Stochastic mirror descent method for linear ill-posed problems in Banach spaces
Abstract.
Consider linear ill-posed problems governed by the system for , where each is a bounded linear operator from a Banach space to a Hilbert space . In case is huge, solving the problem by an iterative regularization method using the whole information at each iteration step can be very expensive, due to the huge amount of memory and excessive computational load per iteration. To solve such large-scale ill-posed systems efficiently, we develop in this paper a stochastic mirror descent method which uses only a small portion of equations randomly selected at each iteration steps and incorporates convex regularization terms into the algorithm design. Therefore, our method scales very well with the problem size and has the capability of capturing features of sought solutions. The convergence property of the method depends crucially on the choice of step-sizes. We consider various rules for choosing step-sizes and obtain convergence results under a priori early stopping rules. In particular, by incorporating the spirit of the discrepancy principle we propose a choice rule of step-sizes which can efficiently suppress the oscillations in iterates and reduce the effect of semi-convergence. Furthermore, we establish an order optimal convergence rate result when the sought solution satisfies a benchmark source condition. Various numerical simulations are reported to test the performance of the method.
1. Introduction
Due to rapid growth of data sizes in practical applications, in recent years stochastic optimization methods have received tremendous attention and have been proved to be efficient in various applications of science and technology including in particular the machine learning researches ([5, 13]). In this paper we will develop a stochastic mirror descent method for solving linear ill-posed inverse problems in Banach spaces.
We will consider linear ill-posed inverse problems governed by the system
| (1.1) |
consisting of linear equations, where, for each , is a bounded linear operator from a Banach space to a Hilbert space . Such systems arise naturally in many practical applications. For instance, many linear ill-posed inverse problems can be described by an integral equation of the first kind ([10, 14])
where and are bounded domains in Euclidean spaces and the kernel is a bounded continuous function on . Clearly is a bounded linear operator from to for any . By taking sample points in , then the problem of determining a solution using only the knowledge of for reduces to solving a linear system of the form (1.1), where is given by
for each . Further examples of (1.1) can be found in various tomographic techniques using multiple measurements [27].
Throughout the paper we always assume (1.1) has a solution. The system (1.1) may have many solutions. By taking into account of a priori information about the sought solution, we may use a proper, lower semi-continuous, convex function to select a solution of (1.1) such that
| (1.2) |
which, if exists, is called a -minimizing solution of (1.1). In practical applications, the exact data is in general not available, instead we only have noisy data satisfying
| (1.3) |
where denotes the noise level corresponding to data in the space . How to use the noisy data to construct an approximate solution of the -minimizing solution of (1.1) is an important topic.
Let and define by
Then (1.2) can be equivalently stated as
| (1.4) |
which has been considered by various variational and iterative regularization methods, see [4, 7, 21, 23, 35] for instance. In particular, the Landweber iteration in Hilbert spaces has been extended for solving (1.4), leading to the iterative method of the form
| (1.5) | ||||
where denotes the adjoint of and is the step-size. This method can be derived as a special case of the mirror descent method; see Section 2 for a brief account. The method (1.5) has been investigated in a number of references, see [4, 12, 21, 22, 23]. In particular, the convergence and convergence rates have been derived in [21] when the method is terminated by either an a priori stopping rule or the discrepancy principle
where
denotes the total noise level of the noisy data. We remark that the minimization problem in (1.5) for defining can be solved easily in general as it does not depend on ; in fact can be given by an explicit formula in many interesting cases; even if does not have an explicit formula, there exist fast algorithms for determining efficiently. However, note that
Therefore, updating to requires calculating for all . In case is huge, using the method (1.5) to solve (1.4) can be inefficient because it requires a huge amount of memory and excessive computational work per iteration.
In order to relieve the drawback of the method (1.5), by extending the Kaczmarz-type method [15] in Hilbert spaces, a Landweber-Kaczmarz method in Banach spaces has been proposed in [20, 23] to solve (1.2) which cyclically considers each equation in (1.2) in a Gauss-Seidel manner and the iteration scheme takes the form
| (1.6) | ||||
where . The convergence of this method has been shown in [23] in which the numerical results demonstrate its nice performance. However, it should be pointed out that the efficiency of the method (1.6) depends crucially on the order of the equations and its convergence speed is difficult to be quantified. In order to resolve these issues, in this paper we will consider a stochastic version of (1.6), namely, instead of taking cyclically, we will choose from randomly at each iteration step. The corresponding method will be called the stochastic mirror descent method and more details will be presented in Section 2 where we also propose the mini-batch version of the stochastic mirror descent method.
The stochastic mirror descent method, that we will consider in this paper, includes the stochastic gradient descent as a special case. Indeed, when is a Hilbert space and , the method (1.6) becomes
| (1.7) |
which is exactly the stochastic gradient descent method studied in [18, 19, 25, 33] for solving linear ill-posed problems in Hilbert spaces. In many applications, however, the sought solution may sit in a Banach space instead of a Hilbert space, and the sought solution may have a priori known special features, such as nonnegativity, sparsity and piecewise constancy. Unfortunately, the stochastic gradient descent method does not have the capability to incorporate these information into the algorithm. However, this can be handled by the stochastic mirror descent method with careful choices of a suitable Banach space and a strongly convex penalty functional .
In this paper we will use tools from convex analysis in Banach spaces to analyze the stochastic mirror descent method. The choice of the step-size plays a crucial role on the convergence of the method. We consider several rules for choosing the step-sizes and provide criteria for terminating the iterations in order to guarantee a convergence when the noise level tends to zero. The iterates produced by the stochastic mirror descent method exhibit salient oscillations and, due to the ill-posedness of the underlying problems, the method using noisy data demonstrates the semi-convergence property, i.e. the iterate tends to the sought solution at the beginning and, after a critical number of iterations, the iterates diverges. The oscillations and semi-convergence make it difficult to determine an output with good approximation property, in particular when the noise level is relatively large. When the information on noise level is available, by incorporating the spirit of the discrepancy principle we propose a rule for choosing step-size. This rule enables us to efficiently suppress the oscillations of iterates and remove the semi-convergence of the method as indicated by the extensive numerical simulations. Furthermore, we obtain an order optimal convergence rate result for the stochastic mirror descent method with constant step-size when the sought solution satisfies a benchmark source condition. We achieve this by interpreting the stochastic mirror descent method equivalently as a randomized block gradient method applied to the dual problem of (1.1). Even for the stochastic gradient descent method, our convergence rate result supplements the existing results since only sub-optimal convergence rates have been derived under diminishing step-sizes, see [18, 25].
This paper is organized as follows. In Section 2 we first collect some basic facts on convex analysis in Banach spaces and then give an account on the stochastic mirror descent method. In Section 3 we prove some convergence results on the stochastic mirror descent method under various choices of the step-sizes. When the sought solution satisfies a benchmark source condition, in Section 4 we establish an order optimal convergence rate result. Finally, in Section 5 we present extensive numerical simulations to test the performance of the stochastic mirror descent method.
2. The method
2.1. Preliminaries
In this section, we will collect some basic facts on convex analysis in Banach spaces which will be used in the analysis of the stochastic mirror descent method; for more details one may refer to [34, 38] for instance.
Let be a Banach space whose norm is denoted by , we use to denote its dual space. Given and we write for the duality pairing; in case is a Hilbert space, we also use to denote the inner product. For a convex function , its effective domain is denoted by
If , is called proper. Given , an element is called a subgradient of at if
The collection of all subgradients of at is denoted as and is called the subdifferential of at . If , then is called subdifferentiable at . Thus defines a set-valued mapping whose domain of definition is defined as
Given and , the Bregman distance induced by at in the direction is defined by
which is always nonnegative.
A proper function is called strongly convex if there exists a constant such that
| (2.1) |
for all and . The largest number such that (2.1) holds true is called the modulus of convexity of . It is easy to see that for a proper, strongly convex function with modulus of convexity there holds
| (2.2) |
for all , and .
For a proper function , its Legendre-Fenchel conjugate is defined by
which is a convex function taking values in . By definition we have the Fenchel-Young inequality
| (2.3) |
for all and . If is proper, lower semi-continuous and convex, is also proper and
| (2.4) |
The following important result gives further properties of which in particular shows that the strong convexity of implies the continuous differentiability of with gradient mapping to ; see [38, Corollary 3.5.11]
Proposition 2.1.
Let be a Banach space and let be a proper, lower semi-continuous, strongly convex function with modulus of convexity . Then , is Fréchet differentiable and its gradient maps into satisfying
for all .
Given a proper strongly convex function , we may consider for each the convex minimization problem
| (2.5) |
which is involved in the formulation of the stochastic mirror descent method below. According to [38, Theorem 3.5.8], (2.4) and Proposition 2.1 we have
Proposition 2.2.
If is a proper, lower semi-continuous, strongly convex function, then for any the minimization problem (2.5) has a unique minimizer given by .
2.2. Description of the method
In order to motivate our method, we first briefly review how to extend the gradient method in Hilbert spaces to solve the minimization problem
| (2.6) |
in Banach spaces, where is a Fréchet differentiable function defined on a Banach space . When is a Hilbert space, the gradient method for solving (2.6) takes the form which can be equivalently stated as
| (2.7) |
where denotes the inner product on and denotes the induced norm. When is a general Banach space, inner product is no longer available and is not necessarily an element in ; instead is an element in . Therefore, in order to guarantee to be meaningful, this expression should be understood as the dual pairing between and . On the other hand, since no Hilbert space norm is available, in (2.2) should be replaced by other suitable distance-like functionals. In order to capture the feature of the sought solution, a suitable convex penalty function is usually chosen to enhance the feature. In such a situation, one may use the Bregman distance induced by to fulfill the purpose. To be more precise, if , we may take suitably and then use the Bregman distance
to replace in (2.2). This leads to the new updating formula
for . By the expression of , we have
Let , then
If is well-defined, then by the optimality condition on we have . Therefore, we can repeat the above procedure, leading to the algorithm
| (2.8) | ||||
for solving (2.6) in Banach spaces, which is called the mirror descent method in optimization community; see [1, 6, 30, 31].
In order to apply the mirror descent method to solve (1.2) when only noisy data are available, we may consider a problem of the form (2.6) with
Note that . Therefore, an application of (2.8) gives
| (2.9) | ||||
This is exactly the method (1.5) which has been considered in [4, 21, 23]. Clearly, the implementation of (2.9) requires to calculate for all at each iteration. In case is huge, each iteration step in (2.9) requires a huge amount of computational work. In order to reduce the computational load per iteration, one may randomly choose a subset from with small size to form the partial term
of and use its gradient at as a replacement of in (2.9). This leads to the following mini-batch stochastic mirror descent method for solving (1.2) with noisy data.
Algorithm 1.
Fix a batch size , pick the initial guess in and set . For do the following:
-
(i)
Calculate by solving
(2.10) -
(ii)
Randomly select a subset with via the uniform distribution;
-
(iii)
Choose a step-size ;
-
(iv)
Define by
(2.11)
It should be pointed out that the choice of the step-size plays a crucial role on the convergence of Algorithm 1. We will consider in Section 3 several rules for choosing the step-size. Note also that, at each iteration step of Algorithm 1, is defined by a minimization problem (2.10). When is proper, lower semi-continuous and strongly convex, it follows from Proposition 2.2 that is well-defined. Moreover, for many important choices of , can be given by an explicit formula, see Section 5 for instance, and thus the calculation of does not take much time.
There exist extensive studies on the mirror descent method and its stochastic variants in optimization, see [6, 8, 28, 29, 39] for instance. The existing works either depend crucially on the finite-dimensionality of the underlying spaces or establish only error estimates in terms of objective function values, and therefore they are not applicable to our Algorithm 1 for ill-posed problems. We need to develop new analysis. Our analysis of Algorithm 1 is based on the following assumption which is assumed throughout the paper.
Assumption 1.
-
(i)
is a Banach space, is a Hilbert space and is a bounded linear operator for each ;
-
(ii)
is a proper, lower semi-continuous, strongly convex function with modulus of convexity ;
-
(iii)
The system , , has a solution in .
According to Assumption 1 (ii) and Proposition 2.1, the Legendre-Fenchel conjugate of is continuous differentiable with Lipschitz continuous gradient, i.e.
| (2.12) |
Moreover, by virtue of Assumption 1 and Proposition 2.2, the linear system (1.1) has a unique -minimizing solution and Algorithm 1 is well-defined. By the optimality condition on and Proposition 2.2 we have
| (2.13) |
which is the starting point of our convergence analysis.
3. Convergence
In order to establish a convergence result on Algorithm 1, we need to specify a probability space on which the analysis will be carried out. Let and let denote the -algebra consisting of all subsets of . Recall that, at each iteration step, a subset of indices is randomly chosen from via the uniform distribution. Therefore, for each , it is natural to consider and on the sample space
equipped with the -algebra and the uniform distributed probability, denoted as . According to the Kolmogorov extension theorem ([2]), there exists a unique probability defined on the measurable space such that each is consistent with . Let denote the expectation on the probability space . Given a Banach space , we use to denote the space consisting of all random variables with values in such that is finite; this is a Banach space under the norm
Concerning Algorithm 1 we will use to denote the natural filtration, where for each . We will frequently use the identity
| (3.1) |
for any random variable on . where denotes the expectation of conditioned on .
In this section we will prove some convergence results on Algorithm 1 under suitable choices of the step-sizes. The convergence of Algorithm 1 will be established by investigating the convergence property of its counterpart for exact data together with its stability property. For simplicity of exposition, for each index set of size we set
and define by
Let denote the adjoint of . Then the updating formula (2.11) of from can be rephrased as
We start with the following result.
Lemma 3.1.
Proof.
Note that
By using (2.13) and (2.4) we have
for all . Therefore
Using in (2.13) and the inequality (2.12) on , we can obtain
According to the definition of and , we can further obtain
By the given condition on and the Cauchy-Schwarz inequality, we then obtain
By taking the expectation and using to denote a sum over all subsets with , we have
which shows the desired inequality. ∎
Next we consider Algorithm 1 with exact data and drop the superscript for every quantity defined by the algorithm, Thus denote the corresponding iterative sequences and denotes the step-size. We now show a convergence result for Algorithm 1 with exact data by demonstrating that is a Cauchy sequence in .
Theorem 3.2.
Proof.
Let be any solution of (1.1) in and define
By the similar argument in the proof of Lemma 3.1 we can obtain
Consequently
| (3.3) |
This shows that is monotonically decreasing and therefore
| (3.4) |
where
If for some , we must have
along any sample path since there exist only finite many such sample paths each with a positive probability; consequently and and hence for all . Based on these properties of , it is possible to choose a strictly increasing sequence of integers by setting and, for each , by letting be the first integer satisfying
It is easy to see that for this sequence there holds
| (3.5) |
For the above chosen sequence of integers, we are now going to show that
| (3.6) |
By the definition of the Bregman distance we have for any that
Taking the expectation gives
| (3.7) |
By using the definition of we have
Therefore, by taking the expectation and using the Cauchy-Schwarz inequality, we can obtain
Since is -measurable, we have
We can not treat the term in the same way because is not necessarily -measurable. However, by noting that
we have
Therefore, with , we obtain
| (3.8) |
By virtue of (3.5) and (3) we then have
| (3.9) |
Combining this with (3.7) yields
which together with the first equation in (3.4) shows (3.6) immediately.
By using the strong convexity of , we can obtain from (3.6) that
which means that is a Cauchy sequence in . Thus there exists a random vector such that
| (3.10) |
By taking a subsequence of if necessary, we can obtain from (3.10) and the second equation in (3.4) that
| (3.11) |
almost surely. Consequently
i.e. is a solution of (1.1) almost surely.
We next show that almost surely. It suffices to show . Recall that , we have
| (3.12) |
By using (3.12) with , taking the expectation, and noting , we can obtain from (3.9) that
Therefore, it follows from the first equation in (3.11), the lower semi-continuity of and Fatou’s Lemma that
| (3.13) |
We have thus shown that is a solution of (1.1) in almost surely.
In order to proceed further, we will show that, for any that is a solution of (1.1) in almost surely, there holds
| (3.14) |
To see this, for any we write
Since is a solution of (1.1) in almost surely, by the definition of and we can use the similar argument for deriving (3.8) to obtain
This and the second equation in (3.4) imply for any fixed that as . Hence
for all . By virtue of (3.9) and letting we thus obtain (3.14).
Based on (3.12) with and (3.14), we can obtain
which together with (3.13) then implies
| (3.15) |
By using (3.15), (3.12) with , and (3.14) with , we have
Since is a solution of (1.1) in almost surely, we have almost surely which implies . Consequently and thus it follows from (3.15) that
| (3.16) |
Finally, from (3.16) and (3.14) with it follows that
By the monotonicity of we can conclude
and hence by the strong convexity of . The proof is therefore complete. ∎
In order to use Theorem 3.2 to establish the convergence of Algorithm 1 with noisy data, we need to investigate the stability of the algorithm, i.e. the behavior of and as for each fixed . In the following we will provide stability results of Algorithm 1 under the following three choices of step-sizes:
-
(s1)
depends only on , i.e. and for all with .
-
(s2)
is chosen according to the formula
where and are two positive constants with .
-
(s3)
In case the information of is available, choose the step-size according to the rule
where , and are preassigned numbers with .
The step-size chosen in (s1) is motivated by the Landweber iteration which uses constant step-size. Along the iterations in Algorithm 1, when the same subset is repeatedly chosen, (s1) suggests to use the same step-size in computation. The step-sizes chosen by (s1) could be small and thus slows down the computation. The rules given in (s2) and (s3) use the adaptive strategy which may produce large step-sizes. The step-size chosen by (s2) is motivated by the deterministic minimal error method, see [24]. The step-size given in (s3) is motivated by the work on deterministic Landweber-Kaczmarz method, see [15, 20], and it incorporates the spirit of the discrepancy principle into the selection.
Let be defined by Algorithm 1 with exact data, where the step-size is chosen by (s1), (s2) or (s3) with the superscript dropped and with replaced by . It is easy to see that satisfies (3.2) in Theorem 3.2. Therefore, Theorem 3.2 is applicable to .
The following result gives a stability property of Algorithm 1 with the step-sizes chosen by (s1), (s2) or (s3).
Lemma 3.3.
Proof.
We show the result by induction on . The result is trivial for because . Assuming the result holds for some , we will show it also holds for . Since there are only finitely many sample paths of the form each with positive probability, we can conclude from the induction hypothesis that
| (3.17) |
along every sample path . We now show that along each sample path there hold
| (3.18) |
To see this, we first show as by considering two cases.
We first consider the case . For this case we have and hence
Note that for all the choices of the step-sizes given in (s1), (s2) and (s3) we have , where is a constant independent of and . Note also that . Therefore
Consequently, by using (3.17) we can obtain as .
Next we consider the case . By using (3.17) we have when is sufficiently small. Note that
which implies that . Thus the step-size chosen by (s2) or (s3) is given by
By using again (3.17) we have
| (3.19) |
For the step-size chosen by (s1) the equation (3.19) holds trivially as . Therefore, by noting that
Now by virtue of the formula , and the continuity of , we have as . We thus obtain (3.18).
Finally, since there are only finitely many sample paths of the form , we can use (3.18) to conclude
as . The proof is thus complete by the induction principle. ∎
Theorem 3.4.
Proof.
Let for all . By the strong convexity of it suffices to show as . According to Lemma 3.1 we have
for all . Let be any fixed integer. Since as , we have for small . Thus, we may repeatedly use the above inequality to obtain
Since as , we thus have
for any . With the help of Cauchy-Schwarz inequality we have
Thus, we may use Lemma 3.3 to conclude
According to the proof of Lemma 3.3 we have as along each sample path . Thus, from the lower semi-continuity of and Fatou’s lemma it follows
Consequently
for all . Letting and using Theorem 3.2 we therefore obtain as . ∎
Theorem 3.4 provides convergence results on Algorithm 1 under various choices of the step-sizes. For the step-size chosen by (s3), if further conditions are imposed and and , we can show that the iteration error of Algorithm 1 always decreases.
Lemma 3.5.
Proof.
Theorem 3.6.
Proof.
We remark that, unlike Theorem 3.4, the convergence result given in Theorem 3.6 requires only to satisfy as . This is not surprising because the discrepancy principle has been incorporated into the choice of the step-size by (s3). Theorem 3.6 can be viewed as a stochastic extension of the corresponding result for the deterministic Landweber-Kaczmarz method ([20]) for solving ill-posed problems. It should be pointed out that, due to (3.20), the application of Theorem 3.6 requires either to be sufficiently large or to be sufficiently small which may lead the corresponding algorithm to lose accuracy or converge slowly. However, our numerical simulations in Section 5 demonstrate that using step-sizes chosen by (s3) without satisfying (3.20) still has the effect of decreasing errors as the iteration proceeds.
4. Rate of convergence
In Section 3 we have proved the convergence of Algorithm 1 under various choices of the step-sizes. In this section we will focus on deriving convergence rates. For ill-posed problems, this requires the sought solution to satisfy suitable source conditions. We will consider the benchmark source condition of the form ([7])
| (4.1) |
for some , where, here and below, for any we use to denote its -th component in . Deriving convergence rates under general choices of step-sizes can be very challenging. Therefore, in this section we will restrict ourselves to the step-sizes chosen by (s1) that includes the constant step-sizes. The corresponding algorithm can be reformulated as follows.
Algorithm 2.
Fix a batch size , pick the initial guess in and step-sizes for all with . Set . For do the following:
For Algorithm 2 we have the following convergence rate result.
Theorem 4.1.
Let Assumption 1 hold and consider Algorithm 2. Assume that for all subsets with ; furthermore with a constant for all such in case . If the sought solution satisfies the source condition (4.1) and the integer is chosen such that is of the magnitude of , then
where is a positive constant independent of , and .
When is a Hilbert space and , the stochastic mirror descent method becomes the stochastic gradient method. In the existing literature on stochastic gradient method for solving ill-posed problems, sub-optimal convergence rates have been derived for diminishing step-sizes under general source conditions on the sought solution, see [18, 25]. Our result given in Theorem 4.1 supplements these results by demonstrating that the stochastic gradient method can achieve the order optimal convergence rate under constant step-sizes if the sought solution satisfies the source condition (4.1).
The result in Theorem 4.1 also demonstrates the role played by the batch size : to achieve the same convergence rate, less number of iterations is required if a larger batch size is used. However, this does not mean the corresponding algorithm with larger batch size is faster because the computational time at each iteration can increase as increases. How to determine a batch size with the best performance is an outstanding challenging question.
The proof of Theorem 4.1 is based on considering an equivalent formulation of Algorithm 2 which we will derive in the following. The derivation is based on applying the randomized block gradient method ([26, 32, 36]) to the dual problem of (1.4) with replaced by . The associated Lagrangian function is
where and . Thus the dual function is
which means the dual problem is
| (4.2) |
Note that is continuous differentiable and
Therefore we may solve (4.2) by the randomized block gradient method which iteratively selects partial components of at random to be updated by a partial gradient of and leave other components unchanged. To be more precisely, for any and any subset , let denote the group of components of with . Assume is a current iterate. We then choose a subset of indices from with randomly with uniform distribution and define by setting if and
| (4.3) |
with step-sizes depending only on , where, for each , denotes the partial gradient of with respect to . Note that
Therefore, by setting , we can rewrite (4.3) as
By using the definition of and (2.4) we have which implies
and thus
| (4.4) |
Combining the above analysis we thus obtain the following mini-batch randomized dual block gradient method for solving (1.2) with noisy data.
Algorithm 3.
Fix a batch size , pick the initial guess and step-sizes for all with . Set . For do the following:
-
(i)
Calculate by using (4.4);
-
(ii)
Randomly select a subset with via the uniform distribution;
-
(iii)
Define by setting and
(4.5) where denotes the complement of in .
Let us demonstrate the equivalence between Algorithm 2 and Algorithm 3. If is defined by Algorithm 3, by defining we have
Therefore can be produced by Algorithm 1. Conversely, if is defined by Algorithm 1, by using one can easily see that , the range of . By writing for some , we have
Define by setting and . We can see that and can be generated by Algorithm 3. Therefore we obtain
Based on Algorithm 3, we will derive the estimate on under the benchmark source condition (4.1). Let
which is obtained from with replaced by . From (4.1) and (2.4) it follows that . Thus, by using we have
Since is convex, this shows that is a global minimizer of on .
According to (4.4) we have . Thus, we may consider the Bregman distance
By using (4.1), , and (2.4) we have
Therefore
Consequently, by virtue of the strong convexity of we have
Taking the expectation gives
| (4.6) |
This demonstrates that we can achieve our goal by bounding .
Note that the sequence is defined via the function . Although is a minimizer of , it may not be a minimizer of . In order to overcome this gap, we will make use of the relation
| (4.7) |
between and for all .
Lemma 4.3.
Proof.
For any and any with we may write up to a permutation. Since the partial gradient of with respect to is given by , it follows from (2.12) that
where . Consequently, by recalling the relation between and , we can obtain
By using (4.7) and the definition of , we can see that
Combining the above two equations and using the definition of , we thus have
By taking the expectation, using (3.1), and noting that , we finally obtain
which completes the proof. ∎
Lemma 4.4.
Proof.
We will only prove the result for ; the result for can be proved similarly. By using the definition of and we have
Taking the expectation and using (3.1), it gives
Noting that
Therefore
By the convexity of , the Cauchy-Schwarz inequality and the definition of , we can obtain
Therefore
Since , we thus obtain the desired inequality. ∎
Lemma 4.5.
Proof.
In order to proceed further, we need an estimate on . We will use the following elementary result.
Lemma 4.6.
Let and be two sequences of nonnegative numbers such that
where is a constant. If is non-decreasing, then
Proof.
We show the result by induction. The result is trivial for . Assume that the result is valid for all for some . We show it is also true for . If , then for some . Thus, by the induction hypothesis and the monotonicity of we have
If , then
which implies that
Taking square roots shows again. ∎
Now we are ready to show the following result which together with Lemma 4.2 implies Theorem 4.1 immediately.
Theorem 4.7.
Proof.
According to (4.6), it suffices to show (4.8). Since is a minimizer of over , we have for all . Thus, by noting that , it follows from Lemma 4.5 that
for all . Applying Lemma 4.6 and using the inequality for any , we can obtain
Consequently
Combining this with the estimate in Lemma 4.5 we obtain
By using the inequality
we can further obtain
| (4.9) |
According to Lemma 4.3 we have for any that
Therefore
Combining this with (4) and noting that and
we obtain
where
Note that as . Dividing the both sides of the above equation by shows
which completes the proof. ∎
5. Numerical results
In this section we will present numerical simulations to test the performance of the stochastic mirror descent method for solving linear ill-posed problems in which the sought solutions have various special features that require to make particular choices of the regularization functional and the solution space . Except Example 5.2, all the numerical simulations are performed on the linear ill-posed system
| (5.1) |
obtained from linear integral equations of first kind on by sampling at with , where the kernel is continuous on and for .
Example 5.1.
Consider the linear system (1.1) where and are all Hilbert spaces. In case the minimal norm solution is of interest, we may take in Algorithm 1, then the definition of shows . Consequently, Algorithm 1 becomes the form
| (5.2) |
where is a randomly selected subset with via the uniform distribution for a preassigned batch size . This is exactly the mini-batch stochastic gradient descent method for solving linear ill-posed problems in Hilbert spaces which has been studied recently in [17, 18, 25]. In these works the convergence analysis has been performed under diminishing step-sizes. Our work supplements the existing results by providing convergence results under new choices of step-sizes, in particular, for the method (5.2) with batch size , we obtain convergence and convergence rate results for the step-size
| (5.3) |
which obeys (s1) and (s2), where is the index chosen at the -th iteration step.
We now test the performance of the method (5.2) by considering the system (5.1) with , and , where . We assume the sought solution is
Instead of the exact data , we use the noisy data
| (5.4) |
where is the relative noise level and are random noises obeying the standard Gaussian distribution, i.e. . We execute the method (5.2) with the batch size and the initial guess together with the step-sizes given by (5.3); the integrals involved in the method are approximated by the trapezoidal rule based on the partition of into subintervals of equal length. To illustrate the dependence of convergence on the magnitude of step-size, we consider the three distinct values and . We also use noisy data with three distinct relative noise levels and . In Figure 1 we plot the corresponding reconstruction errors; the first row plots the relative mean square errors which are calculated approximately by the average of independent runs and the second row plots for a particular individual run. From these plots we can observe that, for each individual run, the iteration errors exhibit oscillations which are in particular dramatic when the noisy data have relative large noise levels. We can also observe that the method (5.2) demonstrates the semi-convergence property, i.e. the iterates converges to the sought solution at the beginning and, after a critical number of iterations, the iterates begin to diverge. This is typical for any iterative methods for solving ill-posed problems. Furthermore, for a fixed noise level, the semi-convergence occurs earlier if a larger step-size is used. We also note that, for noisy data with relatively large noise level, if a large step-size is used, the iterates can quickly produce a reconstruction result with minimal error and then diverge quickly from the sought solution; this makes it difficult to decide how to stop the iteration to produce a good reconstruction result. The use of small step-sizes has the advantage of suppressing oscillations and deferring semi-convergence. However, it slows down the convergence and hence makes the method time-consuming.






In order to efficiently suppress the oscillations and reduce the effect of semi-convergence, we next consider the method (5.2) using the step-size chosen by (s3) whose realization relies on the information of noise level. We now assume that the noisy data have the form (5.4), where are noise uniformly distributed on . Note that are the noise levels with . Assuming the information on is known, the step-size chosen by (s3) takes the form
| (5.7) |
which incorporates the spirit of the discrepancy principle. To illustrate the advantage of this choice of step-size, we compare the computed results with the ones obtained by the step-size chosen by (5.3). In Figure 2 we present the numerical results of reconstruction errors by the method (5.2) with batch size for various noise levels using the step-sizes chosen by (5.3) and (5.7) with and . where “DP” and “No DP” represent the results corresponding to the step-sizes chosen by (5.7) and (5.3) respectively. The first row in Figure 2 plots the mean square errors which are calculate approximately by the average of 100 independent runs and the second row plots the reconstruction errors for a typical individual run. The results show clearly that using the step-size (5.7) can significantly suppress the oscillations in reconstruction errors in particular when the data are corrupted by noise with relatively large noise level. We have performed extensive simulations which indicate that, due to the regularization effect of the discrepancy principle, using the step-size (5.7) has the tendency to decrease the iteration error as the number of iterations increases and has the ability to reduce the effect of semi-convergence.






Example 5.2.
We consider the linear system (1.1) in which and are all Hilbert spaces and the sought solution satisfies the constraint , where is a closed convex set. Finding the unique solution of (1.1) in with minimal norm can be stated as (1.2) with , where denotes the indicator function of . Let denote the metric projection of onto . Then the mini-batch stochastic mirror descent method for determining takes the form
| (5.8) |
In case for some domain and , the iteration scheme (5.8) becomes
| (5.9) |
with an initial guess , where is a randomly selected subset of via the uniform distribution with for a preassigned batch size .
As a testing example, we consider the computed tomography which consists in determining the density of cross sections of a human body by measuring the attenuation of X-rays as they propagate through the biological tissues [27]. Mathematically, it requires to determine a function supported on a bounded domain from its line integrals. We consider here only the standard 2D parallel-beam tomography; tomography with other scan geometries can be considered similarly. We consider a full angle problem using projection angles evenly distributed between and degrees, with lines per projection. Assuming the sought image is discretized on a pixel grid, we may use the function paralleltomo in the MATLAB package AIR TOOLS [16] to discretize the problem. After deleting those rows with zero entries, it leads to a linear system , where is a matrix with size . This gives a problem of the form (1.1) with , where corresponds to the -th row of and is the -th component of .




We assume that the true image is the Shepp-Logan phantom shown in figure 3 (a) discretized on a pixel grid with nonnegative pixel values. This phantom is widely used in evaluating tomographic reconstruction algorithms. Let denote the vector formed by stacking all the columns of the true image and let be the true data. By adding Gaussian noise to we get the noisy data of the form (5.4), where and . Since the sought solution is nonnegative, we may reconstruct it by using the method (5.9). As a comparison, we also consider reconstructing the sought phantom by the method (5.2) for which the nonnegative constraint is not incorporated. For the both methods, we use the batch size and the step-size chosen by (s2) with . We execute the methods for 600 iterations and plot the reconstruction results in Figure 3 (b) and (c). In Figure 3 (d) we also plot the squares of the relative errors which indicate that incorporating the nonnegative constraint can produce more accurate reconstruction results. This example demonstrates that available a priori information on sought solutions should be incorporated into algorithm design to assist with better reconstruction results.
Example 5.3.
Let be a bounded domain. Consider the linear system (1.1), where is a bounded linear operator and is a Hilbert space for each . We assume the sought solution is a probability density function, i.e. a.e. on and . To determine such a solution, we take where denotes the indicator function of
and
is the negative of the Boltzmann-Shannon entropy. Here . The Boltzmann-Shannon entropy has been used in Tikhonov regularization as a regularization functional to determine nonnegative solutions, see [9, 11] for instance. According to [3, 9], is strongly convex on with modulus of convexity . By the Karush-Kuhn-Tucker theory, for any the unique minimizer of
is given by . Therefore the corresponding stochastic mirror descent method takes the form
| (5.10) |
where is a randomly selected subset via the uniform distribution with a preassigned batch size and is the step-size.
For numerical simulations we consider the linear system (5.1) with , and . We assume the sought solution is
where is a constant to ensure that so that is a probability density function. By adding random noise to the exact data we get the noisy data ; we then use these noisy data and the method (5.10) with batch size to reconstruct the sought solution ; the integrals involved in the method are approximated by the trapezoidal rule based on the partition of into subintervals of equal length.






We first test the performance of the method (5.10) using the noisy data given by (5.4) corrupted by Gaussian noise, where and is the relative noise level. We execute the method (5.10) using the batch size , the initial guess and the step-size chosen by (s2) with three distinct values and . In Figure 4 we plot the reconstruction errors for three distinct relative noise levels and . The first row plots the mean square errors which are calculated approximately by the average of 100 independent runs. The second row plots for a particular individual run. These plots demonstrate that the method (5.10) admits the semi-convergence property and the iterates exhibit dramatic oscillations. Furthermore, using large step-sizes can make convergence fast at the beginning but the iterates can diverge quickly; while using small step-sizes can suppress the oscillations and delay the occurrence of semi-convergence, it however makes the method converge slowly.






In order to efficiently remove oscillations and semi-convergence, we next consider the method (5.10) using the step-size chosen by (s3) whose realization relies on the information of noise level. We consider noisy data of the form (5.4), where are uniform noise distributed on . Note that are the noise levels such that for all ; we assume the information on is known. To illustrate the advantage of the step-size chosen by (s3), we compare the computed results with the ones obtained by the step-size chosen by (s2). In Figure 5 we plot the reconstruction errors by the method (5.10) for various relative noise levels using the step-sizes chosen by (s2) and (s3) with and , where “DP” and “No DP” represent the results corresponding to the step-size chosen by (s3) and (s2) respectively. The first row in Figure 5 plots the mean square errors calculated approximately by the average of 100 independent runs and the second row plots the reconstruction errors for a particular individual run. The results show clearly that using step-size by (s3) can significantly suppress the oscillations in iterates and relieve the method from semi-convergence.
Example 5.4.
Let be a bounded domain. We consider reconstructing a sparse solution in the linear system (1.1), where is a bounded linear operator and is a Hilbert space for each . To determine such a solution, we take , where is a sufficiently large number whose choice reflects the role of the term in the reconstruction of sparse solutions. Note that for any we have
Therefore the corresponding stochastic mirror descent method takes the form
| (5.11) |
where is a randomly selected subset satisfying via the uniform distribution with the preassigned batch size and is the step-size. We remark that, when and , the corresponding method is the sparse-Kaczmarz method which was first proposed in [23] to reconstruct sparse solutions of ill-posed inverse problems. For finite-dimensional linear systems with well-conditioned matrices, a randomized sparse-Kaczmarz method of the form (5.11) was introduced in [37] in which is chosen with a probability proportional to and a linear convergence rate is derived. The theoretical result in [37] however is not applicable to ill-posed problems because the analysis depends heavily on the finite-dimensionality of the underlying spaces and the well-conditioning property of the matrices.
For numerical simulations we consider the linear system (5.1) with and . We assume the sought solution is
which is sparse on . By adding random noise to the exact data we get the noisy data ; we then use these noisy data and the method (5.11) with batch size to reconstruct the sought solution . In our numerical computation we take and and the integrals involved in the method are approximated by the trapezoidal rule based on the partition of into subintervals of equal length.





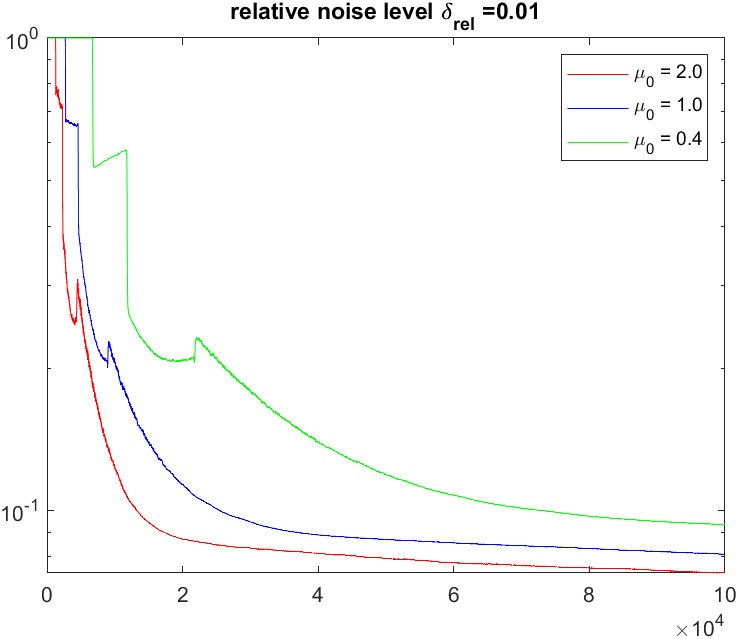
We first test the performance of the method (5.11) using the noisy data given by (5.4) corrupted by Gaussian noise, where . We execute the method (5.11) using the batch size , the initial guess and the step-size chosen by (s2) with three distinct values and . In Figure 6 we plot the reconstruction errors for three distinct relative noise levels and . The first row plots the relative mean square errors calculated approximately by the average of 100 independent runs, and the second row plots the relative errors for a particular individual run. From these plots we can observe the oscillations in iterates, the semi-convergence of the method, and the influence of the magnitude of step-sizes.






We next consider the method (5.11) using the step-size chosen by (s3). We use noisy data of the form (5.4) with being uniformly distributed over and assume that the noise levels are known. In Figure 7 we plot the reconstruction errors of the method (5.11) using the step-sizes chosen by (s3) with and which are labelled as “DP”; as comparisons we also plot the corresponding results using step-sizes chosen by (s2) with which are labelled as “No DP”. Sharply contrast to (s2), these results illustrate that using step-size by (s3) can significantly suppress the oscillations in iterates and reduce the effect of semi-convergence.
Example 5.5.
In this final example we consider using the stochastic mirror descent method to reconstruct piecewise constant solutions. We consider again the linear system (5.1) with and and assume that the sought solution is piecewise constant. By dividing into subintervals of equal length and approximating integrals by the trapezoidal rule, we have a discrete ill-posed system , where is a row vector for each . To reconstruct a piecewise constant solution, we use the model
| (5.12) |
where denotes the discrete gradient operator and is a large positive number. If we apply the stochastic mirror descent method to solve (5.12) directly, we need to solve a minimization problem related to to obtain at each iteration step. This can make the algorithm time-consuming since those minimization problems can not be solved explicitly. To circumvent this difficulty, we introduce and rephrase (5.12) as
| (5.13) |
where . Assuming, instead of , we have the noisy data . By applying the stochastic mirror descent method with batch size to (5.13) we can obtain
By calculating and noting , we therefore obtain the following iteration scheme
| (5.14) | ||||
with the initial guess and , where is a randomly selected index via the uniform distribution and denotes the step-size.



Assuming the sought solution is piecewise constant whose graph is plotted in Figure 8. By adding noise to the exact data , we produce the noisy data . We then use these noisy data in the method (5.14) to reconstruct . In the numerical computation we use and . For the method (5.14) using step-size chosen by (s2), i.e.
| (5.15) |
we have performed the numerical computation for several distinct values of and observed semi-convergence property, oscillations of iterates and the effect of the magnitude of the step-sizes. Since these observations are very similar to the previous examples, we will not report them here. Instead we will focus on the computational effect of the step-size chosen by (s3). As before, the noisy data are generated by (5.4) with being uniform noise on and we assume the noise levels are known. The step-size chosen by (s3) then takes the formula
| (5.18) |
In Figure 8 we plot the reconstruction results by the method (5.14) after iterations using noise data for three distinct relative noise levels and , where “DP” and “No DP” represent the reconstruction results by the step-size chosen by (5.18) and (5.15) respectively; we use and . These results demonstrate that the method (5.14) can capture the piecewise constant feature very well. In order to give further comparison on the reconstruction results by the step-sizes (5.15) and (5.18), we present in Figure 9 the reconstruction errors, the first row plots approximations of the relative mean square errors by an average of 100 independent runs and the second row plots the reconstruction errors for a typical individual run. The results show clearly that using the step-size (5.18) can significantly suppress the oscillations in the iterates and reduce the effect of semi-convergence of the method.






Acknowledgement
Q. Jin would like to thank Peter Mathé from Weierstrass Institute for discussions on stochastic gradient descent. The work of Q. Jin is partially supported by the Future Fellowship of the Australian Research Council (FT170100231). The work of X. Lu is partially supported by the National Key Research and Development Program of China (No. 2020YFA0714200) and the National Science Foundation of China (No. 11871385).
References
- [1] A. Beck and M. Teboulle, Mirror descent and nonlinear projected subgradient methods for convex optimization, Oper. Res. Lett., 31 (2003), no. 3, 167–175.
- [2] R. Bhattacharya and E. C. Waymire, A basic course in probability theory, Second edition. Universitext. Springer, Cham, 2016.
- [3] J. M. Borwein and C. S. Lewis, Convergence of best entropy estimates, SIAM J. Optim., 1 (1991), pp. 191–205.
- [4] R. Boţ and T. Hein, Iterative regularization with a geeral penalty term – theory and applications to and TV regularization, Inverse Problems, 28 (2012), 104010.
- [5] L. Bottou, F. E. Curtis and J. Nocedal, Optimization methods for large-scale machine learning, SIAM Rev., 60 (2018), no. 2, 223–311.
- [6] S. Bubeck, Convex Optimization: Algorithms and Complexity, Foundations and Trends in Machine Learning: 8 (2015), no. 3-4, pp 231–357.
- [7] M. Burger and S. Osher, Convergence rates of convex variational regularization, Inverse Problems 20 (2004), no. 5, 1411–1421.
- [8] J. C. Duchi, Introductory lectures on stochastic convex optimization, In The Mathematics of Data, IAS/Park City Mathematics Series. American Mathematical Society, 2018.
- [9] P. P. B. Eggermont, Maximum entropy regularization for Fredholm integral equations of the first kind, SIAM J. Math. Anal., 24 (1993), no. 6, 1557–1576.
- [10] H. W. Engl, M. Hanke and A. Neubauer, Regularization of Inverse Problems, Kluwer, Dordrecht, 1996.
- [11] H. W. Engl and G. Landl, Convergence rates for maximum entropy regularization, SIAM J. Numer. Anal., 30 (1993), 1509–1536.
- [12] K. Frick and O. Scherzer,Regularization of ill-posed linear equations by the non-stationary augmented Lagrangian method, J. Integral Equ. Appl., 22 (2010), no. 2, 217–257.
- [13] I. Goodfellow, Y. Bengio and A. Courville, Deep Learning, Adaptive Computation and Machine Learning series, Cambridge, United States, 2017.
- [14] C. W. Groetsch, The theory of Tikhonov regularization for Fredholm equations of the first kind, Research Notes in Mathematics, 105. Pitman (Advanced Publishing Program), Boston, MA, 1984.
- [15] M. Haltmaier, A. Leitao and O. Scherzer, Regularization of systems of nonlinear ill-posed equations: I. Convergence Analysis, Inverse Problems and Imaging, 1 (2007), no. 2, 289–298.
- [16] P. C. Hansen and M. Saxild-Hansen, AIR Tools–a MATLAB package of algebraic iterative reconstruction methods, J. Comput. Appl. Math. 236 (2012), 2167–2178.
- [17] Y. Jiao, B. Jin and X. Lu, Preasymptotic convergence of randomized Kaczmarz method, Inverse Problems, 33 (2017), 125012, 21 pp.
- [18] B. Jin and X. Lu, On the regularizing property of stochastic gradient descent, Inverse Problems, 35 (2019), no. 1, 015004, 27 pp.
- [19] B. Jin, Z. Zhou and J. Zou, On the convergence of stochastic gradient descent for nonlinear ill-posed problems, SIAM J. Optim., 30 (2020), no. 2, 1421–1450.
- [20] Q. Jin, Landweber-Kaczmarz method in Banach spaces with inexact inner solvers, Inverse Problems, 32 (2016), no. 10, 104005, 26 pp.
- [21] Q. Jin, Convergence rates of a dual gradient method for linear ill-posed problems, Numer. Math., accepted for publication, 2022.
- [22] Q. Jin and X. Lu, A fast nonstationary iterative method with convex penalty for inverse problems in Hilbert spaces, Inverse Problems, 30 (2014), 04501, 21 pp.
- [23] Q. Jin and W. Wang, Landweber iteration of Kaczmarz type with general non-smooth convex penalty functionals, Inverse Problems, 29 (2013), no. 8, 085011, 22 pp.
- [24] B. Kaltenbacher, A. Neubauer and O. Scherzer, Iterative Regularization Methods for Nonlinear Ill-Posed Problems, Berlin: de Gruyter, 2008.
- [25] S. Lu and P. Mathé, Stochastic gradient descent for linear inverse problems in Hilbert spaces, Math. Comput., 91 (2022), 1763–1788.
- [26] Z. Lu and L. Xiao, On the complexity analysis of randomized block-coordinate descent methods, Math. Program., 152 (2015), no. 1–2, Ser. A, 615–642.
- [27] F. Natterer,The Mathematics of Computerized Tomography, SIAM, Philadelphia, 2001.
- [28] A. Nedic and S. Lee, On stochastic subgradient mirror-descent algorithm with weighted averaging, SIAM J. Optim., 24 (2014), pp. 84–107.
- [29] A. Nemirovski, A. Juditsky, G. Lan and A. Shapiro, Robust stochastic approximation approach to stochastic programming, SIAM J. Optim., 19 (2009), 1574–1609.
- [30] S. Nemirovski and D. B. Yudin, Problem Complexity and Method Efficiency in Optimization, Wiley, New York, 1983.
- [31] Y. Nesterov, Primal-dual subgradient methods for convex problems, Math. Program., Ser. B 120 (2009), 221–259.
- [32] Y. Nesterov, Efficiency of coordinate descent methods on huge-scale optimization problems, SIAM J. Optim., 22 (2012), no. 2, 341–362.
- [33] J. C. Rabelo, Y. F. Saporito and A. Leitão, On stochastic Kaczmarz type methods for solving large scale systems of ill-posed equations, Inverse Problems, 38 (2022), 025003.
- [34] R. T. Rockafellar, Convex Analysis, Princeton University Press, Princeton, NJ, 1970.
- [35] T. Schuster, B. Kaltenbacher, B. Hofmann and K. S. Kazimierski,Regularization Methods in Banach Spaces, Radon Series on Computational and Applied Mathematics 10 Walter de Gruyter, Berlin 2012.
- [36] P. Richtárik and M. Takác̆, Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function, Math. Program., 144 (2014), no. 1–2, 1–38.
- [37] F. Schöpfer and D. A. Lorenz, Linear convergence of the randomized sparse Kaczmarz method, Math. Program., 173 (2019), no. 1-2, Ser. A, 509–536.
- [38] C. Zălinscu, Convex Analysis in General Vector Spaces, World Scientific Publishing Co., Inc., River Edge, New Jersey, 2002.
- [39] Z. Zhou, P. Mertikopoulos, N. Bambos, S. P. Boyd and P. W. Glynn, On the convergence of mirror descent beyond stochastic convex programming, SIAM J. Optim., 30 (2020), no. 1, 687–716.