Substitute adjustment via recovery of latent variables
Abstract.
The deconfounder was proposed as a method for estimating causal parameters in a context with multiple causes and unobserved confounding. It is based on recovery of a latent variable from the observed causes. We disentangle the causal interpretation from the statistical estimation problem and show that the deconfounder in general estimates adjusted regression target parameters. It does so by outcome regression adjusted for the recovered latent variable termed the substitute. We refer to the general algorithm, stripped of causal assumptions, as substitute adjustment. We give theoretical results to support that substitute adjustment estimates adjusted regression parameters when the regressors are conditionally independent given the latent variable. We also introduce a variant of our substitute adjustment algorithm that estimates an assumption-lean target parameter with minimal model assumptions. We then give finite sample bounds and asymptotic results supporting substitute adjustment estimation in the case where the latent variable takes values in a finite set. A simulation study illustrates finite sample properties of substitute adjustment. Our results support that when the latent variable model of the regressors hold, substitute adjustment is a viable method for adjusted regression.
1. Introduction
The deconfounder was proposed by Wang & Blei (2019) as a general algorithm for estimating causal parameters via outcome regression when: (1) there are multiple observed causes of the outcome; (2) the causal effects are potentially confounded by a latent variable; (3) the causes are conditionally independent given a latent variable . The proposal spurred discussion and criticism; see the comments to (Wang & Blei, 2019) and the contributions by D’Amour (2019); Ogburn et al. (2020) and Grimmer et al. (2023). One question raised was whether the assumptions made by Wang & Blei (2019) are sufficient to claim that the deconfounder estimates a causal parameter. Though an amendment by Wang & Blei (2020) addressed the criticism and clarified their assumptions, it did not resolve all questions regarding the deconfounder.
The key idea of the deconfounder is to recover the latent variable from the observed causes and use this substitute confounder as a replacement for the unobserved confounder. The causal parameter is then estimated by outcome regression using the substitute confounder for adjustment. This way of adjusting for potential confounding has been in widespread use for some time in genetics and genomics, where, e.g., EIGENSTRAT based on PCA (Patterson et al., 2006; Price et al., 2006) was proposed to adjust for population structure in genome wide association studies (GWASs); see also (Song et al., 2015). Similarly, surrogate variable adjustment (Leek & Storey, 2007) adjusts for unobserved factors causing unwanted variation in gene expression measurements.
In our view, the discussion regarding the deconfounder was muddled by several issues. First, issues with non-identifiablity of target parameters from the observational distribution with a finite number of observed causes lead to confusion. Second, the causal role of the latent variable and its causal relations to any unobserved confounder were difficult to grasp. Third, there was a lack of theory supporting that the deconfounder was actually estimating causal target parameters consistently. We defer the treatment of the thorny causal interpretation of the deconfounder to the discussion in Section 5 and focus here on the statistical aspects.
In our view, the statistical problem is best treated as adjusted regression without insisting on a causal interpretation. Suppose that we observe a real valued outcome variable and additional variables . We can then be interested in estimating the adjusted regression function
| (1) |
where denotes all variables but . That is, we adjust for all other variables when regressing on . The adjusted regression function could have a causal interpretation in some contexts, but it is also of interest without a causal interpretation. It can, for instance, be used to study the added predictive value of , and it is constant (as a function of ) if and only if ; that is, if and only if is conditionally mean independent of given (Lundborg et al., 2023).
In the context of a GWAS, is a continuous phenotype and represents a single nucleotide polymorphism (SNP) at the genomic site . The regression function (1) quantifies how much a SNP at site adds to the prediction of the phenotype outcome on top of all other SNP sites. In practice, only a fraction of all SNPs along the genome are observed, yet the number of SNPs can be in the millions, and estimation of the full regression model can be impossible without model assumptions. Thus if the regression function (1) is the target of interest, it is extremely useful if we, by adjusting for a substitute of a latent variable, can obtain a computationally efficient and statistically valid estimator of (1).
From our perspective, when viewing the problem as that of adjusted regression, the most pertinent questions are: (1) when is adjustment by the latent variable instead of appropriate; (2) can adjustment by substitutes of the latent variable, recovered from the observe -s, be justified; (3) can we establish an asymptotic theory that allows for statistical inference when adjusting for substitutes?
With the aim of answering the three questions above, this paper makes two main contributions:
A transparent statistical framework. We focus on estimation of the adjusted mean, thereby disentangling the statistical problem from the causal discussion. This way the target of inference is clear and so are the assumptions we need about the observational distribution in terms of the latent variable model. We present in Section 2 a general framework with an infinite number of -variables, and we present clear assumptions implying that we can replace adjustment by with adjustment by . Within the general framework, we subsequently present an assumption-lean target parameter that is interpretable without restrictive model assumptions on the regression function.
A novel theoretical analysis. By restricting attention to the case where the latent variable takes values in a finite set, we give in Section 3 bounds on the estimation error due to using substitutes and on the recovery error—that is, the substitute mislabeling rate. These bounds quantify, among other things, how the errors depend on ; the actual (finite) number of -s used for recovery. With minimal assumptions on the conditional distributions in the latent variable model and on the outcome model, we use our bounds to derive asymptotic conditions ensuring that the assumption-lean target parameter can be estimated just as well using substitutes as if the latent variables were observed.
To implement substitute adjustment in practice, we leverage recent developments on estimation in finite mixture models via tensor methods, which are computationally and statistically efficient in high dimensions. We illustrate our results via a simulation study in Section 4. Proofs and auxiliary results are in Appendix A. Appendix B contains a complete characterization of when recovery of is possible from an infinite in a Gaussian mixture model.
1.1. Relation to existing literature
Our framework and results are based on ideas by Wang & Blei (2019, 2020) and the literature preceding them on adjustment by surrogate/substitute variables. We add new results to this line of research on the theoretical justification of substitute adjustment as a method for estimation.
There is some literature on the theoretical properties of tests and estimators in high-dimensional problems with latent variables. Somewhat related to our framework is the work by Wang et al. (2017) on adjustment for latent confounders in multiple testing, motivated by applications to gene expression analysis. More directly related is the work by Ćevid et al. (2020) and Guo, Ćevid & Bühlmann (2022), who analyze estimators within a linear modelling framework with unobserved confounding. While their methods and results are definitely interesting, they differ from substitute adjustment, since they do not directly attempt to recover the latent variables. The linearity and sparsity assumptions, which we will not make, play an important role for their methods and analysis.
The paper by Grimmer et al. (2023) comes closest to our framework and analysis. Grimmer et al. (2023) present theoretical results and extensive numerical examples, primarily with a continuous latent variable. Their results are not favorable for the deconfounder and they conclude that the deconfounder is “not a viable substitute for careful research design in real-world applications”. Their theoretical analyses are mostly in terms of computing the population (or -asymptotic) bias of a method for a finite (the number of -variables), and then possibly investigate the limit of the bias as tends to infinity. Compared to this, we analyze the asymptotic behaviour of the estimator based on substitute adjustment as and tend to infinity jointly. Moreover, since we specifically treat discrete latent variables, some of our results are also in a different framework.
2. Substitute adjustment
2.1. The General Model
The full model is specified in terms of variables , where is a real valued outcome variable of interest and is a infinite vector of additional real valued variables. That is, with for . We let , and define (informally) for each and the target parameter of interest
| (2) |
That is, is the mean outcome given when adjusting for all remaining variables . Since is generally not uniquely defined for all by the distribution of , we need some additional structure to formally define . The following assumption and subsequent definition achieve this by assuming that a particular choice of the conditional expectation is made and remains fixed. Throughout, is equipped with the Borel -algebra and with the corresponding product -algebra.
Assumption 1 (Regular Conditional Distribution).
Fix for each a Markov kernel on . Assume that is the regular conditional distribution of given for all , and . With the distribution of , suppose additionally that
for all .
Definition 1.
Under Assumption 1 we define
| (3) |
Remark 1.
Definition 1 makes the choice of conditional expectation explicit by letting
be defined in terms of the specific regular conditional distribution that is fixed according to Assumption 1. We may need additional regularity assumptions to identify this Markov kernel from the distribution of , which we will not pursue here.
The main assumption in this paper is the existence of a latent variable, , that will render the -s conditionally independent, and which can be recovered from in a suitable way. The variable will take values in a measurable space , which we assume to be a Borel space. We use the notation and to denote the -algebras generated by and , respectively.
Assumption 2 (Latent Variable Model).
There is a random variable with values in such that:
-
(1)
are conditionally independent given ,
-
(2)
.
The latent variable model given by Assumption 2 allows us to identify the adjusted mean by adjusting for the latent variable only.
Proposition 1.
The joint distribution of is, by Assumption 2, Markov w.r.t. to the graph in Figure 1. Proposition 1 is essentially the backdoor criterion, since blocks the backdoor from to via ; see Theorem 3.3.2 in (Pearl, 2009) or Proposition 6.41(ii) in (Peters et al., 2017). Nevertheless, we include a proof in Appendix A for two reasons. First, Proposition 1 does not involve causal assumptions about the model, and we want to clarify that the mathematical result is agnostic to such assumptions. Second, the proof we give of Proposition 1 does not require regularity assumptions, such as densities of the conditional distributions, but it relies subtly on Assumption 2(2).
Example 1.
Suppose for all and some finite constant , and assume, for simplicity, that . Let and define
The infinite sum converges almost surely since . With being -distributed and independent of consider the outcome model
Letting denote the -sequence with the -th coordinate removed, a straightforward, though slightly informal, computation, gives
To fully justify the computation, via Assumption 1, we let be the -distribution for the -almost all where is well defined. For the remaining we let be the -distribution. Then is a regular conditional distribution of given ,
and follows from (3). It also follows from (4) that for -almost all ,
That is, with , the regression model
is a partially linear model.
Example 2.
While Example 1 is explicit about the outcome model, it does not describe an explicit latent variable model fulfilling Assumption 2. To this end, take , let be i.i.d. -distributed and set . By the Law of Large Numbers, for any ,
almost surely for . Setting
we get that for any and almost surely. Thus, Assumption 2 holds.
Continuing with the outcome model from Example 1, we see that for -almost all ,
thus with . In this example it is actually possible to compute the regular conditional distribution, , of given explicitly. It is the -distribution where .
2.2. Substitute Latent Variable Adjustment
Proposition 1 tells us that under Assumptions 1 and 2 the adjusted mean, , defined by adjusting for the entire infinite vector , is also given by adjusting for the latent variable . If the latent variable were observed we could estimate in terms of an estimate of the following regression function.
Definition 2 (Regression function).
If we had i.i.d. observations, , of , a straightforward plug-in estimate of is
| (7) |
where is an estimate of the regression function . In practice we do not observe the latent variable . Though Assumption 2(2) implies that can be recovered from , we do not assume we know this recovery map, nor do we in practice observe the entire , but only the first coordinates, .
We thus need an estimate of a recovery map, , such that for the substitute latent variable we have111We can in general only hope to learn a recovery map of up to a Borel isomorphism, but this is also all that is needed, cf. Assumption 2. that approximately contains the same information as . Using such substitutes, a natural way to estimate is given by Algorithm 1, which is a general three-step procedure returning the estimate .
The regression estimate in Algorithm 1 is computed on the basis of the substitutes, which likewise enter into the final computation of . Thus the estimate is directly estimating , and it is expected to be biased as an estimate of . The general idea is that under some regularity assumptions, and for and appropriately, and the bias vanishes asymptotically. Section 3 specifies a setup where such a result is shown rigorously.
Note that the estimated recovery map in Algorithm 1 is the same for all . Thus for any fixed , the -s are used for estimation of the recovery map, and the -s are used for the computation of the substitutes. Steps 4 and 5 of the algorithm could be changed to construct a recovery map independent of the -th coordinate. This appears to align better with Assumption 2, and it would most likely make the -s slightly less correlated with the -s. It would, on the other hand, lead to a slightly larger recovery error, and worse, a substantial increase in the computational complexity if we want to estimate for all .
Algorithm 1 leaves some options open. First, the estimation method used to compute could be based on any method for estimating a recovery map, e.g., using a factor model if or a mixture model if is finite. The idea of such methods is to compute a parsimonious such that: (1) conditionally on the observations are approximately independent for ; and (2) is minimally predictive of for . Second, the regression method for estimation of the regression function could be any parametric or nonparametric method. If we could use OLS combined with the parametric model , which would lead to the estimate
If is finite, we could still use OLS but now combined with the parametric model , which would lead to the estimate
The relation between the two datasets in Algorithm 1 is not specified by the algorithm either. It is possible that they are independent, e.g., by data splitting, in which case is independent of the data in . It is also possible that and for . While we will assume and independent for the theoretical analysis, the -s from will in practice often be part of , if not all of .
2.3. Assumption-Lean Substitute Adjustment
If the regression model in the general Algorithm 1 is misspecified we cannot expect that is a consistent estimate of . In Section 3 we investigate the distribution of a substitute adjustment estimator in the case where is finite. It is possible to carry out this investigation assuming a partially linear regression model, , but the results would then hinge on this model being correct. To circumvent such a model assumption we proceed instead in the spirit of assumption-lean regression (Berk et al., 2021; Vansteelandt & Dukes, 2022). Thus we focus on a univariate target parameter defined as a functional of the data distribution, and we then investigate its estimation via substitute adjustment.
Assumption 3 (Moments).
It holds that , and .
Algorithm 2 gives a procedure for estimating based on substitute latent variables. The following proposition gives insight on the interpretation of the target parameter .
Proposition 2.
We include a proof of Proposition 2 in Appendix A.1 for completeness. The arguments are essentially as in (Vansteelandt & Dukes, 2022).
Remark 2.
If it follows from Proposition 1 that , where the coefficient may differ from given by (10). In the special case where the variance of given is constant across all values of , the weights in (10) are all , in which case . For the partially linear model, , with not depending on , it follows from (10) that irrespectively of the weights.
Remark 3.
If then , and the contrast is an unweighted mean of differences, while it follows from (10) that
| (11) |
If we let , we see that the weights are given as
We summarize three important take-away messages from Proposition 2 and the remarks above as follows:
- Conditional mean independence:
-
The null hypothesis of conditional mean independence,
implies that . The target parameter thus suggests an assumption-lean approach to testing this null without a specific model of the conditional mean.
- Heterogeneous partial linear model:
-
If the conditional mean,
is linear in with an -coefficient that depends on (heterogeneity), the target parameter is a weighted mean of these coefficients, while with the unweighted mean.
- Simple partial linear model:
-
If the conditional mean is linear in with an -coef-ficient that is independent of (homogeneity), the target parameter coincides with this -coefficient and . Example 1 is a special case where the latent variable model is arbitrary but the full outcome model is linear.
Just as for the general Algorithm 1, the estimate that Algorithm 2 outputs, , is not directly estimating the target parameter . It is directly estimating
| (12) |
Fixing the estimated recovery map and letting , we can expect that is consistent for and not for .
Pretending that the -s were observed, we introduce the oracle estimator
Here, and denote estimates of the regression functions and , respectively, using the -s instead of the substitutes. The estimator is independent of , , and , and when are i.i.d. observations, standard regularity assumptions (van der Vaart, 1998) will ensure that the estimator is consistent for (and possibly even -rate asymptotically normal). Writing
| (13) |
we see that if we can appropriately bound the error, , due to using the substitutes instead of the unobserved -s, we can transfer asymptotic properties of to . It is the objective of the following section to demonstrate how such a bound can be achieved for a particular model class.
3. Substitute adjustment in a mixture model
In this section, we present a theoretical analysis of assumption-lean substitute adjustment in the case where the latent variable takes values in a finite set. We provide finite-sample bounds on the error of due to the use of substitutes, and we show, in particular, that there exist trajectories of , and along which the estimator is asymptotically equivalent to the oracle estimator , which uses the actual latent variables.
3.1. The mixture model
To be concrete, we assume that is generated by a finite mixture model such that conditionally on a latent variable with values in a finite set, the coordinates of are independent. The precise model specification is as follows.
Assumption 4 (Mixture Model).
There is a latent variable with values in the finite set such that are conditionally independent given . Furthermore,
-
(1)
The conditional distribution of given has finite second moment, and its conditional mean and variance are denoted
for and .
-
(2)
The conditional means satisfy the following separation condition
(14) for all with .
-
(3)
There are constants that bound the conditional variances;
(15) for all .
-
(4)
for all .
Algorithm 3 is one specific version of Algorithm 2 for computing when the latent variable takes values in a finite set . The recovery map in Step 5 is given by computing the nearest mean, and it is thus estimated in Step 4 by estimating the means for each of the mixture components. How this is done precisely is an option of the algorithm. Once the substitutes are computed, outcome means and -means are (re)computed within each component. The computations in Steps 6 and 7 of Algorithm 3 result in the same estimator as the OLS estimator of when it is computed using the linear model
on the data . This may be relevant in practice, but it is also used in the proof of Theorem 1. The corresponding oracle estimator, , is similarly an OLS estimator.
Note that Assumption 4 implies that
Hence Assumption 4, combined with , ensure that the moment conditions in Assumption 3 hold.
The following proposition states that the mixture model given by Assumption 4 is a special case of the general latent variable model.
Remark 4.
The proof of Proposition 3 is in Appendix A.3. Technically, the proof only gives almost sure recovery of from , and we can thus only conclude that is contained in up to negligible sets. We can, however, replace by a variable, , such that and almost surely. We can thus simply swap with in Assumption 4.
Remark 5.
The arguments leading to Proposition 3 rely on Assumptions 4(2) and 4(3)—specifically the separation condition (14) and the upper bound in (15). However, these conditions are not necessary to be able to recover from . Using Kakutani’s theorem on equivalence of product measures it is possible to characterize precisely when can be recovered, but the abstract characterization is not particularly operational. In Appendix B we analyze the characterization for the Gaussian mixture model, where given has a -distribution. This leads to Proposition 5 and Corollary 1 in Appendix B, which gives necessary and sufficient conditions for recovery in the Gaussian mixture model.
3.2. Bounding estimation error due to using substitutes
In this section we derive an upper bound on the estimation error, which is due to using substitutes, cf. the decomposition (13). To this end, we consider the (partly hypothetical) observations , which include the otherwise unobserved -s as well as their observed substitutes, the -s. We let and , and and denote the -norms of and , respectively. We also let
for , and
Furthermore,
and we define the following three quantities
| (16) | ||||
| (17) | ||||
| (18) |
The proof of Theorem 1 is given in Appendix A.2. Appealing to the Law of Large Numbers, the quantities in the upper bound (19) can be interpreted as follows:
-
•
The ratio is approximately a fixed and finite constant (unless is constantly zero) depending on the marginal distributions of and only.
-
•
The fraction is approximately
(20) which is strictly positive by Assumption 4(4) (unless recovery is working poorly).
-
•
The quantity is a standardized measure of the residual variation of the -s within the groups defined by the -s or the -s. It is approximately equal to the constant
which is strictly positive if the probabilities in (20) are strictly positive and not all of the conditional variances are .
-
•
The fraction is the relative mislabeling frequency of the substitutes. It is approximately equal to the mislabeling rate .
The bound (19) tells us that if the mislabeling rate of the substitutes tends to , that is, if , the estimation error tends to roughly like . This could potentially be achieved by letting and . We formalize this statement in Section 3.4.
3.3. Bounding the mislabeling rate of the substitutes
In this section we give bounds on the mislabeling rate, , with the ultimate purpose of controlling the magnitude of in the bound (19). Two different approximations are the culprits of mislabeling. First, the computation of is based on the variables in only, and it is thus an approximation of the full recovery map based on all variables in . Second, the recovery map is an estimate and thus itself an approximation. The severity of the second approximation is quantified by the following relative errors of the conditional means used for recovery.
Definition 4 (Relative errors, -separation).
For the mixture model given by Assumption 4 let for . With for any collection of -vectors, define the relative errors
| (21) |
for , . Define, moreover, the minimal -separation as
| (22) |
Note that Assumption 4(2) implies that for . This convergence could be arbitrarily slow. The following definition captures the important case where the separation grows at least linearly in .
Definition 5 (Strong separation).
We say that the mixture model satisfies strong separation if there exists an such that eventually.
Strong separation is equivalent to
A sufficient condition for strong separation is that eventually for all , and some . That is, for . When we have strong separation, then for large enough
and we note that it is conceivable222Parametric assumptions, say, and marginal estimators of each that, under Assumption 4, are uniformly consistent over can be combined with a simple union bound to show the claim, possibly in a suboptimal way, cf. Section 3.5. that we can estimate by an estimator, , such that for appropriately, .
The following proposition shows that a bound on is sufficient to ensure that the growth of controls how fast the mislabeling rate diminishes with . The proposition is stated for a fixed , which means that when is an estimate, we are effectively assuming it is independent of the template observation used to compute .
Proposition 4.
Suppose that Assumption 4 holds. Let for and let
Suppose also that for all with . Then
| (23) |
If, in addition, the conditional distribution of given is sub-Gaussian with variance factor , independent of and , then
| (24) |
Remark 6.
The proof of Proposition 4 is in Appendix A.3. It shows that the specific constants, and , appearing in the bounds above hinge on the specific bound, , on the relative error. The proof works for any bound strictly smaller than . Replacing by a smaller bound on the relative errors decreases the constant, but it will always be larger than .
The upshot of Proposition 4 is that if the relative errors, , are sufficiently small then Assumption 4 is sufficient to ensure that for . Without additional distributional assumptions the general bound (23) decays slowly with , and even with strong separation, the bound only gives a rate of . With the additional sub-Gaussian assumption, the rate is improved dramatically, and with strong separation it improves to for some constant . If the -s are bounded, their (conditional) distributions are sub-Gaussian, thus the rate is fast in this special but important case.
3.4. Asymptotics of the substitute adjustment estimator
Suppose takes values in and that are observations of . Then Assumption 3 ensures that the oracle OLS estimator is -consistent and that
There are standard sandwich formulas for the asymptotic variance parameter . In this section we combine the bounds from Sections 3.2 and 3.3 to show our main theoretical result; that is a consistent and asymptotically normal estimator of for if also appropriately.
Assumption 5.
Theorem 2.
Suppose Assumption 1 holds and , and consider the mixture model fulfilling Assumption 4. Consider data satisfying Assumption 5 and the estimator given by Algorithm 3. Suppose that such that . Then the following hold:
-
(1)
The estimation error due to using substitutes tends to in probability, that is,
and is a consistent estimator of .
-
(2)
If and , then .
-
(3)
If conditionally on is sub-Gaussian, with variance factor independent of and , and if and , then .
In addition, in case (2) as well as case (3), , where the asymptotic variance parameter is the same as for the oracle estimator .
Remark 7.
Remark 8.
The general growth condition on in terms of in case (2) is bad; even with strong separation we would need , that is, should grow faster than . In the sub-Gaussian case this improves substantially so that only needs to grow faster than .
3.5. Tensor decompositions
One open question from both a theoretical and practical perspective is how we construct the estimators . We want to ensure consistency for , which is expressed as in our theoretical results, and that the estimator can be computed efficiently for large and . We indicated in Section 3.3 that simple marginal estimators of can achieve this, but such estimators may be highly inefficient. In this section we briefly describe two methods based on tensor decompositions (Anandkumar et al., 2014) related to the third order moments of . Thus to apply such methods we need to additionally assume that the -s have finite third moments.
Introduce first the third order tensor as
where is the standard basis vector with a in the -th coordinate and elsewhere, and where
In terms of the third order raw moment tensor and we define the tensor
| (25) |
Letting denote the set of indices of the tensors with all entries distinct, we see from the definition of that for . Thus
for . In the following, denotes the incomplete tensor obtained by restricting the indices of to .
The key to using the -tensor for estimation of the -s is the following rank- tensor decomposition,
| (26) |
see Theorem 3.3 in (Anandkumar et al., 2014) or the derivations on page 2 in (Guo, Nie & Yang, 2022).
Guo, Nie & Yang (2022) propose an algorithm based on incomplete tensor decomposition as follows: Let denote an estimate of the incomplete tensor ; obtain an approximate rank- tensor decomposition of the incomplete tensor ; extract estimates from this tensor decomposition. Theorem 4.2 in (Guo, Nie & Yang, 2022) shows that if the vectors satisfy certain regularity assumptions, they are estimated consistently by their algorithm (up to permutation) if is consistent. We note that the regularity assumptions are fulfilled for generic vectors in .
A computational downside of working directly with is that it grows cubically with . Anandkumar et al. (2014) propose to consider , where is a whitening matrix. The tensor decomposition is then computed for the corresponding tensor . When is fixed and grows, this is computationally advantageous. Theorem 5.1 in Anandkumar et al. (2014) shows that, under a generically satisfied non-degeneracy condition, the tensor decomposition of can be estimated consistently (up to permutation) if can be estimated consistently.
To use the methodology from Anandkumar et al. (2014) in Algorithm 3, we replace Step 4 by their Algorithm 1 applied to . This will estimate the transformed mean vectors . Likewise, we replace Step 5 in Algorithm 3 by
where . The separation and relative errors conditions should then be expressed in terms of the -dependent -vectors .
4. Simulation Study
Our analysis in Section 3 shows that Algorithm 3 is capable of consistently estimating the -parameters via substitute adjustment for appropriately. The purpose of this section is to shed light on the finite sample performance of substitute adjustment via a simulation study.
The -s are simulated according to a mixture model fulfilling Assumption 4, and the outcome model is as in Example 1, which makes a partially linear model. Throughout, we take and in Algorithm 3. The simulations are carried out for different choices of , , and -s, and we report results on both the mislabeling rate of the latent variables and the mean squared error (MSE) of the -estimators.
4.1. Mixture model simulations and recovery of
The mixture model in our simulations is given as follows.
-
•
We set and fix and .
-
•
We draw -s independently and uniformly from for and .
-
•
Fixing the -s and a choice of , we simulate independent observations of , each with the latent variable uniformly distributed on , and given being -distributed.
We use the algorithm from Anandkumar et al. (2014), as described in Section 3.5, for recovery. We replicate the simulation outlined above times, and we consider recovery of for and . For replication the actual values of the latent variables are denoted . For each combination of and the substitutes are denoted . The mislabeling rate for fixed and is estimated as






Figure 2 shows the estimated mislabeling rates from the simulations. The results demonstrate that for reasonable choices of and , the algorithm based on (Anandkumar et al., 2014) is capable of recovering quite well.
The theoretical upper bounds of the mislabeling rate in Proposition 4 are monotonely decreasing as functions of . These are, in turn, monotonely increasing in and in . The results in Figure 2 support that this behavior of the upper bounds carry over to the actual mislabeling rate. Moreover, the rapid decay of the mislabeling rate with is in accordance with the exponential decay of the upper bound in the sub-Gaussian case.
4.2. Outcome model simulation and estimation of
Given simulated -s and -s as described in Section 4.1, we simulate the outcomes as follows.
-
•
Draw independently and uniformly from for .
-
•
Fix and let for .
-
•
With simulate independent outcomes as


The simulation parameter captures a potential effect of unobserved -s for . We refer to this effect as unobserved confounding. For , adjustment using the naive linear regression model would lead to biased estimates even if , while the naive linear regression model for would be correct when . When , adjusting via naive linear regression for all observed -s would still lead to biased estimates due to the unobserved confounding.
We consider the estimation error for and . Let denote the -th parameter in the -th replication, and let denote the corresponding estimate from Algorithm 3 for each combination of and . The average MSE of is computed as
Figure 3 shows the MSE for the different combinations of and and for different choices of . Unsurprisingly, the MSE decays with sample size and increases with the magnitude of unobserved confounding. More interestingly, we see a clear decrease with the dimension indicating that the lower mislabeling rate for larger translates to a lower MSE as well.





Finally, we compare the results of Algorithm 3 with two other approaches. Letting denote the model matrix for the -s and the -vector of outcomes, the ridge regression estimator is given as
with chosen by five-fold cross-validation. The augmented ridge regression estimator is given as
where is the model matrix of dummy variable encodings of the substitutes. Again, is chosen by five-fold cross-validation.
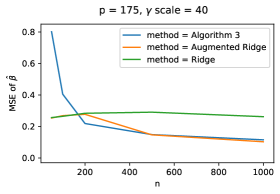
The average MSE is computed for ridge regression and augmented ridge regression just as for substitute adjustment. Figure 4 shows results for and . These two values of correspond to asymptotic (as stays fixed and ) mislabeling rates around and , respectively.
We see that both alternative estimators outperform Algorithm 3 when the sample size is too small to learn reliably. However, naive linear regression is biased, and so is ridge regression (even asymptotically), and its performance does not improve as the sample size, , increases. Substitute adjustment as well as augmented ridge regression adjust for , and their performance improve with , despite the fact that is too small to recover exactly. When and the amount of unobserved confounding is sufficiently large, both of these estimators outperform ridge regression. Note that it is unsurprising that the augmented ridge estimator performs similarly to Algorithm 3 for large sample sizes, because after adjusting for the substitutes, the -residuals are roughly orthogonal if the substitutes give accurate recovery, and a joint regression will give estimates similar to those of the marginal regressions.
We made a couple of observations (data not shown) during the simulation study. We experimented with changing the mixture distributions to other sub-Gaussian distributions as well as to the Laplace distribution and got similar results as shown here using the Gaussian distribution. We also implemented sample splitting, and though Proposition 4 assumes sample splitting, we found that the improved estimation accuracy attained by using all available data for the tensor decomposition outweighs the benefit of sample splitting in the recovery stage.
In conclusion, our simulations show that for reasonable finite and , it is possible to recover the latent variables sufficiently well for substitute adjustment to be a better alternative than naive linear or ridge regression in settings where the unobserved confounding is sufficiently large.
5. Discussion
We break the discussion into three parts. In the first part we revisit the discussion about the causal interpretation of the target parameters treated in this paper. In the second part we discuss substitute adjustment as a method for estimation of these parameters as well as the assumption-lean parameters . In the third part we discuss possible extensions of our results
5.1. Causal interpretations
The main causal question is whether a contrast of the form has a causal interpretation as an average treatment effect. The framework in (Wang & Blei, 2019) and the subsequent criticisms by D’Amour (2019) and Ogburn et al. (2020) are based on the -s all being causes of , and on the possibility of unobserved confounding. Notably, the latent variable to be recovered is not equal to an unobserved confounder, but Wang & Blei (2019) argue that using the deconfounder allows us to weaken the assumption of “no unmeasured confounding” to “no unmeasured single-cause confounding”. The assumptions made in (Wang & Blei, 2019) did not fully justify this claim, and we found it difficult to understand precisely what the causal assumptions related to were.
Mathematically precise assumptions that allow for identification of causal parameters from a finite number of causes, , via deconfounding are stated as Assumptions 1 and 2 in (Wang & Blei, 2020). We find these assumptions regarding recovery of (also termed “pinpointing” in the context of the deconfounder) for finite implausible. Moreover, the entire framework of the deconfounder rests on the causal assumption of “weak unconfoundedness” in Assumption 1 and Theorem 1 of (Wang & Blei, 2020), which might be needed for a causal interpretation but is unnecessary for the deconfounder algorithm to estimate a meaningful target parameter.
We find it beneficial to disentangle the causal interpretation from the definition of the target parameter. By defining the target parameter entirely in terms of the observational distribution of observed (or, at least, observable) variables, we can discuss the properties of the statistical method of substitute adjustment without making causal claims. We have shown that substitute adjustment under our Assumption 2 on the latent variable model targets the adjusted mean irrespectively of any unobserved confounding. Grimmer et al. (2023) present a similar view. The contrast might have a causal interpretation in specific applications, but substitute adjustment as a statistical method does not rely on such an interpretation or assumptions needed to justify such an interpretation. In any specific application with multiple causes and potential unobserved confounding, substitute adjustment might be a useful method for deconfounding, but depending on the context and the causal assumptions we are willing to make, other methods could be preferable (Miao et al., 2023).
5.2. Substitute adjustment: interpretation, merits and deficits
We define the target parameter as an adjusted mean when adjusting for an infinite number of variables. Clearly, this is a mathematical idealization of adjusting for a large number of variables, but it also has some important technical consequences. First, the recovery Assumption 2(2) is a more plausible modelling assumption than recovery from a finite number of variables. Second, it gives a clear qualitative difference between the adjusted mean of one (or any finite number of) variables and regression on all variables. Third, the natural requirement in Assumption 2(2) that can be recovered from for any replaces the minimality of a “multi-cause separator” from (Wang & Blei, 2020). Our assumption is that is sufficiently minimal in a very explicit way, which ensures that does not contain information unique to any single .
Grimmer et al. (2023) come to a similar conclusion as we do: that the target parameter of substitute adjustment (and the deconfounder) is the adjusted mean , where you adjust for an infinite number of variables. They argue forcefully that substitute adjustment, using a finite number of variables, does not have an advantage over naive regression, that is, over estimating the regression function directly. With , say, they argue that substitute adjustment is effectively assuming a partially linear, semiparametric regression model
with the specific constraint that . We agree with their analysis and conclusion; substitute adjustment is implicitly a way of making assumptions about . It is also a way to leverage those assumptions, either by shrinking the bias compared to directly estimating a misspecified (linear, say) , or by improving efficiency over methods that use a too flexible model of . We believe there is room for further studies of such bias and efficiency tradeoffs.
We also believe that there are two potential benefits of substitute adjustment, which are not brought forward by Grimmer et al. (2023). First, the latent variable model can be estimated without access to outcome observations. This means that the inner part of could, potentially, be estimated very accurately on the basis of a large sample in cases where it would be difficult to estimate the composed map accurately from alone. Second, when is very large, e.g., in the millions, but is low-dimensional, there can be huge computational advantages to running small parallel regressions compared to just one naive linear regression of on all of , let alone naive partially linear regressions.
5.3. Possible extensions
We believe that our error bound in Theorem 1 is an interesting result, which in a precise way bounds the error of an OLS estimator in terms of errors in the regressors. This result is closely related to the classical literature on errors-in-variables models (or measurement error models) (Durbin, 1954; Cochran, 1968; Schennach, 2016), though this literature focuses on methods for bias correction when the errors are non-vanishing. We see two possible extensions of our result. For one, Theorem 1 could easily be generalized to . In addition, it might be possible to apply the bias correction techniques developed for errors-in-variables to improve the finite sample properties of the substitute adjustment estimator.
Our analysis of the recovery error could also be extended. The concentration inequalities in Section 3.3 are unsurprising, but developed to match our specific needs for a high-dimensional analysis with as few assumptions as possible. For more refined results on finite mixture estimation see, e.g., (Heinrich & Kahn, 2018), and see (Ndaoud, 2022) for optimal recovery when and the mixture distributions are Gaussian. In cases where the mixture distributions are Gaussian, it is also plausible that specialized algorithms such as (Kalai et al., 2012; Gandhi & Borns-Weil, 2016) are more efficient than the methods we consider based on conditional means only.
One general concern with substitute adjustment is model misspecification. We have done our analysis with minimal distributional assumptions, but there are, of course, two fundamental assumptions: the assumption of conditional independence of the -s given the latent variable , and the assumption that takes values in a finite set of size . An important extension of our results is to study robustness to violations of these two fundamental assumptions. We have also not considered estimation of , and it would likewise be relevant to understand how that affects the substitute adjustment estimator.
Acknowledgments
We thank Alexander Mangulad Christgau for helpful input. JA and NRH were supported by a research grant (NNF20OC0062897) from Novo Nordisk Fonden. JA also received funding from the European Union’s Horizon 2020 research and innovation programme under Marie Skłodowska-Curie grant agreement No 801199.
Appendix A Proofs and auxiliary results
A.1. Proofs of results in Section 2.1
Proof of Proposition 1.
Since as well as take values in Borel spaces, there exists a regular conditional distribution given of each (Kallenberg, 2021, Theorem 8.5). These are denoted and , respectively. Moreover, Assumption 2(2) and the Doob-Dynkin lemma (Kallenberg, 2021, Lemma 1.14) imply that for each there is a measurable map such that . This implies that for measurable.
Since it holds that , and furthermore that . Assumption 2(1) implies that and are conditionally independent given , thus for and measurable sets and ,
Hence is a regular conditional distribution of given .
We finally find that
∎
A.2. Auxiliary results related to Section 3.2 and proof of Theorem 1
Let denote the matrix of dummy variable encodings of the -s, and let denote the similar matrix for the substitutes -s. With and the orthogonal projections onto the column spaces of and , respectively, we can write the estimator from Algorithm 3 as
| (27) |
Here denote the -vectors of -s and -s, respectively, and is the standard inner product on , so that, e.g., . The estimator, had we observed the latent variables, is similarly given as
| (28) |
The proof of Theorem 1 is based on the following bound on the difference between the projection matrices.
Lemma 1.
Proof.
When , the matrices and have full rank . Let and denote the Moore-Penrose inverses of and , respectively. Then and . By Theorems 2.3 and 2.4 in (Stewart, 1977),
The operator -norm is the square root of the largest eigenvalue of
Whence . The same bound is obtained for , which gives
We also have that
because precisely for those with and otherwise. Combining the inequalities gives (29). ∎
A.3. Auxiliary concentration inequalities. Proofs of Propositions 3 and 4
Lemma 2.
Suppose that Assumption 4 holds. Let for and let . Suppose that for all with then
| (30) |
Proof.
Since is fixed throughout the proof, we simplify the notation by dropping the subscript and use, e.g., and to denote the -vectors and , respectively.
Fix also with and observe first that
The objective is to bound the probability of the event above using Chebyshev’s inequality. To this end, we first use the Cauchy-Schwarz inequality to get
where
The triangle and reverse triangle inequality give that
and dividing by combined with the bound on the relative errors yield
This gives
since the function is increasing for .
Introducing the variables we conclude that
| (31) |
Note that and , and by Assumption 4, the -s are conditionally independent given , so Chebyshev’s inequality gives that
where we, for the last inequality, used that . ∎
Before proceeding to the concentration inequality for sub-Gaussian distributions, we use Lemma 2 to prove Proposition 3.
Proof of Proposition 3.
Suppose that for convenience. We take for all and and write for the prediction of based on the coordinates . With this oracle choice of , the relative errors are zero, thus the bound (30) holds, and Lemma 2 gives
with a constant independent of . By (14), for , and by choosing a subsequence, , we can ensure that Then , and by Borel-Cantelli’s lemma,
That is, , which shows that we can recover from and thus from (with probability ). Defining
we see that and almost surely. Thus if we replace by in Assumption 4 we see that Assumption 2(2) holds. ∎
Lemma 3.
Proof.
Recall that given being sub-Gaussian with variance factor means that
for . Consequently, with as in the proof of Lemma 2, and using conditional independence of the -s given ,
Using (31) in combination with the Chernoff bound gives
where we, as in the proof of Lemma 2, have used that the bound on the relative error implies that . ∎
A.4. Proof of Theorem 2
Proof of Theorem 2.
Now rewrite the bound (19) as
From the argument above, . We will show that the second factor, , tends to a constant, , in probability under the stated assumptions. This will imply that
which shows case (1).
Observe first that
by the Law of Large Numbers, using the i.i.d. assumption and the fact that by Assumption 4. Similarly, .
Turning to , we first see that by the Law of Large Numbers,
for and . Then observe that for any
Since , also
thus
Combining the limit results,
To complete the proof, suppose first that . Then
By (33) we have, under the assumptions given in case (2) of the theorem, that , and case (2) follows.
Finally, in the sub-Gaussian case, and if just , then we can replace (33) by the bound
Multiplying by , we get that the first term in the bound equals
for . We conclude that the relaxed growth condition on in terms of in the sub-Gaussian case is enough to imply , and case (3) follows.
By the decomposition
it follows from Slutsky’s theorem that in case (2) as well as case (3),
∎
Appendix B Gaussian mixture models
This appendix contains an analysis of a latent variable model with a finite , similar to the one given by Assumption 4, but with Assumption 4(1) strengthened to
Assumptions 4(2), 4(3) and 4(4) are dropped, and the purpose is to understand precisely when Assumption 2(2) holds in this model. That is, when can be recovered from . To keep notation simple, we will show when can be recovered from , but the analysis and conclusion is the same if we left out a single coordinate.
The key to this analysis is a classical result due to Kakutani. As in Section 2, the conditional distribution of given is denoted , and the model assumption is that
| (34) |
where is the conditional distribution of given . For Kakutani’s theorem below we do not need the Gaussian assumption; only that and are equivalent (absolutely continuous w.r.t. each other), and we let denote the Radon-Nikodym derivative of w.r.t. .
Theorem 3 (Kakutani (1948)).
Let and . Then and are singular if and only if
| (35) |
Note that
is known as the Bhattacharyya coefficient, while and are known as the Bhattacharyya distance and the Hellinger distance, respectively, between and . Note also that if and for a reference measure , then
Proposition 5.
Let be the -distribution for all and . Then and are singular if and only if either
| (36) | ||||
| (37) |
Corollary 1.
References
- (1)
- Anandkumar et al. (2014) Anandkumar, A., Ge, R., Hsu, D., Kakade, S. M. & Telgarsky, M. (2014), ‘Tensor decompositions for learning latent variable models’, Journal of Machine Learning Research 15, 2773–2832.
- Berk et al. (2021) Berk, R., Buja, A., Brown, L., George, E., Kuchibhotla, A. K., Su, W. & Zhao, L. (2021), ‘Assumption lean regression’, The American Statistician 75(1), 76–84.
- Ćevid et al. (2020) Ćevid, D., Bühlmann, P. & Meinshausen, N. (2020), ‘Spectral deconfounding via perturbed sparse linear models’, Journal of Machine Learning Research 21(232), 1–41.
- Cochran (1968) Cochran, W. G. (1968), ‘Errors of measurement in statistics’, Technometrics 10(4), 637–666.
- Durbin (1954) Durbin, J. (1954), ‘Errors in variables’, Revue de l’Institut International de Statistique / Review of the International Statistical Institute 22(1/3), 23–32.
- D’Amour (2019) D’Amour, A. (2019), On multi-cause approaches to causal inference with unobserved counfounding: Two cautionary failure cases and a promising alternative, in ‘The 22nd International Conference on Artificial Intelligence and Statistics’, PMLR, pp. 3478–3486.
- Gandhi & Borns-Weil (2016) Gandhi, K. & Borns-Weil, Y. (2016), ‘Moment-based learning of mixture distributions’.
- Grimmer et al. (2023) Grimmer, J., Knox, D. & Stewart, B. (2023), ‘Naive regression requires weaker assumptions than factor models to adjust for multiple cause confounding’, Journal of Machine Learning Research 24(182), 1–70.
- Guo, Nie & Yang (2022) Guo, B., Nie, J. & Yang, Z. (2022), ‘Learning diagonal Gaussian mixture models and incomplete tensor decompositions’, Vietnam Journal of Mathematics 50, 421–446.
- Guo, Ćevid & Bühlmann (2022) Guo, Z., Ćevid, D. & Bühlmann, P. (2022), ‘Doubly debiased lasso: High-dimensional inference under hidden confounding’, The Annals of Statistics 50(3), 1320 – 1347.
- Heinrich & Kahn (2018) Heinrich, P. & Kahn, J. (2018), ‘Strong identifiability and optimal minimax rates for finite mixture estimation’, The Annals of Statistics 46(6A), 2844 – 2870.
- Kakutani (1948) Kakutani, S. (1948), ‘On equivalence of infinite product measures’, Annals of Mathematics 49(1), 214–224.
- Kalai et al. (2012) Kalai, A. T., Moitra, A. & Valiant, G. (2012), ‘Disentangling Gaussians’, Communications of the ACM 55(2), 113–120.
- Kallenberg (2021) Kallenberg, O. (2021), Foundations of modern probability, Probability and its Applications (New York), third edn, Springer-Verlag, New York.
- Leek & Storey (2007) Leek, J. T. & Storey, J. D. (2007), ‘Capturing heterogeneity in gene expression studies by surrogate variable analysis’, PLOS Genetics 3(9), 1–12.
- Lundborg et al. (2023) Lundborg, A. R., Kim, I., Shah, R. D. & Samworth, R. J. (2023), ‘The projected covariance measure for assumption-lean variable significance testing’, arXiv:2211.02039 .
- Miao et al. (2023) Miao, W., Hu, W., Ogburn, E. L. & Zhou, X.-H. (2023), ‘Identifying effects of multiple treatments in the presence of unmeasured confounding’, Journal of the American Statistical Association 118(543), 1953–1967.
- Ndaoud (2022) Ndaoud, M. (2022), ‘Sharp optimal recovery in the two component Gaussian mixture model’, The Annals of Statistics 50(4), 2096 – 2126.
- Ogburn et al. (2020) Ogburn, E. L., Shpitser, I. & Tchetgen, E. J. T. (2020), ‘Counterexamples to ”the blessings of multiple causes” by Wang and Blei’, arXiv:2001.06555 .
- Patterson et al. (2006) Patterson, N., Price, A. L. & Reich, D. (2006), ‘Population structure and eigenanalysis’, PLOS Genetics 2(12), 1–20.
- Pearl (2009) Pearl, J. (2009), Causality, Cambridge University Press.
- Peters et al. (2017) Peters, J., Janzing, D. & Schölkopf, B. (2017), Elements of Causal Inference: Foundations and Learning Algorithms, MIT Press, Cambridge, MA, USA.
- Price et al. (2006) Price, A. L., Patterson, N. J., Plenge, R. M., Weinblatt, M. E., Shadick, N. A. & Reich, D. (2006), ‘Principal components analysis corrects for stratification in genome-wide association studies’, Nature Genetics 38(8), 904–909.
- Schennach (2016) Schennach, S. M. (2016), ‘Recent advances in the measurement error literature’, Annual Review of Economics 8, 341–377.
- Song et al. (2015) Song, M., Hao, W. & Storey, J. D. (2015), ‘Testing for genetic associations in arbitrarily structured populations’, Nat Genet 47(5), 550–554.
- Stewart (1977) Stewart, G. W. (1977), ‘On the perturbation of pseudo-inverses, projections and linear least squares problems’, SIAM Review 19(4), 634–662.
- van der Vaart (1998) van der Vaart, A. W. (1998), Asymptotic statistics, Vol. 3 of Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, Cambridge.
- Vansteelandt & Dukes (2022) Vansteelandt, S. & Dukes, O. (2022), ‘Assumption-lean inference for generalised linear model parameters’, Journal of the Royal Statistical Society: Series B (Statistical Methodology) 84(3), 657–685.
- Wang et al. (2017) Wang, J., Zhao, Q., Hastie, T. & Owen, A. B. (2017), ‘Confounder adjustment in multiple hypothesis testing’, Ann. Statist. 45(5), 1863–1894.
- Wang & Blei (2019) Wang, Y. & Blei, D. M. (2019), ‘The blessings of multiple causes’, Journal of the American Statistical Association 114(528), 1574–1596.
- Wang & Blei (2020) Wang, Y. & Blei, D. M. (2020), ‘Towards clarifying the theory of the deconfounder’, arXiv:2003.04948 .