Temporal Knowledge Graph Reasoning Triggered by Memories
Abstract
Inferring missing facts in temporal knowledge graphs is a critical task and has been widely explored. Extrapolation in temporal reasoning tasks is more challenging and gradually attracts the attention of researchers since no direct history facts for prediction. Previous works attempted to apply evolutionary representation learning to solve the extrapolation problem. However, these techniques do not explicitly leverage various time-aware attribute representations and are not aware of the event dissolution process. To alleviate the time dependence when reasoning future missing facts, we propose a Memory-Triggered Decision-Making (MTDM) network, which incorporates transient memories, long-short-term memories, and deep memories. Specifically, the transient learning network considers transient memories as a static knowledge graph, and the time-aware recurrent evolution network learns representations through a sequence of recurrent evolution units from long-short-term memories. Each evolution unit consists of a structural encoder to aggregate edge information, a time encoder with a gating unit to update attribute representations of entities. MTDM utilizes the crafted residual multi-relational aggregator as the structural encoder to solve the multi-hop coverage problem. For better understanding the event dissolution process, we introduce the dissolution learning constraint. Extensive experiments demonstrate the MTDM alleviates the time dependence and achieves state-of-the-art prediction performance. Moreover, compared with the most advanced baseline, MTDM shows a faster convergence speed and training speed.
Index Terms:
The memory-triggered decision-making network, residual multi-relational aggregator, temporal knowledge graphs reasoning.I Introduction
Reasoning on Temporal Knowledge Graphs (TKGs) aggregate the time-aware real-world scenarios to infer missing facts and is applied in various tasks, such as event prediction [1], question answering [2], and recommendation systems [3]. Different from static knowledge graphs (KGs), each fact in TKGs additionally associates with temporal information and is represented in the form of ( , , , ), where in most temporal reasoning tasks is sparsity.
Reasoning tasks on TKGs contain the entity reasoning task and the relation reasoning task. The former predicts the missing entity under a specific entity and relation, i.e. ( , , , ). Similarly, the latter is represented as ( , , , ). Additionally, according to the occurrence time of missing facts, temporal reasoning tasks are categorized into two subtasks, [4] and [5]. Given training facts within the interval [, ], predicts missing facts that happened in [, ], while makes predictions for future missing facts . Therefore, is more challenging because there is no real-time information for reference. This paper mainly focuses on the entity reasoning task.
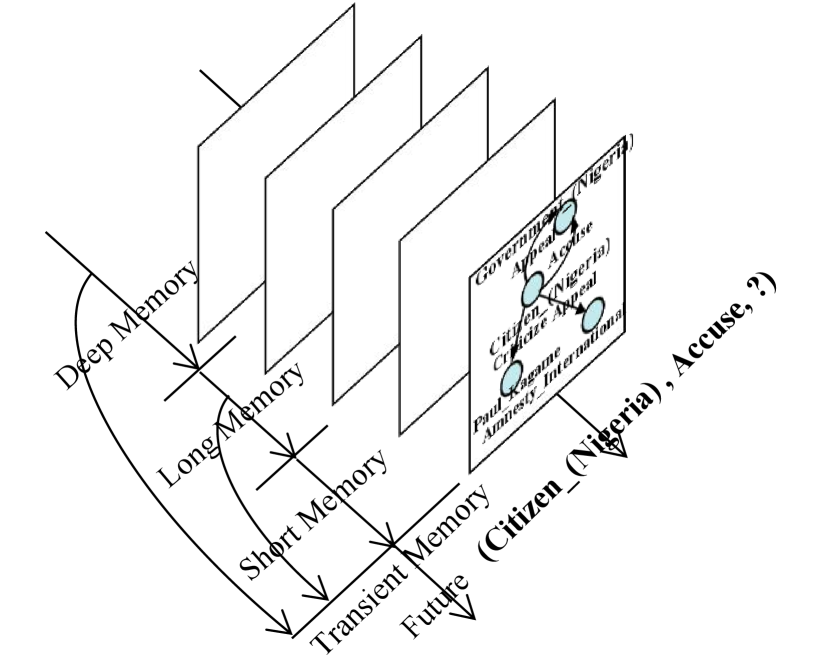
Recent methods [6] realize excellent prediction performance. For instance, the recurrent event network (RE-Net) [7] extracted temporally adjacent history facts for the given entity as a sequential to predict future events. The temporal copy-generation network (CyGNet) [8] mainly focused on learning repetitive patterns from historical facts. Considering RE-Net and CyGNet extracted information from pre-assigned history facts and neglected the structural dependencies, the recurrent evolutional graph convolution network (RE-GCN) [9] adopted all temporally adjacent facts to extract sequential patterns by the evolutional representation method. For the task, existing methods have the following restrictions: (1) Neglecting the impact of time dependence on the reasoning performance; (2) Ignoring the associations between transient memories, long-short-term memories, and deep memories; (3) Multi-hop aggregation in the structural encoder affects the earlier aggregated information; (4) No clear events dissolution constraint.
Specifically, recent facts show greater influences on future predictions than earlier facts [7]. Namely, long-term memories are more likely to ignore recent changes in target entities. However, transient memories are difficult to dive deeply into historical facts. Therefore, to accurately predict the missing entities in the future, it is necessary to adaptively understand the correlation between the missing entities and historical facts. We annotate restrictions (1-2) as a unified question - how to incorporate various memories and jointly make predictions. Another question exists in extracting multi-relational information. The multi-relational graph aggregator [10], which can aggregate information from multi-relational and multi-hop neighbors, is applied in many TKGs reasoning methods [7, 9]. However, the aggregation operation for multi-hop neighbors will gradually destroy the earlier aggregated information. Additionally, previous methods pay less attention to the dissolution of facts, such as ‘ , ’. In fact, the dissolved facts should not be considered again in future predictions, i.e. ‘ , ’.
Considering these problems, we propose a Memory-Triggered Decision-Making network (MTDM) and introduce the dissolution learning constraint for training the network, which utilizes deep memories, long-short term memories, and transient memories, as shown in Fig. 1. MTDM consists of a transient learning network that simulates unconditional reflex and a time-aware recurrent evolution network that simulates conditioned reflex. For instance, the central nervous system gives instructions after the knee responds when it is struck. We treat the transient learning network as a static knowledge graph reasoning task and the time-aware recurrent evolutional network as a sequence of recurrent evolution units. The recurrent evolution unit gradually updates the attribute representations of entities based on the initial entity representations. Assume that entity representations are static and attributes of entities are dynamic. For instance, given a series of triplets, ( , , ) ( , , ) ( , , ) ( , , ), the initial embedding of denotes the static entity representations, and is a kind of dynamic attribute.
The transient learning network and time-aware recurrent evolutional network jointly encode historical facts into entity attribute representations to make predictions. Since the problem of excessive information coverage during the multi-hop aggregation process, the structural encoder is implemented by a novel crafted Residual GCN (Res-GCN). Additionally, the evolution unit still includes a time encoder and a reset gating unit. Since the gated recurrent unit (GRU) exhibits powerful analytical capabilities in fields like dialogue generation [11] and machine translation [12], we use GRU as the time encoder of the evolution unit to record beneficial long-term information. To break through the time constraints in the reasoning process and automatically determine the history length, we introduce a reset gating unit to aggregate long-short-term memories and deep memories. Next, the control gating unit that selects the evolutional entity representations or transient entity representations is adopted. Finally, we introduce the dissolution learning constraint by constructing dissolved facts as negative samples to enhance the network reasoning performance.
In summary, this paper has the following contributions: (1) We propose a Memory-Triggered Decision-Making network (MTDM). MTDM combines transient memories, long-short-term memories, and deep memories, which alleviates the time dependence problem in temporal reasoning tasks. (2) We introduce a dissolution learning constraint for MTDM, which can improves the cognitive ability of MTDM on facts dissolution. (3) The combination of various memories accelerates the model convergence speed, e.g. MTDM reaches the optimal performance in the 8th epoch on the ICEWS14 dataset [4], while the best available work converges in the 25th epoch. Therefore, MTDM enables up to 2.85 times the training speedup compared to the most advanced model. (4) MTDM achieves state-of-the-art performance on several standard TKGs benchmarks, including WIKI [1], YAGO [13], ICEWS14 [4].

II Related work
A knowledge graph is a multi-relational graph, which consists of entities, relations, and attributes descriptions [14].
II-A Reasoning based on Static knowledge graphs (KGs)
Static knowledge graphs ignore the sequence of events. Recent researches in knowledge reasoning based on KGs (KGs reasoning) focus on knowledge representation learning, namely, mapping entities and relations into low-dimensional vectors. TransE [15] proposed to embed entities and relationships of multi-relational data into low-dimensional vector spaces. TransH [16] took relations as a hyperplane, which aimed to incorporate mapping properties between relations. TransR [17] built entity and relation representations in separate spaces and then learn embeddings by projecting entities from entity space to corresponding relation space. ComplEx [18] introduced complex value embedding, which can handle various binary relationships, including symmetric and antisymmetric relations. RotatE [19] realized the KG embedding by relational rotation in complex space and defined each relation as a rotation from the source entity to the target entity in the complex vector space. DistMult [20] proved that generalized bilinear formulation achieved excellent link prediction performance. Researchers also adopted learned relation representations to learn logical rules. SimplE [21] proposed a simple enhancement of Canonical Polyadic (CP) decomposition to learn embeddings of entities dependently and the complexity grows linearly with the size of embeddings. ConvE [22] used neural convolution to build the interactions between entities and relations after mapping entities and relations into variables. RSN [23] was proposed to exploit long-term relational dependencies in knowledge graphs, which employed a skipping mechanism to bridge the gaps between entities. The designed recurrent skip mechanism helped distinguish relations and entities.
Moreover, researchers [24] applied the transformer into the KGs completion and named their framework as knowledge graph bidirectional encoder representations from the transformer (KG-BERT). KG-BERT treated facts in KGs as a textual sequence. The structure-aware convolutional network (SACN) [25] combined the benefit of the graph convolution network (GCN) [26] and ConvE, which consisted of a weighted graph convolutional network as an encoder and a convolutional network called Conv-TransE as a decoder.
II-B Reasoning based on Temporal knowledge graphs (TKGs)
Temporal knowledge graphs gradually attract the attention of researchers for the structured knowledge existing within a specific period and the evolution of facts following the time order.
Researchers of [1] considered the temporal knowledge graphs by annotating relations between entities within time intervals. HyTE [27] projected entities and relations into a hyperplane that associated with the corresponding timestamp. [28] introduced a temporal order constraint based on a manifold regularization term considering the happen time of facts. Han et.al [29] introduced the Hawkes process into the TKG reasoning task. Sankalp Garg et.al [30] proposed the temporal attribute prediction, in which each entity extra contained the attribute description. RE-Net [7] was an autoregressive architecture for predicting future missing facts. History facts that share the same subject entity with the predictive event are selected as past knowledge. Tao et.al [6] proposed a TKGs reasoning method based on the reinforcement learning technique. Researchers trained a time-aware agent to navigate the graph conditioned on known facts to find predictive routes. CluSTeR [31] predicted future missing facts in a two-stage manner, Clue Searching and Temporal Reasoning. The clue searching stage induced clues from historical facts based on reinforcement learning. The temporal reasoning stage deduced answers from clues using a graph convolution network. RE-GCN [9] learned the evolutional representations of entities and relations at each timestamp recurrently. All history facts are adopted to construct a knowledge graph to learn structural dependencies.
Compared with these temporal reasoning methods, this work also combines deep memories and transient memories by constructing a joint prediction network for solving the time dependence of the reasoning process under the supervision of the dissolution learning constraint.
III Problem Formulation
We consider a static knowledge graph as a multi-relational graph, = {, , }, where , , are sets of entities, relations and facts. Each fact in the graph can be represented in the form of triples (, , ), where denotes subject entities, denotes object entities, and is relations between subject entities and object entities. Then, a TKG is formalized as a sequence of snapshots within a temporal interval [, ], , where - denotes the time length of selected history facts. represents the historical snapshots closest to the predictive timestamp . For convenience, we provide symbolic descriptions of time intervals in Table I. Our goal is to predict events that happened in the future , including the object entity prediction, (, , ?, ), and subject entity prediction, (?, , , ). Towards this end, there are two different reasoning modes. The first one [9] directly utilizes the known facts as recent historical facts to predict the future missing facts. The other [7] first generates possible events that happened in the future based on known facts and then makes predictions for the future by using these generated events as historical facts. This work adopts the first reasoning mode.
Taking the object entity prediction as an example, given the constructed TKGs by known historical facts, subject entities and specific relations in predictive timestamp , the problem of the temporal reasoning is solved by:
| (1) |
where denotes the initial entity embeddings, describes the initial relation embeddings, and represents all network parameters. Strictly speaking, the relation embeddings show little relevance to time. For instance, “ , ”, where ‘ ’ denotes a specific meaning regardless of when the fact happens. Therefore, we structure the relation representations as unified static embeddings.
| Time Interval | Descriptions |
|---|---|
| The predictive timestamp. | |
| [, ] | The time interval of the training data. |
| [, ] | The time interval of the evaluation data. |
| [, ] | Recent historical facts. |
IV Overview of MTDM
MTDM combines a Transient Learning Network (TLN) and a Time-aware Recurrent Evolutional Network (TREN). TLN makes predictions towards the missing entities by learning knowledge from transient memories. Then, TREN concludes the entity attribute representations by incorporating new knowledge following the chronological order, from the deep memory, the long-term memory to the short-term memory. In this work, all facts within a temporal interval (or in a timestamp) constitute a snapshot of TKGs . Given recent historical snapshots, TLN uses the multi-residual aggregator to extract the attribute representations of entities by mapping each entity to low-dimensional embeddings. TREN consists of a sequence of evolution units, which recursively updates the entity attribute representations based on the initial entity embeddings . Next, the entity attribute representations extracted by the TLN and TREN are selected through the control gating unit for decision-making.
Figure 2 describes the overall framework of the MTDM. The core sight is that the input of the encoder links the transient memories, long-short-term memories, and deep memories of TKGs. The input of the decoder depends on the control gating unit of TLN. When TLN performs non-ignorable prediction errors, only entity representations of TREN participate in the final decision.
IV-A The time-aware recurrent evolutional network, TREN
We first introduce TREN since the final outputs of it are used in TLN.
TREN can be regarded as a sequence of evolution units. Although recent historical facts contribute more than earlier historical facts when reasoning future events, long-term memories still play an indispensable role. To extract as much historical information as possible, TREN incorporates all facts that occurred in history.
IV-A1 Deep memory
Considering limited computer resources and computing efficiency, evolution networks only incorporate all recent historical facts within a period (), which means it is difficult to extract information beyond the coverage interval (). To take advantage of historical facts, we apply all historical facts not covered by TREN to construct a static knowledge graph, which we call deep memories. Then, RGCN [32] is adopted to extract entity attribute representations that used as the initial embeddings of TREN () from deep memories. Formally, the RGCN aggregator is defined as follows:
| (2) |
where denotes the learnable relation embedding matrix of the -layer, and = . In this way, TREN can extract helpful information ( = ) from deep memories that have never been covered.
IV-A2 The structural encoder
Next, we propose a novel structural encoder Res-GCN to extract structural information from long-short-term memories. The structural encoder aims to capture the association between entities through concurrent facts, which generates entity attribute representations based on recent historical snapshots . Considering the multi-hop aggregation in relation-aware GCN [9] is less sensitive to the earlier aggregated information, an -layer Res-GCN is built to model the entity attribute representations. Specifically, given the set of all known historical facts at timestamp , the entity attribute representations of -hop aggression layer () aggregate information from its historical entity attribute representations .
| (3) |
| (4) |
| (5) |
where denotes the self-loop embedding matrix of entities, is the initial attribute representations in timestamp , and aim to map entity attribute representations and relation representations to the same space. Subject entities and object entities share the same entity embedding matrix. represents the set of neighboring entities of , and its size serves as a normalization constant for averaging neighborhood information. describes the residual attribute representations learned by -hop aggregation and means activation function.
For convenience, the formula description of the extraction process for the structural knowledge is,
| (6) |
Here is the initial entity attribute representations, and denotes known historical facts.
IV-A3 The time encoder & reset gate
Finally, the time encoder recursively updates the entity attribute representations by combining the extracted aggregation information []. Compared with TLN, TREN behaves more sensitive to temporal information and is prone to over-smoothing. Therefore, we use GRU as the time encoder in TREN. The input of the time encoder at timestamp includes the aggregate information extracted by the structural encoder and the GRU output at timestamp .
| (7) |
After that, to automatically determine the history length and effectively retain deep memories, we introduce a reset gating unit after each time encoder.
| (8) |
| (9) |
The TREN will automatically neglect previous historical facts once the model assigns initial values to , = 0. After the -layer time encoders and gating units, we obtain the final long-term entity attribute representations .
IV-B The transient learning network, TLN
TLN consists of a structural encoder Res-GCN and a time encoder that selects entity attribute representations - the control gating unit.
IV-B1 The structural encoder
Similar to TREN, TLN also adopts the Res-GCN as the structural encoder.
| (10) |
We use the final multi-hop aggregate information as attribute representations of entities at timestamp = .
IV-B2 The Time encoder
As we have mentioned, not all representations extracted by TLN and TREN can efficiently make predictions about missing facts. Thus, we introduce a control gating unit to dynamic select the attribute representations, as follows,
| (11) |
| (12) |
where and represent the final attribute representations of extracted from the TLN and TREN for predicting the missing facts in , respectively. In the training process, = . However, in the testing process, . The time gate is determined by the . Namely, replaces as the attribute representations of entities once transient memories seviously affect the prediction performance, , in .
IV-C The Decoder
Previous works [33, 34] show that KG reasoning tasks with the convolutional neural network as the decoder displays excellent performance. Thus, we choose the ConvTransE as the network decoder following [25], which contains several convolution layers, and a fully connected layer. For reasoning missing entity facts (), both entity attribute representations () extracted by the MTDM and static relation representations are used as decoder inputs. Thus, the entity prediction probability is defined as,
| (13) |
| (14) |
| (15) |
where , are sets of , , , denotes the matrix concatenate, is the entity prediction vector decoded by the ConvTransE, denotes the matrix multiplication, means matrix transpose, and is the sigmoid function. Since the static relation representations significantly affect the entity reasoning performance, we construct the relation prediction probability for better extracting relation representations, which is expressed as,
| (16) |
| (17) |
IV-D Parameter Learning
Based on pediction probabilities , the loss function for entity prediction is defined as,
| (18) |
where . We experimentally assign the value for the hyper-parameter .
To reflect the deep memories in learned entity attribute representations, following [9], we constraint the difference between the deep memory representations and the entity attribute representations of the same entity to not exceed the threshold . Additionally, the embedding threshold will increase over time since recent historical facts gradually modify the deep memory.
| (19) |
where = , represents the angle stride.
We have experimentally found that transient memories greatly affect long-term memory-dependent decisions. Therefore, we introduce a 0-1 constraint on gating parameters .
| (20) |
where denotes the average value of gating parameters.
IV-E Dissolution Learning
By observing training data in TKGs reasoning tasks, we found that most relations between two observed entities do not change, while only a few new relations have formatted and dissolved since the last observation. Thus, we construct dissolved events for each prediction timestamp. Specifically, for predicted facts (, , ?, ), , we collect historical facts within a temporal interval [], , . Then we assign temporal information for these newly constructed facts, {, }.
| (21) |
Based on above mentioned loss functions, the final loss constraint is defined as:
| (22) |
are hyper-parameters that distinguish the importance of different tasks. = 0 by default. We ablatively study the impact of dissolution learning constraint on the reasoning performance in Section V-D3. The process for entity prediction task based on MTDM is highlighted in Algorithm 1.
V Experiments
V-A Experimental Setup
We evaluate the performance of the MTDM on three standard datasets and compare it with recent temporal reasoning models. Code to reproduce our experimental results will be publicly available in https://github.com/Dlut-lab-zmn/MTDM.
V-A1 Datesets
Three kinds of TKG datasets are used in our experiments, including the Integrated Crisis Early Warning System sub-dataset, ICEWS14 [4], corresponding to the facts in 2014, two datasets with temporally associated facts as (, , , [, ]), where is the starting timestamp and is the ending timestamp, WIKI [1] and YAGO [13]. We follow [9] to divide ICEWS14 into training, validation, and testing sets with a proportion of 80%, 10%, and 10% by timestamps, namely, (timestamps of the training data) (timestamps of the validation data) (timestamps of the testing data).
V-A2 Evaluation Metrics
We employ two widely used metrics to evaluate the model performance on extrapolated link predictions, Mean Reciprocal Rank (MRR) and Hits@ {1, 3, 10}. We report experimental results under the time-aware filtered setting following [35, 36] that only filters out quadruples with query time . Namely, instead of removing corrupted facts that appear either in the training, validation, or test sets, we only filter from the list all the events that occur on the predictive timestamp [29]. Compared with the raw setting and the temporal filtered setting used in [7], the setting of [35, 36] gets more reasonable ranking scores. For instance, given an evaluation quadruple ( , , , ) and make predictions for quadruple (, , ?, ), (, , , ) in the training set should not be filtered out from the ranking list since the triplet (, , ) is only temporally valid on instead of .
V-A3 Experimental Settings
All experiments are evaluated on an Nvidia GeForce RTX 3090 GPU. Adam is adopted for updating parameters with a learning rate of 0.001. We set both embedding dimensions of entities and relations to 200, the lengths of long-short-term memories and transient memories to 10, 1. The number of layers of the structural encoder is set to 2. For ConvTransE, we following the related settings mentioned in RE-GCN [9]. The hyperparameters , , , are set to 0.3, 1, 1, 0. The initial similarity angle is 10∘, and increases over timestamp with a stride of 10∘. All experimental results are obtained under the same experimental conditions, i.e. no additional auxiliary information. By default, the MTDM takes all known facts as historical facts than generating new possible events as historical information and does not combine the event dissolution learning module.
V-A4 Baselines
We compare the MTDM model with interpolation reasoning models (TTransE [1], TA-DistMult [37], DE-SimplE [5], TNTComplEx [38]), and state-of-the-art extrapolation reasoning models, including (CyGNet [8], ReNet [7], TANGO [36], RE-GCN [9], xERTE [39]).
| Method | YAGO | WIKI | ICEWS14s | |||||||||||
| State | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 | ||
| TTransE [1] | - | 31.19 | 18.12 | 40.91 | 51.21 | 29.27 | 21.67 | 34.43 | 42.39 | 13.43 | 3.14 | 17.32 | 34.65 | |
| TA-DistMult [37] | - | 54.92 | 48.15 | 59.61 | 66.71 | 44.53 | 39.92 | 48.73 | 51.71 | 26.47 | 17.09 | 30.22 | 45.41 | |
| DE-SimplE [5] | - | 54.91 | 51.64 | 57.30 | 60.17 | 45.43 | 42.60 | 47.71 | 49.55 | 32.67 | 24.43 | 35.69 | 49.11 | |
| TNTComplEx [38] | - | 57.98 | 52.92 | 61.33 | 66.69 | 45.03 | 40.04 | 49.31 | 52.03 | 32.12 | 23.35 | 36.03 | 49.13 | |
| TANGO TuckER [36] | - | 62.50 | 58.77 | 64.73 | 68.63 | 51.60 | 49.61 | 52.45 | 54.87 | - | - | - | - | |
| TANGO Distmult [36] | - | 63.34 | 60.04 | 65.19 | 68.79 | 53.04 | 51.52 | 53.84 | 55.46 | - | - | - | - | |
| CyGNet [8] | - | 60.27 | 55.35 | 63.80 | 68.01 | 49.05 | 45.61 | 51.48 | 53.88 | 36.45 | 26.72 | 40.84 | 55.46 | |
| w. eval | 71.66 | 66.03 | 74.50 | 83.33 | 59.67 | 53.74 | 63.27 | 69.89 | 37.22 | 27.59 | 41.74 | 55.96 | ||
| ReNet [7] | - | 60.89 | 55.86 | 63.93 | 69.24 | 49.11 | 46.76 | 50.37 | 53.06 | 36.67 | 27.39 | 40.77 | 54.81 | |
| w. eval | 73.68 | 68.12 | 77.31 | 82.80 | 60.28 | 55.68 | 63.01 | 68.27 | 37.82 | 28.35 | 42.00 | 56.03 | ||
| RE-GCN [9] | His1 | 74.69 | 70.60 | 77.35 | 81.78 | 62.15 | 59.01 | 63.93 | 67.07 | 35.47 | 26.45 | 39.38 | 53.07 | |
| His4 | 72.39 | 67.68 | 75.30 | 80.44 | 62.17 | 59.06 | 64.15 | 67.12 | 35.62 | 26.63 | 39.08 | 53.24 | ||
| His10 | 70.14 | 65.81 | 72.27 | 77.96 | 59.97 | 56.21 | 62.28 | 66.24 | 35.85 | 27.02 | 39.16 | 53.53 | ||
| MTDM | - | 77.66 | 73.85 | 80.82 | 83.79 | 63.18 | 60.24 | 65.31 | 67.89 | 37.12 | 28.15 | 41.00 | 54.52 | |
| xERTE [39] | w. GT | 84.19 | 80.09 | 88.02 | 89.78 | 71.14 | 68.05 | 76.11 | 79.01 | - | - | - | - | |
| RE-GCN [9] | 81.91 | 78.18 | 84.19 | 88.62 | 78.18 | 74.48 | 81.00 | 84.12 | 40.26 | 30.34 | 45.33 | 59.32 | ||
| MTDM | 86.27 | 83.01 | 88.67 | 91.41 | 80.04 | 76.63 | 83.13 | 85.64 | 41.40 | 31.49 | 46.43 | 60.56 | ||

V-B Experimental results
We evaluate the model performance on the time-aware filtered matrix. Table II summarizes entity prediction performance comparison on three benchmark datasets, where denotes utilizing the evaluation data and training data to train the model. By default, only training data is used in the training process. The training data and evaluation data are adopted as historical facts in the reasoning process. Specificlly, given triples with timestamps in [, ] as the training set, [, ] as the evaluation set, triples with timestamps in [, ] as historical evaluation facts, predicting triples with the timestamp .
Results in Table II demonstrate that MTDM outperforms all interpolation baselines on three standard datasets, which illustrates the effectiveness of utilizing evolutionary representation learning on entity predictions. Additionally, MTDM achieves state-of-the-art performance than all extrapolation baselines. It is worth noting that only xERTE, RE-GCN, MTDM can tackle unseen entities by dynamically updating new entity representations based on temporal message aggregation, namely, incorporating evaluation data as historical facts to predict future missing entities but not using the evaluation data to train the model. Therefore, we also provide the prediction performance with or without utilizing evaluation data when training the model for methods CyGNet, RE-Net. As we can see, MTDM performs better than CyGNet and RE-Net even these methods combine the evaluation data in the training process. For instance, the MRR of MTDM is 5.1% and 7.7% higher than RE-Net and CyGNet under the YAGO dataset, 4.6% and 5.6% higher than RE-Net and CyGNet under the WIKI dataset (). For clarifying the impact of history length on the prediction performance, three history lengths are set for RE-GCN [9], 1, 4, 10. We observe that RE-GCN reaches optimal performance for YAGO, WIKI, and ICEWS14 when we set the history length to 1, 4, and 10. In comparison, MTDM leverages deep memories, long-short-term memories, and transient memories, which alleviates the history dependence on history length. Thus, MTDM sets the fixed history length for convenience, 10 for TREN, and 1 for TLN. Even so, MTDM performs better prediction performance than the best RE-GCN, i.e. the MRR of MTDM achieves 3.8% performance improvement than RE-GCN on the YAGO dataset, 1.6% improvement on WIKI, and 3.4% improvement on ICEWS14.
We can draw the following conclusions through the experimental results. For WIKI and YAGO, short-term memories perform better than long-term memories in predicting future missing entities, i.e. the MRR of RE-GCN under the latest knowledge graph as historical facts achieve 74.69% prediction accuracy, 6.1% performance improvement compared with lengths of history to 10 on the YAGO dataset. For ICEWS14, short-term memories combined with long-term memories perform better than only using short-term memories. Therefore, MTDM combines the entity attribute representations in TLN selected by the gating unit C-Gate, and the entity attribute representations in TREN that neglect invalid long-term memories for reasoning all standard benchmarks.
In addition, Table II also provides the comparative experiment results of MTDM, RE-GCN, xERTE with the ground truth events (GT) as historical evaluation facts, where MTDM realizes a 5.1% MRR improvement than RE-GCN for the YAGO dataset, 2.3% improvement for WIKI, and 2.8% improvement for ICEWS14. Specifically, GT means given triples with timestamps in [, ] as the training set, triples with timestamps in [, ] as historical evaluation facts, and predicting triples with the timestamp (). Evaluation with GT as historical evaluation facts can better illustrate the transferability of models, namely, incorporating the newest information for predicting the following possible events. In summary, the MTDM successfully alleviates the temporal dependence problem and outperforms previous works in the temporal reasoning task.
V-C Running speed
To evaluate the efficiency of MTDM, we compare MTDM with the newest TKG reasoning methods, including RE-GCN, RE-Net, and CyGNet, in terms of total training time under the same setting. Comparison results are shown in Fig. 3. We observe that RE-Net takes amounts of time consumption than MTDM, RE-GCN. That is because RE-Net needs to extract temporally adjacent history facts for each given entity as a sequential to predict future events, while MTDM and RE-GCN utilize the evolutionary representation learning. Meanwhile, MTDM performs better than CyGNet and RE-GCN in time cost, about 4.1 times faster than CyGNet, and 2.9 times faster than RE-GCN. On the one hand, MTDM only contains a structural encoder, a time encoder with a reset gating unit, and the deep memory learning module that takes less computational time, which means MTDM trains fast in a single epoch. On the other hand, the memory combination operation accelerates the model convergence speed. For example, MTDM reaches the optimal performance in the 6th and 8th epoch for YAGO and ICEWS14, while the best available work converges in the 24th and 25th epoch.
V-D Abalation study
This subsection investigates the impact of variations in MTDM on reasoning performance, including memory-related variants, model structure-related variants, and data source-related variants. For ablation studies towards various memories, we conduct three sub-MTDM, without the deep memory - w.o DM, without the time-aware recurrent evolutional network - w.o TREN, and without the transient learning network - w.o TLN. Additionally, we experimentally analyze the impact of reset gating units - w.o RGate, different structural encoders, different time encoders, and various recurrent modes towards the model prediction. Finally, we conduct researches towards the event dissolution constraint, w. ED, namely, adding dissolved events as negative samples into the training data. Meanwhile, we experimentally analyze the influence of various hyper-parameters on MTDM.
V-D1 Memory related variants
As we have mentioned in section IV, MTDM incorporates transient memories, long-short-term memories, and deep memories by combining a transient learning network and a time-aware recurrent evolutional network. To evaluate the effectiveness of various memories, we conduct ablation studies by removing deep memories, the TREN that incorporating the long-short term memories, and the TLN that extracting the transient memories. Experimental results are illustrated in Table IV. We observe that the default MTDM shows better reasoning performance than MTDM w.o DM in the ICEWS14 dataset, which proves deep memories are beneficial to reasoning events with long-term dependence. For instance, the triplet (‘’, ‘ ’, ‘ ’) is closely correlated with the triplet (‘’, ‘ ’, ‘ ’), while deep memories contain amounts of information like these correlations.
Meanwhile, both the inference accuracies of MTDM on the YAGO and ICEWS14 datasets are affected by TREN. For instance, compared with MTDM, MTDM w.o TREN reduces the prediction accuracy by 2% on the YAGO dataset and 8.7% on the ICEWS14 dataset. On the one hand, compared with TLN, TREN can excavate the structural information hidden in long-term memories. This structural knowledge contributes a lot in reasoning long-term dependencies in TKGs. On the other hand, the evolutional representations extracted from TREN are helpful for reasoning short-term dependence facts, which are different from representations extracted from transient memories.
Similarly, the prediction performance of MTDM on the YAGO dataset outperforms that of MTDM w.o TLN, which demonstrates the effectiveness of TLN on short-term TKGs prediction.

V-D2 Structure-related variants
For model structure-related variants, we pay attention to four aspects, w.o RGate, w. , w. , and w. Tsf, where w. denotes replacing the Res-GCN in MTDM by the structural encoder in [9], w. Tsf means replacing GRU in MTDM with the transformer encoder, w. represents using the proportion method in Fig. 4. Fig. 4 uses the output of the time encoder and reset gating unit as the input of the next evolution unit. The formula of Fig. 4 is,
| (23) |
Ablation results for various structural variations are illustrated in Table V and evaluated on two standard datasets, YAGO and ICEWS14. We observe that RGate slightly improves the prediction accuracy of the model on the ICEWS14 dataset.
Compared with the default MTDM, MTDM w. causes a 2.6% accuracy decrease on the YAGO dataset. However, only a 0.3% performance decreases on the ICEWS14 dataset. This phenomenon proves the effectiveness of Res-GCN in predicting missing entities with short-term dependence, which also proves that the multi-hop aggregation will hurt early aggregation information.
Next, by replacing the GRU with the encoder of the transformer, we found that the prediction performance of the model decrease significantly. Therefore, considering the memory consumption and method performance, MTDM applies the GRU as the time encoder.
By replacing the Eq. (6) with the Eq. (23) in Algorithm 1, we study the influence of different proportion modes on MTDM prediction performance. It is worth noting that MTDM with the recurrent proportion mode in Fig. 4 (w. ) is worse than the default MTDM. In our opinion, this is because insufficient memories introduce reasoning errors when it contributes to the temporal reasoning task. Meanwhile, the recurrent method will accumulate inference errors. That is, the dissolved facts are reactivated in the next evolution.



| Ground Truth Triplets | Mode | Predictions | Probability | Reason |
|---|---|---|---|---|
| (SouthKorea,Intent intelligence,Japan?) | - | NorthKorea | 0.5328 | (SouthKorea, Host a visit, NorthKorea) |
| China | 0.0859 | (SouthKorea, Consult, China) | ||
| Japan | 0.0603 | (SouthKorea, Express intent to meet or negotiate, Japan) | ||
| Mexico | 0.0391 | No direct links between SouthKorea and Mexico | ||
| Colombia | 0.0364 | No direct links between SouthKorea and Colombia | ||
| GT | Japan | 0.2955 | (SouthKorea, Intent intelligence, Japan) | |
| China | 0.1801 | No direct links between SouthKorea and China | ||
| Thailand | 0.1139 | No direct links between SouthKorea and Thailand | ||
| PopeFrancis | 0.0590 | No direct links between SouthKorea and PopeFrancis | ||
| NorthKorea | 0.0378 | No direct links between SouthKorea and NorthKorea | ||
| (Japan,Intent cooperate,China?) | - | SouthKorea | 0.3685 | (Japan, Engage in negotiation, SouthKorea) |
| China | 0.3473 | (China, Intent cooperate, Japan) | ||
| NorthKorea | 0.0747 | (NorthKorea, Criticize or denounce, Japan) | ||
| France | 0.0627 | No direct links between Japan and France | ||
| Iran | 0.0170 | No direct links between Japan and Iran | ||
| GT | SouthKorea | 0.5975 | (Japan, Consult, SouthKorea) | |
| China | 0.1356 | (Japan, Consult, China) | ||
| NorthKorea | 0.0785 | No direct links between SouthKorea and NorthKorea | ||
| Philippines | 0.0321 | No direct links between SouthKorea and Philippines | ||
| Vietnam | 0.0318 | No direct links between SouthKorea and Vietnam | ||
| (NorthKorea, Criticize or denounce, Japan?) | - | UNSecurityCouncil | 0.3142 | No direct links between NorthKorea and UNSecurityCouncil |
| SouthKorea | 0.2883 | No direct links between NorthKorea and SouthKorea | ||
| Japan | 0.0832 | No direct links between NorthKorea and Japan | ||
| China | 0.0223 | No direct links between NorthKorea and China | ||
| Head (SouthKorea) | 0.0219 | No direct links between NorthKorea and Head (SouthKorea) | ||
| GT | SouthKorea | 0.3242 | (NorthKorea, Criticize or denounce, SouthKorea) | |
| UNSecurityCouncil | 0.1800 | No direct links between SouthKorea and UNSecurityCouncil | ||
| BarackObama | 0.1159 | (NorthKorea, Criticize or denounce, BarackObama) | ||
| Japan | 0.0646 | No direct links between SouthKorea and Japan | ||
| Citizen(NorthKorea) | 0.0393 | No direct links between SouthKorea and Citizen(NorthKorea) | ||
| (China, Intent cooperate, Japan?) | - | France | 0.4799 | (China, Intent cooperate, France) |
| SouthKorea | 0.1704 | No direct links between China and SouthKorea | ||
| Japan | 0.0448 | (China, Consult, Japan) | ||
| Malaysia | 0.0302 | No direct links between China and Malaysia | ||
| Philippines | 0.0276 | No direct links between Philippines and Philippines | ||
| GT | SouthKorea | 0.2719 | No direct links between China and SouthKorea | |
| Japan | 0.2012 | (China, Intentcooperate, Japan) | ||
| Vietnam | 0.1550 | No direct links between China and Vietnam | ||
| Thailand | 0.0487 | No direct links between China and Thailand | ||
| Afghanistan | 0.0353 | No direct links between China and Afghanistan |
V-D3 Data source-related variants
To improve the understanding ability of MTDM towards events dissolution, We introduce dissolution learning constraint. We experimentally assign value for , = 0.01, and denote it as MTDM w. ED. Experimental results are depicted in Table VI. We can observe that MTDM w. ED performs better than the default MTDM in the YAGO and ICEWS14 datasets but is worse than the default MTDM in the WIKI dataset. The insignificant improvement in TKGs inference indirectly proves that MTDM has the well cognitive ability to dissolved events. When removing the dissolution learning module, we find that the confidence of MTDM towards the training data is much greater than the dissolved data. We believe that the poor performance of MTDM w. ED in WIKI is due to the strong correlation between several entities in the dataset. When some dissolved entities are selected as negative samples, they will affect the prediction accuracy of undissolved entities.
V-D4 Various Hyper-parameters
To be fair, we maintain values of other hyper-parameters and only modify the researched hyper-parameter. The initial angle (IA) in the similarity function Eq. (19) directly impacts the learned representations of TREN. That is, we constraint the minimum similarity between the evolutional representations and the initial representations . Comparative experiments are evaluated on ICEWS14 by setting IA to 0∘, 10∘, 30∘, 90∘. The results in Fig. 5 indicate that the proposed MTDM realizes the best performance under IA = 10∘.
V-E Case Study
We provide several case studies in Table III. The first case (SouthKorea, Intent intelligence, Japan?) indicates that evaluation with performs better than with . Historical facts in tend to associate SouthKorea to NorthKorea, i.e. (SouthKorea, Host a visit, NorthKorea). However, there are directly related historical facts in , (SouthKorea, Intent intelligence, Japan).
Meanwhile, closely related entities affect the prediction results. For instance, both historical facts in and contain amounts of triplets (Japan, , SouthKorea), as a result, the prediction probability of SouthKorea for (Japan, Intent cooperate, China?) is higher than of China even though there is directly related historical facts (Japan, Intent cooperate, China) in .
The third case indicates that recent facts will greatly affect the reasoning results even these intentions are not correct for the prediction, i.e. MTDM assigns SouthKorea and BarackObama as the targets of (NorthKorea, Criticize or denounce, Japan?) for historical facts (NorthKorea, Criticize or denounce, SouthKorea) and (NorthKorea, Criticize or denounce, BarackObama).
Finally, we observe that reasoning results are affected by the frequency of entities. We list Top10 entities and their occurrence times summarized within recent historical facts, that is, (‘Vietnam’, 38), (‘Afghanistan’, 38), (‘NorthKorea’, 43), (‘SouthKorea’, 46), (‘Thailand’, 48), (‘Japan’, 67), (‘Citizen(India)’, 77), (‘Iraq’, 83), (‘Iran’, 136), (‘China’, 181). Therefore, ‘Vietnam’, ‘Afghanistan’, ‘Thailand’ are selected as the targets for the prediction of (China, Intent cooperate, Japan?) even there are no direct links between entities.
| MTDM | YAGO | ICEWS14 | |||||
|---|---|---|---|---|---|---|---|
| Mode | MRR | H@3 | H@10 | MRR | H@3 | H@10 | |
| # | - | 77.66 | 80.82 | 83.79 | 37.12 | 41.00 | 54.52 |
| w.o DM | 77.66 | 80.82 | 83.79 | 35.38 | 39.23 | 53.11 | |
| w.o TREN | 76.08 | 79.27 | 83.02 | 33.86 | 37.40 | 50.81 | |
| w.o TLN | 74.04 | 76.62 | 80.64 | 37.12 | 41.00 | 54.52 | |
| MTDM | YAGO | ICEWS14 | |||||
|---|---|---|---|---|---|---|---|
| Mode | MRR | H@3 | H@10 | MRR | H@3 | H@10 | |
| # | - | 77.66 | 80.82 | 83.79 | 37.12 | 41.00 | 54.52 |
| w.o RGate | 77.76 | 81.06 | 83.81 | 36.73 | 40.79 | 54.71 | |
| w. | 75.66 | 78.81 | 82.99 | 37.00 | 41.02 | 54.48 | |
| w. | 77.13 | 80.07 | 83.37 | 34.92 | 38.88 | 52.77 | |
| w. Tsf | 75.36 | 78.63 | 82.78 | 35.61 | 39.52 | 53.55 | |
| MTDM | YAGO | WIKI | ICEWS14 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mode | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 | |
| # | - | 77.66 | 73.85 | 80.82 | 83.79 | 63.18 | 60.24 | 65.31 | 67.89 | 37.12 | 28.15 | 41.00 | 54.52 |
| w. ED | 77.79 | 74.00 | 80.61 | 83.86 | 62.46 | 59.32 | 64.71 | 67.31 | 37.15 | 28.16 | 41.05 | 54.48 | |
VI Conclusions
In this paper, we propose a memory-triggered decision-making network (MTDM), which consists of a transient learning network and a time-aware recurrent evolutional network. Extensive experiments demonstrate the superior of MTDM on the extrapolation temporal reasoning task. MTDM successfully alleviates its dependence on historical length and protects the multi-hop aggregation information by utilizing the residual structural encoder. Additionally, the dissolution constraint helps MTDM understand events dissolution. Since the transient learning network and the time-aware recurrent evolutional network jointly encodes entity attribute representations, MTDM spends less time than the best baselines on the training process.
References
- [1] J. Leblay and M. W. Chekol, “Deriving validity time in knowledge graph,” in Companion Proceedings of the The Web Conference 2018, 2018, pp. 1771–1776.
- [2] Z. Jia, A. Abujabal, R. Saha Roy, J. Strötgen, and G. Weikum, “Tequila: Temporal question answering over knowledge bases,” in Proceedings of the 27th ACM International Conference on Information and Knowledge Management, 2018, pp. 1807–1810.
- [3] R. Trivedi, M. Farajtabar, P. Biswal, and H. Zha, “Dyrep: Learning representations over dynamic graphs,” in International conference on learning representations, 2019.
- [4] R. Trivedi, H. Dai, Y. Wang, and L. Song, “Know-evolve: Deep temporal reasoning for dynamic knowledge graphs,” in international conference on machine learning. PMLR, 2017, pp. 3462–3471.
- [5] R. Goel, S. M. Kazemi, M. Brubaker, and P. Poupart, “Diachronic embedding for temporal knowledge graph completion,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 3988–3995.
- [6] Y. Tao, Y. Li, and Z. Wu, “Temporal link prediction via reinforcement learning,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 3470–3474.
- [7] W. Jin, M. Qu, X. Jin, and X. Ren, “Recurrent event network: Autoregressive structure inference over temporal knowledge graphs,” arXiv preprint arXiv:1904.05530, 2019.
- [8] C. Zhu, M. Chen, C. Fan, G. Cheng, and Y. Zhan, “Learning from history: Modeling temporal knowledge graphs with sequential copy-generation networks,” arXiv preprint arXiv:2012.08492, 2020.
- [9] Z. Li, X. Jin, W. Li, S. Guan, J. Guo, H. Shen, Y. Wang, and X. Cheng, “Temporal knowledge graph reasoning based on evolutional representation learning,” arXiv preprint arXiv:2104.10353, 2021.
- [10] R. Hataya, H. Nakayama, and K. Yoshizoe, “Graph energy-based model for molecular graph generation,” in Energy Based Models Workshop-ICLR 2021, 2021.
- [11] V.-K. Tran and L.-M. Nguyen, “Semantic refinement gru-based neural language generation for spoken dialogue systems,” in International Conference of the Pacific Association for Computational Linguistics. Springer, 2017, pp. 63–75.
- [12] B. Zhang, D. Xiong, J. Xie, and J. Su, “Neural machine translation with gru-gated attention model,” IEEE transactions on neural networks and learning systems, vol. 31, no. 11, pp. 4688–4698, 2020.
- [13] F. Mahdisoltani, J. Biega, and F. Suchanek, “Yago3: A knowledge base from multilingual wikipedias,” in 7th biennial conference on innovative data systems research. CIDR Conference, 2014.
- [14] S. Ji, S. Pan, E. Cambria, P. Marttinen, and S. Y. Philip, “A survey on knowledge graphs: Representation, acquisition, and applications,” IEEE Transactions on Neural Networks and Learning Systems, 2021.
- [15] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” Advances in neural information processing systems, vol. 26, 2013.
- [16] Z. Wang, J. Zhang, J. Feng, and Z. Chen, “Knowledge graph embedding by translating on hyperplanes,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 28, no. 1, 2014.
- [17] Y. Lin, Z. Liu, M. Sun, Y. Liu, and X. Zhu, “Learning entity and relation embeddings for knowledge graph completion,” in Twenty-ninth AAAI conference on artificial intelligence, 2015.
- [18] T. Trouillon, J. Welbl, S. Riedel, É. Gaussier, and G. Bouchard, “Complex embeddings for simple link prediction,” in International conference on machine learning. PMLR, 2016, pp. 2071–2080.
- [19] Z. Sun, Z.-H. Deng, J.-Y. Nie, and J. Tang, “Rotate: Knowledge graph embedding by relational rotation in complex space,” arXiv preprint arXiv:1902.10197, 2019.
- [20] B. Yang, W.-t. Yih, X. He, J. Gao, and L. Deng, “Embedding entities and relations for learning and inference in knowledge bases,” arXiv preprint arXiv:1412.6575, 2014.
- [21] S. M. Kazemi and D. Poole, “Simple embedding for link prediction in knowledge graphs,” arXiv preprint arXiv:1802.04868, 2018.
- [22] T. Dettmers, P. Minervini, P. Stenetorp, and S. Riedel, “Convolutional 2d knowledge graph embeddings,” in Thirty-second AAAI conference on artificial intelligence, 2018.
- [23] L. Guo, Z. Sun, and W. Hu, “Learning to exploit long-term relational dependencies in knowledge graphs,” in International Conference on Machine Learning. PMLR, 2019, pp. 2505–2514.
- [24] L. Yao, C. Mao, and Y. Luo, “Kg-bert: Bert for knowledge graph completion,” arXiv preprint arXiv:1909.03193, 2019.
- [25] C. Shang, Y. Tang, J. Huang, J. Bi, X. He, and B. Zhou, “End-to-end structure-aware convolutional networks for knowledge base completion,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 3060–3067.
- [26] S. Zhang, H. Tong, J. Xu, and R. Maciejewski, “Graph convolutional networks: a comprehensive review,” Computational Social Networks, vol. 6, no. 1, pp. 1–23, 2019.
- [27] S. S. Dasgupta, S. N. Ray, and P. Talukdar, “Hyte: Hyperplane-based temporally aware knowledge graph embedding,” in Proceedings of the 2018 conference on empirical methods in natural language processing, 2018, pp. 2001–2011.
- [28] T. Jiang, T. Liu, T. Ge, L. Sha, S. Li, B. Chang, and Z. Sui, “Encoding temporal information for time-aware link prediction,” in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2016, pp. 2350–2354.
- [29] Z. Han, Y. Ma, Y. Wang, S. Günnemann, and V. Tresp, “Graph hawkes neural network for forecasting on temporal knowledge graphs,” arXiv preprint arXiv:2003.13432, 2020.
- [30] S. Garg, N. Sharma, W. Jin, and X. Ren, “Temporal attribute prediction via joint modeling of multi-relational structure evolution,” arXiv preprint arXiv:2003.03919, 2020.
- [31] Z. Li, X. Jin, S. Guan, W. Li, J. Guo, Y. Wang, and X. Cheng, “Search from history and reason for future: Two-stage reasoning on temporal knowledge graphs,” arXiv preprint arXiv:2106.00327, 2021.
- [32] M. Schlichtkrull, T. N. Kipf, P. Bloem, R. Van Den Berg, I. Titov, and M. Welling, “Modeling relational data with graph convolutional networks,” in European semantic web conference. Springer, 2018, pp. 593–607.
- [33] C. Malaviya, C. Bhagavatula, A. Bosselut, and Y. Choi, “Commonsense knowledge base completion with structural and semantic context,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 03, 2020, pp. 2925–2933.
- [34] S. Vashishth, S. Sanyal, V. Nitin, N. Agrawal, and P. Talukdar, “Interacte: Improving convolution-based knowledge graph embeddings by increasing feature interactions,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 03, 2020, pp. 3009–3016.
- [35] H. Sun, J. Zhong, Y. Ma, Z. Han, and K. He, “Timetraveler: Reinforcement learning for temporal knowledge graph forecasting,” arXiv preprint arXiv:2109.04101, 2021.
- [36] Z. Ding, Z. Han, Y. Ma, and V. Tresp, “Temporal knowledge graph forecasting with neural ode,” arXiv preprint arXiv:2101.05151, 2021.
- [37] A. García-Durán, S. Dumančić, and M. Niepert, “Learning sequence encoders for temporal knowledge graph completion,” arXiv preprint arXiv:1809.03202, 2018.
- [38] T. Lacroix, G. Obozinski, and N. Usunier, “Tensor decompositions for temporal knowledge base completion,” arXiv preprint arXiv:2004.04926, 2020.
- [39] Z. Han, P. Chen, Y. Ma, and V. Tresp, “Explainable subgraph reasoning for forecasting on temporal knowledge graphs,” in International Conference on Learning Representations, 2020.