STAR-GNN: Spatial-Temporal Video Representation for Content-based Retrieval
Abstract
We propose a video feature representation learning framework called STAR-GNN, which applies a pluggable graph neural network component on a multi-scale lattice feature graph. The essence of STAR-GNN is to exploit both the temporal dynamics and spatial contents as well as visual connections between regions at different scales in the frames. It models a video with a lattice feature graph in which the nodes represent regions of different granularity, with weighted edges that represent the spatial and temporal links. The contextual nodes are aggregated simultaneously by graph neural networks with parameters trained with retrieval triplet loss. In the experiments, we show that STAR-GNN effectively implements a dynamic attention mechanism on video frame sequences, resulting in the emphasis for dynamic and semantically rich content in the video, and is robust to noise and redundancies. Empirical results show that STAR-GNN achieves state-of-the-art performance for Content-Based Video Retrieval.
Index Terms— Content-base Video Retrieval, Graph Neural Networks, Spatial-Temporal Graph, Multi-scale
1 Introduction
The amount of video data in video-sharing APPs such as as YouTube and TikTok has grown exponentially. Content-Based Video Retrieval(CBVR) has attracted tremendous attention from both the academia and the industry in the past decade due to its significant role in many video applications, such as video search, video annotation, personalized recommendation and copyright infringement detection.
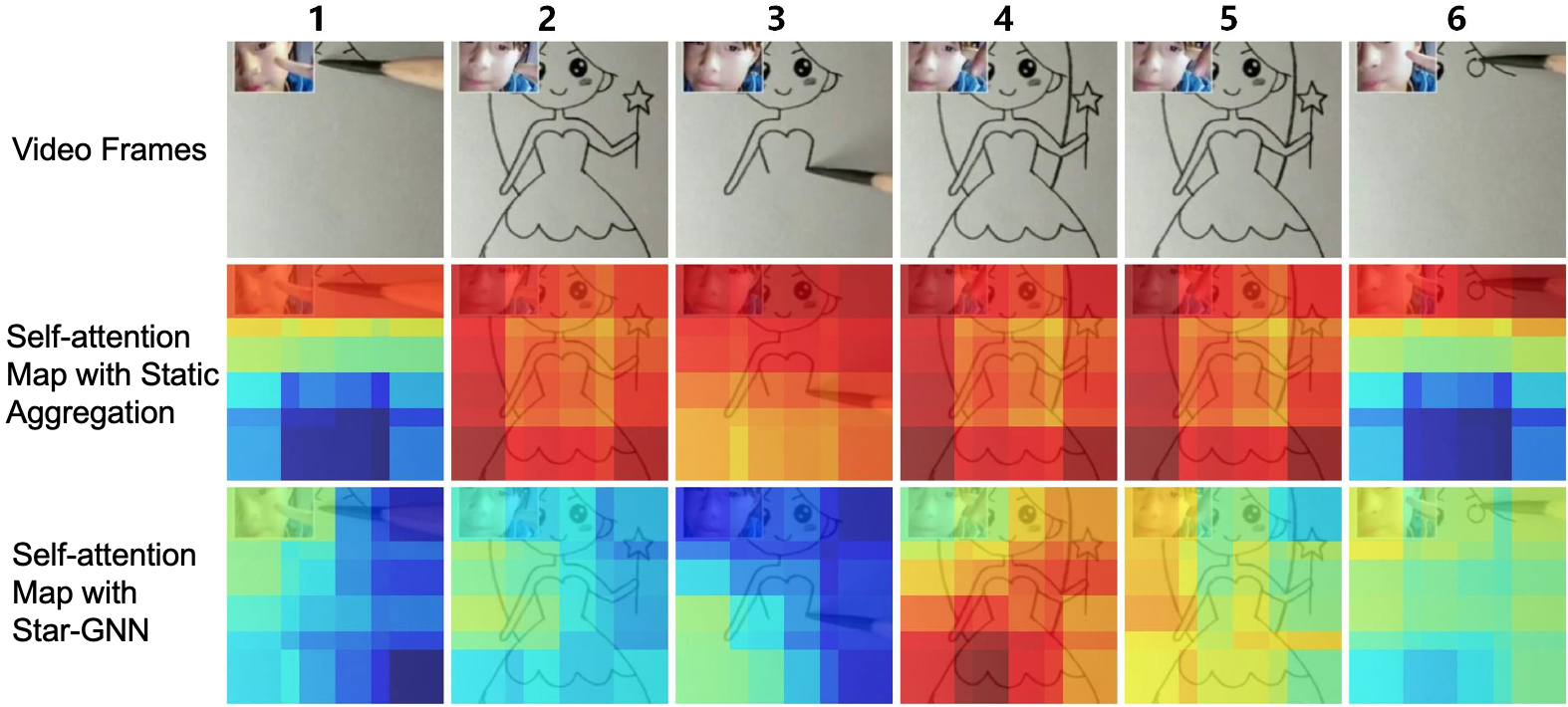
The performance of CBVR depends on representativeness and discriminativeness of the video features. There are two common video feature representation extraction/learning methods based on their granularity: frame-level[1] methods and video-level[2] methods. The feature representation of a video in frame-level methods is the set of frame features, and the similarity between videos is determined by the similarity of the frames features from the videos. Such frame-level methods have major limitations. They regard a video as a series of static images without integrating spatial and temporal information contained in the video. In addition, frame-level methods have a significantly larger memory and complexity costs. Video-level methods use a compact feature to represent the entire video. An intuitive approach to generate video-level representations is to aggregate the frame-level CNN features into a compact global descriptor, e.g., by using global max-pooling [3], global average-pooling [4] or LSTM[5]. Moreover, the way of feature aggregation by directly pooling the frame-level features is prone to visual noise, video transformations, and content redundancy. In order to address these current issues, we propose a spatio-temporal graph-based framework for CBVR, called Spatial-TemporAl video Representation GNN (STAR-GNN). We first split frames into interlinked regions and then represent a video via a lattice feature graph. By transforming and aggregating the spatio-temporal context of regionalized video features with pluggable GNN modules, it effectively implements a dynamic attention mechanism in the process of video feature extraction.
Figure 1 depicts the dynamic attention effect that STAR-GNN achieves by a visualization method named self-attention map. It shows an attention heat map between a video’s final representation and its original frame regions. The first row shows the original video content, while the second and third rows illustrate the self-attention heat maps generated from the static aggregation and STAR-GNN, respectively. Static aggregation directly aggregates frame regions’ CNN features with a fixed regionalization scheme without modeling the spatio-temporal context. Evidently, for identical/near-identical frames (2, 4, 5 and 1, 6 in Figure 1), the attention heat maps are identical too. The painter’s face is highly repetitive in the sequence, and as a result it is over-represented in the final video feature. Similar phenomenon is observed for the drawing in frames 2, 4 and 5. On the contrary, STAR-GNN’s video representation is highly representative for semantically rich regions and dynamic contents through time. STAR-GNN represents the content of the anime figure mainly in frame 4, and then captures the changes in frame 3 as the bottom part disappears. For frames 2 and 5, which are highly repetitive, STAR-GNN lowers its attention on them. It also preserves the visual information for the painter in a more reasonable way. Across the entire sequence, it is evident that STAR-GNN always focuses on the key and dynamic visual content and overcomes the over-representation problem.
STAR-GNN is a pioneer work to use graph-based spatio-temporal aggregation and contrastive learning for content-based video retrieval, and achieves SOTA results. There are a few papers using spatial-temporal aggregation on videos [6, 7, 8], however they focus on classification or person-ReID and have limitations when applied to video retrieval as they require a set of “known classes”. STAR-GNN is not limited to any “known classes” and is therefore more robust to video retrieval. Our main contributions are two-fold:
-
•
We propose an video feature extraction framework that starts with formulating a video as a lattice graph and then harnesses the representative power of pluggable GNN modules to extract distinctive features.
-
•
We conduct an extensive empirical evaluation for STAR-GNN, exploring its performance with different GNN components, and on different datasets.
2 Related Work
DNN-based CBVR can be divided into frame-level methods and video-level methods. Frame-level methods need compute the similarity of visual content between frames. Podlesnaya et al. [9] took advantage of the pre-trained CNN to extract features of key frames, then build complicated spatial and temporal index of frames. Kordopatis et al. [10] calculate video-to-video similarity by refined frame-to-frame similarity matrices. Han et.al[11] modelled the video similarity as the mask map predicted from frame-level spatial similarity. However, most of these frame-level methods ignore the temporal sequence information between frames, and some studies have turned to video-level features. Zhao et al. [12] emphasized the temporal dynamics of a video, and they proposed a self-supervised recurrent neural network to learn video-level features. Kordopatis et al. [2] used the deep metric learning framework to learn feature representations of videos. Xu et al. [13] used 3D convolutional neural networks to extract features for clips and proposed a self-supervised model by predicting frame orders.
Graph neural networks (GNNs) have received growing attention in recent years due to their power of modelling non-linear structures in the graph topology. Among them, graph convolutional networks (GCNs) have been widely used for feature representation. GCNs can be classified into two major categories, namely spectral graph convolutional networks [14] and spatial graph convolutional networks[15, 16]. GCNs have been used to model video features in some scenarios, such as action recognition [17], object relation detection [7] and video person ReID [8]. Different from this work, our STAR-GNN is the first to apply the GNNs for video retrieval task.

3 The STAR-GNN Framework
3.1 Overview
We introduce the proposed STAR-GNN framework for video feature extraction. As illustrated in Figure 2, the training process of STAR-GNN can be described in four steps. First, for a video, we sample frames at a given rate and take the pre-trained backbone network to extract the raw frame feature map. Multi-scale regional features are then generated from the frame feature map. Second, each video is transformed into a regional graph with spatial-temporal links. Third, we train the graph neural network in the STAR-GNN framework with retrieval triplet loss or contrastive loss. Fourth, each regional graph is processed with the trained STAR-GNN using shared parameters. The feature for a video is represented as the average of all regional node representations in its regional graph. The rest of this section provides further details.
3.2 Spatial-Temporal Graph Construction
A video consists of frames with a temporal order, and each frame contains semantic contents appearing in various locations. A video is therefore a collection of inter-related temporal-spatial information in three dimensions. To integrate these aspects into a unified feature space, we construct an undirected/weighted graph for each video, to model both the spatial and temporal domains.
First, we divide a single frame into multi-scale regions to model the local visual coherence and enable the modeling of regional relationships through time. Considering that the regions of interest among different frames may vary in size, we use different scales. These scales are applied on frame feature maps extracted by the backbone network to obtain region-level features with corresponding strides. Consequently, each frame is split into several regions, with each region corresponding to a node in the regional graph. And a frame will have types of regions which are represented by , in which stands for the region index and is the scale index. See Figure 2 STEP 1.
Second, to take advantage of a video’s local temporal dynamics, we inter-connect all regional nodes at the same spatial location across all frames in a video to form a complete temporal sub-graph. The graph construction strategy of STAR-GNN is formally defined as (STEP 2 in Figure 2):
-
1.
Node formulation: Each region () is represented as a node in graph . And the edge weight between node and node is the cosine similarity of corresponding region features.
-
2.
Spatial Connectivity: Every pair of regions belonging to the same frame are connected, i.e. for a fixed , the sub-graph defined by the node set and the edges among them is a complete graph.
-
3.
Temporal Connectivity: Regions of the same scale and the same location are connected through different frames. Given , the sub-graph defined by the node set and the edges among them is a complete graph.
The spatio-temporal graph constructed with the procedure described above has a few desirable properties for a GCN. Details are provided in the Analysis part.
3.3 GNN for Spatio-temporal Feature Extraction
We consider an undirected graph . When applied to feature representation learning for a graph, graph neural networks are designed to learn a transition function as well as an output function . Such that:
| (1) |
| (2) |
where is all features, is the graph’s hidden states, denotes all the node features and denotes the final feature representation for all the graph nodes.
In this STAR-GNN frame work, instead of outputting all node representations, we use a global aggregation function to compress all these learned features into a single feature vector to represent the entire graph. That is, the graph neural networks in the STAR-GNN framework can be written as:
| (3) |
Here, is the GNN layer-wise operator and is the aggregate function which takes in a feature matrix for all the graph nodes and outputs a single feature vector.
In particular, the GNN layer-wise operator here can be replaced by any specific GNN implementation, such as the vanilla GCN layer [14] , cluster GCN layer [16] and so on. Here, is a renormalized adjacency matrix, denotes a learnable parameters. Correspondingly, function can be replaced by different strategies such mean aggregation, max pooling aggregation and so on.
In order to train STAR-GNN, we use the GCN mini-batch training strategy. But instead of mini-batches of nodes from the same graph as in most of the literature [16, 18], we spilt the training video set into mini-batches with videos in each, and use the set of spatio-temporal feature graphs that correspond to the videos as the input signal to STAR-GNN. We then use triplet loss to update the model’s parameters at each iteration on a mini-batch, which is defined as:
| (4) |
can be a triplet loss or contrastive loss, denotes the output graph features for an anchor video sample, denotes that for a positive retrieval sample and is that of a negative sample. Here we regard a labelled positive sample in the dataset for a given query as , and a random sample outside the labelled positive sample sets as . The gradient is then updated for each mini-batch iteration:
| (5) |
4 Experiments
4.1 Experimental Settings
Datasets. We verify the effectiveness of STAR-GNN and compare its performance with state-of-the-art methods on the widely-used VCDB [19] and the more recent SVD [20] datasets. The VCDB dataset contains 100,528 videos, with 528 queries and 6,139 manually annotated as positive retrieval samples. It was initially used for partial copy detection in videos, and then also widely used to evaluate the performance of video retrieval models. The SVD dataset is recent introduced for large-scale short video retrieval, which contains 562,013 short videos from Douyin (TikTok China). It contains 1,206 queries and 34,020 labeled videos, of which 10,211 are positive retrieval samples and 26,927 are negative. To make a fair comparison, we follow the setting in [20]: we use labeled queries for training and the other labeled queries for testing. We then take the model trained on SVD-train to perform further tests with VCDB.
Pluggable GNN Methods. We use different GNN methods to verify the stability of STAR-GNN. Initially we use vanilla GCN [14], which is one of the most classic GNN models. In addition, we also estimate the effects of SGCN [21] as well as Cluster-GCN. [16].
Evaluation Metrics. We measure the retrieval performance with mean Average Precision (mAP), which is a standard evaluation protocol in video retrieval.
Implementation Details. For frame features, we utilize the feature maps output from the last convolutional layer of the backbone network, which is VGG16 pre-trained on Imagenet in our experiments. A raw video’s smaller edge is resized into 256, then center-cropped into 224 224, and is extracted with the feature map of 7 7 512. We then use sliding windows of three different scales, namely , and , to obtain 9, 4 and 1 regional features respectively. Consequently, each frame is split into 14 regions. Then, we apply the global max-pooling operation on the regional feature. After extracting node features from STAR-GNN, we use zero-mean and L2-normalization, to generate the final video-level features. And We set for STAR-GNN’s graph neural network and set the activation function to ReLU. For training, we set the margin = 0.5 in the triplet loss function, and train the model with batch size of 128. We used online hard triplet mining strategy. For each anchor, we select the hardest negative (smallest distance to anchor) in the batch.
| SVD | VCDB | ||||||||
| 0 | 10K | 50K | 100K | 520K | 0 | 10K | 50K | 100K | |
| MAC[3] | 0.8974 | 0.8031 | 0.7787 | 0.7725 | 0.7499 | 0.7307 | 0.6268 | 0.5405 | 0.5068 |
| R-MAC [3] | 0.8981 | 0.8163 | 0.7918 | 0.7852 | 0.7642 | 0.7362 | 0.6395 | 0.5524 | 0.5170 |
| SPOC [4] | 0.8845 | 0.8002 | 0.7745 | 0.7643 | 0.7271 | 0.6849 | 0.5786 | 0.5003 | 0.4667 |
| 3D-shufflenetv2[22] | 0.4244 | 0.0019 | 0.0004 | 0.0002 | 0.0000 | 0.1258 | 0.0724 | 0.0697 | 0.0693 |
| DML[2] | 0.9063 | 0.8287 | 0.8074 | 0.8014 | 0.7706 | 0.7681 | 0.6670 | 0.5760 | 0.5373 |
| 3D-shufflenetv2(Supervised) | 0.6532 | 0.1413 | 0.1108 | 0.1023 | 0.0816 | 0.2102 | 0.1328 | 0.1221 | 0.1204 |
| RGB[23] | 0.9140 | - | - | - | - | - | - | - | - |
| STAR-GNN(CL+Cluster-GCN) | 0.9278 | 0.8812 | 0.8597 | 0.8528 | 0.8234 | 0.7561 | 0.6675 | 0.5888 | 0.5541 |
| STAR-GNN(TL+Cluster-GCN) | 0.9329 | 0.8782 | 0.8563 | 0.8462 | 0.8110 | 0.7954 | 0.714 | 0.6356 | 0.5997 |
| STAR-GNN (TL+vanilla GCN) | 0.9216 | 0.7965 | 0.7965 | 0.7965 | 0.7965 | 0.7742 | 0.6665 | 0.5807 | 0.5447 |
| STAR-GNN (TL+SGCN) | 0.9321 | 0.8704 | 0.8522 | 0.8416 | 0.8054 | 0.8025 | 0.7201 | 0.6424 | 0.6077 |
4.2 Comparative Results
In the experiments, we compare the proposed method with six state-of-the-art content-based video retrieval methods, including MAC[3], RMAC[3], SPOC[4], 3D-shuffenetv2[22], DML[2], 3D-shuffenetv2(Supervised)[22] and RGB[23]. Among them, MAC, RMAC, and SPOC used VGG pre-trained on ImageNet as feature extractor, and 3D-shuffenetV2 used a 3D convolutional network pre-trained on video classification dataset Kinetics-600[24]. For DML and 3D-shuffenetV2(Supervised), we use the same training set with STAR-GNN. RGB is a attention-based deep metric learning model, which we use the data from the source paper. For STAR-GNN, CL denote Contrastive Loss and TL denote Triplet Loss. Comparative results for retrieval mAP on SVD and VCDB datasets are shown in Table 1. The top half of Table 1 includes the results for some previous methods while the lower half shows the methods using STAR-GNN framework. Additional Distraction stands for the number of distractor videos, which are randomly selected, unlabeled videos (apart from the positive samples and negative samples labelled) in test datasets. They drastically increase the volume of the candidate set and raise the difficulty significantly for retrieval. For each configuration, we use bold text to mark the best performing results.
From the Table 1, we can see that STAR-GNN outperform all other baselines under all distraction settings. On SVD, our method gives mAP=0.9329 without distractor, which is a 2.67% relative improvement compared to the current state-of-the-art supervised CBVR method, i.e., DML[2], and a 5.28% relative improvement when the number of distractor videos is 520,000. A similar trend was reported on VCDB dataset, STAR-GNN outperforms other baselines with a consistent margin (+0.0273 +0.0624) on VCDB. Importantly, with the size of the distraction set increasing, the mAP of all methods will decrease, but STAR-GNN decreases the least, which means STAR-GNN is significantly more stable to the feature representation of the videos. On SVD, with an increasing additional distraction set from 0 to 520K, the mAP of our proposed method are 92.78%, 88.12%, 85.97%, 85.28%, 82.34%, respectively. On VCDB, the mAP of our proposed method are 80.25%, 88.12%, 72.01%, 64.24%, 60.77%, respectively. All reported results show that STAR-GNN has significant benefit to content-based video retrieval.
4.3 Ablation studies
4.3.1 Effect of Network Structure Settings
The Table 1 shows the evaluation results of the different components of our proposed method. The best results are achieved by the STAR-GNN(Contrastive Loss+Cluster-GCN) on SVD and STAR-GNN(Triplet Loss+SGCN) on VCDB. The results reflect that Cluster-GCN and SGCN work better than vanilla GCN. The impact of the loss function is not certain. The contrastive loss performance is better on the SVD dataset, while on the VCDB, the triplet loss has an advantage.
4.3.2 Effect of Region Size
We use the multi-scale regions on CNN feature map to construct the spatio-temporal feature graph. The region size affects the number of areas, so we evaluate the effect region size. Table 2 shows the experimental results of different region sizes. With single-scale regions, as the size decreases, retrieval performance improves. However, as we utilise combined, multi-scale regions, the method exhibits a substantial performance gain.
| Region Size | Number of Regions | SVD | VCDB |
|---|---|---|---|
| 7x7 | 1 (1×1) | 0.6937 | 0.4552 |
| 4x4 | 4 (2×2) | 0.7648 | 0.5002 |
| 3x3 | 9 (3×3) | 0.7858 | 0.5246 |
| Multi-scale | 14(1+4+9) | 0.8234 | 0.6077 |
4.3.3 Effect of Edge Weights
We also evaluated whether to use the similarity between regions as the weight of edges when constructing the spatio-temporal feature graph. Table 3 verifies that by formulating the spatio-temporal feature graph into a weighted graph, STAR-GNN is able to better reflect each video’s spatio-temporal characteristics through its graph topology. It should be noted that the weighted graph can be further improved performance, but the weighted graph needs to calculate the similarity between connected node, which causes huge computational cost. Therefore, this part of the experiment is only carried out on SVD-10K, which is a subset of SVD.
| STAR-GNN | STAR-GNN (Unweighted) | |
| SVD-10K | 0.9112 | 0.8812 |
4.3.4 Effect of Training Dataset Size
To evaluate the the impact of the training set size on the experimental results, Table 4 shows the mAP with different training dataset ratios. The mAP on both datasets improves as the ratio of the train set increases. For example, on SVD as we increase the train ratio from 10% to 100%, the mAP also climbs from 0.7749 to 0.8110. Similar results are observed on VCDB too. This shows that as the training set increases, the retrieval performance of STAR-GNN will improve. It is worth noting that STAR-GNN achieves competitive performance with only a small amount of labeled training data (even 10%), and is able to learn from more labelled samples.
| Ratio | 10% | 20% | 50% | 70% | 100% |
|---|---|---|---|---|---|
| SVD | 0.7749 | 0.7945 | 0.7981 | 0.7936 | 0.8110 |
| VCDB | 0.5321 | 0.5704 | 0.5603 | 0.5880 | 0.5997 |
5 Conclusion
We propose a novel method called STAR-GNN as a video feature extractor for CBVR. STAR-GNN employs graph neural networks to perform spatial-temporary context aggregation so that the video feature representation is sensitive to the dynamic and semantic-rich part. We show that it effectively implements a dynamic attention mechanism for CBVR, hence is robust to the perturbation and over-representation introduced by back banners, logos, subtitles, overlays, or identical frames, etc, in the video. We also show the spatio-temporal feature graph that STAR-GNN constructs have a few properties that are beneficial to the quality of GNN-generated features. The method achieves SOTA retrieval performance on two public datasets and exhibits strong evidence for its capability of preserving dynamic and semantically meaningful contents in its feature representation. In the future, we will extend our work into video recommendation and caption.
References
- [1] Xirong Li, Chaoxi Xu, Gang Yang, Zhineng Chen, and Jianfeng Dong, “W2vv++ fully deep learning for ad-hoc video search,” in ACM MM, 2019, pp. 1786–1794.
- [2] Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and Yiannis Kompatsiaris, “Near-duplicate video retrieval with deep metric learning,” in ICCVW, 2017, pp. 347–356.
- [3] Giorgos Tolias, Ronan Sicre, and Hervé Jégou, “Particular object retrieval with integral max-pooling of cnn activations,” ICLR, 2016.
- [4] Artem Babenko and Victor Lempitsky, “Aggregating local deep features for image retrieval,” in ICCV, 2015, pp. 1269–1277.
- [5] Yun Gu, Chao Ma, and Jie Yang, “Supervised recurrent hashing for large scale video retrieval,” in ACM MM, 2016, pp. 272–276.
- [6] Andrei Nicolicioiu, Iulia Duta, and Marius Leordeanu, “Recurrent space-time graph neural networks,” in NeurIPS, 2019.
- [7] Xiaolong Wang and Abhinav Gupta, “Videos as space-time region graphs,” in ECCV, 2018, pp. 399–417.
- [8] Yichao Yan, Jie Qin, Jiaxin Chen, Li Liu, Fan Zhu, Ying Tai, and Ling Shao, “Learning multi-granular hypergraphs for video-based person re-identification,” in CVPR, 2020, pp. 2899–2908.
- [9] Anna Podlesnaya and Sergey Podlesnyy, “Deep learning based semantic video indexing and retrieval,” in IntelliSys, 2016, pp. 359–372.
- [10] Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and Ioannis Kompatsiaris, “Visil: Fine-grained spatio-temporal video similarity learning,” in ICCV, 2019, pp. 6351–6360.
- [11] Zhen Han, Xiangteng He, Mingqian Tang, and Yiliang Lv, “Video similarity and alignment learning on partial video copy detection,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 4165–4173.
- [12] Na Zhao, Hanwang Zhang, Richang Hong, Meng Wang, and Tat-Seng Chua, “Videowhisper: Toward discriminative unsupervised video feature learning with attention-based recurrent neural networks,” IEEE Transactions on Multimedia, vol. 19, no. 9, pp. 2080–2092, 2017.
- [13] Dejing Xu, Jun Xiao, Zhou Zhao, Jian Shao, Di Xie, and Yueting Zhuang, “Self-supervised spatiotemporal learning via video clip order prediction,” in CVPR, 2019, pp. 10334–10343.
- [14] Thomas N Kipf and Max Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [15] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip, “A comprehensive survey on graph neural networks,” TNNLS, 2020.
- [16] Wei-Lin Chiang, Xuanqing Liu, Si Si, Yang Li, Samy Bengio, and Cho-Jui Hsieh, “Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks,” in KDD, 2019, pp. 257–266.
- [17] Sijie Yan, Yuanjun Xiong, and Dahua Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” in Thirty-second AAAI conference on artificial intelligence, 2018.
- [18] Will Hamilton, Zhitao Ying, and Jure Leskovec, “Inductive representation learning on large graphs,” in NeurIPS, 2017, pp. 1024–1034.
- [19] Yu-Gang Jiang, Yudong Jiang, and Jiajun Wang, “Vcdb: a large-scale database for partial copy detection in videos,” in ECCV. Springer, 2014, pp. 357–371.
- [20] Qing-Yuan Jiang, Yi He, Gen Li, Jian Lin, Lei Li, and Wu-Jun Li, “Svd: A large-scale short video dataset for near-duplicate video retrieval,” in ICCV, 2019, pp. 5281–5289.
- [21] Felix Wu, Amauri H. Souza Jr., Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Q. Weinberger, “Simplifying graph convolutional networks,” in ICML, 2019, pp. 6861–6871.
- [22] Okan Köpüklü, Neslihan Kose, Ahmet Gunduz, and Gerhard Rigoll, “Resource efficient 3d convolutional neural networks,” in ICCVW, 2019, pp. 1910–1919.
- [23] Kuan-Hsun Wang, Chia-Chun Cheng, Yi-Ling Chen, Yale Song, and Shang-Hong Lai, “Attention-based deep metric learning for near-duplicate video retrieval,” in ICPR. IEEE, 2021, pp. 5360–5367.
- [24] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al., “The kinetics human action video dataset,” arXiv:1705.06950, 2017.