Tag, Copy or Predict: A Unified Weakly-Supervised Learning Framework for Visual Information Extraction using Sequences
Abstract
Visual information extraction (VIE) has attracted increasing attention in recent years. The existing methods usually first organized optical character recognition (OCR) results into plain texts and then utilized token-level entity annotations as supervision to train a sequence tagging model. However, it expends great annotation costs and may be exposed to label confusion, and the OCR errors will also significantly affect the final performance. In this paper, we propose a unified weakly-supervised learning framework called TCPN (Tag, Copy or Predict Network), which introduces 1) an efficient encoder to simultaneously model the semantic and layout information in 2D OCR results; 2) a weakly-supervised training strategy that utilizes only key information sequences as supervision; and 3) a flexible and switchable decoder which contains two inference modes: one (Copy or Predict Mode) is to output key information sequences of different categories by copying a token from the input or predicting one in each time step, and the other (Tag Mode) is to directly tag the input sequence in a single forward pass. Our method shows new state-of-the-art performance on several public benchmarks, which fully proves its effectiveness.
1 Introduction
With the fast development of information interaction, document intelligent processing Ferilli et al. (2011) has attracted considerable attention. As an important part of it, visual information extraction (VIE) technique has been integrated into many real-world applications.
The existing VIE methods usually first organized text blocks (text bounding boxes and strings, which were provided by the ground truth or parsed by an OCR system) into plain texts according to the reading order and utilized effective encoding structures such as Katti et al. (2018); Liu et al. (2019a); Xu et al. (2020) to extract the most distinguishable representations for each input token from multi-sources. After this, a sequence tagging model like Lample et al. (2016) was trained with token-level category supervision.
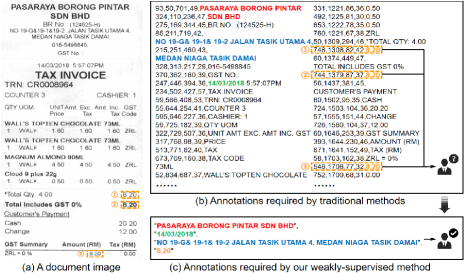
However, the token-level category supervision expends great annotation costs and may be exposed to label ambiguity. Given a document image as shown in Figure 1 (a), the most widely used annotation scheme is to label the bounding box and string of each utterance, and further point out which category does each token/box belongs to, as shown in Figure 1 (b). In this way, a heuristic label assignment procedure is needed to train the aforementioned tagging model, of which the core idea is matching the detected boxes and recognized transcriptions with the given annotations and then assign label to each token/box of OCR results. However, this procedure may encounter problems from mainly two aspects. First, wrong recognition results will bring troubles to the matching operation, especially for key information sequences. Second, the repeated contents will bring label ambiguities. As shown in Figure 1(a) and (b), three values with same content can be regarded as the answer of the key Total Amount. In most cases, it is hard to establish a uniform annotation specification to determine which one should be regarded as ground truth.
To address the aforementioned limitations, in this paper, we propose an end-to-end weakly-supervised learning framework, which can supervise the decoding process directly using the target key information sequences. The benefits it brings are mainly two-folds: first, it greatly saves the annotation costs, as shown in Figure 1 (c), and shortens the training process by skipping the matching between OCR results and the ground truth; second, our method solves the label ambiguity problem by automatically learning the alignment between OCR results and ground truth, which can adaptively distinguish the most likely one in the repeated contents. In addition, we also propose a flexible decoder, which is combined with our weakly-supervised training strategy and have two switchable modes – Copy or Predict Mode (TCPN-CP) and Tag Mode (TCPN-T), to balance the effectiveness and efficiency. In TCPN-CP, our decoder can generate key information sequences by copying a token from the input or predicting one in each time step, which can both retain novel contents in input and correct OCR errors. And in TCPN-T, our decoder can directly label each token’s representations into a specific category in a single forward pass, which maintains the fast speed. It is notable that our decoder only needs to be trained once to work in different modes.
Besides, we propose an efficient encoder structure to simultaneously model the semantic and layout information in 2D OCR results. In our design, the semantic embeddings of different tokens in a document are re-organized into a vector matrix (here , and are the height dimension, the width dimension and the number of channels, respectively), which we called TextLattice, according to the center points of token-level bounding boxes. After this, we adopt a modified light-weight ResNet He et al. (2016) combined with the U-Net Ronneberger et al. (2015) architecture to generate the high-level representations for the subsequent decoding. It is notable that the most relevant work of our encoding method was CharGrid Katti et al. (2018), which first used CNN to integrate semantic clues in a layout. However, it initialized an empty vector of the same size as the original document image, and then repeatedly filled each token’s embedding at every pixel within its bounding box. This simple and direct approach may lead to the following limitations: 1) Larger tokens would be filled in more times, and it might result in the risk of category imbalance; 2) A pixel could completely represent a token, and repeated filling would waste extra cost; 3) The lack of concentration of information would make it difficult for the network to capture global clues. By comparison, our method greatly saves computing resources while maintains the space information of document. For example, for a receipt image in SROIE Huang et al. (2019) benchmark whose size is generally more than , the side length of after our processing is less than 100. In this way, both holistic and local clues can be captured, the relative position relationship between utterances are retained, and distance can be perceived in a more intuitive way through the receptive field.
Experiments on the two public SROIE and EPHOIE Wang et al. (2021) benchmarks demonstrate that our method shows competitive and even new state-of-the-art performance. Our main contributions can be summarized as follows:
-
•
We propose an efficient 2D document representation called TextLattice, and the corresponding light-weight encoder structure.
-
•
We propose a flexible decoder which has two inference modes - TCPN-CP for OCR error correction and TCPN-T for fast inference speed.
-
•
We propose a weakly-supervised learning framework which guides decoding process directly using the key information sequences. This greatly saves the annotation costs and avoids label ambiguity.
-
•
Our method achieves competitive performances even compared with the setting of token-level full supervision, which totally proves its superior.
2 Related Work

Early works of visual information extraction mainly utilized rule-based Muslea and others (1999) or template-based Huffman (1995) methods, which might tend to poor performance when the document layout was variable. With the development of deep learning, more advanced researches commonly extracted a feature sequence from the input plain text and used token-level supervision to train a sequence tagging model. Lample et al. (2016) first used a bidirectional long short-term memory Hochreiter and Schmidhuber (1997) (BiLSTM) network to model sequential information and a conditional random field (CRF) layer to decode the optimal classification path. Most of the follow-up works mainly focused on the feature encoding part: Liu et al. (2019a), GraphIE Qian et al. (2019) and PICK Yu et al. (2020) tried to use graph neural networks (GNNs) to extract node embeddings for better representation. LayoutLM Xu et al. (2020) embedded multi-source information into a common feature space, and utilized a BERT-like Devlin et al. (2019) model for feature fusion. TRIE Zhang et al. (2020) and VIES Wang et al. (2021) proposed the end-to-end VIE methods directly from image to key information, which introduced multi-head self-attention Bahdanau et al. (2015) to integrate multimodal clues during encoding.
As for the decoding part, EATEN Guo et al. (2019) first utilized sequence-level supervision to guide training. It generated feature maps directly from document image, and used several entity-aware attention-based decoders to iteratively parse the key information sequences. However, its efficiency could be significantly reduced as the number of entities increased, and it can only process simple and fixed layout since it had to overcome the difficulties of both OCR and VIE at the same time. When the given text blocks were accurate or directly the ground truth but the model still performed inference by step-by-step prediction, it might greatly slow down the speed and lead to the severe over-fitting problem of sequence generation due to the lack of corpus in VIE task.
3 Method
Here we provide the details of the proposed TCPN. First we describe the approach of generating TextLattice, and how to encode higher-level features. Next we introduce details of our switchable decoder and weakly-supervised training strategy. Finally, we explain when and how to inference in different modes. Figure 2 gives an overview of our approach.
3.1 Document Representation
In this section, we introduce how to re-organize the OCR results into our 2D document representation - TextLattice. The whole process can be summarized as: 1) We first normalize coordinates of detected bounding boxes , sort from top to bottom and left to right, and utilize heuristic rules to modify coordinates to divide into multiple rows; 2) Then, is divided into token-level according to lengths of the recognized strings ; 3) Next, the coordinates of are also normalized and modified to avoid information loss caused by overlapping; 4) Finally, we initialize an all-zero matrix where and are determined by the ranges of and coordinates of , and fill in according to the correspondence between token-level center points and -dimensional token embeddings. The detailed procedure is shown in Appendix.
3.2 Feature Encoding
After acquiring , we adopt ResNet He et al. (2016) as CNN encoder to capture more holistic features. The U-Net Ronneberger et al. (2015) structure is also combined to restore the down-sampled features to the same size as the input and adaptively fuse both local and global clues extracted under diverse receptive fields. Vanilla ResNet adopts a Conv2d as the conv1 layer to capture association between local pixels in an RGB image. However, it may not be applicable in our scenario since the features of adjacent tokens also need to be separable, instead of high fusion of features in the first few layers. To this end, we replace conv1 with a Conv2d and remove the original maxpool layer. Thanks to the efficient design of TextLattice, both speed and superiority can be retained.
In order to further preserve the location clues, inspired by CoordConv Liu et al. (2018), two extra channels are concatenated to the incoming representation , which contain horizontal and vertical relative location information in the layout of range from to . The whole procedure of feature encoding can be formulated as:
| (1) | ||||
| (2) |
Here, is the concatenation operator, is the extra coordinate vector. Since the output of CNNs has the same size as , we add them together as a residual connection. Finally, the features at the center points of token-level bounding boxes are retrieved to form , where is the number of tokens. We regard the rest pixels as useless and discard them directly for calculation efficiency.
3.3 Weakly-Supervised Training
As shown in Figure 2, the VIE task can be regarded as a set-to-sequence problem after feature encoding, since is order-independent. We introduce the class embedding to control the category of information parsed by the decoder, which is taken from a pre-defined trainable look-up table. Given , our attention-based decoder takes it into account at each time step and iteratively predicts target sequence. Such novel design avoids class-specific decoders, alleviates the shortage of isolated class corpus, and decouples the serial correlation between different categories in the traditional sequence tagging model into parallel.
When generating sequences, we need the model to be able to switch between copying tokens from input or directly predicting ones. The copying operation make the model be able to reproduce accurate information and retain novel words, while the predicting operation introduces the ability of correcting OCR errors. Inspired by See et al. (2017), which implemented a similar architecture for abstractive text summarization, our model recurrently generates the hidden state by referring to the current input tokens and the context vector in the previous step :
| (3) | ||||
| (4) | ||||
| (5) | ||||
| (6) |
Here, is the attention score where the historical accumulated values are also referenced during calculation. All s and s are learnable parameters.
Then, the probability distribution of tokens in a fixed dictionary is calculated and a copy score is generated as a soft switch to choose between different operations in each time step :
| (7) | |||
| (8) | |||
| (9) | |||
is the probability score of token in time step , where is the current target token. is the sequence alignment loss function. In this way, our method acquires the ability to produce out-of-vocabulary (OOV) tokens, and can adaptively perform optimal operations.
As of now, our method can be seen as a sequence generation model trained with sequence-level supervision. However, it is notable that since the class embedding of entity category is given, when the model decides to copy a token from the input at a step, ’s feature vector in should be also classified as by a linear classifier. More generally speaking, our method can first learn the alignment relationship, and then train a classifier using the matched tokens. This novel idea enables our approach the ability of supervising the sequence tagging model. We adopt a linear layer to model the entity probability distribution, which can be formulated as: (a)
| Method | F1-Score |
|---|---|
| Token-level Fully-Supervised | |
| Lample et al. (2016) | 90.85 |
| LayoutLMXu et al. (2020) | 95.24 |
| Liu et al. (2019a) | 95.10 |
| PICK Yu et al. (2020) | 96.12 |
| TRIE Zhang et al. (2020) | 96.18 |
| VIESWang et al. (2021) | 96.12 |
| TextLattice(Ours) | 96.54 |
| Sequence-level Weakly-Supervised | |
| TCPN-T(Ours) | 95.46 |
(b) Table 3: Performance comparison on (a) EPHOIE and (b) SROIE under ground truth setting. ‘Token-level Fully-Supervised’ indicates the token-level category annotation, and ‘Sequence-level Weakly-Supervised’ means the key information sequence annotation.
4.2.2 Effects of Components in TextLattice
We also conduct experiments to verify the effectiveness of different components in our encoding structure, such as CoordConv, the U-Net structure and the residual connection in equation (1). It can be seen in Table LABEL:tab:enabs that each design has a significant contribution to the final performance. Although CNN can capture the relative position relationship, CoordConv can further provide the global position clues relative to the whole layout, which brings higher discernibility; we also try to use ResNet only where all stride and the U-Net structure are removed to perform feature encoding. However, the performance decreases obviously, which indicates the importance of semantic feature fusion under different receptive fields; Residual Connection gives model the chance to directly receive token-level semantic embedding, which further improves the performance.
4.3 Comparison with the State-of-the-Arts
We compare our method with several state-of-the-arts on the SROIE and EPHOIE benchmarks. The following Ground Truth Setting indicates that the OCR ground truth is adopted, while End-to-End Setting indicates the OCR engine result.
| Method | F1-Score |
|---|---|
| Rule-based Matching | |
| Lample et al. (2016) | 71.95 |
| Liu et al. (2019a) | 75.07 |
| TRIEZhang et al. (2020) | 80.31 |
| VIESWang et al. (2021) | 83.81 |
| Automatic Alignment | |
| TCPN-T(Ours, 112.11FPS) | 86.19 |
| TCPN-CP(Ours, 5.57FPS) | 84.67 |
(a)
| Method | F1-Score |
|---|---|
| Rule-based Matching | |
| NER Ma and Hovy (2016) | 69.09 |
| Chargrid Katti et al. (2018) | 78.24 |
| Lample et al. (2016) | 78.60 |
| Liu et al. (2019a) | 80.76 |
| TRIE Zhang et al. (2020) | 82.06 |
| VIES Wang et al. (2021) | 91.07 |
| Automatic Alignment | |
| TCPN-T(Ours, 88.16FPS) | 91.21 |
| TCPN-CP(Ours, 5.20FPS) | 91.93 |
(b)
4.3.1 Results under Ground Truth Setting
As shown in Table 3.3, our method exhibits superior performance on both SROIE and EPHOIE in the case of token-level full-supervision, which totally proves the effectiveness of our feature encoding method. Furthermore, the results under sequence-level weakly-supervised setting achieve competitive performance. This fully confirms the superiority of our learning strategy, which can model the correspondence between the input tokens and the output sequences.
Compared with SROIE, EPHOIE usually has less content and more token types, which reduces the difficulty of learning alignment. Relatively, since a receipt in SROIE often contains abundant tokens and the same token may appear repeatedly, which may lead to the alignment confusion, the gap between full- and weak-supervision is further widened.
4.3.2 Results under End-to-End Setting
We adopt BDNLiu et al. (2019b) as text detector and CRNNShi et al. (2016) as text recognizer, and train them using the official annotations to get OCR results. It is worth noting that since there may inevitably exist errors in OCR results, all of our experiments under end-to-end setting are trained using our weakly-supervised manner, which avoids the matching process between OCR results and ground truth. The performances are shown in Table 4.3. Our method shows new state-of-the-art performance in every mode.
It can be inferred that an important basis for choosing TCPN-CP or TCPN-T mode is the richness of semantics and corresponding corpus. On SROIE, TCPN-CP obviously outperforms TCPN-T, which mainly benefits the ability to error correction; however, on EPHOIE, although both modes outperform counterparts, TCPN-T beats TCPN-CP by a large margin, where the main reason should be the diversity of Chinese tokens and the resulting lack of corpus.
4.3.3 Results on A Business License Dataset
In order to further explore the effectiveness of our framework in real-world applications, we collect an in-house dataset of business license. It contains 2331 photos taken by mobile phone or camera with real user needs, and most of images are inclined, distorted or the brightness changes dramatically. We randomly select 1863 images for training and 468 images for testing, and there are 13 types of entities to be extracted. Furthermore, the OCR results are generated by our off-the-shelf engines, which definitely contains OCR errors due to the poor image quality.
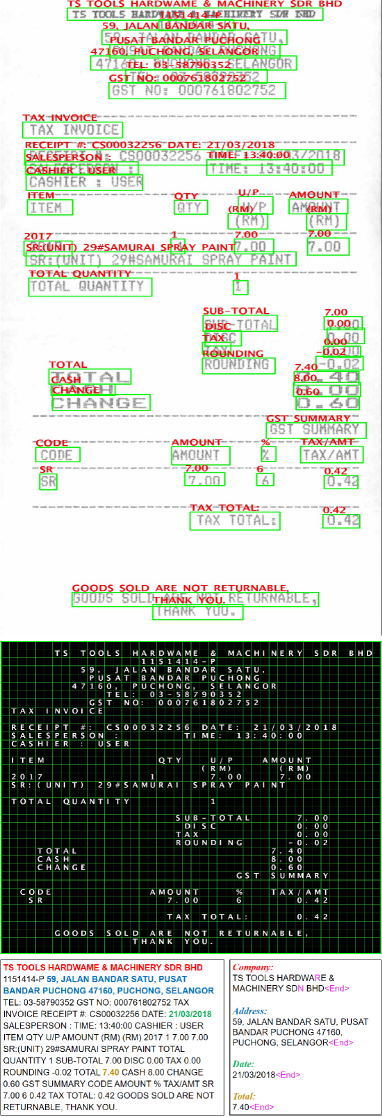
The detailed results are shown in Table 5. Our end-to-end weakly-supervised learning framework outperforms traditional rule-based matching method by a large margin, which can also greatly reduce the annotation cost. Compared with TCPN-T, the implicit semantic relevance learned by TCPN-CP can further boost the final performance by correcting OCR errors. Some qualitative results are shown in Appendix.
5 Conclusion
In this paper, we propose a unified weakly-supervised learning framework called TCPN for visual information extraction, which introduces an efficient encoder, a novel training strategy and a switchable decoder. Our method shows significant gain on EPHOIE dataset and competitive performance on SROIE dataset, which fully verifies its effectiveness.
Visual information extraction task is in the cross domain of natural language processing and computer vision, and our approach aims to alleviate the over-reliance on complete annotations and the negative effects caused by OCR errors. For future research, we will explore the potential of our framework through large-scale unsupervised data. In this way, the generalization of encoder, the alignment capability of decoder and the performance of our TCPN-CP can be further improved.
Acknowledgments
This research is supported in part by NSFC (Grant No.: 61936003, 61771199), GD-NSF (no.2017A030312006).
Appendix
Appendix A TextLattice Generation
Algorithm 1 shows the detailed procedure of our TextLattice Generation Algorithm introduced in Section 3.1.
Appendix B Qualitative Results
\fname@algorithm 1 TextLattice Generation Algorithm
Input: Utterance-level detected bounding boxes and corresponding recognized strings
Parameter: Normalization threshold and ratio . Output: TextLattice


References
- Bahdanau et al. [2015] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
- Cui et al. [2020] Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. Revisiting pre-trained models for Chinese natural language processing. In EMNLP: Findings, pages 657–668, 2020.
- Devlin et al. [2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT (1), 2019.
- Ferilli et al. [2011] Stefano Ferilli, Floriana Esposito, Teresa MA Basile, Domenico Redavid, and Incoronata Villani. Dominus plus-document management intelligent universal system (plus). In Italian Research Conference on Digital Libraries, pages 123–126, 2011.
- Guo et al. [2019] He Guo, Xiameng Qin, Jiaming Liu, Junyu Han, Jingtuo Liu, and Errui Ding. Eaten: Entity-aware attention for single shot visual text extraction. In ICDAR, pages 254–259, 2019.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
- Hochreiter and Schmidhuber [1997] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Huang et al. [2019] Zheng Huang, Kai Chen, Jianhua He, Xiang Bai, Dimosthenis Karatzas, Shijian Lu, and CV Jawahar. Icdar2019 competition on scanned receipt ocr and information extraction. In ICDAR, pages 1516–1520, 2019.
- Huffman [1995] Scott B Huffman. Learning information extraction patterns from examples. In IJCAI, pages 246–260, 1995.
- Katti et al. [2018] Anoop R Katti, Christian Reisswig, Cordula Guder, Sebastian Brarda, Steffen Bickel, Johannes Höhne, and Jean Baptiste Faddoul. Chargrid: Towards understanding 2d documents. In EMNLP, pages 4459–4469, 2018.
- Lample et al. [2016] Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. Neural architectures for named entity recognition. In NAACL-HLT, pages 260–270, 2016.
- Liu et al. [2018] Rosanne Liu, Joel Lehman, Piero Molino, Felipe Petroski Such, Eric Frank, Alex Sergeev, and Jason Yosinski. An intriguing failing of convolutional neural networks and the coordconv solution. In Advances in neural information processing systems, pages 9605–9616, 2018.
- Liu et al. [2019a] Xiaojing Liu, Feiyu Gao, Qiong Zhang, and Huasha Zhao. Graph convolution for multimodal information extraction from visually rich documents. In NAACL-HLT, pages 32–39, 2019.
- Liu et al. [2019b] Yuliang Liu, Sheng Zhang, Lianwen Jin, Lele Xie, Yaqiang Wu, and Zhepeng Wang. Omnidirectional scene text detection with sequential-free box discretization. In IJCAI, pages 3052–3058, 2019.
- Ma and Hovy [2016] Xuezhe Ma and Eduard Hovy. End-to-end sequence labeling via bi-directional lstm-cnns-crf. In ACL, pages 1064–1074, 2016.
- Muslea and others [1999] Ion Muslea et al. Extraction patterns for information extraction tasks: A survey. In The AAAI-99 workshop on machine learning for information extraction, volume 2, 1999.
- Qian et al. [2019] Yujie Qian, Enrico Santus, Zhijing Jin, Jiang Guo, and Regina Barzilay. GraphIE: A graph-based framework for information extraction. In NAACL-HLT, pages 751–761, 2019.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241, 2015.
- See et al. [2017] Abigail See, Peter J Liu, and Christopher D Manning. Get to the point: Summarization with pointer-generator networks. In ACL (Volume 1: Long Papers), pages 1073–1083, 2017.
- Shi et al. [2016] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. TPAMI, 39(11):2298–2304, 2016.
- Wang et al. [2021] Jiapeng Wang, Chongyu Liu, Lianwen Jin, Guozhi Tang, Jiaxin Zhang, Shuaitao Zhang, Qianying Wang, Yaqiang Wu, and Mingxiang Cai. Towards robust visual information extraction in real world: New dataset and novel solution. In AAAI, 2021.
- Xu et al. [2020] Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. Layoutlm: Pre-training of text and layout for document image understanding. In ACM-SIGKDD, pages 1192–1200, 2020.
- Yu et al. [2020] Wenwen Yu, Ning Lu, Xianbiao Qi, Ping Gong, and Rong Xiao. PICK: Processing key information extraction from documents using improved graph learning-convolutional networks. In ICPR, 2020.
- Zeiler [2012] Matthew D Zeiler. Adadelta: an adaptive learning rate method. arXiv preprint arXiv:1212.5701, 2012.
- Zhang et al. [2020] Peng Zhang, Yunlu Xu, Zhanzhan Cheng, Shiliang Pu, Jing Lu, Liang Qiao, Yi Niu, and Fei Wu. Trie: End-to-end text reading and information extraction for document understanding. In ACM-MM, 2020.