StillFast: An End-to-End Approach for
Short-Term Object Interaction Anticipation
Abstract
Anticipation problem has been studied considering different aspects such as predicting humans’ locations, predicting hands and objects trajectories, and forecasting actions and human-object interactions. In this paper, we studied the short-term object interaction anticipation problem from the egocentric point of view, proposing a new end-to-end architecture named StillFast. Our approach simultaneously processes a still image and a video detecting and localizing next-active objects, predicting the verb which describes the future interaction and determining when the interaction will start. Experiments on the large-scale egocentric dataset EGO4D [19] show that our method outperformed state-of-the-art approaches on the considered task. Our method is ranked first in the public leaderboard of the EGO4D short term object interaction anticipation challenge 2022. Please see the project web page for code and additional details: https://iplab.dmi.unict.it/stillfast/.
1 Introduction
Anticipating human behavior in the near future from the first person (egocentric) point of view allows to build intelligent systems able to support users in different domains. Anticipation is crucial in scenarios where one needs to react before actions are executed, such as in autonomous driving, where a vehicle has to anticipate pedestrians’ trajectories before they even begin crossing the street [23, 27], in kitchens where smartglasses could alert the users when they are about to touch the hot stove [3, 4] or in the industrial domain, where an intelligent helmet can improve the worker’s safety alerting them in case of a dangerous interaction [32, 33].
Previous works have investigated different forms of anticipation tasks, including next-active object predictions [11, 21, 32, 5, 19], predicting future actions [12, 13, 14, 30, 37, 10, 35], forecasting human-object interactions [26], predicting future hands [6, 20] or user trajectory prediction [31].
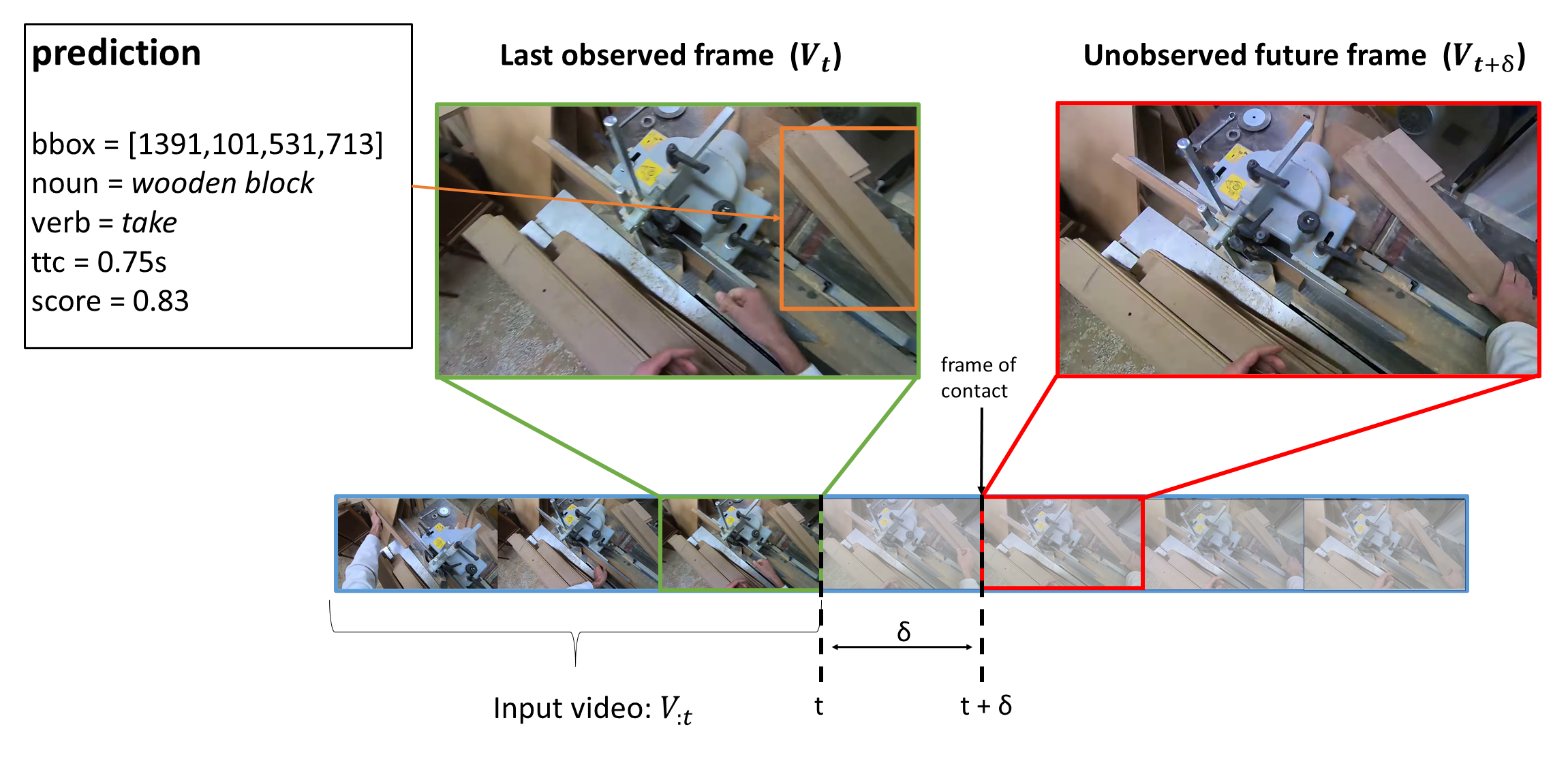
In this paper we address the problem of short-term object interaction anticipation [19] which consists in detecting and localizing the next-active objects in the scene, predicting the verb which describes the interaction and determining when the interaction will start. This task has been studied considering multiple domains [19] as well as focusing specifically on the industrial scenario [32]. We define the task as proposed in [19]. Given a video and a timestamp , models can process the video up to time (denoted as ) and are required to output a set of future object interaction predictions which will happen after a time interval . Each prediction consists in:
-
•
A bounding box localizing the future interacted object (also referred to as next-active object);
-
•
A noun label describing the class of the detected object (e.g., “wooden block”);
-
•
A verb label describing the interaction which will take place in the future (e.g., “take”);
-
•
A real number indicating the “time to contact”, i.e., the time in seconds between the current timestamp and the beginning of the interaction (e.g., );
-
•
A confidence score used to rank future predictions for evaluation.
Figure 1 illustrates the considered task.
Current state-of-the-art works [19, 32] have addressed this task in two steps: 1) an object detector detects and recognizes next-active objects in still frames, 2) a 3D network predicts the verb and the time to contact analyzing a video segment. Also in [8], the authors figured out the action detection task on AVA dataset considering a two steps approach. Since past works showed that composite methods have been outperformed by end-to-end methods [17, 16, 34], we believe that a similar behavior could be obtained even in the considered task. Therefore, we propose StillFast network. Similarly to SlowFast networks [8], StillFast has two branches which simultaneously process two versions of the input video. The “still” branch processes a high resolution still image, i.e., a video with a high spatial resolution, but low temporal resolution (a single frame), whereas the “fast” branch processes a video with a low spatial resolution, but a high temporal resolution (different frames). Our method can be trained end-to-end in a single stage increasing the training speed over traditional two-branches approaches [19].
Experiments on the large-scale dataset of egocentric videos EGO4D [19] show that the proposed method outperforms state-of-the-art approaches highlight that the proposed architecture benefits from the unified branches trained simultaneously. Additionally, we performed an ablation study to assess the impact of each component of the proposed method on the overall performance. To encourage future research in the field, we release the code implementing the proposed approach at: https://iplab.dmi.unict.it/stillfast/.
The contributions of this work are as follows: 1) we proposed a new approach which is able to simultaneously processes a still image and a fast video, 2) by performing experiments with state-of-the art approaches and several ablation, we show the effectiveness of the proposed design, 3) we release the source code of the proposed approach as an extensible framework to encourage future research.
2 Related Work
Our work is related to past research on anticipation considering both third and first-person point of view.

2.1 Anticipation in Third Person Vision
Different works aimed to predict future actions before they happen from a third person point of view[22, 37, 10, 14]. The authors of [22] proposed a new hierarchical representation called hierarchical movemes which describes human movements considering multiple levels of granularity to infer future actions from still images or short video clips. The authors of [37] explored the task of anticipating future actions and objects learning to predict future visual representations from unlabeled videos. The authors of [14] proposed a reinforced encoder-decoder architecture (RED) for action anticipation which contains a reinforcement module to encourage the system to predict the correct action as early as possible. Also long-term action anticipation task has been explored in previous works [18] with the aim to predict minutes-long sequences of future actions. Even in the sport domain the problem of forecasting human moves has been explored [10]. Indeed, the authors of [10] proposed a generic framework to anticipate future events in team sports videos directly from visual inputs. The anticipation problem has been explored even predicting the future location of users which allows to build an advanced surveillance systems able to predict people’s activities[29, 23] or for autonomous vehicles to understand pedestrian intents to avoid accidents[27, 28]. In particular, the authors of [27] tackled the problem to jointly predicting the future spatial position and the body keypoints of pedestrians to have a deeper understanding of pedestrians behavior. The authors of [28] proposed a factorized multimodal approach to predict long-term trajectories of the user focusing on RGB observations and past motion history. Recently, the authors of [29] studied the problem of using few input observations to predict accurate pedestrians position proposing a new teacher-student technique.
While prediction’s tasks addressed from the third person point of view are useful in different scenarios, we focused on user-object interactions anticipation for which the egocentric point of view offers several advantages, therefore, we considered this anticipation problem relying on the large-scale egocentric dataset EGO4D[19].
2.2 Anticipation in First Person Vision
Different past works have explored problems related to anticipation from the first person point of view. Furnari et al. [12, 13] proposed a model based on LSTM networks to encode past features and predict future actions from egocentric videos. The authors of [30] extended RULSTM [13] with a novel attention-based technique to consider simultaneously “slow” and “fast” features. The authors of [40] proposed a novel transform-based fusion approach which combines multi-modal features (i.e., audio and visual) to predict future actions. To better understand future human’s behavior, past works also focused on predicting future hands and objects locations. The authors of [26] presented a two-stream fully convolutional network to forecast the presence and location of hands and objects in egocentric videos. Liu et al. [26] focused on hands movements as visual representations to predict future interaction hotspots and future actions.
While different tasks related to the anticipation problem have been deeply studied, the considered task have not been addressed systematically.
2.3 Short-Term Object Interaction Anticipation
The problem of Short-Term Object Interaction Anticipation has been addressed in different forms. Some works studied the problem of predicting the objects which will be involved in a future human interaction (next-active objects). The authors of [11] have been the first to explore explicitly this task proposing to analyze objects trajectories. The authors of [5] focused on the prediction of hand-objects contact representations to anticipate future actions. The authors of [21] investigated the prediction of a visual attention probability map from images considering hands and objects features. The authors of [32] presented a new egocentric dataset captured in a procedural scenario specifically annotated to address the next-active object detection task, which is tackled using simple object detectors. All these works addressed different versions of the considered task, which made the proposed approaches difficult to compare and extend over. The first attempt to systematically study the problem of Short-Term Object Interaction Anticipation has been done by the authors of [19], provided a formal definition of the task which includes the prediction of next-active objects and associated verbs and time to contact (see Figure 1). Despite this effort, few approaches have been proposed so far to tackle the task in the form defined in [19]. Among them, the baseline proposed in [19] consists of two components trained independently: A Faster R-CNN [34] object detector to detect next-active objects in the last frame of the input video, and a SlowFast [9] action recognition model to attach each bounding box a verb and a time to contact prediction. The model works as a two-branch network. The 2D Faster R-CNN model processes a high resolution image (the most recent frame of the input video) to predict next-active objects and their related classes. The high resolution is needed to have enough detail in order to detect objects at different scales. The 3D SlowFast model processes a low-resolution video clip ending at the current timestamp to predict verb labels and time-to-contact values. The approach is trained in two stages. First, the Faster RCNN model is trained using all training next-active object bounding box and class labels. This object detector is hence run over the training, validation and test data examples to complement them with a set of next-active object bounding box proposals with associated noun labels and detection scores. In a separate stage, a SlowFast model is trained to predict a verb label and a positive time-to-action real number for each bounding box proposal. The authors of [2] extended this approach by employing a DINO[39] object detector to detect and recognize next-active objects in keyframes and a VideoMAE-pretrained transformer network [36] to extract features to predict verbs and time to contact for each detected bounding box.
In this work, we propose an end-to-end approach specifically designed to anticipate the location of next-active objects, the verb which describes the future interaction and how soon the interaction will take place (time to contact). The proposed method can be trained in a single stage, reducing training times nd simplifying the research cycle.
3 Still Fast Network

The proposed approach simultaneously processes a still image, i.e., a video with a high spatial resolution, but a low temporal resolution (a single frame) and a video with a low spatial resolution, but a high temporal resolution (different frames). We refer to the first branch as the “still” branch, as it processes a still image, whereas we refer to the second branch as the “fast” branch, as it processes a video with high temporal resolution. We hence term our model “StillFast” network. The model processes the two inputs simultaneously and can be trained end-to-end in a single stage, which increases training speed and allows to better optimize the feature extraction process. The proposed method is comprised of two main components: a backbone with processes 2D (still image) and 3D (video) inputs and outputs a set of spatial features, and a prediction head, which takes as input the spatial features and outputs the detected next active objects together with the associated verbs and time to contact predictions.
The following subsections detail the main components of the proposed method.
3.1 StillFast Backbone
Figure 2 reports a diagram of the StillFast backbone. Given an input video and a timestamp , the proposed model takes as input a high resolution frame sampled from video at time and a low resolution video which is obtained by spatially subsampling with function the video of length (observation time) starting at time and ending at time .
To process the input image and video simultaneously, the proposed model comprises a two-branch backbone.
A 2D CNN (the “still” branch) processes the high resolution frame and produces a stack of 2D features at different spatial resolutions . The stack of features is obtained by collecting activations at the inner layers of the 2D network. As detailed later, we follow [24] to obtain the stack of features to produce a feature pyramid in order to enable multi-scale object detection as done in the standard [34] architecture.
A 3D CNN (the “fast” branch) processes the video and outputs a stack of 3D features . We perform mid-level feature fusion by combining the 2D and the 3D feature stacks with a Combined Feature Pyramid Layer illustrated in the center part of Figure 2. This layer first up-samples the 3D feature map with nearest neighbor interpolation to match the spatial resolution of the 2D features and averages over the temporal dimension to obtain the features, which now have the same shape as the 2D features . These features are hence passed through a 3x3 convolutional layer, summed to the 2D features and then passed through another 3x3 convolutional layer. The rationale behind these 2D convolutional layers is to cope with artifacts introduced with the up-sampling and sum operations. The resulting feature map is fed to a standard Feature Pyramid Layer [24] to obtain the final feature pyramid .
In our experiment we use a ResNet-50 as 2D CNN and an X3D-M as 3D CNN. See the supplementary material for more details.
3.2 Prediction Head
Figure 3 shows a diagram of the proposed prediction head, which is based on the Faster R-CNN prediction head [34] as implemented in Detectron2 [38]. A Region Proposal Network (RPN) predicts region proposals from the feature pyramid . A RoiAlign layer is used to extract local features from the region proposals. We found it useful to enrich these local features with global representations of the scene. To do so, we apply global average pooling to the upper layer of the combined feature pyramid and obtain a global image representation, which we concatenate to each local feature extracted from the region proposals. The concatenated features are passed through a fusion network comprising two fully connected layers. The resulting representations are summed to the original local features through a residual connection. This allows to use global features to modulate the content of local features rather than to replace them. These fused local-global representations are used to predict object (noun) probability distributions and class-specific bounding box regression offsets using linear layers as in [34]. The predicted noun probability distributions include a background class to reduce the magnitude of positive prediction probabilities in the case of uncertain predictions or proposals falling in background areas. The same features are used to predict a verb probability distribution and time-to-contact TTC using linear layers. We include a background class in the verb prediction layer as well to further discard false positives when the verb cannot be reliably predicted. A softplus activation is used to predict positive TTC values. For each object proposal, we multiply the noun probability by the predicted probability of the Top-1 verb, excluding the background class. This is done to make sure that the uncertainty in verb prediction influences the final prediction score . The final predictions are obtained by considering objects with a prediction score larger than or equal to . The model is trained end-to-end adding a cross entropy verb loss and a smooth L1 [34] time-to-contact loss to the standard Faster R-CNN losses. We weigh the with and the with in our experiments. See the supplementary material for more details.
4 Experimental Settings
In this section, we report details on the considered dataset and evaluation measures (Section 4.1) and the compared methods (Section 4.2). Please see the supplementary material for the implementation details.
4.1 Dataset and Evaluation Measures
We performed experiments on the large-scale egocentric dataset EGO4D[19]. We consider both the initial version of the dataset described in [19] (denoted as “v1” in this paper), and the recently released update of the dataset (denoted as “v2”), described at this page: https://ego4d-data.org/docs/updates/#v20-update, following the official training/evaliuation/testing splits. We focus on the subset of the EGO4D dataset which has been explicitly labeled for the Short-Term Object Interaction Anticipation task. Version v1 of this dataset consists in hours of annotated clips, including training, validation, and test examples, annotated with a taxonomy of noun and verb classes. Version v2 consists in hours of annotated clips, including training, validation, and test examples, annotated with a taxonomy of noun and verb classes. It should be noted that v1 and v2 have different training and validation sets, but they share the same test set, which makes test results obtained on the two dataset comparable. Annotations for this shared test set are not publicly available and results can be obtained by sending predictions to an evaluation server111https://eval.ai/web/challenges/challenge-page/1623/.
The evaluation has been performed using Top-K mean Average Precision, which does not penalize methods predicting up to K - 1 next-active objects which are not annotated as defined in [19]. In particular, we evaluated methods with different Top-5 mAP measures, i.e., Top-5 mAP Noun, Top-5 mAP Noun+Verb, Top-5 mAP Noun+TTC and Top-5 mAP Noun+Verb+TTC which we named Top-5 mAP Overall, to assess the ability of the model to anticipate next-active object interactions considering different levels of granularity (i.e., nouns, verbs, time-to-contact). We used as defined in [19].
4.2 Compared Methods
We compare our method with respect to different approaches which addressed the considered Short-Term Object Interaction Anticipation problem.
-
•
Faster R-CNN + Random[19]: uses Faster R-CNN to detect and recognize next active objects, then predicts verbs and time to contact randomly following the distributions of training labels;
- •
- •
-
•
Faster R-CNN + Features: a Faster R-CNN object detector is used to detect and recognize next active objects, then pre-extracted Ominvore features [15] are used to predict the associated verb and time to contact. This baseline has been proposed as a quickstart approach with the EGO4D dataset. In our experiments, we consider the results reported in this document: https://colab.research.google.com/drive/1Ok_6F1O6K8kX1S4sEnU62HoOBw_CPngR.
5 Results
This section compares the proposed StillFast method to competitors (Section 5.1) and analyses the contribution of the different components of the approach to performance (Section 5.2).
| Set | Method | Ver | Noun | N+V | N+TTC | Overall |
|---|---|---|---|---|---|---|
| Val | FRCNN+Rnd. [19] | v1 | 17.55 | 1.56 | 3.21 | 0.34 |
| Val | FRCNN+SF [19] | v1 | 17.55 | 5.19 | 5.37 | 2.07 |
| Val | StillFast (ours) | v1 | 16.20 | 7.47 | 4.94 | 2.48 |
| Val | FRCNN+SF [19] | v2 | 21.00 | 7.45 | 7.04 | 2.98 |
| Val | StillFast (ours) | v2 | 20.26 | 10.37 | 7.16 | 3.96 |
| Test | FRCNN+Rnd. [19] | v1 | 20.45 | 2.22 | 3.86 | 0.44 |
| Test | FRCNN+SF [19] | v1 | 20.45 | 6.78 | 6.17 | 2.45 |
| Test | FRCNN+Feat. | v1 | 20.45 | 4.81 | 4.40 | 1.31 |
| Test | InternVideo [2] | v1 | 24.60 | 9.18 | 7.64 | 3.40 |
| Test | StillFast (ours) | v1 | 19.51 | 9.95 | 6.45 | 3.49 |
| Test | FRCNN+SF [19] | v2 | 26.15 | 9.45 | 8.69 | 3.61 |
| Test | StillFast (ours) | v2 | 25.06 | 13.29 | 9.14 | 5.12 |
5.1 Comparison with the State of the Art
Table 1 reports the results of the compared methods the validation and test sets of both v1 and v2 of the EGO4D dataset [19] using the aforementioned Top-5 mAP evaluation measure. As can be noted from Table 1, the proposed method improves over the FRCNN+Rnd. and FRCNN+SF baselines by significant margins in the v1 validation set on verb-related metrics: vs Noun+Verb Top-5 mAP (), and vs Overall Top-5 mAP (). These results suggest that the ability of the proposed approach to process images and video with a unified backbone and accounting for the uncertainty in verb prediction as described in Section 3.2 is beneficial to performance. Indeed, it should be noted that both are based on components with similar performance: a ResNet-50 2D backbone in both cases, a SlowFast 3D backbone for FRCNN+SF and an X3D-M backbone for StillFast. On the downside, the proposed StillFast approach achieves worse performance on Noun Top-5 mAP ( vs , hence ) and on Noun + TTC Top-5 mAP ( vs , hence ). We speculate that this is due to training instabilities due to the multi-task nature of our training procedure, as compared with FRCNN+SF, which is trained in two separate stages (Section 5.2 further analyses performance when multi-tasking is reduced within our architecture). This seems to be mitigated when more training data is available. Indeed, when training on v2 (fourth and fifth row of Table 1), StillFast consistently outperforms FRCNN+SF on Noun + Verb, Noun + TTC and Overall Top-5 mAP, while the loss of performance on Noun Top-5 mAP is much smaller ( vs , hence only ).
The advantages of StillFast are more evident in the test set, which suggests better generalization of the proposed approach. In v1, the proposed method outperforms FRCNN+SF by ( vs ) according to Noun+Verb Top-5 mAP, ( vs ) according to Noun+TTC Top-5 mAP, and ( vs ) according to Overall Top-5 mAP. Noun Top-5 mAP results are still lower, but closer to the ones of FRCNN+SF ( vs , hence ). Also in the test set, using more training data brings larger performance margins to StillFast. In v2 test set, the proposed approach surpasses FRCNN+SF by ( vs ) according to Noun + Verb Top-5 mAP, ( vs ) according to Noun + TTC Top-5 mAP, and ( vs ) according to Overall Top-5 mAP. If we consider that v1 and v2 share the same test set, StillFast jumps from a of v1 to of v2 Noun + Verb Top-5 mAP and from of v1 to of v2 Overall mAP, by merely adding more training data, which suggests that the proposed approach can scale in the presence of larger datasets.
In the v1 test set, we are able to also compare StillFast with other methods for which results are publicly available, including InternVideo [2] and FRCNN+Feat. StillFast outperforms FRCNN+Feat. on all evaluation measures except Noun Top-5 mAP, where it achieves slightly worse performance ( vs ). Note that FRCNN+Feat. uses the same Faster RCNN object detector component as FRCNN+SF and is trained in two stages, hence similar considerations as the ones made while comparing the proposed approach with FRCNN+SF apply here as well. StillFast still outperforms InternVideo with respect to Noun+Verb Top-5 mAP ( vs ) and Overall Top-5 mAP ( vs ) despite being based on less advanced components (StillFast relies on a Faster R-CNN object detector, while InternVideo relies on DINO [39], StillFast relies on an X3D video backbone, while InternVideo relies on Video-MAE [36] pre-trained transform-based video backbones) and being trained end-to-end (InternVideo is trained in two stages as FRCNN+SF). We leave the integration of higher performing components in StillFast to future works.
Figure 4 reports two success (left) and two failure examples (right). The model struggles with uncertain future actions (“put cement” vs “mold cement”) and unusual actions (“clean book” vs “put book”).




5.2 Ablation study
In this section, we further investigate other aspects of the proposed StillFast architecture including the verb/noun prediction trade-off introduced by the prediction head described in Section 3.2, and the contribution of different architectural choices to the overall performance. The tables in this section report validation results of experiments performed on EGO4D v1 data. All results are in Top-5 mAP%.
| Method | Noun | N+V | N+TTC | Overall |
|---|---|---|---|---|
| FRCNN+SF [19] | 17.55 | 5.19 | 5.37 | 2.07 |
| Nouns Only | 19.69 | - | - | - |
| Standard Head | 18.42 | 6.39 | 5.28 | 2.17 |
| Proposed Head | 16.20 | 7.47 | 4.94 | 2.48 |
| Method | Noun | N+V | N+TTC | Overall |
|---|---|---|---|---|
| Proposed Head | 16.20 | 7.47 | 4.94 | 2.48 |
| -global features | 16.90 | 5.77 | 4.60 | 1.94 |
| -res. connections | 15.44 | 6.40 | 4.80 | 2.25 |
| -verb-noun product | 14.95 | 6.29 | 4.28 | 1.78 |
| Sum Fusion | 15.26 | 6.68 | 4.93 | 2.49 |
Prediction Head Table 2 compares the results obtained by the proposed model when different prediction heads are used. The results of FRCNN+SF are also reported for reference. “Nouns Only” predicts only next-active objects and does not predict any verb or time to contact, “Standard Head” refers to the standard prediction head proposed in [19] which uses a SlowFast model to attach a verb and a time to contact prediction to each detected bounding box. “Proposed Head” refers to the head described in 3.2, including global features and accounting for verb prediction uncertainty. As can be noted, predicting only nouns outperforms the FRCNN+SF baseline by ( vs ) with respect to Noun Top-5 mAP. Adding verb and time to contact prediction with a standard head decreases Noun Top-5 mAP performance to , which still outperforms FRCNN+SF (), while obtaining better or comparable performance on the other metrics. This suggests that the proposed approach is penalized by the training instabilities caused by multi-tasking (i.e., predicting simultaneously nouns, verbs and time to contact). The proposed head achieves the best results in terms of Noun+Verb Top-5 mAP and Overall performance thanks to the use of global features and verb-noun score product, which effectively accounts for the uncertainty in the prediction of verbs. Table 3 assesses the impact of the main components of the proposed head, comparing the performance of the overall module with versions in which we remove global features, residual connections, and the verb-noun score product module. We also compare the head with a version which replaces the proposed global-local fusion mechanism by a simple sum (last row). As can be observed, the proposed architecture obtains overall the best results. Sum fusion achieves slightly better overall Top-5 mAP (), but lower results according to the other metrics, for which we prefer the proposed concatenation + residual connection design.
| Noun | N+V | N+TTC | Overall | |
|---|---|---|---|---|
| Proposed backbone | 16.20 | 7.47 | 4.94 | 2.48 |
| w/o 3D backbone | 14.54 | 6.17 | 4.10 | 1.82 |
| w/o conv. block post sum | 15.13 | 6.79 | 4.80 | 2.25 |
| post-pyramid fusion | 15.01 | 6.74 | 4.69 | 2.34 |
Backbone Table 4 shows the impact of the different components in the backbone when the proposed head is used. We observe that without a 3D branch (second row) the performance of the method drops according to all mAP measures by significant margins (e.g., vs Overall Top-5 mAP). This suggests that the proposed backbone design succesfully combines 3D and 2D features to anticipate future interactions. The third row shows that removing 2D convolutional blocks after the sum operation in the combined feature pyramid layer negatively affect performance (e.g., vs Top-5 Overall mAP). We speculate that the use of these layers allows to deal with artifacts potentially introduced in the upsampling and sum operations. The last row reports the performance of an alternative design of the network which attaches a 2D feature pyramid to the 2D network and a 3D feature pyramid to the 3D network and then fuses the resulting feature pyramids. As can be noted, this design is less effective than the proposed one, with a Top-5 Overall mAP score equal to (vs of the proposed design).
6 Conclusion
In this paper, we have presented StillFast, an end-to-end approach to tackle the Short Term Object Interaction Anticipation task. Differently from previous methods, StillFast is designed to process video and image inputs simultaneously and encourage future research in this field by providing a practical framework designed to be easily extensible. To facilitate future research, we will release the source code which can be used to replicate the experiments reported in this paper. While the proposed method achieves promising performance EGO4D, we are aware of some of the limitations of the approach, which we leave to future works. Specifically, the current implementation of the method is based on convolutional 2D and 3D backbones, while benefits may arise from the use of more recent transformer-based components as done in previous works [2]. Moreover, the current end-to-end training procedure seems to be penalized by the multi-tasking arising from predicting noun, verb and time to contact within a single model. We trust that future works will be able to address such limitations and extend on the proposed work. Future investigations may also explore the potential benefit of the proposed architecture on other tasks requiring the simultaneous analysis of images and videos, such as for instance action detection.
ACKNOWLEDGEMENTS
This research is supported by Next Vision222Next Vision: https://www.nextvisionlab.it/ s.r.l., by the project Future Artificial Intelligence Research (FAIR) – PNRR MUR Cod. PE0000013 - CUP: E63C22001940006 and by the project MISE - PON I&C 2014-2020 - Progetto ENIGMA - Prog n. F/190050/02/X44 – CUP: B61B19000520008.
SUPPLEMENTARY MATERIAL
This document is intended for the convenience of the reader and reports additional information about the
implementation details. This supplementary material is related to the following submission:
F. Ragusa, G. M. Farinella, A. Furnari. StillFast: An End-to-End Approach for Short-Term Object Interaction Anticipation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2023.
7 Implementation Details
We train the model on the training data, whereas we use the validation set to choose the best performing checkpoint according to the overall mAP measure. We then report the results of such model on both the validation and the test set. At training time, we follow the standard Faster R-CNN multi-scale procedure and feed high-resolution images with a short side in the range and a maximum long side of . As a result, we obtain a still image with height . The low resolution video is obtained by re-scaling the input high resolution video with linear interpolation in such a way that the height of re-scaled video is equal to . We set in all our experiments. In this way, a still image of height pixels will correspond to a video of height pixels, which is a standard resolution for video backbones. At test time, we feed to the networks still images of height pixels and videos of height pixels. We sample video clips of frames with a sampling stride of frame. During training, we weigh the loss with and the loss with . The 2D backbone is a ResNet-50 architecture. The weights of this backbone and the ones of the standard feature pyramid layer are initialized from a Faster R-CNN model pre-trained on the COCO dataset [25]. The 3D network is an X3D-M model [7] pre-trained on Kinetics [1]. The global-local fusion network included in the prediction head has two connected layers with a ReLU activation in between. The first layer maps features from features to features, whereas the second layer maps features from to dimensions. The weights of the local-global module are initialized randomly. The model is trained with a base learning rate of and a weight decay of . The learning rate is lowered by a factor of after and epochs. The model is trained in half precision on four NVIDIA V100 GPUs with a batch size of . The convolutional layers included in the Combined Feature Pyramid Layers are randomly initialized and have a kernel with a padding equal to . The first convolutional layer (pre-sum) maps features from the numbers of channels of the 3D network () to numbers of channels of the 2D network (), whereas the second convolutional layer (post-sum) maps features from the number of channels of the 2D network () to the same number of channels. The standard feature pyramid layer maps features to channels. Following the 2D and 3D backbone branch initialization, input still images are normalized with means and standard deviations, whereas the input videos are normalized with means and standard deviations.
References
- [1] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017.
- [2] Guo Chen, Sen Xing, Zhe Chen, Yi Wang, Kunchang Li, Yizhuo Li, Yi Liu, Jiahao Wang, Yin-Dong Zheng, Bingkun Huang, Zhiyu Zhao, Junting Pan, Yifei Huang, Zun Wang, Jiashuo Yu, Yinan He, Hongjie Zhang, Tong Lu, Yali Wang, Liming Wang, and Yu Qiao. Internvideo-ego4d: A pack of champion solutions to ego4d challenges. ArXiv, abs/2211.09529, 2022.
- [3] D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray. Scaling egocentric vision: The epic-kitchens dataset. In ECCV, 2018.
- [4] D. Damen, H. Doughty, G. M. Farinella, A. Furnari, J. Ma, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray. Rescaling egocentric vision. CoRR, abs/2006.13256, 2020.
- [5] E. Dessalene, C. Devaraj, M. Maynord, C. Fermuller, and Y. Aloimonos. Forecasting action through contact representations from first person video. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2021.
- [6] Chenyou Fan, Jangwon Lee, and M. Ryoo. Forecasting hand and object locations in future frames. ArXiv, abs/1705.07328, 2017.
- [7] Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 203–213, 2020.
- [8] C. Feichtenhofer, H. Fan, J. Malik, and K. He. Slowfast networks for video recognition. In ICCV, pages 6202–6211, 2018.
- [9] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019.
- [10] Panna Felsen, Pulkit Agrawal, and Jitendra Malik. What will happen next? forecasting player moves in sports videos. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 3362–3371, 2017.
- [11] Antonino Furnari, Sebastiano Battiato, Kristen Grauman, and Giovanni Maria Farinella. Next-active-object prediction from egocentric videos. J. Vis. Commun. Image Represent., 49:401–411, 2017.
- [12] Antonino Furnari and Giovanni Maria Farinella. What would you expect? anticipating egocentric actions with rolling-unrolling lstms and modality attention. In International Conference on Computer Vision (ICCV), 2019.
- [13] Antonino Furnari and Giovanni Maria Farinella. Rolling-unrolling lstms for action anticipation from first-person video. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2020.
- [14] J. Gao, Zhenheng Yang, and Ramakant Nevatia. Red: Reinforced encoder-decoder networks for action anticipation. ArXiv, abs/1707.04818, 2017.
- [15] Rohit Girdhar, Mannat Singh, Nikhil Ravi, Laurens van der Maaten, Armand Joulin, and Ishan Misra. Omnivore: A single model for many visual modalities. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16081–16091, 2022.
- [16] R. Girshick. Fast R-CNN. In ICCV, 2015.
- [17] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
- [18] Dayoung Gong, Joonseok Lee, Manjin Kim, Seong Jong Ha, and Minsu Cho. Future transformer for long-term action anticipation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3052–3061, June 2022.
- [19] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, Vincent Cartillier, Sean Crane, Tien Do, Morrie Doulaty, Akshay Erapalli, Christoph Feichtenhofer, Adriano Fragomeni, Qichen Fu, Christian Fuegen, Abrham Gebreselasie, Cristina Gonzalez, James Hillis, Xuhua Huang, Yifei Huang, Wenqi Jia, Weslie Khoo, Jachym Kolar, Satwik Kottur, Anurag Kumar, Federico Landini, Chao Li, Yanghao Li, Zhenqiang Li, Karttikeya Mangalam, Raghava Modhugu, Jonathan Munro, Tullie Murrell, Takumi Nishiyasu, Will Price, Paola Ruiz Puentes, Merey Ramazanova, Leda Sari, Kiran Somasundaram, Audrey Southerland, Yusuke Sugano, Ruijie Tao, Minh Vo, Yuchen Wang, Xindi Wu, Takuma Yagi, Yunyi Zhu, Pablo Arbelaez, David Crandall, Dima Damen, Giovanni Maria Farinella, Bernard Ghanem, Vamsi Krishna Ithapu, C. V. Jawahar, Hanbyul Joo, Kris Kitani, Haizhou Li, Richard Newcombe, Aude Oliva, Hyun Soo Park, James M. Rehg, Yoichi Sato, Jianbo Shi, Mike Zheng Shou, Antonio Torralba, Lorenzo Torresani, Mingfei Yan, and Jitendra Malik. Ego4d: Around the World in 3,000 Hours of Egocentric Video. In IEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2022.
- [20] Wenqi Jia, Miao Liu, and James M. Rehg. Generative adversarial network for future hand segmentation from egocentric video. In European Conference on Computer Vision, 2022.
- [21] Jingjing Jiang, Zhixiong Nan, Hui Chen, Shitao Chen, and Nanning Zheng. Predicting short-term next-active-object through visual attention and hand position. Neurocomputing, 433:212–222, 2021.
- [22] Tian Lan, Tsung-Chuan Chen, and Silvio Savarese. A hierarchical representation for future action prediction. volume 8691, pages 689–704, 09 2014.
- [23] Lihuan Li, Maurice Pagnucco, and Yang Song. Graph-based spatial transformer with memory replay for multi-future pedestrian trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2231–2241, June 2022.
- [24] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- [25] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- [26] Miao Liu, Siyu Tang, Yin Li, and James M. Rehg. Forecasting human-object interaction: Joint prediction of motor attention and actions in first person video. In Computer Vision – ECCV 2020, pages 704–721, Cham, 2020. Springer International Publishing.
- [27] Karttikeya Mangalam, Ehsan Adeli, Kuan-Hui Lee, Adrien Gaidon, and Juan Carlos Niebles. Disentangling human dynamics for pedestrian locomotion forecasting with noisy supervision. 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 2773–2782, 2019.
- [28] Karttikeya Mangalam, Yang An, Harshayu Girase, and Jitendra Malik. From goals, waypoints & paths to long term human trajectory forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15233–15242, October 2021.
- [29] Alessio Monti, Angelo Porrello, Simone Calderara, Pasquale Coscia, Lamberto Ballan, and Rita Cucchiara. How many observations are enough? knowledge distillation for trajectory forecasting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6553–6562, June 2022.
- [30] Nada Osman, Guglielmo Camporese, Pasquale Coscia, and Lamberto Ballan. Slowfast rolling-unrolling lstms for action anticipation in egocentric videos. CoRR, abs/2109.00829, 2021.
- [31] Hyun Soo Park, Jyh-Jing Hwang, Yedong Niu, and Jianbo Shi. Egocentric future localization. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4697–4705, 2016.
- [32] Francesco Ragusa, Antonino Furnari, and Giovanni Maria Farinella. Meccano: A multimodal egocentric dataset for humans behavior understanding in the industrial-like domain, 2022.
- [33] Francesco Ragusa, Antonino Furnari, Antonino Lopes, Marco Moltisanti, Emanuele Ragusa, Marina Samarotto, Luciano Santo, Nicola Picone, Leo Scarso, and Giovanni Maria Farinella. Enigma: Egocentric navigator for industrial guidance, monitoring and anticipation. In International Conference on Computer Vision Theory and Applications (VISAPP), 2023.
- [34] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NeurIPS, pages 91–99, 2015.
- [35] Debaditya Roy and Basura Fernando. Action anticipation using latent goal learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2745–2753, January 2022.
- [36] Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In Advances in Neural Information Processing Systems, 2022.
- [37] Carl Vondrick, Hamed Pirsiavash, and Antonio Torralba. Anticipating visual representations from unlabeled video. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 98–106, 2015.
- [38] Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2. https://github.com/facebookresearch/detectron2, 2019.
- [39] Hao Zhang, Feng Li, Siyi Liu, Lei Zhang, Hang Su, Jun-Juan Zhu, Lionel Ming shuan Ni, and Heung yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. ArXiv, abs/2203.03605, 2022.
- [40] Zeyun Zhong, David Schneider, Michael Voit, Rainer Stiefelhagen, and Jürgen Beyerer. Anticipative feature fusion transformer for multi-modal action anticipation, 2022.