TalkingEyes: Pluralistic Speech-Driven 3D Eye Gaze Animation
Abstract
Although significant progress has been made in the field of speech-driven 3D facial animation recently, the speech-driven animation of an indispensable facial component, eye gaze, has been overlooked by recent research. This is primarily due to the weak correlation between speech and eye gaze, as well as the scarcity of audio-gaze data, making it very challenging to generate 3D eye gaze motion from speech alone. In this paper, we propose a novel data-driven method which can generate diverse 3D eye gaze motions in harmony with the speech. To achieve this, we firstly construct an audio-gaze dataset that contains about 14 hours of audio-mesh sequences featuring high-quality eye gaze motion, head motion and facial motion simultaneously. The motion data is acquired by performing lightweight eye gaze fitting and face reconstruction on videos from existing audio-visual datasets. We then tailor a novel speech-to-motion translation framework in which the head motions and eye gaze motions are jointly generated from speech but are modeled in two separate latent spaces. This design stems from the physiological knowledge that the rotation range of eyeballs is less than that of head. Through mapping the speech embedding into the two latent spaces, the difficulty in modeling the weak correlation between speech and non-verbal motion is thus attenuated. Finally, our TalkingEyes, integrated with a speech-driven 3D facial motion generator, can synthesize eye gaze motion, eye blinks, head motion and facial motion collectively from speech. Extensive quantitative and qualitative evaluations demonstrate the superiority of the proposed method in generating diverse and natural 3D eye gaze motions from speech. The project page of this paper is: https://lkjkjoiuiu.github.io/TalkingEyes_Home/.
Index Terms:
Eye Gaze, Speech-driven, 3D Facial AnimationI Introduction
The computer graphics and vision community has witnessed a significant progress in the field of speech-driven 3D facial animation, largely due to the recent boom in generative models [1, 2, 3, 4, 5, 6, 7, 8] and audio-visual datasets [9, 10, 11, 12, 13]. Recent speech-driven 3D facial animation research is dedicated to generating mouth movements [12, 14, 15, 16, 17, 18, 19], head gestures [20, 21, 19] and emotional facial expressions [22, 23, 24], solely from speech signals. A considerable focus is on achieving synchronization between the animated mouth movements and the corresponding speech. However, the speech-driven animation of an indispensable facial component, eye gaze, has been overlooked by the recent research. Eyes, our “windows to the soul”, serve a crucial role in indicating an individual’s emotions, thoughts, feelings and intentions, thus enabling us to “see someone’s soul” through observing their eyes. In the absence of animated eye gaze, the synthesized 3D talking faces [12, 14, 15, 16, 17, 20, 21, 18, 19, 22, 23, 24] tend to look straight ahead with a static eye pose, resulting in an unnatural and wooden looking facial behavior. Although the recent scene-driven methods [25, 26] achieve impressive eye gaze animation for virtual characters, they require other multi-modal cues besides speech as input, such as scene image, scene context, director script and others.
In this work, we focus on task of generating the expressive 3D eye gaze motion from speech alone, which is in practice challenging for two reasons. 1) Weak Correlation. Eye gaze is one of many non-verbal cues used in communication. It is possible for a speaker to direct his gaze elsewhere while still effectively communicating his message via other verbal means. Mouth strongly correlates with speech, while eye gaze is weakly correlated. As a result, there exists a cross-modal one-to-many mapping between speech signal and eye gaze motion, which is in practice hard to be captured. 2) Data Scarcity. Existing audio-mesh datasets including VOCASET [12], BIWI [13], Speech4Mesh [27], Audio2Mesh [28] and DiffPoseTalk [21] focus on collecting facial motions (mainly mouth movements), but neglect the eye gaze capturing. A 3D dataset consisted of eye gaze motion, head motion and facial motion and their corresponding speech recordings is really scarce.
When we revisit the early research on computer animation, we find that pioneers in this field had proposed a few potential solutions [29, 30, 31, 32, 33], roughly divided into rule-based [29, 30] and learning-based methods [31, 32, 33]. However, both types of methods can only establish a one-to-one mapping between speech signal and eye gaze motion, resulting in deterministic and over-smoothed motion. Additionally, their motion capture systems used to collect eye gaze data in the lab, are costly and time-consuming for constructing large-scale in-the-wild dataset. Ultimately, these methods are mostly customized for specific avatars, making them difficult to integrate with generic 3D face models like FLAME [34].

To address the above challenges in task and the limitations in existing methods, we propose TalkingEyes, a data-driven method which can generate pluralistic 3D eye gaze motions in tune with the speech. To this end, we firstly construct 3D TalKing Eyes Dataset (TKED) by conducting 3D eye gaze fitting and 3D face reconstruction on the videos from audio-visual datasets to obtain pseudo ground truth. A lightweight 3D eye gaze fitting method named LightGazeFit is tailored to estimate the eyeball rotation from the low-quality Internet videos. TKED contains 14 hours of high-quality audio-mesh sequences featuring eye gaze, head and facial motions, thus facilitating the generation of 3D talking eyes, 3D talking head and 3D talking face simultaneously.
Secondly, we propose to model the eye gaze motion and head motion across two latent spaces, and subsequently predict them from speech via a temporal autoregressive model. A cascade of a variational autoencoder alongside a vector-quantized variational autoencoder (VAE-VQVAE) is utilized to learn continuous latent space for head motion and discrete latent space for eye gaze motion. This distinction is rooted in the different degrees of motion diversity, caused by the different rotation ranges of eyeballs and head. The head motion is generated and then used as condition in the generation of eye gaze motion, with respect to the synchronous nature of head and eye movements [37, 38, 32]. Furthermore, eye blinks are synthesized based on a statistical analysis on TKED. To create holistic animation, a speech-driven facial animation method [19] is employed to produce mouth and upper-face movements.
The contributions of this paper are summarized as follows:
-
•
TalkingEyes is the first holistic 3D talking avatar that can automatically and collectively generate eye gaze motion, eye blinks, head motion and facial motion from speech alone, as shown in Fig. 1.
-
•
TKED is the first audio-mesh dataset that contains three types of resources for speech-driven animation research: 3D talking eyes, 3D talking head and 3D talking face.
-
•
The cascade of VAE and VQVAE is proposed to model different degrees of diversity in head and eye gaze motions. This facilitates the generation of non-deterministic, diverse and natural eye gaze motions, in contrast with the deterministic generation in existing methods.
-
•
LightGazeFit is proposed to process large-scale low-quality internet videos, without the requirement of accurate segmentation and user-specific calibration as existing 3D eye gaze fitting methods.
II Related Work
The 3D eye gaze animation can be driven by audio, image and video, and is also close related to 3D facial animation. We introduce representative works in these fields, and recommend a comprehensive review [39] of inter-disciplinary research on eye gaze.
II-A Speech-Driven 3D Eye Gaze Animation
It’s a challenging task to generate 3D eye gaze animation from speech, and most existing methods were proposed a decade ago. The methods can be roughly categorized into rule-based [29, 30] and learning-based [31, 32, 33].
Rule-based methods construct the mapping between conversation states and eye gaze patterns by defining animation rules. Masuko and Hoshino [29] designed a set of empirical rules to map the conversation states (e.g. utterance, listening and waiting) to the amount of gaze and gaze duration. Marsella et al. [30] proposed a rule system to sequentially convert the audio and text features to communicative functions, behavior classes, specific behaviors and finally animation.
In contrast, learning-based methods capture the relationship between speech signal and eye movements by training on data. Mariooryad and Busso [31] employed three Dynamic Bayesian Networks to model the coupling between speech, eyebrow and head motion. Le et al. [32] utilized non-linear dynamical canonical correlation analysis to synthesize gaze from head motion and speech features. Jin et al. [33] proposed a LSTM-based machine learning model to predict the direction-of-focus of all the interlocutors in a three-party conversation. All the above learning-based methods can generate head-eye animation from speech, but they only establish a one-to-one mapping between speech feature and eye gaze motion, without the modeling of uncertainty in nonverbal communication.
To reduce uncertainty, some recent scene-driven (not solely speech-driven) methods [25, 26] forced the animated eye gaze to focus on the interlocutors or on the salient points within the scene. Our method only takes the speech as input and achieves the goal of generating plausible eye gaze motion in a speech-centric setting.
II-B Eye Gaze Fitting in Video
Compared with speech, using video to generate eye gaze motion is more straightforward and convenient. The researchers in computer graphics have proposed several 3D face trackers for video. These trackers can reconstruct not only 3D face model but also 3D eye gaze in each frame, by fitting the parameters of both 3D face state and eye gaze state to the image cues. Wang et al. [40] utilized a random forest classifier to extract the iris and pupil pixels in the eye region, and then used them to sequentially infer the most likely state of the 3D eye gaze at each frame in the MAP framework. Wang et al. [41] improved the work [40] by using CNN rather than random forest classifier for the iris and pupil pixels classification. Wen et al. [42] introduced a method for estimating eyeball motions for RGBD inputs by minimizing the differences between a rendered eyeball and a recorded image.
The above 3D eye gaze fitting methods require accurate segmentation of iris and pupil pixels and user-specific calibration, which is difficult to be achieved in low resolution videos.
II-C Gaze Estimation from Image
The computer vision community starts very early to estimate gaze from image. The estimated gaze is usually in the form of a unit gaze direction vector in 3D space or a point of gaze (PoG) on 2D plane. Early gaze estimation methods are mainly template-matching-based, appearance-based and feature-based, while recent methods are mostly based on deep learning [43]. Zhang et al. [44] introduced the first CNN-based method for gaze estimation, which jointly utilizes eye images and head poses to predict gaze directions. Accounting for the potential asymmetry between human eyes, Cheng et al. [45] proposed to firstly predict the 3D gaze direction for each eye individually and then employ a reliability evaluation network to adaptively adjust the weighting strategy throughout the optimization. Park et al.[46] introduced a novel graphical representation of 3D gaze direction, which serves as intermediate supervision to improve the estimation accuracy. Owing to individual differences, some methods [47, 48] employed a few-shot approach to achieve user-specific gaze adaptation. To address the challenge of occluded eyes, Kellnhofer et al. [49] utilized visible head features to predict gaze direction, even when the eyes are completely obscured, and indicated the prediction’s limited accuracy by outputting a higher uncertainty value accordingly.
These deep-learning-based gaze estimation methods focus on eyes, without considering the relationship between gaze estimation and 3D face reconstruction.
II-D Speech-Driven 3D Facial Animation
Methods in this field are roughly categorized into linguistics-based [50, 51, 52, 53] and learning-based [12, 14, 15, 16, 17, 21, 19, 22, 23, 24]. Linguistics-based methods typically establish a set of mapping rules between phonemes and visemes, thus providing explicit control over the animation. JALI [50] is a representative recent linguistics-based method, which utilizes two anatomical actions (jaw and lip) to animate a 3D facial rig. As a lot of manual effort is required for tuning animation parameters, a wide variety of data-driven methods have been proposed as an alternative. The generative models are utilized in these methods to directly learn the mapping from speech features to 3D facial motion, which include CNN [12, 14], Transformer [15, 16, 22, 23, 19] and Diffusion Model [17, 21, 24]. VOCASET [12] and BIWI [13] are two widely used 3D audio-visual datasets to train the audio-to-mesh regression networks in the learning-based methods.
Considering that Learn2Talk [19] has achieved impressive lip-sync facial animation, we choose it as the 3D facial motion generator in our proposed method.
| Dataset | Motion Types | Year | Number of Sequences | Number of Subjects | Hours | Data Acquisition Mode | Video Sources | ||
|---|---|---|---|---|---|---|---|---|---|
| Face | Head | Eyes | |||||||
| VOCASET[12] | ✓ | - | - | 2019 | 480 | 12 | 0.48 | 3D Scanning | / |
| BIWI[13] | ✓ | - | - | 2010 | 1109 | 14 | 1.43 | 3D Scanning | / |
| Speech4Mesh[27] | ✓ | - | - | 2023 | 2000 | / | / | Generated from video | MEAD[10], VoxCeleb2[9] |
| Audio2Mesh[28] | ✓ | - | - | 2024 | >1M | 6112 | / | Generated from video | VoxCeleb2[9] |
| DiffPoseTalk[21] | ✓ | ✓ | - | 2024 | 1052 | 588 | 26.5 | Generated from video | TFHP[21], HDTF[11] |
| Our TKED | ✓ | ✓ | ✓ | 2025 | 5982 | 669 | 14.0 | Generated from video | VoxCeleb2[9], HDTF [11] |

III Dataset: TKED
Existing audio-mesh datasets have focused on collecting 3D facial motions isolated from eye gaze. To develop a learning-based 3D eye gaze motion generation method, it is essential to firstly construct an audio-gaze dataset with a sufficient amount of data and diverse subjects. We provide detailed description of our proposed dataset TKED in Sect. III-A, the construction pipeline of TKED in Sect. III-B and the 3D eye gaze fitting method in Sect. III-C.
III-A Dataset Description
The way of utilizing motion capture systems or eye tracking devices to capture eye gaze and microphone to record audio in a laboratory setting is limited in its ability to collect large-scale and diverse data. Considering that 2D audio-visual datasets are more accessible and offer broader coverage, it’s possible to construct the audio-gaze dataset by reconstructing both 3D face mesh and 3D eye gaze from video. Motivated by this, we propose TKED which is obtained by performing 3D face reconstruction and 3D eye gaze fitting on the VoxCeleb2 [9] and HDTF [11] datasets.
VoxCeleb2 is a large-scale dataset collected from YouTube, comprising short interview videos cropped and resized to a resolution. The speakers in the dataset span a wide range of different ethnicities, accents, professions and ages. A distinct aspect of the VoxCeleb2 videos is the frequent movement of the speakers’ eyeballs, which contributes to a diverse range of eyeball rotation patterns. To mitigate the potential bias in TKED towards the specific eyeball movement style present in the VoxCeleb2 videos, we have added a small number of videos from HDTF as the complement. HDTF is a high-quality collection of talking face videos of 720P or 1080P, carefully gathered from YouTube. In contrast to VoxCeleb2, the videos from HDTF exhibit relatively stationary eyeballs.
TKED consists of 5,982 videos featuring 669 subjects, amounting to approximately 14 hours of footage in total. Out of the 5,982 videos, 5,912 are from VoxCeleb2, with a total duration of about 12 hours, while the remaining 70 videos are from HDTF, totaling about 2 hours. To ensure consistency, the videos from HDTF have been resampled to match the 25 fps in VoxCeleb2. We have conducted 3D face reconstruction and 3D eye gaze fitting on each frame of these videos to obtain the pseudo ground truth FLAME parameters [34], which include two eyeballs’ rotation, head rotation and facial motion parameters. Fig. 2 shows four sequences of the reconstructed 3D FLAME model. Along with the audio stored in the original videos, TKED is first dataset in the research community to simultaneously contain the three types of resources: 3D talking eyes, 3D talking head and 3D talking faces. The comprehensive comparison between TKED and existing audio-mesh datasets [12, 13, 27, 28, 21] is presented in Tab. I. The proportion of training, validation and testing data in TKED is 8:1:1.
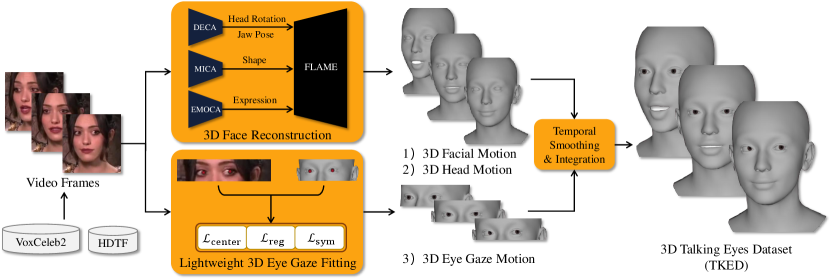
III-B Dataset Construction Pipeline
As shown in Fig. 3, the pipeline mainly consists of four stages: video pre-processing, 3D face reconstruction, 3D eye gaze fitting and data post-processing.
III-B1 Video pre-processing
The visibility of the subject’s eyes in video is paramount for the subsequent 3D eye gaze fitting. Hence, the videos need be excluded if the eyes are obscured. For videos where the invisibility of eyes is caused by head turning, we perform a preliminary exclusion by detecting significant disparities in the distance between the left and right eye corners and the side of the face. Then, the videos featuring individuals with obstructions such as sunglasses, which inherently mask the eyes, are excluded by manual screening.
III-B2 3D Face Reconstruction
We perform frame-by-frame reconstruction on videos to generate the 3D facial motion and 3D head motion. In order to obtain the highest quality possible, we utilize the 3D face reconstruction network proposed in EMOTE [23], which combines the strengths of four SOTA methods: EMOCA[54], SPECTRE[55], DECA[56] and MICA[57]. All the four SOTA methods use FLAME as 3D face representation. On the output side, DECA outputs the global rotation of head, forming the 3D head motion; MICA outputs the facial shape vector, EMOCA outputs the expression vector and DECA outputs the jaw pose, together forming the 3D facial motion. SPECTRE is only used in network training to enhance lip articulation by lip-reading loss.
III-B3 3D Eye Gaze Fitting
The above 3D face reconstruction network can’t generate 3D eye gaze motion. Hence, we propose a lightweight 3D eye gaze fitting method to capture 3D eye gaze from Internet videos. This method is introduced in the next subsection.
III-B4 Post-processing
Post-processing is needed to refine the motion data obtained in the previous step. When processing frames that contain blinking, we maintain the eye pose based on the last known open-eye state. This is because the iris’s position cannot be reliably detected during a blink. By doing so, we can ensure the continuity and naturalness of the facial animation, effectively preventing sudden movement of eyes that might occur during a blink event. Then, we conduct temporal convolutional smoothing individually on the three types of motion data to reduce unnatural jitter and combine them in one FLAME model.
III-C LightGazeFit
The deep-learning-based gaze estimation methods [43] proposed in computer vision provide a number of potential solutions for reconstructing eye gaze from video, but their estimated 3D gaze directions are not always compatible with the reconstructed 3D face mesh. Alternatively, 3D eye gaze fitting methods [40, 41, 42] from computer graphics seem to offer a better fit, but their code has not been publicly released.
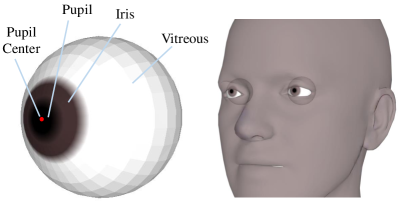
The proposed LightGazeFit is a lightweight yet effective 3D eye gaze fitting method tailored for processing videos from VoxCeleb2 and HDTF. Existing fitting methods [40, 41] heavily rely on accurate segmentation of iris and pupil pixels to formulate mask or edge likelihood. However, due to the relatively poor quality of VoxCeleb2 videos, which are only available in a resolution, achieving precise segmentation of iris and pupil is nearly impossible. LightGazeFit overcomes this issue by utilizing only the pupil center to form the likelihood, yet it still generates good results across all videos from VoxCeleb2 and HDTF.
The 3D eyeball model used in LightGazeFit comes from FLAME and it’s shown in Fig. 4. We manually annotate the iris vertices, the pupil vertices and the pupil center vertex on the 3D model. Then, we assign a brown color to the iris vertices and a black color to the pupil vertices. As the precise segmentation of iris and pupil is not available, LightGazeFit eliminates the need of eyeball calibration [40, 41, 42] which estimates the iris and pupil size for each subject. With the iris and pupil size fixed, we found that it performs well in the eyeball rotation estimation.
The objective function used in LightGazeFit is defined as:
| (1) |
where and are hyper-parameters and are set to and respectively. The pupil center loss is defined as the difference between the predicted 2D pupil center and the point projected from the pupil center vertex on 3D eyeball model to the 2D image plane:
| (2) |
The 2D pupil center in the image is predicted by a neural network [41]. Given the 2D pupil center , their exists many 3D eyeball rotation solutions to generate . To reduce such ambiguity, we use regularization loss to make the eyeball rotate as little as possible. The regularization loss is defined as:
| (3) |
where denotes the 3D rotation of two eyeballs. Finally, based on the assumption that left and right eyeball share the similar behaviour, the symmetry loss is defined as:
| (4) |
IV Method: TalkingEyes
Our ultimate goal is to synthesize eye gaze motion, eye blinks, head motion and facial motion collectively from the speech, under the unified 3D face representation FLAME [34]. For facial motion, we directly use Learn2Talk [19] as the generator which has achieved impressive 3D lip-sync performance. The eye gaze motion and head motion are jointly generated by a cascade VAE-VQVAE mechanism and a temporal autoregressive model. We introduce the motivation of using VAE and VQVAE in Sect. IV-A, the pipeline of TalkingEyes in Sect. IV-B, the two main stages in training in Sect. IV-C and IV-D, and the synthesis of eye blinks in Sect. IV-E.
| Diversity | Realism | |
|---|---|---|
| Head: VAE | high | natural |
| Head: VQVAE | extremely high | exaggerated |
| Eye Gaze: VAE | low | nearly stationary |
| Eye Gaze: VQVAE | high | natural |
IV-A Latent Spaces Learning by VAE-VQVAE
To model the weak correlation between speech signals and non-verbal cues in conversation, such as head gesture [58], hand gesture [59, 60] and body poses [61], the generative models VAE [1, 62] and VQVAE [2, 63] are commonly used. These models are capable of learning a compact representation for the non-verbal motion data. Through mapping the speech to the compact latent space, the difficulty in capturing the weak correlation between speech and motion is significantly attenuated and hence promotes the quality of motion synthesis. Following this, TalkingEyes also employ VAE and VQVAE to learn the latent space of motion.
On the other hand, there is a key difference between VAE and VQVAE in terms of motion diversity. VAE tends to output the mean of a Gaussian distribution, thus limiting the diversity in outputs. VQVAE uses discrete codebook to capture a diverse set of latent representations, allowing for a wider range of possible outputs. Since the rotation range of head usually exceeds that of eyeballs, the variation of the head motions is generally higher than that of eye gaze motions. As summarized in Tab. II, VAE is capable of producing head motions with adequate diversity (e.g. PoseVAE [58, 19]), while VQVAE may sometimes produce excessive diverse and exaggerated head motions. In contrast, VAE struggles to produce sufficiently diverse eye gaze motions, while VQVAE effectively achieve this. To support our claims, we have conducted quantitative experiments which are introduced in Sect. V-D. To conclude, we use VAE in the latent space learning for head motions, and use VQVAE in that for eye gaze motions.
IV-B Pipeline
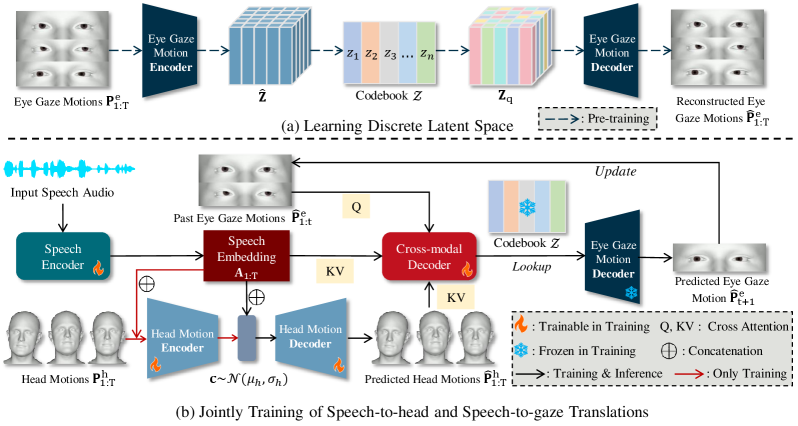
The pipeline of TalkingEyes is shown in Fig. 5, featuring the translations from speech signals to 3D eye gaze motions (left and right eyes) and 3D head motions in one framework, where denotes the number of frames.
The training of TalkingEyes comprises two main stages: firstly learn a discrete latent space for eye gaze motions by pre-training VQVAE, and then jointly train the VAE-based speech-to-head translation and the VQVAE-based speech-to-gaze translation in an autoregressive manner. In the first stage, we pre-train a VQVAE to model the latent space of eye gaze motions as a discrete codebook . The codebook is learned by self-reconstruction over the ground truth motions . In the second stage, a conditional VAE is employed to reconstruct the head motions from the ground truth motions . This motion reconstruction is conditioned on the speech embedding that is extracted by the speech encoder (wav2vec2.0 [64]) from the input speech. Then the predicted head motions and the previously predicted eye gaze motions are used as conditions in the mapping of the speech embedding to the target motion codes. This mapping is accomplished through multi-modal alignment and codebook lookup. The motion codes are further decoded into the eye gaze motion at current frame , which will serve as one frame of past motions in the next round of autoregression.
In the inference, the ground truth head motions and the head motion encoder in VAE are not used. The head latent code in VAE is randomly sampled from a standard Gaussian.
IV-C Discrete Latent Space of Eye Gaze Motion
We construct a discrete codebook to form the discrete latent space, thus allowing any frame in a eye gaze motion sequence to be represented by a codebook item . The Transformer-based VQVAE model that consists of a motion encoder , a motion decoder and a codebook , is pre-trained under the self-reconstruction of ground truth motions . As shown in Fig. 5, the motions is firstly encoded into a temporal feature vector . Then, is quantized to the feature vector via a element-wise quantization function that maps each item in to its nearest entry in codebook :
| (5) |
is finally decoded into the reconstructed motions via:
| (6) |
Similar to [2, 16], the training losses of VQVAE include a motion-level loss and two intermediate code-level losses:
| (7) |
where the first term is a motion reconstruction loss, the latter two terms update the codebook by reducing the distance between codebook and embedded feature , stands for a stop-gradient operation and is a weighting factor.
IV-D Speech-to-head and Speech-to-gaze Translations
We adopt a conditional VAE model to model the translation from speech to head motions. The head motion encoder accepts ground truth motions concatenated with speech embedding as input. The encoder outputs the continuous latent code that adheres a Gaussian distribution with the learned mean and learned variance . The latent code is further concatenated with , and then be inputted to the head motion decoder to predict head motions as . All the -frames of motions in are generated by once reconstruction, which can be formulated as:
| (8) |
Subsequent to the VAE model, a VQVAE-based autoregressive model is cascaded for the eye gaze motion generation. The predicted head motions is used as condition to guide the translation from speech to eye gaze motions. Specifically, we adopt a Transformer cross-modal decoder to algin three different modalities, namely speech audio, head motions and eye gaze motions. is equipped with causal self-attention to learn the dependencies between each frame in the context of -frames of past eye gaze motions . Additionally, is equipped with cross-modal attention to align the past eye gaze motions respectively with the head motions and the speech embedding . We set the cross-attention keys (K) and values (V) as the concatenation of the predicted head motions embedding and the speech embedding, and set the queries (Q) as the past eye gaze motions embedding. The cross-modal decoder outputs the features as:
| (9) |
where and are linear projection layers to extract eye gaze motions embedding and head motions embedding respectively. is further quantized into via Eq. 5 and decoded by the pre-trained VQVAE decoder into via Eq. 6, which can be formulated as:
| (10) |
The newly predicted motion is used to update the past motions, in preparation for the next prediction.
Training Losses. We train the head motion encoder , the head motion decoder , the cross-modal decoder , the projection layers and part of the speech encoder, while keeping the codebook and eye gaze motion decoder frozen. The training losses consist of four terms: reconstruction loss , velocity loss , KL-divergence loss and feature regularity loss .
The reconstruction loss measures the difference between predicted motions and ground truth motions for both head and eye gaze:
| (11) |
The velocity loss measures the discrepancy between the first-order derivative of predicted motions and that of ground truth motions for both head and eye gaze:
| (12) |
The KL-divergence loss forces the Gaussian distribution of the predicted head motions close to a standard Gaussian . has a simplified form [1]:
| (13) |
The feature regularity loss measures the deviation between the predicted eye gaze motion feature and the quantized feature from codebook:
| (14) |
The final training loss is formulated as follows:
| (15) |
where is set to 1e-4.
IV-E Eye Blink
To generate more vivid animation, we have also implemented the synthesis of eye blinks. Blinking is primarily influenced by personal habits, environmental factors and other conditions. Liu et al. [65] counted the number of blinks in their dataset and found that the frequency of human blinking, measured in blinks per minute, typically follows a log-normal distribution. Following their work, we conducted a statistical analysis on our dataset TKED to derive a suitable blink frequency that well aligns with our eye gaze animation. We counted the number of blinks in each video in TKED and then converted these counts into blinks per minute based on the video’s duration. For blink detection, we calculated the Eye Aspect Ratio (EAR) [66], which is defined as the ratio of the eye’s height to its width. When the eyes are closed, the EAR approaches zero. After statistical analysis, we found that the blinks per minute follow a Gaussian distribution with a mean of 40.10 and a deviation of 15.42. When generating animations, we first sample the number of blinks per minute from the distribution and then convert that into blink intervals. Subsequently, we adjust the expression parameters within a 5-frame window for each blink to create the blinking action.
V Experiments
V-A Training Details
VQVAE is pre-trained by Adam optimizer for 100 epochs with a learning rate . The pre-training takes about hour on a NVIDIA RTX 4090 GPU. Then the VAE and the autoregressive model are trained by Adam optimizer for 100 epochs with a learning rate . The training takes about hours on the same GPU.
V-B Experimental Setup
V-B1 Dataset
Our method and the baselines are trained and evaluated on TKED, following its training (TKED-Train), validation (TKED-Val) and testing (TKED-Test) splits.
V-B2 Baselines
Since the recent speech-driven 3D eye gaze animation methods are scarce and early computer animation methods [29, 30, 31, 32, 33] targeted at this task have not released their codes or datasets, we implemented four 3D eye gaze motion generation methods as the baselines for quantitative comparison.
-
–
Mean. For any input audio in TKED-Test, this method always outputs the average value of eye rotation vectors in TKED-Train. As a result, the generated eye gaze by this method is always stationary.
-
–
Random. For an input audio in TKED-Test, this method randomly selects a eye gaze motion sequence in TKED-Train that does not correspond to the input audio as prediction. This method can produce sufficient diverse motions for the same input.
-
–
Similar Sample. For an input audio in TKED-Test, this method firstly extracts features from the input, then identifies the audio in TKED-Train with the most similar features to the input, and uses the corresponding eye gaze motion sequence as prediction. This method seems more reasonable than Mean and Random.
-
–
VAE. Similar to the speech-to-head translation (Sect. IV-D), this method uses conditional VAE model to predict eye gaze motions from speech. Through concatenation, both the head motions and the speech embedding are used as condition.
V-B3 Evaluation Metrics
We assess the quality of the generated 3D eye gaze motions by different methods in the following aspects.
-
–
Motion Diversity. Because we model the motion generation as a non-deterministic task, we manage to measure how much the generated motions diversify with the same audio input. Specifically, we run a motion generation method multiple times for the same input audio, and obtain a set of plausible motions. The average distance of all paired motions in the sets represents the diversity score.
-
–
Audio-Motion Correlation. Although audio weakly correlates with eye gaze motion, we still explore to measure the degree of association between them. We use contrast learning to compute the similarity between audio and motion features. A binary classification network is trained with positive and negative samples. The positive samples consist of audio clips and their well synchronized motion clips, while the negative samples comprise mismatched audio and motion clips. Given a pair of audio and motion, the correlation is measured by the cosine similarity between the two features extracted by the classification network.
-
–
Motion Discrepancy. The discrepancy is measured by the distance between the predicted motions and the ground truth motions. As this metric doesn’t reflect the intrinsic correlation between audio and the generated diverse motions, we list it in the evaluation for reference only.
| Method | Div. ↑ | Corr. ↑ | ↓ |
|---|---|---|---|
| Mean | 0.0 | 0.45685 | 0.17162 |
| Random | 0.23383 | 0.49117 | 0.23989 |
| Similar Sample | 0.06170 | 0.57849 | 0.23479 |
| VAE | 0.06655 | 0.45796 | 0.17887 |
| TalkingEyes (ours) | 0.26398 | 0.60435 | 0.26570 |

V-C Evaluation of TalkingEyes
V-C1 Quantitative Comparison
Tab. III shows the quantitative evaluation results over TKED-Test. Our TalkingEyes outperforms other methods in terms of motion diversity and audio-motion correlation. TalkingEyes is capable of generating more diverse motions than the “Random” selection, thanks to VQVAE’s ability to learn a structured and clustered representation from the original data. Additionally, TalkingEyes achieves the highest score in audio-motion correlation, indicating that mapping the audio signal to the discrete motion space is a more effective and robust way for modeling the weak relationship between audio and eye gaze motion compared to other approaches, such as searching for similar samples in the audio feature space. When it comes to distance, TalkingEyes slightly compromises accuracy in matching the ground truth, which is a common trade-off in non-deterministic tasks [67, 68]. It is worth noting that “VAE” achieves very similar performance to that of “Mean” with respect to the three evaluation metrics. This further supports our motivation in the choice of VAE or VQVAE, as discussed in Sect. IV-A: VAE tends to output the mean of the Gaussian constructed on the eye gaze motions.
| Ours vs. Baseline | Realism |
|---|---|
| Ours vs. Mean | 85 (3.3e-9) |
| Ours vs. Random | 86 (7.5e-15) |
| Ours vs. Similar Sample | 93 (5.7e-22) |
| Ours vs. VAE | 83 (5.7e-10) |
V-C2 Perceptual User Study
For more comprehensive evaluation, we have conducted a perceptual user study to evaluate the realism of the animated 3D eye gaze. Specifically, we adopt the A/B test in a random order to compare our TalkingEyes with the four baselines. In each comparison, the participants were asked to answer the question with A or B: which recording exhibits more natural eyeball movements with fewer artifacts, such as exaggerated movements, static poses and motion jitter? We randomly selected 20 audios from TKED-Test, and used them to generate animations in the four kinds of comparisons (5 audios 4 comparisons). 20 participants took part in the study, finally yielding 400 entries. We calculated the ratio of participants who prefer our method over the baseline. The percentage of A/B testing is tabulated in Tab. IV, which shows that participants favor our method over all the four baselines. We have also conducted ANOVA tests in the user study, in which the p-value less than 0.05 indicates a statistically significant difference between our method and the competitor.

V-C3 Qualitative Comparison
We visually compare our method with the four baselines in Fig. 6. It could be observed that, “Mean” can only generate stationary eye gaze motion, “Random” and “Similar Sample” tend to produce disorganized and speech-unrelated eyeball movement, and “VAE” results in motion that is nearly stationary. We strongly recommend readers to watch the supplementary video for more intuitive comparison. We also conduct a visual comparison with three recent speech-driven 3D facial animation methods, namely FaceFormer [15], CodeTalker [16] and Learn2Talk [19]. In Fig. 7, we illustrate three typical frames of synthesized facial animations that speak at specific syllables. It’s obvious that our method can generate the most vivid animation with the animated eye gaze in tune with the speech. In the supplementary video, we also show the visual comparison with an early speech-driven eye gaze animation method [32].

| Method | ↑ | ↑ | ↑ | ↑ | ↓ | ↓ |
|---|---|---|---|---|---|---|
| Head: VAE, Eye Gaze: VAE | 0.09645 | 0.06655 | 0.52148 | 0.45796 | 0.23699 | 0.17887 |
| Head: VAE, Eye Gaze: VQVAE (ours) | 0.05143 | 0.26398 | 0.51913 | 0.60435 | 0.22731 | 0.26570 |
| Head: VQVAE, Eye Gaze: VQVAE | 0.29852 | 0.25439 | 0.45164 | 0.59900 | 0.40460 | 0.26225 |
V-D Ablation Analysis
V-D1 Different choices of VAE and VQVAE
We have conducted an ablation study on the different choices of VAE and VQVAE in the latent space learning for head motion and eye gaze motion. The quantitative evaluation results are reported in Tab. V. We use the same three evaluation metrics to access the quality of the generated 3D head motions. It could be observed that: 1) compared to eye gaze motions generated by VAE (1st row in Tab. V), those generated by VQVAE (2nd row) exhibit higher motion diversity while maintaining a robust correlation with the audio; 2) compared to head motions generated by VAE (2nd row), those generated by VQVAE (3rd row) achieve higher motion diversity but show a lower correlation with the audio. Notwithstanding high diversity, the head motions produced by VQVAE appear exaggerated and unnatural, as shown in Fig. 8.
V-D2 Items in Training Losses
We have also conducted an ablation study on the two terms of the training losses, namely the velocity loss defined as Eq. 12 and the feature regularity loss defined as Eq. 14. The other two terms in training losses, including the reconstruction loss and the KL-divergence loss , are essential losses that can’t be removed, as removing them would result in failed training. The quantitative evaluation results are reported in Tab. VI.
Compared with the full model, removing leads to the degeneration in almost all metrics. The artifacts such as motion jitter may arise in the generated long motion sequences. Without the regularization loss in the quantized features, it’s difficult for the training to converge, resulting in the production of stationary 3D eye gaze motions, where the diversity score is zero.
V-D3 Number of Codebook Items
The quantitative study on the number of items in the codebook is reported in Tab. VII. With the number of codebook items decreasing, the diversity of 3D eye motions increases, while the correlation with audio decreases. This phenomenon may be due to the more clustered representation of eye motions, which introduces diversity but diminishes the feature similarity with audio. To balance the diversity and the correlation with audio, we set to 1024.
| Method | ↑ | ↑ | ↑ | ↑ | ↓ | ↓ |
|---|---|---|---|---|---|---|
| w/o | 0.05086 | 0.24881 | 0.48854 | 0.59182 | 0.22873 | 0.26941 |
| w/o | 0.00434 | 0.0 | 0.35083 | 0.45581 | 0.48944 | 0.19682 |
| Full model | 0.05143 | 0.26398 | 0.51913 | 0.60435 | 0.22731 | 0.26570 |
| Num. | ↑ | ↑ | ↑ | ↑ | ↓ | ↓ |
|---|---|---|---|---|---|---|
| 0.05119 | 0.26278 | 0.54150 | 0.60268 | 0.22990 | 0.27397 | |
| 0.05143 | 0.26398 | 0.51913 | 0.60435 | 0.22731 | 0.26570 | |
| 0.04966 | 0.27578 | 0.53699 | 0.59932 | 0.22959 | 0.27345 | |
| 0.05027 | 0.31291 | 0.52527 | 0.58959 | 0.22762 | 0.32000 |

V-E Evaluation of LightGazeFit
We compare our LightGazeFit with a 3D eye gaze fitting method, Wang et al.’s method [40], and a deep-learning-based gaze estimation method, Gaze360 [49].
V-E1 Comparison with Wang et al.’s method
As shown in Fig. 9, our method exhibits competitive performance in 3D eye gaze reconstruction, matching that of Wang et al.’s method [40], across both front view and side views. Our method employs only the pupil center as the fitting constraint, omitting the need for precise segmentation of the iris and pupil, as required by Wang et al.’s method. In this qualitative comparison, the input videos and the 3D reconstruction results of Wang et al.’s method are fetched from the supplementary video in [40], since the code of Wang et al.’s method has not been publicly released yet.
V-E2 Comparison with Gaze360
Gaze360 [49] trains a deep neural network to predict 3D eye gaze direction from an input facial image. We conduct a quantitative comparison with Gaze360 and report the results in Tab. VIII. Specifically, we construct a evaluation dataset by manually annotating the 2D pupil centers in the facial images as ground truth. Then the 3D pupil centers generated by Gaze360 and our LightGazeFit are projected to the image plane and then compared with ground truth to measure the errors. Tab. VIII clearly show that our LightGazeFit achieves smaller prediction errors. Fig. 10 shows the visual comparison. There exists a deviation from the actual angle of eyeball rotation in Gaze360, indicating that the gaze direction produced by Gaze360 can’t be directly converted into the eye pose parameters in FLAME.
| Method | ↓ |
|---|---|
| Gaze360 | 2.73 |
| LightGazeFit (ours) | 1.64 |

VI Conclusion and Limitations
In this paper, we study the speech-driven animation of an important facial component, eye gaze, which has been overlooked by the recent research. Through constructing the audio-gaze 3D dataset TKED and the explicit modeling of the translation from speech to 3D eye gaze motion, our proposed TalkingEyes can synthesize eye gaze motion, eye blinks, head motion and facial motion collectively from speech. Thanks to the cascade of VAE and VQVAE in learning two separate latent spaces, TalkingEyes can generate pluralistic and natural eye gaze motions and head motions.
One limitation of our method is that, currently the generation of eye gaze motion is not controlled by emotional labels. In addition to speech, eye gaze is weakly associated with human emotion. Implementing emotional control or constraint can help address the ill-posed problem in speech-driven 3D eye gaze animation. Another limitation is that the eye gaze and mouth movement are now separately generated. The coherence between these two parts can be enhanced to yield more coordinated and holistic motions. In future, we plan to continue improving our method along the above two directions.
References
- [1] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proc. of ICLR, 2014.
- [2] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” in Proc. of NIPS, 2017, pp. 6306–6315.
- [3] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial nets,” in Proc. of NIPS, 2014, pp. 2672–2680.
- [4] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in Proc. of CVPR, 2019, pp. 4401–4410.
- [5] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. of NIPS, 2017, pp. 5998–6008.
- [6] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Proc. of NIPS, 2020.
- [7] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proc. of CVPR, 2022, pp. 10 674–10 685.
- [8] R. Liu, B. Ma, W. Zhang, Z. Hu, C. Fan, T. Lv, Y. Ding, and X. Cheng, “Towards a simultaneous and granular identity-expression control in personalized face generation,” in Proc. of CVPR, 2024, pp. 2114–2123.
- [9] J. S. Chung, A. Nagrani, and A. Zisserman, “Voxceleb2: Deep speaker recognition,” arXiv preprint arXiv:1806.05622, 2018.
- [10] K. Wang, Q. Wu, L. Song, Z. Yang, W. Wu, C. Qian, R. He, Y. Qiao, and C. C. Loy, “Mead: A large-scale audio-visual dataset for emotional talking-face generation,” in Proc. of ECCV, 2020, pp. 700–717.
- [11] Z. Zhang, L. Li, Y. Ding, and C. Fan, “Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset,” in Proc. of CVPR, 2021, pp. 3661–3670.
- [12] D. Cudeiro, T. Bolkart, C. Laidlaw, A. Ranjan, and M. J. Black, “Capture, learning, and synthesis of 3d speaking styles,” in Proc. of CVPR, 2019, pp. 10 101–10 111.
- [13] G. Fanelli, J. Gall, H. Romsdorfer, T. Weise, and L. V. Gool, “A 3-d audio-visual corpus of affective communication,” IEEE Trans. Multim., vol. 12, no. 6, pp. 591–598, 2010.
- [14] A. Richard, M. Zollhöfer, Y. Wen, F. D. la Torre, and Y. Sheikh, “Meshtalk: 3d face animation from speech using cross-modality disentanglement,” in Proc. of ICCV, 2021, pp. 1153–1162.
- [15] Y. Fan, Z. Lin, J. Saito, W. Wang, and T. Komura, “Faceformer: Speech-driven 3d facial animation with transformers,” in Proc. of CVPR, 2022, pp. 18 749–18 758.
- [16] J. Xing, M. Xia, Y. Zhang, X. Cun, J. Wang, and T. Wong, “Codetalker: Speech-driven 3d facial animation with discrete motion prior,” in Proc. of CVPR, 2023, pp. 12 780–12 790.
- [17] S. Stan, K. I. Haque, and Z. Yumak, “Facediffuser: Speech-driven 3d facial animation synthesis using diffusion,” in ACM Conference on Motion, Interaction and Games, 2023, pp. 13:1–13:11.
- [18] H. Cao, B. Cheng, Q. Pu, H. Zhang, B. Luo, Y. Zhuang, J. Lin, L. Chen, and X. Cheng, “DNPM: A neural parametric model for the synthesis of facial geometric details,” in Proc. of ICME, 2024, pp. 1–6.
- [19] Y. Zhuang, B. Cheng, Y. Cheng, Y. Jin, R. Liu, C. Li, X. Cheng, J. Liao, and J. Lin, “Learn2talk: 3d talking face learns from 2d talking face,” IEEE Trans. Vis. Comput. Graph., vol. Early Access, 2024.
- [20] C. Zhang, S. Ni, Z. Fan, H. Li, M. Zeng, M. Budagavi, and X. Guo, “3d talking face with personalized pose dynamics,” IEEE Trans. Vis. Comput. Graph., vol. 29, no. 2, pp. 1438–1449, 2023.
- [21] Z. Sun, T. Lv, S. Ye, M. G. Lin, J. Sheng, Y. Wen, M. Yu, and Y. Liu, “Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models,” ACM Trans. Graph., vol. 43, no. 4, pp. 46:1–46:9, 2024.
- [22] Z. Peng, H. Wu, Z. Song, H. Xu, X. Zhu, J. He, H. Liu, and Z. Fan, “Emotalk: Speech-driven emotional disentanglement for 3d face animation,” in Proc. of ICCV, 2023, pp. 20 630–20 640.
- [23] R. Danecek, K. Chhatre, S. Tripathi, Y. Wen, M. J. Black, and T. Bolkart, “Emotional speech-driven animation with content-emotion disentanglement,” in Proc. of SIGGRAPH Asia, 2023, pp. 41:1–41:13.
- [24] Q. Zhao, P. Long, Q. Zhang, D. Qin, H. Liang, L. Zhang, Y. Zhang, J. Yu, and L. Xu, “Media2face: Co-speech facial animation generation with multi-modality guidance,” in Proc. of SIGGRAPH, 2024, p. 18.
- [25] I. Goudé, A. Bruckert, A. Olivier, J. Pettré, R. Cozot, K. Bouatouch, M. Christie, and L. Hoyet, “Real-time multi-map saliency-driven gaze behavior for non-conversational characters,” IEEE Trans. Vis. Comput. Graph., vol. 30, no. 7, pp. 3871–3883, 2024.
- [26] Y. Pan, R. Agrawal, and K. Singh, “S3: speech, script and scene driven head and eye animation,” ACM Trans. Graph., vol. 43, no. 4, pp. 47:1–47:12, 2024.
- [27] S. He, H. He, S. Yang, X. Wu, P. Xia, B. Yin, C. Liu, L. Dai, and C. Xu, “Speech4mesh: Speech-assisted monocular 3d facial reconstruction for speech-driven 3d facial animation,” in Proc. of CVPR, 2023, pp. 14 192–14 202.
- [28] K. D. Yang, A. Ranjan, J.-H. R. Chang, R. Vemulapalli, and O. Tuzel, “Probabilistic speech-driven 3d facial motion synthesis: New benchmarks methods and applications,” in Proc. of CVPR, 2024, pp. 27 294–27 303.
- [29] S. Masuko and J. Hoshino, “Head-eye animation corresponding to a conversation for CG characters,” Comput. Graph. Forum, vol. 26, no. 3, pp. 303–312, 2007.
- [30] S. Marsella, Y. Xu, M. Lhommet, A. W. Feng, S. Scherer, and A. Shapiro, “Virtual character performance from speech,” in Proc. of SCA, 2013, pp. 25–35.
- [31] S. Mariooryad and C. Busso, “Generating human-like behaviors using joint, speech-driven models for conversational agents,” IEEE Trans. Speech Audio Process., vol. 20, no. 8, pp. 2329–2340, 2012.
- [32] B. H. Le, X. Ma, and Z. Deng, “Live speech driven head-and-eye motion generators,” IEEE Trans. Vis. Comput. Graph., vol. 18, no. 11, pp. 1902–1914, 2012.
- [33] A. Jin, Q. Deng, Y. Zhang, and Z. Deng, “A deep learning-based model for head and eye motion generation in three-party conversations,” Proc. ACM Comput. Graph. Interact. Tech., vol. 2, no. 2, pp. 9:1–9:19, 2019.
- [34] T. Li, T. Bolkart, M. J. Black, H. Li, and J. Romero, “Learning a model of facial shape and expression from 4d scans,” ACM Trans. Graph., vol. 36, no. 6, pp. 194:1–194:17, 2017.
- [35] B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,” ACM Trans. Graph., vol. 42, no. 4, pp. 139:1–139:14, 2023.
- [36] S. Qian, T. Kirschstein, L. Schoneveld, D. Davoli, S. Giebenhain, and M. Nießner, “Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians,” in Proc. of CVPR, 2024, pp. 20 299–20 309.
- [37] E. Bizzi, R. E. Kalil, P. Morasso, and V. Tagliasco, “Central programming and peripheral feedback during eye-head coordination in monkeys,” Bibl. Ophthal., vol. 82, pp. 220–232, 1972.
- [38] T. Warabi, “The reaction time of eye-head coordination in man,” Neurosci. Lett., vol. 6, pp. 47–51, 1977.
- [39] K. Ruhland, C. E. Peters, S. Andrist, J. B. Badler, N. I. Badler, M. Gleicher, B. Mutlu, and R. McDonnell, “A review of eye gaze in virtual agents, social robotics and HCI: behaviour generation, user interaction and perception,” Comput. Graph. Forum, vol. 34, no. 6, pp. 299–326, 2015.
- [40] C. Wang, F. Shi, S. Xia, and J. Chai, “Realtime 3d eye gaze animation using a single RGB camera,” ACM Trans. Graph., vol. 35, no. 4, pp. 118:1–118:14, 2016.
- [41] Z. Wang, J. Chai, and S. Xia, “Realtime and accurate 3d eye gaze capture with dcnn-based iris and pupil segmentation,” IEEE Trans. Vis. Comput. Graph., vol. 27, no. 1, pp. 190–203, 2021.
- [42] Q. Wen, F. Xu, and J. Yong, “Real-time 3d eye performance reconstruction for RGBD cameras,” IEEE Trans. Vis. Comput. Graph., vol. 23, no. 12, pp. 2586–2598, 2017.
- [43] Y. Cheng, H. Wang, Y. Bao, and F. Lu, “Appearance-based gaze estimation with deep learning: A review and benchmark,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 7509–7528, 2024.
- [44] X. Zhang, Y. Sugano, M. Fritz, and A. Bulling, “Appearance-based gaze estimation in the wild,” in Proc. of CVPR, 2015, pp. 4511–4520.
- [45] Y. Cheng, X. Zhang, F. Lu, and Y. Sato, “Gaze estimation by exploring two-eye asymmetry,” IEEE Trans. Image Process., vol. 29, pp. 5259–5272, 2020.
- [46] S. Park, A. Spurr, and O. Hilliges, “Deep pictorial gaze estimation,” in Proc. of ECCV, 2018, pp. 721–738.
- [47] S. Park, S. D. Mello, P. Molchanov, U. Iqbal, O. Hilliges, and J. Kautz, “Few-shot adaptive gaze estimation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9368–9377.
- [48] Y. Yu, G. Liu, and J.-M. Odobez, “Improving few-shot user-specific gaze adaptation via gaze redirection synthesis,” in Proc. of CVPR, 2019, pp. 11 937–11 946.
- [49] P. Kellnhofer, A. Recasens, S. Stent, W. Matusik, and A. Torralba, “Gaze360: Physically unconstrained gaze estimation in the wild,” in Proc. of ICCV, 2019, pp. 6912–6921.
- [50] P. Edwards, C. Landreth, E. Fiume, and K. Singh, “JALI: an animator-centric viseme model for expressive lip synchronization,” ACM Trans. Graph., vol. 35, no. 4, pp. 127:1–127:11, 2016.
- [51] M. M. Cohen, R. Clark, and D. W. Massaro, “Animated speech: research progress and applications,” in Proc. of Auditory-Visual Speech Processing, 2001, p. 200.
- [52] S. L. Taylor, M. Mahler, B. Theobald, and I. A. Matthews, “Dynamic units of visual speech,” in Proc. of SCA, 2012, pp. 275–284.
- [53] Y. Xu, A. W. Feng, S. Marsella, and A. Shapiro, “A practical and configurable lip sync method for games,” in Proc. of Motion in Games, 2013, pp. 131–140.
- [54] R. Danecek, M. J. Black, and T. Bolkart, “EMOCA: emotion driven monocular face capture and animation,” in Proc. of CVPR, 2022, pp. 20 279–20 290.
- [55] P. P. Filntisis, G. Retsinas, F. P. Papantoniou, A. Katsamanis, A. Roussos, and P. Maragos, “Visual speech-aware perceptual 3d facial expression reconstruction from videos,” arXiv preprint arXiv:2207.11094, 2022.
- [56] Y. Feng, H. Feng, M. J. Black, and T. Bolkart, “Learning an animatable detailed 3d face model from in-the-wild images,” ACM Trans. Graph., vol. 40, no. 4, pp. 88:1–88:13, 2021.
- [57] W. Zielonka, T. Bolkart, and J. Thies, “Towards metrical reconstruction of human faces,” in Proc. of ECCV, 2022, pp. 250–269.
- [58] W. Zhang, X. Cun, X. Wang, Y. Zhang, X. Shen, Y. Guo, Y. Shan, and F. Wang, “Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation,” in Proc. of CVPR, 2023, pp. 8652–8661.
- [59] H. Yi, H. Liang, Y. Liu, Q. Cao, Y. Wen, T. Bolkart, D. Tao, and M. J. Black, “Generating holistic 3d human motion from speech,” in Proc. of CVPR, 2023, pp. 469–480.
- [60] T. Ao, Z. Zhang, and L. Liu, “Gesturediffuclip: Gesture diffusion model with CLIP latents,” ACM Trans. Graph., vol. 42, no. 4, pp. 42:1–42:18, 2023.
- [61] H. Liu, Z. Zhu, G. Becherini, Y. Peng, M. Su, Y. Zhou, X. Zhe, N. Iwamoto, B. Zheng, and M. J. Black, “EMAGE: towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling,” in Proc. of CVPR, 2024, pp. 1144–1154.
- [62] Y. Pu, Z. Gan, R. Henao, X. Yuan, C. Li, A. Stevens, and L. Carin, “Variational autoencoder for deep learning of images, labels and captions,” in Proc. of NIPS, 2016, pp. 2352–2360.
- [63] A. Razavi, A. van den Oord, and O. Vinyals, “Generating diverse high-fidelity images with VQ-VAE-2,” in Proc. of NIPS, 2019, pp. 14 837–14 847.
- [64] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proc. of NIPS, 2020.
- [65] C. Liu, Q. Lin, Z. Zeng, and Y. Pan, “Emoface: Audio-driven emotional 3d face animation,” in Proc. of Virtual Reality, 2024, pp. 387–397.
- [66] T. Soukupova and J. Cech, “Real-time eye blink detection using facial landmarks,” Cent. Mach. Perception, Dep. Cybern. Fac. Electr. Eng. Czech Tech. Univ. Prague, pp. 1–8, 2016.
- [67] C. Zheng, T. Cham, and J. Cai, “Pluralistic image completion,” in Proc. of CVPR, 2019, pp. 1438–1447.
- [68] Z. Wan, J. Zhang, D. Chen, and J. Liao, “High-fidelity and efficient pluralistic image completion with transformers,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 9612–9629, 2024.