive primitives across queries, thereby facilitating overall execution and reducing average latency by up to 19.2%.
7.4. Overhead Analysis
| Partial Prefilling | Full Prefilling | Total | Single Prefilling |
|---|---|---|---|
| 76.03 (200) | 215.89 (800) | 291.92 (1000) | 260.36 (1000) |
| 217.67 (850) | 222.66 (850) | 440.33 (1700) | 414.09 (1700) |
| 582.95 (2500) | 159.65 (500) | 742.60 (3000) | 720.15 (3000) |
We have shown that Teola provides substantial performance improvements over existing solutions. Here in order to better understand Teola’s overheads we provide a more detailed analysis in mainly three aspects: graph optimization, data communication, and execution efficiency. First, e-graph optimization incurs new overhead for each query, but this is often minor due to the limited number of primitives in an LLM-based workflow and the ability to cache the results for queries of the same app. Second, communication across primitives also leads to higher compared to existing coarse-grained approach. Teola’s pre-scheduling mechanism mitigates this, and the pipelined execution also allows partially conveyed data to be processed earlier. Third, decomposing certain operations, such as LLM prefilling, may compromise execution efficiency (e.g., repeatedly moving KV cache into SRAM or failing to fully utilize the GPU) compared to a single complete operation. Nevertheless, this performance sacrifice is minimal, as demonstrated by a comparison in Table 3, where the slowdown is only between 3.11% and 12.12%. Moreover, the gained parallelism further outweighs the slight loss and provides a larger end-to-end speedup.
We provide a latency breakdown for document QA with advanced RAG on the TruthfulQA dataset as a case study. We observe that graph optimization overhead is minimal, ranging from 1.3% to 3% of the total latency, when leveraging caching optimizations. Similarly, the communication overhead remains low, accounting for only 3.1% to 6.2%. Under increased request rates on fixed resources, queuing latency dominates end-to-end time, further diminishing the relative impact of these overheads on overall execution time.


8. Limitations and Future Work.
In this section, we point out some limitations of Teola and identify future research directions.
Dynamic workflows. LLM-based workflows typically require upfront human design but offer stable performance, leading to widespread adoption in both open-source projects (llamaindex, ; langchain, ; haystack, ; lazyllm, ) and production environments (alibaba_llmapp_observation, ; pairag, ; azurerag, ). Teola is primarily designed for such structured scenarios. However, autonomous agents operating without human intervention have emerged, wherein the LLM plans and executes actions dynamically without a fixed workflow. Teola’s ahead-of-time graph optimization would struggle with dynamic workflows, especially those involving self-reflection (madaan2024selfreflection, ), as it cannot capture the complete primitive-level graph before execution. Adapting Teola for such dynamic workflows is a very promising avenue for future research.
Coupling with the backends. To enable finer-grained orchestration, we have to modify several engine-side mechanisms (e.g. support decomposed primitive operations and certain batching strategies), which requires extra engineering efforts compared to frameworks (llamaindex, ; langchain, ) that decouple the orchestration and execution and work with pluggable engines. This is an essential trade-off between performance and modularity. These optimization details remain encapsulated from the user’s perspective.
Exploitation of critical path. Critical-path information in the e-graph can be further leveraged. For resource allocation, we can adjust resources for operations on critical and non-critical paths to maximize utilization based on workload patterns. For request scheduling, prioritizing critical nodes for specific queries can enhance the current topological batching, but this requires accurate online predictions of critical paths and coordination complexities.
9. Related Work
LLM inference optimization. LLM inference has garnered significant attention, with numerous studies focusing on various optimization directions, including kernel acceleration (xiao2023smoothquant, ; dao2022flashattention, ; hong2023flashdecoding++, ), request scheduling (yu2022orca, ; agrawal2024taming, ; agrawal2023sarathi, ; sheng2023fairness, ), model parallelism (li2023alpaserve, ; zhong2024distserve, ; miao2023spotserve, ), semantic cache (bang2023gptcache, ; zhu2023optimalcache, ), KV cache management (kwon2023vllm, ; wu2024loongserve, ; lin2024infinite, ), KV cache reusing (kwon2023vllm, ; zheng2023sglang, ; gim2023promptcache, ; liu2024optimrelation, ; jin2024ragcache, ) and advanced decoding algorithms (ou2024losslessdecoding, ; liu2023onlinespec, ; miao2024specinfer, ). Recent works (patel2023splitwise, ; zhong2024distserve, ; hu2024inferencewithoutinterference, ) disaggregate the deployment of the prefilling and decoding phases to increase goodput. This philosophy aligns well with Teola’s decomposition approach and could be seamlessly integrated. While most works provide point solutions in the LLM domain, Teola takes a holistic view, optimizing the entire application workflow and facilitating cooperation among diverse components. Thus, the optimizations in LLM inference would complement Teola’s efforts.
Frameworks for LLM applications. Apart from frameworks mentioned before (llamaindex, ; langchain, ; promptflow, ), several studies (kim2023llmcompiler, ; khattab2023dspy, ; zheng2023sglang, ; lin2024parrot, ) focus on optimizing complex LLM tasks involving multiple LLM calls. They explore opportunities such as parallelism and KV cache sharing by developing specific programming interfaces or compilers. AI agent frameworks (langgraph, ; shen2023hugginggpt, ; hong2023metagpt, ; hong2024data, ) enable LLMs to make decisions, select tools, and interact with other LLMs, reducing the need for human intervention but introducing specific challenges. Teola is more related to (llamaindex, ; langchain, ; promptflow, ), working with an application of various components with a pre-defined workflow while focusing on end-to-end efficiency. Parrot (lin2024parrot, ) also captures the application-level affinity of multiple LLM requests and facilitates joint scheduling. SGlang (zheng2023sglang, ) explores the relationship between LLM requests and attempts to reuse the history KV cache efficiently. They share a similar spirit with us in exploiting opportunities beyond a single inference request. The difference is also clear: Teola focuses on end-to-end optimization at the application level that involve both LLM and non-LLM components, which were not considered before.
Data analytics systems. Data analytics systems (isard2007dryad, ; zaharia2016apachespark, ; gog2015musketeer, ; bauer2012legion, ) employ various graph based dependency analysis to enhance distributed task execution of big data analytics workloads. Teola draws upon these techniques to perform its graph optimization. However, these systems are designed for general-purpose data processing. Teola introduces a new set of abstractions specifically designed for LLM-based workflows, which allows it to explore a much larger optimization space beyond graph optimization or those mentioned in this work.
10. Conclusion
We present Teola, a fine-grained orchestration framework for LLM-based applications. The core idea is orchestration using primitive-level dataflow graphs. This explicitly exposes the attributes of primitive operations and their interactions, enabling natural exploration of workflow-level optimizations for parallel execution. By leveraging the primitive relationships from the graph, Teola employs a topology-aware batching heuristic to intelligently fuse requests from primitives for execution. Testbed experiments demonstrate that Teola can outperform existing schemes across different applications.
References
- [1] LlamaIndex. https://github.com/jerryjliu/llama_index, 2022.
- [2] Promptflow. https://https://github.com/microsoft/promptflow, 2023.
- [3] Autogpt. https://github.com/Significant-Gravitas/AutoGPT, 2024.
- [4] Bing Copilot. https://www.bing.com/chat, 2024.
- [5] Character.ai/. https://character.ai/, 2024.
- [6] contextual-retrieval. https://www.anthropic.com/news/contextual-retrieval, 2024.
- [7] Fastapi. https://fastapi.tiangolo.com/, 2024.
- [8] Finqabench Dataset. https://huggingface.co/datasets/lighthouzai/finqabench, 2024.
- [9] Google custom search. https://programmablesearchengine.google.com/, 2024.
- [10] Gpt-rag. https://github.com/Azure/GPT-RAG, 2024.
- [11] haystack. https://github.com/deepset-ai/haystack, 2024.
- [12] Langchain. https://github.com/langchain-ai/langchain, 2024.
- [13] LangGraph. https://python.langchain.com/docs/langgraph/, 2024.
- [14] Lazyllm. https://github.com/LazyAGI/LazyLLM, 2024.
- [15] Observability of llm applications: Exploration and practice from the perspective of trace. https://www.alibabacloud.com/blog/observability-of-llm-applications-exploration-and-practice-from-the-perspective-of-trace_601604, 2024.
- [16] Openai function calling. https://platform.openai.com/docs/guides/function-calling, 2024.
- [17] Pairag. https://github.com/aigc-apps/PAI-RAG, 2024.
- [18] Perplexity ai. https://www.perplexity.ai/, 2024.
- [19] Pgvector. https://github.com/pgvector/pgvector, 2024.
- [20] Postgresql. https://www.postgresql.org/, 2024.
- [21] Privatellm. https://privatellm.app/en, 2024.
- [22] Triton inference server. https://github.com/triton-inference-server, 2024.
- [23] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: A system for Large-Scale machine learning. In Proc. USENIX OSDI, 2016.
- [24] Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve. arXiv preprint arXiv:2403.02310, 2024.
- [25] Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachandran Ramjee. Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills. arXiv preprint arXiv:2308.16369, 2023.
- [26] Fu Bang. Gptcache: An open-source semantic cache for llm applications enabling faster answers and cost savings. In Proc. the 3rd Workshop for Natural Language Processing Open Source Software, 2023.
- [27] Michael Bauer, Sean Treichler, Elliott Slaughter, and Alex Aiken. Legion: Expressing locality and independence with logical regions. In Proc. IEEE SC, 2012.
- [28] Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on Freebase from question-answer pairs. In Proc. EMNLP, October 2013.
- [29] Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J Franklin, Joseph E Gonzalez, and Ion Stoica. Clipper: A Low-Latency online prediction serving system. In Proc. USENIX NSDI, 2017.
- [30] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. In Proc. NeurIPS, 2022.
- [31] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proc. ACL, 2018.
- [32] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
- [33] In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference. arXiv preprint arXiv:2311.04934, 2023.
- [34] Ionel Gog, Malte Schwarzkopf, Natacha Crooks, Matthew P Grosvenor, Allen Clement, and Steven Hand. Musketeer: all for one, one for all in data processing systems. In Proc. ACM Eurosys, 2015.
- [35] Arpan Gujarati, Reza Karimi, Safya Alzayat, Wei Hao, Antoine Kaufmann, Ymir Vigfusson, and Jonathan Mace. Serving DNNs like clockwork: Performance predictability from the bottom up. In Proc. USENIX OSDI, 2020.
- [36] Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Hanyu Dong, and Yu Wang. Flashdecoding++: Faster large language model inference on gpus. In Proc. Machine Learning and Systems, 2023.
- [37] Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, Li Zhang, Lingyao Zhang, Min Yang, Mingchen Zhuge, Taicheng Guo, Tuo Zhou, Wei Tao, Wenyi Wang, Xiangru Tang, Xiangtao Lu, Xiawu Zheng, Xinbing Liang, Yaying Fei, Yuheng Cheng, Zongze Xu, and Chenglin Wu. Data interpreter: An llm agent for data science. arXiv preprint arXiv:2402.18679, 2024.
- [38] Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 2023.
- [39] Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi Wang, Sa Wang, Yungang Bao, et al. Inference without interference: Disaggregate llm inference for mixed downstream workloads. arXiv preprint arXiv:2401.11181, 2024.
- [40] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232, 2023.
- [41] Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, and Xiaofan Zhang. Tool calling: Enhancing medication consultation via retrieval-augmented large language models. arXiv preprint arXiv:2404.17897, 2024.
- [42] Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. In Proc. ACM Eurosys, 2007.
- [43] Rolf Jagerman, Honglei Zhuang, Zhen Qin, Xuanhui Wang, and Michael Bendersky. Query expansion by prompting large language models. arXiv preprint arXiv:2305.03653, 2023.
- [44] Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity. arXiv preprint arXiv:2403.14403, 2024.
- [45] Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Xin Liu, Xuanzhe Liu, and Xin Jin. Ragcache: Efficient knowledge caching for retrieval-augmented generation. arXiv preprint arXiv:2404.12457, 2024.
- [46] Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714, 2023.
- [47] Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. An llm compiler for parallel function calling. arXiv preprint arXiv:2312.04511, 2023.
- [48] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proc. ACM SOSP, 2023.
- [49] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2020.
- [50] Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, et al. AlpaServe: Statistical multiplexing with model parallelism for deep learning serving. In Proc. USENIX OSDI, 2023.
- [51] Bin Lin, Tao Peng, Chen Zhang, Minmin Sun, Lanbo Li, Hanyu Zhao, Wencong Xiao, Qi Xu, Xiafei Qiu, Shen Li, et al. Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache. arXiv preprint arXiv:2401.02669, 2024.
- [52] Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. Parrot: Efficient serving of llm-based applications with semantic variable. In Proc. USENIX OSDI, 2024.
- [53] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
- [54] Shu Liu, Asim Biswal, Audrey Cheng, Xiangxi Mo, Shiyi Cao, Joseph E Gonzalez, Ion Stoica, and Matei Zaharia. Optimizing llm queries in relational workloads. arXiv preprint arXiv:2403.05821, 2024.
- [55] Shu Liu, Asim Biswal, Audrey Cheng, Xiangxi Mo, Shiyi Cao, Joseph E Gonzalez, Ion Stoica, and Matei Zaharia. Optimizing llm queries in relational workloads. arXiv preprint arXiv:2403.05821, 2024.
- [56] Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Ion Stoica, Zhijie Deng, Alvin Cheung, and Hao Zhang. Online speculative decoding. arXiv preprint arXiv:2310.07177, 2023.
- [57] Yanming Liu, Xinyue Peng, Xuhong Zhang, Weihao Liu, Jianwei Yin, Jiannan Cao, and Tianyu Du. Ra-isf: Learning to answer and understand from retrieval augmentation via iterative self-feedback. arXiv preprint arXiv:2403.06840, 2024.
- [58] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. In Proc. NeurIPS, 2024.
- [59] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, et al. Specinfer: Accelerating large language model serving with tree-based speculative inference and verification. In Proc. ACM ASPLOS, 2024.
- [60] Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. Spotserve: Serving generative large language models on preemptible instances. In Proc. ACM ASPLOS, 2024.
- [61] Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. Ray: A distributed framework for emerging AI applications. In Proc. USENIX OSDI, 2018.
- [62] Jie Ou, Yueming Chen, and Wenhong Tian. Lossless acceleration of large language model via adaptive n-gram parallel decoding. arXiv preprint arXiv:2404.08698, 2024.
- [63] Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Aashaka Shah, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. arXiv preprint arXiv:2311.18677, 2023.
- [64] Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. In Proc. NeurIPS, 2023.
- [65] Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E Gonzalez, and Ion Stoica. Fairness in serving large language models. arXiv preprint arXiv:2401.00588, 2023.
- [66] Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, and Ji-Rong Wen. Small models, big insights: Leveraging slim proxy models to decide when and what to retrieve for llms. arXiv preprint arXiv:2402.12052, 2024.
- [67] Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024.
- [68] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [69] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [70] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In Proc. NeurIPS, 2017.
- [71] Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. arXiv preprint arXiv:2404.09526, 2024.
- [72] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155, 2023.
- [73] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In Proc. ICML, 2023.
- [74] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighof. C-pack: Packaged resources to advance general chinese embedding. arXiv preprint arXiv:2309.07597, 2023.
- [75] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proc. EMNLP, 2018.
- [76] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for Transformer-Based generative models. In Proc. USENIX OSDI, 2022.
- [77] Matei Zaharia, Reynold S Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J Franklin, et al. Apache spark: a unified engine for big data processing. Communications of the ACM, 2016.
- [78] Hong Zhang, Yupeng Tang, Anurag Khandelwal, and Ion Stoica. SHEPHERD: Serving DNNs in the wild. In Proc. USENIX NSDI, 2023.
- [79] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Efficiently programming large language models using sglang. arXiv preprint arXiv:2312.07104, 2023.
- [80] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. arXiv preprint arXiv:2401.09670, 2024.
- [81] Banghua Zhu, Ying Sheng, Lianmin Zheng, Clark Barrett, Michael I Jordan, and Jiantao Jiao. On optimal caching and model multiplexing for large model inference. arXiv preprint arXiv:2306.02003, 2023.