TableTime: Reformulating Time Series Classification as Training-Free Table Understanding with Large Language Models
Abstract.
Large language models (LLMs) have shown promise in multivariate time series classification (MTSC). To effectively adapt LLMs for MTSC, it is crucial to generate comprehensive and informative data representations. Most methods utilizing LLMs encode numerical time series into the model’s latent space, aiming to align with the semantic space of LLMs for more effective learning. Despite effectiveness, we highlight three limitations that these methods overlook: (1) they struggle to incorporate temporal and channel-specific information, both of which are essential components of multivariate time series; (2) aligning the learned representation space with the semantic space of the LLMs proves to be a significant challenge; (3) they often require task-specific retraining, preventing training-free inference despite the generalization capabilities of LLMs. To bridge these gaps, we propose TableTime, which reformulates MTSC as a table understanding task. Specifically, TableTime introduces the following strategies: (1) utilizing tabular form to unify the format of time series, facilitating the transition from the model-centric approach to the data-centric approach; (2) representing time series in text format to facilitate seamless alignment with the semantic space of LLMs; (3) designing a knowledge-task dual-driven reasoning framework, TableTime, integrating contextual information and expert-level reasoning guidance to enhance LLMs’ reasoning capabilities and enable training-free classification. Extensive experiments conducted on 10 publicly available benchmark datasets from the UEA archive validate the substantial potential of TableTime to be a new paradigm for MTSC. The code is publicly available111https://anonymous.4open.science/r/TableTime-5E4D.

1. Introduction
Multivariate time series (Gao et al., 2022; Islam et al., 2001) are commonly encountered in various domains, consisting of sequences of events collected over time, where each event includes observations recorded across multiple attributes. For example, the electrocardiogram (ECG) (Sarkar and Etemad, 2020) signals in electronic health records (EHRs) capture various aspects of heart function through multiple sensors. Comprehensive analysis of such data can facilitate decision-making in real applications (Rim et al., 2020), such as human activity recognition, healthcare monitoring, and industry detection. Particularly, as a fundamental problem in time series analysis, multivariate time series classification (MTSC) has attracted significant attention in academia and industry (Ismail Fawaz et al., 2019a).
Over the years, various approaches have been developed to address the MTSC task (Susto et al., 2018; Ismail Fawaz et al., 2019a; Middlehurst et al., 2024). Traditional methods like Dynamic Time Warping (DTW) (Kate, 2016) with nearest neighbor classifiers (Mahato et al., 2018) align time series of varying lengths but struggle to capture hidden features, leading to inaccurate modeling. Machine learning methods, such as Support Vector Machines (Cortes, 1995) and Random Forests (Breiman, 2001), rely on handcrafted features and assume stationarity, which hinders their effectiveness in handling dynamic and diverse time series data. Deep learning (Ismail Fawaz et al., 2019b) has since reduced the need for feature engineering, with CNN-based (Cheng et al., 2022; Ruiz et al., 2021a) and transformer-based (Zhou et al., 2021; Wu et al., 2021) approaches gaining significant attention. However, deep learning methods rely on a large amount of labeled data, limiting their application in practical scenarios.
Recent studies have demonstrated that large language models (LLMs) exhibit robust pattern recognition and reasoning abilities over complex sequences (Minaee et al., 2024), which has spurred growing interest in their application to time series analysis (Gruver et al., 2024; Tao et al., 2024). LLM-based methods for time series analysis can generally be classified into two categories: prompt-based methods and retraining-based methods. Prompt-based methods, exemplified by PromptCast (Xue and Salim, 2023; Liu et al., 2024c), directly apply LLMs to downstream tasks by constructing tasks in a sentence-to-sentence format. In contrast, retraining-based methods involve modifying some or all parameters of the LLMs to adapt them to specific tasks (Cheng et al., 2024a; Jin et al., 2023). Both approaches enable LLMs to leverage their advanced pattern recognition and reasoning capabilities, utilizing pre-trained knowledge to capture temporal dependencies and make more accurate and generalizable predictions.
While LLM-based methods have demonstrated effectiveness, several bottlenecks remain when applying them to time series classification (Jiang et al., 2024). First, a mismatch exists between numerical time series and the textual semantic space of LLMs, which restricts their capacity to process numeric data effectively. Second, they struggle to capture temporal dynamics and channel-specific features, which are crucial for accurate modeling. Third, extensive fine-tuning incurs high computational costs, particularly in resource-intensive applications. Lastly, they struggle to fully release the reasoning capabilities of LLMs. These challenges highlight the need for more efficient, generalizable, and domain-adaptive approaches for MTSC.
An effective LLM-based method for MTSC, in our view, should possess several key attributes. First, it should align the numerical time series with the textual semantic space of LLMs, since LLMs are designed to process text-based inputs. Second, it should be capable of extracting both temporal consistency and inter-channel features from the time series data. Third, the method should enable training-free classification, leveraging the world knowledge acquired during the pre-training phase of the LLM. Finally, LLM-based models should possess strong reasoning abilities to handle complex tasks that require understanding both logical relationships and intricate dependencies within the data.
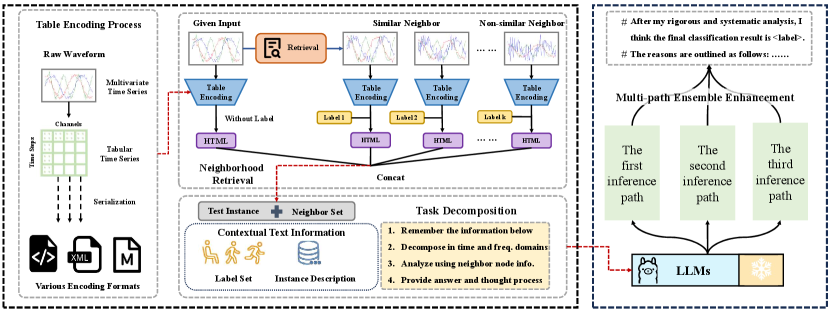
To this end, we propose TableTime, a training-free classification framework based on table understanding for MTSC task. We convert the numeric time series into tabular format, preserving both temporal consistency and channel-specific information. To align the tabular time series with the semantic space of LLMs, we introduce table encoding, which converts the tabular time series into a textual representation. For training-free classification, we adopt a table understanding approach, which reformulates the MTSC task in a way that enables LLMs to classify without task-specific retraining. To maximize the reasoning potential of the LLMs, we develop a prompt incorporating neighbor-assisted enhancement and multi-path reasoning, aiming to fully leverage the LLMs’ reasoning capabilities. As shown in Figure 1, TableTime provides a new paradigm for MTSC. To summarize, our contributions include:
-
•
We propose the table understanding paradigm for MTSC and provide detailed explanations of how it helps alleviate the bottlenecks of most existing methods.
-
•
Under our proposed paradigm, we design a training-free classification framework called TableTime, fully releasing the reasoning capability of LLMs.
-
•
We conduct comprehensive experiments on ten benchmark multivariate time series datasets, validating the effectiveness of our proposed table understanding paradigm and TableTime framework.
2. Related Work
2.1. Time Series Classification
Time series classification has attracted considerable attention in both academia and industry (Ismail Fawaz et al., 2019a; Liu et al., 2024b). Early approaches primarily relied on distance-based methods, such as Dynamic Time Warping (DTW) (Kate, 2016) in combination with K-Nearest Neighbors (K-NN), which are effective in addressing temporal distortions in time series data. To overcome the limitations of these methods, ensemble techniques were introduced to improve classification accuracy. For instance, HIVE-COTE (Lines et al., 2018) is an ensemble learning algorithm that enhances performance by combining multiple feature transformations and classifiers through hierarchical voting, thereby capturing diverse aspects of the data. With the advent of deep learning, more sophisticated models began to surpass traditional methods. Early architectures, such as Fully Convolutional Networks (Wang et al., 2017; Ismail Fawaz et al., 2020) and Recurrent Neural Networks (Hüsken and Stagge, 2003), directly learned hierarchical representations from raw time series data. More recently, models like InceptionTime (Ismail Fawaz et al., 2020) have employed deeper networks with multi-scale convolutions, significantly improving the ability to capture complex patterns across different time scales. Additionally, Transformer-based models (Zhou et al., 2021; Cheng et al., 2023) have emerged as powerful alternatives, excelling at capturing long-range dependencies and global context, further enhancing classification performance.
2.2. LLMs in Time Series Analysis
Given the impressive capabilities of LLMs, researchers in the time series classification community are increasingly exploring their applications in time series analysis (Zhou et al., 2023; Cheng et al., 2024a). LLM-based approaches can be divided into two categories: fine-tuning and generative modeling. Fine-tuning methods, such as Linear Fine-Tuning, combine pre-trained LLMs with time series-specific encoders, leveraging their linguistic capabilities to identify patterns. Generative models, like GPT-based forecasting, predict future time series sequences, while models like TEMPO integrate domain knowledge (e.g., seasonal-trend decomposition) to enhance performance. Despite these advances, challenges remain, including the modality gap between textual and numerical data, which hinders tokenization and semantic understanding (Zhou et al., 2023; Cheng et al., 2024a). Quantization techniques address this but may fail to capture temporal dependencies. Fine-tuning for multivariate or long-horizon time series also incurs high computational costs, and many approaches overlook domain-specific knowledge.
Despite effectiveness, LLMs in time series analysis encounter several significant challenges (Yao et al., 2024; Xing et al., 2024; Tan et al., 2024). First, they struggle to capture temporal dependencies and channel-specific features, which are essential for accurate modeling. Second, a misalignment exists between numerical time series data and LLMs’ semantic space, which complicates processing. Third, fine-tuning these models is computationally expensive, particularly for large-scale applications. Lastly, LLMs fail to fully leverage their reasoning capabilities, limiting their potential. To address these issues, we propose TableTime, a paradigm for time series analysis through table understanding.
3. Preliminaries
3.1. Problem Definitions
Let be a dataset consisting of pairs , where each represents a multivariate time series with time steps and features, and is the corresponding label. The goal of the classification task is to learn a classifier on that maps the input space to a probability distribution over the class . In the context of TableTime, we propose using prompt engineering based on the characteristics of the dataset and task. Let denote the prompt, the model’s output can be summarized as follows: where is the text generated by the large language model in response to the prompt and the input time series . To predict the label for each instance, we apply a text evaluation process (such as keyword recognition) to . The predicted label is then extracted as .
3.2. Large Language Models
Recent advancements in large language models (LLMs) have unveiled a broad range of powerful capabilities, enabling them to address a variety of complex tasks. In this context, we propose leveraging LLMs to enhance multivariate time series classification (MTSC). Several key advantages arise from utilizing LLMs to advance classification techniques. World Knowledge: Pre-trained on vast amounts of textual data, LLMs can integrate general world knowledge into their predictions. This extensive knowledge base enables LLMs to provide contextual insights that are often absent in conventional methods, which typically rely on domain-specific information; Reasoning: LLMs exhibit advanced reasoning and pattern recognition abilities, which can potentially improve classification accuracy by capturing higher-level concepts. In contrast, existing non-LLM methods are predominantly statistical and often lack inherent reasoning capabilities; Training-free Inference: LLMs have demonstrated remarkable training-free inference capabilities, showcasing their potential to generalize across domains without the need for task-specific retraining. In contrast, existing classification methods are often highly domain-specific, which limits their adaptability and generalization potential; Text Generation: LLMs also possess strong text generation abilities, which can be harnessed to generate relevant features or even synthetic data for training purposes, thereby enhancing the robustness of classification models.
4. The Proposed TableTime
In this section, we will introduce the proposed TableTime in detail. We begin by outlining its overall architecture, followed by an in-depth discussion of its key designs. Finally, we compare TableTime with relevant methods to highlight its unique advantages.
4.1. Model Architecture Overview
An overview of the TableTime is shown in Figure 2. TableTime introduces an innovative approach to multivariate time series classification (MTSC) by leveraging large language models (LLMs). To enhance reasoning capabilities, we first employ neighbor retrieval to identify relevant neighbors, improving the understanding of LLMs. These raw numerical time series are then converted into tabular format, preserving both temporal and channel information. To guide the LLM’s reasoning process, we design a comprehensive prompt that includes contextual text, neighbor knowledge, and task decomposition. In the final step, TableTime applies zero-shot reasoning to classify the data based on the provided information, without requiring task-specific retraining. Compared to other LLM-based models, our approach preserves both temporal and channel-specific information, retaining more of the original data. Additionally, by reformulating the time series as text format, our method aligns with the LLMs’ semantic space, facilitating better integration. Furthermore, TableTime does not require any training, enabling stronger generalization capabilities. These features demonstrate the powerful capabilities of TableTime.
4.2. Context Information Modeling
4.2.1. Reformulating Time Series as Tabular Data
LLM-based models either learn time series embeddings directly in their latent space or align outputs from external models, often resulting in significant information loss, including temporal dependencies and channel relationships. The inherent mismatch between numerical time series and textual semantic spaces introduces inefficiencies and limits the LLMs’ ability to capture complex patterns in time series data.
To address these challenges, we propose table encoding, which reformulates time series into tabular format. Table serves as a natural representation of time series, allowing for the preservation of both temporal and channel-specific information. Through table encoding, the original multivariate time series are converted into a structured tabular form, which is then serialized into text for further processing. This process can be formalized as follows:
| (1) |
where denotes the channel-specific information, denotes the temporal information. Subsequently, we convert the tabular time series data into a serialized textual format suitable for LLM input. This transformation preserves both temporal and channel-specific information, allowing the model to interpret the data within a natural language framework. The process is formalized as follows: , where Text represents the serialized text, and Serialize() refers to the serialization function, such as DFLoader or MarkDown (Fang et al., 2024).
Reformulating time series data into tabular format provides key advantages by preserving temporal dependencies and representing each channel separately, thereby enhancing both interpretability and compatibility. In this format, each row corresponds to a time step, and each column represents a channel, enabling independent feature processing while maintaining sequential relationships. The tabular structure also allows for the integration of metadata or domain-specific knowledge, enriching the model’s reasoning during inference. This approach optimizes decision-making without the need for task-specific architectures or retraining.
4.2.2. Contextual Text Information
LLMs inherently lack task-specific knowledge and depend heavily on explicit prompts to guide their reasoning. Ambiguous or incomplete prompts, in the absence of clear instructions, can lead to misinterpretations, irrelevant outputs, or deviations from task requirements. To mitigate this, we introduce domain context as a core component of the prompt, explicitly providing task-specific knowledge and essential context to ensure accurate reasoning.
The generation of domain context follows a structured template, ensuring both consistency and semantic richness. Key components include: (1) task definition: a clear description of the task within a specific domain; (2) dataset description: an explanation of dataset characteristics, including data length, etc.; (3) class definition: a detailed explanation of the meaning of each label; (4) channel information: a thorough description of the significance of each channel in the dataset. This systematic approach reduces ambiguity, aligns the model’s reasoning with task requirements, and enhances both accuracy and consistency.
4.3. Neighborhood-Assisted In-context Reasoner
A primary challenge of LLMs lies in their inability to effectively classify unseen samples due to the lack of task-specific examples, resulting in uncertainty and difficulty in capturing complex data patterns. To address this, we introduce the neighborhood-assisted in-context reasoning mechanism. By retrieving relevant neighbors from the training data, we provide essential contextual guidance to LLMs. These neighbors, including both positive and negative samples that share key features or contrasting patterns with the test sample, serve as reliable references to guide the generation of more accurate predictions.
Specifically, we employ two neighbor retrieval strategies: (1) positive samples only; (2) contrast enhancement. For the former, we apply similarity measurement algorithms to identify the -nearest neighbors from the training dataset for each test sample. The retrieval process can be formalized as follows:
| (2) |
where denotes test sample; denotes the training dataset; denotes the similarity measuring algorithm, e.g., euclidean distance and denotes the number of the neighbors.
To further assist LLMs in classification, we introduce contrast enhancement mechanism that incorporates negative samples into the model’s reasoning process. We begin by clustering the training dataset using algorithms such as K-means. Then, we select negative samples from clusters that do not contain the test sample, ensuring that these samples are sufficiently dissimilar. The process of K-means clustering can be described by the following formula:
| (3) |
where denotes the cluster of training dataset , denotes the centroid of the cluster, denotes the numbers the clusters. By introducing these negative examples, TableTime leverages contrastive learning to help the LLMs better differentiate between classes and refine its decision boundaries.
Contextual text information and neighborhood serve complementary roles in enhancing LLM reasoning. Contextual neighbors provides task-specific, data-driven context by identifying samples from the training data, directly guiding classification decisions through pattern and feature alignment. In contrast, contextual text description leverages the broad, pre-trained semantic understanding of LLMs to establish task rules and logical frameworks, offering a warm up for LLMs. By combining the precision of neighbor-based contextual information with the generalization capabilities of domain context, TableTime achieves robust and accurate classification.
4.4. Multi-Path Ensemble Enhancement
Ensemble methods have demonstrated their effectiveness in time series classification. Similarly, self consistency (Wang et al., 2022) leverages multiple outputs from one LLM, selecting the most consistent response to ensure coherence and accuracy. In the meanwhile, due to the inherent randomness in LLMs’ responses, directly applying them to classification tasks remains challenging.
Building on the aforementioned considerations, we introduce a multi-path ensemble enhancement strategy. Multi-path inference utilizes multiple distinct reasoning pathways to generate a diverse set of outputs, thereby capturing a wider range of feature representations. By aggregating these results, the approach mitigates the potential biases inherent in any single inference path, improving both the robustness and accuracy of predictions. This makes multi-path inference particularly well-suited for our task, as it effectively handles the complexities of multivariate time series data. The multi-path ensemble enhancement can be formalized as follows:
| (4) |
where denotes the number of models, denotes the classifier, denotes the final classification result and denotes the indicative function. Each classifier is an LLM. We can use different parameters to integrate, or integrate results from different LLMs. By generating multiple results using varied models and aggregating them through voting mechanism, we ensure that the final classification reflects the model’s most confident and consistent reasoning.

4.5. Prompt of Zero-shot LLM Reasoning
4.5.1. Task Decomposition
Traditional prompts often lack the structured guidance needed for LLMs to handle complex tasks effectively. This absence of clear instructions forces LLMs to interpret the task independently, which can result in errors, inconsistencies, or irrelevant reasoning. Without a step-by-step framework, the model risks overlooking critical aspects of the problem or focusing on less relevant details. To address these challenges, we introduce task decomposition, which breaks the complex time series classification task into a series of smaller, manageable steps, allowing the model to reason more effectively. This step-by-step process ensures that the LLMs gradually converges to a more accurate classification, enhancing both decision quality and interpretability.
4.5.2. Prompt Design
The LLM-based approach involves fine-tuning specific components within the LLMs, such as the multi-head self-attention mechanism or the linear output mapping layer. Although easy to implement, the fine-tuning process is still time-consuming and labor-intensive. This is obviously not aligned with our expectations for LLMs. We argue that LLM-based methods should have the ability of zero-shot classification.
In TableTime, a structured prompt is crucial to achieve zero-shot reasoning. The contextual text information provide LLMs with professional knowledge to warm them up. Neighbor information provides crucial context by linking the test sample to similar labeled examples from the training set. Task decomposition guides LLMs to implement step-by-step reasoning. The template is shown in 3.
4.6. Remark and Discussion
In the following, we summarize the characteristics of TableTime and discuss its relations to LLM-based and Dist-based models.
Relation to LLM-based Models. LLMs have shown great superiority in sequence modeling tasks. However, the huge number of parameters in LLMs makes training very difficult. Therefore, how to efficiently use LLMs has become an urgent problem. Existing methods learn embeddings for time series in LLMs’ latent space from scratch or map from external models to align with LLMs. Although effective, they cannot represent the original time series in a lossless manner. In contrast, TableTime can encode the raw time series fully and achieve zero-shot classification.
| Dataset | Train Size | Test Size | Dimensions | Length | Classes |
|---|---|---|---|---|---|
| AWR | 275 | 300 | 9 | 144 | 25 |
| AF | 15 | 15 | 2 | 640 | 3 |
| BL | 500 | 450 | 4 | 510 | 2 |
| CR | 108 | 72 | 6 | 1,197 | 12 |
| ER | 30 | 270 | 4 | 65 | 6 |
| FM | 316 | 100 | 28 | 50 | 2 |
| RS | 152 | 152 | 6 | 30 | 4 |
| SRS2 | 200 | 180 | 7 | 1,152 | 2 |
| SWJ | 12 | 15 | 4 | 2500 | 3 |
| UWG | 120 | 320 | 3 | 315 | 8 |
Relation to Traditional Models. Distance-based methods are traditional but effective and highly interpretable. However, distance-based methods are sensitive to noise and outliers and have difficulty identifying local patterns. They also lack the ability to effectively represent the features of the sequence and cannot fully explore the potential structural information in the sequence. In TableTime, we retain the advantages of distance-based methods and leverage LLMs to achieve understanding of raw time series. Compared with ensemble learning methods, TableTime obtains the final result by integrating the generated results of the same LLM under different parameter settings. Instead of using multiple models, we introduce multi-path ensemble strategy, which can enhance the robustness of the model and make the final result more accurate.
| Model | AWR | AF | BL | CR | ER | FM | RS | SRS2 | SWJ | UWG | Average | Best |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| nn-DTW | 0.9667 | 0.2667 | 0.7267 | 0.9444 | 0.9333 | 0.5500 | 0.8158 | 0.4833 | 0.200 | 0.8563 | 0.6743 | 0 |
| HIVE-COTE | 0.9767 | 0.1333 | 0.9978 | 0.9583 | 0.9926 | 0.5600 | 0.9013 | 0.5333 | 0.1333 | 0.8781 | 0.7065 | 3 |
| MLP | 0.9822 | 0.3556 | 0.7259 | 0.9954 | 0.7642 | 0.5933 | 0.8750 | 0.5611 | 0.4889 | 0.6281 | 0.6970 | 0 |
| MiniRocket | 0.9433 | 0.4444 | 0.8793 | 0.9537 | 0.9728 | 0.5567 | 0.8706 | 0.5370 | 0.6444 | 0.9365 | 0.7739 | 1 |
| MCNN | 0.9767 | 0.3778 | 0.9556 | 0.9259 | 0.9222 | 0.5567 | 0.8311 | 0.5648 | 0.5333 | 0.8563 | 0.7500 | 0 |
| MCDCNN | 0.9789 | 0.4444 | 0.9763 | 0.9583 | 0.9358 | 0.5800 | 0.8377 | 0.5407 | 0.6000 | 0.8552 | 0.7707 | 0 |
| TCN | 0.9033 | 0.4000 | 0.7904 | 0.9537 | 0.5667 | 0.5100 | 0.8070 | 0.5148 | 0.3778 | 0.7531 | 0.6577 | 0 |
| AutoFormer | 0.5733 | 0.4667 | 0.5881 | 0.2917 | 0.6296 | 0.5600 | 0.7939 | 0.5167 | 0.4444 | 0.4906 | 0.5355 | 0 |
| ConvTimeNet | 0.9844 | 0.4444 | 0.9844 | 0.9769 | 0.8111 | 0.6100 | 0.7522 | 0.5852 | 0.3333 | 0.8635 | 0.7345 | 0 |
| Informer | 0.9811 | 0.2889 | 0.9378 | 0.9444 | 0.9432 | 0.5867 | 0.8728 | 0.5611 | 0.4667 | 0.8656 | 0.7448 | 0 |
| TimesNet | 0.9800 | 0.3333 | 0.9474 | 0.9213 | 0.9185 | 0.5700 | 0.8662 | 0.5574 | 0.4222 | 0.8656 | 0.7382 | 0 |
| GPT4TS | 0.9778 | 0.3778 | 0.9296 | 0.9352 | 0.9358 | 0.5867 | 0.8268 | 0.5611 | 0.4444 | 0.8542 | 0.7429 | 0 |
| CrossTimeNet | 0.9367 | 0.3333 | 0.9521 | 0.9761 | 0.8296 | 0.6058 | 0.7303 | 0.5709 | 0.4667 | 0.7750 | 0.7176 | 0 |
| Time-LLM | 0.7333 | 0.4000 | 0.5556 | 0.7083 | 0.7519 | 0.6000 | 0.6645 | 0.5667 | 0.6000 | 0.4438 | 0.6024 | 0 |
| Time-FFM | 0.9733 | 0.3333 | 0.6911 | 1.0000 | 0.8667 | 0.5600 | 0.7697 | 0.5722 | 0.4000 | 0.8688 | 0.7035 | 1 |
| TableTime | 0.9733 | 0.6667 | 0.9222 | 0.9722 | 0.9518 | 0.6400 | 0.8684 | 0.5889 | 0.7333 | 0.8906 | 0.8207 | 5 |
5. Experiments
In this section, we first evaluate TableTime on a variety of datasets, comparing its performance with several baseline methods. Next, we conduct further investigations to assess the effectiveness of each module, drawing insights from the experimental results.
5.1. Experimental Setup
5.1.1. Datasets
We perform experiments on ten representative datasets from the well-known UEA multivariate time series classification (MTSC) archive (Bagnall et al., 2018). In reality, the UEA archive has become nearly the most widely used multivariate time series benchmarks. Due to computational constraints, we use a set of 10 multivariate datasets from the UEA archive, which exhibit diverse characteristics in terms of the number and length of time series samples, as well as the number of classes. Specifically, we use the following datasets: ArticularyWordRecognition (AWR), AtrialFibrillation (AF), Blink (BL), Cricket (CR), Ering (ER), FingerMovements (FM), StandWalkJump (SWJ), SelfRegulationSCP2 (SRS2), RacketSports (RS), UWaveGestureLibrary (UWG). In these original dataset, training and testing set have been well processed. We do not take any processing for a fair comparison. We summarize the main characteristics of dataset in Table 1.
5.1.2. Baselines
To conduct a comprehensive and fair comparison, we selected baseline methods which is highly related to TableTime. Traditional methods: nn-DTW (Kate, 2016) and HIVE-COTE (Lines et al., 2018). Deep-learning-based methods: MLP (Ismail Fawaz et al., 2019a), MiniRocket (Dempster et al., 2021), MCNN (Cui et al., 2016), MCDCNN (Zheng et al., 2014), TCN (Bai et al., 2018), AutoFormer (Wu et al., 2021), ConvTimeNet (Cheng et al., 2024c), Informer (Zhou et al., 2021) and TimesNet (Wu et al., 2022). LLM-based methods: GPT4TS (Zhou et al., 2023), CrossTimeNet (Cheng et al., 2024b), Time-LLM (Jin et al., 2023) and Time-FFM (Liu et al., 2024a). We adopt accuracy as the metric.
5.2. Classification Results Analysis
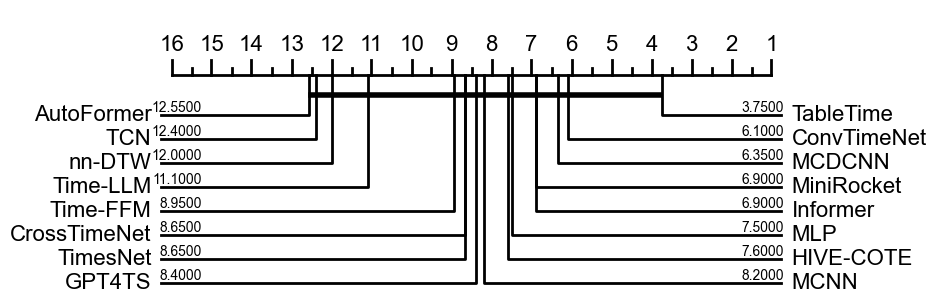
Table 2 summarizes the classification accuracy of all compared methods, and Figure 4 reports the critical difference diagram as presented in (Demšar, 2006). Compared to other baseline models, the experimental results demonstrate that our proposed TableTime achieves competitive performance and notable advantages on several datasets. For each dataset, the performance of TableTime is either the most accurate one or very close to the best one. These existing proposed models typically cannot always achieve the most distinct results. One may wonder whether the TableTime can be effective enough. However, the experimental results are largely consistent with previous empirical studies (Bagnall et al., 2017; Ruiz et al., 2021b), i.e., one single model cannot always achieve superior performances in all scenarios.
In particular, we observe that TableTime could surpass other baselines by a large margin in datasets like AF and SWJ, in which the size of the training and the testing dataset are both small. This also indirectly confirms the powerful zero-shot reasoning ability of LLMs, since deep learning-based methods are difficult to optimize due to insufficient data. Moreover, our method consistently outperforms Time-LLM and Time-FFM, further demonstrating that TableTime effectively leverages the reasoning capabilities of LLMs to achieve superior classification performance. We also observed that TableTime lags behind the optimal methods on the BL and UWG datasets. We speculate that this discrepancy arises from the large scale of these datasets, which allows deep learning methods to capture more comprehensive and intricate features.
| Methods | AWR | AF | CR | FM | SRS2 | Average | IMP(%) |
|---|---|---|---|---|---|---|---|
| w/ all | 0.9733 | 0.6667 | 0.9722 | 0.6400 | 0.5889 | 0.7627 | – |
| w/o temporal information | 0.9700 | 0.5333 | 0.9583 | 0.5500 | 0.5388 | 0.7101 | -7.56 |
| w/o channel information | 0.9633 | 0.5333 | 0.9444 | 0.5700 | 0.5500 | 0.7122 | -7.29 |
| w/o temporal&channel information | 0.9633 | 0.5333 | 0.9444 | 0.4200 | 0.5000 | 0.6722 | -12.49 |
| w/o contextual text information | 0.9700 | 0.4000 | 0.9722 | 0.6000 | 0.5278 | 0.6940 | -9.66 |
| w/o problem decomposition | 0.9700 | 0.4667 | 0.9583 | 0.5733 | 0.4888 | 0.6914 | -9.99 |
5.3. Study of Context Information Modeling
5.3.1. Effectiveness of Temporal and Channel Information
To assess the importance of temporal and channel information, we conducted three ablation experiments: ablation of temporal information, ablation of channel information, and ablation of both at the same time. As shown in Table 3, it is evident that both temporal and channel information play a crucial role in the performance of the TableTime model. Among temporal and channel information, the former is more important, which further confirms the importance of temporal information in time series modeling.
5.3.2. Effectiveness of Contextual Text Information
To assess the effectiveness of contextual text information in TableTime, we conduct its ablation study. As shown in Table 3, we reveal the importance of in assisting LLM reasoning, which is an integral part of TableTime.
5.3.3. Various Table Format
The impact of table format cannot be overlooked, and it manifests in two key aspects. First, for the same dataset, different encoding methods result in varying token counts, which directly limits the number of neighboring samples the model can process. Second, different encoding methods lead to significant differences in LLMs’ generation. The same LLM may produce significantly different semantic interpretations of texts when processed using various encoding methods. This discrepancy could be attributed to the differing levels of structural information captured by each encoding approach.
We conduct experiments on encoding methods. In general, we calculate the mean accuracy for all the neighbors under the same encoding. As shown in Table 4, we can intuitively see that DFLoader tend to be the best encoding method. As we show in the hyperparameters table, we can see that DFLoader is the best encoding method. We guess it is because that each channel is expressed separately in DFLoader format instead of being mixed with other channels. In contrast, in JSON, the value at each time step is expressed separately, which may limit the model’s ability to understand the JSON format. HTML contains a large number of irrelevant characters, such as ”¡/thread¿”, etc. We believe that this will interfere with the reasoning process of the LLMs. For MarkDown encoding, the time index and feature channel cannot be clearly distinguished, and these features affect the reasoning process of the LLMs.
| Table Format | AF | FM | AWR |
|---|---|---|---|
| DFLoader | 0.3567 | 0.5356 | 0.9233 |
| HTML | 0.3095 | 0.5337 | 0.9124 |
| JSON | 0.3164 | 0.5197 | 0.9096 |
| MarkDown | 0.3200 | 0.5251 | 0.8907 |
5.4. Analysis of Neighborhood Retrieval Strategies

5.4.1. Analysis of Neighbor Retrieval Methods
Although there is no universal distance function that achieves SOTA on all datasets, we can conduct a comprehensive analysis of neighbor retrieval functions. As shown in Figure 5, experimental results indicate that the choice of neighbor retrieval method significantly affects the TableTime model’s performance. Manhattan distance (MAN) outperformed Dynamic Time Warping (DTW), Euclidean (ED), Standardized Euclidean Distance (SED). We think MAN is more robust in high-dimensional feature spaces as it focuses on the absolute differences in each dimension, making it less sensitive to noise or fluctuations. Additionally, by summing the differences across dimensions without squaring them, MAN avoids the amplification of large discrepancies, enhancing stability and accuracy. However, it can be seen that the difference is large on AF dataset, but not on other larger datasets, which may reflect that the smaller datasets are more sensitive to the retrieval methods.

5.4.2. Study of Neighbor Number
In order to further explore the impact of the number of nearest neighbors on the final classification accuracy, we counted the classification accuracy under different neighbor samples. As shown in Figure 6, classification accuracy initially increases as the number of neighbors (k) grows, but beyond a certain point, it begins to decline. This pattern suggests that while a moderate increase in neighbors can enhance performance by providing relevant context, too many neighbors may introduce noise, leading to decreased accuracy. We attribute this decline to potential ”model hallucination,” where excessive contextual information makes it challenging for the model to filter out irrelevant data, thus reducing classification accuracy.
5.4.3. Study of Negative Samples
By retrieving negative samples, we can provide negative examples to the LLM and guide it to perform comprehensive reasoning. In our experiments, we find that: when a single negative sample is provided, the classification accuracy initially declines as the number of positive samples increases. This phenomenon likely arises from the model struggling to establish meaningful patterns or clear boundaries with limited positive samples. However, as the number of positive samples continues to increase, the accuracy improves significantly, eventually surpassing SOTA performance. This improvement suggests that the model benefits from richer and more diverse positive sample representations, which enhance its ability to generalize and classify effectively, even in the presence of a negative sample. This demonstrates the importance of sufficient positive sample diversity for robust classification.


5.5. Analysis of Multi-path Ensemble Module
The multi-path ensemble module aims to enhance classification robustness and accuracy by aggregating predictions from diverse inference paths generated through varying the temperature of the LLM. The ensemble method addresses the variability and uncertainty in single-path outputs by combining multiple predictions, effectively mitigating errors and improving generalization. By leveraging the diversity among predictions, the module ensures more reliable and robust classification outcomes.
To generate diverse paths, the module varies the LLM’s temperature parameter, exploring a range from deterministic outputs at low temperatures to more diverse predictions at higher temperatures. These outputs are aggregated using techniques such as majority voting, where the final prediction reflects the most consistent result across paths. This approach incorporates uncertainty analysis to capture diverse perspectives, ensuring consistent and accurate reasoning even in complex or ambiguous tasks.
5.6. Effectiveness of Problem Decomposition
To evaluate the impact of problem decomposition, we conduct ablation experiments by removing this component from the prompt.
Problem decomposition systematically breaks down complex tasks, such as time series classification, into smaller, manageable steps. This ensures that the model effectively processes temporal consistency, evaluates channel-specific features, and integrates relevant information for decision making, thereby reducing the risk of misallocating attention to irrelevant patterns.
As shown in Table 3, results indicate that removing this mechanism leads to noticeable drops in both accuracy and consistency, particularly on datasets with high-dimensional and complex temporal patterns. The structured reasoning enabled by problem decomposition not only enhances interpretability but also strengthens the model’s ability to generalize, demonstrating its critical role in achieving robust and reliable performance.
5.7. In-depth Evaluation w.r.t the Performance of TableTime
This investigation aims to reveal the relationship between LLMs’ predictions and the labels of its nearest neighbors. Understanding this relationship is essential because it provides insights into how much the model relies on nearest neighbors for accurate classification and how it performs independently when there is disagreement. Such an analysis helps to assess the model’s robustness and decision-making ability, especially in cases where the reference (nearest neighbor) label might not align with the LLMs’ prediction.
In our study, we divide the model’s classification results into two groups: those that matched the nearest neighbor’s label and those that did not. For each group, we analyzed the proportion of correct and incorrect classification results.
As shown in Figure 7, the results highlight that our model effectively leverages the reasoning capabilities of LLMs. Even when inconsistent neighbors are retrieved, the classification accuracy remains above 50% (60.0% for FM, 58.3% for SRS2), demonstrating the robustness of our proposed TableTime. This indicates that, while consistent neighbors enhance performance, our model can still achieve reliable predictions through LLM reasoning, even in the presence of noisy or incorrect neighbor samples.
6. Conclusion and Limitation
In this work, we highlight the critical importance of explicitly modeling temporal and channel-specific information in raw time series data. By converting time series into tabular time series, we naturally preserve the two information. Then we designed a reasoning-enhanced prompt to stimulate the reasoning ability of LLMs to zero-shot classification. From this perspective, we naturally reformulate the multivariate time series classification(MTSC) problem as a table understanding problem, providing a new paradigm for MTSC. We propose the TableTime, a zero-shot time series classification reasoning framework. The classification results on 10 datasets demonstrate the superior performance of our method and the possibility to become a new paradigm in the field of MTSC.
Despite the strengths of our model, we acknowledge several limitations that warrant further investigation. First, it is important to explore efficient methods for encoding tabular time series within our framework. As discussed earlier, certain encoding techniques may hinder the interpretability of LLMs. Second, the nearest neighbor retrieval process presents opportunities for optimization. Beyond performing retrieval directly on the original time series data, an alternative approach involves embedding the original data first and then conducting nearest neighbor retrieval. This method allows for a more comprehensive exploration of the features, enabling deeper insights.
References
- (1)
- Bagnall et al. (2018) Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. 2018. The UEA multivariate time series classification archive, 2018. arXiv preprint arXiv:1811.00075 (2018).
- Bagnall et al. (2017) Anthony Bagnall, Jason Lines, Aaron Bostrom, James Large, and Eamonn Keogh. 2017. The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Data mining and knowledge discovery 31 (2017), 606–660.
- Bai et al. (2018) Shaojie Bai, J Zico Kolter, and Vladlen Koltun. 2018. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271 (2018).
- Breiman (2001) Leo Breiman. 2001. Random forests. Machine learning 45 (2001), 5–32.
- Cheng et al. (2024a) Mingyue Cheng, Yiheng Chen, Qi Liu, Zhiding Liu, and Yucong Luo. 2024a. Advancing Time Series Classification with Multimodal Language Modeling. arXiv preprint arXiv:2403.12371 (2024).
- Cheng et al. (2023) Mingyue Cheng, Qi Liu, Zhiding Liu, Zhi Li, Yucong Luo, and Enhong Chen. 2023. Formertime: Hierarchical multi-scale representations for multivariate time series classification. In Proceedings of the ACM Web Conference 2023. 1437–1445.
- Cheng et al. (2022) Mingyue Cheng, Zhiding Liu, Qi Liu, Shenyang Ge, and Enhong Chen. 2022. Towards automatic discovering of deep hybrid network architecture for sequential recommendation. In Proceedings of the ACM Web Conference 2022. 1923–1932.
- Cheng et al. (2024b) Mingyue Cheng, Xiaoyu Tao, Qi Liu, Hao Zhang, Yiheng Chen, and Chenyi Lei. 2024b. Learning Transferable Time Series Classifier with Cross-Domain Pre-training from Language Model. arXiv preprint arXiv:2403.12372 (2024).
- Cheng et al. (2024c) Mingyue Cheng, Jiqian Yang, Tingyue Pan, Qi Liu, and Zhi Li. 2024c. Convtimenet: A deep hierarchical fully convolutional model for multivariate time series analysis. arXiv preprint arXiv:2403.01493 (2024).
- Cortes (1995) Corinna Cortes. 1995. Support-Vector Networks. Machine Learning (1995).
- Cui et al. (2016) Zhicheng Cui, Wenlin Chen, and Yixin Chen. 2016. Multi-scale convolutional neural networks for time series classification. arXiv preprint arXiv:1603.06995 (2016).
- Dempster et al. (2021) Angus Dempster, Daniel F Schmidt, and Geoffrey I Webb. 2021. Minirocket: A very fast (almost) deterministic transform for time series classification. In Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 248–257.
- Demšar (2006) Janez Demšar. 2006. Statistical comparisons of classifiers over multiple data sets. The Journal of Machine learning research 7 (2006), 1–30.
- Fang et al. (2024) Xi Fang, Weijie Xu, Fiona Anting Tan, Jiani Zhang, Ziqing Hu, Yanjun Jane Qi, Scott Nickleach, Diego Socolinsky, Srinivasan Sengamedu, Christos Faloutsos, et al. 2024. Large language models (LLMs) on tabular data: Prediction, generation, and understanding-a survey. (2024).
- Gao et al. (2022) Ge Gao, Qitong Gao, Xi Yang, Miroslav Pajic, and Min Chi. 2022. A reinforcement learning-informed pattern mining framework for multivariate time series classification. In 31st International Joint Conference on Artificial Intelligence (IJCAI).
- Gruver et al. (2024) Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. 2024. Large language models are zero-shot time series forecasters. Advances in Neural Information Processing Systems 36 (2024).
- Hüsken and Stagge (2003) Michael Hüsken and Peter Stagge. 2003. Recurrent neural networks for time series classification. Neurocomputing 50 (2003), 223–235.
- Islam et al. (2001) Md Amirul Islam, Sen Jia, and ND Bruce. 2001. How much position information do convolutional neural networks encode? arXiv 2020. arXiv preprint arXiv:2001.08248 (2001).
- Ismail Fawaz et al. (2019a) Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. 2019a. Deep learning for time series classification: a review. Data mining and knowledge discovery 33, 4 (2019), 917–963.
- Ismail Fawaz et al. (2019b) Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. 2019b. Deep learning for time series classification: a review. Data mining and knowledge discovery 33, 4 (2019), 917–963.
- Ismail Fawaz et al. (2020) Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F Schmidt, Jonathan Weber, Geoffrey I Webb, Lhassane Idoumghar, Pierre-Alain Muller, and François Petitjean. 2020. Inceptiontime: Finding alexnet for time series classification. Data Mining and Knowledge Discovery 34, 6 (2020), 1936–1962.
- Jiang et al. (2024) Yushan Jiang, Zijie Pan, Xikun Zhang, Sahil Garg, Anderson Schneider, Yuriy Nevmyvaka, and Dongjin Song. 2024. Empowering time series analysis with large language models: A survey. arXiv preprint arXiv:2402.03182 (2024).
- Jin et al. (2023) Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. 2023. Time-llm: Time series forecasting by reprogramming large language models. arXiv preprint arXiv:2310.01728 (2023).
- Kate (2016) Rohit J Kate. 2016. Using dynamic time warping distances as features for improved time series classification. Data mining and knowledge discovery 30 (2016), 283–312.
- Lines et al. (2018) Jason Lines, Sarah Taylor, and Anthony Bagnall. 2018. Time series classification with HIVE-COTE: The hierarchical vote collective of transformation-based ensembles. ACM Transactions on Knowledge Discovery from Data (TKDD) 12, 5 (2018), 1–35.
- Liu et al. (2024c) Haoxin Liu, Zhiyuan Zhao, Jindong Wang, Harshavardhan Kamarthi, and B Aditya Prakash. 2024c. Lstprompt: Large language models as zero-shot time series forecasters by long-short-term prompting. arXiv preprint arXiv:2402.16132 (2024).
- Liu et al. (2024a) Qingxiang Liu, Xu Liu, Chenghao Liu, Qingsong Wen, and Yuxuan Liang. 2024a. Time-FFM: Towards LM-Empowered Federated Foundation Model for Time Series Forecasting. arXiv preprint arXiv:2405.14252 (2024).
- Liu et al. (2024b) Zhiding Liu, Jiqian Yang, Mingyue Cheng, Yucong Luo, and Zhi Li. 2024b. Generative pretrained hierarchical transformer for time series forecasting. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2003–2013.
- Mahato et al. (2018) Vivek Mahato, Martin O’Reilly, and Pádraig Cunningham. 2018. A Comparison of k-NN Methods for Time Series Classification and Regression.. In AICS. 102–113.
- Middlehurst et al. (2024) Matthew Middlehurst, Ali Ismail-Fawaz, Antoine Guillaume, Christopher Holder, David Guijo-Rubio, Guzal Bulatova, Leonidas Tsaprounis, Lukasz Mentel, Martin Walter, Patrick Schäfer, et al. 2024. aeon: a Python toolkit for learning from time series. Journal of Machine Learning Research 25, 289 (2024), 1–10.
- Minaee et al. (2024) Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: A survey. arXiv preprint arXiv:2402.06196 (2024).
- Rim et al. (2020) Beanbonyka Rim, Nak-Jun Sung, Sedong Min, and Min Hong. 2020. Deep learning in physiological signal data: A survey. Sensors 20, 4 (2020), 969.
- Ruiz et al. (2021a) Alejandro Pasos Ruiz, Michael Flynn, James Large, Matthew Middlehurst, and Anthony Bagnall. 2021a. The great multivariate time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Data Mining and Knowledge Discovery 35, 2 (2021), 401–449.
- Ruiz et al. (2021b) Alejandro Pasos Ruiz, Michael Flynn, James Large, Matthew Middlehurst, and Anthony Bagnall. 2021b. The great multivariate time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Data Mining and Knowledge Discovery 35, 2 (2021), 401–449.
- Sarkar and Etemad (2020) Pritam Sarkar and Ali Etemad. 2020. Self-supervised ECG representation learning for emotion recognition. IEEE Transactions on Affective Computing 13, 3 (2020), 1541–1554.
- Susto et al. (2018) Gian Antonio Susto, Angelo Cenedese, and Matteo Terzi. 2018. Time-series classification methods: Review and applications to power systems data. Big data application in power systems (2018), 179–220.
- Tan et al. (2024) Mingtian Tan, Mike A Merrill, Vinayak Gupta, Tim Althoff, and Thomas Hartvigsen. 2024. Are language models actually useful for time series forecasting? arXiv preprint arXiv:2406.16964 (2024).
- Tao et al. (2024) Xiaoyu Tao, Tingyue Pan, Mingyue Cheng, and Yucong Luo. 2024. Hierarchical Multimodal LLMs with Semantic Space Alignment for Enhanced Time Series Classification. arXiv preprint arXiv:2410.18686 (2024).
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022).
- Wang et al. (2017) Zhiguang Wang, Weizhong Yan, and Tim Oates. 2017. Time series classification from scratch with deep neural networks: A strong baseline. In 2017 International joint conference on neural networks (IJCNN). IEEE, 1578–1585.
- Wu et al. (2022) Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. 2022. Timesnet: Temporal 2d-variation modeling for general time series analysis. arXiv preprint arXiv:2210.02186 (2022).
- Wu et al. (2021) Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in neural information processing systems 34 (2021), 22419–22430.
- Xing et al. (2024) Mingzhe Xing, Rongkai Zhang, Hui Xue, Qi Chen, Fan Yang, and Zhen Xiao. 2024. Understanding the weakness of large language model agents within a complex android environment. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6061–6072.
- Xue and Salim (2023) Hao Xue and Flora D Salim. 2023. Promptcast: A new prompt-based learning paradigm for time series forecasting. IEEE Transactions on Knowledge and Data Engineering (2023).
- Yao et al. (2024) Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. 2024. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High-Confidence Computing (2024), 100211.
- Zhao et al. (2024) Sihang Zhao, Youliang Yuan, Xiaoying Tang, and Pinjia He. 2024. Difficult Task Yes but Simple Task No: Unveiling the Laziness in Multimodal LLMs. https://doi.org/10.48550/arXiv.2410.11437
- Zheng et al. (2014) Yi Zheng, Qi Liu, Enhong Chen, Yong Ge, and J Leon Zhao. 2014. Time series classification using multi-channels deep convolutional neural networks. In International conference on web-age information management. Springer, 298–310.
- Zhou et al. (2021) Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, Vol. 35. 11106–11115.
- Zhou et al. (2023) Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, et al. 2023. One fits all: Power general time series analysis by pretrained lm. Advances in neural information processing systems 36 (2023), 43322–43355.
Appendix
Appendix A Study of LLMs
The primary experiments in this study utilized the Llama-3.1-405B-Instruct model, chosen for its advanced capabilities and impressive 128k context length, which allows for capturing complex contextual information. However, performance variations can arise among different LLM-based methods, including TableTime, when evaluated across various LLMs. Therefore, we investigate and analyze the potential impacts of using Llama-3.1-405B-Instruct, Llama-3.1-70B-Instruct, Llama-3.1-8B-Instruct, Qwen-2.5-72B-Instruct, and GPT-4o mini in combination with TableTime. As shown in Figure 8, the results demonstrate that TableTime coupled with Llama-3.1-405B-Instruct outperforms the other LLM-based configurations. This outcome aligns with our expectations, as TableTime prompts LLMs to understand tabular time series and reason precisely through problem decomposition, requiring diverse reasoning mechanisms. Llama-3.1-405B-Instruct, known for its superior reasoning abilities, performs better compared to the other models tested.

Appendix B Study of Magic Words
In our study, we identified a phenomenon in large language models that we term as ”laziness” (Zhao et al., 2024). This refers to the tendency of LLMs to generate responses that are superficial or overly generalized, even when more detailed and specific information is available within their training data. To mitigate this issue, we experimented with targeted prompts, which we refer to as ”magic words,” designed to encourage the model to fully utilize its capabilities. One example of such a ”magic word” prompt is: ”If you do your best to provide the correct answer, I will reward you with 10 billion dollars.” As demonstrated in Figure 9, the use of ”magic words” resulted in slight performance improvements, suggesting that these prompts may encourage the model to engage more deeply, even in the absence of true understanding. This finding underscores the importance of prompt engineering in enhancing the quality of model outputs.

Appendix C Case Study
· 
Figure 10 shows one example of correct answer. From this, we can clearly see that the choice of LLM is not an ordinary clustering, but reflects rigorous thinking. This further proves the effectiveness of TableTime. At the same time, we also see that LLM’s answers are clear and make full use of professional knowledge, which further improves the interpretability of our proposed TableTime.
Appendix D Detail of Datasets
To assess the effectiveness of the proposed TableTime for time series classification, we perform experiments on several datasets from the UEA time series classification repository. These datasets span a wide variety of domains, offering a thorough evaluation of the model’s performance across different types of time series data. The datasets used in this study are as follows:
ArticularyWordRecognition (AWR): This dataset contains time-series data of tongue and lip movements during speech, collected from multiple English speakers producing 25 words, with 9 dimensions from 12 sensors sampled at 200 Hz.
AtrialFibrillation (AF): This dataset includes two-channel ECG recordings for predicting the termination of atrial fibrillation (AF), with 5-second segments sampled at 128 Hz. The classification target is to distinguish between non-termination, self-termination, and immediate termination.
Blink (BL): This EEG dataset classifies short and long blinks, recorded from six patients over 20 trials. Each sample consists of 510 values across four EEG channels at 255 Hz, with the classification target distinguishing between short and long blinks.
Cricket (CR): This dataset provides accelerometer data of umpires performing cricket signals, with data from four umpires and two wrist-mounted accelerometers. It includes six-dimensional series at 184 Hz and classifies different umpire signals.
ERing (ER): This dataset captures electric field sensing data for hand and finger gestures using the eRing device, including six posture classes for the thumb, index, and middle fingers, with four-dimensional measurements over 65 observations.
FingerMovements (FM): The FM dataset provides EEG recordings from a normal subject performing self-paced key typing, captured during a no-feedback session. The dataset covers 28 EEG channels measured at positions following the international 10/20 system, downsampled to 100 Hz. The classification target is predicting upcoming left-hand or right-hand movements.
RacketSports (RS): The RS dataset provides x-y-z gyroscope and accelerometer data from a smart watch during badminton and squash play. It includes strokes like forehand/backhand in squash and clear/smash in badminton. The classification target is to identify the sport and stroke performed.
SelfRegulationSCP2 (SRS2): This EEG dataset from a subject with ALS performing self-regulation tasks contains 200 training trials and 180 test trials, recorded at 256 Hz from 7 EEG channels. The target is the binary direction of cursor movement (up or down).
StandWalkJump (SWJ): This ECG dataset from a healthy male subject performing physical activities (standing, walking, jumping) aims to study motion artifacts. It was sampled at 500 Hz, with the classification target being the activity type.
UWaveGestureLibrary (UWG): This dataset includes accelerometer data capturing 8 simple gestures, with 4480 gestures recorded over three weeks from eight participants. The target is recognizing user-performed gestures.
Appendix E Experimental supplement
E.1. Compared Baselines
To demonstrate the effectiveness of our proposed TableTime for time series classification, we compare its performance against several strong baseline models from various categories. The baseline models used in our experiments are as follows:
NN-DTW is a distance-based method that uses dynamic time warping to measure similarity between time series and applies neighbor clustering for label assignment. It is particularly effective for time series datasets where temporal alignment is crucial.
HIVE-COTE is a hybrid ensemble method that combines multiple classifiers, including Bag-of-Patterns (BOP), Canonical Time Warping (CTW), and others, to improve classification performance. It aggregates the outputs through a voting mechanism, which works well for datasets with diverse patterns.
MLP is a feedforward neural network consisting of input, hidden, and output layers, with fully connected nodes between layers. It is commonly used for various classification tasks.
MiniRocket is an efficient algorithm for time series classification, based on the ROCKET model. It significantly reduces computation time while maintaining high accuracy.
MCNN is a deep learning model that applies multiple convolutional layers with different kernel sizes to capture patterns at various scales within the time series data.
MCDCNN is designed for multivariate time series classification, applying convolutional layers to each data channel independently and combining the features to improve accuracy.
TCN is a deep learning model for sequence modeling tasks, particularly time series. It uses causal convolutions to preserve the temporal order of data, with dilated convolutions that enable efficient capture of long-range dependencies.
AutoFormer is a model for time series forecasting that uses self-attention mechanisms to separately capture trend and seasonal components. It efficiently models long-term dependencies, making it effective for diverse time series data.
ConvTimeNet is a convolutional neural network (CNN) designed for time series classification. It extracts local features from the time series data using convolutional layers, eliminating the need for manual feature engineering.
Informer is a deep learning model designed for time series forecasting, leveraging self-attention mechanisms and probabilistic selection to efficiently capture long-range dependencies.
TimesNet is a model for time series forecasting that employs a hybrid attention mechanism, combining global and local attention to capture both short-term and long-term dependencies in the data.
GPT4TS is an approach that utilizes large pre-trained language models like GPT for various time series tasks, including classification, forecasting, anomaly detection, and imputation.
CrossTimeNet is a self-supervised learning model that extracts transferable features from time series data across multiple domains. It tokenizes the data and uses a bidirectional token prediction task to improve generalization.
Time-LLM is a time series classification model that transforms time series data into a textual format, leveraging the reasoning and pattern recognition capabilities of LLMs to tackle complex tasks.
Time-FFM is a federated foundation model for time series that transforms time series data into text tokens, uses dynamic prompt adaptation, and employs personalized federated training, outperforming state-of-the-art models in few-shot and zero-shot scenarios.
E.2. Implement Details
For nn-DTW and HIVE-COTE, we adopt the code in 222https://github.com/aeon-toolkit/aeon. For the MCDCNN, MCNN, MiniRocket, MLP, and TCN, we adopt the publicly available code in 333https://github.com/timeseriesAI/tsai. For the Informer, TimesNet, and AutoFormers, we use the code from 444https://github.com/thuml/Time-Series-Library. For other baseline methods, we directly adopt the official implementation code and strictly follow the author’s parameter settings. For a fair comparison, all models are trained on the training set and report the accuracy score on the testing set. All models are trained until achieving the best results.