Symphony: Improving Memory Management for LLM Inference Workloads
Abstract
Large Language Models (LLMs) are increasingly being deployed in applications such as chatbots, code editors, and conversational agents. A key feature of LLMs is their ability to engage in multi-turn interactions with humans or external tools, enabling a wide range of tasks. Each new request in a multi-turn interaction depends on the intermediate state, specifically the key-value (K,V) caches, from previous requests in the ongoing interaction. Existing serving engines either recompute the K,V caches or offload them to main memory. Profiling reveals that recomputation can result in over 99% of processed tokens being redundant. On the other hand, offloading K,V caches from GPU memory makes inference serving stateful, leading to load imbalances across the cluster. To address these challenges, we developed Symphony. Symphony leverages the observation that multi-turn workloads provide additional hints that allow K,V caches to be migrated off the critical serving path. By utilizing these hints, Symphony dynamically migrates K,V caches to enable fine-grained scheduling of inference requests. Our experiments demonstrate that Symphony can handle over 8× the number of requests compared to state-of-the-art baselines, with a similar latency profile.
1 Introduction
Large Language Models (LLMs) have demonstrated remarkable capabilities across a diverse range of tasks, including question-answering, code generation, and text summarization. Given their immense potential, LLMs have been extensively integrated into various applications such as chatbots [26], code editors [34, 5], and agents [30, 12].
Given the central role of LLMs in several emerging ML applications, improving LLM inference has garnered significant attention [16, 53, 1, 2, 25, 37, 9, 38]. However, unlike the "single-request-and-response" pattern typically studied in these works, LLM workloads such as chatbots, code suggestions, and AI agents are primarily "multi-turn." For example, in a chatbot scenario, users submit an initial prompt (request) with a query, and based on the response, they ask follow-up questions (additional requests). In such workloads, a "session" can often involve over 400 requests [26, 35].
Serving multi-turn workloads introduces a new state management challenge. Since each new request in a session needs access to the intermediate representations (K, V cache) from all prior requests within that session, the LLM serving system needs to manage the K,V cache across requests. This is challenging as the caches can grow quite large; e.g., at 32K context length, LLama-3.1-70B, a medium-sized model, needs approximately 10GB of K,V cache size. Furthermore, with the unpredictable arrival pattern of requests, the cache state may need to be held for an arbitrary amount of time. Unfortunately, the large combined size of K,V caches across requests within a session eliminates the possibility of storing them in constrained accelerator memory.
Existing works have used two primary approaches to perform state management during LLM inference. The first is to discard and recompute; systems like vLLM [16], TensorRT-LLM [22], discard all K,V cache state at the end of each request and then recompute the state for all prior requests and responses in the session upon a new request arriving. The second approach, employed by some recent works [1, 53, 9], is to offload K,V cache state onto the host (CPU) memory or disk and load it back when a new request arrives in a session.
Both approaches are flawed. Recomputation is, by nature, redundant and wasteful111We observe that in a real-world multi-turn chatbot dataset, more 99% of tokens processed are redundant. . Offloading, on the other hand, makes the workload sticky, i.e., all requests in a session need to be forwarded to the same node that has the corresponding K,V cache stored; otherwise, cache state needs to be migrated on-demand to the location where a request is routed, which adds high overhead given the large K, V cache state. Unfortunately, stickiness forces coarse-grained load balancing at the session granularity, which leads to load imbalance. For example, as shown in Figure 1, one node can end up serving the median load on a cluster. A high load imbalance can in turn heavily slow down requests as shown in Figure 2. Finally, despite optimizations, both recomputation and loading the K,V cache from the host to GPU HBM operate on the critical serving path [9], impacting inference latency.
We aim to develop a state management solution for session-oriented "multi-turn" LLM inference that: (a) avoids wasting compute resources, (b) helps balance load and optimize performance at a fine granularity, and (c) introduces no critical path overheads. Such an approach would enable high-performance LLM serving across machines, with high throughput, low latency, and high efficiency.
Our solution is based on a key observation: the interactive nature and well-defined structure of many LLM workloads provide useful hints about future request patterns and arrivals. We term these advisory requests. We show that advisory requests can enable near-ideal state management by facilitating zero critical-path-overhead K,V cache prefetching and, consequently, fine-grained load balancing at the request level.
Consider the case of chatbots; here, we can obtain additional information when a user starts typing; advisory requests capturing this can indicate which particular user session will be active soon (with high probability). In fact, based on the shareGPT dataset, we observe that advisory requests can be sent on average 11.3 seconds earlier than the actual LLM inference request!


Similarly, in the case of agent workloads [29] where multiple LLMs interact with each other, the call graph is known ahead of time; furthermore, at each LLM, we can lower-bound a request’s processing time via offline profiling (this is the minimum time needed to process the prompt and generate the first token). During online request processing, when a prompt is being processed by an upstream agent, an advisory request can be sent to the next downstream agent(s) with information about the session and the approximate (lower bounded) request arrival time. On evaluating MetaGPT, an agentic code system being served using 4 A100s, we observe that advisory requests can be issued on average 5.8 seconds earlier than the actual inference request.
However, effectively using advisory requests to realize high-performance serving is not straightforward. On workloads like chatbots and code editors advisory requests only provide information about the potential arrival of a request, and not the prompt length or the potential number of tokens that a prompt will generate. This makes it challenging to accurately estimate the GPU memory requirements. Secondly, the order of request arrival across sessions is unknown; e.g., in the case of a chatbot a request whose advisory request arrived sooner doesn’t necessarily indicate that the actual request for performing inference will arrive earlier. In turn, the lack of information about ordering and GPU memory requirements limits our ability to perform precise K,V cache prefetching and memory management.
We address these issues in our inference system, named Symphony. Symphony consists of two primary components – scheduler and node manager. The Symphony scheduler makes high-level decisions about scheduling at request granularity using both advisory requests and partial information about the state of the local machines. The Symphony node manager integrates with the serving framework to perform cooperative memory management to carefully prioritize and manage GPU memory, thereby aiding K, V cache prefetching.
Furthermore, we describe how advisory requests help Symphony support interesting and novel management policies, such as the use of tiered- and far-memory storage for K, V caches, and customizable policies for prioritizing sessions from different users without impacting overall performance, load, and efficiency goals.
We evaluate Symphony on the two latest LLaMa models, using the shareGPT [26] dataset that consists of real conversations collected from ChatGPT. We show that Symphony achieves reduction in end-to-end latency on average compared to vLLM. Further, Symphony can serve the requests served by vLLM with just inflation in average end-to-end latency.
2 Background and Motivation
In this section we first describe the transformer architecture. Then we provide an overview of the current LLM serving landscape and discuss how popular LLM workloads introduce additional challenges related to serving.
2.1 Generative LLM Inference
Decoder Only Transformer.
A decoder-only transformer serves as the foundational building block of popular LLMs [7]. Each decoder block comprises a self-attention layer and an MLP layer. During next-word prediction, an input token passes through the decoder block. The self-attention layer utilizes the query (Q), key (K), and value (V) vectors associated with the current token, which are computed via linear projections of the input using the block’s query, key, and value weight matrices.
To formally define Multi-Head Attention (MHA), let , , and be positive integers, where denotes the number of attention heads, the sequence length, and the model dimension. Let represent the input to the MHA layer. For a single attention head , the corresponding key, query, and value vectors are computed as follows:
The attention matrix for head is then calculated as:
The output of MHA is denoted by:
This output is then passed to a Fully Connected Layer, which processes the result before forwarding it to the next decoder block. Large LLMs typically consist of hundreds of such decoder blocks, enabling their sophisticated capabilities.
KV Cache.
For inference, self-attention requires access to the current query vector as well as all keys and values associated with prior tokens. To avoid re-computation, inference-serving systems store these prior tokens in a structure known as the K,V cache [28]. The size of the K,V cache has been rapidly growing due to increases in both model size and supported context length. For instance, the latest LLaMa models now support up to 128K tokens. For a medium-sized model like LLaMa-70B, a full 128K context length results in a maximum K,V cache size of 40 GB.
2.2 LLM Inference
LLM inference primarily consists of two distinct phases [2]:
Prefill Phase
The prefill phase processes the user prompt and generates the K,V caches associated with it. This phase can efficiently utilize GPU compute resources, as the K,V cache entries for the prompt can be computed in parallel.
Decode Phase
The decode phase generates output tokens iteratively. It uses the latest generated token and all prior K,V caches within the model’s context length to perform an auto-regressive decoding step. This process continues iteratively until either an end-of-sequence token is produced or a user-defined limit on the number of tokens is reached.
Scheduling LLM Inference
Given the unique resource requirements of the prefill and decode phases, several prior works have explored strategies to enhance hardware utilization [52, 37]. Research has also extensively examined scheduling techniques for LLM requests [2, 16, 37, 52]. For instance, [52, 37] investigated the disaggregation of the prefill and decode phases to optimize hardware usage, while [2] focused on scheduling prefill and decode requests to minimize end-to-end latency. In addition, [36] introduced a fairness-oriented scheduler for LLM inference. Similarly, works such as [14, 38] proposed intelligent mechanisms for batching LLM requests by predicting their compute and memory requirements.
All these works assume that requests are stateless, i.e., each incoming request is treated independently, with no prior associated state. However, in the next section, we demonstrate that this assumption does not hold for the majority of LLM workloads.
2.3 LLM Workloads
LLMs have demonstrated remarkable capabilities, such as In-Context Learning [6] and Chain-of-Thought Prompting [46]. These enable users to provide relevant information as prompts and guide the LLMs to produce desired responses. Additionally, LLMs support multi-turn interactions, where they can iteratively process prior and new inputs to generate coherent and context-aware outputs.
These unique properties have facilitated the integration of LLMs into applications like chatbots, code editors, and AI agents. Emerging applications leverage the concept of agents, where multiple LLMs collaborate to accomplish complex tasks such as software development [30, 31, 19] or creating realistic gameplay experiences [23].
These trends suggest that the majority of LLM-serving workloads in the future will consist of turn-by-turn interactions encapsulated in sessions. Within each session, multiple requests are made, requiring access to the K,V caches from previous requests. To better illustrate this, we will first examine two common applications and their corresponding request patterns.


Chatbots. One of the most common applications today of LLMs is in chatbots. In this use case, users interact with the LLM by providing prompts, and after receiving a response, they may choose to continue the conversation with additional questions or inputs. Figure 3 illustrates a typical chatbot interaction. For every new interaction, access to all prior inputs and responses is required to maintain context.
Figure 4 shows the cumulative distribution function (CDF) of the number of conversation turns based on the ShareGPT dataset. Notably, 73.4% of conversations are "multi-turn," with some chatbot sessions extending beyond 400 turns.
Agents. Another emerging application of LLMs is in agent-based workloads. In these scenarios, multiple LLMs collaborate to achieve a high-level objective. For instance, ChatDev [30] and MetaGPT [12] introduce agents designed to tackle software development tasks.
During interactions between these LLM agents, at each agent, it is essential to retain access to prior prompts and the associated K,V caches from all previous exchanges with other agents. This ensures continuity and context-aware responses.
2.4 Serving LLM Workloads



As discussed in the previous section, LLM workloads have unique characteristics that necessitate careful management of the K,V cache state.
These distinct properties introduce challenges, such as: 1. Efficient Access: How can requests be granted access to the K,V cache without incurring significant overhead? 2. Cache Retention: How long should K,V caches be retained, and where should they be stored? Addressing these challenges is critical for optimizing LLM-serving workloads. To tackle these existing systems primarily use three approaches that we describe next. In Figure 5 we provide a schematic that visually describes the available design choices.
Retain.
To avoid recomputation, some systems [13, 51] retain the previous K,V cache in GPU memory. However, this quickly leads to the exhaustion of the GPU’s high-bandwidth memory (HBM). For example, when serving LLaMa-8b with just 36 requests from the ShareGPT dataset, we observed that the GPU HBM became saturated.

Recompute.
Existing systems like vLLM and Tensor-RT LLM treat each request as a new, independent request, meaning they recompute the K,V cache for prior tokens every time a new request arrives. This results in redundant computation. In Figure 6, we show the number of wasted pre-filled tokens in the ShareGPT dataset. We observe that, as the number of conversation turns exceeds 3, more than 50% of the pre-filled tokens are wasted.

Swap.
Some recent systems [1, 9] implement mechanisms to swap K,V caches between GPU memory and host memory, migrating them back to the GPU when the next request in the session arrives. In Figure 7, we present the breakdown between Swap and Recompute, for serving 1000 samples from the ShareGPT dataset on an A100 GPU. We observe that using Swap reduces total pre-fill time by a factor of 4.9 and decode time by a factor of 1.68 for LLaMa-7B. The reduction in decode time is due to continuous batching, which accelerates pre-fill and allows a larger number of requests to be processed simultaneously, thereby reducing overall decode time as well.
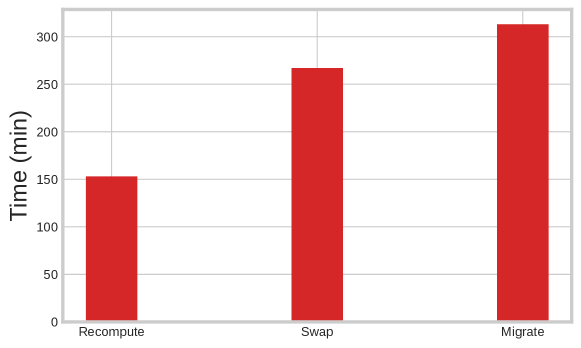
Swap, however, has two key limitations: (i) Offloading from GPU HBM introduces statefulness into the workload, requiring future requests in the same session to be handled by the same machine. (ii) It only allows offloading to host memory, as transferring the caches to lower-level storage (e.g., disk or remote storage) incurs significant overhead when serving requests. We observe that these limitations are significant. In Figure 1, we show that making machine assignments stateful leads to load imbalances, which negatively affect throughput (Figure 2). To assess the impact of load imbalance, we ran an experiment with 8 A100 GPUs, each serving an instance of LLaMa-3.2 8B with a swapping baseline (InferCept [1]). We ensured that each new request was routed to the same GPU that had previously handled the request in the session. In Figure 8, we observe that the swapping baseline takes 1.7 times longer than the Recompute baseline, despite the reduction in compute. This performance degradation is primarily due to load imbalance, where some GPUs are idle while others are overloaded, resulting in reduced overall throughput.
One way to address this load imbalance is by migrating the K,V caches to balance the load across GPUs. We conducted a similar experiment, as described in the previous paragraph. However, in Figure 8, we observe that migrating the K,V cache further increases the time required to serve requests. The cost of migration is significant, leading to a reduction in throughput as requests must wait for the cache to be migrated.
Additionally, the ability to offload to main memory is limited by the finite amount of available memory. For example, when serving LLaMa-3.1 8B, each token requires approximately 1.1 MB of K,V cache. A system with 256 GB of main memory can support only about 238K tokens. Given that the average session in the ShareGPT dataset is around 2.2K tokens, a single A100 GPU can serve a maximum of 108 concurrent sessions if offloading to host memory. This limitation further restricts the number of users that can be served effectively.
2.5 Design Goals
The challenges outlined in the previous section highlight the need for a system with the following design goals: (i) Minimize redundant computation by retaining K,V caches across requests within the same session, (ii) Perform dynamic load balancing to avoid load imbalances in the cluster, without incurring the overhead of K,V cache migrations, (iii) Enable offloading of K,V caches to disk or remote storage without introducing delays in fetching the K,V caches during request serving.
Our design approach is informed by the workload patterns in LLM workloads, and we demonstrate that there are additional signals in LLM workloads that can be leveraged to intelligently prefetch the K,V cache. Building on this insight, we propose the design of Symphony.

3 Symphony Design
We first begin by discussing the key insight which enables Symphony.
3.1 Key Insight
Symphony builds on the observation that in typical LLM workloads, additional information often exists which can indicate, with high probability, the arrival of future requests.
Consider a typical workflow involving a user interacting with a chatbot: the user submits a query, the chatbot generates a response, and the user reads it. After processing the information, the user begins typing a follow-up query. This process introduces a natural delay of several seconds between requests due to the time taken for comprehension and typing. Once the user submits their new query, the cycle repeats.
We refer to these anticipatory signals as advisory requests. By making minor modifications to the chatbot interface, it is possible to trigger an advisory request as soon as the user starts typing. This signal is sufficient to predict, with high confidence, that a new request is imminent. Figure 10 illustrates an example of an advisory request in the context of a chatbot.
Similarly, for agent workloads, profiling can provide an estimate of the lower bound on the runtime of the current agent LLM. During this interval, the current agent LLM can send an advisory request to the LLM associated with the next agent in the workflow. Figure 11 provides an example of an advisory request in an agent workload scenario.
We developed Symphony as a unified framework to leverage these advisory requests toward K,V cache prefetching and request-level scheduling that, as we show empirically later in the paper, play a key role in meeting our inference design goals. The following section outlines the design of Symphony.
3.2 Design Overview
Symphony comprises two key components: a scheduler which performs request level scheduling and node managers which enable K,V cache prefetching.
Symphony Scheduler
As illustrated in Figure 9, the Symphony scheduler functions as a top-level scheduler and provides two public-facing interfaces: (i) An interface for accepting LLM inference requests, and (ii) An interface for accepting advisory requests.
Upon receiving an advisory request, the Symphony scheduler performs request-level scheduling. Based on the scheduling policy, it augments the advisory request with information about the existing K,V cache location (i.e., the node storing the cache) and forwards it to a Symphony node manager. Additionally, the scheduler updates its internal state to reflect the new K,V cache location. When the actual inference request arrives, the Symphony scheduler routes it to the node identified during the processing of the corresponding advisory request.
In this work, Symphony employs a straightforward load-balancing policy, which distributes requests evenly across nodes. However, as discussed in Section 3.5, Symphony can support a variety of customizable policies tailored to different workloads and system configurations.
Symphony Node Manager
The Symphony node manager resides on each node and oversees Symphony ’s hierarchical memory system, which stores K,V caches. It exposes an interface to handle three types of requests: (i) advisory requests forwarded by the Symphony scheduler, (ii) LLM inference requests, and (iii) K,V cache fetch requests from other Symphony node managers.
An advisory request received from the scheduler contains two pieces of information: the session ID of the expected inference request and the current location of the associated K,V cache. Upon receiving an advisory request, the node manager verifies the cache’s location. If the cache resides on a different node, the node manager issues an RPC call to retrieve it. If the cache is locally available, the node manager, subject to memory constraints, moves it to the fastest memory tier possible. We describe how Symphony manages hierarchical memory tiers in nthe ext section.
When an LLM inference request arrives, it is routed to the underlying serving library, such as vLLM or TensorRT-LLM. Section 3.3 discusses how the Symphony node manager interfaces with these schedulers (vLLM and TensorRT-LLM) to efficiently manage GPU high-bandwidth memory (HBM) cooperatively.
3.3 Challenges and their Solutions
Using advisory requests for scheduling and hierarchical memory management of K,V caches presents several challenges. In the following, we discuss these challenges and outline the techniques we’ve developed to address them.
Hierarchical memory management.
When utilizing storage mediums such as host memory or disks, which exhibit significantly higher access latencies, reading and writing K,V caches can introduce substantial overhead. This slow access latency can block inference operations, resulting in performance slowdowns.
Approach: To mitigate the impact of these delays, we adopt layer-wise asynchronous reading and writing techniques inspired by prior work [9]. By enabling reads and writes to occur in parallel, we reduce the bottleneck associated with slow storage media.
Deep neural networks (DNNs) inherently process data layer by layer, requiring access to K,V caches only for the current layer being computed. Leveraging this property, we implement layerwise asynchronous reads and writes, allowing the system to load and store K,V caches in parallel with inference execution.
To support disk writes, we run a background thread that continuously updates the disk with newly generated K,V caches. In Symphony, we always maintain one copy of the K,V cache in the slowest memory hierarchy (disk). This design ensures data persistence, enabling us to perform on-demand evictions from higher memory tiers without risking data loss. For example, if high GPU HBM demand necessitates immediate memory clearance, we can safely purge data from the HBM, knowing that a complete copy of the K,V cache exists on disk.
Unpredictable arrival patterns.
Serving turn-by-turn workloads presents challenges due to limited information about the order and timing of requests. For instance, in chatbot scenarios, advisory requests indicate, with high probability, that a request associated with a specific session ID is likely to arrive. However, these advisory requests do not provide details about the order of requests or their precise arrival times. In agent workloads, where requests are sent by preceding agents, it is possible to estimate a minimum arrival time. Even so, this limited information complicates decisions about which K,V caches to prioritize, especially under memory constraints.
To illustrate the underlying issue, consider a high-load scenario where an LLM is being served. Suppose an advisory request is received for Session ID-2, prompting the movement of its K,V cache into the GPU HBM. This action fully utilizes the GPU memory. Subsequently, another advisory request arrives for Session ID-3, but the GPU HBM is already full. Without additional information–specifically, whether the inference request for Session ID-2 or Session ID-3 will arrive first–it is unclear which request should take priority.
Approach: Since with this limited information we are unable to make a decision about which Session IDs’ K,V cache to prioritize we instead try to reason about which K,V caches we really need and whose access latency can we hide based on overlapping with the forward pass. To address this challenge, we introduce a Priority-Based K,V Cache scheme. This approach prioritizes portions of the K,V cache that are most likely to be on the critical serving path.
The prioritization scheme builds on an observation like above - that, like other deep neural networks (DNNs), LLMs perform computations in a layerwise manner. If the K,V cache for the first few layers is available, the model can begin autoregressive decoding immediately while simultaneously prefetching the K,V cache for later layers.
In this scheme, K,V caches are assigned priorities based on their corresponding layers. When inserting K,V caches into the GPU HBM, blocks associated with lower layers are given higher priority, as they are required earlier in the computation. This prioritization ensures that critical portions of the cache are readily available, minimizing delays in inference. In the above example of multiple advisory requests arriving for different sessions, the priority-based approach would result in KV cache from lower layers of both sessions being moved to HBM, while other layers will be moved once the request arrives.
Imperfect estimate of memory requirement.
The GPU memory required to serve an LLM request primarily depends on the number of prompt tokens and the number of generated tokens. Estimating the memory requirements for an LLM request is challenging [14, 16], as the number of tokens generated by a request is not known a priori. This uncertainty makes it difficult to accurately determine the amount of free GPU memory, complicating GPU memory management.
Consider the following example: a GPU is serving an LLM request associated with Session ID: 1. While this request is being processed, an advisory request arrives for Session ID: 2. Based on the current free GPU memory, the system decides to prefetch the K,V cache for Session ID: 2 onto the GPU in anticipation of the actual inference request. However, as the inference for Session ID: 1 continues, the size of its K,V cache grows, eventually consuming all available GPU memory. This situation leaves no memory for the decoding process of the ongoing LLM request, causing a bottleneck.
In this scenario, the optimal decision would have been to avoid prefetching the K,V cache for Session ID: 2. However, the information needed to take this action was not available beforehand.
Approach: To address these challenges, we propose that Symphony’s node manager collaborate with the framework-level scheduler to dynamically release memory based on high-bandwidth memory (HBM) requirements. This concept, which we refer to as cooperative memory management, integrates Symphony with a framework scheduler, such as the one used in vLLM, to manage GPU memory more effectively and ensure smooth operation under constrained resources.
In cooperative memory management, the Symphony node manager greedily transfers the K,V cache to occupy available GPU memory whenever it is free. However, under increased memory pressure, the underlying serving library can overwrite this memory by purging parts of the K,V cache. Since a copy of the K,V cache is already stored in host memory, this operation requires no additional data transfer. Since K,V cache blocks are overwritten based on their assigned priority. Blocks associated with later layers in the network are given the lowest priority, followed by K,V caches with the smallest size, which are assigned the second-lowest priority. We would like to highlight we use cooperative memory management only for managing GPU HBM. For
3.4 Scheduling with Symphony
To demonstrate how Symphony’s optimizations, layerwise asynchronous reads and writes, priority-based K,V cache management, and cooperative memory management enhance performance, we analyze three scenarios. These examples illustrate the impact of our techniques in practical use cases.
Setup: Assume we have two nodes, Node-1 and Node-2. Node-1 is serving two requests, while Node-2 is handling four requests. When an advisory request arrives for Session ID: 1, the Symphony scheduler assigns it to Node-1 to balance the request load. However, the K,V cache for Session ID: 1 resides on Node-2. The Symphony node manager at Node-1 requests the K,V cache from Node-2. We explore three cases to understand how Symphony handles different scenarios:
Case 1: High GPU Memory Availability. In this scenario, Node-1 has abundant GPU HBM available. The Symphony node manager moves the K,V cache for Session ID: 1 to the GPU, host memory, and disk, ensuring quick access when there are no memory constraints.
Case 2: High GPU Memory Availability with Increasing Memory Pressure. Here, the Symphony node manager initially moves the K,V cache for Session ID: 1 to the GPU, host memory, and disk. As memory pressure increases and the serving framework requires more GPU memory, cooperative scheduling is applied. Based on the priority of K,V cache blocks, evictions are performed to free up memory. When the inference request for Session ID: 1 arrives, the layerwise asynchronous read mechanism incrementally reloads the required data from host memory to the GPU, minimizing delays and ensuring efficient memory usage.
Case 3: No GPU Memory Available. In this case, the Symphony node manager moves the K,V cache for Session ID: 1 to host memory and disk, bypassing the GPU due to lack of available memory. During inference, asynchronous layerwise reads are employed to hide latency by gradually fetching the required data from host memory to the GPU, ensuring smooth execution despite the memory constraints.
3.5 Discussion
Enabling additional scheduling policies
Symphony scheduler provides a flexible interface that allows cluster administrators to implement any desired scheduling policy atop the building block of request-level scheduling. To demonstrate this flexibility, beyond load balancing, we also implement request prioritization. This helps serve a common requirement in LLM serving, namely user prioritization; for instance, users on a paid plan for a chatbot might be given higher priority than free-tier users. An approach to achieve this would involve preempting low-tier requests on a node when a new prioritized request arrives and then running the priority request. However, this approach can lead to significant slowdowns if multiple high-priority requests arrive on the same node, leading to poor load balancing. Additionally, prioritizing one request can negatively impact the latency of other non-priority requests. Using Symphony, we can migrate high-priority requests evenly across nodes based on advisory requests and selectively pause low-priority requests only when their execution impacts latency. We implement a request prioritization scheduler and evaluate it in Sec 4.5.
Accuracy impact of Symphony
Symphony performs scheduling transparently, i.e., it does not change the underlying model or the data. It only provides a mechanism to manage K,V caches when serving multi-turn LLM workloads. However, Symphony can be easily made compatible with approximation-based methods like [21, 20] which compress the K,V cache.
Compatibility with existing schedulers
Existing schedulers like [2, 36, 38] perform scheduling for "single-request-and-response". These schedulers do not account for "mult-turn" session-based LLM workloads. Symphony on the other hand performs request-level scheduling. It can be used in conjunction with any of the existing schedulers; e.g., at the node level we can have a fairness scheduler running [38] while at the cluster level, we can have Symphony’s load balance policy running.
Limitations of Symphony.
Symphony assumes that advisory requests arrive early enough to allow sufficient time for K,V cache migrations. However, in extreme cases where there is insufficient time between the advisory request (or there was no advisory request) and the associated inference request, performance may be impacted. We evaluate this scenario in Section 4.5 and observe that, due to asynchronous layerwise reads and writes we are able to load the K,V cache from the host memory with only 6% loss in latency when 10% of requests arrive without sending an advisory request.
4 Evaluation








We next evaluate the performance Symphony using traces derived from real-world LLM chatbot sessions and study the benefits Symphony offers in terms of time per output token and load balance across a GPU cluster.
Baseline Systems
We compare Symphony with two popular baselines, vLLM [16] and InferCept [1]. vLLM treats each request in a multi-round session as a new request and performs recomputation of the K,V cache every time. InferCept is a system that offloads K,V caches to the main memory of the host. However, InferCept does not perform request-level routing. To test these systems we build a top-level scheduler. For vLLM our top-level scheduler performs the same routine as for Symphony, and minimizes the load imbalance across the serving machines. For InferCept for the first request in each session, we route the request to the node with the least number of requests. However, for each successive request within the same session, we route the request to the same node as chosen for the first request.
Testbed Setup
All our experiments unless otherwise stated are performed on 2 nodes, with each node having 4 Nvidia A100 GPUs with 80 GB of HBM. Each node is equipped with 256 GB of DRAM and 4 TB of SSDs. The nodes are interconnected using a 100Gbps Ethernet link.
Models
Trace Generation
We evaluate our system on the ShareGPT dataset [26] a widely used real-world dataset of conversations from ChatGPT. ShareGPT contains a number of user sessions and we evaluate Symphony (and the baselines) on a fixed number of users. Each user session in ShareGPT contains a set of user requests and responses from the LLM model. We generate the arrival time of each request within a session by calculating the time to read a response and type a query based on human reading and typing speed (derived from [27, 43]). After initializing the reading and typing speed based on these scientific studies, we send the next request by estimating the time it will take to read the response from the chatbot and the time to type out a response. Our trace generator maintains a fixed number of active users. For all evaluations in this paper, we use 1000 samples of the shareGPT dataset unless otherwise stated.
Evaluation Metrics
Similar to prior works in LLM inference we first evaluate the performance of Symphony on three metrics: Normalized Latency, Time to first token (TTFT), and Number of requests served. Similar to the definition used in prior work [50, 16, 1], average normalized latency represents the mean of each request’s end-to-end latency divided by its output length.
4.1 Implementation
Symphony is primarily implemented in around 2400 lines of Python. Symphony uses gRPC [11] to integrate Symphony scheduler with Symphony node manager. Further, each Symphony node manager is connected with all other Symphony node managers which enables a Symphony node manager to perform on-demand K,V cache migration from one machine to another. Further, to perform LLM inference we integrate with vLLM a commonly used library designed to serve LLMs. For performing cooperative memory management Symphony integrates with vLLM’s scheduler and performs block management.
4.2 Comparing Symphony
We first evaluate Symphony by comparing it against existing systems. Then we dive deeper into understanding where the benefits of Symphony come from.
Normalized Latency
In Figure 12(a), we compare Symphony with vLLM [16] and InferCept [1] while serving LLaMa-3.1 8B while varying the number of concurrent users. The results show that Symphony reduces normalized end-to-end latency by a factor of to compared to vLLM. Similarly, in Figure 13(a), we observe that when serving LLaMa-2-13B, Symphony achieves latency reductions of to .
These improvements are primarily due to two factors. First, unlike vLLM, Symphony eliminates redundant computations, resulting in significant compute savings. Second, since Symphony, like vLLM, employs continuous batching, the faster prefill phase allows more requests to transition to the decode phase faster improving the overall throughput of the system. vLLM does not benefit from continuous batching during the pre-fill phase as the throughput of prefill stays constant with increased batch size.
When compared to InferCept, Symphony delivers a speedup of up to . This improvement is primarily because InferCept uses a stateful serving model, which causes significant load imbalances across the cluster. In some cases, the number of requests on a single server can be as much as the median load across the cluster. This imbalance leads to severe latency increases and suboptimal hardware utilization.
Time to First Token
In Figures 13(b) and 12(b), we observe that Symphony reduces the time to first token by up to compared to the vLLM and InferCept baselines. vLLM suffers from redundant prefill operations when recomputing KV caches of prior requests, which significantly increases the time to the first token. In contrast, while InferCept avoids wasteful decoding, it prioritizes completing the decode step on sequences whose K,V cache are stored in host memory, rather than focusing on prefill as vLLM does. On the other hand, Symphony uses vLLM’s scheduler and only manages state, avoiding redundant steps and improving time to the first token.
Requests Served/Sec
In Figures 12(c) and 13(c), we observe that Symphony can serve up to the number of users while maintaining a similar time per output token. For example, when serving 64 users, vLLM has an average time per output token of 18ms, whereas Symphony can serve 512 users with an average time per output token of 20.5ms while using the same number of GPUs. The primary reason Symphony outperforms vLLM is its ability to minimize redundant computation of K,V caches for multi-turn chatbot requests.
When compared to InferCept, Symphony can handle over the number of requests at high load (1024 users). The main reason InferCept is significantly slower is due to load imbalance, which causes poor cluster utilization.
4.3 Load Imbalance
Next, we plot the load imbalance while serving LLaMa-3.1-8b with 256 concurrent users. In Figure 14, we observe that, unlike vLLM and Symphony, InferCept exhibits significant load imbalance. Specifically, the maximum number of users served by a single instance is more than the median load across machines.

4.4 Serving Agent workloads
Next, we evaluate the performance of Symphony in serving agent workloads. For this, we use MetaGPT [12], a multi-agent framework designed to simulate an AI software development company. In MetaGPT, different roles are defined for each LLM. The framework proposes three main roles: an architect who defines the project, designs data structures and APIs, and writes multiple design documents; engineers who take over coding tasks, each focusing on specific files; and QA engineers who review the code, followed by engineers making revisions. This review and revision cycle occurs three times.
We observe that this is an interactive workload, with documents and reviews being shared among engineers and QA. We serve MetaGPT requests using Symphony, utilizing LLaMa-3.1-8b across 8 GPUs. Our results show that Symphony reduces the overall time by because advisory requests enable K,V cache offloading and request load balancing.

4.5 Ablation
We systematically study certain key properties of Symphony.
Performance under prefill-heavy requests
To understand the importance of load balancing, we evaluate a new workload that should significantly benefit both InferCept and Symphony. In this "pre-fill-heavy" workload, we replace all requests with a 1024-token prompt and a 1-token response while keeping the original arrival times. This configuration benefits both systems, as they retain the K,V cache associated with previous prompts and responses. However, the key difference is load imbalance. As shown in Figure 16, despite the favorable setup, InferCept struggles to achieve high throughput due to load imbalance.

Performance under lack of advisory requests
One of the key observations in Symphony is the use of advisory requests for prefetching the K,V cache. To evaluate the performance of Symphony in the absence of advisory requests, we set up an experiment where advisory requests are missed. In Figure 17, we observe that as the proportion of missed advisory requests increases, the normalized token latency also increases. For a 10% miss rate, the latency to produce one token increased from 21.3ms to 24.4ms by approximately 6% The primary reason for this increase is the inability to efficiently perform load balancing and prefetch the K,V cache.


Prioritization Policy.
To demonstrate that Symphony supports additional policies beyond load balancing, we implement a prioritization policy. For sessions marked as high priority, the K,V cache for the associated request is immediately moved to the GPU HBM to prevent delays in processing. We vary the percentage of high-priority requests (10%, 30%, 50%) and compare this approach with vLLM’s priority scheduling. Our results (Figure 18) show that, due to the absence of redundant computation and zero overhead in K,V cache migration, Symphony delivers better tokens per second for both prioritized and regular jobs.
5 Related Work
There have been several prior works that have studied scheduling for LLM workloads.
Scheduling for LLMs
Several prior works have studied scheduling in the context of Large language models. Saarthi-Serve [2] studied scheduling from the perspective of trading throughput vs latency. VTC [36] introduces the idea of fairness in serving multiple LLM requests. Serveless LLMs [8] introduced the idea of locality for LLM serving.
Large Language Models. Attention first introduced by [44] forms the basic building block in various language understanding tasks such as text generation, text classification, and question answering [45, 33]. Recent works, e.g. GPT [32, 4], LLaMA [41, 7, 42], Qwen [3, 48], and Gemma [39, 40] have shown that scaling foundation models can achieve high accuracy on many downstream tasks.
K,V cache managment
There have been several works that looked at minimizing the K,V cache requirements for LLMs. [21] looks at reducing the size of KV caches, exploiting the contextual sparsity in inference. [49] allows KV caches to be shared between layers, achieving layer-wise compression while preserving the model performance. [47, 20] introduce frameworks that reduce the cost of LLM inference by retaining specific parts of the KV cache. Several recent works have also explored swapping-based mechanisms to facilitate large language model inference. [10] proposes a CachedAttention mechanism, which uses a hierarchical KV caching system to store KV caches in cost-effective memory and storage mediums. [17] introduces the idea of KV cache loading based on the importance of tokens. [37] addresses pipeline bubbles in distributed LLM serving and proposes a solution through efficient KV cache management.
6 Conclusion
In this work, we introduce Symphony, a scheduling framework designed to facilitate request-level scheduling for "multi-turn" workloads. Symphony builds on the key observation that popular LLM workloads often exhibit sufficient information to predict, with high probability, the arrival of future requests. Leveraging this insight, Symphony employs advisory requests—signals that indicate the likely arrival of subsequent requests—to perform K, V cache migration proactively in the background. This proactive caching mechanism enables more efficient high-level scheduling and ensures the system is better prepared to handle modern inference workloads well.
References
- [1] Reyna Abhyankar, Zijian He, Vikranth Srivatsa, Hao Zhang, and Yiying Zhang. Infercept: Efficient intercept support for augmented large language model inference. In Forty-first International Conference on Machine Learning.
- [2] Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming Throughput-Latency tradeoff in LLM inference with Sarathi-Serve. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117–134, 2024.
- [3] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- [4] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [5] cursor. cursor. https://cursor.com/, 2023. Accessed: November 11, 2024.
- [6] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, et al. A survey on in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- [7] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- [8] Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. Serverlessllm: Locality-enhanced serverless inference for large language models. arXiv preprint arXiv:2401.14351, 2024.
- [9] Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. Attentionstore: Cost-effective attention reuse across multi-turn conversations in large language model serving. arXiv preprint arXiv:2403.19708, 2024.
- [10] Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. Cost-Efficient large language model serving for multi-turn conversations with CachedAttention. In 2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 111–126, 2024.
- [11] Google. Grpc:a high performance, open source universal rpc framework. https://grpc.io/, 2012. Accessed: May 18, 2022.
- [12] Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 2023.
- [13] InternLM/lmdeploy. lmdeploy. https://github.com/InternLM/lmdeploy, 2023. Accessed: November 11, 2024.
- [14] Kunal Jain, Anjaly Parayil, Ankur Mallick, Esha Choukse, Xiaoting Qin, Jue Zhang, Íñigo Goiri, Rujia Wang, Chetan Bansal, Victor Rühle, et al. Intelligent router for llm workloads: Improving performance through workload-aware scheduling. arXiv preprint arXiv:2408.13510, 2024.
- [15] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- [16] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023.
- [17] Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. InfiniGen: Efficient generative inference of large language models with dynamic KV cache management. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 155–172, Santa Clara, CA, July 2024. USENIX Association.
- [18] Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023.
- [19] Wei Liu, Chenxi Wang, Yifei Wang, Zihao Xie, Rennai Qiu, Yufan Dnag, Zhuoyun Du, Weize Chen, Cheng Yang, and Chen Qian. Autonomous agents for collaborative task under information asymmetry. arXiv preprint arXiv:2406.14928, 2024.
- [20] Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36, 2024.
- [21] Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR, 2023.
- [22] NVIDIA/TensorRT-LLM. Tensorrt-llm. https://github.com/NVIDIA/TensorRT-LLM, 2024. Accessed: November 11, 2024.
- [23] Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023.
- [24] Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132. IEEE, 2024.
- [25] Archit Patke, Dhemath Reddy, Saurabh Jha, Haoran Qiu, Christian Pinto, Chandra Narayanaswami, Zbigniew Kalbarczyk, and Ravishankar Iyer. Queue management for slo-oriented large language model serving. In Proceedings of the 2024 ACM Symposium on Cloud Computing, pages 18–35, 2024.
- [26] philschmid/sharegpt raw. sharegpt. https://huggingface.co/datasets/philschmid/sharegpt-raw/tree/main/sharegpt_90k_raw_dataset, 2023. Accessed: November 11, 2024.
- [27] Svetlana Pinet, Christelle Zielinski, F-Xavier Alario, and Marieke Longcamp. Typing expertise in a large student population. Cognitive Research: Principles and Implications, 7(1):77, 2022.
- [28] Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems, 5:606–624, 2023.
- [29] Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. Communicative agents for software development. arXiv preprint arXiv:2307.07924, 6:3, 2023.
- [30] Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. Chatdev: Communicative agents for software development. arXiv preprint arXiv:2307.07924, 2023.
- [31] Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large-language-model-based multi-agent collaboration. arXiv preprint arXiv:2406.07155, 2024.
- [32] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [33] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
- [34] replit. replit. https://replit.com/, 2023. Accessed: November 11, 2024.
- [35] Semrush. Insights from chatgpt conversations. https://www.semrush.com/news/251916-user-strategies-and-insights-from-real-chatgpt-conversations., 2024. Accessed: November 11, 2024.
- [36] Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E Gonzalez, and Ion Stoica. Fairness in serving large language models. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 965–988, 2024.
- [37] Foteini Strati, Sara Mcallister, Amar Phanishayee, Jakub Tarnawski, and Ana Klimovic. D’ejavu: Kv-cache streaming for fast, fault-tolerant generative llm serving. arXiv preprint arXiv:2403.01876, 2024.
- [38] Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. Llumnix: Dynamic scheduling for large language model serving. arXiv preprint arXiv:2406.03243, 2024.
- [39] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- [40] Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024.
- [41] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [42] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [43] Susanne Trauzettel-Klosinski, Klaus Dietz, IReST Study Group, et al. Standardized assessment of reading performance: The new international reading speed texts irest. Investigative ophthalmology & visual science, 53(9):5452–5461, 2012.
- [44] A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017.
- [45] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- [46] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [47] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023.
- [48] An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024.
- [49] Yifei Yang, Zouying Cao, Qiguang Chen, Libo Qin, Dongjie Yang, Hai Zhao, and Zhi Chen. Kvsharer: Efficient inference via layer-wise dissimilar kv cache sharing. arXiv preprint arXiv:2410.18517, 2024.
- [50] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for Transformer-Based generative models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, 2022.
- [51] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Efficiently programming large language models using sglang. arXiv e-prints, pages arXiv–2312, 2023.
- [52] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. arXiv preprint arXiv:2401.09670, 2024.
- [53] Kan Zhu, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Yufei Gao, Qinyu Xu, Tian Tang, Zihao Ye, et al. Nanoflow: Towards optimal large language model serving throughput. arXiv preprint arXiv:2408.12757, 2024.