State Constrained Stochastic Optimal Control for Continuous and Hybrid Dynamical Systems Using DFBSDE
Abstract
We develop a computationally efficient learning-based forward-backward stochastic differential equations (FBSDE) controller for both continuous and hybrid dynamical (HD) systems subject to stochastic noise and state constraints. Solutions to stochastic optimal control (SOC) problems satisfy the Hamilton–Jacobi–Bellman (HJB) equation. Using current FBSDE-based solutions, the optimal control can be obtained from the HJB equations using deep neural networks (e.g., long short-term memory (LSTM) networks). To ensure the learned controller respects the constraint boundaries, we enforce the state constraints using a soft penalty function. In addition to previous works, we adapt the deep FBSDE (DFBSDE) control framework to handle HD systems consisting of continuous dynamics and a deterministic discrete state change. We demonstrate our proposed algorithm in simulation on a continuous nonlinear system (cart-pole) and a hybrid nonlinear system (five-link biped).
keywords:
Stochastic control, Optimal control, Forward and backward stochastic differential equations, , ,
1 Introduction
Optimal control has been applied in various applications, e.g., robotic control [17] [5] and navigation [10]. Optimal control problems are often cast as the minimization of a cost function, which the solution can be found via numerical optimization techniques [11] [8] [9]. Recently, optimal control has been used to solve increasingly complex control problems [18] thanks to the enhanced computational abilities and optimization software and the adoption of neural networks [2]. Applying optimal control requires accurate modeling of the system of interest. However, unmodeled processes are common in real-world systems, e.g., measurement noise and external forces with unknown distributions [16] [12]. We adopt SOC [4] techniques to consider the uncontrolled inputs explicitly.
Recently, neural networks have been widely used to solve SOC problems [20] [7]. A promising direction for deep neural network (DNN) based SOC solutions is formulating the problem as an FBSDE [22]. FBSDE enables the numerical estimation of the solution to the HJB equation, i.e., the value function with respect to a cost function. The optimal control at each state then can be analytically obtained using the estimated value function. The introduction of deep neural networks [22] to FBSDEs improves the value function estimation. Compared to nonlinear model predictive control (MPC) approaches, DFBSDE-based approaches are computationally more efficient during inference by moving the heavy computation offline. On top of the vanilla DFBSDE, work has been done in introducing state constraints using penalty functions [6] and appending a differentiable quadratic program [19]. In this work, we explore a penalty function based approach since it is faster in training and inference.
Another key aspect of this paper is the control of HD systems. The type of HD systems considered consists of two phases: first, a phase of continuously evolving dynamics, and second, a phase of a discrete jump. Such HD systems are very common, e.g., walking robots [14]. Thus, it is worthwhile to understand how it is typically controlled. The control of walking robots is traditionally achieved with a hierarchical control architecture. A reduced-order model is used for motion generation. The generated motion is tracked via a tracking controller [17]. Another approach is to see the HD system as a combination of multiple phases of continuous dynamics [21]. Using this approach, the controller only needs to work well for the continuous dynamics and be robust to changes caused by discrete jumps. This formulation is end-to-end, which better suits DFBSDE.
This paper proposes a SOC setting for nonlinear systems that incorporates state constraints and adapts the method to handle HD systems. The main contribution of this paper is threefold: (1) proposed the state constraint DFBSDE algorithm and adapted it to handle HD systems; (2) devised a new training loss and controller ensemble setting for high-dimensional HD systems; (3) provided simulation studies on both continuous and HD systems to show the efficacy of our approach. In relationship with our previous work [6], this paper provides a more detailed development of the methodology, extension to hybrid systems, and application to bipeds. The remainder of this paper is structured as follows. In Section II, the state-constrained SOC formulation is given. Section III presents a derivation connecting the SOC formulation and FBSDEs. Also, Section III presents the incorporation of control saturation and state constraints. Then using the derived formulation, a deep neural network-based algorithm is presented to solve the FBSDE with state constraints and control saturation. The last part of Section III discusses adapting the DFBSDE algorithm to HD systems. In Section IV, simulation studies are presented for a continuous dynamical system, namely the cart-pole, and a five-link biped [15], which is HD.
2 Problem Formulation
In this section, we outline the SOC problem under state constraints. We consider a filtered probability space , where is the sample space, is the -algebra over , is a probability measure, and is a filtration with index denoting time. A controlled affine system with noise represented by stochastic processes can be described using a stochastic differential equation (SDE)
| (1) |
with initial state and an -adapted Brownian motion. Throughout this paper, we will write and other stochastic processes with argument omitted whenever appropriate. The states are denoted by and the control input by . In (1), represents the drift, represents the control influence, and represents the diffusion (influence of the Brownian motion to the state). We assume that , i.e., the noise enters wherever the control input appears (in addition to possibly elsewhere). The state constrained SOC problem is to find a controller that minimizes an objective function under a set of state constraints. The objective function is denoted as
| (2) |
where represents expectation, is the terminal time, is the terminal state cost, is the instantaneous state cost, and the instantaneous control cost is . The controller is a function of the state, this dependency will be omitted in the remainder of this paper for brevity, and the controller will be written as . Without loss of generality, we consider state constraints in the following form , where is a vector of functions of the state, and represents the element-wise upper bound of . Control saturation (with ) can also be introduced into the SOC formulation
| (3) |
where and are the element of and , respectively. Note that all operations with stochastic processes are understood a.s. (almost surely, i.e., with probability 1) unless specifically indicated. In summary, we have the SOC problem as
| (4) |
3 Method
In this section, we first show how (4) can be written as an FBSDE. Then, state constraints are considered. Subsequently, adaptations for HD systems are presented. Finally, a DNN-based solution to the FBSDE is proposed.
3.1 SOC to FBSDE
The derivation presented in this section was originally proposed in [22], it is summarized here for completeness. Let be the value function defined as
| (5) |
Using (2) and Bellman’s principle [1] yields
| (6a) | |||
| (6b) | |||
where denotes the Hamiltonian
| (7) |
the differential operator of is given by
| (8) |
is the partial derivative of with respect to , and and denote the first and second partial derivatives, respectively, of with respect to . To consider control constraints [22], we define as
| (9) |
with being the -th element of and
| (10) |
In (9), weights the importance between different control inputs. Using first-order conditions to solve for an analytic solution of the optimal control action that achieves the infimum of the Hamiltonian yields
| (11) |
with . Solving (11) for in yields
| (12) |
with “” denoting element-wise multiplication. The control is saturated between . Define . From (7), we can write a stochastic system for the optimal value function
| (13a) | ||||
| (13b) | ||||
| (13c) | ||||
| (13d) | ||||
which is in the form of a FBSDE (the forward part consists of (13b) (13d), the backward part consists of (13a) (13c)). The forward and backward parts are of the form of a forward SDE (FSDE) and a backward SDE (BSDE), respectively. For details regarding the derivation from (7) to (13), the reader is referred to [22][6].
3.2 Handling State Constraints
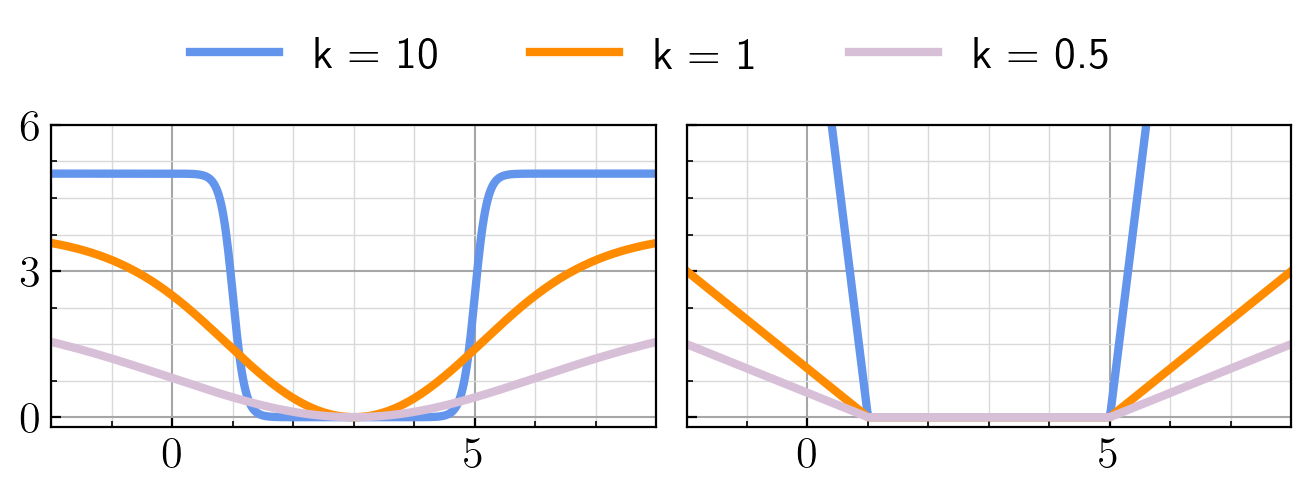
In this section, we consider incorporating state constraints into the FBSDE framework using a penalty function based approach. A perfect penalty function would be zero inside the constraint boundary and infinity outside. We propose two differentiable and numerically stable alternatives to a perfect penalty function. The first option is a penalty function based on logistic functions (PFL). When the state constraint has both an upper bound and lower bound , the -th element of PFL would be
| (14) |
where determines the maximum value of the penalty, determines the steepness of the boundary (larger leads to steeper boundaries), and . The proposed penalty function consists of two parts: the first consists of two logistics functions, which give the valley shape; the second sets the minimum value of the penalty function to zero. The second option is a rectified-linear-unit (ReLU) based function which is defined as . When an upper and lower bound exist, the penalty function is
| (15) |
Similar to (3.2), represents steepness of the constraint boundaries. However, in (3.2), there is no bound on the penalty function magnitude. An example of these two types of penalty functions with varying steepness is shown in Fig. 1. When only an upper bound exists, i.e., , the lower bound is set to be , and when only a lower bound exists, i.e., , the upper bound is set to be . The main difference between these two penalty functions is their values within the constraint boundary. For PFL, the value of the penalty function is only close to zero when a large value is utilized. Otherwise, states within but close to constraint boundaries will have a positive penalty function value. The ReLU-based penalty function is always zero within the bound. Specific use cases are demonstrated in Section 4. After applying penalty function , the instantaneous state cost is . Ideally, we would pick larger and to ensure a steeper boundary and larger penalty. While a controller without access to measurements of future noise can not guarantee that state constraints will be met for all time due to stochastic nature of the system dynamics, note that the penalty functions guide the learning towards a robust controller that does not violate state constraints (at least under the disturbances seen during training). The expected value of the integral of is at most . If is finite and is a perfect penalty function, the constraint is satisfied except on a set of measure zero.
3.3 Deep FBSDE Algorithm
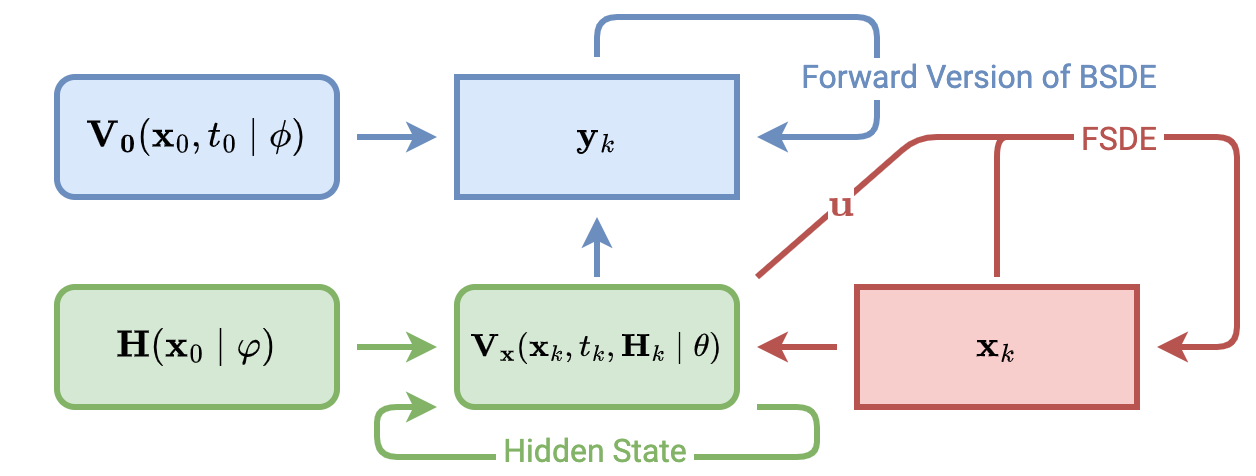
The solution of the FBSDE in (13) requires backward integration in time and the fact that is unknown creates additional difficulties in utilizing classical numerical integration approaches. To deal with backward integration in time, following the formulation in [22], we can estimate the value function at time zero using a DNN, which is parameterized by , i.e., . This allows the forward integration of the BSDE. We can then rewrite the FBSDE as two FSDEs. For unknown values, it can also be estimated using a DNN parameterized by , i.e., . We deploy an LSTM-based architecture [13] for , which has been shown to be superior to dense-layer-based architectures [22]. Linear regression based approaches have also been considered, but are inferior due to compounding error. Assuming the initial state and time horizon are fixed [22], the initial value function is a learned fixed value . Due to the use of LSTMs, two changes need to be made to the DFBSDE algorithm. First, a separate network is used to estimate the initial hidden state values. Second, will also depend on the hidden state values . The FBSDE can be forward integrated by discretizing the time as follows
| (16a) | ||||
| (16b) | ||||
where , , and . The calculation of and is illustrated in Fig. 2. To learn the weights, we minimize the least square loss between the estimated terminal value function and the measured terminal cost,
| (17) |
where is the batch size and the superscript denotes the -th set of data in the batch. The detailed DFBSDE algorithm is shown in Algorithm 1.
3.4 Penalty Function Update
For the penalty function, if is set to a large value in the initial stage of training, numerical instabilities can arise due to large gradients generated by states within the steep region near the constraint boundary. On the other hand, if the values of are kept small, it would not be effective since the penalty for constraint violation is small. Thus, we propose to update during training so that it gradually increases. The update scheme is as follows. For a given , the DNN is trained until convergence; then, is updated. A metric to check for convergence is the variance of the episode-wise cost over a few episodes; the episode window size is denoted as . If the iterates are converging, the variance will be small. Convergence is determined by comparing the square root of the variance with a threshold ; if it is smaller than , is updated as . This condition is checked every iterations. Additionally, if the condition is not satisfied after iterations, then also is updated since it could be stuck at a local minimum. Empirically, we have found , , , and to be reasonable values to start with. Both and can be increased if training is stable and faster growth of is desired; otherwise, and/or should be reduced. During training, the variance decreases. Thus, should also decrease after each update: , with . To make the decrease in smoother, we gradually increase to 1 using with . Similarly, the acceleration of is made negative, i.e., , with , leading to finer-grained changes in at later stages of training. The initial value of can be determined after the training converges for the first iteration of Algorithm 2. From empirical evaluations, we find and to be reasonable values. The penalty function update scheme is shown in Algorithm 2.
3.5 Adaptation to Hybrid Dynamics
This section will discuss the adaptations required for the DFBSDE algorithm to handle HD systems. HD systems consist of two phases: a continuous dynamic phase and a phase of a deterministic discrete jump. Such an HD system is very common, e.g., a biped. The FBSDE formulation in (13) is only for continuous dynamics. Inspired by the cyclic motion in human walking, we treat the hybrid dynamics as having multiple cycles, where the dynamics are continuous within each cycle. For the case of bipedal locomotion, each cycle will be a footstep; at the end of each cycle, the swing foot lands on the ground (more on this in Section 4). The main challenges in adapting the DFBSDE framework to HD systems are robustness to the initial state and assurance of cyclic motion. This requires the initial value function estimator to be robust to a wide range of states. The loss function (17) only trains the estimator for a fixed . To ensure that the learned value function estimator is robust to variations in the initial state, we can train it such that it provides an accurate estimation for all of the states recorded. The measured cost-to-go can approximate the value function
| (18) |
Using (18), we can learn the initial value function using
| (19) |
Thus, the loss function for the Hybrid FBSDE (HFBSDE) becomes
| (20) |
with the terminal cost calculated using the state after the jump and adjusts the weighting between the two losses. This terminal cost encourages cyclic motion.
4 Simulations
In this section, we show the performance of our control algorithm using a continuous nonlinear system: the cart-pole for a swing-up task; and a hybrid nonlinear system: a five-link biped for walking. The trained model was evaluated over 256 trials for all systems. For the cart-pole experiments, two LSTM layers with size 16 are used at each time step, followed by a dense layer with an output size corresponding to the state dimension. For fixed initial states, the initial value function estimation uses a trainable weight of size one. The initial hidden state and cell state for the LSTM layers are estimated using a trainable weight of size 16. For the five-link biped experiments, we used two LSTM layers with size 32, followed by a dense layer with size 10. The initial value function network has four layers with size . The initial hidden state network consists of four different networks for estimating the initial hidden state and the initial cell state of the two LSTM layers; they all consist of two dense layers that have an output size of 8.
4.1 Cart-pole Swing-Up Task I
The task for the cart-pole system is to swing the pole up and stabilize it at the top. The cart-pole dynamics are
| (21) | ||||
| (22) |
The cart position and pendulum angle are represented by and , respectively. The pendulum angle is zero when it is pointed downwards. The state of the cart-pole system is . In our experiments, we set the cart mass to kg, the pole mass to kg (point mass at the tip), the pole length to m, , and the target state as . The control is saturated at N, the cart position is constrained between m, and the cart velocity is constrained between m. The time horizon is chosen to be sec and the time step is sec (this specific value of is chosen randomly). We use the state cost function
| (23a) | ||||
| (23b) | ||||
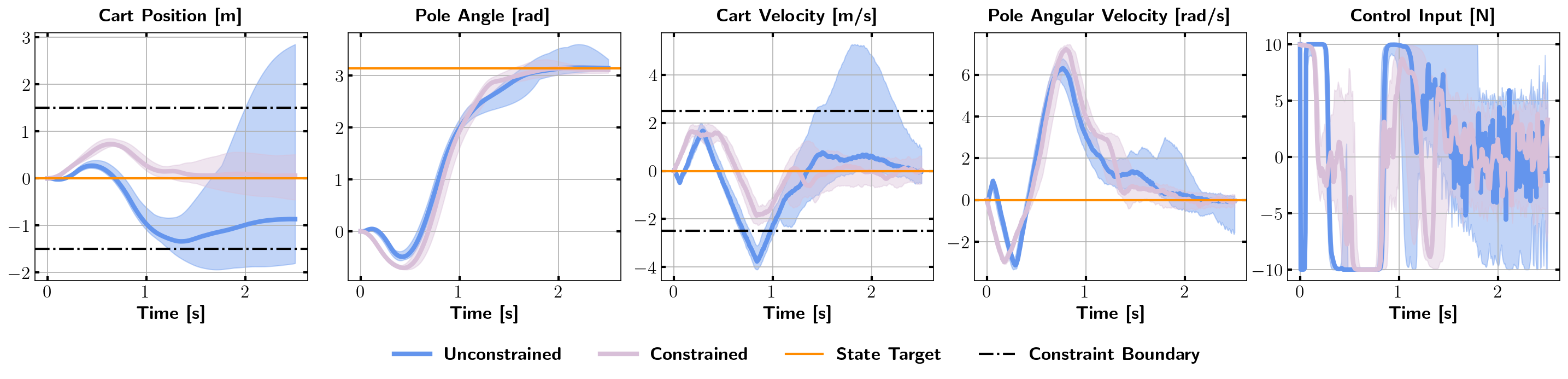
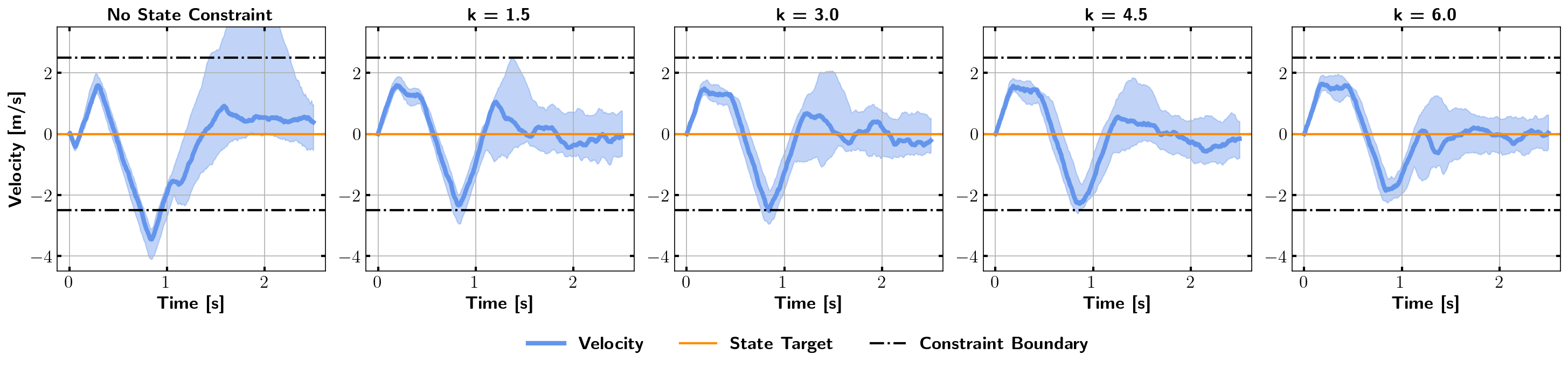
where is the target state, is the cost weight matrix for the state, and is the terminal state cost matrix. We use the control cost defined in (9). The cost matrices are chosen as and . is the penalty function, in this example is a logistics function-based penalty function (3.2), with and . Fig. 3 shows the state trajectories generated by the trained controller. The state trajectory generated by the trained constrained DFBSDE controller satisfies the state constraints, while they are violated significantly under the trained unconstrained controller. The effect of the penalty function can be immediately seen in Fig. 4, even with a small value. With , the part of the trajectory that lies outside the constraint boundaries is greatly reduced. After gradually increasing to , following Algorithm 2, the entire cart velocity trajectory lies within the constraint boundaries. We also tested directly training with without the adaptive update. The algorithm becomes numerically unstable after one epoch due to large gradients. This demonstrates that our method provides a stable training scheme.
4.2 Five-Link Biped Walking Task
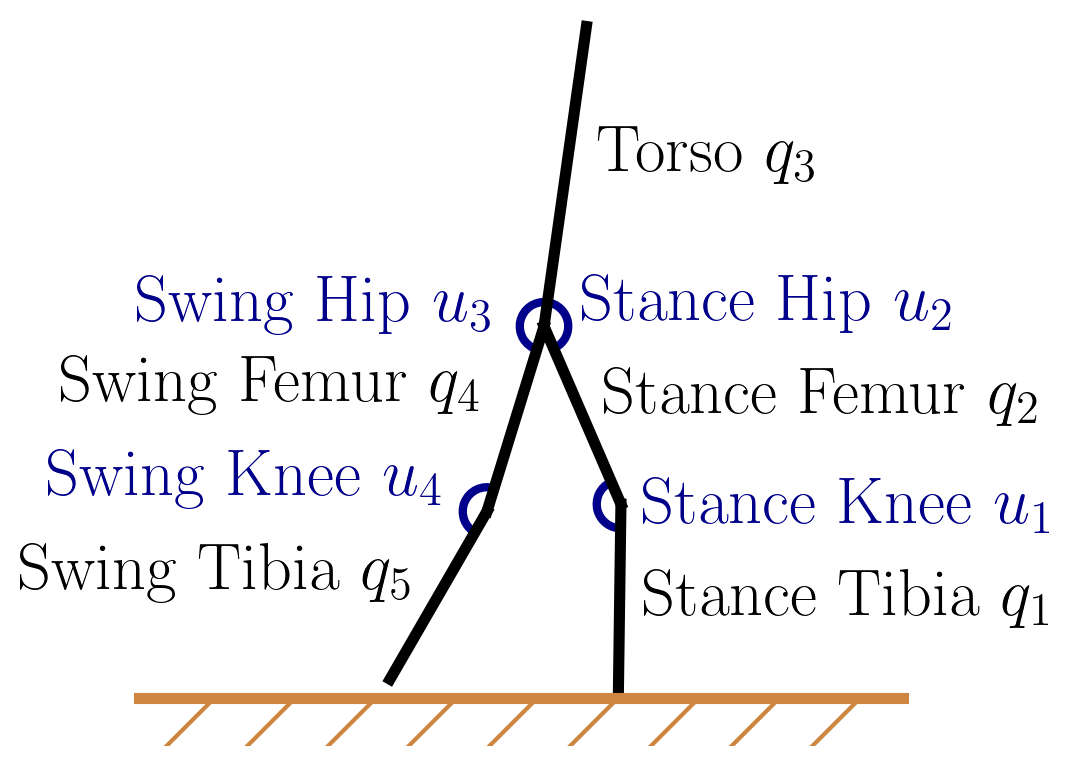
The biped model of interest is shown in Fig. 5, derived from [3]. The leg on the ground is the stance leg, the leg in the air is the swing leg, and the link representing the upper body is the torso. The biped state consists of the link angles with respect to the horizontal plane and the link angular velocities , i.e., . Note that the denoted here is different from the state cost function . The biped model has four actuated joints at the knee and hip joints. The control consists of the applied torque at the actuated joints , where the corresponds to the unactuated stance ankle. The output of the controller will only consist of , then a mapping matrix is used to obtain . The parameters of the biped model can be found in [15]. The five-link biped dynamics is
| (24) |
where is the inertia matrix, the Coriolis matrix, and the gravitational terms. The dynamics is in the form of (1) after considering stochastic noise. A heel strike (HS) occurs when the biped comes into contact with the ground, which signals the termination of the current step, and initiation of the next step. During this transition, the swing and stance legs are swapped. We assume this transition is instantaneous, the biped is symmetric, and the new swing leg leaves the ground once the HS occurs (i.e., no double support phase). The joint indexing depends on the current swing and stance leg definition. Defining the joint angles right before HS as and the joint angles right after HS as , we have , where is the anti-diagonal matrix. The HS creates an instantaneous change in angular velocity. Defining the angular velocity before HS as and the angular velocity after HS as , we have , with being the deterministic HS transition map [15].
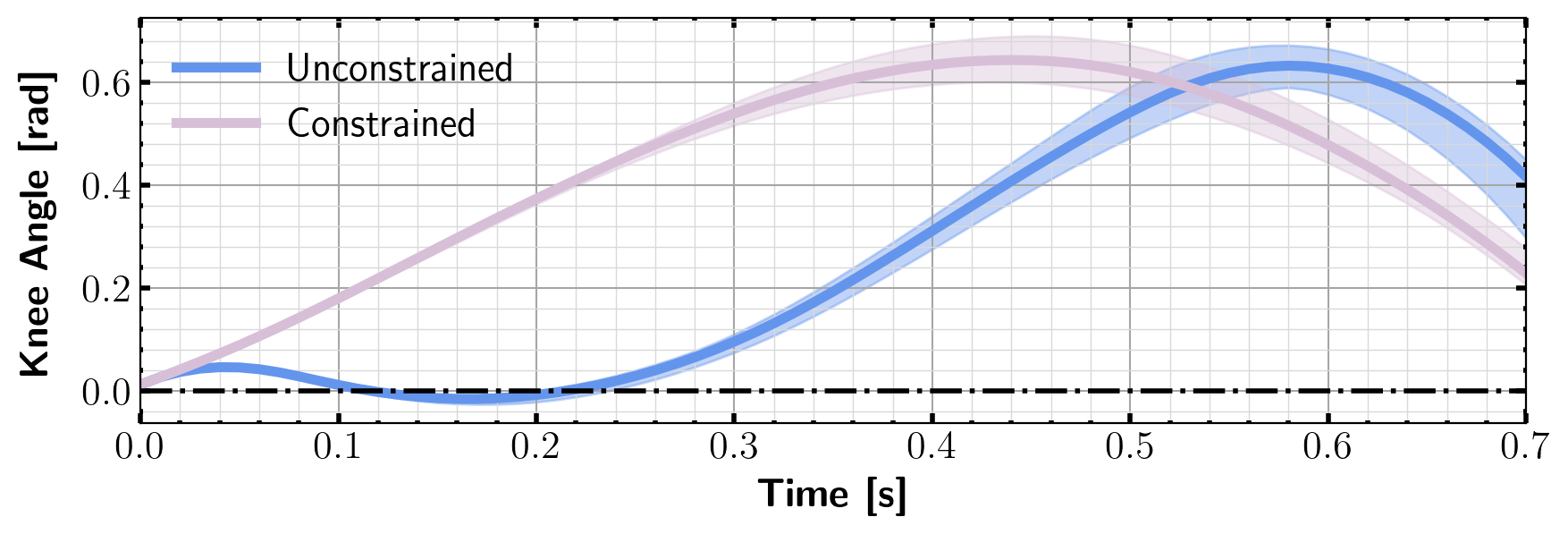
To generate realistic walking motion, we need to avoid hyperextension in the knee. We transform this constraint into a variant of the ReLU-based penalty function in (3.2): where is a weighting coefficient for the penalty function, and and are defined in Fig. 5. A quadratic cost is applied to the control. We choose . This choice of implies that hip motors are more powerful than knee motors, which is true for many robots. The state cost is the weighted distance between the state and a nominal terminal state plus the penalty
| (25) |
with . The terminal state cost has the same form as (25), the sole difference is replacing the state cost matrix with . The target state is chosen to be
| (26) |
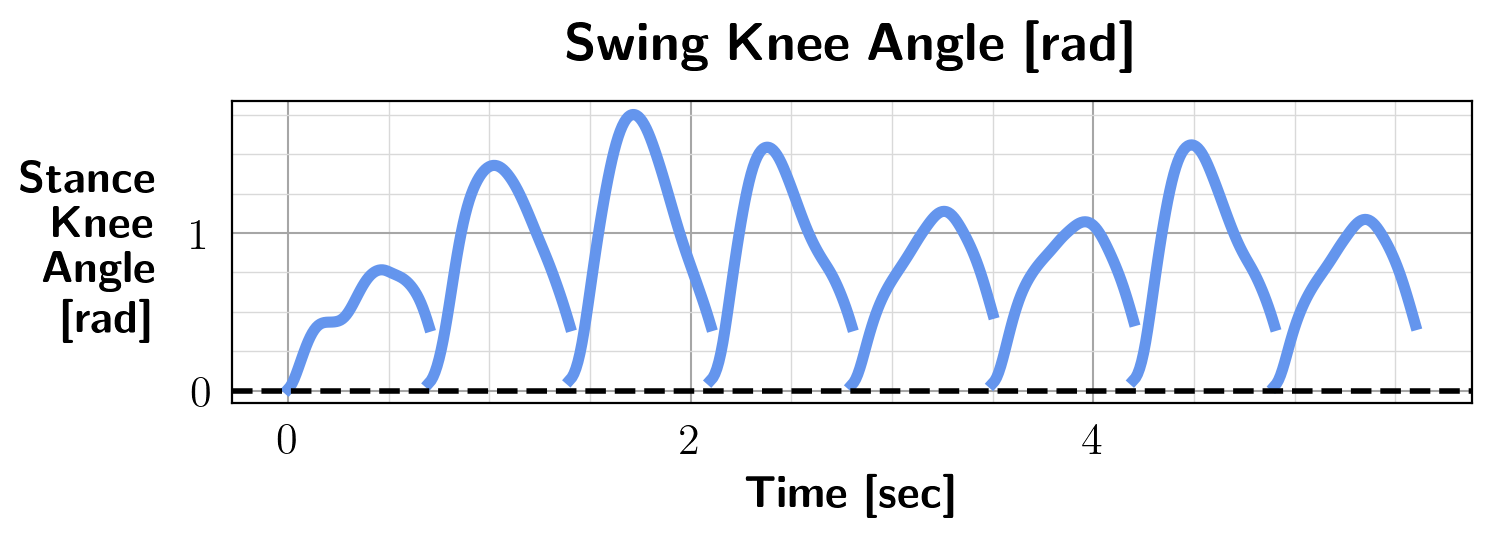
A comparison between the motion generated by the constrained and unconstrained DFBSDE controller is given in Fig. 6. The unconstrained controller hyperextends the swing knee, while the constrained controller does not. Since the chosen penalty function could constrain the system directly, the value doesn’t need to be updated. In previous examples, the penalty functions are logistic function based. This works well when the constraint set is large since it creates a buffer between the interior of the constraint set and its boundary. However, the constraint set for locomotion tasks is relatively small, making ReLU functions a better candidate. For the five-link biped experiments, we use a time step of 0.01s.
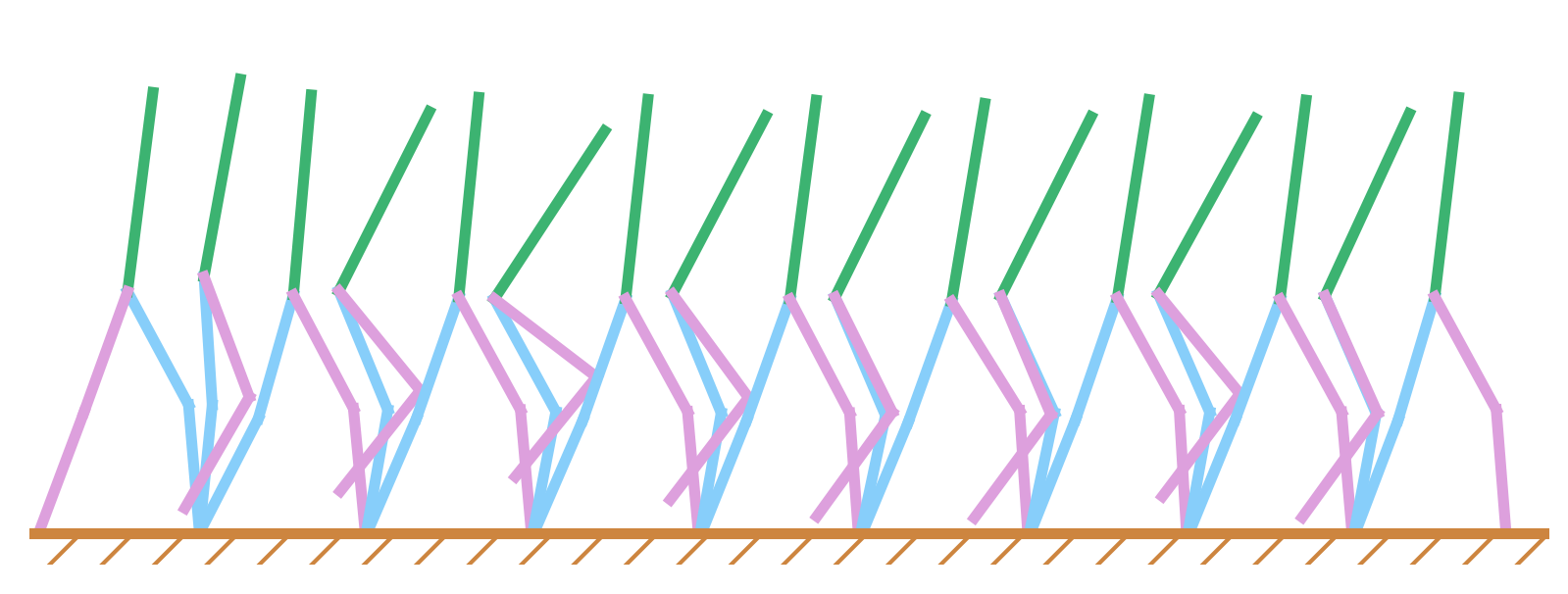
Variations in the initial states make dissecting a multi-step walking problem into multiple single-step walking problems a challenging task. We train a robust controller to deal with this issue. We find it difficult for a single controller to handle all possible initial configurations. Thus, we use an ensemble of controllers, where each controller handles a range of initial configurations around a nominal state. For the duration of one footstep, only one controller is used, which is the controller in the ensemble that has the shortest distance between the initial state and its nominal state. The nominal state of a controller is known a priori. After training, the motion generated by this approach is shown in Fig. 7, where the ensemble size is three. The corresponding swing knee angle is shown in Fig. 6. It can be seen that no hyperextension occurred, which shows the effectiveness of enforcing the state constraints. On average, the initial range each controller can handle spans 6.03 deg for the joint angles and 19.01 deg/sec for the joint velocities. Fig. 7 shows a tucking motion generated by the torso and the swing leg. This is due to our biped model’s relatively small control authority over the torso. Without the forward angular momentum generated by the tucking motion, the torso gradually tilts back over multiple steps. Since there is no direct control over the torso, it is difficult for the DFBSDE controller to recover. We also compared the computation time of our proposed method for obtaining the control for one time step with trajectory optimization [15] (TO). As expected, our approach generates comparable results while being computationally more efficient. Solving for the control action requires 0.96s for a Hermite-Simpson TO approach, compared with 5.6ms for our proposed method.
5 Conclusion
In this paper, we solved SOC problems with state constraints using an LSTM-based DFBSDE framework which alleviates the curse of dimensionality and numerical integration issues. The state constraints are applied using an adaptive update scheme, significantly improving training stability. We also show how to adapt the algorithm to handle HD systems in addition to the continuous dynamics setting. The efficacy of our approach is demonstrated on a cart-pole system and a five-link biped which has hybrid dynamics.
References
- [1] R.E. Bellman. Dynamic programming. Dover, New York, 2003.
- [2] Y. Chen, Y. Shi, and B. Zhang. Optimal control via neural networks: A convex approach. In Proceedings of International Conference on Learning Representations, New Orleans, LA, May 2019.
- [3] C. Chevallereau, G. Abba, Y. Aoustin, F. Plestan, E.R. Westervelt, C. Canudas-De-Wit, and J.W. Grizzle. RABBIT: a testbed for advanced control theory. IEEE Control Systems Magazine, 23(5):57–79, 2003.
- [4] L.G. Crespo and J. Sun. Stochastic optimal control via bellman’s principle. Automatica, 39(12):2109–2114, 2003.
- [5] B. Dai, P. Krishnamurthy, and F. Khorrami. Learning a better control barrier function. In Proceedings of IEEE Conference on Decision and Control, Cancun, Mexico, pages 945–950, December 2022.
- [6] B. Dai, P. Krishnamurthy, A. Papanicolaou, and F. Khorrami. State constrained stochastic optimal control using LSTMs. In Proceedings of the American Control Conference, New Orleans, LA, pages 1294–1299, May 2021.
- [7] B. Dai, V.R. Surabhi, P. Krishnamurthy, and F. Khorrami. Learning locomotion controllers for walking using deep FBSDE. CoRR, abs/2107.07931, 2021.
- [8] Bolun Dai, Heming Huang, Prashanth Krishnamurthy, and Farshad Khorrami. Data-efficient control barrier function refinement. In Proceedings of the American Control Conference, San Diego, CA, May 2023. (To Appear).
- [9] Bolun Dai, Rooholla Khorrambakht, Prashanth Krishnamurthy, Vinícius Gonçalves, Anthony Tzes, and Farshad Khorrami. Safe navigation and obstacle avoidance using differentiable optimization based control barrier functions. CoRR, abs/2304.08586, 2023.
- [10] M. Demetriou and E. Bakolas. Navigating over 3d environments while minimizing cumulative exposure to hazardous fields. Automatica, 115:108859, 2020.
- [11] M. Diehl, H.J. Ferreau, and N. Haverbeke. Efficient numerical methods for nonlinear mpc and moving horizon estimation. Nonlinear model predictive control, pages 391–417, 2009.
- [12] L. Hewing and M.N. Zeilinger. Scenario-based probabilistic reachable sets for recursively feasible stochastic model predictive control. IEEE Control Systems Letters, 4(2):450–455, 2019.
- [13] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.
- [14] R. Sinnet J. Grizzle, C. Chevallereau and A. Ames. Models, feedback control, and open problems of 3d bipedal robotic walking. Automatica, 50(8):1955–1988, 2014.
- [15] M. Kelly. An introduction to trajectory optimization: How to do your own direct collocation. SIAM Review, 59(4):849–904, 2017.
- [16] M. Lorenzen, F. Dabbene, R. Tempo, and F. Allgöwer. Stochastic mpc with offline uncertainty sampling. Automatica, 81:176–183, 2017.
- [17] M.N. Mistry, J. Buchli, and S. Schaal. Inverse dynamics control of floating base systems using orthogonal decomposition. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, pages 3406–3412, May 2010.
- [18] M. Neunert, M. Stäuble, M. Giftthaler, C.D. Bellicoso, J. Carius, C. Gehring, M. Hutter, and J. Buchli. Whole-body nonlinear model predictive control through contacts for quadrupeds. IEEE Robotics and Automation Letters, 3(3):1458–1465, 2018.
- [19] M. Pereira, Z. Wang, I. Exarchos, and E.A. Theodorou. Safe optimal control using stochastic barrier functions and deep forward-backward sdes. In Proceedings of Conference on Robot Learning, Cambridge, MA, volume 155, pages 1783–1801, November 2020.
- [20] L. Di Persio and M. Garbelli. Deep learning and mean-field games: A stochastic optimal control perspective. Symmetry, 13(1):14, 2021.
- [21] J. Viereck and L. Righetti. Learning a centroidal motion planner for legged locomotion. In Proceedings of the IEEE International Conference on Robotics and Automation, Xi’an, China, pages 4905–4911, May 2021.
- [22] Z. Wang, M.A. Pereira, and E.A. Theodorou. Learning deep stochastic optimal control policies using forward-backward SDEs. In Proceedings of Robotics: Science and Systems XV, Freiburg im Breisgau, Germany, June 2019.