Stochastic Optimal Control of a Sailboat
Abstract
In match race sailing, competitors must steer their boats upwind in the presence of unpredictably evolving weather. Combined with the tacking motion necessary to make upwind progress, this makes it natural to model their path-planning as a hybrid stochastic optimal control problem. Dynamic programming provides the tools for solving these, but the computational cost can be significant. We greatly accelerate a semi-Lagrangian iterative approach of Ferretti and Festa [1] by reducing the state space dimension and designing an adaptive timestep discretization that is very nearly causal. We also provide a more accurate tack-switching operator by integrating over potential wind states after the switch. The method is illustrated through a series of simulations with varying stochastic wind conditions.
I INTRODUCTION
In recent years, advances in numerical and mathematical methods have greatly impacted the sport of sailing. Yacht path planning algorithms are now heavily employed both as a part of match simulation software, and as a tool to provide live guidance on optimal decision-making during a race. Here, we focus on the problem of finding the optimal feedback control to perform live path planning in the presence of a stochastically-evolving weather system.
Weather conditions greatly impact the performance capabilities of a sailboat in a race. While it is possible to produce meteorological forecasts, there is an inevitable stochastic component to how weather conditions evolve during the course of a race which is impossible to predict exactly. It is critical that algorithms used for decision making correctly factor this randomness into their control policy. In [2], this randomness is modeled as a discrete-time Markov chain process which updates weather conditions at a fixed tick rate. In [3] this idea is extended to a continuous-time Markov chain, formulating the system as a free boundary problem whose solution is a switching curve giving the optimal control policy. Here, we will take the approach of [1] and describe optimality through dynamic programming, yielding a system of two coupled quasi-variational inequalities of Hamilton-Jacobi-Bellman (HJB) type with degenerate ellipticity.
For full physical accuracy, a model would have to include both the position and velocity of the sailboat in the state space, and model the forces on the sailboat in different state configurations, leading to at best coupled first-order equations in state variables. An approach along these lines can be found in [2]. But in long course matches, inertial effects associated with accelerating up to the equilibrium speed are (in general) secondary, allowing one to reduce the system to coupled first-order equations by assuming that the velocity vector can be changed instantaneously.
However, this assumption cannot be made in modeling the process of tacking, which is necessary when attempting to travel upwind. To make progress, sailors must travel at angles to the wind, repeatedly switching directions to steer in a zig-zag pattern on ether side of the wind direction. Each time the bow is swung to the other side of the wind (a single tack), the boat is significantly slowed down for the period of time in which the wind pushes against the boat. In previous works ([1],[4]), this is incorporated by modeling the system as a hybrid control problem, with a continuous control corresponding to the angle of the sails and a discrete control corresponding to which tack we should be on. The lost inertia has been modeled as a fixed switching delay, reflecting the time lost due to the reduced speed from performing the tack.
In this work, we extend and improve upon the methods of Ferretti and Festa [1], who solve the problem using a semi-Lagrangian discretization. In Sec. II, we give the original problem statement and recast it to a reduced coordinate system in 2D, which alone greatly reduces the time needed to solve the problem numerically. In Sec. III, we set up the optimal control problem following the structure of Ref. [1], and provide an improvement to their switching operator to incorporate the wind evolution during the process of a tack. In Sec. IV, we describe our semi-Lagrangian numerical methods, including a discretization in which the system is nearly-causal and can be solved in a handful of iterations. We present the results of numerical simulations in Sec. V, producing optimal switching maps and highlighting the effect of our improved switching operator. We conclude by listing directions for future work in Sec. VI.
II System Dynamics
We consider a problem introduced in [1]: time-optimal sailboat navigation to a closed target set when the wind direction evolves stochastically. For simplicity, we focus on their simplified model where the wind speed is fixed, and the angle of the upwind direction (measured counterclockwise from the -axis) evolves under a drift-diffusion process:
| (1) |
where is the drift rate, is the strength of the Brownian motion, and is the differential of a Wiener process.
We control the angle of the boat’s velocity relative to the upwind direction. But at any given time we are also restricted to an interval of angles determined by the sailboat’s current tack, or configuration of sails. We represent the tack as a controlled discrete variable ; represents the starboard tack, which we model as having access to the angles , while the port tack has access to . For notational convenience, we will use to encode the velocity angle relative to the upwind direction, with the steering control variable So, the steering angle is measured counterclockwise for and clockwise for with corresponding to motion directly against the wind. Due to our inertia-less approximation, whenever changes, the boat is assumed to instantly start travelling in the new direction with the angle-dependent speed . The speed profile (termed the polar plot) capturing this dependence is determined by the exact geometry of a specific boat. A typical example [5] is provided in Fig. 1(a).
Assuming that the boat’s location is the system dynamics in absolute coordinates is then
| (2) | ||||
We now simplify by focusing on radially symmetric problems: if we assume that the target is circular, we no longer care about an absolute angle of the boat’s position relative to the target. Shifting to a coordinate system centered at we can reduce the state space to just two coordinates , where is the radial distance of the boat from the center of and is the angle of the wind measured counterclockwise relative to the straight line between the boat and the target; see Fig. 1(b). In this reduced representation, the dynamics are governed by
| (3) |
which describe the projections of the velocity vector onto the radial and angular components, combined with the drift-diffusion evolution of the wind. We refer to the coefficients on in each equation as and , respectively. New from the original system is the relationship, which will force us to utilize an adaptive timestepping scheme that chooses smaller timesteps near the target to counteract the rapidly increasing angular speed. We note that still remains bounded since has positive radius.
III Stochastic Optimal Control
Assuming we start from a position and tack , the total time-to-target is a random variable whose expectation we are trying to minimize111 Strictly speaking, the objective in [1] is different since they minimize where is a time-discounting coefficient chosen to improve the convergence of value iterations. Our objective is obtained by taking the limit with and the numerical tests indicate that value iterations based on our discretization converge even in this “undiscounted” case. by choosing a feedback steering/tack-switching policy . This can be split into two pieces: the time spent continuously controlling the sails plus the time spent performing tack-switches. Each tack-switch incurs a switching delay due to the speed loss from the wind pushing directly against the boat’s intended direction during the maneuver222For simplicity of modeling, we will treat this delay as constant, though state-dependent would not present additional computational challenges. . We model the boat’s propelled speed as falling to zero (i.e., ) during a tack-switch.
We thus define the value function to encode the minimal expected time to form each starting configuration:
| (4) |
By Bellman’s Optimality Principle, this must satisfy
| (5) |
where the first argument to the is to be interpreted as the best expected time-to- if we stay on the current tack at least for a small time , while the second is the best expected time if we switch tacks immediately. More formally, we define the operators and as:
| (6) | ||||
| (7) |
where we employ the compact notation to indicate the expectation of a function over evolved positions , starting from position and using control policy for a time . In (7), the symbol in place of the control policy indicates that during the tacking time , no steering control is taking place as for the duration. Importantly, the version of operator (7) used in [1] does not treat as evolving during the tack, instead setting . As we show in section V, correctly incorporating these switch-duration dynamics is critical in high-drift problems.
A standard argument based on an Ito-Taylor expansion of (5) yields the quasi-variational inequality that must be satisfied by a smooth value function:
| (8) |
with the Hamiltonian
| (9) |
If is not smooth, one can still interpret it as a weak solution (in particular, the unique viscosity solution [6]) of (8).
As is the only randomly evolving variable and obeys drift-diffusive dynamics, both expectations in (6) and (7) take a similar form as averaging over Gaussian-distributed final . For small , an approximation to (6) taking and constant for a time yields:
| (10) |
where is interpreted as -periodic in , and both implicitly depend on . Eq. (7) is the same formula under the substitutions .
IV Numerical Implementation
IV-A Semi-Lagrangian Discretization
For a fixed small , an approximation of the value function can be obtained as a fixed point of the mapping defined by ignoring the term in (5). It can be shown that if the schemes approximating both arguments in the are monotone, stable, and consistent with (8), then iterating this mapping is guaranteed to converge [7]. As in [1], to build a monotone scheme we discretize the state space on a rectangular grid and perform value iterations of (5) starting from an initial guess to produce a sequence of approximate value functions converging to the solution of the discretized version of (5). Using monotone schemes, choosing such that the first iteration produces everywhere is sufficient to ensure convergence [8].
To approximate the continuous-control operator we change the variable of integration in (10) to and use the Gauss-Hermite quadrature [9]:
| (11) |
where is the number of quadrature points used, are the roots of the th Hermite polynomial , and are
| (12) |
The sum in (11) requires evaluating off-grid, which we accomplish through interpolation, as is common for semi-Lagrangian schemes [10]. The latter are guaranteed to be monotone as long as the interpolation used is zeroth or first order [11]. In our implementation, we define the numerical operator by the sum of (11) evaluated using bilinear interpolation between the 4 closest gridpoints. We use quadrature points, which reduces to the form in [1], averaging between the two points
Due to rapidly increasing as near the target, we adaptively choose our time discretization as:
| (13) |
We choose the constant of proportionality in (13) to be , to step into the middle of the first grid cell along the direction of motion. We then denote the scheme as the optimization of this operator over control angles :
| (14) |
The optimal control policy solution is then precisely the of (14). In practice, since our polar plot datasets contain a discrete set of values, we perform this minimization by a simple grid search over the tabulated angles. The accuracy of this procedure can be also improved by expanding the available set of control angles through interpolation.
The same reparameterization and Gauss-Hermite quadrature approach is used to produce a numerical operator which approximates the switching operator of (7) as
| (15) |
To improve the accuracy, our implementation uses for this switching quadrature since in our experiments.
Our full method is summarized below in Algorithm 1.
IV-B Gauss-Seidel Iterations
Gauss-Seidel relaxation can greatly reduce the number of iterations needed to reach convergence. We heuristically find that time-parameterized stochastic-optimal paths almost always have monotone decreasing . Wherever this holds, the value function at any point will only depend on the values of gridpoints with smaller This can be exploited by updating the value function estimates in-place, sweeping along increasing direction. As a result, grid points later in the sweep will see already-updated values at smaller rather than the old values from the previous iteration.
An additional change can be made to our discretization to further take advantage of this causal dependence. To ensure the currently updated point only depends on those at smaller , we choose the adaptive timestep so that we always step at least a full grid length along the axis:
| (16) |
We refer to this second discretization as “row-wise Gauss-Seidel” (rwGS) relaxation. Our experiments show that it requires a nearly-constant number of iterations, only slowly beginning to increase at really fine grids. Meanwhile, both the Gauss-Jacobi (GJ) and the standard Gauss-Seidel (GS) require a number of iterations roughly linear in (the number of grid points along the direction). As shown in Fig. 2, on the finest tested grid, GJ requires a factor of more iterations than GS, which itself requires a factor of more iterations than the rwGS. However, this massive speedup in the latter is not completely free. Comparing (13) and (16), we see that the row-wise iteration uses larger timesteps than the standard discretization in areas of the domain where , in particular close to the target. Additional numerical tests (summarized in Supplementary Materials) show that, despite slightly larger discretization errors in rwGS, these errors decrease with the same rate as in GS under the grid refinement.
IV-C Live Simulations / Control Synthesis
Using the grid approximation of the value function obtained above, we can perform live sailboat navigation using two derived data structures. Our “switchgrid”, indicates the gridpoints for which it was optimal to switch to the opposite tack (i.e., wherever in Algorithm 1). We can also similarly keep track of a “direction grid,” recording the controls that minimize at each gridpoint.
In our simulations, we evolve the system (3) using a simple Euler–Maruyama method, with the stochastic component of the evolution sampled from in each timestep. We switch to the opposite tack whenever at least of the surrounding gridpoints have ; otherwise, we stay on the current tack and use the optimal control value of the nearest gridpoint in the direction grid.
V Numerical Experiments
We now apply our algorithm to solve the optimal control problem (3)-(4) for a variety of system parameters, and sample stochastic optimal trajectories for each scenario333 To ensure the computational reproducibility, we provide the full source code, movies illustrating these simulations, and additional convergence data at https://eikonal-equation.github.io/Stochastic_Sailing/ . For all results shown, the target radius is and the domain is . Target boundary conditions are set as and exit boundary conditions are
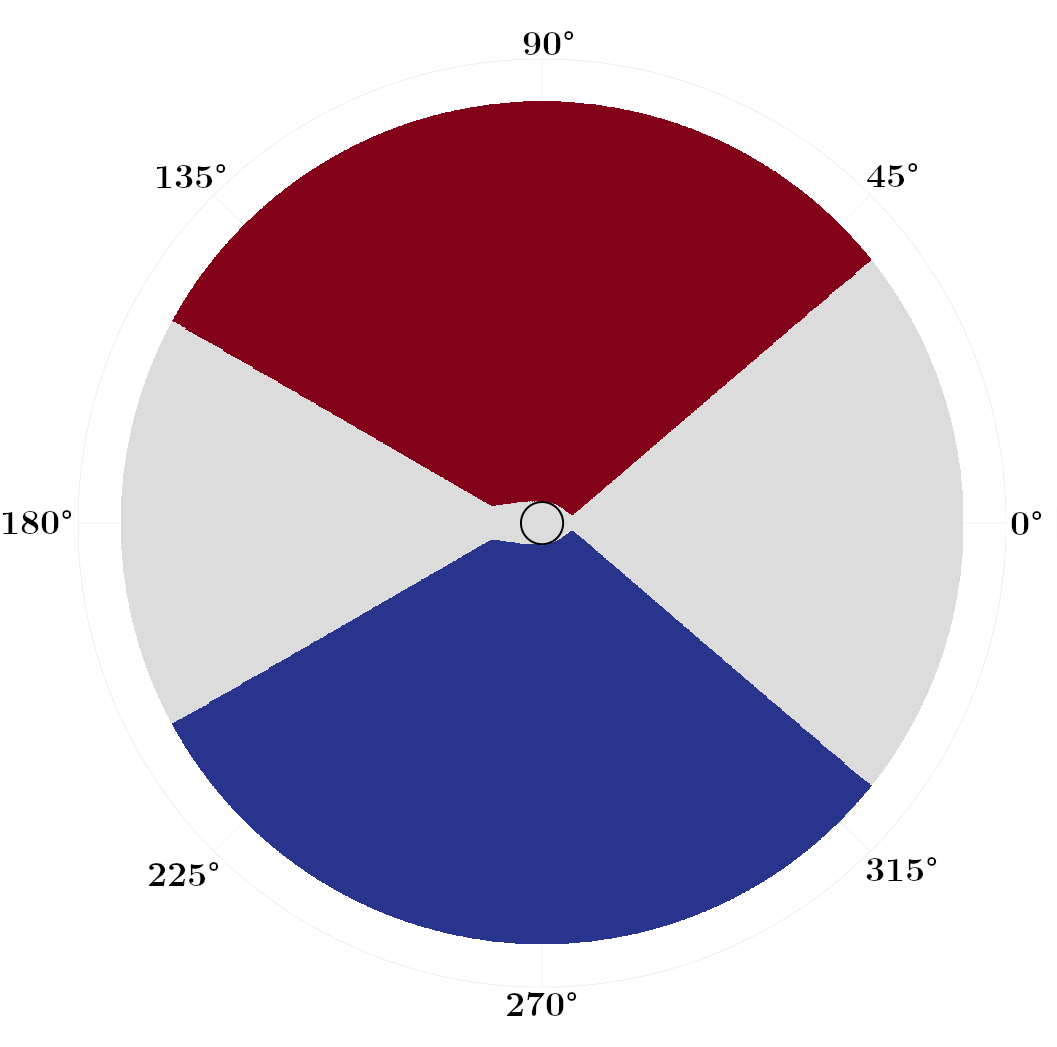
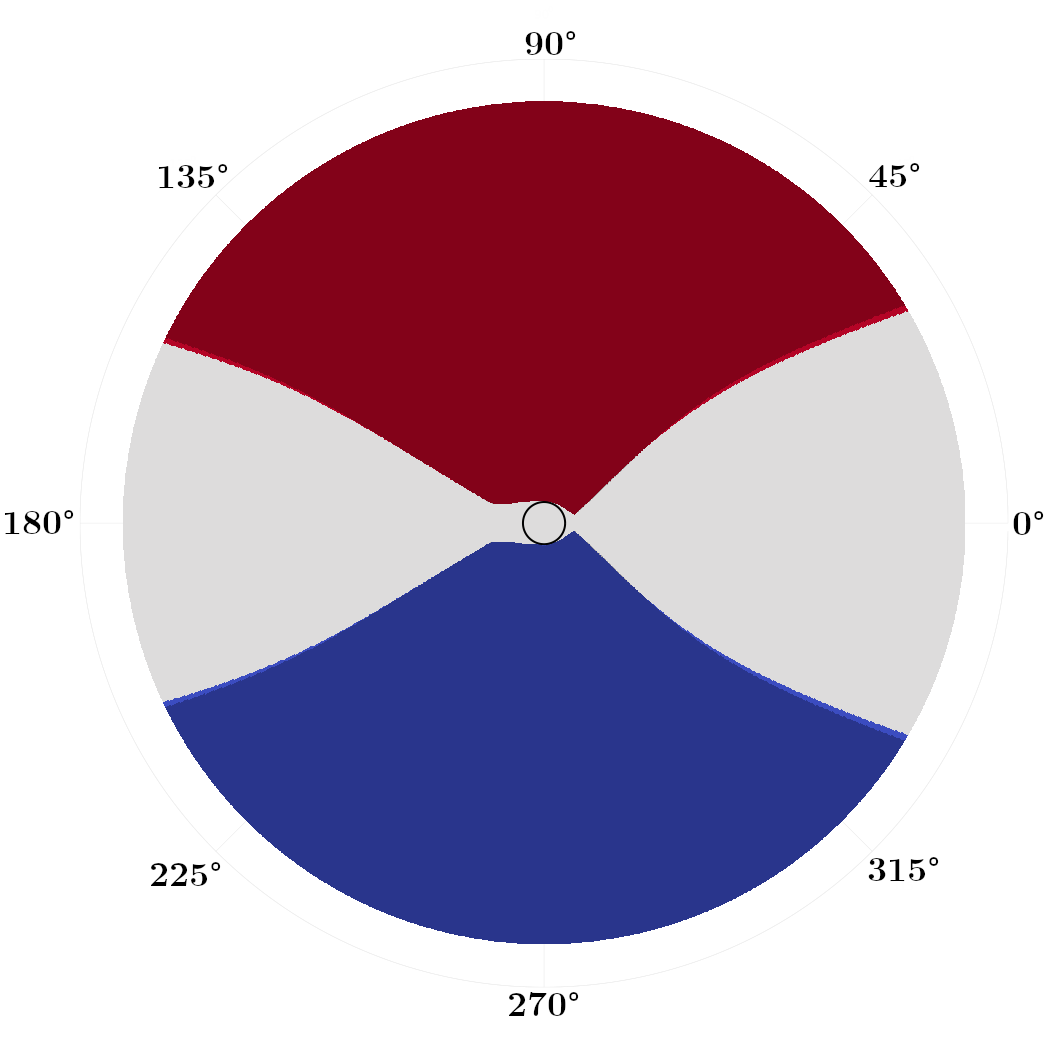
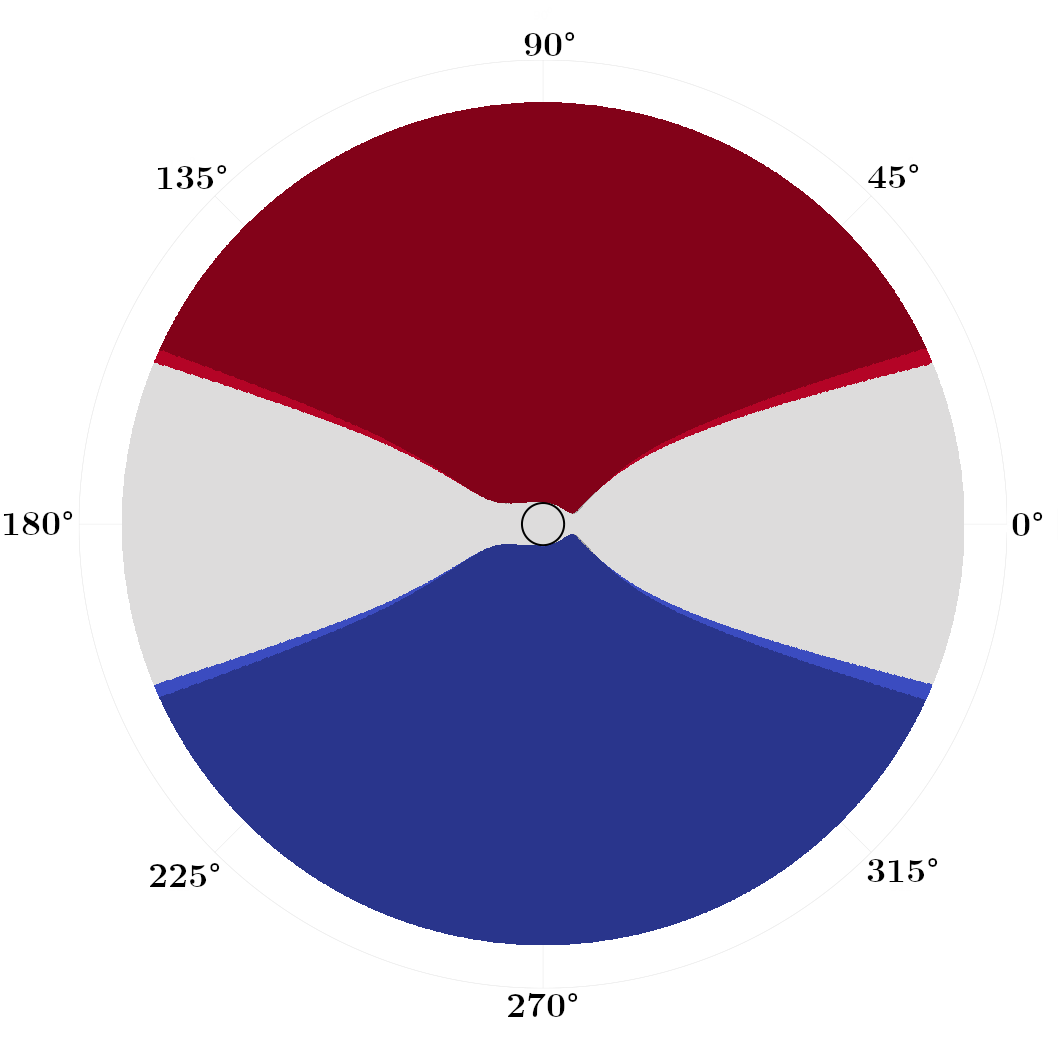
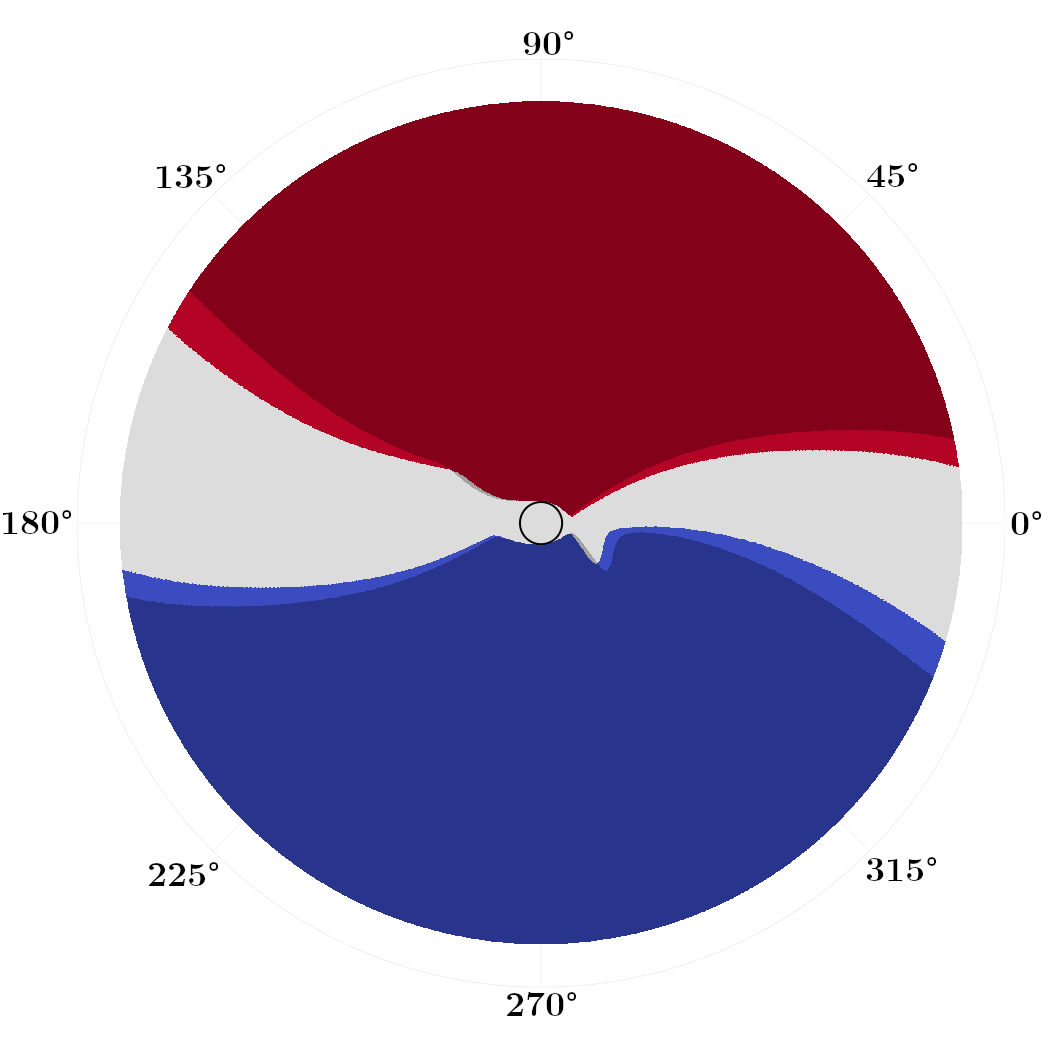
We first focus on problems with zero drift , but varying the diffusivity coefficient . In Fig. 3, we plot switchgrid solutions for a collection of values, noting that these grids are defined and plotted in state space, not the absolute position space. Points are marked red if , blue if , and white if both are . The darker shaded regions correspond to the switchgrids obtained if we use the zero-evolution switching operator of [1] as compared to our (7). The black circle at the center marks the target set . In general, stochastic optimal trajectories “bounce” between these red and blue switching fronts as they approach .
With the switching fronts lie at constant , corresponding to the angles that locally maximize the projection of the polar speed plot (Fig. 1(a)) onto the axis of the wind. Once a sailboat hits this front, it can switch tack and stay at this constant angle that maximizes its speed towards the target (see Fig. 4(a)). As increases, these switching fronts contract more tightly around . As the future wind state grows more uncertain with larger , the optimal policy becomes more conservative and constrains the boat to smaller excursions in before switching to the opposite tack. We observe that in these zero-drift problems, our improved switching operator makes the switching grids modestly more conservative, switching earlier by a few degrees in Fig. 3(b,c).
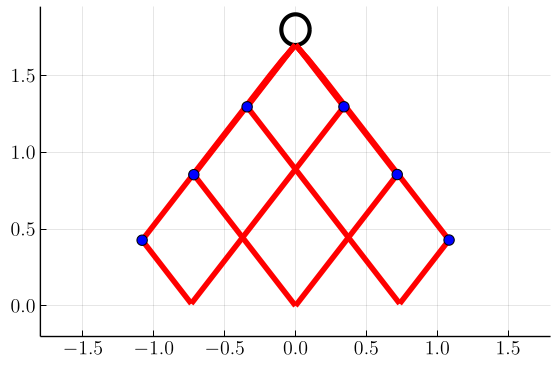
In Fig. 4, we plot samples of stochastic optimal trajectories corresponding to these control policies, with blue markers indicating where tack switches occur. Similarly to [1], we initialize six boats at positions and tacks . We then evolve and control each boat’s state until it reaches its target as described in Sec. IV-C. We can see that, as foreshadowed by the switchgrids, at higher values of the trajectories tend to stay within tighter cones from the target.
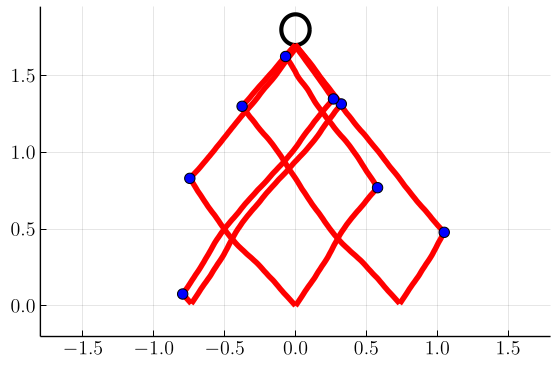
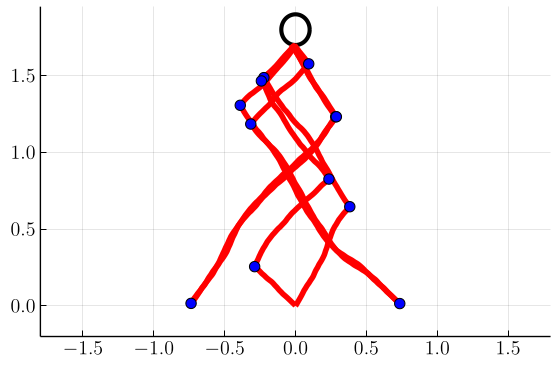
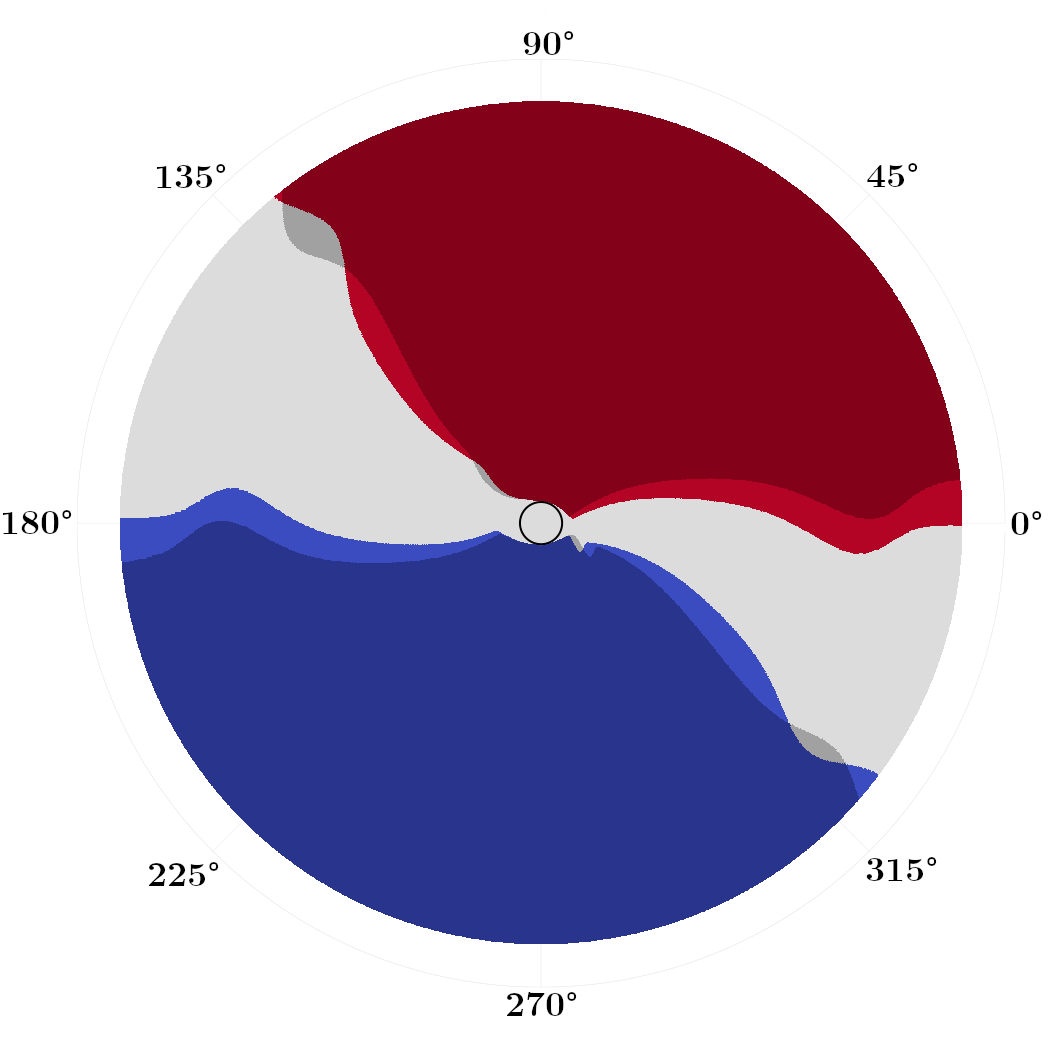
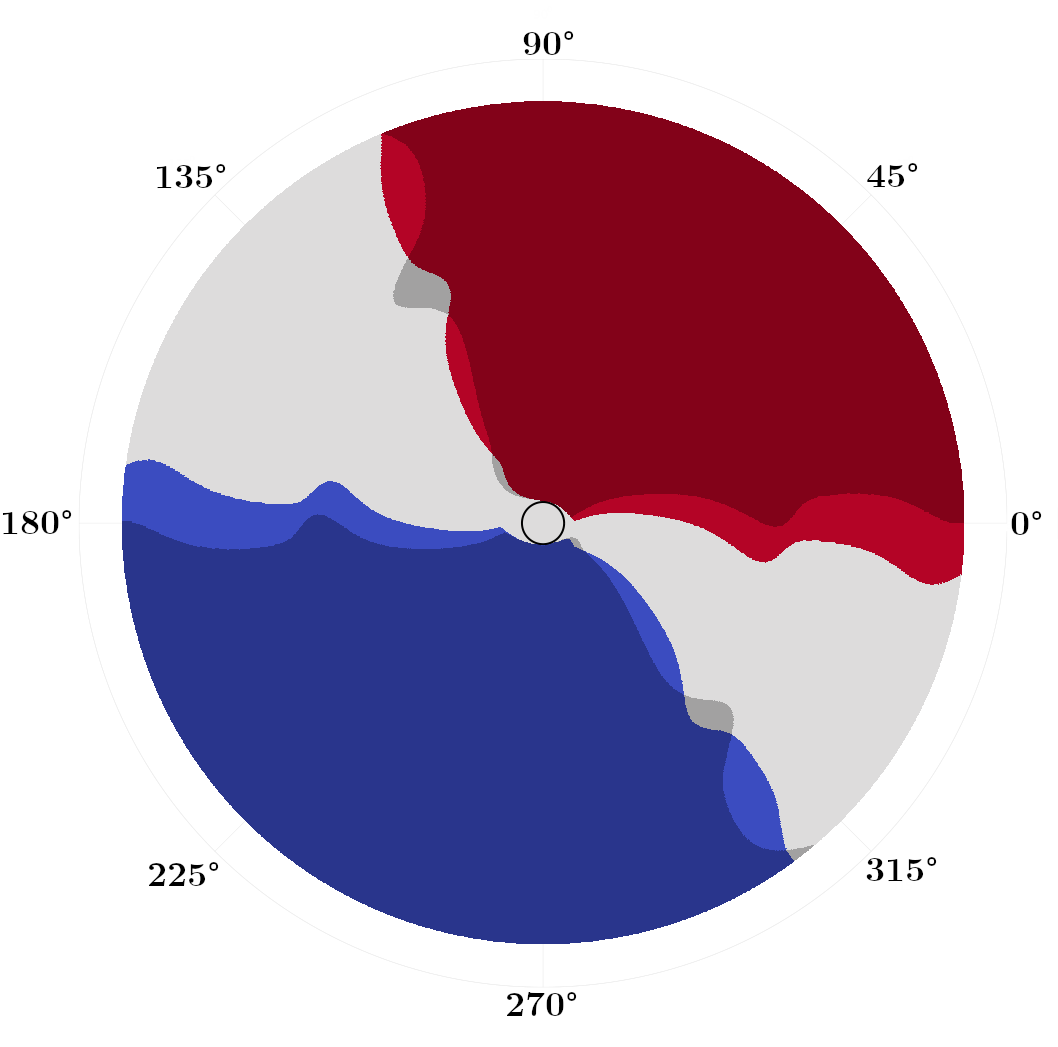
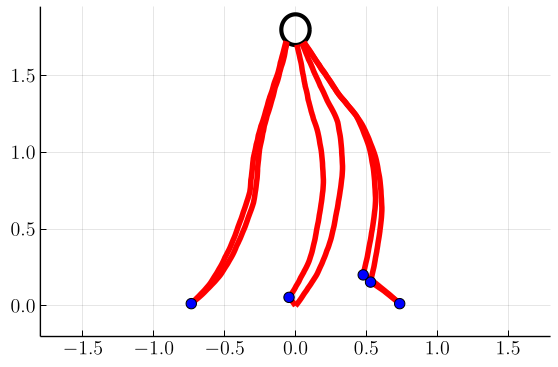
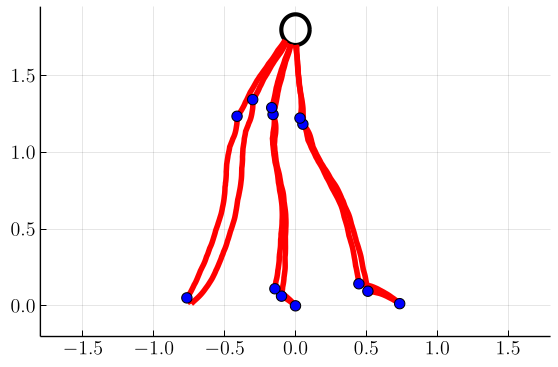
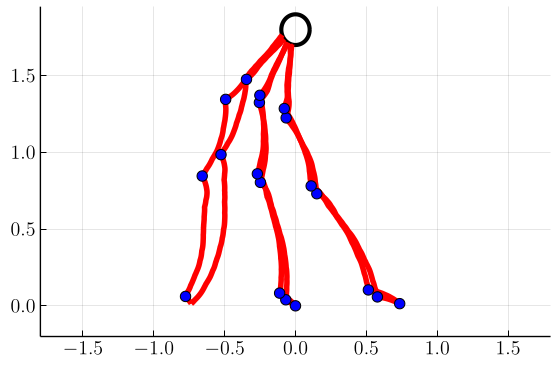
Next, in Figs. 5 and 6 we show switchgrids and sampled trajectories for problems in which the drift parameter is nonzero, with a fixed . As the drift increases, we observe the switchgrids and the trajectories becoming skewed and asymmetric towards negative . This reflects that it is optimal to “lead” the wind in anticipation of future wind evolution, allowing the boat to stay in the portion of state space that allows it to steer at the optimal angle while the wind evolves.
Additionally, some “wave”-like features start to emerge in the switchgrids for large . Empirically, we observe that the number of “waves” in the switchgrid corresponds to the number of turns the wind tends to make by the time an average boat at reaches the target. Each “wave” can thus be interpreted as corresponding to the optimal control during one (average) half-cycle of the wind. We notice that accurately modeling the switching operator is critical in these high-drift scenarios, as the two options produce dramatically different wave-like structures in the switchgrids.
VI Conclusions
We have introduced an accelerated semi-Lagrangian approach to solve a hybrid stochastic optimal control problem arising in match race sailing. By working in a reduced coordinate system and designing a nearly-causal discretization, we were able to produce control policies on high-resolution grids which provide insight into tack-switching strategies under unpredictable weather.
While the conversion to reduced coordinates greatly accelerates our solution, it also introduces several limitations since we had to assume that the problem is radially symmetric. This restricts the target shape to a circle, and does not allow the inclusion of state constraints such as obstacles or nearby coastline. However, it does still allow for modeling match races between multiple agents. Our approach will require keeping track of coordinates for each agent, yielding an overall state space with one less dimension than in [4]. For this reason, we hope that our approach will allow to rapidly test the implications of various weather models or match strategies in “ideal” conditions far away from any barriers.
This paper is focused on a risk-neutral task of finding a feedback policy that minimizes the expected time to target . However, practitioners often prefer robust control policies more suitable when bad outcomes are costly. Two such popular approaches are the “risk-sensitive” control [12, 13] and control [14]. But neither of these provides any direct bounds on the likelihood of bad scenarios; i.e., An efficient method for minimizing for all threshold values simultaneously was recently introduced for piecewise-deterministic Markov processes in [15]. We hope that it can be similarly extended to the current context. It would be also interesting to extend the methods of multiobjective optimal control (e.g., [16, 17]) to find Pareto-optimal policies reflecting the rational tradeoffs between conflicting optimization criteria (e.g., vs or even vs ).
Acknowledgements: The authors are grateful to Roberto Ferretti for sparking their interest in this class of problems.
References
- [1] R. Ferretti and A. Festa, “Optimal Route Planning for Sailing Boats: A Hybrid Formulation,” Journal of Optimization Theory and Applications, vol. 181, no. 3, pp. 1015–1032, 2019.
- [2] A. B. Philpott, S. G. Henderson, and D. Teirney, “A Simulation Model for Predicting Yacht Match Race Outcomes,” Operations Research, vol. 52, no. 1, pp. 1–16, Feb. 2004.
- [3] L. Vinckenbosch, “Stochastic Control and Free Boundary Problems for Sailboat Trajectory Optimization,” 2012, publisher: Lausanne, EPFL.
- [4] S. Cacace, R. Ferretti, and A. Festa, “Stochastic hybrid differential games and match race problems,” Applied Mathematics and Computation, vol. 372, p. 124966, 2020.
- [5] “ORC sailboat data,” Tech. Rep. [Online]. Available: https://jieter.github.io/orc-data/site/
- [6] A. Bensoussan and J. Menaldi, “Stochastic hybrid control,” J. Math. Anal. Appl., vol. 249, no. 1, pp. 261–288, 2000.
- [7] G. Barles and P. Souganidis, “Convergence of approximation schemes for fully nonlinear second order equations,” Asymptotic Analysis, vol. 4, no. 3, pp. 271–283, 1991.
- [8] R. Ferretti and H. Zidani, “Monotone Numerical Schemes and Feedback Construction for Hybrid Control Systems,” Journal of Optimization Theory and Applications, vol. 165, no. 2, pp. 507–531, 2015.
- [9] M. Abramowitz and I. A. Stegun, Eds., Handbook of mathematical functions: with formulas, graphs, and mathematical tables, 9th ed., ser. Dover books on mathematics. Dover Publ, 2013.
- [10] M. Falcone and R. Ferretti, Semi-Lagrangian approximation schemes for linear and Hamilton-Jacobi equations. SIAM, 2014, vol. 133.
- [11] R. Ferretti, “A Technique for High-order Treatment of Diffusion Terms in Semi-Lagrangian Schemes,” Communications in Computational Physics, vol. 8, no. 2, pp. 445–470, June 2010.
- [12] R. A. Howard and J. E. Matheson, “Risk-Sensitive Markov Decision Processes,” Management Science, vol. 18, no. 7, pp. 356–369, 1972.
- [13] W. H. Fleming and W. M. McEneaney, “Risk-sensitive control on an infinite time horizon,” SIAM Journal on Control and Optimization, vol. 33, no. 6, pp. 1881–1915, 1995.
- [14] T. Başar and P. Bernhard, -optimal control and related minimax design problems. Birkhauser, 1995.
- [15] E. Cartee, A. Farah, A. Nellis, J. Van Hook, and A. Vladimirsky, “Quantifying and managing uncertainty in piecewise-deterministic Markov processes,” preprint: https://arxiv.org/abs/2008.00555, 2020.
- [16] A. Kumar and A. Vladimirsky, “An efficient method for multiobjective optimal control and optimal control subject to integral constraints,” Journal of Computational Mathematics, vol. 28, pp. 517–551, 2010.
- [17] A. Desilles and H. Zidani, “Pareto front characterization for multi-objective optimal control problems using Hamilton-Jacobi approach,” SIAM J. Control Optim., vol. 57, no. 6, pp. 3884–3910, 2018.