Stronger NAS with Weaker Predictors
Abstract
Neural Architecture Search (NAS) often trains and evaluates a large number of architectures. Recent predictor-based NAS approaches attempt to alleviate such heavy computation costs with two key steps: sampling some architecture-performance pairs and fitting a proxy accuracy predictor. Given limited samples, these predictors, however, are far from accurate to locate top architectures due to the difficulty of fitting the huge search space. This paper reflects on a simple yet crucial question: if our final goal is to find the best architecture, do we really need to model the whole space well?. We propose a paradigm shift from fitting the whole architecture space using one strong predictor, to progressively fitting a search path towards the high-performance sub-space through a set of weaker predictors. As a key property of the weak predictors, their probabilities of sampling better architectures keep increasing. Hence we only sample a few well-performed architectures guided by the previously learned predictor and estimate a new better weak predictor. This embarrassingly easy framework, dubbed WeakNAS, produces coarse-to-fine iteration to gradually refine the ranking of sampling space. Extensive experiments demonstrate that WeakNAS costs fewer samples to find top-performance architectures on NAS-Bench-101 and NAS-Bench-201. Compared to state-of-the-art (SOTA) predictor-based NAS methods, WeakNAS outperforms all with notable margins, e.g., requiring at least 7.5x less samples to find global optimal on NAS-Bench-101. WeakNAS can also absorb their ideas to boost performance more. Further, WeakNAS strikes the new SOTA result of 81.3% in the ImageNet MobileNet Search Space. The code is available at: https://github.com/VITA-Group/WeakNAS.
1 Introduction

Neural Architecture Search (NAS) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] methods aim to find the best network architecture by exploring the architecture-to-performance manifold, using reinforced-learning-based [13], evolution-based [14, 15] or gradient-based [1, 16] approaches. In order to cover the entire search space, they often train and evaluate a large number of architectures, leading to tremendous computation cost.
Recently, predictor-based NAS methods alleviate this problem with two key steps: one sampling step to sample some architecture-performance pairs, and another performance modeling step to fit the performance distribution by training a proxy accuracy predictor. An in-depth analysis of existing methods [2] found that most of those methods [5, 6, 17, 7, 8, 9, 18] consider these two steps independently and attempt to model the performance distribution over the whole architecture space using a strong111“Strong” vs “Weak” predictors: we name a “weak” predictor if it only predicts a local subspace of the search space thus can be associated with our iterative sampling scheme; such predictors therefore usually do not demand very heavily parameterized models. On the contrary, “strong” predictors predict the global search space and are often associated with uniform sampling. The terminology of strong versus weak predictors does not represent their number of parameters or the type of NAS predictor used. An overparameterized NAS predictor with our iterative sampling scheme may still be considered as a “weak” predictor. predictor. However, since the architecture space is often exponentially large and highly non-convex, even a very strong predictor model has difficulty fitting the whole space given limited samples. Meanwhile, different types of predictors often demand handcraft design of the architecture representations to improve their performance.
This paper reflects on a fundamental question for predictor-based NAS: “if our final goal is to find the best architecture, do we really need to model the whole space well?”. We investigate the alternative of utilizing a few weak1 predictors to fit small local spaces, and to progressively move the search space towards the subspace where good architecture resides. Intuitively, we assume the whole space could be divided into different sub-spaces, some of which are relatively good while some are relatively bad. We tend to choose the good ones while discarding the bad ones, which makes sure more samples will be focused on modeling only the good subspaces and then find the best architecture. It greatly simplifies the learning task of each predictor. Eventually, a line of progressively evolving weak predictors can connect a path to the best architecture.
We present a novel, general framework that requires only to estimate a series of weak predictors progressively along the search path, we denoted it as WeakNAS in the rest of the paper. To ensure moving towards the best architecture along the path, at each iteration, the sampling probability of better architectures keep increasing through the guidance of the previous weak predictor. Then, the consecutive weak predictors with better samples will be trained in the next iteration. We iterate until we arrive at an embedding subspace where the best architectures reside and can be accurately assessed by the final weak predictor.
Compared to the existing predictor-based NAS, our proposal represents a new line of attack and has several merits. First, since only weak predictors are required, it yields better sample efficiency. As shown in Figure 1, it costs significantly fewer samples to find the top-performance architecture than using one strong predictor, and yields much lower variance in performance over multiple runs. Second, it is flexible to the choices of architecture representation (e.g., different architecture embeddings) and predictor formulation (e.g., multilayer perceptron (MLP), gradient boosting regression tree, or random forest). Experiments show our framework performs well in all their combinations. Third, it is highly generalizable to other open search spaces, e.g. given a limited sample budget, we achieve the state-of-the-art ImageNet performance on the NASNet and MobileNet search spaces. Detailed comparison with state-of-the-art predictor-based NAS [19, 20, 21, 8] is presented in Section 4.

2 Our Framework
2.1 Reformulating Predictor-based NAS as Bi-Level Optimization
Given a search space of network architectures and an architecture-to-performance mapping function from the architecture set to the performance set , the objective is to find the best neural architecture with the highest performance in the search space :
| (1) |
A naïve solution is to estimate the performance mapping through the full search space. However, this is prohibitively expensive since all architectures have to be exhaustively trained from scratch. To address this problem, predictor-based NAS learns a proxy predictor to approximate by using some architecture-performance pairs, which significantly reduces the training cost. In general, predictor-based NAS can be re-cast as a bi-level optimization problem:
| (2) | ||||
where is the loss function for the predictor , is a set of all possible approximation to , all architectures satisfying the sampling budget . is directly related to the total training cost, e.g., the total number of queries. Our objective is to minimize the loss based on some sampled architectures .
Previous predictor-based NAS methods attempt to solve Equation 2 with two sequential steps: (1) sampling some architecture-performance pairs and (2) learning a proxy accuracy predictor. For the first step, a common practice is to sample training pairs uniformly from the search space to fit the predictor. Such sampling is however inefficient considering that the goal of NAS is only to find well-performed architectures without caring for the bad ones.
2.2 Progressive Weak Predictors Emerge Naturally as A Solution to the Optimization
Optimization Insight: Instead of first (uniformly) sampling the whole space and then fitting the predictor, we propose to jointly evolve the sampling and fit the predictor , which helps achieve better sample efficiency by focusing on only relevant sample subspaces. That could be mathematically formulated as solving Equation 2 in a new coordinate descent way, that iterates between optimizing the architecture sampling and predictor fitting subproblems:
| (Sampling) | (3) | |||
| (4) |
In comparison, existing predictor-based NAS methods could be viewed as running the above coordinate descent for just one iteration – a special case of our general framework.
As well known in optimization, many iterative algorithms only need to solve (subsets of) their subproblems inexactly [22, 23, 24] for properly ensuring convergence either theoretically or empirically. Here, using a strong predictor to fit the whole space could be treated as solving the predictor fitting subproblem relatively precisely, while adopting a weak predictor just imprecisely solves that. Previous methods solving Equation 2 truncate their solutions to “one shot" and hinge on solving subproblems with higher precision. Since we now take a joint optimization view and allow for multiple iterations, we can afford to only use weaker predictors for the fitting subproblem per iteration.
Implementation Outline: The above coordinate descent solution has clear interpretations and is straightforward to implement. Suppose our iterative methods has iterations. We initialize by randomly sampling a few samples from , and train an initial predictor . Then at iterations , we jointly optimize the sampling set and predictor in an alternative manner.




Subproblem 1: Architecture Sampling.
At iteration , we first sort all architectures222One only exception is the Section 3.2 open-domain experiments: we will sub-sample all architectures in the search space before sorting. More details can be found in Appendix Section H in the search space (excluding all the samples already in ) according to its predicted performance at every iteration . We then randomly sample new architectures from the top ranked architectures in . Note this step both reduces the sample budget, and controls the exploitation-exploration trade-off (see Section 3.1). The newly sampled architectures together with become .
Subproblem 2: (Weak) Predictor Fitting.
We learn a predictor , by minimizing the loss of the predictor based on sampled architectures . We then evaluate architectures using the learned predictor to get the predicted performance .
As illustrated in Figure 2, through alternating iterations, we progressively evolve weak predictors to focus on sampling along the search path, thus simplifying the learning workload of each predictor. With these coarse-to-fine iterations, the predictor would guide the sampling process to gradually zoom into the promising architecture samples. In addition, the promising samples would in turn improve the performance of the updated predictor among the well-performed architectures, hence the ranking of sampling space is also refined gradually. In other words, the solution quality to the subproblem 2 will gradually increase as a natural consequence of the guided zoom-in. For derivation, we simply choose the best architecture predicted by the final weak predictor. This idea is related to the classical ensembling [25], yet a new regime to NAS.
Proof-of-Concept Experiment.
Figure 3 (a) shows the progressive procedure of finding the optimal architecture and learning the predicted best architecture over iterations. As we can see from Figure 3 (a), the optimal architecture and the predicted best one are moving towards each other closer and closer, which indicates that the performance of predictor over the optimal architecture(s) is growing better. In Figure 3 (b), we use the error empirical distribution function (EDF) [26] to visualize the performance distribution of architectures in the subspace. We plot the EDF of the top- models based on the predicted performance over iterations. As is shown, the subspace of top-performed architectures is consistently evolving towards more promising architecture samples over iterations. Then in Figure 3 (c), we validate that the probabilities of sampling better architectures within the top predictions keep increasing. Based on this property, we can just sample a few well-performing architectures guided by the predictive model to estimate another better weak predictor. The same plot also suggests that the NAS predictor’s ranking among the top-performed models is gradually refined, since more and more architectures in the top region are sampled.
In Figure 4, we also show the t-SNE visualization of the search dynamic in NAS-Bench-201 search space. We can observe that: (1) NAS-Bench-201 search space is highly structured; (2) the sampling space and sampled architectures are both consistently evolving towards more promising regions, as can be noticed by the increasingly warmer color trend.
2.3 Relationship to Bayesian Optimization: A Simplification and Why It Works
Our method can be alternatively regarded as a vastly simplified variant of Bayesian Optimization (BO). It does not refer to any explicit uncertainty-based modeling such as Gaussian Process (which are often difficult to scale up); instead it adopts a very simple step function as our acquisition function. For a sample in the search space , our special “acquisition function" can be written as:
| (5) |
where the step function is 1 if , and 0 otherwise; is a random variable from the uniform distribution ; and is the threshold to split Top from the rest, according to their predicted performance . We then choose the samples with the largest acquisition values:
| (6) |
Why such “oversimplified BO" can be effectively for our framework? We consider the reason to be the inherently structured NAS search space. Specifically, existing NAS spaces are created either by varying operators from a pre-defined operator set (DARTS/NAS-Bench-101/201 Search Space) or by varying kernel size, width or depth (MobileNet Search Space). Therefore, as shown in Figure 4, the search spaces are often highly-structured, and the best performers gather close to each other.
Here comes our underlying prior assumption: we can progressively connect a piecewise search path from the initialization, to the finest subspace where the best architecture resides. At the beginning, since the weak predictor only roughly fits the whole space, the sampling operation will be “noisier", inducing more exploration. When it comes to the later stage, the weak predictors fit better on the current well-performing clusters, thus performing more exploitation locally. Therefore our progressive weak predictor framework provides a natural evolution between exploration and exploitation, without explicit uncertainty modeling, thanks to the prior of special NAS space structure.
Another exploration-exploitation trade-off is implicitly built in the adaptive sampling step of our subproblem 1 solution. To recall, at each iteration, instead of choosing all Top models by the latest predictor, we randomly sample models from Top models to explore new architectures in a stochastic manner. By varying the ratio and the sampling strategy (e.g., uniform, linear-decay or exponential-decay), we can balance the sampling exploitation and exploration per step, in a similar flavor to the -greedy [27] approach in reinforcement learning.
2.4 Our Framework is General to Predictor Models and Architecture Representations



Our framework is designed to be generalizable to various predictors and features. In predictor-based NAS, the objective of fitting the predictor is often cast as a regression [7] or ranking [5] problem. The choice of predictors is diverse, and usually critical to final performance [5, 6, 2, 7, 8, 9]. To illustrate our framework is generalizable and robust to the specific choice of predictors, we compare the following predictor variants.
-
•
Multilayer perceptron (MLP): MLP is the common baseline in predictor-based NAS [5] due to its simplicity. For our weak predictor, we use a 4-layer MLP with hidden layer dimension of (1000, 1000, 1000, 1000).
- •
-
•
Random Forest: random forests differ from GBRT in that they combines decisions only at the end rather than along the hierarchy, and are often more robust to noise. For each weak predictor, we use a random forest consisting of 1000 Forests.
The features representations to encode the architectures are also instrumental. Previous methods hand-craft various features for the best performance, e.g., raw architecture encoding [6], supernet statistics [30], and graph convolutional network encoding [7, 5, 8, 19] Our framework is also agnostic to various architecture representations, and we compare the following:
-
•
One-hot vector: In NAS-Bench-201 [31], its DARTS-style search space has fixed graph connectivity, hence the one-hot vector is commonly used to encode the choice of operator.
- •
As shown in Figure 5, all predictor models perform similarly across different datasets. Comparing performance on NAS-Bench-101 and NAS-Bench-201, although they use different architecture encoding methods, our method still performs similarly well among different predictors. This demonstrates that our framework is robust to various predictor and feature choices.
3 Experiments
Setup: For all experiments, we use an Intel Xeon E5-2650v4 CPU and a single Tesla P100 GPU, and use the Multilayer perceptron (MLP) as our default NAS predictor, unless otherwise specified.
NAS-Bench-101 [32] provides a Directed Acyclic Graph (DAG) based cell structure. The connectivity of DAG can be arbitrary with a maximum number of 7 nodes and 9 edges. Each nodes on the DAG can choose from operator of 11 convolution, 33 convolution or 33 max-pooling. After removing duplicates, the dataset consists of 423,624 diverse architectures trained on CIFAR10[33].
NAS-Bench-201 [31] is a more recent benchmark with a reduced DARTS-like search space. The DAG of each cell is fixed, and one can choose from 5 different operations (11 convolution, 33 convolution, 33 avg-pooling, skip, no connection), on each of the 6 edges, totaling 15,625 architectures. It is trained on 3 different datasets: CIFAR10, CIFAR100 and ImageNet16-120 [34]. For experiments on both NAS-Benches, we followed the same setting as [8].
Open Domain Search Space: We follow the same NASNet search space used in [35] and MobileNet Search Space used in [36] to directly search for the best architectures on ImageNet[37]. Due to the huge computational cost to evaluate sampled architectures on ImageNet, we leverage a weight-sharing supernet approach. On NASNet search space, we use Single-Path One-shot [38] approach to train our SuperNet, while on MobileNet Search Space we reused the pre-trained supernet from OFA[36]. We then use the supernet accuracy as the performance proxy to train weak predictors. We clarify that despite using supernet, our method is more accurate than existing differentiable weight-sharing methods, meanwhile requiring less samples than evolution based weight-sharing methods, as manifested in Table 6 and 7. We adopt PyTorch and image models library (timm) [39] to implement our models and conduct all ImageNet experiments using 8 Tesla V100 GPUs. For derived architecture, we follow a similar training from scratch strategies used in LaNAS[21].
3.1 Ablation Studies
We conduct a series of ablation studies on the effectiveness of proposed method on NAS-Bench-101. To validate the effectiveness of our iterative scheme, In Table 1, we initialize the initial Weak Predictor with 100 random samples, and set , after progressively adding more weak predictors (from 1 to 191), we find the performance keeps growing. This demonstrates the key property of our method that probability of sampling better architectures keeps increasing as more iteration goes. It’s worth noting that the quality of random initial samples may also impact on the performance of WeakNAS, but if is sufficiently large, the chance of hitting good samples (or its neighborhood) is high, and empirically we found =100 to already ensure highly stable performance at NAS-Bench-101: a more detailed ablation can be found in the Appendix Section D.
| Sampling | #Predictor | #Queries | Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank |
| Uniform | 1 Strong Predictor | 2000 | 93.92 | 0.08 | 0.40 | 135.0 |
| Iterative | 1 Weak Predictor | 100 | 93.42 | 0.37 | 0.90 | 6652.1 |
| 11 Weak Predictors | 200 | 94.18 | 0.14 | 0.14 | 5.6 | |
| 91 Weak Predictors | 1000 | 94.25 | 0.04 | 0.07 | 1.7 | |
| 191 Weak Predictors | 2000 | 94.26 | 0.04 | 0.06 | 1.6 | |
| Optimal | - | - | 94.32 | - | 0.00 | 1 |
| Sampling (M from TopN) | M | TopN | #Queries | Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank |
|---|---|---|---|---|---|---|---|
| Exponential-decay | 10 | 100 | 1000 | 93.96 | 0.10 | 0.36 | 85.0 |
| Linear-decay | 10 | 100 | 1000 | 94.06 | 0.08 | 0.26 | 26.1 |
| Uniform | 10 | 100 | 1000 | 94.25 | 0.04 | 0.07 | 1.7 |
| Uniform | 10 | 1000 | 1000 | 94.10 | 0.19 | 0.22 | 14.1 |
| Uniform | 10 | 100 | 1000 | 94.25 | 0.04 | 0.07 | 1.7 |
| Uniform | 10 | 10 | 1000 | 94.24 | 0.04 | 0.08 | 1.9 |
| Method | #Queries | Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank |
|---|---|---|---|---|---|
| WeakNAS | 1000 | 94.25 | 0.04 | 0.07 | 1.7 |
| WeakNAS (BO Variant) | 1000 | 94.12 | 0.15 | 0.20 | 8.7 |
| Optimal | - | 94.32 | - | 0.00 | 1.0 |

We then study the exploitation-exploration trade-off in Table 2 in NAS-Bench-101 (a similar ablation in Mobilenet Search space on ImageNet is also included in Appendix Table 13) by investigating two settings: (a) We gradually increase to allow for more exploration, similar to controlling in the epsilon-greedy [27] approach in the RL context; (b) We vary the sampling strategy from Uniform, Linear-decay to Exponential-decay (top models get higher probabilities by following either linear-decay or exponential-decay distribution). We empirically observed that: (a) The performance drops more (Test Regret 0.22% vs 0.08%) when more exploration (TopN=1000 vs TopN=10) is used. This indicates that extensive exploration is not optimal for NAS-Bench-101; (b) Uniform sampling method yields better performance than sampling method that biased towards top performing model (e.g. linear-decay, exponential-decay). This indicates good architectures are evenly distributed within the Top 100 predictions of Weak NAS, therefore a simple uniform sampling strategy for exploration is more optimal in NAS-Bench-101. To conclude, our Weak NAS Predictor strikes a good balance between exploration and exploration.
Apart from the above exploitation-exploration trade-off of WeakNAS, we also explore the possibility of integrating other meta-sampling methods. We found that the local search algorithm could achieve comparable performance, while using Semi-NAS [20] as a meta sampling method could further boost the performance of WeakNAS: more details are in Appendix Section G.
3.2 Comparison to State-of-the-art (SOTA) Methods
NAS-Bench-101: On NAS-Bench-101 benchmark, we compare our method with several popular methods [14, 40, 21, 2, 7, 20, 19, 41, 42, 43, 44].
Table 5 shows that our method significantly outperforms baselines in terms of sample efficiency. Specifically, our method costs 964, 447, 378, 245, 58, and 7.5 less samples to reach the optimal architecture, compared to Random Search, Regularized Evolution [14], MCTS [40], Semi-NAS[20], LaNAS[21], BONAS[19], respectively. We then plot the best accuracy against number of samples in Table 4 and Figure 6 to show the sample efficiency on the NAS-Bench-101, from which we can see that our method consistently costs fewer sample to reach higher accuracy.
| Method | #Queries | Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank |
| Random Search | 2000 | 93.64 | 0.25 | 0.68 | 1750.0 |
| NAO [2] | 2000 | 93.90 | 0.03 | 0.42 | 168.1 |
| Reg Evolution [14] | 2000 | 93.96 | 0.05 | 0.36 | 85.0 |
| Semi-NAS [20] | 2000 | 94.02 | 0.05 | 0.30 | 42.1 |
| Neural Predictor [7] | 2000 | 94.04 | 0.05 | 0.28 | 33.5 |
| WeakNAS | 2000 | 94.26 | 0.04 | 0.06 | 1.6 |
| Semi-Assessor [42] | 1000 | 94.01 | - | 0.31 | 47.1 |
| LaNAS [21] | 1000 | 94.10 | - | 0.22 | 14.1 |
| BONAS [19] | 1000 | 94.22 | - | 0.10 | 3.0 |
| WeakNAS | 1000 | 94.25 | 0.04 | 0.07 | 1.7 |
| Arch2vec [41] | 400 | 94.10 | - | 0.22 | 14.1 |
| WeakNAS | 400 | 94.24 | 0.04 | 0.08 | 1.9 |
| LaNAS [21] | 200 | 93.90 | - | 0.42 | 168.1 |
| BONAS [19] | 200 | 94.09 | - | 0.23 | 18.0 |
| WeakNAS | 200 | 94.18 | 0.14 | 0.14 | 5.6 |
| NASBOWLr [45] | 150 | 94.09 | - | 0.23 | 18.0 |
| CATE (cate-DNGO-LS) [43] | 150 | 94.10 | - | 0.22 | 12.3 |
| WeakNAS | 150 | 94.10 | 0.19 | 0.22 | 12.3 |
| Optimal | - | 94.32 | - | 0.00 | 1.0 |
| Method | NAS-Bench-101 | NAS-Bench-201 | ||
|---|---|---|---|---|
| Dataset | CIFAR10 | CIFAR10 | CIFAR100 | ImageNet16-120 |
| Random Search | 188139.8 | 7782.1 | 7621.2 | 7726.1 |
| Reg Evolution [14] | 87402.7 | 563.2 | 438.2 | 715.1 |
| MCTS [40] | 73977.2 | 528.3 | 405.4 | 578.2 |
| Semi-NAS [20] | 47932.3 | - | - | - |
| LaNAS [21] | 11390.7 | 247.1 | 187.5 | 292.4 |
| BONAS [19] | 1465.4 | - | - | - |
| WeakNAS | 195.2 | 182.1 | 78.4 | 268.4 |
NAS-Bench-201: We further evaluate on NAS-Bench-201, and compare with random search, Regularized Evolution [14], Semi-NAS[20], LaNAS[21], BONAS[19]. . As shown in Table 5, we conduct searches on all three subsets (CIFAR10, CIFAR100, ImageNet16-120) and report the average number of samples needed to reach global optimal on the testing set over 100 runs. It shows that our method has the smallest sample cost among all settings.
Open Domain Search: we further apply our method to open domain search without ground-truth, and compare with several popular methods [35, 14, 46, 2, 47, 48, 21]. As shown in Tables 6 and 7, using the fewest samples (and only a fraction of GPU hours) among all, our method can achieve state-of-the-art ImageNet top-1 accuracies with comparable parameters and FLOPs. Our searched architecture is also competitive to expert-design networks. On the NASNet Search Space, compared with the SoTA predictor-based NAS method LaNAS (Oneshot) [21], our method reduces 0.6% top-1 error while using less GPU hours. On the MobileNet Search Space, we improve the previous SoTA LaNAS [21] to 81.3% top-1 accuracy on ImageNet while costing less FLOPs.
3.3 Discussion: Further Comparison with SOTA Predictor-based NAS Methods
BO-based NAS methods [19, 45]: BO-based methods in general treat NAS as a black-box optimization problem, for example, BONAS [19] customizes the classical BO framework in NAS with GCN embedding extractor and Bayesian Sigmoid Regression to acquire and select candidate architectures. The latest BO-based NAS approach, NASBOWL [45], combines the Weisfeiler-Lehman graph kernel in BO to capture the topological structures of the candidate architectures.
Compare with those BO-based method, our WeakNAS is an “oversimplified" version of BO as explained in Section 2.3. Interestingly, results in Table 4 suggests that WeakNAS is able to outperform BONAS [19], and is comparable to NASBOWLr [45] on NAS-Bench-101, showcasing that the simplification does not compromise NAS performance. We hypothesize that the following factors might be relevant: (1) the posterior modeling and uncertainty estimation in BO might be noisy; (2) the inherently structured NAS search space (shown in Figure 4) could enable a “shortcut" simplification to explore and exploit. In addition, the conventional uncertainty modeling in BO, such as the Gaussian Process used by [45], is not as scalable when the number of queries is large. In comparison, the complexity of WeakNAS scales almost linearly, as can be verified in Appendix Table 8. In our experiments, we observe WeakNAS to perform empirically more competitively than current BO-based NAS methods at larger query numbers, besides being way more efficient.
To further convince that WeakNAS is indeed an effective simplification compared to the explicit posterior modeling in BO, we report an apple-to-apple comparison, by use the same weak predictor from WeakNAS, plus obtaining its uncertainty estimation by calculating its variance using a deep ensemble of five model [49]; we then use the classic Expected Improvement (EI) [50] acquisition function. Table 3 confirms that such BO variant of WeakNAS is inferior our proposed formulation.
Advanced Architecture Encoding [41, 43] We also compare WeakNAS with NAS using custom architecture representation either in a unsupervised way such as arch2vec [41], or a supervised way such as CATE [43]. We show our WeakNAS could achieve comparable performance to both methods. Further, those architecture embedding are essentially complementary to our method to further boost the performance of WeakNAS, as shown in Appendix Section C.
LaNAS [21]: LaNAS and our framework both follow the divide-and-conquer idea, yet with two methodological differences: (a) How to split the search space: LaNAS learns a classifier to do binary “hard” partition on the search space (no ranking information utilized) and split it into two equally-sized subspaces. Ours uses a regressor to regress the performance of sampled architectures, and utilizes the ranking information to sample a percentage of the top samples (“soft” partition), with the sample size being controllable. (b) How to do exploration: LaNAS uses Upper Confidence Bound (UCB) to explore the search space by not always choosing the best subspace (left-most node) for sampling, while ours always chooses the best subspace and explore new architectures by adaptive sampling within it, via adjusting the ratio to randomly sample models from Top . Tables 4 and 5 shows the superior sample efficiency of WeakNAS over LaNAS on NAS-Bench-101/201.
Semi-NAS [20] and Semi-Assessor[42]: Both our method and Semi-NAS/Semi-Assessor use an iterative algorithm containing prediction and sampling. The main difference lies in the use of pseudo labels: Semi-NAS and Semi-Assessor use pseudo labels as noisy labels to augment the training set, therefore being able to leverage “unlabeled samples" (e.g., architectures without true accuracies, but with only accuracies generated by the predictors) to update their predictors. Our method explores an orthogonal innovative direction, where the “pseudo labels" generated by the current predictor guide our sampling procedure, but are never used for training the next predictor.
That said, we point out that our method can be complementary to those semi-supervised methods [20, 42], thus they can further be integrated as one, For example, Semi-NAS can be used as a meta sampling method, where at each iteration we further train a Semi-NAS predictor with pseudo labeling strategy to augment the training set of our weak predictors. We show in Appendix Table 12 that the combination of our method with Semi-NAS can further boost the performance of WeakNAS.
BRP-NAS [8]: BRP-NAS uses a stronger GCN-based binary relation predictor which utilize extra topological prior, and leveraged a different scheme to control exploitation and exploration trade-off compare to our WeakNAS. Further, BRP-NAS also use a somehow unique setting, i.e. evaluating Top-40 predictions by the NAS predictor instead of the more common setting of Top-1 [2, 19, 21, 20]. Therefore, we include our comparison to BRP-NAS and more details in Appendix Section F.
| Model | Queries(#) | Top-1 Err.(%) | Top-5 Err.(%) | Params(M) | FLOPs(M) | GPU Days |
| MobileNetV2 | - | 25.3 | - | 6.9 | 585 | - |
| ShuffletNetV2 | - | 25.1 | - | 5.0 | 591 | - |
| SNAS[51] | - | 27.3 | 9.2 | 4.3 | 522 | 1.5 |
| DARTS[1] | - | 26.9 | 9.0 | 4.9 | 595 | 4.0 |
| P-DARTS[52] | - | 24.4 | 7.4 | 4.9 | 557 | 0.3 |
| PC-DARTS[53] | - | 24.2 | 7.3 | 5.3 | 597 | 3.8 |
| DS-NAS[53] | - | 24.2 | 7.3 | 5.3 | 597 | 10.4 |
| NASNet-A [35] | 20000 | 26.0 | 8.4 | 5.3 | 564 | 2000 |
| AmoebaNet-A [14] | 10000 | 25.5 | 8.0 | 5.1 | 555 | 3150 |
| PNAS [46] | 1160 | 25.8 | 8.1 | 5.1 | 588 | 200 |
| NAO [2] | 1000 | 24.5 | 7.8 | 6.5 | 590 | 200 |
| LaNAS [21] (Oneshot) | 800 | 24.1 | - | 5.4 | 567 | 3 |
| LaNAS [21] | 800 | 23.5 | - | 5.1 | 570 | 150 |
| WeakNAS | 800 | 23.5 | 6.8 | 5.5 | 591 | 2.5 |
| Model | Queries(#) | Top-1 Acc.(%) | Top-5 Acc.(%) | FLOPs(M) | GPU Days |
| Proxyless NAS[54] | - | 75.1 | 92.9 | - | - |
| Semi-NAS[20] | 300 | 76.5 | 93.2 | 599 | - |
| BigNAS[47] | - | 76.5 | - | 586 | - |
| FBNetv3[48] | 20000 | 80.5 | 95.1 | 557 | - |
| OFA[36] | 16000 | 80.0 | - | 595 | 1.6 |
| LaNAS[21] | 800 | 80.8 | - | 598 | 0.3 |
| WeakNAS | 1000 | 81.3 | 95.1 | 560 | 0.16 |
| 800 | 81.2 | 95.2 | 593 | 0.13 |
4 Conclusions and Discussions of Broad Impact
In this paper, we present a novel predictor-based NAS framework named WeakNAS that progressively shrinks the sampling space, by learning a series of weak predictors that can connect towards the best architectures. By co-evolving the sampling stage and learning stage, our weak predictors can progressively evolve to sample towards the subspace of best architectures, thus greatly simplifying the learning task of each predictor. Extensive experiments on popular NAS benchmarks prove that the proposed method is both sample-efficient and robust to various combinations of predictors and architecture encoding means. However, WeakNAS is still limited by the human-designed encoding of neural architectures, and our future work plans to investigate how to jointly learn the predictor and encoding in our framework.
For broader impact, the excellent sample-efficiency of WeakNAS reduces the resource and energy consumption needed to search for efficient models, while still maintaining SoTA performance. That can effectively serve the goal of GreenAI, from model search to model deployment. It might meanwhile be subject to the potential abuse of searching for models serving malicious purposes.
Acknowledgment
Z.W. is in part supported by an NSF CCRI project (#2016727).
References
- [1] Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. arXiv preprint arXiv:1806.09055, 2018.
- [2] Renqian Luo, Fei Tian, Tao Qin, Enhong Chen, and Tie-Yan Liu. Neural architecture optimization. In Advances in neural information processing systems, pages 7816–7827, 2018.
- [3] Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10734–10742, 2019.
- [4] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, 2019.
- [5] Xuefei Ning, Yin Zheng, Tianchen Zhao, Yu Wang, and Huazhong Yang. A generic graph-based neural architecture encoding scheme for predictor-based nas. arXiv preprint arXiv:2004.01899, 2020.
- [6] Chen Wei, Chuang Niu, Yiping Tang, and Jimin Liang. Npenas: Neural predictor guided evolution for neural architecture search. arXiv preprint arXiv:2003.12857, 2020.
- [7] Wei Wen, Hanxiao Liu, Hai Li, Yiran Chen, Gabriel Bender, and Pieter-Jan Kindermans. Neural predictor for neural architecture search. arXiv preprint arXiv:1912.00848, 2019.
- [8] Lukasz Dudziak, Thomas Chau, Mohamed Abdelfattah, Royson Lee, Hyeji Kim, and Nicholas Lane. Brp-nas: Prediction-based nas using gcns. Advances in Neural Information Processing Systems, 33, 2020.
- [9] Renqian Luo, Xu Tan, Rui Wang, Tao Qin, Enhong Chen, and Tie-Yan Liu. Neural architecture search with gbdt. arXiv preprint arXiv:2007.04785, 2020.
- [10] Yunhe Wang, Yixing Xu, and Dacheng Tao. Dc-nas: Divide-and-conquer neural architecture search. arXiv preprint arXiv:2005.14456, 2020.
- [11] Xiyang Dai, Dongdong Chen, Mengchen Liu, Yinpeng Chen, and Lu Yuan. Da-nas: Data adapted pruning for efficient neural architecture search. ECCV 2020, 2020.
- [12] Zhaohui Yang, Yunhe Wang, Xinghao Chen, Jianyuan Guo, Wei Zhang, Chao Xu, Chunjing Xu, Dacheng Tao, and Chang Xu. Hournas: Extremely fast neural architecture search through an hourglass lens. arXiv preprint arXiv:2005.14446, 2020.
- [13] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, 2016.
- [14] Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for image classifier architecture search. In Proceedings of the aaai conference on artificial intelligence, volume 33, pages 4780–4789, 2019.
- [15] Zhaohui Yang, Yunhe Wang, Xinghao Chen, Boxin Shi, Chao Xu, Chunjing Xu, Qi Tian, and Chang Xu. Cars: Continuous evolution for efficient neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1829–1838, 2020.
- [16] Weijun Hong, Guilin Li, Weinan Zhang, Ruiming Tang, Yunhe Wang, Zhenguo Li, and Yong Yu. Dropnas: Grouped operation dropout for differentiable architecture search. In International Joint Conference on Artificial Intelligence, 2020.
- [17] Yixing Xu, Yunhe Wang, Kai Han, Shangling Jui, Chunjing Xu, Qi Tian, and Chang Xu. Renas: Relativistic evaluation of neural architecture search. arXiv preprint arXiv:1910.01523, 2019.
- [18] Yanxi Li, Minjing Dong, Yunhe Wang, and Chang Xu. Neural architecture search in a proxy validation loss landscape. In International Conference on Machine Learning, pages 5853–5862. PMLR, 2020.
- [19] Han Shi, Renjie Pi, Hang Xu, Zhenguo Li, James Kwok, and Tong Zhang. Bridging the gap between sample-based and one-shot neural architecture search with bonas. Advances in Neural Information Processing Systems, 33, 2020.
- [20] Renqian Luo, Xu Tan, Rui Wang, Tao Qin, Enhong Chen, and Tie-Yan Liu. Semi-supervised neural architecture search. arXiv preprint arXiv:2002.10389, 2020.
- [21] Linnan Wang, Saining Xie, Teng Li, Rodrigo Fonseca, and Yuandong Tian. Sample-efficient neural architecture search by learning actions for monte carlo tree search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [22] Rachael Tappenden, Peter Richtárik, and Jacek Gondzio. Inexact coordinate descent: complexity and preconditioning. Journal of Optimization Theory and Applications, 170(1):144–176, 2016.
- [23] Mark Schmidt, Nicolas Le Roux, and Francis Bach. Convergence rates of inexact proximal-gradient methods for convex optimization. arXiv preprint arXiv:1109.2415, 2011.
- [24] William W Hager and Hongchao Zhang. Convergence rates for an inexact admm applied to separable convex optimization. Computational Optimization and Applications, 2020.
- [25] Zhi-Hua Zhou. Ensemble methods: foundations and algorithms. CRC press, 2012.
- [26] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dollár. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10428–10436, 2020.
- [27] Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018.
- [28] Julien Siems, Lucas Zimmer, Arber Zela, Jovita Lukasik, Margret Keuper, and Frank Hutter. Nas-bench-301 and the case for surrogate benchmarks for neural architecture search. arXiv preprint arXiv:2008.09777, 2020.
- [29] Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016.
- [30] Yiming Hu, Yuding Liang, Zichao Guo, Ruosi Wan, Xiangyu Zhang, Yichen Wei, Qingyi Gu, and Jian Sun. Angle-based search space shrinking for neural architecture search. arXiv preprint arXiv:2004.13431, 2020.
- [31] Xuanyi Dong and Yi Yang. Nas-bench-201: Extending the scope of reproducible neural architecture search. In International Conference on Learning Representations, 2020.
- [32] Chris Ying, Aaron Klein, Eric Christiansen, Esteban Real, Kevin Murphy, and Frank Hutter. Nas-bench-101: Towards reproducible neural architecture search. In International Conference on Machine Learning, pages 7105–7114, 2019.
- [33] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [34] Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter. A downsampled variant of imagenet as an alternative to the cifar datasets. arXiv preprint arXiv:1707.08819, 2017.
- [35] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8697–8710, 2018.
- [36] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment. arXiv preprint arXiv:1908.09791, 2019.
- [37] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [38] Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, and Jian Sun. Single path one-shot neural architecture search with uniform sampling. arXiv preprint arXiv:1904.00420, 2019.
- [39] Ross Wightman. Pytorch image models. https://github.com/rwightman/pytorch-image-models, 2019.
- [40] Linnan Wang, Yiyang Zhao, Yuu Jinnai, Yuandong Tian, and Rodrigo Fonseca. Alphax: exploring neural architectures with deep neural networks and monte carlo tree search. arXiv preprint arXiv:1903.11059, 2019.
- [41] Shen Yan, Yu Zheng, Wei Ao, Xiao Zeng, and Mi Zhang. Does unsupervised architecture representation learning help neural architecture search? Advances in Neural Information Processing Systems, 33, 2020.
- [42] Yehui Tang, Yunhe Wang, Yixing Xu, Hanting Chen, Boxin Shi, Chao Xu, Chunjing Xu, Qi Tian, and Chang Xu. A semi-supervised assessor of neural architectures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1810–1819, 2020.
- [43] Shen Yan, Kaiqiang Song, Fei Liu, and Mi Zhang. Cate: Computation-aware neural architecture encoding with transformers. arXiv preprint arXiv:2102.07108, 2021.
- [44] Colin White, Willie Neiswanger, and Yash Savani. Bananas: Bayesian optimization with neural architectures for neural architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10293–10301, 2021.
- [45] Binxin Ru, Xingchen Wan, Xiaowen Dong, and Michael Osborne. Interpretable neural architecture search via bayesian optimisation with weisfeiler-lehman kernels. In International Conference on Learning Representations, 2021.
- [46] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), pages 19–34, 2018.
- [47] Jiahui Yu, Pengchong Jin, Hanxiao Liu, Gabriel Bender, Pieter-Jan Kindermans, Mingxing Tan, Thomas Huang, Xiaodan Song, Ruoming Pang, and Quoc Le. Bignas: Scaling up neural architecture search with big single-stage models. In European Conference on Computer Vision, pages 702–717. Springer, 2020.
- [48] Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Bichen Wu, Zijian He, Zhen Wei, Kan Chen, Yuandong Tian, Matthew Yu, Peter Vajda, et al. Fbnetv3: Joint architecture-recipe search using neural acquisition function. arXiv preprint arXiv:2006.02049, 2020.
- [49] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. arXiv preprint arXiv:1612.01474, 2016.
- [50] Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions. Journal of Global optimization, 13(4):455–492, 1998.
- [51] Sirui Xie, Hehui Zheng, Chunxiao Liu, and Liang Lin. Snas: stochastic neural architecture search. arXiv preprint arXiv:1812.09926, 2018.
- [52] Xin Chen, Lingxi Xie, Jun Wu, and Qi Tian. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation. In Proceedings of the IEEE International Conference on Computer Vision, pages 1294–1303, 2019.
- [53] Yuhui Xu, Lingxi Xie, Xiaopeng Zhang, Xin Chen, Guo-Jun Qi, Qi Tian, and Hongkai Xiong. Pc-darts: Partial channel connections for memory-efficient differentiable architecture search. arXiv preprint arXiv:1907.05737, 2019.
- [54] Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv preprint arXiv:1812.00332, 2018.
- [55] Renqian Luo, Xu Tan, Rui Wang, Tao Qin, Enhong Chen, and Tie-Yan Liu. Accuracy prediction with non-neural model for neural architecture search. arXiv preprint arXiv:2007.04785, 2020.
Appendix A Implementation details of baselines methods
For random search and regularized evolution[14] baseline, we use the public implementation from this link333https://github.com/D-X-Y/AutoDL-Projects. For random search, we selection 100 random architectures at each iteration. For regularized evolution, We set the initial population to 10, and the sample size each iteration to 3.
Appendix B Runtime comparsion of WeakNAS
We show the runtime comparison of WeakNAS and its BO variant in Table 8. We can see the BO variant is much slower in training proxy models due the ensembling of multiple models. Moreover, it’s also several magnitude slower when deriving new samples, due to the calculation of its Expected Improvement (EI) acquisition function [50] being extremely costly.
| Method | Predictors | Config | Train proxy model (s/arch) | Derive new samples (s/arch) |
|---|---|---|---|---|
| WeakNAS | MLP | 4 layers @1000 hidden | ||
| Gradient Boosting Tree | 1000 Trees | |||
| Random Forrest | 1000 Forests | |||
| WeakNAS (BO Variant) | 5 x MLPs | EI acquisition |
Appendix C Ablation on the architecture encoding
We compare the effect of using different architecture encodings in in Table 9. We found when combined with CATE embedding [43], the performance of WeakNAS can be further improved, compared to WeakNAS baseline with adjacency matrix encoding used in [32]. This also leads to stronger performance than cate-DNGO-LS baseline in CATE [43], which demonstrates that CATE embedding [43] is an orthogonal contribution to WeakNAS, and they are mutually compatible.
Appendix D Ablation on number of initial samples
We conduct a controlled experiment in varying the number of initial samples in Table 10. On NAS-Bench-101, we vary from 10 to 200, and found a "warm start" with good initial samples is crucial for good performance. Too small number of might makes the predictor lose track of the good performing regions. As shown in Table 10. We empirically found =100 can ensure highly stable performance on NAS-Bench-101.
| #Queries | Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank | |
|---|---|---|---|---|---|
| 10 | 1000 | 94.14 | 0.10 | 0.18 | 9.1 |
| 100 | 1000 | 94.25 | 0.04 | 0.07 | 1.7 |
| 200 | 1000 | 94.19 | 0.08 | 0.13 | 5.2 |
| 10 | 200 | 94.04 | 0.13 | 0.28 | 33.5 |
| 100 | 200 | 94.18 | 0.14 | 0.14 | 5.6 |
| 200 | 200 | 93.78 | 1.45 | 0.54 | 558.0 |
| Optimal | - | 94.32 | - | 0.00 | 1.0 |
Appendix E More comparison on NAS-Bench-201
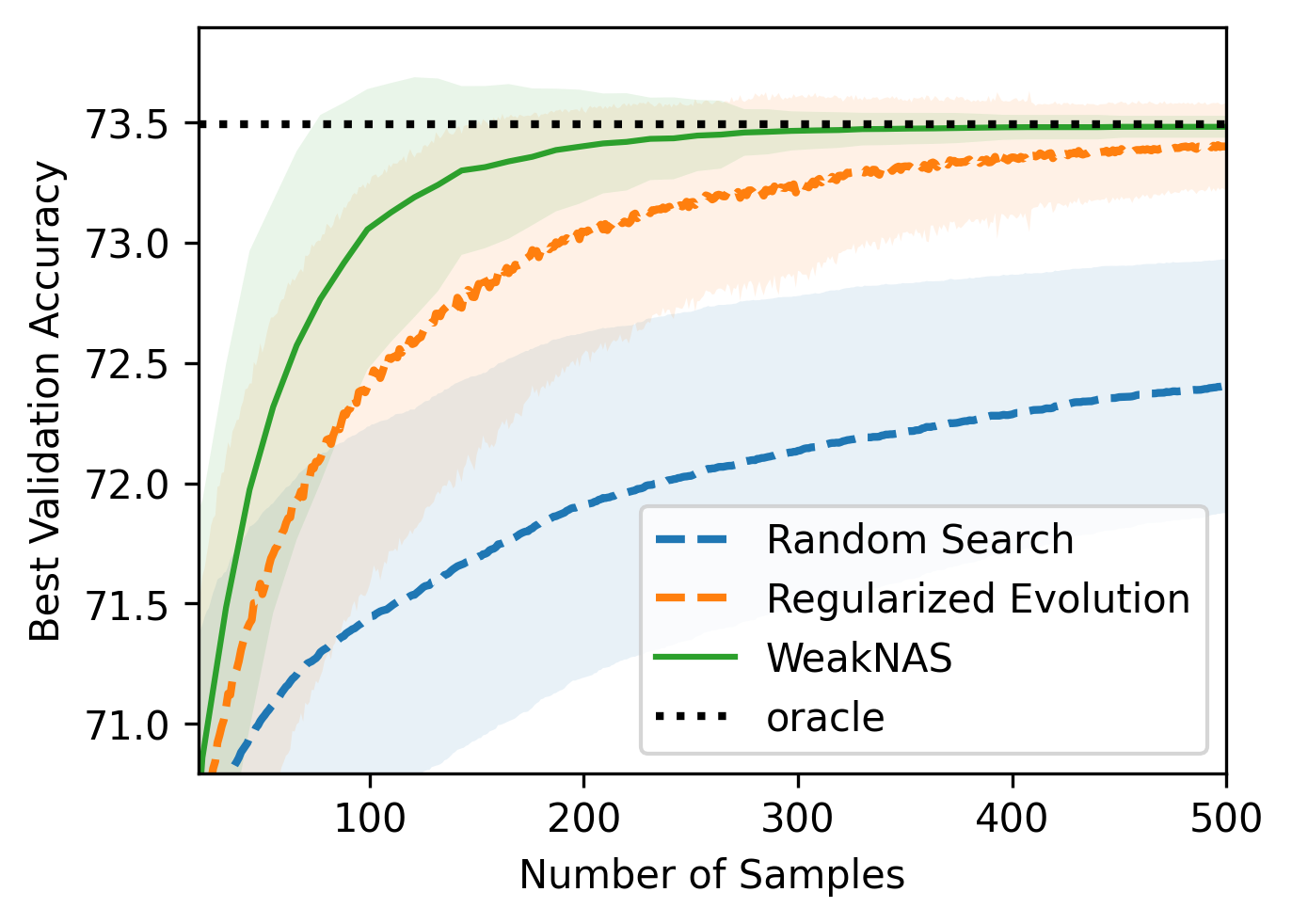
We conduct a controlled experiment on NAS-Bench-201 by varying number of samples. As shown in Figure 7, our average performance over different number of samples is clearly better than Regularized Evolution [14] in all three subsets, with better stability indicated by confidence intervals.


Appendix F Comparison to BRP-NAS
Evaluation strategy: BRP-NAS[8] uses a unique setting that differs from other predictor-based NAS, i.e., evaluating Top 40 predictions by the NAS predictor instead of Top 1 prediction, and the later was commonly followed by others[2, 19, 21, 20] and WeakNAS.
Sampling strategy: WeakNAS uses a different sampling strategy than that of BRP-NAS, given a sample budget of , BRP-NAS picks both samples from Top- and random models from the entire search space, while our WeakNAS only picks random models in Top-, thus is a more “greedy” strategy. BRP-NAS controls the exploitation and exploration trade-off by adjusting , however they did not have any ablation discussing the exploitation and exploration trade-off and only empirically choose as the default ratio. Our WeakNAS instead controls the exploitation and exploration trade-off by adjusting ratio, and we did a comprehensive analysis on the exploitation and exploration trade-off on both NAS-Bench and MobileNet Search Space on ImageNet in Section 3.1.
NAS predictor: BRP-NAS uses a stronger GCN-based binary relation predictors which utilizes extra topological prior, on the other hand, our framework generalizes to all choices of predictors, including MLP, Regression Tree and Random Forest, thus is not picky on the choice of predictors.
To fairly compare with BRP-NAS, we follow the exact same setting for our WeakNAS predictor, e.g., incorporating the same graph convolutional network (GCN) based predictor and using Top-40 evaluation. As shown in Table 11, at 100 training samples, WeakNAS can achieve comparable performance to BRP-NAS [8].
| Method | #Train | #Queries | Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank |
| BRP-NAS [8] | 100 | 140 | 94.22 | - | 0.10 | 3.0 |
| WeakNAS | 100 | 140 | 94.23 | 0.09 | 0.09 | 2.3 |
| Optimal | - | - | 94.32 | - | 0.00 | 1.0 |
Appendix G Comparsion of meta-sampling methods in WeakNAS
We also show that local search algorithm (hill climbing) or Semi-NAS [20] can be used as a meta sampling method in WeakNAS, which could further boost the performance of WeakNAS, here are the implementation details.
Local Search Given a network architecture embedding in NAS-Bench-101 Search Space, we first define a nearest neighbour function as architecture that differ from by a edge or a operation. At each iteration, we random sample a initial sample from TopN predictions and sample all of its nearest neighbour architecture in . We then let the new . We repeat the process iteratively until we reach a local maximum such that or the sampling budget of the iteration is reached.
Semi-NAS At the sampling stage of each iteration in WeakNAS, we further use Semi-NAS as a meta-sampling methods. Given a meta search space of 1000 architectures and a sample budget of 100 queries each iteration. We following the setting in Semi-NAS, using the same 4-layer MLP NAS predictor in WeakNAS and uses pseudo labels as noisy labels to augment the training set, therefore we are able to leverage “unlabeled samples" (e.g., architectures with accuracy generated by the predictors) to update the predictor. We set the initial sample to be 10, and sample 10 more samples each iteration. Note that at the start of -th WeakNAS iteration, we inherent the weight of Semi-NAS predictor from the previous (-1)-th WeakNAS iteration.
| Sampling (M from TopN) | M | N | #Queries | Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank |
|---|---|---|---|---|---|---|---|
| WeakNAS | 100 | 1000 | 1000 | 94.25 | 0.04 | 0.07 | 1.7 |
| Local Search | - | - | 1000 | 94.24 | 0.03 | 0.08 | 1.9 |
| Semi-NAS | - | - | 1000 | 94.26 | 0.02 | 0.06 | 1.6 |
Appendix H Details of Implementation on Open Domain Search Space
We extend WeakNAS to open domain settings by (a) Construct the evaluation pool by uniform sampling the whole search space (b) Apply WeakNAS in the evaluation space to find the best performer. (c) Train the best performer architecture from scratch.
For instance, when working with MobileNet search space that includes architectures, we uniformly sample 10K models as an evaluation pool, and further apply WeakNAS with a sample budget of 800 or 1000. When working with NASNet search space that includes architectures, we uniformly sample 100K models as an evaluation pool, and further apply WeakNAS with a sample budget of 800.
In the following part, we take MobileNet open domain search space as a example, however we follow a similar procedure for NASNet search space.
(a) Construct the evaluation pool from the search space We uniformly sample an evaluation pool to handle the extremely large MobileNet search space (), since its not doable to predict the performance of all architectures in . We use uniform sampling due to a recent study [26] reveal that human-designed NAS search spaces usually contain a fair proportion of good models compared to random design spaces, for example, in Figure 9 of [26], it shows that in NASNet/Amoeba/PNAS/ENAS/DARTS search spaces, Top 5% of models only have a <1% performance gap to the global optima. In practice, the uniform sampling strategy has been widely verified as effective in other works of predictor-based NAS such as [7, 55, 48], For example, [7] [55][48] set to be 112K, 15K, 20K in a search space of networks. In our case, we set = 10K.
(b) Apply WeakNAS in the evaluation space We then further apply WeakNAS in the evaluation pool . This is because even with the evaluation pool = 10K, it still takes days to evaluate all those models on ImageNet (in a weight-sharing SuperNet setting). Since the evaluation pool was uniformly sampled from NAS search space , it preserves the highly-structured nature of . As a result, we can leverage WeakNAS to navigate through the highly-structured search space. WeakNAS build a iterative process, where it searches for some top-performing cluster at the initial search iteration and then “zoom-in” the cluster to find the top performers within the same cluster (as shown in Figure 4). At iteration, WeakNAS balance the exploration and exploitation trade-off by sampling 100 models from the Top 1000 predictions of the predictor , it use the promising samples to further improve performance of the predictor in the next iteration . We leverage WeakNAS to further decrease the number of queries to find the optimal in by 10 times, the search cost has dropped from 25 GPU hours (evaluate all 10K samples in random evaluation pool) to 2.5 GPU hours (use WeakNAS in 10K random evaluation pool), while still achieving a solid performance of 81.3% on ImageNet (MobileNet Search Space).
(c) Train the best performer architecture from scratch. We follow a similar setting in LaNAS[21], where we use Random Erase and RandAug, a drop out rate of 0.3 and a drop path rate of 0.0, we also use exponential moving average (EMA) with a decay rate of 0.9999. During training and evaluation, we set the image size to be 236x236 (In NASNet search space, we set the image size to be 224x224). We train for 300 epochs with warm-up of 3 epochs, we use a batch size of 1024 and RMSprop as the optimizer. We use a cosine decay learning rate scheduler with a starting learning rate of 1e-02 and a terminal learning rate of 1e-05.
Appendix I Ablation on exploitation-exploration trade-off in Mobilenet Search space on ImageNet
For the ablation on open-domain search space, we follow the same setting in the Section H, however due to the prohibitive cost of training model from scratch in Section H (c), we directly use accuracy derived from supernet.
WeakNAS uniformly samples M samples from TopN predictions at each iteration, thus we can adjust N/M ratio to balance the exploitation-exploration trade-off. In Table 13, we set the total number of queries at 100, fix at 10 and while adjusting from 10 (more exploitation) to 1000 (more exploration), and use optimal in the 10K evaluation pool to measure the ranking and test regret. We found WeakNAS is quite robust within the range where N/M = 2.5 - 10, achieving the best performance at the sweet spot of N/M = 5. However, its performance drops significantly (by rank), while doing either too much exploitation (N/M <2.5) or too much exploration (N/M >25).
| Sampling methods | M | TopN | #Queries | SuperNet Test Acc.(%) | SD(%) | Test Regret(%) | Avg. Rank |
|---|---|---|---|---|---|---|---|
| Uniform | - | - | 100 | 79.0609 | 0.0690 | 0.1671 | 94.58 |
| Iterative | 10 | 10 | 100 | 79.1552 | 0.0553 | 0.0728 | 20.69 |
| 10 | 25 | 100 | 79.1936 | 0.0289 | 0.0344 | 4.68 | |
| 10 | 50 | 100 | 79.2005 | 0.0300 | 0.0275 | 4.05 | |
| 10 | 100 | 100 | 79.1954 | 0.0300 | 0.0326 | 4.63 | |
| 10 | 250 | 100 | 79.1755 | 0.0416 | 0.0525 | 10.58 | |
| 10 | 500 | 100 | 79.1710 | 0.0388 | 0.0570 | 10.80 | |
| 10 | 1000 | 100 | 79.1480 | 0.0459 | 0.0800 | 19.70 | |
| 10 | 2500 | 100 | 79.1274 | 0.0597 | 0.1006 | 33.64 |
Appendix J Founded Architecture on Open Domain Search
We show the best architecture founded by WeakNAS with 800/1000 queries in Table 14.
| Id | Block | Kernel | #Out Channel | Expand Ratio |
|---|---|---|---|---|
| WeakNAS @ 593 MFLOPs, #Queries=800 | ||||
| 0 | Conv | 3 | 24 | - |
| 1 | IRB | 3 | 24 | 1 |
| 2 | IRB | 3 | 32 | 4 |
| 3 | IRB | 5 | 32 | 6 |
| 4 | IRB | 7 | 48 | 4 |
| 5 | IRB | 5 | 48 | 3 |
| 6 | IRB | 7 | 48 | 4 |
| 7 | IRB | 3 | 48 | 6 |
| 8 | IRB | 3 | 96 | 4 |
| 9 | IRB | 7 | 96 | 6 |
| 10 | IRB | 5 | 96 | 6 |
| 11 | IRB | 7 | 96 | 3 |
| 12 | IRB | 3 | 136 | 6 |
| 13 | IRB | 3 | 136 | 6 |
| 14 | IRB | 5 | 136 | 6 |
| 15 | IRB | 5 | 136 | 3 |
| 16 | IRB | 7 | 192 | 6 |
| 17 | IRB | 5 | 192 | 6 |
| 18 | IRB | 3 | 192 | 4 |
| 19 | IRB | 5 | 192 | 3 |
| 20 | Conv | 1 | 192 | - |
| 21 | Conv | 1 | 1152 | - |
| 22 | FC | - | 1536 | - |
| Id | Block | Kernel | #Out Channel | Expand Ratio |
|---|---|---|---|---|
| WeakNAS @ 560 MFLOPs, #Queries=1000 | ||||
| 0 | Conv | 3 | 24 | - |
| 1 | IRB | 3 | 24 | 1 |
| 2 | IRB | 5 | 32 | 3 |
| 3 | IRB | 3 | 32 | 3 |
| 4 | IRB | 3 | 32 | 4 |
| 5 | IRB | 3 | 32 | 3 |
| 6 | IRB | 5 | 48 | 4 |
| 7 | IRB | 5 | 48 | 6 |
| 8 | IRB | 5 | 48 | 4 |
| 9 | IRB | 7 | 96 | 4 |
| 10 | IRB | 5 | 96 | 6 |
| 11 | IRB | 7 | 96 | 6 |
| 12 | IRB | 3 | 136 | 6 |
| 13 | IRB | 5 | 136 | 6 |
| 14 | IRB | 5 | 136 | 6 |
| 15 | IRB | 7 | 192 | 6 |
| 16 | IRB | 5 | 192 | 6 |
| 17 | IRB | 3 | 192 | 6 |
| 18 | IRB | 5 | 192 | 3 |
| 19 | Conv | 1 | 192 | - |
| 20 | Conv | 1 | 1152 | - |
| 21 | FC | - | 1536 | - |