Symmetric generalized Heckman models
Abstract
The sample selection bias problem arises when a variable of interest is correlated with a latent variable, and involves situations in which the response variable had part of its observations censored. Heckman, (1976) proposed a sample selection model based on the bivariate normal distribution that fits both the variable of interest and the latent variable. Recently, this assumption of normality has been relaxed by more flexible models such as the Student- distribution (Marchenko and Genton,, 2012; Lachos et al.,, 2021). The aim of this work is to propose generalized Heckman sample selection models based on symmetric distributions (Fang et al.,, 1990). This is a new class of sample selection models, in which variables are added to the dispersion and correlation parameters. A Monte Carlo simulation study is performed to assess the behavior of the parameter estimation method. Two real data sets are analyzed to illustrate the proposed approach.
Keywords. Generalized Heckman models Symmetric distributions Variable dispersion Variable correlation.
1 Introduction
It is common in the areas of economics, statistics, sociology, among others, that in the sampling process there is a relationship between a variable of interest and a latent variable, in which the former is observable only in a subset of the population under study. This problem is called sample selection bias and was studied by Heckman, (1976). The author proposed a sample selection model by joint modeling the variable of interest and the latent variable. The classical Heckman sample selection (classical Heckman-normal model) model received several criticisms, due to the need to assume bivariate normality and the difficulty in estimating the parameters using the maximum likelihood (ML) method, which led to the introduction of an alternative estimation method known as the two-step method; see Heckman, (1979). Some studies on Heckman models have been done by Nelson, (1984), Paarsch, (1984), Manning et al., (1987), Stolzenberg and Relles, (1990) and Leung and Yu, (1996). These works suggested that the Heckman sample selection model can reduce or eliminate selection bias when the assumptions hold, but deviation from normality assumption may distort the results.
The normality assumption of the classical Heckman-normal model (Heckman,, 1976) has been relaxed by more flexible models such as the Student- distribution (Marchenko and Genton,, 2012; Ding,, 2014; Lachos et al.,, 2021), the skew-normal distribution (Ogundimu and Hutton,, 2016) and the Birnbaum-Saunders distribution (Bastos and Barreto-Souza,, 2021). Moreover, the classical Heckman-normal model assumes that the dispersion and correlation (sample selection bias parameter) are constant, which may not be adequate. In this context, the present work aims to propose generalized Heckman sample selection models based on symmetric distributions (Fang et al.,, 1990). In the proposed model, covariates are added to the dispersion and correlation parameters, then we have covariates explaining possible heteroscedasticity and sample selection bias, respectively. Our proposed methodology can be seen as a generalization of the generalized Heckman-normal model with varying sample selection bias and dispersion parameters proposed by Bastos et al., (2021) and the Heckman-Student- model proposed by Marchenko and Genton, (2012). We demonstrate that the proposed symmetric generalized Heckman model outperforms the generalized Heckman-normal and Heckman-Student- models in terms of model fitting, making it a practical and useful model for modelling data with sample selection bias.
The rest of this work proceeds as follows. In Section 2, we briefly describe the bivariate symmetric distributions. We then introduce the symmetric generalized Heckman models. In this section, we also describe the maximum likelihood (ML) estimation of the model parameters. In Section 3, we derive the generalized Heckman-Student- model, which is a special case of the symmetric generalized Heckman models. In Section 4, we carry out a Monte Carlo simulation study for evaluating the performance of the estimators. In Section 5, we apply the generalized Heckman-Student- to two real data sets to demonstrate the usefulness of the proposed model, and finally in Section 6, we provide some concluding remarks.
2 Symmetric generalized Heckman models
Let be a random vector following a bivariate symmetric (BSY) distribution (Fang et al.,, 1990) with location (mean) vector , covariance matrix
| (2.1) |
and density generator , with , , for . We use the notation . Then, the probability density function (PDF) of is given by
| (2.2) |
where and is a normalization constant so that is a PDF, that is,
The density generator in (2.2) leads to different bivariate symmetric distributions, which may contain an extra parameter (or extra parameter vector).
We propose a generalization of the classical Heckman-normal model (Heckman,, 1976) by considering independent errors terms following a BSY distribution with regression structures for the sample selection bias () and dispersion () parameters:
| (2.3) |
In the above equation and are are the mean, dispersion and correlation parameters, respectively, with the following regression structure , , and , where , , and are vectors of regression coefficients, , , and are the values of , , and covariates, and . The links and are strictly monotone and twice differentiable. The link functions , , and must be strictly monotone, and at least twice differentiable, with , , , and being the inverse functions of , , , and , respectively. For and the most common choice is the identity link, whereas for and the most common choices are logarithm and arctanh (inverse hyperbolic tangent) links, respectively.
We can agglutinate the information from in the following indicator function .
Let be the observed outcome, for . Only out of observations for which are observed. This model is known as “Type 2 tobit model” in the econometrics literature. Notice that . By using law of total probability, for , the random variable has distribution function
The function has only one jump, at , and . Therefore, is a random variable that is neither discrete nor absolutely continuous, but a mixture of the two types. In other words,
where and . Hence, the PDF of is given by
| (2.4) | ||||
wherein for , and is the Dirac delta function. That is, the density of is composed of a discrete component described by the probit model , for , and a continuous part given by the conditional PDF .
2.1 Finding the conditional density of , given that
In the context of sample selection models, the interest lies in finding the PDF of given that follows the BSY distribution (2.3); see Theorem 2.5.
Before stating and proving the main result (Theorem 2.5) of this section, throughout the paper we will adopt the following notations:
| (2.5) |
and
| (2.6) |
where
| (2.7) |
have the joint PDF and denotes the PDF corresponding to a random variable . Here, the random variables , , , and are mutually independent and , . The random variable in (2.7) is positive and has PDF
The random variable in (2.7) is positive and is called the generator of the random vector . Moreover, has PDF given by
where is the density generator in (2.2).
Proposition 2.1.
Let us denote and .
-
1.
The PDFs of and are given by
(2.8) -
2.
The PDFs of and are
Proof.
Using the known formula for the PDF of product of two random variables and :
the proof of (2.8) follows.
The proof of second item follows by combining the law of total probability with (2.8). ∎
Proposition 2.2.
The random vector is jointly symmetric about . That is, .
Proof.
Let and . Since and are mutually independent, by using change of variables (Jacobian Method), the joint density of and is
| (2.9) |
Moreover, since are mutually independent, by law of total probability we get
| (2.10) |
where denotes the (joint) distribution function of . Using the following well-known identity:
we have
By replacing the last three identities in (2.10) and then by differentiating with respect to and , we obtain
where in the last line we used the Equation (2.9). Note that the function above is not defined on the abscise or ordinate axes (neither at the origin), but this is not relevant because these events have a null probability measure. Therefore, we can say that
| (2.11) |
From (2.11) it is clear that the vector is jointly symmetric about . ∎
Proposition 2.3.
-
1.
The marginal PDFs of and , denoted by and , respectively, are given by
where and are given in Proposition 2.1.
-
2.
The random vector is marginally symmetric about . That is, and .
Proof.
Proposition 2.4.
The function in (2.5) satisfies the following identity:
That is, is the conditional CDF of , given that . Consequently, is a distribution symmetric about .
Proof.
The proof immediately follows by applying Proposition 2.2. ∎
We now proceed to establish the main result of this section.
Theorem 2.5.
If then the PDF of is given by
| (2.12) |
where , and are given in Proposition 2.4, (2.6) and (2.7), respectively.
As a by-product of the proof we get that .
Proof.
Since the random vector follows the BSY distribution (2.3), this one admits the stochastic representation (Abdous,, 2005)
| (2.15) |
where and are as in (2.7). If then . So, the conditional distribution of , given that is the same as the distribution of
Consequently, the PDF of given that is given by
| (2.16) |
Further,
| (2.17) |
By using the identity
and by employing identities (2.16) and (2.17), we get
where in the last line a change of variables was used. Finally, by using the notations of and given in (2.5) and (2.6), respectively, from the above identity and from Proposition 2.4 the proof follows. ∎
Corollary 2.6 (Gaussian density generator).
If , where is the density generator of the bivariate normal distribution, then the PDF of is given by
wherein and denote the PDF and CDF of the standard normal distribution, respectively.
Proof.
If follows the bivariate normal distribution then there exist independent standard normal random variables and such that a stochastic representation of type (2.15) is satisfied. Therefore, and are distributed according to the standard normal distribution. Hence, and , given in Proposition 2.4 and Item (2.6), respectively, are written as:
and
Applying Theorem 2.5 the proof concludes. ∎
Remark 2.7.
It is well-known that, if is distributed from a bivariate Student- distribution, notation , where and is as in (2.1), then both the marginal and the conditional distributions of given are also univariate Student’s distributions: and
The above statement is equivalent to
Corollary 2.8 (Student- density generator).
If , where is the density generator of the bivariate Student- distribution with degrees of freedom, then the PDF of is given by
wherein and denote the PDF and CDF of a classic Student- distribution with degrees of freedom, respectively.
Proof.
It is well-known that the vector following a bivariate Student- distribution has the stochastic representation; see Subsection 9.2.6, p. 354 of Balakrishnan and Lai, (2009):
| (2.20) |
where and are Student- random variables, wherein (chi-square with degrees of freedom) is independent of and , and are independent.
When , from Remark 2.7 we have
Hence,
By using the representation (2.20), a simple algebraic manipulation shows that the right-hand of the above probability is
Setting and we obtain
Therefore, the function , given in Proposition 2.4, is
On the other hand, note that is distributed according to the a Student- distribution with degrees of freedom because . Then
Applying Theorem 2.5 the proof follows. ∎
Given the density generator we can directly determine the PDF of as follows.
Corollary 2.9.
If then the PDF of is given by
where .
2.2 Maximum likelihood estimation
By combining Equation (2) with Theorem 2.5, the following formula for the PDF of is valid:
where , , if and otherwise, , , and .
The log-likelihood of the symmetric generalized Heckman model for is given by
| (2.22) |
To obtain the ML estimate of , we maximize the log-likelihood function (2.2) by equating the score vector to zero, providing the likelihood equations. They are solved by means of an iterative procedure for non-linear optimization, such as the Broyden-Fletcher-Goldfarb-Shanno (BFGS) quasi-Newton method.
The likelihood equations are given by
where
3 Generalized Heckman-Student- model
The generalized Heckman-normal model proposed by Bastos et al., (2021) is a special case of (2.3) when the underlying distribution is bivariate normal. In this work, we focus on the generalized Heckman- model, which is based on the bivariate Student- (B) distribution. This distribution is a good alternative in the symmetric family of distributions because it possesses has heavier tails than the bivariate normal distribution. From (2.2), if follows a B distribution, then the associated PDF is given by
| (3.1) |
where is the number of degrees of freedom. Here, the density generator of the B distribution is given by , and is a normalization constant. Therefore, if follow a B distribution, then, by Corollary 2.8, the PDF of is written as
where and are the PDF and CDF, respectively, of a univariate Student- distribution with degrees of freedom, and . The log-likelihood for is given by
| (3.2) |
where if and otherwise, , , and are as in (2.3). The ML estimate of is obtained by maximizing the log-likelihood function (3), that is, by equating the score vector (given in Subsection 2.2) to zero, providing the likelihood equations. They are solved using an iterative procedure for non-linear optimization, such as the BFGS quasi-Newton method.
4 Monte Carlo simulation
In this section, we carry out Monte Carlo simulation studies to evaluate the performance of the ML estimators under the symmetric generalized Heckman model. We focus on the generalized Heckman- model and consider three different set of true parameter value, which leads to scenarios covering moderate to high censoring percentages. The studies consider simulated data generated from each scenario according to
| (4.1) |
| (4.2) |
| (4.3) |
| (4.4) |
for , , and are covariates obtained from a normal distribution in the interval (0,1). Moreover, the simulation scenarios consider sample size and , with Monte Carlo replicates for each sample size. In the structure presented in (4.1) - (4.4), is the primary interest equation, while represents the selection equation. The R software has been used to do all numerical calculations; see R Core Team, (2022).
The performance of the ML estimators are evaluated through the bias and mean squared error (MSE), computed from the Monte Carlo replicas as
| (4.5) |
where and are the true parameter value and its respective -th ML estimate, and NREP is the number of Monte Carlo replicas.
We consider the following sets of true parameter values for the regression structure in (4.1)-(4.4):
-
•
Scenario 1) , , and and .
-
•
Scenario 2) , , , and or .
-
•
Scenario 3) , , , and (moderate correlation) or (strong correlation).
To keep the censoring proportion around 50%, in Scenario 1 a threshold greater than zero was used, so . According to Bastos et al., (2021), in general the value of is zero, as any other value would be absorbed by the intercept, so considering another value does not cause problems for the model. In Scenario 2, the dispersion and correlation parameters were changed and the censoring proportion was maintained around 30%. In Scenario 3, the censoring rate around 50% was obtained by changing the parameters of the selection equation .
The ML estimation results for the Scenarios 1), 2) and 3) are presented in Tables 1-3, respectively, wherein the bias and MSE are all reported. As the ML estimators are consistent and asymptotically normally distributed, we expect the bias and MSE to approach zero as grows. Moreover, we expect that the performances of the estimates deteriorate as the censoring proportion (%) grows. A look at the results in Tables 1-3 allows us to conclude that, as the sample size increases, the bias and MSE both decrease, as expected. In addition, the performances of the estimates decrease when the censoring proportion increases.
| Generalized Heckman- | Generalized Heckman- | ||||||
|---|---|---|---|---|---|---|---|
| Parameters | n | Censoring | Bias | MSE | Censoring | Bias | MSE |
| 1.1 | 500 | 30.8878 | 0.0034 | 0.0053 | 54.0284 | 0.0082 | 0.0148 |
| 1000 | 30.9352 | 0.0019 | 0.0025 | 53.421 | 0.0016 | 0.0060 | |
| 2000 | 31.0035 | 0.0021 | 0.0011 | 52.8706 | 0.0058 | 0.0030 | |
| 0.7 | 500 | 30.8878 | 0.0037 | 0.0014 | 54.0284 | 0.0060 | 0.0034 |
| 1000 | 30.9352 | 0.0020 | 0.0007 | 53.421 | 0.0033 | 0.0013 | |
| 2000 | 31.0035 | 0.0016 | 0.0003 | 52.8706 | 0.0020 | 0.0005 | |
| 0.1 | 500 | 30.8878 | 0.0009 | 0.002 | 54.0284 | -0.0014 | 0.0045 |
| 1000 | 30.9352 | -0.0003 | 0.0008 | 53.421 | 0.0003 | 0.0017 | |
| 2000 | 31.0035 | 0.0008 | 0.0004 | 52.8706 | -0.0022 | 0.0008 | |
| 0.9 | 500 | 30.8878 | 0.0163 | 0.0137 | 54.0284 | -1.0167 | 1.0443 |
| 1000 | 30.9352 | 0.0055 | 0.0065 | 53.421 | -1.0095 | 1.0246 | |
| 2000 | 31.0035 | -0.0008 | 0.0032 | 52.8706 | -0.9981 | 0.9980 | |
| 0.5 | 500 | 30.8878 | 0.0066 | 0.0091 | 54.0284 | 0.0071 | 0.0077 |
| 1000 | 30.9352 | 0.0064 | 0.0044 | 53.421 | 0.0026 | 0.0039 | |
| 2000 | 31.0035 | 0.0025 | 0.0021 | 52.8706 | 0.0021 | 0.0019 | |
| 1.1 | 500 | 30.8878 | 0.0177 | 0.0194 | 54.0284 | 0.0131 | 0.0170 |
| 1000 | 30.9352 | 0.0081 | 0.0085 | 53.421 | 0.0090 | 0.0074 | |
| 2000 | 31.0035 | 0.0032 | 0.0041 | 52.8706 | 0.0044 | 0.0038 | |
| 0.6 | 500 | 30.8878 | 0.0091 | 0.0110 | 54.0284 | 0.0076 | 0.0089 |
| 1000 | 30.9352 | 0.0081 | 0.0085 | 53.421 | 0.0043 | 0.0045 | |
| 2000 | 31.0035 | 0.0028 | 0.0026 | 52.8706 | 0.0020 | 0.0020 | |
| 0.3 | 500 | 30.8878 | 0.0139 | 0.0564 | 54.0284 | 0.0034 | 0.0467 |
| 1000 | 30.9352 | 0.0048 | 0.0048 | 53.421 | 0.0080 | 0.0207 | |
| 2000 | 31.0035 | -0.0005 | 0.0102 | 52.8706 | -0.0029 | 0.0097 | |
| 0.5 | 500 | 30.8878 | 0.0589 | 0.0554 | 54.0284 | 0.0416 | 0.0383 |
| 1000 | 30.9352 | 0.0054 | 0.0225 | 53.421 | 0.0202 | 0.0157 | |
| 2000 | 31.0035 | 0.0120 | 0.0083 | 52.8706 | 0.0136 | 0.0064 | |
| -0.4 | 500 | 30.8878 | 0.0011 | 0.0049 | 54.0284 | -0.0029 | 0.0075 |
| 1000 | 30.9352 | 0.0210 | 0.018 | 53.421 | 0.0009 | 0.0035 | |
| 2000 | 31.0035 | 0.0018 | 0.0011 | 52.8706 | -0.0014 | 0.0018 | |
| 0.7 | 500 | 30.8878 | 0.0017 | 0.0031 | 54.0284 | 0.0037 | 0.0046 |
| 1000 | 30.9352 | 0.0006 | 0.0023 | 53.421 | 0.0026 | 0.0021 | |
| 2000 | 31.0035 | 0.0007 | 0.0007 | 52.8706 | 0.0006 | 0.0010 | |
| 4 | 500 | 30.8878 | 0.3633 | 2.3387 | 54.0284 | 0.6463 | 8.4442 |
| 1000 | 30.9352 | 0.1506 | 0.5565 | 53.421 | 0.2221 | 0.8141 | |
| 2000 | 31.0035 | 0.0833 | 0.2377 | 52.8706 | 0.0820 | 0.3078 | |
| Generalized Heckman- | Generalized Heckman- | |||||||
|---|---|---|---|---|---|---|---|---|
| n | Parameters | Censoring | Bias | MSE | Parameters | Censoring | Bias | MSE |
| 500 | 1.0 | 31.017 | 0.0048 | 0.0045 | 1.0 | 30.9268 | 0.0052 | 0.0039 |
| 1000 | 30.9395 | 0.0031 | 0.0022 | 30.8644 | -0.0002 | 0.0016 | ||
| 2000 | 30.9098 | 0.0013 | 0.0009 | 30.9734 | 0.0005 | 0.0009 | ||
| 500 | 0.7 | 31.017 | 0.0013 | 0.0009 | 0.7 | 30.9268 | 0.0045 | 0.0008 |
| 1000 | 30.9395 | -0.0002 | 0.0046 | 30.8644 | 0.0010 | 0.0003 | ||
| 2000 | 30.9098 | 0.0002 | 0.0001 | 30.9734 | 0.0006 | 0.0001 | ||
| 500 | 1.1 | 31.017 | -0.001 | 0.0011 | 1.1 | 30.9268 | 0.0001 | 0.0007 |
| 1000 | 30.9395 | 0.0015 | 0.0008 | 30.8644 | 0.0009 | 0.0003 | ||
| 2000 | 30.9098 | -0.0007 | 0.0002 | 30.9734 | 0.0003 | 0.0001 | ||
| 500 | 0.9 | 31.017 | 0.0071 | 0.0141 | 0.9 | 30.9268 | 0.0108 | 0.0153 |
| 1000 | 30.9395 | 0.0165 | 0.0814 | 30.8644 | 0.0205 | 0.0555 | ||
| 2000 | 30.9098 | 0.0036 | 0.0031 | 30.9734 | 0.0027 | 0.0034 | ||
| 500 | 0.5 | 31.017 | 0.0072 | 0.0090 | 0.5 | 30.9268 | 0.0111 | 0.0096 |
| 1000 | 30.9395 | 0.0076 | 0.0101 | 30.8644 | 0.0115 | 0.0270 | ||
| 2000 | 30.9098 | -0.0005 | 0.0020 | 30.9734 | 0.0016 | 0.0035 | ||
| 500 | 1.1 | 31.017 | 0.013 0 | 0.0180 | 1.1 | 30.9268 | 0.0143 | 0.0175 |
| 1000 | 30.9395 | 0.0151 | 0.0254 | 30.8644 | 0.0170 | 0.0450 | ||
| 2000 | 30.9098 | 0.0020 | 0.0041 | 30.9734 | 0.0028 | 0.0051 | ||
| 500 | 0.6 | 31.017 | 0.0067 | 0.0102 | 0.6 | 30.9268 | -0.0003 | 0.0094 |
| 1000 | 30.9395 | 0.0064 | 0.0195 | 30.8644 | 0.0077 | 0.0139 | ||
| 2000 | 30.9098 | 0.001 | 0.0023 | 30.9734 | 0.0023 | 0.0024 | ||
| 500 | 0.7 | 31.017 | 0.0299 | 0.0560 | -0.7 | 30.9268 | -0.0449 | 0.0662 |
| 1000 | 30.9395 | 0.0197 | 0.0628 | 30.8644 | -0.0198 | 0.033 | ||
| 2000 | 30.9098 | 0.0031 | 0.0089 | 30.9734 | -0.0058 | 0.0218 | ||
| 500 | 0.3 | 31.017 | 0.052 | 0.0702 | 0.3 | 30.9268 | 0.0363 | 0.067 |
| 1000 | 30.9395 | 0.0197 | 0.0576 | 30.8644 | 0.0141 | 0.0632 | ||
| 2000 | 30.9098 | 0.0097 | 0.0097 | 30.9734 | 0.0108 | 0.0345 | ||
| 500 | -0.2 | 31.017 | 0.0004 | 0.0053 | -0.2 | 30.9268 | 0.0043 | 0.0054 |
| 1000 | 30.9395 | -0.0018 | 0.0041 | 30.8644 | -0.0031 | 0.0039 | ||
| 2000 | 30.9098 | 0.0019 | 0.0012 | 30.9734 | -0.0004 | 0.0013 | ||
| 500 | 1.2 | 31.017 | 0.0032 | 0.0038 | 1.2 | 30.9268 | 0.0096 | 0.0035 |
| 1000 | 30.9395 | 0.0018 | 0.0020 | 30.8644 | 0.0058 | 0.0016 | ||
| 2000 | 30.9098 | -0.0001 | 0.0007 | 30.9734 | 0.0024 | 0.0010 | ||
| 500 | 4 | 31.017 | 0.4404 | 2.3837 | 4 | 30.9268 | 0.5096 | 17.9132 |
| 1000 | 30.9395 | 0.1418 | 0.6321 | 30.8644 | 0.1619 | 0.6922 | ||
| 2000 | 30.9098 | 0.1234 | 0.2899 | 30.9734 | 0.0789 | 0.2731 | ||
| Generalized Heckman- | Generalized Heckman- | |||||||
|---|---|---|---|---|---|---|---|---|
| n | Parameters | Censoring | Bias | MSE | Parameters | Censoring | Bias | MSE |
| 500 | 1.1 | 49.8604 | -0.0037 | 0.0094 | 1.1 | 49.9824 | -0.0109 | 0.0072 |
| 1000 | 49.9469 | -0.0008 | 0.0035 | 49.9075 | -0.0049 | 0.003 | ||
| 2000 | 50.0265 | -0.0012 | 0.0017 | 49.925 | -0.0046 | 0.0011 | ||
| 500 | 0.7 | 49.8604 | -0.0025 | 0.0016 | 0.7 | 49.9824 | -0.0057 | 0.0014 |
| 1000 | 49.9469 | -0.0006 | 0.0005 | 49.9075 | -0.0026 | 0.0005 | ||
| 2000 | 50.0265 | -0.0009 | 0.0002 | 49.925 | -0.0025 | 0.0002 | ||
| 500 | 0.1 | 49.8604 | 0.0001 | 0.0014 | 0.1 | 49.9824 | 0.0017 | 0.0011 |
| 1000 | 49.9469 | ¡0.0001 | 0.0005 | 49.9075 | 0.0004 | 0.0004 | ||
| 2000 | 50.0265 | 0.0005 | 0.0002 | 49.925 | -0.0002 | 0.0002 | ||
| 500 | 0 | 49.8604 | 0.0025 | 0.0065 | 0 | 49.9824 | 0.0012 | 0.0063 |
| 1000 | 49.9469 | 0.0036 | 0.003 | 49.9075 | 0.0029 | 0.004 | ||
| 2000 | 50.0265 | -0.0023 | 0.0015 | 49.925 | 0.0022 | 0.0014 | ||
| 500 | 0.5 | 49.8604 | 0.0067 | 0.0078 | 0.5 | 49.9824 | 0.0051 | 0.0071 |
| 1000 | 49.9469 | 0.0061 | 0.0035 | 49.9075 | 0.0036 | 0.0051 | ||
| 2000 | 50.0265 | 0.0009 | 0.0019 | 49.925 | 0.0003 | 0.0015 | ||
| 500 | 1.1 | 49.8604 | 0.009 | 0.0161 | 1.1 | 49.9824 | 0.0095 | 0.0155 |
| 1000 | 49.9469 | 0.0047 | 0.008 | 49.9075 | 0.0116 | 0.0185 | ||
| 2000 | 50.0265 | 0.0024 | 0.0037 | 49.925 | 0.0046 | 0.0035 | ||
| 500 | 0.6 | 49.8604 | 0.0010 | 0.0091 | 0.6 | 49.9824 | 0.0048 | 0.0083 |
| 1000 | 49.9469 | 0.0014 | 0.0042 | 49.9075 | 0.0056 | 0.0086 | ||
| 2000 | 50.0265 | -0.001 | 0.0023 | 49.925 | 0.0038 | 0.002 | ||
| 500 | -0.3 | 49.8604 | -0.0105 | 0.04 | -0.7 | 49.9824 | -0.0166 | 0.0437 |
| 1000 | 49.9469 | -0.0107 | 0.0173 | 49.9075 | -0.0061 | 0.0183 | ||
| 2000 | 50.0265 | -0.0015 | 0.0085 | 49.925 | -0.0034 | 0.0078 | ||
| 500 | -0.3 | 49.8604 | -0.0302 | 0.0394 | -0.7 | 49.9824 | -0.0831 | 0.0609 |
| 1000 | 49.9469 | -0.0189 | 0.0163 | 49.9075 | -0.0317 | 0.0195 | ||
| 2000 | 50.0265 | -0.0053 | 0.007 | 49.925 | -0.0214 | 0.0086 | ||
| 500 | -0.4 | 49.8604 | 0.0032 | 0.0067 | -0.4 | 49.9824 | -0.0041 | 0.0072 |
| 1000 | 49.9469 | -0.0003 | 0.0035 | 49.9075 | -0.006 | 0.0034 | ||
| 2000 | 50.0265 | 0.0005 | 0.0016 | 49.925 | -0.0033 | 0.0018 | ||
| 500 | 1.2 | 49.8604 | 0.0062 | 0.004 | 1.2 | 49.9824 | 0.0039 | 0.0038 |
| 1000 | 49.9469 | 0.0057 | 0.0019 | 49.9075 | 0.0029 | 0.0018 | ||
| 2000 | 50.0265 | 0.0026 | 0.0009 | 49.925 | 0.0016 | 0.0008 | ||
| 500 | 4 | 49.8604 | 0.5755 | 3.9653 | 4 | 49.9824 | 0.546 | 8.083 |
| 1000 | 49.9469 | 0.2316 | 0.8686 | 49.9075 | 0.1677 | 0.793 | ||
| 2000 | 50.0265 | 0.1139 | 0.3197 | 49.925 | 0.0841 | 0.4107 | ||
5 Application to real data
In this section, two real data sets, corresponding to outpatient expense and investments in education, are analyzed. The outpatient expense data data set has already been analyzed in the literature by Heckman models Marchenko and Genton, (2012), whereas the education investment data is new and is analyzed for the first time here.
5.1 Outpatient expense
In this subsection, a real data set corresponding to outpatient expense from the 2001 Medical Expenditure Panel Survey (MEPS) is used to illustrate the proposed methodology. This data set has information about the cost and provision of outpatient services, and is the most complete coverage about health insurance in the United States, according to the Agency for Healthcare Research and Quality (AHRQ).
The MEPS data set contains information collected from 3328 individuals between 21 and 64 years. The variable of interest is the expenditure on medical services in the logarithm scale (), while the latent variable () is the willingness of the individual to spend; corresponds the decision of the individual to spend. It was verified that 526 (15.8%) of the outpatient costs are identified as zero (censored). The covariates considered in the are: is the age measured in tens of years; is a dummy variable that assumed value 1 for women and 0 for men; is the years of education; is a dummy variable for ethnicity (1 for black or Hispanic and 0 if non-black and non-Hispanic); is the total number of chronic diseases; is the insurance status; and denotes the individual income.
Table 4 reports descriptive statistics of the observed medical expenditures, including the minimum, mean, median, maximum, standard deviation (SD), coefficient of variation (CV), coefficient of skewness (CS) and coefficient of (excess) kurtosis (CK) values. From this table, we note the following: the mean is almost equal to the median; a very small negative skewness value; and a very small kurtosis value. The symmetric nature of the data is confirmed by the histogram shown in Figure Figure 1(a). The boxplot shown in Figure 1(b) indicates some potential outliers. Therefore, we observe that a symmetric distribution is a reasonable assumption, more specifically a Student- model, since since we have to accommodate outliers.
| minimum | Mean | Median | maximum | SD | CV | CS | CK | |
| 0.693 | 6.557 | 6.659 | 10.819 | 1.406 | 21.434% | -0.315 | 0.006 | 2801 |


We then analyze the medical expenditure data using the generalized Heckman- model, expressed as
| (5.1) |
| (5.2) |
| (5.3) |
| (5.4) |
We initially compare the adjustments of the generalized Heckman- (GH) model, in terms of Akaike (AIC) and Bayesian information (BIC), with the adjustments of the classical Heckman-normal (CHN) (Heckman,, 1976) and generalized Heckman-normal (GHN) (Bastos et al.,, 2021) models; see Table 5. The AIC and BIC values reveal that the GH model provides the best adjustment, followed by the GHN model.
| CHN | GHN | GH | |
|---|---|---|---|
| AIC | 11706.44 | 11660.29 | 11635.05 |
| BIC | 11810.31 | 11794.71 | 11775.59 |
Table 6 presents the estimation results of the GHN and GH models. From this table, we observe the following results: the explanatory variables and that model the dispersion are significant, in both models, indicating the presence of heteroscedasticity in the data. The explanatory variable is only significant in the GHN model. For the correlation term, the covariates and are significant for both models, which indicates the presence of selection bias in the data.
In the outcome equation, when we look at both models, , , and are significant at the 5% level, and is not significant. The explanatory variable is significant at the 5% and 10% levels in the GHN and GH models, respectively; see Table 6. We can interpret the estimated coefficients in terms of the effect on the expenditure on medical services; see Weisberg, (2014, p.82). For example, a 1-year increase in rises by and the expected value of the expenditure on medical services according to the GHN and GH, respectively. Moreover, a 1-unit increase in rises by and the expected value of the response according to the GHN and GH models, respectively.
In the case of the selection equation, we observe that, for both models, the explanatory variables , , , , and are significant at the 5% level and is significant at the 10% level; see Table 6. The interpretation is made in terms of odds ratio, which is obtained by exponentiating the estimated explanatory variable coefficient. For example, for the GH case, the odds ratio for is , suggesting that each additional year of age raises the likelihood of an individual having expenditures on medical services by .
| Probit selection equation | ||||||||
|---|---|---|---|---|---|---|---|---|
| Variables | Estimates | Std. Error | Value | -value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| -0.5903 | -0.6406 | 0.1867 | 0.2014 | -3.1620 | -3.1800 | <0.001 | <0.001 | |
| 0.0863 | 0.0930 | 0.0264 | 0.0288 | 3.2610 | 3.2230 | <0.001 | <0.001 | |
| 0.6299 | 0.7087 | 0.0597 | 0.0681 | 1.0543 | 1.0395 | <0.001 | <0.001 | |
| 0.0569 | 0.0590 | 0.0114 | 0.0122 | 4.9830 | 4.8110 | <0.001 | <0.001 | |
| -0.3368 | -0.3726 | 0.0596 | 0.0647 | -5.6430 | -5.7590 | <0.001 | <0.001 | |
| 0.7585 | 0.8728 | 0.0686 | 0.0858 | 1.1043 | 1.0168 | <0.001 | <0.001 | |
| 0.1727 | 0.1863 | 0.0611 | 0.0665 | 2.8240 | 2.7990 | <0.001 | <0.001 | |
| 0.0022 | 0.0025 | 0.0012 | 0.0013 | 1.8380 | 1.8750 | 0.0661 | 0.0610 | |
| Outcome equation | ||||||||
| Variables | Estimates | Std. Error | Value | -value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| 5.7041 | 5.6078 | 0.1930 | 0.1912 | 2.9553 | 2.9316 | <0.001 | <0.001 | |
| 0.1838 | 0.1895 | 0.0234 | 0.0230 | 7.8460 | 8.2350 | <0.001 | <0.001 | |
| 0.2498 | 0.2555 | 0.0587 | 0.0580 | 4.2530 | 4.4000 | <0.001 | <0.001 | |
| 0.0013 | 0.0062 | 0.0101 | 0.0100 | 0.1290 | 0.6240 | 0.8970 | 0.5329 | |
| -0.1283 | -0.1344 | 0.0577 | 0.0569 | -2.2210 | -2.3630 | 0.0264 | 0.0182 | |
| 0.4306 | 0.4464 | 0.0305 | 0.0297 | 1.4115 | 1.5002 | <0.001 | <0.001 | |
| -0.1027 | -0.0976 | 0.0513 | 0.0501 | -2.000 | -1.9470 | 0.0456 | 0.0516 | |
| Dispersion | ||||||||
| Variables | Estimates | Std. Error | Value | -value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| 0.5081 | 0.4172 | 0.0573 | 0.0643 | 8.8550 | 6.4820 | <0.001 | <0.001 | |
| -0.0249 | -0.0209 | 0.0125 | 0.0136 | -1.9870 | -1.5360 | 0.0469 | 0.1246 | |
| -0.1046 | -0.1118 | 0.0191 | 0.0208 | -5.4760 | -5.3720 | <0.001 | <0.001 | |
| -0.1070 | -0.1117 | 0.0277 | 0.0303 | -3.8630 | -3.6810 | <0.001 | <0.001 | |
| Correlation | ||||||||
| Variables | Estimates | Std. Error | Value | -value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| -0.6475 | -0.6051 | 0.1143 | 0.1118 | -5.666 | -5.413 | <0.001 | <0.001 | |
| -0.4040 | -0.4220 | 0.1356 | 0.1489 | -2.978 | -2.835 | <0.001 | <0.001 | |
| -0.4379 | -0.4999 | 0.1862 | 0.2102 | -2.351 | -2.378 | 0.0187 | 0.0174 | |
| - | 12.3230 | - | 2.7570 | - | 4.4690 | - | <0.001 | |
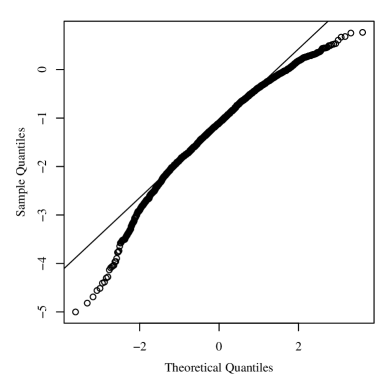
Figure 2 displays the quantile versus quantile (QQ) plots of the martingale-type (MT) residuals for the GHN and GH models. This residual is given by
| (5.5) |
where , is the fitted survival function, and or indicating that case is censored or not, respectively; see Therneau et al., (1990). The MT residual is asymptotically standard normal, if the model is correctly specified whatever the specification of the model is. From Figure 2, we see clearly that the GH model provides better fit than GHN model.

5.2 Investments in education
In this subsection, data on education investments are used to illustrate the proposed methodology. We consider the investments made by municipalities of two Brazilian states: Sao Paulo (SP) and Minas Gerais (MG). This data set was obtained from the Brazilian National Fund for Educational Development (FNDE) website111Filtered data are available at https://repositorio.shinyapps.io/plataforma_de_dados_municipais., which is a federal agency under the Ministry of Education. The origin of these investments comes from the Fund for the Maintenance and Development of Basic Education and the Valorization of Education Professionals (FUNDEB). The resources are distributed to 27 federative units (26 states plus the Federal District), according to the number of students enrolled in their basic education network. This rule is established for the previous year’s school census data, e.g., 2018 resources were based on 2017 student numbers. This method helps to better distribute resources across the country, as it takes into account the size of education networks.
The variable of interest is education investments with 1503 observations, of which 102 (7%) correspond to unobserved investment values identified as zero investment. The explanatory variables considered in the study were: 333http://www.ipeadata.gov.br/Default.aspx. represents per capita revenue collected by the municipality; 333http://www.ipeadata.gov.br/Default.aspx. is the Gross National Product of the municipality; 222https://dados.gov.br/dataset/sistema-arrecadacao. is a dummy variable indicating if the municipality receives resources from the Financial Compensation for Exploration of Mineral Resources (CFEM); this resource must be destined to investments in the areas of health, education and infrastructure for the community; is an indicator variable for state ( receives value 1); 444https://www.gov.br/inep/pt-br/areas-de-atuacao/pesquisas-estatisticas-e-indicadores/censo-escolar. is the school census enrollment numbers.
As in the previous study, the response variable, investment in education, is in the logarithm scale . The latent variable () denotes the willingness of the th municipality to invest education; corresponds to the decision or not of the th municipality to invest in education.
The descriptive statistics for the investments in education are reported in Table 7. From this table, we note the following: the mean is almost equal to the median; a very small negative skewness value, and a high kurtosis value. The symmetric nature of the data is confirmed by the histogram shown in Figure Figure 3(a). The boxplot shown in Figure 3(b) indicates potential outliers. Therefore, we observe that a Student- model is a reasonable assumption.
| minimum | Mean | Median | maximum | SD | CV | CS | CK | |
| 4.271 | 12.212 | 12.575 | 18.511 | 1.903 | 15.587% | -0.5864 | 3.70 | 1401 |


We then analyze the education investment data using the GH model, expressed as
| (5.6) |
| (5.7) |
| (5.8) |
| (5.9) |
Table 8 reports the AIC and BIC of the CHN, GHN and GH models. From Table 8, we observe that the GH model provides better adjustment than other models based on the values of AIC and BIC.
| CHN | GHN | GH | |
|---|---|---|---|
| AIC | 8269.058 | 5873.579 | 5719.590 |
| BIC | 8306.147 | 5953.055 | 5804.365 |
Table 9 presents the estimation results of the GHN and GH models. From this table, we note that the explanatory variables and associated with the dispersion are significant, in both models, suggesting the presence of heteroscedasticity. For the explanatory variables related to the correlation parameter, is significant at the 5% and 10% levels in the GHN and GH models, respectively, while is significant at the 10% and 5% levels in the GHN and GH models, respectively. Therefore, there is evidence of the presence of sample selection bias in the data.
From Table 9, we observe that in the outcome equation , , and are significant, according to the GHN and GH models. Note that increasing by one unit is associated with and decrease in the average investment in education according to the GHN and GH models, respectively. Note also that when the municipality is located in the state of Sao Paulo (), the average investment in education increases by and , according to the GHN and GH models, respectively. These results show that the municipalities of the state of Sao Paulo invest much more in education than the municipalities of the state of Minas Gerais.
In the selection equation, we observe that the explanatory variables , and are significant in the GH model. On the other hand, and are not significant in the GHN model; see Table 9. We observe that, for the GH case, the odds ratio for is , that is, the likelihood of a municipality to spend on medical services increases by when the municipality is located in the state of Sao Paulo
| Probit selection equation | ||||||||
|---|---|---|---|---|---|---|---|---|
| Variables | Estimate | Std. Error | t Value | p-Value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| 1.0523 | 1.4222 | 0.1013 | 0.0955 | 10.3870 | 14.8880 | <0.01 | <0.001 | |
| -0.0058 | -0.0530 | 0.0223 | 0.0164 | -0.2630 | -3.2330 | 0.7920 | <0.001 | |
| 0.1065 | 0.3674 | 0.0990 | 0.1032 | 1.0750 | 3.5600 | 0.2820 | <0.001 | |
| 0.0311 | 0.0537 | 0.0032 | 0.0026 | 9.6380 | 20.6150 | <0.001 | <0.001 | |
| Outcome equation | ||||||||
| Variables | Estimate | Std. Error | t Value | p-Value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| 12.4789 | 12.4058 | 0.1252 | 0.1208 | 99.6480 | 102.6960 | <0.001 | <0.001 | |
| -0.2683 | -0.2167 | 0.0332 | 0.0274 | -8.0640 | -7.9030 | <0.001 | <0.001 | |
| 1.0714 | 1.0063 | 0.1003 | 0.0881 | 10.6810 | 11.4190 | <0.001 | <0.001 | |
| 0.0031 | 0.0226 | 0.0005 | 0.0025 | 5.6670 | 8.8410 | <0.001 | <0.001 | |
| 0.0202 | 0.0151 | 0.0023 | 0.0005 | 8.4630 | 27.4250 | <0.001 | <0.001 | |
| Dispersion | ||||||||
| Variables | Estimate | Std. Error | t Value | p-Value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| 0.5921 | 0.2947 | 0.0503 | 0.0623 | 11.7560 | 4.7250 | <0.001 | <0.001 | |
| 0.0382 | 0.0546 | 0.0130 | 0.0146 | 2.9330 | 3.7180 | <0.001 | <0.001 | |
| -0.3142 | -0.4745 | 0.0416 | 0.0534 | -7.5470 | -8.8800 | <0.001 | <0.001 | |
| Correlation | ||||||||
| Variables | Estimate | Std. Error | t Value | p-Value | ||||
| GHN | GH | GHN | GH | GHN | GH | GHN | GH | |
| -3.7263 | -6.7669 | 0.5463 | 0.9682 | -6.8210 | -6.9890 | <0.001 | <0.001 | |
| 0.1686 | 0.2274 | 0.0839 | 0.1161 | 2.0080 | -6.9890 | 0.0448 | 0.0500 | |
| 0.8298 | 3.1118 | 0.4411 | 0.6867 | 1.8810 | 1.9580 | 0.0602 | <0.001 | |
| - | 3.6240 | - | 0.4320 | - | 8.3900 | - | <0.001 | |
Figure 4 displays the QQ plots of the MT residuals. This figure indicates that the MT residuals in the GH model shows better agreement with the reference distribution.


6 Concluding Remarks
In this paper, a class of Heckman sample selection models were proposed based symmetric distributions. In such models, covariates were added to the dispersion and correlation parameters, allowing the accommodation of heteroscedasticity and a varying sample selection bias, respectively. A Monte Carlo simulation study has showed good results of the parameter estimation method. We have considered high/low censoring rates and the presence of strong/weak correlation. We have applied the proposed model along with some other two existing models to two data sets corresponding to outpatient expense and investments in education. The applications favored the use of the proposed generalized Heckman- model over the classical Heckman-normal and generalized Heckman-normal models. As part of future research, it will be of interest to propose sample selection models based on skew-symmetric distributions. Furthermore, the behavior of the Wald, score, likelihood ratio and gradient tests can be investigated. Work on these problems is currently in progress and we hope to report these findings in future.
References
- Abdous, (2005) Abdous, B., F. A.-L. G. K. (2005). Extreme behaviour for bivariate elliptical distributions. The Canadian Journal of Statistics, 33:317–334.
- Balakrishnan and Lai, (2009) Balakrishnan, N. and Lai, C. D. (2009). Continuous Bivariate Distributions. Springer-Verlag, New York, NY.
- Bastos and Barreto-Souza, (2021) Bastos, F. S. and Barreto-Souza, W. (2021). Birnbaum-Saunders sample selection model. Journal of Applied Statistics, 48:1896–1916.
- Bastos et al., (2021) Bastos, F. S., Barreto-Souza, W., and Genton, M. G. (2021). A generalized heckman model with varying sample election bias and dispersion parameters. Statistica Sinica.
- Ding, (2014) Ding, P. (2014). Bayesian robust inference of sample selection using selection-t models. Journal of Multivariate Analysis, pages 124:451–464.
- Fang et al., (1990) Fang, K. T., Kotz, S., and Ng, K. W. (1990). Symmetric Multivariate and Related Distributions. Chapman and Hall, London, UK.
- Heckman, (1976) Heckman, J. J. (1976). The common structure of statistical models of truncation, sample selection and limited dependent variables and a simple estimator for such models. Annals of Economic and Social Measurement, 5:475–492.
- Heckman, (1979) Heckman, J. J. (1979). Sample selection bias as a specification error. Econometrica, 47:153–161.
- Lachos et al., (2021) Lachos, V. H., Prates, M. O., and Dey, D. K. (2021). Heckman selection-t model: Parameter estimation via the em-algorithm. Journal of Multivariate Analysis, 184:104737.
- Leung and Yu, (1996) Leung, S. F. and Yu, S. (1996). On the choice between sample selection and twopart models. Journal of Econometrics, pages 72:197–229.
- Manning et al., (1987) Manning, W., Duan, N., and Rogers, W. (1987). Monte carlo evidence on the choice between sample selection and two-part models. Journal of Econometrics, pages 35:59 –82.
- Marchenko and Genton, (2012) Marchenko, Y. V. and Genton, M. G. (2012). A heckman selection-t model. Journal of the American Statistical Association, 107:304–317.
- Nelson, (1984) Nelson, F. D. (1984). Eciency of the two-step estimator for models with endogenous sample selection. pages 24:181 – 196.
- Ogundimu and Hutton, (2016) Ogundimu, E. O. and Hutton, J. L. (2016). A sample selection model with skew-normal distribution. Scandinavian Journal of Statistics, pages 43:172–190.
- Paarsch, (1984) Paarsch, H. J. (1984). A monte carlo comparison of estimators for censored regression models. pages 24:197–213.
- R Core Team, (2022) R Core Team (2022). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria.
- Stolzenberg and Relles, (1990) Stolzenberg, R. M. and Relles, D. A. (1990). heory testing in a world of constrained research design: The significance of heckman’s censored sampling bias correction for nonexperimental research. Sociological Methods & Research, pages 18:395–415.
- Therneau et al., (1990) Therneau, T., Grambsch, P., and Fleming, T. (1990). Martingale-based residuals for survival models. Biometrika, 77:147–160.
- Weisberg, (2014) Weisberg, S. (2014). Applied Linear Regression. John Wiley & Sons, Hoboken, New Jersey, fourth edition edition.