Stability Guarantees for Feature Attributions with Multiplicative Smoothing
Abstract
Explanation methods for machine learning models tend not to provide any formal guarantees and may not reflect the underlying decision-making process. In this work, we analyze stability as a property for reliable feature attribution methods. We prove that relaxed variants of stability are guaranteed if the model is sufficiently Lipschitz with respect to the masking of features. We develop a smoothing method called Multiplicative Smoothing (MuS) to achieve such a model. We show that MuS overcomes the theoretical limitations of standard smoothing techniques and can be integrated with any classifier and feature attribution method. We evaluate MuS on vision and language models with various feature attribution methods, such as LIME and SHAP, and demonstrate that MuS endows feature attributions with non-trivial stability guarantees.
1 Introduction
Modern machine learning models are incredibly powerful at challenging prediction tasks but notoriously black-box in their decision-making. One can therefore achieve impressive performance without fully understanding why. In settings like medical diagnosis [1, 2] and legal analysis [3, 4], where accurate and well-justified decisions are important, such power without proof is insufficient. In order to fully wield the power of such models while ensuring reliability and trust, a user needs accurate and insightful explanations of model behavior.
One popular family of explanation methods is feature attributions [5, 6, 7, 8]. Given a model and input, a feature attribution method generates a score for each input feature that denotes its importance to the overall prediction. For instance, consider Figure 1, in which the Vision Transformer [9] classifier predicts the full image (left) as “Goldfish”. We then use a feature attribution method like SHAP [7] to score each feature and select the top-25%, for which the masked image (middle) is consistently predicted as “Goldfish”. However, adding a single patch of features (right) alters the prediction confidence so much that it now yields “Axolotl”. This suggests that the explanation is brittle [10], as small changes easily cause it to induce some other class. In this paper, we study how to overcome such behavior by analyzing the stability of an explanation: we consider an explanation to be stable if, once the explanatory features are included, the addition of more features does not change the prediction.

Goldfish (98.72%)
Cockroach (0.0218%)

Goldfish (95.86%)
Axolotl (1.62%)

Axolotl (55.14%)
Goldfish (30.24%)

Pneumonia (25.50%)

Pneumonia (29.56%)

Pneumonia (50.05%)
Stability implies that the selected features are enough to explain the prediction [12, 13, 14] and that this selection maintains strong explanatory power even in the presence of additional information [10, 15]. Similar properties are studied in literature and identified as useful for interpretability [16], and we emphasize that our main focus is on analyzing and achieving provable guarantees. Stability guarantees, in particular, are useful as they allow one to predict how model behavior varies with the explanation. Given a stable explanation, one can include more features, e.g., adding context, while maintaining confidence in the consistency of the underlying explanatory power. Crucially, we observe that such guarantees only make sense when jointly considering the model and explanation method: the explanation method necessarily depends on the model to yield an explanation, and stability is then evaluated with respect to the model.
Thus far, existing works on feature attributions with formal guarantees face computational tractability and explanatory utility challenges. While some methods take an axiomatic approach [17, 8], others use metrics that appear reasonable but may not reliably reflect useful model behavior, a common and known limitation [18]. Such explanations have been criticized as a plausible guess at best, and completely misleading [19] at worst.
In this paper, we study how to construct explainable models with provable stability guarantees. We jointly consider the classification model and explanation method and present a formalization for studying such properties that we call explainable models. We focus on binary feature attributions [20] wherein each feature is either marked as explanatory (1) or not explanatory (0). We present a method to solve this problem, inspired by techniques from adversarial robustness, particularly randomized smoothing [21, 22]. Our method can take any off-the-shelf classifier and feature attribution method to efficiently yield an explainable model that satisfies provable stability guarantees. In summary, our contributions are as follows:
-
•
We formalize stability as a key property for binary feature attributions and study this in the framework of explainable models. We prove that relaxed variants of stability are guaranteed if the model is sufficiently Lipschitz with respect to the masking of features.
-
•
To achieve the sufficient Lipschitz condition, we develop a smoothing method called Multiplicative Smoothing (MuS). We show that MuS achieves strong smoothness conditions, overcomes key theoretical and practical limitations of standard smoothing techniques, and can be integrated with any classifier and feature attribution method.
-
•
We evaluate MuS on vision and language models along with different feature attribution methods. We demonstrate that MuS-smoothed explainable models achieve strong stability guarantees at a small cost to accuracy.
2 Overview
We observe that formal guarantees for explanations must take into account both the model and explanation method, and for this, we present in Section 2.1 a pairing that we call explainable models. This formulation allows us to describe the desired stability properties in Section 2.2. We show in Section 2.3 that a classifier with sufficient Lipschitz smoothness with respect to feature masking allows us to yield provable guarantees of stability. Finally, in Section 2.4, we show how to adapt existing feature attribution methods into our explainable model framework.
2.1 Explainable Models
We first present explainable models as a formalism for rigorously studying explanations. Let be the space of inputs, a classifier maps inputs to class probabilities that sum to , where the class of is taken to be the largest coordinate. Similarly, an explanation method maps an input to an explanation that indicates which features are considered explanatory for the prediction . In particular, we may pick and adapt from among a selection of existing feature attribution methods like LIME [6], SHAP [7], and many others [5, 8, 23, 24, 25], wherein may be thought of as a top- feature selector. Note that the selection of input features necessarily depends on the explanation method executing or analyzing the model, and so it makes sense to jointly study the model and explanation method: given a classifier and explanation method , we call the pairing an explainable model. Given some , the explainable model maps to both a prediction and explanation. We show this in Figure 2, where pairs the class probabilities and the feature attribution.

For an input , we will evaluate the quality of the binary feature attribution through its masking on . That is, we will study the behavior of on the masked input , where is the element-wise vector product. To do this, we define a notion of prediction equivalence: for two , we write to mean that and yield the same class. This allows us to formalize the intuition that an explanation should recover the prediction of under .
Definition 2.1.
The explainable model is consistent at if .
Evaluating on this way lets us apply the model as-is and therefore avoids the challenge of constructing a surrogate model that is accurate to the original [26]. Moreover, this approach is reasonable, especially in domains like vision — where one intuitively expects that a masked image retaining only the important features should induce the intended prediction. Indeed, architectures like Vision Transformer [9] can maintain high accuracy with only a fraction of the image present [27].
Particularly, we would like for to generate explanations that are stable and concise (i.e. sparse). The former is our central guarantee and is ensured through smoothing. The latter implies that has few ones entries, and is a desirable property since a good explanation should not contain too much redundant information. However, sparsity is a more difficult property to enforce, as this is contingent on the model having high accuracy with respect to heavily masked inputs. For sparsity, we present a simple heuristic in Section 2.4 and evaluate its effectiveness in Section 4.
2.2 Stability Properties of Explainable Models
Given an explainable model and some , stability means that the prediction does not change even if one adds more explanatory features to . For instance, the model-explanation pair in Figure 1 is not stable, as the inclusion of a single feature group (patch) changes the prediction. To formalize this notion of stability, we first introduce a partial ordering: for , we write iff for all . That is, iff includes all the features selected by .
Definition 2.2.
The explainable model is stable at if for all .
Note that the constant explanation , the vector of ones, makes trivially stable at every , though this is not a concise explanation. Additionally, stability at implies consistency at .
Unfortunately, stability is a difficult property to enforce in general, as it requires that satisfy a monotone-like behavior with respect to feature inclusion — which is especially challenging for complex models like neural networks. Checking stability without additional assumptions on is also hard: if is the number of ones in , then there are possible to check. This large space of possible motivates us to examine instead relaxations of stability. We introduce lower and upper relaxations of stability below.
Definition 2.3.
The explainable model is incrementally stable at with radius if for all where .
Incremental stability is the lower relaxation since it considers the case where the mask has only a few features more than . For instance, if one can probably add up to features to a masked without altering the prediction, then would be incrementally stable at with radius . We next introduce the upper relaxation that we call decremental stability.
Definition 2.4.
The explainable model is decrementally stable at with radius if for all where .
Decremental stability is a subtractive form of stability, in contrast to the additive nature of incremental stability. Particularly, decremental stability considers the case where has much more features than . If one can provably remove up to non-explanatory features from the full without altering the prediction, then is decrementally stable at with radius . Note also that decremental stability necessarily entails consistency of , but for simplicity of definitions, we do not enforce this for incremental stability. Furthermore, observe that for a sufficiently large radius of , incremental and decremental stability together imply stability.
Remark 2.5.
Similar notions to the above have been proposed in the literature, and we refer to [16] for an extensive survey. In particular, for [16], consistency is akin to preservation, and stability is similar to continuity, except we are concerned with adding features. In this regard, incremental stability is most similar to incremental addition and decremental stability to incremental deletion.
2.3 Lipschitz Smoothness Entails Stability Guarantees
If is Lipschitz with respect to the masking of features, then we can guarantee relaxed stability properties for the explainable model . In particular, we require for all that is Lipschitz with respect to the mask . This then allows us to establish our main result (Theorem 3.3), which we preview below in Remark 2.6.
Remark 2.6 (Sketch of main result).
Consider an explainable model where for all the function is -Lipschitz in with respect to the norm. Then at any , the radius of incremental stability and radius of decremental stability are respectively:
where is called the confidence gap, with the top-two class probabilities:
| (1) |
2.4 Adapting Existing Feature Attribution Methods
Most existing feature attribution methods assign a real-valued score to feature importance, rather than a binary value. We therefore need to convert this to a binary-valued method for use with a stable explainable model. Let be such a continuous-valued method like LIME [6] or SHAP [7], and fix some desired incremental stability radius and decremental stability radius . Given some a simple construction for binary is described next.
Remark 2.7 (Iterative construction of ).
Consider any and let be an index ordering on from high-to-low (i.e. most probable class first). Initialize , and for each : assign then check whether is now consistent, incrementally stable with radius , and decrementally stable with radius . If so, terminate with , and continue otherwise.
Note that the above method of constructing does not impose sparsity guarantees in the way that we may guarantee stability through Lipschitz smoothness. Instead, the ordering from a continuous-valued serves as a greedy heuristic for constructing . We show in Section 4 that some feature attributions (e.g., SHAP [7]) tend to yield sparser selections on average compared to others (e.g., Vanilla Gradient Saliency [5]).
3 Multiplicative Smoothing for Lipschitz Constants
In this section, we present our main technical contribution of Multiplicative Smoothing (MuS). The goal is to transform an arbitrary base classifier into a smoothed classifier that is Lipschitz with respect to the masking of features. This then allows one to couple with an explanation method in order to form an explainable model with provable stability guarantees.
We give an overview of our MuS in Section 3.1, where we illustrate that a principal motivation for its development is because standard smoothing techniques may violate a property that we call masking equivalence. We present the Lipschitz constant of the smoothed classifier in Section 3.2 and show how this is used to certify stability. Finally, we give an efficient computation of MuS in Section 3.3, allowing us to exactly evaluate at a low sample complexity.

3.1 Technical Overview of MuS
Our key insight is that randomly dropping (i.e., zeroing) features will attain the desired smoothness. In particular, we uniformly drop features with probability by sampling binary masks from some distribution where each coordinate is distributed as . Then define as:
| (2) |
where is the Beronulli distribution with parameter . We give an overview of evaluating in Figure 3. Importantly, our main results on smoothness (Theorem 3.2) and stability (Theorem 3.3) hold provided each coordinate of is marginally Bernoulli with parameter , and so we avoid fixing a particular choice for now. However, it will be easy to intuit the exposition with , the coordinate-wise i.i.d. Bernoulli distribution with parameter .
We can equivalently parametrize using the mapping , where it follows that:
| (3) |
Note that one could have alternatively first defined and then due to the identity . We require that the relationship between and follows an identity that we call masking equivalence:
| (4) |
This follows by the definition of , and the relevance to stability is this: if masking equivalence holds, then we can rewrite stability properties involving in terms of ’s second parameter as follows:
| (c.f. Definition 2.2) |
where incremental and decremental stability may be analogously defined. This translation is useful, as we will prove that is -Lipschitz in its second parameter (Theorem 3.2), which then allows us to establish the desired stability properties (Theorem 3.3).
Since many choices are valid, we have not given an explicit construction for . Rather, so long as each coordinate of obeys then the Lipschitz properties for follow. The implication here is that although simple distributions like suffice for , they may not be sample efficient. We show in Section 3.3 how to exploit a structured statistical dependence in order to reduce the sample complexity of computing MuS.
Importantly, we are motivated to develop MuS because standard smoothing techniques, namely additive smoothing [21, 22], may fail to satisfy masking equivalence. Additive smoothing is by far the most popular smoothing technique and differs from our scheme (3) in how noise is applied, where let and be any two distributions on :
Particularly, additive smoothing has counterexamples for masking equivalence.
Proposition 3.1.
There exists and distribution , where for
we have for some and .
Proof.
Observe that it suffices to have such that for a non-empty set of . Let be a distribution on these , then:
∎
Intuitively, this occurs because additive smoothing primarily applies noise by perturbing feature values, rather than completely masking them. As such, there might be “information leakage” when non-explanatory bits of are changed into non-zero values. This then causes each sample of within to observe more features of than it would have been able to otherwise.
3.2 Certifying Stability Properties with Lipschitz Classifiers
Our core technical result is in showing that as defined in (2) is Lipschitz to the masking of features. We present MuS in terms of , where it is parametric with respect to the distribution : so long as satisfies a coordinate-wise Bernoulli condition, then it is usable with MuS.
Theorem 3.2 (MuS).
Let be any distribution on where each coordinates of is distributed as . Consider any and define as
Then the function is -Lipschitz in the norm for all .
The strength of this result is in its weak assumptions. First, the theorem applies to any model and input . It further suffices that each coordinate is distributed as , and we emphasize that statistical independence between different is not assumed. This allows us to construct with structured dependence in Section 3.3, such that we may exactly and efficiently evaluate at a sample complexity of . A low sample complexity is important for making MuS practically usable, as otherwise, one must settle for the expected value subject to probabilistic guarantees. For instance, simpler distributions like do satisfy the requirements of Theorem 3.2 — but costs samples because of coordinate-wise independence. Whatever choice of , one can guarantee stability so long as is Lipschitz in its second argument.
Theorem 3.3 (Stability).
Consider any with coordinates . Fix and let be the respectively smoothed coordinates as in Theorem 3.2, using which we analogously define . Also define . Then for any explanation method and input , the explainable model is incrementally stable with radius and decrementally stable with radius :
where is the confidence gap as in (1).
Note that it is only in the case where the radius that non-trivial stability guarantees exist. Because each has range in , this means that a Lipschitz constant of is necessary to attain at least one radius of stability. We present in Appendix A.2 some extensions to MuS that allow one to achieve higher coverage of features.
3.3 Exploiting Structured Dependency
We now present , a distribution on that allows for efficient and exact evaluation of a MuS-smoothed classifier. Our construction is an adaption of [28] from uniform to Bernoulli noise, where the primary insight is that one can parametrize -dimensional noise using a single dimension via structured coordinate-wise dependence. In particular, we use a seed vector , where with an integer quantization parameter there will only exist distinct choices of . All the while, we still enforce that any such is coordinate-wise Bernoulli with . Thus, for a sufficiently small quantization parameter (i.e., ), we may tractably enumerate through all possible choices of and thereby evaluate a MuS-smoothed model with only samples.
Proposition 3.4.
Fix integer and consider any vector and scalar . Define to be a random vector in with coordinates given by
Then there are distinct values of and each coordinate is distributed as .
Proof.
First, observe that each of the distinct values of defines a unique value of since we have assumed and to be fixed. Next, observe that each has unique values uniformly distributed as . Because we therefore have , which implies that . ∎
The seed vector is the source of our structured coordinate-wise dependence, and the one-dimensional source of randomness is used to generate the -dimensional . Such then satisfies the conditions for use in MuS (Theorem 3.2), and this noise allows for an exact evaluation of the smoothed classifier in samples. We have found to be sufficient in practice and that values as low as also yield good performance. We remark that one drawback is that one may get an unlucky seed , but we have not yet observed this in our experiments.
4 Empirical Evaluations
We evaluate the quality of MuS on different classification models and explanation methods as they relate to stability guarantees. To that end, we perform the following experiments.
(E1) How good are the stability guarantees? A natural measure of quality for stability guarantees over a dataset exists: what radii are achieved, and at what frequency. We investigate how different combinations of models, explanation methods, and affect this measure.
(E2) What is the cost of smoothing? To increase the radius of a provable stability guarantee, we must decrease the Lipschitz constant . However, as decreases, more features are dropped during the smoothing process. This experiment investigates this stability-accuracy trade-off.
(E3) Which explanation method is best? We evaluate which existing feature attribution methods are amenable to strong stability guarantees. We examine LIME [6], SHAP [7], Vanilla Gradient Saliency (VGrad) [5], and Integrated Gradients (IGrad) [8], with focus on the size of the explanation.
(Experimental Setup) We use on two vision models (Vision Transformer [9] and ResNet50 [29]) and one language model (RoBERTa [30]). We use ImageNet1K [31] as our vision dataset and TweetEval [32] sentiment analysis as our language dataset. We use feature grouping from Appendix A.2.1 on ImageNet1K to reduce the dimensional input into superpixel patches. We report stability radii in terms of the fraction of features, i.e., . In all our experiments, we use the quantized noise as in Section 3.3 with unless specified otherwise. We refer to Appendix B for training details and the comprehensive experiments.

4.1 (E1) Quality of Stability Guarantees
We study how much radius of consistent and incremental (resp. decremental) stability is achieved, and how often. We take an explainable model where is Vision Transformer and is SHAP with top-25% feature selection. We plot the rate at which a property holds (e.g., consistent and incrementally stable with radius ) as a function of radius (expressed as a fraction of features ).
We show our results in Figure 4, where on the left we have the certified guarantees for samples from ImageNet1K; on the right we have the empirical radii for samples obtained by applying a standard box attack [33] strategy with . We observe from the certified results that the decremental stability radii are larger than those of incremental stability. This is reasonable since the base classifier sees much more of the input when analyzing decremental stability and is thus more confident on average, i.e., achieves a larger confidence gap. Moreover, our empirical radii often cover up to half of the input, which suggests that our certified analysis is quite conservative.
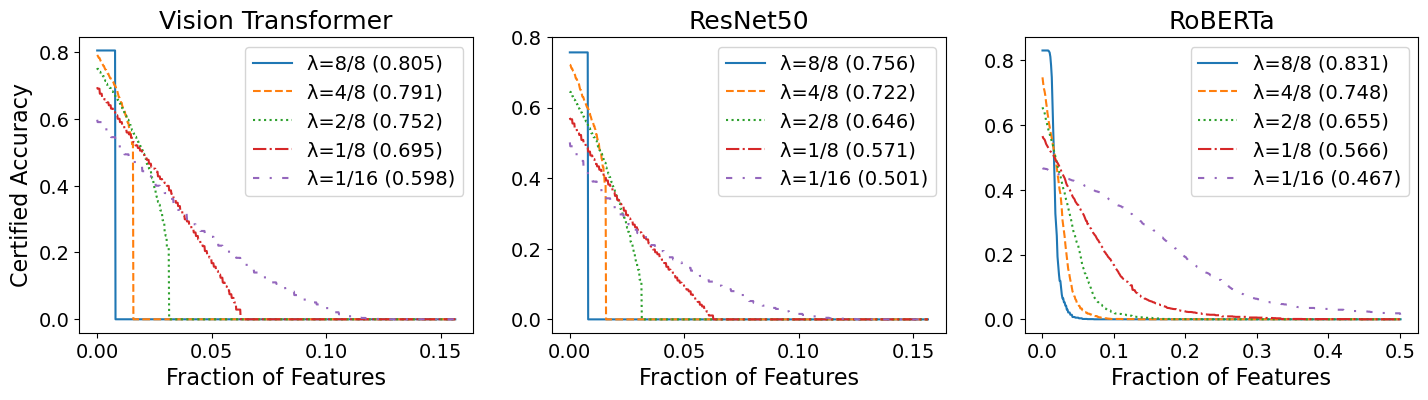
4.2 (E2) Stability-Accuracy Trade-Offs
We next investigate how smoothing impacts the classifier accuracy. As decreases due to more smoothing, the base classifier sees increasingly zeroed-out features — which should hurt accuracy. We took samples for each classifier on their respective datasets and plotted the certified accuracy vs. radius of decremental stability.
We show the results in Figure 5, where the clean accuracy (in parentheses) decreases with as expected. This accuracy drop is especially pronounced for ResNet50, and we suspect that the transformer architecture of Vision Transformer and RoBERTa makes them more resilient to the randomized masking of features. Nevertheless, this experiment demonstrates that large models, especially transformers, can tolerate non-trivial noise from MuS while maintaining high accuracy.

4.3 (E3) Which Explanation Method to Pick?
Finally, we explore which feature attribution method is best suited to stability guarantees of explainable model . All four methods are continuous-valued, for which we samples inputs from each model’s respective dataset. For each input , we use the feature importance ranking generated by to iteratively build in a greedy manner like in Section 2.4. For some , let be the number fraction of features needed for to be consistent, incrementally stable with radius , and decrementally stable with radius . We then plot the average for different methods at in Figure 6, where note that SHAP tends to require fewer features to achieve the desired properties, while VGrad tends to require more. However, we do not believe these to be decisive results, as many curves are relatively close, especially for Vision Transformer and ResNet50.
5 Related Works
For extensive surveys on explainability methods see [20, 34, 35, 16, 36, 37, 38]. Notable feature attribution methods include Vanilla Gradient Saliency [5], SmoothGrad [23], Integrated Gradients [8], Grad-CAM [39], Occlusion [40], LIME [6], SHAP [7], and their variants. Of these, Shapley value-based [17] methods [7, 24, 25] are rooted in axiomatic principles, as are Integrated Gradients [8, 41]. The work of [42] finds confidence intervals over attribution scores. A study of common feature attribution methods is done in [43]. Similar to our approach is [44], which studies binary-valued classifiers and presents an algorithm with succinctness and probabilistic precision guarantees. Different metrics for evaluating feature attributions are studied in [45, 46, 47, 48, 49, 50, 16, 51, 18]. Whether an attribution correctly identifies relevant features is a well-known issue [52, 53]. Many methods are also susceptible to adversarial attacks [54, 55]. As a negative result, [56] shows that feature attributions have provably poor performance on sufficiently rich model classes. Related to feature attributions are data attributions [57, 58, 59], which assigns values to training data points. Also related to formal guarantees are formal methods-based approaches towards explainability [60].
6 Conclusion
We study provable stability guarantees for binary feature attribution methods through the framework of explainable models. A selection of features is stable if the additional inclusion of other features does not alter its explanatory power. We show that if the classifier is Lipschitz with respect to the masking of features, then one can guarantee relaxed variants of stability. To achieve this Lipschitz condition, we develop a smoothing method called Multiplicative Smoothing (MuS). This method is parametric to the choice of noise distribution, allowing us to construct and exploit distributions with structured dependence for exact and efficient evaluation. We evaluate MuS on vision and language models and demonstrate that MuS yields strong stability guarantees at only a small cost to accuracy.
Acknowledgements
This research was partially supported by NSF award SLES 2331783 and a gift from AWS AI.
References
- [1] Mauricio Reyes, Raphael Meier, Sérgio Pereira, Carlos A Silva, Fried-Michael Dahlweid, Hendrik von Tengg-Kobligk, Ronald M Summers, and Roland Wiest. On the interpretability of artificial intelligence in radiology: challenges and opportunities. Radiology: artificial intelligence, 2(3):e190043, 2020.
- [2] Erico Tjoa and Cuntai Guan. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE transactions on neural networks and learning systems, 32(11):4793–4813, 2020.
- [3] Sandra Wachter, Brent Mittelstadt, and Chris Russell. Counterfactual explanations without opening the black box: Automated decisions and the gdpr. Harv. JL & Tech., 31:841, 2017.
- [4] Adrien Bibal, Michael Lognoul, Alexandre De Streel, and Benoît Frénay. Legal requirements on explainability in machine learning. Artificial Intelligence and Law, 29:149–169, 2021.
- [5] Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
- [6] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016.
- [7] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017.
- [8] Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International conference on machine learning, pages 3319–3328. PMLR, 2017.
- [9] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [10] Amirata Ghorbani, Abubakar Abid, and James Zou. Interpretation of neural networks is fragile. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 3681–3688, 2019.
- [11] Joseph Paul Cohen, Joseph D. Viviano, Paul Bertin, Paul Morrison, Parsa Torabian, Matteo Guarrera, Matthew P Lungren, Akshay Chaudhari, Rupert Brooks, Mohammad Hashir, and Hadrien Bertrand. TorchXRayVision: A library of chest X-ray datasets and models. In Medical Imaging with Deep Learning, 2022.
- [12] Gavin Brown. A new perspective for information theoretic feature selection. In Artificial intelligence and statistics, pages 49–56. PMLR, 2009.
- [13] Jianbo Chen, Le Song, Martin Wainwright, and Michael Jordan. Learning to explain: An information-theoretic perspective on model interpretation. In International Conference on Machine Learning, pages 883–892. PMLR, 2018.
- [14] Xiaoping Li, Yadi Wang, and Rubén Ruiz. A survey on sparse learning models for feature selection. IEEE transactions on cybernetics, 52(3):1642–1660, 2020.
- [15] Akhilan Boopathy, Sijia Liu, Gaoyuan Zhang, Cynthia Liu, Pin-Yu Chen, Shiyu Chang, and Luca Daniel. Proper network interpretability helps adversarial robustness in classification. In International Conference on Machine Learning, pages 1014–1023. PMLR, 2020.
- [16] Meike Nauta, Jan Trienes, Shreyasi Pathak, Elisa Nguyen, Michelle Peters, Yasmin Schmitt, Jörg Schlötterer, Maurice van Keulen, and Christin Seifert. From anecdotal evidence to quantitative evaluation methods: A systematic review on evaluating explainable ai. arXiv preprint arXiv:2201.08164, 2022.
- [17] L.S. Shapley. A value for n-person games. Contributions to the Theory of Games, pages 307–317, 1953.
- [18] Yilun Zhou, Serena Booth, Marco Tulio Ribeiro, and Julie Shah. Do feature attribution methods correctly attribute features? In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 9623–9633, 2022.
- [19] Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4198–4205, 2020.
- [20] Jundong Li, Kewei Cheng, Suhang Wang, Fred Morstatter, Robert P Trevino, Jiliang Tang, and Huan Liu. Feature selection: A data perspective. ACM computing surveys (CSUR), 50(6):1–45, 2017.
- [21] Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. In International Conference on Machine Learning, pages 1310–1320. PMLR, 2019.
- [22] Greg Yang, Tony Duan, J Edward Hu, Hadi Salman, Ilya Razenshteyn, and Jerry Li. Randomized smoothing of all shapes and sizes. In International Conference on Machine Learning, pages 10693–10705. PMLR, 2020.
- [23] Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825, 2017.
- [24] Mukund Sundararajan and Amir Najmi. The many shapley values for model explanation. In International conference on machine learning, pages 9269–9278. PMLR, 2020.
- [25] Yongchan Kwon and James Zou. Weightedshap: analyzing and improving shapley based feature attributions. arXiv preprint arXiv:2209.13429, 2022.
- [26] Reza Alizadeh, Janet K Allen, and Farrokh Mistree. Managing computational complexity using surrogate models: a critical review. Research in Engineering Design, 31:275–298, 2020.
- [27] Hadi Salman, Saachi Jain, Eric Wong, and Aleksander Madry. Certified patch robustness via smoothed vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15137–15147, 2022.
- [28] Alexander J Levine and Soheil Feizi. Improved, deterministic smoothing for l_1 certified robustness. In International Conference on Machine Learning, pages 6254–6264. PMLR, 2021.
- [29] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [30] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [31] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115:211–252, 2015.
- [32] Francesco Barbieri, Jose Camacho-Collados, Leonardo Neves, and Luis Espinosa-Anke. Tweeteval: Unified benchmark and comparative evaluation for tweet classification. arXiv preprint arXiv:2010.12421, 2020.
- [33] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM workshop on artificial intelligence and security, pages 15–26, 2017.
- [34] Nadia Burkart and Marco F Huber. A survey on the explainability of supervised machine learning. Journal of Artificial Intelligence Research, 70:245–317, 2021.
- [35] Jianlong Zhou, Amir H Gandomi, Fang Chen, and Andreas Holzinger. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics, 10(5):593, 2021.
- [36] Qing Lyu, Marianna Apidianaki, and Chris Callison-Burch. Towards faithful model explanation in nlp: A survey. arXiv preprint arXiv:2209.11326, 2022.
- [37] Xuhong Li, Haoyi Xiong, Xingjian Li, Xuanyu Wu, Xiao Zhang, Ji Liu, Jiang Bian, and Dejing Dou. Interpretable deep learning: Interpretation, interpretability, trustworthiness, and beyond. Knowledge and Information Systems, 64(12):3197–3234, 2022.
- [38] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- [39] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017.
- [40] Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13, pages 818–833. Springer, 2014.
- [41] Daniel D Lundstrom, Tianjian Huang, and Meisam Razaviyayn. A rigorous study of integrated gradients method and extensions to internal neuron attributions. In International Conference on Machine Learning, pages 14485–14508. PMLR, 2022.
- [42] Dylan Slack, Anna Hilgard, Sameer Singh, and Himabindu Lakkaraju. Reliable post hoc explanations: Modeling uncertainty in explainability. Advances in neural information processing systems, 34:9391–9404, 2021.
- [43] Tessa Han, Suraj Srinivas, and Himabindu Lakkaraju. Which explanation should i choose? a function approximation perspective to characterizing post hoc explanations. arXiv preprint arXiv:2206.01254, 2022.
- [44] Guy Blanc, Jane Lange, and Li-Yang Tan. Provably efficient, succinct, and precise explanations. Advances in Neural Information Processing Systems, 34:6129–6141, 2021.
- [45] Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. Advances in neural information processing systems, 31, 2018.
- [46] Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. A benchmark for interpretability methods in deep neural networks. Advances in neural information processing systems, 32, 2019.
- [47] Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C Wallace. Eraser: A benchmark to evaluate rationalized nlp models. arXiv preprint arXiv:1911.03429, 2019.
- [48] Jasmijn Bastings, Sebastian Ebert, Polina Zablotskaia, Anders Sandholm, and Katja Filippova. " will you find these shortcuts?" a protocol for evaluating the faithfulness of input salience methods for text classification. arXiv preprint arXiv:2111.07367, 2021.
- [49] Yao Rong, Tobias Leemann, Vadim Borisov, Gjergji Kasneci, and Enkelejda Kasneci. A consistent and efficient evaluation strategy for attribution methods. arXiv preprint arXiv:2202.00449, 2022.
- [50] Yilun Zhou and Julie Shah. The solvability of interpretability evaluation metrics. arXiv preprint arXiv:2205.08696, 2022.
- [51] Julius Adebayo, Michael Muelly, Harold Abelson, and Been Kim. Post hoc explanations may be ineffective for detecting unknown spurious correlation. In International Conference on Learning Representations, 2022.
- [52] Mengjiao Yang and Been Kim. Benchmarking attribution methods with relative feature importance. arXiv preprint arXiv:1907.09701, 2019.
- [53] Pieter-Jan Kindermans, Sara Hooker, Julius Adebayo, Maximilian Alber, Kristof T Schütt, Sven Dähne, Dumitru Erhan, and Been Kim. The (un) reliability of saliency methods. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, pages 267–280. Springer, 2019.
- [54] Dylan Slack, Anna Hilgard, Himabindu Lakkaraju, and Sameer Singh. Counterfactual explanations can be manipulated. Advances in neural information processing systems, 34:62–75, 2021.
- [55] Adam Ivankay, Ivan Girardi, Chiara Marchiori, and Pascal Frossard. Fooling explanations in text classifiers. arXiv preprint arXiv:2206.03178, 2022.
- [56] Blair Bilodeau, Natasha Jaques, Pang Wei Koh, and Been Kim. Impossibility theorems for feature attribution. arXiv preprint arXiv:2212.11870, 2022.
- [57] Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In International conference on machine learning, pages 1885–1894. PMLR, 2017.
- [58] Andrew Ilyas, Sung Min Park, Logan Engstrom, Guillaume Leclerc, and Aleksander Madry. Datamodels: Predicting predictions from training data. arXiv preprint arXiv:2202.00622, 2022.
- [59] Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale. arXiv preprint arXiv:2303.14186, 2023.
- [60] Shahaf Bassan and Guy Katz. Towards formal xai: Formally approximate minimal explanations of neural networks. In International Conference on Tools and Algorithms for the Construction and Analysis of Systems, pages 187–207. Springer, 2023.
- [61] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [62] Alexey Kurakin, Ian Goodfellow, and Samy Bengio. Adversarial machine learning at scale. arXiv preprint arXiv:1611.01236, 2016.
- [63] Logan Engstrom, Andrew Ilyas, Hadi Salman, Shibani Santurkar, and Dimitris Tsipras. Robustness (python library), 2019.
Appendix A Proofs and Theoretical Discussions
In this Section, we present the proofs of our main results and some extensions to MuS.
A.1 Proofs of Main Results
A.1.1 Proof of Theorem 3.2
Proof.
By linearity, we have:
so it suffices to analyze an arbitrary term by fixing some . Consider any , let , and define . Observe that exactly when and . Since , we thus have , and applying the union bound:
and so:
Note that , and so
Thus, is -Lipschitz in the norm. ∎
A.1.2 Proof of Theorem 3.3
Proof.
We first show incremental stability. Consider any , then by masking equivalence:
and let be the top-two class probabilities of as defined in (1). By Theorem 3.2, both are Lipschitz in their second parameter, and so for all :
Observe that if is sufficiently close to , i.e.:
then the top-class index of and are the same. This means that and thus , thus proving incremental stability with radius .
The decremental stability case is similar, except we replace with . ∎
A.2 Some Basic Extensions
Below, we present some extensions to MuS that help increase the fraction of the input to which we can guarantee stability.
A.2.1 Feature Grouping
We have so far assumed that , but sometimes it may be desirable to group features together, e.g., color channels of the same pixel. Our results also hold for more general , where for such and we lift as
All of our proofs are identical under this construction, with the exception of the dimensionalities of terms like . Figure 1 gives an example of feature grouping.
Appendix B All Experiments
Models, Datasets, and Explanation Methods
We evaluate on two vision models (Vision Transformer [9] and ResNet50 [29]) and one language model (RoBERTa [30]). For the vision dataset, we use ImageNet1K [31]; for the language dataset, we use TweetEval [32] sentiment analysis. We use four explanation methods in SHAP [7], LIME [6], Integrated Gradients (IGrad) [8], and Vanilla Gradient Saliency (VGrad) [5]; where we take as the top- weighted features.
Training Details
We used Adam [61] as our optimizer with default parameters and a learning rate of for epochs. Because we consider and , there are a total of different models for most experiments. To train with a particular : for each training input , we generate two random maskings — one where of the features are zeroed and one where of the features are zeroed. This additional zeroing is to account for the fact that inputs to a smoothed model will be subject to masking by as well as , where the scaling factor of is informed by our prior experience about the size of a stable explanation.
Miscellaneous Preprocessing
For images in ImageNet1K we use feature grouping (Section A.2.1) to group the dimensional image into patches of size , such that there remains feature groups. Each feature of a feature group then receives the same value of noise during smoothing. We report radii of stability as a fraction of the feature groups covered. For example, if at some input from ImageNet1K, we get an incremental stability radius of , then we report as the fraction of features up to which we are guaranteed to be stable. This is especially amenable to evaluating RoBERTa on TweetEval where inputs do not have uniform token lengths, i.e., do not have uniform feature dimensions. In all of our experiments, we use the quantized noise as in Section 3.3 with a quantization parameter of , with the exception of Appendix B.2 and Appendix B.3. Our experiments are organized as follows:
-
•
(Section B.1) What is the quality of stability guarantees?
-
•
(Section B.2) What is the theoretical vs empirical stability that can be guaranteed?
-
–
We for theoretical guarantees, for empirical guarantees.
-
–
-
•
(Section B.3) What are the stability-accuracy trade-offs?
-
–
We use to study the effect of on MuS-smoothed performance.
-
–
-
•
(Section B.4) Which explanation method is best?
-
•
(Section B.5) Does additive smoothing improve empirical stability?
-
•
(Section B.6) Does adversarial training improve empirical stability?
B.1 Quality of Stability Guarantees
Here we study what radii of stability are certifiable, and how often these can be achieved with different models and explanation methods. We therefore consider explainable models constructed from base models and explanation methods with top- feature selection. We take samples from each model’s respective datasets and compute the following value for each radius:
Plots of incremental stability are on the left; plots of decremental stability are on the right.












B.2 Theoretical vs Empirical
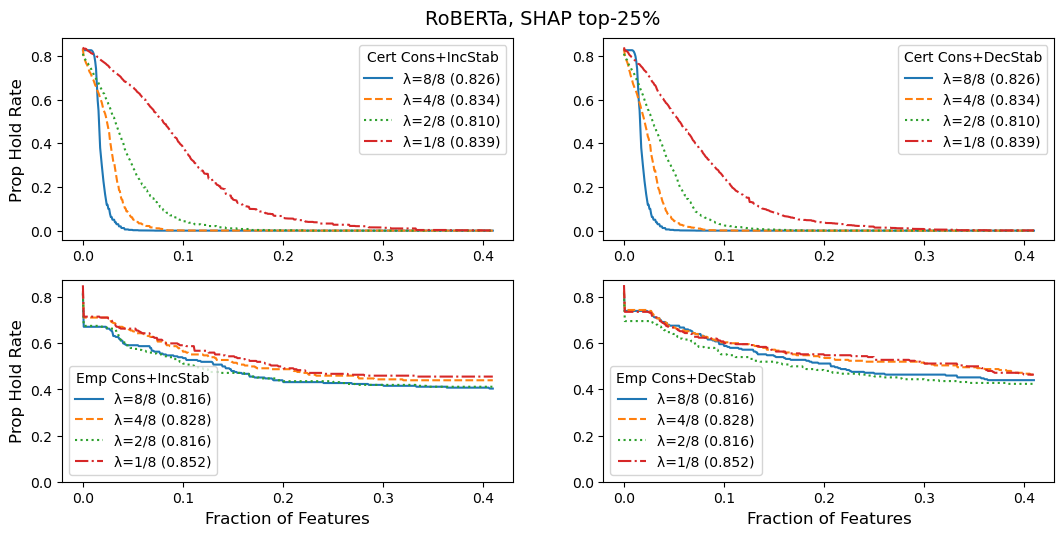
We compare the certifiable theoretical stability guarantees with what is empirically attained via a standard box attack search [33]. This is an extension of Section 4.2, where we now show all models as evaluated with SHAP-top25%. We take with for the certified plots, and with for the empirical plots. This is because box attack is time-intensive.


B.3 Stability-Accuracy Trade-Offs
We study how the accuracy degrades with . We consider a smoothed model constructed from a base classifier and vary . We then take samples from each respective dataset and measure the accuracy of at different radii. We use to mean that attained the correct prediction at , and we plot the following value at each radius :
Below, we show the plots for different quantization parameters of . The plots are identical to that of Figure 5. We see that increasing generally improves the performance of MuS, but at a computational cost since this requires evaluations of .




B.4 Which Explanation Method is the Best?
We first investigate how many features are needed to yield consistent and non-trivially stable explanations, as done by the greedy selection algorithm in Section 2.4. For some , let denote the fraction of features that needs to be consistent, incrementally stable, and decrementally stable with radius . We vary , where recall is needed for non-trivial stability, and use samples to plot the average . This part is identical to Section 4.3.
We next investigate the ability of each method to predict features that lead to high accuracy. Let , mean that the masked input yields the correct prediction. We then plot this accuracy as we vary the top- for different methods , and , using samples.



B.5 Empirical Stability of Additive Smoothing
We now study how well additive smoothing impacts empirical robustness compared to multiplicative smoothing. Although additive smoothing cannot yield theoretical stability guarantees (c.f. Proposition 3.1), we nevertheless investigate its empirical performance. We use explanations generated by SHAP top-25% and use Vision Transformer as our base model . We fine-tuned different variants of Vision Transformer at and used these in two general classes of models: Vision Transformer with multiplicative smoothing, and Vision Transformer with additive smoothing. We call these two and respectively, and define them as follows:
where for multiplicative smoothing, is as in Theorem 3.2. Over samples from ImageNet1K, we check how often incremental stability of radius is obtained, and plot our results in Figure 17 (left). We see that multiplicative smoothing yields better empirical performance than additive smoothing.
B.6 Empirical Stability of Adversarial Training
Similar to Section B.5, we also check how adversarial training [62] affects empirical stability. We consider ResNet50 with different adversarial training setups from the Robustness Python library [63] and compare them to their respective MuS-wrapped variants. As with Section B.5 we take samples from ImageNet1K, and plot our results in Figure 17 (right).


B.7 Discussion
Effect of Smoothing
We observe that smoothing can yield non-trivial stability guarantees, especially for Vision Transformer and RoBERTa, as evidenced in Appendix B.1. We see that smoothing is least detrimental on these two transformer-based architectures, and most negatively impacts the performance of ResNet50. We conjecture that although different training set-ups may improve performance across every category, this still serves to illustrate the general trend.
Theoretical vs Empirical
It is expected that the certifiable radii of stability is more conservative than what is empirically observed. As mentioned in Section 3.2, for each , there is a maximum radius to which stability can be guaranteed, which is an inherent limitation of using confidence gaps and Lipschitz constants as the main theoretical technique. We emphasize that the notion of stability need not be tied to smoothing, though we are currently not aware of other viable approaches.
Why these Explanation Methods?
We chose SHAP, LIME, IGrad, and VGrad from among the large variety of methods available primarily due to their popularity, and because we believe that they are collectively representative of many techniques. In particular, we believe that LIME remains a representative baseline for surrogate model-based explanation methods. SHAP and IGrad are, to our knowledge, the two most well-known families of axiomatic feature attribution methods. Finally, we believe that VGrad is representative of a traditional gradient saliency-based approach.
Which Explanation Method is the Best?
Based on our experiments in Appendix B.4 we see that SHAP generally achieves higher accuracy using the same amount of top- features as other methods. On the other hand, VGrad tends to perform poorly. We remark that there are well-known critiques against the usefulness of saliency-based explanation methods [53].
Appendix C Miscellaneous
Relevance to Other Explanation Methods
Our key theoretical contribution of MuS in Theorem 3.2 is a general-purpose smoothing method that is distinct from standard smoothing techniques, namely additive smoothing. Therefore, MuS is applicable to other problem domains beyond what is studied in this paper and would be useful where small Lipschitz constants with respect to maskings are desirable.
Broader Impacts
Reliable explanations are necessary for making well-informed decisions and are increasingly important as machine learning models are integrated with fields like medicine, law, and business — where the primary users may not be well-versed in the technical limitations of different methods. Formal guarantees are thus important for ensuring the predictability and reliability of complex systems, which then allows users to construct accurate mental models of interaction and behavior. In this work, we study a particular kind of guarantee known as stability, which is key to feature attribution-based explanation methods.