Stochastic approximation algorithm for estimating mixing distribution for dependent observations
Abstract
Estimating the mixing density of a mixture distribution remains an interesting problem in statistics. Using a stochastic approximation method, Newton and Zhang [1] introduced a fast recursive algorithm for estimating the mixing density of a mixture. Under suitably chosen weights the stochastic approximation estimator converges to the true solution. In Tokdar et al. [2] the consistency of this recursive estimation method was established. However the current results of consistency of the resulting recursive estimator use independence among observations as an assumption. We extend the investigation of performance of Newton’s algorithm to several dependent scenarios. We prove that the original algorithm under certain conditions remains consistent even when the observations are arising from a weakly dependent stationary process with the target mixture as the marginal density. We show consistency under a decay condition on the dependence among observations when the dependence is characterized by a quantity similar to mutual information between the observations.
,
1 Introduction
Stochastic approximation (SA) algorithms which are stochastic optimization techniques based on recursive update, have many applications in optimization problems arising in different fields such as engineering and machine learning. A classical and pioneering example of an SA can be found in Robbins and Monro [3] where a recursive method is introduced for finding the root of a function. In particular, suppose we have a non-increasing , where values of are observed with errors, i.e., we observe the value of at a point , as . Here ’s are i.i.d errors with mean zero and finite variance. The Robins–Monro stochastic algorithm recursively approximate the solution of as
| (1.1) |
where is a sequence of weights satisfying . Under (1.1), the sequence approaches the true root , such that . Subsequent developments include rate of convergence, optimum step-size, convergence under convexity etc (see Chung [4], Fabian et al. [5], Polyak and Juditsky [6] ). Also see Sharia [7],Kushner [8] for recent developments such as adaptively truncating the solution to some domain. More generally, for a predictable sequence with the recursive solution is a limit to the recursion
| (1.2) |
where is the initial value, possibly state dependent matrix of step sizes, and is a mean zero random process. The idea of stochastic approximation was cleverly used in a predictive recursion (PR) algorithm in Newton and Zhang [1] for finding the mixing component of a mixture distribution.
Mixture models are popular statistical models that provide a nice compromise between the flexibility offered by nonparametric approaches and the efficiency of parametric approaches. Mixture models are increasingly used in messy data situations where adequate fit is not obtained using conventional parametric models. Many algorithms, mostly variants of expectation maximization (EM) algorithm and Markov chain Monte Carlo (MCMC) algorithms, are currently available for fitting mixture models to the data. Specifically, these algorithms would fit a marginal model of the form
| (1.3) |
to the data assuming a form of the mixing kernel A related problem is recovering (estimating) the mixing distribution . The problem of estimating the density of (with respect to some dominating measure ) in a nonparametric set up can be a challenging exercise and can be numerically taxing when full likelihood procedures (such as nonparametric MLE or nonparametric Bayesian) are used. However the full likelihood procedures generally enjoy desirable large sample properties, such as consistency.
Let be a random variable with distribution , where is the latent variable and be the mixing density. Let and be the sigma-finite measures associated with and . The recursive estimation algorithm Newton and Zhang [1] for estimating then starts with some initial which has the same support as the true mixing density . The update with each new observation is given by
| (1.4) |
where is the marginal density of at the th iteration based on the mixing density obtained at the previous iteration.
From equation (1.4) calculating the marginals on both sides, we have the associated iterations for the marginal densities as
| (1.5) |
One way to connect the PR update to SA algorithm is to minimize the Kullback–Leibler (KL) distance between the proposed marginal and the true marginal and considering the minimizer of the corresponding Lagrange multiplier (Ghosh and Tokdar [9]; Martin and Ghosh [10]). The support of can be misspecified. In such cases PR estimate can be shown to concentrate around a density in the space of proposed mixture densities that is nearest in KL distance to the true marginal (Martin and Tokdar [11]). Similar results can be found for general posterior consistency such as developments in Kleijn and van der Vaart [12] where posterior consistency under misspecification was shown under conditions like convexity.
The PR algorithm is computationally much faster than the full likelihood methods. Ghosh and Tokdar [9], and later Tokdar et al. [2] established the consistency of Newton’s predictive recursion algorithm, thereby putting the PR algorithm on solid theoretical footing. Some subsequent developments on the rate of convergence can be found in Martin and Ghosh [10], Martin and Tokdar [11]. Later developments focus on application on semiparametric model, predictive distribution calculation in Hahn et al. [13], Martin and Han [14]. Like the proof of original SA algorithm the proving the consistency for the recursive estimate of the mixture distribution depends on a Martingale difference sum construction. Because the algorithm depends on the order of ’s, the resulting estimator is not a function of sufficient statistics, the consistency of the PR solution cannot be drawn from the consistency of frequentist and Bayesian method (e.g using DP mixture model; see Ghosal et al. [15], Lijoi et al. [16] ). In Ghosh and Tokdar [9] and Tokdar et al. [2] the martingale based method from Robbins and Monro [3] was adapted in density estimation setting in a novel way to show the almost sure convergence of the estimator in the weak topology and Kullback–Leibler (KL) divergence. The PR solution was shown to be the Kullback–Leibler divergence minimizer between the true marginal and the set of proposed marginals.
One of the key assumptions in the existing proof of consistency is that the observations are independent. This assumptions significantly limits the scope of application for the PR algorithm, where some naturally occurring dependence may be present, for example cases of mixture of Markov processes. The main result of this paper is that the predictive recursion continues to provide consistent solution even under weakly dependent stationary processes as long as the dependence decays reasonably fast. This vanishing dependence can be connected with and can be quantified by the information theoretic quantities such as mutual information between the marginal and the conditional densities of the process. We use a novel sub-sequence argument to tackle the dependence among the observations and prove consistency of the PR algorithm when such vanishing dependence is present. At the same time we derive a bound for the convergence rate for the PR algorithm under such dependence. As a special case, we later consider the example of general dependent cases, where the consistency of the recursive estimator holds under weaker conditions. In all the cases we also investigate convergence under misspecification of the support of the mixing density and concentration around the KL projection to the misspecified model.
The arrangement of this article is the following. In Section 2, we provide the background and basic framework for the martingale based argument. Section 3 presents the main results regarding convergence and the rates for the weakly dependent cases, and address the special case of mixture of Markov processes. In Section 4, we consider the special case of - dependent sequences.
2 Preliminaries and revisiting the independent case
Our notation and initial framework will follow the original martingale type argument of Robbins and Monro [3] and the developments for the independent case in the literature, especially in Ghosh and Tokdar [9] and Tokdar et al. [2]. Thus, we first introduce the notation and revisit the main techniques used in the proof of consistency of the PR estimator in Tokdar et al. [2]. The discussion will also illustrate the need for generalization of the techniques to the dependent case.
A recursive formulation using KL divergence along with martingale based decomposition was used in Tokdar et al. [2] who established convergence of the recursive estimators for the mixing density and that of the marginal density. Specifically, if and is the algebra generated by the first observations, then the following recursion can be established:
| (2.1) |
where
and is defined through the relation for The remainder term satisfies . The corresponding similar recursion for the KL divergence of the marginal densities, , is then
| (2.2) |
where
It is assumed that and , corresponding to initial starting point , are finite. The main idea in Tokdar et al. [2] was to recognize that , are mean zero square integrable martingales and hence almost surely convergent, , are positive, and , have finite limits almost surely. Putting these facts together Tokdar et al. [2] established that necessarily converges to zero limit almost surely, thereby establishing consistency of the predictive recursion sequences and in weak topology. Using developments in Robbins and Siegmund [17] it can be argued that the PR solution converges to the KL minimizer if the support is misspecified.
Hence, the theoretical results regarding convergence of such PR algorithms in current literature relies on independence of and also assumed that the true marginals at each were the same and equal to . There does not seem any obvious way of extending the proof to the case when the observations are not independent.
We propose a proof for convergence of the predictive recursion algorithm in the case when the observations are dependent. While the proof will use martingale construction technique similar to that of Tokdar et al. [2], there are significant differences in the approach that allows us to address the case of dependent observations, and tools required to address the dependence will be detailed in next section. The main contributions of the paper are summarized in the following:
-
1.
We show that the PR algorithm continues to be consistent under weakly dependent processes where the marginal stationary distribution at each is a mixture with respect to a fixed kernel. The consistency is obtained under additional conditions on the kernel and the parameter space. If the dependence decays exponentially, under additional conditions, the original PR estimate is shown to be consistent. The decaying dependence is characterized by a special case of expected divergence between marginal and conditional densities.
-
2.
We establish the convergence rate when the support is correctly specified and or misspecified with decaying dependence.
-
3.
We show the result for finite mixture of Markov processes and general -dependent processes under milder conditions.
The next section describes the main results as well the tools needed for the proof of consistency in the dependent case that uses a novel sub-indexing argument.
3 Main results
To establish consistency of the PR algorithm when observations are dependent, we will need to control the expectation of ratios of -fold products () of densities at two different parameter values. Suppose the parameter lies in a compact subset of an Euclidean space. Let denote a closed convex set containing and assume is well defined for . Assume there is a finite set (typically will be the extreme points when is a convex polytope) and a compact set such that the following holds.
-
C1. For any there exists such that , for some . This condition is satisfied with for and .
-
C2. There exists such that .
-
C3. There exists such that .
Without loss of generality, we can assume that . Under C1—C3, the ratio of the marginals can be bounded by the ratios of conditionals on the finite set and a function of and . For many common problems, such as location mixtures of , a finite set exists that satisfies the assumption. This condition can be seen as a generalization of Monotone Likelihood Ratio property in higher dimensions. The condition is satisfied in a general multivariate normal mean mixture with known covariance matrix, where the mean parameter is constrained to a set in , contained in a closed large convex polytope , and the set then consists of suitable selected points on the boundary of and .
Proposition 1.
Under C1–C3 , for any two distribution and on compact , the ratio of the marginals under mixing densities and can be bounded as
| (3.1) |
Proof.
Given in the Appendix. ∎
Remark 1.
For finite the result in Proposition 3.1 holds trivially using in place of .
When ’s have a fixed marginal density , PR algorithm can still be applied in spite of dependence if the dependence decreases rapidly with distance along the sequential order in which ’s enter the algorithm. We assume the following -mixing type condition for the sequence. The decaying dependence is expressed as a special case of expected divergence (expected -distance) between the marginal and the conditional densities.
Let and let be the conditional density/pmf of given . We assume,
| (3.2) |
where and .
Let denote the mutual information between and and let . The condition given in (3.2) implies exponential decay of mutual information . When the conditional densities are uniformly bounded and uniformly bounded away from zero, (3.2) is satisfied if decays exponentially. This result can be summarized in the following proposition.
Proposition 2.
Proof.
The result follows from the relationship between -divergence and mutual information and is omitted. ∎
In addition, we assume the following conditions which are similar to those in Tokdar et al. [2]:
-
B1
, and , .
-
B2
For ’s for , for some and where and are distinct, and . Assume, without loss of generality.
-
B3
-
B4
The map is bounded and continuous for .
Condition is needed for fold products over different indices for the dependent case. This condition will later be verified for some of the examples considered. Condition can be omitted if stricter moment condition is assumed, which is given later. We can now state our main results. Theorem 3.1 shows consistency when the support of the mixing density is finite while Theorem 3.2 establishes consistency for general support under slightly more restrictive conditions.
Theorem 3.1.
Let be a sequence of random variables satisfying (3.2) where has a fixed marginal density given by and the support of , , is a finite set. Assume that the initial estimate in (1.4) has the same support as . Then under B1–B4, C1–C3, the estimator in (1.4) converges to the true mixing density with probability one, as the number of observations goes to infinity.
Proof.
The terms in the decomposition of the KL divergence, (2) can no longer be handled in the manner as in the independent case. We use further sub-indexing of the terms to obtain appropriate convergence results under the dependence condition (3.2).
We first partition the positive natural numbers into sub-sequences. Let denote the th term in th sub-sequence and let denote its value. Then the sub-sequences are constructed in the following manner:
-
1.
Let .
-
2.
Let for some fixed positive integer .
-
3.
The terms in the th sub-sequence are immediately followed by the next available term in the th sub-sequence unless there are no such terms in which case it is followed by the next term in the first sub-sequence.
By construction, .
For convenience of notation, we denote by the integer whenever and . We define if . Let denote the -algebra generated by the collection .
Similarly, Let, denote the conditional density of given .
Let be the number of subsequences constructed for , that is we consider such that for some . Clearly, . Also, let be the number of terms in the th sequence upto , such that
As an example, for the following pattern arises for the sub-sequences
Thus, , and in this example.
From equation (1.4), similar to equation (2) we have
| (3.3) |
where
and is as defined following (2). Next we show convergence of the different parts.
Convergence of We have for some . This implies that is mean zero a squared integrable martingale with filtration , and therefore converges almost surely [18]. Thus, outside a set of probability zero ’s converges for all , as varies over a countable set.
Next, we show that only finitely many martingale sequences in the will make significant contribution with probability one for large . Choose and choose large enough such that . From Lemma 1,
where is a constant.
Hence, outside a null set, say (possibly depending on ), we have for all but finitely many ’s and ’s converge. Fix , where is the underlying product-probability space. For any , we can choose (possibly depending upon ), such that for , and . Let large enough such that for we have whenever . Finally,
As is arbitrary and we can choose going to zero over a sequence. This implies is a Cauchy sequence with probability one and therefore converges with probability one.
Convergence of : Using the expression for , we have,
as for for some , as . Hence, converges almost surely from Proposition 4. Hence, converges almost surely.
Decomposing : We have from (3.3),
By Cauchy-Schwarz and using [B3] to bound the expression for in (3.1), we have
Let . If , then by condition (3.2) and Jensen’s inequality, we have . By construction of the sequences, a gap is equal to at most times. Also by (3.1), for some . Thus, . Hence, converges absolutely with probability one and hence, converges with probability one.
Convergence of : By Proposition 4, it is enough to show converges.
Let be the cardinality of . By condition [B3], , where . Then, by condition [B2] any -fold product .
Expanding as product of ratios of successive marginals,
When , where is minimized and maximized at and , respectively. When , then we have .
Hence,
where be the set .
Coefficients for the -fold products are bounded by , for some . The expectations of each of those -fold product bounded by . Let . Then there are many terms consisting of -fold products of .
As , for any . Choosing and large enough, we have , when and , and we have
By Proposition 4, we have the result.
Combining the parts: Having established that all converge with probability one to finite quantities, we essentially follow the arguments given in Tokdar et al. [2] . Since , we have converging to zero in a sub sequence with probability one, as LHS in (3.3) is finite, because otherwise from the fact , RHS will be .
Hence, as , has to converge, as all other sequences converge and therefore converges to zero in a subsequence almost surely. Now, using finiteness of , the proof follows as converges and over that subsequence has to converge to , as otherwise cannot converge to zero in that subsequence (Ghosh and Tokdar [9]).
In particular, if and if in some sub-subsequence of then corresponding marginal converges to weakly. But, as , converges to in Hellinger distance and also weakly, which is a contradiction. Hence, and therefore . Therefore, and we have with probability one. ∎
In general a bigger value of in (3.2) would indicate stronger dependence among and hence the convergence rate will be expected to be slower for bigger . Even though it is hard to write explicitly how affects the convergence, some insight can be gleaned by studying the different components of the decomposition of the KL divergence and their convergence.
Under the setting of Theorem 3.1, for convergence of , we need for the Cauchy increments, to go to zero. From equation (3.3), the Cauchy difference is essentially made up of a martingale difference sequence, an increment of non-negative sequence, and other terms that constitute error terms. The main term in that is influenced directly by the dependence parameter is . Following calculations of bounds on in (LABEL:wdep_decmp), we have
for some . Thus, convergence of the conditional mean sequence, and hence the KL sequence is expected to be slower for larger values of . This intuition is reinforced in Example 1 where the AR coefficient plays the role of the dependence parameter in (3.2). Numerically, we see that convergence is faster for smaller and slower with larger values of .
As mentioned earlier, consistency of the recursive algorithm can be established in much more generality, even under mild dependence, provided we can assume a slightly stronger condition. The following condition is stronger than [B2], but maybe more readily verifiable.
-
. , for some ,
The condition is sufficient for establishing consistency in the non-finite support with dependent data. However, it need not be necessary. It may not hold in some cases where the support of is unbounded. For example, the condition does not hold in normal location mixture with dependent data but it does hold when the a truncated normal kernel is used.
In the proof of Theorem 3.1, one could work with instead of [B2].
Remark 2.
The proof of the corollary is straight-forward and is omitted. The condition is in essence equivalent to [B2] and [B3], when the kernel is bounded and bounded away from zero.
Remark 3.
If and then B2, B3 and are satisfied.
Theorem 3.2.
Let be sequence of random variables satisfying (3.2) where has a fixed marginal density given by and the support of , , is a compact subset of the corresponding Euclidean space. Assume the initial estimate in (1.4) has the same support as . Let and denote the cdfs associated with and , respectively. Then under , C1–C3, the estimate from equation (1.4) converges to in weak topology with probability one, as the number of observations goes to infinity.
Proof.
Given in the Appendix. ∎
3.1 Misspecification of support
The predictive recursion algorithm requires specification of the support of the mixing density. The support of could be misspecified, in which case the solution cannot converge to the true density , however one could still investigate convergence for the sequence . Let the support of the initial density in the predictive recursion (1.4) be , a compact set possibly different from , the support of the true mixing density . Let be the class of all densities with the same support as . Specifically, let
| (3.5) |
Let
| (3.6) |
Thus, assuming uniqueness, the minimizer is the information projection of to . This minimizer is related to the Gateaux differential of KL divergence (Patilea [19]). For independent observations misspecification of the support has been addressed in the literature; for example see Ghosh and Tokdar [9], Martin and Ghosh [10]. Using the decomposition for dependent case in the proof of Theorems 3.2, 3.3, we extend the result for dependent cases. Let where is defined in (2.2).
Theorem 3.3.
Note that since is convex, so is the set of corresponding marginals. Thus, uniqueness of is guaranteed if the model is identifiable.
3.2 Convergence rate of the recursive algorithm
Convergence of PR type algorithms has been explored in recent work such as Martin and Tokdar [11] where the fitted PR marginal shown to be in radius Hellinger ball around the true marginal almost surely. Martin [20] establishes a better bound for finite mixture under misspecification. PR convergence rates are similar to nonparametric rate in nature and in current literature does not have the minimax rate (up to logarithmic factors) such as the rates shown in Ghosal and Van Der Vaart [21] and subsequent developments. The convergence rate calculations ([11], [20]) follow from the super martingale convergence theorem from Robbins-Siegmund (Robbins and Siegmund [17], Lai [22]) for independent cases and yield a rate similar to Genovese and Wasserman [23].
In the presence of dependence, we show the rate calculation assuming a faster rate of decay for the weights . Instead of condition B1 we will assume
-
, and , .
We use the subsequence construction technique described in 3 to do the rate calculations. Following the arguments given in the proofs of Theorems 3.1 and 3.2, we establish almost sure concentration in radius Hellinger ball around the true marginal for . The rate is slower than the rate for the independent case. Let the squared Hellinger distance between densities.
Theorem 3.4.
Assume the conditions of Theorem 3.3 hold with B1 replaced with . Then
for some . Moreover, if is bounded away from zero and infinity, then .
Proof.
From the proof of Theorem 3.2 and 3.3 (in Appendix), converges where if . By construction and . Hence, converges almost surely. Let, . Then, from A.1,
| (3.7) |
Here
Writing , , from the proof of Theorem 3.2, it can be shown that , , converge almost surely. We already established that converges almost surely. Hence, has to converge almost surely and would imply that goes to zero over a subsequence.
As, converges to a finite number for each outside a set of probability zero, and , then goes to zero with probability one for . As is bounded away from zero and infinity, , the conclusion about the Hellinger distance follows as Kullback Leibler divergence is greater than squared Hellinger distance.
∎
3.3 Finite Mixture of Markov processes and other examples
We consider a few examples of dependent processes, e.g. mixtures of Markov processes, where the marginal density is a mixture. Uniqueness of such representation has been studied extensively in the literature. Some of the earliest work can be found in Freedman [24], Freedman [25]. Also see related work in Diaconis and Freedman [26]. We here look at variants of stationary autoregressive processes of order one, AR(1), plus noise and Gaussian processes with constant drift. While simulation is done for different sample sizes, our main objective is to study the effect of dependence on convergence of the PR algorithm and not the rate of convergence. In fact, we use throughout for which . Thus, condition and hence Theorem 3.4 are not applicable for these examples.
The condition given in (3.2) is a sufficient condition, and if the marginal, is a finite mixture of marginals of latent Markov processes which individually satisfy 3.2, and B2 then a similar but slightly weaker condition will hold for , and Theorem 3.1 will hold for the mixture. In particular, if we have where ’s are independent Markov processes with stationary marginal densities and and the marginal distribution ’s are parametrized by ’s( i.e. of the form ), we can state the following result.
Proposition 3.
Let where ’s are independent Markov processes with stationary marginal densities and . Suppose, for each there exists and such that
| (3.8) |
Then Theorem 3.1 holds for the mixture process.
Proof.
By assumption, the marginal of is . Let be the event, , for and the last time , for for . Then
where Hence,
| (3.9) | |||||
From the calculation following equation (LABEL:wdep_decmp), it follows that with given in equation (3.8) and is as defined in the proof of Theorem 3.1, where denotes less than equal to up to a constant multiple. For between and , . Hence, we have .
Similarly, B2 can be verified by conditioning on the indicators and rest of the argument from Theorem 3.1 follows. ∎
Example 1. AR(1). As an example of mixture of independent Markov processes, we consider a mixture where one component is a Gaussian white noise and other component is a stationary AR(1) process. Let with marginal . and let , independent of . Let , where s are independent Bernoulli(0.3). We consider different values for the AR(1) parameter, , and investigate the effect on the convergence. To have the stationary variance of the AR(1) process to be one we choose the innovation variance to be equal to . For the AR(1) process, the dependence parameter in condition (3.2), is a monotone function of . Specifically, we use . A typical example is given in Figure 1, where we see the higher the value of the slower the convergence. While for moderate values of , the effect is negligible, for strong dependence, the effect on convergence is very pronounced. In this example for starting mixing probability has been used where the true mixing probability is 0.3.
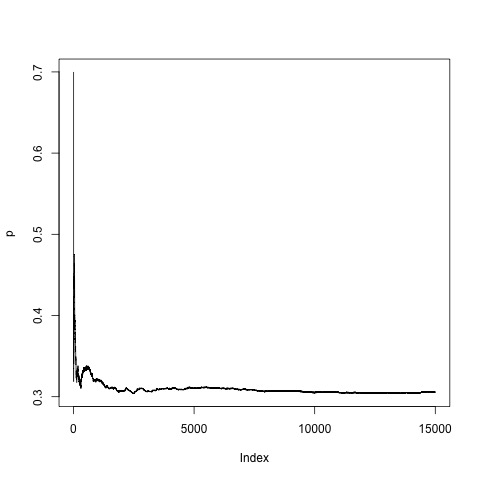



Here it is easy to see that the individual components satisfy (3.2). Thus, the PR algorithm based on will consistent for the marginal provided satisfy the moment conditions assumed in Theorem 3.1. This part follows from conditioning on the indicators and then calculating given the indicators by recursively conditioning on the observed ’s from the earlier indices. In particular, it will be sufficient to show for the case when , , and the values of for all that is comes from the latent process. Note that where are uniformly bounded (say by ). For convenience we write .
Let . Let denote the event that . Hence,
Similarly,
Applying the bounds recursively we have the result.
Example 2. A continuous mixture of AR(1). Next we consider a continuous mixture in the mean with error term following an AR(1) dependence. Let where follows an AR(1) model with parameter . Let , a standard normal distribution truncated to [-3,3]. Using a uniform[-3,3] as in (1.4), the fitted values are given in the left box in Figure 2. The true mixing density is given in solid blue. Solid and dashed black show the fit using , respectively.
The following argument verifies the conditions for consistency for the PR algorithm for a mean mixture of AR(1) process, . Here follows and are i.i.d with density , where is bounded and bounded away from zero and has compact support. We write,
Here, , and is the conditional density of given . Hence,
where , using the fact that the support of is bounded and is bounded away from zero and infinity. Hence, all the moments of are finite (in particular, for any ). The result follows by noticing that ; where are constants. It should be noted that , where and bounded. Using a similar argument, writing the joint density of in convolution form, where all the moments of are finite.
Now, , where . Hence, using Cauchy-Schwartz inequality we have,
Hence the dependence condition is satisfied. Next we verify condition for the mixture process. For , such that , and for , where , let , and such that . Choosing, large enough, and small enough,
where follows with parameter . Then by computing expectations recursively and noting that , the moment condition is established using arguments similar to those in Example 1.
Example 3. An irregular mixture with AR(1) error. Consider the last example but for a mixing distribution that has more structure. Specifically, let . Here . Using a continuous uniform on [-8,8] the fitted densities are given in the middle box of Figure 2 for sample sizes , respectively. The algorithm converges to a mixture structure for with probability around zero in the interval (-.5,.5) approximately equal to 0.45. The true mixing distribution is given by the solid line and the fit are given by the dotted line. While the estimated density is showing bimodality, a much larger sample size was also used to see explicitly the effect of large . The right box in Figure 2 shows the estimated mixture density for . The estimate is markedly better around the continuous mode and the other mode is more concentrated around zero indicating recovery of the discrete part. How the convergence is markedly slower than that in Example 2. Verification for conditions of consistency follows from the previous example.



Example 4. Gaussian process paths.
We consider two sub-examples with observations from a latent Gaussian process with known covariance kernel. In first case, the observations are shifted by a fixed mean with some unknown probability. In the second case, we consider a unknown constant drift along with the mean function. We observe from the marginal distribution.
a) Zero drift. Consider a continuous time process observed at times , where the observed process is the sum of two independent latent processes. Suppose, with covariance kernel and the observed process where and independent of .
Using known support i.e support at and for the mean we can plot the predictive recursion update for the probability at -1 in Figure 3 left panel (true value is 0.7). Suppose, we start with a continuous support on and uniform then the predictive recursion solution for is given in right panel.


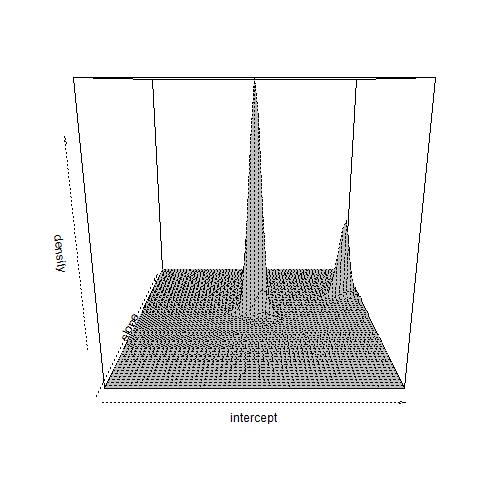
b) Constant drift. A similar setting as in part (a) is considered with , and , where there is a drift given by and the observed points are at ’s, , and . Figure 4 top panel shows the fitted marginal and joint mixing densities for the slope and intercept parameters and by the SA algorithm, where initial density is uniform on the rectangle . We have concentration around and for the intercept parameter, and, and for the slope parameter.
Figure 4 bottom panel shows the marginal fit when the starting density is uniform on and the support does not contain the true intercept parameter. In that case the mixing density for intercept concentrates around and , corresponding to nearest KL distance point.




4 -dependent processes
An important subclass of the weakly dependent processes are the -dependent processes where and are independent if for some positive integer . Heuristically, if the process is -dependent for some positive integer , one expects the original PR algorithm to provide consistent estimates over different subsequences where consecutive indices are apart and hence provides overall consistent estimator. Thus, one expects that the sufficient conditions assumed for general weakly dependent processes can be significantly relaxed. It is indeed the case and the proof for the -dependent processes is also significantly different. Hence we present the case of -dependent processes separately.
Consider an -dependent sequence with fixed marginal distribution of the form (1.3). From the definition of the process , are independent for all and for some positive integer . An example of such a process would be a th order moving average, , defined as
where are fixed parameters and are independent mean zero random variables with density . Let the marginal density of be of the mixture form (1.3). Note that the process considered is stationary, but for the PR example we merely need the marginal density to not change with the index. As mentioned, the assumptions could be relaxed in the -dependent case. The new assumptions are
-
A1
as ; for ; and .
-
A2
The map is injective; that is the mixing density is identifiable from the mixture
-
A3
The map is bounded and continuous for .
-
A4
For , and in , for some and for .
The conditions needed for convergence in dependent sequence is similar to that of independent case other than [A4] and [A1]. Condition [A1] is needed, as we will look at gap martingale sum, instead of the subsequence construction in Theorem 3.1, 3.2 for the gradually vanishing dependence. Condition [A4] is needed to account for the difference for the conditional mean terms, which will involve fold products of terms similar to ’s. Under the assumed conditions we have the following result.
Theorem 4.1.
Proof.
Given in the Appendix. ∎
Analogous to the general case, a statement can be made about convergence under misspecification of support in the -dependent case. Assume the set up of Theorem 3.3.
Theorem 4.2 (Convergence under miss-specification).
Assume the are generated from a -dependent process with fixed marginal density . Assume A1-A4 and C1-C3 hold. Then with probability one where is defined in Theorem 3.3.
The proof is given in the Appendix.
4.1 Convergence rate for -dependent case
Next we investigate the convergence rate of the PR algorithm in the -dependent case. We will assume as the decay rate for the weights .
Theorem 4.3.
For unique , , under the setting of Theorem 4.2, for , with probability one and , if is bounded away from zero and infinity.
5 Discussion
We have established consistency of the solution of the predictive recursion algorithm under various dependence scenarios. For the dependent cases considered, we have also explored convergence rate for the solution to the predictive recursion algorithm. The theoretical development provides justification for using the original algorithm in many cases. Under stationarity but misspecification about dependence structure the original algorithm continues to work as long as the dependence decays reasonably fast. Best possible nonparametric rate for dependent cases may be an interesting problem to explore and conditions for feasibility of minimax rate needs to be studied.
The proposed theoretical development justifies the possible use of stochastic approximation even when we have error in observations coming from an moving average or autoregressive mean zero distribution, if certain conditions are satisfied. It is well known that stochastic approximation or predictive recursion algorithms do not give a posterior estimate. However, similar extension for posterior consistency under the misspecification of independence under conditions analogous to equation (3.2) may be explored.
6 Acknowledgement
The first author Nilabja Guha is supported by the NSF grant #2015460.
A Appendix
We first prove a simple proposition which we use throughout the proofs. This is a standard result from probability theory, which we restate and prove for convenience.
Proposition 4.
Let be a sequence of random variables such that . Then converges almost surely and the limit is finite almost surely.
Proof.
Let be the probability space corresponding to the joint distribution. For some , if converges then converges. Let be the limit of which is defined to be infinity at some incase diverges to positive infinity.
By Monotone Convergence Theorem, (or equivalently can be argued using Fatou’s lemma on the sequence of partial sums ). Hence is finite with probability one. Therefore, converges with probability one and hence converges with probability one. ∎
Lemma 1.
From equation (3.3), , for , some universal constant not depending on .
Proof.
From the derivation after equation (3.3) and using Proposition 3.1, , for some universal constant , using condition A4. From the martingale construction of the equation 3 , . By construction, the coefficients belonging to each block is less for the higher the index is, that is if and is in then if . Hence, , where are universal constants.
A.1 Proof of Proposition 3.1
Proof.
Note that , where at and , is minimized and maximized, respectively when (note that continuous function on a compact set).
If then .
∎
A.2 Proof of Theorem 3.2
Proof.
Following (2.2) and the decomposition (3.3) in the dependent case, we can have an analogous KL decomposition for the marginals in the dependent case. We have,
| (A.1) |
Here
where is defined in (2.2). From the proof of Theorem 3.1 it follows that the sequence converges and converges to zero over a subsequence with probability one, as in that case was finite. Therefore, we first show that converges to zero with probability one by showing that converges almost surely.
Convergence of : From earlier calculations, . Hence, convergence of follows exactly same as in the same way as convergence of in Theorem 3.1. As, are squared integrable martingales each of them converge almost surely. From the fact, that we have for some fixed . Therefore, argument similar to those in Lemma 1, we have
for . Hence, only finitely many martingales make contribution to the tail sum with probability one as and for all but finitely many ’s with probability one with . Thus, is Cauchy almost surely and therefore, convergent almost surely.
Convergence of : Let,
and let . Note that
Hence, in the fold products of ’s where the index appears at most twice in . In the terms are products of terms like and where are in . Let . Using and Holder’s inequality, expectation of any fold such product would be bounded by . The number of such products of is less than , for any . Also, fold product contains many terms for which expectation can be bounded by for . Hence, for some universal constants, and greater than zero, for and large enough . Thus, , where for sequences , ,, implies that for some . Hence, converges with probability one.
Convergence of : Note that
where . Using Cauchy-Schwartz inequality and condition B3, the expectation of the second term is bounded by from some . Number of times is equal to is less than where is defined in the martingale construction 3. Therefore, for the sum over all is absolutely convergent.
The first term,
Hence, either converges or diverges to . Given that LHS in equation A.1 cannot be and the other terms in RHS in A.1 converges, has to converge with probability one.
Hence, we have converging to zero in a sub-sequence with probability one, and converging with probability one. Hence, converges to zero with probability one.
We now argue that this implies converges weakly to . Suppose not. Since is compact, is tight and hence have convergent subsequence. Let be a subsequence that converges to Let be the marginal corresponding to . Then by [B4], converges pointwise to and hence by Scheffe’s theorem it converges in and hence in Hellinger norm to . However, by the previous calculations, converges to almost surely in Kullback Leibler distance and therefore in Hellinger norm, which is a contradiction as . Hence, converges to weakly in every subsequence. ∎
A.3 Proof of Theorem 4.1
line
Proof.
For , define . Also let for each the subsequences be denoted by By construction are iid with marginal distribution . Let denote the field generated by all ’s up to and including . Also let the marginals generated during the iterations be denoted by and the weights be denoted by . From equation (2.1)
| (A.2) |
Here
where is defined as in (2). We follow the same argument as in the general case; first we show that converges with probability one and converges to zero over some subsequence with probability one. Then we show convergence of . As before, we show convergence of , the remainder term and the error term . We simplify some of the expressions first. From (1.5), for
We have
| (A.3) |
by using triangle inequality and using Proposition 3.1 on . By Holder’s inequality and assumption A4, we have
for Thus
Similarly, we can bound By Cauchy-Schwartz we have where is a constant. Hence by Proposition 4, converges almost surely. Therefore, , a finite random variable, with probability one. Note that for greater than some positive integer , as for large enough . Applying A4, we have and hence converges and hence by Proposition 4, converges almost surely. Similarly, and is a martingale with filtration and and hence, converges almost surely to a finite random variable as it is an square integrable martingale.
From equation (A.2) we have convergence of with probability one. This statement holds as in L.H.S in (A.2) is a fixed quantity subtracted from a positive quantity and , and converges with probability one. As and , for . Hence, any can not diverge to infinity. Moreover, as for , has to go zero in some subsequence almost surely.
Next we show convergence of . Analogously, replacing and by and from the above derivation, from equation (2.2) we get
| (A.4) |
where the martingale sequences, which converges due to squared integrability.
Then for ,
| (A.5) |
Also converges, using argument similar to that of . The proof of martingale squared integrability and the convergence of follows similarly as in . The convergences of the difference term follows similarly to the first part and given in the next subsection. Hence, we have ’s converging to finite quantities with probability one for each , as is positive. Hence, converges with probability one.
From the fact converges almost surely as goes to infinity and it converges to zero in a subsequence almost surely, we have it converging to zero almost surely. Therefore, by arguments given in the proof of Theorem 3.2, converges weakly to with probability one. ∎
A.3.1 Convergence of and
line
The proof of martingale squared integrability and convergences of the reminder terms and from Theorem 4.1:
Convergence of : We show that is a square integrable martingale. Note that . From A4, using Holder’s inequality. Thus, we have which proves our claim.
Convergence of :
Note that
from A4 and A1, and from the fact and and (following A4). Hence, and converges with probability one.
Convergence of : Let,
and . From the fact
and we have
Similarly
The part of R.H.S for can be bounded by the sum of fold product of and ’s multiplied by coefficient less than . Similarly. for we have fold products of ’s. Hence, integrating with respect to and taking expectation we have a universal bound for any such product term from Holder’s inequality. Hence, for , for some universal constant . As, , converges absolutely with probability one. Therefore, it converges with probability one.
A.4 Proof of Theorem 4.2
Proof.
From the derivation of equation (A.2) using instead of , i.e writing , we have, for ,
| (A.6) |
Here
For , . Convergence of , , follows from the proof of 4.1. Thus, similarly each has to converge and hence, converges to zero in some subsequence with probability one. Convergence of follows from the proof of Theorem 4.1, and completes the proof.
∎
A.5 Proof of Theorem 3.3
Proof.
From the proof of Theorem 3.1, we decompose , and have an equation analogous to (3.3)
| (A.7) |
which is derived by using instead of . Analogous to equation (LABEL:wdep_decmp) we have,
Using argument similar to Theorem 4.2, goes to zero in some subsequence with probability one, as goes to infinity. Convergence of is essentially same proof as in Theorem 3.2. Together they complete the proof. ∎
A.6 Proof of Theorem 4.3
Proof.
Since , from the proof of 4.1 we can conclude that with converges with probability one.
Let , . Hence, for for Theorem 4.2
| (A.8) |
and
| (A.9) |
Let and , For dependent case, from the proof of Theorem 4.1, writing instead of we can show the almost sure convergence . Convergence of and also follow in similar fashion. From the fact the term converges with probability one. Hence following A1, we have converging and going to zero in a subsequence with probability one for all as goes to infinity, and converging with probability one.
We have, converging to a finite number for each outside a set of probability zero, and , then goes to zero with probability one for . The conclusion about the Hellinger distance follows from the relation between KL and Hellinger distance from argument as in Theorem 3.4 proof.
∎
References
- Newton and Zhang [1999] Michael A Newton and Yunlei Zhang. A recursive algorithm for nonparametric analysis with missing data. Biometrika, 86(1):15–26, 1999.
- Tokdar et al. [2009] Surya T Tokdar, Ryan Martin, and Jayanta K Ghosh. Consistency of a recursive estimate of mixing distributions. The Annals of Statistics, 37(5A):2502–2522, 2009.
- Robbins and Monro [1951] Herbert Robbins and Sutton Monro. A stochastic approximation method. The Annals of Mathematical Statistics, 22(3):400–407, 1951.
- Chung [1954] Kai Lai Chung. On a stochastic approximation method. The Annals of Mathematical Statistics, 25(3):463–483, 1954.
- Fabian et al. [1968] Vaclav Fabian et al. On asymptotic normality in stochastic approximation. The Annals of Mathematical Statistics, 39(4):1327–1332, 1968.
- Polyak and Juditsky [1992] Boris T Polyak and Anatoli B Juditsky. Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 30(4):838–855, 1992.
- Sharia [2014] Teo Sharia. Truncated stochastic approximation with moving bounds: convergence. Statistical Inference for Stochastic Processes, 17(2):163–179, 2014.
- Kushner [2010] Harold Kushner. Stochastic approximation: a survey. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1):87–96, 2010.
- Ghosh and Tokdar [2006] Jayanta K Ghosh and Surya T Tokdar. Convergence and consistency of newton’s algorithm for estimating mixing distribution. In Frontiers in statistics, pages 429–443. World Scientific, 2006.
- Martin and Ghosh [2008] Ryan Martin and Jayanta K Ghosh. Stochastic approximation and newton’s estimate of a mixing distribution. Statistical Science, 23(3):365–382, 2008.
- Martin and Tokdar [2009] Ryan Martin and Surya T Tokdar. Asymptotic properties of predictive recursion: robustness and rate of convergence. Electronic Journal of Statistics, 3:1455–1472, 2009.
- Kleijn and van der Vaart [2006] Bas JK Kleijn and Aad W van der Vaart. Misspecification in infinite-dimensional bayesian statistics. The Annals of Statistics, 34(2):837–877, 2006.
- Hahn et al. [2018] P Richard Hahn, Ryan Martin, and Stephen G Walker. On recursive bayesian predictive distributions. Journal of the American Statistical Association, 113(523):1085–1093, 2018.
- Martin and Han [2016] Ryan Martin and Zhen Han. A semiparametric scale-mixture regression model and predictive recursion maximum likelihood. Computational Statistics & Data Analysis, 94:75–85, 2016.
- Ghosal et al. [1999] Subhashis Ghosal, Jayanta K Ghosh, and RV Ramamoorthi. Posterior consistency of dirichlet mixtures in density estimation. Ann. Statist, 27(1):143–158, 1999.
- Lijoi et al. [2005] Antonio Lijoi, Igor Prünster, and Stephen G Walker. On consistency of nonparametric normal mixtures for bayesian density estimation. Journal of the American Statistical Association, 100(472):1292–1296, 2005.
- Robbins and Siegmund [1971] Herbert Robbins and David Siegmund. A convergence theorem for non negative almost supermartingales and some applications. In Optimizing methods in statistics, pages 233–257. Elsevier, 1971.
- Durrett [2019] Rick Durrett. Probability: theory and examples, volume 49. Cambridge university press, 2019.
- Patilea [2001] Valentin Patilea. Convex models, mle and misspecification. Annals of statistics, pages 94–123, 2001.
- Martin [2012] Ryan Martin. Convergence rate for predictive recursion estimation of finite mixtures. Statistics & Probability Letters, 82(2):378–384, 2012.
- Ghosal and Van Der Vaart [2001] Subhashis Ghosal and Aad W Van Der Vaart. Entropies and rates of convergence for maximum likelihood and bayes estimation for mixtures of normal densities. Annals of Statistics, 29(5):1233–1263, 2001.
- Lai [2003] Tze Leung Lai. Stochastic approximation. The Annals of Statistics, 31(2):391–406, 2003.
- Genovese and Wasserman [2000] Christopher R Genovese and Larry Wasserman. Rates of convergence for the gaussian mixture sieve. The Annals of Statistics, 28(4):1105–1127, 2000.
- Freedman [1962a] David A Freedman. Mixtures of markov processes. The Annals of Mathematical Statistics, 33(1):114–118, 1962a.
- Freedman [1962b] David A Freedman. Invariants under mixing which generalize de finetti’s theorem. The Annals of Mathematical Statistics, 33(3):916–923, 1962b.
- Diaconis and Freedman [1980] Persi Diaconis and David Freedman. de finetti’s theorem for markov chains. The Annals of Probability, pages 115–130, 1980.