TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
Abstract
In this paper, we establish a benchmark for table visual question answering, referred to as the TableVQA-Bench, derived from pre-existing table question-answering (QA) and table structure recognition datasets. It is important to note that existing datasets have not incorporated images or QA pairs, which are two crucial components of TableVQA. As such, the primary objective of this paper is to obtain these necessary components. Specifically, images are sourced either through the application of a stylesheet or by employing the proposed table rendering system. QA pairs are generated by exploiting the large language model (LLM) where the input is a text-formatted table. Ultimately, the completed TableVQA-Bench comprises 1,500 QA pairs. We comprehensively compare the performance of various multi-modal large language models (MLLMs) on TableVQA-Bench. GPT-4V achieves the highest accuracy among commercial and open-sourced MLLMs from our experiments. Moreover, we discover that the number of vision queries plays a significant role in TableVQA performance. To further analyze the capabilities of MLLMs in comparison to their LLM backbones, we investigate by presenting image-formatted tables to MLLMs and text-formatted tables to LLMs, respectively. Our findings suggest that processing visual inputs is more challenging than text inputs, as evidenced by the lower performance of MLLMs, despite generally requiring higher computational costs than LLMs. The proposed TableVQA-Bench and evaluation codes are available at https://github.com/naver-ai/tablevqabench.
1 Introduction
Tabular data is one of the most prevalent formats for representing structured text, playing a significant role in the efficient delivery of text-based information. A large proportion of these tables can be found in image form, created from text sources, such as HTML and markdown formats. Therefore, understanding visual tabular data can be deemed a crucial endeavor within the realm of the visual documentation domain. In light of recent advancements in multi-modal large language models (MLLMs) [17, 13, 30, 9, 14], it is now possible to harbor this capability within a single model. However, despite its significance, the evaluation of visual table data has been less vigorous due to the absence of evaluation datasets.
Meanwhile, in natural language processing (NLP), textual table question answering (TableQA) datasets have been widely proposed. For instance, Panupong et al. provide WikiTableQuestion (WTQ) [22] that is a question-answering task based on a text-based table. Chen et al. also release TabFact [4] dataset determining whether a statement is entailed or refuted with a given table. Unfortunately, these datasets do not provide table images, making it challenging to apply them directly to table visual question answering.

In this paper, we construct a new TableVQA-Bench dataset as shown in Fig. 1 by leveraging existing TableQA and table structure recognition (TSR) datasets. As for the TableQA dataset, real table images are sourced by attaching a stylesheet of original source (Wikipedia) into HTML that contains both the content and style of the table. Acquired images can be contaminated, given that Wikipedia is often utilized as a primary source for constructing the web-crawled base for pre-training data, as suggested by Pix2Struct [10]. To circumvent this issue, the proposed table rendering system is also utilized to obtain synthetic table images. As for TSR dataset, QA pairs are required for constructing TableVQA. To generate QA pairs, we propose to exploit GPT-4 [2] by feeding the text-formatted table as an input.
Through comparisons among MLLMs on TableVQA-Bench, we found that GPT-4V [1] outperforms other methods including commercial and open-sourced models across all table domains. We also observed that preserving the original information of visual features can be a crucial factor for TableVQA. For example, GPT-4V and CogVLM achieved enhanced performance when the resolution of the input image was higher.


To provide a better analysis of the model’s capability, we conduct a comprehensive investigation of table formats and their performance. As illustrated in Fig. 2, text-formatted tables, including HTML and markdown, tended to outperform their vision-formatted counterparts. Furthermore, to enhance the analysis, a two-stage approach is explored, which initially involves extracting content from images for HTML representation and subsequently applying it to the TableQA task.
2 Related Works
The significance of benchmarks for assessing the performance of MLLMs has grown as MLLMs advance rapidly. MMBench [18] evaluates perception and reasoning across approximately 3,000 questions in 20 different ability dimensions, including the ‘image-text understanding’ dimension. SEED-Bench [12] is categorized into 12 evaluation dimensions with about 19,000 questions covering scenes, detection, OCR, and various other types. SEED-Bench-2 [11] increases the number of questions to 24K to its predecessor, and the complexity of questions has been heightened to represent multi-modal content on both input and output sides. MathVista [19] is a mathematically specialized evaluation set, consisting of 6,141 subjective and objective questions. This dataset encompasses questions related to seven types of mathematical reasoning and covers five primary tasks, incorporating a small portion in tabular format. Recently, chart question-answering benchmarks [20, 25, 15] have been introduced, examining specific domains of tasks. While these aforementioned datasets may partially encompass or relate to TableVQA, they do not primarily focus on TableVQA. Therefore, a dataset meticulously designed for the thorough investigation of TableVQA is indispensable and our TableVQA-Bench dutifully fulfills this requirement. Furthermore, we believe that the extensive investigation provided in this paper will be helpful in interpreting the table-related performance in previous datasets.

3 TableVQA-Bench
As illustrated in Fig. 3, we construct the TableVQA-Bench. TableVQA-Bench encompasses VWTQ, VTabFact, and FinTabNetQA, which are extended from pre-existing databases such as WTQ [22], TabFact [4], and FinTabNet [27] correspondingly. The components of TableVQA consist of three parts; table image, text-representation (HTML), and QA pairs IMG, HTML, QA. To acquire images for VWTQ and VTabFact, we source images by attaching the stylesheet of Wikipedia or by utilizing our table rendering system. Conversely, FinTabNet is devoid of the QA pair, which is generated by employing the GPT-4. In the final stage of these processes, any samples with more than 50 table rows are methodically filtered out and the authors carry out a meticulous review.
3.1 VWTQ

VWTQ is constructed by incorporating an image collection into the WTQ [22] while maintaining its QA pairs and accuracy-based evaluation metric. As shown in Fig. 4(a), WTQ provides HTML that represents both the content and style of a table. To reproduce the original table images from Wikipedia, we applied the stylesheet of Wikipedia to the HTML. Finally, we obtained the images by capturing screenshots, which are presented in Fig. 4(b). Since images from Wikipedia can be web-crawled to gather pre-training data for MLLMs, we also generate table images using our table rendering system. It takes HTML as input and generates tables with various styles, featuring random attributes, as detailed in Section 3.4. The datasets generated from the attaching Wikipedia stylesheet and our rendering system have been named VWTQ and VWTQ-Synthesized (VWTQ-Syn), respectively.
3.2 VTabFact
TabFact [4] represents a verification task that verifies whether a statement derived from a table is either entailed or refuted, thus categorizing it as a variant of the TableQA task. In our empirical experiments, it was observed that prompts framed as “True or False” yielded higher efficacy compared to those framed as “entailed or refuted”. Consequently, we replace the answer format to “True” or “False” accordingly and we employ the evaluation metric as accuracy following the TabFact. Given that TabFact has not provided the original HTML format of the tables, the acquisition of images is feasible only through the utilization of the proposed rendering system. It takes pseudo-HTML as an input, which is converted from the simple CSV file, and generates the images.
3.3 FinTabNetQA
FinTabNet [27] is a dataset for TSR task [28, 21, 8] that extracts an HTML format from a given table image. Unlike WTQ and TabFact, which use Wikipedia as their data source, FinTabNet’s sources are the annual reports of S&P 500 companies, allowing it to evaluate tables from new domains. For the construction of FinTabNetQA, a generation process of QA pairs is required, and we utilized GPT-4 with HTML as an input. During the generation process, two issues were encountered and resolved in the following manners:
-
•
The first question is often answered in the first non-header cell. This issue persisted even with the use of additional instructions, thus we opted to generate numerous QA pairs from a single table and conducted random sampling from QA pairs.
-
•
We observed inconsistent inclusion of scale units, such as thousand, million, and billion at the answer. Particularly when the scale unit is in thousands, most generated answers often do not include the scale unit. We rectify this issue with a meticulous human revision procedure.
In terms of the evaluation metric, we employ accuracy. It should be noted that the majority of financial tables encompass scale units, for instance, thousand, million, billion, trillion, and percentage. For the FinTabNetQA, the accuracy measure referred to as relieved-accuracy is employed, whereby these units are intentionally excluded during evaluation. To provide an illustrative example, when the ground truth is “128 million”, predictions such as “128 million”, “128,000,000” and “128” are all approved as accurate responses. This methodology is justified due to the fact that MLLMs presently fail to attain substantial performance in a strict accuracy evaluation. Both the strict-accuracy and the relieved-accuracy scripts will be made available for further research.

3.4 Table Rendering System
Our rendering framework employs a rule-based methodology for rendering table images, engaging diverse styles applied to HTML sources. This framework bifurcates into two principal phases: style generation and image generation.
In the first stage, style tags are added to the original HTML to generate a styled HTML where the most of original HTML only incorporates the structure of the table. Leveraging the Bootstrap framework111https://getbootstrap.com, the system facilitates a diverse representation of table styles encompassing elements such as cells, borders, and texts. The specific style attributes include:
-
•
Table: background-color and margin
-
•
Cell: background-color and padding
-
•
Border: border-width, border-style, and border-color
-
•
Text: font-family, font-size, text-align, and color
where these components are randomly determined. Fig. 5 presents the example when each attribute is changed from the default setting. The second phase, image generation, involves rendering the styled HTML within a web browser to capture a screenshot. Utilizing the Puppeteer library222https://pptr.dev, we obtain rendered images by randomly selecting parameters such as image dimensions and JPEG quality. To generate diverse table images, most attributes are randomly determined. However, certain attribute combinations may yield images that appear unnatural. To mitigate this, a human review process is conducted to filter out such anomalous images.
| Real Image | Human Generated QA | #Image | #QA | |
|---|---|---|---|---|
| VWTQ | ✓ | ✓ | 315 | 750 |
| VWTQ-Syn | ✗ | ✓ | 150 | 250 |
| VTabFact | ✗ | ✓ | 224 | 250 |
| FinTabNetQA | ✓ | ✗ | 205 | 250 |
| Total | - | - | 894 | 1,500 |


























3.5 Data Statistics
Table 1 provides data statistics, comprising a total of 894 images and 1500 QA pairs for evaluation. VWTQ includes 750 QA pairs gathered from purely authentic data. An equal quantity of QA pairs is amassed from partial real data, originating from VWTQ-syn, VTabFact-syn, and FintabNetQA. The QA pairs of VWTQ-syn are sampled from VWTQ.
The distribution of each dataset is examined and visualized for analytical purposes in Fig. 6. The observed statistics in Fig. 6(a) reveal that the length of the questions originating from FintabNetQA is generally longer than the other datasets. This trend is possibly due to its machine-generated characteristics, where GPT-4 tends to construct more elaborate question structures. As shown in Fig. 6(b), the answer length distribution for VTabFact seems to branch out into two distinctive categories, with “true” or “false” being its definitive responses. Frequent instances of elongated answers in FintabNetQA primarily occur due to the common inclusion of units. As shown in Fig. 6(c), 6(d), and 6(e), a prominent correlation between the number of rows and the aspect ratio can be established. VWTQ is distinctively characterized by the presence of numerous tables with lengthy rows. While comparing the number of rows, FintabNetQA often exhibits a larger aspect ratio. This might be attributed to two possible explanations: 1) the cell height is relatively larger, and 2) the cell content is abundant, leading to an increase in the number of line breaks.
As illustrated in Fig. 6(f) and 6(g), our analysis extends to examining the token length with the Vicuna-7B tokenizer [5] when tables are encoded in HTML format. We found that the tokenizer does not incorporate HTML tags such as , , and as individual tokens. Although incorporating these tags as special tokens slightly increases the vocabulary size, it significantly reduces the number of required input tokens. Typically, open-sourced MLLMs [16, 13] integrate vision queries and text queries by concatenating them before feeding them into the LLMs. Consequently, comparing the length of text tokens with the length of vision tokens becomes feasible when tables are represented in both image and text formats. As shown in Table 2, the length of vision tokens varies widely, ranging from 32 to 1445. It is observed that the efficiency of image-formatted tables significantly decreases compared to those text-formatted with special tokens when the length of a vision query exceeds 1,000 tokens.
4 Experiments
4.1 Experimental Setup
Evaluation Protocol.
In the inference phase, minor prompt tuning was conducted for each model in order to acquire a suitable answer format for subsequent evaluation. In instances where answer parsing was required, rule-based methods are deployed. The chosen metric for evaluation is accuracy, the specifics of which are explained in Section 3. When the rule-based parsing fails to acquire a properly formatted answer, we also evaluate its performance using a modified accuracy metric. This metric specifically assesses whether the answer is contained within the response. These aforementioned processes will be incorporated into the upcoming project page.
| Models | Size | LLM Branch | Size | Vision Branch | Size | #Vision-Queries |
|---|---|---|---|---|---|---|
| BLIP-2 [13] | 12.1B | FlanT5-XXL | 11B | EVA-CLIP-g/14 | 1B | 32 |
| InstructBLIP [6] | 8.2B | Vicuna-7B | 7B | EVA-CLIP-g/14 | 1B | 32 |
| CogVLM [24] | 17B | Vicuna-7B | 7B | EVA-02-CLIP-E/14 | 4.4B | 256 |
| CogVLM-1k [24] | 17B | Vicuna-7B | 7B | EVA-02-CLIP-E/14 | 4.4B | 1225 |
| CogVLM-Agent-VQA [7] | 17B | Vicuna-7B | 7B | Mixed | 4.4B | 256+ |
| mPLUG-Owl2 [26] | 8.2B | LLaMA-7B | 7B | CLIP ViT-L/14 | 0.3B | 64 |
| SPHINX-v1 [14] | 15.7B | LLaMA-13B | 13B | Mixed | 2.7B | 289 |
| SPHINX-v1-1k [14] | 15.7B | LLaMA-13B | 13B | Mixed | 2.7B | 1445 |
| LLaVA-v1.5 [16] | 13.4B | Vicuna-13B | 13B | CLIP ViT-L/14 | 304M | 576 |
| Qwen-VL(-Chat) [3] | 9.6B | Qwen-7B | 7.7B | OpenCLIP ViT-G/14 | 1.9B | 256 |
Compared Models.
Comparative analysis is conducted on MLLMs, including commercial models such as Gemini-ProV333gemini-pro-vision and gemini-pro are employed for MLLM and LLM, respectively. [23] and GPT-4V444gpt-4-vision-preview and gpt-4-1106-preview are employed for MLLMs and LLM, respectively. For gpt-4-vision-preview, we adopt ‘auto’ as a detail option [1], and several open-source models as outlined in Table 2. Since SPHINX-MoE and SPHINX-v2 have not been published, we exploited huggingface models555https://huggingface.co/Alpha-VLLM/LLaMA2-Accessory/tree/main/finetune/mm/SPHINX. To examine the capabilities of their underlying LLMs on TableQA, Vicuna-7B-v1.5 [5], Vicuna-13B-v1.5 [5], Gemini-Pro [23], GPT-3.5, and GPT-4 [2] are evaluated by feeding them HTML-encoded tables as input. We also employ two-stage inference methods. We extract the HTML of tables using MLLMs and then conduct the QA task with LLMs where these methods are denoted as GPT-4V GPT-4 and Gemini-ProV Gemini-Pro. We expect this to reveal the correlation between textual and visual modalities.
4.2 Experimental Results
We present the comprehensive comparisons of multi-modal inputs in Table 3. The average score is achieved from the sample average.
| Input Modality | Model | VWTQ | VWTQ-Syn | VTabFact | FinTabNetQA | Avg. |
|---|---|---|---|---|---|---|
| Multi-modal Large Language Models (MLLMs) | ||||||
| Vision | GPT-4V [1] | 42.5 | 52.0 | 68.0 | 79.6 | 54.5 |
| Gemini-ProV [23] | 26.7 | 33.2 | 55.6 | 60.8 | 38.3 | |
| SPHINX-MoE-1k | 27.2 | 33.6 | 61.6 | 36.0 | 35.5 | |
| SPHINX-v2-1k | 25.3 | 28.0 | 66.8 | 31.2 | 33.7 | |
| QWEN-VL-Chat [3] | 19.0 | 23.2 | 60.4 | 29.6 | 28.4 | |
| QWEN-VL [3] | 17.2 | 21.2 | 52.0 | 34.0 | 26.5 | |
| SPHINX-MoE | 15.3 | 16.8 | 58.8 | 2.8 | 20.7 | |
| SPHINX-v1-1k [14] | 13.2 | 17.2 | 58.0 | 3.2 | 19.7 | |
| mPLUG-Owl2 [26] | 10.7 | 14.4 | 56.8 | 2.8 | 17.7 | |
| LLaVA-1.5 [16] | 12.4 | 12.4 | 55.6 | 0.8 | 17.7 | |
| CogVLM-1k [24] | 9.7 | 11.6 | 52.0 | 4.8 | 16.3 | |
| SPHINX-v1 [14] | 7.1 | 9.6 | 55.2 | 1.2 | 14.5 | |
| CogAgent-VQA [7] | 0.3 | 0.8 | 58.4 | 22.8 | 13.8 | |
| InstructBLIP [6] | 5.9 | 6.4 | 50.4 | 0.4 | 12.5 | |
| BLIP-2 [13] | 5.2 | 5.6 | 51.6 | 0.4 | 12.2 | |
| CogVLM [24] | 0.8 | 0.8 | 40.8 | 1.2 | 7.5 | |
| CogAgent-VQA* [7] | 37.2 | 41.2 | 58.4 | 22.8 | 39.0 | |
| Table Structure Reconstruction + Large Language Models (LLMs) | ||||||
| Vision | GPT-4V [1] GPT-4 [2] | 45.2 | 55.6 | 78.0 | 95.2 | 60.7 |
| Gemini-ProV Gemini-Pro [23] | 34.8 | 40.4 | 71.0 | 75.6 | 48.6 | |
| Large Language Models (LLMs) | ||||||
| Text | GPT-4 [2] | 68.1 | 69.6 | 80.0 | 98.8 | 75.5 |
| Gemini-Pro [23] | 56.4 | 61.2 | 69.6 | 96.4 | 66.1 | |
| GPT-3.5 | 50.5 | 54.4 | 68.0 | 93.2 | 61.2 | |
| Vicuna-13B [5] | 32.8 | 39.2 | 57.6 | 84.8 | 46.7 | |
| Vicuna-7B [5] | 21.5 | 34.4 | 54.0 | 68.8 | 37.0 | |
Comparisons between MLLMs.
Among MLLMs, commercial models outperform open-source alternatives. To elaborate further, the high performance of GPT-4V can be attributed to the use of GPT-4 in creating QA in FintabNetQA. However, GPT-4V demonstrates the highest performance across all datasets, not just this specific instance. On TableVQA, we also find that the pivotal role is played by the number of vision queries. In a specific comparison, SPHINX-MoE-1k, SPHINX-v1-1k, and CogVLM-1k surpass SPHINX-MoE, SHPHINX, and CogVLM, respectively. These findings, along with observations from Fig. 6(g), indicate that vision input generally requires a higher number of queries than text input to achieve promising performance. Notably, despite LLaVA-1.5 has not been trained on OCR-abundant documents, it exhibits competitive performance to models that included such documents in their training sets.
MLLMs vs. LLMs.
From a performance perspective, the text modality outperforms the vision modality as an input source. Specifically, on average, GPT-4 achieves a performance enhancement of 21 % points more than GPT-4V, while Gemini-pro outperforms Gemini-proV by 27.8 % points. Similarly, open-sourced MLLMs generally have lower performance than their backbone LLMs such as Vicuna-7B and Vicuna-13B. Although the spatial information in vision inputs might enable easier comprehension of the instance’s location relation, a performance critically dependent on the aspect ratio cannot be overlooked, as seen in Fig. 2(b). Such findings indicate that in terms of performance, using text inputs still might be advantageous if both vision and text tables are presented. Meanwhile, even in non-GPT models such as Gemini-Pro and Vicuna-13B, a high level of performance is obtained on FintabNetQA, suggesting that the inherent complexity of the QA pair in the dataset is relatively low.
| VQWTQ | VWTQ-Syn | VTabFact | FinTabNetQA | Avg. | |
|---|---|---|---|---|---|
| TSR SoTA [8] | 89.7 | 84.5 | 76.8 | 52.0 | 80.4 |
| Gemini-ProV | 72.7 | 78.4 | 73.0 | 65.8 | 72.6 |
| GPT-4V | 64.0 | 76.7 | 72.8 | 72.6 | 69.0 |

Two-stage Inference.
Two-stage inference leads to significant performance enhancements within the same vision input on both GPT and Gemini families. Despite such enhancements, it is evident that the performance still falls short compared to when text input is used. While it might be feasible to conduct experiments extracting HTML and answers through prompt tuning in the single MLLM, unfortunately, we were unable to obtain results in our desired format. Employing TEDs [29] evaluation metric, we compare the MLLMs’ performance on TSR with that of the state-of-the-art (SoTA) model [8]. For a fair comparison, we utilize the SoTA model trained only on PubTabNet [28], which can be regarded as a held-out dataset for TableVQA-Bench. As shown in Table 4, the SoTA model usually performs better than MLLMs. These findings indicate that MLLMs exhibit limitations in efficiently extracting information from visual tables.
Qualitative Evaluation.
We present qualitative results in Fig. 7. The incorrect answers are usually derived from words not presented in the table, which may be attributed to the limitations of OCR capability. A longer length of the vision query appears to alleviate these issues, as demonstrated by the correct answers in the second example.
GPT-4V Details.
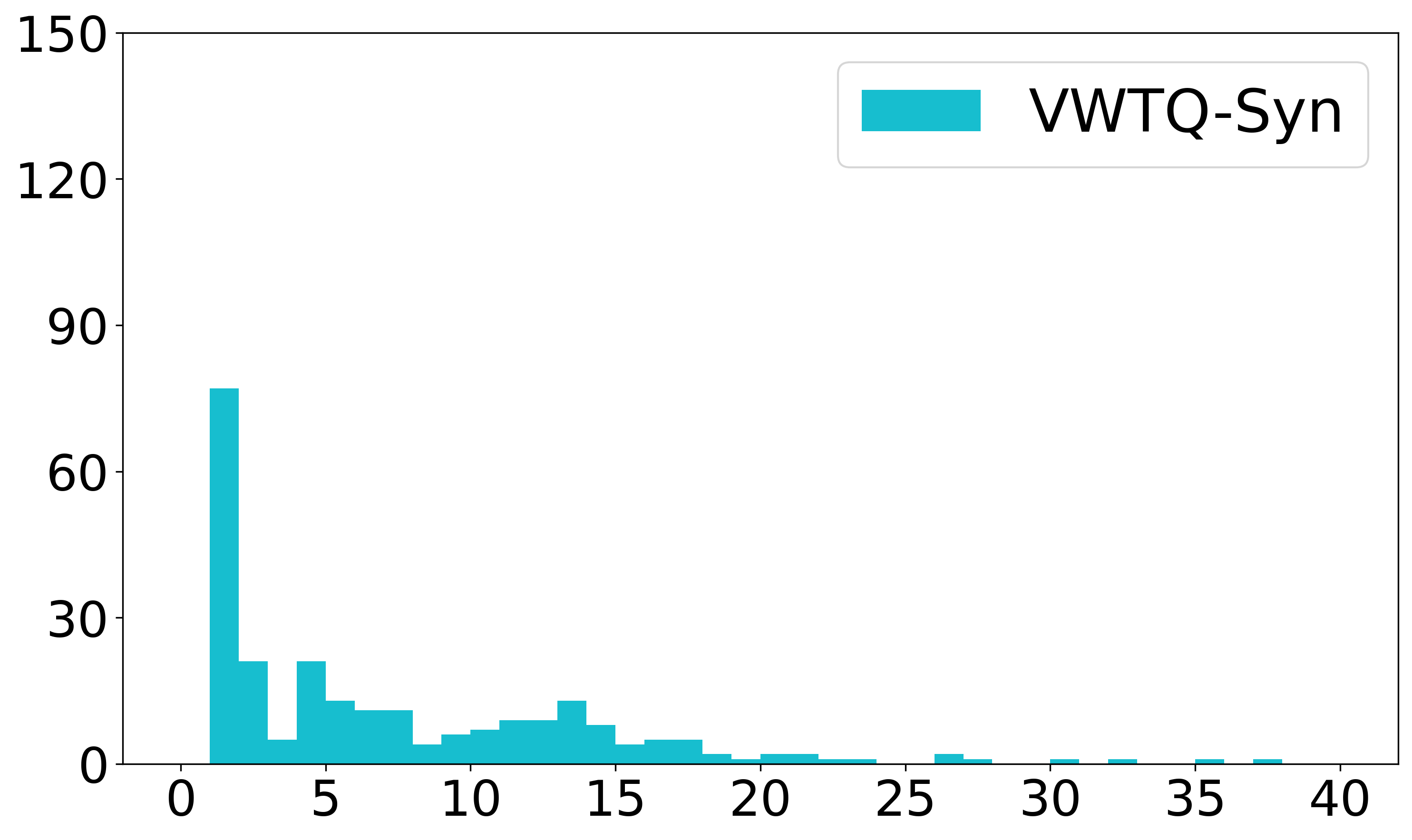
The size of table images can vary significantly depending on their content. In this experiment, we explored the impact on model performance when preserving or not preserving the original size of table images. The GPT-4V offers a ‘high’ option that preserves the input resolution, in contrast to a ‘low’ option that appears to resize the image to a fixed size without preserving the original resolution. Additionally, an ‘auto’ option exists that adaptively determines the resolution based on the input image. For each image ratio, we sampled 20 instances and then measured the performance across these resolution modes. As can be seen in Fig. 8, the ‘low’ demonstrated relatively lower performance. Hence, maintaining the original resolution constitutes a critical factor for accuracy, which is similarly observed in comparisons among MLLMs.
5 Conclusion
In this paper, we present the TableVQA-Bench, a comprehensive benchmark specifically designed for evaluating table visual question-answering capabilities. To ensure a wide-ranging domain, we have leveraged a multitude of pre-existing table-related tasks, procuring essential elements such as images and question-answer pairs. Our study includes an extensive evaluation of various models on the TableVQA-Bench. Through a comparison among MLLMs, it was observed that GPT-4V outperformed other methods across all evaluated domains. Based on observations from the comparison with LLMs and the application of a two-stage inference approach, we believe there is significant potential for further enhancements in MLLMs’ performance on visual table understanding tasks.
Acknowledgements
We greatly appreciate Bado Lee and YoungSang Yoo for their help with the initial project setup.
References
- [1] Gpt-4v(ision) system card (2023), https://api.semanticscholar.org/CorpusID:263218031
- [2] Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
- [3] Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966 (2023)
- [4] Chen, W., Wang, H., Chen, J., Zhang, Y., Wang, H., Li, S., Zhou, X., Wang, W.Y.: Tabfact: A large-scale dataset for table-based fact verification. In: International Conference on Learning Representations (2020), https://openreview.net/forum?id=rkeJRhNYDH
- [5] Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., Stoica, I., Xing, E.P.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality (March 2023), https://lmsys.org/blog/2023-03-30-vicuna/
- [6] Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. arxiv 2023. arXiv preprint arXiv:2305.06500
- [7] Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., et al.: Cogagent: A visual language model for gui agents. arXiv preprint arXiv:2312.08914 (2023)
- [8] Kim, D., Kim, Y., Kim, D., Lim, Y., Kim, G., Kil, T.: Scob: Universal text understanding via character-wise supervised contrastive learning with online text rendering for bridging domain gap. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19562–19573 (2023)
- [9] Kim, G., Lee, H., Kim, D., Jung, H., Park, S., Kim, Y., Yun, S., Kil, T., Lee, B., Park, S.: Cream: Visually-situated natural language understanding with contrastive reading model and frozen large language models. arXiv preprint arXiv:2305.15080 (2023)
- [10] Lee, K., Joshi, M., Turc, I.R., Hu, H., Liu, F., Eisenschlos, J.M., Khandelwal, U., Shaw, P., Chang, M.W., Toutanova, K.: Pix2struct: Screenshot parsing as pretraining for visual language understanding. In: International Conference on Machine Learning. pp. 18893–18912. PMLR (2023)
- [11] Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: Seed-bench-2: Benchmarking multimodal large language models. arXiv preprint arXiv:2311.17092 (2023)
- [12] Li, B., Wang, R., Wang, G., Ge, Y., Ge, Y., Shan, Y.: Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125 (2023)
- [13] Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597 (2023)
- [14] Lin, Z., Liu, C., Zhang, R., Gao, P., Qiu, L., Xiao, H., Qiu, H., Lin, C., Shao, W., Chen, K., et al.: Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575 (2023)
- [15] Liu, F., Wang, X., Yao, W., Chen, J., Song, K., Cho, S., Yacoob, Y., Yu, D.: Mmc: Advancing multimodal chart understanding with large-scale instruction tuning. arXiv preprint arXiv:2311.10774 (2023)
- [16] Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744 (2023)
- [17] Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023)
- [18] Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281 (2023)
- [19] Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255 (2023)
- [20] Masry, A., Do, X.L., Tan, J.Q., Joty, S., Hoque, E.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In: Findings of the Association for Computational Linguistics: ACL 2022. pp. 2263–2279 (2022)
- [21] Nassar, A., Livathinos, N., Lysak, M., Staar, P.: Tableformer: Table structure understanding with transformers. arXiv preprint arXiv:2203.01017 (2022)
- [22] Pasupat, P., Liang, P.: Compositional semantic parsing on semi-structured tables. In: Zong, C., Strube, M. (eds.) Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 1470–1480. Association for Computational Linguistics, Beijing, China (Jul 2015). https://doi.org/10.3115/v1/P15-1142, https://aclanthology.org/P15-1142
- [23] Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
- [24] Wang, W., Lv, Q., Yu, W., Hong, W., Qi, J., Wang, Y., Ji, J., Yang, Z., Zhao, L., Song, X., et al.: Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079 (2023)
- [25] Xu, Z., Du, S., Qi, Y., Xu, C., Yuan, C., Guo, J.: Chartbench: A benchmark for complex visual reasoning in charts. arXiv preprint arXiv:2312.15915 (2023)
- [26] Ye, Q., Xu, H., Ye, J., Yan, M., Liu, H., Qian, Q., Zhang, J., Huang, F., Zhou, J.: mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. arXiv preprint arXiv:2311.04257 (2023)
- [27] Zheng, X., Burdick, D., Popa, L., Zhong, P., Wang, N.X.R.: Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. Winter Conference for Applications in Computer Vision (WACV) (2021)
- [28] Zhong, X., ShafieiBavani, E., Jimeno Yepes, A.: Image-based table recognition: data, model, and evaluation. In: European conference on computer vision. pp. 564–580. Springer (2020)
- [29] Zhong, X., ShafieiBavani, E., Jimeno Yepes, A.: Image-based table recognition: data, model, and evaluation. In: European conference on computer vision. pp. 564–580. Springer (2020)
- [30] Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)