stochprofML: Stochastic Profiling Using Maximum Likelihood Estimation in \proglangR
Lisa Amrhein, Christiane Fuchs
\PlaintitlestochprofML: Stochastic Profiling Using Maximum Likelihood Estimation in R
\ShorttitlestochprofML in \proglangR
\Abstract
Tissues are often heterogeneous in their single-cell molecular expression, and this can govern the regulation of cell fate. For the understanding of development and disease, it is important to quantify heterogeneity in a given tissue. We introduce the \proglangR package \pkgstochprofML which is designed to parameterize heterogeneity from the cumulative expression of small random pools of cells. This method outweighs the demixing of mixed samples with a saving in cost and effort and less measurement error. The approach uses the maximum likelihood principle and was originally presented in Bajikar et al. (2014); its extension to varying pool sizes was used in Tirier et al. (2019). We evaluate the algorithm’s performance in simulation studies and present further application opportunities.
\KeywordsstochprofML, stochastic profiling, gene expression, cell-to-cell hetereogeneity, mixture models, \proglangR
\PlainkeywordsstochprofML, stochastic profiling, gene expression, cell-to-cell hetereogeneity, mixture models, R
\Address
Lisa Amrhein
Institute of Computational Biology
Helmholtz Zentrum München, Germany
and
Department of Mathematics
Technical University Munich, Germany
Email:
Christiane Fuchs
Faculty of Business Administration and Economics
Bielefeld University, Germany
and
Institute of Computational Biology
Helmholtz Zentrum München, Germany
and
Department of Mathematics
Technical University Munich, Germany
Email:
URL: https://tinyurl.com/CFuchslab
1 Introduction: Stochastic Profiling
Tissues are built of cells which contain their genetic information on DNA strings, so-called genes. These genes can lead to the generation of messenger RNA (mRNA) which transports the genetic information and induces the production of proteins. Such mRNA molecules and proteins are modes of expression by which a cell reflects the presence, kind and activity of its genes. In this paper, we consider such gene expression in terms of quantities of mRNA molecules.
Gene expression is stochastic. It can differ significantly between, e.g., types of cells or tissues, and between individuals. In that case, one refers to differential gene expression. In particular, cells can be differentially expressed between healthy and sick tissue samples from the same origin. Moreover, cells can differ even within a small tissue sample, e.g. within a tumour that consists of several mutated cell populations. Mathematically, we regard two populations to be different if their mRNA counts follow different probability distributions. If there is more than one population in a tissue, we call it heterogeneous. The expression of such tissues is often described by mixture models. Detecting and parameterising heterogeneities is of utmost importance for understanding development and disease.
The amount of mRNA molecules of a gene in a tissue sample can be assessed by various techniques such as microarray measurements (Kurimoto, 2006; Tietjen et al., 2003) or sequencing (Sandberg, 2014; Ziegenhain et al., 2017). Measurements of single cells yield the highest possible resolution. They are best suited for identification and description of heterogeneity in large and error-free datasets. In practice, however, single-cell data often comes along with high cost, effort and technical noise (Grün et al., 2014). Instead of considering single-cell data, we analyze the cumulative gene expression of small pools of randomly selected cells (Janes et al., 2010). The pool size should be large enough to substantially reduce measurement error and cost, and at the same time small enough such that heterogeneity is still identifiable.
We developed the algorithm \pkgstochprofML to infer single-cell regulatory states from such pools (Bajikar et al., 2014). In contrast to previously existing methods, we neither require a priori knowledge about the mixing weights (such as Shen-Orr et al., 2010) nor about expression profiles (such as Erkkilä et al., 2010); other than most bulk deconvolution methods, like CIBERSORT (Newman et al., 2015), so-called signature matrices for the populations are not needed to infer population fractions.
In Bajikar et al. (2014), we applied \pkgstochprofML to measurements from human breast epithelial cells and revealed the functional relevance of the heterogeneous expression of a particular gene. In a second study, we applied the algorithm to clonal tumor spheroids of colorectal cancer (Tirier et al., 2019). Here, a single tumor cell was cultured, and after several rounds of replication, each resulting spheroid was imaged and sequenced. However, pool sizes differed between tissue samples as each spheroid contained a different number of cells ranging from less than ten to nearly 200 cells. Therefore, we extended \pkgstochprofML to be able to handle pools of different sizes.
In this work, we explain the statistical reasoning and \pkgR implementation of \pkgstochprofML (Amrhein and Fuchs, 2020). In Section 2, we derive the statistical model. After a first description of the nomenclature, we introduce basic statistical descriptions of continuous univariate single-cell gene expression. The complexity of the model is increased step by step: First, we account for cell-to-cell heterogeneity through the use of mixture distributions. Then, we extend the modeling from single-cell to small-pool measurements by introducing convolutions of statistical distributions. Finally, we calculate the likelihood and present ways for model selection. Section 3 shows how the \pkgR package can be used to generate data and to infer model parameters. This is followed by simulation studies in Section 4, investigating the influence of pool sizes, differences in parameter settings and uncertainty about cell counts on the resulting parameter inference. In Section 5, we elaborate the interpretation of inferred heterogeneity. Section 6 concludes the work.
2 Models and software
The \pkgstochprofML algorithm aims at maximum likelihood estimation of the corresponding model parameters. Hence, we derive the likelihood functions of the parameters and show details of the estimation and its implementation. The new elements of the most recent version of the algorithm are introduced along the line.
2.1 Single-cell models of heterogeneous gene expression
Suppose there are (tissue) samples, indexed by . From each tissue sample , we collect a pool of a known number of cells. The cells are either indexed by if the cell pool size is the same in all measurements, or, as possible in the latest implementation, by in case cell pool sizes vary between measurements. In the latter, more general case, the cell numbers are variable over the cell pools and summarized by . From each sample, the gene expression of genes is measured, indexed by . We assume that each cell stems from one out of cell populations, indexed by . If in the set of all cells of interest, the tissue is called heterogeneous. The notation is illustrated in Figure 1.
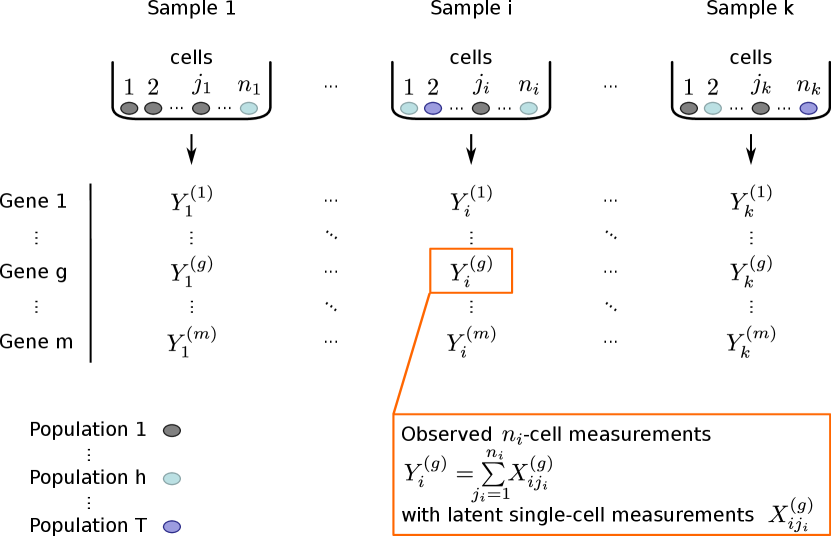
Biologically, the different cell populations correspond to different regulatory states or — especially in the context of cancer — to different (sub-)clones. For example, there might be two populations within a considered tissue: one occupying a basal regulatory state, where the expression of genes is at a low level, and one from a second regulatory state, where genes are expressed at a higher level.
As described in Section 1, there are various technologies to measure gene expression. In case of microarray techniques as done in previous applications of stochastic profiling, see Janes et al., 2010 and Bajikar et al., 2014, the measured gene expression is typically described in terms of continuous probability distributions. Conditioned on the cell population, \pkgstochprofML provides two choices for the distribution of the expression of one gene:
Lognormal distribution.
The two parameters defining a univariate lognormal distribution are called log-mean and log-standard deviation . These are the mean and the standard deviation of the normally distributed random variable , the natural logarithm of . The probability density function (PDF) of is given by
A random variable has expectation and variance
| (1) |
Exponential distribution.
An exponential distribution is defined by the rate parameter . The PDF is given by
A random variable has expectation and variance
In general, the lognormal distribution is an appropriate description of continuous gene expression. With its two parameters, it is more flexible than the exponential distribution. However, the lognormal distribution cannot model zero gene expression. In case of zeros in the data, it could be modified by adding very small values such as 0.0001, or one uses the exponential distribution to model this kind of expression.
In case of cell populations, we describe the expression of one gene by a stochastic mixture model. Let with denote the fractions of populations in the overall set of cells. \pkgstochprofML offers the following three mixture models:
-
1.
Lognormal-lognormal (LN-LN): Each population is represented by a lognormal distribution with population-specific parameter (different for each population ) and identical for all populations. The single-cell expression that originates from such a mixture of populations then follows
-
2.
Relaxed lognormal-lognormal (rLN-LN): This model is similar to the LN-LN model, but each population is represented by a lognormal distribution with a different parameter set (, ). The single-cell expression follows
-
3.
Exponential-lognormal (EXP-LN): Here, one population is represented by an exponential distribution with parameter , and all remaining populations are modeled by lognormal distributions analogously to LN-LN, i.e. with population-specific parameters and identical . The single-cell expression then follows
The LN-LN model is a special case of the rLN-LN model. It assumes identical across all populations. Biologically, this assumption is motivated by the fact that, for the lognormal distribution, identical lead to identical coefficient of variation
even for different values of . In other words, the linear relationship between the mean expression and the standard deviation is maintained across cell populations in the LN-LN model. The appropriateness of the different mixture models can be discussed both biologically and in terms of statistical model choice (see Section 2.5).
Within one set of genes under consideration, we assume that the same type of model (LN-LN, rLN-LN, EXP-LN) is appropriate for all genes. The parameter values, however, may differ. In case of cell populations, we describe the single-cell gene expression for gene by a mixture distribution with PDF
where with represents the PDF of population that can be either lognormal or exponential, and are the (not necessarily disjoint) distribution parameters of the populations for gene .
Example: Mixture of two populations - Part 1.
We exemplify the two-population case. Here, the PDF of the mixture distribution for gene reads
where is the probability of the first population. The univariate distributions and depend on the chosen model :
-
1.
LN-LN: and , i.e. there are four unknown parameters: and .
-
2.
rLN-LN: and i.e. there are five unknown parameters: and .
-
3.
EXP-LN: and . i.e. there are four unknown parameters: , and .
Note that although each lognormal population has its individual , these -values remain identical across genes.
2.2 Small-pool models of heterogeneous gene expression
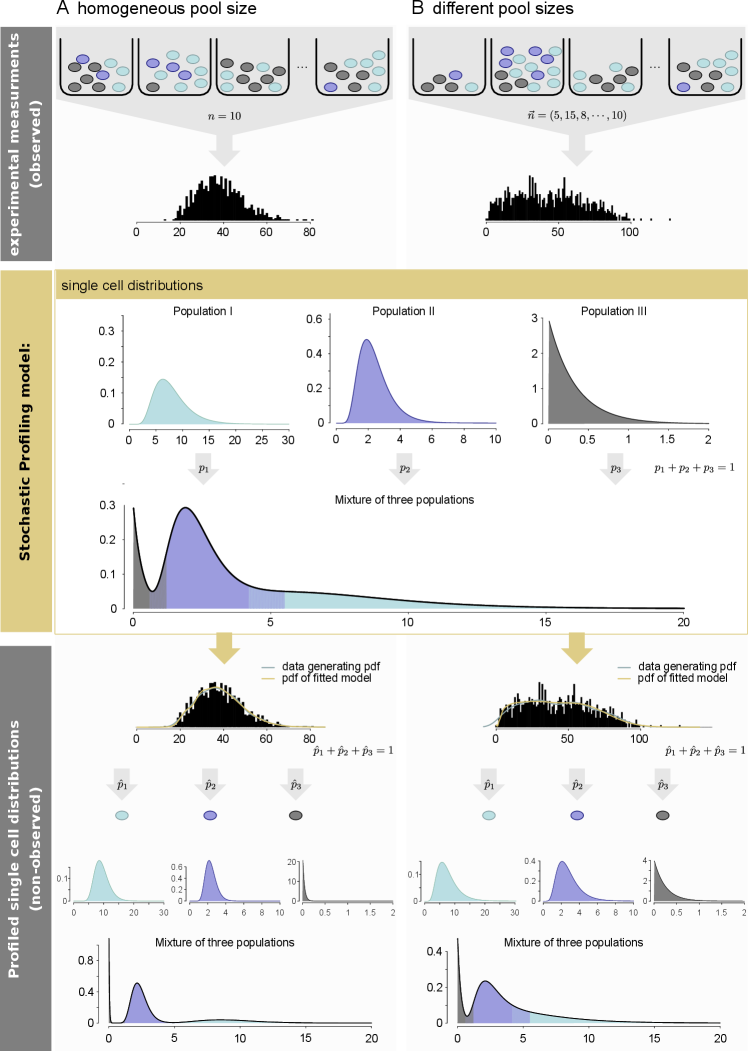
stochprofML is tailored to analyze gene expression measurements of small pools of cells, beyond the analysis of standard single-cell gene expression data. In other words, the single-cell gene expression described in Section 2.1 is assumed latent. Instead, we consider observations
| (2) |
for , which represent the overall gene expression of the th cell pool for gene . In the first version of \pkgstochprofML, pools had to be of equal size , i.e. for each measurement one had to extract the same number of cells from each tissue sample. This was a restrictive assumption from the experimental point of view. The recent extension of \pkgstochprofML allows each cell pool to contain a different number of cells (see also Figures 1 and 2).
The algorithm aims to estimate the single-cell population parameters despite the fact that measurements are available only in convoluted form. To that end, we derive (in Section 2.3) the likelihood function of the parameters in the convolution model (2), where we assume the gene expression of the single cells to be independent within a tissue sample. For better readability, we suppress for now the superscript and introduce it again in Section 2.3.
The derivation of the distribution of is described in Appendix A. The corresponding PDF of an observation which represents the overall gene expression from sample (consisting of cells) is given by
| (3) |
where and . Here, describes the PDF of a pool of cells with known composition of the single populations, i.e. it is known that there are cells from population , cells from population etc. represents the multinomial probability of obtaining exactly this composition using the multinomial coefficient . Equation (3) sums up over all possible compositions with and . Taken together, determines the PDF of with respect to each possible combination of cells of populations.
Thus, the calculation of requires knowledge of . The derivation of this PDF depends on the choice of the single-cell model (LN-LN, rLN-LN, or EXP-LN; see Section 2.1) that was made for .
-
1.
LN-LN:
is the density of a sum of independent random variables with
with . is the convolution of random variables , which is here the convolution of sub-convolutions: a convolution of times , plus a convolution of times , and so on, up to a convolution of times .
There is no analytically explicit form for the convolution of lognormal random variables. Hence, is approximated using the method by Fenton (1960). That is, the distribution of the sum of independent random variables is approximated by the distribution of a random variable such that
According to Equation (1), that means that and are chosen such that the following equations are fulfilled:
and
That is achieved by choosing
This approximation is implemented in the function \coded.sum.of.lognormals(). The overall PDF is computed through \coded.sum.of.mixtures.LNLN().
-
2.
rLN-LN:
is the PDF of a sum of independent random variables with
with . Again, is approximated using the method by Fenton (1960), analogously to the LN-LN model. It is implemented in \coded.sum.of.mixtures.rLNLN().
-
3.
EXP-LN:
is the density of a sum of independent random variables with
with . The sum of independent exponentially distributed random variables with equal intensity parameter follows an Erlang distribution (Feldman and Valdez-Flores, 2010), which is a gamma distribution with integer-valued shape parameter that represents the number of exponentially distributed summands. Thus, the PDF for the EXP-LN mixture model is the convolution of one Erlang (or gamma) distribution (namely the sum of all exponentially distributed summands) and one lognormal distribution (namely the sum of all lognormally distributed summands, again using the approximation method by Fenton, 1960). The PDF for this convolution is not known in analytically explicit form but expressed in terms of an integral that is solved numerically through the function \codelognormal.exp.convolution(). The overall PDF of the EXP-LN model is implemented in \coded.sum.of.mixtures.EXPLN().
Example: Mixture of two populations - Part 2. In this example of the two-population model, let each observation consist of the same number of cells. Then is a -fold convolution, and the PDF (3) simplifies to
| (4) |
where is the PDF of the sum of ten independent random variables, that is. This PDF depends on the particular chosen model:
-
1.
LN-LN
is the PDF of a sum of ten independent random variables with
-
2.
rLN-LN
is the PDF of a sum of ten independent random variables with
-
3.
EXP-LN
is the PDF of a sum of ten independent random variables with
2.3 Likelihood function
Overall, after re-introducing the superscript for measurements of genes , we obtain the PDF
| (5) |
with model-specific choice of . While is considered known, we aim to infer the unknown model parameters by maximum likelihood estimation. Assuming independent observations of for genes and tissue samples, where sample contains cells, the likelihood function is given by
Consequently, the log-likelihood function of the model parameters reads
| (6) |
Example: Mixture of two populations - Part 3. Returning to the two-population example with 10-cell pools, the log-likelihood for tissue samples and genes is given by
where is given by Equation (4).
2.4 Maximum likelihood estimation
The \pkgstochprofML algorithm aims to infer the unknown model parameters using maximum likelihood estimation. As input, we expect an data matrix of pooled gene expression, known cell numbers , the assumed number of populations and the choice of single-cell distribution (LN-LN, rLN-LN, EXP-LN). Based on this input, the algorithm aims to find parameter values of that maximize as given by Equation (6). This section describes practical aspects of the optimization procedure.
Example: Mixture of two populations - Part 4. Several challenges occur during parameter estimation. We explain these on the two-population LN-LN example: First, we aim to ensure parameter identifiability. This is achieved for the two-population LN-LN model by constraining the parameters to fulfil either or . Otherwise, the two combinations and would yield identical values of the likelihood function and could cause computational problems. For our implementation, we preferred the second possibility, i. e. . The alternative, i. e. requiring , led to switchings between and in case of . As a second measure, we implement unconstrained rather than constrained optimization: Instead of estimating under the constraints , and , the parameters are transformed to , and an unconstrained optimization method is used. This is substantially faster.
The aforementioned transformations are likewise employed for all other models (rLN-LN and EXP-LN) and population numbers. In particular, and are log-transformed, and the lognormal populations are ordered according to the log-means of the first gene in the gene list. The population probabilities are transformed to such that they still sum up to one after back-transformation. For details, see Appendix C.
The log-likelihood function is multimodal. Thus, a single application of some gradient-based optimization method does not suffice to find a global maximum. Instead, two approaches are combined which are alternately executed: First, a grid search is performed, where the log-likelihood function is computed at randomly drawn parameter values. This way, high likelihood regions can be identified with low computational cost. In the second step, the Nelder-Mead algorithm (Nelder and Mead, 1965) is repeatedly executed. Its starting values are randomly drawn from the high likelihood regions found before. The following grid search then again explores the regions around the obtained local maxima, and so on.
If a dataset contains gene expressions for genes, and if we assume populations, there are at minimum parameters which one seeks to estimate depending on the model framework. This is computationally difficult, because the number of modes of the log-likelihood function increases with the number of parameters. The performance of the numerical optimization crucially depends on the quality of the starting values, and a large number of restarts is required. When analyzing a large gene cluster, it is advantageous to start by considering small clusters and use the derived estimates as initial guesses for larger clusters. This is implemented in the function \codestochprof.loop() (parameter \codesubgroups) and demonstrated in \codeanalyze.toycluster().
Approximate marginal 95% confidence intervals for the parameter estimates are obtained as follows: We numerically compute the Hessian matrix of the negative log-likelihood function on the unrestricted parameter space and evaluate it at the (transformed) maximum likelihood estimator. Denote by the th diagonal element of the inverse of this matrix. Then the confidence bounds for the th transformed parameter are
We obtain respective marginal confidence intervals for the original true parameters by back-transformation of the above bounds. This approximation is especially appropriate in the two-population example for the parameters and when conditioning on and . In this case, in practice, the profile likelihood is seemingly unimodal.
2.5 Model choice
By increasing the number of populations, we can describe the observed data more precisely, but this comes at the cost of potential overfitting. For example, a three-population LN-LN model may lead to a larger likelihood at the maximum likelihood estimator than a two-population LN-LN model on the same dataset. However, the difference may be small, and the additional third population may not lead to a gain of knowledge. For example, the estimated population probability may be tiny, or the log-means of the second and third population, and might hardly be distinguished from each other.
To objectively find a trade-off between necessary complexity and sufficient interpretability, we employ the Bayesian information criterion (BIC, Schwarz, 1978):
where is the maximum likelihood estimate of the respective model, the number of parameters and the size of the dataset. From the statistics perspective, the model with smallest BIC is considered most appropriate among all considered models.
In practice, it is required to estimate all models of interest separately with the \pkgstochprofML algorithm, e. g. the LN-LN model with one, two and three populations, and/or the respective rLN-LN and EXP-LN models. The BIC values are returned by the function \codestochprof.loop().
3 Usage of stochprofML
This section illustrates the usage of the \pkgstochprofML package for simulation and parameter estimation. There are two ways two use the \pkgstochprofML package: (i) Two interactive functions\codestochasticProfilingData() and \codestochasticProfilingML() provide low-level access to synthetic data generation and maximum likelihood parameter estimation without requiring advanced programming knowledge. They guide the user through entering the relevant input parameters: Working as question-answer functions, they ask for prompting the data (or file name), the number of cells per sample, the number of genes etc. An example of the use of the interactive functions can be found in Appendix E. (ii) The direct usage of the package’s \pkgR functions allows more flexibility and is illustrated in the following.
3.1 Synthetic data generation
We first generate a dataset of sample observations, where each sample consists of cells. We choose a single-cell model with two populations, both of lognormal type, i.e. we use the LN-LN model. Let us assume that the overall population of interest is a mixture of of population and of population , i.e. . As population parameters we choose , and . Synthetic gene expression data for one gene is generated as follows: {Schunk} {Sinput} R> library("stochprofML") R> set.seed(10) R> k <- 1000 R> n <- 10 R> TY <- 2 R> p <- c(0.62, 0.38) R> mu <- c(0.47, -0.87) R> sigma <- 0.03 R> gene_LNLN <- r.sum.of.mixtures.LNLN(k = k, n = n, p.vector = p, + mu.vector = mu, sigma.vector = rep(sigma, TY))
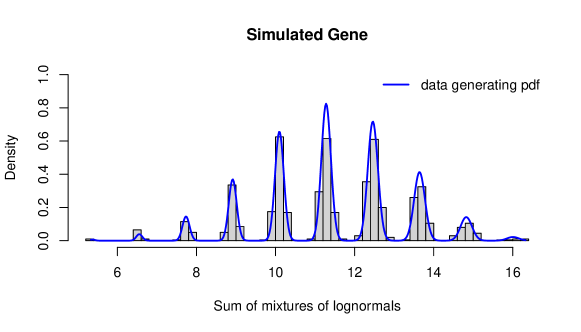
Figure 3 shows a histogram of the simulated data as well as the theoretical PDF of the 10-cell mixture. The following code produces this figure: {Schunk} {Sinput} R> x <- seq(from = min(gene_LNLN), to = max(gene_LNLN), length = 500) R> stochprofML:::set.model.functions("LN-LN") R> y <- d.sum.of.mixtures(x, n, p, mu,rep(sigma,TY), logdens = FALSE) R> hist(gene_LNLN, main = paste("Simulated Gene"), breaks = 50, + xlab = "Sum of mixtures of lognormals", ylab = "Density", + freq = FALSE, col = "lightgrey") R> lines(x, y, col="blue", lwd = 2) R> legend("topright", legend = "data generating pdf", col = "blue", + lwd = 2, bty = "n")
3.2 Parameter estimation
Next, we show how the parameters used above can be back-inferred from the generated dataset using maximum likelihood estimation. {Schunk} {Sinput} R> set.seed(20) R> result <- stochprof.loop(model = "LN-LN", + dataset = matrix(gene_LNLN, ncol = 1), n = n, TY = TY, + genenames = "SimGene", fix.mu = FALSE, loops = 10, + until.convergence = FALSE, print.output = FALSE, show.plots = TRUE, + plot.title = "Simulated Gene", use.constraints = FALSE) When the fitting is done, pressing <enter> causes \proglangR to show plots of the estimation process, see Figure 4, and displays the results in the following form.
Maximum likelihood estimate (MLE): p_1 mu_1_gene_SimGene mu_2_gene_SimGene sigma 0.6146 0.4710 -0.8720 0.0310
Value of negative log-likelihood function at MLE: 1204.371
Violation of constraints: none
BIC: 2436.373
Approx. 95lower upper p_1 0.60501813 0.6240938 mu_1_gene_SimGene 0.46972264 0.4722774 mu_2_gene_SimGene -0.87827704 -0.8657230 sigma 0.02967451 0.0323847
Top parameter combinations: p_1 mu_1_ge_SimGene mu_2_gene_SimGene sigma target p_1 mu_1_gene_SimGene mu_2_gene_SimGene sigma target [1,] 0.6146 0.471 -0.872 0.031 1204.371 [2,] 0.6146 0.470 -0.872 0.031 1204.371 [3,] 0.6146 0.471 -0.872 0.031 1204.371 [4,] 0.6146 0.470 -0.872 0.031 1204.371 [5,] 0.6145 0.471 -0.872 0.031 1204.371 [6,] 0.6146 0.471 -0.872 0.031 1204.371
Hence, the marginal confidence intervals cover the true parameter values.
4 Simulation studies
This section demonstrates the performance of the estimation depending on pool sizes (Section 4.1), true parameter values (Section 4.2) and in case of uncertainty about pool sizes (Section 4.3). All scripts used in these studies can be found in our open GitHub repository https://github.com/fuchslab/Stochastic_Profiling_in_R.
4.1 Simulation study on optimal pool size
Stochastic profiling, i.e. the analysis of small-pool gene expression measurements, is a compromise between the analysis of single cells and the consideration of large bulks: Single-cell information is most immediate, but a fixed number of samples will only cover cells. In pools of cells, on the other hand, information is convoluted, but pools of size cover times as much material. An obvious question is the optimal pool size . The answer is not available in analytically closed form. We hence study this question empirically.
For this simulation study, first, we generate synthetic data for different pool sizes with identical parameter values and settings. Then, we re-infer the model parameters using the \pkgstochprofML algorithm. This is repeated 1,000 times for each choice of pool size, enabling us to study the algorithm’s performance by simple summary statistics of the replicates.
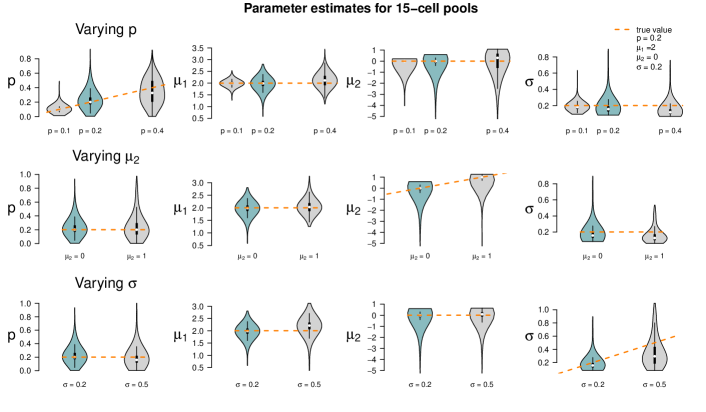
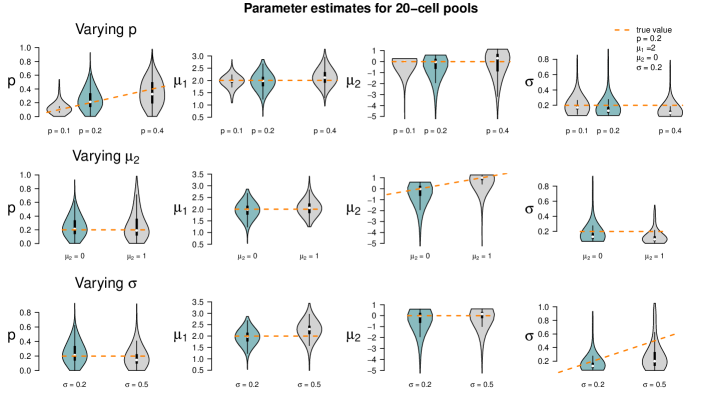
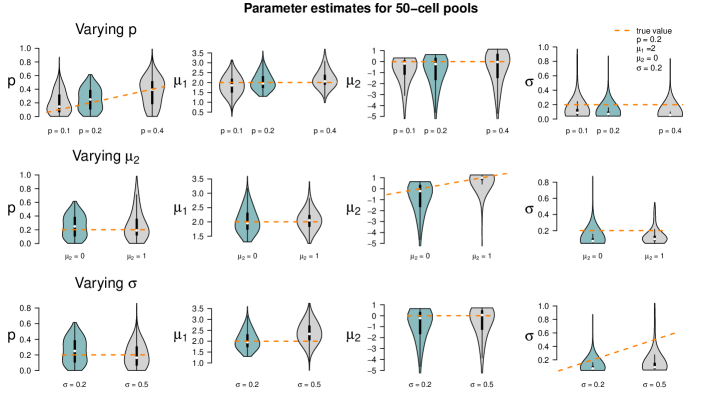
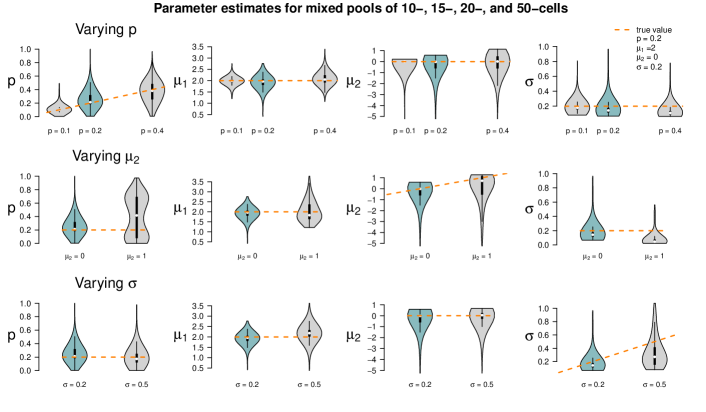
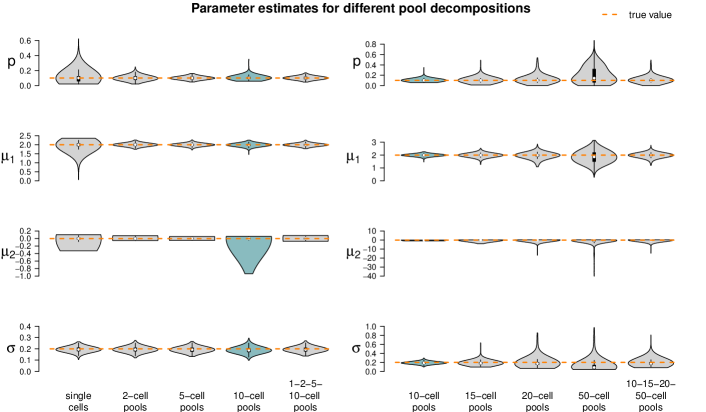
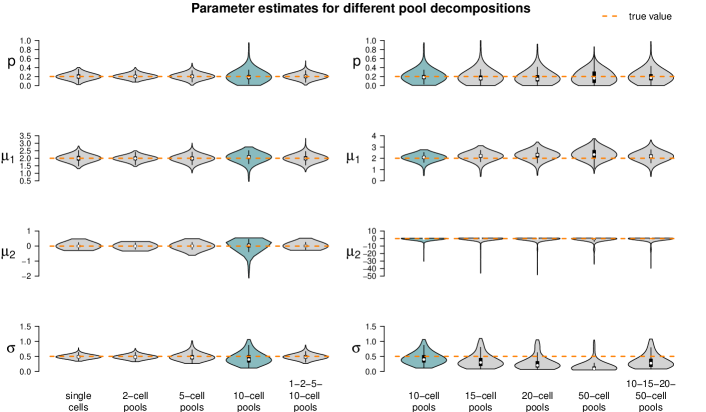
The fixed settings are as follows: We use the two-population LN-LN model to generate data for one gene with , , and . For each pool size we simulate observations. The pool sizes are chosen in nine different ways: In seven cases, pool sizes are identical for each sample, namely . In two additional cases, pool sizes are mixed, i.e. each of the samples within one dataset represents a pool of different size or .
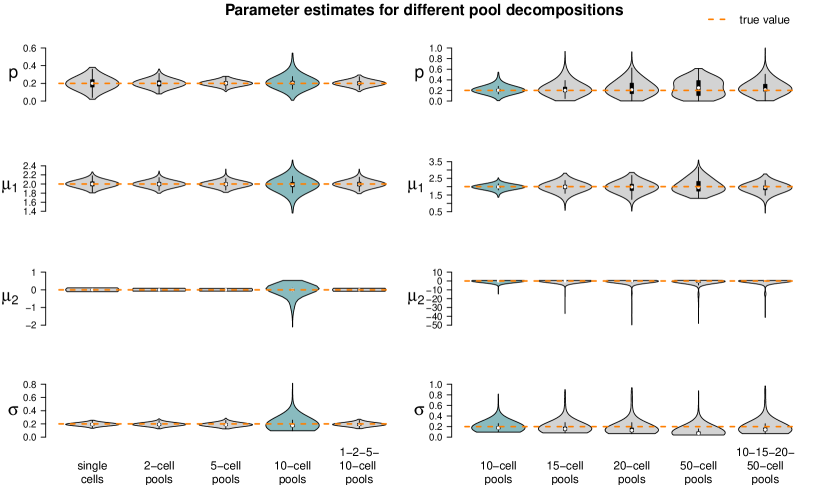
Figure 5 summarizes the point estimates of the 1,000 datasets for each of the nine pool size settings. It seems that (for this particular choice of model parameter values) parameter estimation works reliably for pool sizes up to ten cells, with smaller variance from single-cells to 5-cells. This applies also for the mixture of pool sizes for the small cell numbers. For cell numbers larger than ten, the range of estimated values becomes considerably larger, but without obvious bias, which also applies to the mixture of the larger pool sizes. Appendix F shows repetitions of this study for different choices of population parameters. The results there confirm the observations made here.
Figure 5 suggests or varying small pool sizes as ideal choices since its estimates show smaller variance than the other pool sizes. This simulation study, however, has been performed in an idealized in silico setting: We did not include any measurement noise. In practice, however, it is well known that single-cells suffer more from such noise than samples with many cells. The ideal choice of pool size may hence be larger in practice.
4.2 Simulation study on impact of parameter values
The underlying data-generating model obviously influences the ability of the maximum likelihood estimator to re-infer the true parameter values: Values of close to , small differences between and and large blur the data and complicate parameter inference in practice. In the simulation study of this section, we investigate the sensitivity of parameter inference and which scenarios could be realistically identified.
We use the same datasets as in the previous simulation study: The parameter choices from Section 4.1 are considered as the standard and compared to those from Appendix F. In detail, is reduced from to in one setting and increased to in the next. is increased from to , and increases from to . is kept fixed to in all settings. As before, we consider 1,000 data sets for every parameter setting and compare the resulting estimates to the true values. This was done for all pool sizes considered in Section 4.1, but here we only comment on the results of the 10-cell pools and refer to Appendix F for all other pool size settings.

Figure 6 shows the results of the study. In each row of the plot, we compare the estimates of the datasets that were simulated with the standard parameters to the estimates of the datasets that were simulated with one of the parameters changed. Even if only one parameter is changed all parameters are estimated. Each violin accumulates the estimates of 1,000 datasets. For easier comparison, each of the twelve tiles shows the standard setting as turquoise violin, which means those are repeated in each row.
When changing the parameter values, they can still be derived without obvious additional bias, but accuracy decreases for increasing , decreasing and increasing (with few exceptions). Result for other pool sizes (see Appendix F) show that these observations can be transferred to other pool sizes with some additions: Larger pool sizes infer parameters more accurately if is smaller. In an increased first population setting (), can be better inferred if the data set consists of smaller pools. For larger pools, the estimation of and works comparably well after increasing . In general, the estimation of is the most difficult one; already in pools of ten cells with increased , is underestimated. This worsens in larger pools.
4.3 Simulation study on the uncertainty of pool sizes
One key assumption of the \pkgstochprofML algorithm is that the exact number of cells in each cell pool is known. In Janes et al. (2010), accordingly, ten cells were randomly taken from each sample by experimental design. However, different experimental protocols may not reveal the exact cell number: In Tirier et al. (2019), for example, tissue samples were taken as whole cancer spheroids. Here, the cell numbers were experimentally unknown but estimated using light sheet microscopy and 3D image analysis. Since the \pkgstochprofML algorithm requires the pool sizes as input parameter, some estimate has to be passed to it. It is intuitively obvious that the better the prior knowledge about the cell pool sizes, the better the final model parameter estimate. In this simulation study, we investigate the consequences of misspecification.
In a first simulation study, we reuse from Section 4.1 the 1,000 synthetic 10-cell datasets. Each of these contains 50 10-cell samples, simulated with underlying model parameters , , and . As before, we re-infer the population parameters using the \pkgstochprofML algorithm. This time, however, we use varying pool sizes from to as input parameters of the algorithm. This is a misspecification except for the true value . The resulting parameter estimates (empirical median and 2.5%-/97.5%-quantiles across the 1,000 datasets) are depicted in Figure 7. Estimates are optimal or at least among the best in terms of empirical bias and variance when using the correct pool size. With increasing assumed cell number, the estimates of decrease, i. e. the fraction of cells from the higher expressed population is assumed to be smaller. This is a reasonable consequence of overestimating , because in this case the surplus cells are assigned to the second population with lower (or even close-to-zero) expression. Consequently, at the same time the estimates of decrease to be even smaller.
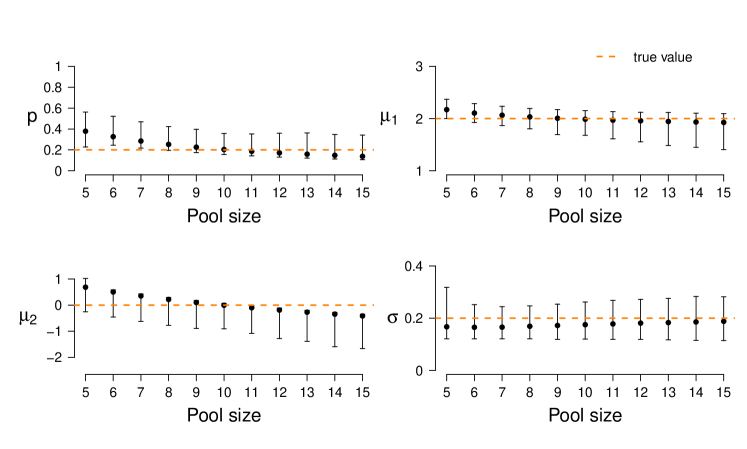
In a second simulation study, we use the two settings with mixed cell pool sizes as introduced in Section 4.1. One setting embraces cell pools with rather small cell numbers (single-, 2-, 5- and 10-cell samples), the other one pools with larger cell numbers (10-, 15-, 20- and 50-cell samples). For each of the two scenarios, we generate one dataset with 50 samples. We denote the true 50-dimensional pool size vectors by and and employ these vectors for re-estimating the model parameters , , and . Then, we estimate the parameters again for the same two datasets for 1,000 times, but this time using perturbed pool size vectors as input to the algorithm, introducing artificial misspecification. These 50-dimensional pool size vectors are generated as follows: For each component, we draw a Poisson-distributed random variable with intensity parameter equal to the respective component of the true vectors or . Zeros are set to one, the minimum pool size. Figure 8 shows these parameter estimates as compared to the true parameter values and those for which the true size vectors and were used as input.
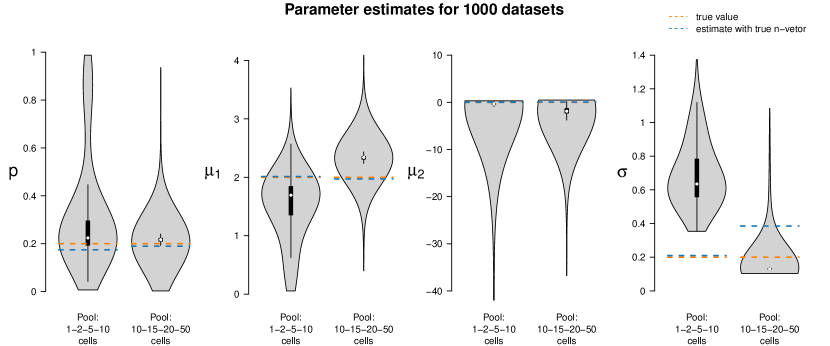
The violins of the estimates for the smaller cell pools (based on ) indicate that the estimates of and are fairly accurate, but the estimates of have large variance, and is overestimated in all 1,000 runs. This is plausible as population 1 (the one with higher log-mean gene expression) is only present on average in 20% of the cells; even when misspecifying the pool sizes, the cells of population 1 are still detectable since this is the population responsible for most gene expression. Consequently, all remaining cells are assigned to population 2, which has lower or even almost no expression. If the pool size is assumed too low, this second population will be estimated to have on average a higher expression; if it is assumed too large, the second population will be estimated to have a lower expression. This leads to a broader distribution and thus an overestimation of .
The results for the larger cell pools (based on ) show a similar pattern. In this case, however, the impact of misspecification is less visible, as also confirmed by additional simulations in Appendix F. For large cell pools, the averaging effect across cells is strong anyway and in that sense more robust. In the study here, the parameter is often even better estimated when using a misspecified pool size vector than when using the true one.
Taken together, \pkgstochprofML can be used even if exact pool sizes are unknown. In that case, the numbers should be approximated as well as possible.
5 Interpretation of estimated heterogeneity
We investigate what we can learn from the parameter estimates about the heterogeneous populations (Section 5.1) and about sample compositions (Section 5.2).
5.1 Comparison of inferred populations
The \pkgstochprofML algorithm estimates the assumed parameterized single-cell distributions underlying the samples and; as described in Section 2.5, we can select the most appropriate number of cell populations using the BIC. Assume we have performed this estimation for samples from two different groups, cases and controls. One may in practice then want to know whether the inferred single-cell populations are substantially different between the two groups, e.g. in case the estimated log-means and are close to each other. A related question is whether the difference is biologically relevant.
We hence seek a method that can judge statistical significance and potentially reject the null hypothesis that two single-cell populations are the same; and at the same time allow the interpretation of similarity. Direct application of Kolmogorov-Smirnov or likelihood-ratio tests to the observed data is impossible here since the single-cell data is unobserved: We only measure the overall gene expression of pools of cells. Calculation of the Kullback-Leibler divergence of the two distributions would be possible; however, it is not target-oriented for our application where we seek an interpretable measure of similarity rather than a comparison between more than two population densities.
For our purposes, we use a simple intuitive measure of similarity — the overlap of two PDFs, that is the intersection of the areas under both PDF curves:
| (7) |
for two continuous one-dimensional PDFs and (see also Pastore and Calcagnì, 2019). The overlap lies between zero and one, with zero indicating maximum dissimilarity and one implying (almost sure) equality. In our case, we are particularly interested in the overlap of two lognormal PDFs: {Code} OVL_LN_LN <- function(mu_1, mu_2, sigma_1, sigma_2) f1 <- function(x)dlnorm(x, meanlog = mu_1, sdlog = sigma_1) f2 <- function(x)dlnorm(x, meanlog = mu_2, sdlog = sigma_2) f3 <- function(x)pmin(f1(x), f2(x)) integrate(f3, lower = 0, upper = Inf, abs.tol = 0)
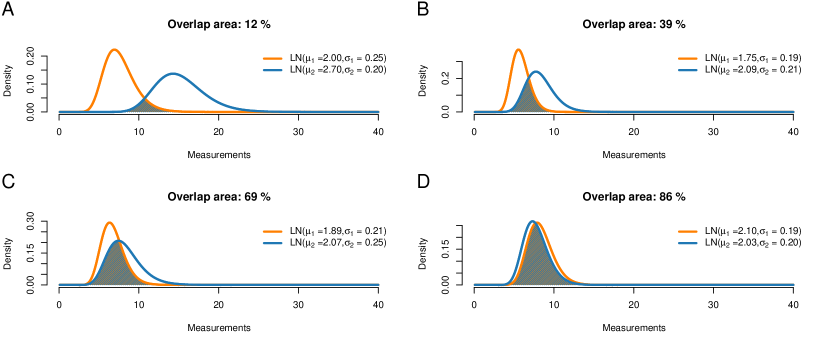
Figure 9 shows examples of such overlaps. Here, the overlap ranges from 12% for two quite different distributions to 86% for two seemingly similar distributions. The question is where to draw a cutoff, that is, at what point we decide to label two distributions as different. Current literature considers two cases: Either the parametric case (e.g. Inman and Bradley, 1989), where both distributions are given by their distribution families and parameter values; or the nonparametric case (e.g. Pastore and Calcagnì, 2019), where observations (but no theoretical distributions) are available for the two populations. Our application builds a third case: On the one hand, we want to compare two parametric distributions, but the model parameters are just given as estimates based on (potentially small) datasets, thus they are uncertain; on the other hand, we do not directly observe the single-cell gene expression but just the pooled one.

To address this issue, we suggest to again take into account the original data that led to the estimated parametric PDFs. As an example, assume that we consider two sets of pooled gene expression, one for a group of cases and one for a group of controls. In both groups, pooled gene expression is available as 10-cell measurements, but the two groups differ in sample size. Let’s say the cases contain 50 samples and the controls 100. We assume the LN-LN model with two populations and estimate the mixture and population parameters using the \pkgstochprofML algorithm separately for each group, leading to estimates , , , and , , , . We now aim to assess whether the first populations in both groups have identical characteristics, i. e. whether and are the same.
Figure 9 displays the single-cell PDFs of the first population and their overlaps for various values of the estimates. For example, in Figure 9D, the orange curve shows the single-cell PDF of population 1 inferred from the cases, yielding , and the blue one shows the inferred single-cell PDF of population 1 from the controls, . The overlap of these two inferred PDFs equals 86%.
We now aim to test the null hypothesis that these populations are the same versus the experimental hypothesis that they are different. We perform a sampling-based test: Taking into account the inferred population probabilities and and the number of samples and cells in the data, we can estimate the number of cells which the estimates and relied on. The larger this cell number, the less expected uncertainty about the estimated population distributions and (neglecting the impact of pool sizes).
In our example, let . Then, approximately 12% of the 500 cells from the cases group ( 10-cell samples) belonged to population 1, that is 60 cells. For , 200 cells were expected to be from the first population (that is 20% of 1,000 cells, coming from the 100 10-cell measurements for the controls). In our procedure, we compare parameter estimates that are based on the respective numbers of single cells, i. e. 60 cells for cases and 200 cells for controls. We perform the following steps:
-
•
Calculate , the overlap of the PDFs of and .
-
•
Under the null hypothesis, the two distributions are identical. We approximate the parameters of this identical distribution as and .
-
•
Repeat times:
-
–
Draw dataset of size from .
-
–
Draw dataset of size from .
-
–
Estimate the log-mean and log-sd for these two datasets using the method of maximum likelihood, yielding , , and .
-
–
Calculate .
-
–
-
•
Sort the overlap values and select the empirical 5% quantile .
-
•
Compare the overlap from the original data to this quantile:
-
–
If , the null hypothesis that both populations are the same can be rejected.
-
–
If , the null hypothesis cannot be rejected.
-
–
This proceeding is related to the idea of parametric bootstrap with the difference that our original data is on the -cell level and the parametrically simulated data is on the single-cell level.
The left panel of Figure 10 shows one outcome of the above-described procedure (i. e. the stochastic, sampling-based algorithm was run once) with the above-specified values of the parameter estimates. Here, lies in the critical range such that we reject the null hypothesis that the gene expression of the populations in question stem from the same lognormal distribution. We thus assume a difference here. The right panel of Figure 10 demonstrates the importance of taking into account the number of cells which the original estimates were based on: Here, we show one outcome of the above described steps, but this time we assume that for the control group there were only 30 10-cell samples (i.e. 300 cells in total). With the same population fraction as before (), the datasets now contain only 60 cells. Here, the value does not fall into the critical range, and therefore we would not reject the null hypothesis that the two populations of interest are the same.
When testing for heterogeneity for several genes simultaneously, multiple testing issues should be taken into account. However, genes will in general not be independent from each other.
5.2 Prediction of sample compositions
The \pkgstochprofML algorithm estimates the parameters of the mixture model, i. e. — in case of at least two populations — the probability for each cell within a pool to fall into the specific populations. It does not reveal the individual pool compositions. In some applications, however, exactly this information is of particular interest. Here, we present how one can infer likely population compositions of a particular cell pool.
This is done in a two-step approach via conditional prediction: First, one estimates the model parameters from the observed pooled gene expression, i. e. one obtains an estimate of . Then, one assumes that equals and derives the most probable population composition via maximizing the conditional probability of a specific composition given the pooled gene expression (for calculations, see Appendix D).
We evaluate this procedure via a simulation study. As before, we simulate data using the \pkgstochprofML package. In particular, we use the LN-LN model with two populations with parameters , and . Each simulated measurement shall contain the pooled expression of cells, and we sample such measurements. We store the original true cell pool compositions from the data simulation step in order to later compare the composition predictions to the ground truth.
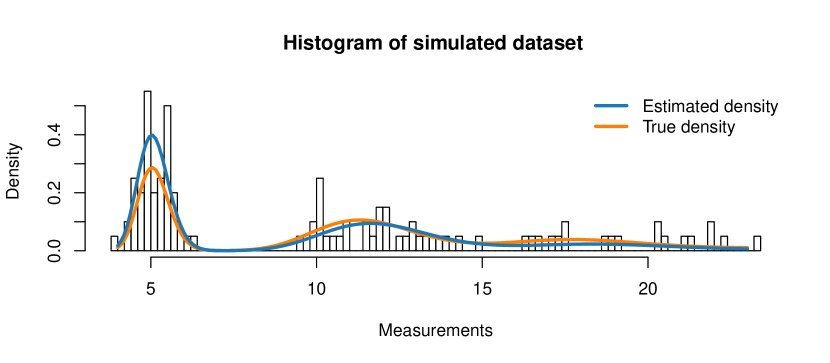
Having generated the synthetic data, we apply \pkgstochprofML to estimate the model parameters , and . Figure 11 shows a histogram of one simulated data set along with the PDF of the true population mixture and the PDF of the estimated population mixture (that is the LN-LN model with parameters , and ).
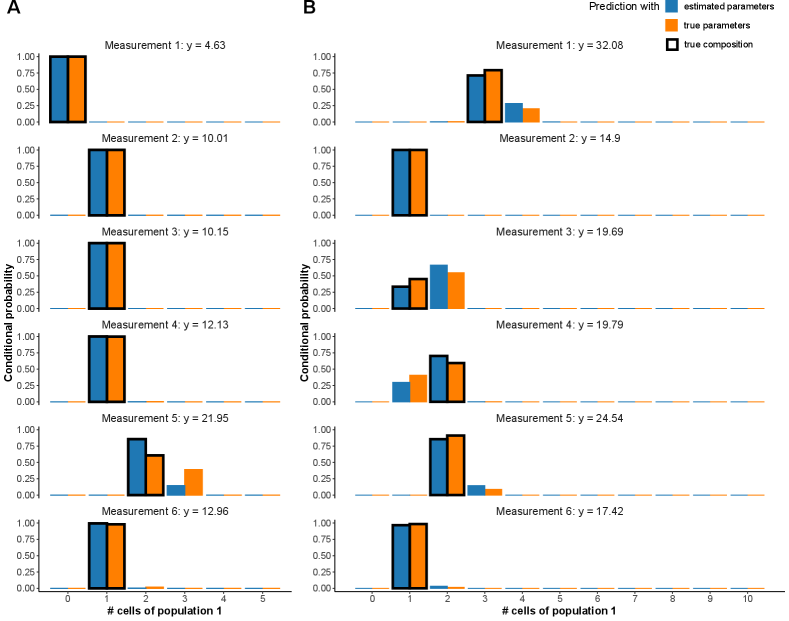
Next, we calculate the conditional probability mass function (PMF; see Appendix D for details) for each possible population composition conditioned on the particular pooled gene expression measurement. Figure 12A and Table 1 show results for the first six (out of 100) pooled measurements.
In particular, Figure 12A displays the conditional PMF of all possible compositions (i. e. times population 1 and times population 2 for ). Blue bars stand for these probabilities when is used as model parameter value. Orange stands for the hypothetical case where the true value is known and used. These two scenarios are in good agreement with each other.
| Estimator for # of cells in pop. 1 | Measurement index | # of hits | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | |||
| Estimated parameters | Mean | 0.00 | 1.00 | 1.00 | 1.00 | 2.14 | 1.01 | 98 |
| MLE (CI) | 0 (0,0) | 1 (1,1) | 1 (1,1) | 1 (1,1) | 2 (2,3) | 1 (1,1) | 98 (100) | |
| True parameters | Mean | 0.00 | 1.00 | 1.00 | 1.00 | 2.39 | 1.02 | 97 |
| MLE (CI) | 0 (0,0) | 1 (1,1) | 1 (1,1) | 1 (1,1) | 2 (2,3) | 1 (1,1) | 97 (100) | |
| True # of cells from population 1 | 0 | 1 | 1 | 1 | 2 | 1 | ||
We regard the most likely sample composition to be the one that maximizes the conditional PMF (maximum likelihood principle). The true composition (ground truth) is marked with a black box around the blue and orange bars. We observe in Figure 12A that the composition is in all six cases inferred correctly and mostly unambiguously. Only for the fifth measurement, there is visible probability mass on a composition other than the true one. In fact, it is the only pool (out of the six considered ones) with two cells from the first population. Alternatively to the maximum likelihood estimator, one can also regard the expected composition — the empirical weighted mean of numbers of cells in the first population — or confidence intervals for this number. The respective estimates for the first six measurements of the dataset are shown in Table 1. The results are consistent with the interpretation of Figure 12A.
Certainly, the precision of the prediction depends on the employed pool sizes, the underlying true model parameters and how reliably these were inferred during the first step. We showed in Section 4 that larger cell pools lead to less precise parameter inference. Hence, we repeat the prediction of sample compositions on another dataset, this time based on -cell pools. All other parameters remain unchanged. The resulting conditional probabilities are depicted in Figure 12B. Since , one expects on average two cells to be from the first population in each 10-cell pool. As in the previous -cell case, most predictions show a clear pattern. However, probability masses are spread more widely. Measurements 3 and 4 exemplify that almost identical gene expression measurements ( and ) can arise from different underlying pool compositions (two times population 1 in measurement 3 vs. three times population 1 in measurement 4). For more similar population parameters, the estimation will get worse, which will then propagate to the well composition prediction. In such cases, to predict the pool compositions, one may use additional parallel measurements of other genes that might separate the population better by their different expression profiles while the pool composition stays the same across genes.
6 Summary and Discussion
With the \pkgstochprofML package, we provide an environment to profile gene expression measurements obtained from small pools of cells. Experimentalists may choose this approach if single-cell measurements are impossible in their lab (e. g. for bacteria), if the drop-out rate is high in single-cell libraries, if budget or time are limited, or if one prefers to avoid the stress which is put on the cells during separation. The latest implementation even allows to combine information from different pool sizes, in particular, to simultaneously analyze single-cell and and n-cell data.
We demonstrated the usage and performance of the \pkgstochprofML algorithm in various examples and simulation studies. These have been performed in an idealized in silico environment. This should be kept in mind when incorporating the results into experimental planning and analysis. The interpretation of heterogeneity will be informative if based on a good model estimate. The assumption of independent expression across genes within the same tissue sample is a simplification of nature that leads to less complex parameter estimation. The optimal pool size with respect to bias and variance of the corresponding parameter estimators will depend on unknown properties such as numbers of populations and their characteristics, and also on the relationship between the pool size and the amount of technical measurement noise. The latter aspect has been excluded from the studies here but further supports the application of stochastic profiling.
Computational details
We used \proglangR version 3.5.3 (R Core Team, 2019). In addition to our \pkgstochprofML version 2.0.1 (Amrhein and Fuchs, 2020), we attached the following \proglangR packages \pkgMASS version 7.3-51.1 (Venables and Ripley, 2002), \pkgnumDeriv version 2016.8-1.1 (Gilbert and Varadhan, 2019), \pkgEnvStats version 2.3.1 (Millard, 2013), \pkgvioplot version 0.3.4. (Adler and Kelly, 2019), \pkgzoo version 1.8-7 (Zeileis and Grothendieck, 2005), \pkgsm version 2.2-5.6 (Bowman and Azzalini, 2018), \pkgcowplot version 1.0.0 (Wilke, 2019), \pkgggplot2 version 3.2.1 (Wickham, 2016), \pkgknitr version 1.27 (Xie, 2014), and \pkgRcolorBrewer version 1.1-2 (Neuwirth, 2014). All calculations were performed on a 64-bit x86_64-redhat-linux-gnu platform running under Fedora 28.
Acknowledgments
Our research was supported by the German Research Foundation within the SFB 1243, Subproject A17, by the German Federal Ministry of Education and Research under grant number 01DH17024, by the Helmholtz Initiating and Networking Funds, Pilot Project Uncertainty Quantification, and by the National Institutes of Health under grant number U01-CA215794. We thank Susanne Amrhein and Xiaoling Zhang for code contributions to the simulation studies and Mercè Garí for feedback. The paper was designed by LA and CF. CF developed the first version of the software, LA developed the second version and performed the simulation studies. LA and CF wrote the paper.
References
- Adler and Kelly (2019) Adler D, Kelly ST (2019). vioplot: Violin Plot. R package version 0.3.4, URL https://github.com/TomKellyGenetics/vioplot.
- Amrhein and Fuchs (2020) Amrhein L, Fuchs C (2020). stochprofML: Stochastic Profiling using Maximum Likelihood Estimation. R package version 2.0.1, URL https://CRAN.R-project.org/package=stochprofML.
- Bajikar et al. (2014) Bajikar SS, Fuchs C, Roller A, Theis FJ, Janes KA (2014). “Parameterizing Cell-to-Cell Regulatory Heterogeneities via Stochastic Transcriptional Profiles.” Proceedings of the National Academy of Sciences, 111(5), E626–E635. 10.1073/pnas.1311647111.
- Bowman and Azzalini (2018) Bowman AW, Azzalini A (2018). R package sm: nonparametric smoothing methods (version 2.2-5.6). University of Glasgow, UK and Università di Padova, Italia. URL http://www.stats.gla.ac.uk/~adrian/sm/.
- Erkkilä et al. (2010) Erkkilä T, Lehmusvaara S, Ruusuvuori P, Visakorpi T, Shmulevich I, Lähdesmäki H (2010). “Probabilistic analysis of gene expression measurements from heterogeneous tissues.” Bioinformatics, 26(20), 2571–2577. 10.1093/bioinformatics/btq406.
- Feldman and Valdez-Flores (2010) Feldman RM, Valdez-Flores C (2010). Applied Probability and Stochastic Processes. Springer Berlin Heidelberg. 10.1007/978-3-642-05158-6.
- Fenton (1960) Fenton L (1960). “The Sum of Log-Normal Probability Distributions in Scatter Transmission Systems.” IEEE Transactions on Communications, 8(1), 57–67. 10.1109/TCOM.1960.1097606.
- Gilbert and Varadhan (2019) Gilbert P, Varadhan R (2019). numDeriv: Accurate Numerical Derivatives. R package version 2016.8-1.1, URL https://CRAN.R-project.org/package=numDeriv.
- Grün et al. (2014) Grün D, Kester L, van Oudenaarden A (2014). “Validation of noise models for single-cell transcriptomics.” Nature Methods, 11(6), 637–640. 10.1038/nmeth.2930.
- Inman and Bradley (1989) Inman HF, Bradley EL (1989). “The Overlapping Coefficient As a Measure of Agreement Between Probability Distributions and Point Estimation of the Overlap of Two Normal Densities.” Communications in Statistics - Theory and Methods, 18(10), 3851–3874. 10.1080/03610928908830127.
- Janes et al. (2010) Janes KA, Wang CC, Holmberg KJ, Cabral K, Brugge JS (2010). “Identifying Single-Cell Molecular Programs by Stochastic Profiling.” Nature Methods, 7(4), 311–317. 10.1038/nmeth.1442.
- Kurimoto (2006) Kurimoto K (2006). “An Improved Single-Cell cDNA Amplification Method for Efficient High-Density Oligonucleotide Microarray Analysis.” Nucleic Acids Research, 34(5), e42–e42. 10.1093/nar/gkl050.
- Millard (2013) Millard SP (2013). EnvStats: An R Package for Environmental Statistics. Springer, New York. ISBN 978-1-4614-8455-4. URL http://www.springer.com.
- Nelder and Mead (1965) Nelder JA, Mead R (1965). “A Simplex Method for Function Minimization.” The Computer Journal, 7(4), 308–313. 10.1093/comjnl/7.4.308.
- Neuwirth (2014) Neuwirth E (2014). RColorBrewer: ColorBrewer Palettes. R package version 1.1-2, URL https://CRAN.R-project.org/package=RColorBrewer.
- Newman et al. (2015) Newman AM, Liu CL, Green MR, Gentles AJ, Feng W, Xu Y, Hoang CD, Diehn M, Alizadeh AA (2015). “Robust enumeration of cell subsets from tissue expression profiles.” Nature Methods, 12(5), 453–457. 10.1038/nmeth.3337.
- Pastore and Calcagnì (2019) Pastore M, Calcagnì A (2019). “Measuring Distribution Similarities Between Samples: A Distribution-Free Overlapping Index.” Frontiers in Psychology, 10, 1089. 10.3389/fpsyg.2019.01089.
- R Core Team (2019) R Core Team (2019). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
- Sandberg (2014) Sandberg R (2014). “Entering the Era of Single-Cell Transcriptomics in Biology and Medicine.” Nature Methods, 11(1), 22–24. 10.1038/nmeth.2764.
- Schwarz (1978) Schwarz G (1978). “Estimating the Dimension of a Model.” The Annals of Statistics, 6(2), 461–464. Publisher: Institute of Mathematical Statistics, URL www.jstor.org/stable/2958889.
- Shen-Orr et al. (2010) Shen-Orr SS, Tibshirani R, Khatri P, Bodian DL, Staedtler F, Perry NM, Hastie T, Sarwal MM, Davis MM, Butte AJ (2010). “Cell type–specific gene expression differences in complex tissues.” Nature Methods, 7(4), 287–289. 10.1038/nmeth.1439.
- Tietjen et al. (2003) Tietjen I, Rihel JM, Cao Y, Koentges G, Zakhary L, Dulac C (2003). “Single-Cell Transcriptional Analysis of Neuronal Progenitors.” Neuron, 38(2), 161–175. 10.1016/S0896-6273(03)00229-0.
- Tirier et al. (2019) Tirier SM, Park J, Preusser F, Amrhein L, Gu Z, Steiger S, Mallm JP, Waschow M, Eismann B, Gut M, Gut IG, Rippe K, Schlesner M, Theis F, Fuchs C, Ball CR, Glimm H, Eils R, Conrad C (2019). “Pheno-seq - Linking Visual Features and Gene Expression in 3D Cell Culture Systems.” Scientific Reports, 9, 2045–2322. 10.1038/s41598-019-48771-4.
- Venables and Ripley (2002) Venables WN, Ripley BD (2002). Modern Applied Statistics with S. Fourth edition. Springer, New York. ISBN 0-387-95457-0, URL http://www.stats.ox.ac.uk/pub/MASS4.
- Wickham (2016) Wickham H (2016). ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. ISBN 978-3-319-24277-4. URL https://ggplot2.tidyverse.org.
- Wilke (2019) Wilke CO (2019). cowplot: Streamlined Plot Theme and Plot Annotations for ’ggplot2’. R package version 1.0.0, URL https://CRAN.R-project.org/package=cowplot.
- Xie (2014) Xie Y (2014). “knitr: A Comprehensive Tool for Reproducible Research in R.” In V Stodden, F Leisch, RD Peng (eds.), Implementing Reproducible Computational Research. Chapman and Hall/CRC. ISBN 978-1466561595, URL http://www.crcpress.com/product/isbn/9781466561595.
- Zeileis and Grothendieck (2005) Zeileis A, Grothendieck G (2005). “zoo: S3 Infrastructure for Regular and Irregular Time Series.” Journal of Statistical Software, 14(6), 1–27. 10.18637/jss.v014.i06.
- Ziegenhain et al. (2017) Ziegenhain C, Vieth B, Parekh S, Reinius B, Guillaumet-Adkins A, Smets M, Leonhardt H, Heyn H, Hellmann I, Enard W (2017). “Comparative Analysis of Single-Cell RNA Sequencing Methods.” Molecular Cell, 65(4), 631–643.e4. 10.1016/j.molcel.2017.01.023.
Appendix A PDF of -cell measurements of cell populations
Equation (3) in Section 2.2 displays the PDF of the overall gene expression of a cell pool of size , where each single cell from the pool can originate from any of cell populations. We derive this PDF here. To make it easier to follow the lengthy calculations, we build up the formulas in four steps: We start with the simplest case of 2-cell measurements in the presence of two populations. Then, we continue with 2-cell samples and three populations. Next, we increase the cell number to and finally raise the population number to .
PDF of 2-cell measurements of two populations (, )
First, we derive the PDF of a measurement of a 2-cell pool, i.e. of . Assume we know that two cell populations are present in the tissue, and each of them is described by an individual distribution. In this section, we denote the univariate population distributions by , . In Section 2, they are replaced by the distributions that were presented in Section 2.1: or with population-specific parameter values. For now, we consider for
where . Hence, the PDF of each is
with . To determine the distribution of , we use the convolution of the single-cell PDFs, which are the same functions for both and :
Each of these integrals is the PDF of a random variable evaluated at , where and are independent. This holds for both and . We denote this density by . All together, we get
An alternative formulation is
| (8) |
where and show how often a cell of population 1 and 2 is present in the pool. The two PDFs and are directly connected: considers how often populations 1 and 2 are represented, and denotes which populations are present. For example, and .
PDF of 2-cell measurements of three populations (, )
Next, we derive the PDF of a measurement of a 2-cell pool, i.e. of . Now, we assume three cell populations to be present in the tissue. Again, each of them is described by an individual distribution for :
for where and . Hence, the PDF of each is
with . To determine the distribution of , we again use the convolution of the single-cell PDFs:
leading to
Once more, we make use of the fact that is the PDF of the sum of two independent random variables, where and (now with ). As before, we denote this density by . Overall, we obtain
or alternatively
| (9) |
where show how often cells of population 1, 2 and 3 are present in the pool. Again, is connected to .
For example, and .
PDF of -cell measurements of three populations ( arbitrary, )
Next, we suppose that we measure pools of cells originating from three cell populations. Let . Then Equation (9) turns into
| (10) |
where and .
PDF of -cell measurements of populations ( and arbitrary)
Finally, we extend Equation (10) to the most general case, where -cell pools are measured from a tissue that consists of cell populations. Here, we obtain
where and . The binomial coefficients form together the multinomial coefficient
Taken together, this leads to the final PDF (3) from Section 2.2:
The terms are probabilities arising from the multinomial distribution and can be seen as multinomial weights of the densities .
Appendix B PDF of pooled gene expression for mixed pool size vectors
When estimating a gene expression model from data, one may want to verify whether the estimated model adequately describes the data. In Figure 11, we did this by comparing the estimated PDF to the histogram of the data and to the true PDF: The orange curve was known since we treated the case of synthetic data. For the blue curve, we first estimated the model parameters and then plugged these in into the general model PDF. In case of a uniform pool size across all measurements, this procedure is straightforward. For a vector of pool sizes, i. e. a mix of e. g. 1-cell, 2-cell and 10-cell data, the PDF (see e. g. Figure 2B) is less obvious. We calculate this function as follows:
-
•
For each cell number contained in the -vector, calculate the PDF of the respective pool size and plug in the parameter estimates.
-
•
Calculate the weighted sum of these PDFs — weighted according to the times the respective pool size occurs in the -vector.
The resulting PDF approximates the PDF of a sample where the observations are based on the pool sizes of the considered -vector. While this PDF describes a mixture distribution with randomly drawn pool sizes (according to the weights used), we in our applications assume the pool sizes to be known for each measurement. {Code} mix.d.sum.of.mixtures.LNLN <- function(y, n.vector, p.vector, mu.vector, + sigma.vector) + densmix <- matrix(0, ncol = length(y), nrow = length(n.vector)) + for(i in 1:length(n.vector)) + densmix[i, ] <- d.sum.of.mixtures.LNLN(y = y, n = n.vector[i], + p.vector = p.vector, mu.vector = mu.vector, + sigma.vector = sigma.vector, logdens = FALSE) + + Dens<-colSums(densmix)/length(n.vector) +
Appendix C Transformation of population probabilities
As described in Section 2.4, we transform the model parameters before optimization of the likelihood function such that no constraints of the parameter space have to be accounted for. Here, we provide details about the transformation of the population probabilities.
In case of two populations, there is only one parameter that determines the probabilities and of populations 1 and 2. We transform to
and later back-transform this via
The advantage of as compared to is the unrestricted range instead of .
In case of populations, the probabilities have to fulfill for all and . We set and use the following transformations
For the back-transformations, we start at and calculate
in reverse order. We set to ensure that the probabilities sum up to one. Additionally, one has as for all . Obviously, , and the remaining population probabilities are given by
The (back-)transformations are implemented in \codetransform.par() and \codebacktransform.par().
Appendix D Derivation of sample composition probabilities
We describe how to predict the population composition of a cell pool, as applied in Section 5.2. A key formula here is the conditional probability of a cell composition given the measured gene expression, which we derive here. We use the following notations and assumptions:
-
•
The overall gene expression of a cell pool is denoted by and assumed a continuous random variable with PDF .
-
•
denotes the specific cell population combinations, i. e. is the number of cells of population for all , within a pool of cells. is a discrete random vector with PMF .
-
•
is the conditional PDF of the overall gene expression in a cell pool whose composition is known to equal . For shorter notation, this was referred to as in Section 2.2.
-
•
In turn, is the conditional PMF of the cell pool composition given the pool gene expression measurement .
We use Bayes’ theorem to derive the latter PMF:
| (11) |
where is the set of all possible compositions of the cell pool, i. e. the set of all vectors with and .
The terms in Equation (11) depend on the population probabilities and the gene expression model (in this work: LN-LN, rLN-LN, or EXP-LN), characterized by its respective parameters. We assume the expression model to be fixed and denote all model parameters (including ) by . In practice, is unknown, and hence we use its maximum likelihood estimates here.
Given the estimate of , approximately follows a multinomial distribution with parameters and . The PMF of the cell pool composition hence reads
where is the multinomial coefficient. With this, the conditional PMF of the cell pool composition given the pooled gene expression measurement reads:
| (12) | ||||
Appendix E Interactive Functions
As indicated in Section 3, we show an example of the interactive functions for data generation, \codestochasticProfilingData(), and parameter estimation, \codestochasticProfilingML().
Synthetic data generation: \codestochasticProfilingData()
R> library("stochprofML") R> set.seed(10) R> stochprofML::stochasticProfilingData() {Soutput} This function generates synthetic data from the stochastic profiling model. In the following, you are asked to specify all settings. By pressing ’enter’, you choose the default option.
———
Please choose the model you would like to generate data from:
1: LN-LN
2: rLN-LN
3: EXP-LN
(default: 1)
{Sinput}
R> 1
{Soutput}
———
Please enter the number of different populations you would like to consider:
(default: 2)
{Sinput}
R> 2
{Soutput}
———
Please enter the number of stochastic profiling observations you wish to generate:
(default: 100)
{Sinput}
R> 1000
{Soutput}
———
Next we enter the number of cells that should enter each observation,
which case do you want:
1: all observations should contain the same number of cells, or
2: each observation contains a different number of cells
(default: 1).
{Sinput}
R> 1
{Soutput}
———
Please enter the number of cells that should enter each sample:
(default: 10)
{Sinput}
R> 10
{Soutput}
———
Please enter the number of co-expressed genes you would like to collect
in one cluster
(default: 1)
{Sinput}
R> 1
{Soutput}
———
Please enter the probabilities for each of the 2 populations, e.g. type
0.62, 0.38
or
0.62 0.38.
It is recommended to choose the order of the populations such that
(for the first gene, if there is more than one)
log-mean for population 1 >= log-mean for population 2 >= …
{Sinput}
R> 0.62, 0.38
{Soutput}
———
Please enter the log-means for each of the 2 populations, e.g. type
0.47, -0.87.
{Sinput}
R> 0.47, -0.87
{Soutput}
———
Please enter the log-standard deviation, which is the same for all
populations, i.e. type e.g.
0.03
irrespectively of the number of populations.
{Sinput}
R> 0.03
{Soutput}
———
Would you like to write the generated dataset to a file? (Be careful not to
overwrite any existing file!) Please type ’yes’ or ’no’.
{Sinput}
R> yes
{Soutput}
Please enter a valid path and filename, either a full path, e.g.
D:/Users/lisa.amrhein/Desktop/mydata.txt
or just a file name, e.g.
mydata.txt.
The current directory is
D:/Users/lisa.amrhein/Desktop.
{Sinput}
test.txt
{Soutput}
Hit <Return> to see next plot:
{Sinput}
R> <Return>
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3df0c89a-7a54-4adb-8205-79e77b05ab79/x16.png) {Soutput}
The dataset has been generated. The first 50 observations are:
{Soutput}
The dataset has been generated. The first 50 observations are:
gene 1 observation 1 12.444051 observation 2 12.406390 observation 3 12.412508 observation 4 11.274005 observation 5 12.455432 observation 6 11.255553 observation 7 11.281351 observation 8 13.587420 observation 9 11.222902 observation 10 12.586923 observation 11 12.278757 observation 12 14.746502 observation 13 12.313032 observation 14 12.387004 observation 15 10.007876 observation 16 9.978140 observation 17 11.461335 observation 18 10.015642 observation 19 12.575700 observation 20 12.411795 observation 21 9.965103 observation 22 10.139115 observation 23 12.437228 observation 24 10.039271 observation 25 12.489048 observation 26 11.218177 observation 27 13.217671 observation 28 13.683550 observation 29 8.877630 observation 30 12.550239 observation 31 9.922716 observation 32 10.110123 observation 33 8.720011 observation 34 10.237112 observation 35 11.223407 observation 36 12.468208 observation 37 12.561782 observation 38 15.013314 observation 39 10.151065 observation 40 12.405660 observation 41 13.490263 observation 42 14.675084 observation 43 11.432289 observation 44 13.565312 observation 45 10.076739 observation 46 12.414651 observation 47 8.861460 observation 48 12.401696 observation 49 11.271324 observation 50 13.750237
The full dataset has been written to test.txt. It is also stored in the .Last.value variable.
Parameter estimation: \codestochasticProfilingML()
R> library("stochprofML") R> set.seed(20) R> stochprofML::stochasticProfilingML() {Soutput} This function performs maximum likelihood estimation for the stochastic profiling model. In the following, you are asked to enter your data and specify some settings. By pressing ’enter’, you choose the default option.
——— How would you like to input your data? 1: enter manually 2: read from file 3: enter the name of a variable (default: 1). {Sinput} R> 2 {Soutput} ——— The file should contain a data matrix with one dimension standing for genes and the other one for observations. Fields have to be separated by tabs or white spaces, but not by commas. If necessary, please delete the commas in the text file using the ’replace all’ function of your text editor.
Please enter a valid path and filename, either a full path, e.g. D:/Users/lisa.amrhein/Desktop/mydata.txt or just a file name, e.g. mydata.txt. The current directory is D:/Users/lisa.amrhein/Desktop. {Sinput} R> test.txt {Soutput} Does the file contain column names? Please enter ’yes’ or ’no’. {Sinput} R> yes {Soutput} Does the file contain row names? Please enter ’yes’ or ’no’. {Sinput} R> no {Soutput} Do the columns stand for different genes or different observations? 1: genes 2: observations. {Sinput} R> 1 {Soutput} This is the head of the dataset (columns contain different genes): gene.1 [1,] 12.44405 [2,] 12.40639 [3,] 12.41251 [4,] 11.27400 [5,] 12.45543 [6,] 11.25555
If the matrix does not look correct to you, there must have been an error in the answers above. In this case, please quit by pressing ’escape’ and call stochasticProfilingML() again.
The file contained the following gene names: gene.1 {Sinput} R> no {Soutput} ——— Please choose the model you would like to estimate: 1: LN-LN 2: rLN-LN 3: EXP-LN (default: 1) {Sinput} R> 1 {Soutput} ——— Please enter the number of different populations you would like to estimate: (default: 2) {Sinput} R> 2 {Soutput} ——— Please enter the number of cells that entered each observation, either 1: all observations contain the same number of cells, or 2: each observation contains a different number of cells (default: 1). {Sinput} R> 1 {Soutput} ——— Please enter the number of cells that should enter each observation: (default: 10) {Sinput} R> 10 {Soutput}
***** Estimation started! *****
Maximum likelihood estimate (MLE): p_1 mu_1_gene_gene.1 mu_2_gene_gene.1 sigma 0.6142 0.4690 -0.8650 0.0290
Value of negative log-likelihood function at MLE: 1124.932
Violation of constraints: none
BIC: 2277.496
Approx. 95lower upper p_1 0.60461644 0.62369584 mu_1_gene_gene.1 0.46779634 0.47020366 mu_2_gene_gene.1 -0.87085629 -0.85914371 sigma 0.02774407 0.03031279
Top parameter combinations: p_1 mu_1_gene_gene.1 mu_2_gene_gene.1 sigma target [1,] 0.6142 0.469 -0.865 0.029 1124.932 [2,] 0.6142 0.469 -0.865 0.029 1124.932 [3,] 0.6141 0.469 -0.865 0.029 1124.932 [4,] 0.6142 0.469 -0.865 0.029 1124.932 [5,] 0.6142 0.469 -0.865 0.029 1124.933 [6,] 0.6142 0.469 -0.865 0.029 1124.933
Appendix F Details on Simulation Studies
The general procedure of the simulation studies shown in Section 4 is to first generate synthetic datasets with some predefined population parameters and frequencies using\coder.sum.of.mixtures(). Thereby datasets with either fixed or varying pool sizes are generated, i. e. the numbers of cells contained in one pool are fixed or vary from cell pool to cell pool within a dataset. Next, we assume that we do not know the predefined model parameters and estimate them using \codestochprof.loop(). Then we compare the estimates of the parameters in different ways, e. g. how they are influenced by increasing cell numbers or how their variance differs when the dataset was generated with differing population parameters.
Here, we give an overview about the different model parameter settings and pool sizes used in data generation: We use datasets with fixed pool sizes that contain single-cells, 2 cells, 5 cells, 10 cells, 15 cells, 20 cells or 50 cells. Additionally, we chose two types of datasets with varying pool sizes. The first contains small cell pools with 1, 2, 5 and 10 cells, the second contains larger cell pools with 10, 15, 20 and 50 cells. Thus, in total we have nine different cell pool settings that we use for data generation.
In all simulation studies, we use the LN-LN model with five different parameter settings, given in Table 2. While the first set is considered to be the default, each of the other parameter sets differs from it in one of the population parameters.
| Set 1 | 0.2 | 2 | 0 | 0.2 |
| Set 2 | 0.1 | 2 | 0 | 0.2 |
| Set 3 | 0.4 | 2 | 0 | 0.2 |
| Set 4 | 0.2 | 2 | 1 | 0.2 |
| Set 5 | 0.2 | 2 | 0 | 0.5 |
Taken together, for each of the nine cell pool settings and each of the five parameter settings 1,000 datasets are generated using \coder.sum.of.mixtures.LNLN(), so that in total we have 5*9*1000 = simulated datasets.
Impact of pool sizes
In the first simulation study (Section 4.1), we investigate how parameter estimation is influenced by increasing cell numbers within the cell pools. The results for parameter set 1 are displayed in the main part of the manuscript. Here, we show the corresponding results for the remaining four parameter settings.
In the second parameter setting, the fraction of the first population was reduced to as compared to the first parameter setting. The results are shown in Figure 13. They are similar to the results of the first parameter set in Figure 5. For set 2, however, single cells lead to large variance of estimates, supposedly due to the small sample size of 50 in combination with the small probability (10%) of the first population: We can only expect five single cells of the first population to be measured on average. In some datasets, this will be too low to estimate the parameters of the first population and/or their proportion satisfactorily. Consequently, the violins of the single-cell estimates show a higher variance, especially for the estimates of the parameters of the first population.
In the third parameter setting, the fraction of the first population was increased to . The resulting estimates are shown in Figure 14. In this setting, both populations are similarly frequent; hence, it seems plausible that the single-cell estimates show similar variability as for example the 2-cell estimates. The estimates of the mixed pools of the lower cell numbers provide estimates that are as accurate as the ones for single-cell and 2-cell data. From a pool size of five cells on, the estimates vary strongly. Apparently, low cell numbers are advisable if a tissue is not dominated by one cell population.
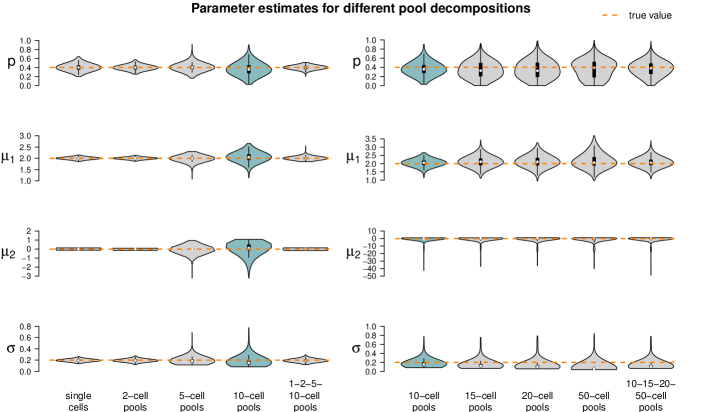
In the fourth parameter setting, is increased to and thus larger than in the first parameter setting. The two populations are more similar. The resulting estimates are shown in Figure 15. Starting from a pool size of 10 cells, it seems as if the variance of the estimates did not increase any more. The estimates for the mixed pools with larger cell numbers can sometimes not distinguish the populations, therefore the violin of is bi-modal. We draw the same conclusion as for two populations with similar frequencies that more similar populations should be investigated in pools with lower cell numbers because their individual expression profile is blurred for small pool sizes already.
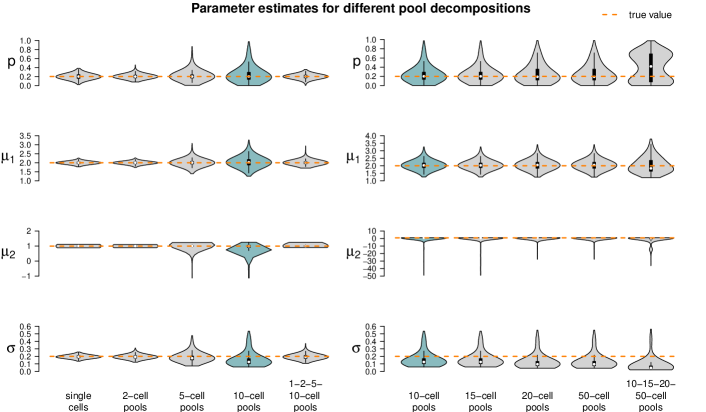
Finally, we investigate the effect of different pool sizes in the fifth parameter set, where the log-sd of both populations is increased to . The resulting estimates of the model parameters are shown in Figure 16. With an increase of , both populations have broader distributions. It appears that there is an increase in variance in the estimates between the 5-cell and the 10-cell measurements. Increasing cell numbers in the pools mainly influences the estimate of , which is increasingly underestimated.
Impact of parameter values
In Section 4.2, we investigate the influence of the model parameter values on the estimation performance while fixing the pool size. In the main part of the manuscript, we presented results for 10-cell pools (see Figure 6). Here, corresponding analyses for the remaining eight cell pool sizes ( and two mixtures) are shown.
Results for single-cell and 2-cell pools look alike (Figures 17 and 18). As discussed before, the variance of the estimates become large for a small value of in combination with the small pool sizes. For both single-cell and 2-cell data, varying does not affect the estimation accuracy of the estimation, whereas a larger value of leads to higher variance of all parameter estimates but for .
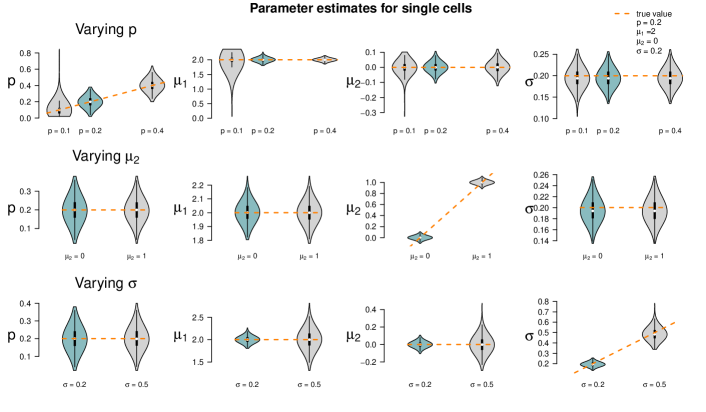
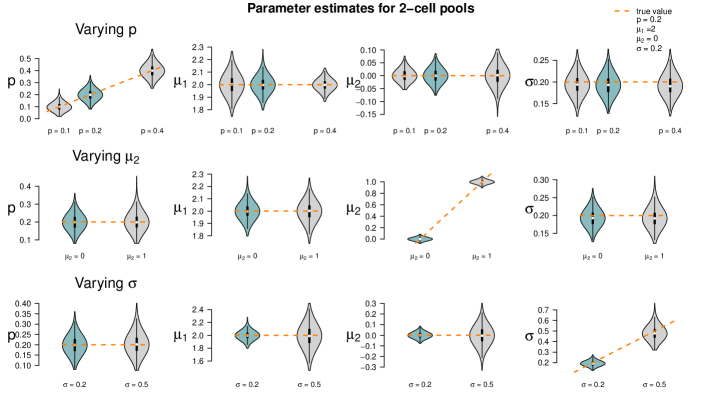
In contrast to this, the 5-cell data results in a different pattern (Figure 19): As compared to the estimates from the standard setting, the estimates show a larger variance. The mixture of small cell pool numbers (Figure 20), however, lead to similar results as the pure 2-cell datasets.

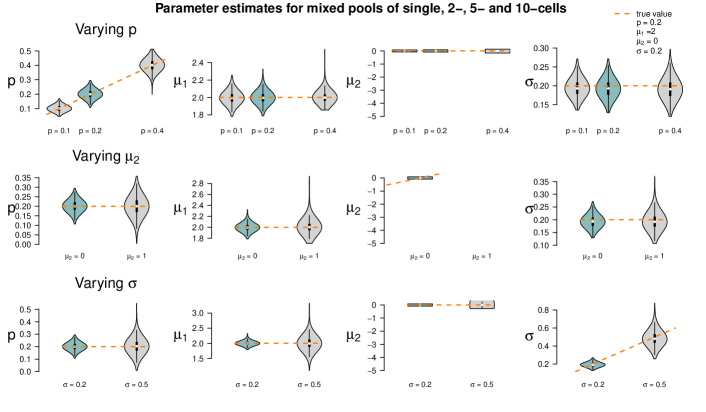
Figure 21 displays the results for the 15-cell data. For most parameter combinations, the variance of the estimates does not change dramatically. The most accurate estimates are achieved for small , the least accurate ones for large , in which case gets underestimated. The same holds true for the 20- and 50-cell datasets (Figures 22 and 23), with even larger variance. For the mixture of large cell pools (Figure 24), estimation performance is comparable to the one for the pure 50-cell measurements.