Stochastic Alternating Direction Method of Multipliers
for Byzantine-Robust Distributed Learning
Abstract
This paper aims to solve a distributed learning problem under Byzantine attacks. In the underlying distributed system, a number of unknown but malicious workers (termed as Byzantine workers) can send arbitrary messages to the master and bias the learning process, due to data corruptions, computation errors or malicious attacks. Prior work has considered a total variation (TV) norm-penalized approximation formulation to handle the Byzantine attacks, where the TV norm penalty forces the regular workers’ local variables to be close, and meanwhile, tolerates the outliers sent by the Byzantine workers. To solve the TV norm-penalized approximation formulation, we propose a Byzantine-robust stochastic alternating direction method of multipliers (ADMM) that fully utilizes the separable problem structure. Theoretically, we prove that the proposed method converges to a bounded neighborhood of the optimal solution at a rate of under mild assumptions, where is the number of iterations and the size of neighborhood is determined by the number of Byzantine workers. Numerical experiments on the MNIST and COVERTYPE datasets demonstrate the effectiveness of the proposed method to various Byzantine attacks.
keywords:
Distributed machine learning, alternating direction method of multipliers (ADMM), Byzantine attacks1 Introduction
Most of the traditional machine learning algorithms require to collect training data from their owners to a single computer or data center, which is not only communication-inefficient but also vulnerable to privacy leakage [1, 2, 3]. With the explosive growth of the big data, federated learning has been proposed as a novel privacy-preserving distributed machine learning scheme, and received extensive research interest recently [4, 5, 6]. In federated learning, the training data are stored at distributed workers, and the workers compute their local variables using local training data, under the coordination of a master. This scheme effectively reduces the risk of data leakage and protects privacy.
However, federated learning still faces significant security challenges. Some of the distributed workers, whose identities are unknown, could be unreliable and send wrong or even malicious messages to the master, due to data corruptions, computation errors or malicious attacks. To characterize the worse-case scenario, we adopt the Byzantine failure model, in which the Byzantine workers are aware of all information of the other workers, and able to send arbitrary messages to the master [7, 8, 9, 10]. In this paper, we aim at solving the distributed learning problem under Byzantine attacks that potentially threat federated learning applications.
Related works. With the rapid popularization of federated learning, Byzantine-robust distributed learning has become an attractive research topic in recent years. Most of the existing algorithms modify distributed stochastic gradient descent (SGD) to the Byzantine-robust variants. In the standard distributed SGD, at every iteration, all the workers send their local stochastic gradients to the master, while the master averages all the received stochastic gradients and updates the optimization variable. When Byzantine workers are present, they can send faulty values other than true stochastic gradients to the master so as to bias the learning process. It is shown that the standard distributed SGD with mean aggregation is vulnerable to Byzantine attacks [11].
When the training data are independently and identically distributed (i.i.d.) at the workers, the stochastic gradients of the regular workers are i.i.d. too. This fact motivates two mainstream methods to deal with Byzantine attacks: attack detection and robust aggregation. For attack detection, [12] and [13] propose to offline train an autoencoder, which is used to online calculate credit scores of the workers. The messages sent by the workers with lower credit scores will be discarded in the mean aggregation. The robust subgradient push algorithm in [14] operates over a decentralized network. Each worker calculates a score for each of its neighbors, and isolates those with lower scores. The works of [15, 16] detect the Byzantine workers with historic gradients so as to ensure robustness. The work of [17] uses redundant gradients for attack detection. However, it requires overlapped data samples on multiple workers, and does not fit for the federated learning setting. For robust aggregation, the master can use geometric median, instead of mean, to aggregate the received messages [18, 19, 20]. When the number of Byzantine workers is less than the number of regular workers, geometric median provides a reliable approximation to the average of regular workers’ stochastic gradients. Other similar robust aggregation rules include marginal trimmed mean and dimensional median [21, 22, 23]. Some aggregation rules select a representative stochastic gradient from all the received ones to update the global variable, e.g., Medoid [19] and Krum [11]. Medoid selects the stochastic gradient with the smallest distance from all the others, while Krum selects the one with the smallest squared distance to a fixed number of nearest stochastic gradients. An extension of Krum, termed as -Krum, selects stochastic gradients with Krum and uses their average. Bulyan [24] first selects a number of stochastic gradients with Krum or other robust selection/aggregation rules, and then uses their trimmed dimensional median.
When the training data and the stochastic gradients are non-i.i.d. at the workers, which is common in federated learning applications [25], naive robust aggregation of stochastic gradients no longer works. The works of [26, 27] adopt a resampling strategy to alleviate the effect caused by non-i.i.d. training data. With a larger resampling parameter, the algorithms can handle higher data heterogeneity, at the cost of tolerating less Byzantine workers. Robust stochastic aggregation (RSA) aggregates local variables, instead of stochastic gradients [28]. To be specific, it considers a total variation (TV) norm-penalized approximation formulation to handle Byzantine attacks, where the TV norm penalty forces the regular workers’ local variables to be close, and meanwhile, tolerates the outliers sent by the Byzantine workers. Although the stochastic subgradient method proposed in [28] is able to solve the TV norm-penalized approximation formulation, it ignores the separable problem structure.
Other related works include [29, 30, 31, 32], which shows that the stochastic gradient noise affects the effectiveness of robust aggregation rules. Thus, the robustness of the Byzantine-resilience methods can be improved by reducing the variance of stochastic gradients. The asynchronous Byzantine-robust SGD is considered in [33, 34, 35]. The work of [36] addresses the saddle-point attacks in the non-convex setting, and [37, 38, 39, 40] consider Byzantine robustness in decentralized learning.
Our contributions. Our contributions are three-fold.
(i) We propose a Byzantine-robust stochastic alternating direction method of multipliers (ADMM) that utilizes the separable problem structure of the TV norm-penalized approximation formulation. The stochastic ADMM updates are further simplified, such that the iteration-wise communication and computation costs are the same as those of the stochastic subgradient method.
(ii) We theoretically prove that the proposed stochastic ADMM converges to a bounded neighborhood of the optimal solution at a rate of under mild assumptions, where is the number of iterations and the size of neighborhood is determined by the number of Byzantine workers.
(iii) We conduct numerical experiments on the MNIST and COVERTYPE datasets to demonstrate the effectiveness of the proposed stochastic ADMM to various Byzantine attacks.
2 Problem Formulation
Let us consider a distributed network with a master and workers, among which workers are Byzantine and the other workers are regular. The exact value of and the identities of the Byzantine workers are all unknown. We are interested in solving a stochastic optimization problem in the form of
| (1) |
where is the optimization variable, is the regularization term known to the master, and is the loss function of worker with respect to a random variable . Here we assume that the data distributions on the workers can be different, which is common in federated learning applications.
Define and as the sets of regular workers and Byzantine workers, respectively. We have and . Because of the existence of Byzantine workers, directly solving (1) without distinguishing between regular and Byzantine workers is meaningless. A less ambitious alternative is to minimize the summation of the regular workers’ local expected cost functions plus the regularization term, in the form of
| (2) |
Our proposed algorithm and RSA [28] both aggregate optimization variables, instead of stochastic gradients. To do so, denote as the local copy of at a regular worker , and as the local copy at the master. Collecting the local copies in a vector , we know that (2) is equivalent to
| (3) | ||||
where , are the consensus constraints to force the local copies to be the same.
RSA [28] considers a TV norm-penalized approximation formulation of (3), in the form of
| (4) |
where is a positive constant and is the TV norm penalty for the constraints in (3). The TV norm penalty forces the regular workers’ local optimization variables to be close to the master’s, and meanwhile, tolerates the outliers when the Byzantine attackers are present. Due to the existence of the nonsmooth TV norm term, RSA solves (4) with the stochastic subgradient method. The updates of RSA, at the existence of Byzantine workers, are as follows. At time , the master sends to the workers, every regular worker sends to the master, while every Byzantine worker sends an arbitrary malicious vector to the master. Then, the updates of for every regular worker and for the master are given by
| (5) |
where is a stochastic gradient at respect to a random sample for regular worker , is the element-wise sign function ( if , if , and if ), and is the diminishing learning rate at time .
Although RSA has been proven as a robust algorithm under Byzantine attacks [28], the sign functions therein enable the Byzantine workers to send slightly modified messages that remarkably biases the learning process. In addition, RSA fully ignores the special separable structure of the TV norm penalty. In this paper, we also consider the TV norm-penalized approximation formulation (4), propose a stochastic ADMM that utilizes the problem structure, and develop a novel Byzantine-robust algorithm.
3 Algorithm Development
In this section, we utilize the separable problem structure of (4) and propose a robust stochastic ADMM to solve it. The challenge is that the unknown Byzantine workers can send faulty messages during the optimization process. At this stage, we simply ignore the existence of Byzantine workers and develop an algorithm to solve (4). Then, we will consider the influence of Byzantine workers on the algorithm. We begin with applying the stochastic ADMM to solve (4), and then simplify the updates such that the iteration-wise communication and computation costs are the same as those of the stochastic subgradient method in [28].
Stochastic ADMM. Suppose that all the workers are regular such that . To apply the stochastic ADMM, for every worker , introduce auxiliary variables on the directed edges , respectively. By introducing consensus constraints and , (4) is equivalent to
| (6) | ||||
For the ease of presentation, we stack these auxiliary variables in a new variable . As we will see below, the introduction of is to split the expectation term and the TV norm penalty term so as to utilize the separable problem structure.
The augmented Lagrangian function of (6) is
| (7) |
where is a positive constant, while and are the Lagrange multipliers attached to the consensus constraints and , respectively. For convenience, we also collect all the Lagrange multipliers in a new variable .
Given the augmented Lagrangian function (3), the vanilla ADMM works as follows. At time , it first updates through minimizing the augmented Lagrangian function at and , then updates through minimizing the Lagrangian function at and , and finally updates through dual gradient ascent. The updates are given by
| (8a) | ||||
| (8b) | ||||
| (8c) | ||||
However, the -update in (8a) is an expectation minimization problem and hence nontrivial. To address this issue, [41] proposes to replace the augmented Lagrangian function with its stochastic counterpart, given by
| (9) |
where is the random variable of worker at time and is the positive stepsize. Observe that (3) is a stochastic first-order approximation to (3), in the sense that
at the points and , respectively.
With the stochastic approximation, the explicit solutions of and are
| (10) |
For simplicity, we replace the parameter by and by . Thus, (10) is equivalent to
| (11) |
Simplification. Observe that the -update in (8b) is also challenging as the variables and are coupled by the TV norm penalty term. Next, we will simplify the three-variable updates in (11), (8b) and (8c) to eliminate the -update and obtain a more compact algorithm. Note that the decentralized deterministic ADMM can also be simplified to eliminate auxiliary variables [42]. However, we are considering the distributed stochastic ADMM, and the TV norm penalty term makes the simplification much more challenging.
Proposition 1 (Simplified stochastic ADMM).
Proof.
See A.
Presence of Byzantine workers. Now we start to consider how the stochastic ADMM updates (12), (13) and (14) are implemented when the Byzantine workers are present. At time , every regular worker updates with (12) and with (14), and then sends to the master. Meanwhile, every Byzantine worker can cheat the master by sending where the elements are arbitrary within . Otherwise, the Byzantine worker can be directly detected and eliminated by the master. This amounts to that every Byzantine worker follows an update rule similar to (14), as
| (15) |
where is an arbitrary vector. After receiving all messages from the regular workers and from the Byzantine workers , the master updates via
| (16) |
The Byzantine-robust stochastic ADMM for distributed learning is outlined in Algorithm 1 and illustrated in Figure 1. Observe that the communication and computation costs are the same as those in the stochastic subgradient method in [28]. The only extra cost is that every worker must store the dual variable .
Comparing the stochastic subgradient updates (5) with the stochastic ADMM updates (12), (13) and (14), we can observe a primal-dual connection. In the stochastic subgradient method, the workers upload primal variables , while in the stochastic ADMM, the workers upload dual variables . The stochastic subgradient method controls the influence of a malicious message by the sign function. No matter what the malicious message is, its modification on each dimension is among , , and a value within if the values of the malicious worker and the master are identical. The stochastic ADMM controls the influence of a malicious message by the projection function. The modification of the malicious message on each dimension is within .
Master
Initialize , , and .
Regular Worker
Initialize , , and .

4 Convergence Analysis
In this section, we analyze the convergence of the proposed Byzantine-robust stochastic ADMM. We make the following assumptions, which are common in analyzing distributed stochastic optimization algorithms.
Assumption 1 (Strong convexity).
The local cost functions and the regularization term are strongly convex with constants and , respectively.
Assumption 2 (Lipschitz continuous gradients).
The local cost functions and the regularization term have Lipschitz continuous gradients with constants and , respectively.
Assumption 3 (Bounded variance).
Within every worker , the data sampling is i.i.d. with . The variance of stochastic gradients is upper bounded by , as
| (17) |
4.1 Main Results
First, we show the equivalence between (2) and (6). When the penalty parameter is sufficiently, it has been shown in Theorem 1 of [28] that the optimal primal variables of (6) are consensual and identical to the minimizer of (2). We repeat this conclusion in the following lemma.
Lemma 1 (Consensus and equivalence).
Intuitively, setting a sufficiently large penalty parameter ensures the variables and to be consensual, since a larger gives more weight on the consensus constraints. When the training data at the workers are non-i.i.d., the local expected gradients deviate from 0, which leads to a large lower bound to maintain consensus. Once the variables are consensual, (6) is equivalent to (2).
Now, we present the main theorem on the convergence of the proposed Byzantine-robust stochastic ADMM.
Theorem 1 (-convergence).
Proof.
See C.
Theorem 1 guarantees that if we choose the stepsizes for both the workers and the master in the order of , then the Byzantine-robust stochastic ADMM asymptotically approaches to the neighborhood of the optimal solution of (2) (which equals and , according to Lemma 1) in an rate. Note that the stepsizes are sensitive to their initial values [28]. Therefore, we set the stepsizes in the numerical experiments. We also provide in D an ergodic convergence rate of with stepsizes.
In (18), the asymptotic learning error is in the order of , which is the same as that of RSA [28]. When more Byzantine workers are present, is larger and the asymptotic learning error increases. Using a larger helps consensus as indicated in Lemma 1, but incurs higher asymptotic learning error. In the numerical experiments, we will imperially demonstrate the influence of and .
4.2 Comparison with RSA: Case Studies
The proposed Byzantine-robust stochastic ADMM and RSA [28] solve the same problem, while the former takes advantages of the separable problem structure. Below we briefly discuss the robustness of the two algorithms to different Byzantine attacks.
RSA is relatively sensitive to small perturbations. To perturb the update of in (5), Byzantine worker can generate malicious that is very close to , but its influence on each dimension is still or . Potentially, this attack is able to lead the update to move toward a given wrong direction. In contrast, for the Byzantine-robust stochastic ADMM, small perturbations on change little on the update of in (16). To effectively attack the Byzantine-robust stochastic ADMM, Byzantine worker can set each element of to be , then its influence on each dimension will oscillate between and . In comparison, the influence of this attack for RSA is just or on each dimension. However, these large oscillations are easy to distinguish by the master through screening the received messages. In addition, it is nontrivial for this attack to lead the update to move toward a given wrong direction.
Developing Byzantine attacks that are most harmful to the Byzantine-robust stochastic ADMM and RSA, respectively, is beyond the scope of this paper. Instead, we give a toy example and develops two Byzantine attacks to justify the discussions above.
Example 1.
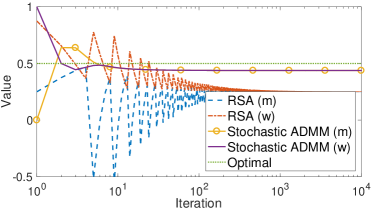
Consider a one-dimensional distributed machine learning task with regular workers (numbered by and ) and Byzantine worker (numbered by ). The functions are deterministic and quadratic, with , , and . Therefore, is the minimizer of (2) and by Lemma 1. The local primal variables are initialized as their local optima, i.e., and for both algorithms. The local dual variables of the Byzantine-robust stochastic ADMM are initialized as for . We construct two simple attacks.
Small value attack. Byzantine worker generates , where is a perturbation parameter.
Large value attack. Byzantine worker generates .
We choose the parameters and , with stepsizes and . The perturbation parameter is set as for the small value attack. Figure 2 shows the values of the local primal variables on the master and the regular workers. For both algorithms and both attacks, the master and the regular workers are able to asymptotically reach consensus as asserted by Lemma 1. Under the small value attack, RSA has larger asymptotic learning error than the Byzantine-robust stochastic ADMM as we have discussed, while under the large value attack, both algorithms coincidentally have zero asymptotic learning errors. In addition, we can observe that the Byzantine-robust stochastic ADMM is more stable than RSA under both attacks.

5 Numerical Experiments
In this section, we evaluate the robustness of the proposed algorithm to various Byzantine attacks. We compare the proposed Byzantine-robust Stochastic ADMM with the following benchmark algorithms: (i) Ideal SGD without Byzantine attacks; (ii) SGD subject to Byzantine attacks; (iii) Geometric median stochastic gradient aggregation [18, 19]; (iv) Median stochastic gradient aggregation [18, 19]; (v) RSA [28]. All the parameters of the benchmark algorithms are hand-tuned to the best. Although the stochastic ADMM and RSA are rooted in the same problem formulation (4), they perform differently for the same value of due to Byzantine attacks, as we have observed in Example 1. Therefore, we hand-tune the best for the stochastic ADMM and RSA, respectively. In the numerical experiments, we use two datasets, MNIST111http://yann.lecun.com/exdb/mnist and COVERTYPE222https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets. The statistics of these datasets are shown in Table 1. We launch one master and 20 workers. In the i.i.d case, we conduct experiments on both datasets by randomly and evenly splitting the data samples to the workers, while in the non-i.i.d. case we only use the MNIST dataset. Each regular worker uses a mini-batch of 32 samples to estimate the local gradient at each iteration. The loss functions of workers are softmax regressions, and the regularization term is given by . Performance is evaluated by the top-1 accuracy.
| Name | Training Samples | Testing Samples | Attributes |
|---|---|---|---|
| COVERTYPE | 465264 | 115748 | 54 |
| MNIST | 60000 | 10000 | 784 |
Gaussian attack. Under Gaussian attack, at every iteration every Byzantine worker sends to the master a random vector, whose elements follow the Gaussian distribution with standard deviation . Here we set the number of Byzantine workers . For Stochastic ADMM on the MNIST dataset, we set = 0.5, , , and . As shown in Figure 3(a), SGD fails, Stochastic ADMM, RSA and Geometric median perform very similarly and are close to Ideal SGD, while Median is a little worse than the others. On the COVERTYPE dataset, we set = 0.5, , , and for Stochastic ADMM. As shown in Figure 3(b), SGD performs the worst, while Stochastic ADMM, Geometric median, and median are close to Ideal SGD. Among all the Byzantine-robust algorithms, Stochastic ADMM has the fastest converge speed.


Sign-flipping attack. Under sign-flipping attack, at every iteration every Byzantine worker calculates its local variable, but flips the sign by multiplying with a constant , and sends to the master. Here we set and the number of Byzantine workers . On the MNIST dataset, we set the parameters of Stochastic ADMM as , , , and . Figure 4(a) shows that SGD also fails in this situation. Stochastic ADMM, RSA, and Geometric median are close to Ideal SGD, and achieve better accuracy than median. In Figure 4(b), shows the performance on the COVERTYPE dataset. The parameters of Stochastic ADMM are , , ,and . Stochastic ADMM and RSA are close to Ideal SGD, while outperform Geometric median and Median.


Without Byzantine attack. We also investigate the case without Byzantine attack in both MNIST and COVERTYPE datasets, as shown in Figure 5. In Figure 5(a), Stochastic ADMM on MNIST dataset chooses the parameters , , , and . Without Byzantine attack, performance of Stochastic ADMM, RSA, and Geometric median is very similar to Ideal SGD, while Median is worse than the other Byzantine-robust algorithms. On the COVERTYPE dataset, we set the parameters of Stochastic ADMM as , , , and . As shown in Figure 5(b), Stochastic ADMM is the best among all the algorithms, and RSA outperforms Geometric median and Median. We conclude that although Stochastic ADMM introduces bias to the updates, it still works well in the attack-free case.


Impact of . Here we show how the performance of the proposed algorithm on the two datasets are affected by the choice of the penalty parameter . We use sign-flipping attack with in the numerical experiments, and the number of Byzantine workers is . The parameters , and are hand-tuned to the best. As depicted in Figure 6, on both datasets, the performance of Stochastic ADMM degrades when is too small. The reason is that, when is too small the regular workers are rely more on their local data, leading to deficiency of the distributed learning system [28]. Meanwhile, being too large also leads to worse performance.


Non-i.i.d. data. To demonstrate the robustness of the proposed algorithm against Byzantine attacks on non-i.i.d. data, we redistribute the MNIST dataset by letting every two workers share one digit. All Byzantine workers choose one regular worker indexed by , and send to the master at every iteration . When the number of Byzantine workers is , the best reachable accuracy is around 0.8, because of the absence of two handwriting digits’ data. Similarly, when the number of Byzantine workers is , the best reachable accuracy is around 0.6. Here, we set the parameters of Stochastic ADMM as , , , and when . As shown in Figure 7(a), Median fails, Stochastic ADMM are close to Ideal SGD and outperforms all the other Byzantine-robust algorithms. When the number of Byzantine worker increases to , in Stochastic ADMM, we set , , , and . As depicted in Figure 7(b), Geometric median and Median fail because the stochastic gradients of regular worker dominate, such that only one digit can be recognized. Stochastic ADMM and RSA both work well, but Stochastic ADMM converges faster than RSA.


6 Conclusions
We proposed a stochastic ADMM to deal with the distributed learning problem under Byzantine attacks. We considered a TV norm-penalized approximation formulation to handle Byzantine attacks. Theoretically, we proved that the stochastic ADMM converges in expectation to a bounded neighborhood of the optimum at an -rate under mild assumptions. Numerically, we compared the proposed algorithm with other Byzantine-robust algorithms on two real datasets, showing the competitive performance of the Byzantine-robust stochastic ADMM.
Acknowledgement. Qing Ling is supported in part by NSF China Grant 61973324, Fundamental Research Funds for the Central Universities, and Guangdong Province Key Laboratory of Computational Science Grant 2020B1212060032. A preliminary version of this paper has appeared in IEEE International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, May 4–8, 2020.
References
- [1] R. Agrawal and R. Srikant. “Privacy-preserving Data Mining,” Proceedings of ACM SIGMOD, 2000.
- [2] S. Sicari, A. Rizzardi, L. Grieco, and A. Coen-Porisini, “Security, Privacy and Trust in Internet of Things: The Road Ahead,” Computer Networks, vol. 76, pp. 146–164, 2015.
- [3] L. Zhou, K. Yeh, G. Hancke, Z. Liu, and C. Su, “Security and Privacy for the Industrial Internet of Things: An Overview of Approaches to Safeguarding Endpoints,” IEEE Signal Processing Magazine, vol. 35, no. 5, pp. 76–87, 2018.
- [4] J. Konecny, H. McMahan, and D. Ramage, “Federated Optimization: Distributed Optimization Beyond the Datacenter,” arXiv: 1511.03575, 2015.
- [5] J. Konecny, H. McMahan, F. Yu, P. Richtarik, A. Suresh, and D. Bacon, “Federated Learning: Strategies for Improving Communication Efficiency,” arXiv: 1610.05492, 2016.
- [6] P. Kairouz and H. McMahan. “Advances and Open Problems in Federated Learning,” Foundations and Trends in Machine Learning, vol. 14, no. 1, 2021.
- [7] L. Lamport, R. Shostak, and M. Pease, “The Byzantine Generals Problem,” ACM Transactions on Programming Languages and Systems, vol. 4, no. 3, pp. 382–401, 1982.
- [8] N. Lynch, Distributed Algorithms, Morgan Kaufmann Publishers, San Francisco, USA, 1996.
- [9] A. Vempaty, L. Tong, and P. K. Varshney, “Distributed Inference with Byzantine Data: State-of-the-Art Review on Data Falsification Attacks.” IEEE Signal Processing Magazine, vol. 30, no. 5, pp. 65–75, 2013.
- [10] Y. Chen, S. Kar, and J. M. F. Moura, “The Internet of Things: Secure Distributed Inference.” IEEE Signal Processing Magazine, vol. 35, no. 5, pp. 64–75, 2018.
- [11] P. Blanchard, E. M. E. Mhamdi, R. Guerraoui, and J. Stainer, “Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent,” Proceedings of NeurIPS, 2017.
- [12] S. Li, Y. Cheng, W. Wang, Y. Liu, and T. Chen, “Abnormal Client Behavior Detection in Federated Learning,” arXiv: 1910.09933, 2019.
- [13] S. Li, Y. Cheng, W. Wang, Y. Liu, and T. Chen, “Learning to Detect Malicious Clients for Robust Federated Learning,” arXiv: 2002.00211, 2020.
- [14] N. Ravi and A. Scaglione, “Detection and Isolation of Adversaries in Decentralized Optimization for Non-Strongly Convex Objectives,” Proceedings of IFAC Workshop on Distributed Estimation and Control in Networked Systems, 2019.
- [15] D. Alistarh, Z. Allen-Zhu, and J. Li, “Byzantine Stochastic Gradient Descent,” Proceedings of NeuIPS, 2018.
- [16] Z. Allen-Zhu, F. Ebrahimianghazani, J. Li, and D. Alistarh, “Byzantine-Resilient Non-Convex Stochastic Gradient Descent,” Proceedings of ICLR, 2021.
- [17] L. Chen, H. Wang, Z. Charles, and D. Papailiopoulos, “DRACO: Byzantine-resilient Distributed Training via Redundant Gradients,” Proceedings of ICML, 2018.
- [18] Y. Chen, L. Su, and J. Xu, “Distributed Statistical Machine Learning in Adversarial Settings: Byzantine Gradient Descent,” Proceedings of the ACM on Measurement and Analysis of Computing Systems, 2018.
- [19] C. Xie, O. Koyejo, and I. Gupta, “Generalized Byzantine Tolerant SGD,” arXiv: 1802.10116, 2018.
- [20] X. Cao and L. Lai, “Distributed Approximate Newton’s Method Robust to Byzantine Attackers,” IEEE Transactions on Signal Processing, vol. 68, pp. 6011–6025, 2020.
- [21] D. Yin, Y. Chen, K. Ramchandran, and P. Bartlett, “Byzantine-robust Distributed Learning: Towards Optimal Statistical Rates,” Proceedings of ICML, 2018.
- [22] C. Xie, S. Koyejo, and I. Gupta, “Zeno: Distributed Stochastic Gradient Descent with Suspicion-based Fault-tolerance,” Proceedings of ICML, 2019.
- [23] C. Xie, O. Koyejo, and I. Gupta, “Phocas: Dimensional Byzantine-resilient Stochastic Gradient Descent,” arXiv: 1805.09682, 2018.
- [24] E. M. E. Mhamdi, R. Guerraoui, and S. Rouault, “The Hidden Vulnerability of Distributed Learning in Byzantium,” Proceedings of ICML, 2018.
- [25] K. Hsieh, A. Phanishayee, O. Mutlu, and P. B. Gibbons, “The Non-IID Data Quagmire of Decentralized Machine Learning,” Proceedings of ICML, 2020.
- [26] L. He, S. P. Karimireddy, and M. Jaggi, “Byzantine-robust Learning on Heterogeneous Datasets via Resampling,” arXiv: 2006.09365, 2020.
- [27] J. Peng, Z. Wu, Q. Ling, and T. Chen, “Byzantine-Robust Variance-Reduced Federated Learning over Distributed Non-i.i.d. Data,” arXiv: 2009.08161, 2020.
- [28] L. Li, W. Xu, T. Chen, G. Giannakis, and Q. Ling, “RSA: Byzantine-robust Stochastic Aggregation Methods for Distributed Learning from Heterogeneous Datasets,” Proceedings of AAAI, 2019.
- [29] Z. Wu, Q. Ling, T. Chen, and G. Giannakis, “Federated Variance-Reduced Stochastic Gradient Descent with Robustness to Byzantine Attacks,” IEEE Transactions on Signal Processing, vol. 68, pp. 4583–4596, 2020.
- [30] E. M. E. Mhamdi, R. Guerraoui, and S. Rouault, “Distributed Momentum for Byzantine-resilient Learning,” Proceedings of ICLR, 2021.
- [31] P. Khanduri, S. Bulusu, P. Sharma, and P. Varshney, “Byzantine Resilient Non-Convex SVRG with Distributed Batch Gradient Computations,” arXiv: 1912.04531, 2019.
- [32] S. P. Karimireddy, L. He, and M. Jaggi, “Learning from History for Byzantine Robust Optimization,” Proceedings of ICML, 2021.
- [33] G. Damaskinos, E. M. E. Mhamdi, R. Guerraoui, R. Patra, and M. Taziki, “Asynchronous Byzantine Machine Learning (the Case of SGD),” Proceedings of ICML, 2018.
- [34] Y. Yang and W. Li, “BASGD: Buffered Asynchronous SGD for Byzantine Learning,” arXiv: 2003.00937, 2020.
- [35] C. Xie, S. Koyejo, and I. Gupta, “Zeno++: Robust Fully Asynchronous SGD,” Proceedings of ICML, 2020.
- [36] D. Yin, Y. Chen, R. Kannan, and P. Bartlett, “Defending Against Saddle Point Attack in Byzantine-Robust Distributed Learning,” Proceedings of ICML, 2019.
- [37] Z. Yang and W. U. Bajwa, “ByRDiE: Byzantine-Resilient Distributed Coordinate Descent for Decentralized Learning,” IEEE Transactions on Signal and Information Processing over Networks, vol. 5, no. 4, pp. 611–627, 2019.
- [38] Z. Yang and W. U. Bajwa, “BRIDGE: Byzantine-resilient Decentralized Gradient Descent,” arXiv: 1908.08098, 2019.
- [39] S. Guo, T. Zhang, X. Xie, L. Ma, T. Xiang, and Y. Liu, “Towards Byzantine-resilient Learning in Decentralized Systems,” arXiv: 2002.08569, 2020
- [40] J. Peng, W. Li, and Q. Ling, “Byzantine-robust Decentralized Stochastic Optimization over Static and Time-varying Networks,” Signal Processing, vol. 183, no. 108020, 2021.
- [41] H. Ouyang, N. He, and A. Gray, “Stochastic ADMM for Nonsmooth Optimization,” arXiv: 1211.0632, 2012.
- [42] W. Ben-Ameur, P. Bianchi, and J. Jakubowicz, “Robust Distributed Consensus Using Total Variation,” IEEE Transactions on Automatic Control, vol. 61, no. 6, pp. 1550–1564, 2016.
- [43] Y. Nesterov, Introductory Lectures on Convex Optimization: A Basic Course, Springer, Boston, USA, 2004.
Appendix A Proof of Proposition 1
The proof of Proposition 1 relies on the following Lemma.
Lemma 2.
Let , where . Then
| (19) |
Proof.
Note that together with their difference is also optimal to the bi-level minimization problem
That is, we first optimize the constrained minimization problem with an artificially imposed constraint over , and then optimize over .
For the inner-level constrained minimization problem, from its KKT (Karush-Kuhn-Tucker) conditions we know the minimizer is , and accordingly, the optimal value is . Therefore, for the outer-level unconstrained minimization problem, from its KKT conditions we know the minimizer can be written as . Substituting this result to yields and . From them we obtain (19) and complete the proof.
Now we begin to prove Proposition 1. Since (8b) is separable with respect to , it is equivalent to
| (20) | ||||
According to Lemma 2, (20) leads to
| (21a) | ||||
| (21b) | ||||
Appendix B Supporting Lemmas
Lemma 3 (Optimality conditions of (6)).
The sufficient and necessary optimality conditions of (6) are
| (26) |
for all , where . In particular, defining , we have for all that
| (27) |
Proof.
Lemma 5.
Proof.
We first show the inequality in (30), and then modify it to prove (31). The relationships derived during the proof of Lemma 2 are useful here. Since , the right-hand side of (21b) is exactly . Combining this fact with (21a) yields
| (32) |
Recall that in (20), we minimize the function
with respect to . From the first order optimality condition, there exists a subgradient of at , denoted as , such that
| (33) |
Applying the definition of subgradient of at points and gives
| (34) | ||||
| (35) |
where is defined in Lemma 3. Summing up (34) and (35), we have
where the last equality comes from (32) and (33). Rearranging the terms gives (30).
Appendix C Proof of Theorem 1
Restatement of Theorem 1. Suppose Assumptions 1, 2, and 3 hold. let and the stepsizes be
for some positive constants , , and . Define constants
Also denote . Then we have
| (36) |
where . Consequently, it holds
| (37) |
with
Proof.
Recall that the updates satisfy
| (38) | ||||
| (39) | ||||
| (40) |
Step 1. At the master side, we have
| (41) |
For the second term in (41), the inequality gives
| (42) |
Applying the inequality to the third term in (41) with yields
| (43) |
Substituting (42) and (43) into (41) gives
| (44) |
where the last inequality comes from that .
Step 2. Accordingly, at the regular worker side, we have for any that
| (45) | ||||
For the second term in (45), the inequality gives that
| (46) |
where the last inequality comes from (17) and (40). Then the third term in (45) can be upper-bounded as
| (47) |
where the first equality comes from taking expectation of the conditional expectation; that is, with denoting the sigma-field generated by .
Step 3. Now combine (44) with (48). Using the notation , we have
| (49) | ||||
For the last term in (49), notice that
| (50) |
where the first equality comes from Corollary 1 that . For the first term in (50), Lemma 5 suggests that
| (51) |
For the second therm in (50), the projection operator in the -update gives that
| (52) |
provided . For the third term in (50), we apply the equality with to obtain
| (53) |
Appendix D -ergodic convergence
Theorem 2.
Proof.
Step 1. At the master side, we still have (41), in the form of
| (57) |
For the second term in (57), we also have (42), which can be further bounded by
| (58) |
Here we use the fact that has Lipschitz continuous gradients in Assumption 2. In addition, using the fact that is strongly convex in Assumption 1 leads to
| (59) |
Applying the inequality to the third term in (57) with yields
| (60) |
Substituting (58) and (60) into (57) gives
| (61) | ||||
where the last inequality comes from that .
Step 2. Accordingly, at the worker side, we have for any that (45) holds, as
| (62) |
For the second term, we still have (46), which can be further bounded by
| (63) |
Here we use the fact that has Lipschitz continuous gradients in Assumption 2. Then, using as is strongly convex in Assumption 1, we bound the third term in (62) as
| (64) |
Substituting (63) and (64) into (62) gives
| (65) | ||||
where the last inequality holds from the bound of , such that
Step 3. Denote
and define a Lyapunov function . From (31), we have
| (66) |
Consequently, combining (61), (D), and (66) together gives
| (67) |
where and Summing up (67) from to , we obtain
| (68) |
Dividing both sides by gives
| (69) |
The convexity of and leads to . Combining this inequality and (69), we complete the proof.