Structured Convolutions for Efficient Neural Network Design
Abstract
In this work, we tackle model efficiency by exploiting redundancy in the implicit structure of the building blocks of convolutional neural networks. We start our analysis by introducing a general definition of Composite Kernel structures that enable the execution of convolution operations in the form of efficient, scaled, sum-pooling components. As its special case, we propose Structured Convolutions and show that these allow decomposition of the convolution operation into a sum-pooling operation followed by a convolution with significantly lower complexity and fewer weights. We show how this decomposition can be applied to 2D and 3D kernels as well as the fully-connected layers. Furthermore, we present a Structural Regularization loss that promotes neural network layers to leverage on this desired structure in a way that, after training, they can be decomposed with negligible performance loss. By applying our method to a wide range of CNN architectures, we demonstrate ‘structured’ versions of the ResNets that are up to 2 smaller and a new Structured-MobileNetV2 that is more efficient while staying within an accuracy loss of 1% on ImageNet and CIFAR-10 datasets. We also show similar structured versions of EfficientNet on ImageNet and HRNet architecture for semantic segmentation on the Cityscapes dataset. Our method performs equally well or superior in terms of the complexity reduction in comparison to the existing tensor decomposition and channel pruning methods.
1 Introduction
Deep neural networks deliver outstanding performance across a variety of use-cases but quite often fail to meet the computational budget requirements of mainstream devices. Hence, model efficiency plays a key role in bridging deep learning research into practice. Various model compression techniques rely on a key assumption that the deep networks are over-parameterized, meaning that a significant proportion of the parameters are redundant. This redundancy can appear either explicitly or implicitly. In the former case, several structured [12, 23], as well as unstructured [8, 9, 27, 46], pruning methods have been proposed to systematically remove redundant components in the network and improve run-time efficiency. On the other hand, tensor-decomposition methods based on singular values of the weight tensors, such as spatial SVD or weight SVD, remove somewhat implicit elements of the weight tensor to construct low-rank decompositions for efficient inference [5, 14, 19].
Redundancy in deep networks can also be seen as network weights possessing an unnecessarily high degrees of freedom (DOF). Alongside various regularization methods [17, 33] that impose constraints to avoid overfitting, another approach for reducing the DOF is by decreasing the number of learnable parameters. To this end, [14, 29, 38] propose using certain basis representations for weight tensors. In these methods, the basis vectors are fixed and only their coefficients are learnable. Thus, by using a smaller number of coefficients than the size of weight tensors, the DOF can be effectively restricted. But, note that, this is useful only during training since the original higher number of parameters are used during inference. [29] shows that systematically choosing the basis (e.g. the Fourier-Bessel basis) can lead to model size shrinkage and flops reduction even during inference.
In this work, we explore restricting the degrees of freedom of convolutional kernels by imposing a structure on them. This structure can be thought of as constructing the convolutional kernel by super-imposing several constant-height kernels. A few examples are shown in Fig. 1, where a kernel is constructed via superimposition of linearly independent masks with associated constant scalars , hence leading to degrees of freedom for the kernel. The very nature of the basis elements as binary masks enables efficient execution of the convolution operation as explained in Sec. 3.1.
In Sec. 4, we introduce Structured Convolutions as a special case of this superimposition and show that it leads to a decomposition of the convolution operation into a sum-pooling operation and a significantly smaller convolution operation. We show how this decomposition can be applied to convolutional layers as well as fully connected layers. We further propose a regularization method named Structural Regularization that promotes the normal convolution weights to have the desired structure that facilitates our proposed decomposition. Overall, our key contributions in this work are:
-
1.
We introduce Composite Kernel structure, which accepts an arbitrary basis in the kernel formation, leading to an efficient convolution operation. Sec. 3 provides the definition.
-
2.
We propose Structured Convolutions, a realization of the composite kernel structure. We show that a structured convolution can be decomposed into a sum-pooling operation followed by a much smaller convolution operation. A detailed analysis is provided in Sec. 4.1.
-
3.
Finally, we design Structural Regularization, an effective training method to enable the structural decomposition with minimal loss of accuracy. Our process is described in Sec. 5.1.

(a)

(b)

(c)
Color combinations are chosen to reflect the summations, this figure is best viewed in color.
2 Related Work
The existing literature on exploiting redundancy in deep networks can be broadly studied as follows.
Tensor Decomposition Methods. The work in [47] proposed a Generalized SVD approach to decompose a convolution (where and are output and input channels, and is the spatial size) into a convolution followed by a convolution. Likewise, [14] introduced Spatial SVD to decompose a kernel into and kernels. [36] further developed a non-iterative method for such low-rank decomposition. CP-decomposition [15, 20] and tensor-train decomposition [28, 35, 43] have been proposed to decompose high dimensional tensors. In our method, we too aim to decompose regular convolution into computationally lightweight units.
Structured Pruning. [11, 12, 22] presented channel pruning methods where redundant channels in every layer are removed. The selection process of the redundant channels is unique to every method, for instance, [12] addressed the channel selection problem using lasso regression. Similarly, [41] used group lasso regularization to penalize and prune unimportant groups on different levels of granularity. We refer readers [19] for a survey of structured pruning and tensor decomposition methods. To our advantage, the proposed method in this paper does not explicitly prune, instead, our structural regularization loss imposes a form on the convolution kernels.
Semi-structured and Unstructured Pruning. Other works [21, 25, 6] employed block-wise sparsity (also called semi-structured pruning) which operates on a finer level than channels. Unstructured pruning methods [1, 8, 18, 46] prune on the parameter-level yielding higher compression rates. However, their unstructured nature makes it difficult to deploy them on most hardware platforms.
Using Prefixed Basis. Several works [29, 38] applied basis representations in deep networks. Seminal works [26, 32] used wavelet bases as feature extractors. Choice of the basis is important, for example, [29] used Fourier-Bessel basis that led to a reduction in computation complexity. In general, tensor decomposition can be seen as basis representation learning. We propose using structured binary masks as our basis, which leads to an immediate reduction in the number of multiplications.
3 Composite Kernels
We first give a definition that encompasses a wide range of structures for convolution kernels.
Definition 1.
For , a Composite Basis is a linearly independent set of binary tensors of dimension as its basis elements. That is, , each element of , and .
The linear independence condition implies that . Hence, the basis spans a subspace of . The speciality of the Composite Basis is that the basis elements are binary, which leads to an immediate reduction in the number of multiplications involved in the convolution operation.
Definition 2.
A kernel is a Composite Kernel if it is in the subspace of the Composite Basis. That is, it can be constructed as a linear combination of the elements of : such that .
Note that, the binary structure of the underlying Composite Basis elements defines the structure of the Composite Kernel. Fig. 1 shows a Composite Kernel (with ) constructed using different examples of a Composite Basis. In general, the underlying basis elements could have a more random structure than what is demonstrated in those examples shown in Fig. 1.
Conventional kernels (with no restrictions on DOF) are just special cases of Composite Kernels, where and each basis element has only one nonzero element in its grid.
3.1 Convolution with Composite Kernels
Consider a convolution with a Composite Kernel of size , where is the spatial size and is the number of input channels. To compute an output, this kernel is convolved with a volume of the input feature map. Let’s call this volume . Therefore, the output at this point will be:
| (1) |
where ‘’ denotes convolution, ‘’ denotes element-wise multiplication. Since is a binary tensor, is same as adding the elements of wherever , thus no multiplications are needed. Ordinarily, the convolution would involve multiplications and additions. In our method, we can trade multiplications with additions. From (1), we can see that we only need multiplications and the total number of additions becomes:
| (2) |
4 Structured Convolutions

Figure best viewed in color.

Definition 3.
A kernel in is a Structured Kernel if it is a Composite Kernel with for some , and if each basis tensor is made of a cuboid of ’s, while rest of its coefficients being .
A Structured Kernel is characterized by its dimensions and its underlying parameters . Convolutions performed using Structured Kernels are called Structured Convolutions.
Fig. 1(b) depicts a 2D case of a structured kernel where . As shown, there are basis elements and each element has a sized patch of ’s.
Fig. 2 shows a 3D case where . Here, there are basis elements and each element has a cuboid of ’s. Note how these cuboids of ’s (shown in colors) cover the entire grid.
4.1 Decomposition of Structured Convolutions
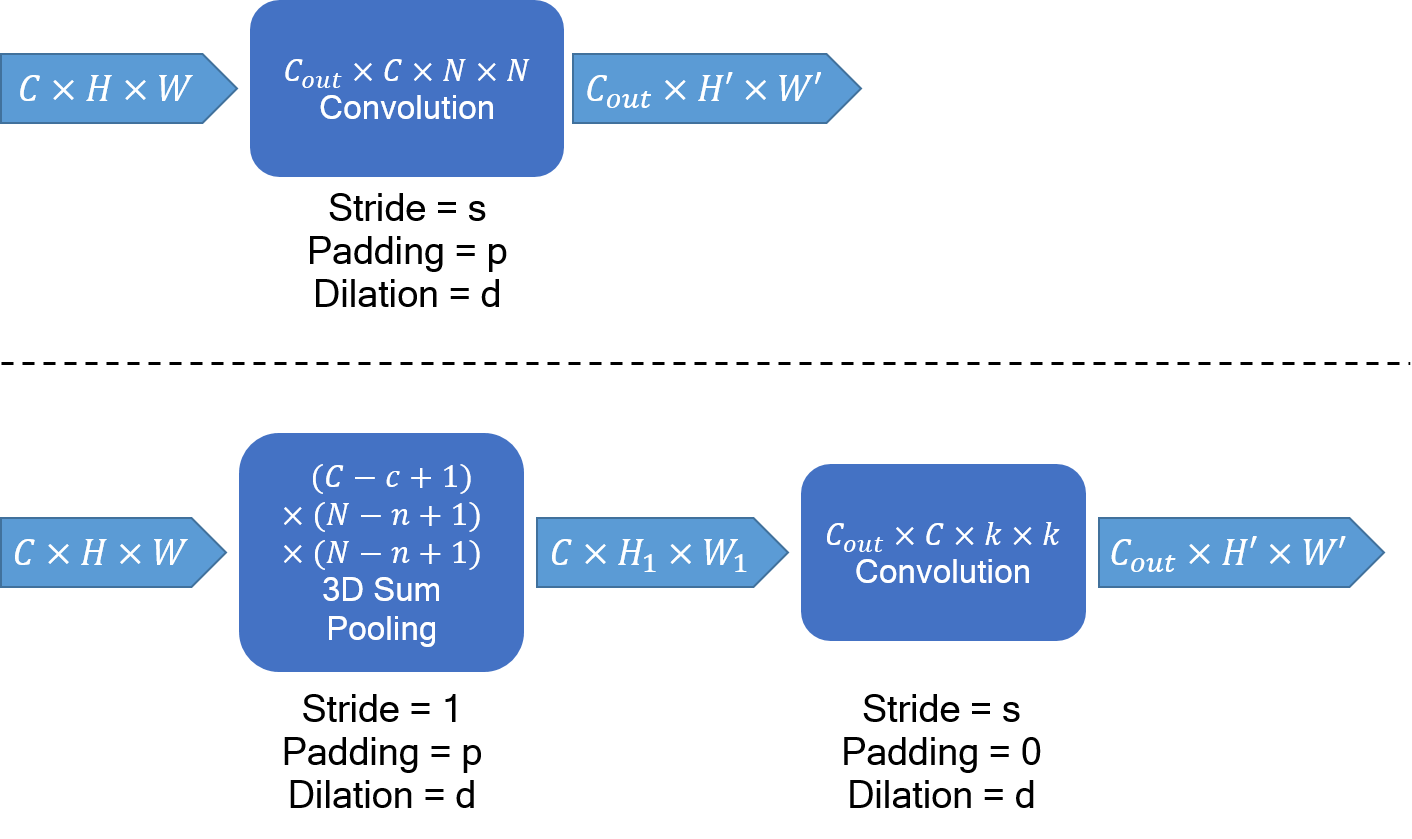
A major advantage of defining Structured Kernels this way is that all the basis elements are just shifted versions of each other (see Fig. 2 and Fig. 1(b)). This means, in Eq. (1), if we consider the convolution for the entire feature map , the summed outputs for all ’s are actually the same (except on the edges of ). As a result, the outputs can be computed using a single sum-pooling operation on with a kernel size of . Fig. 3 shows a simple example of how a convolution with a structured kernel can be broken into a sum-pooling followed by a convolution with a kernel made of ’s.
Furthermore, consider a convolutional layer of size that has kernels of size . In our design, the same underlying basis is used for the construction of all kernels in the layer. Suppose any two structured kernels in this layer with coefficients and , i.e. and . The convolution output with these two kernels is respectively, and . We can see that the computation is common to all the kernels of this layer. Hence, the sum-pooling operation only needs to be computed once and then reused across all the kernels.
A Structured Convolution can thus be decomposed into a sum-pooling operation and a smaller convolution operation with a kernel composed of ’s. Fig. 4 shows the decomposition of a general structured convolution layer of size .
Notably, standard convolution (), depthwise convolution (), and pointwise convolution () kernels can all be constructed as 3D structured kernels, which means that this decomposition can be widely applied to existing architectures. See supplementary material for more details on applying the decomposition to convolutions with arbitrary stride, padding, dilation.

4.2 Reduction in Number of Parameters and Multiplications/Additions
The sum-pooling component after decomposition requires no parameters. Thus, the total number of parameters in a convolution layer get reduced from (before decomposition) to (after decomposition). The sum-pooling component is also free of multiplications. Hence, only the smaller convolution contributes to multiplications after decomposition.
Before decomposition, computing every output element in feature map involves multiplications and additions. Hence, total multiplications involved are and total additions involved are .
After decomposition, computing every output element in feature map involves multiplications and additions. Hence, total multiplications and additions involved in computing are and respectively. Now, computing every element of the intermediate sum-pooled output involves additions. Hence, the overall total additions involved can be written as:
We can see that the number of parameters and number of multiplications have both reduced by a factor of . And in the expression above, if is large enough, the first term inside the parentheses gets amortized and the number of additions . As a result, the number of additions also reduce by approximately the same proportion . We will refer to as the compression ratio from now on.
Due to amortization, the additions per output are , which is basically since .
4.3 Extension to Fully Connected layers
For image classification networks, the last fully connected layer (sometimes called linear layer) dominates w.r.t. the number of parameters, especially if the number of classes is high. The structural decomposition can be easily extended to the linear layers by noting that a matrix multiplication is the same as performing a number of convolutions on the input. Consider a kernel and input vector . The linear operation is mathematically equivalent to the convolution , where is the same as but with dimensions and is the same as but with dimensions . In other words, each row of can be considered a convolution kernel of size .
Now, if each of these kernels (of size ) is structured with underlying parameter (where ), then the matrix multiplication operation can be structurally decomposed as shown in Fig. 5.

Same as before, we get a reduction in both the number of parameters and the number of multiplications by a factor of , as well as the number of additions by a factor of .
5 Imposing Structure on Convolution Kernels
To apply the structural decomposition, we need the weight tensors to be structured. In this section, we propose a method to impose the desired structure on the convolution kernels via training.
From the definition, , we can simply define matrix such that its column is the vectorized form of . Hence, , where .
Another way to see this is from structural decomposition. We may note that the sum-pooling can also be seen as a convolution with a kernel of all ’s; we refer to this kernel as . Hence, the structural decomposition is:
That implies, . Since the stride of the sum-pooling involved is , this can be written in terms of a matrix multiplication with a Topelitz matrix [34]:
Hence, the structure matrix referred above is basically .
5.1 Training with Structural Regularization
Now, for a structured kernel characterized by , there exists a length such that . Hence, a structured kernel satisfies the property: , where is the Moore-Penrose inverse [2] of . Based on this, we propose training a deep network with a Structural Regularization loss that can gradually push the deep network’s kernels to be structured via training:
| (3) |
where denotes Frobenius norm and is the layer index. To ensure that regularization is applied uniformly to all layers, we use normalization in the denominator. It also stabilizes the performance of the decomposition w.r.t . The overall proposed training recipe is as follows:
Proposed Training Scheme:
-
•
Step 1: Train the original architecture with the Structural Regularization loss.
-
–
After Step 1, all weight tensors in the deep network will be almost structured.
-
–
-
•
Step 2: Apply the decomposition on every layer and compute .
-
–
This results in a smaller and more efficient decomposed architecture with ’s as the weights. Note that, every convolution / linear layer from the original architecture is now replaced with a sum-pooling layer and a smaller convolution / linear layer.
-
–
The proposed scheme trains the architecture with the original kernels in place but with a structural regularization loss. The structural regularization loss imposes a restrictive degrees of freedom while training but in a soft or gradual manner (depending on ):
-
1.
If , it is the same as normal training with no structure imposed.
-
2.
If is very high, the regularization loss will be heavily minimized in early training iterations. Thus, the weights will be optimized in a restricted dimensional subspace of .
-
3.
Choosing a moderate gives the best tradeoff between structure and model performance.
We talk about training implementation details for reproduction, such as hyperparameters and training schedules, in Supplementary material, where we also show our method is robust to the choice of .
6 Experiments
We apply structured convolutions to a wide range of architectures and analyze the performance and complexity of the decomposed architectures. We evaluate our method on ImageNet [30] and CIFAR-10 [16] benchmarks for image classification and Cityscapes [4] for semantic segmentation.
| Architecture | Adds () | Mults () | Params () | Acc. (in %) |
| ResNet50 | ||||
| Struct-50-A (ours) | ||||
| Struct-50-B (ours) | ||||
| ChPrune-R50-2x [12] | ||||
| WeightSVD-R50 [48] | ||||
| Ghost-R50 (s=2) [7] | ||||
| Versatile-v2-R50 [40] | ||||
| ShiftResNet50 [42] | – | – | ||
| Slim-R50 x [45] | ||||
| ResNet34 | ||||
| Struct-34-A (ours) | ||||
| Struct-34-B (ours) | ||||
| ResNet18 | ||||
| Struct-18-A (ours) | ||||
| Struct-18-B (ours) | ||||
| WeightSVD-R18 [48] | ||||
| ChPrune-R18-2x [12] | ||||
| ChPrune-R18-4x |
6.1 Image Classification
We present results for ResNets [10] in Tables 4 and 4. To demonstrate the efficacy of our method on modern networks, we also show results on MobileNetV2 [31] and EfficientNet111Our Efficientnet reproduction of baselines (B0 and B1) give results slightly inferior to [37]. Our Struct-EffNet is created on top of this EfficientNet-B1 baseline. [37] in Table 4 and 4.
To provide a comprehensive analysis, for each baseline architecture, we present structured counterparts, with version "A" designed to deliver similar accuracies and version "B" for extreme compression ratios. Using different configurations per-layer, we obtain structured versions with varying levels of reduction in model size and multiplications/additions (please see Supplementary material for details). For the "A" versions of ResNet, we set the compression ratio () to be 2 for all layers. For the "B" versions of ResNets, we use nonuniform compression ratios per layer. Specifically, we compress stages 3 and 4 drastically (4) and stages 1 and 2 by . Since MobileNet is already a compact model, we design its "A" version to be smaller and "B" version to be smaller.
We note that, on low-level hardware, additions are much power-efficient and faster than multiplications [3, 13]. Since the actual inference time depends on how software optimizations and scheduling are implemented, for most objective conclusions, we provide the number of additions / multiplications and model sizes. Considering observations for sum-pooling on dedicated hardware units [44], our structured convolutions can be easily adapted for memory and compute limited devices.
Compared to the baseline models, the Struct-A versions of ResNets are smaller, while maintaining less than loss in accuracy. The more aggressive Struct-B ResNets achieve - model size reduction with about - accuracy drop. Compared to other methods, Struct-56-A is better than AMC-Res56 [11] of similar complexity and Struct-20-A exceeds ShiftResNet20-6 [42] by while being significantly smaller. Similar trends are observed with Struct-Res18 and Struct-Res50 on ImageNet. Struct-56-A and Struct-50-A achieve competitive performance as compared to the recent GhostNets [7]. For MobileNetV2 which is already designed to be efficient, Struct-MV2-A achieves further reduction in multiplications and model size with SOTA performance compared to other methods, see Table 4. Applying structured convolutions to EfficientNet-B1 results in Struct-EffNet that has comparable performance to EfficientNet-B0, as can be seen in Table 4.



The ResNet Struct-A versions have similar number of adds and multiplies (except ResNet50) because, as noted in Sec. 4.2, the sum-pooling contribution is amortized. But sum-pooling starts dominating as the compression gets more aggressive, as can be seen in the number of adds for Struct-B versions. Notably, both "A" and "B" versions of MobileNetV2 observe a dominance of the sum-pooling component. This is because the number of output channels are not enough to amortize the sum-pooling component resulting from the decomposition of the pointwise ( conv) layers.
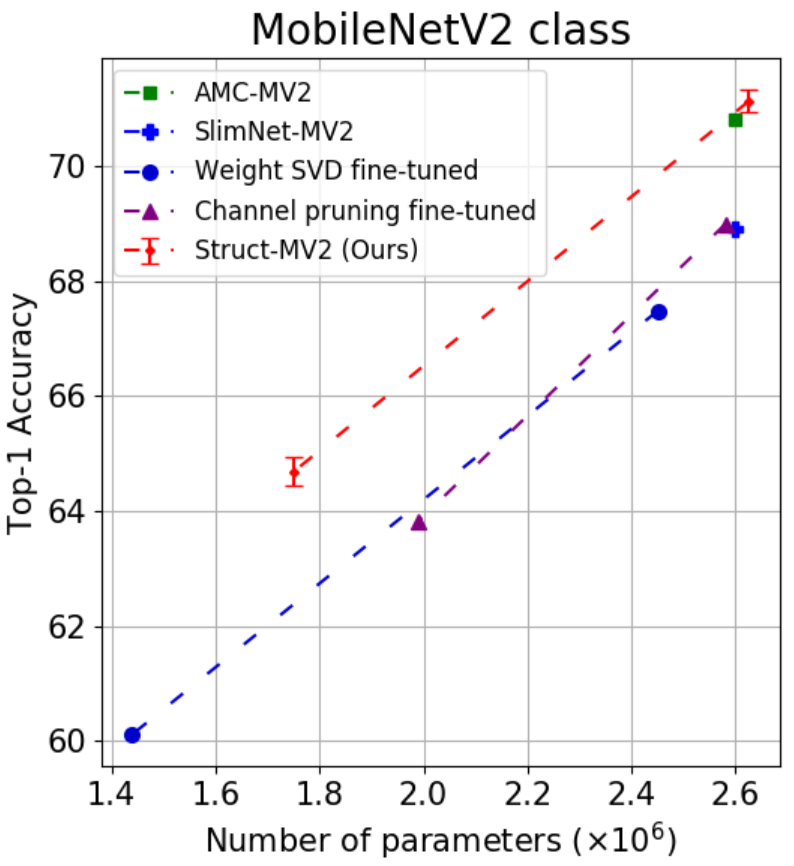
Fig. 6 compares our method with state-of-the-art structured compression methods - WeightSVD [48], Channel Pruning [12], and Tensor-train [35]. Note, the results were obtained from [19]. Our proposed method achieves approximately improvement over the second best method for ResNet18 () and MobileNetV2 (). Especially for MobileNetV2, this improvement is valuable since it significantly outperforms all the other methods (see Struct-V2-A in Table 4).
6.2 Semantic Segmentation
| HRNetV2-W18 -Small-v2 | #adds () | #mults () | #params () | Mean IoU (in %) |
| Original | ||||
| Struct-HR-A |
After demonstrating the superiority of our method on image classification, we evaluate it for semantic segmentation that requires reproducing fine details around object boundaries. We apply our method to a recently developed state-of-the-art HRNet [39]. Table 5 shows that the structured convolutions can significantly improve our segmentation model efficiency: HRNet model is reduced by 50% in size, and 30% in number of additions and multiplications, while having only 1.5% drop in mIoU. More results for semantic segmentation can be found in the supplementary material.
6.3 Computational overhead of Structural Regularization term
The proposed method involves computing the Structural Regularization term (3) during training. Although the focus of this work is more on inference efficiency, we measure the memory and time-per-iteration for training with and w/o the Structural Regularization loss on an NVIDIA V100 GPU. We report these numbers for Struct-18-A and Struct-MV2-A architectures below. As observed, the additional computational cost of the regularization term is negligible for a batchsize of . This is because, mathematically, the regularization term, , is independent of the input size. Hence, when using a large batchsize for training, the regluarization term’s memory and runtime overhead is relatively small (less than for Struct-MV2-A and for Struct-18-A).
| Training costs (batchsize=256) | Struct-18-A | Struct-MV2-A | ||
| Mem | seconds / iter | Mem | seconds / iter | |
| With SR loss | GB | s | GB | s |
| Without SR loss | GB | s | GB | s |
6.4 Directly training Structured Convolutions as an architectural feature
In our proposed method, we train the architecture with original kernels in place and the regularization loss imposes desired structure on these kernels. At the end of training, we decompose the kernels and replace each with a sum-pooling layer and smaller layer of kernels.
A more direct approach could be to train the decomposed architecture (with the sum-pooling + layers in place) directly. The regularization term is not required in this direct approach, as there is no decomposition step, hence eliminating the computation overhead shown in Table 6. We experimented with this direct training method and observed that the regularization based approach always outperformed the direct approach (by % for Struct-18-A and by % for Struct-MV2-A). This is because, as pointed out in Sec. 5.1, the direct method optimizes the weights in a restricted subspace of kernels right from the start, whereas the regularization based approach gradually moves the weights from the larger () subspace to the restricted subspace with gradual imposition of the structure constraints via the regularization loss.
7 Conclusion
In this work, we propose Composite Kernels and Structured Convolutions in an attempt to exploit redundancy in the implicit structure of convolution kernels. We show that Structured Convolutions can be decomposed into a computationally cheap sum-pooling component followed by a significantly smaller convolution, by training the model using an intuitive structural regularization loss. The effectiveness of the proposed method is demonstrated via extensive experiments on image classification and semantic segmentation benchmarks. Sum-pooling relies purely on additions, which are known to be extremely power-efficient. Hence, our method shows promise in deploying deep models on low-power devices. Since our method keeps the convolutional structures, it allows integration of further model compression schemes, which we leave as future work.
Broader Impact
The method proposed in this paper promotes the adaption of deep learning neural networks into memory and compute limited devices, allowing a broader acceptance of machine learning solutions for a spectrum of real-life use cases. By reducing the associated hardware costs of the neural network systems, it aims at making such technology affordable to larger communities. It empowers people by facilitating access to the latest developments in this discipline of science. It neither leverages biases in data nor demands user consent for the use of data.
Acknowledgements
We would like to thank our Qualcomm AI Research colleagues for their support and assistance, in particular that of Andrey Kuzmin, Tianyu Jiang, Khoi Nguyen, Kwanghoon An and Saurabh Pitre.
References
- [1] Kambiz Azarian, Yash Bhalgat, Jinwon Lee, and Tijmen Blankevoort. Learned threshold pruning. arXiv preprint arXiv:2003.00075, 2020.
- [2] Adi Ben-Israel and Thomas NE Greville. Generalized inverses: theory and applications, volume 15. Springer Science & Business Media, 2003.
- [3] Hanting Chen, Yunhe Wang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, and Chang Xu. Addernet: Do we really need multiplications in deep learning? arXiv preprint arXiv:1912.13200, 2019.
- [4] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [5] Emily L. Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Exploiting linear structure within convolutional networks for efficient evaluation. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 1269–1277, 2014.
- [6] Erich Elsen, Marat Dukhan, Trevor Gale, and Karen Simonyan. Fast sparse convnets. arXiv preprint arXiv:1911.09723, 2019.
- [7] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, and Chang Xu. Ghostnet: More features from cheap operations. arXiv preprint arXiv:1911.11907, 2019.
- [8] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- [9] Song Han, Jeff Pool, John Tran, and William J. Dally. Learning both weights and connections for efficient neural networks. CoRR, abs/1506.02626, 2015.
- [10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, pages 770–778. IEEE Computer Society, 2016.
- [11] Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, and Song Han. AMC: automl for model compression and acceleration on mobile devices. In Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part VII, volume 11211 of Lecture Notes in Computer Science, pages 815–832. Springer, 2018.
- [12] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural networks. In IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 1398–1406, 2017.
- [13] Mark Horowitz. 1.1 computing’s energy problem (and what we can do about it). In 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), pages 10–14. IEEE, 2014.
- [14] Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. Speeding up convolutional neural networks with low rank expansions. arXiv preprint arXiv:1405.3866, 2014.
- [15] Tamara G Kolda and Brett W Bader. Tensor decompositions and applications. SIAM review, 51(3):455–500, 2009.
- [16] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [17] Anders Krogh and John A Hertz. A simple weight decay can improve generalization. In Advances in neural information processing systems, pages 950–957, 1992.
- [18] Aditya Kusupati, Vivek Ramanujan, Raghav Somani, Mitchell Wortsman, Prateek Jain, Sham Kakade, and Ali Farhadi. Soft threshold weight reparameterization for learnable sparsity. arXiv preprint arXiv:2002.03231, 2020.
- [19] Andrey Kuzmin, Markus Nagel, Saurabh Pitre, Sandeep Pendyam, Tijmen Blankevoort, and Max Welling. Taxonomy and evaluation of structured compression of convolutional neural networks. arXiv preprint arXiv:1912.09802, 2019.
- [20] Vadim Lebedev, Yaroslav Ganin, Maksim Rakhuba, Ivan Oseledets, and Victor Lempitsky. Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv preprint arXiv:1412.6553, 2014.
- [21] Vadim Lebedev and Victor Lempitsky. Fast convnets using group-wise brain damage. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2554–2564, 2016.
- [22] Fengfu Li and Bin Liu. Ternary weight networks. arXiv preprint arxiv:1605.04711, 2016.
- [23] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017.
- [24] Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision, pages 7083–7093, 2019.
- [25] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. arXiv preprint arXiv:1810.05270, 2018.
- [26] Stéphane Mallat. Group invariant scattering. Communications on Pure and Applied Mathematics, 65(10):1331–1398, 2012.
- [27] Franco Manessi, Alessandro Rozza, Simone Bianco, Paolo Napoletano, and Raimondo Schettini. Automated pruning for deep neural network compression. In 24th International Conference on Pattern Recognition, ICPR 2018, Beijing, China, August 20-24, 2018, pages 657–664. IEEE Computer Society, 2018.
- [28] Ivan V Oseledets. Tensor-train decomposition. SIAM Journal on Scientific Computing, 33(5):2295–2317, 2011.
- [29] Qiang Qiu, Xiuyuan Cheng, Robert Calderbank, and Guillermo Sapiro. Dcfnet: Deep neural network with decomposed convolutional filters. arXiv preprint arXiv:1802.04145, 2018.
- [30] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015.
- [31] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [32] Laurent Sifre and Stéphane Mallat. Rotation, scaling and deformation invariant scattering for texture discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1233–1240, 2013.
- [33] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
- [34] Gilbert Strang. A proposal for toeplitz matrix calculations. Studies in Applied Mathematics, 74(2):171–176, 1986.
- [35] Jiahao Su, Jingling Li, Bobby Bhattacharjee, and Furong Huang. Tensorized spectrum preserving compression for neural networks. arXiv preprint arXiv:1805.10352, 2018.
- [36] Cheng Tai, Tong Xiao, Yi Zhang, Xiaogang Wang, et al. Convolutional neural networks with low-rank regularization. arXiv preprint arXiv:1511.06067, 2015.
- [37] Mingxing Tan and Quoc V Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2019.
- [38] Muhammad Tayyab and Abhijit Mahalanobis. Basisconv: A method for compressed representation and learning in cnns. arXiv preprint arXiv:1906.04509, 2019.
- [39] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, and Bin Xiao. Deep high-resolution representation learning for visual recognition. TPAMI, 2019.
- [40] Yunhe Wang, Chang Xu, XU Chunjing, Chao Xu, and Dacheng Tao. Learning versatile filters for efficient convolutional neural networks. In Advances in Neural Information Processing Systems, pages 1608–1618, 2018.
- [41] Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Learning structured sparsity in deep neural networks. In Advances in neural information processing systems, pages 2074–2082, 2016.
- [42] Bichen Wu, Alvin Wan, Xiangyu Yue, Peter Jin, Sicheng Zhao, Noah Golmant, Amir Gholaminejad, Joseph Gonzalez, and Kurt Keutzer. Shift: A zero flop, zero parameter alternative to spatial convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9127–9135, 2018.
- [43] Yinchong Yang, Denis Krompass, and Volker Tresp. Tensor-train recurrent neural networks for video classification. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3891–3900. JMLR. org, 2017.
- [44] Reginald Clifford Young and William John Gulland. Performing average pooling in hardware, July 24 2018. US Patent 10,032,110.
- [45] Jiahui Yu, Linjie Yang, Ning Xu, Jianchao Yang, and Thomas Huang. Slimmable neural networks. arXiv preprint arXiv:1812.08928, 2018.
- [46] Tianyun Zhang, Shaokai Ye, Kaiqi Zhang, Jian Tang, Wujie Wen, Makan Fardad, and Yanzhi Wang. A systematic DNN weight pruning framework using alternating direction method of multipliers. In Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part VIII, volume 11212 of Lecture Notes in Computer Science, pages 191–207. Springer, 2018.
- [47] Xiangyu Zhang, Jianhua Zou, Kaiming He, and Jian Sun. Accelerating very deep convolutional networks for classification and detection. IEEE Trans. Pattern Anal. Mach. Intell., 38(10):1943–1955, 2016.
- [48] Xiangyu Zhang, Jianhua Zou, Kaiming He, and Jian Sun. Accelerating very deep convolutional networks for classification and detection. IEEE transactions on pattern analysis and machine intelligence, 38(10):1943–1955, 2016.
- [49] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017.
- [50] Huasong Zhong, Xianggen Liu, Yihui He, and Yuchun Ma. Shift-based primitives for efficient convolutional neural networks. arXiv preprint arXiv:1809.08458, 2018.
Appendix A Appendix
A.1 Structured Convolutions with arbitrary Padding, Stride and Dilation
In the main paper, we showed that a Structured Convolution can be decomposed into a Sum-Pooling component followed by a smaller convolution operation with a kernel composed of the ’s. In this section, we discuss how to calculate the equivalent stride, padding and dilation needed for the resulting decomposed sum-pooling and convolution operations.
A.1.1 Padding
The easiest of these three attributes is padding. Fig. 7 shows an example of a structured convolution with a kernel (i.e. ) with underlying parameter . Hence, it can be decomposed into a sum-pooling operation followed by a convolution. As shown in the figure, to preserve the same output after the decomposition, the sum-pooling component should use the same padding as the original convolution, whereas the smaller convolution is performed without padding.
This leads us to a more general result that - if the original convolution uses a padding of , then, after the decomposition, the sum-pooling should be performed with padding and the smaller convolution (with ’s) should be performed without padding.

A.1.2 Stride
The above rule can be simply extended to the case where the original structured convolution has a stride associated with it. The general rule is - if the original convolution uses a stride of , then, after the decomposition, the sum-pooling should be performed with a stride of and the smaller convolution (with ’s) should be performed with a stride of .
A.1.3 Dilation
Dilated or atrous convolutions are prominent in semantic segmentation architectures. Hence, it is important to consider how we can decompose dilated structured convolutions. Fig. 8 shows an example of a structured convolution with a dilation of . As can be seen in the figure, to preserve the same output after decomposition, both the sum-pooling component and the smaller convolution (with ’s) has to be performed with a dilation factor same as the original convolution.

Fig. 9 summarizes the aforementioned rules regarding padding, stride and dilation.
A.2 Training Implementation Details
Image Classification. For both ImageNet and CIFAR-10 benchmarks, we train all the ResNet architectures from scratch with the Structural Regularization (SR) loss. We set to for the Struct-A versions and for the Struct-B versions throughout training. For MobileNetV2, we first train the deep network from scratch without SR loss (i.e. ) for epochs to obtain pretrained weights and then apply SR loss with for further epochs. For EfficientNet-B0, we first train without SR loss for epochs and then apply SR loss with for further epochs.
For CIFAR-10, we train the ResNets for epochs using a batch size of and an initial learing rate of which is decayed by a factor of at and epochs. We use a weight decay of throughout training. On ImageNet, we use a cosine learning rate schedule with an SGD optimizer for training all architectures. We train the ResNets using a batch size of and weight decay of for epochs starting with an initial learning rate of .
For MobileNetV2, we use a weight decay of and batch size throughout training. In the first phase (with ), we use an initial learning rate of for epochs and in the second phase, we start a new cosine schedule with an initial learning rate of for the next epochs. We train EfficientNet-B0 using Autoaugment, a weight decay of and batch size . We use an initial learning rate of in the first phase and we start a new cosine schedule for the second phase with an initial learning rate of for the next epochs.
Semantic Segmentation. For training Struct-HRNet-A on Cityscapes, we start from a pre-trained HRNet model and train using structural regularization loss. We set to . We use a cosine learning rate schedule with an initial learning rate of . The use image resolution of for training, same as the original image size. We train for 90000 iterations using a batch size of 4.
A.3 Additional results on Semantic Segmentation
In Table 8 and 8, we present additional results for HRNetV2-W18-Small-v1 [39] (note this is different from HRNetV2-W18-Small-v2 reported in the main paper) and PSPNet101 [49] on Cityscapes dataset.
| HRNetV2-W18 -Small-v1 | #adds () | #mults () | #params () | mIoU (in %) |
| Original | ||||
| Struct-HR-A-V1 |
| PSPNet101 | #adds () | #mults () | #params () | mIoU (in %) |
| Original | ||||
| Struct-PSP-A | 76.6 |
A.4 Layer-wise compression ratios for compared architectures
As mentioned in the Experiments section of the main paper, we use non-uniform selection for the per-layer compression ratios () for MobileNetV2 and EfficientNet-B0 as well as HRNet for semantic segmentation. Tables 13 and 13 show the layerwise parameters for each layer of the Struct-MV2-A and Struct-MV2-B architectures. Table 14 shows these per-layer parameters for Struct-EffNet.
For Struct-HRNet-A, we apply Structured Convolutions only in the spatial dimension, i.e. we use , hence there’s no decomposition across the channel dimension. For convolutional kernels, we use , which means a convolution is decomposed into a sum pooling followed by a convolution. And for convolutions, where , we use which is the only possiblility for since . We do not use Structured Convolutions in the initial two convolution layers and last convolution layer.
For Struct-PSPNet, similar to Struct-HRNet-A, we apply use structured convolutions in all the convolution layers except the first and last layer. For convolutions, the structured convolution uses and . For convolutions, the structured convolution uses and .
A.5 Sensitivity of Structural Regularization w.r.t
In Sec. 5.1, we introduced the Structural Regularization (SR) loss and proposed to train the network using this regularization with a weight . In this section, we investigate the variation in the final performance of the model (after decomposition) when trained with different values of .
We trained Struct-Res18-A and Struct-Res18-B with different values of . Note that when training both "A" and "B" versions, we start with the original architecture for ResNet18 and train it from scratch with the SR loss. After this first step, we then decompose the weights using to get the decomposed architecture. Tables 10 and 10 show the accuracy of Struct-Res18-A and Struct-Res18-B both pre-decomposition and post-decomposition.
| Acc. (before decomposition) | Top-1 Acc. (after decomposition) | |
| Acc. (before decomposition) | Top-1 Acc. (after decomposition) | |
| Architecture | Acc. (before decomposition) | Top-1 Acc. (after decomposition) |
| Struct-50-A | ||
| Struct-50-B | ||
| Struct-V2-A | ||
| Struct-V2-B | ||
| Struct-EffNet |
From Table 10, we can see that the accuracy after decomposition isn’t affected much by the choice of . When varies from to , the post-decomposition accuracy only changed by . Similar trends are observed in Table 10 when we are compressing more aggressively. But the sensitivity of the performance w.r.t. is slightly higher in the "B" version. Also, we can see that when , the difference between pre-decomposition and post-decomposition accuracy is significant. Since is very small in this case, the Structural Regularization loss does not impose the desired structure on the convolution kernels effectively. As a result, after decomposition, it leads to a loss in accuracy.
In Table 11, we show the ImageNet performance of other architectures (from Tables 1, 2, 3, 4 of main paper) before and after the decomposition is applied.
A.6 Expressive power of the Sum-Pooling component
To show that the sum-pooling layers indeed capture meaningful features, we perform a toy experiment where we swap all depthwise convolution kernels in MobileNetV2 with kernels and train the architecture. We observed that this leads to a severe performance degradation of compared to the Struct-V2-A counterpart. This, we believe, is due to the loss of receptive field that was being captured by the sum-pooling part of structured convolutions.
A.7 Inference Latency
In Sec. 6.1 of the paper, we pointed out that the actual inference time of our method depends on how the software optimizations and scheduling are implemented. Additions are much faster and power efficient than multiplications on low-level hardware [3, 13]. However, this is not exploited on conventional platforms like GPUs which use FMA (Fused Multiply-Add) instructions. Considering hardware accelerator implementations [44] for sum-pooling, the theoretical gains of structured convolutions can be realized. We provide estimates for the latencies based on measurements on a Intel Xeon CPU W-2123 platform assuming that the software optimizations and scheduling for the sum-pooling operation are implemented. Please refer the table below.
| ResNet18 | 0.039s | MobilenetV2 | 0.088s | EfficientNet-B1 | 0.114s |
| Struct-18-A | 0.030s | Struct-MV2-A | 0.078s | Struct-EffNet | 0.101s |
| Idx | Dimension | ||
| 1 | 3 | 3 | |
| 2 | 1 | 3 | |
| 3 | 32 | 1 | |
| 4 | 16 | 1 | |
| 5 | 1 | 3 | |
| 6 | 96 | 1 | |
| 7 | 24 | 1 | |
| 8 | 1 | 3 | |
| 9 | 144 | 1 | |
| 10 | 24 | 1 | |
| 11 | 1 | 3 | |
| 12 | 144 | 1 | |
| 13 | 32 | 1 | |
| 14 | 1 | 3 | |
| 15 | 192 | 1 | |
| 16 | 32 | 1 | |
| 17 | 1 | 3 | |
| 18 | 192 | 1 | |
| 19 | 32 | 1 | |
| 20 | 1 | 3 | |
| 21 | 192 | 1 | |
| 22 | 64 | 1 | |
| 23 | 1 | 3 | |
| 24 | 384 | 1 | |
| 25 | 64 | 1 | |
| 26 | 1 | 3 | |
| 27 | 384 | 1 | |
| 28 | 64 | 1 | |
| 29 | 1 | 3 | |
| 30 | 384 | 1 | |
| 31 | 64 | 1 | |
| 32 | 1 | 3 | |
| 33 | 384 | 1 | |
| 34 | 96 | 1 | |
| 35 | 1 | 3 | |
| 36 | 576 | 1 | |
| 37 | 96 | 1 | |
| 38 | 1 | 3 | |
| 39 | 576 | 1 | |
| 40 | 96 | 1 | |
| 41 | 1 | 3 | |
| 42 | 576 | 1 | |
| 43 | 160 | 1 | |
| 44 | 1 | 3 | |
| 45 | 960 | 1 | |
| 46 | 160 | 1 | |
| 47 | 1 | 3 | |
| 48 | 960 | 1 | |
| 49 | 160 | 1 | |
| 50 | 1 | 3 | |
| 51 | 840 | 1 | |
| 52 | 160 | 1 | |
| classifier | 640 | 1 |
| Idx | Dimension | ||
| 1 | 3 | 3 | |
| 2 | 1 | 3 | |
| 3 | 32 | 1 | |
| 4 | 16 | 1 | |
| 5 | 1 | 3 | |
| 6 | 48 | 1 | |
| 7 | 12 | 1 | |
| 8 | 1 | 3 | |
| 9 | 72 | 1 | |
| 10 | 12 | 1 | |
| 11 | 1 | 3 | |
| 12 | 72 | 1 | |
| 13 | 16 | 1 | |
| 14 | 1 | 3 | |
| 15 | 96 | 1 | |
| 16 | 16 | 1 | |
| 17 | 1 | 2 | |
| 18 | 96 | 1 | |
| 19 | 16 | 1 | |
| 20 | 1 | 2 | |
| 21 | 96 | 1 | |
| 22 | 32 | 1 | |
| 23 | 1 | 2 | |
| 24 | 192 | 1 | |
| 25 | 32 | 1 | |
| 26 | 1 | 2 | |
| 27 | 192 | 1 | |
| 28 | 32 | 1 | |
| 29 | 1 | 2 | |
| 30 | 192 | 1 | |
| 31 | 32 | 1 | |
| 32 | 1 | 2 | |
| 33 | 192 | 1 | |
| 34 | 48 | 1 | |
| 35 | 1 | 2 | |
| 36 | 288 | 1 | |
| 37 | 48 | 1 | |
| 38 | 1 | 2 | |
| 39 | 288 | 1 | |
| 40 | 48 | 1 | |
| 41 | 1 | 2 | |
| 42 | 288 | 1 | |
| 43 | 80 | 1 | |
| 44 | 1 | 2 | |
| 45 | 480 | 1 | |
| 46 | 80 | 1 | |
| 47 | 1 | 2 | |
| 48 | 480 | 1 | |
| 49 | 80 | 1 | |
| 50 | 1 | 3 | |
| 51 | 480 | 1 | |
| 52 | 160 | 1 | |
| classifier | 560 | 1 |
| Idx | Dimension | ||
| 1 | 3 | 3 | |
| 2 | 1 | 3 | |
| 3 | 32 | 1 | |
| 4 | 1 | 3 | |
| 5 | 16 | 1 | |
| 6 | 16 | 1 | |
| 7 | 1 | 3 | |
| 8 | 96 | 1 | |
| 9 | 24 | 1 | |
| 10 | 1 | 3 | |
| 11 | 144 | 1 | |
| 12 | 24 | 1 | |
| 13 | 1 | 3 | |
| 14 | 144 | 1 | |
| 15 | 24 | 1 | |
| 16 | 1 | 5 | |
| 17 | 144 | 1 | |
| 18 | 40 | 1 | |
| 19 | 1 | 5 | |
| 20 | 240 | 1 | |
| 21 | 40 | 1 | |
| 22 | 1 | 5 | |
| 23 | 240 | 1 | |
| 24 | 40 | 1 | |
| 25 | 1 | 3 | |
| 26 | 240 | 1 | |
| 27 | 64 | 1 | |
| 28 | 1 | 3 | |
| 29 | 360 | 1 | |
| 30 | 64 | 1 | |
| 31 | 1 | 3 | |
| 32 | 360 | 1 | |
| 33 | 64 | 1 | |
| 34 | 1 | 3 | |
| 35 | 360 | 1 | |
| 36 | 64 | 1 | |
| 37 | 1 | 5 | |
| 38 | 360 | 1 | |
| 39 | 80 | 1 | |
| 40 | 1 | 5 | |
| 41 | 560 | 1 | |
| 42 | 96 | 1 | |
| 43 | 1 | 5 | |
| 44 | 560 | 1 | |
| 45 | 96 | 1 | |
| 46 | 1 | 5 | |
| 47 | 560 | 1 | |
| 48 | 96 | 1 | |
| 49 | 1 | 5 | |
| 50 | 560 | 1 | |
| 51 | 100 | 1 | |
| 52 | 1 | 5 | |
| 53 | 640 | 1 | |
| 54 | 100 | 1 | |
| 55 | 1 | 5 | |
| 56 | 640 | 1 | |
| 57 | 100 | 1 | |
| 58 | 1 | 5 | |
| 59 | 640 | 1 | |
| 60 | 100 | 1 | |
| 61 | 1 | 5 | |
| 62 | 576 | 1 | |
| 63 | 160 | 1 | |
| 64 | 1 | 3 | |
| 65 | 576 | 1 | |
| 66 | 160 | 1 | |
| 67 | 1 | 3 | |
| 68 | 960 | 1 | |
| 69 | 160 | 1 | |
| classifier | 480 | 1 |