TabSec: A Collaborative Framework for Novel Insider Threat Detection
Abstract
In the era of the Internet of Things (IoT) and data sharing, users frequently upload their personal information to enterprise databases to enjoy enhanced service experiences provided by various online services. However, the widespread presence of system vulnerabilities, remote network intrusions, and insider threats significantly increases the exposure of private enterprise data on the internet. If such data is stolen or leaked by attackers, it can result in severe asset losses and business operation disruptions. To address these challenges, this paper proposes a novel threat detection framework, TabITD. This framework integrates Intrusion Detection Systems (IDS) with User and Entity Behavior Analytics (UEBA) strategies to form a collaborative detection system that bridges the gaps in existing systems’ capabilities. It effectively addresses the blurred boundaries between external and insider threats caused by the diversification of attack methods, thereby enhancing the model’s learning ability and overall detection performance. Moreover, the proposed method leverages the TabNet architecture, which employs a sparse attention feature selection mechanism that allows TabNet to select the most relevant features at each decision step, thereby improving the detection of rare-class attacks. We evaluated our proposed solution on two different datasets, achieving average accuracies of 96.71% and 97.25%, respectively. The results demonstrate that this approach can effectively detect malicious behaviors such as masquerade attacks and external threats, significantly enhancing network security defenses and the efficiency of network attack detection.
Index Terms:
masquerader attacks, TabNet, intrusion detection, insider threat detectionI Introduction
Internet threats pose the foremost risk to the security of enterprise assets [1, 2, 3], IoT applications [4, 5, 6, 7], security or privacy-sensitive machine learning systems [8, 9, 10] or some edge-cloud cooperation applications [11, 12, 13, 14, 15]. These threats are characterized by diverse and complex attack methods, which, once occurred, can lead to severe customer privacy breaches and significant asset losses [16, 17]. Therefore, detecting internet security threats is of utmost importance. To ensure asset security, enterprises traditionally employ IDS and UEBA technologies to detect both external and insider threats. Due to their legitimate access, insiders can be challenging to detect when they launch attacks on the system. Traditional UEBA techniques attempt to classify normal and abnormal users by establishing user group profiles [1, 7]. However, these methods struggle to distinguish users who have been long-term masqueraders within the system or those who gain access through User to Root (U2R) and Remote to Local (R2L) attacks [18], resulting in low prediction accuracy.
With the vast attack surface of the internet, enterprises face the challenge of dual threats from both internal and external sources[19]. Attackers may exploit U2R and R2L attacks to gain system access, allowing them to escalate their privileges to that of internal users. The growing sophistication of these attacks has blurred the boundaries between external and insider threats. This shift in attack trends reveals the limitations of traditional standalone detection techniques, which often have low detection rates against unknown attacks. Furthermore, the scarcity of robust and representative attack data hinders the ability of existing machine learning models to effectively learn and generalize attack behaviors. This limitation exacerbates the shortcomings of detection techniques, resulting in suboptimal performance and reduced efficacy in identifying and mitigating complex threats. This inability to effectively differentiate between normal and malicious actions poses a serious security risk, as it allows sophisticated attackers to bypass detection, escalate privileges, and operate within the system as trusted users. The failure of these traditional methods to detect such nuanced and covert threats underscores a significant vulnerability in current cybersecurity defenses, highlighting the urgent need for more advanced and adaptive detection strategies.
In summary, current threat detection technologies face the following critical issues:
-
1.
Traditional threat detection techniques often struggle to effectively distinguish between legitimate activities and sophisticated evasive behaviors, particularly when dealing with external attackers who leave backdoors, such as those executing U2R and R2L attacks.
-
2.
Traditional threat detection technologies struggle with the critical issue of effectively learning from rare class data[20, 21, 22], leading to significantly low prediction accuracy for these uncommon yet highly consequential attacks. This inadequacy poses a severe risk, as rare class attacks — often representing the most sophisticated and damaging threats — go undetected or are misclassified.
-
3.
Traditional threat detection technologies typically operate independently and fail to account for the transition from external to insider threats, which has become increasingly common in sophisticated attack scenarios. This limitation undermines their effectiveness in modern security environments, as attackers often exploit initial external breaches to gain insider access. As a result, traditional systems are frequently unable to provide comprehensive coverage, leaving critical blind spots in threat detection and response.
The main contribution of this paper can be summarized as:
-
1.
We integrated IDS and UEBA technologies to detect masquerader attacks evolving from U2L and R2L, and validated this approach using the NSL-UEBA and KDD-UEBA datasets. The results demonstrate that this combined strategy significantly improves detection accuracy and effectively identifies advanced masquerader attacks, while addressing the detection blind spots present in traditional insider threat solutions (Section VI).
-
2.
We utilize the TabNet classifier for threat detection. TabNet’s superior Attentive Transformer can generate feature selection masks to choose the most relevant features at each decision step, thereby enhancing the detection stability (Section IV).
-
3.
The integrated system effectively identifies complex, multi-stage attacks, particularly those involving the progression from external to insider threats (such as U2R and R2L attacks). By leveraging collaborative analysis and cross-domain threat correlation, the integrated approach addresses the blind spots present in traditional detection methods, significantly enhancing the system’s responsiveness to emerging and unknown threats. This integration strategy optimizes the monitoring and analysis of the entire attack chain (Section IV).
II Related work
Previous research has extensively studied ontologies and detection methods for insider threats. Homoliak et al. [1] conducted a survey on the classification, modeling, and mitigation of insider threats, categorizing them into two groups as malicious and unintentional. Existing work employs data logging and behavioral analysis to detect insider threats [2, 3]. Rashid et al. [23] utilized hidden Markov models to learn the behavioral characteristics of normal users within the system, thereby enhancing the ability to identify anomalous behavior. This approach is effective in analyzing long-term user behavior and detecting threats. Zhang et al. [24] proposed a behavior log detection method based on ensemble learning and self-supervised learning. This method employs a TF-IDF-based entity embedding technique and performs a self-supervised classification task on detecting inputs, distinguishing between valid and malicious behaviors of specific users. Other studies have also applied various machine learning methods, such as one-class SVM [25] and clustering techniques [26].
However, the exceptional performance of deep learning in tasks such as representation learning, sequence modeling, and heterogeneous data integration offers significant advantages for insider threat modeling and detection [27]. Various neural networks, including RNN and CNN, have been employed to extract behavioral features from user activity sequences or malicious sessions [28, 29, 30]. To address the issue of critical information loss due to the lack of emphasis on the connectivity between entities, Wei et al. [31] first proposed a Graph Neural Network model to construct the relationships between user behaviors and entities. They employed a weighting function to quantify the structural information between users, thereby matching behavior logs with known attack patterns. He et al. [32] utilized LSTM to extract user behavior sequences and differentiate between various user behaviors to identify anomalies. Their work leveraged an attention mechanism based on users’ historical behaviors to learn the distinctions in user behavior.

Despite the aforementioned works providing feasible detection methods, most of these models primarily detect unintentional and malicious attacks based on behavioral characteristics, but cannot analyze the process by which external attackers gain legitimate access to the system through U2R or R2L attacks. Our model integrates IDS and UEBA, in the meanwhile having the ability to track and identify masqueraders and lurkers inside the system.
III Methodology
TabITD consists of the following three main components, as illustrated in Fig. 1. The network architecture related to TabNet is shown in Fig. 2.

In TabNet, feature selection is facilitated through a learnable mask matrix , enabling the adaptive selection of the most salient features. This approach ensures that the model’s learning capacity is focused on the most relevant features, thereby enhancing parameter efficiency. The mask operation is multiplicative, represented as , and an attentive transformer is employed to generate the masks from the processed features of the previous step, . As shown in (1), The mask is determined using the sparsemax function.
| (1) |
Sparsemax normalization encourages sparsity by mapping the Euclidean projection onto the probabilistic simplex, thus ensuring the model concentrates on the most critical features. The mask values are normalized such that, as illustrated in (2), the sum over the elements equals one.
| (2) |
To regulate the sparsity of the selected features, a sparsity regularization term is incorporated into the overall loss function, as defined in (3). This term, derived from entropy, is formulated as:
| (3) |
where is a small value for numerical stability. This regularization term encourages the selection of fewer features, providing a favorable inductive bias, particularly beneficial for datasets with many redundant features.
The filtered features are processed using a feature transformer, which is split to handle decision step output and subsequent step information. Formally, for each decision step , we have (4).
| (4) |
where and .
To ensure parameter efficiency and robust learning with high capacity, the feature transformer should consist of layers that are shared across all decision steps and layers that are decision step-specific. This is implemented as a concatenation of two shared layers and two step-dependent layers.
Each fully connected (FC) layer is followed by batch normalization (BN) and a gated linear unit (GLU) nonlinearity, as shown in (5).
| (5) |
This structure is eventually connected to a normalized residual connection. Normalization with stabilizes learning by maintaining consistent variance throughout the network.
To expedite training, large batch sizes with BN are employed. For input features, we use ghost BN, where the virtual batch size and momentum form, as expressed in (6), BN normalizes the input features by subtracting the mean and dividing by the standard deviation.
| (6) |
For non-input features, we employ standard BN. Finally, inspired by decision-tree-like aggregation, the decision output is computed by (7).
| (7) |
A linear mapping is used for the output construction.
TabNet’s feature selection masks illuminate the importance of features at each decision step. When , the -th feature of the -th sample contributes nothing to the decision. If were a linear function, would directly reflect the importance of feature . Despite each decision step employing non-linear processing, their outputs are aggregated linearly. To measure the combined importance of features across steps, we introduce a coefficient that weighs the significance of each decision step for the -th sample. Specifically, we have (8).
| (8) |
This coefficient denotes the aggregate decision contribution at the -th decision step. Intuitively, if , all features at step have zero contribution to the final decision. As increases, it indicates a greater role in the overall linear combination. Scaling the decision mask at each step by , we propose the aggregate feature importance mask , which is defined in (9).
| (9) |
This aggregate mask quantifies the overall importance of each feature by integrating its significance across all decision steps.
There is a decoder architecture aimed at reconstructing tabular features from TabNet encoded representations. The decoder comprises feature transformers, followed by fully connected (FC) layers at each decision step. These outputs are aggregated to generate the reconstructed features. The task involves predicting missing feature columns from others, using a binary mask .
The TabNet encoder inputs and the decoder outputs the reconstructed features, . We initialize in the encoder to ensure the model focuses solely on known features, while the decoder’s final FC layer is multiplied by to output the unknown features.
The reconstruction loss during the self-supervised phase, as defined in (10), is:
| (10) |
This normalization uses the population standard deviation of the ground truth, beneficial due to potential range differences in features. The mask is sampled independently from a Bernoulli distribution with parameter at each iteration.
IV Experiment Setup
In this section, we comprehensively describe the experimental environment utilized in our study. We also identify and discuss the current leading detection models chosen for comparison, establishing the basis for the subsequent evaluation of our proposed model’s performance.
IV-A Experiment Environment
Our model was trained on the Google Colab platform. The implementation and testing of the model were performed using Python 3.10.12 and PyTorch 2.1.0.
IV-B Dataset
The synthetic datasets we used, KDD-UEBA and NSL-UEBA, are composed of KDDCup99 and NSL-KDD, along with the benchmark dataset CVUEBA commonly utilized in the domain of insider threat detection.
IV-C Comparing Approaches
We chose to compare TabNet with CatBoost, XGBoost, and LGBM because these are among the most commonly used methods for tabular data processing. These traditional decision tree models, especially ensemble-based approaches, are highly interpretable, allowing for easy tracking of decision nodes and explanations. One of TabNet’s main advantages is its intrinsic interpretability. By comparing it with these methods, we can validate whether TabNet can maintain or enhance interpretability while achieving superior performance.
| Method | Metrics | Benign | DoS | Malicious | Normal | Probe | R2L | U2R |
|---|---|---|---|---|---|---|---|---|
| Precision | 0.9534 | 0.9405 | 1.0000 | 0.9255 | 0.9456 | 0.9286 | 0.9303 | |
| XGBoost | Recall | 0.9625 | 0.9507 | 0.5000 | 0.9331 | 0.9479 | 0.9592 | 0.9565 |
| F1-Score | 0.9572 | 0.9557 | 0.6667 | 0.9333 | 0.9474 | 0.9441 | 0.9778 | |
| Precision | 0.9506 | 0.9437 | 0.3332 | 0.9359 | 0.9324 | 0.9449 | 0.4138 | |
| LGBM | Recall | 0.9470 | 0.9517 | 0.3332 | 0.9353 | 0.9549 | 0.9348 | 0.5217 |
| F1-Score | 0.9245 | 0.9371 | 0.3332 | 0.9319 | 0.8788 | 0.9391 | 0.4615 | |
| Precision | 0.9413 | 0.9315 | 0.0000 | 0.9208 | 0.9365 | 0.9510 | 0.0000 | |
| CatBoost | Recall | 0.9786 | 0.9508 | 0.0000 | 0.9553 | 0.9393 | 0.9790 | 0.0000 |
| F1-Score | 0.9357 | 0.9599 | 0.0000 | 0.9276 | 0.9372 | 0.9648 | 0.0000 | |
| Precision | 0.9639 | 0.9699 | 0.9642 | 0.9658 | 0.9668 | 0.9520 | 0.9615 | |
| Ours | Recall | 0.9542 | 0.9691 | 0.9700 | 0.9696 | 0.9651 | 0.9685 | 0.9137 |
| F1-Score | 0.9590 | 0.9695 | 0.9671 | 0.9677 | 0.9660 | 0.9602 | 0.9370 |
| Method | Metrics | Benign | DoS | Malicious | Normal | Probe | R2L | U2R |
|---|---|---|---|---|---|---|---|---|
| Precision | 0.9209 | 0.9325 | 1.0000 | 0.9498 | 1.0000 | 0.9955 | 1.0000 | |
| XGBoost | Recall | 0.9559 | 0.9294 | 0.6667 | 0.9300 | 0.9241 | 0.9822 | 0.6000 |
| F1-Score | 0.8872 | 0.9558 | 0.8000 | 0.9285 | 0.9215 | 0.9888 | 0.7500 | |
| Precision | 0.9383 | 0.9561 | 0.0000 | 0.9492 | 0.9638 | 0.8765 | 0.0000 | |
| LGBM | Recall | 0.9261 | 0.9589 | 0.0000 | 0.9362 | 0.9372 | 0.9167 | 0.0000 |
| F1-Score | 0.9415 | 0.9317 | 0.0000 | 0.9678 | 0.9503 | 0.9103 | 0.0000 | |
| Precision | 0.9494 | 0.9697 | 0.0000 | 0.9694 | 0.9684 | 1.0000 | 0.0000 | |
| CatBoost | Recall | 0.9693 | 0.9697 | 0.0000 | 0.9700 | 0.7810 | 0.0844 | 0.0000 |
| F1-Score | 0.9592 | 0.9697 | 0.0000 | 0.9697 | 0.8765 | 0.1557 | 0.0000 | |
| Precision | 0.9600 | 0.9811 | 0.9522 | 0.9300 | 1.0000 | 0.9594 | 0.9599 | |
| Ours | Recall | 0.9732 | 0.9661 | 0.9400 | 0.9689 | 1.0000 | 0.9997 | 1.0000 |
| F1-Score | 0.9693 | 0.9680 | 0.9310 | 0.9695 | 1.0000 | 0.9996 | 0.9549 |
V Experimental Analysis
V-A Experiment Result Analysis




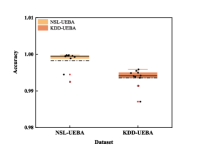



In the threat detection experiments, we evaluated our model against CatBoost, XGBoost and LGBM, on the NSL-UEBA, and KDD-UEBA datasets. The results for each detection method are presented in Tables I and II, respectively. It is evident that the proposed model exhibits robust performance across various threat categories, particularly excelling in scenarios involving rare classes. Unlike other methods, our approach demonstrates superior balance and consistency in class detection, achieving commendable precision, recall, and F1-Score, especially in the ”Malicious,” ”R2L,” and ”U2R” categories, where traditional models often struggle.
The tree structures in XGBoost, CatBoost, and LGBM are capable of handling imbalanced data effectively. However, each decision tree in XGBoost is constructed independently without sharing information between trees. While increasing tree depth and number can enhance model complexity, the inherent structure of decision trees has limited ability to capture high-order feature interactions. CatBoost employs target encoding to handle categorical features. For rare categories, the target encoding values can be highly influenced by a small number of samples, resulting in significant volatility. This volatility can lead to instability in the model during training and prediction. LGBM segments feature data into multiple discrete bins and performs statistics within these bins. This binning approach can cause subtle feature differences in rare categories to be overlooked. Due to these reasons, all three tree-based gradient boosting frameworks—XGBoost, CatBoost, and LGBM face challenges in detecting rare classes effectively.
TabNet stands out with its sequential attention mechanism, which dynamically selects features at each decision step. This approach allows the model to focus on the most relevant features for each instance, enhancing both interpretability and learning efficiency. Besides, TabNet performs end-to-end learning using gradient descent optimization, seamlessly integrating feature selection and model training, which is particularly advantageous for complex tabular data. Unlike traditional models that use static feature selection, TabNet dynamically selects features for each instance, providing a tailored approach that adapts to varying data distributions and patterns. By addressing the shortcomings of traditional models, TabNet offers several improvements. Firstly, its dynamic, instance-wise feature selection mechanism avoids the static and global feature selection approach of traditional models like XGBoost, CatBoost, and LGBM. This allows TabNet to capture instance-specific nuances more effectively, reducing the risk of overfitting and improving performance on high-dimensional sparse data. Secondly, TabNet’s sequential attention mechanism focuses on the most relevant features, enhancing model efficiency and interpretability, and reducing the computational cost associated with extensive feature engineering and tuning.
V-B Stability Analysis
To evaluate the performance of our model, we tested its False Alarm Rate, Accuracy, Detection Rate, and False Negative Rate on the NSL-UEBA and KDD-UEBA datasets. The experimental results demonstrate that our model exhibits strong stability in threat detection. This stability is primarily attributed to the use of resampling techniques, which increase the representation of rare class samples, thereby ensuring a more balanced distribution in the training data. Such balance facilitates TabNet’s ability to effectively learn the characteristics of these rare classes during training, thereby enhancing the model’s performance on these classes, as shown in Fig. 3.
TabNet’s multi-layer feature transformers progressively extract complex feature relationships at each hierarchical level. This deep transformation, coupled with a rich feature representation, enables the model to capture intricate patterns within the data. Furthermore, the embedded sparse attention mechanism in TabNet dynamically selects the most relevant features, effectively filtering out noise and irrelevant features, thereby reducing the risk of overfitting. When combined with resampling techniques, the model can stably extract relevant features across different sample classes without disproportionately relying on the majority class samples.
This approach enhances the model’s capability to generalize well across varied data distributions, contributing to its robust performance in threat detection tasks.
VI Conclusion
With the increasing frequency of insider threat incidents, their detection has become a critical issue. This paper proposes a collaborative detection-based insider threat detection scheme, aiming to address the shortcomings of traditional insider threat detection techniques. This scheme utilizes TabNet for threat behavior detection, and performance test results demonstrate that our approach can identify various malicious activities. Currently, the main limitation of this study lies in the adaptive hyperparameter tuning, which is crucial for selecting optimal model parameters and thus affects the model’s detection performance. The hyperparameters of TabNet are often interdependent, with complex relationships between certain hyperparameters. This interdependence makes simple grid search or random search methods insufficient for effective hyperparameter tuning, necessitating the use of more advanced optimization algorithms. Therefore, improving hyperparameter tuning remains a challenge, and further research is needed to optimize and refine this scheme. In the future, we plan to employ Hyperband optimization and adopt a resource allocation strategy based on bandit algorithms to dynamically allocate computational resources for evaluating different hyperparameter combinations, testing this approach in real-world wireless testbed [33] scenarios.
References
- [1] I. Homoliak, F. Toffalini, J. Guarnizo, Y. Elovici, and M. Ochoa, “Insight into insiders and it: A survey of insider threat taxonomies, analysis, modeling, and countermeasures,” ACM Computing Surveys (CSUR), vol. 52, no. 2, pp. 1–40, 2019.
- [2] H. Eldardiry, E. Bart, J. Liu, J. Hanley, B. Price, and O. Brdiczka, “Multi-domain information fusion for insider threat detection,” in 2013 IEEE Security and Privacy Workshops, pp. 45–51, IEEE, 2013.
- [3] G. Gavai, K. Sricharan, D. Gunning, R. Rolleston, J. Hanley, and M. Singhal, “Detecting insider threat from enterprise social and online activity data,” in Proceedings of the 7th ACM CCS international workshop on managing insider security threats, pp. 13–20, 2015.
- [4] B. Liu, L. Wang, M. Liu, and C.-Z. Xu, “Lifelong federated reinforcement learning: a learning architecture for navigation in cloud robotic systems,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4555–4562, 2019.
- [5] B. Liu, L. Wang, M. Liu, and C.-Z. Xu, “Federated imitation learning: A novel framework for cloud robotic systems with heterogeneous sensor data,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3509–3516, 2019.
- [6] E. Bout, V. Loscri, and A. Gallais, “How machine learning changes the nature of cyberattacks on iot networks: A survey,” IEEE Communications Surveys & Tutorials, vol. 24, no. 1, pp. 248–279, 2021.
- [7] B. Liu, L. Wang, X. Chen, L. Huang, D. Han, and C.-Z. Xu, “Peer-assisted robotic learning: a data-driven collaborative learning approach for cloud robotic systems,” in 2021 IEEE international conference on robotics and automation (ICRA), pp. 4062–4070, IEEE, 2021.
- [8] Z. Zheng, Y. Zhou, Y. Sun, Z. Wang, B. Liu, and K. Li, “Applications of federated learning in smart cities: recent advances, taxonomy, and open challenges,” Connection Science, vol. 34, no. 1, pp. 1–28, 2022.
- [9] B. Liu, B. Yan, Y. Zhou, Y. Yang, and Y. Zhang, “Experiments of federated learning for covid-19 chest x-ray images,” arXiv preprint arXiv:2007.05592, 2020.
- [10] B. Yan, B. Liu, L. Wang, Y. Zhou, Z. Liang, M. Liu, and C.-Z. Xu, “Fedcm: A real-time contribution measurement method for participants in federated learning,” in 2021 International joint conference on neural networks (IJCNN), pp. 1–8, IEEE, 2021.
- [11] B. Liu, L. Wang, and M. Liu, “Elasticros: An elastically collaborative robot operation system for fog and cloud robotics,” arXiv preprint arXiv:2209.01774, 2022.
- [12] S. Zhang, W. Li, X. Li, and B. Liu, “Authros: Secure data sharing among robot operating systems based on ethereum,” in 2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS), pp. 147–156, IEEE, 2022.
- [13] B. Liu, L. Wang, and M. Liu, “Roboec2: A novel cloud robotic system with dynamic network offloading assisted by amazon ec2,” IEEE Transactions on Automation Science and Engineering, 2023.
- [14] Y. Wei, S. Zhou, S. Leng, S. Maharjan, and Y. Zhang, “Federated learning empowered end-edge-cloud cooperation for 5g hetnet security,” IEEE Network, vol. 35, no. 2, pp. 88–94, 2021.
- [15] B. Liu, J. Tong, and Y. Zhuang, “Edgeloc: A communication-adaptive parallel system for real-time localization in infrastructure-assisted autonomous driving,” arXiv preprint arXiv:2405.12120, 2024.
- [16] S. Yuan and X. Wu, “Deep learning for insider threat detection: Review, challenges and opportunities,” Computers & Security, vol. 104, p. 102221, 2021.
- [17] L. Liu, O. De Vel, Q.-L. Han, J. Zhang, and Y. Xiang, “Detecting and preventing cyber insider threats: A survey,” IEEE Communications Surveys & Tutorials, vol. 20, no. 2, pp. 1397–1417, 2018.
- [18] N. Chaabouni, M. Mosbah, A. Zemmari, C. Sauvignac, and P. Faruki, “Network intrusion detection for iot security based on learning techniques,” IEEE Communications Surveys & Tutorials, vol. 21, no. 3, pp. 2671–2701, 2019.
- [19] B. Liu, J. Cheng, K. Cai, P. Shi, and X. Tang, “Singular point probability improve lstm network performance for long-term traffic flow prediction,” in Theoretical Computer Science: 35th National Conference, NCTCS 2017, Wuhan, China, October 14-15, 2017, Proceedings, pp. 328–340, Springer, 2017.
- [20] P. Mishra, V. Varadharajan, U. Tupakula, and E. S. Pilli, “A detailed investigation and analysis of using machine learning techniques for intrusion detection,” IEEE communications surveys & tutorials, vol. 21, no. 1, pp. 686–728, 2018.
- [21] S. Elhag, A. Fernández, A. Bawakid, S. Alshomrani, and F. Herrera, “On the combination of genetic fuzzy systems and pairwise learning for improving detection rates on intrusion detection systems,” Expert Systems with Applications, vol. 42, no. 1, pp. 193–202, 2015.
- [22] M. Liu, Z. Xue, X. Xu, C. Zhong, and J. Chen, “Host-based intrusion detection system with system calls: Review and future trends,” ACM computing surveys (CSUR), vol. 51, no. 5, pp. 1–36, 2018.
- [23] T. Rashid, I. Agrafiotis, and J. R. Nurse, “A new take on detecting insider threats: exploring the use of hidden markov models,” in Proceedings of the 8th ACM CCS International workshop on managing insider security threats, pp. 47–56, 2016.
- [24] C. Zhang, S. Wang, D. Zhan, T. Yu, T. Wang, and M. Yin, “Detecting insider threat from behavioral logs based on ensemble and self-supervised learning,” Security and Communication Networks, vol. 2021, pp. 1–11, 2021.
- [25] M. Aldairi, L. Karimi, and J. Joshi, “A trust aware unsupervised learning approach for insider threat detection,” in 2019 IEEE 20th International Conference on Information Reuse and Integration for Data Science (IRI), pp. 89–98, IEEE, 2019.
- [26] J. Kim, M. Park, H. Kim, S. Cho, and P. Kang, “Insider threat detection based on user behavior modeling and anomaly detection algorithms,” Applied Sciences, vol. 9, no. 19, p. 4018, 2019.
- [27] S. Yuan and X. Wu, “Deep learning for insider threat detection: Review, challenges and opportunities,” Computers & Security, vol. 104, p. 102221, 2021.
- [28] A. Tuor, S. Kaplan, B. Hutchinson, N. Nichols, and S. Robinson, “Deep learning for unsupervised insider threat detection in structured cybersecurity data streams,” in Workshops at the Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [29] T. Hu, W. Niu, X. Zhang, X. Liu, J. Lu, Y. Liu, et al., “An insider threat detection approach based on mouse dynamics and deep learning,” Security and communication networks, vol. 2019, 2019.
- [30] S. Yuan, P. Zheng, X. Wu, and Q. Li, “Insider threat detection via hierarchical neural temporal point processes,” in 2019 IEEE international conference on big data (big data), pp. 1343–1350, IEEE, 2019.
- [31] R. Wei, L. Cai, L. Zhao, A. Yu, and D. Meng, “Deephunter: A graph neural network based approach for robust cyber threat hunting,” in Security and Privacy in Communication Networks: 17th EAI International Conference, SecureComm 2021, Virtual Event, September 6–9, 2021, Proceedings, Part I 17, pp. 3–24, Springer, 2021.
- [32] W. He, X. Wu, J. Wu, X. Xie, L. Qiu, and L. Sun, “Insider threat detection based on user historical behavior and attention mechanism,” in 2021 IEEE Sixth International Conference on Data Science in Cyberspace (DSC), pp. 564–569, IEEE, 2021.
- [33] B. Liu, J. Tong, and J. Zhang, “Llm-slice: Dedicated wireless network slicing for large language models,” arXiv preprint arXiv:2410.18499, 2024.