Task-Adaptive Feature Transformer with Semantic Enrichment
for Few-Shot Segmentation
Abstract
Few-shot learning allows machines to classify novel classes using only a few labeled samples. Recently, few-shot segmentation aiming at semantic segmentation on low sample data has also seen great interest. In this paper, we propose a learnable module that can be placed on top of existing segmentation networks for performing few-shot segmentation. This module, called the task-adaptive feature transformer (TAFT), linearly transforms task-specific high-level features to a set of task agnostic features well-suited to conducting few-shot segmentation. The task-conditioned feature transformation allows an effective utilization of the semantic information in novel classes to generate tight segmentation masks. We also propose a semantic enrichment (SE) module that utilizes a pixel-wise attention module for high-level feature and an auxiliary loss from an auxiliary segmentation network conducting the semantic segmentation for all training classes. Experiments on PASCAL- and COCO- datasets confirm that the added modules successfully extend the capability of existing segmentators to yield highly competitive few-shot segmentation performances.
1 Introduction
Deep neural networks have made significant advances in computer vision tasks such as image classification (Krizhevsky et al., 2012; Szegedy et al., 2015, 2016; He et al., 2016), object detection (Ren et al., 2015; Redmon et al., 2016), and semantic segmentation (Long et al., 2015; Ronneberger et al., 2015; Zhao et al., 2017; Chen et al., 2017a, b, 2018). However, training a deep neural network requires a large amount of labeled data, which are scarce or expensive in many cases. Few-shot learning algorithms aim to tackle this problem. Advances in few-shot learning allows machines to handle previously unseen classification tasks with only a few labeled samples in some cases (Vinyals et al., 2016; Finn et al., 2017; Snell et al., 2017; Yoon et al., 2019).
Recently, more complicated few-shot learning problems such as few-shot object detection (Fu et al., 2019; Kang et al., 2019; Karlinsky et al., 2019) and few-shot semantic segmentation (Amirreza Shaban & Boots, 2017; Rakelly et al., 2018; Zhang et al., 2019b) have seen much interest. Labels for object detection or semantic segmentation are even harder to obtain, naturally occasioning the formulation of few-shot detection and few-shot segmentation problems. In this paper, we tackle the few-shot semantic segmentation problem. The goal of few-shot segmentation is to conduct semantic segmentation on previously unseen classes with only a few examples. Few-shot segmentation tends to be even more challenging than few-shot classification, since segmentation labels contain more information than classification labels.
Specifically, we propose a learnable module, a task-adaptive feature transformer (TAFT), that can extend existing segmentation networks to acquire few-shot segmentation capability. TAFT can be plugged into any existing semantic segmentation algorithm employing an encoder-decoder structure. In encoder-decoder-based segmentators, the encoder extracts features from input images, and the decoder generates segmentation masks using the features. Although multi-scale features can be utilized, it is the high level features that contain the most semantic information. The proposed TAFT method is able to convert the semantic information from novel classes into a form that is more comprehensible to the decoder, by transforming the high-level features to task-agnostic features that contain the information sufficient for segmentation regardless of the given task. Few-shot segmentation can be done effectively by the decoder generating the segmentation mask based on these task-agnostic features.
The transformation matrix in TAFT, which is the only moving part that changes according to the given task, realizes the linear transformation that brings all the class prototypes in the embedded feature space close to a set of task-independent class references in the task-agnostic feature space. These task-independent reference vectors are meta-learned with the update taking place at the end of every episode processing stage, but are completely decoupled from the current task. The references are shown to provide a highly stable target point for the linear transformation, and the decoder more easily generates the segmentation mask based on the transformed task-agnostic features.
Since the feature transformation of TAFT relies on the high-level features extracted from the encoder, it is essential to obtain the informative high-level features in the first place. To improve the quality of the high-level features, we propose a semantic enrichment (SE) method using following techniques. First, we adopt a pixel-wise self-attention module to enhance the quality of the semantic information in the high-level features by reflecting the context among feature pixels. Second, we use an auxiliary segmentation loss from an auxiliary decoder that conducts the multi-class semantic segmentation using the encoder features. By doing so, the encoder can learn to extract the more general high-level features which are advantageous for the few-shot adaptation to the novel classes.
Because our TAFT and SE are simple add-on modules, we do not expect the extended segmentators to perform as well as the tailored state-of-the-art (SOTA) few-shot segmentators designed from the scratch, on extremely low-shot cases like one-shot. Our goal, however, is to see that as the number of shots increases to a few shots, e.g., 5 shots, the TAFT-SE add-on modules would learn quickly and allow the existing segmentator to compete strongly with fully-optimized SOTA few-shot segmentation models.
We evaluate the few-shot learning capability of the proposed modules by combining them with the well-known segmentation algorithm, Deeplab V3+. We indeed observe that while the resulting one-shot performance is not SOTA, for 5-shot testing on both PASCAL- and COCO- datasets, TAFT-SE plugged into Deeplab V3+ beats the SOTA few-shot segmentation algorithms by substantial margins.
2 Proposed Method
2.1 Problem Definition
The goal of few-shot segmentation is to meta-train the model so that it can adapt to unseen classes and perform segmentation with only a few labeled samples from new classes. For meta-training and evaluation, training set and test set with no-overlapping categories are used. In both meta-training and evaluation phases, episodes are composed with classes randomly selected from and , respectively. For 1-way -shot segmentation, each episode consists of a support set with image-label pairs and a query set with image-label pairs, where and represent images and and indicate the corresponding binary masks for the given class. In each episode, the model adapts to the given class using , and then predicts the segmentation masks from the query images . At the end of each episode, the predicted segmentation masks are compared with the query masks . In the meta-training phase, a loss is computed based on the difference between the predicted masks and the query masks and used to update the model parameters. In the evaluation phase, the model performance is evaluated from the comparison between the predicted masks and the query masks.
2.2 Task-Adaptive Feature Transformer
TAFT is a plug-in module which enables few-shot segmentation for an existing segmentation network composed of an encoder and a decoder. By transforming the features from the encoder, TAFT provides an effective task-conditioning to the segmentation network. As seen in Figure 1, when an episode with and is given, TAFT computes prototypes , which are the pixel averages of the embedded features from the support images for foreground and background classes as done in (Wang et al., 2019; Zhang et al., 2019b, 2020). Unlike in previous few-shot segmentation methods, however, TAFT also makes use of another set of class references, . The reference vectors ’s are randomly initialized and meta-trained with the encoder and the decoder of the segmentation network. While the prototypes ’s are apparently driven by and thus depend on the current task’s input images, ’s are completely decoupled from the current task. Given the prototypes and references , TAFT constructs a linear transformation matrix such that the transformed prototype is brought near for all .
By using the reference vectors, we can utilize a stable task-agnostic feature space instead of a highly varying feature space from the images of the unseen class. We observe that while the prototypes may change significantly from one task to next as inputs vary, the references change only by little from one episode to next. As such, offers a stable feature space, while the linear transformation , which is constructed anew in every episode, provides quick task-conditioning. See Figure 5 of Appendix for visual illustration of the stability of the references . The decoder makes use of the query features transformed to the space where reside. In this sense, the stability of helps the decoder to develop a steady and reliable strategy to generate the segmentation mask.

Figure 1 visualizes 1-way 1-shot segmentation. The reference vectors for foreground and background have the length matching the number of channels in the high-level feature. Encoder extracts the high-level feature from the support image . The downsized labels and of the same size as the high-level feature are generated by average pooling. Although we can use a simple resizing when generating the downsized labels, resizing often leads to binary hard labels with all foreground or all background when the object in the image is too large or too small; this is problematic in prototype computation. On the other hand, average pooling generates soft labels with continuous values between 0 and 1, and we can compute both foreground and background prototypes for all cases. Using the downsized soft label and feature , the foreground prototype is computed as
| (1) |
where and denote the pixels in and , respectively. Likewise, using soft label and feature the background prototype is computed as
| (2) |
where are the pixels in . For -shot setting with support images and support labels, the prototypes are computed as the means of the sample prototypes computed by equations (1) and (2). Given the prototypes and reference vectors , we compute the prototype matrix as and reference matrix as .
We can construct the transformation matrix by finding a matrix such that . In general, is not a square matrix and does not have an inverse. One way to find a reasonable is to compute , where is the pseudo-inverse of computed as . This gives the least square fit between and . Note that in 1-way segmentation the matrix is , and the inversion of this matrix requires very little computation. Matrix depends on , which is driven by the encoder input representing the current task. Thus, it can be said that task-conditioning is achieved via application of the linear transformation using . Given the high-level feature from a query image, TAFT transforms it to the task-agnostic feature pixel-by-pixel using . The pixel-wise feature transformation can be easily done using a convolution layer with weight . With this task-adaptive feature transformation, the pixels of the task-agnostic feature get to settle close to the corresponding reference vectors, and the decoder can easily distinguish the foreground and background pixels in the task-agnostic feature. Note that the reference vectors are the only learned part in TAFT. The transformation matrix is not trained but rather computed for each task.
2.3 Semantic Enrichment
While the proposed TAFT module allows the model to adapt to a new task, the quality of the segmentation prediction is highly dependent on the quality of the high-level features from the encoder. If the encoder fails to provide the informative high-level features, it is impossible to obtain the useful task-agnostic features and therefore the decoder fails to predict the exact segmentation masks. To improve the quality of the high-level features from the encoder, we propose a semantic enrichment (SE) module that utilizes the following two additional components.
First, we adopt a pixel-wise self-attention module on the top of the encoder. Using the self-attention module, we can correlate pixels in the feature with the other feature pixels in the same feature and capture the context among the feature pixels. For the self-attention, we utilize a multi-head scaled dot-product attention proposed in (Vaswani et al., 2017). To apply the self-attention, we first flatten each feature into a one-dimensional feature sequence . Then, we process the feature sequence through the attention layer and obtain the attended feature sequence having the same size with the input sequence. Finally, we reshape the sequence into a two-dimensional attended feature . By processing the feature using the self-attention module, the high-level features are refined considering the context among the feature pixels, and the quality of semantic information in the high level features is improved.
Our second component in SE module is an auxiliary decoder that conducts multi-class semantic segmentation. While the labels of the 1-way segmentation episodes contain only the information about the target class, there exist multiple objects of various classes in the corresponding training images in general. To make use of the various classes in the training images, we utilize an auxiliary decoder which predicts the segmentation masks of training classes from the features of the training images. For the supervision of the auxiliary decoder, we generate auxiliary segmentation labels for the training images from the original segmentation labels, by making the all test classes as the background. Using the auxiliary decoder and the auxiliary labels, we obtain an auxiliary loss to train the auxiliary decoder and the encoder network. By training the encoder for the various classes in the image via auxiliary loss, the encoder learns to extract the more general features with the richer semantic information which is useful for few-shot segmentation.
Since the attention module operates on the high-level feature reduced to 1/16 of the original image, the pixel-wise attention does not require significant additional computation. Note that the auxiliary decoder is used only during training and not utilized for evaluation.
2.4 Combination with Segmentation Algorithm
Algorithm 1 shows processing of a given episode for the TAFT-SE modules combined with a segmentation algorithm during meta-training (which is the same as the inference process except for the loss computation, the auxiliary decoder and parameter update part). The prototypes are computed using the downsized labels and the pixel-wise attended encoder features from the support set (line 2 to 10). Then the transformation matrix is constructed using the prototypes and reference vectors (line 11 to 12). For training the reference vectors, we utilize a regression loss . Using the reference vectors and task-agnostic features, we generate the downsized predictions and compare them with downsized labels (line 16). In prediction, we use the pixel-wise inner product with the reference vectors and normalize the prediction scores for each pixel using the softmax activation function. Since the downsized labels contain continuous values in , the mean-squared-error (MSE) loss for regression is utilized as the regression loss and computed over all pixels of downsized predictions. Using , the reference vectors are trained so that the pixels in task-agnostic features can be easily distinguished. Using the task-agnostic features, the decoder predicts the segmentation masks (line 17). The segmentation loss is computed between the labels and the predicted segmentation masks (line 18). The segmentation loss is a cross-entropy loss computed over all pixels in images, which is generally used for semantic segmentation. Through meta-learning using , the decoder learns to generate segmentation masks using the task-agnostic features where each pixel is close to the corresponding reference vector. At the same time, the auxiliary decoder predicts the segmentation masks and the auxiliary segmentation loss is computed using the auxiliary labels. The auxiliary loss is also a cross-entropy loss computed over whole pixels as the segmentation loss (line 19). The auxiliary loss helps the encoder learn to extract more general features.
Input: Encoder , decoder , reference vectors , attention module , auxiliary decoder
,
Output: Updated encoder , decoder , reference vectors , attention module , auxiliary decoder
In this paper, we test the TAFT-SE modules in conjunction with Deeplab V3+. Deeplab V3+ consists of an encoder, a decoder, and the Atrous Spatial Pyramid Pooling (ASPP) module. For segmentation, the high-level feature containing the semantic information is extracted from the image by the encoder. The low-level feature including the shape information is also extracted from the middle layer of the encoder. The high-level feature is then processed by the ASPP module to capture the multi-scale information, and the decoder network generates the segmentation mask using the ASPP output feature and the low-level feature.

Figure 2 illustrates how TAFT-SE modules are plugged in with Deeplab V3+. The attention module is applied on the top of encoder and refines the high-level features. TAFT operates on the high-level feature and generates the task-agnostic features. The task-agnostic features are then further processed by the ASPP module, which is included as a part of the decoder in the figure. Then, the decoder generates the segmentation masks using the low-level features and the ASPP-processed task-agnostic features together. At the same time, the auxiliary decoder takes high-level features and low-level features as input, and predicts the multi-class segmentation masks. Note that in Deeplab V3+, TAFT-SE does not process the low-level feature, since the low-level feature mostly contains the shape information which can be considered general.
Figure 3 displays some qualitative results of TAFT-SE combined with Deeplab V3+. We visualize the 1-shot segmentation results of aeroplane, bus, dog and sheep classes from each split of PASCAL-. The images in the first row are support images, with the support labels shown together at the bottom left of the support images. The images in the second and row show the query images with the prediction results. We can see that TAFT-SE on Deeplab V3+ successfully segments the objects from the query images using only a single support sample in each class. More qualitative results can be found in Appendix.

3 Related Work
3.1 Semantic Segmentation
Semantic segmentation is a computer vision problem that aims to predict the label for each pixel of the image. The fully-convolutional network (FCN) of (Long et al., 2015) utilizes the convolutional neural network (CNN) architectures designed for classification such as VGG or ResNet by convolutionalization. The convolutionalization process transforms the fully connected layers as convolution layers. In this way, the network can preserve the location information while predicting the class of each pixel. UNet of (Ronneberger et al., 2015) modifies the FCN architecture to utilize the multi-scale features to obtain better segmentation performance with less data. PSPNet of (Zhao et al., 2017) proposes a Pyramid Pooling Module (PPM) to effectively aggregate context information over different regions to predict the detailed segmentation masks. Deeplab of (Chen et al., 2017a) and Dilation of (Yu & Koltun, 2016) introduce a dilated convolution which is able to expand the receptive field without a parameter increase. The advanced versions of Deeplab (Chen et al., 2017b, 2018) propose the Atrous Spatial Pyramid Pooling (ASPP) module based on dilated convolution to utilize the multi-scale receptive field. Although the segmentation methods work well when trained with ample data, they cannot be easily adapted to a previously unseen class with only a few data samples, since they are designed to be trained with large datasets. On the other hand, the proposed TAFT-SE modules can be easily combined with an existing segmentation method to enable few-shot segmentation.
3.2 Few-Shot Learning
Few-shot learning aims to develop a general classifier that can quickly adapt to the unseen task with only a few labeled samples. In carrying out few-shot classification, two main strategies have been developed. One is metric-based few-shot learning (Oreshkin et al., 2018; Snell et al., 2017; Vinyals et al., 2016; Yoon et al., 2019), the goal of which is to learn a mapping to the metric space where samples from the same category cluster together while those from different categories are kept far apart.
Another is the optimization-based meta-learner (Finn et al., 2017; Jamal & Qi, 2019; Nichol & Schulman, 2018; Ravi & Larochelle, 2017; Rusu et al., 2018). This approach aims to train a meta-learner which in turn trains an actual learner. The meta-learner supports learning of the actual learner so that the learner can adapt well to a new task using only a small number of updates based on a few samples.
Among the few-shot learning algorithms, TapNet of (Yoon et al., 2019) is most closely related to our TAFT module in that stand-alone meta-learned reference vectors , which are similar in spirit to of the present method, are employed and linear transformation is used. Despite the similarity, there are some key differences in both philosophical viewpoints as well as design methodologies. In TAFT, the reference vectors are viewed as a more stable form of prototypes residing in a task-agnostic space, which serves as the destination for linear transformation. TAFT brings the embedded features all the way to this task-agnostic space, where inference and reference updates take place. This tends to make the references in TAFT more stable than those in TapNet, helping reliable generation of segmentation masks in the decoder and subsequent training of decoder modules. As for specific design methodology, TapNet’s linear transformation attempts to align in-class pairs of vectors while at the same time distancing out-class vectors as much as possible, to maximize classification accuracy. TapNet employs linear nulling of errors for this purpose. In comparison, for TAFT, the least square fit criterion is more appropriate for linear transformation, as it is well-suited for segmentation.
3.3 Few-Shot Segmentation
OSLSM of (Amirreza Shaban & Boots, 2017) is a first algorithm adopting the few-shot learning strategy to semantic segmentation. OSLSM learns to generate the conditioning parameters for element-wise scaling and shifting. Co-FCN of (Rakelly et al., 2018) generates a globally pooled prediction predicts the segmentation mask by fusing it with query features in segmentation branch. Recent methods utilize the prototype idea of (Snell et al., 2017), to use the information in the support set efficiently. SG-One of (Zhang et al., 2020) computes the prototype by the masked-average pooling and compute cosine-similarity map to guide segmentation. Following SG-One, many methods utilize the prototype computed by the masked-average pooling for few-shot segmentation (Liu et al., 2020a, b; Nguyen & Todorovic, 2019; Wang et al., 2019; Yang et al., 2020; Zhang et al., 2019b). For example, CANet of (Zhang et al., 2019b) predicts the mask via dense comparison between query feature and prototype, and iteratively updates it using optimization module. PANet of (Wang et al., 2019) introduces a novel regularization method of prototype alignment for more effective meta-training. PMMs of (Yang et al., 2020), PPNet of (Liu et al., 2020b), ASGNet of (Li et al., 2021) and SCL of (Zhang et al., 2021a) utilize multiple prototypes to leverage the semantic information of different regions of support images. Instead of using prototypes, PGNet of (Zhang et al., 2019a) and DAN of (Wang et al., 2020) adopt the graph attention mechanism to model the relationship between support feature pixels and query feature pixels. PFENet of (Tian et al., 2020) utilizes the prior mask computed from pixel-wise cosine similarity between query feature and masked support feature instead of prototype. PFENet also introduces a feature enrichment module which is able to utilize the multi-scale information with hierarchical relations across different scales. CWT of (Lu et al., 2021) utilizes the encoder and decoder pretrained with training classes and adopts a self-attention mechanism to adapt the classifier weights to a given task. MMNet of (Wu et al., 2021) adopts a learnable memory embeddings to memorize the middle-level meta-class embeddings during meta training and utilize them for few-shot learning.
Our TAFT is similar to the works of (Wang et al., 2019; Zhang et al., 2019b, 2020) in the sense that the prototypes are utilized to represent the pixels. The prior works directly utilize the prototypes that vary widely from task to task in comparing the pixels of the feature with the prototypes. However, the proposed TAFT method does not rely on comparison between the prototypes and the pixels of feature. Instead, TAFT utilizes feature transformation converting task-specific features into fairly stable, task-agnostic features. While the prototype-based approaches require sample-specific comparison between the prototypes and pixels of the feature for each image sample, TAFT does not require any sample-specific process; it generates the transformation matrix and use it for every query image. This enables an efficient parallel computation to predict the segmentation masks of different samples at the same time.
Our SE module is similar to CWT of (Lu et al., 2021) in terms of adopting a self-attention mechanism. While CWT conducts self-attention between features and classifier weights to adapt the model to the given task, our attention module performs self-attention among the pixels from the same feature to enrich the semantic information in the feature. Our SE module and CWT are also similar in terms of conducting semantic segmentation for all training classes during training. However, while CWT utilizes the encoder and decoder pretrained for semantic segmentation task in few-shot adaptation, our SE module conducts the multi-class segmentation only to assist the training of the encoder through the auxiliary loss.
4 Experiment Results
4.1 Dataset and Evaluation Metric
PASCAL- is used for our experiments. PASCAL- is a dataset based on PASCAL VOC 2012, proposed by (Amirreza Shaban & Boots, 2017) for few-shot segmentation. The 20 classes of VOC 2012 are divided into 4 splits, and each split contains 5 disjoint classes. In our experiments, the 5 classes in one of 4 splits are selected as the test classes, and the remaining classes are used as the training classes. The training samples of training classes and the test samples of test classes are used for training and testing, respectively. The details of class split can be found in (Amirreza Shaban & Boots, 2017). Data augmentation is not applied.
COCO- is also utilized for our experiment. It is constructed from the MS-COCO dataset. The 80 classes of MS-COCO are divided into 4 splits, and each split contains 20 disjoint classes. We utilize the class split suggested in (Nguyen & Todorovic, 2019); the details of the split can be found in (Nguyen & Todorovic, 2019). Again, data augmentation is not applied.
We use the mean Intersection-over-Union(mIoU) score as the evaluation metric. As done in prior works, we compute the foreground IoU for each class, and use the averaged per-class foreground IoU as mIoU. We also report the evaluation result with another metric, the Foreground-Background IoU(FBIoU) score suggested in (Rakelly et al., 2018). The FBIoU score is computed as the average of foreground IoU and background IoU computed over all test images.
4.2 TAFT-SE Architecture
TAFT is implemented as a single convolutional layer between encoder and decoder. The weights of this layer reflects the elements of the linear transformation matrix P, so that every pixels of feature can be transformed by P.
For the self-attention in SE, we adopt a scale-dot product attention layer with a single head. In the attention module, the dimensions of query-key-value in self-attention are the same as the input feature dimension. The auxiliary decoder has the same shape with the original decoder, except the last convolutional layer that conducts the pixel-wise classification; the auxiliary decoder has more output channels for more classes.
4.3 Experimental Settings
For training TAFT-SE on Deeplab V3+, we use stochastic gradient descent with the learning rate of 0.01 and a momentum of 0.9 for both PASCAL- and COCO- datasets. For the encoder, we utilize ResNet-50 and ResNet-101 networks. We initialize the encoder with the ImageNet pretrained ResNet-50 or ResNet-101, so we apply a 10 times smaller learning rate to the encoder as done in Deeplab V3+.
We modified the strides in the ResNet encoders so that the low-level features and high-level features are downsized by a factor of 4 and 16, respectively. Since PASCAL- include many small objects, we use the optimized atrous rates of in the ASPP module.
For all experiments, episodes are used for meta-training and the learning rate is decayed by a factor of 10 after training episodes. The weight decay with the rate of is applied for regularization. Training is done using episodes with 12 queries.
For every experiment, we use the images and labels resized to , considering the crop size used in Deeplab V3+. In evaluation, 30,000 episodes are used. For PASCAL- experiments, the multi-scale input test with scale factors is used as done in prior works of (Zhang et al., 2019a, b). In evaluation, the support and query samples are scaled with a specific ratio, and the corresponding predictions are scaled again into the original ratio. The final prediction is done by averaging 3 predictions from different scales.
4.4 Experimental Results
| Models | Backbone | mIoU | FBIoU | ||||
| 1-shot | 5-shot | 1-shot | 5-shot | ||||
| CANet (Zhang et al., 2019b) | ResNet-50 | 55.4 | 57.1 | 1.7 | 66.2 | 69.6 | 3.4 |
| PGNet (Zhang et al., 2019a) | 56.0 | 58.5 | 2.5 | 69.9 | 70.5 | 0.6 | |
| CRNet (Liu et al., 2020a) | 55.7 | 58.8 | 3.1 | 69.9 | 71.5 | 1.6 | |
| RPMMs (Yang et al., 2020) | 56.34 | 57.30 | 0.96 | - | - | - | |
| PPNet (Liu et al., 2020b) | 51.50 | 61.96 | 10.46 | 69.19 | 75.76 | 6.17 | |
| PFENet (Tian et al., 2020) | 60.8 | 61.9 | 1.1 | 73.3 | 73.9 | 0.6 | |
| ASGNet (Li et al., 2021) | 59.29 | 63.94 | 4.65 | 69.2 | 74.2 | 5.0 | |
| SCL (PFENet) (Zhang et al., 2021a) | 61.8 | 62.9 | 1.1 | 71.9 | 72.8 | 0.9 | |
| CWT (Lu et al., 2021) | 56.4 | 63.7 | 7.3 | - | - | - | |
| MMNet (Wu et al., 2021) | 60.2 | 61.8 | 1.6 | - | - | - | |
| TAFT-SE on Deeplab V3+(Ours) | 56.69 | 65.16 | 8.47 | 72.51 | 77.68 | 5.17 | |
| FWB (Nguyen & Todorovic, 2019) | ResNet-101 | 56.2 | 59.92 | 3.73 | - | - | - |
| DAN (Wang et al., 2020) | 58.2 | 60.5 | 2.3 | 71.9 | 72.3 | 0.4 | |
| PFENet (Tian et al., 2020) | 60.1 | 61.4 | 1.3 | 72.9 | 73.5 | 0.6 | |
| ASGNet (Li et al., 2021) | 59.31 | 64.36 | 5.05 | 71.7 | 75.2 | 3.5 | |
| CWT (Lu et al., 2021) | 58.0 | 64.7 | 6.7 | - | - | - | |
| TAFT-SE on Deeplab V3+ (Ours) | 57.98 | 67.50 | 9.52 | 73.48 | 79.40 | 5.92 | |
| Models | Backbone | mIoU | ||
| 1-shot | 5-shot | |||
| PANet (Wang et al., 2019) | ResNet-50 | 20.9 | 29.7 | 8.8 |
| RPMMs (Yang et al., 2020) | 30.58 | 35.52 | 4.94 | |
| PPNet (Liu et al., 2020b) | 29.03 | 38.53 | 9.50 | |
| ASGNet (Li et al., 2021) | 34.56 | 42.48 | 7.92 | |
| CWT (Lu et al., 2021) | 32.9 | 41.3 | 8.4 | |
| MMNet (Wu et al., 2021) | 37.2 | 38.0 | 0.8 | |
| TAFT-SE on Deeplab V3+(Ours) | 32.62 | 45.64 | 13.62 | |
| FWB (Nguyen & Todorovic, 2019) | ResNet-101 | 21.19 | 23.65 | 2.46 |
| DAN (Wang et al., 2020) | 24.4 | 29.6 | 5.2 | |
| PFENet (Tian et al., 2020) | 32.4 | 37.4 | 5.0 | |
| SCL (PFENet) (Zhang et al., 2021a) | 37.0 | 39.9 | 2.9 | |
| CWT (Lu et al., 2021) | 32.4 | 42.0 | 9.6 | |
| TAFT-SE on Deeplab V3+ (Ours) | 33.89 | 47.01 | 13.12 | |
| TAFT | 1-shot | 5-shot | |||
|---|---|---|---|---|---|
| ✔ | ✘ | ✘ | ✘ | 51.41 | 62.14 |
| ✔ | ✔ | ✘ | ✘ | 52.80 | 62.85 |
| ✔ | ✔ | ✔ | ✘ | 55.23 | 64.33 |
| ✔ | ✔ | ✔ | ✔ | 56.69 | 65.16 |
We compare TAFT-SE on Deeplab V3+ with prior approaches. In Table 1, we display the mean mIoU and FBIoU scores for both 1-shot and 5-shot segmentations for PASCAL-. For both ResNet-50 and ResNet-101 backbones, our 1-shot mean mIoU scores fall somewhat lower than previous SOTA methods. However, for 5-shots, TAFT-SE modules do indeed extend Deeplab V3+’s few-shot capability to beyond what is possible with the SOTA performance by prior methods by a fair margin. Accordingly, the value, which represents the ability of the few-shot segmentator to learn from an increasing number of shots, is also the largest except for PPNet in ResNet-50 experiments, and the largest in ResNet-101 experiments. In fact, as shown in Table 7 of Appendix, when compared with PFENet (which gives a SOTA 1-shot mIoU performance in ResNet-101 experiments) across a wider range of 1, 3, 5, 7 and 10 shots, our method already starts to outperform PFENet from 3 shots and on, by a significant margin.
For FBIoU scores, our TAFT-SE on Deeplab V3+ with ResNet-50 backbone falls short of SOTA performance on 1-shot. But for 5-shot, our extension yields the best FBIoU score. In ResNet-101 experiments, TAFT-SE extension exhibits the best 1-shot and 5-shot scores and the best value, highlighting its ability to learn quickly from an increasing number of examples. The higher FBIoU score means that the proposed method achieves a higher background IoU than prior works. We conjecture that the usage of background pixel information results in higher background IoU and FBIoU scores, as in PANet of (Wang et al., 2019) and PPNet of (Liu et al., 2020b). While most prior works only utilize the foreground prototype or foreground pixel information, TAFT-SE utilizes the prototypes and reference vectors for both foreground and background.
Table 2 displays the mean mIoU scores for COCO-. Again, for both ResNet-50 and ResNet-101 backbone, our TAFT-SE extension on Deeplab V3+ gives the best 5-shot performance with large margins.
Table 3 shows the results of our ablation experiments with PASCAL- dataset. For the all ablation experiments, we use Deeplab V3+ with the ResNet-50 backbone as a base segmentator, with the same hyperparameter setting. We can see that the attention module and the auxiliary loss consistently improve the performances. For both 1-shot and 5-shot, the auxiliary loss provides more gains compared to the attention module. In Appendix, we show the performance of TAFT-SE extension on FCN of (Long et al., 2015), another well-known segmentation model.
5 Conclusion
In this paper, we propose a task-adaptive feature transformer module to extend existing segmentation models to acquire few-shot segmentation capabilities. TAFT transforms high-level features containing the semantic information into task-agnostic features. The feature transformation converts the semantic information in the high-level features to a form more suitable for the decoder to generate the segmentation mask. We also introduce a semantic enrichment module that enriches the semantic information in the high-level features using the pixel-wise self-attention and the auxiliary segmentation network performing multi-class semantic segmentation. The proposed TAFT-SE modules can be easily plugged into existing semantic segmentation algorithms such as Deeplab V3+. Extensive experiments show that while TAFT-SE extensions of existing segmentators are not always SOTA on 1-shot setting, TAFT-SE quickly improves as more shots of examples become available. On 5-shot, TAFT-SE on Deeplab V3+ beats all known tailored few-shot segmentation models.
References
- Amirreza Shaban & Boots (2017) Amirreza Shaban, Shray Bansal, Z. L. I. E. and Boots, B. One-shot learning for semantic segmentation. In BMVC, 2017.
- Chen et al. (2017a) Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and Yuille, A. L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017a.
- Chen et al. (2017b) Chen, L.-C., Papandreou, G., Schroff, F., and Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, 2017b.
- Chen et al. (2018) Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., and Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pp. 801–818, 2018.
- Finn et al. (2017) Finn, C., Abbeel, P., and Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning, pp. 1126–1135, 2017.
- Fu et al. (2019) Fu, K., Zhang, T., Zhang, Y., Yan, M., Chang, Z., Zhang, Z., and Sun, X. Meta-ssd: Towards fast adaptation for few-shot object detection with meta-learning. IEEE Access, 7:77597–77606, 2019.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Jamal & Qi (2019) Jamal, M. A. and Qi, G.-J. Task agnostic meta-learning for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 11719–11727, 2019.
- Kang et al. (2019) Kang, B., Liu, Z., Wang, X., Yu, F., Feng, J., and Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE International Conference on Computer Vision, pp. 8420–8429, 2019.
- Karlinsky et al. (2019) Karlinsky, L., Shtok, J., Harary, S., Schwartz, E., Aides, A., Feris, R., Giryes, R., and Bronstein, A. M. Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5197–5206, 2019.
- Krizhevsky et al. (2012) Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105, 2012.
- Li et al. (2021) Li, G., Jampani, V., Sevilla-Lara, L., Sun, D., Kim, J., and Kim, J. Adaptive prototype learning and allocation for few-shot segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8334–8343, 2021.
- Liu et al. (2020a) Liu, W., Zhang, C., Lin, G., and Liu, F. Crnet: Cross-reference networks for few-shot segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4165–4173, 2020a.
- Liu et al. (2020b) Liu, Y., Zhang, X., Zhang, S., and He, X. Part-aware prototype network for few-shot semantic segmentation. In European Conference on Computer Vision, pp. 142–158. Springer, 2020b.
- Long et al. (2015) Long, J., Shelhamer, E., and Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3431–3440, 2015.
- Lu et al. (2021) Lu, Z., He, S., Zhu, X., Zhang, L., Song, Y.-Z., and Xiang, T. Simpler is better: Few-shot semantic segmentation with classifier weight transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8741–8750, 2021.
- Nguyen & Todorovic (2019) Nguyen, K. and Todorovic, S. Feature weighting and boosting for few-shot segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pp. 622–631, 2019.
- Nichol & Schulman (2018) Nichol, A. and Schulman, J. Reptile: a scalable metalearning algorithm. arXiv preprint arXiv:1803.02999, 2018.
- Oreshkin et al. (2018) Oreshkin, B. N., Lacoste, A., and Rodriguez, P. Tadam: Task dependent adaptive metric for improved few-shot learning. In Advances in Neural Information Processing Systems, 2018.
- Rakelly et al. (2018) Rakelly, K., Shelhamer, E., Darrell, T., Efros, A., and Levine, S. Conditional networks for few-shot semantic segmentation. ICLR Workshop, 2018.
- Ravi & Larochelle (2017) Ravi, S. and Larochelle, H. Optimization as a model for few-shot learning. In International Conference on Learning Representations, 2017.
- Redmon et al. (2016) Redmon, J., Divvala, S., Girshick, R., and Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779–788, 2016.
- Ren et al. (2015) Ren, S., He, K., Girshick, R., and Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pp. 91–99, 2015.
- Ronneberger et al. (2015) Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pp. 234–241. Springer, 2015.
- Rusu et al. (2018) Rusu, A. A., Rao, D., Sygnowski, J., Vinyals, O., Pascanu, R., Osindero, S., and Hadsell, R. Meta-learning with latent embedding optimization. arXiv preprint arXiv:1807.05960v2, 2018.
- Snell et al. (2017) Snell, J., Swersky, K., and Zemel, R. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems, pp. 4080–4090, 2017.
- Szegedy et al. (2015) Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9, 2015.
- Szegedy et al. (2016) Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2818–2826, 2016.
- Tian et al. (2020) Tian, Z., Zhao, H., Shu, M., Yang, Z., Li, R., and Jia, J. Prior guided feature enrichment network for few-shot segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, pp. 5998–6008, 2017.
- Vinyals et al. (2016) Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., and Wierstra, D. Matching networks for one shot learning. In Advances in Neural Information Processing Systems, pp. 3630–3638, 2016.
- Wang et al. (2020) Wang, H., Zhang, X., Hu, Y., Yang, Y., Cao, X., and Zhen, X. Few-shot semantic segmentation with democratic attention networks. In European Conference on Computer Vision, pp. 730–746. Springer, 2020.
- Wang et al. (2019) Wang, K., Liew, J. H., Zou, Y., Zhou, D., and Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE International Conference on Computer Vision, pp. 9197–9206, 2019.
- Wu et al. (2021) Wu, Z., Shi, X., Lin, G., and Cai, J. Learning meta-class memory for few-shot semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 517–526, 2021.
- Yang et al. (2020) Yang, B., Liu, C., Li, B., Jiao, J., and Ye, Q. Prototype mixture models for few-shot semantic segmentation. In European Conference on Computer Vision, pp. 763–778. Springer, 2020.
- Yoon et al. (2019) Yoon, S. W., Seo, J., and Moon, J. Tapnet: Neural network augmented with task-adaptive projection for few-shot learning. In International Conference on Machine Learning, pp. 7115–7123, 2019.
- Yu & Koltun (2016) Yu, F. and Koltun, V. Multi-scale context aggregation by dilated convolutions. ICLR, 2016.
- Zhang et al. (2021a) Zhang, B., Xiao, J., and Qin, T. Self-guided and cross-guided learning for few-shot segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8312–8321, 2021a.
- Zhang et al. (2019a) Zhang, C., Lin, G., Liu, F., Guo, J., Wu, Q., and Yao, R. Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pp. 9587–9595, 2019a.
- Zhang et al. (2019b) Zhang, C., Lin, G., Liu, F., Yao, R., and Shen, C. Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5217–5226, 2019b.
- Zhang et al. (2021b) Zhang, G., Kang, G., Wei, Y., and Yang, Y. Few-shot segmentation via cycle-consistent transformer. In Advances in Neural Information Processing Systems, 2021b.
- Zhang et al. (2020) Zhang, X., Wei, Y., Yang, Y., and Huang, T. S. Sg-one: Similarity guidance network for one-shot semantic segmentation. IEEE Transactions on Cybernetics, 2020.
- Zhao et al. (2017) Zhao, H., Shi, J., Qi, X., Wang, X., and Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2881–2890, 2017.
Appendix A Additional Experimental Results
In Tables 4, 5 and 6, we display mIoU and FBIoU for PASCAL-, and mIoU for COCO-, for all splits. We show the results of the prior works using the smaller VGG-16 backbone, as well as the results of a concurrent work, Cycle-Consistent Transformer (CyCTR). We also present the performances of TAFT-SE combined with Fully Convolutional Network (FCN).
A.1 Combination with FCN
In the main paper, we argue that TAFT-SE can be combined with the existing semantic segmentation algorithm achieving few-shot segmentation capability. As an example, we showed that TAFT-SE combined with Deeplab V3+ achieved state-of-the-art few-shot segmentation performance. To further demonstrate the extendibility and versatility of TAFT-SE, we plug TAFT-SE into another well-known segmentation algorithm, Fully Convolutional Network (FCN). FCN utilizes the convolutional neural network (CNN) architectures designed for classification by convolutionalization. The convolutionalization process transforms the fully connected layers as convolution layers. In this way, the network can preserve the location information while predicting the class of each pixel. After prediction, FCN upsamples the scores into the original image size. In FCN, the convolution layers or the feature extractor of classification network is considered as encoder, and the convolutionalized layers and upsampling layers are considered as decoder.

Since FCN can utilize different classification networks, there can be many different variations. Among them, we utilize the FCN architecture with the ResNet-50 and the ResNet-101 encoders provided by the pytorch framework in our experiments. Figure 4 illustrates this version of FCN combined with the TAFT-SE modules. The feature transformation by TAFT is applied to the attended high-level feature from the encoder and attention module. The downsized prediction is generated with the task-agnostic feature and the reference vectors, and the regression loss is computed with downsized label and prediction. The convolutional decoder generates the segmentation mask with the task-specific high-level feature. The segmentation loss is then computed using the original label and the generated segmentation mask. At the same time, the auxiliary prediction is made by the auxiliary decoder, and the auxiliary segmentation loss is computed from the auxiliary prediction and the auxiliary label. For training TAFT-SE on FCN, we utilize the learning rate of . We employ the training episodes with 7 queries for 1-shot, and 3 queries for 5-shot. For the remaining hyperparameter, we adopt the same hyperparameters as those of TAFT-SE on Deeplab V3+. In Tables 4 and 5, we display the mean Intersection-over-Union (mIoU) scores and foreground-background Intersection-over-Union (FBIoU) scores of TAFT-SE on FCN and TAFT-SE on Deeplab V3+ for the all splits of PASCAL-, in comparison with those of other methods. We can see that for 5-shot, TAFT-SE on FCN shows the mIoU and FBIoU scores comparable to most of the prior works. For FBIoU scores, TAFT-SE on FCN outperforms all the prior works except PPNet in ResNet-50, and performs better than all the other method in ResNet-101. In Table 6, we show the mean Intersection-over-Union (mIoU) scores of TAFT-SE on FCN and TAFT-SE on Deeplab V3+ for the all splits of COCO-, with the scores of other methods. Again, TAFT-SE on FCN shows the competitive performances compared to SOTA methods. Especially in ResNet-101 experiments, TAFT-SE on FCN outperforms all the prior methods. For value, TAFT-SE on FCN shows largest except TAFT-SE on Deeplab V3+.
| Models | Backbone | mIoU | ||||||||||
| split-0 | split-1 | split-2 | split-3 | mean | ||||||||
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | |||
| OSLSM (Amirreza Shaban & Boots, 2017) | VGG-16 | 33.6 | 35.9 | 55.3 | 58.1 | 40.9 | 42.7 | 33.5 | 39.1 | 40.8 | 43.9 | 3.1 |
| co-FCN (Rakelly et al., 2018) | 36.7 | 37.5 | 50.6 | 50.0 | 44.9 | 44.1 | 32.4 | 33.9 | 41.1 | 41.4 | 0.3 | |
| SG-One (Zhang et al., 2020) | 40.2 | 41.9 | 58.4 | 58.6 | 48.4 | 48.6 | 38.4 | 39.4 | 46.3 | 47.1 | 0.8 | |
| PANet (Wang et al., 2019) | 42.3 | 51.8 | 58.0 | 64.6 | 51.1 | 59.8 | 41.2 | 46.5 | 48.1 | 55.7 | 7.6 | |
| FWB (Nguyen & Todorovic, 2019) | 47.04 | 50.87 | 59.64 | 62.86 | 52.61 | 56.48 | 48.27 | 50.09 | 51.90 | 55.08 | 3.18 | |
| CANet (Zhang et al., 2019b) | ResNet-50 | 52.5 | 55.5 | 65.9 | 67.8 | 51.3 | 51.9 | 51.9 | 53.2 | 55.4 | 57.1 | 1.7 |
| PGNet (Zhang et al., 2019a) | 56.0 | 57.9 | 66.9 | 68.7 | 50.6 | 52.9 | 50.4 | 54.6 | 56.0 | 58.5 | 2.5 | |
| CRNet (Liu et al., 2020a) | - | - | - | - | - | - | - | - | 55.7 | 58.8 | 3.1 | |
| RPMMs (Yang et al., 2020) | 55.16 | 56.28 | 66.91 | 67.34 | 52.61 | 54.52 | 50.68 | 51.00 | 56.34 | 57.30 | 0.96 | |
| PPNet (Liu et al., 2020b) | 47.83 | 58.39 | 58.75 | 67.83 | 53.80 | 64.88 | 45.63 | 56.73 | 51.50 | 61.96 | 10.46 | |
| PFENet (Tian et al., 2020) | 61.7 | 63.1 | 69.5 | 70.7 | 55.4 | 55.8 | 56.3 | 57.9 | 60.8 | 61.9 | 1.1 | |
| ASGNet (Li et al., 2021) | 58.84 | 63.66 | 67.86 | 70.55 | 56.79 | 64.17 | 53.66 | 57.38 | 59.29 | 63.94 | 4.65 | |
| SCL (PFENet) (Zhang et al., 2021a) | 63.0 | 64.5 | 70.0 | 70.9 | 56.5 | 57.3 | 57.7 | 58.7 | 61.8 | 62.9 | 1.1 | |
| CWT (Lu et al., 2021) | 56.3 | 61.3 | 62.0 | 68.5 | 59.9 | 68.5 | 47.2 | 56.6 | 56.4 | 63.7 | 7.3 | |
| MMNet (Wu et al., 2021) | 58.0 | 60.0 | 70.0 | 70.6 | 58.0 | 56.3 | 55.0 | 60.3 | 60.2 | 61.8 | 1.6 | |
| CyCTR (Zhang et al., 2021b) | 67.8 | 71.1 | 72.8 | 73.2 | 58.0 | 60.5 | 58.0 | 57.5 | 64.2 | 65.6 | 1.4 | |
| TAFT-SE on FCN(Ours) | 46.75 | 55.21 | 60.55 | 68.79 | 55.14 | 64.94 | 51.12 | 59.26 | 53.39 | 62.05 | 8.66 | |
| TAFT-SE on Deeplab V3+(Ours) | 49.97 | 58.27 | 64.08 | 70.63 | 57.11 | 68.24 | 55.61 | 63.50 | 56.69 | 65.16 | 8.47 | |
| FWB (Nguyen & Todorovic, 2019) | ResNet-101 | 51.30 | 54.84 | 64.49 | 67.38 | 56.71 | 62.16 | 52.24 | 55.30 | 56.19 | 59.92 | 3.73 |
| DAN (Wang et al., 2020) | 54.7 | 57.9 | 68.6 | 69.0 | 57.8 | 60.1 | 51.6 | 54.9 | 58.2 | 60.5 | 2.3 | |
| PFENet (Tian et al., 2020) | 60.5 | 62.8 | 69.4 | 70.4 | 54.4 | 54.9 | 55.9 | 57.6 | 60.1 | 61.4 | 1.3 | |
| ASGNet (Li et al., 2021) | 59.84 | 64.55 | 67.43 | 71.32 | 55.59 | 64.24 | 54.39 | 57.33 | 59.31 | 64.36 | 5.05 | |
| CWT (Lu et al., 2021) | 56.9 | 62.6 | 65.2 | 70.2 | 61.2 | 68.8 | 48.8 | 57.2 | 58.0 | 64.7 | 6.7 | |
| CyCTR (Zhang et al., 2021b) | 69.3 | 73.5 | 72.7 | 74.0 | 56.5 | 58.6 | 58.6 | 60.2 | 64.3 | 66.6 | 2.3 | |
| TAFT-SE on FCN(Ours) | 49.98 | 58.57 | 61.36 | 69.90 | 55.15 | 66.18 | 53.30 | 60.68 | 54.95 | 63.83 | 8.88 | |
| TAFT-SE on Deeplab V3+ (Ours) | 51.70 | 61.58 | 64.99 | 72.60 | 58.29 | 70.96 | 56.92 | 64.86 | 57.98 | 67.50 | 9.52 | |
| Models | Backbone | mIoU | ||||||||||
| split-0 | split-1 | split-2 | split-3 | mean | ||||||||
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | |||
| OSLSM (Amirreza Shaban & Boots, 2017) | VGG-16 | - | - | - | - | - | - | - | - | 61.3 | 61.5 | 0.2 |
| co-FCN (Rakelly et al., 2018) | - | - | - | - | - | - | - | - | 60.1 | 60.2 | 0.1 | |
| SG-One (Zhang et al., 2020) | - | - | - | - | - | - | - | - | 63.1 | 65.9 | 2.8 | |
| PANet (Wang et al., 2019) | - | - | - | - | - | - | - | - | 66.5 | 70.7 | 4.2 | |
| CANet (Zhang et al., 2019b) | ResNet-50 | 71.0 | 74.2 | 76.7 | 80.3 | 54.0 | 57.0 | 67.2 | 66.8 | 66.2 | 69.6 | 3.4 |
| PGNet (Zhang et al., 2019a) | - | - | - | - | - | - | - | - | 69.9 | 70.5 | 0.6 | |
| CRNet (Liu et al., 2020a) | - | - | - | - | - | - | - | - | 69.9 | 71.5 | 1.6 | |
| PPNet (Liu et al., 2020b) | - | - | - | - | - | - | - | - | 69.19 | 75.76 | 6.17 | |
| PFENet (Tian et al., 2020) | - | - | - | - | - | - | - | - | 73.3 | 73.9 | 0.6 | |
| ASGNet (Li et al., 2021) | - | - | - | - | - | - | - | - | 69.2 | 74.2 | 5.0 | |
| SCL (PFENet) (Zhang et al., 2021a) | - | - | - | - | - | - | - | - | 71.9 | 72.8 | 0.9 | |
| TAFT-SE on FCN(Ours) | 67.40 | 71.52 | 74.44 | 79.96 | 68.15 | 76.07 | 68.23 | 74.87 | 69.56 | 75.61 | 6.05 | |
| TAFT-SE on Deeplab V3+(Ours) | 69.04 | 73.37 | 78.56 | 81.52 | 70.27 | 78.27 | 72.15 | 77.55 | 72.51 | 77.68 | 5.17 | |
| DAN (Wang et al., 2020) | ResNet-101 | - | - | - | - | - | - | - | - | 71.9 | 72.3 | 0.4 |
| PFENet (Tian et al., 2020) | - | - | - | - | - | - | - | - | 72.9 | 73.5 | 0.6 | |
| ASGNet (Li et al., 2021) | - | - | - | - | - | - | - | - | 71.7 | 75.2 | 3.5 | |
| CyCTR (Zhang et al., 2021b) | - | - | - | - | - | - | - | - | 72.9 | 75.0 | 2.1 | |
| TAFT-SE on FCN(Ours) | 68.83 | 73.71 | 75.89 | 80.41 | 67.38 | 77.04 | 69.80 | 76.30 | 70.41 | 76.87 | 6.46 | |
| TAFT-SE on Deeplab V3+ (Ours) | 70.20 | 75.51 | 78.82 | 83.28 | 72.32 | 80.39 | 72.57 | 78.42 | 73.48 | 79.40 | 5.92 | |
| Models | Backbone | mIoU | ||||||||||
| split-0 | split-1 | split-2 | split-3 | mean | ||||||||
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | |||
| PANet (Wang et al., 2019) | ResNet50 | - | - | - | - | - | - | - | - | 20.9 | 29.7 | 8.8 |
| RPMMs (Yang et al., 2020) | 29.53 | 33.82 | 36.82 | 41.96 | 28.94 | 32.99 | 27.02 | 33.33 | 30.58 | 35.52 | 4.94 | |
| PPNet (Liu et al., 2020b) | 28.09 | 38.97 | 30.81 | 40.81 | 29.49 | 37.07 | 27.70 | 37.28 | 29.03 | 38.53 | 9.50 | |
| ASGNet (Li et al., 2021) | 34.89 | 40.99 | 36.94 | 48.28 | 34.33 | 40.10 | 32.08 | 40.54 | 34.56 | 42.48 | 7.92 | |
| CWT (Lu et al., 2021) | 32.2 | 40.1 | 36.0 | 43.8 | 31.6 | 39.0 | 31.6 | 42.4 | 32.9 | 41.3 | 8.4 | |
| MMNet (Wu et al., 2021) | 34.9 | 38.5 | 41.0 | 39.6 | 37.8 | 38.4 | 35.2 | 35.5 | 37.2 | 38.0 | 0.8 | |
| CyCTR (Zhang et al., 2021b) | 38.9 | 41.1 | 43.0 | 48.9 | 39.6 | 45.2 | 39.8 | 47.0 | 40.3 | 45.6 | 5.3 | |
| TAFT-SE on FCN(Ours) | 29.96 | 39.73 | 32.64 | 45.25 | 31.08 | 41.96 | 29.64 | 39.03 | 30.83 | 41.49 | 10.66 | |
| TAFT-SE on Deeplab V3+(Ours) | 31.12 | 43.45 | 35.23 | 49.26 | 33.04 | 46.66 | 31.07 | 43.21 | 32.62 | 45.64 | 13.02 | |
| FWB (Nguyen & Todorovic, 2019) | ResNet101 | 16.98 | 19.13 | 17.98 | 21.46 | 20.96 | 23.93 | 28.85 | 30.08 | 21.19 | 23.65 | 2.46 |
| DAN (Wang et al., 2020) | - | - | - | - | - | - | - | - | 24.4 | 29.6 | 5.2 | |
| PFENet (Tian et al., 2020) | 34.3 | 38.5 | 33.0 | 38.6 | 32.3 | 38.2 | 30.1 | 34.3 | 32.4 | 37.4 | 5.0 | |
| SCL (PFENet) (Zhang et al., 2021a) | 36.4 | 38.9 | 38.6 | 40.5 | 37.5 | 41.5 | 35.4 | 38.7 | 37.0 | 39.9 | 2.9 | |
| CWT (Lu et al., 2021) | 30.3 | 38.5 | 36.6 | 46.7 | 30.5 | 39.4 | 32.2 | 43.2 | 32.4 | 42.0 | 9.6 | |
| TAFT-SE on FCN(Ours) | 31.00 | 41.95 | 32.81 | 46.00 | 32.32 | 44.02 | 30.37 | 40.53 | 31.63 | 43.13 | 11.50 | |
| TAFT-SE on Deeplab V3+ (Ours) | 32.08 | 46.01 | 36.10 | 49.61 | 34.96 | 48.47 | 32.40 | 43.94 | 33.89 | 47.01 | 13.12 | |
A.2 Comparison with Concurrent Work
As of writing of our present submission, we came across a concurrent work that is worthy of mentioning. CyCTR of (Zhang et al., 2021b) proposes to use a transformer block to establish cycle consistency relationship among query and support features through cross-attention between features. The method is used in conjunction with the existing PFENet architecture. Similar to our work, CyCTR transforms the feature to conduct few-shot segmentation. Also, our SE module and CyCTR both utilize the same multi-head scaled-dot product attention for self-attention. Our method, however, is different from CyCTR in the sense that our method transforms the feature via linear transformation, while CyCTR transforms the features nonlinearly through the attention layer. Also, while CyCTR conducts the attention between the pixels from the different features to correlate different features, the attention module in our SE module conducts the self-attention among the pixels from the same feature to capture the context in the feature. Furthermore, CyCTR is applied upon the different few-shot segmentation method of PFENet and enhances few-shot segmentation capability of PFENet. On the other hand, our TAFT-SE method is combined with the semantic segmentation model such as Deeplab V3+, which is not designed for few-shot setting, and newly adds the few-shot segmentation capability to the model. CyCTR outperforms the previous SOTA methods in both 1-shot mIoU and 5-shot mIoU, for both PASCAL- and COCO-. We compare the performance of CyCTR with our TAFT-SE on Deeplab V3+ in Tables 4,5 and 6. For 1-shot mIoU, CyCTR performs better than our TAFT-SE on Deeplab V3+ in both PASCAL- and COCO- datasets, for both ResNet-50 and ResNet-101 backbones. However for 5-shot mIoU, TAFT-SE on Deeplab V3+ outperforms CyCTR in COCO- dataset. For PASCAL-, TAFT-SE on Deeplab V3+ shows the similar level of performance in ResNet-50 backbone, and shows better performance in ResNet-101 backbone compared to CyCTR. For PASCAL- FBIoU, our TAFT-SE surpasses the CyCTR in both 1-shot and 5-shot. In all experiments, TAFT-SE on Deeplab V3+ shows greater than CyCTR.
A.3 Additional Experiments with Various Numbers of Shots
In order to confirm the quickly improving performance of the TAFT-SE extended segmentator with the number of shots, we compare mean mIoU scores from 1-shot to 10-shot in Table 7 between TAFT-SE on Deeplab V3+ and the tailor-designed few-shot segmentator PFENet. Between PASCAL- and COCO-, we chose the PASCAL- dataset on which our method showed relatively weaker performance. The results clearly show that PFENet gains only little as the shot number increases. In fact, its 10-shot performance is actually worse than 7-shot performance. On the other hand, TAFT-SE on Deeplab V3+ improves quickly as the number of shots increases, starting to outperform PFENet on 3 shots. The performance gain of the TAFT-SE based extension grows as it is exposed to more shots.
| Models | 1-shot | 3-shot | 5-shot | 7-shot | 10-shot | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | mIoU | mIoU | mIoU | mIoU | ||||||
| PFENet∗ (Tian et al., 2020) | 60.84 | - | 61.60 | 0.76 | 61.81 | 0.21 | 62.03 | 0.22 | 61.77 | -0.26 |
| TAFT-SE on Deeplab V3+ | 56.69 | - | 63.90 | 7.21 | 65.16 | 1.26 | 65.98 | 0.82 | 66.64 | 0.66 |
-
•
∗ PFENet performances are measured with our reproduction based on github code of (Tian et al., 2020).
A.4 Visualization of Prototype and Reference Vectors
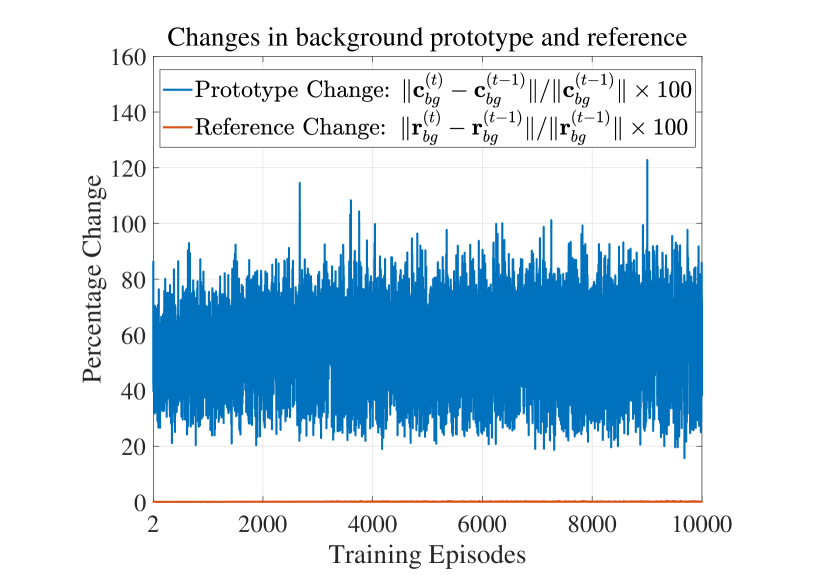
In Section 2.2, we stated that the prototypes change significantly while the reference vectors changes only by little. To confirm this, we collect the prototypes and the reference vectors of foreground and background classes from the first episode to the 10,000th episode during meta-training. Then we compute the Euclidean distances and for and to measure the changes. In Figure 5, we visualize the percentage changes of the prototypes and reference vectors during meta-training. To focus on the reference vector in TAFT module, we utilize TAFT on Deeplab V3+ without SE module for this experiment. We adopt the ResNet-50 network as the backbone encoder. We can see that the prototypes undergo significant changes while the relative changes in the reference vectors are nearly invisible. Although the class in each episode is randomly sampled and the class may or may not change from one episode to the next, the changes in prototype are always much larger than the changes in reference vectors, with or without class changes.

A.5 Ablation Study on Transforming Low Level Feature
In the experiments on TAFT-SE on Deeplab V3+ in the main paper, we do not apply the feature transformation via TAFT to the low-level feature, since it contains shape information which can be considered general. In Tables 8 and 9, we explore the effect of applying feature transformation to the low-level feature of Deeplab V3+. We apply the low-level feature transformation by adding another reference vector set for low-level feature, and training it using additional regression loss. The transformation matrix is constructed using the additional reference vectors and the prototypes computed from low-level support features. In order to more clearly understand the effect of low-level feature transformation, we do not utilize the SE module in this experiment again; we use the TAFT on Deeplab V3+ model. The results in Tables 8 and 9 show that applying feature transformation at low-level feature does not bring any gain in performance; it actually degrades 1-shot and 5-shot mIoU by 1.39 and 0.74, and 1-shot and 5-shot FBIoU by 0.70 and 0.61.
| Models | split-0 | split-1 | split-2 | split-3 | mean |
|---|---|---|---|---|---|
| TAFT on Deeplab V3+ (1-shot, w/ low-level TAFT) | 45.59 | 56.98 | 50.01 | 47.48 | 50.02 |
| TAFT on Deeplab V3+ (1-shot) | 48.00 | 57.64 | 52.75 | 47.26 | 51.41 |
| TAFT on Deeplab V3+ (5-shot, w/ low-level TAFT) | 55.91 | 67.88 | 62.93 | 58.86 | 61.40 |
| TAFT on Deeplab V3+ (5-shot) | 57.36 | 68.03 | 63.71 | 59.45 | 62.14 |
| Models | split-0 | split-1 | split-2 | split-3 | mean |
|---|---|---|---|---|---|
| TAFT on Deeplab V3+ (1-shot, w/ low-level TAFT) | 66.82 | 74.27 | 67.83 | 66.75 | 68.91 |
| TAFT on Deeplab V3+ (1-shot) | 67.00 | 75.12 | 69.44 | 66.87 | 69.61 |
| TAFT on Deeplab V3+ (5-shot, w/ low-level TAFT) | 72.07 | 79.81 | 74.90 | 74.70 | 75.37 |
| TAFT on Deeplab V3+ (5-shot) | 72.94 | 80.15 | 75.49 | 75.35 | 75.98 |
Appendix B Additional Qualitative Results
In Figures 6 and 7, we display additional qualitative results of TAFT-SE on Deeplab V3+. The 1-shot and 5-shot segmentation results of airplane, bird, bus, car, dog, motorcycle, sheep and train classes are visualized. As done in the main paper, we show the support set images with the support labels together at the bottom left, and the query images with the prediction results. From these results, we can observe that the quality of segmentation is improved from 1-shot to 5-shot.

