remarkRemark \newsiamremarkhypothesisHypothesis \newsiamthmclaimClaim \headersSubspace Recycling-based Regularization MethodsR. Ramlau and K. M. Soodhalter and Victoria Hutterer
Subspace Recycling-based Regularization Methods††thanks: DATE.
Abstract
Subspace recycling techniques have been used quite successfully for the acceleration of iterative methods for solving large-scale linear systems. These methods often work by augmenting a solution subspace generated iteratively by a known algorithm with a fixed subspace of vectors which are “useful” for solving the problem. Often, this has the effect of inducing a projected version of the original linear system to which the known iterative method is then applied, and this projection can act as a deflation preconditioner, accelerating convergence. Most often, these methods have been applied for the solution of well-posed problems. However, they have also begun to be considered for the solution of ill-posed problems.
In this paper, we consider subspace augmentation-type iterative schemes applied to linear ill-posed problems in a continuous Hilbert space setting, based on a recently developed framework describing these methods. We show that under suitable assumptions, a recycling method satisfies the formal definition of a regularization, as long as the underlying scheme is itself a regularization. We then develop an augmented subspace version of the gradient descent method and demonstrate its effectiveness, both on an academic Gaussian blur model and on problems arising from the adaptive optics community for the resolution of large sky images by ground-based extremely large telescopes.
keywords:
ill-posed problems, augmented methods, recycling, iterative methods, Landweber, gradient descent68Q25, 68R10, 68U05
1 Introduction
This paper concerns the use of subspace recycling iterative methods in the context of solving linear ill-posed problems. There have already been a number of augmented or subspace recycling methods proposed specifically to treat ill-posed problems (e.g., [4, 3, 9, 5]), but these methods have yet to be formally analyzed as regularization schemes. More recently, an augmented scheme to accelerate the regularization of a problem in adaptive optics, producing a large improvement in performance, was proposed [32]. However, the augmentation was done after the regularized problem was set up rather than actually combining these techniques. It would thus be helpful to place all these methods into a common framework to streamline the development of new methods and to enable them to be analyzed using a common language and framework. In particular, it enables us in this paper to prove under what conditions augmented approaches described by the framework are regularizations.
We take advantage of a newly-proposed general framework [36] which can be used to describe the vast majority of these methods. This framework allows us to perform a general analysis of augmentation and recycling schemes as regularizations. From this, we develop sufficient conditions for a recycled iterative method to be a regularization, namely that a subspace recycling scheme is a regularization if it is built from an underlying regularization method. As a proof-of-concept, we then leverage the framework and our analysis to propose augmented steepest descent and Landweber methods, which we then apply to some test problems.
The linear inverse problem we consider is of the form
| (1) |
whereby we approximately reconstruct from noisy data where , and represents the perturbation of our data which satisfies . Here, is a continuous mapping between separable Hilbert spaces . In many relevant applications, the operator is ill-posed, i.e., (1) violates Hadamard’s conditions: a solution either might not exist, it might be non-unique or it may not depend continuously on the data. In this case regularization techniques have to be employed for the stable solution of (1), see [12, 13] and Section 2 for a summary on these methods.
The quality of the reconstruction for a specific problem depends heavily on available additional information on the solution, which is often directly included into the chosen reconstruction approach. E.g., source conditions of the solution are used to estimate the reconstruction error [13, 27]. Alternatively, information on the smoothness of the solution can be incorporated into Tikhonov regularization by choosing a penalty term that enforces the reconstruction to be smooth. For iterative regularization methods, the iteration can be started with a rough guess for the solution, leading generally to shorter reconstruction times and better results. Those approaches are of particular interest for inverse problems that have to be solved repeatedly in time and where the previous reconstruction can be considered as a good guess for the solution of the current problem. This would be the case, e.g., for Adaptive Optics applications in Astronomy, where the image quality loss due to turbulences in the atmosphere is corrected by a suitable shaped deformable mirror. The shape of the deformable mirrors has to be adjusted within milliseconds. The optimal shape of the mirror is derived by solving the atmospheric tomography problem repeatedly (about every 1-2ms). Although the atmosphere changes rapidly it can be regarded frozen on a sub-millisecond timescale, meaning that the previous reconstruction of the atmospheric tomography problem can be regarded as a good approximation to the new solution [40, 31].
In this paper we want to consider the case that we know a finite-dimensional subspace that contains a significant part of the solution which we seek. As we will see, this part can be easily and stably be reconstructed. What then remains is to reconstruct the part that belongs to the orthogonal complement of , possibly induces an acceleration in the convergence rate of the resulting iterative method, cf. Section 5.
For finite dimensional problems, this approach is known as a subspace recycling method and is currently a hot topic in numerical linear algebra. The goal of this paper is therefore to extend the theory to ill-posed problems in an infinite dimensional setting. Specifically, we will show that the concept of subspace recycling can be used in connection with most of the standard regularization methods.
The paper is organized as follows: In Section 2 we give a short introduction to Inverse Problems and regularization methods, whereas Section 3 discusses the state of research of subspace recycling methods. In Sections 4 and 5 we show that standard linear regularization method can be combined with subspace recycling and prove that the resulting method is still a regularization. Finally, Section 6 considers recycled gradient descent methods, and Section 7 presents some numerical results.
2 Regularization of linear ill-posed problems
We begin with a brief review of some basic regularization theory, which we mainly base on [12, 13, 27]. As mentioned above, a solution to the problem might not exist; if it exists it might not be unique and/or might not depend continuously on the data. The first two problems can be circumvented by using the generalized inverse , whereas stability is enforced by using regularization methods. To be more specific, an operator
| (2) |
is a regularization for a linear operator iff for any right hand side with there exists a parameter choice rule
| (3) |
such that
| (4) |
holds. Here, the parameter is chosen such that . Over the last decades, many regularization methods have been investigated, most prominently Tikhonov regularization and iterative methods like Landweber iteration [13, 24] and the conjugate gradient method. For Tikhonov regularization, the approximation to the generalized solution is computed as the minimizer of the Tikhonov functional
| (5) |
where is a suitable penalty term, e.g., . For more general penalties we refer, e.g., to [12, 35]. For Tikhonov to be rendered a regularization method, one appropriate method of choosing the regularization parameter is the discrepancy principle, where is chosen such that
| (6) |
Iterative methods are popular as their computational realization is often straightforward. Landweber iteration computes as
| (7) |
For iterative methods the iteration index plays the role of the regularization parameter. According to the discrepancy principle, the iteration is terminated at step when for the first time with fixed. The Landweber iteration with the discrepancy principle is a regularization method [13]. It is well known that the convergence of regularization methods for can be arbitrarily slow. Convergence rates can be obtained by using source conditions. Popular are Hölder type source conditions
| (8) |
for some and . A regularization method is called order optimal iff the reconstruction error can be estimated as
| (9) |
provided a source condition (8) is fulfilled. Both Tikhonov and Landweber equipped with suitable source conditions are order optimal [13].
In this paper we will show that subspace recycling-based methods also form a regularization.
3 Augmented iterative methods
Augmented iterative methods, as we discuss them here, have been proposed in the literature beginning in the mid- to late-nineties; see [36] for a survey of this history. They can be considered as a specialized version of the class of iterative methods called residual constraint or residual projection methods. We discuss these methods briefly to put them into context, but for more details, the reader should see the survey paper [36], and references therein.
3.1 Iterations determined by residual constraint
Many iterative methods which are commonly used to treat both well- and ill-posed linear problems can be formulated according to a correction/constraint setup. Our discussion here in Section 3 focuses on the well-posed problem case for simplicity. Let and , respectively, be the inner products for and and .
Consider the case wherein we are solving Eq. 1 with no initial approximation; i.e., . The strategies we outline here take the abstract form of approximating the solution by such that the residual satisfies , where and are such that . They are called the correction and constraint spaces, respectively. A common example of a case for which is steepest descent (i.e., gradient descent with step size chosen to minimize the -norm of the error); see, e.g., [34, Section 5.3.1].
Proposition 3.1.
The st step of steepest descent can be formulated as
| (10) |
where ; i.e., , and .111One could also, with some work, use this result to obtain a residual constraint formulation for a more general Landweber method, but it is not clear that this brings an analytic advantage.
Proof 3.2.
Suppose we have constructed the approximation at the previous iteration. Recall that gradient descent methods compute , where . The choice of (called the step size) determines the method’s behavior. Steepest descent computes
Differentiating the right-hand side, setting it equal to zero, and solving for yields the minimizer . One must simply show that Eq. 10 produces the same choice of . However, this constraint condition is equivalent to solving the equation
which when solved for produces the same -norm-minimizing choice of .
Steepest descent is an example of a method for which . There are many methods for which the size of the correction and constraint spaces grows at each iteration. It is a well-known result that one can characterize the method of conjugate gradients in this way, which we present without proof; see [33, 34] for proofs.
Proposition 3.3.
The st iterate produced by the method of conjugate gradients applied to the normal equations associated to Eq. 1 can be formulated as
| (11) |
where .
3.2 Augmentation via constraint over a pair of spaces
Many flavors of augmented iterative methods have been proposed to treat both well- and ill-posed problems. These methods treat the situation in which we wish to approximate the solution using an iterative method, but we also have a fixed subspace which we also want to use to build the approximation. Using the correction/constraint formulation in Section 3.1, we can describe many of these methods as selecting approximations from a correction space with a residual constraint space , where and are spaces of fixed dimension and and are generated iteratively, with dimension at step . It has been shown that this correction/constraint over the sum of subspaces reduces mathematically to applying the underlying iterative method to a projected problem, obtaining part of the approximation from and then obtaining the corrections from afterward. This will be explained in more detail in Section 5, but we give a brief outline here.
A projector is uniquely defined by its range and its null space. A standard result from linear algebra shows that this is equivalent to defining the ranges of the projector and its complement. In this setting, consider the projectors and having the relationship that
| (12) |
Let and , and and . One can easily show that defining the null spaces is equivalent to defining and . For example, let be chosen arbitrarily. It can be decomposed as with and . As expected, . We can then observe that . As was chosen arbitrarily, we see that . The same can be shown for .
Approximating the solution of Eq. 1 by subject to the constraint has been shown to be equivalent to approximating the solution to the projected problem
| (13) |
by with residual constraint space and setting the approximation to be
| (14) |
For well-posed problems, the space often contains vectors from previous iteration cycles applied to the current or previously-solved related problem; see, e.g., [2, 23, 29, 38]. These vectors are often (but not always) approximate eigenvectors (of a square operator) or left singular vectors, guided by Krylov subspace method convergence theory. For ill-posed problems, the strategy is generally to include some known features of the image/signal being reconstructed (see, e.g., [3, 4, 9]), but some current work by [5] still seeks to augment a Lanczos bidiagonalization-based solver for ill-posed, tall, skinny least-squares problems using approximate left singular vectors to accelerate semi-convergence and reduce the influence of smaller singular values to achieve a regularizing effect. See Section 5.1 for further discussion.
There is an alternative approach (originally proposed in the context of domain decomposition in, e.g., [14]) which begins with the projectors and (rather than treating them as a consequence of the correction/constraint formulation) and produces the same algorithms but provides more flexibility to use methods like Landweber which do not have a clean residual constraint condition. This will be derived in detail in Section 5, but it is built on the simple idea that the projector can be used to get the decomposition . We will show that can be cheaply computed and we can use an iterative method to approximate .
4 Linear Projection Methods
We consider here the case that . For a finite dimensional subspace with , we denote the sibling subspace and assume it also has dimension . We can represent these subspaces in terms of bases, which we denote with a matrix-like notation. Let
| (15) |
be -tuples of elements from and , respectively, which are bases for these spaces.
Remark 4.1.
To get a sense of these objects, observe that if then we would have ; so this is just the generalization of the notion of a tall, skinny matrix.
We can consider and to be linear mappings induced by a basis expansion operation, with and , defined by
| (16) |
Let
| (17) |
Furthermore, for , we define the bilinear mapping
| (18) |
We similarly define the corresponding bilinear mapping for two elements from
In particular, we have the following relation:
Lemma 4.2.
For the operator (and similarly ) holds
| (19) |
Proof 4.3.
With , follows
Lemma 4.4.
For and as above holds
| (21) |
Proof 4.5.
5 Projected Regularization Method
Let be a -dimensional subspace, and be its image under the action of . Here it is important that we assume that the restricted operator is invertible, so as to guarantee that holds. This allows us express clearly the structure of projectors onto these spaces.
Proposition 5.1.
Assume that the vectors are linear independent, and that
| (24) |
is invertible on its range . Then is continuously invertible.
Proof 5.2.
According to (15), with . As is invertible on , the vectors in are linear independent if the vectors in are linear independent. Moreover,
| (25) |
is the Gramian matrix of the linear independent system contained in and therefore an invertible matrix. Additionally, as maps between finite dimensional spaces, its inverse is also bounded.
In general, the operator is ill posed and might have a non-trivial null space, i.e., is not continuously invertible. However, on a finite dimensional subspace invertibility might be achieved easily.
Now let be the -orthogonal projector onto and be the -orthogonal projector onto . The orthogonal projector induces a direct sum splitting . Consider . We represent the action of as . Similarly, induces a direct sum splitting of with respect to , namely where denotes the orthogonal complement of with respect to the inner product . We represent the action of as . We also can construct these projectors explicitly.
Proposition 5.3.
Let be a basis of and be a basis of . Then we have
Proof 5.4.
This is a standard result, particularly in the setting where and , but it is helpful to see why this is true in this more general setting, as well. From Proposition 5.1, we know that is continuously invertible. Let be a basis for . Then for any , we can write
Since by definition for all , we can write
| (26) |
Observe that, according to the definitions in Eq. 17 and Eq. 18, the vector is the th column of the matrix . Thus,
the th Cartesian basis vector. Thus, we have
| (27) |
and thus according to Eq. 26
| (28) |
As was chosen arbitrarily, this is true for any element of meaning the action of is the action of . This completes the proof for . The same line of reasoning yields the proof for .
We assume that with exact data that Eq. 1 is consistent. Using the projector , we decompose the exact true solution,
With exact data, would be exactly computable, since we can rewrite
| (29) |
However, we do no have exact data. We have disturbed data such that . Rewriting
| (30) |
we can define
| (31) |
which can be computed inexpensively to high precision and may be used as an approximation . We obtain
Proposition 5.5.
The approximation error between and is given by
| (32) |
which can be estimated as
| (33) |
Remark 5.7.
Often with such recycling methods, one takes either or to be represented with an orthonormal basis, for the purposes of convenience with regard to analysis and implementation. We assume here that is represented by an orthonormal basis. If we scale such that is an orthonormal system spanning , we can write Eq. 33 more compactly as
Furthermore, and can be expressed more compactly,
due to the fact that when is an orthonormal system.
It remains to find a suitable approximation for . We have the following result:
Proposition 5.8.
Under the assumption
| (38) |
holds
| (39) |
where
| (40) |
Proof 5.9.
Proof 5.11.
Remark 5.12.
Furthermore, the way we construct our projectors ensures that the assumption holds.
Proof. This follows from the fact that the product of complementary projectors is the zero operator, since from Eq. 12, we have
With the above results we can now compute as a solution of equation (38). However, as always in Inverse Problems, we might not have the exact right hand side but some noisy version , where we define . The data error can be approximated as follows:
Proposition 5.14.
We are now ready to formulate our solution approach:
data fulfilling
, finite dimensional
a regularization method for the equation with parameter choice rule
Proposition 5.16.
Proof 5.17.
Remark 5.18.
We can thus extend any existing regularization to its augmented method and still obtain a regularization method.
Example 1.
Let us illustrate this for the Landweber method, which has been defined in (7). If the iteration is stopped by the discrepancy principle, i.e., if the stopping index is determined as the first index such that
| (51) |
holds, then it is a regularization method, see e.g., [8]. For given data , the augmented Landweber method would read as
| (52) |
where is defined in (31) and is the th iterate of the Landweber iteration applied to the equation
| (53) |
Using
| (54) |
the iteration for reads as
| (55) | |||||
Usually such an iteration is started with . Instead, we can incorporate directly into the iteration by setting .
5.1 What to recycle
One question we have not addressed thus far concerns what should the subspace encode? This is a question that hinges very much on the application. Suffice it to say, a detailed review of recycling strategies is beyond the scope of this paper, but we refer the reader to [36, Section 6] for a more detailed discussion. Some common choices for augmentation vectors are approximate solutions or solutions to related problems, approximate or (when available) exact eigenvectors/singular vectors, and vectors satisfying convergence model optimality properties.
The use of approximate eigenvectors as a recycling strategy was first suggested for recycling between cycles of GMRES applied to one linear system to mitigate the effects on convergence speed of restarting [28]. The algorithmic choices in that paper necessitated that the approximate eigenvectors be harmonic Ritz vectors. Ritz-type eigenvector approximations with respect to a square matrix are obtained applying a Galerkin or Petrov-Galerkin approximation strategy to the eigenvalue problem of the form
for some . The spaces and are usually spaces which have been generated during the iteration, so that the solution to the Ritz problem reduces to a (generalized) eigenvalue problem. This strategy was extended and combined with GCRO-type optimal methods in a way that did not require augmentation by harmonic Ritz vectors, and this enabled recycling between multiple linear systems [29]. This has been further extended to the case of short-recurrence schemes not requiring restart; see, e.g., [5, 23, 38]. In that case, one stores and updates a running recycle window but not to use in the current iteration. Rather, it is being built to be used in subsequent systems.
It should be noted that in the context of discrete ill-posed problems, a poor or noisy choice of may induce a projected problem Eq. 13 which is even more ill-posed. However, it has been demonstrated that there are many good choices for ; see, e.g., [3, 4, 9]. More recently, a recycled LSQR algorithm has been proposed where approximate eigenvectors are used as well as other data which become available in real-time [5]. As LSQR is a short-recurrence method, the authors employ a windowed recycling strategy, where the recycled subspace is updated every iterations so that only a window of vectors generated by the short recurrence iteration must be stored. They propose a few different recycling approaches appropriate for ill-posed problems: truncated singular vectors, solution- or sparsity-oriented compression, and reduced basis decomposition.
In the next section, we use the recycling method framework from [36] to develop augmented versions of steepest descent and Landweber methods. In Section 7, we combine this method with recycling strategies appropriate to each individual application, building on strategies from the literature but adjusted to fit the particular applications.
6 Augmented gradient descent methods
We now delve further into the case that we apply a gradient descent-type method (i.e., Landweber) to the projected problem, in order to produce a practical implementation of this algorithm. In particular, we first explore augmenting the steepest descent method, which can be understood as a Landweber-type method with a step-length that is dynamically chosen to minimize the residual norm. We have shown in Proposition 3.1 that this is a projection method and thus can be augmented in the above-discussed framework. Augmented methods such as this rely on certain identities to achieve algorithmic advantages.
Lemma 6.1.
Proof. This result has been shown in a number of papers for finite-dimensional, well-posed problems; see, [7] and [6, 15, 16, 18]. We show it here for completeness by direct calculation, by first writing
Then we observe that it follows from Proposition 5.3 and Eq. 12 that this is equivalent to
It follows directly that . Note that this proof holds in the presence or absence of noise and whether or not the problem being treated is consistent. In the case that the right-hand side is noise-free and the problem is consistent, we have from Eq. 30 that
| (56) |
meaning it is the best approximation of in with respect to the -norm. In the presence of noise, we previously characterized and bounded the error introduced into Eq. 56 in Proposition 5.5.
It directly follows that the construction of the gradient descent direction for Landweber applied to Eq. 13 can be simplified.
Corollary 6.2.
With these simplifications, we now show that indeed the above-described fully augmented Landweber construction is indeed updating the approximation to the solution to the full problem Eq. 1 in the optimal direction at each iteration. Furthermore, if when applying Landweber to Eq. 13, we choose the step length dynamically such that we are applying the method of steepest descent to Eq. 13, this will be shown in the following theorem to be equivalent to minimizing the residual over the sum of subspaces .
As this should be a steepest descent-type method which is a -norm minimization method, the correct constraint space is the image of the correction space under the action of the operator, namely . At step , we have where and are determined by the minimization constraint. The following is an adaption of a more general result, proven in [7].
Theorem 6.3.
The st approximate solution to the augmented steepest descent problem minimization,
satisfies
-
1.
with
(57) (58) where ,
-
2.
and satisfies
(59)
i.e., is obtained via applying an iteration of steepest descent to the projected problem, where and .
Proof. As this is a minimization problem, we prove the result by studying the structure of the associated orthogonal projector. We can rewrite this minimization as
Thus, we seek the pair giving the -norm best approximation of in the space . This is equivalent to computing the -orthogonal projection of into that space, which we denote . Recalling that , from Proposition 5.3, we can express this as
where . This means that form the solution of
To prove the statement of the theorem, we eliminate from the second block of equations (following [30]) yielding the two sets of equations,
We can consolidate the second set of equations, yielding
Recalling the definition of the projector , we substitute and then take advantage of the self-adjointness of orthogonal projectors,
Thus, the minimizer satisfies
As , then we see that is the solution of
From Proposition 3.1, we then see that this is the residual constraint formulation of the st step of steepest descent applied to Eq. 59. We can then solve for ,
Expanding to obtain the contribution from yields
and we observe that second term in this sum is Eq. 58. For the first term, we must consider two cases. If , then , and . Thus, we can write
From Proposition 5.5, we have that . It is established in Eq. 56 that is the minimizer in Eq. 57. Lastly, if , Lemma 6.1 tells us that ; thus .
Corollary 6.4.
The full augmented steepest descent approximation can be represented as
with optimal step length
We note that can be computed one time initially, as it comes only from initial data. We encapsulate all of this in the case of augmented steepest descent with dynamically determined optimal step length as Algorithm 2.
Note: the reader may notice that Line 3 of Algorithm 2 asks that the user compute a QR-factorization of , which essentially has a finite number of elements from an infinite-dimensional space as its “columns”. By QR-factorization in this context, we mean performing steps of the Gram-Schmidt process and storing the orthogonalization and normalization coefficients in an upper-triangular matrix . Right-multiplication of by a matrix should be understood as applying the definition in Eq. 16 for each column of , thereby recovering the relationship between and arising from the Gram-Schmidt process. This is a well-defined procedure and process which is discussed, e.g., in [37, Lecture 7].
Furthermore, it is then clear that if we no longer choose dynamically according to a minimization criteria and instead fix that we can propose an augmented Landweber method, which we encapsulate as Algorithm 3.
7 Numerical experiments
We present here experiments from two subproblems from the field of adaptive optics for large ground-based telescopes as well as for a toy blurring problem presented as a proof-of-concept for an alternative use of these methods.
7.1 Gaussian blurring model


Our first experiment concerns an academic problem which serves as a proof of concept. However, we still execute a large-scale version of this experiment using an implicitly-defined, matrix free problem generated by the IR-Tools software package [17]. The IR-tools package does provide an out-of-the-box generator function for the Gaussian blurring problem, PRBlurGauss(); however, it does not allow one to specify precise standard deviation (i.e., the spread) of the point-spread function (PSF). Looking under the hood, though, one sees that there is a helper function called psfGauss() which generates a PSF function for a Gaussian with specified spread, which can then be fed into the general purpose PRBlur() problem generator, which outputs a matrix-free operator which convolves images with the PSF as well as the true solution and noisy right-hand side. A variety of solution images are available; we choose a predefined geometric pattern for this experiment. To make the problem sufficiently large-scale, we choose the image size to be , meaning the implicit side of the matrix induced by the PSF is . The IR-tools package is careful to not generate exact right-hand side data unless it is specified. We rerun PRBlur() with the option CommitCrime=‘true’ to obtain , but this is only used to understand the effects of noise in generating the recycling vectors. In these experiments, we generated the problem for standard deviation . To construct an augmentation subspace , we selected vectors resulting from applying two iterations of steepest descent to the right-hand side data but for different Gaussian blurring operators with five smaller standard deviations chosen equally-spaced from the interval . An orthonormal basis for the span of these (nine) vectors was obtained and taken as . We also generated a set of “clean” recycled vectors using the noise-free , to see what effect noise has on the recycling process itself. It is demonstrated that such vectors do indeed offer better performance as recycled vectors, meaning that noise does effect the recycling process.
In Figure 1, we see that for both problems, this strategy yields an improvement in convergence, both for the noise-free and noise-contaminated problems. This is a promising numerical result and a proof of concept, but it requires further analysis and experimentation to understand it in the proper concept to guide the use of this strategy for real-world, non-academic problems.








7.2 Adaptive optics: wavefront reconstruction
Turbulences in the atmosphere have a significant impact on the imaging quality of modern ground based telescopes. In order to correct for the impact of the atmosphere, Adaptive Optics (AO) systems are utilized. In these systems, the incoming light from bright guide stars is measured by wavefront sensors in order to obtain information of the actual turbulence in the atmosphere. In a next step, deformable mirrors use this information for an improvement of the obtained scientific images. For a review on the different mathematical aspects of AO systems we refer to [11]. E.g., Single Conjugate Adaptive Optics (SCAO) systems use one sensor and one mirror for the correction and are able to obtain a good image quality close to the direction of the guide star. Figure 4 shows a setup for a SCAO system. For the instruments of the new generation of telescopes, e.g., the Extremely Large Telescope (ELT) of the European Southern Observatory (ESO), the Pyramid sensor (P-WFS) will be used frequently to obtain the wavefront. A linear approximation of the connection between the incoming wavefront and and the sensor measurements - assuming a non-modulated sensor - can be described as
| (60) |
analogous for . An overview of existing reconstruction methods for the P-WFS can be found in [22, 20, 19], and a throughout analysis of the various P-WFS models is given in [21, 21].

The linear models can be used in case of small wavefront aberrations which is the case in a closed loop setting, i.e., if the wavefront sensor is optically located behind the deformable mirror. Due to the rapidly changing atmosphere, the shape of the deformable mirror has to be readjusted every 1-2 milliseconds over the whole imaging process, which might last several minutes. Therefore, the reconstructions of the wavefronts have to be accurate and have to be obtained in real-time. As a quality measure we use the Strehl ratio (), which relates the imaging quality of the telescope without disturbing atmosphere () to the corrected imaging quality, i.e.. . In the beginning of the observation the Strehl ratio is low, as the deformable mirror is not yet adjusted to the turbulence conditions. After a few time steps, the mirror is in a state where only small adjustments are necessary - the loop has been closed. This happens in our case when . In this state, the linear modes for the P-WFS are valid. We show the utility of the recycled steepest descent method for multiple steps of an closed-loop iteration for a wavefront reconstruction for the instrument METIS of the ELT. The recycling subspaces were formed by the previous reconstructions, see Fig. 5 for the results. In the long run, both steepest descent with recycling and warm restart (i.e, where the last reconstruction is used as a starting value for the new reconstruction) yield the same Strehl ratio. However, the method with recycling is able to close the loop much faster, which is important for a stable and efficient imaging of the scientific object.

7.3 Adaptive optics: Image reconstruction
Our final example concerns another problem related to astronomical imaging. As for any optical system, the design of the system determines the obtainable imaging quality: Instead of the ”true” image one always obtains a blurred image. The extend of blurring is described mathematically by the point spread function (PSF) of the optical system, and the measured image can be modeled as the convolution of the true image and the PSF:
| (61) |
Thus, the original image can be recovered - assuming the PSF is known - by solving the linear ill-posed problem (61). In this example we want to reconstruct an astronomical image from the measured image obtained by a telescope using the approximate PSF of the telescope. It is well known that the PSF of a telescope without a turbulent atmosphere above the telescope (e.g., a telescope in space) is given by
| (62) |
where is the characteristic function of the aperture of the main mirror of the telescope (usually an annulus) and represents the Fourier transform of the argument. Please note that the recovery of the original image from the measured one results in most cases in an ill posed problem, at least for smooth PSF, which is, e.g., the case for (62). For ground based telescopes, however, the turbulent atmosphere above the telescope has to be taken into account. The related PSF can be modeled as
| (63) |
Here, describes the turbulence above the telescope. As we have seen above, an AO systems aims to reduce the impact of the turbulence to the imaging process - see Section 7.2. For various reasons, e.g., the time delay between measuring the turbulences and their correction or the limited resolution of wavefront sensors and deformable mirrors, such an correction will never be perfect and therefore there will always remain a residual (uncorrected) turbulence. Based on the data from the AO system it is, however, possible to estimate those uncorrected turbulences and obtain an approximation of of the observation.
A full description of this problem, i.e. the reconstruction of the PSF from AO data of the scientific observation, can be found, e.g., in [10, Section 5.4] and references therein.
As astronomical images are acquired over a period of time, one actually recovers a time-averaged PSF, denoted .
In our experiments, the time averaged with residual turbulences taken into account is simulated by OCTOPUS [26, 25], the simulation tool of the European Southern Observatory.
In addition, we use a representation of , the PSF of the telescope without turbulences. Both PSFs are represented by matrices, i.e., as the functions
spatially discretized for images of a certain size. Please note that the recovery of the original image from the convolution data remains ill-posed in both cases.
Convolution of images with PSFs was performed using the function psfMatrix() available, .e.g., as a part of the Matlab toolbox IRTools [17]. We use the Star Cluster image, which can be obtained from the test problems of the Matlab package Restore Tools [1]. The provided artificial Star Cluster image is ; so for these experiments, the discretized PSFs are resized (i.e., downscaled) to also be using the imresize() function of Matlab. A psfMatrix object is then instantiated which can be applied via multiplication to an image to perform a convolution, i.e.,
where and , the center coordinate of the image, and we use periodic boundary conditions. Entry of the PSF indicates where the value of the PSF at is located, where we assume the square image is centered at the origin. The PSF inducing the adjoint operator can be created via the relation which, along with the image being centered at the origin, can be used to construct the discrete PSF inducing the discretized adjoint operator [39]. In Figure 6, we show log plots of the true Star Cluster image and its blurred counterpart convolved with the PSF representing the atmospheric distortion. The blurred image was perturbed with random noise generated with uniform distribution using Matlab’s rand() function, which was then scaled to have norm , where represents the convolved true image shown on the right in Figure 6.


In this study, we demonstrate that subspace recycling works well for the considered deconvolution problem. As for a telescope with a good AO system is at least a coarse approximation of , we propose to form the recycling subspace from a few eigenvectors of the matrix representing . Here, we take advantage of the fact that although changes for every observation, remains constant. This enables us to pre-calculate eigenvectors of its induced convolution operator ahead of time offline.
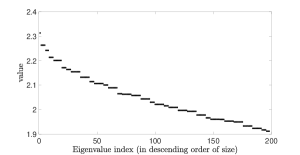
We calculated the telescope eigenvectors via the matrix-free eigs() routine of Matlab which uses a Krylov-based iteration to compute eigenvalues and eigenvectors for a few of the largest eigenvalues of the operator. In this experiment, we chose to compute the top 200 but had to perform post-processing step to eliminate the spurious complex eigenvalues/-vectors that are created in pairs, leaving us with 198 eigenvalues. Ordering the eigenvalues thereof in descending order, we augment with different collections of these pre-computed eigenvectors, starting with just the first, then the first two, and so on, up to all 198. In Figure 7, we show the residual and error curves for all experiments together. One sees that augmenting with these eigenvectors is effective in increasing the speed of convergence of the steepest descent method, with acceleration increasing as we add more vectors, but with diminishing returns.
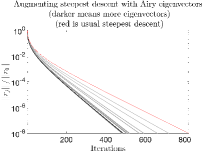

It is important to investigate how long it takes to achieve some manner of semiconvergence. Thus, for each experiment, we track at which iteration semiconvergence is achieved and also at which iteration the residual-based discrepancy principle is achieved. For the operator induced by the telescope PSF, we also monitor jumps in eigenvalue magnitude, and these are plotted separately. This is shown in Figure 8. We also show for completeness the first nine eigenvectors (i.e., eigenimages) of the operator induced by the telescope PSF in Figure 9.










Lastly, for the case in which we augmented with the first 37 eigenvectors, we show the actual image produced at the iteration in which semiconvergence was reached. We show both the raw image produced by augmented steepest descent, as well as one post-processed by thresholding pixels with values less than to be zero. This is shown (again in log plot) in Figure 10. Augmentation of additional eigenvectors beyond the first 37 produced no additional improvement for this problem.


8 Conclusions
In this paper, we have shown that under basic assumptions, the subspace recycling scheme can be combined with any known regularization scheme, and the resulting augmented scheme is still a regularization. This opens many possibilities for schemes for developing new augmented regularization schemes. We have further demonstrated this by proposing an augmented gradient descent scheme, and we show how useful recycling easily-computed information within the augmented gradient descent method can be for accelerating semi-convergence, both in an academic problem and in problems arising from applications in astronomy.
Acknowledgments
Victoria Hutterer and Ronny Ramlau are partialy supported by the SFB ”Tomography Across the Scales” (Austrian Science Fund Project F68-N36). The work in this paper was initiated during a visit by the second author to RICAM. The authors would like to thank Roland Wagner for providing sample PSFs for the last numerical experiment. Furthermore, the third author thanks Roland Wagner for his help in using the PSF to induce the adjoint operator needed for applying Landweber-type iterations. Lastly, the authors thank the referees for their constructive comments.
References
- [1] Restoretools: An object oriented matlab package for image restoration, 2012, http://www.mathcs.emory.edu/~nagy/RestoreTools/. Accessed on 28. June 2020.
- [2] K. Ahuja, E. de Sturler, S. Gugercin, and E. R. Chang, Recycling BiCG with an application to model reduction, SIAM J. Sci. Comput., 34 (2012), pp. A1925–A1949, https://doi.org/10.1137/100801500, http://dx.doi.org/10.1137/100801500.
- [3] J. Baglama and L. Reichel, Augmented GMRES-type methods, Numerical Linear Algebra with Applications, 14 (2007), pp. 337–350, https://doi.org/10.1002/nla.518, http://dx.doi.org/10.1002/nla.518.
- [4] J. Baglama and L. Reichel, Decomposition methods for large linear discrete ill-posed problems, Journal of Computational and Applied Mathematics, 198 (2007), pp. 332–343, https://doi.org/10.1016/j.cam.2005.09.025, http://dx.doi.org/10.1016/j.cam.2005.09.025.
- [5] J. Chung, E. de Sturler, and J. Jiang, Hybrid projection methods with recycling for inverse problems, (2020), https://arxiv.org/abs/2007.00207.
- [6] E. de Sturler, Nested Krylov methods based on GCR, Journal of Computational and Applied Mathematics, 67 (1996), pp. 15–41, https://doi.org/10.1016/0377-0427(94)00123-5, http://dx.doi.org/10.1016/0377-0427(94)00123-5.
- [7] E. de Sturler, M. Kilmer, and K. M. Soodhalter, Krylov subspace augmentation for the solution of shifte systems: a review. in preparation.
- [8] M. Defrise and C. D. Mol, A note on stopping rules for iterative methods and filtered svd, in Inverse Problems: An Interdisciplinary Study, P. C. Sabatier, ed., Academic Press, 1987, pp. 261–268.
- [9] Y. Dong, H. Garde, and P. C. Hansen, R3GMRES: including prior information in GMRES-type methods for discrete inverse problems, Electron. Trans. Numer. Anal., 42 (2014), pp. 136–146.
- [10] L. Dykes, R. Ramlau, L. Reichel, K. M. Soodhalter, and R. Wagner, Lanczos-based fast blind deconvolution methods, Journal of Computational and Applied Mathematics, (To Appear).
- [11] B. Ellerbroek and C. Vogel, Inverse problems in astronomical adaptive optics, Inverse Problems, 25 (2009), p. 063001.
- [12] H. Engl and R. Ramlau, Regularization of Inverse Problems, Springer, New York, 2015, pp. 1233–1241.
- [13] H. W. Engl, M. Hanke, and A. Neubauer, Regularization of inverse problems., Dordrecht: Kluwer Academic Publishers, 1996.
- [14] Y. A. Erlangga and R. Nabben, Deflation and balancing preconditioners for Krylov subspace methods applied to nonsymmetric matrices, SIAM Journal on Matrix Analysis and Applications, 30 (2008), pp. 684–699.
- [15] A. Gaul, Recycling Krylov subspace methods for sequences of linear systems: Analysis and applications, PhD thesis, Technischen Universität Berlin, 2014.
- [16] A. Gaul, M. H. Gutknecht, J. Liesen, and R. Nabben, A framework for deflated and augmented Krylov subspace methods, SIAM Journal on Matrix Analysis and Applications, 34 (2013), pp. 495–518, https://doi.org/10.1137/110820713, http://dx.doi.org/10.1137/110820713.
- [17] S. Gazzola, P. C. Hansen, and J. G. Nagy, IR Tools: a MATLAB package of iterative regularization methods and large-scale test problems, Numer. Algorithms, 81 (2019), pp. 773–811, https://doi.org/10.1007/s11075-018-0570-7, https://doi-org.libproxy.temple.edu/10.1007/s11075-018-0570-7.
- [18] M. H. Gutknecht, Deflated and augmented Krylov subspace methods: a framework for deflated BiCG and related solvers, SIAM J. Matrix Anal. Appl., 35 (2014), pp. 1444–1466, https://doi.org/10.1137/130923087, https://doi-org.libproxy.temple.edu/10.1137/130923087.
- [19] V. Hutterer and R. Ramlau, Nonlinear wavefront reconstruction methods for pyramid sensors using Landweber and Landweber-Kaczmarz iteration, Applied Optics, 57 (2018), pp. 8790–8804.
- [20] V. Hutterer and R. Ramlau, Wavefront reconstruction from non-modulated pyramid wavefront sensor data using a singular value type expansion, Inverse Problems, 34 (2018), p. 035002.
- [21] V. Hutterer, R. Ramlau, and I. Shatokhina, Real-time adaptive optics with pyramid wavefront sensors: part I. a theoretical analysis of the pyramid sensor model, Inverse Problems, 35 (2019), p. 045007, https://doi.org/10.1088/1361-6420/ab0656, https://doi.org/10.1088%2F1361-6420%2Fab0656.
- [22] R. R. I. Shatokhina, V. Hutterer, Review on methods for wavefront reconstruction from pyramid wavefront sensor data, Journal of Astronomical Telescopes, Instruments and Systems, 6 (2020), p. 010901, https://doi.org/10.1117/1.JATIS.6.1.010901.
- [23] M. E. Kilmer and E. de Sturler, Recycling subspace information for diffuse optical tomography, SIAM Journal on Scientific Computing, 27 (2006), pp. 2140–2166, https://doi.org/10.1137/040610271, http://dx.doi.org/10.1137/040610271.
- [24] L. Landweber, An Iteration Formula for Fredholm Integral Equations of the First Kind, American Journal of Mathematics, 73 (1951), pp. 615–624.
- [25] M. Le Louarn, C. Vérinaud, V. Korkiakoski, and E. Fedrigo, Parallel simulation tools for AO on ELTs, in Advancements in Adaptive Optics, Proc. SPIE 5490, 2004, pp. 705–712.
- [26] M. Le Louarn, C. Vérinaud, V. Korkiakoski, N. Hubin, and E. Marchetti, Adaptive optics simulations for the European Extremely Large Telescope - art. no. 627234, in Advances in Adaptive Optics II, Prs 1-3, vol. 6272, 2006, pp. U1048–U1056.
- [27] A. K. Louis, Inverse und schlecht gestellte Probleme, Teubner Studienbücher Mathematik, Vieweg+Teubner Verlag, 1989.
- [28] R. B. Morgan, GMRES with deflated restarting, SIAM J. Sci. Comput., 24 (2002), pp. 20–37, https://doi.org/10.1137/S1064827599364659, https://doi-org.libproxy.temple.edu/10.1137/S1064827599364659.
- [29] M. L. Parks, E. de Sturler, G. Mackey, D. D. Johnson, and S. Maiti, Recycling Krylov subspaces for sequences of linear systems, SIAM Journal on Scientific Computing, 28 (2006), pp. 1651–1674, https://doi.org/10.1137/040607277, http://dx.doi.ofrrg/10.1137/040607277.
- [30] M. L. Parks, K. M. Soodhalter, and D. B. Szyld, A block recycled gmres method with investigations into aspects of solver performance, (2016), https://arxiv.org/abs/1604.01713.
- [31] R. Ramlau and M. Rosensteiner, An efficient solution to the atmospheric turbulence tomography problem using Kaczmarz iteration, Inverse Problems, 28 (2012), p. 095004.
- [32] R. Ramlau and B. Stadler, An augmented wavelet reconstructor for atmospheric tomography, 2020, https://arxiv.org/abs/2011.06842.
- [33] Y. Saad, Krylov subspace methods for solving large unsymmetric linear systems, Mathematics of Computation, 37 (1981), pp. 105–126, https://doi.org/10.2307/2007504, http://dx.doi.org/10.2307/2007504.
- [34] Y. Saad, Iterative Methods for Sparse Linear Systems, SIAM, Philadelphia, Second ed., 2003.
- [35] O. Scherzer, M. Grasmair, H. Grossauer, M. Haltmeier, and F. Lenzen, Variational Methods in Imaging, Springer, New York, 2009.
- [36] K. M. Soodhalter, E. de Sturler, and M. Kilmer, A survey of subspace recycling iterative methods, GAMM Mitteilungen, (2020). Applied and numerical linear algebra topical issue.
- [37] L. N. Trefethen and D. Bau, III, Numerical linear algebra, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 1997, https://doi.org/10.1137/1.9780898719574, https://doi-org.libproxy.temple.edu/10.1137/1.9780898719574.
- [38] S. Wang, E. de Sturler, and G. H. Paulino, Large-scale topology optimization using preconditioned Krylov subspace methods with recycling, International Journal for Numerical Methods in Engineering, 69 (2007), pp. 2441–2468, https://doi.org/10.1002/nme.1798, http://dx.doi.org/10.1002/nme.1798.
- [39] R. Wanger. Personal Communication, Mar. 2020.
- [40] M. Yudytskiy, T. Helin, and R. Ramlau, Finite element-wavelet hybrid algorithm for atmospheric tomography, J. Opt. Soc. Am. A, 31 (2014), pp. 550–560, https://doi.org/10.1364/JOSAA.31.000550, http://josaa.osa.org/abstract.cfm?URI=josaa-31-3-550.