Tensor Network Methods for Extracting CFT Data from Fixed-Point Tensors and Defect Coarse Graining
Abstract
We present a comprehensive study on extracting CFT data using tensor network methods, especially, from the fixed point tensor of the linearized tensor renormalization group (lTRG) for the classical 2D Ising model near the critical temperature. Utilizing two different methods, we extract operator scaling dimensions and operator product expansion (OPE) coefficients by introducing defects on the lattice and by employing the fixed-point tensor. We also explore the effects of point-like defects in the lattice on the coarse-graining process. We find that there is a correspondence between coarse-grained defect tensors and conformal states obtained from the lTRG fixed point equation. We also analyze the capabilities and limitations of our proposed coarse-graining scheme for tensor networks with point-like defects, including graph-independent local truncation (GILT) and higher-order tensor renormalization group (HOTRG). Our results provide a better understanding of the capacity and limitations of the tenor renormalization group scheme in coarse-graining defect tensors, and we show that GILT+HOTRG can be used to give accurate two- and four-point functions under specific conditions. We also find that employing the minimal canonical form further improves the stability of the RG flow.
I Introduction
The study of the renormalization group (RG) is of central importance in the study of critical phenomena in statistical mechanics and many-body quantum systems [1, 2]. The basic idea is to remove the short-range information from a given system while keeping its long-range behavior intact. For critical systems, there is a similarity for behaviors at different length scales and, often, they can be described by conformal field theory (CFT) [3], which emerges at fixed points of the RG. By studying the perturbative behavior of the RG near fixed points, one can extract useful information about the CFT, such as the central charge, the scaling dimensions of conformal operators, and the operator product expansion (OPE) coefficients between them.
The tensor network (TN) is a versatile framework for describing strongly correlated systems by encoding the correlation and/or the entanglement structure into mutually connected tensors. It can be used to describe partition functions of classical statistical models and wave functions of quantum many-body ground states. It can also be used to study topological order [4] and, as toy models, to study conformal field theory and holography [5, 6, 7]. In particular, tensor network renormalization provides a new perspective of the RG flow, where the properties of the coarse-grained system are parametrized by a tensor. Given the comparison that CFTs are fixed points of the RG flow when ‘integrating out’ the UV (short-distance) details, it is a natural question whether one can build a correspondence or relationship between the fixed-point tensor and the CFT. One particular direction of the above question is whether it is possible to determine the CFT data of a critical lattice system when given the fixed-point tensor from coarse-graining the lattice model. This question has previously been asked and discussed using tensor network methods [8, 9, 10, 11, 12, 13].
Tensor-based real-space RG methods have been developed over the past several decades, offering certain advantages over traditional numerical methods, such as Monte Carlo methods. The density matrix renormalization group (DMRG) [14, 15, 16, 17] method, which can be understood in terms of the matrix product state (MPS) [18, 19, 20, 21] ansatz, has been the most successful numerical method for gapped one-dimensional many-body systems. The multiscale entanglement renormalization ansatz (MERA) [13, 22, 23] is a tree-like tensor network that provides reliable and accurate results for studying one-dimensional gapless systems.
Projected entangled pair states (PEPS) [24, 25, 26], proposed by Cirac and Verstraete, are a natural extension of the MPS for quantum systems on a lattice of two or higher dimensions that obey the area entanglement law. However, contracting the tensor network in two and higher dimensions is a computationally difficult task. Approximations are necessary to make this computation efficient. One of the early coarse-graining methods is the corner transfer matrix, originally developed by Baxter [27, 28], which has since been applied to quantum systems [29]. Another approach for the real-space coarse-graining scheme in two-dimensional systems is the tensor renormalization group (TRG) by Levin and Nave [30], which led to several variants and further ideas [31, 32, 33, 34, 35], including the higher-order TRG (HOTRG) [33] that we will use in this work.
Although these methods give an accurate estimate of the free-energy density and local observables, they still do not generate a correct RG flow in the tensor space. Gu and Wen [36] discovered that real-space TN RG methods do not remove all short-distance correlations, and local entanglement filtering was needed to achieve a fixed point tensor. In particular, during the real-space RG, the local correlations residing across the boundary of the coarse-graining blocks survive, which can be illustrated by a toy model called corner double-line (CDL) tensors. Various methods have been proposed to deal with the issue of CDL tensors [36, 34, 35, 37]. With these methods, the fixed-point tensors of the RG flow can be found approximately [38].
Among these entanglement filtering methods, graph-independent local truncation (GILT), proposed by Hauru, Delcamp, and Mizera [37], has the advantage of simplicity, especially since it is compatible with several coarse graining methods, such as TRG and HOTRG. It also offers a clear geometric meaning of how CDLs are removed in coarse-graining. Using HOTRG + GILT, as well as a gauge fixing procedure, Lyu, Xu, and Kawashima demonstrated that the scaling dimensions can be extracted by linearizing the equation that relates successive coarse-graining tensors around the fixed point [39], which is a procedure referred to as the linearized TRG (lTRG) and is analogous to the traditional RG equation. Scaling dimensions were also extracted from the transfer matrix at the fixed point [36], or from the eigenvalues of the local-scale transformation [34, 40, 9].
It was emphasized in [39] that a good gauge fixing is essential in making the notion of a fixed-point tensor well defined and in getting the correct scaling dimensions from lTRG. Here, in this work, in addition to the gauge fixing employed in Ref. [39], we also employ the minimal canonical form (MCF), proposed recently by Acuaviva et al. [41], who showed how to identify gauge-equivalent tensors by an iterative scheme. We adopt the MCF into the lTRG and obtain a more consistent RG flow of coarse-grained tensors, allowing better characterization of how the system approaches and flows away from the fixed point. This allows us to study the 2D classical Ising model and reproduce the CFT data of the Ising CFT, including the scaling dimensions , , and the OPE coefficients , from the fixed point tensor.
Our results of the scaling dimensions and OPE coefficients are consistent with calculations of the two-point and four-point correlation functions. However, we encounter and resolve issues in computing the latter to achieve the comparison. The correlation functions calculated from HOTRG suffer from a smearing effect. Despite removing CDL local correlations, we find that GILT suffers from inaccuracy in evaluating correlation functions at longer distances. We provide a solution through an averaging procedure (described in detail in the following). Furthermore, we compare the coarse-grained lattice-level defect tensors with the tensors extracted from the lTRG spectrum, confirming that both represent conformal states. We also explore whether our coarse-graining method can accommodate excited states in addition to the ground state.
The remainder of this paper is as follows. In Sec. II, we review the Tensor Renormalization Group concept and the coarse graining techniques that we employ, which include HOTRG, MCF, and GILT. We also review the concept of lTRG. In Sec. III, we present our main numerical findings. In Sec. III.1, we demonstrate that our coarse-graining scheme successfully obtains a fixed point tensor, and this allows us to extract the full CFT data of the Ising CFT, including scaling dimensions , , and OPEs , respectively in Sec. III.2 and Sec. III.3. For comparison, in Sec. III.4 and Sec. III.5, we calculated the two- and four-point correlation functions to extract the full CFT data. We also compute the two-point function on a finite-size torus in Sec. III.6. In Sec. III.7 and Sec. III.8, we compare the coarse-grained lattice-level defect tensors and the tensors extracted from the lTRG spectrum, confirming that both represent conformal states. In Sec. IV, we explore whether our coarse-graining method can accommodate excited states in addition to the ground state. We identify the primary error of HOTRG and GILT as resulting from the ”smearing” of point-like defects and suppression of edge modes. To address this, we recommend sampling points randomly and avoiding placing impurity tensors at corners and edges of coarse-grained blocks. Moreover, we demonstrate that the advanced gauge-fixing method MCF improves TRG flow stability and propose a method for detecting CDL tensors along the RG flow. We also provide evidence that coarse graining introduces an error that breaks conformal symmetry and ultimately drives the system away from the fixed point. In Sec. V, we summarize our work and suggest potential research directions. In the appendix, we present further details to supplement the main text, such as the algorithmic procedures that we use in this paper. In addition, we also review some related CFT background and our proposed TN approach to relevant CFT data.
II Background
In this section, we review the connection between the conventional RG flow and their tensor network counterpart. We start by introducing the tensor network and the concept of TRG in Sec. II.1. Then we briefly review the concept of RG flow, their fixed points, and CFT in Sec. II.2. After that, we describe some of the previous studies on TRG, including HOTRG, local entanglement filtering, and GILT, in Secs. II.2 and II.4, as these are the main tools we will use in this work. Further details are presented in the Appendix. We also discuss the gauge redundancy in the tensor network and the newly proposed gauge fixing method that we will use, that is, MCF in Sec. II.5. We then discuss the linearized tensor renormalization group proposed in Ref. [39] to extract scaling dimensions of operators in Sec II.6. Finally, we describe our coarse-graining scheme, which involves a combination of HOTRG, GILT, MCF, and a residual gauge fixing procedure in Sec. II.7. In addition, we describe how we produce coarse-grain defect tensors, which can be used to compute correlation functions.
II.1 Tensor Network and Tensor Renormalization Group
The translation invariant tensor network is a natural way to describe the partition function of many statistical models and the wave functions of quantum systems, such as the Ising model on a square lattice [42] and the ground state wave function of the Affleck-Kennedy-Lieb-Tasaki model [43]. By replacing certain tensors with a “defect tensor”, one can further compute the -point expectation value or correlation function.
Eq. (1) below shows the tensor network representation of the vacuum partition function (or, in turn, the free energy via ) of a lattice model on a square lattice with periodic boundary condition,
| (1) |
Eq. (2) below shows how to evaluate the two-point correlator,
| (2) |
where means contracting opposite pairs of edges, according to the periodic boundary condition.
We denote the “virtual” Hilbert space as associated with tensor indices on one leg, where is the corresponding bond dimension of the tensor leg. A tensor on the lattice has legs, where is the spacetime dimension of the lattice used to describe the system. For example, in the classical Ising model on the square lattice. Thus, the vector space of all the -legged tensors is .
To evaluate the contraction of the tensor network in Eq. (1) on an infinitely large lattice, which yields the partition function of the system at the continuum limit, one iteratively transforms the tensor network into a new tensor network on a coarse-grained lattice until the boundary effect and the finite-size effect are negligible. This is generally called the real-space tensor renormalization procedure, as illustrated below. (We note that in the infinite system instead of the value of the partition function, we obtain the free-energy density instead.)
| (3) |
The bond dimension of the coarse-grained tensor under exact merging will grow exponentially. To make it feasible for numerical computation, one needs to truncate the Hilbert space of the virtual degrees of freedom (i.e., bond dimensions) in each leg. Various numerical methods such as TRG [39], HOTRG [33], TEFR [36], TNR [34, 40], SRG [31], and GILT [37] are proposed to properly truncate the Hilbert space in the coarse-graining process.
Truncation to finite bond dimension. When coarse-graining the tensor toward a fixed point, scale invariance requires that , which implies that or strictly. So in principle, one needs infinitely many iterations so that the coarse-grained tensor network can reach either a trivial or an infinite-dimensional tensor. In practice, we assume that the system approximately reaches the thermodynamic limit after a finite but large number of steps, and the higher-index components of the coarse-grained tensors are negligible, and we truncate the Hilbert space on each leg to retain only its most significant -dimensional subspace.
One has to bear in mind that the truncation error introduces an artificial length scale to the coarse-grained system, which breaks the conformal symmetry. This issue will be demonstrated in Sec. III.2; for example, see Fig. 17. In this paper, we focus on a combination of methods using HOTRG and GILT [39]. The description of our coarse-grain scheme is given in Sec. II.7.
II.2 Renormalization Group Flow and Conformal Field Theory
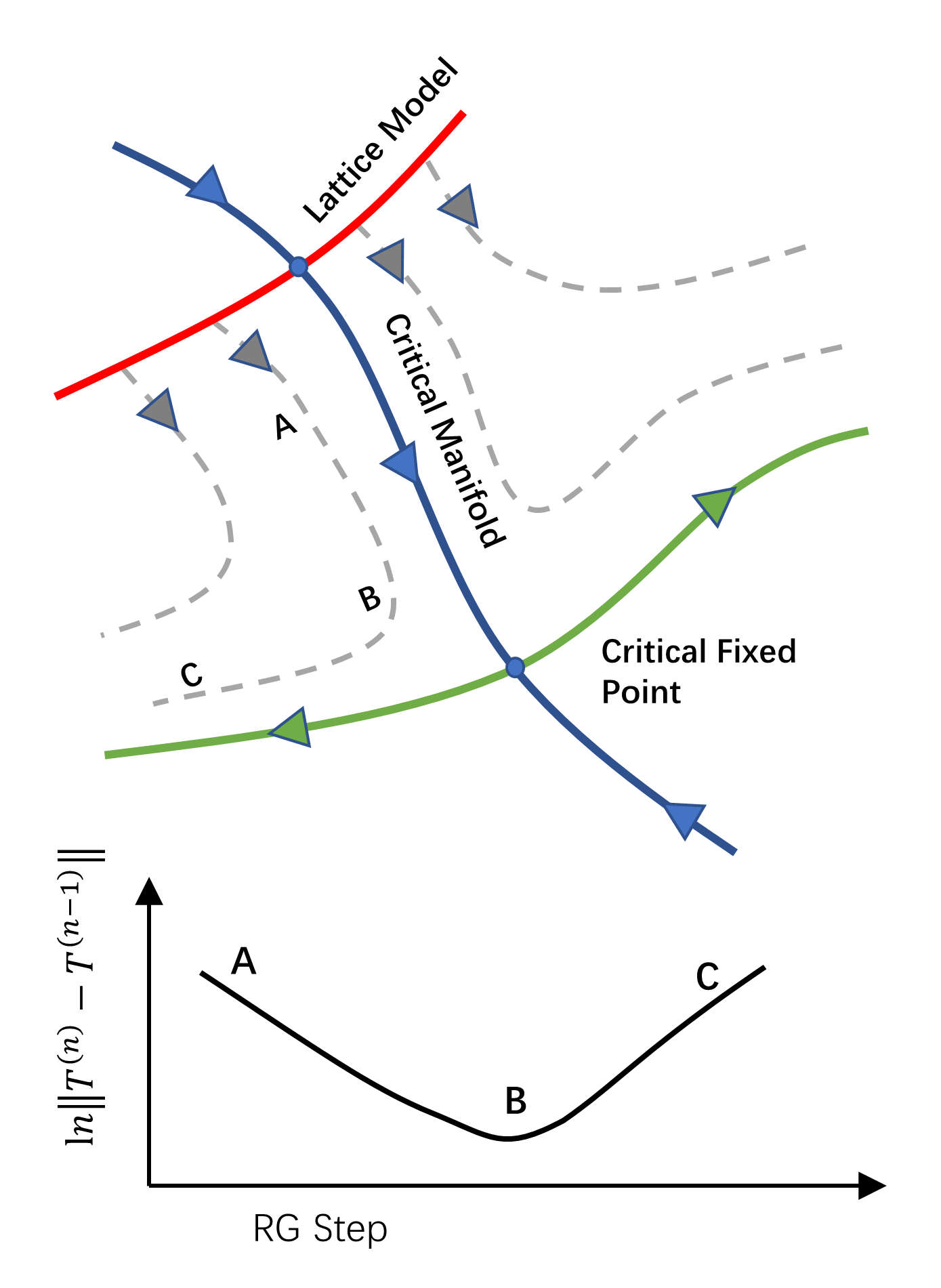
The behavior of statistical and quantum systems at different length scales can be described using the renormalization group flow in the system parameter space, as illustrated in Fig. 1.
At criticality, the system flows into a certain type of fixed point, which sometimes can be described by a CFT, where there is an emergence of scale invariance at long distances. As a result, the two-point functions obey a power law
| (4) |
where is the scaling dimension of the operator . Further information about CFT will be summarized in App. B and App. C.
When the system is near the critical manifold of the system parameters, it can firstly converge to someplace near the critical manifold and then deviate from it exponentially, moving towards perhaps another fixed point. On the logarithmic scale, the change in the tensor is represented by a V-shaped curve after each RG step, as demonstrated in Fig. 1.
In TRG, the difference between coarse-grained tensors from successive RG steps also follows a curve schematically shown in Fig. 1, which was previously reported in Refs. [44, 34, 39] and can be used as a method to determine how close the flow is to the criticality 111See also Fig. 3 from our numerical simulations. We expect the change of the system after each RG transformation to behave as a V-shaped curve on the logarithmic scale. For example, the location B in Fig. 1 is the closest to a nearby critical manifold, and for length scales where the system is at the proximity of B, the system behaves like a CFT at the corresponding fixed point. As a result, the system can behave like different CFTs at corresponding length scales, depending on the detailed RG flow.
A CFT can be uniquely determined by its CFT data. The CFT data consists of the list of primary operators , their conformal dimensions , and the OPE coefficients between them. With these, one can compute all the -point correlation functions. In the context of tensor networks, the conformal dimensions describe how a defect tensor scales under coarse graining, and the OPE coefficients describe how two defect tensors fuse into another defect tensor during this process.
II.3 Higher Order Tensor Renormalization Group
Now we describe the key coarse-graining procedure that we shall use, i.e., the HOTRG. The idea is to find a coarse-grained tensor and isometry : , which specifies the subspace to keep after one step of coarse-graining, as illustrated in the equations below.
| (5) |
| (6) |
One can repeat the coarse-graining procedure horizontally and then vertically at alternative steps.
II.4 Local Entanglement Filtering and Graph Independent Local Truncation
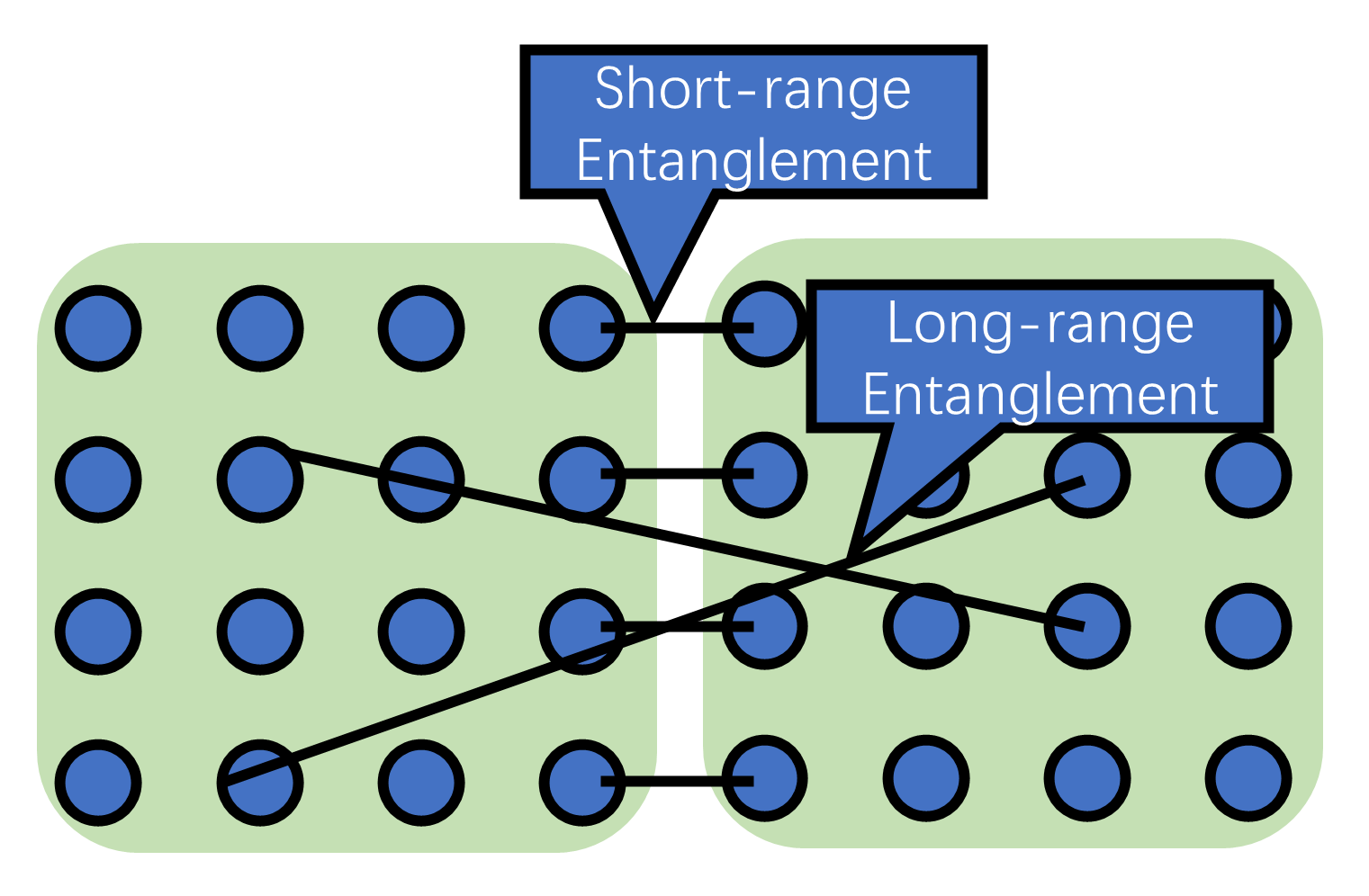
Real-space RG methods suffer from accumulating microscopic entanglement between the pair of sites adjacent to the boundary of coarse-grained regions. As illustrated in Fig. 2, the entanglement between two blocks, which determines the necessary bond dimension required to faithfully represent the system, arises from the contribution of short-distance pairs across the boundary of the two blocks.
On a square lattice, local entanglement can be parameterized by corner-double-line tensors [36],
| (8) |
To effectively capture the long-wavelength behavior of the system using a tensor with a finite bond dimension, local entanglement removal must be done. The basic idea of local entanglement removal involves gluing two tensors together and then slicing them apart again.
CDL tensors can be removed by graph-independent local truncation [37]. The idea of GILT is to modify a subset of a tensor network such as a plaquette, so that the modified sub-network still looks the same from external legs, but the entanglement through a certain internal leg is reduced,
| (9) |
II.5 Gauge Fixing and Minimal Canonical Form
The “virtual” Hillbert space on each leg is unphysical, suffering from a gauge redundancy [41], as shown in Eq. (10). We recall that is the bond dimension and is the ‘spacetime’ dimension of the lattice. It is essential to fix the gauge to compare the tensors of different RG steps component-wise; a gauge transformation on the four legs is illustrated in the equation below.
| (10) |
Ref. [39] introduced a rudimentary gauge-fixing procedure, which is based on the eigenvalue decomposition during the standard HOTRG procedure Eq. (38). Their method successfully yields a V-shaped curve 222 The Figure 9 in [39] does not show a clear V-shaped curve, indicating that the gauge is not completely fixed when comparing tensors at successive RG steps. However, the GitHub code they provide yields a clear V-shaped curve, as shown in Fig. 13..
Recently, it has been proposed in Ref. [41] that the tensor can be iteratively gauge-transformed to a “minimal canonical form” (MCF) [41], which is unique among gauge-equivalent tensors up to a gauge ambiguity,
| (11) |
where . The overline means that we take the closure of the gauge orbit, i.e., including the limits of any sequence of group actions. (The consideration of closure is for mathematical rigor and does not need to be explicitly considered in our scenario.)
We summarize the prescription for obtaining the MFC in Alg. A.3 (App. A.3). The residual gauge can be robustly fixed using an improved method based on the preliminary method in Ref. [39]. The method is summarized in Alg. A.4 (App. A.4). With the implementation of MCF, we obtain a more consistent gauge fixing when comparing coarse-grained tensors between successive RG steps, and it produces a V-shaped curve; see the discussion in Sec. IV.
II.6 Linearized Tensor Renormalization Group
The lTRG [39] studies how the perturbation in the input tensor changes the flow of the coarse-grained tensor. It is defined as follows,
| (12) |
where and are tensors before and after coarse-graining. At the critical point, the eigenvalues of give the conformal dimensions of the CFT operators,
| (13) |
where
| (14) |
and is the linear scaling of the system after two RG steps (which merge four sites by a vertical and a horizontal coarse-graining steps). Note that proper normalization is required; see App. G.
Ref. [39] shows that the scaling dimensions of the first few operators in the Ising CFT can be obtained from the linearized HOTRG scheme with GILT and a preliminary ( for the complex case) gauge-fixing procedure. One can also compare the lTRG result with the scaling dimensions obtained from the transfer matrix method [36], as well as the known analytical results from conformal field theory [3]. For example, in Ref. [40], the first 101 scaling dimensions of local and non-local operators in the Ising CFT are calculated using the transfer matrix method on the coarse-grained tensor obtained from the TNR method, which confirms well with the expected analytical result.
In this paper, we will further demonstrate that the eigenvectors of lTRG in Eq. (12) have a clear physical meaning. They are the conformal states associated with the corresponding operators . The conformal states are obtained by inserting conformal primaries and descendants into the vacuum state (see App. B). In this paper, the states are defined on the boundary of a coarse-graining block. Thus, we place the operator at the center of the block. At the lattice level, these states can be achieved by coarse-graining the tensor network Eq. (1) with the operator insertion as defect tensors:
| (15) |
By also calculating the two-point correlation function of the Ising model on the square lattice using the TRG method, we find that the position of the operator in the coarse-grained defect tensor is encoded by its projections onto the primary and descendant tensors or lTRG.
II.7 Coarse Graining using HOTRG, GILT and MCF
Here, we integrate GILT and MCF into the HOTRG steps,
| (16) |
In the above, at each coarse-graining layer, , are the isometry tensors from HOTRG, and , , , and are the entanglement truncation matrices from GILT. They filter out certain local correlations that cannot be removed by and . Moreover, and are the gauge-fixing matrices, determined by MCF, and the residual gauge redundancy is fixed by the sign-fixing procedure in Ref. [39].
Adapting GILT to HOTRG. In GILT, one has to repeat the process on all the possible plaquette-leg combinations to remove all the local entanglements. In practice, as suggested in [39], it is sufficient only to apply GILT on the following plaquette-legs:
| (17) |
The tensor in the gray shade is to be coarse-grained, with circle-shaped GILT tensors being split using the SVD. We only truncate half of the CDL loops across the legs to be coarse-grained.
II.8 Coarse-graining the Defect Tensors
To compute the -point correlation function in Eq. (2), we iteratively apply the coarse-graining step Eq. (16) to each pair of tensors in all coarse-graining blocks, as shown in Eq. (18) below:
| (18) |
where , are two defect operators, and means the two defects are fused together.
The coarse-graining of tensors is performed according to Eq. (16), in which we use the same set of coarse-graining tensors , , as when coarse-graining vacuum tensors. The symbol indicates contracting opposite pairs of edges, according to periodic boundary conditions. Note that the coarse-grained tensor is dependent on not only the type of defect but also the position of the defect relative to the coarse-graining block.
Similarly, when calculating the linearized TRG Eq. (12), on the other hand, we also keep the coarse-graining tensors , , as constants, that is, their variation with respect to the change of the input tensor is discarded.
As a result, the coarse-grained tensor is quad-linear in the four input tensors:
III Main Results
Here we present our results of the CFT data from the fixed point tensor of the linearized Tensor Renormalization Group [39], using the improved gauging fixing via MCF. We obtain the CFT data by two distinct approaches: one involving the introduction of defects on the lattice and the other relying solely on the fixed-point tensor, without any information about the lattice. We also compare the tensors corresponding to conformal operators extracted from the two methods.
We first follow the work of Lyu et al. [39], who extracted the conformal dimension spectrum from the eigenvalues of lTRG. Our first contribution is to improve the stability of the RG flow by introducing MCF for gauge fixing. The results of the RG flow and scaling dimensions are summarized in Sections III.1 and III.2.
Next, we go beyond reproducing scaling dimensions and propose and implement how to extract the OPE coefficients, such as , through the fusion of eigenvectors and lTRG fixed point equations (note that these eigenvectors are themselves tensors). The results agree with known values and are summarized in Section III.3.
Additionally, we verify that eigenvectors of lTRG serve as a useful representation of conformal states at low-energy sectors. To do this, specifically, we also construct these conformal states by placing lattice-level operators on the lattice (see Table 1) and then coarse-graining them. We compare these with the eigenvectors of lTRG and find that the latter align well with the coarse-grained tensors in the low-energy subspace (i.e., the subspace consists of states of small scaling), as demonstrated in Section III.7. Moreover, by expanding the coarse-grained tensor using the basis of primary and descendant states, it becomes evident that the position of the primary operator inserted in the lattice is encoded in the components of the descendant basis, similar to the standard Taylor expansion used for operators. This observation is discussed in Section III.8.
However, it remains unclear whether coarse graining introduces significant truncation errors in such states with higher excited levels. To characterize the quality of the coarse-graining on the defect tensors, we calculate their two-point and four-point correlation functions using HOTRG+GILT. They agree well with the analytical result, and we can also use them to extract the CFT data , and by fitting the correlation functions. However, the error is noticeably larger than the one we obtained from the fusion method. Additionally, we calculate the two-point function on a finite-size torus and find that the numerical result agrees well with the analytical one and that the correlation function respects the periodic boundary condition of the torus geometry. These results are summarized in sections III.4, III.5, and III.6.
By studying the -point correlation functions, we can better understand the capability and limitations of our real-space RG scheme in coarse-graining defect tensors. A technical discussion is provided in section IV. With this knowledge, we are confident that the coarse-grained tensor can serve as a reference for conformal states.
In summary, we demonstrate two different methods for extracting CFT data from a critical lattice model. The first method involves extracting operator scaling dimensions from two-point correlation functions and OPE coefficients from four-point correlation functions by introducing defects on the lattice. The second method utilizes the fixed-point tensor to extract the CFT data without relying on lattice-level knowledge (i.e., only from the fixed-point tensor and equation). Specifically, we obtain the scaling dimensions from the eigenvalues of lTRG and the OPE coefficients from the fusion rules of the eigenvectors of lTRG, which correspond to conformal states. Our findings demonstrate a good agreement between the conformal states obtained from lTRG and those obtained from coarse-graining lattice-level defects.
III.1 Convergence onto the Conformal Fixed Point in Higher-order Tensor Renormalization Group
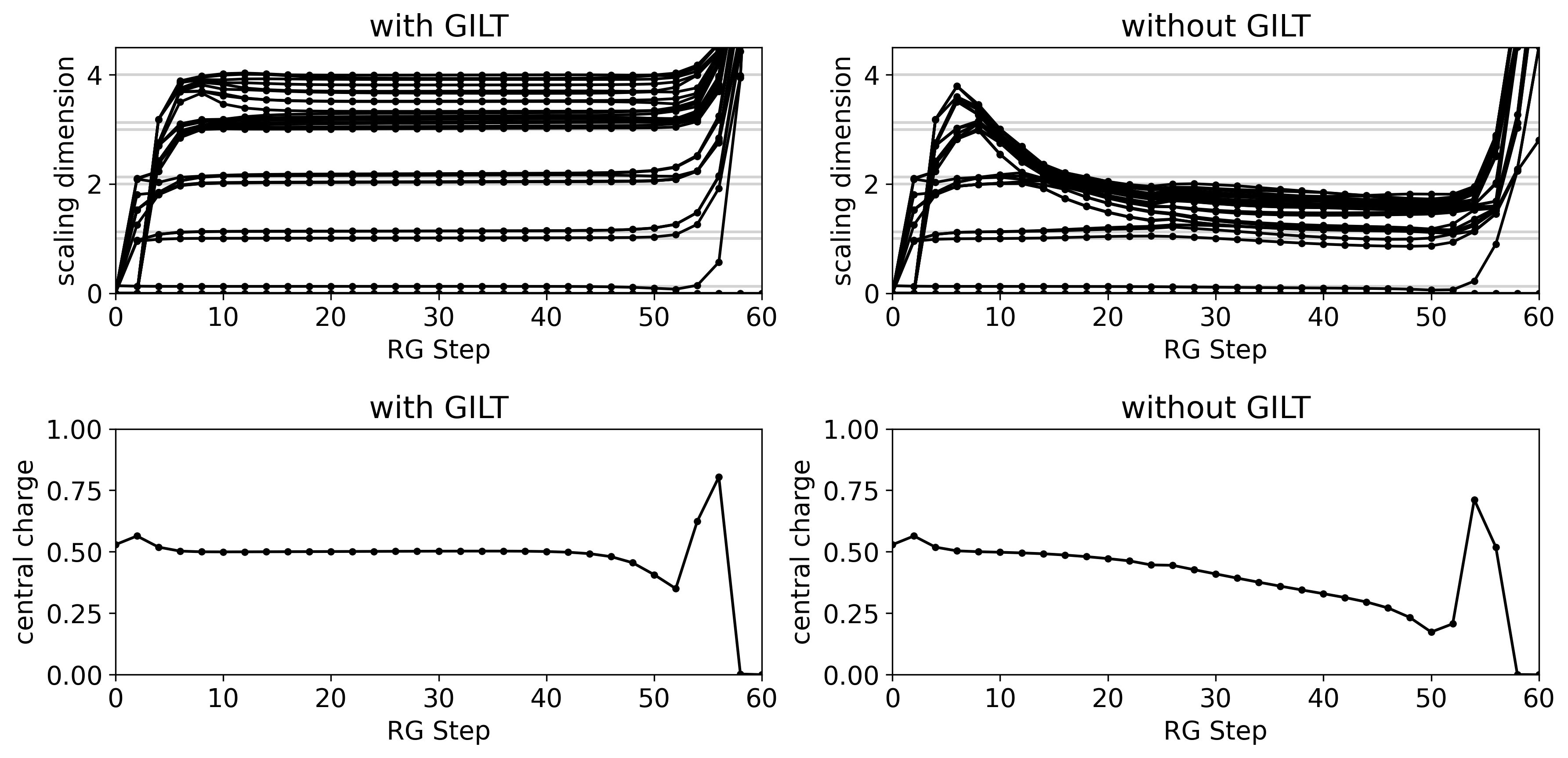
After applying GILT [37] to remove local entanglement and performing the MCF [41] for gauge-fixing, we can identify a non-trivial fixed point in HOTRG [33], where the tensor remains almost the same after coarse-graining. This fixed point from the 2D classical Ising model corresponds to the Ising CFT , with a central charge of [3].
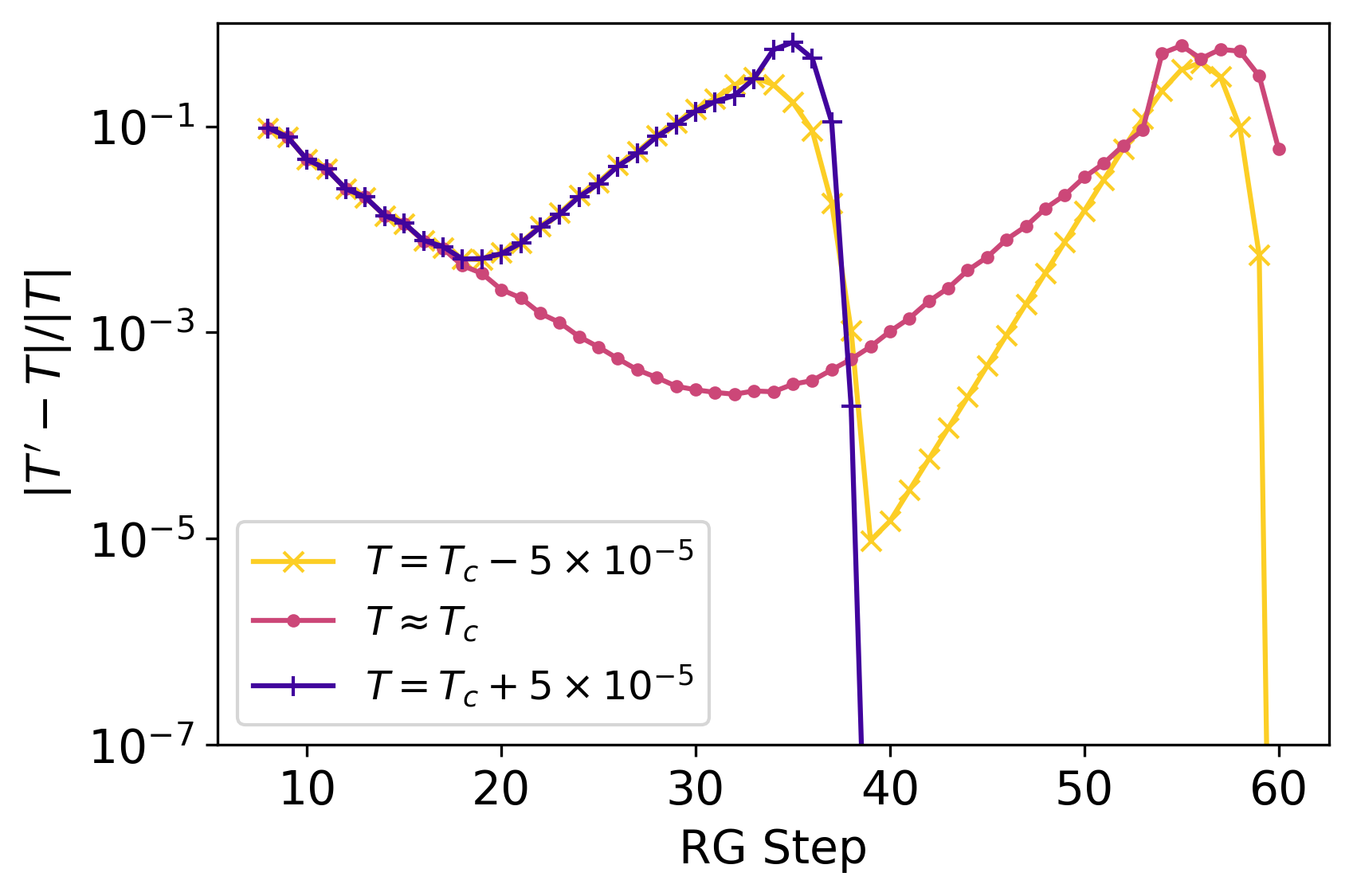
In Fig. 3, we present the tensor difference of the coarse-grained Ising model on a 2D square lattice as a function of the HOTRG iterations near the critical temperature (see purple circles in the figure). As the system approaches the critical point around step 30, the coarse-grained tensor approximately converges to a fixed point, where the tensor remains almost the same after the coarse-graining steps (with the change in the tensors being less than ). After step 30, the tensor deviates exponentially, because the critical fixed point is an unstable fixed point, and any error, such as the numerical error, truncation error, or fluctuation of initial values, will result in a spontaneous symmetry broken after RG iterations.
This behavior of first approaching and then deviating from the fixed point is a hallmark of the RG flow near a critical point that can be identified from a V-shaped curve in the logarithmic plot. Figure 3 also illustrates how the system evolves into distinct fixed points as the temperature is slightly perturbed. When starting at a temperature slightly away from (above and below), the system does not converge as closely to the critical fixed point as the one at the critical temperature. The flows in both cases approach their “perihelions” of the fixed point around step 20.
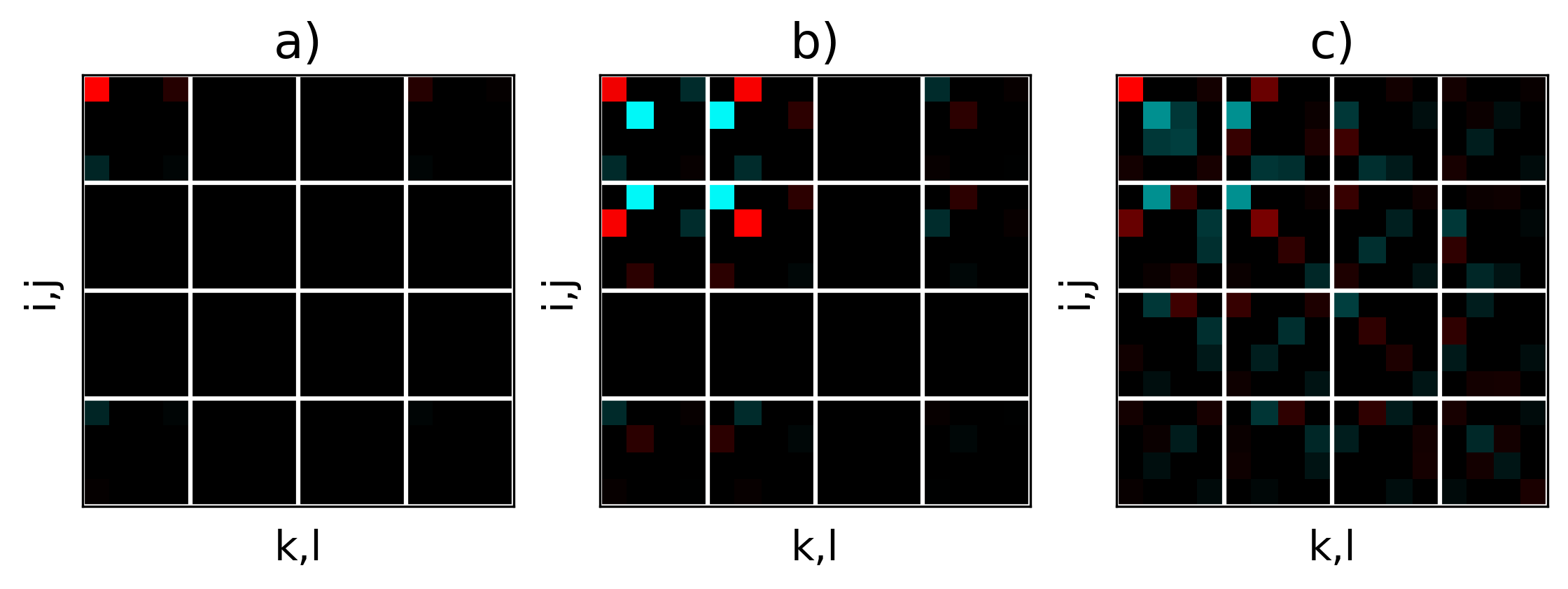
In the low-temperature phase, the system first flows to a degenerate low-temperature fixed point (with the only two nonzero elements being ) before eventually flowing to a tensor of the form , due to spontaneous symmetry breaking caused by perturbations from numerical errors, since we did not enforce the symmetry during coarse graining. In the high temperature phase, the system converges directly to the high-temperature fixed point, with one nonzero element being (whose tensor form is nevertheless equivalent to by a basis transformation in the virtual indices Eq. (10)). The tensor components at the three fixed points are shown in Fig. 4.
The numerical scheme for the critical temperature is obtained using a bisection algorithm, as suggested in [39]. We assume that there is an abrupt change in the coarse-grained tensors across the phase transition. The critical point can be identified by comparing the gauge-fixed coarse-grained tensors . The detailed procedure is described in Alg. J in App. J.
The curves in Fig. 3 exhibits more fluctuation and discontinuities in the range where is large. It is because when two tensors are more different from each other, it is more likely that the MCF fails to find the correct gauge to compare the two tensors. More specifically, a gauge fixing scheme could introduce discontinuities; that is, two physically nearly identical tensors are separated by the “cut” of a gauge choice, resulting in an O(1) inconsistent in their gauge-fixed form. This problem might be diagnosed by inspecting the level crossing incident in the SVD spectrum.
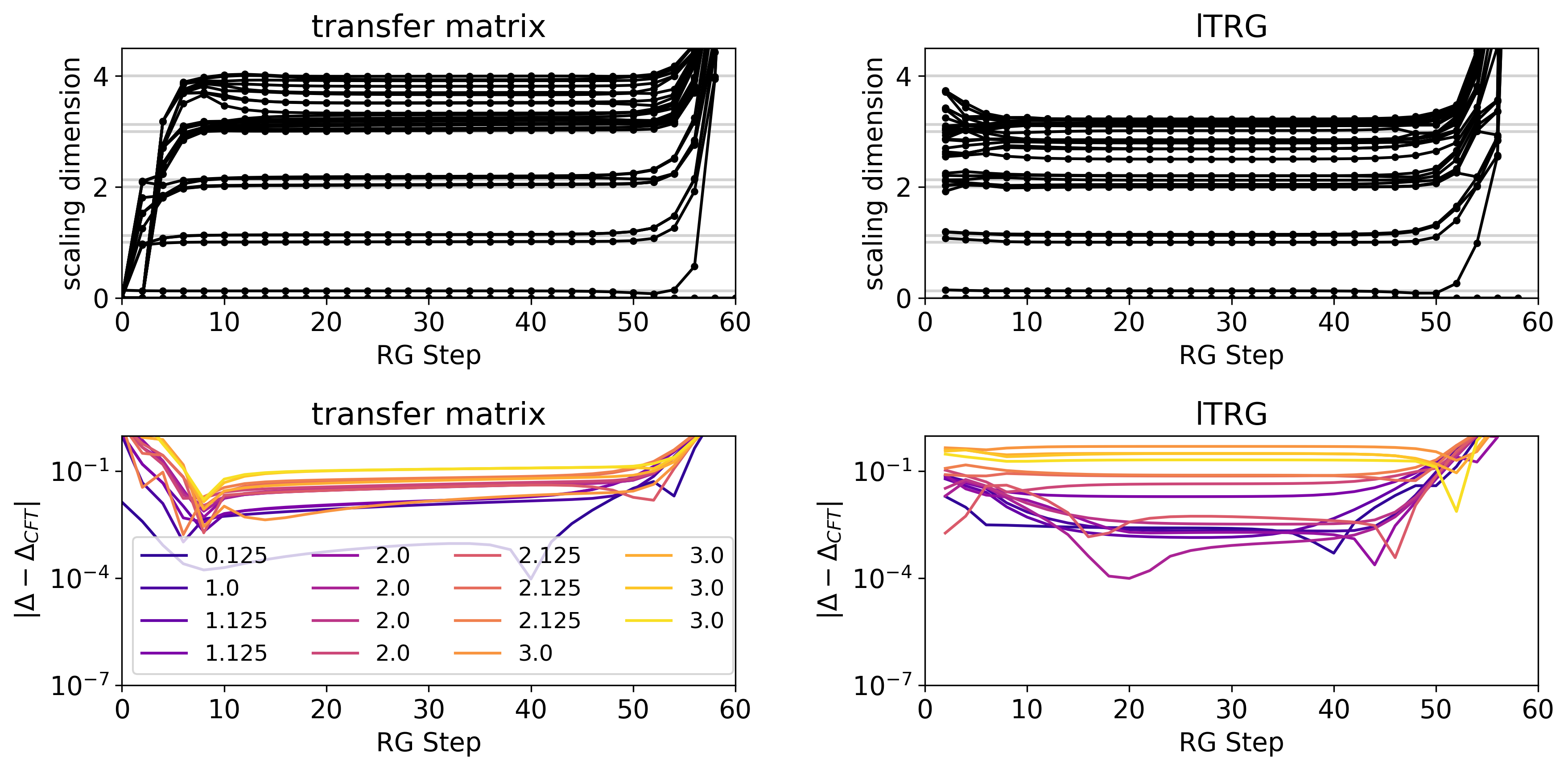
III.2 Scaling Dimension from Linearized Tensor Renormalization group
In Table 1, we compare the results of the scaling dimensions obtained by two different methods: (1) diagonalizing the transfer matrix on a cylinder and (2) solving the eigenvalues of lTRG Eq. (12). We also compare for each case how the results depend on whether GILT is used or not. First, we confirm that GILT generally improves the numerical results for scaling dimensions [37], especially for higher values. However, we observe that the transfer matrix spectrum achieves more accurate information on higher conformal dimensions compared to the lTRG method (see their values for operators having or higher).
| with GILT | without GILT | Ref.[39] | |||||
| exact | |||||||
| 0 | |||||||
| 0.1259 | 0.1275 | 0.1101 | 0.1065 | 0.125 | 0.127 | ||
| 1 | 1.0116 | 1.0021 | 1.0041 | 1.2844 | 1.002 | 1.009 | |
| , | 1.1395 | 1.1264 | 1.1600 | 1.4137 | 1.128 | 1.125 | |
| 1.1399 | 1.1446 | 1.2380 | 1.4269 | 1.128 | 1.128 | ||
| , | 2.0354 | 1.9981 | 1.2586 | 2.0431 | 2.014 | 2.002 | |
| , | 2.0357 | 2.0008 | 1.2587 | 2.0431 | 2.014 | 2.004 | |
| , | 2.0382 | 2.0033 | 1.3253 | 2.0462 | 2.016 | 2.068 | |
| , | 2.0428 | 2.0447 | 1.3525 | 2.0471 | 2.016 | 2.073 | |
| , | 2.1607 | 2.1197 | 1.4917 | 2.0512 | |||
| , | 2.1831 | 2.1987 | 1.5193 | 2.0651 | |||
| , | 2.1897 | 2.2031 | 1.6390 | 2.0719 | |||
| 3 | 3.0145 | 2.5010 | 1.6434 | 2.0720 | |||
| 3.0548 | 2.6845 | 1.6479 | 2.0931 | ||||
| 3.1142 | 2.6845 | 1.6512 | 2.0931 | ||||
| 3.1145 | 2.7911 | 1.6582 | 2.0993 | ||||
| 3.1306 | 2.8228 | 1.6639 | 2.0993 | ||||
| … | 3.1359 | 2.8264 | 1.6641 | 2.1025 | |||
The spectrum of the transfer matrix, , can be used to represent the quality of the coarse-grained tensor. The method with GILT enabled produces the correct scaling dimensions and their degeneracy number up to . Without GILT, the number of degeneracy errors starts from , and the error in the scaling dimensions is much larger.
The lTRG scaling dimension spectrum, , is of greater interest to us, since we shall extend the approach to OPE coefficients. The method with GILT enabled does not provide the correct scaling dimensions from and above, but it does show a gap between and , with the correct number of degeneracy at . On the other hand, the case without GILT has the last meaningful gap between and . Furthermore, the GILT case has fewer errors at .
III.3 OPE Coefficient from Linearized Tensor Renormalization Group
Despite that lTRG performs worse than the transfer matrix in scaling dimensions, we demonstrate in this subsection that using lTRG one can extract the OPE coefficients only from its fixed point tensor , without any knowledge about the lattice-level details. In particular, what one needs is the coarse-graining , and the conformal states , , and , which are the first few eigenvectors of the lTRG transformation .
We recall the OPE expansion and its coefficients in terms of the conformal states rather than operators,
| (20) |
where denotes states orthogonal to .
From our coarse-graining scheme, we have that
| (21) |
where is the 8-legged tensor from contracting the corresponding tensor sub-network, is the coarse-graining procedure Eq. (16) that converts the 8-legged tensor to the 4-legged coarse-grained tensor. The inner product . and are renormalized so that:
| (22) |
| (23) |
The detailed scheme is further explained in Appendix G. Note that in practice, we place defect tensors on different combinations of sites in the coarse-graining block and average over the resulting renormalization coefficients and the OPE coefficients.
The result of the OPE coefficients of Ising CFT is shown in Table 2. The scaling dimensions and the fusion between two ’s are fairly accurate; however, the values that incur slightly larger errors are and . This is because as an operator of higher scaling dimensions, , suffers more error than from the coarse-graining process. We remark that OPE coefficients (and scaling dimensions) can also be extracted from four-point correlation functions, as will be discussed in Sec. III.5. However, the results there are not as accurate.
| exact | lTRG | |
| 1/8 | 0.127 | |
| 1 | 1.002 | |
| 0 | ||
| 1/2 | 0.512 | |
| 0 | ||
| 0 | 0.168 | |
| 1/2 | 0.409 | |
| 0 |
III.4 Scaling Dimension from Two-point Correlators
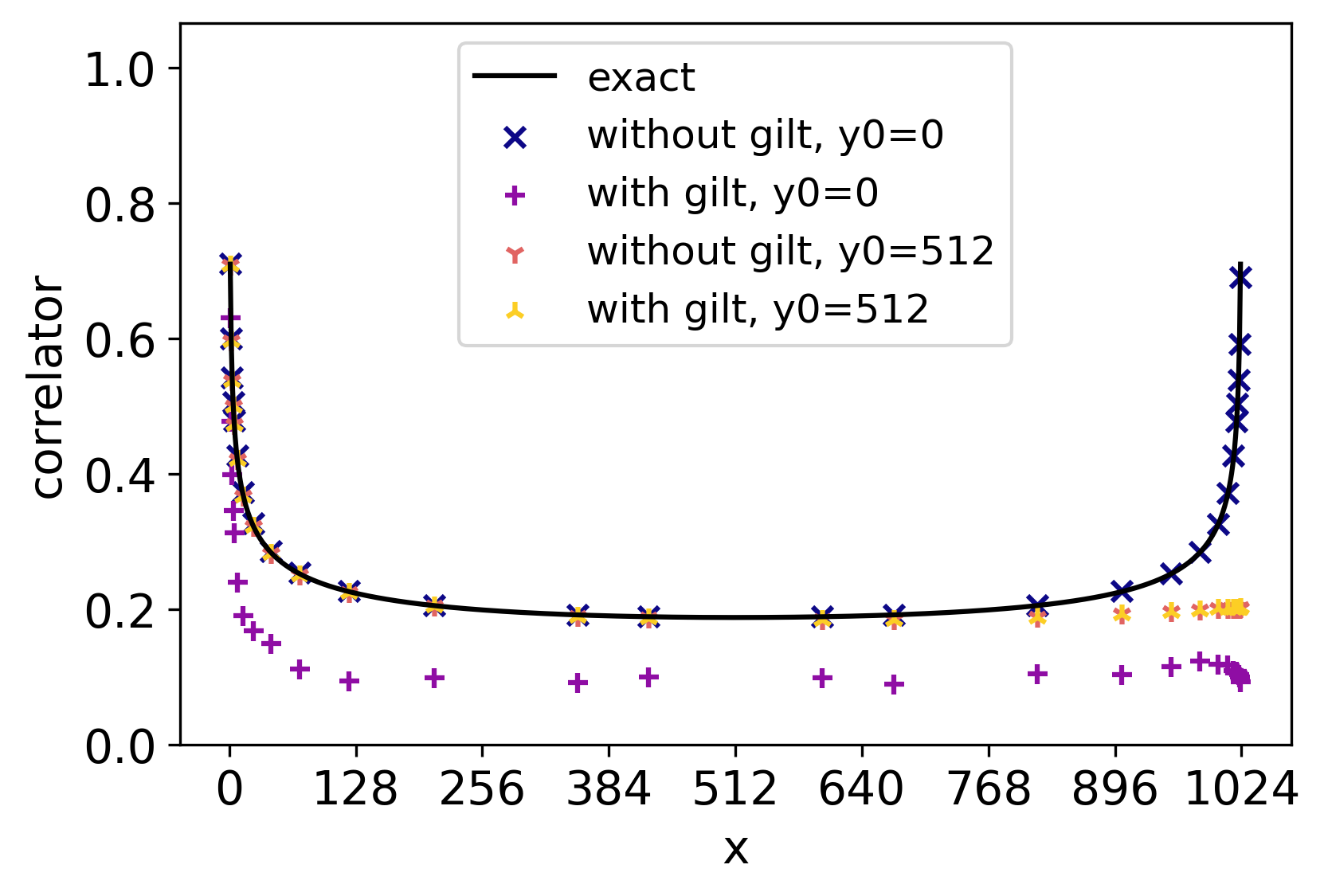
It is well known that the two-point correlation function at criticality scales as , where the anomalous dimension is related to the scaling dimension , via . Thus, it provides an alternative approach to extracting scaling dimensions. Figure 5 shows the two-point correlation function of the square lattice Ising model near the critical temperature.
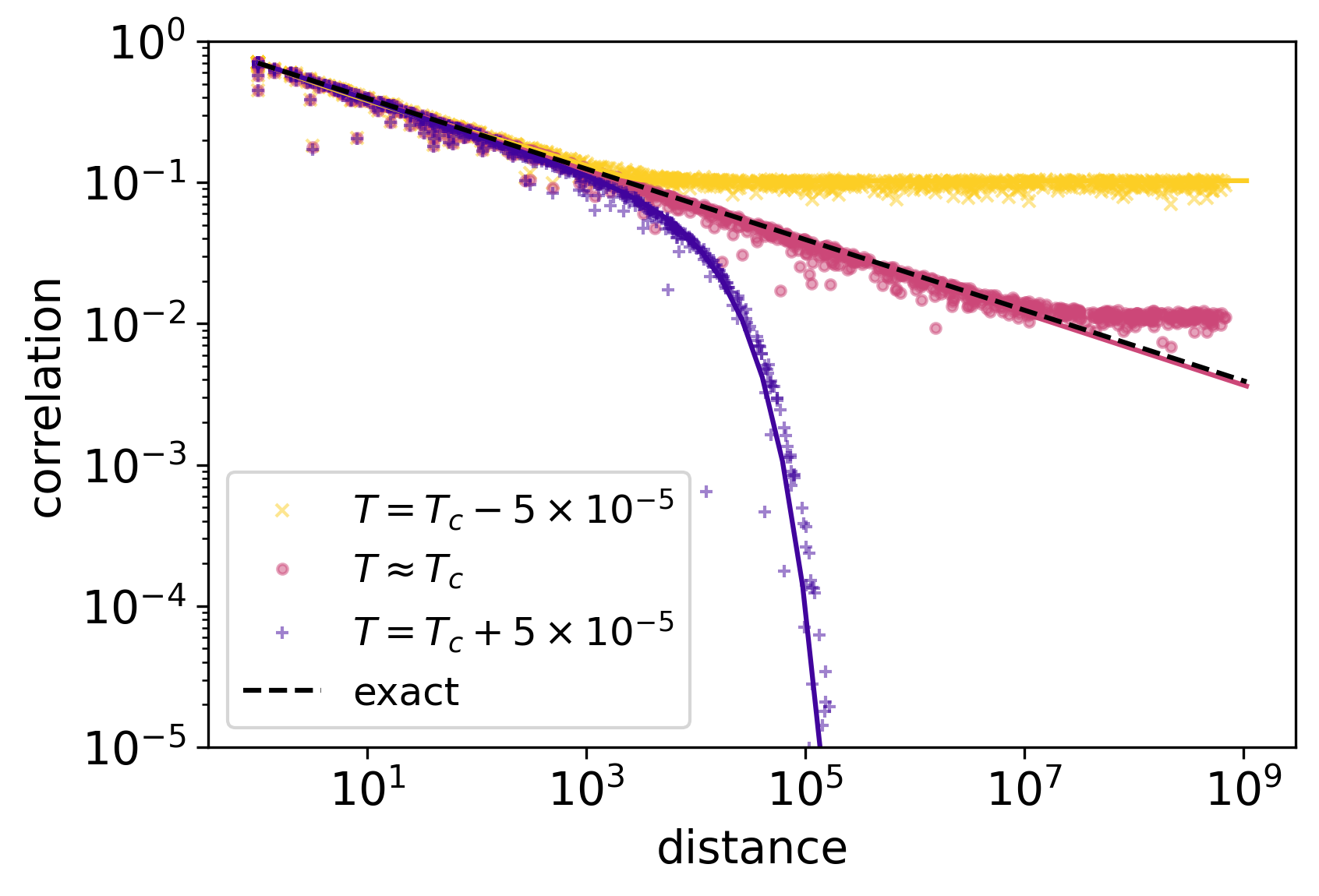
The points and were randomly sampled on the xy plane. The correlation function is determined by the distance between and , irrespective of the relative orientation or absolute positions for most cases. This indicates that the translational symmetry is preserved and the rotational symmetry has emerged at large distances.
To calculate the two-point function using coarse-grain tensors. We place two defect tensors , on a square lattice tensor network with periodic boundary conditions, where the tensors at the other sites are the vacuum tensor . Then we coarse-grain every adjacent pair of tensors as described in Sec. II.8. Then the coarse-grained vacuum tensor and the coarse-grained defect tensors , are obtained. Furthermore, when two defects are met in the same coarse grain block, they fuse into one defect tensor .
At the final coarse-graining step, all defects fuse into one tensor . The correlation function is computed using the following
| (24) |
where indicates contracting the opposite pairs of legs of the tensor.
We used three different temperatures. (1) When , the correlation function saturates at a finite distance, indicating a long-range order. (2) When , the correlation function follows a power-law behavior, with a slope in the log-log scale determined by the scaling dimension, indicating the critical behavior, discussed in more detail below. (3) When , the correlation function decays at a finite distance, indicating the absence of long-range order.
We now analyze the results of the two-point correlations in more detail and aim to extract the scaling dimension. To do this, we fit the correlation functions to the following ansatzes, in the respective temperature ranges,
| (25) | ||||
| (26) | ||||
| (27) |
where is the scaling dimension of the magnetization operator fitted at the corresponding temperature. is the correlation length, is the magnetization in the ordered phase, is the “scaling dimension” of , where is the one-point function averaged at every lattice site.
Regarding the outliers in the data, we adopt Huber loss Eq. (98) (explained in App. I) with (in log-log space) to suppress their excessive effects. Since the fitting is done in the log-log space, we also give the data points a weight that is proportional to the magnitude of its correlation.
When , we obtain ; when , we obtain and ; when , we obtain , , and .
The three correlation functions behave in a similar way at short distance . By fitting with Eq. (26), we get for low, critical, and high temperatures, respectively. The above results agree well with each other and with the analytic result .
We remark that, in order to get the correct scaling dimension, it is necessary to average over the positions of the correlated pairs, due to an issue in the coarse-graining of impurity operators. Also, Huber loss is used to take into account the outliers. We elaborate on these issues later in Sec. IV.
III.5 OPE Coefficient from Four-point Correlators
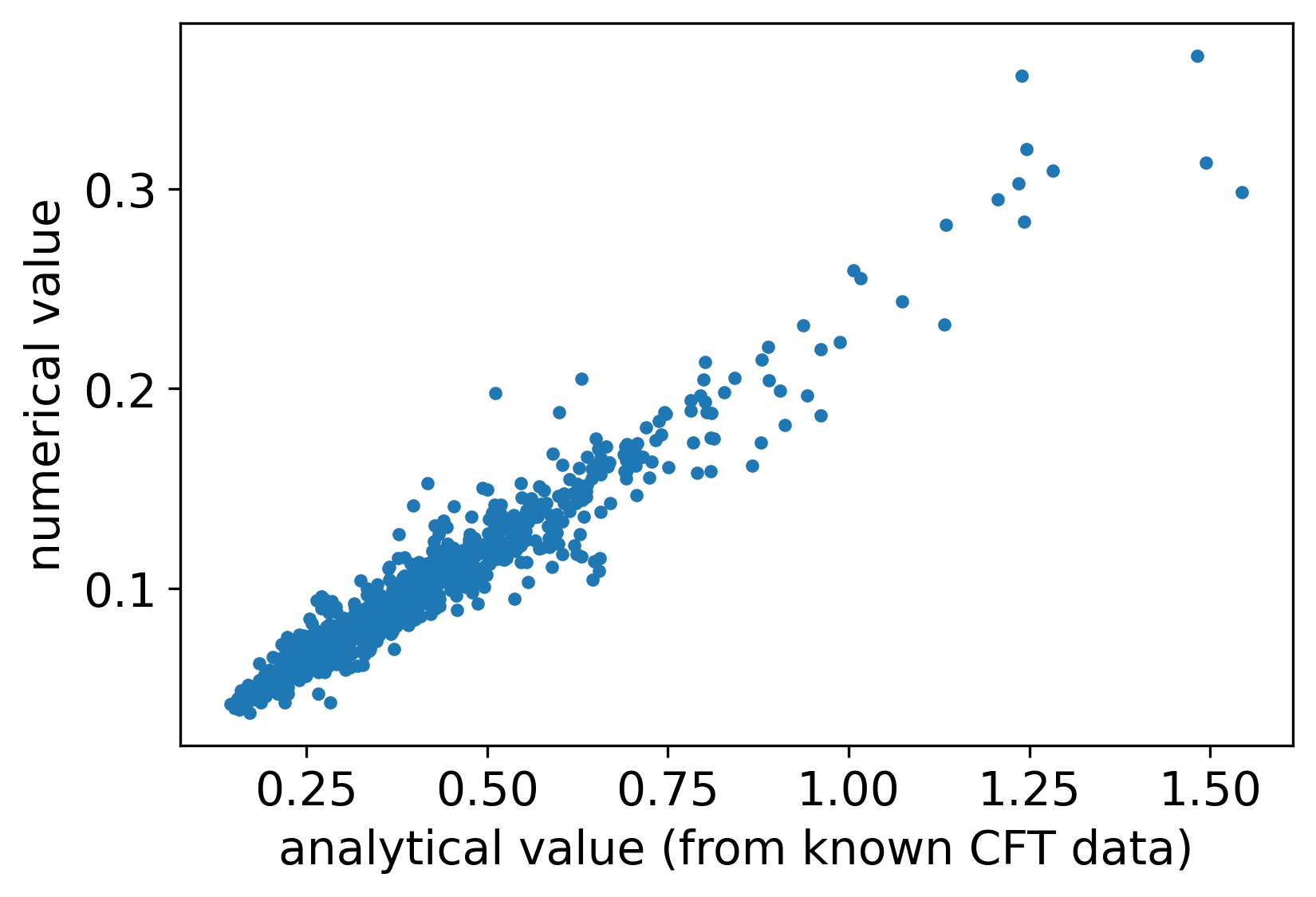
The essential data for Ising CFT are the scaling dimensions , , and the OPE coefficient . In 2D CFT, the four-point function can be uniquely determined by the CFT data according to Eq. (74). Thus, we compute the four-point correlation function of the square lattice Ising model near the critical temperature. To confirm that we can extract the OPE coefficients, we first compare our numerical values of the four-point correlation function with the analytical CFT prediction, shown in Fig. 6. The horizontal axis is the analytical value, and the vertical is the numerical value obtained from our TN procedure. One can see that, although the data is noisy, the trend indicates that they are proportional to each other up to some normalization factor, resulting from the normalization of the spin operators.
With the above comparison, we further use Eq. (74) for the fitting and thus extract the CFT data from our numerical results. We use the Huber loss Eq. (98) with to fit the curve in the logarithmic space, where the input data are the distances between pairs of points. The fitted values (vs. known values) are , , and , respectively. Thus, four-point functions provide a crude estimation of all the essential data of Ising CFT and give another confirmation of our previous results using lTRG.
III.6 Two-point Correlator on a Torus
We also compute the two-point correlation function on a torus using the HOTRG method. The results are shown in Figure 7.
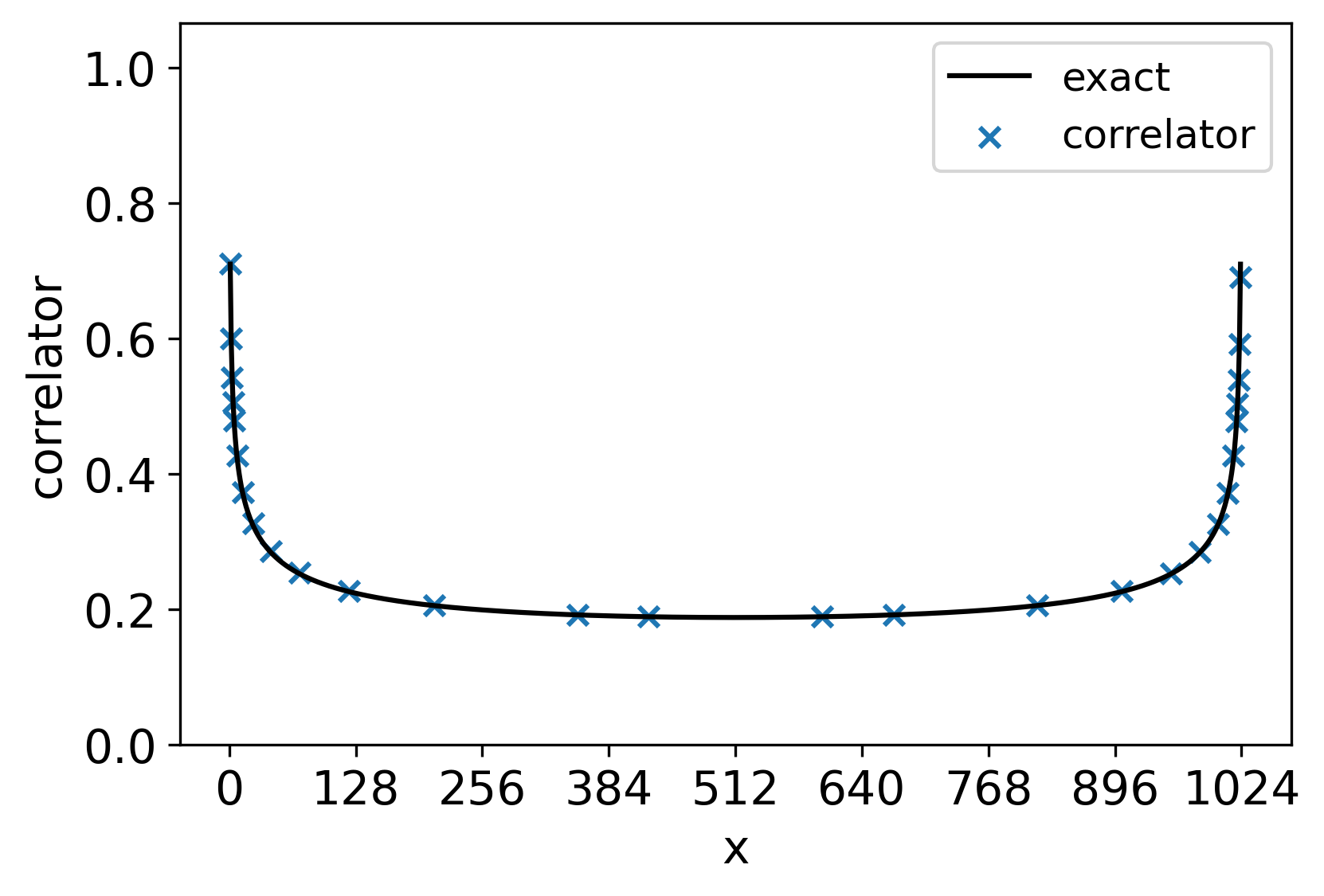
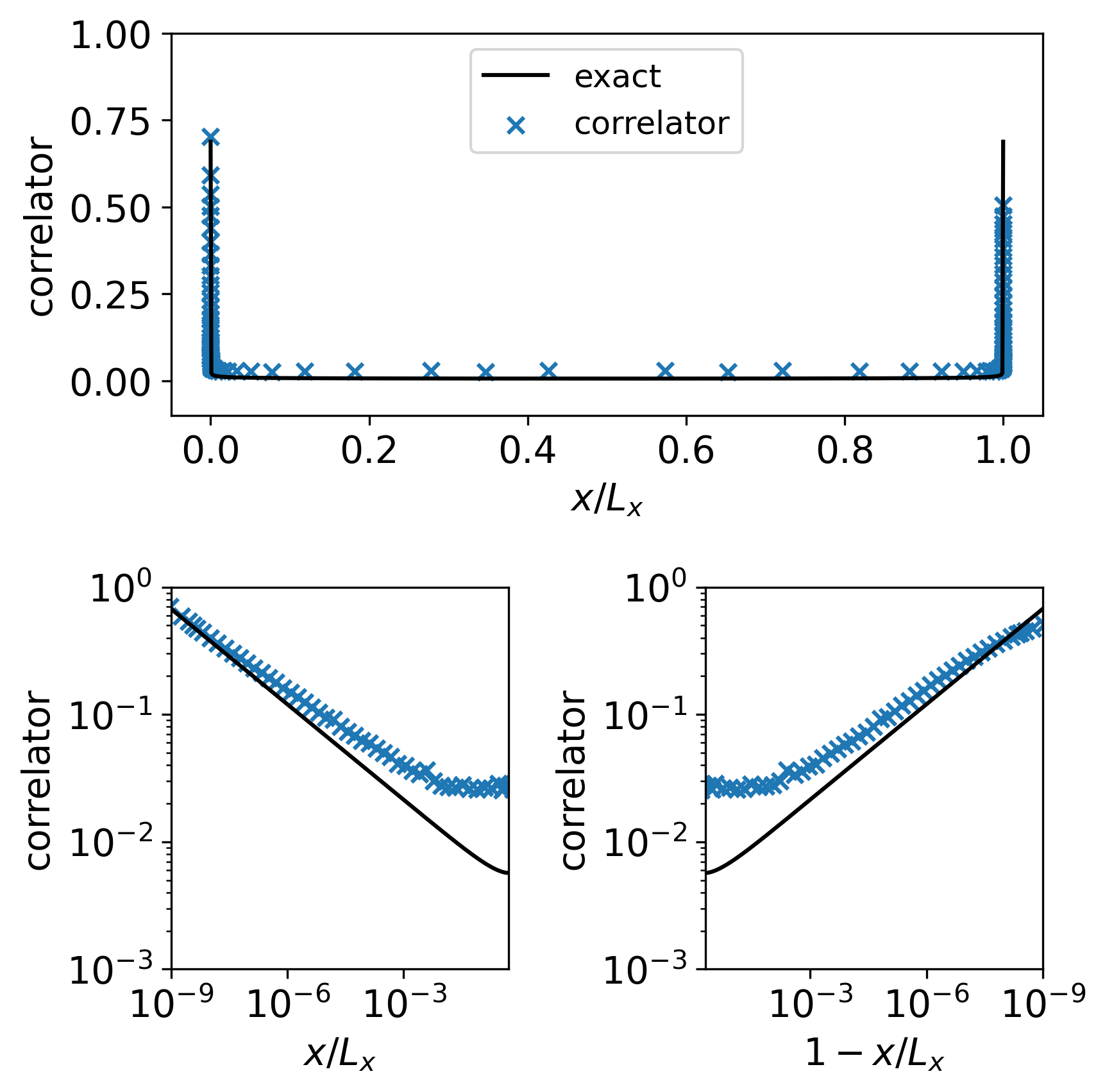
The result confirms well with the spin-spin correlation of the Ising CFT on a torus [47] (12.108):
| (28) |
where is the complex coordinate, , are the size of the lattice, , and ’s are the elliptic theta functions, following the convention in [48]. We only examine the case with here.
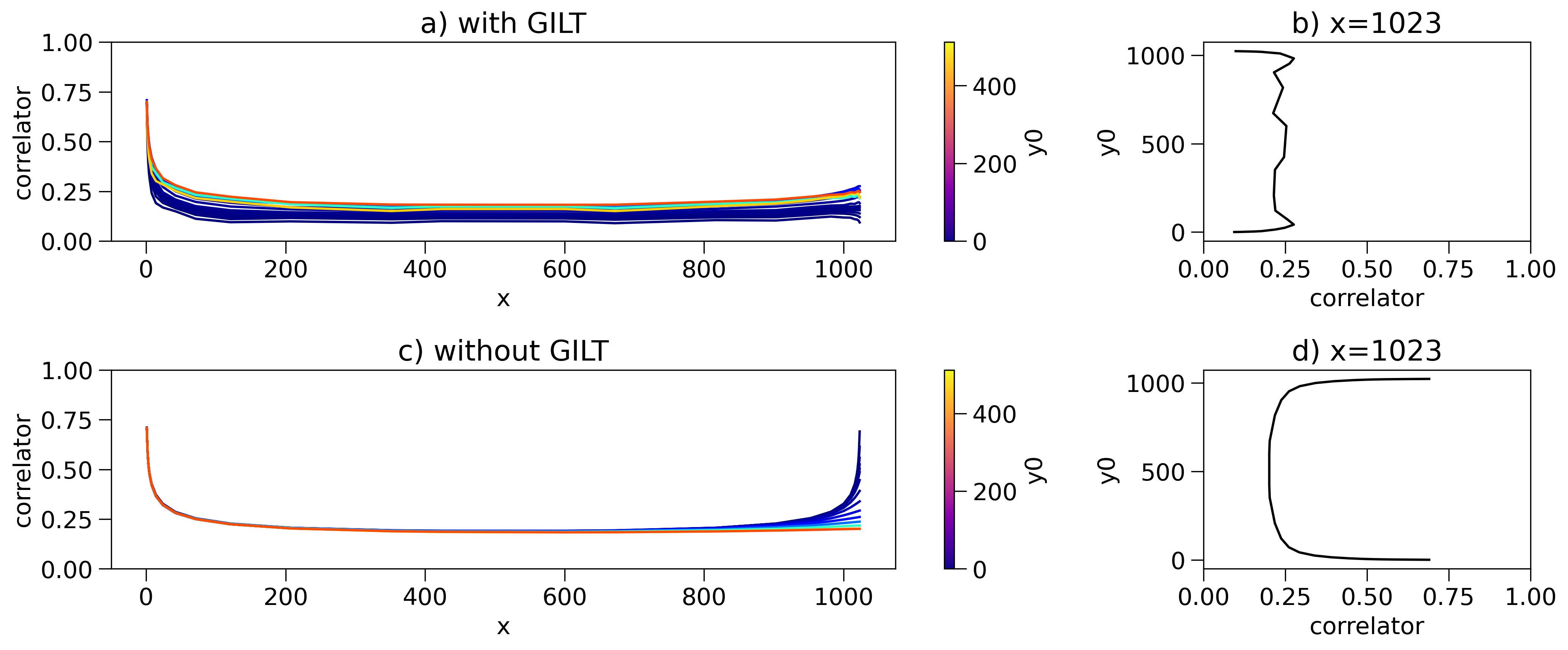
Fig. 8 shows the two-point function on a much larger torus, corresponding to 60 layers in the coarse graining. The correlator looks like the high-temperature correlation function as in Fig. 5 and Eq. (27) from both sides. This is because the coarse-grained tensors we use had already flowed away from the conformal fixed point on the length scale , as shown in Fig. 3 and Fig. 5.
As expected by the periodic boundary condition, the curves in Fig. 7 and Fig. 8 both exhibit a peak when . However, the sharp peak in seemingly contradicts the purpose of the coarse graining in HOTRG: removing microscopic details. The peak is the result of correlations between two point-like defects. However, in the case , the two defects meet in the very last step of the coarse-graining process. So, what was computed instead is the correlation function between two “smeared” operators, which gives a much smoother curve compared to that of the “bare” operators. Further discussions will be presented in Sec. IV.
The fact that a sharp peak can be obtained when indicates that the truncated Hilbert space of the coarse-grained tensor still captures the modes in which the excitation is sharply localized on the boundary of the coarse-grained regions, as described in Sec. IV. Figure 8 further illustrates that those point-like localized modes are kept throughout the entire RG flow.
III.7 Comparison between Eigenvectors of linearized Tensor Renormalization Group with Coarse-Grained Defect Tensors
As demonstrated in Sec. III.2 that lTRG via HOTRG+GILT+MCF gives good estimates of scaling dimensions, we now propose that additionally the eigenvectors of the lTRG coarse graining equation (Eq. (12)) at the fixed point correspond to the physical states of conformal primaries and their descendants. This claim is supported by a direct comparison between the coarse-grained tensors with operator insertion and the first few eigenvectors of the lTRG Eq. (12) near the conformal point, as shown in Fig. 9.
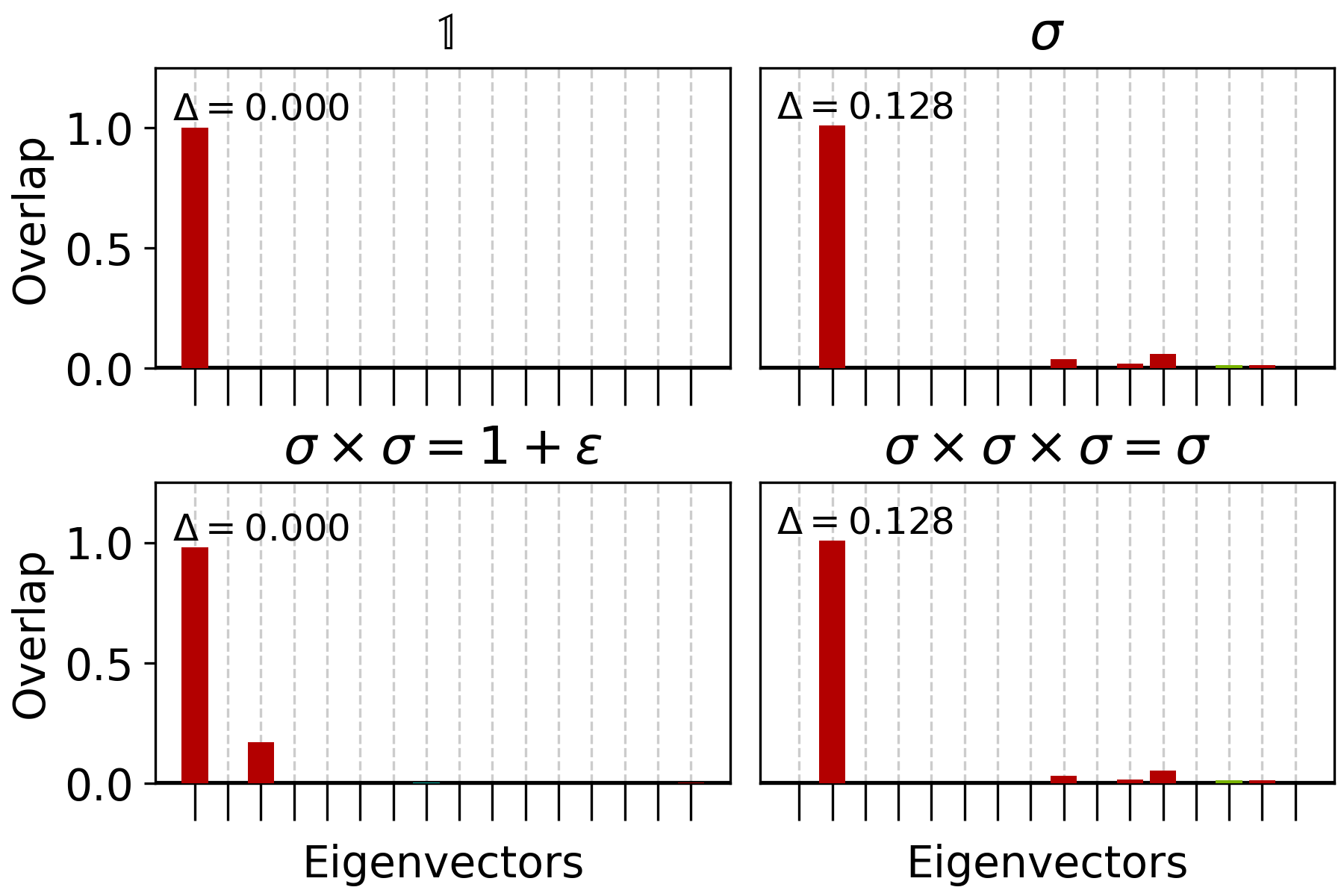
From there we observe that the coarse-grained vacuum tensor lies in the eigenspace with conformal dimension 0, which corresponds to the identity operator . The coarse-grained tensor with an insertion of one operator lies in the 0.125 conformal dimension eigenspace, which corresponds to the spin operator . However, as can be seen in Fig. 9, there are also significant projections on higher eigenvectors, which may be due to numerical errors and/or the operator insertion position not being exactly in the middle. Next, the coarse-grained tensor with two operator insertions lies in the joint subspace of and . This is consistent with the fusion rule of the Ising CFT: , where is the energy density operator with . Lastly, the coarse-grained tensor with three operator insertions further confirms the fusion rule and .
However, we note that there are also undesired projections on eigenspaces with . This is likely due to limitations in the numerical precision or to the fact that the eigenspaces are not strictly orthogonal. We also note that the above comparison is done in the subspace spanned by the first few eigenvectors of lTRG, in order to avoid the UV details from lattice implementation and the “junk” part [35] that corresponds to the higher indices of the tensor.
We further compare the higher eigenvectors with the conformal descendants obtained by finite-differencing the coarse-grained tensors with different operator insertion positions. The scheme is elaborated in Table 3. The procedure consists of inserting operators at different positions in the original lattice and then coarse-graining the resultant tensors. Finally, finite differences are taken between the coarse-grained tensors with operator insertions to obtain the lattice version of conformal descendants.
| Coarse-grained tensor | Inserted operator at lattice level | |
|---|---|---|
| 0 | ||
| 1/8 | ||
| 0,1 | ||
| 1/8 | ||
| 1+1/8 | ||
| 1+1/8 | ||
| 2 | ||
| 2 | ||
| 2 | ||
| 2 | ||
| 2+1/8 | ||
| 2+1/8 | ||
| 2+1/8 |
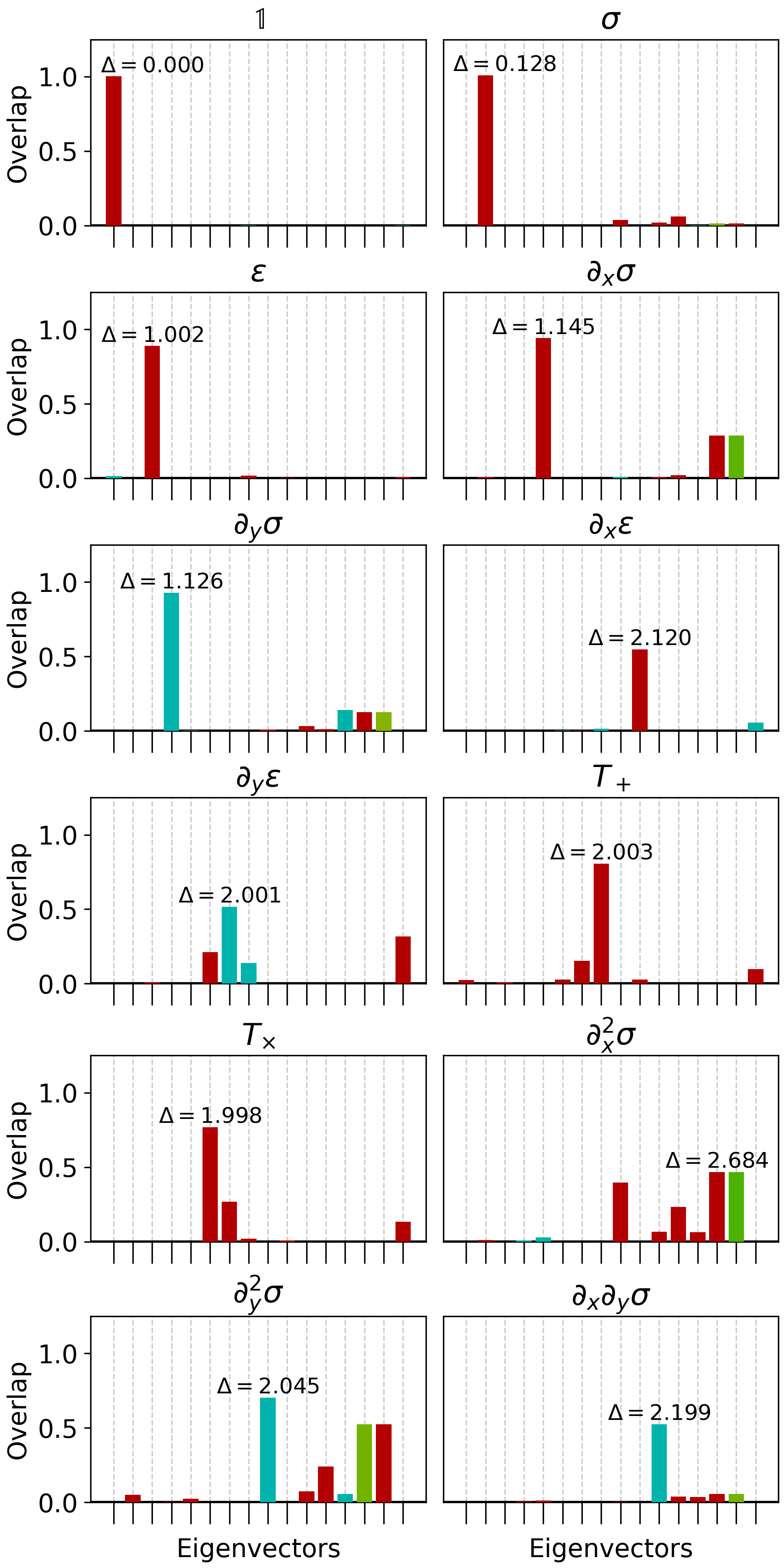
Figure 10 displays the projection of the conformal descendants realized in the lattice onto the eigenvectors of lTRG. We observe that and belong to a nearly degenerate 2-dimensional subspace with a conformal dimension of approximately 1.125. Similarly, the other descendants, such as , , , and have their maximal overlap near conformal dimension 2. Meanwhile, the descendants , , and appear near the subspace corresponding to .
However, we note that the order of the eigenvalues of the eigenvectors with the most significant overlap between and are not correct. The most significant overlap of is at 2.120, which shows a great discrepancy with the overlap of between 1.998 and 2.003. Moreover, the most significant overlaps of the next two operators, and , are at the scaling dimension 2.045, which is smaller than 2.120. So the order of the scaling dimensions of some operators is wrong, and operators at different degeneracy subspaces are being mixed up due to numerical error.
We also note that the pair , , and the pair , are not very distinguishable at the first few eigenvectors. This indicates that the information to distinguish those states is lost during the coarse-graining. This results in the unexpected behavior of in Fig. 11, which will be discussed in the next subsection.
III.8 Expansion of One-point Operators into the Conformal Family
Expansion on flat space. Another way to show that tensors such as and obtained from lTRG eigenvectors in the previous subsection have physical meaning just as their name suggests, i.e., one can check if the one-point tensor can be Taylor expanded into the conformal family as follows,
| (29) | ||||
We thus compute operators on both sides and compare whether the above expansion holds. Figure 11 shows the decomposition of onto the conformal tensors , , .
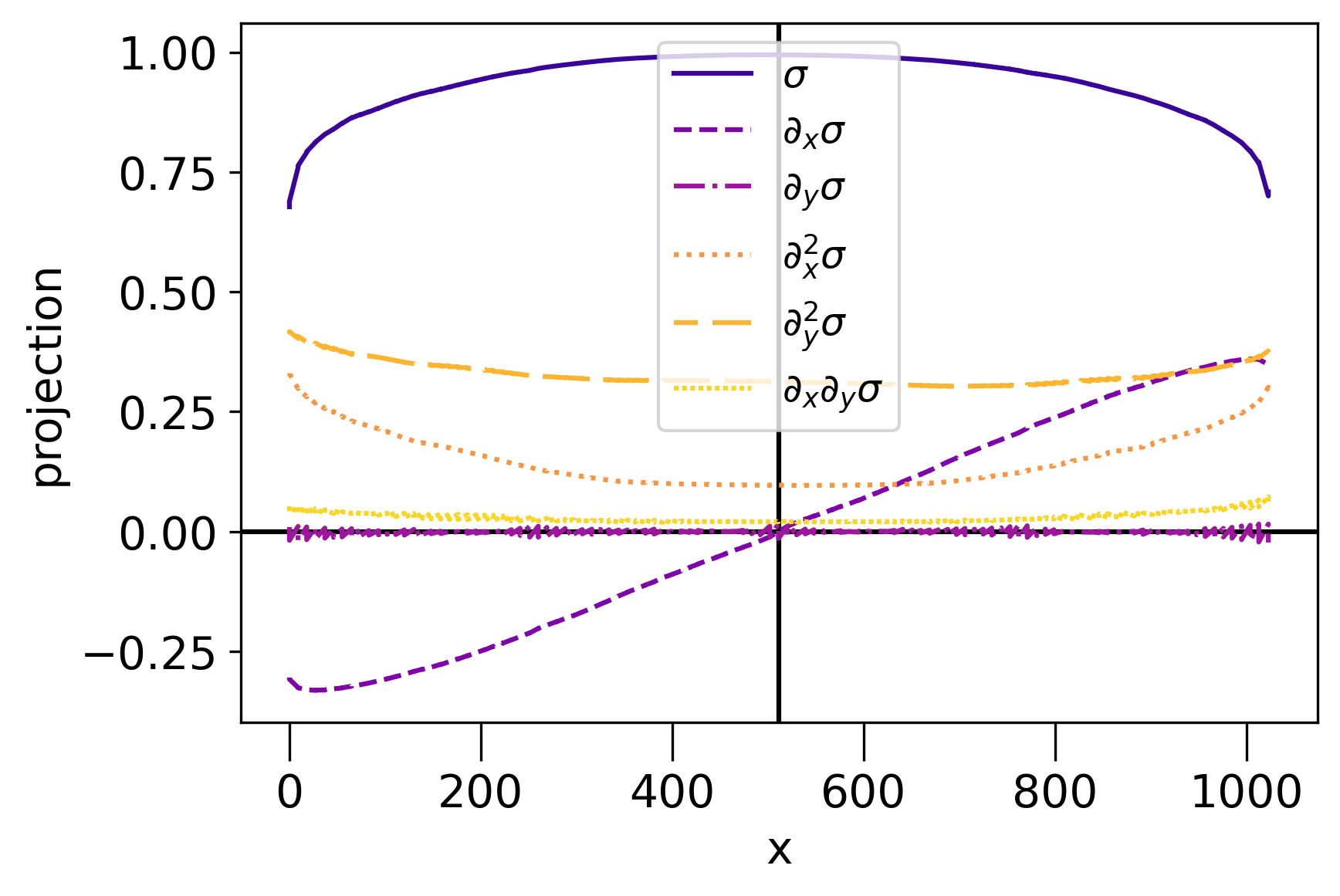
We see that, as the operator moves along the x-axis, its projection on changes linearly and its projection on changes quadratically. Also, its projection on remains almost constant, except near the edge. This confirms the Taylor expansion shown in Eq. (29). However, the unexpected behavior of projections in might be a result of a numerical error. From Fig. 10, one can see that the lattice tensors of and are not quite distinguishable from the projection onto the first few eigenvectors of lTRG. Therefore, one can conclude that the coarse-graining process erroneously removes the information that is crucial to distinguish the two operators. This results in the unexpected value in Fig. 10.
The suppression of near the edges of the coarse-grained block and may be the result that GILT artificially suppresses defects near the edges and corners of the coarse-grained block, which will be discussed in Sec. IV.8.
We do not directly compare with coarse-grained tensors , … It is because, as suggested by [35], the higher index components of the coarse-grained tensors, or equivalently, the subspace spanned by less significant eigenvectors, suffer substantially from the unphysical ‘noise’ of bond dimension truncation and numerical errors. So we only did the comparison in the subspace spanned by the most significant eigenvectors.
Expansion on a cylinder. In parallel with the eigenvalues of lTRG, it is well-known that scaling dimensions can also be extracted from the eigenvalues of the transfer matrix. In particular, we consider the periodic boundary condition where the transfer matrix is a chain of coarse-grained tensors:
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/552b4db7-1669-478a-8f2a-073406636178/x35.png)
|
(30) |
At the radial quantization, one would expect the following expansion,
| (31) |
where indicates omitting the coefficient at each term.
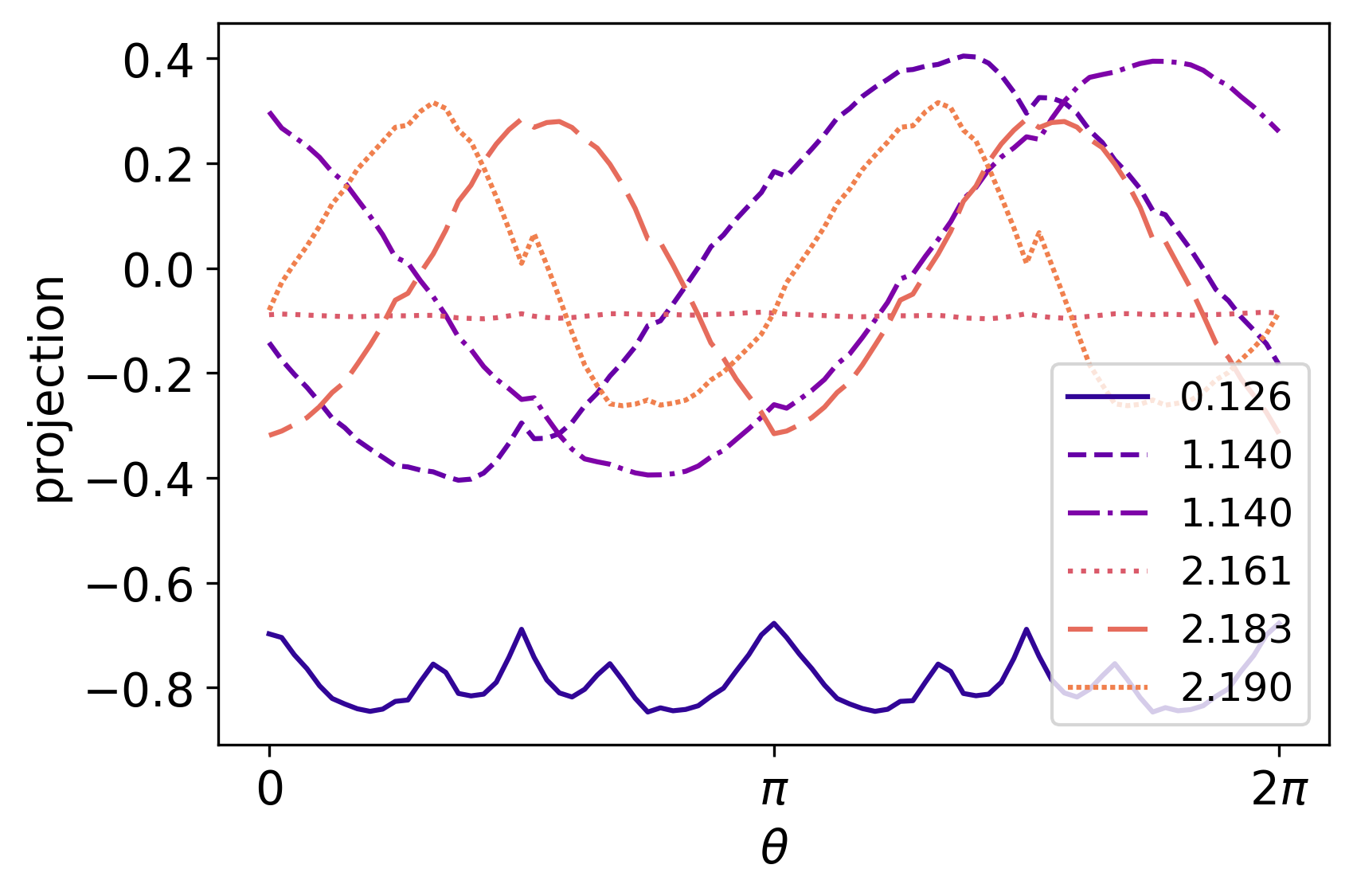
Figure 12 compares the eigenvectors of the transfer matrix Eq. (30) and the lattice state associated with the placement of a defect at . The lattice state is obtained by applying a chain of coarse-grained tensors (or ) to the ground state of the transfer matrix. The size of the coarse-grained block is . At , the defect is in the first tensor. At , the defect is in the second tensor.
In Fig. 12, one can see that the eigenvector of the scaling dimension , which corresponds to , is approximately constant in expansion Eq. (31); the eigenvectors of the scaling dimension , which correspond to and , have a sine and cosine coefficients in the expansion; similarly, eigenvectors associated with have coefficients , and , respectively. This observation confirms that, as in lTRG, the eigenvectors of the transfer matrix can also be seen as conformal states.
IV Further discussions
In this section, we evaluate the capabilities and limitations of our adopted coarse-graining scheme for tensor networks on a lattice with point-like defects, consisting of HOTRG coarse-graining, GILT local entanglement filtering, and MCF gauge fixing as outlined in Sec. II.7.
Initially, we focused on improving our numerical method without the presence of defects, as having a good vacuum tensor could facilitate further computations with defects. Following the work of [39], we have analyzed the change in the tensor components (see the result presented earlier in Fig. 3) and the scaling dimension spectrum (see Table 1). Here, our goal is to confirm the crucial role of GILT in achieving stable RG flow and show that the MCF gauge fixing method further enhances stability by showing the per-component tensor differences, the scaling dimension spectrum, and the central charge (extracted via the transfer matrix method) throughout the RG flow in Sec. IV.1.
We also demonstrate how GILT effectively suppresses the accumulation of the CDL tensor by comparing the transfer matrix spectrum between even and odd RG steps in Sec. IV.3. (Note that in our HOTRG procedure, we define each step of the RG as coarse-graining two tensors either horizontally to vertically, reducing the effective number of sites by half.) However, in Sec. IV.4, we show that even with the GILT truncation implemented, the error in the scaling dimensions from the transfer matrix spectrum and the lTRG spectrum continues to accumulate along the coarse grain flow. This eventually results in the system flowing away from the conformal fixed point.
With a good vacuum tensor at hand, a natural next step is to study the two-point function. However, our initial “on-paper” discussion in Sec. IV.5 suggests that GILT might introduce a significant error when calculating correlation functions with more than one defect point, compared to the vanilla HOTRG. Surprisingly, our actual numerical calculations in Sec. IV.6 show that GILT can achieve results in two-point functions as well as the vanilla HOTRG, as long as the two points are randomly sampled within the coarse graining region, and outliers are properly treated. However, if the points are located at the corner or edge of the coarse-graining region, GILT introduces a significantly larger error.
Further evidence shows that corners and edges are special places that can be seen in the two-point function on a torus, as discussed in Sec. IV.8. Only without GILT and when the two operators are located at the corners of the coarse-grained region can the two distantly separated defects give a strong correlation value when they are reunited after the region is wrapped around the torus, under the periodic boundary condition.
The above clue strongly suggests the smearing of point-like operators due to coarse graining, which is a consequence of removing short-distance details in traditional RG techniques. For a pair of smeared operators, when close to each other, they yield a much lower and smoother peak compared to their unsmeared counterparts. In the vanilla HOTRG, the modes at the edges and the corners experience less smearing, because of the algorithm’s preference for retaining more information about the CDL tensors. This explains why it produces a significant correlation function when two corner defects reunite after the region is wrapped around the torus. In contrast, GILT introduces some suppression of the boundary modes, which explains why it yields a much smaller correlation function when the two points are located on the boundary of the coarse-graining region.
Suppose that the smearing radius is correlated with the size of the coarse-graining block; when the operators are randomly sampled within the region, it is less likely for them to be within each other’s smearing radius. This results in a more reliable calculation of the correlation function.
To verify our conjecture, in Sec. IV.7, we compare the correlation function between points with different degrees of smearing. The more coarse grain two defect points have experienced before they fuse into one tensor, the more smearing we believe they have suffered. We find that the correlation for points at the same coarse-graining level before fusion aligns well with the smeared two-point function between two Gaussian profiles. The outlier in our data confirms our conjecture that GILT and non-GILT treat boundary modes differently.
We further investigated the relationship between the smearing radius and the size of the coarse-graining blocks. Unfortunately, we find that the smearing radius grows faster than the size of the coarse-graining blocks. This implies that as the coarse-graining process continues, the smearing radius eventually overtakes the block size, leading to an increasing loss of information in the correlation functions.
In summary, we conclude that it is possible to evaluate -point functions using HOTRG+GILT. To avoid the issue of operator smearing, it is necessary to sample the points randomly in the bulk, avoid the edges and corners of the coarse-grained regions, and filter out the outliers, e.g., using Huber loss. GILT introduces some artificial suppression for operators at the boundary, but this minor flaw can be ameliorated as discussed above and is compensated by the method’s ability to stabilize the RG flow and facilitate the extraction of the fixed-point tensor.
IV.1 Improved Stability of RG Flow with GILT and MCF
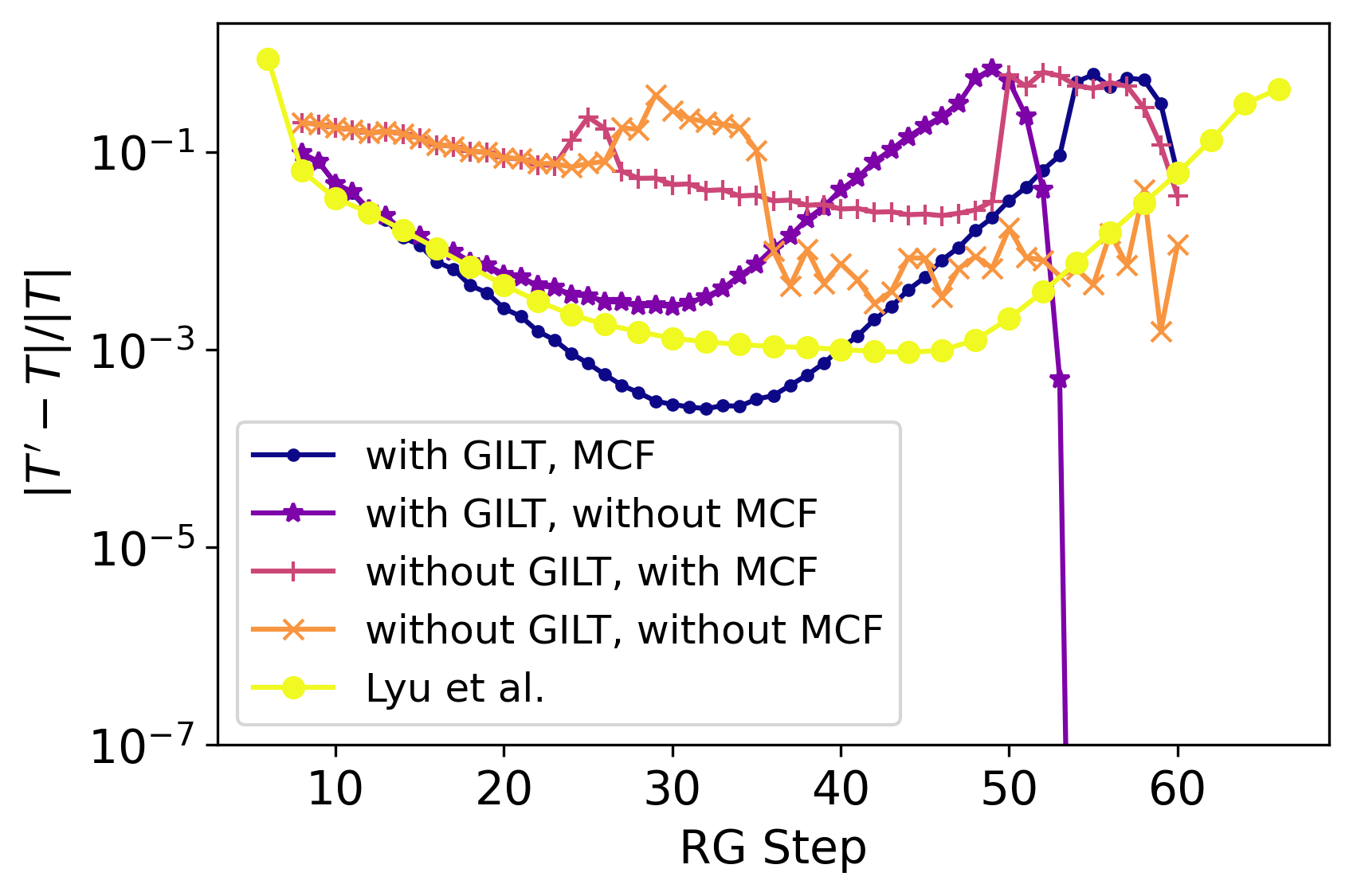
The use of GILT, as discussed in Ref. [37] and briefly reviewed in Sec. II.4, is critical to ensure the stability of the RG flow. As shown in Fig. 13, GILT enables the coarse-grained tensor to converge to a fixed point tensor, with the change in coarse-grained tensors decreasing exponentially after each RG iteration. On the contrary, without GILT, the change in coarse-grained tensors remains constant, indicating either continued system evolution during the RG steps or the failure of the gauge-fixing procedure due to degeneracy in spectrum decomposition (see App. F). The use of MCF furthermore increases stability. As shown in Fig. 13, with GILT and without MCF, the stability of our RG flow is comparable to Ref. [39]. With the introduction of MCF, the stability of our RG flow has improved further.
Figure 14 illustrates the scaling dimensions and central charge extracted from the spectrum of the transfer matrix of the coarse-grained tensors. The method is described in App. E. With GILT, the scaling dimensions and the central charge remain consistent throughout most of the RG flow. In contrast, without GILT, information about the scaling dimension is lost at the beginning of the coarse-graining process, and the central charge is less stable during the flow.
IV.2 Finite Size Effect
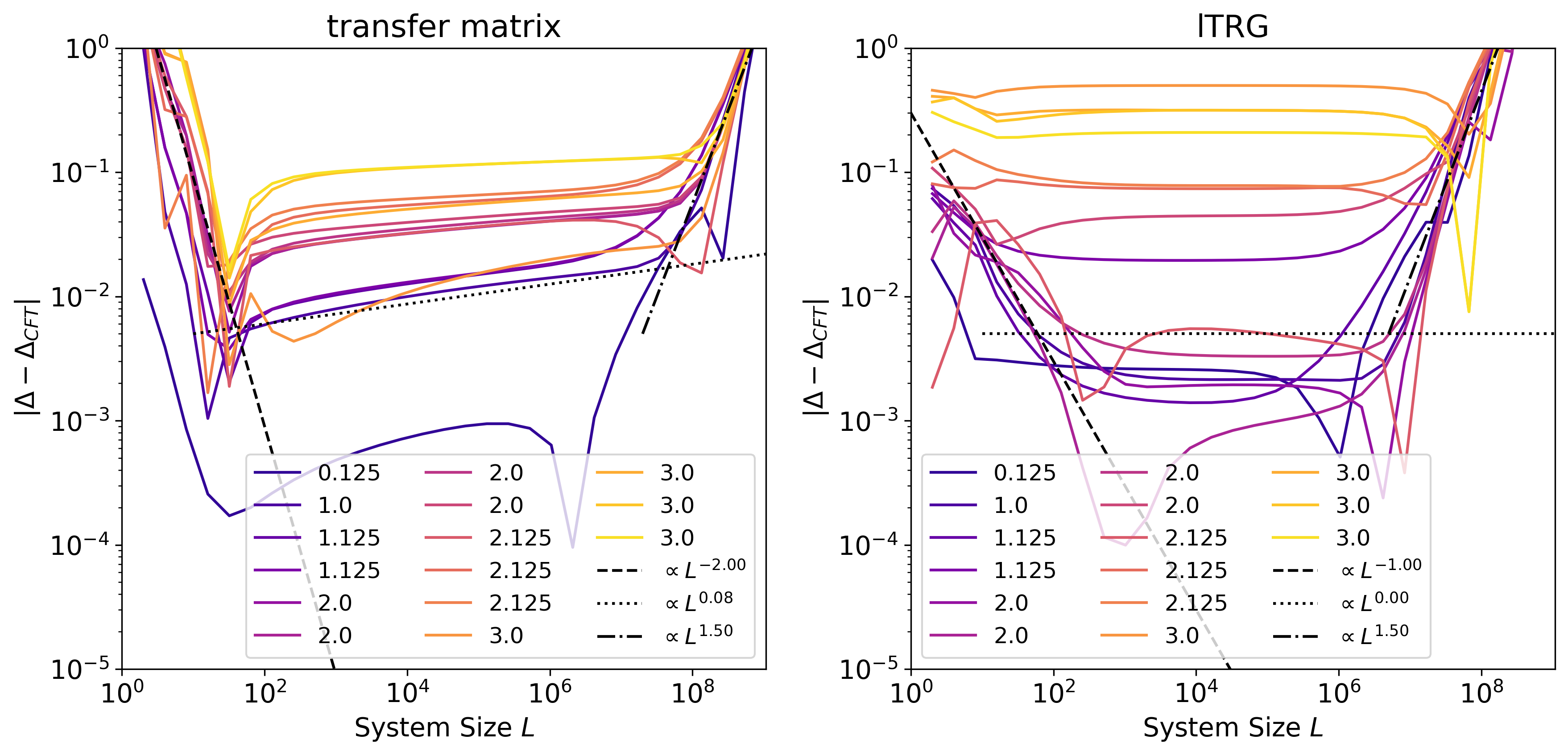
At the critical point, but with a finite-size lattice, the extracted scaling dimension is subject to both finite-size and finite-bond-dimension effects, as depicted in Fig. 15. At the beginning of the RG flow, the shift in the scaling dimension , as estimated from the transfer matrix, scales proportionally to , where is the size of the system. This behavior aligns with the expectations for the finite-size effect, as discussed in Ref. [49]. However, the shift estimated from the lTRG method is .
During the RG flow, when the system reaches a relatively stable state in the “valley”, the shifts obtained from both the transfer matrix and the lTRG method exhibit a scaling behavior of and , respectively. As the system deviates from the RG fixed point, both methods produce shifts that scale as .
In contrast to the findings in Ref. [49], our observations do not reveal the emergence of perturbations such as (scaling as ) and (scaling as ) at larger length scales due to finite- effects. This discrepancy may be attributed to the difference that Ref. [49] employed the Loop-TNR method, whereas we utilized the HOTRG+GILT scheme.
IV.3 Removal of CDL Tensors
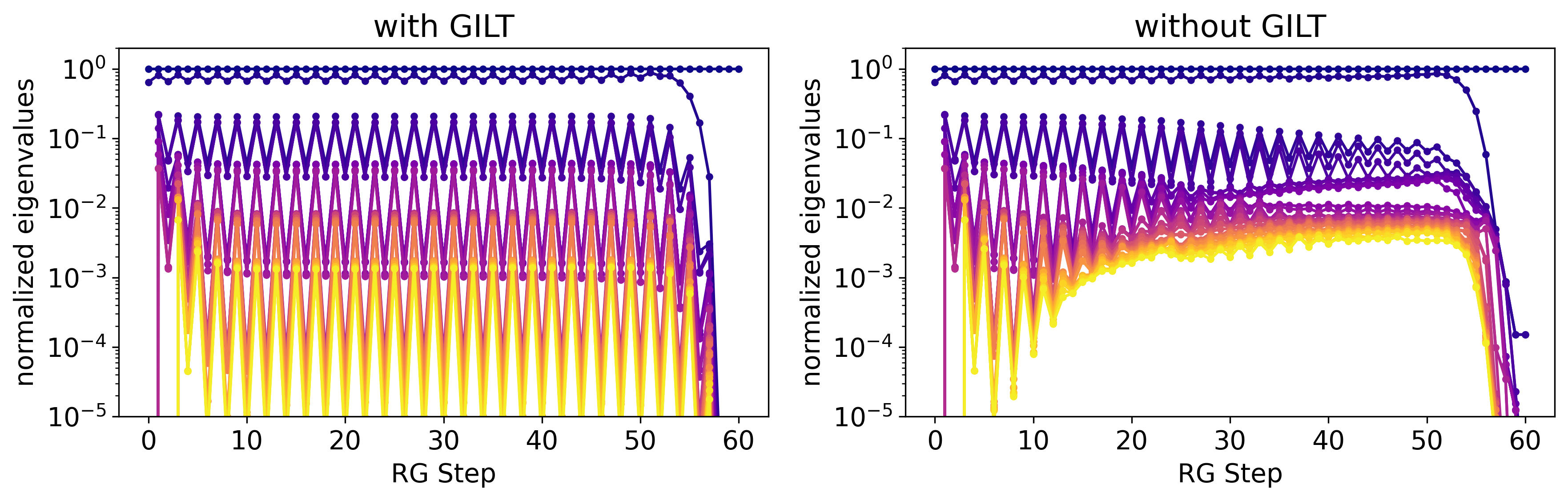
As suggested in Ref. [37], the accumulating error during coarse graining without GILT may be due to the accumulation of CDL tensors during the RG process (i.e., after vertical and horizontal graining steps, respectively), which consume all the bond-dimension resources at the end. To investigate this, we compare the spectrum of the transfer matrix between even and odd RG steps, normalized by the largest eigenvalue . At odd RG steps, the coarse-grained region of each tensor is a 2:1 rectangle compared to the square at even RG steps. Therefore, we expect near the fixed point. However, for the fixed point of the CDL tensor network, we expect . Figure 16 shows the oscillation of the eigenvalues of the transfer matrix between odd and even RG steps. Without GILT, the oscillation decays during the coarse-graining process, indicating that the tensor network behaves more like CDL tensors after coarse-graining. This result confirms the capability of GILT to remove CDL tensors.
IV.4 Accumulation of Error from Truncations
The scaling dimensions error obtained from the transfer matrix and from the lTRG method is summarized in Fig. 17. The error in the transfer matrix spectrum increases monotonically because, in principle, one can extract the precise scaling dimension from the initial tensor before coarse-graining if the chain length is infinitely long. Thus, when the chain length is long enough to suppress finite-size effects, the only source of error is the truncation error after each RG step, which accumulates throughout the RG flow. This accumulation starts far before the system reaches its proximity to the conformal fixed point (around step 30).
However, the error in the linearized Tensor Renormalization Group generally improves as the system approaches the conformal fixed point. This improvement is due to the scaling invariance on which the lTRG equation is based, which emerges at the continuous limit. Thus, as the system becomes more conformal, the lTRG method becomes more accurate, leading to a reduced error in the calculated scaling dimensions.
In Fig. 3, one can see that at approximately the critical temperature, the coarse-grained tensor will still flow away from the fixed point tensor. This can be due to floating-point errors or to the imprecision of the critical temperature we found. Note that due to the finite dimension of the bonds, we do not just use the exact value but optimize the temperature using the method described in Ref. [39] to find the corresponding effective . We also want to emphasize that the truncation from HOTRG and GILT introduces an artificial length scale that breaks conformal symmetry. This might be the reason for the instability of the critical fixed-point tensor and the shift of the critical temperature.
IV.5 Theoretical Insufficiency of HOTRG and GILT in Coarse-graining the Lattice with Defects
Most prior use cases in HOTRG and GILT have focused on translational invariant tensor networks, where the same tensor is placed at all the lattice sites. These studies typically consider the partition function/free energy without any defects/impurity operators inserted. The coarse-graining tensor network, with insertions , , and , can be seen as a tree-like tensor network ansatz that tries to approximate the ground-state wavefunction (, are omitted) or the partition function:
| (32) |
In this section, we discuss how the vanilla HOTRG and HOTRG+GILT may respond if we replace certain tensors in the MERA-like coarse-graining scheme with defect tensors, i.e., we change a few of the tensors in Eq. (32) to defect tensors such as , but keep the , , invariant. HOTRG can produce good fidelity of one-point functions as long as the bond dimension is sufficiently large for the fidelity of the ‘vacuum’ partition function (or free energy). Note that the HOTRG equation Eq. (7) holds if both and are vacuum tensors. Therefore, the environment of a defect tensor , which is the contraction of the tensor network with removed and only contains vacuum tensors, can be faithfully computed using the HOTRG coarse grain method.
What about two-point functions and higher? The environment can still be obtained from coarse-graining the remaining vacuum tensor. The source of error comes from the insertion of between two coarse-grained defect tensors. Note that only one side of is connected to a vacuum tensor, sufficient for the HOTRG equation to hold.
The GILT equation Eq. (9) holds only when the tensors in the subnetwork Eq. (9) are all vacuum tensors. One may ask whether the Hilbert space that GILT truncates is the subspace corresponding to the defect tensors. This conjecture is supported by the results shown in Fig. 21 showing that HOTRG + GILT gives a lower estimation of the two-point correlation function.
In calculating the two-point function, the HOTRG equation only fails when the two coarse-grained defects meet each other in the coarse-graining. On the contrary, the GILT equation introduces some errors at each coarse-grained level. This suggests that GILT introduces more errors in two-point functions. This is consistent with what we have observed. Nevertheless, we will demonstrate that it is still possible to make HOTRG+GILT yield as good results as the vanilla HOTRG for correlation functions.
IV.6 Comparison of Two-point Correlation Functions with and without GILT
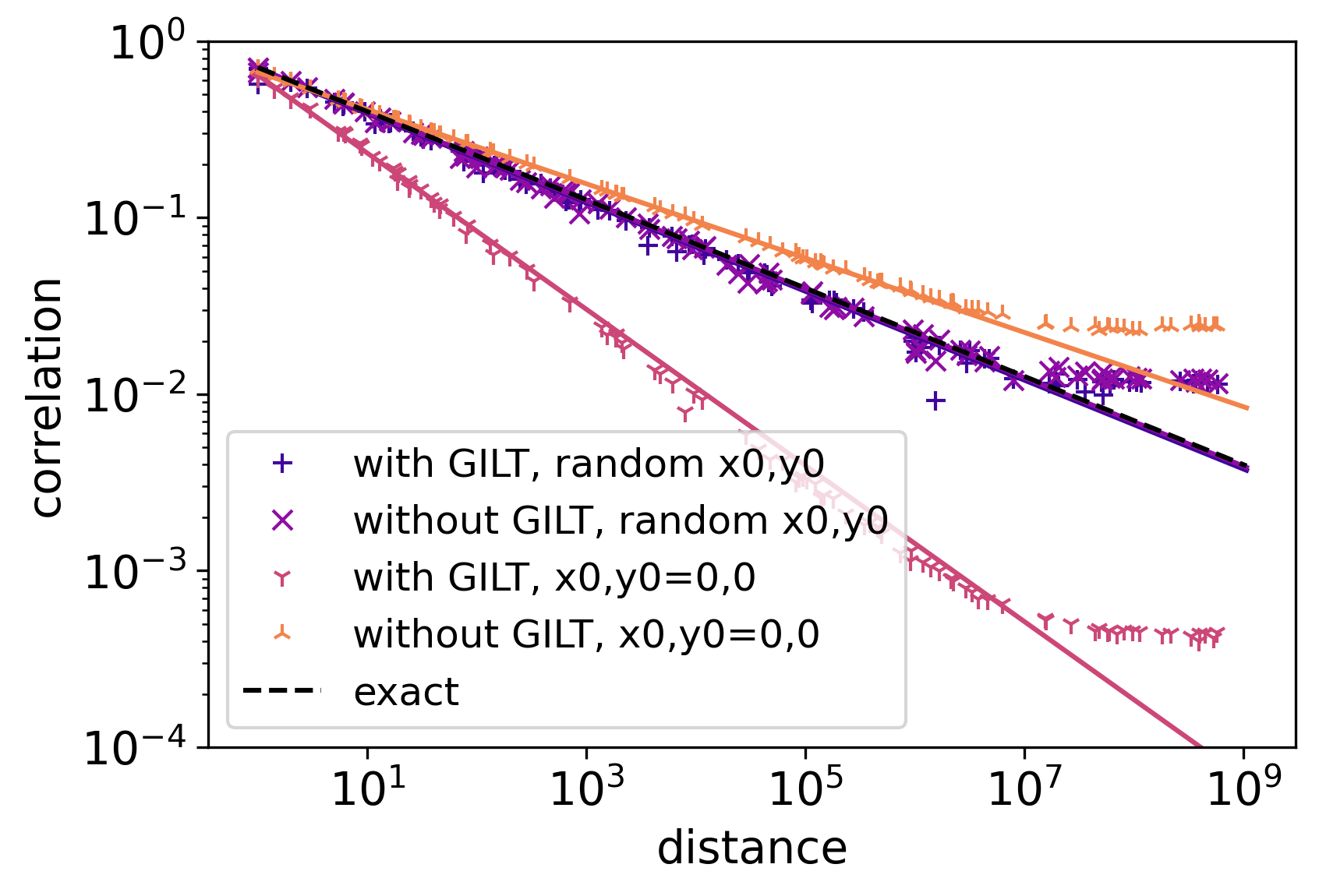
Figure 18 shows the two-point correlation function calculated by different methods. When GILT is used, the correlator gives the wrong scaling dimension when one of the defects is localized at a corner of the coarse-grained block. The reason seems to be that the corner modes are artificially suppressed by GILT, as discussed in Sec. IV.8.
The overall best results are given when GILT is used, but the correlation function is averaged over the positions of the defects. GILT gives a more reliable vacuum tensor, and the averaging helps to avoid corners of coarse-grained blocks at various levels. We used this strategy for the earlier part of our results.
IV.7 Smearing of Point Defects
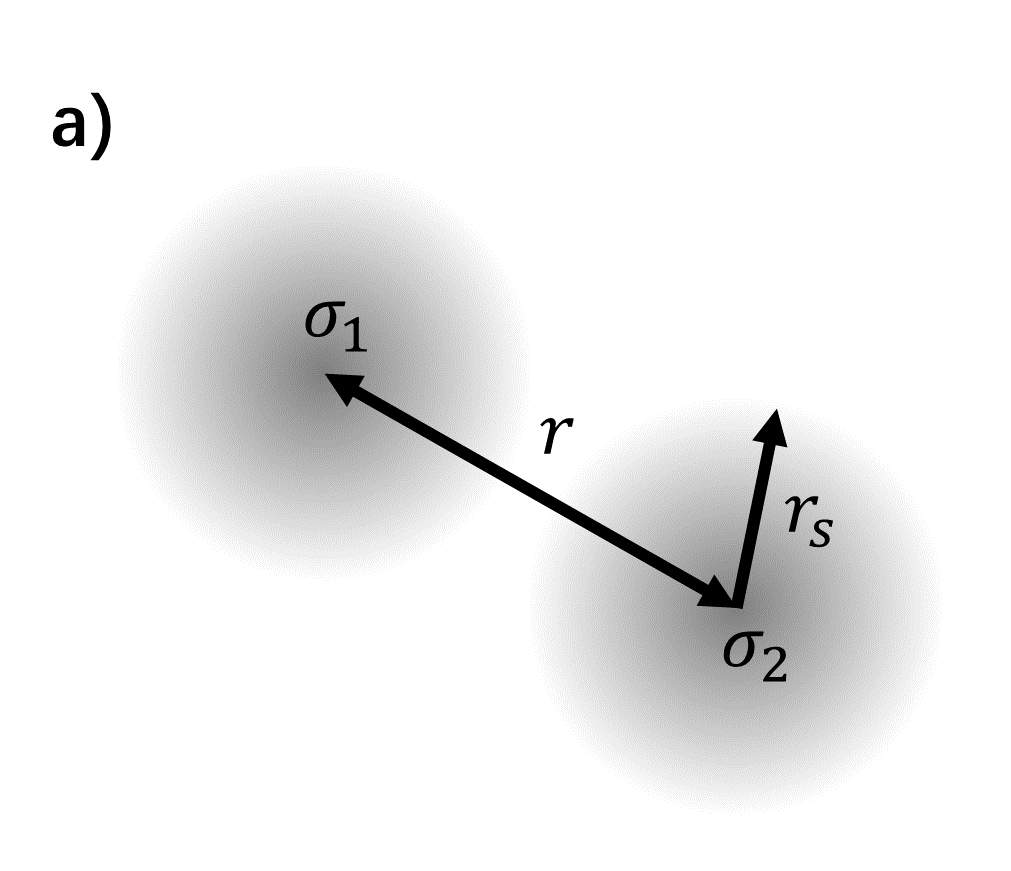
In the coarse-graining process, a point-like defect is expected to be “smeared” into a “particle cloud”. When the two smeared defects move toward each other, one might expect a regularized two-point correlation function, with a smoother, lower peak compared to the correlation function between two “bare” defects. Eq. (33) below shows a type of regularized two-point function, where the point-like defect is replaced by a Gaussian profile Eq. (34), as illustrated in Fig. 19. In the log-log graph, Eq. (33) features a flat line, which indicates the smeared tip of the correlation function, followed by a negative slope, which indicates the unsmeared part of the correlation function, which follows the power law Eq. (35),
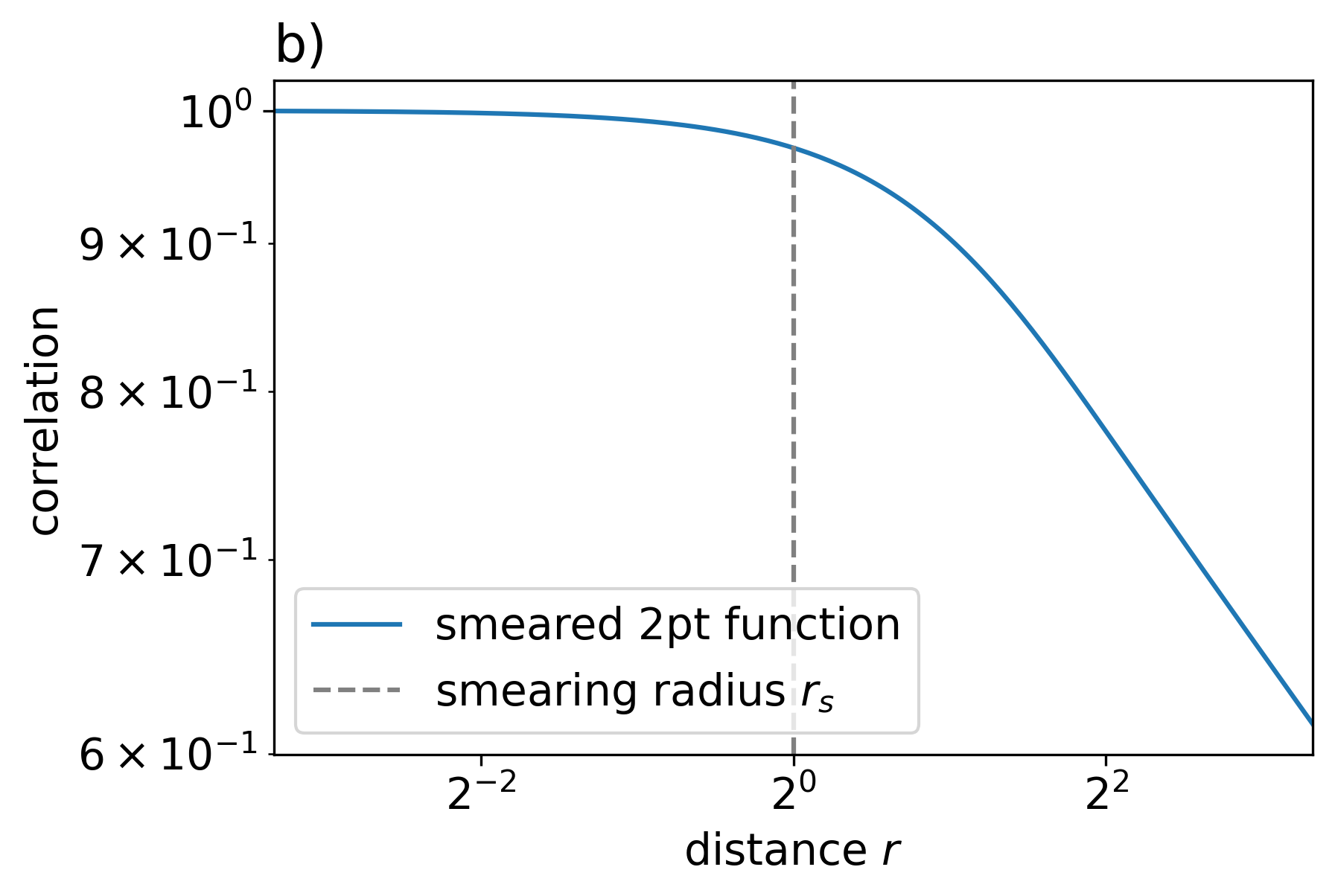
| (33) | ||||
| (34) |
| (35) |
In HOTRG, the fusion of two defects occurs when two coarse-grained tensors, each with one defect in its region, are coarse-grained into a larger tensor. As illustrated in Fig. 20, the two point defects and meets in a block at level . Naturally, one would expect that the amount of smearing that the two defects suffer is related to the block size of the largest coarse-grained tensor before the two defects meet.
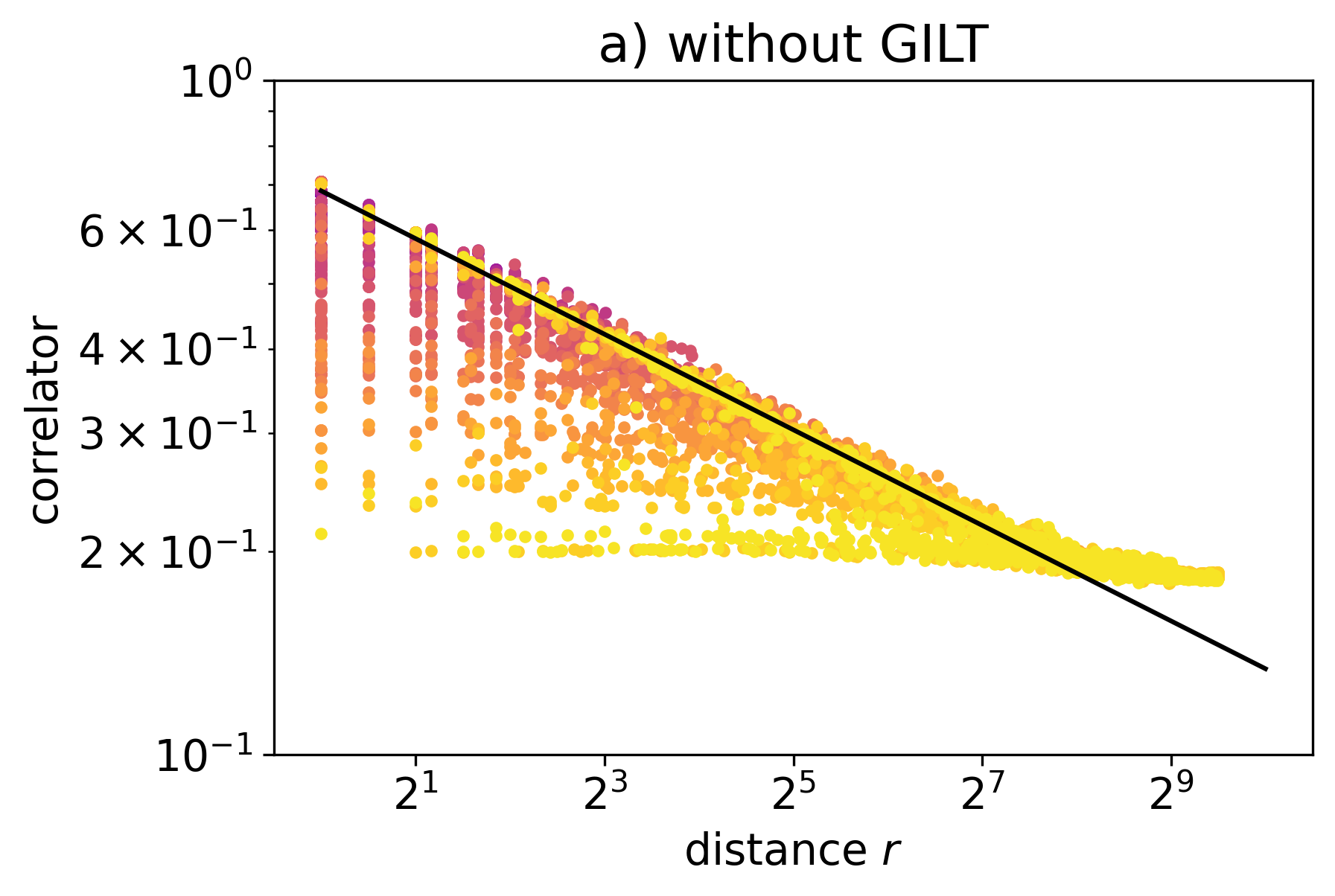
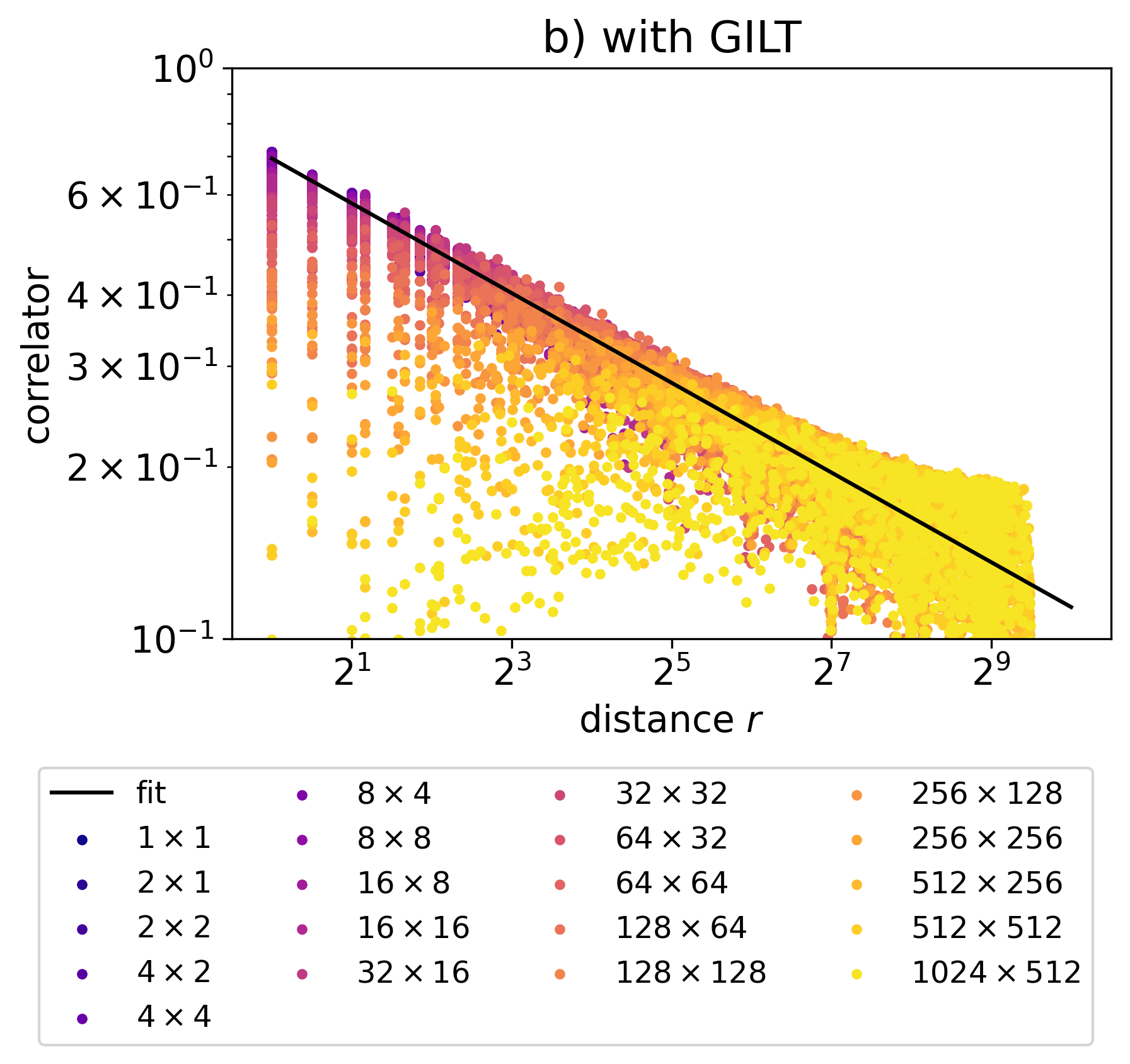
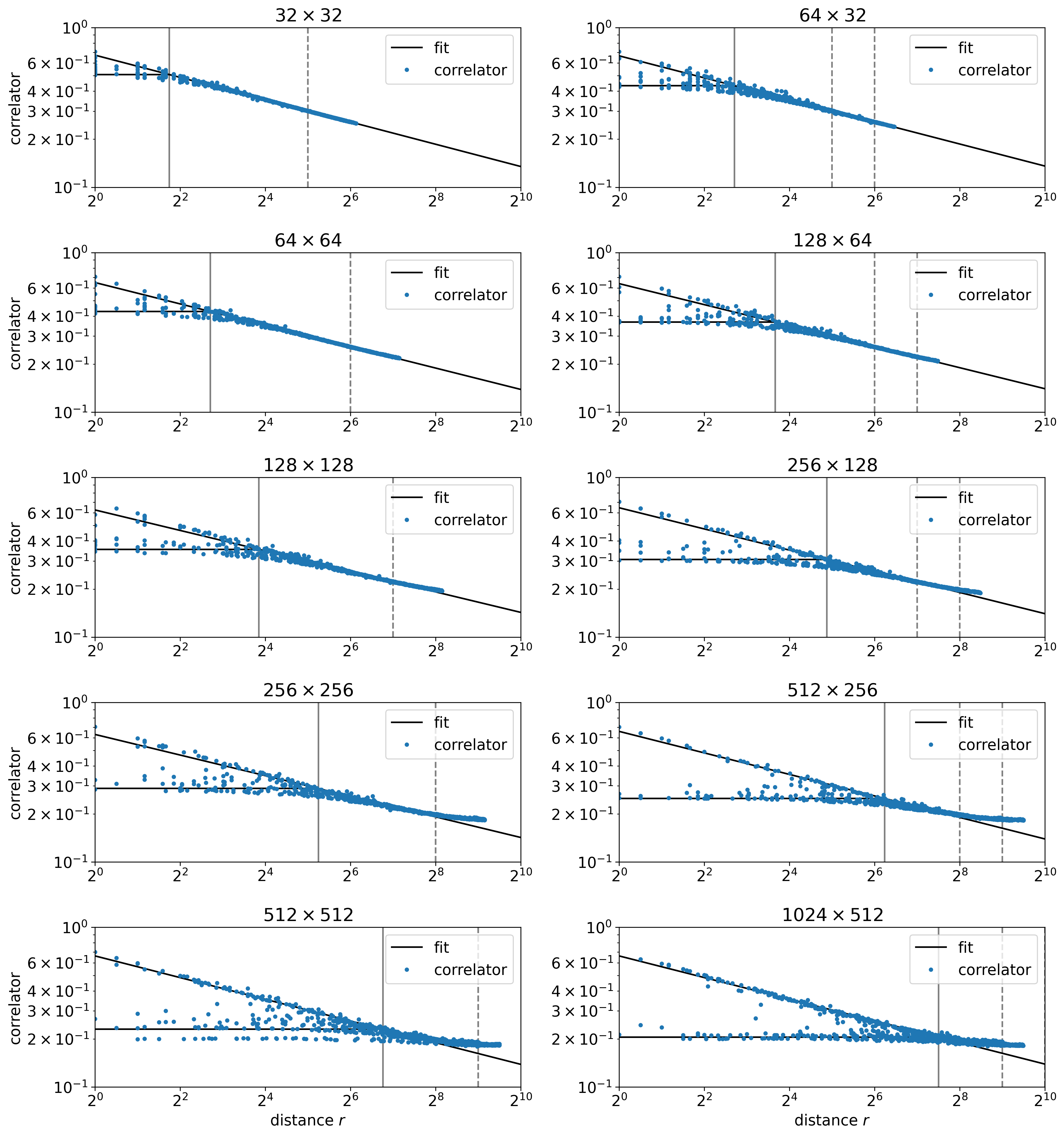
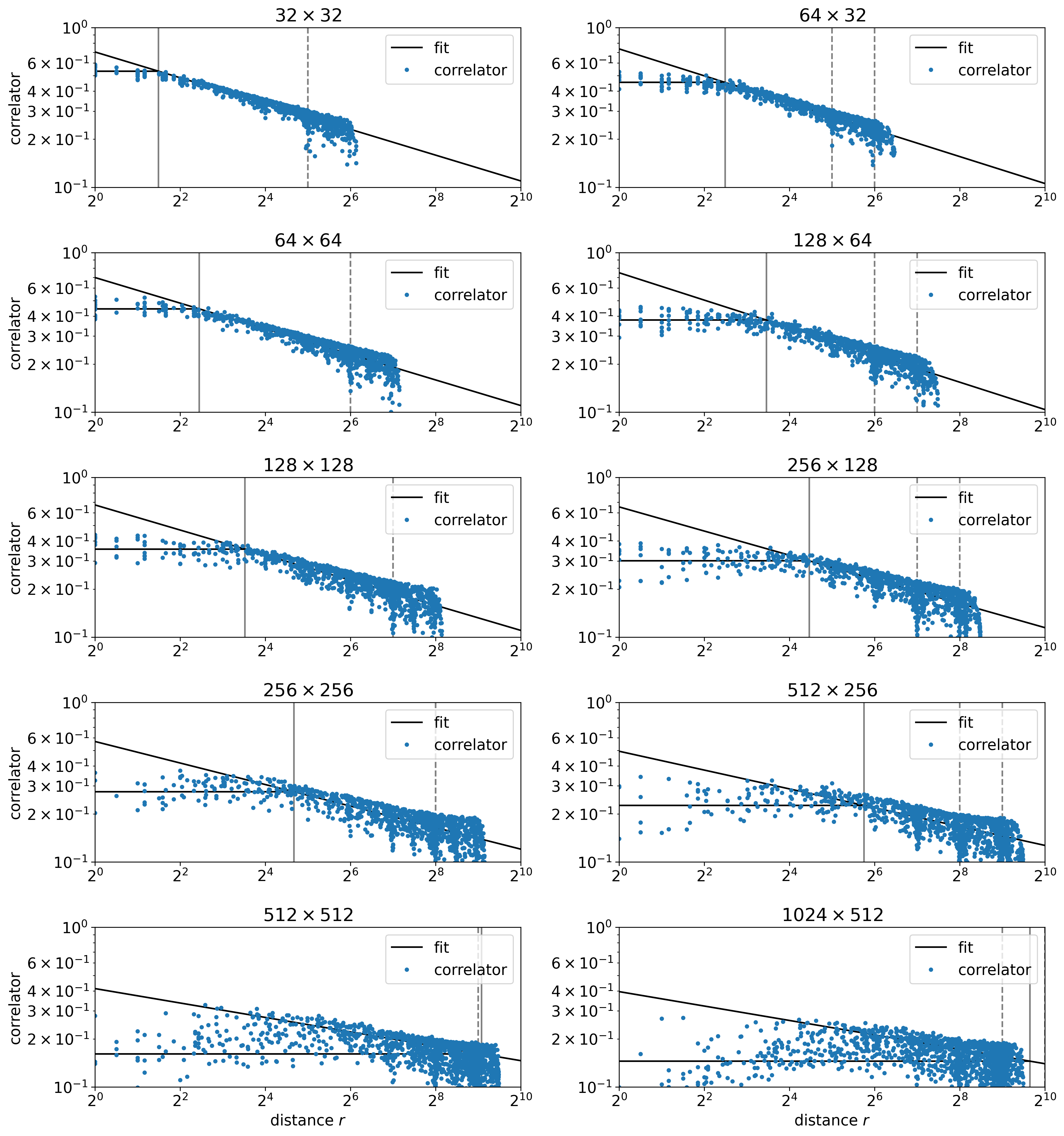
Figure 21 illustrates how the size of the coarse-grained block, , just before two defects fuse, regulates the short-distance behavior of the two-point correlators. The color indicates the size of the biggest block before the two defects are fused into one block. The black line is fitted at the log2-log2 scale by a one-sided Huber loss with for with respective fitted scaling dimensions and . The points are sampled with a fine-tuned probability distribution that prioritizes the outliers below the main trend to illustrate the smearing effect.
As mentioned earlier, the size of the coarse-grained block implies the amount of regularization that the two-point correlator suffers. For correlators with the same separation , the larger the coarse-grained block, the lower the regularized correlator. Also note that the amount of smearing is determined not only by the size of the block but also by the relative position of a defect inside a block, which has not been examined carefully yet.
Figures 22 and 23 further demonstrate the trend of the smeared correlation function for a given coarse grain size . There are two main trends in the data. On the log-log plot, the first one is a straight line with a negative slope, implying the unsmeared exact correlation function. The second trend is a flat line, indicating the smeared two-point function. Together, the two trends confirm the smearing picture described in Eq. (33). Note that there are also data scattered between the two trends, as we have already seen in Fig. 21.
The first trend resembles the exact, unsmeared correlation function. In Fig. 21, the first trend of data with various block sizes almost overlaps with each other, showing consistency between different levels of coarse graining. It might indicate that certain pairs of defects do not suffer from smearing or that the smearing radius is much smaller than the separation .
The second trend resembles the smeared correlation function, which is a flat line that clipped the tip of the first trend at short distances. The flat line indicates that the correlation function is almost invariant when the separation of the smearing operator changes. It might be explained by the picture that the separation is less than the smearing radius . The smearing radius is estimated by the intersection of the first and the second trend.
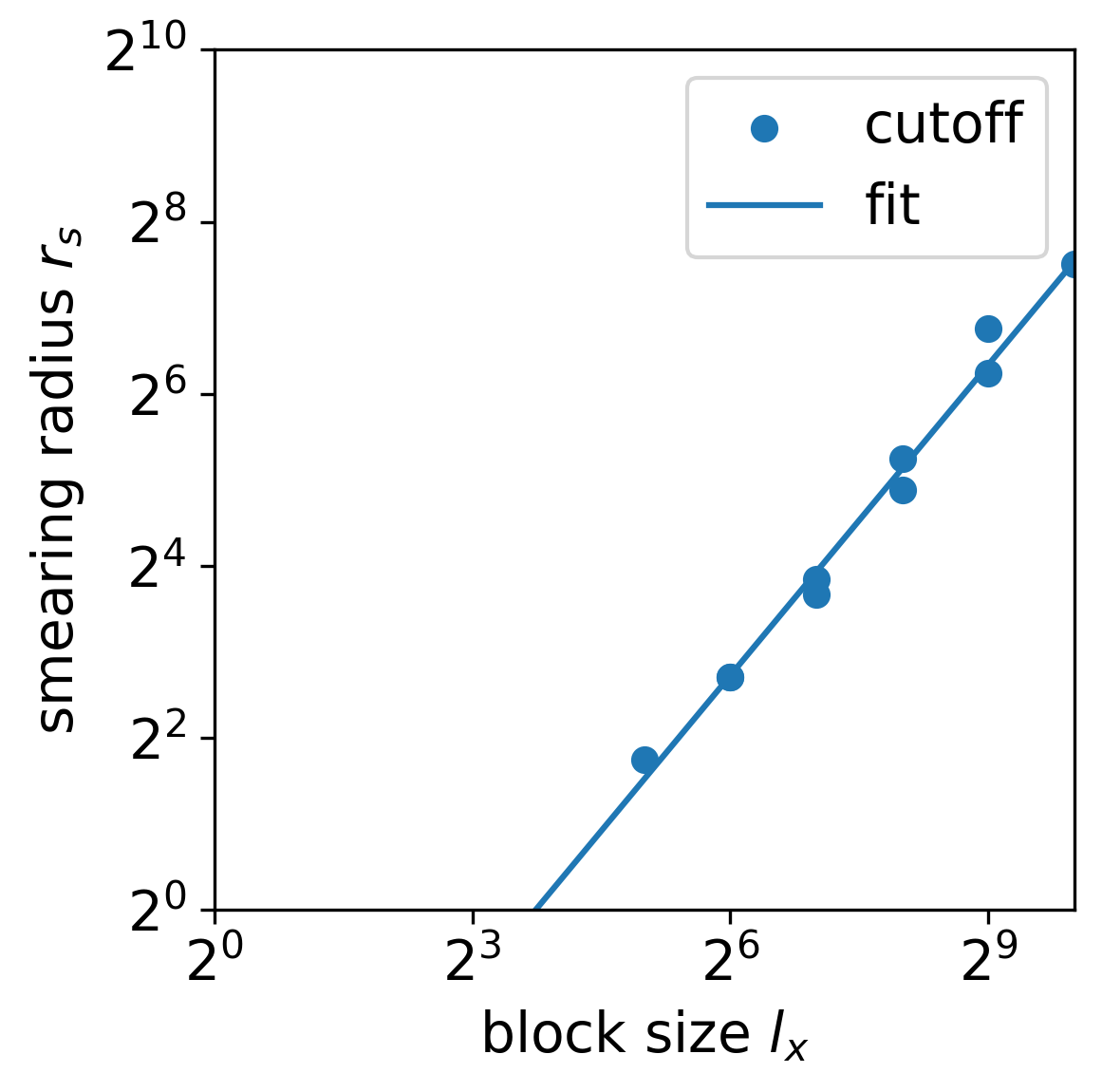
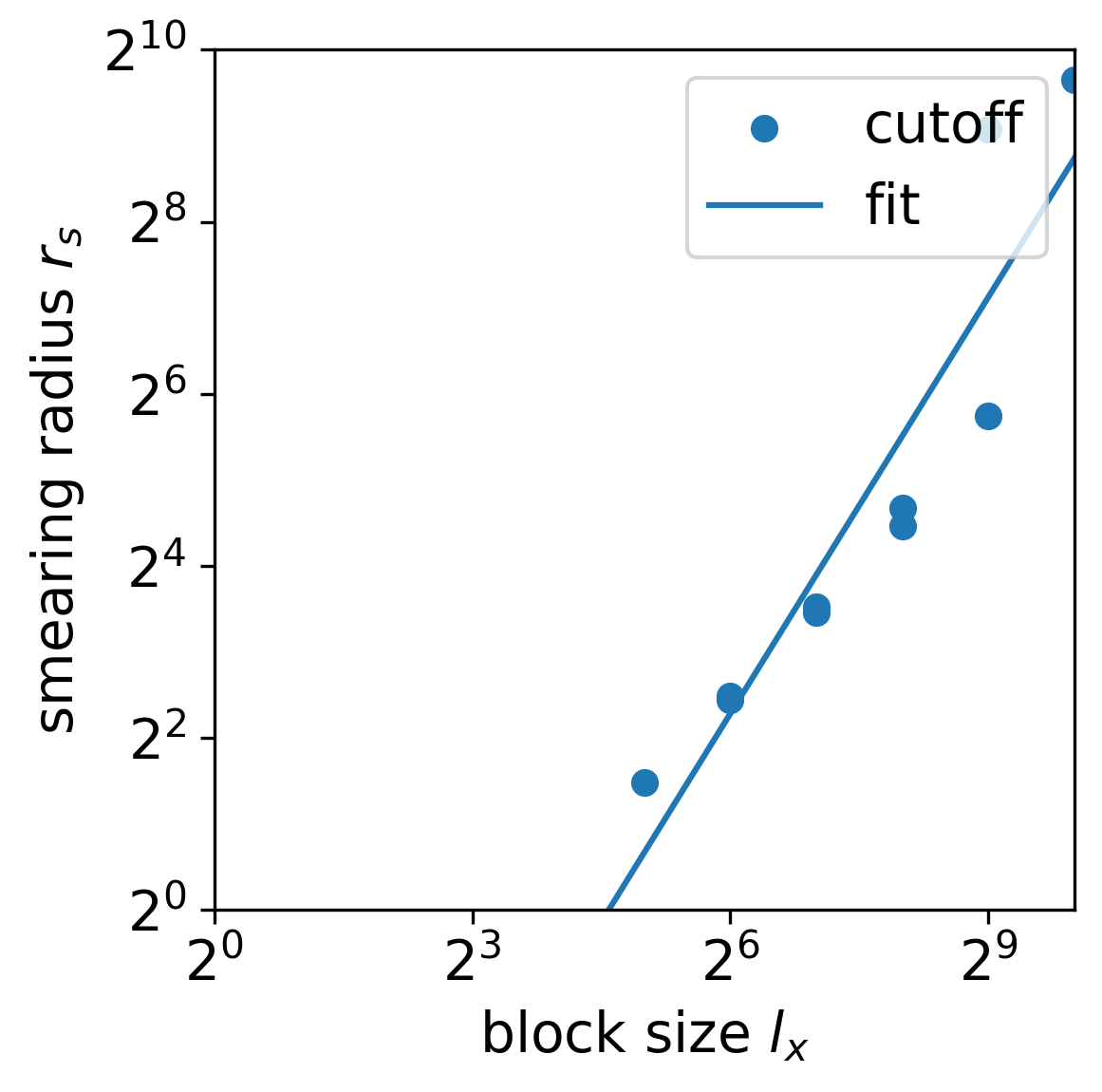
The smearing radius increases with the increase of the coarse grain block size () before two defect tenors merge, as shown in Fig. 24 and Fig. 25. However, the smearing radius grows faster than the growth of the block size: , with and . This indicates that as the coarse-graining iteration proceeds, the smearing radius will catch up with the lattice size and may result in errors in further coarse-graining.
Now, we compare the cases with and without GILT. When GILT is applied, most of the short-distance correlation points on the first (unsmeared) trend are moved to the second (smeared) trend. This means that GILT successfully removes most of the short-distance details of the system, compared to the case without GILT. However, at the long-distance end, the data without GILT follow more precisely to the fitted line, while the data with GILT have a more significant error with a much lower value. This means that GILT also removes some of the information on the long-range behavior of the defects.
The data analysis in this subsection confirms that the defect is smeared after coarse graining. Without GILT, defects in certain places might not be smeared as much. With GILT, most defects are smeared to approximately the same degree, but GILT also substantially removes some of the long-range information about the defects, resulting in an error that lowers the calculated two-point function value.
We also find the positioning of the defects plays a crucial role in determining whether the defects are being missed from smearing in the non-GILT case, and the defects are being over-suppressed in the GILT case. There is a sign that the corner of the largest unfused block is the aforementioned special place, but further numerical evidence is required to support this conjecture.
Finally, we provide an explanation for why naive averaging in different places when sampling the two-point function in Fig. 5 yields the best result for the scaling dimension when GILT is used. As shown in Fig. 23, to obtain the unsmeared two-point function, we require . When points are randomly sampled, it is most likely that the size of the largest block before merging is comparable to the distance between the two points and . The only situation where is when is located at the corner or edge of the largest unfused block, which is a very unlikely scenario. Thus, in Fig. 23, we intentionally increase the probability that is inside the smearing radius, so we can observe the reduction in correlation function due to smearing, and the fitted scaling dimension has a larger error.
However, in Fig. 5, when the points are randomly sampled, most of them satisfy , which guarantees that smearing occurs only on a shorter scale compared to , thus ensuring the correctness of the two-point function. Therefore, the naive averaging over different places yields the best scaling dimension result in this case.
IV.8 Removal of Localized Edge Modes
When GILT is not applied, the dominance of the CDL tensor suggests that the truncated Hilbert space of the coarse-grained tensor mainly captures the exciting modes near the boundaries and corners of the coarse-grained block. This can be shown from the observation that there is no smearing at the corner of the coarse-grained block when GILT is turned off.
In particular, we compare the torus correlation function at and . As shown in Fig. 27, the correlator at is evaluated by contracting opposite edges of a block. So, the largest coarse-grained block containing a single defect is of size . One would expect a very large smearing effect, resulting in a vanishing peak at . However, Fig. 26 shows that the peak at is as sharp as the bare correlation function evaluated at smaller scales at , in the case where GILT is not used and the two defects are localized at the corner of the block.
It suggests that the defect is not smeared after the coarse-graining iterations. In other words, the truncated Hilbert space contains point-like excitations at the corners of the block. To further verify it, we plot the height of the peak when moves from the corner to the midpoint of the block edge. As shown in Fig. 28c,d, the smearing effect is stronger when the two defects are on the midpoint of the opposite edges. Given the finiteness of the dimension of the truncated Hilbert space, it suggests that the defects are smeared into a one-dimensional “cloud” along the edge.
In the case of GILT, one would expect that the edge modes are being suppressed, and there is no peak at , as confirmed in Fig. 28a,b. Note that there are some inconsistencies in the correlation function when the defects are located in the corners. It suggests that GILT introduces some artificial suppression for corner excitation.
V Conclusion
In this work, we have integrated the MCF gauge-fixing method [41], with the tensor renormalization scheme [39] that combines the local entanglement filtering method GILT [37] and the HOTRG coarse graining method [33]. The combined method enhances the stability of the RG flow, which is manifested visually in the space of the tensor components. Additionally, we have demonstrated the detection of CDL-like effects from the oscillation of the transfer matrix spectrum between horizontal and vertical coarse-graining steps.
Following [39], we have calculated the scaling dimensions for conformal states with in the critical square lattice Ising model using two different methods: the transfer matrix spectrum [36] and the lTRG approach [39]. Both methods agree well with the analytical results. We have also calculated the OPE coefficient from lTRG and its eigenvectors.
Important quantities to calculate in TN include correlation functions. We have computed the two-point spin-spin correlation function for the square-lattice Ising model at temperatures near the critical point (at, above, and below). The extracted exponent is in good agreement with the scaling dimension. We have also examined the correlation function on a finite-size torus and obtained results consistent with analytical results. In addition, we have also computed four-point correlation functions, and from those we were able to extract the scaling dimensions and the OPE coefficient, although the quality was not as good as other approaches we have used.
We have extended the use of lTRG beyond the computation of scaling dimensions and compared the eigenvectors of the lTRG fixed point equation with coarse-grained defect tensors, discovering that inserting operators on the lattice allows for the construction of conformal states/operators, which corroborate well with those obtained from lTRG. We have also found that the position of the inserted operator is reflected in its decomposition onto the conformal states numerically.
Our work has explored the effects of coarse-graining (HOTRG) and local entanglement filtering (GILT) on lattice defects/impurities. We have observed that point-like defects become “smeared” into “particle clouds” after coarse graining and that the degree of smearing varies depending on the position of the defect in the coarse graining region, particularly when it is located at the corner or edge of the region. GILT also exhibits artificial suppression for edge modes; despite this, we were able to mitigate this and demonstrate that a good quality two-point function on the plane or torus can still be retrieved if the smearing effect and the edge mode suppression are properly circumvented.
We now conclude this work by discussing possible future directions. The HOTRG and GILT algorithms we used in this do not account for lattice defects when determining truncation and filtering strategies. It may be possible to modify these coarse-graining algorithms to be sensitive to lattice defects. Therefore, it is interesting to explore whether this modification leads to more robust coarse graining in -point functions and whether it can improve the overall quality of fixed-point tensors. We also expect that by studying the tensor-space RG flow, oscillation of CDL tensors, and smearing of point-like operators, one can troubleshoot the current limitations of coarse-graining and local entanglement filtering methods and develop more precise and efficient computational methods for tensor-based RG approaches. Furthermore, we note that our methods can be extended to other systems, including quantum spin models, such as the transverse-field Ising model, and possibly to 3D classical systems. It may also be interesting to study the tensor-based RG flow of extended defect objects, such as defect lines in 2D and defect planes in 3D. Finally, it might be useful to investigate the reverse. In this paper, we extract the CFT data from a fixed-point tensor. Then, a natural question is where there exist some prescriptions for constructing a fixed-point tensor from the given CFT data, which might pave a new way of conformal bootstrapping via studying the fixed points of the tensor renormalization group in the tensor space.
Note added: Close to the completion of our initial manuscript, we became aware of a recent work by Atsuhi Ueda and Masaki Oshikawa on “finite-size and finite bond dimension effects of tensor network renormalization” [49]. The part that the two works overlap most is how to extract CFT data, including OPE coefficients and scaling dimensions. They use eigenvectors of the transfer matrix. We compare the method with the transfer matrix and our new proposed method with lTRG. The main focus of their paper is on the finite-size effect, and one focus of ours is the eigenvectors of lTRG and coarse-graining defects. We have further provided a new section (Sec. IV.2) for some comparison.
VI Acknowledgements
We are grateful for many useful and valuable discussions with Ning Bao, Nikko Pomata, Andreas Weichselbaum, and Alexander B. Zamolodchikov. We acknowledge support from the Materials Science and Engineering Divisions, Office of Basic Energy Sciences of the U.S. Department of Energy under Contract No. DESC0012704.
References
- [1] Leo P Kadanoff. Scaling laws for ising models near t c. Physics Physique Fizika, 2(6):263, 1966.
- [2] Kenneth G Wilson. The renormalization group: Critical phenomena and the kondo problem. Reviews of modern physics, 47(4):773, 1975.
- [3] Philippe Francesco, Pierre Mathieu, and David Sénéchal. Conformal field theory. Springer Science & Business Media, 2012.
- [4] J. Ignacio Cirac, David Pérez-García, Norbert Schuch, and Frank Verstraete. Matrix product states and projected entangled pair states: Concepts, symmetries, theorems. Rev. Mod. Phys., 93:045003, Dec 2021.
- [5] Guifre Vidal. Entanglement renormalization. Physical review letters, 99(22):220405, 2007.
- [6] Brian Swingle. Entanglement renormalization and holography. Physical Review D, 86(6):065007, 2012.
- [7] Ning Bao, ChunJun Cao, Sean M Carroll, Aidan Chatwin-Davies, Nicholas Hunter-Jones, Jason Pollack, and Grant N Remmen. Consistency conditions for an ads multiscale entanglement renormalization ansatz correspondence. Physical Review D, 91(12):125036, 2015.
- [8] Ashley Milsted and Guifre Vidal. Geometric interpretation of the multi-scale entanglement renormalization ansatz. arXiv preprint arXiv:1812.00529, 2018.
- [9] Glen Evenbly and Guifre Vidal. Local scale transformations on the lattice with tensor network renormalization. Physical review letters, 116(4):040401, 2016.
- [10] Jutho Haegeman, Tobias J Osborne, Henri Verschelde, and Frank Verstraete. Entanglement renormalization for quantum fields in real space. Physical review letters, 110(10):100402, 2013.
- [11] Yijian Zou, Ashley Milsted, and Guifre Vidal. Conformal fields and operator product expansion in critical quantum spin chains. Phys. Rev. Lett., 124:040604, Jan 2020.
- [12] Frank Verstraete, Valentin Murg, and J Ignacio Cirac. Matrix product states, projected entangled pair states, and variational renormalization group methods for quantum spin systems. Advances in physics, 57(2):143–224, 2008.
- [13] Glen Evenbly and Guifre Vidal. Quantum criticality with the multi-scale entanglement renormalization ansatz. Strongly correlated systems: numerical methods, pages 99–130, 2013.
- [14] Steven R. White. Density matrix formulation for quantum renormalization groups. Phys. Rev. Lett., 69:2863–2866, Nov 1992.
- [15] Steven R. White. Density-matrix algorithms for quantum renormalization groups. Phys. Rev. B, 48:10345–10356, Oct 1993.
- [16] U. Schollwöck. The density-matrix renormalization group. Rev. Mod. Phys., 77:259–315, Apr 2005.
- [17] Ulrich Schollwöck. The density-matrix renormalization group in the age of matrix product states. Annals of Physics, 326(1):96–192, 2011. January 2011 Special Issue.
- [18] F. Verstraete, D. Porras, and J. I. Cirac. Density matrix renormalization group and periodic boundary conditions: A quantum information perspective. Phys. Rev. Lett., 93:227205, Nov 2004.
- [19] A Klümper, A Schadschneider, and J Zittartz. Groundstate properties of a generalized vbs-model. Zeitschrift für Physik B Condensed Matter, 87:281–287, 1992.
- [20] Stellan Östlund and Stefan Rommer. Thermodynamic limit of density matrix renormalization. Physical review letters, 75(19):3537, 1995.
- [21] Guifré Vidal. Efficient classical simulation of slightly entangled quantum computations. Physical Review Letters, 91(14), oct 2003.
- [22] G. Vidal. Entanglement renormalization. Physical Review Letters, 99(22), nov 2007.
- [23] G. Evenbly and G. Vidal. Algorithms for entanglement renormalization. Physical Review B, 79(14), apr 2009.
- [24] F. Verstraete and J. I. Cirac. Renormalization algorithms for quantum-many body systems in two and higher dimensions, 2004.
- [25] F. Verstraete and J. I. Cirac. Valence-bond states for quantum computation. Phys. Rev. A, 70:060302, Dec 2004.
- [26] F. Verstraete, M. M. Wolf, D. Perez-Garcia, and J. I. Cirac. Criticality, the area law, and the computational power of projected entangled pair states. Physical Review Letters, 96(22), jun 2006.
- [27] RJ Baxter. Corner transfer matrices. Physica A: Statistical Mechanics and its Applications, 106(1-2):18–27, 1981.
- [28] Tomotoshi Nishino and Kouichi Okunishi. Corner transfer matrix renormalization group method. Journal of the Physical Society of Japan, 65(4):891–894, 1996.
- [29] Román Orús. Exploring corner transfer matrices and corner tensors for the classical simulation of quantum lattice systems. Phys. Rev. B, 85:205117, May 2012.
- [30] Michael Levin and Cody P. Nave. Tensor renormalization group approach to two-dimensional classical lattice models. Phys. Rev. Lett., 99:120601, Sep 2007.
- [31] Zhi-Yuan Xie, Hong-Chen Jiang, Qinjun N Chen, Zheng-Yu Weng, and Tao Xiang. Second renormalization of tensor-network states. Physical review letters, 103(16):160601, 2009.
- [32] Bin-Bin Chen, Yuan Gao, Yi-Bin Guo, Yuzhi Liu, Hui-Hai Zhao, Hai-Jun Liao, Lei Wang, Tao Xiang, Wei Li, and Z. Y. Xie. Automatic differentiation for second renormalization of tensor networks. Physical Review B, 101(22), Jun 2020.
- [33] Z. Y. Xie, J. Chen, M. P. Qin, J. W. Zhu, L. P. Yang, and T. Xiang. Coarse-graining renormalization by higher-order singular value decomposition. Phys. Rev. B, 86:045139, Jul 2012.
- [34] Glen Evenbly and Guifre Vidal. Tensor network renormalization. Physical review letters, 115(18):180405, 2015.
- [35] Shuo Yang, Zheng-Cheng Gu, and Xiao-Gang Wen. Loop optimization for tensor network renormalization. Physical review letters, 118(11):110504, 2017.
- [36] Zheng-Cheng Gu and Xiao-Gang Wen. Tensor-entanglement-filtering renormalization approach and symmetry-protected topological order. Physical Review B, 80(15):155131, 2009.
- [37] Markus Hauru, Clement Delcamp, and Sebastian Mizera. Renormalization of tensor networks using graph independent local truncations. Phys. Rev. B, 97(4):045111, 2018.
- [38] Nigel Goldenfeld. Lectures on phase transitions and the renormalization group. CRC Press, 2018.
- [39] Xinliang Lyu, Ruqing G. Xu, and Naoki Kawashima. Scaling dimensions from linearized tensor renormalization group transformations. Phys. Rev. Res., 3(2):023048, 2021.
- [40] Glen Evenbly. Algorithms for tensor network renormalization. Physical Review B, 95(4):045117, 2017.
- [41] Arturo Acuaviva, Visu Makam, Harold Nieuwboer, David Pérez-García, Friedrich Sittner, Michael Walter, and Freek Witteveen. The minimal canonical form of a tensor network. 9 2022.
- [42] Barry M McCoy. Advanced statistical mechanics, volume 146. OUP Oxford, 2009.
- [43] Ian Affleck, Tom Kennedy, Elliott H. Lieb, and Hal Tasaki. Rigorous results on valence-bond ground states in antiferromagnets. Phys. Rev. Lett., 59:799–802, Aug 1987.
- [44] Y Meurice. Accurate exponents from approximate tensor renormalizations. Physical Review B, 87(6):064422, 2013.
- [45] See also Fig. 3 from our numerical simulations.
- [46] The Figure 9 in [39] does not show a clear V-shaped curve, indicating that the gauge is not completely fixed when comparing tensors at successive RG steps. However, the GitHub code they provide yields a clear V-shaped curve, as shown in Fig. 13.
- [47] P. Di Francesco, P. Mathieu, and D. Senechal. Conformal Field Theory. Graduate Texts in Contemporary Physics. Springer-Verlag, New York, 1997.
- [48] The mpmath development team. Jacobi theta functions. https://mpmath.org/doc/current/functions/elliptic.html#jacobi-theta-functions, 2023. Accessed: May 8, 2023.
- [49] Atsushi Ueda and Masaki Oshikawa. Finite-size and finite bond dimension effects of tensor network renormalization. arXiv preprint arXiv:2302.06632, 2023.
- [50] Matthew Headrick. A package that teaches mathematica the virasoro algebra. https://people.brandeis.edu/~headrick/Mathematica/, 2010. Accessed: 2023-02-26.
- [51] David Simmons-Duffin. The conformal bootstrap. In New Frontiers in Fields and Strings: TASI 2015 Proceedings of the 2015 Theoretical Advanced Study Institute in Elementary Particle Physics, pages 1–74. World Scientific, 2017.
- [52] Peter J Huber. Robust estimation of a location parameter. Annals of Statistics, 53(1):73–101, 1964.
Appendix A List of Algorithms in TRG
A.1 Higher-Order Tensor Renormalization Group
Here, we recapitulate the essence of the HOTRG coarse-graining procedure, as schematically shown in Algorithm A.1. We define one HOTRG step as merging two tensors into one. The first (or odd number of) step involves finding the isometry to merge two tensors along the horizontal directions, resulting in a rectangular shape of the whole system. The second (or even number of) step involves merging two resultant tensors from the previous step into one, restoring the whole system to a square shape. Algorithm 1 Higher-Order Tensor Renormalization Group [33]
| (36) |
| (37) |
Inputs: A translational invariant tensor network on a lattice. The tensor at each site is .
Outputs: The coarse-grained tensor by grouping every two adjacent tensors in the chosen spatial dimension, and an isometry that truncates the bond dimension of the coarse-grained tensor from to .
Steps:
To minimize the truncation error:
| (38) |
the isometry can be estimated from the singular value decomposition of the two-site reduced density matrix :
| (39) |
On a 2D square lattice, one does the vertical and horizontal coarse-graining step alternatively, as shown in Eq. (36) and Eq. (37).
We note that the memory complexity of a HOTRG step is , and the time complexity is [33].
A.2 Graph Independent Local Truncation
Next, we describe the GILT procedure [37] that aims to remove CDL-like tensors. It is shown in Algorithm A.2. It involves a local truncation that interrupts loop-like correlations.
Algorithm 2 Graph Independent Local Truncation [37]
| (40) |
Inputs: a subgraph of a tensor network and an edge in the subgraph to truncate.
Outputs: a truncation matrix to insert in the chosen edge, or equivalently, a pair of linear transformations and , to apply to the legs of the adjacent tensors, which partially remove local entanglements passing through the edge.
Steps:
| (41) |
The environment of an edge is defined by removing that edge from the tensor network. is interpreted as an isometry from the two ends of broken edges to the external edges.
| (42) |
By spectral decomposing , one can see that the subspace of variations of which does not significantly affect the tensor output, is spanned by the singular vectors corresponding to smaller singular values.
In particular, we choose in the following way:
| (43) |
| (44) |
Split into and by SVD, and absorb them into the adjacent tensors, as in Eq. (9). Furthermore, the local entanglement can be truncated by repeating the process on the edge between and .
We note that the memory complexity of a GILT step is , and the time complexity is [37].
A.3 Minimal Canonical Form
In order to compare tensors in different coarse-graining steps and determine the change in RG flow, it is necessary to convert them into certain canonical forms. One key tool that we use is the recently proposed MCF [41]. This fixes the redundancy under the group up to a residue , where is the bond dimension of each leg. MCF uses an iterative procedure, described in Algorithm A.3.
Algorithm 3 Minimal Canonical Form[41]
| (45) |
| (46) |
Inputs: A translationally invariant tensor network on a lattice. The tensor at each site is .
Outputs: A linear transformation , which gauge transforms the tensor into its minimal canonical form:
| (47) |
where is the spatial dimension of the lattice, is the bond dimension, and is the closure of the gauge orbit generated by the gauge transform Eq. (46).
Steps:
The object to minimize is:
| (48) |
Its first-order variation with respect to gauge transformation is:
| (49) |
where the reduced density matrices , are:
| (50) |
According to [41], the global minimum can be reached by gradient descent. We apply the following gauge transform by the gradient in Eq. (49) and the step length suggested in [41],
| (51) |
and repeat the whole process until converges.
A.4 Preliminary procedure of fixing the gauge
After fixing the gauge using MCF, there is a remaining gauge. Ref. [39] states that one only needs to fix the residue subgroup, which reduces to the sign ambiguity at each index for the case of real tensors. However, we found that, after fixing the signs using an improved method modified from Ref. [39], one can further minimize the difference of from the reference tensor by applying a standard local minimization procedure for the two gauging matrices by a singular value decomposing the corresponding environment tensors iteratively. This is because the argument in Ref. [39] relies on the assumption that there is no level crossing between eigenvalues when one obtains through the HOTRG method Eq. (39). The potential level crossing mixes two of these indices and can be fixed by the gauge.
Here we show our procedure to fix the gauge in Algorithm A.4.
Algorithm 4 Procedure of fixing the gauge [39]
Input: , the tensor to be gauge-fixed. , the reference tensor for the gauge choice.
Output: , the gauge-fixed tensor
Steps:
We note that in Algorithm A.4, the overlap is evaluated as
| (52) |
where the environment tensor of is the tensor subnetwork after removing from the network, and the standard iteratively optimization method for unitary is: , with and obtained from SVD the environment tensor: . The tensor can be updated similarly.
Appendix B Counting the number of conformal states
This section discusses how to obtain the number of conformal states at each conformal level in Ising CFT . It is a brief summary of some relevant formulas from Chapters 7 and 8 in Ref. [47]. For comparison, we also list the number of degeneracy states of the first 12 scaling dimensions of Ising CFT in Table. 4.
| Total | ||||
|---|---|---|---|---|
| 0 | 1 | 1 | ||
| 1 | 1 | |||
| 1 | 1 | 0 | 1 | |
| 2 | 2 | |||
| 2 | 4 | 2 | 2 | |
| 3 | 3 | |||
| 3 | 5 | 2 | 3 | |
| 6 | 6 | |||
| 4 | 9 | 5 | 4 | |
| 9 | 9 | |||
| 5 | 13 | 6 | 7 | |
| 14 | 14 |
| level | |||
|---|---|---|---|
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 2 | 1 | 1 | 1 |
| 3 | 1 | 2 | 1 |
| 4 | 2 | 2 | 2 |
| 5 | 2 | 3 | 2 |
| 6 | 3 | 4 | 3 |
| 7 | 3 | 5 | 4 |
| 8 | 5 | 6 | 5 |
| 9 | 5 | 8 | 6 |
| 10 | 7 | 10 | 8 |
In Ising CFT , there are three primary operators (states): , , . Their conformal dimensions are , , . They are the tensor product of the left and right chiral representations of the Virasoro algebra:
| (53) | ||||
| (54) | ||||
| (55) |
The corresponding descendant states can be achieved by applying left and right Virasoro operators on those highest-weight states:
| (56) |
The conformal dimension of a state is the sum of the left and right conformal spin:
| (57) |
The operators , satisfies the Virasoro Algebra:
| (58) |
where
| (59) |
and the primary state satisfies:
| (60) |
Given and , the inner product between states of the form is uniquely defined and can be computed by moving all annihilation operators to the right and creation operators to the left using the commutator relationship Eq. (58). For example, the inner product between and is:
| (61) |
Note that different descendent states of the same primary state might be linearly dependent if they are at the same level. It can be seen from the inner product of different states. In particular, define the Kac matrix:
| (62) |
where , are the descendent states of the primary state and have the level .
For example, the explicit expression of of given and :
| (63) |
which represents the inner products between and .
The rank of determines the number of linearly independent descendants of at the level . To compute the degeneracy, one might write down the Kac matrix manually or use symbolic packages such as [50].
Instead, the general expression for degeneracy can also be read from the character of irreducible Verma module :
The expression of is found as follows (see 8.17 in [47]):
| (65) |
where is given as
| (66) |
and the is defined via
where labels the minimal model . Moreover, labels the highest weight state . The central charge is given as follows,
| (68) |
and the scaling dimension is given by
| (69) |
Appendix C The OPE Coefficient of Ising Model
The three-point function in CFT has a general form,
| (70) |
where is the distance between operators and the scaling behavior is determined by the scaling dimensions of the operators.
The OPE coefficient is the only thing not fixed by conformal symmetry. In 2D Ising CFT , the OPE coefficients are:
| (71) |
Note that the first line indicates field operators and need to be properly rescaled such that:
| (72) | ||||
In terms of state-operator correspondence, the OPE coefficient can also be written as:
| (73) |
where is normalized to 1, and … denotes operators other than , such as the descendent states of like and the other operators which also have a nonvanishing three-point function with .
Appendix D Four-point Function of 2D Ising CFT
Here we briefly conclude the calculation of the four-point function of Ising CFT, following the lecture notes in Ref. [51]. For simplicity, we consider only the CFT on a plane.
In a CFT, the -point correlation functions can be completely determined from the “CFT data”, which are the scaling dimensions and the OPE coefficients . In particular, Eq. (73) is used to replace the product of two operators into the sum of single operators and iteratively convert the problem to the problem of calculating -point functions.
By fusing the first and second pair of operators, the four-spin correlation function in 2D Ising CFT can be written as:
| (74) |
where are the two families (primary and its descendants) of operators that appear in the OPE of , and is the corresponding OPE coefficient. In the above, and are the cross-ratios of the four points ,,,, which captures the degree of freedom for the points which is invariant under conformal transformation. They can be further summarized by a single complex variable , which is the position of the fourth point when one transforms the first three points to , , and :
| (75) | |||
| (76) |
where is the conformal block for the operator family . and are the scaling dimension and the spin, respectively. (, ). captures the correlation function between the primaries and their descendants in the OPE of the first and second pair of operators on the family . In 2D, the conformal block can be conveniently calculated using the hypergeometric function :
| (77) | ||||
| (78) |
Appendix E Scaling Dimension and Central Charge from Transfer Matrix
For a cylinder of shape , when conformally mapped to an annulus of inner radius , the outer radius is:
| (79) |
One can extract the scaling dimension of each eigenvector of the transfer matrix as follows, where are the eigenvalues of the transfer matrix,
| (80) |
The central charge can be estimated from the largest eigenvalue of the transfer matrix [36]:
| (81) |
where the tensor is required to be renormalized such that [36] and indicate contracting the opposite pairs of legs of the tensor. When GILT is not applied, using trace to renormalize the tensor yields better results than using the tensor norm .
Appendix F Fixing the degeneracy of conformal states
From linearized TRG we obtain its ’raw’ eigenvectors and eigenvalues:
| (82) |
Ideally, they should correspond to the conformal states:
| (83) |
However, only from conformal dimensions one cannot different states which share the same conformal dimension, such as and . Moreover, in practice, the truncation error from finite bond dimensions, the anisotropy introduced by our HOTRG scheme, and the truncation from GILT introduced various numerical errors. We have observed that higher-level states with different conformal dimensions will also mix with each other. Furthermore, if the lTRG matrix is not strictly hermitian, the eigenvectors might not be orthogonal to each other.
To calibrate the above issues, we first orthonormalize the eigenvectors using the standard Gram-Schmidt process, where the eigenvectors with lower conformal dimensions have higher priorities. The next step is to rotate the basis to build the conformal states :
| (84) |
We use the scheme described in Table. 3 to build the implementation of conformal operators at the lattice level using the finite difference method and operator fusion. Note that ’s are the corresponding coarse-grained tensors and contain higher states in the conformal tower of . For example:
| (85) | ||||
The Gram matrix is the dot product between and :
| (86) |
We expect the block-diagonal part of will cancel the rotation matrix, and the off-block-diagonal part is the higher terms that correspond to finite-difference error like Eq. (85):
| (87) |
where means restricted on eigenspace .
However, in practice, some states with different scaling dimensions, such as and , are mixed with each other, as well as with eigenvectors of higher conformal dimensions. It is shown in Fig. 10. An easy fix is to use a larger block that contains both and . One might also include more eigenvectors and replace the submatrix inverse with the submatrix pseudoinverse. We find that we can assume all the eigenvectors are somehow mixed and do the pseudo-inverse for the whole matrix regardless of the theoretical degeneracy, which will give the best result. So, rather than “fixing the degeneracy of the eigenvectors of lTRG using lattice operators”, what we actually did is more like projecting the lattice operators onto the low energy (conformal dimension) subspace of lTRG.
Appendix G Renormalization of fixed-point tensors and extraction of OPE coefficient
To extract the CFT data from the fusion rules of coarse-grained tensors, it is tempting to identify the coarse-grained tensors with the ket vectors in Eq. (73). From it, one may extract the OPE coefficient by comparing the coarse-grained tensor of two defect tensors with the third one. However, proper renormalization is required to get the correct result. It is due to the following reasons.
1. We want the coarse-graining operation, which maps the states on a square of length to the states on the square of length , to have the same behavior as the scaling operator in CFT, when acting on defects, as illustrated in Eq. (88) and Eq. (89). It requires the vacuum tensor to be properly normalized.
2. The size of the coarse-grained block is related to the lattice detail that we should be agnostic of when only the fixed-point tensor is provided. One needs to reassign with a finite number (e.g. ) and renormalize the spin operators according to Eq. (72).
3. The inner product, compatible with the states in Eq. (73), is defined using radial quantization, which is different from the inner product defined on contracting the corresponding external legs of two tensor networks. A simple fix is to rescale the bra tensors.
4. The spatial slice in our radial quantization is a square of length . The coarse-graining process introduces an additional scale transformation to map it to a square of length . We should scale the bra vector accordingly to compensate for the scaling.
For convenience, we use to denote the coarse-grained tensor of the four tensors listed inside the ket, where is the coarse-grain operation that maps the tensor state from the larger square to the states at the original square. We also note that has a different normalization factor than . The inner product is the naive contraction of the corresponding legs of the two tensors (with complex conjugation on the tensor). Now, we list the whole procedure as follows.
1. Rescale such that
| (88) |
2. The scaling dimensions satisfies:
| (89) | |||
3. Choose the “renormalized” length scale as an arbitrary number. Here, we choose .
4. Rescale (renormalize) such that
| (90) |
or equivalently,
| (91) |
5. Repeat the same process to rescale .
6. Rescale , , and such that
| (92) |
| (93) |
| (94) |
7. Now one can read off the OPE coefficient:
| (95) |
or equivalently,
| (96) |
and similarly for .
Appendix H Determining Operator Families from the fixed-point tensor of an unknown CFT
In the previous discussion, we already know the list of primary Ising CFT operators and their spectrum. When given an arbitrary fixed-point tensor, since one does not know the list of conformal families, it is unknown which of the eigenvectors of lTRG belong to which conformal family.
To determine which of the eigenvectors of lTRG corresponds to primaries, we can examine the two-point function. Only primaries and descendants within the same conformal family have a non-vanishing two-point function. However, for certain symmetric conditions, the correlation between the primaries and descendants may also be zero, so it is necessary to break the symmetry when placing the two points.
By examining the two-point function, we can classify the eigenvectors into different conformal families. The primary operator is the one within the family that has the smallest scaling dimension. If the primary has a symmetry structure, such as spins or internal symmetry, there may be degeneracy. We also need to pay special attention to the descendants of the identity operator. The first two descendants are the stress energy tensors, which are easy to identify because they have a conformal dimension of .
Appendix I Huber Loss
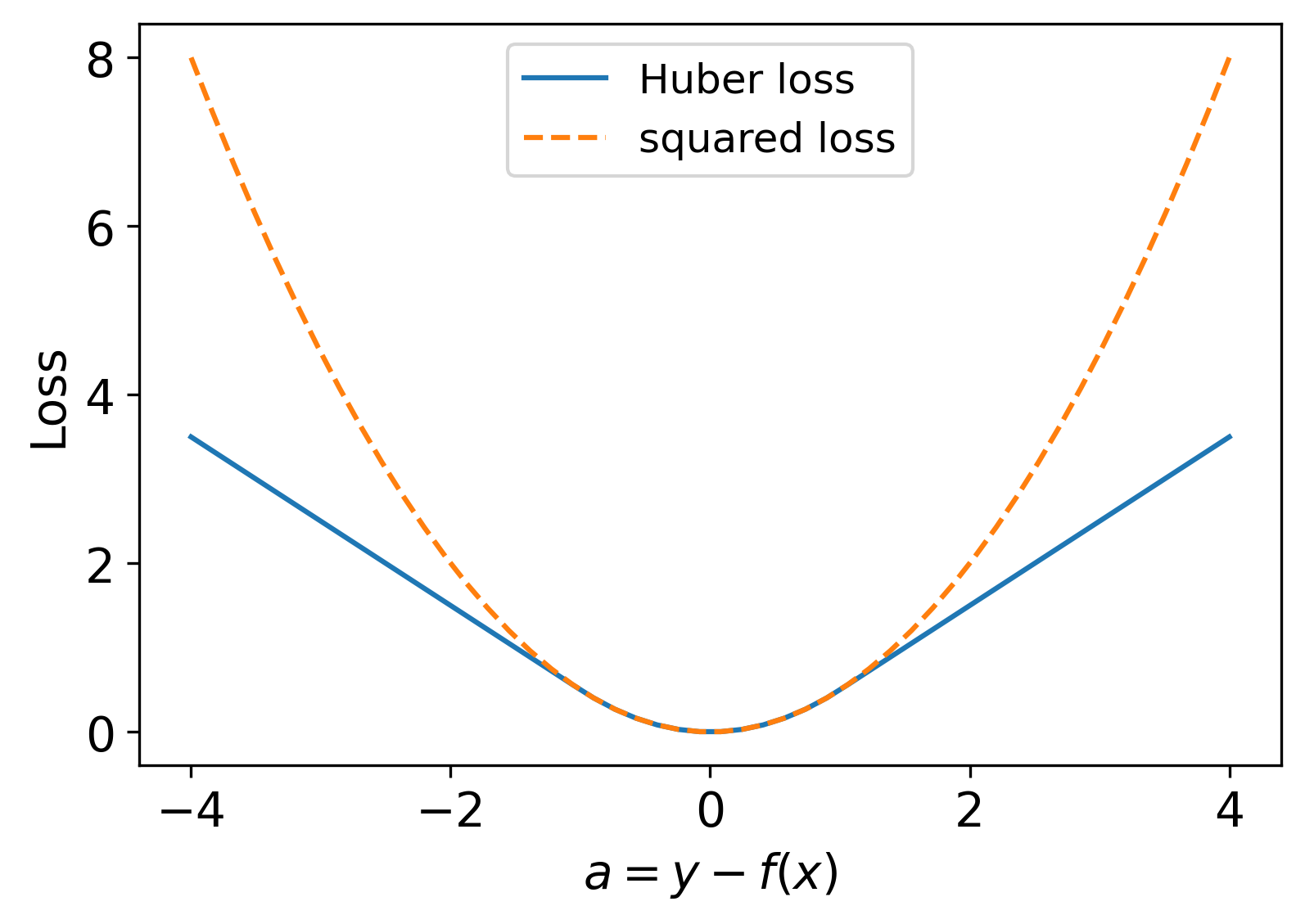
When outliers are present in the data, they can introduce a significant error in the fitting, even in case the number of outliers takes only a small portion of the data. It is because in traditional least squares fitting , the impact of a data point on the fitted function is proportional to its residual :
| (97) |
So, the outliers with a greater residual take a more significant weight in determining the fitting function.
The Huber loss[52] is supposed to suppress the excessive impact of outliers. Which is defined as:
| (98) |
Where , are the data to fit and is the fitted function. is an empirical parameter that determines the range in which a data point is considered an outlier.
Huber loss results in a bounded impact of outliers on the fitting:
| (99) |
Appendix J Numerically finding the critical temperature
Here we demonstrate how to find the optimal input inverse temperature which corresponds to the most stable HOTRG flow using the bisection algorithm. This method is modified from the code provided by [39].
Algorithm 5 Finding the critical (inverse) temperature using bisection method
Input: The bisection search range , , bisection search cutoff , the initial tensor , and the coarse-graining scheme which returns properly normalized coarse-grained tensors after steps, truncated with maximal bond dimension : .
Output: , the “critical (inverse) temperature” which corresponds to the most stable RG flow in the specified numerical scheme and bond dimension .
Steps:
In the above procedure, characterizes how the two systems are different from each other. One can also use other quantities (derived from the tensors), such as the magnetization to characterize the distance: We found that, in practice, using the tensors themselves may not be stable compared to using physical observables.
Appendix K Effects of maximal bond dimension
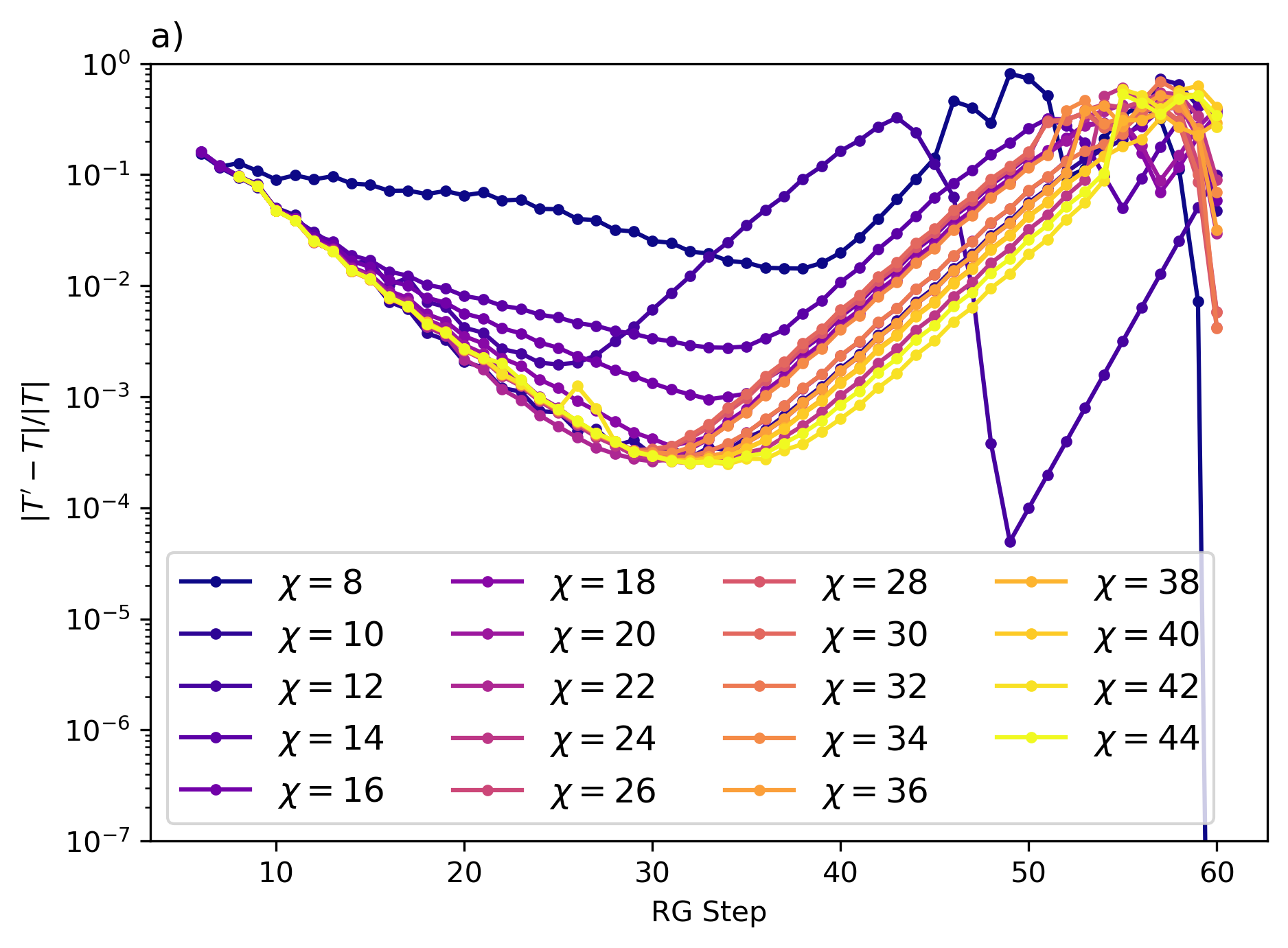
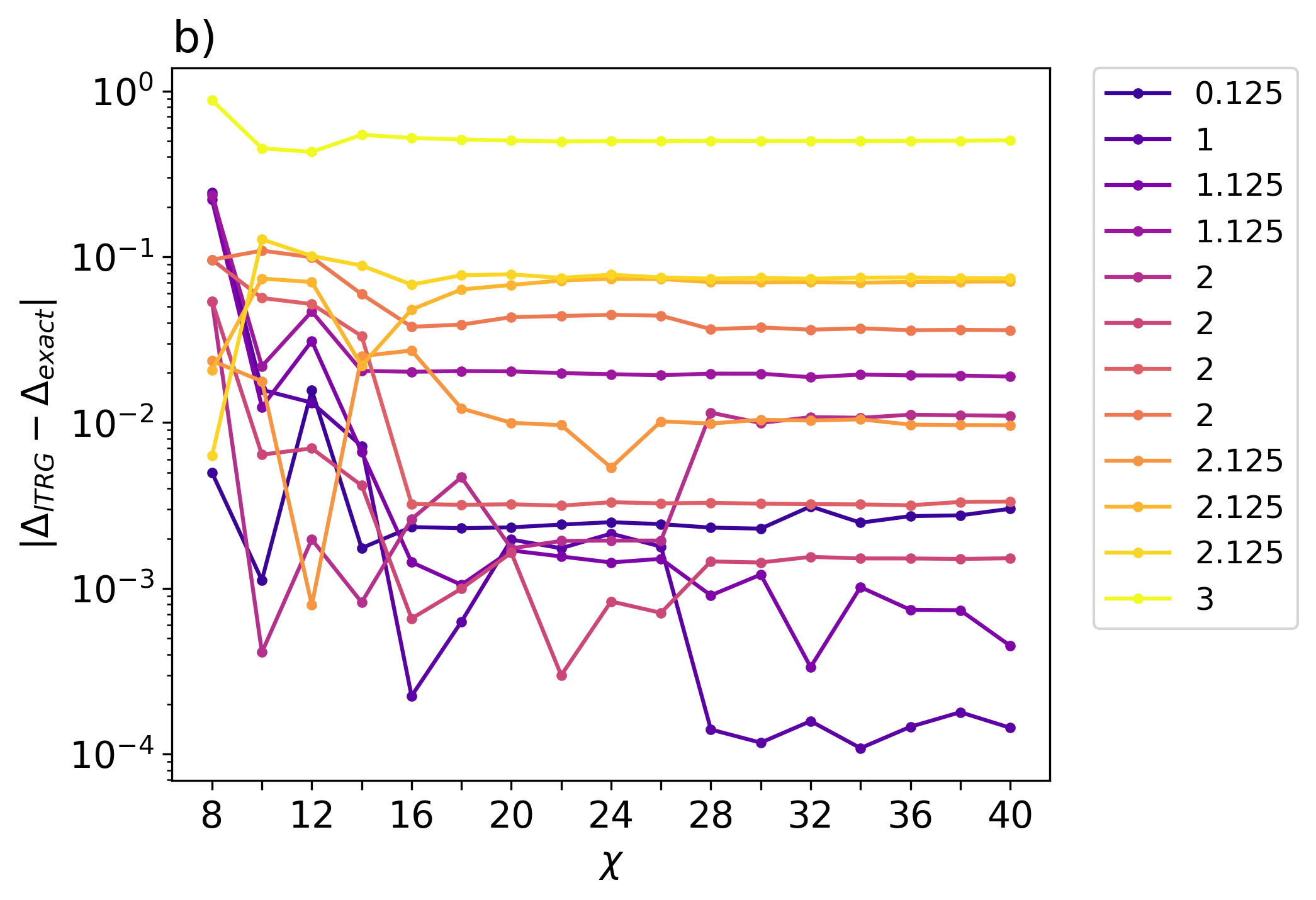
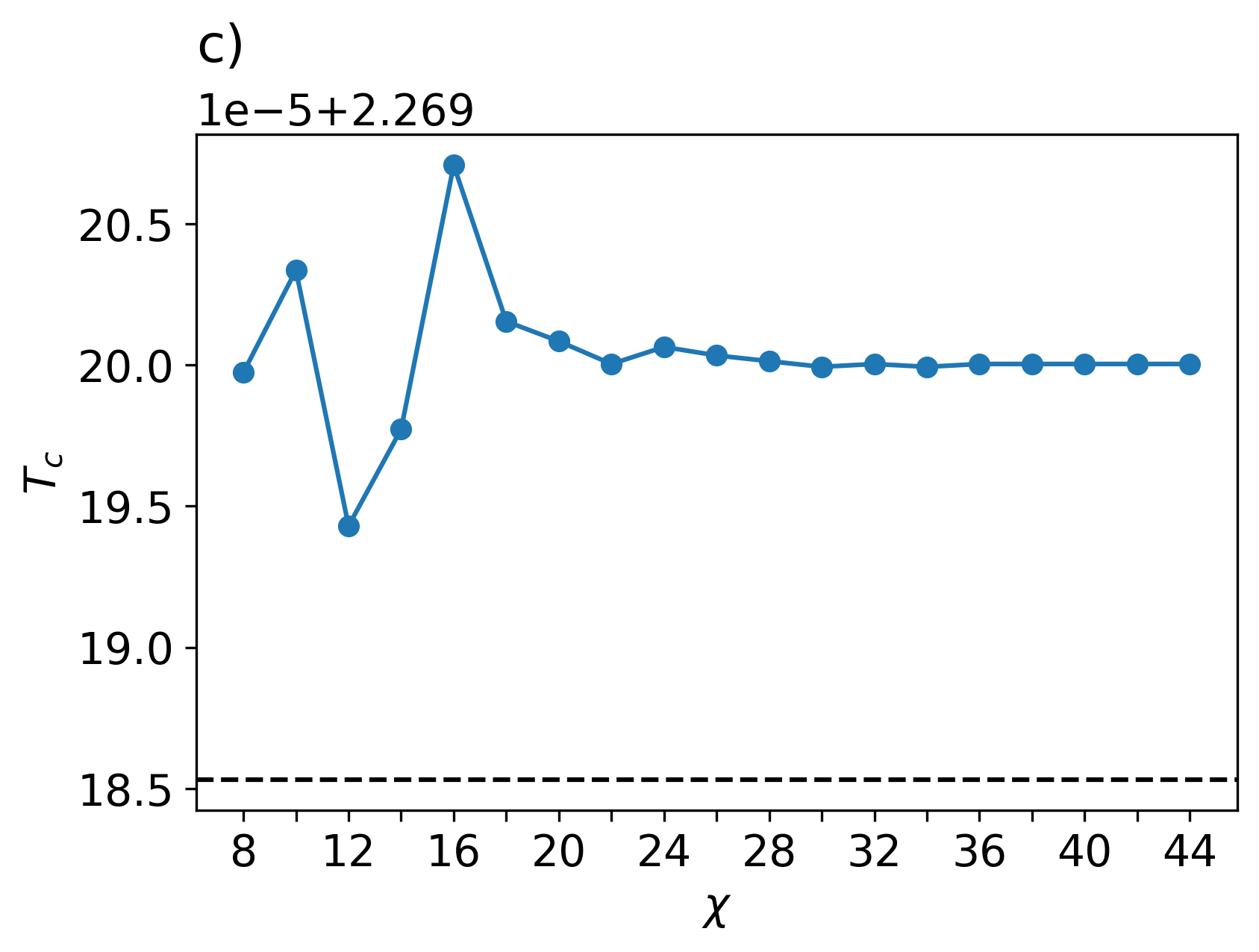
Here we demonstrate the effect of the maximal bond dimension on numerical errors. Regarding the stability of RG flow, the precision of scaling dimensions of higher-order operators, and the critical temperature, there is no significant improvement at , as shown in Fig. 30. The only improvement from increasing from 24 to 40 is the scaling dimension of the first few operators. It indicates that the error of higher-order operators might be from the other part of the algorithm which we could not identify. Thus, for convenience, we have used for the main part of our paper.