Superclusters from velocity divergence fields
Abstract
Superclusters are a convenient way to partition and characterize the large scale structure of the Universe. In this Letter we explore the advantages of defining superclusters as watershed basins in the divergence velocity field. We apply this definition on diverse datasets generated from linear theory and N-body simulations, with different grid sizes, smoothing scales and types of tracers. From this framework emerges a linear scaling relation between the average supercluster size and the autocorrelation length in the divergence field, a result that holds for one order of magnitude from 10 Mpc up to 100 Mpc . These results suggest that the divergence-based definition provides a robust context to quantitatively compare results across different observational or computational frameworks. Through its connection with linear theory, it can also facilitate the exploration of how supercluster properties depend on cosmological parameters, paving the way to use superclusters as cosmological probes.
keywords:
cosmology: large-scale structure of Universe1 Introduction
Superclusters are the largest structures that can be discriminated on the large scale structure of the Universe. From the early studies (Oort, 1983) through the most recent efforts to define our home supercluster Laniakea (Tully et al., 2014) a great variety of superclusters definitions have been proposed and explored, mostly motivated by the improvements in observational techniques and advances in computational models.
Supercluster definitions span a broad conceptual range that includes: the manual segmentation of peculiar velocity fields (Tully et al., 2014), matter overdensity thresholds (Chon et al., 2015), percolation properties (Bagchi et al., 2017), thresholds on multi-scale density fields (Einasto et al., 2019; Einasto et al., 2020) and streamlines in the peculiar velocity data (Dupuy et al., 2019), among others. In general, all these definitions are different even if they operate on the same inputs. This means that the cross-algorithm comparison of supercluster properties, even as simple as their sizes, has to be done with caution.
A common feature in most of these studies is that the supercluster properties depend on the physical scale used to describe the underlying density or velocity fields. For instance, Dupuy et al. (2020) reported strong changes in the supercluster abundance as a function of the smoothing scale used to define the velocity field. Suhhonenko et al. (2011) also performed controled numerical experiments to measure how the cosmic web features, such as filaments, clusteras and voids, depend on the density perturbations at different scales.
Furthermore, the complexity in the algorithm used to actually find the superclusters in simulated or observed data also has an impact on the intepretation of the results. A large number of free parameters could produce a large variability on the detected superclusters and raise the question as to what are the optimal combination of parameters values to define the superclusters (Dupuy et al., 2020).
In this Letter we present a conceptual framework that allows us to reach a quantitative understanding of how the supercluster properties depend on the smoothing scale and develop a supercluster finding algorithm with low complexity. The supercluster definition is based on the velocity divergence field while the supercluster finding algorithm uses a watershed concept.
This Letter is structured as follows. In Section 2 we present our characterization of the velocity divergence field. Next, in Section 3, we describe the supercluster finding algorithm. In Section 4 we describe how we generate divergence fields on a grid to test our definitions and supercluster finding algorithm. In Section 5 we present our main results to finally conclude in Section 6 with future applications of the framework presented here.
2 autocorrelation length in the divergence field
We use the velocity divergence field, , as the main quantity to study over cosmological scales. From it we define a dimensionless divergence field, , as follows:
| (1) |
where is the Hubble parameter and is the growth rate of structure. This is a purely computational definition motivated by the linear theory of structure formation where the equality between the two sides of Equation (1) is expected to actually hold when represents the matter overdensity.
We compute the power spectrum of this scalar field and denote it as . From this power spectrum we calculate the autocorrelation function as
| (2) |
From the autocorrelation function we define the autocorrelation length, , as the value of at which drops by a factor of ten from the value it has for . In practice, we compute the autocorrelation function in the interval and is defined by the value at which
| (3) |
We show in the following sections how by using this definition we obtain a linear relationship between the autocorrelation length, , and the average supercluster size.
| Field | ||||
|---|---|---|---|---|
| type | (km s-1) | ( Mpc ) | ( Mpc ) | |
| Gaussian | - | {, , , , } | ||
| Gaussian | - | {, , , , } | ||
| Gaussian | - | {, , , , } | ||
| N-body | {, , , , } | |||
| N-body | {, , , , } | |||
| N-body | {, , , , } |




3 Watershed Superclusters
We find the superclusters using a watershed algorithm (Beucher & Meyer, 1993) on the dimensionless divergence fields. The algorithm segments the whole volume by assigning each voxel to a unique supercluster.
Our implementation works as follows. We sweep the voxels in the dimensionless divergence grid from the highest values to the lowest, i.e. from the high density regions with converging flows to the lowest density regions with divergent flows. For the -th voxel under consideration we check whether its 26 neighbors have already been assigned to a group. If all the neighbors are unassigned, then this -th voxel starts a new group; if the majority of already assigned voxels belongs to the -th group, then this voxel belongs to that group. In case of a draw between groups, the voxel is assigned to the supercluster with the lowest value. At the end of the sweep all voxels have been assigned to a group. In all our calculations we take periodical boundary conditions into account.
Finally, each group found by the algorithm is interpreted as a supercluster with a volume, , calculated by the total volume of the voxels belonging to it. From the volume we compute the equivalent radius , that is the radius of the sphere with the same volume, . We describe the supercluster population in a divergence field by the average value of the equivalent radius, .
Once the divergence field is provided, this algorithm does not have free parameters based either on divergence, density or distance thresholds. The algorithm has a single free parameter: the number of neighbors to make the search for assigned superclusters. In our case we use , but our tests show that using lower values down to neighbors do not impact the main scaling results reported in this Letter. A lower number of neighbors only results in a larger tail of small superclusters composed by a handful of voxels.
Figure 1 illustrates the results of the watershed algorithm. This shows how the typical supercluster size follows the typical size of the features in the divergence field.
4 Divergence Fields on a Grid
We use dimensionless divergence fields computed on a cubic grid. We generate them in two different ways. The first corresponds to Gaussian fields with a truncated power spectrum coming from linear theory. The second kind are fields generated by interpolation of biased tracers and smoothed with a Gaussian filter, with the tracers coming from N-body cosmological simulations. In both cases the cosmological parameters correspond to the CDM Planck 2015 cosmology (Planck Collaboration et al., 2016) with a Hubble parameter of km s-1 Mpc-1, a matter density parameter and a spectral index . We use a total of different divergence fields, summarized in Table 1, generated as follows.
4.1 Gaussian fields with truncated power Spectrum
We start by generating a density field with a power spectrum that follows no-wiggle parameterization of Eisenstein & Hu (1998). The power spectrum is extrapolated at using linear theory and truncated at . This procedure can be thought as erasing fluctuations smaller than . This density field is generated over a cubic grid with voxels over a cube of length on a side. From this Gaussian density field we compute the overdensity and directly use it as the dimensionless divergence field. We generate different Gaussian fields by changing the values for , and . Table 1 summarizes the different values for those parameters.
4.2 N-body fields from biased tracers with Gaussian smoothing
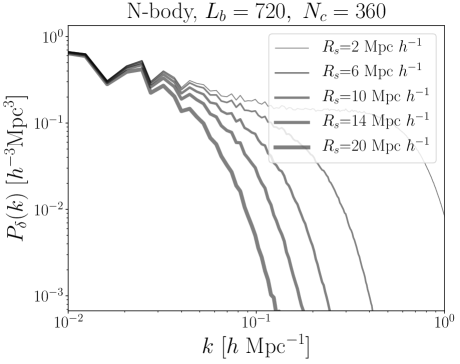
We use the public Friend-of-Friends catalogs at redshift from the Abacus Project simulations (Garrison et al., 2018) to interpolate the haloes’ peculiar velocity over a grid with voxels. The simulations were performed on a cube of side length Mpc with particles, corresponding to a DM particle mass resolution of M⊙ . We start by selecting haloes with maximum circular velocity larger than . Then we assign to each voxel the value of the average velocity of the haloes in that voxel, which is equivalent to a Nearest Grid Point interpolation scheme. If the voxel is empty we assign a value of km s-1 . After this interpolation step we smooth the velocity field using a Gaussian filter of physical scale . We generate different N-body based divergence fields by changing the values for , and . Table 1 summarizes the different values for those parameters.

5 Results
We start by quantifying the effect of the truncation/smoothing scale. Figure 2 and Figure 3 show the power spectrum and the corresponding autocorrelation function. In both cases, the right panel shows that the autocorrelation length increases with larger values.
Figure 4 shows the relationship between the truncation/smoothing scale and the autocorrelation length . We find that below Mpc the two scales almost follow a linear proportionality. Beyond that scale, the Gaussian fields continue that linearity up to Mpc , while the N-body fields saturates around Mpc .


Our most important result is summarized in Figure 5. The plot shows that the average supercluster size linearly follows the autocorrelation length as defined in Equation 3. The linear correlations holds both for Gaussian and N-body fields over one order of magnitude from Mpc up to Mpc . In other words, the autocorrelation formalism over the velocity divergence fields is able to estimate the typical supercluster size. We parameterize this strong linear dependence as , the best fit gives for Gaussian fields and for N-body fields.
This linear scaling relation with depends on the constant used in the definition in Equation 3). Using values larger than in that definition breaks the linear scaling above Mpc for N-body fields. Furthermore, the regions where the linear scaling still holds, show values of smaller than unity. Using values smaller than also breaks the linearity. It also has the inconvenient of probing scales where the autocorrelation function might oscillate, making ambiguous the autocorrelation length definition.
We finalize this Section by showing how the supercluster size distribution differs in Gaussian fields compared to the N-body fields. Figure 6 shows the probability density function for the equivalent radius distributions from two different divergence fields. We pick these two distributions because they have similar mean values of Mpc and Mpc for the Gaussian and N-body fields, respectively. However, the distribution in the N-body field is wider (standard deviation of Mpc ) than it is for the Gaussian field (standard deviation of Mpc ), meaning that there are more superclusters with extreme values, say above Mpc , in the non-linear divergence field than in the Gaussian field.
What do these results have to say about Laniakea? The horizontal stripe in Figure 5 shows recent estimates of Laniakea’s equivalent radius (Dupuy et al., 2019). If Laniakea is to be considered as an average supercluster, then our results predict that the autocorrelation length in the divergence fields from the Cosmicflows data should be on the order of 60 Mpc to 85 Mpc . Having a measurement of the autocorrelation length on the divergence field from Cosmicflows-2, would allow to quantify to what extent Laniakea is a typical supercluster in a cosmological context.
6 Conclusions
In this Letter we presented the peculiar velocity divergence field as a central element to define and understand superclusters. We computed its autocorrelation function to give a precise definition of an autocorrelation length. To define the superclusters we performed a watershed partition over the same velocity divergence field. We tested this picture using different velocity divergence fields (Gaussian fields and fields from N-body simulations) computed over different grid sizes, smoothing scales and types of dark matter halos as tracers.
We found a linear scaling relation between the average supercluster size and the autocorrelation length. This result holds for one order of magnitude from Mpc up to Mpc . Comparing the full size distribution in the Gaussian and N-body divergence fields, selected to have average supercluster size similar to Laniakea, we found that the distributions are narrower and more symmetric in the Gaussian field.
The concepts we have presented here are straightforward to apply both to observational data and simulations. For instance the velocity divergence field has already been used in CosmicFlows-2 reconstruction data to define cosmic web elements (Libeskind et al., 2015) and could thus be used to find superclusters and compute its autocorrelation length.
There are multiple directions that could be addressed in future work. For instance, measuring to what extent the linearity between scales in Figure 4 depends on the box size, comparing supercluster sizes from different definitions that take similar data as an input (Einasto et al., 2020), finding scaling relationships between sizes, 3D shapes, maximum divergence depth, and the dependence of supercluster properties on cosmological parameters together with its redshift evolution.
Finally, studying the link between divergence based superclusters, their density field (Einasto et al., 2020) and graph properties (García-Alvarado et al., 2020) computed on top of the galaxy spatial distribution could provide a potential way to define superclusters where velocity information is not available and also quantifying the relationship between large scale structure topology and dynamics.
Data Availability Statement
The N-body data used to build the interpolated divergence fields are available through https://lgarrison.github.io/AbacusCosmos/. The code to generate the gaussian random fields and find the superclusters is available at https://github.com/astroandes/WatershedDivergenceSuperclusters
References
- Bagchi et al. (2017) Bagchi J., Sankhyayan S., Sarkar P., Raychaudhury S., Jacob J., Dabhade P., 2017, ApJ, 844, 25
- Beucher & Meyer (1993) Beucher S., Meyer F., 1993, Mathematical morphology in image processing, 34, 433
- Chon et al. (2015) Chon G., Böhringer H., Zaroubi S., 2015, A&A, 575, L14
- Dupuy et al. (2019) Dupuy A., et al., 2019, MNRAS, 489, L1
- Dupuy et al. (2020) Dupuy A., Courtois H. M., Libeskind N. I., Guinet D., 2020, MNRAS, 493, 3513
- Einasto et al. (2019) Einasto J., Suhhonenko I., Liivamägi L. J., Einasto M., 2019, A&A, 623, A97
- Einasto et al. (2020) Einasto M., et al., 2020, A&A, 641, A172
- Eisenstein & Hu (1998) Eisenstein D. J., Hu W., 1998, ApJ, 496, 605
- García-Alvarado et al. (2020) García-Alvarado M. V., Li X. D., Forero-Romero J. E., 2020, MNRAS, 498, L145
- Garrison et al. (2018) Garrison L. H., Eisenstein D. J., Ferrer D., Tinker J. L., Pinto P. A., Weinberg D. H., 2018, ApJS, 236, 43
- Libeskind et al. (2015) Libeskind N. I., Hoffman Y., Tully R. B., Courtois H. M., Pomarède D., Gottlöber S., Steinmetz M., 2015, MNRAS, 452, 1052
- Oort (1983) Oort J. H., 1983, ARA&A, 21, 373
- Planck Collaboration et al. (2016) Planck Collaboration et al., 2016, A&A, 594, A13
- Suhhonenko et al. (2011) Suhhonenko I., et al., 2011, A&A, 531, A149
- Tully et al. (2014) Tully R. B., Courtois H., Hoffman Y., Pomarède D., 2014, Nature, 513, 71