TAOTF: A Two-stage Approximately Orthogonal Training Framework in Deep Neural Networks
Abstract
The orthogonality constraints, including the hard and soft ones, have been used to normalize the weight matrices of Deep Neural Network (DNN) models, especially the Convolutional Neural Network (CNN) and Vision Transformer (ViT), to reduce model parameter redundancy and improve training stability. However, the robustness to noisy data of these models with constraints is not always satisfactory. In this work, we propose a novel two-stage approximately orthogonal training framework (TAOTF) to find a trade-off between the orthogonal solution space and the main task solution space to solve this problem in noisy data scenarios. In the first stage, we propose a novel algorithm called polar decomposition-based orthogonal initialization (PDOI) to find a good initialization for the orthogonal optimization. In the second stage, unlike other existing methods, we apply soft orthogonal constraints for all layers of DNN model. We evaluate the proposed model-agnostic framework both on the natural image and medical image datasets, which show that our method achieves stable and superior performances to existing methods.
1 Introduction
In the past decades, Deep Neural Network (DNN) models, especially the Convolutional Neural Network (CNN) and Vision Transformer (ViT), have developed rapidly in the computer vision field. Although these models can automatically learn the hidden deep features from images, there still exist several problems with them. For example, the parameterization or model capacity utilization is insufficient, gradient explosion or disappearance, and there exists significant redundancy among different feature channels [Wang et al., 2020].
In view of this, orthogonality constraints, including the hard and soft ones, were recently used in the field of deep learning to improve model performance. When the filters are learned to be as orthogonal as possible, they become irrelevant and reduce the redundancy of learning features [Wang et al., 2020]. Then the model capacity is made full use of, and the ability of feature expression is improved as well. For example, a hard orthogonality constraint was imposed in CNN [Harandi and Fernando, 2016], and retraction-based Riemannian optimization algorithms were used to solve it. A soft orthogonality constraint was imposed in CNN [Wang et al., 2020] with an orthogonal penalty loss.
However, in these works, inappropriate orthogonal constraints are often imposed, ignoring a more important advantage of orthogonal constraints: robustness to noise samples (e.g., noise, blur, exposure and so on). Applying appropriate orthogonal constraints can make each layer of the model closer to a 1-Lipschitz function. Given a small perturbation to input , the change of output is bounded to be low. Therefore, the model enjoys robustness under noisy data. for example, if we only use the hard orthogonality constraint, one issue is that the solution set of the primary optimization objective does not necessarily intersect with the hard orthogonality constraints [Fei et al., 2022]. In other words, if the weight matrices of these models are too close to orthogonal matrices, the performance may be worse. Meanwhile, the computing cost of the hard constraints is always expensive. On the other hand, if we only use the soft orthogonality constraint, it is ineffective to make the weight matrix orthogonal enough, and thus reduces layers’ 1-Lipschitz property. More detailed explanations about these issues will be presented in Sec. 3.1.
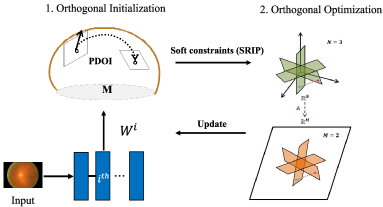
In this work, to solve the above issues, we propose a two-stage approximately orthogonal training framework (TAOTF) to find the trade-off between the Stiefel manifold and the main task solution set. More specifically, in the first stage, we propose a novel algorithm called polar decomposition-based orthogonal initialization (PDOI) to find a starting point in the Stiefel manifold. This process is somewhat similar to the hard orthogonal constraints but with a much smaller computational cost. Then, in the second stage, we implement soft orthogonal regulation with an orthogonal penalty loss (e.g., spectral restricted isometry property (SRIP) [Bansal et al., 2018]) on all layers of DNN, and use a common European optimizer (e.g., Adam) to find an optimal point. We train the CNN and ViT models using the proposed TAOTF framework and then evaluate these TAOTF-based models on both natural and medical images.
To evaluate the robustness of our framework compared to other methods, we simulate possible data challenges with datasets and conduct comparative experiments, which demonstrate the superiority of our framework. Except for these two models, this novel framework can be also used together with other DNN models, e.g., the Recurrent Neural Network (RNN), to further improve the robustness performances in real scene datasets.
In summary, three contributions can be summarized as follows:
-
(1)
We propose a novel model-agnostic framework called TAOTF by combining the advantages of soft and hard orthogonality constraints to improve the robustness performances in DNNs, especially the CNN and ViTs.
-
(2)
In the first stage of TAOTF, to find a good starting point for orthogonal optimization, we propose a novel algorithm called PDOI to search near the initial point and update parameter matrices.
-
(3)
We also conduct extensive experiments in many image datasets, including natural and medical ones. The experimental results show that TAOTF-based models have better robustness performances to noisy perturbations than existing methods.
2 Related Works
In this section, we mainly review some related works in the literature about the applications of hard and soft orthogonality constraints in the DNN models, especially the CNN and Transformers.
2.1 Hard orthogonality constraints
To our knowledge, the first work using hard orthogonality constraints in CNN was [Harandi and Fernando, 2016], where the Stiefel layer was introduced, and Riemannian optimization techniques on matrix manifolds were used in AlexNet and VGG. Then, a new backpropagation with a variant of stochastic gradient descent (SGD) on Stiefel manifolds [Huang and Van Gool, 2017] was exploited to update the structured connection weights. In [Huang et al., 2018a], the authors generalized such square orthogonal matrices to rectangular ones, and formulated this problem in Feed-forward Neural Networks (FNNs) as an optimization problem over multiple dependent Stiefel manifolds. Recently, in [Lezcano-Casado and Martınez-Rubio, 2019], an alternative approach was proposed based on a parameterization stemming from Lie group theory, and the constrained optimization problem was transformed into an unconstrained one over a Euclidean space.
2.2 Soft orthogonality constraints
The soft orthogonality constraints were mainly solved using a penalty loss function calculating the discrepancy between the identity matrix and the product of weight matrix and its transpose , e.g., . To our knowledge, the first work using this soft orthogonality constraint in training DNNs was [Pascanu et al., 2013], where it was used in Recurrent Neural Networks (RNNs) to help avoid gradient vanishing/ explosion, and the first work using the soft orthogonality constraint in CNNs was [Xie et al., 2017], which helped to stabilize the layer-wise distribution of activations. In [Bansal et al., 2018], to enforce the orthogonality regularizations, the authors used a novel regularization form for orthogonality in CNNs, named Spectral Restricted Isometry Property (SRIP). In [Wang et al., 2020], a new orthogonality based CNN (OCNN) was proposed, and good results on multiple natural datasets were achieved approving their robustness under attack. In [Gehlot et al., 2021], class vectors were applied to improve the ability of the model to resist the label noise of datasets for cancer diagnosis.
In transformers, orthogonal weights can also improve numerical stability during training and upper-bound the Lipschitz constant of linear transformations. In [Zhang et al., 2021], they first applied the basic orthogonality constraint on transformers and achieved good results in several NLP tasks such as neural machine translation and sequence-to-sequence dialogue generation. In [Fei et al., 2022], they developed an orthogonal Vision Transformer (O-ViT), which also used methods like [Lezcano-Casado and Martınez-Rubio, 2019] to impose orthogonality constraints on self-attention layers.
3 Methods
In this section, we will detailedly introduce the new training framework TAOTF (Fig. 1). In Sec. 3.1, we will explain the reason why we propose a new two-stage orthogonal training framework. In Sec. 3.2, the proposed algorithm PDOI to find a good optimization starting point in the first stage will be introduced. In Sec. 3.3, we will introduce the soft constraints we use in the second stage.
3.1 Why we need a two-stage framework?
In a DNN model, it is well known that, if is the weight matrix of the -th layer, then the training of is to solve the following optimization problem:
| (1) |
where is the loss function. Let
be the Stiefel manifold, where , and denotes the identity matrix of size . As explained in Sec. 1, to reduce the redundancy of learning features, we would like to impose orthogonality on the weight matrix .
One approach is to use a hard orthogonality constraint, and then problem (1) becomes a Riemannian optimization problem [Absil et al., 2009] on the Stiefel manifold [Li et al., 2019], i.e.,
| (2) |
In the iterations of the algorithm to solve problem [Absil et al., 2009], the weight matrix will always stay in , and thus can be kept columnly orthogonal. The other approach is to use a soft orthogonality constraint, and then problem (1) becomes
| (3) |
where and is a regularization term to enforce the orthogonality of .

As introduced in Sec. 2, the above hard and soft orthogonality constraints were both used to improve the robustness performances of DNN or ViT models. However, as explained in Fig. 2, the solution matrices of problem (1) maybe not be in . Therefore, if we only use the hard orthogonality constraint to solve problem (2), the solution may be too restrictive. In other words, the solution set of the primary optimization objective does not necessarily intersect with the hard orthogonality constraints [Fei et al., 2022], and thus the performance of the trained DNN models may degrade. On the other hand, if we only use the soft orthogonality constraint to solve problem (3), the solution may be far away from , and thus the DNN models may still suffer from the parameter redundancy, and it is not robust enough as well.
Enforcing proper orthogonality constraints can generate a more uniform spectrum [Wang et al., 2020], which makes network layers closer to a 1-Lipschitz function like
| (4) |
Given a slight perturbation to the input , the variation of the output is bounded low, producing a robust and less sensitive representation of data perturbations.
Therefore, in this work, we propose a novel TAOTF framework, which includes two stages at each iteration to find the trade-off between the search space of the main task and the orthogonality constraint. From a perspective of optimization theory, it can be understood that we first solve problem (2) to calculate a good starting point, and then solve problem (3). It will be seen in Sec. 4 that, although the TAOTF framework includes two stages, it still has competitive convergence speed. One reason is the use of a projection-based PDOI algorithm in the first stage, which does not need to calculate the retraction map. The other reason is that we control the iteration numbers at the first stage.
3.2 First Stage: Orthogonal Initialization
To solve the problem (2), the retraction-based optimization algorithm [Absil et al., 2009] was proposed in recent years. However, as the retraction-based algorithms are generally expensive, in this work, inspired by low-rank orthogonal approximation of tensors [Chen and Saad, 2009], we propose a novel algorithm PDOI in Algorithm 1, to find a local optimum as the starting point for orthogonal optimization of the second stage. Although the global convergence of the is not determined, under this mild condition, the input point can be converged (locally) to an extreme point by the PDOI algorithm nearby, which can be used as the starting point for the next stage. The initial point found in this way, on the one hand, satisfies the constraint of the Stifel manifold, and on the other hand, finds a point closer to the main task search space on the Stifel manifold with low computing costs.
Input: a starting point , a positive constant .
Output: , .
| (5) |
The PDOI algorithm employs an alternating procedure (iterating through , ,…,,…,), where in each step all but one () parameters are fixed. In general, algorithms of this type, including alternating least squares, are not guaranteed to global convergence, but the iterations can search for points closer to the main task on the Stiefel manifold. Moreover, of the generated parameter sequence, every converging subsequence converges to a stationary point of the objective function, which can be a good starting point from the perspective of optimization theory.
As proved in [Hu et al., 2020], the initial weights from the orthogonal group not only speeds up convergence relative to the standard Gaussian initialization with iid weights but close to isometry during training to enable efficient convergence and the 1-Lipschitz property. The algorithm PDOI not only guarantees that the starting point must be on the Stiefel manifold (initial weights in the orthogonal group), but, through several iterations, can find the better starting point near the input point suitable for both orthogonal constraints and main tasks. Extensive experiments have been conducted to prove this view.
3.3 Second Stage: Orthogonal Optimization
Recall that the Restricted Isometry Property (RIP) condition of a matrix means that, for all vectors that are -sparse, there exists a small such that
| (6) |
The positive constant in equation (6) is called the constrained isometric constant. If is very small, it can be interpreted as those columns are approximately orthogonal. If the equation (6) is satisfied with for all -sparse vectors , then the matrix satisfies the isometric characteristics of k-order constraints. The RIP can be used to measure the similarity between the subset composed of columns in a matrix and an orthogonal matrix.
The extreme case with was also considered in [Bansal et al., 2018], where the RIP condition will force the whole matrix to be very close to an orthogonal one, i.e.,
| (7) |
In this case, the RIP condition (7) is termed as the Spectral Restricted Isometry Property (SRIP) regularization.
Existing methods [Wang et al., 2020, Zhang et al., 2021, Bansal et al., 2018, Fei et al., 2022, Harandi and Fernando, 2016, Gong et al., 2021] always only impose orthogonality constraints on the deep convolutional layers or the self-attention layer of Transformers. However, if we only impose orthogonality constraints on only some layers of the network, the different levels of orthogonality will destroy the 1-Lipschitz property of the global model and damage model robustness against small perturbations. And we proved this view through extensive experiments in Sec. 4. Therefore, we impose soft constraints like SRIP regulation (7) on all layers of the model to solve the orthogonal optimization in the second stage.
This process is to separate the starting point found in the first stage from the Stiefel manifold, and further explore the main task solution space but is still limited by the Stiefel manifold. Through such a process, the trade-off of the main task and the orthogonal constraints can be well found, and the final loss function in (3) is
| (8) |
| Experiment on Noisy APTOS 2019 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clean | Noise | Blur | Weather | Digital | |||||||||
| Methods | Clean | Gaussian. | ISO. | Multiplicative. | Gauss. | Median | Motion | Optical | Rotate | RGB | Bright | Frog | Saturation |
| ResNet | |||||||||||||
| ResNet+SRIP [Bansal et al., 2018] | |||||||||||||
| ResNet+OCNN [Wang et al., 2020] | |||||||||||||
| ResNet+hard constraints | |||||||||||||
| ResNet+WaveCNet [Li et al., 2021a] | 86.23 | ||||||||||||
| TAOTF-ResNet (Ours) | 92.53 | 93.30 | 92.12 | 92.66 | 89.76 | 82.84 | 84.87 | 76.93 | 92.66 | 91.76 | 88.38 | 92.84 | |
| ViT3 | |||||||||||||
| ViT3+orth-initialization | |||||||||||||
| ViT3+hard constraints | |||||||||||||
| ViT3+SRIP | |||||||||||||
| ViT3+satge2 (self-attention layers) | |||||||||||||
| ViT3+satge2 (transformer blocks) | 75.79 | ||||||||||||
| ViT3+satge2 (patch embdding) | |||||||||||||
| TAOTF-ViT3 (Ours) | 95.87 | 95.87 | 95.81 | 95.82 | 86.23 | 80.92 | 87.14 | 74.94 | 95.87 | 95.56 | 74.70 | 95.29 | |
| ViT6 | |||||||||||||
| ViT6+hard constraints | |||||||||||||
| ViT6+SRIP | |||||||||||||
| TAOTF-ViT6 (Ours) | 94.06 | 94.05 | 93.12 | 93.51 | 78.82 | 76.30 | 76.45 | 79.62 | 69.82 | 93.30 | 92.84 | 76.48 | 90.67 |
| Experiment on Skin Lesion Classification | |||||||||||||
| ResNet50 | |||||||||||||
| ResNet50+OCNN | |||||||||||||
| ResNet50+WaveCNet | |||||||||||||
| ResNet50+SRIP | |||||||||||||
| ResNet50+hard constraints | |||||||||||||
| TAOTF-ResNet50 (Ours) | 94.08 | 94.06 | 92.26 | 94.02 | 93.69 | 92.63 | 91.72 | 94.36 | 63.54 | 91.29 | 90.68 | 88.12 | 86.95 |
| Experiment on Glaucoma Detection | |||||||||||||
| ResNet | |||||||||||||
| ResNet+SRIP | |||||||||||||
| ResNet+OCNN | |||||||||||||
| ResNet+hard constraints | |||||||||||||
| TAOTF-ResNet (Ours) | 94.67 | 94.50 | 94.00 | 93.97 | 93.92 | 93.17 | 93.67 | 93.77 | 84.00 | 93.97 | 93.67 | 91.09 | 92.84 |
4 Experiments
In this section, to evaluate the efficiency of the proposed TAOTF framework, we conduct several experiments of the TAOTF-based DNN models on various datasets, including natural and medical ones. We implement these models on top of the deep learning framework PyTorch. Unless otherwise stated, the experimental results are measured in Top-1 Accuracy.
4.1 Experiments on Kaggle APTOS 2019
4.1.1 Dataset
We first use the public dataset Kaggle APTOS 2019, which was collected by the Aravind Eye Hospital in India’s rural areas, to evaluate the proposed TAOTF-CNN and TAOTF-ViT models.
This dataset contains 3662 retinal images, and the labels were provided by the clinicians who rated the development of Diabetic retinopathy (DR) in each image by a scale of “0, 1, 2, 3, 4”, meaning “no DR”, “mild”, “moderate”, “severe” and “proliferative DR”, respectively. Note that this dataset doesn’t have equal distributions among the different classes. For example, it has far more normal data with the label “0” than other classes. We randomly shuffle the entire dataset into three subgroups, i.e., training (70), validation (10), and testing (20).
4.1.2 Image Preprocessing
As different fundus images have different length-width ratios, and the width of different black edges around the eyeball is also different, we can not straightly resize the images based on their sizes. Therefore, in this experiment, we resize the fundus images based on the eyeball radius (), and then use the feature enhancement method. In this process, the difference between the original image and the Gaussian blurred one (equivalent to the background) is used to enhance the feature.
4.1.3 Models and Settings
We choose the ResNet18, ViT3 (3 transformer blocks), and ViT6 (6 transformer blocks) models to test the robustness performances of TAOTF-based models on the Diabetic Retinopathy classification task. For training these models, the total epoch of the training is 200. We start the learning rate with , with weight decay 1e-4. The weight of the regularization loss is , the model is trained using Adam, and the batch size is 8. In the above training process, we use CrossEntropyLoss (CE) for the criterion.
4.1.4 Experimental Results on Clean Dataset
Proper orthogonality constraints can help fully utilize the model capacity. We also have conducted ablation experiments for each part of the framework based on the ViT3 model.
The experimental results show that adding soft orthogonal constraints to all layers of DNN can help improve the model performance. The experimental results on the clean dataset are summarized in Tab. 2. It can be seen that the proposed TAOTF-based models have better performances than other methods.
4.1.5 Noisy Dataset for Testing Roubustness
To evaluate the robustness of TAOTF-based models compared with other methods, we ask for ophthalmologists and conclude 13 common data corruption of fundus images and classified into 4 types. Then we simulated these possible data challenges to build a noisy test set for test model robustness performances. For example, the geometric transformation could test model performance to the position deviation, viewing angle deviation, and data size deviation, the spatial transformation could test the model performance to the change of light, color, contrast, and brightness, and finally test the model performance to fuzzy images and images with more noise.
4.1.6 Experimental Results on Noisy Data
We also have conducted ablation experiments for each part of the framework based on the ViT3 model. The experimental results show that all parts of our framework have improved the robustness of the model to a certain extent. And the results of the test set are summarized in Tab. 1. It can be seen that the proposed TAOTF-based models have better robustness performances than other existing methods in this task. Because proper orthogonality makes each DNN layer more approximately a 1-Lipschitz function, yields representations that are robust and less sensitive to perturbations.
|
|
|
||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
92.53 | 92.46 | 92.53 | |||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
95.87 | 95.81 | 95.80 |
| Experiment on CIFAR-100 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Clean | Noise | Blur | Weather | Digital | |||||||||
| Methods | Clean | Gaussian. | ISO. | Multiplicative. | Gauss. | Median | Motion | Optical | Rotate | RGB | Bright | Frog | Saturation |
| WideResnet | |||||||||||||
| WideResnet+SRIP | |||||||||||||
| WideResnet+hard constraints | |||||||||||||
| TAOTF-WideResnet (Ours) | 71.09 | 61.06 | 45.66 | 56.02 | 20.24 | 33.89 | 47.15 | 57.56 | 59.04 | 69.52 | 69.21 | 71.01 | 65.35 |
| Experiment on CIFAR-10 | |||||||||||||
| MobileViT | |||||||||||||
| MobileViT+SRIP | 84.35 | ||||||||||||
| MobileViT+hard constraints | |||||||||||||
| TAOTF-MobileViT (Ours) | 81.44 | 75.33 | 77.94 | 75.10 | 74.32 | 77.72 | 82.20 | 72.35 | 83.49 | 84.97 | 84.57 | 83.17 | |


4.2 Experiments on Glaucoma Detection Dataset
4.2.1 Experimental Setup
For datasets, we choose a Kaggle Glaucoma Detection Dataset to test our framework performance. The dataset contains 650 images/OCT scans of the eyes. The labels were provided by clinicians who rated the Glaucoma in each image on a scale of “0, 1”, which means “No Glaucoma”, and “Glaucoma” respectively. We randomly shuffle the entire dataset into three subgroups, i.e., training (70), validation (10), and testing (20).
For the training process, in the experiments, we choose the ResNet18 model to classify Glaucoma and test the performance of our framework. We use the Ranger with , with weight decay 1e-3, and train it for 130 epochs. The weight of the regularization loss is . In the above training process, we use CE Loss as the criterion.
4.2.2 Experimental Results
4.3 Experiments on Skin Lesion Classification
4.3.1 Experiment Setup
For datasets, this dataset contains the training data for the ISIC 2019 challenge [Combalia et al., 2019], and datasets from previous years (2018 and 2017). [Tschandl et al., 2018] [Gutman et al., 2016]. The dataset contains 25331 images available to classify dermoscopic images among nine diagnostic categories. The labels were provided by clinicians who rated the classification of a skin lesion in each image on a scale of “0, 1, 2, 3, 4, 5, 6, 7, 8”, which means “Melanoma”, “Melanocytic nevus”, “Basal cell carcinoma”, “Actinic keratosis”, “Benign keratosis”, “Dermatofibroma”, “Vascular lesion”, “Squamous cell carcinoma”, “None of the above”. We randomly shuffled the entire dataset into three subgroups, i.e., training (80), validation (10), and testing (10).
|
|
|
||||
|---|---|---|---|---|---|---|
|
0.00713 | 0.996 | 0.837 | |||
|
0.00949 | 0.996 | 0.811 | |||
|
0.00697 | 0.997 | 0.843 |
For training, we choose ResNet-50 to test our framework. We use the Adam with , and train it for 100 epochs. The weight of the regularization loss is . In the above trainings, we use the CE Loss as the criterion.
4.3.2 Experimental Results
We compare our framework TAOTF with other methods. See Tab. 1 for a detailed comparison. The above results confirm that imposing proper orthogonality constraints for models has stronger robustness performances on this noisy test dataset.
4.4 Experiments on Brain MRI segmentation
4.4.1 Experiment Setup
The dataset contains brain MR images together with manual FLAIR abnormality segmentation masks. The dataset containing 3929 images was obtained from The Cancer Imaging Archive (TCIA). They correspond to 110 patients included in The Cancer Genome Atlas (TCGA) lower-grade glioma collection with at least fluid-attenuated inversion recovery (FLAIR) sequence and genomic cluster data available. We randomly shuffle the entire dataset into three subgroups, i.e., training (70), validation (10), and testing (20). We choose UNet [Ronneberger et al., 2015], which is composed of 10 convolution layers. Training takes 30 epochs with the TAOTF regularizer applied to the model. The weight of the regularization loss is and all of other settings retain as standard default.
4.4.2 Experiment Results
We compare TAOTF-based UNet with other methods. See Tab. 4 for a detailed comparison. The above results confirm that TAOTF-based models can help improve segmentation tasks.
|
|
|
||||
|---|---|---|---|---|---|---|
|
26.697 | 0.893 | 0.092 | |||
|
29.117 | 0.942 | 0.084 |
4.5 Experiments on CIFAR-10/CIFAR-100
4.5.1 Experiment Setup
For datasets, the CIFAR-10 dataset has a total of 60000 color images. These images are and are divided into 10 categories, with 6000 images in each category. Among them, 50000 images are used for training, another 10000 images are used for testing. The CIFAR-100 dataset has 100 categories, with 500 training images and 100 testing images per category.
For training, in the first dataset CIFAR-10, we choose the MobileViT-s [Mehta and Rastegari, 2021], which combined with the transformers and CNNs, to test our framework performance on the CIFAR-10 dataset. We use the AdamW with to train it for 60 epochs. In the second dataset, we choose 28-depth WideResNet [Zagoruyko and Komodakis, 2016] to test our framework performance on the CIFAR-100 dataset further. We use the Adam with to train it for 80 epochs. The weight of the regularization loss is . In the above trainings, the criterion chosen is CE Loss with 0.1 label smoothing to reduce overfitting.
4.5.2 Experimental Results
We compare our framework TAOTF with other methods. See Tab. 3 for a detailed comparison. The above results confirm that TAOTF-based models can also resist the corruption of natural images to a certain extent.
To better understand how our framework works, we design a simple auxiliary denoising experiment on CIFAR-10. We add the same intensity of noise on CIFAR-10 and use a simple CNN model (16 layers) to denoising it. See Tab. 5 for a detailed comparison. Our TAOTF-based models can ignore small input perturbations(e.g., noise, blur), enjoying robustness under noisy data.
5 Conclusion
According to the practical difficulties encountered in data quality, we proposed a new two-stage training framework TAOTF, which can find a trade-off between the orthogonality constraint and the main task solution set, and propose an orthogonal initialization algorithm PDOI in the first stage that can find a good starting point for orthogonal optimization. Our framework was tested both on transformers and CNNs, and the experimental results show that our framework can significantly improve the robustness performances of these models facing noisy data.
References
- [Absil et al., 2009] Absil, P.-A., Mahony, R., and Sepulchre, R. (2009). Optimization algorithms on matrix manifolds. In Optimization Algorithms on Matrix Manifolds. Princeton University Press.
- [Alpher, 2002] Alpher, F. (2002). Frobnication. IEEE TPAMI, 12(1):234–778.
- [Alpher and Fotheringham-Smythe, 2003] Alpher, F. and Fotheringham-Smythe, F. (2003). Frobnication revisited. Journal of Foo, 13(1):234–778.
- [Alpher et al., 2004] Alpher, F., Fotheringham-Smythe, F., and Gamow, F. (2004). Can a machine frobnicate? Journal of Foo, 14(1):234–778.
- [Alpher and Gamow, 2005] Alpher, F. and Gamow, F. (2005). Can a computer frobnicate? In CVPR, pages 234–778.
- [Alshammari et al., 2022] Alshammari, S., Wang, Y.-X., Ramanan, D., and Kong, S. (2022). Long-tailed recognition via weight balancing.
- [Bansal et al., 2018] Bansal, N., Chen, X., and Wang, Z. (2018). Can we gain more from orthogonality regularizations in training deep networks? Advances in Neural Information Processing Systems, 31.
- [Bouville, 2008] Bouville, M. (2008). Crime and punishment in scientific research.
- [Chen and Saad, 2009] Chen, J. and Saad, Y. (2009). On the tensor svd and the optimal low rank orthogonal approximation of tensors. SIAM journal on Matrix Analysis and Applications, 30(4):1709–1734.
- [Clancey, 1979] Clancey, W. J. (1979). Transfer of Rule-Based Expertise through a Tutorial Dialogue. Ph.D. diss., Dept. of Computer Science, Stanford Univ., Stanford, Calif.
- [Clancey, 1983] Clancey, W. J. (1983). Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. In Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83), pages 556–560, Menlo Park, Calif. IJCAI Organization.
- [Clancey, 1984] Clancey, W. J. (1984). Classification Problem Solving. In Proceedings of the Fourth National Conference on Artificial Intelligence, pages 45–54, Menlo Park, Calif. AAAI Press.
- [Clancey, 2021] Clancey, W. J. (2021). The Engineering of Qualitative Models. Forthcoming.
- [Combalia et al., 2019] Combalia, M., Codella, N. C., Rotemberg, V., Helba, B., Vilaplana, V., Reiter, O., Carrera, C., Barreiro, A., Halpern, A. C., Puig, S., et al. (2019). Bcn20000: Dermoscopic lesions in the wild. arXiv preprint arXiv:1908.02288.
- [Dalmaz et al., 2021] Dalmaz, O., Yurt, M., and Çukur, T. (2021). Resvit: Residual vision transformers for multi-modal medical image synthesis. arXiv preprint arXiv:2106.16031.
- [Dosovitskiy et al., 2020] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR).
- [Engelmore and Morgan, 1986] Engelmore, R. and Morgan, A., editors (1986). Blackboard Systems. Addison-Wesley, Reading, Mass.
- [Fei et al., 2022] Fei, Y., Liu, Y., Wei, X., and Chen, M. (2022). O-vit: Orthogonal vision transformer. arXiv e-prints.
- [Fischer and Alemi, 2020] Fischer, I. and Alemi, A. A. (2020). Ceb improves model robustness. Entropy, 22(10):1081.
- [Gehlot et al., 2021] Gehlot, S., Gupta, A., and Gupta, R. (2021). A cnn-based unified framework utilizing projection loss in unison with label noise handling for multiple myeloma cancer diagnosis. Medical Image Analysis, page 102099.
- [Golub and Van Loan, 2013] Golub, G. H. and Van Loan, C. F. (2013). Matrix computations. JHU press.
- [Gong et al., 2021] Gong, C., Wang, D., Li, M., Chandra, V., and Liu, Q. (2021). Vision transformers with patch diversification. arXiv preprint arXiv:2104.12753.
- [Gutman et al., 2016] Gutman, D., Codella, N. C., Celebi, E., Helba, B., Marchetti, M., Mishra, N., and Halpern, A. (2016). Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (isbi) 2016, hosted by the international skin imaging collaboration (isic). arXiv preprint arXiv:1605.01397.
- [Harandi and Fernando, 2016] Harandi, M. and Fernando, B. (2016). Generalized backpropagation,’E tude de cas: Orthogonality. arXiv preprint arXiv:1611.05927.
- [He et al., 2016] He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pages 770–778.
- [Hu et al., 2020] Hu, W., Xiao, L., and Pennington, J. (2020). Provable benefit of orthogonal initialization in optimizing deep linear networks. arXiv preprint arXiv:2001.05992.
- [Huang et al., 2018a] Huang, L., Liu, X., Lang, B., Yu, A., Wang, Y., and Li, B. (2018a). Orthogonal weight normalization: Solution to optimization over multiple dependent stiefel manifolds in deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
- [Huang and Van Gool, 2017] Huang, Z. and Van Gool, L. (2017). A riemannian network for spd matrix learning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
- [Huang et al., 2018b] Huang, Z., Wu, J., and Van Gool, L. (2018b). Building deep networks on grassmann manifolds. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 32.
- [Jiang et al., 2019] Jiang, H., Yang, K., Gao, M., Zhang, D., Ma, H., and Qian, W. (2019). An interpretable ensemble deep learning model for diabetic retinopathy disease classification. In 2019 41st annual international conference of the IEEE engineering in medicine and biology society (EMBC), pages 2045–2048. IEEE.
- [Kumar and Karthikeyan, 2021] Kumar, N. S. and Karthikeyan, B. R. (2021). Diabetic retinopathy detection using cnn, transformer and mlp based architectures. In 2021 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), pages 1–2. IEEE.
- [LastName, 2014a] LastName, F. (2014a). The frobnicatable foo filter. Face and Gesture submission ID 324. Supplied as supplemental material fg324.pdf.
- [LastName, 2014b] LastName, F. (2014b). Frobnication tutorial. Supplied as supplemental material tr.pdf.
- [Lezcano-Casado and Martınez-Rubio, 2019] Lezcano-Casado, M. and Martınez-Rubio, D. (2019). Cheap orthogonal constraints in neural networks: A simple parametrization of the orthogonal and unitary group. In International Conference on Machine Learning (ICML), pages 3794–3803. PMLR.
- [Li et al., 2019] Li, J., Li, F., and Todorovic, S. (2019). Efficient riemannian optimization on the stiefel manifold via the cayley transform. In International Conference on Learning Representations (ICLR).
- [Li and Zhang, 2019] Li, J. and Zhang, S. (2019). Polar decomposition based algorithms on the product of stiefel manifolds with applications in tensor approximation. arXiv preprint arXiv:1912.10390.
- [Li et al., 2021a] Li, Q., Shen, L., Guo, S., and Lai, Z. (2021a). Wavecnet: Wavelet integrated cnns to suppress aliasing effect for noise-robust image classification. IEEE Transactions on Image Processing, 30:7074–7089.
- [Li et al., 2021b] Li, Q., Shen, L., Guo, S., and Lai, Z. (2021b). Wavecnet: Wavelet integrated cnns to suppress aliasing effect for noise-robust image classification. IEEE Transactions on Image Processing, 30:7074–7089.
- [Meghwanshi et al., 2018] Meghwanshi, M., Jawanpuria, P., Kunchukuttan, A., Kasai, H., and Mishra, B. (2018). Mctorch, a manifold optimization library for deep learning. arXiv preprint arXiv:1810.01811.
- [Mehta and Rastegari, 2021] Mehta, S. and Rastegari, M. (2021). Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. In International Conference on Learning Representations.
- [NASA, 2015] NASA (2015). Pluto: The ’other’ red planet. https://www.nasa.gov/nh/pluto-the-other-red-planet. Accessed: 2018-12-06.
- [Pascanu et al., 2013] Pascanu, R., Mikolov, T., and Bengio, Y. (2013). On the difficulty of training recurrent neural networks. In International conference on machine learning (ICML), pages 1310–1318. PMLR.
- [Rice, 1986] Rice, J. (1986). Poligon: A System for Parallel Problem Solving. Technical Report KSL-86-19, Dept. of Computer Science, Stanford Univ.
- [Robinson, 1980a] Robinson, A. L. (1980a). New ways to make microcircuits smaller. Science, 208(4447):1019–1022.
- [Robinson, 1980b] Robinson, A. L. (1980b). New Ways to Make Microcircuits Smaller—Duplicate Entry. Science, 208:1019–1026.
- [Rojas and Vinzamuri, 2020] Rojas, S. D. and Vinzamuri, B. (2020). Orthogonal laguerre recurrent neural networks. In Annual Conference on Neural Information Processing Systems.
- [Ronneberger et al., 2015] Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer.
- [Sun et al., 2021] Sun, R., Li, Y., Zhang, T., Mao, Z., Wu, F., and Zhang, Y. (2021). Lesion-aware transformers for diabetic retinopathy grading. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10938–10947.
- [Tschandl et al., 2018] Tschandl, P., Rosendahl, C., and Kittler, H. (2018). The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data, 5(1):1–9.
- [Wang et al., 2020] Wang, J., Chen, Y., Chakraborty, R., and Yu, S. X. (2020). Orthogonal convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 11505–11515.
- [Wang et al., 2018] Wang, X., Lu, Y., Wang, Y., and Chen, W.-B. (2018). Diabetic retinopathy stage classification using convolutional neural networks. In 2018 IEEE International Conference on Information Reuse and Integration (IRI), pages 465–471. IEEE.
- [Xie et al., 2017] Xie, D., Xiong, J., and Pu, S. (2017). All you need is beyond a good init: Exploring better solution for training extremely deep convolutional neural networks with orthonormality and modulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6176–6185.
- [Yong et al., 2020] Yong, H., Huang, J., Hua, X., and Zhang, L. (2020). Gradient centralization: A new optimization technique for deep neural networks. In European Conference on Computer Vision (ECCV), pages 635–652. Springer.
- [Zagoruyko and Komodakis, 2016] Zagoruyko, S. and Komodakis, N. (2016). Wide residual networks. In British Machine Vision Conference 2016. British Machine Vision Association.
- [Zhang et al., 2021] Zhang, A., Chan, A., Tay, Y., Fu, J., Wang, S., Zhang, S., Shao, H., Yao, S., and Lee, R. K.-W. (2021). On orthogonality constraints for transformers. In ACL/IJCNLP (2).
- [Zhou et al., 2016] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., and Torralba, A. (2016). Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pages 2921–2929.