Statistical inference for Gumbel Type-II distribution under simple step-stress life test using Type-II censoring*
1,3Department of Mathematics, National Institute of
Technology, Rourkela-769008, India.
2 Department of Mathematics, Indian Institute of Information Technology, Guwahati-781015, India
Abstract
In this paper, we focus on the parametric inference based on the Tampered Random Variable (TRV) model for simple step-stress life testing (SSLT) using Type-II censored data. The baseline lifetime of the experimental units, under normal stress conditions, follows the Gumbel Type-II distribution with and being the shape and scale parameters, respectively. Maximum likelihood estimator (MLE) and Bayes estimator of the model parameters are derived based on Type-II censored samples. We obtain asymptotic intervals of the unknown parameters using the observed Fisher information matrix. Bayes estimators are obtained using Markov Chain Monte Carlo (MCMC) method under squared error loss and LINEX loss functions. We also construct highest posterior density (HPD) intervals of the unknown model parameters. Extensive simulation studies are performed to investigate the finite sample properties of the proposed estimators. Three different optimality criteria have been considered to determine the optimal censoring plans. Finally, the methods are illustrated with the analysis of two real data sets.
Keywords: Step-stress life testing; Tampered random variable model, Bayesian Analysis, MCMC method, Metropolis-Hastings algorithm, Highest posterior density credible interval, Optimality.
1 Introduction
In reliability analysis, there are many problems with life testing experiments which require a long time to acquire the test data such as for highly reliable products at the specified use condition. To get enough information about these products’ lifespan characteristics, the typical life test of these products under normal working settings is too time-consuming and expensive. This is a significant concern for the high-tech industries since it could cause significant delays in the release of newly developed or improved products, resulting in lost commercial opportunities and market share losses. Accelerated life tests (ALT) are used to address this issue since they allow for the collection of more failure data in a shorter amount of time by subjecting test units to higher stress levels (temperature, pressure, voltage, vibration, etc.) than usual. The constant-stress accelerated life test (CSALT) enables the experimenters to divide the items into various groups, with each group being tested at various stress levels. However, in CSALT, the experiment may last excessively long because there is frequently a large scatter in failure times under low stress levels. To overcome such issues a special class of ALTs, known as step-stress life testing (SSLT) is introduced. As a result, the step-stress accelerated life test (SSALT) is suggested. With the SSLT, the stress levels can be altered during the experiment at predetermined time points or after a predetermined number of failures. In such life testing experiment with two stress levels , (say), and identical units are placed on test initially under normal stress level . The stress level is changed from to , at the pre-fixed time , known as the tampering time. There may be more stress levels and corresponding to each stress change there would be more than one tampering time points, we call it multiple step-stress life testing. If there are only two stress levels with one tampering time, then it is known as the simple step-stress life testing, or simple SSLT. The lifetime distribution under the initial normal stress level is termed as the baseline lifetime distribution. Some key references on the ALT model are Nelson [1], Bhattacharyya and Soejoeti [2], Madi [3], Bai and Chung [4].
Modern products and technologies are getting more sophisticated and reliable due to ongoing advancements in engineering technology and production techniques. Industries like electrical gadgets, computer equipment, vehicle parts, and others have quite high mean times to failure. It is generally impractical, expensive, and time-consuming to conduct life tests under typical operating conditions. In order to end the life testing experiment in a controlled manner before all the items fail, censoring is a standard statistical strategy. There are many situations in life testing and reliability experiments in which the experiment stops earlier (before all units fail) and all remaining units at this time point are censored at once. The most commonly used censoring schemes are Type-I and Type-II censoring schemes. In the conventional Type-II censoring scheme the experiment continues until a pre-specified number , (say), of failures () occurs. Therefore, the Type-II censoring always ensures number of failures during the life testing experiment.
For a simple SSLT, the cumulative exposure (CE) model has been widely used in statistical literature. Sedyakin [5] proposed this CE model and then it has been extensively studied by Nelson [1]. Under two different stress conditions, if and represent two different distributions, then the lifetime distribution under CE model can be expressed as
| (1.1) |
where can be determined by solving the equation .
Bhattacharyya and Soejoeti [6] proposed another SSLT model, named as tampered failure rate (TFR) model which has gained a lot of attention in recent years. If denotes the failure time of the overall lifetime distribution under SSLT, then the TFR model can be expressed as
| (1.2) |
where is the initial failure rate in normal stress condition and is an unknown factor (usually greater than ).
Goel [7] first introduced the tampered random variable (TRV) modeling in the context of a simple SSLT (see also DeGroot and Goel [8]), which assumes that the effect of change of the stress level at time is equivalent to changing the remaining life of the experimental unit by an unknown positive factor, say (usually, less than 1). Let be the random variable representing the baseline lifetime under normal stress condition. Then, the overall lifetime, denoted by the random variable , is defined as
where the scale factor , called the tampering coefficient, depends on both the stress levels , and possibly on as well. The time point is called the tampering time. Note that all these three above discussed models are equivalent if the baseline lifetime follows exponential distribution. For more details one can see Sultana and Dewanji [9]. In literature many authors considered TRV model for estimating different lifetime distributions. Abdel-Ghaly et al. [10] considered the estimation problem of the Weibull distribution in ALT. Maximum likelihood estimators (MLEs) are obtained for the distribution parameters and the acceleration factor in both Type-I and Type-II censored samples. The modified quasilinearization method is used to solve the nonlinear maximum likelihood equations. Also, the confidence intervals of the estimators are obtained. Wang et al. [11] studied the estimation of the parameters of the Weibull distribution in step-stress ALT under multiply censored data. The MLEs are used to obtain the parameters of the Weibull distribution and the acceleration factor under multiply censored data. Additionally, the confidence intervals for the estimators are also obtained. Ismail [12] obtained the MLEs of Weibull distribution parameters and the acceleration factor under adaptive Type-II progressively hybrid censored data. The method has been extended for an adaptive Type-I progressive hybrid censored data by Ismail [13]. El-Sagheer et al. [14] discussed point and interval estimates of the parameters for Weibull-exponential distribution using partially accelerated step-stress model under progressive Type-II censoring. Amleh and Raqab [15] obtained statistical inference for Lomax distribution based on simple step-stress under Type-II censoring. Nassar et al. [16] discussed expected Bayes estimation using simple step-stress under Type-II censoring scheme. Ramzan et al. [17] discussed classical and Bayesian estimation using simple SSLT based on TRV model for modified Weibull distribution under Type-I censoring scheme.
Let us consider the baseline lifetime follows the Gumbel Type-II distribution and the corresponding probability density function (PDF) and cumulative distribution function (CDF) are, respectively,
| (1.4) |
and
| (1.5) |
where , are the shape and scale parameters, respectively. The hazard rate function of the Gumbel Type-II distribution is decreasing or upside-down bathtub (UTB) shape depends on the parameters values. Due to these shapes of the hazard rate function, the Gumbel Type-II distribution is very flexible to model meteorological phenomena such as floods, earthquakes, and natural disasters, also in medical and epidemiological applications. In recent years many authors have studied statistical properties of the estimators of the model parameters of the Gumbel Type-II distribution. Abbas et al. [18] discussed the Bayesian estimation of the model parameters of the Gumbel Type-II distribution. Then E-Bayesian estimation of the unknown model shape parameter has been studied by Reyad and Ahmed [19]. Sindhu et al. [20] obtained the Bayes estimates and corresponding risk of the model parameters based on left censored data.
When failure data are acquired through a life test, statistical inference of the product based failure data is a crucial issue. In view of the above discussed concerns, statistical techniques, and time restrictions in many tests, we consider the statistical inference of the Gumbel Type-II distribution under simple SSLT based on Type-II censoring. To the best of our knowledge, this problem has not been studied yet. The maximum likelihood and Bayesian estimation techniques are considered in the inferential aspects. Additionally, we present a set of recommendations for selecting the most effective estimating technique to estimate the unknown model parameters under the SSLT model, which we believe would be of great interest to applied statisticians and reliability engineers. The objective of the optimization of this model is to identify the censoring plan which leads to the most precise estimation of criteria. Under this consideration, three different optimality criteria have been considered based on the observed Fisher information matrix. The rest of the article is organized as follows. In Section 2, we introduce the TRV modelling under simple SSLT and derive the corresponding CDF and PDF for Gumbel Type-II baseline lifetimes. Also, the MLEs of the unknown parameters, , , and are derived using Type-II censored samples. We also construct asymptotic confidence intervals based on the observed Fisher information matrix and bootstrap confidence intervals of unknown parameters. Further, Bayes estimates are obtained under the squared error loss as well as LINEX loss functions in Section 3. We compute these estimates using the MH-algorithm of MCMC method. The HPD credible intervals of unknown parameters are discussed as well. Section 4 presents some simulation studies to investigate the finite sample properties of the MLEs. In Section 5, optimal censoring schemes based on different optimality criteria have been investigated. We illustrate the proposed methods through the analysis of two real life data sets in Section 6 while Section 7 ends with some concluding remarks.
2 Model Description and MLEs
In a simple SSLT model, let us consider that number of experimental units are placed with initial stress . After a prefixed time , the initial stress level is changed from to . The experiment will be terminated when failure occurs, where is a pre-fixed integer. Therefore, the time of failures , are denoted as the observed data. The following are all possible types of data we can get from the Type-II censoring under simple SSLT:
Case-I : ,
Case-II : ,
Case-III : ,
where N is the number of failures at normal stress level . In particular, for Case-I, and for Case-III, . Basically Case-I and Case-III are the special cases of Case-II, thereafter we will only focus on Case-II in the remaining part of this paper.
Let us assume that the baseline lifetime follows the Gumbel Type-II distribution with , are shape and scale parameters, respectively. Also, assume that the experimental units are independent and identically distributed (i.i.d.) in the life testing experiment. Now, under the assumption of TRV model, the CDF , of is given by
| (2.1) |
The corresponding PDF is given by
| (2.2) |
Next we will discuss about the MLEs of the unknown model parameters.
2.1 Maximum Likelihood Estimation
In this section, we will determine MLEs for the unknown model parameters under Type-II censored sample using TRV modeling based on simple SSLT. Let be the random sample of size from the Gumbel Type-II distribution described in (2.1) with the unknown model parameters , , and . Therefore, the likelihood function for TRV modeling under Type-II censoring can be written as
Thus, the likelihood function for the Gumbel Type-II distribution can be written as
| (2.3) |
Therefore, the log-likelihood function can be written as
| (2.4) |
where, and . Note that, for notational simplicity, in the rest of the paper we write and as and respectively.
Now, taking partial derivatives of with respect to unknown parameters we get likelihood equations as given below
| (2.5) | ||||
| (2.6) | ||||
| and | ||||
| (2.7) |
where and .
As the likelihood equations are in implicit form of the unknown parameters, thus we cannot solve it explicitly to determine the MLEs of , , and as , , and . Therefore we solve (2.5), (2.6), and (2.7) numerically by using some numerical method, such as Newton-Raphson.
2.2 Approximate Confidence Intervals
In this section we want to construct the asymptotic confidence intervals for the unknown model parameters. To obtain confidence intervals with significance level of the unknown parameters of the Gumbel Type-II distribution under simple SSLT, we have to calculate the asymptotic variance-covariance matrix. Using asymptotic normality properties of MLEs of the parameters, an asymptotic variance-covariance matrix can be obtained. In doing so, the variance of , , and are required. These can be obtained from the diagonal elements of the inverse of the observed Fisher information matrix, , where
| (2.8) |
and for where . So here,
and
Then the approximate confidence intervals for , , and are given by
where is the upper -th percentile of a standard normal distribution.
2.3 Bootstrap Confidence Intervals
To obtain confidence intervals, normal approximation works well when the sample size is large enough. In case of small sample size, bootstrap re-sampling technique provides more accurate result to obtain the confidence intervals. In this section, two commonly used parametric bootstrap such as bootstrap- (Boot-) and bootstrap- (Boot-) confidence intervals are derived for , and . We recall that Efron [21] introduced Boot- interval as an alternative to approximate confidence interval and Hall [22] introduced another bootstrap method, called Boot- method. These two methods are non-parametric bootstrap methods. Later, Kundu et. al [23] proposed two parametric confidence intervals. To construct these two parametric bootstrap confidence intervals, the following steps can be used.
Boot- confidence intervals
Step 1: Generate a simple step-stress sample from the Gumbel Type-II distribution and compute the MLEs , , and under Type-II censoring scheme using TRV modeling.
Step 2: Generate a bootstrap sample using the MLEs , , and and calculate the bootstrap MLEs, denoted by , , and .
Step 3: Repeat Step 2 up to times and obtain , , and .
Step 4: Rearrange all these , and in an ascending order, and we then obtain
, , and .
Now, the Boot- confidence intervals for , and are respectively given by
Boot- confidence intervals
Step 1: Generate a simple step-stress sample from the Gumbel Type-II distribution and compute the MLEs , , and under Type-II censoring scheme using TRV modeling.
Step 2: Generate a bootstrap sample using the MLEs , , and based on simple step-stress sample under Type-II censoring scheme and calculate the bootstrap MLEs , , and .
Step 3: Compute -statistics for , , and as , and , respectively.
Step 4: Repeat Steps and up to number of times and we obtain , , and .
Step 5: Rearrange these , , and in an ascending order and obtain , , and .
Then, the two-sided Boot- confidence intervals for , and are respectively given by
3 Bayesian Estimation
In this section, we will determine the Bayes estimates of the unknown parameters , , and based on different loss functions using Type-II censored data from the Gumble Type-II distribution. The most commonly used symmetric loss function is squared error loss (SEL) function and an asymmetric loss function is LINEX loss (LL) function. These loss functions are, respectively, defined as
| and | |||
where is an estimate of a parametric function and is a real number. All the parameters , , and are unknown. In this case, there doesn’t exist any natural joint conjugate prior distribution. Thus, according to Kundu and Pradhan [24] we assume independent priors for , , and as Gamma(a,b), Gamma(c,d), and Beta(p,q) distributions, respectively. We recall that , if its PDF is given by
| (3.1) |
Further, if , then its PDF is
| (3.2) |
Now, the joint prior distribution of the unknown parameters is obtained as
| (3.3) |
where, and are the hyper parameters. Note that the hyper parameters reflect the prior knowledge about the unknown parameters, and can take the value from any positive real numbers. After some calculations, the joint posterior PDF of the unknown parameters , , and can be obtained as
| (3.4) |
where
Under the loss functions SEL and LL, the Bayes estimates of can be written, respectively, as and where
| (3.5) | ||||
| and | ||||
| (3.6) |
Since and can not be solved explicitly, hence we use a numerical method to solve these equations.
3.1 MCMC Method
In this subsection, Markov Chain Monte Carlo (MCMC) method is adopted to enumerate the Bayes estimates of unknown parameters , , and under both the loss functions SEL and LL. In addition, HPD intervals are also composed by using the generated MCMC samples. From the posterior density function given by , the conditional posterior densities can be written as
| (3.7) | ||||
| (3.8) | ||||
| and | ||||
| (3.9) |
The above density functions , , and can not be written in the form of any well known distributions. Therefore, the MCMC samples can not be generated from these densities given in , , and directly. So, the Metropolis-Hastings algorithm is used to generate MCMC samples from the conditional densities. Then the Bayes estimates can be obtained by using the following steps:
Step 1: Choose initial values as , , , and set .
Step 2: Generate , , and with normal distribution as , , and .
Step 3: Compute , , and .
Step 4: Generate samples for , , and , where , , and .
Step 5: Set
Step 6: Set .
Step 7: Repeat steps to , M times to get ; , and .
Then, the Bayes estimates of , , and under SEL function are given as
Further, the Bayes estimates of , , and under LL function are given as
Furthermore, to construct HPD credible intervals for , , and , we use the method given by Chen and Shao [25]. According to the method, the samples are re-arranged in increasing order and these are obtained as , , and . Then, the HPD credible intervals are obtained as
where is the nominal significance level.
4 Simulation Study
In this section, a simulation study is carried out to compare the performance of different estimates of parameters for the Gumbel Type-II distribution under simple SSLT based on Type-II censoring. The performance of estimates are compared on the basis of the average estimate (AE) values and mean squared error (MSE). To observe the changes in the values of the parameters, the simulation study is constructed based on Type-II censored samples under simple SSLT. Three different choices of the sample size n= 50, 150, and 250 are taken to study the behavior of the estimates with change in the sample size. Also, corresponding to each sample size we choose some moderate values for . We have also considered the Gumbel Type-II baseline lifetime distribution with two choices of the shape parameter and the common scale parameter . In the case of LL function, we consider the values of as and . Average bias (AB) and mean squared error (MSE) of the estimates are displayed in Tables 1 and 3. It is considered that, when the values of AB and MSE of an estimate become smaller then it performs better. Average width (AW) and coverage probabilities (CP) of asymptotic confidence interval (ACI), bootstrap confidence interval (BCI) and HPD credible intervals the corresponding parameters are tabulated in Tables 2 and 4. It is considered that, when AW of an interval becomes small then it performs better. In terms of CP, when CP becomes larger then this intervals performs better than other. To obtain Bayes estimates, different sets of hyperparameters have been chosen for as and , for as , and for as and . From Table 1 and Table 3, the following conclusions have been made:
-
•
In most of the cases the values of ABs and MSEs decrease when values of increase.
-
•
For fixed value of , ABs and MSEs of the estimators decrease when increases.
-
•
For fixed and , ABs and MSEs of the different estimates of the parameters decrease when increases.
-
•
For fixed , and , ABs and MSEs of the estimates decrease in most of the cases when increases.
-
•
Bayes estimates perform better than MLEs in terms of AB and MSE. Further, the Bayes estimate based on LL function (when ) performs better than other estimates.
-
•
When the value of tends to zero, Bayes estimate based on LL function performs as similar as SEL function based on AB and MSE.
Now, from Tables 2 and 4, the following conclusions can been made:
-
•
For fixed , the values of AW of the intervals decrease when increases.
-
•
For fixed and , in most of the cases AW of the intervals decrease when increases.
-
•
For fixed and , in most of the cases AW of the intervals decrease when increases.
-
•
In terms of AW, HPD credible interval performs better than another confidence intervals for any fixed , , and .
-
•
In terms of CP, boot-p confidence interval performs better than another intervals for any fixed , , and .
From the above results, it can be summarized that Bayes estimates under LL function performs better than other estimates in terms of AB and MSE, and HPD credible intervals perform better than other confidence intervals in terms of AW.
| MLE | SEL | LL () | LL () | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.6 | 0.35 | 50 | 30 | 0.1503 | -0.0692 | 0.1388 | -0.0787 | -0.0309 | 0.0521 | -0.0784 | -0.0308 | 0.0519 | -0.0804 | -0.0334 | 0.0563 |
| (0.0691) | (0.0307) | (0.0620) | (0.0319) | (0.0187) | (0.0436) | (0.0318) | (0.0187) | (0.0435) | (0.0322) | (0.0192) | (0.0444) | ||||
| 40 | 0.1449 | -0.0676 | 0.1375 | -0.0735 | -0.0262 | 0.0472 | -0.0732 | -0.0261 | 0.0470 | -0.0746 | -0.0276 | 0.0495 | |||
| (0.0665) | (0.0289) | (0.0605) | (0.0302) | (0.0179) | (0.0413) | (0.0301) | (0.0179) | (0.0412) | (0.0308) | (0.0186) | (0.0423) | ||||
| 150 | 60 | 0.0863 | -0.0358 | 0.0617 | -0.0448 | -0.0208 | 0.0283 | -0.0446 | -0.0206 | 0.0284 | -0.0487 | -0.0226 | 0.0296 | ||
| (0.0455) | (0.0251) | (0.0514) | (0.0223) | (0.0159) | (0.0379) | (0.0221) | (0.0159) | (0.0379) | (0.0227) | (0.0169) | (0.0406) | ||||
| 120 | 0.0693 | -0.0321 | 0.0512 | -0.0327 | -0.0174 | 0.0241 | -0.0325 | -0.0173 | 0.0241 | -0.0359 | -0.0182 | 0.0267 | |||
| (0.0339) | (0.0206) | (0.0321) | (0.0153) | (0.0132) | (0.0287) | (0.0151) | (0.0132) | (0.0286) | (0.0158) | (0.0146) | (0.0295) | ||||
| 250 | 100 | 0.0468 | -0.0258 | 0.0436 | -0.0231 | 0.0115 | -0.0179 | -0.0229 | 0.0114 | -0.0178 | -0.0251 | 0.0126 | -0.0193 | ||
| (0.0286) | (0.0166) | (0.0259) | (0.0116) | (0.0107) | (0.0204) | (0.0115) | (0.0107) | (0.0203) | (0.0120) | (0.0114) | (0.0212) | ||||
| 200 | 0.0371 | -0.0194 | 0.0368 | -0.0171 | 0.0106 | -0.0123 | -0.0169 | 0.0106 | -0.0122 | -0.0194 | 0.0109 | -0.0133 | |||
| (0.0235) | (0.0120) | (0.0167) | (0.0109) | (0.0098) | (0.0175) | (0.0109) | (0.0098) | (0.0175) | (0.0118) | (0.0105) | (0.0194) | ||||
| 0.70 | 50 | 30 | 0.1006 | -0.0450 | 0.1335 | -0.0788 | 0.0325 | 0.0534 | -0.0785 | 0.0324 | 0.0532 | -0.0845 | 0.0332 | 0.0564 | |
| (0.0541) | (0.0289) | (0.0568) | (0.0252) | (0.0194) | (0.0304) | (0.0251) | (0.0194) | (0.0303) | (0.0263) | (0.0203) | (0.0309) | ||||
| 40 | 0.0833 | -0.0360 | 0.1259 | -0.0682 | 0.0306 | 0.0508 | -0.0679 | 0.0306 | 0.0507 | -0.0732 | 0.0311 | 0.0511 | |||
| (0.0523) | (0.0265) | (0.0535) | (0.0231) | (0.0171) | (0.0281) | (0.0230) | (0.0170) | (0.0280) | (0.0239) | (0.0189) | (0.0291) | ||||
| 150 | 60 | 0.0654 | -0.0332 | 0.0654 | -0.0384 | 0.0237 | 0.0467 | -0.0382 | 0.0236 | 0.0465 | -0.0390 | 0.0246 | 0.0478 | ||
| (0.0459) | (0.0209) | (0.0487) | (0.0216) | (0.0165) | (0.0233) | (0.0216) | (0.0165) | (0.0231) | (0.0221) | (0.0169) | (0.0247) | ||||
| 120 | 0.0577 | -0.0314 | 0.0530 | -0.0297 | 0.0216 | -0.0517 | -0.0295 | 0.0215 | -0.0516 | -0.0306 | 0.0227 | -0.0551 | |||
| (0.0326) | (0.0198) | (0.0415) | (0.0217) | (0.0136) | (0.0210) | (0.0216) | (0.0136) | (0.0209) | (0.0222) | (0.0139) | (0.0214) | ||||
| 250 | 100 | 0.0452 | -0.0308 | 0.0467 | -0.0214 | 0.0165 | -0.0388 | -0.0213 | 0.0164 | -0.0387 | -0.0226 | 0.0173 | -0.0392 | ||
| (0.0284) | (0.0161) | (0.0283) | (0.0175) | (0.0112) | (0.0149) | (0.0174) | (0.0111) | (0.0148) | (0.0180) | (0.0119) | (0.0168) | ||||
| 200 | 0.0249 | -0.0205 | 0.0389 | -0.0156 | 0.0142 | -0.0317 | -0.0156 | 0.0141 | -0.0316 | -0.0164 | 0.0172 | -0.0325 | |||
| (0.0172) | (0.0123) | (0.0201) | (0.0106) | (0.0094) | (0.0121) | (0.0105) | (0.0094) | (0.0121) | (0.0109) | (0.0098) | (0.0129) | ||||
| 0.75 | 0.35 | 50 | 30 | 0.1123 | -0.0507 | 0.1333 | -0.0594 | 0.0293 | 0.0427 | -0.0591 | 0.0292 | 0.0428 | -0.0603 | 0.0307 | 0.0433 |
| (0.0487) | (0.0243) | (0.0582) | (0.0279) | (0.0177) | (0.0395) | (0.0279) | (0.0177) | (0.0395) | (0.0282) | (0.0181) | (0.0403) | ||||
| 40 | 0.1025 | -0.0572 | 0.1236 | -0.0558 | 0.0255 | 0.0402 | -0.0555 | 0.0254 | 0.0402 | -0.0564 | 0.0262 | 0.0412 | |||
| (0.0426) | (0.0229) | (0.0504) | (0.0248) | (0.0147) | (0.0350) | (0.0247) | (0.0146) | (0.0349) | (0.0152) | (0.0079) | (0.0358) | ||||
| 150 | 60 | 0.0550 | -0.0279 | 0.0555 | -0.0284 | 0.0183 | 0.0261 | -0.0283 | 0.0182 | 0.0261 | -0.0318 | 0.0187 | 0.0267 | ||
| (0.0353) | (0.0195) | (0.0396) | (0.0190) | (0.0135) | (0.0251) | (0.0190) | (0.0135) | (0.0251) | (0.0192) | (0.0139) | (0.0257) | ||||
| 120 | 0.0453 | -0.0243 | 0.0487 | -0.0243 | 0.0149 | 0.0197 | -0.0242 | 0.0148 | 0.0197 | -0.0252 | 0.0157 | 0.0204 | |||
| (0.0324) | (0.0161) | (0.0317) | (0.0149) | (0.0123) | (0.0198) | (0.0149) | (0.0123) | (0.0197) | (0.0152) | (0.0126) | (0.0205) | ||||
| 250 | 100 | 0.0401 | -0.0219 | 0.0403 | -0.0218 | 0.0114 | 0.0176 | -0.0217 | 0.0114 | 0.0176 | -0.0224 | 0.0120 | 0.0184 | ||
| (0.0292) | (0.0143) | (0.0281) | (0.0127) | (0.0107) | (0.0167) | (0.0127) | (0.0107) | (0.0167) | (0.0129) | (0.0111) | (0.0172) | ||||
| 200 | 0.0319 | -0.0192 | 0.0346 | -0.0194 | 0.0084 | 0.0135 | -0.0193 | 0.0084 | 0.0134 | -0.0198 | 0.0088 | 0.0138 | |||
| (0.0247) | (0.0121) | (0.0233) | (0.0107) | (0.0092) | (0.0144) | (0.0107) | (0.0092) | (0.0144) | (0.0110) | (0.0095) | (0.0148) | ||||
| 0.70 | 50 | 30 | 0.0710 | -0.0473 | 0.1160 | -0.0481 | 0.0249 | -0.0388 | -0.0478 | 0.0247 | -0.0387 | -0.0535 | 0.0263 | -0.0393 | |
| (0.0324) | (0.0211) | (0.0553) | (0.0258) | (0.0135) | (0.0217) | (0.0257) | (0.0135) | (0.0217) | (0.0263) | (0.0139) | (0.0228) | ||||
| 40 | 0.0671 | -0.0430 | 0.1051 | -0.0452 | 0.0214 | -0.0350 | -0.0450 | 0.0213 | -0.0348 | -0.0502 | 0.0225 | -0.0358 | |||
| (0.0308) | (0.0204) | (0.0531) | (0.0239) | (0.0119) | (0.0205) | (0.0238) | (0.0119) | (0.0204) | (0.0245) | (0.0124) | (0.0215) | ||||
| 150 | 60 | 0.0523 | -0.0248 | 0.0529 | -0.0268 | 0.0178 | -0.0228 | -0.0267 | 0.0178 | -0.0227 | -0.0282 | 0.0183 | -0.0236 | ||
| (0.0267) | (0.0171) | (0.0341) | (0.0176) | (0.0104) | (0.0182) | (0.0175) | (0.0104) | (0.0181) | (0.0181) | (0.0110) | (0.0189) | ||||
| 120 | 0.0438 | -0.0219 | 0.0462 | -0.0250 | 0.0145 | -0.0189 | -0.0249 | 0.0145 | -0.0188 | -0.0258 | 0.0150 | -0.0193 | |||
| (0.0241) | (0.0147) | (0.0305) | (0.0142) | (0.0098) | (0.0161) | (0.0141) | (0.0098) | (0.0160) | (0.0146) | (0.0102) | (0.0166) | ||||
| 250 | 100 | 0.0343 | -0.0183 | 0.0363 | -0.0195 | 0.0111 | -0.0151 | -0.0194 | 0.0111 | -0.0150 | -0.0217 | 0.0116 | -0.0159 | ||
| (0.0190) | (0.0125) | (0.0263) | (0.0108) | (0.0089) | (0.0154) | (0.0107) | (0.0089) | (0.0154) | (0.0111) | (0.0092) | (0.0157) | ||||
| 200 | 0.0236 | -0.0165 | 0.0335 | -0.0155 | 0.0105 | -0.0127 | -0.0154 | 0.0105 | -0.0126 | -0.0159 | 0.0111 | -0.0131 | |||
| (0.0163) | (0.0101) | (0.0192) | (0.0092) | (0.0084) | (0.0118) | (0.0092) | (0.0084) | (0.0117) | (0.0096) | (0.0088) | (0.0125) | ||||
| ACI | Boot-p | Boot-t | HPD | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.6 | 0.35 | 50 | 30 | 0.8460 | 0.6748 | 0.4534 | 1.5960 | 0.8149 | 0.5938 | 1.7956 | 1.1379 | 0.8718 | 0.3684 | 0.2291 | 0.2227 |
| (0.9571) | (0.9060) | (0.9461) | (0.9799) | (0.9583) | (0.9543) | (0.9395) | (0.9146) | (0.9424) | (0.9627) | (0.9419) | (0.9526) | ||||
| 40 | 0.8169 | 0.6569 | 0.4416 | 1.6294 | 0.7131 | 0.5355 | 1.8001 | 1.1156 | 0.8932 | 0.3647 | 0.2259 | 0.2204 | |||
| (0.9460) | (0.8952) | (0.9389) | (0.9695) | (0.9517) | (0.9529) | (0.9289) | (0.8894) | (0.9385) | (0.9544) | (0.9253) | (0.9478) | ||||
| 150 | 60 | 0.4672 | 0.4145 | 0.4300 | 0.6713 | 0.5652 | 0.3681 | 1.6115 | 1.1636 | 0.7002 | 0.3019 | 0.2075 | 0.1929 | ||
| (0.9583) | (0.9282) | (0.9344) | (0.9867) | (0.9477) | (0.9473) | (0.9656) | (0.9363) | (0.9274) | (0.9635) | (0.9396) | (0.9395) | ||||
| 120 | 0.4364 | 0.3992 | 0.4019 | 0.6977 | 0.4201 | 0.2078 | 1.6198 | 1.1651 | 0.6652 | 0.2759 | 0.2083 | 0.1721 | |||
| (0.9552) | (0.9395) | (0.9472) | (0.9850) | (0.9567) | (0.9793) | (0.9486) | (0.9262) | (0.9360) | (0.9769) | (0.9410) | (0.9580) | ||||
| 250 | 100 | 0.3615 | 0.3231 | 0.3797 | 0.4937 | 0.4394 | 0.2245 | 1.5871 | 1.1496 | 0.6379 | 0.2630 | 0.1929 | 0.1634 | ||
| (0.9595) | (0.9460) | (0.9536) | (0.9772) | (0.9629) | (0.9825) | (0.9083) | (0.9286) | (0.9119) | (0.9629) | (0.9603) | (0.9742) | ||||
| 200 | 0.3347 | 0.3088 | 0.3022 | 0.5287 | 0.3351 | 0.2461 | 1.6058 | 1.1389 | 0.6206 | 0.2371 | 0.1909 | 0.1475 | |||
| (0.9496) | (0.9485) | (0.9588) | (0.9859) | (0.9608) | (0.9899) | (0.9397) | (0.9509) | (0.9427) | (0.9605) | (0.9534) | (0.9793) | ||||
| 0.70 | 50 | 30 | 0.8191 | 0.6825 | 0.4933 | 1.2686 | 0.7207 | 0.7336 | 1.7295 | 1.1337 | 1.2294 | 0.3711 | 0.2427 | 0.2494 | |
| (0.9784) | (0.9324) | (0.9577) | (0.9879) | (0.9685) | (0.9775) | (0.9762) | (0.9174) | (0.9474) | (0.9830) | (0.9551) | (0.9678) | ||||
| 40 | 0.7718 | 0.6773 | 0.4796 | 1.3073 | 0.8221 | 0.6678 | 1.6823 | 1.1829 | 1.2592 | 0.3486 | 0.2375 | 0.2507 | |||
| (0.9487) | (0.9493) | (0.9381) | (0.9796) | (0.9598) | (0.9798) | (0.9484) | (0.9514) | (0.9456) | (0.9563) | (0.9602) | (0.9459) | ||||
| 150 | 60 | 0.4678 | 0.4172 | 0.4558 | 0.6533 | 0.5504 | 0.6218 | 1.6178 | 1.1628 | 1.2682 | 0.2983 | 0.2162 | 0.2800 | ||
| (0.9469) | (0.9485) | (0.9635) | (0.9756) | (0.9645) | (0.9884) | (0.9497) | (0.9483) | (0.9543) | (0.9662) | (0.9526) | (0.9451) | ||||
| 120 | 0.4355 | 0.3983 | 0.3807 | 0.6921 | 0.4174 | 0.3942 | 1.6244 | 1.1579 | 1.2605 | 0.2674 | 0.2082 | 0.2687 | |||
| (0.9586) | (0.9433) | (0.9472) | (0.9923) | (0.9782) | (0.9836) | (0.9498) | (0.9462) | (0.9414) | (0.9658) | (0.9524) | (0.9625) | ||||
| 250 | 100 | 0.3596 | 0.3218 | 0.3234 | 0.4919 | 0.4382 | 0.4270 | 1.5843 | 1.1482 | 1.2203 | 0.2762 | 0.2047 | 0.2993 | ||
| (0.9521) | (0.9508) | (0.9464) | (0.9832) | (0.9625) | (0.9805) | (0.9411) | (0.9427) | (0.9281) | (0.9616) | (0.9545) | (0.9515) | ||||
| 200 | 0.3341 | 0.3099 | 0.3199 | 0.5261 | 0.3345 | 0.3872 | 1.5894 | 1.1598 | 1.2190 | 0.2563 | 0.2073 | 0.2888 | |||
| (0.9467) | (0.9416) | (0.9574) | (0.9796) | (0.9601) | (0.9853) | (0.9498) | (0.9459) | (0.9401) | (0.9517) | (0.9542) | (0.9548) | ||||
| 0.75 | 0.35 | 50 | 30 | 0.7355 | 0.6006 | 0.4793 | 1.3131 | 0.6987 | 0.6078 | 1.7811 | 1.1371 | 0.9333 | 0.3666 | 0.2287 | 0.2176 |
| (0.9527) | (0.9419) | (0.9577) | (0.9815) | (0.9725) | (0.9798) | (0.9443) | (0.9424) | (0.9591) | (0.9665) | (0.9527) | (0.9689) | ||||
| 40 | 0.7097 | 0.5988 | 0.4606 | 1.3036 | 0.6099 | 0.5271 | 1.7371 | 1.1670 | 0.8620 | 0.3608 | 0.2292 | 0.2162 | |||
| (0.9614) | (0.9522) | (0.9572) | (0.9899) | (0.9688) | (0.9799) | (0.9600) | (0.9475) | (0.9667) | (0.9637) | (0.9623) | (0.9697) | ||||
| 150 | 60 | 0.4098 | 0.3616 | 0.4380 | 0.6778 | 0.4669 | 0.4572 | 1.6333 | 1.1461 | 0.7380 | 0.2845 | 0.2026 | 0.2048 | ||
| (0.9425) | (0.9370) | (0.9494) | (0.9789) | (0.9657) | (0.9799) | (0.9594 | (0.9472) | (0.9612) | (0.9717) | (0.9533) | (0.9701) | ||||
| 120 | 0.3959 | 0.3516 | 0.3865 | 0.6377 | 0.3694 | 0.4324 | 1.6370 | 1.1357 | 0.6652 | 0.2641 | 0.2014 | 0.1774 | |||
| (0.9438) | (0.9326) | (0.9466) | (0.9854) | (0.9732) | (0.9785) | (0.9499) | (0.9592) | (0.9426) | (0.9820) | (0.9520) | (0.9615) | ||||
| 250 | 100 | 0.3123 | 0.2825 | 0.3689 | 0.4933 | 0.3423 | 0.4174 | 1.5624 | 1.1594 | 0.5998 | 0.2368 | 0.1825 | 0.1726 | ||
| (0.9364) | (0.9463) | (0.9614) | (0.9698) | (0.9529) | (0.9781) | (0.9499) | (0.9488) | (0.9605) | (0.9585) | (0.9508) | (0.9708) | ||||
| 200 | 0.3017 | 0.2757 | 0.2892 | 0.4907 | 0.2832 | 0.3646 | 1.5871 | 1.1494 | 0.6183 | 0.2289 | 0.1830 | 0.1651 | |||
| (0.9425) | (0.9438) | (0.9552) | (0.9751) | (0.9656) | (0.9785) | (0.9498) | (0.9548) | (0.9602) | (0.9676) | (0.9520) | (0.9752) | ||||
| 0.70 | 50 | 30 | 0.7158 | 0.6178 | 0.4900 | 1.1718 | 0.6416 | 0.7814 | 1.6753 | 1.1838 | 1.2681 | 0.3612 | 0.2384 | 0.2631 | |
| (0.9374) | (0.9452) | (0.9592) | (0.9738) | (0.9678) | (0.9896) | (0.9384) | (0.9481) | (0.9441) | (0.9605) | (0.9507) | (0.9660) | ||||
| 40 | 0.6945 | 0.6072 | 0.4779 | 1.1588 | 0.5806 | 0.6380 | 1.6403 | 1.1697 | 1.3338 | 0.3471 | 0.2378 | 0.2562 | |||
| (0.9457) | (0.9411) | (0.9477) | (0.9875) | (0.9689) | (0.9792) | (0.9486) | (0.9462) | (0.9672) | (0.9597) | (0.9589) | (0.9578) | ||||
| 150 | 60 | 0.4070 | 0.3602 | 0.3968 | 0.6295 | 0.4241 | 0.4396 | 1.6007 | 1.1449 | 1.2600 | 0.2795 | 0.2047 | 0.2322 | ||
| (0.9562) | (0.9610) | (0.9473) | (0.9875) | (0.9764) | (0.9699) | (0.9499) | (0.9569) | (0.9289) | (0.9687) | (0.9648) | (0.9609) | ||||
| 120 | 0.3919 | 0.3540 | 0.3756 | 0.6318 | 0.3545 | 0.4129 | 1.6154 | 1.1536 | 1.2624 | 0.2644 | 0.2054 | 0.2234 | |||
| (0.9462) | (0.9475) | (0.9483) | (0.9755) | (0.9762) | (0.9782) | (0.9492) | (0.9511) | (0.9505) | (0.9676) | (0.9585) | (0.9631) | ||||
| 250 | 100 | 0.3120 | 0.2835 | 0.3871 | 0.4873 | 0.3357 | 0.4212 | 1.5703 | 1.1562 | 1.1857 | 0.2413 | 0.1873 | 0.2832 | ||
| (0.9552) | (0.9420) | (0.9458) | (0.9766) | (0.9639) | (0.9780) | (0.9521) | (0.9494) | (0.9404) | (0.9699) | (0.9549) | (0.9629) | ||||
| 200 | 0.3019 | 0.2777 | 0.3682 | 0.4912 | 0.2819 | 0.3847 | 1.5572 | 1.1503 | 1.1692 | 0.2339 | 0.1841 | 0.2737 | |||
| (0.9560) | (0.9448) | (0.9427) | (0.9847) | (0.9667) | (0.9749) | (0.9523) | (0.9566) | (0.9438) | (0.9684) | (0.9610) | (0.9623) | ||||
| MLE | SEL | LL () | LL () | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.6 | 0.35 | 50 | 30 | 0.3096 | -0.1097 | 0.1424 | -0.1003 | -0.0592 | 0.0478 | -0.0998 | -0.0591 | 0.0476 | -0.1090 | -0.0617 | 0.0485 |
| (0.2944) | ( 0.0606) | (0.0715) | (0.0644) | (0.0387) | (0.0365) | (0.0642) | (0.0386) | (0.0364) | (0.0665) | (0.0389) | (0.0378) | ||||
| 40 | 0.2836 | -0.0962 | 0.1380 | -0.0851 | -0.0542 | 0.0379 | -0.0847 | -0.0540 | 0.0377 | -0.0861 | -0.0551 | 0.0389 | |||
| (0.2631) | (0.0556) | (0.0655) | (0.0558) | (0.0352) | (0.0337) | (0.0557) | (0.0351) | (0.0336) | (0.0575) | (0.0359) | (0.0372) | ||||
| 150 | 60 | 0.0935 | -0.0622 | 0.0736 | -0.0623 | -0.0362 | 0.0339 | -0.0620 | -0.0361 | 0.0337 | -0.0638 | -0.0372 | 0.0351 | ||
| (0.0799) | (0.0478) | (0.0552) | (0.0470) | (0.0326) | (0.0308) | (0.0469) | (0.0325) | (0.0306) | (0.0478) | (0.0335) | (0.0315) | ||||
| 120 | 0.0850 | -0.0572 | 0.0677 | -0.0605 | -0.0295 | 0.0318 | -0.0602 | -0.0294 | 0.0318 | -0.0658 | -0.0304 | 0.0326 | |||
| (0.0677) | (0.0381) | (0.0441) | (0.0417) | (0.0287) | (0.0255) | (0.0416) | (0.0286) | (0.0255) | (0.0425) | (0.0295) | (0.0264) | ||||
| 250 | 100 | 0.0637 | -0.0245 | 0.0364 | -0.0467 | -0.0108 | 0.0255 | -0.0465 | -0.0108 | 0.0255 | -0.0519 | -0.0124 | 0.0269 | ||
| (0.0356) | (0.0116) | (0.0071) | (0.0194) | (0.0046) | (0.0051) | (0.0193) | (0.0046) | (0.0051) | (0.0212) | (0.0048) | (0.0054) | ||||
| 200 | 0.0532 | -0.0203 | 0.0255 | -0.0384 | -0.0091 | 0.0229 | -0.0342 | -0.0090 | 0.0229 | -0.0391 | -0.0107 | 0.0235 | |||
| (0.0269) | (0.0094) | (0.0061) | (0.0172) | (0.0076) | (0.0050) | (0.0171) | (0.0076) | (0.0050) | (0.0199) | (0.0078) | (0.0053) | ||||
| 0.70 | 50 | 30 | 0.2145 | -0.0728 | 0.1475 | -0.0331 | 0.0177 | -0.0225 | -0.0327 | 0.0178 | -0.0225 | -0.0419 | 0.0185 | -0.0231 | |
| (0.1417) | (0.0337) | (0.0588) | (0.0301) | (0.0090) | (0.0169) | (0.0300) | (0.0090) | (0.0168) | (0.0306) | (0.0092) | (0.0177) | ||||
| 40 | 0.1534 | -0.0431 | 0.1215 | -0.0469 | 0.0196 | -0.0190 | -0.0465 | 0.0196 | -0.0190 | -0.0551 | 0.0205 | -0.0198 | |||
| (0.1083) | (0.0346) | (0.0559) | (0.0265) | (0.0086) | (0.0162) | (0.026) | (0.0085) | (0.0161) | (0.0273) | (0.0089) | (0.0168) | ||||
| 150 | 60 | 0.0708 | -0.0225 | 0.0628 | -0.0396 | 0.0168 | -0.0184 | -0.039 | 0.0168 | -0.0184 | -0.0452 | 0.0175 | -0.0191 | ||
| (0.0504) | (0.0160) | (0.0330) | (0.0182) | (0.0071) | (0.0139) | (0.0182) | (0.0071) | (0.0139) | (0.0187) | (0.0077) | (0.0145) | ||||
| 120 | 0.0660 | -0.0207 | 0.0510 | -0.0329 | 0.0135 | -0.0167 | -0.0327 | 0.135 | -0.0166 | -0.0376 | 0.0166 | -0.0188 | |||
| (0.0392) | (0.0138) | (0.0319) | (0.0143) | (0.0058) | (0.0116) | (0.0143) | (0.0058) | (0.0116) | (0.0149) | (0.0061) | (0.0121) | ||||
| 250 | 100 | 0.0486 | -0.0152 | 0.0388 | -0.0220 | 0.0124 | -0.0149 | -0.0218 | 0.0124 | -0.0148 | -0.0268 | 0.0145 | -0.0163 | ||
| (0.0301) | (0.0106) | (0.0233) | (0.0135) | (0.0055) | (0.0122) | (0.0135) | (0.0055) | (0.0122) | (0.0139) | (0.0060) | (0.0127) | ||||
| 200 | 0.0472 | -0.0141 | 0.0301 | -0.0179 | 0.0111 | -0.0125 | -0.0178 | 0.0111 | -0.0125 | -0.0205 | 0.0119 | -0.0143 | |||
| (0.0261) | (0.0101) | (0.0218) | (0.0119) | (0.0053) | (0.0103) | (0.0118) | (0.0053) | (0.0103) | (0.0124) | (0.0055) | (0.0108) | ||||
| 0.75 | 0.35 | 50 | 30 | 0.1812 | -0.0509 | 0.1115 | 0.0133 | -0.0075 | 0.0407 | 0.0138 | -0.0074 | 0.0407 | 0.0147 | -0.0101 | 0.0417 |
| (0.1398) | (0.0311) | (0.0477) | (0.0285) | (0.0081) | (0.0068) | (0.0286) | (0.0081) | (0.0068) | (0.0297) | (0.0082) | (0.0070) | ||||
| 40 | 0.1789 | -0.0455 | 0.1022 | 0.0264 | -0.0096 | 0.0326 | 0.0267 | -0.0096 | 0.0327 | 0.0281 | -0.0121 | 0.0338 | |||
| (0.1303) | (0.0304) | (0.0431) | (0.0234) | (0.0078) | (0.0054) | (0.0234) | (0.0078) | (0.0054) | (0.0241) | (0.0081) | (0.0056) | ||||
| 150 | 60 | 0.0750 | -0.0257 | 0.0410 | 0.0317 | -0.0120 | 0.0283 | 0.0320 | -0.0120 | 0.0282 | 0.0342 | -0.0139 | 0.0295 | ||
| (0.0337) | (0.0110) | (0.0119) | (0.0162) | (0.0057) | (0.0068) | (0.0162) | (0.0057) | (0.0068) | (0.0176) | (0.0058) | (0.0070) | ||||
| 120 | 0.0668 | -0.0208 | 0.0366 | 0.0257 | -0.0073 | 0.0253 | 0.0260 | -0.0073 | 0.0254 | 0.0277 | -0.0091 | 0.0260 | |||
| (0.0319) | (0.0094) | (0.0093) | (0.0149) | (0.0054) | (0.0050) | (0.0150) | (0.0054) | (0.0050) | (0.0155) | (0.0056) | (0.0051) | ||||
| 250 | 100 | 0.0298 | -0.0094 | 0.0384 | 0.0130 | -0.0074 | 0.0340 | 0.0132 | -0.0074 | 0.0341 | 0.0146 | -0.0082 | 0.0360 | ||
| (0.0189) | (0.0061) | (0.0141) | (0.0134) | (0.0048) | (0.0098) | (0.0134) | (0.0048) | (0.0098) | (0.0137) | (0.0049) | (0.0101) | ||||
| 200 | 0.0232 | -0.0082 | 0.0208 | 0.0110 | -0.0059 | 0.0190 | 0.0110 | -0.0059 | 0.0189 | 0.0121 | -0.0074 | 0.0204 | |||
| (0.0173) | (0.0058) | (0.0109) | (0.0122) | (0.0043) | (0.0087) | (0.0122) | (0.0043) | (0.0087) | (0.0130) | (0.0044) | (0.0096) | ||||
| 0.70 | 50 | 30 | 0.1287 | -0.0328 | 0.1001 | -0.0359 | 0.0147 | -0.0341 | -0.0356 | 0.0145 | -0.0335 | -0.0443 | 0.0154 | -0.0362 | |
| (0.0925) | (0.0251) | (0.0518) | (0.0242) | (0.0161) | (0.0191) | (0.0242) | (0.0161) | (0.0190) | (0.0251) | (0.0183) | (0.0200) | ||||
| 40 | 0.1156 | -0.0315 | 0.0946 | -0.0323 | 0.0131 | -0.0286 | -0.0321 | 0.0131 | -0.0285 | -0.0372 | 0.0135 | -0.0301 | |||
| (0.0885) | (0.0237) | (0.0502) | (0.0235) | (0.0101) | (0.0178) | (0.0234) | (0.0101) | (0.0178) | (0.0241) | (0.0108) | (0.0183) | ||||
| 150 | 60 | 0.0686 | -0.0235 | 0.0402 | -0.0305 | 0.0118 | -0.0273 | -0.0302 | 0.0118 | -0.0272 | -0.0329 | 0.0129 | -0.0286 | ||
| (0.0598) | (0.0194) | (0.0284) | (0.0195) | (0.0085) | (0.0166) | (0.0195) | (0.0085) | (0.0165) | (0.0199) | (0.0092) | (0.0173) | ||||
| 120 | 0.0568 | -0.0192 | 0.0360 | -0.0283 | 0.0107 | -0.0235 | -0.0281 | 0.0107 | -0.0234 | -0.0295 | 0.0118 | -0.0268 | |||
| (0.0395) | (0.0176) | (0.0251) | (0.0136) | (0.0067) | (0.0152) | (0.0136) | (0.0067) | (0.0152) | (0.0141) | (0.0071) | (0.0169) | ||||
| 250 | 100 | 0.0395 | -0.0143 | 0.0331 | -0.0124 | 0.0101 | -0.0204 | -0.0122 | 0.0101 | -0.0202 | -0.0138 | 0.0111 | -0.0221 | ||
| (0.0210) | (0.0154) | (0.0231) | (0.0123) | (0.0054) | (0.0139) | (0.0123) | (0.0054) | (0.0139) | (0.0135) | (0.0056) | (0.0153) | ||||
| 200 | 0.0335 | -0.0128 | 0.0279 | -0.0106 | 0.0074 | -0.0158 | -0.0105 | 0.0074 | -0.0156 | -0.0124 | 0.0085 | -0.0187 | |||
| (0.0171) | (0.0127) | (0.0176) | (0.0115) | (0.0050) | (0.0115) | (0.0115) | (0.0050) | (0.0115) | (0.0121) | (0.0051) | (0.0120) | ||||
| ACI | Boot-p | Boot-t | HPD | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.6 | 0.35 | 50 | 30 | 1.6347 | 0.8261 | 0.8242 | 2.3538 | 1.3013 | 0.5756 | 3.6895 | 1.8203 | 1.1368 | 0.4418 | 0.2312 | 0.1366 |
| (0.9435) | (0.9385) | (0.9481) | (0.9616) | (0.9576) | (0.9726) | (0.9408) | (0.9338) | (0.9565) | (0.9581) | (0.9506) | (0.9685) | ||||
| 40 | 1.5664 | 0.8208 | 0.8130 | 2.1842 | 1.1994 | 0.5254 | 3.3956 | 2.9568 | 1.1120 | 0.4356 | 0.2294 | 0.1381 | |||
| (0.9539) | (0.9551) | (0.9566) | (0.9752) | (0.9721) | (0.9673) | (0.9488) | (0.9532) | (0.9483) | (0.9603) | (0.9691) | (0.9625) | ||||
| 150 | 60 | 0.8705 | 0.5159 | 0.4323 | 1.2824 | 0.9260 | 0.4335 | 2.4847 | 1.1545 | 0.6699 | 0.3911 | 0.2064 | 0.1281 | ||
| (0.9516) | (0.9241) | (0.9461) | (0.9732) | (0.9548) | (0.9686) | (0.9474) | (0.9224) | (0.9589) | (0.9684) | (0.9434) | (0.9623) | ||||
| 120 | 0.8078 | 0.4907 | 0.3981 | 1.4582 | 0.7172 | 0.3989 | 2.5399 | 1.1395 | 0.6817 | 0.3526 | 0.2094 | 0.1221 | |||
| (0.9438) | (0.9506) | (0.9463) | (0.9647) | (0.9805) | (0.9679) | (0.9381) | (0.9615) | (0.9568) | (0.9595) | (0.9763) | (0.9632) | ||||
| 250 | 100 | 0.6653 | 0.4017 | 0.3206 | 0.8556 | 0.7086 | 0.2851 | 2.4474 | 1.1547 | 0.6113 | 0.3538 | 0.1881 | 0.1162 | ||
| (0.9435) | (0.93416) | (0.9462) | (0.9649) | (0.9518) | (0.9699) | (0.9401) | (0.9373) | (0.9511) | (0.9572) | (0.9431) | (0.9623) | ||||
| 200 | 0.6172 | 0.3873 | 0.2975 | 0.9969 | 0.5544 | 0.2653 | 2.4298 | 1.1541 | 0.6116 | 0.3255 | 0.1921 | 0.1150 | |||
| (0.9515) | (0.9437) | (0.9462) | (0.9742) | (0.9608) | (0.9699) | (0.9491) | (0.9489) | (0.9502) | (0.9609) | (0.9584) | (0.9583) | ||||
| 0.70 | 50 | 30 | 1.5655 | 0.8514 | 1.3980 | 1.2818 | 0.6418 | 0.5403 | 2.7711 | 1.1407 | 0.4443 | 0.2408 | 0.2516 | ||
| (0.9492) | (0.9458) | (0.9487) | (0.9686) | (0.9731) | (0.9757) | (0.9471) | (0.9580) | (0.9493) | (0.9534) | (0.9612) | (0.9691) | ||||
| 40 | 1.4489 | 0.8495 | 1.3750 | 1.1231 | 0.6415 | 0.5551 | 2.7080 | 1.1893 | 1.1905 | 0.4306 | 0.2416 | 0.2485 | |||
| (0.9482) | (0.9580) | (0.9542) | (0.9819) | (0.9743) | (0.9777) | (0.9479) | (0.9485) | (0.9494) | (0.9643) | (0.9623) | (0.9603) | ||||
| 150 | 60 | 0.8611 | 0.5192 | 0.8304 | 0.8117 | 0.4619 | 0.5129 | 2.4752 | 1.1774 | 1.0908 | 0.3668 | 0.2144 | 0.2324 | ||
| (0.9561) | (0.9437) | (0.9479) | (0.9716) | (0.9631) | (0.9677) | (0.9493) | (0.9495) | (0.9494) | (0.9642) | (0.9527) | (0.9532) | ||||
| 120 | 0.8038 | 0.4953 | 0.7778 | 0.6871 | 0.4210 | 0.4862 | 2.4626 | 1.1478 | 1.1094 | 0.3380 | 0.2091 | 0.2222 | |||
| (0.9382) | (0.9457) | (0.9572) | (0.9611) | (0.9647) | (0.9835) | (0.9497) | (0.9442) | (0.9595) | (0.9593) | (0.9549) | (0.9736) | ||||
| 250 | 100 | 0.6615 | 0.4055 | 0.6275 | 0.6347 | 0.3745 | 0.4677 | 2.4202 | 1.1619 | 1.0871 | 0.3391 | 0.2038 | 0.2215 | ||
| (0.9535) | (0.9364) | (0.9569) | (0.9710) | (0.9538) | (0.9762) | (0.9492) | (0.9435) | (0.9599) | (0.9685) | (0.9529) | (0.9728) | ||||
| 200 | 0.6155 | 0.3886 | 0.5946 | 0.5542 | 0.3463 | 0.4435 | 2.4039 | 1.1527 | 1.1148 | 0.2985 | 0.1955 | 0.2112 | |||
| (0.9456) | (0.9433) | (0.9473) | (0.9609) | (0.9626) | (0.9799) | (0.9496) | (0.9496) | (0.9596) | (0.9573) | (0.9545) | (0.9647) | ||||
| 0.75 | 0.35 | 50 | 30 | 1.2109 | 0.6579 | 0.7493 | 1.3536 | 0.6052 | 0.6980 | 2.7070 | 1.1750 | 0.8073 | 0.4417 | 0.2341 | 0.2137 |
| (0.9413) | (0.9460) | (0.9371) | (0.9678) | (0.9789) | (0.9673) | (0.9395) | (0.9485) | (0.9412) | (0.9548) | (0.9533) | (0.9644) | ||||
| 40 | 1.2016 | 0.6587 | 0.6855 | 1.3167 | 0.6003 | 0.6600 | 2.756 | 1.1615 | 0.7987 | 0.4281 | 0.2337 | 0.2033 | |||
| (0.9459) | (0.9487) | (0.9369) | (0.9682) | (0.9756) | (0.9642) | (0.9455) | (0.9483) | (0.9498) | (0.9643) | (0.9603) | (0.9517) | ||||
| 150 | 60 | 0.6671 | 0.3930 | 0.3956 | 0.6930 | 0.3826 | 0.4505 | 2.4542 | 1.1540 | 0.6513 | 0.3617 | 0.2034 | 0.1948 | ||
| (0.9486) | (0.9322) | (0.9523) | (0.9659) | (0.9619) | (0.9742) | (0.9497) | (0.9395) | (0.9428) | (0.9564) | (0.9504) | (0.9627) | ||||
| 120 | 0.6537 | 0.3870 | 0.3489 | 0.6812 | 0.3760 | 0.3788 | 2.4388 | 1.1510 | 0.6377 | 0.3480 | 0.2017 | 0.1786 | |||
| (0.9529) | (0.9356) | (0.9457) | (0.9686) | (0.9635) | (0.9603) | (0.9492) | (0.9491) | (0.9439) | (0.9675) | (0.9540) | (0.9581) | ||||
| 250 | 100 | 0.5129 | 0.3073 | 0.4215 | 0.6077 | 0.3559 | 0.5747 | 2.2909 | 1.1403 | 0.6890 | 0.3272 | 0.1854 | 0.2065 | ||
| (0.9543) | (0.9515) | (0.9466) | (0.9735) | (0.9743) | (0.9683) | (0.9489) | (0.9585) | (0.9509) | (0.9672) | (0.9641) | (0.9594) | ||||
| 200 | 0.4993 | 0.3034 | 0.2621 | 0.5105 | 0.2970 | 0.2750 | 2.3674 | 1.1548 | 0.5971 | 0.3097 | 0.1824 | 0.1607 | |||
| (0.9493) | (0.9436) | (0.9561) | (0.9629) | (0.9625) | (0.9719) | (0.9495) | (0.9496) | (0.9479) | (0.9562) | (0.9537) | (0.9618) | ||||
| 0.70 | 50 | 30 | 1.1796 | 0.6641 | 1.2519 | 1.1490 | 0.5880 | 0.5810 | 2.5727 | 1.1875 | 1.1396 | 0.4367 | 0.2387 | 0.2649 | |
| (0.9467) | (0.9419) | (0.9574) | (0.9694) | (0.9639) | (0.9735) | (0.9473) | (0.9486) | (0.9488) | (0.9651) | (0.9517) | (0.9691) | ||||
| 40 | 1.1717 | 0.6552 | 1.2258 | 1.0097 | 0.5587 | 0.5324 | 2.6251 | 1.1533 | 1.1736 | 0.4246 | 0.2387 | 0.2597 | |||
| (0.9532) | (0.9419) | (0.9477) | (0.9748) | (0.9629) | (0.9676) | (0.9483) | (0.9493) | (0.9493) | (0.9645) | (0.9522) | (0.9581) | ||||
| 150 | 60 | 0.6654 | 0.3936 | 0.7660 | 0.6454 | 0.3685 | 0.5117 | 2.4152 | 1.1534 | 1.0870 | 0.3611 | 0.2079 | 0.2476 | ||
| (0.9445) | (0.9395) | (0.9566) | (0.9626) | (0.9634) | (0.9860) | (0.9396) | (0.9497) | (0.9596) | (0.9576) | (0.9533) | (0.9798) | ||||
| 120 | 0.6519 | 0.3891 | 0.6860 | 0.5946 | 0.3534 | 0.4670 | 2.4343 | 1.1501 | 1.1023 | 0.3385 | 0.2058 | 0.2259 | |||
| (0.9455) | (0.9430) | (0.9576) | (0.9618) | (0.9642) | (0.9755) | (0.9496) | (0.9468) | (0.9495) | (0.9571) | (0.9532) | (0.9685) | ||||
| 250 | 100 | 0.5135 | 0.3045 | 0.6306 | 0.6559 | 0.3500 | 0.4319 | 2.2821 | 1.1406 | 1.0532 | 0.3248 | 0.1883 | 0.2204 | ||
| (0.9485) | (0.9452) | (0.9560) | (0.9625) | (0.9641) | (0.9839) | (0.9478) | (0.9487) | (0.9491) | (0.9586) | (0.9526) | (0.9612) | ||||
| 200 | 0.4995 | 0.3037 | 0.5211 | 0.4744 | 0.2861 | 0.4248 | 2.2736 | 1.1323 | 1.0260 | 0.2931 | 0.1855 | 0.2156 | |||
| (0.9524) | (0.9530) | (0.9478) | (0.9719) | (0.9646) | (0.9659) | (0.9499) | (0.9425) | (0.9495) | (0.9570) | (0.9539) | (0.9586) | ||||
5 Optimality Criteria
In reliability and survival analysis, an optimum censoring plan among chosen schemes is desired to get a sufficient amount of information about the unknown model parameters. However, comparing two (or more) different censoring plans has gained a lot of attention in past few years by several authors. For instance one can see Ka et al. [26], Guan and Tang [27], Singh et al. [28], Abd El-Raheem [29], Hakamipour [30] and Dutta and Kayal [31]. Here, three commonly used criteria have been considered based on the variance-covariance matrix (VCM) of the observed Fisher information matrix corresponding to the MLEs of unknown parameters (see Table ).
-optimality
This first criterion is based on the trace of the first order approximation of the variance-covariance matrix (VCM) of the MLEs. The trace of the VCM equals to the sum of the diagonal elements of . This - optimality criterion provides an overall measure of the average variance of the estimates under MLE. The - optimality criterion is defined as .
-optimality
This second criterion is based on maximizing the determinant of the observed Fisher information matrix which is equivalent to minimize the determinant of VCM. We know that, the joint confidence region of is proportional to under some fixed level of confidence. So smaller value of gives a higher precision of the estimators of the parameters. The - optimality criterion is defined as .
-optimality
This criterion is based on the trace of the first order approximation of the Fisher information matrix of the MLEs. The trace of equals to the sum of the diagonal elements of . The - optimality criterion is defined as .
According to these optimality criteria, the corresponding optimal censoring plans have been considered in Table 8 and Table 11.
| Criterion | Goal | |||||
|---|---|---|---|---|---|---|
| A-optimality | minimum trace | |||||
| D-optimality | minimum det | |||||
| F-optimality | maximum trace |
Here is defined in the section 2.2, and yields the corresponding observed Fisher information matrix.
6 Real Data Analysis
In this section, two real life data sets have been analyzed to illustrate the applicability of the proposed methods.
Data Set I:
A real life step-stress data set from Greven et. al [32] has been analyzed to illustrate the estimation methods developed in this paper. This data set represents fish swam initially upto minutes at a flow rate cm/sec. The time at which any fish felt fatigue and changed its position is considered as the failure time. This data set contains four stress levels and those stress levels has been considered by increasing flow rate ( cm/sec) in every minute. As similar as Nassar et. al [16], we consider this data set as a simple step-stress data set by considering the first level as initial stress and merged other stress levels into one. For computational purpose, each data values have been subtracted by and divide by , respectively. The transformed data set has been tabulated in Table 6.
| Stress level | Failure times |
|---|---|
| 0.2733, 0.2867, 0.2933, 0.3213 | |
| 0.4387, 0.4400, 0.4433, 0.4483, 0.5117, 0.5167, 0.6955, 0.7300, 0.7600, 0.8933, 0.9222. |
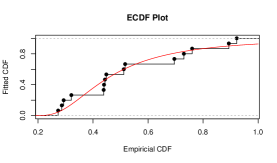
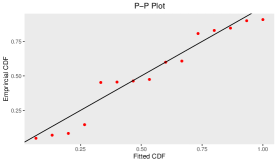
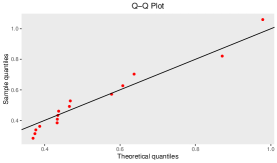
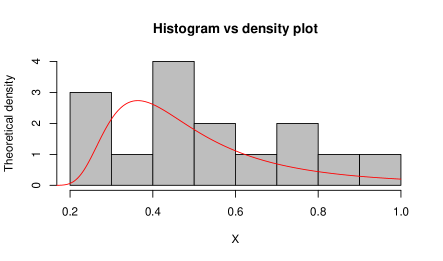
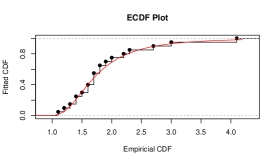
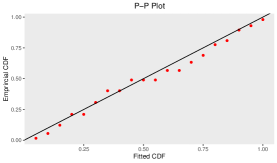
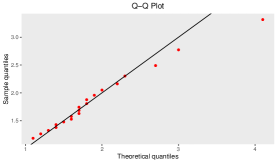
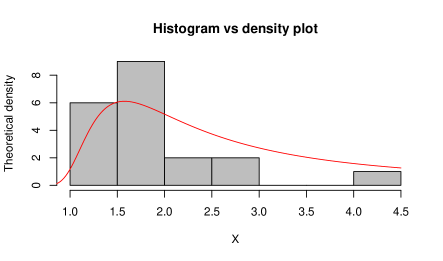
To check the goodness-of-fit of this data to the Gumbel Type-II distribution, K-S test has been employed. From this test, we observe the K-S distance is and the corresponding -value is . The MLEs of the model parameters for complete real data set are and . For this data set, the K-S distance and -value (in bracket) corresponding to Weibull and exponential distributions are and , respectively. This represents that the given data set fits the Gumbel Type-II distribution better than Weibull and exponential distributions. Also, for the purpose of goodness-of-fit test, different plots are considered in Figure and Figure . Figure represents the comparison between the theoretical CDF of the Gumbel Type-II distribution and the empirical CDF, P-P plot and Q-Q plot of the given real data set. If are number of i.i.d. random variables with CDF , then the empirical CDF (ECDF) is given as , where denotes the indicator of the event . Here Q-Q plot represents the points , where denotes the ordered data for . Then Figure represents the comparison between the theoretical density of the Gumbel Type-II distribution and the histogram and box-plot of given real data. From the box-plot, it can be concluded that the given distribution is right-skewed.
Different simple step-stress samples based Type-II censoring scheme are considered by using different values of and when , and . In Table 7 computed values of the MLEs, Bayes estimates based on SEL and LL functions, average length of ACIs, BCIs and HPD credible intervals based on the real data set are tabulated. It is observed that the Bayes estimates perform better than MLEs. Further it has been noticed that the HPD credible interval performs better than asymptotic and bootstrap confidence intervals. From Table 8, we can conclude that censoring plan under consideration and is the optimal plan according to the above discussed three optimality criteria among the other considered censoring plans.

| MLE | SEL | LL() | LL() | ACI | BCI | HPD | |||
|---|---|---|---|---|---|---|---|---|---|
| 0.15 | 8 | 2.7183 | 2.7967 | 2.7968 | 2.7964 | 3.7251 | 5.0523 | 0.4717 | |
| 0.0882 | 0.0818 | 0.0818 | 0.0817 | 0.3876 | 0.2804 | 0.0165 | |||
| 0.1008 | 0.1363 | 0.1363 | 0.1363 | 0.2917 | 0.3620 | 0.0343 | |||
| 10 | 2.7357 | 2.8841 | 2.8844 | 2.8774 | 3.7237 | 4.5014 | 0.4161 | ||
| 0.0863 | 0.0796 | 0.0796 | 0.0796 | 0.3790 | 0.2246 | 0.0154 | |||
| 0.1196 | 0.1472 | 0.1472 | 0.1471 | 0.3096 | 0.3481 | 0.0307 | |||
| 0.25 | 8 | 2.7189 | 2.7933 | 2.7934 | 2.7922 | 3.7285 | 4.8818 | 0.3764 | |
| 0.0881 | 0.0849 | 0.0849 | 0.0846 | 0.3877 | 0.1890 | 0.0192 | |||
| 0.1680 | 0.1735 | 0.1736 | 0.1732 | 0.4867 | 0.3356 | 0.0239 | |||
| 10 | 2.7357 | 2.8401 | 2.8402 | 2.8379 | 3.7242 | 3.9742 | 0.3438 | ||
| 0.0863 | 0.0772 | 0.0772 | 0.0772 | 0.3791 | 0.2292 | 0.0185 | |||
| 0.1993 | 0.2116 | 0.2116 | 0.2115 | 0.5160 | 0.3114 | 0.0213 |
| -optimality | -optimality | -optimality | ||
|---|---|---|---|---|
| 0.15 | 8 | 0.9183 | 1.5899 | 2236.2850 |
| 10 | 0.9179 | 1.3645 | 2377.7000 | |
| 0.25 | 8 | 0.9299 | 4.4225 | 2032.8210 |
| 10 | 0.9293 | 3.7893 | 2150.1210 |
Data Set II: A real life data set containing the relief times of patients who received an analgesic from Gross and Clark [33] has been considered. For computational purpose the data set has been tabulated in Table 9.
| Stress level | Failure times |
|---|---|
| 1.1, 1.2, 1.3, 1.4, 1.4, 1.5, 1.6, 1.6 | |
| 1.7, 1.7, 1.7, 1.8, 1.8, 1.9, 2.0, 2.2, 2.3, 2.7, 3.0, 4.1 . |
To check the goodness-of-fit of this data to the Gumbel Type-II distribution, K-S test has been employed. From this test, we observe the K-S distance is and the corresponding -value is . The MLEs of the model parameters for complete real data set are and . For this data set, the K-S distance and -value (in bracket) corresponding to Weibull and exponential distributions are and , respectively. This represents that the given data set fits the Gumbel Type-II distribution better than Weibull and exponential distributions. Also, for the purpose of goodness-of-fit test, empirical CDF plot, P-P plot, Q-Q plot, theoretical density with histogram plot and boxplot are considered in Figure and Figure .

| MLE | SEL | LL() | LL() | ACI | BCI | HPD | |||
|---|---|---|---|---|---|---|---|---|---|
| 0.25 | 15 | 4.2428 | 4.1892 | 4.1655 | 4.1428 | 1.6211 | 2.0258 | 0.9565 | |
| 6.4260 | 6.1472 | 6.1025 | 6.0883 | 3.4722 | 4.5213 | 1.9156 | |||
| 0.2149 | 0.2327 | 0.2364 | 0.2401 | 0.1453 | 0.1581 | 0.0834 | |||
| 17 | 4.2309 | 4.1563 | 4.1253 | 4.1198 | 1.5639 | 1.9857 | 0.9046 | ||
| 6.4106 | 6.1293 | 6.0934 | 6.0852 | 3.4487 | 4.4651 | 1.8427 | |||
| 0.2208 | 0.2376 | 0.2401 | 0.2423 | 0.1380 | 0.1435 | 0.0798 | |||
| 0.35 | 15 | 4.2426 | 4.1795 | 4.1592 | 4.1405 | 1.6185 | 1.9861 | 0.9486 | |
| 6.4266 | 6.1356 | 6.1008 | 6.0812 | 3.4650 | 4.4894 | 1.9052 | |||
| 0.3052 | 0.3214 | 0.3259 | 0.3295 | 0.1859 | 0.1921 | 0.0936 | |||
| 17 | 4.2148 | 4.1239 | 4.1052 | 4.1016 | 1.5699 | 1.9523 | 0.9172 | ||
| 6.3736 | 6.1208 | 6.0895 | 6.0764 | 3.3568 | 4.3672 | 1.8785 | |||
| 0.3104 | 0.3265 | 0.3287 | 0.3314 | 0.1786 | 0.1897 | 0.0874 |
| -optimality | -optimality | -optimality | ||
|---|---|---|---|---|
| 0.25 | 15 | 5.7792 | 0.1665 | 12.3242 |
| 17 | 5.5784 | 0.0241 | 57.9969 | |
| 0.35 | 15 | 5.8592 | 0.2752 | 9.9783 |
| 17 | 5.7181 | 0.0646 | 24.9099 |
Different simple step-stress samples based Type-II censoring scheme are considered by using different values of and when , and . In Table 10 computed values of the MLEs, Bayes estimates based on SEL and LL functions, average length of ACIs, BCIs and HPD credible intervals based on the real data set are tabulated. It is observed that the Bayes estimates perform better than MLEs. Further it has been noticed that the HPD credible interval performs better than asymptotic and bootstrap confidence intervals. From Table 11, we can conclude that censoring plan under consideration and is the optimal plan according to the above discussed three optimality criteria among the other considered censoring plans.
7 Conclusion
In this paper, we obtained estimates of the unknown model parameters of the Gumbel Type-II distribution under both classical and the Bayesian approaches using TRV modeling for simple SSLT. It has been observed that the MLEs can not be obtained explicitly for all the unknown parameters. Therefore, we used the Newton-Raphson iterative method to compute MLEs by using software. Also, we obtained the Bayes estimates based on the symmetric and asymmetric loss functions under the assumption of independent priors. A Monte Carlo simulation study is performed to compare the performance of the estimates in terms of the average values and MSEs. It has been noticed that the Bayes estimates under LL function perform better than the other point estimates. The asymptotic confidence intervals, bootstrap confidence intervals, and HPD credible intervals are also obtained. It is noticed that the HPD credible intervals perform better than other confidence intervals in terms of average width of the intervals. Further, two real life data sets are considered for illustrative purposes. An optimal censoring plan has been suggested by using different optimality criteria.
Acknowledgement: The authors would like to thank the Editor in Chief, an Associate Editor and two anonymous reviewers for their positive remarks and useful comments.
The author S. Dutta, thanks the Council of Scientific and Industrial Research (C.S.I.R.
Grant No. 09/983(0038)/2019-EMR-I), India, for the financial assistantship received to carry out this
research work. The first and third authors thank the research facilities received from the Department of Mathematics, National Institute of Technology Rourkela, India.
The authors declare that they do not have any conflict of interests.
References
- [1] W. Nelson, “Accelerated life testing-step-stress models and data analyses,” IEEE Transactions on Reliability, vol. 29, no. 2, pp. 103–108, 1980.
- [2] G. Bhattacharyya and Z. Soejoeti, “A tampered failure rate model for step-stress accelerated life test,” Communications in Statistics-Theory and Methods, vol. 18, no. 5, pp. 1627–1643, 1989.
- [3] M. T. Madi, “Multiple step-stress accelerated life test: the tampered failure rate model,” Communications in Statistics–Theory and Methods, vol. 22, no. 9, pp. 295–306, 1993.
- [4] D. Bai and S. Chung, “Optimal design of partially accelerated life tests for the exponential distribution under type-I censoring,” IEEE Transactions on Reliability, vol. 41, no. 3, pp. 400–406, 1992.
- [5] N. Sedyakin, “On one physical principle in reliability theory,” Technical Cybernatics, vol. 3, pp. 80–87, 1966.
- [6] G. K. Bhattacharyya and Z. Soejoeti, “A tampered failure rate model for step-stress accelerated life test,” Communications in Statistics-Theory and Methods, vol. 18, no. 5, pp. 1627–1643, 1989.
- [7] P. K. Goel, “Some estimation problems in the study of tampered random variables,” Technical Report no. 50, Department of Statistics,Carnegie-Mellon University, Pittsburgh, Pennsylvania, vol. 1971, 1971.
- [8] M. H. DeGroot and P. K. Goel, “Bayesian estimation and optimal designs in partially accelerated life testing,” Naval research logistics quarterly, vol. 26, no. 2, pp. 223–235, 1979.
- [9] F. Sultana and A. Dewanji, “Tampered random variable modeling for multiple step-stress life test,” Communications in Statistics-Theory and Methods, pp. 1–20, 2021.
- [10] A. A. Abdel-Ghaly, A. F. Attia, and M. M. Abdel-Ghani, “The maximum likelihood estimates in step partially accelerated life tests for the Weibull parameters in censored data,” Communications in Statistics-Theory and Methods, vol. 31, no. 4, pp. 551–573, 2002.
- [11] F.-K. Wang, Y. Cheng, and W. Lu, “Partially accelerated life tests for the Weibull distribution under multiply censored data,” Communications in Statistics-Simulation and Computation, vol. 41, no. 9, pp. 1667–1678, 2012.
- [12] A. A. Ismail, “Inference for a step-stress partially accelerated life test model with an adaptive Type-II progressively hybrid censored data from Weibull distribution,” Journal of Computational and Applied Mathematics, vol. 260, pp. 533–542, 2014.
- [13] A. A. Ismail, “Statistical inference for a step-stress partially-accelerated life test model with an adaptive Type-I progressively hybrid censored data from Weibull distribution,” Statistical Papers, vol. 57, no. 2, pp. 271–301, 2016.
- [14] R. M. EL-Sagheer, M. A. Mahmoud, and H. Nagaty, “Inferences for Weibull-exponential distribution based on progressive Type-II censoring under step-stress partially accelerated life test model,” Journal of Statistical Theory and Practice, vol. 13, no. 1, pp. 1–19, 2019.
- [15] M. A. Amleh and M. Z. Raqab, “Inference in simple step-stress accelerated life tests for type-II censoring Lomax data,” Journal of Statistical Theory and Applications, vol. 20, no. 2, pp. 364–379, 2021.
- [16] M. Nassar, H. Okasha, and M. Albassam, “E-Bayesian estimation and associated properties of simple step–stress model for exponential distribution based on Type-II censoring,” Quality and Reliability Engineering International, vol. 37, no. 3, pp. 997–1016, 2021.
- [17] Q. Ramzan, M. Amin, and M. Faisal, “Bayesian inference for modified Weibull distribution under simple step-stress model based on Type-I censoring,” Quality and Reliability Engineering International, vol. 38, no. 2, pp. 757–779, 2022.
- [18] K. Abbas, J. Fu, and Y. Tang, “Bayesian estimation of Gumbel type-II distribution,” Data Science Journal, vol. 12, pp. 33–46, 2013.
- [19] H. M. Reyad and S. O. Ahmed, “E-bayesian analysis of the Gumbel Type-II distribution under Type-II censored scheme,” International Journal of Advanced Mathematical Sciences, vol. 3, no. 2, pp. 108–120, 2015.
- [20] T. N. Sindhu, N. Feroze, and M. Aslam, “Study of the left censored data from the Gumbel type-II distribution under a Bayesian approach,” Journal of Modern Applied Statistical Methods, vol. 15, no. 2, p. 10, 2016.
- [21] B. Efron, The jackknife, the bootstrap and other resampling plans. SIAM, 1982.
- [22] P. Hall, “Theoretical comparison of bootstrap confidence intervals,” The Annals of Statistics, vol. 16, no. 3, pp. 927–953, 1988.
- [23] D. Kundu, N. Kannan, and N. Balakrishnan, “Analysis of progressively censored competing risks data,” Handbook of Statistics, vol. 23, pp. 331–348, 2003.
- [24] D. Kundu and B. Pradhan, “Bayesian inference and life testing plans for generalized exponential distribution,” Science in China Series A: Mathematics, vol. 52, no. 6, pp. 1373–1388, 2009.
- [25] M. H. Chen and Q. M. Shao, “Monte Carlo estimation of Bayesian credible and HPD intervals,” Journal of Computational and Graphical Statistics, vol. 8, no. 1, pp. 69–92, 1999.
- [26] C. Ka, P. Chan, H. Ng, and N. Balakrishnan, “Optimal sample size allocation for multi-level stress testing with Weibull regression under Type-II censoring,” Statistics, vol. 45, no. 3, pp. 257–279, 2011.
- [27] Q. Guan and Y. Tang, “Optimal step-stress test under type-I censoring for multivariate exponential distribution,” Journal of Statistical Planning and Inference, vol. 142, no. 7, pp. 1908–1923, 2012.
- [28] S. Singh, Y. M. Tripathi, and S.-J. Wu, “On estimating parameters of a progressively censored lognormal distribution,” Journal of Statistical Computation and Simulation, vol. 85, no. 6, pp. 1071–1089, 2015.
- [29] A. Abd El-Raheem, “Optimal plans and estimation of constant-stress accelerated life tests for the extension of the exponential distribution under Type-I censoring,” Journal of Testing and Evaluation, vol. 47, no. 5, pp. 3781–3821, 2018.
- [30] N. Hakamipour, “Comparison between constant-stress and step-stress accelerated life tests under a cost constraint for progressive type I censoring,” Sequential Analysis, vol. 40, no. 1, pp. 17–31, 2021.
- [31] S. Dutta and S. Kayal, “Inference of a competing risks model with partially observed failure causes under improved adaptive Type-ii progressive censoring,” Proceedings of the Institution of Mechanical Engineers, Part O: Journal of Risk and Reliability, 2022.
- [32] S. Greven, A. John Bailer, L. L. Kupper, K. E. Muller, and J. L. Craft, “A parametric model for studying organism fitness using step-stress experiments,” Biometrics, vol. 60, no. 3, pp. 793–799, 2004.
- [33] A. J. Gross and V. Clark, Survival distributions: reliability applications in the biomedical sciences. John Wiley & Sons, 1975.