Stable Diffusion is Unstable
Abstract
Recently, text-to-image models have been thriving. Despite their powerful generative capacity, our research has uncovered a lack of robustness in this generation process. Specifically, the introduction of small perturbations to the text prompts can result in the blending of primary subjects with other categories or their complete disappearance in the generated images. In this paper, we propose Auto-attack on Text-to-image Models (ATM), a gradient-based approach, to effectively and efficiently generate such perturbations. By learning a Gumbel Softmax distribution, we can make the discrete process of word replacement or extension continuous, thus ensuring the differentiability of the perturbation generation. Once the distribution is learned, ATM can sample multiple attack samples simultaneously. These attack samples can prevent the generative model from generating the desired subjects without compromising image quality. ATM has achieved a 91.1% success rate in short-text attacks and an 81.2% success rate in long-text attacks. Further empirical analysis revealed four attack patterns based on: 1) the variability in generation speed, 2) the similarity of coarse-grained characteristics, 3) the polysemy of words, and 4) the positioning of words.
1 Introduction
In recent years, the field of text-to-image generation has witnessed remarkable advancements, paving the way for groundbreaking applications in computer vision and creative arts. Notably, many significant developments have captured the attention of researchers and enthusiasts, such as Stable Diffusion [20, 24], DALLE [18, 19, 15] and Midjourney [11]. These developments push text-to-image synthesis boundaries, fostering artistic expression and driving computer vision research.
Despite the remarkable progress in text-to-image models, it is important to acknowledge their current limitations. One significant challenge lies in the instability and inconsistency of the generated outputs. In some cases, it can take multiple attempts to obtain the desired image that accurately represents the given textual input. An additional obstacle revealed by recent researches [25, 1, 4] is that the quality of generated images can be influenced by specific characteristics inherent to text prompts. Tang et al. [25] proposes DAAM, which performs a text-image attribution analysis on conditional text-to-image model and produces pixel-level attribution maps. Their research focuses on the phenomenon of feature entanglement and uncovers that the presence of cohyponyms may degrade the quality of generated images and that descriptive adjectives can attend too broadly across the image. Attend-and-Excite [1] investigates the presence of catastrophic neglect in the Stable diffusion model, where the generative model fails to include one or more of the subjects specified in the input prompt. Additionally, they discover instances where the model fails to accurately associate attributes such as colors with their respective subjects. Although those works have some progress, there is still work to be done to enhance the stability and reliability of text-to-image models, ensuring consistent and satisfactory results for a wide range of text prompts.
One prominent constraint observed in those works related to the stability of text-to-image models lies in their dependence on manually crafted prompts for the purpose of vulnerability identification. This approach presents several challenges. Firstly, it becomes difficult to quantify the success and failure cases accurately, as the evaluation largely depends on subjective judgments and qualitative assessments. Additionally, the manual design of prompts can only uncover a limited number of potential failure cases, leaving many unexplored scenarios. Without a substantial number of cases, it becomes challenging to identify the underlying reasons for failures and effectively address them. To overcome these limitations, there is a growing demand for a learnable method that can automatically identify failure cases, enabling a more comprehensive and data-driven approach to improve text-to-image models. By leveraging such an approach, researchers can gain valuable insights into the shortcomings of current methods and develop more robust and reliable systems for generating images from textual descriptions.

In this paper, we propose Auto-attack on Text-to-image Models (ATM), to efficiently generate attack prompts with high similarity to given clean prompts (Fig. 1). We use Stable Diffusion [20, 24], a widely adopted open-source model, as our target model. With the open-source implementation and model parameters, we can generate attack prompts with a white-box attack strategy. Remarkably, those attack prompts can transfer to other generative models, enabling black-box attacks. Two methods to modify a text prompt are considered, including replacing an existing word or extending with new ones. By incorporating a Gumbel Softmax distribution into the word embedding, the discrete modifications can be transformed into continuous ones, thereby ensuring differentiability. To ensure the similarity between clean and the attack prompts, a binary mask that selectively preserves the noun representing the desired object is applied. Moreover, two constraints are imposed: a fluency constraint that ensures the attack prompt is fluent and easy to read, and a similarity constraint that regulates the extent of semantic changes.
After the distribution is learned, ATM can sample multiple attack prompts at once. The attack prompts can prevent the diffusion model from generating desired subjects without modifying the nouns of desired subjects and maintain a high degree of similarity with the original prompt. We have achieved a 91.1% success rate in short-text attacks and a 81.2% success rate in long-text attacks. Moreover, drawing upon extensive experiments and empirical analyses employing ATM, we are able to disclose the existence of four distinct attack patterns, each of which corresponds to a vulnerability in the generative model: 1) the variability in generation speed; 2) the similarity of coarse-grained characteristics; 3) the polysemy of words; 4) the positioning of words. In the following, we will commence with an analysis of the discovered attack patterns in Section 4, followed by a detailed exposition of our attack method in Section 5.
In this paper, we propose a novel method to automatically and efficiently generate plenty of successful attack prompts, which serves as a valuable tool for investigating vulnerabilities in text-to-image generation pipelines. This method enables the identification of a wider range of attack patterns, facilitating a comprehensive examination of the underlying causes. It will inspire the research community and garner increased attention toward exploring the vulnerabilities present in contemporary text-to-image models and will foster further research concerning both attack and defensive mechanisms, ultimately leading to enhanced security within the industry.
2 Related Work
2.1 Diffusion Model.
Recently, the diffusion probabilistic model [22] and its variants [6, 13, 23, 20, 21] have achieved great success in content generation [23, 7, 21], including image generation [6, 23], conditional image generation [20], video generation [7, 27], 3D scenes synthesis [10] and so on. Specifically, DDPM [6] adds noises to images and learns to recover images from noises step by step. Then, DDIM [23] improves the generation speed of the diffusion model by skipping steps inference. Then, the conditional latent diffusion model [20] formulates the image generation in latent space guided by multiple conditions, such as texts, images, and semantic maps, further improving the inference speed and boarding the application of the diffusion model. Stable diffusion [20], a latent text-to-image diffusion model capable of generating photo-realistic images given any text input, and its enhanced versions [28, 8, 12], have been widely used in current AI-generated content products, such as Stability-AI [24], Midjourney [11], DALLE2 [15], and Runaway [3]. However, these methods and products cannot always generate satisfactory results from the given prompt. Therefore, in this work, we aim to analyze the robustness of stable diffusion in the generation process.
2.2 Vulnerabilities in Text-to-image Models.
With the open-source of Stable Diffusion [20], text-to-image generation achieves great process and shows the unparalleled ability on generating diverse and creative images with the guidance of a text prompt. However, there are some vulnerabilities have been discovered in existing works [4, 1, 25]. Typically, StructureDiffusion [4] discovers that some attributes in the prompt are not assigned correctly in the generated images, thus they employ consistency trees or scene graphs to enhance the embedding learning of the prompt. In addition, Attend-and-Excite [1] also introduces that the Stable Diffusion model fails to generate one or more of the subjects from the input prompt and fails to correctly bind attributes to their corresponding subjects. These pieces of evidence demonstrate the vulnerabilities of the current Stable Diffusion model. However, to the best of our knowledge, no work has systematically analyzed the vulnerabilities of the Stable Diffusion model, which is the goal of this work.
3 Preliminary
The architecture of the Stable Diffusion [20] comprises of an encoder and a decoder , where . Additionally, a conditional denoising network and a condition encoder are employed. In the text-to-image task, the condition encoder is a text encoder that maps text prompts into a latent space. The text prompt is typically a sequence of word tokens , where is the sequence length. During the image generation process, a random latent representation is draw from a distribution such as a Gaussian distribution. Then, the reverse diffusion process is used to gradually recover a noise-free latent representation . Specifically, a conditional denoising network is trained to gradually denoise at each time step to gradually reduce the noise level of , where the condition is mapped in to a latent space using maps and the cross-attention between the condition and features is incorporated in to introduce the condition. Finally, the denoised latent representation is decoded by a decoder to produce the final output . The aim of our study is to introduce slight perturbations to the text prompts, thereby inducing the intended object to be blended with other objects or entirely omitted from the generated images. For the sake of simplification, in the forthcoming sections, we shall represent the image generation process using the GM as .
4 Vulnerabilities of Stable Diffusion Model
By applying the attack method proposed in this paper, a variety of attack text prompts can be generated and analyzed. In this section, the identified attack patterns are discussed. Details of the attack method are introduced in Section 5. We have discovered four distinct patterns of impairment in Stable Diffusion model: 1) the variability in generation speed, where the model struggles to reconcile the differences in generation speed among various categories effectively. 2) the similarity of coarse-grained characteristics, which arises from the feature entanglement of global or partial coarse-grained characteristics, which possess a high degree of entanglement. 3) the polysemy of words, which involves the addition of semantically complementary words to the original prompt, resulting in the creation of images that contain brand-new content and are not related to the original category. 4) the positioning of words, where the position of the category word within the prompt influences the final outcome of the generated image.
4.1 Variability in Generation Speed


Observation 1.
When a given text prompt contains a noun representing the object to be generated, the introduction of another noun into the prompt, either through addition or replacement, leads to the disappearance of noun from the generated image, replaced instead by noun .
In Observation 1, we identify a phenomenon when replacing or adding a noun in the description in a text prompt, the new noun will lead to the completely disappear of the desired subject. As shown in Fig. 3, if the noun "peak" is replaced by "peafowl", the desired subject "mountain" disappears and the new subject "peafowl" is generated. To further investigate this phenomenon, we use two short prompts and containing "mountain" and "peafowl", respectively, to exclude the influence of other words in the long prompts. To eliminate the additional impact of all possible extraneous factors, such as contextual relationships, they are embedded separately and then concatenated together: . The result shows that almost no element of the mountain is visible in the generated image (Fig. 3).
Further analysis reveals a nontrivial difference in the generation speeds of the two subjects. To define the generation speed, a metric to measure the distance from a generated image at a given time step to the output image is desired (note, is the initial noise). We use the structural similarity (SSIM) [26] as the distance metrics: . Therefore, the generation speed can be formally defined as the derivative of the SSIM regarding the time step: , where . Thereby, we propose our Pattern 1.
Pattern 1 (Variability in Generation Speed).
Comparing the generation speeds ( and ) of two subjects ( and ), it can be observed that the outline of the object in the generated image will be taken by if . And it can be inferred that will not be visible in the resulting image.
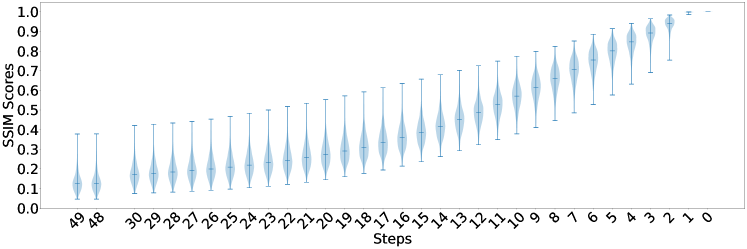
We further generates images of various classes with the same initial noise and visualize their generation speed in Fig. 4 as a violin plot. The SSIM distance from the generated images at each step to the final image is calculated. The horizontal axis represents steps, while the vertical axis represents the SSIM scores. Each violin represents the distribution of the SSIM scores of the images in a step, with the width corresponds to the frequency of images reaches the score. In the early stages of generation, the median of the distribution is positioned closer to the minimum value, indicating that a majority of classes exhibit slow generation speeds. However, the presence of a high maximum value suggests the existence of classes that generate relatively quickly. In the middle stages of generation, the median of the distribution gradually increases, positioning itself between the maximum and minimum values. In the later stages of generation, the median of the distribution is positioned closer to the maximum value, indicating that a majority of classes are nearing completion. However, the persistence of a low minimum value suggests the presence of classes that still exhibit slow generation speeds. This analysis highlights the variation in generation speeds across different classes throughout the entire generation process. This phenomenon can be interpreted as a characteristic of the generation process, where different classes exhibit varying speeds throughout the stages. It is possible that certain classes have inherent complexities or dependencies that cause them to generate more slowly. Conversely, other classes may have simpler structures or fewer dependencies, leading to faster generation.
4.2 Similarity of Coarse-grained Characteristics





Observation 2.
When a text prompt contains a noun representing the object to be generated, the introduction of another noun , which describes an object with similar coarse-grained characteristics to the object represented by noun , into the prompt, either through addition or replacement, results in the generation of an image that contains an object combining elements of both nouns and .
The second case that we observed in our attacks is when two nouns in the text prompt share similar coarse-grained characteristics, the generated image will contain a subject that is a combination of these two nouns. As illustrated in Fig. 6, when given the text "a silver salmon and a feather," the GMs generate an image of a feather with the outline of a salmon. This happens because these two nouns (i.e., salmon and feather) exhibit a certain degree of similarity in their coarse-grained attributes. In contrast, there is no feature entanglement between "salmon" and "magician" because their coarse-grained features are vastly different from each other.
To verify this assumption, we first obtain the generated latent variable for the prompt "a photo of a silver salmon" at the early sampling step (e.g., 42 steps). Using this latent variable, we replace the prompt with "a photo of a feather" and continue generating images. The results confirm that feathers can continue to be generated based on the coarse-grained properties of silver salmon, and the final generated graph has high similarity with the generated graph of the prompt "a photo of a silver salmon and a feather". However, replacing "silver salmon" with "magician" does not seem to generate any object similar to "magician". This observation indicates that there is no coarse-grained feature entanglement between these two subjects. We summarize this observation in Pattern 2.
Pattern 2 (Similarity of Coarse-grained Characteristics).
Let and denote the latent variables generated by the GM for word tokens and , respectively. Suppose is small and let represent the metric that measures the outline similarity between two images. If the text prompt contains both and , and falls below the threshold , then feature entanglement occurs in the generated image.
Based on the observed Pattern 2, The types of feature entanglement can be further divided into, direct entanglement and indirect entanglement. As shown in Fig. 5, direct entanglement represents the direct entanglement triggered by two categories of coarse-grained attributes that have global or local similarities. Indirect entanglement is shown in Fig. 5(d), where the additional attribute trunk brought by the howler monkey has a high similarity with the coarse-grained attribute of the snake, thus triggering the entanglement phenomenon.
4.3 Polysemy of Words








Observation 3.
When a text prompt contains a noun representing the object to be generated, if the semantic scope of noun encompasses multiple distinct objects, the generated image contains one of the objects described by noun . If there exists another word that, when combined with noun , directs its semantics to a particular object, the introduction of word into the prompt, either through addition or replacement, leads to the generation of an image that specifically contains that particular object.
The third scenario we observed in the attack is that the content of the generated image is not directly related to either the desired image or the added word. However, this is again different from a category of disappearance, where the desired target has a clear individual in the image. As illustrated in Figs. 7(a), 7(b) and 7(c), when the cleaning prompt "a photo of a bat" was modified to "a photo of a bat and a ball", the bat disappeared completely from the generated image, but the DDAM[25] heat map showed that the word "bat" is highly associated with the stick-like object in the newly generated image.
Pattern 3 (Polysemy of Words).
When interpreting polysemous words, language models must rely on contextual cues to distinguish meanings. However, in some cases, the available contextual information may be insufficient or confuse the model by modifying specific words, resulting in a model-generated image that deviates from the actual intention of the user.
To further investigate the phenomenon of word polysemy in the Stable diffusion model, we used the prompts "a photo of a bat", "a photo of a baseball bat" and "a photo of a bat and a ball" to generate 100 images each using the stable diffusion model, and transformed these images into embedding form by CLIP image encoder, and transformed "a photo of a bat" into embedding form by CLIP text encoder, then visualized these 301 embeddings by t-SNE. As illustrated in Fig. 7(g), Considering the entire set of bat images, bats (the animal) are closer to the text "a photo of a bat" than baseball bats are, as depicted in the t-SNE visualization. However, the distribution of the two categories also has relatively close proximity, indicating their underlying similarities. The category of "bat and ball" shows a more expansive distribution, almost enveloping the other two. This suggests that by modifying the original text from "a photo of a bat" to "a photo of a bat and a ball", the distribution of the clean text can be pulled towards another meaning in the polysemous nature of the word "bat". From the perspective of text-to-image model, this kind of modification can stimulate the polysemous property of the word, thereby achieving an attack effect.
In addition to this explicit polysemy, our algorithm further demonstrates its aptitude for detecting subtler instances of polysemous words. As depicted in Figure 8, the transformative capacity of our algorithm is evident when an image of a warthog (Fig. 7(d)) transfigures into an image of a military chariot (Fig. 7(e)) with the incorporation of the term "traitor".
4.4 Positioning of Words









In addition to the three aforementioned observations and patterns outlined in the paper, there is a fourth observations (Observation 4), which is related to positioning of words.
Observation 4.
When a text prompt contains a noun representing the object to be generated, there exists a preceding word and a succeeding word around noun . When replacing either word or with another noun , for certain instances of noun , replacing word results in the generation of an image containing noun , while replacing word still results in the generation of an image containing noun . Conversely, for other instances of noun , the opposite scenario occurs.
An example of Pattern 4 is shown in Fig. 9. When "footwear" is replaced by "pistol", the generated image contains a pistol instead of clogs. However, when "Ductch" is replaced by "pistol", the model still generates an image of clogs. In addition to differences in the words being replaced, a significant distinction between the two aforementioned examples of success and failure lies in the relative positioning of the word being replaced with respect to the target class word. We hypothesize that this phenomenon occurs due to the different order of the replaced words or with respect to the noun . To exclude the effects of complex contextual structures, a template for a short prompt, "A photo of , and ", is used, and the order of , , and are swapped (Fig. 10).
When these sentences with different sequences of category words are understood from a human perspective, they all have basically the same semantics: both describe a picture containing a cat, clogs, and a pistol. However, in the processing of language models (including CLIP), the order of words may affect their comprehension. Although positional encoding provides the model with the relative positions of words, the model may associate different orders with different semantics through learned patterns. Therefore, we propose our Pattern 4.
Pattern 4 (Positioning of Words).
Let denote a set of vocabulary. Let denote the subset of all nouns in the vocabulary. Consider a text prompt containing noun representing the object to be generated. Furthermore, assume there exist preceding word and succeeding word surrounding noun . There exists a condition-dependent behavior regarding the replacement of words and with another noun :
5 Auto-attack on Text-to-image Model
We aim to design an automatic attack method that targets the recent popular text-to-image models. The objective of our method is to identify attack prompts based on a clean prompt , which leads to a vision model failing to predict the desired class , i.e. :
| (1) |
where is a text-to-image model, , is a distance measure regularizing the similarity between and , and is a maximum distance. To enable auto-attack, a differentiable method that can be optimized using gradient descent is desired. We introduce a Gumbel-Softmax sampler to enable differentiable modifications on text prompts during the word embedding phase. To minimize the distance , we introduce two constraints, including a fluency constraint and a similarity constraint.
In our experimental setup, the open-source Stable Diffusion model is employed as the targeted generative model . By generating white-box attack prompts for Stable Diffusion, we can subsequently transfer these prompts to other generative models to execute black-box attacks. To facilitate the classification task, we utilize a CLIP classifier as the vision model , benefiting from its exceptional zero-shot classification accuracy. To establish the desired classes, we employ the 1,000 classes derived from ImageNet-1K. In the case of generating short prompts, a fixed template of "A photo of [CLASS_NAME]" is utilized to generate the prompts. Conversely, for the generation of long prompts, we employ ChatGPT 4 [16] as a prompt generation model. Subsequently, human experts verify the correctness of the prompts and check that the prompts indeed contain the noun associated with the desired class.
5.1 Differentiable Text Prompt Modification
A text prompt is typically a sequence of words . Owing to the discrete nature of text prompts , perturbations can be incorporated either by replacing an existing word where or augmenting with new ones . However, the non-differentiable nature of this procedure makes it unsuitable for optimization utilizing gradient-based techniques. Therefore, there is a need for a mechanism that guarantees the differentiability of the word selection process. In this regard, we integrate a Gumbel Softmax sampler into the word embedding phase. The Gumbel Softmax function has the ability to approximate a one-hot distribution as the temperature . Additionally, the Gumbel distribution has the ability to introduce further randomness, thereby enhancing the exploitability during the initial stages of perturbation search.
Differentiable Sampling.
We employ a trainable matrix to learn the word selection distribution, where is the length of the text prompt and is the vocabulary size. In the scenario of augmenting with a new word, the sequence length can be extended to to facilitate the addition of new words. The Gumbel Softmax can be represented as follows:
| (2) |
where are i.i.d. samples from a Gumbel distribution. The word embedding stage employs a matrix , where is the vocabulary size and is for the embedding dimensionality. The discrete process of word embedding is to select from based on the index of a word in the vocabulary. To make this process differentiable , the dot product between and can be calculate:
| (3) |
where is the new word selected according to . As , Eq. 3 can effectively emulate an selection procedure.
Additionally, in order to ensure similarity, it is desired to preserve the noun representing the desired object in the new prompt. This is achieved by utilizing a binary mask , where the position corresponding to the desired noun is set to while other positions are set to . By computing , the desired noun can be retained in the prompt while other words can be modified.
Attack Objective.
To generate images that cannot be correctly classified by the classifier, a margin loss can be used as the loss function in Eq. 1:
| (4) |
where is a margin. Eq. 4 reduces the classifier’s confidence on the true class and improve its confidence on the class with the largest confidence, excluding until a margin is reached.
5.2 Constraints on Fluency and Similarity
Given that we search for perturbations in a space to attack the text prompt, the attack prompts may be too diverse if the added perturbations are not properly constrained, making it easily detectable. Eq. 1 includes a distance constraint such that , which ensures that the added perturbations are subtle and hard to notice. The measurement of distance between two pieces of text can be approached through various methods. We introduce two constraints to reduce this distance, namely a fluency constraint and a semantic similarity constraint. The fluency constraint ensures that the generated sentence is smooth and readable, while the semantic similarity semantic constraint regularize the semantic changes introduced by the perturbations, making the attack prompt closely resemble the clean prompt .
Fluency constraint.
The fluency constraint can be achieved visa a Casual Language Model (CLM) with log-probability outputs. The next token distribution we learn is compared with the next token distribution predicted by . Given a sequence of perturbed text , we use to predict the a token based on . Therefore, we can have a log-likelihood of the possible next word:
| (5) |
The next token distribution we learn can be easily obtained by . Subsequently, a cross-entropy loss function can be employed to optimize the learned distribution:
| (6) |
Eq. 6 serves as a regularizer to encourage the next word selection distribution to resemble the prediction of the CLM , thereby ensuring fluency.
Semantic similarity constraint.
Rather than simply considering a word similarity, we concern more about semantic similarity. One prominent metric used to evaluate semantic similarity is the BERTScore [30]. The calculation of BERTScore requires contextualized word embeddings. The aforementioned CLM is used again to extract the embeddings , where denotes the embedding network used in . The BERTScore between the clean prompt and the attack prompt can be calcualted by
| (7) |
where is the normalized inverse document frequency (), , and is either or depending on whether existing words are being replaced or new words are being added. To improve the similarity, we use as the our loss term.
The constrained objective.
Considering that the addition of constraints may limit the diversity of perturbation search, we introduce two hyper-parameters, and , to control the strength of the constraints. Then, the overall objective function can be written as:
| (8) | ||||
| (9) |
5.3 Generation of Attack Prompts
The overall procedure of ATM is as described in Algorithm 1. It consists of two stages: a search stage, where the Gumbel Softmax distribution is learned, and an attack stage, where we generate attack prompts using the learned distribution. In the search stage, we use gradient descent to optimize the parameters for each clean prompt over a period of iterations. Once is learned, we proceed to the attack stage. In this stage, we sample attack prompts from each learned . An attack prompt is considered successful if the image generated from it cannot be correctly classified by the visual classifier .
6 Experiments
In our experiments, we conduct comprehensive analyses of both long and short prompts. Furthermore, we conduct ablation studies specifically on long prompts, focusing on three key aspects. Firstly, we evaluate our attack method with different numbers of search steps . Secondly, we investigate the influence of our constraints, including fluency and semantic similarity as measured by BERTScore. Lastly, we attack different samplers, including DDIM [23] and DPM-Solver [9]. Moreover, we verify that the generated attack prompt able to influence DALLE2 and mid-journey via black box attack.
6.1 Experimental Setting.
Attack hyperparamters.
The number of search iterations is set to . This value determines the number of iterations in the search stage, during which we aim to find the most effective attack prompts. The number of attack candidates is set to . This parameter specifies the number of candidate attack prompts considered in the attack stage, allowing for a diverse range of potential attack prompts to be explored. The learning rate for the matrix is set to . The margin in the margin loss is set to .
Text prompts.
Our experiments consider the classes from ImageNet-1K [2], which serves as the basis for generating images. To explore the impact of prompt length, we consider both short and long prompts. For clean short prompts, we employ a standardized template: "A photo of [CLASS_NAME]". Clean long prompts, on the other hand, are generated using ChatGPT 4 [16], with a prompt length restriction of 77 tokens to align with the upper limit of the CLIP [17] word embedder.
Evaluation metrics.
To evaluate the effectiveness of our attack method, we generate attack prompts from the clean prompts. We focus on three key metrics: success rate, Fréchet inception distance [5] (FID), Inception Score (IS), and text similarity (TS). Subsequently, images are generated using the attack prompts, ensuring a representative sample of 50 images per class. The success rate is determined by dividing the number of successful attacks by the total of 1,000 classes. FID and IS are computed by comparing the generated images to the ImageNet-1K validation set with (torch-fidelity)[14]. TS is calculated by embedding the attack prompts and clean prompts using the CLIP [17] word embedder, respectively. Subsequently, the cosine similarity between the embeddings is computed to quantify the text similarity.
6.2 Main Results
| Prompt | Method | Success (%) | FID | IS | TS |
|---|---|---|---|---|---|
| Short | Clean | - | 18.51 | 101.331.80 | 1.00 |
| Random | 79.2 | 29.21 | 66.710.87 | 0.69 | |
| ATM (Ours) | 91.1 | 30.09 | 65.981.10 | 0.72 | |
| Long | Clean | - | 17.95 | 103.591.68 | 1.00 |
| Random | 41.4 | 24.16 | 91.331.58 | 0.94 | |
| ATM (Ours) | 81.2 | 29.65 | 66.091.83 | 0.84 |
Table 1 reports our main results, including short-prompt and long-prompt attacks. Compares to long text prompts, short text prompts comprise only a small number of tokens. This leads to a relatively fragile structure that is extremely vulnerable to slight disturbance. Therefore, random attacks can reach an impressive success rate of 79.2% targeting short prompts but a low success rate of 41.4% targeting the long prompts. In the contrast, our algorithm demonstrates its true potential, reaching an impressive success rate of 91.1% and 81.2% targeting short and long prompts, respectively.
As a further evidence of the effectiveness of our algorithm, it’s worth noting the text similarity (TS) metrics between the random attacks and our algorithm’s outputs. For short-prompt attack, the values stand at 0.69 and 0.72, respectively, illustrating that the semantic information of short texts, while easy to disrupt, can be manipulated by a well-designed algorithm with fluency and semantic similarity constraints. Our attacks preserve more similarity with the clean prompts. For long-prompt attacks, the TS score of random attacks (0.94) is higher compared to our attacks (0.84). One possible reason is that random attacks tend to make only minimal modifications as the length of the prompt increases. This limited modification can explain the significantly lower success rate of random attacks on longer prompts.
From the perspective of image generation quality and diversity, we found that as the attack success rate increases, image generation quality and diversity will decrease. For short and long texts, images generated from the clean text have the lowest FID (18.51 and 17.95) and the highest IS (101.331.80 and 103.591.68). As the attack success rate rises, FID shows an upward trend. Examining this situation from the perspective of FID, a metric that gauges the distance between the distribution of generated images and the original data set. As the attack becomes more successful, the image set generated by the attack prompt tends to deviate substantially from the distribution of the original data set. This divergence consequently escalates the FID score, indicating a larger distance between the original and generated distributions. On the other hand, considering this situation from the diversity standpoint, it appears that the suppression of the generation of original categories brought on by the successful attack might instigate a decrease in diversity. This reduction in diversity, in turn, may cause a decrease in the Inception Score (IS).
6.3 Different Search Steps
| #Steps | Success (%) | FID | IS | TS |
|---|---|---|---|---|
| 50 | 68.7 | 34.00 | 93.941.84 | 0.97 |
| 100 | 81.2 | 29.65 | 66.091.83 | 0.84 |
| 150 | 67.2 | 45.23 | 58.510.79 | 0.82 |
Table 2 presents the results of using different numbers of steps in the search stage. For the step configuration, the success rate is 68.7%. The FID value is 34.00, with lower values suggesting better image quality. The IS is reported as 93.941.84, with higher values indicating diverse and high-quality images. The TS value is 0.97, representing a high level of text similarity. Moving on to the step configuration, the success rate increases to 81.2%, showing an improvement compared to the previous configuration. The FID value decreases to 29.65, indicating better image quality. The IS is reported as 66.091.83, showing a slight decrease compared to the previous configuration. The TS value is 0.84, suggesting a slight decrease in text similarity. In the step configuration, the success rate decreases to 67.2%, slightly lower than the initial configuration. The FID value increases to 45.23, suggesting a decrease in image quality. The IS is reported as 58.510.79, indicating a decrease in the diversity and quality of generated images. The TS value remains relatively stable at 0.82.
When using , the attack prompt fails to fit well and exhibits a higher text similarity with the clean prompt. Although the generated images at this stage still maintain good quality and closely resemble those generated by the clean prompt, the success rate of the attack is very low. On the other hand, when , overfitting occurs, resulting in a decrease in text similarity and image quality due to the overfitted attack prompt. Consequently, the success rate of the attack also decreases. Overall, the configuration of proves to be appropriate.
6.4 The Impact of Constraints
| Fluency | BERTScore | Success (%) | FID | IS | TS |
|---|---|---|---|---|---|
| ✗ | ✗ | 91.3 | 39.14 | 47.211.25 | 0.37 |
| ✓ | ✗ | 81.7 | 29.37 | 64.931.57 | 0.79 |
| ✗ | ✓ | 89.8 | 39.93 | 46.940.99 | 0.51 |
| ✓ | ✓ | 81.2 | 29.65 | 66.091.83 | 0.84 |
Table 3 examines the impact of the fluency and semantic similarity (BERTScore) constraints. When no constraints are applied, the attack success rate is notably high at 91.3%. However, this absence of constraints results in a lower text similarity (TS) score of 0.37, indicating a decreased resemblance to clean text and a decrease in image quality. By introducing fluency constraints alone, the attack success rate decreases to 81.7% but increases the text similarity to 0.79. Furthermore, incorporating semantic similarity constraints independently also leads to a slight reduction in success rate to 89.8%, but only marginally improves the text similarity to 0.51. The introduction of constraints, particularly fluency constraints, leads to an increase in text similarity. The fluency constraint takes into account the preceding tokens of each token, enabling the integration of contextual information for better enhancement of text similarity. On the other hand, BERTScore considers a weighted sum, focusing more on the similarity between individual tokens without preserving the interrelation between context. In other words, the word order may undergo changes as a result and leads to a low text similarity. Certainly, this outcome was expected, as BERTScore itself prioritizes the semantic consistency between two prompts, while the order of context may not necessarily impact semantics. This further highlights the importance of employing both constraints simultaneously. When both constraints are utilized together, the text similarity is further enhanced to 0.84. Meanwhile, the success rate of the attack (81.2%) is comparable to that achieved when employing only the fluency constraint, while the text similarity surpasses that obtained through the independent usage of the two constraints.
6.5 Different Samplers
| Sampler | Success (%) | FID | IS | TS |
|---|---|---|---|---|
| DDIM [23] | 81.2 | 29.65 | 66.091.83 | 0.84 |
| DPM-Solver [9] | 76.5 | 27.23 | 81.312.09 | 0.88 |
Table 4 illustrates the effectiveness of our attack method in successfully targeting both DDIM and the stronger DPM-Solver. For the DDIM sampler, our attack method achieves a success rate of 81.2%, indicating its ability to generate successful attack prompts. Similarly, our attack method demonstrates promising results when applied to the DPM-Solver sampler. With a success rate of 76.5%, it effectively generates attack prompts. The TS scores of 0.84 and 0.88, respectively, indicate a reasonable level of text similarity between the attack prompts and clean prompts. These outcomes demonstrate the transferability of our attack method, showcasing its effectiveness against both DDIM and the more potent DPM-Solver sampler.
6.6 Black-box attack







To further investigate whether our generated attack prompts can be transferred to different text-to-image models, we randomly selected attack prompts to attack DALLE2 and mid-journey, respectively. The experimental results (Fig. 11) prove that our attack prompts can also be used for black-box attacks. More results of black-box attacks are reported in the supplementary material.
7 Conclusion
The realm of text-to-image generation has observed a remarkable evolution over recent years, while concurrently exposing several vulnerabilities that require further exploration. Despite the many advancements, there are key limitations, specifically concerning the stability and reliability of generative models, which remain to be addressed. This paper has introduced Auto-attack on Text-to-image Models (ATM), a novel approach that generates a plethora of successful attack prompts, providing an efficient tool for probing vulnerabilities in text-to-image models. ATM not only identifies a broader array of attack patterns but also facilitates a comprehensive examination of the root causes. We believe that our proposed method will inspire the research community to shift their focus toward the vulnerabilities of present-day text-to-image models, stimulating further exploration of both attack and defensive strategies. This process will be pivotal in advancing the security mechanisms within the industry and contributing to the development of more robust and reliable systems for generating images from textual descriptions.
References
References
- Chefer et al. [2023] H. Chefer, Y. Alaluf, Y. Vinker, L. Wolf, and D. Cohen-Or. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. arXiv preprint arXiv:2301.13826, 2023.
- Deng et al. [2009] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Esser et al. [2023] P. Esser, J. Chiu, P. Atighehchian, J. Granskog, and A. Germanidis. Structure and content-guided video synthesis with diffusion models. arXiv preprint arXiv:2302.03011, 2023.
- Feng et al. [2022] W. Feng, X. He, T.-J. Fu, V. Jampani, A. Akula, P. Narayana, S. Basu, X. E. Wang, and W. Y. Wang. Training-free structured diffusion guidance for compositional text-to-image synthesis. arXiv preprint arXiv:2212.05032, 2022.
- Heusel et al. [2017] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho et al. [2020] J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Ho et al. [2022] J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet. Video diffusion models. arXiv preprint arXiv:2204.03458, 2022.
- Huang et al. [2023] L. Huang, D. Chen, Y. Liu, Y. Shen, D. Zhao, and J. Zhou. Composer: Creative and controllable image synthesis with composable conditions. arXiv preprint arXiv:2302.09778, 2023.
- Lu et al. [2022] C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. In Advances in Neural Information Processing Systems, 2022.
- Metzer et al. [2022] G. Metzer, E. Richardson, O. Patashnik, R. Giryes, and D. Cohen-Or. Latent-nerf for shape-guided generation of 3d shapes and textures. arXiv preprint arXiv:2211.07600, 2022.
- Midjourney [2023] Midjourney. Midjourney. https://www.midjourney.com/, 2023. Accessed on 2023-05-17.
- Mou et al. [2023] C. Mou, X. Wang, L. Xie, J. Zhang, Z. Qi, Y. Shan, and X. Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453, 2023.
- Nichol et al. [2021] A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Obukhov et al. [2020] A. Obukhov, M. Seitzer, P.-W. Wu, S. Zhydenko, J. Kyl, and E. Y.-J. Lin. High-fidelity performance metrics for generative models in pytorch, 2020. URL https://github.com/toshas/torch-fidelity. Version: 0.3.0, DOI: 10.5281/zenodo.4957738.
- OpenAI [2023a] OpenAI. Dalle 2. https://openai.com/product/dall-e-2, 2023a. Accessed on 2023-05-17.
- OpenAI [2023b] OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023b.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. [2021] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
- Ramesh et al. [2022] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Rombach et al. [2022] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- Ruan et al. [2022] L. Ruan, Y. Ma, H. Yang, H. He, B. Liu, J. Fu, N. J. Yuan, Q. Jin, and B. Guo. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. arXiv preprint arXiv:2212.09478, 2022.
- Sohl-Dickstein et al. [2015] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- Song et al. [2021] J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021.
- Stability-AI [2023] Stability-AI. Stable diffusion public release. https://stability.ai/blog/stable-diffusion-public-release, 2023. Accessed on 2023-05-17.
- Tang et al. [2022] R. Tang, A. Pandey, Z. Jiang, G. Yang, K. Kumar, J. Lin, and F. Ture. What the daam: Interpreting stable diffusion using cross attention. arXiv preprint arXiv:2210.04885, 2022.
- Wang et al. [2004] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Yin et al. [2023] S. Yin, C. Wu, H. Yang, J. Wang, X. Wang, M. Ni, Z. Yang, L. Li, S. Liu, F. Yang, et al. Nuwa-xl: Diffusion over diffusion for extremely long video generation. arXiv preprint arXiv:2303.12346, 2023.
- Zhang and Agrawala [2023] L. Zhang and M. Agrawala. Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543, 2023.
- Zhang et al. [2018] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
- Zhang et al. [2020] T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations, 2020.
A Vulnerabilities of Stable Diffusion Model
A.1 Pattern 1: Variability in Generation Speed


Fig. A.1 demonstrates the entire 50-step violin diagram which has been discussed before. To eliminate possible bias due to a single metric, we further verified the difference in generation speed of one thousand images based on the LPIPS [29] metric, as shown in Fig. A.2, The calculation of the LPIPS distance from the images generated at each stage to the ultimate image is performed. The horizontal axis signifies the range of steps from 49 down to 0, whereas the vertical axis denotes the respective LPIPS scores. Each violin plot illustrates the distribution of the LPIPS scores associated with 1,000 images at a specific step. The width of the violin plot is proportional to the frequency at which images achieve a certain score. During the initial stages of generation, the distribution’s median is situated nearer to the maximum LPIPS value, suggesting a preponderance of classes demonstrates slower generation velocities. Nonetheless, the existence of a low minimum value indicates the presence of classes that generate at comparatively faster rates. As the generation transitions to the intermediate stages, the distribution’s median progressively decreases, positioning itself between the maximum and minimum LPIPS values. In the concluding stages of generation, the distribution’s median is found closer to the minimum LPIPS value, implying that the majority of classes are nearing completion. However, the sustained high maximum value suggests that there are classes still exhibiting slower generation rates.
A.2 Pattern 2: Similarity of Coarse-grained Characteristics


To further verify that coarse-grained feature similarity is the root cause of feature entanglement, we provide more cases in Fig.A.3. From these cases, we can see that for the two classes where feature entanglement can occur, they can both continue the image generation task based on each other’s coarse-grained information.
A.3 Pattern 3: Polysemy of Words




















As shown in Fig. A.4, when we attack the prompt "A photo of a warthog" to "A photo of a warthog and a traitor", the original animal warthog becomes an object similar to a military vehicle or military aircraft, while the images generated by attack prompt is not directly related to the image of the animal warthog or traitor. From the t-SNE visualization (Fig. A.6), we can see that the distance from the picture generated by the attack prompt to the text "a photo of a warthog" has a similar distance to the animal warthog picture to the text, so we can see that by attacking the original category word that guided the original category word (animal warthog) into its alternative meaning.
From the box plots (Fig. A.6), it can be observed that the image of "warthog" exhibits the highest similarity with the prompt’s embedding, while the image of "traitor" demonstrates the lowest similarity, as anticipated. Simultaneously, the similarity distribution between the images of "warthog" and "traitor" with the prompt text is relatively wide, indicating that some images have a high similarity with "warthog," while others lack features associated with "warthog."
B Cases of Short/Long-Prompt Attacks and Black-box Attacks
B.1 Attack on Long Prompt





In Fig. B.1, we demonstrate more cases of long text prompt attacks.
B.2 Attack on Short Prompt





In Fig. B.2, we demonstrate more cases of long text prompt attacks.
B.3 Black-box Attack




