SRIL: Selective Regularization for Class-Incremental Learning
Abstract
Human intelligence gradually accepts new information and accumulates knowledge throughout the lifespan. However, deep learning models suffer from a catastrophic forgetting phenomenon, where they forget previous knowledge when acquiring new information. Class-Incremental Learning aims to create an integrated model that balances plasticity and stability to overcome this challenge. In this paper, we propose a selective regularization method that accepts new knowledge while maintaining previous knowledge. We first introduce an asymmetric feature distillation method for old and new classes inspired by cognitive science, using the gradient of classification and knowledge distillation losses to determine whether to perform pattern completion or pattern separation. We also propose a method to selectively interpolate the weight of the previous model for a balance between stability and plasticity, and we adjust whether to transfer through model confidence to ensure the performance of the previous class and enable exploratory learning. We validate the effectiveness of the proposed method, which surpasses the performance of existing methods through extensive experimental protocols using CIFAR-100, ImageNet-Subset, and ImageNet-Full. 111Our code will be available at https://github.com/anonymous.
1 Introduction
The successful development of deep learning has created many businesses and has applied to the real-world. However, many studies on deep learning have been evaluated in limited experimental settings. To achieve human-level goals, consideration of changes in real-world environments is required. In this respect, continual learning has recently been receiving a lot of attention from the artificial intelligence community. Continual learning is a methodology that can continuously learn about real-world situations where visual characteristics change, such as robot vision and autonomous driving systems [34]. Although recent studies on continual learning have shown promising results, they still suffer from the problem of losing previous knowledge in the process of learning new knowledge. This phenomenon is called catastrophic forgetting [11, 27], and this problem results in performance degradation of deep learning models. One of the major concerns of recent continual learning approaches is mitigating the catastrophic forgetting problem to prevent such performance deterioration.

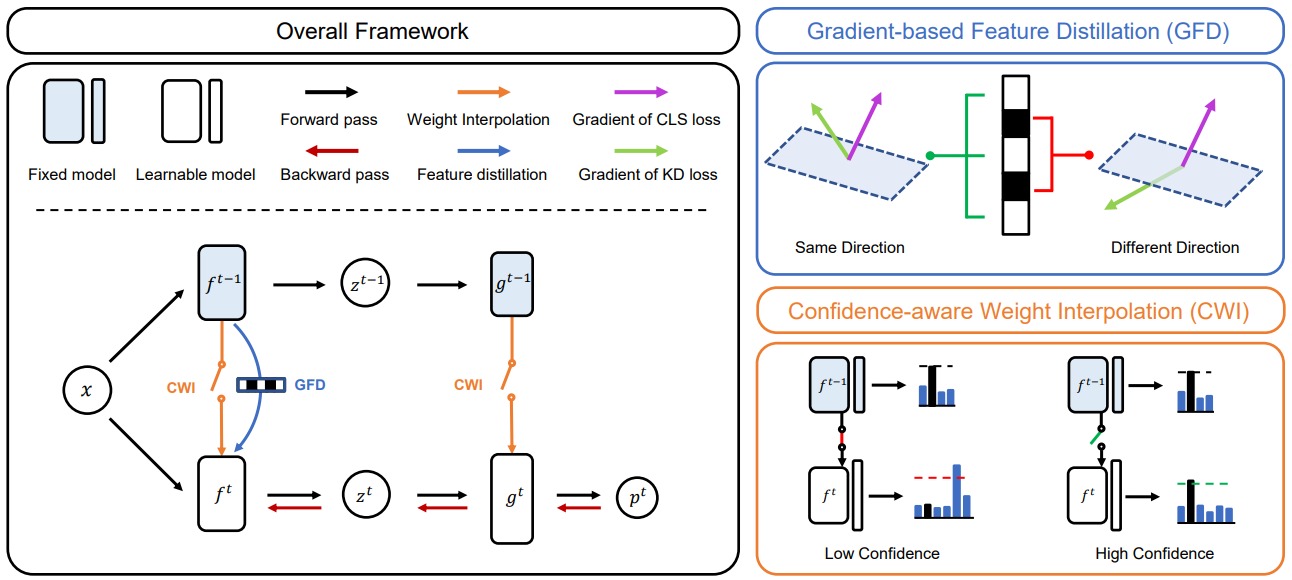
Class-Incremental Learning (CIL) is a special case of the continual learning that seeks to learn new classes that have not been learned before while preserving knowledge from old classes. To this end, recent works have grafted knowledge distillation techniques onto CIL and have achieved considerable results. The major approaches for applying knowledge distillation to CIL can be divided into response-based methods [31, 4, 42], relation-based methods [37, 7], and feature-based methods [15, 8, 19]. Both the response-based and relation-based methods transfer the dark knowledge of the old model considering different characteristics of the semantic information through asymmetric learning strategies for old and new data [3, 12]. On the other hand, the feature-based method directly transfers representation of the old model, making it difficult to consider the different characteristics of the old and new classes. In this paper, we introduce a selective regularization method named SRIL that leverages knowledge distillation and weight interpolation. First, we propose an asymmetric feature distillation method called Gradient-based Feature Distillation. Our intuition begins with pattern completion and pattern separation in cognitive science [30, 33]. The pattern completion means integrating memories by judging that they are existing knowledge when they are newly readjusted by external stimuli, and pattern separation is the process of making memories distinct from existing memories by judging that they are different from the contents in memory. We intend to achieve realignment of knowledge by adopting an asymmetric learning strategy for the previously learned class and the newly learned class in terms of pattern completion and pattern separation. In the process of learning a new class, we utilize the gradient of the knowledge distillation and classification losses to determine whether knowledge distillation is beneficial or harmful. Then, we generate a mask for the channel of each intermediate feature and exploit the mask to apply feature distillation to conflicting channels for the old and new classes. Selective feature distillation through masks generated by this process considers different characteristics by taking an asymmetric strategy for old and new classes. As a result, Figure 1 shows the difference between symmetric feature distillation and our proposed asymmetric feature distillation. Our method has large feature changes for few dominant channels for pattern separation and small feature changes for pattern completion for the remaining channels. Meanwhile, the stability-plasticity dilemma [28, 39] of forgetting old knowledge while learning new knowledge, and failing to accept new knowledge in order to not to forget the old knowledge, is a well-known problem in CIL. To deal with this issue, we introduce a Confidence-aware Weight Interpolation, which determines whether the model retains old knowledge well and performs selective regularization according to the determined result. Here, we determine whether the new model maintains previous knowledge through the confidence of the new model on old data. The existing weight interpolation method is used to improve the generalization performance of a model as a method for approximating an ensemble [41, 40]. In contrast, we ensure that the upper bound of the loss for the old data does not increase by making the new model close to the old model in the weight space to ensure model stability. However, not to move away from the weight space can rather be a constraint on learning new knowledge. Therefore, if the new model’s confidence in the old data exceeds a certain value based on the old model’s confidence, we remove regularization to enable exploratory learning and balance stability and plasticity. Overall, our contributions are as follows:
-
•
We propose a new asymmetric Gradient-based Feature Distillation (GFD) to consider feature characteristics between old and new classes.
-
•
We propose Confidence-aware Weight Interpolation (CWI) to strike a balance between stability and plasticity. CWI ensures the stability of the model and enables exploratory learning by operating selectively.
-
•
We achieve comparable performance to the recent state-of-the-art methods and validate our methods through various experimental settings in CIFAR-100, ImageNet-Subset, and ImageNet-Full.
2 Related Work
Class-Incremental Learning. CIL is largely classified into three types according to how to solve the problem. (i) Regularization based methods regularize the difference between the parameters of the previous network and current network to maintain a low loss area for previous tasks [20, 5, 1]. (ii) Dynamic architecture method is a method that continuously adds sub-networks or expands the network dynamically through pruning and retraining [32, 43, 17]. (iii) Replay based method allows a limited amount of memory composed of data from previous tasks. As a representative method, studies are being conducted to transfer dark knowledge of previously trained networks using knowledge distillation [31, 4, 15] or to improve performance through efficient memory management strategies [26, 25].
Knowledge Distillation. Knowledge distillation (KD) approaches have been proposed to improve the performance of lightweight models by transferring knowledge from large models to small models [14]. Similarly, many studies have been conducted in CIL to solve the catastrophic forgetting problem by transferring the knowledge of the previous model through KD when learning about new data. LwF [23] was the first paper to apply KD to CIL, and uses KD so that the output of the model follows the output of the previous trained model. iCaRL [31] used exemplar to store a small amount of old data samples and applies KD to new data to maintain representation. LUCIR [15] proposed feature distillation in the embedding space rather than prediction by logit. PODNet [8] applied distillation not only in the embedding space but also in the intermediate features. GeoDL [35] also considered the learning path on sub dimension in the KD process through an additional regularization term for the geodesic between features in the embedding space. AFC [19] defined the gradient magnitude of each channel in intermediate features as importance and applies differentiated feature distillation for each channel.
Weight Space Ensemble. Ensemble is the most basic method used to improve the performance of a model in deep learning. However, existing ensemble methods are accompanied by an increase in model size or additional cost in the inference process. SWA [18] showed that by performing weight averaging periodically along the trajectory of SGD in a single model, the model improves in more generalized performance and converges to a wide minima. WiSE-FT [41] demonstrated that the weight space ensemble from the zero-shot model improves the robustness of the model in the fine-tuning process. In a recent study of model soups [40], the performance of the model was improved without additional inference time by applying the weight space-ensemble from the fine-tuned multiple model. Inspired by these weight space ensemble methods, there have been attempts to apply them in CIL. It either transfer the knowledge of new classes to the old model by updating the old model via exponential moving average [36], or apply consistent weight interpolation for the entire learning process. [10].
3 Method
3.1 Problem Definition
CIL aims to improve performance for all classes by starting from learning a limited number of classes and sequentially adding new classes. These sequential stages are called tasks. In CIL scenario, we have sequential training dataset and exemplar containing limited data for previous tasks, where , and denote task, input image and labels, respectively, and denotes from the -st task to the -th task. Each task’s classes are disjoint in CIL scenario, . Since our goal is to maintain the performance of previous tasks while learning new tasks, the optimization problem is defined as follow:
| (1) | ||||
where the is the loss function (e.g., Cross-Entropy), and the is parameters of the model. Since the model converges while learning from current task data and exemplar, there exists some small number higher than loss.
3.2 Gradient-based Feature Distillation
We use the gradients of classification and KD losses for pattern integration and separation, inspired by [9, 44]. We consider that each channel contains information about patterns in the features of the model, therefore we decide whether to apply feature distillation to each channel through the similarity between the gradient of the classification and the KD losses. To achieve this, we build a binary mask whose activation is determined by the cosine similarity of the two gradients.
| (2) |
where is a cosine similarity. The and are the gradients of KD and classification losses for each channel for the features of the -th layer, respectively. The binary mask is activated when directions of the two gradients for the new class data are equal. If the mask is activated, feature distillation is applied. Using the new class data, pattern completion is achieved through KD when the gradients of KD and classification losses have same directions for each channel of the features. On the other hands, applying KD can inhibit the classification performance when the two gradients have different directions [9]. Therefore, in this case, we rule out the KD to achieve the pattern separation. Nonetheless, not regularizing at all for a particular channel may cause problems with the stability of the model. Additionally, in the process of pattern separation, from the perspective of pursuing differentiation from existing knowledge, maintaining the existing pattern can lead to complete differentiation. To achieve this, we apply a mask that is opposite to the binary mask to the old classes data while applying the binary mask to the new data.
Finally, the objective for our GFD is defined as follows:
| (3) |
where,
| (4) |
in which and are new classes data and old classes data, respectively. is the total number of layers and is the total number of channels in each layer. is the frobenius norm and is a channel-wise feature distillation loss, and we normalize each feature for learning stability.
3.3 Confidence-aware Weight Interpolation
Under the stability-plasticity dilemma [28, 39] in the CIL, simultaneously improving stability and plasticity is a challenging problem. However, continual learning considering the balance between the stability and plasticity is essential to improve overall performance. Regarding stability-plasticity, previous methods [8, 19] have had difficulties in ensuring stability enough to expect satisfactory performance improvement despite performing feature distillation that directly transfer the representation. To overcome these limitations, we interpolate the weights of the old model into the new model, thereby preventing loss changes for the old data and ensuring stability for the previous task. In addition, we pursue the plasticity through exploratory learning after the stability of the model is guaranteed enough.
Consequently, we introduce a confidence-aware weight interpolation to improve both stability and plasticity. As the model learns on the new data, we interpolate the weights of the new model through the weights of the old model to prevent the model from getting out of the low error area due to a large difference between parameters with the old model. We update the parameters of the new model through the parameters of the old model , which is expressed as:
| (5) |
where is an interpolation parameter. However, weight interpolation can adversely affect plasticity from a continuous perspective. To solve this problem, we use confidence in the old data to enable exploratory learning without weight interpolation if the model has sufficient knowledge about the old data. We adaptively adjust the interpolation parameter , to apply weight interpolation when the confidence of the new model and the old model for the old data is above the threshold, and not to apply when the confidence is below the threshold. Therefore, interpolation parameter is defined as follows:
| (6) |
in which confidence denotes and is the hyperparmeter, where is the predicted probability for the ground truth , and is the threshold. Since the prediction distribution also changes as the class increases, we set , where is the hyperparameter, and adaptive factor is and is the number of classes in task .
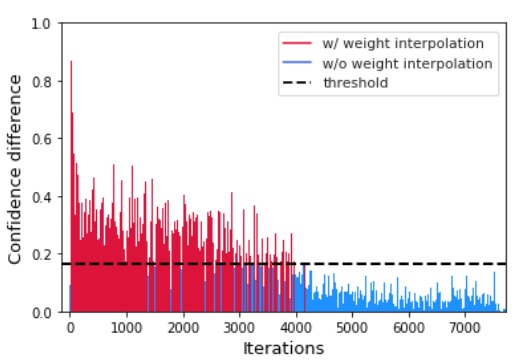
Figure 3 shows the difference in confidence between the old and new model for the previous 50 classes data in the process of learning an additional 10 classes from the model trained for 50 classes on CIFAR-100 as a result of applying CWI. In the initial learning process, while learning new class data, the prediction performance for old classes is destroyed, but the difference in confidence for old classes is reduced through feature distillation and weight interpolation. In addition, in the later learning process, when the difference in confidence between the two models is lower than the threshold, it is confirmed that a certain level of confidence is guaranteed by exploratory learning on new class data without weight interpolation.
3.4 Overall Framework
Our SRIL consists of Gradient-based Feature Distillation and Confidence-aware Weight Interpolation. GFD is a KD method for considering different expressive features of the old class and new class. CWI balances between stability and plasticity. Our overall loss is follow as:
| (7) |
in which distill factor is , where is a hyperparameter, and adaptation factor is . is a well-used adaptation factor in CIL [15, 8, 35, 19]. We also use local similarity classifiers (LSC) following the previous works [8, 19]. LSC allows K proxies for each class. The logit for each class is obtained as the average of K proxies.
| (8) |
where is a classifier weight, and denote the probability by each proxy and the probability for each class. We use LSC loss [8] which is based on NCA loss [29] as follows:
| (9) |
where and are learnable parameter and small margin, respectively, and hinge denotes .
4 Experiment
To verify the experimental validity, we compare performance with the state-of-the-art replay-based methods that share the same problem as ours and use KD. We perform experiments using the small scale CIFAR-100 dataset and the large scale ImageNet dataset, both of which are generally used in CIL. Exemplar stores 20 fixed samples for each class with herding selection [31]. We report both results of CNN predictions and nearest-meaning-of-exemplars [31] classification, denoted as CNN and NME, respectively.
| CIFAR-100 | ||||
| 50 tasks | 25 tasks | 10 tasks | 5 tasks | |
| New classes per task | 1 | 2 | 5 | 10 |
| iCaRL [31] | ||||
| BiC [42] | ||||
| LUCIR (NME) [15] | ||||
| LUCIR (CNN) [15] | ||||
| PODNet (NME) [8] | ||||
| PODNet (CNN) [8] | ||||
| GeoDL [35] | ||||
| DDE [16] | - | - | ||
| AANet [24] | - | |||
| AFC (NME) [19] | ||||
| AFC (CNN) [19] | ||||
| CSCCT [2] | - | |||
| SRIL (NME) | ||||
| SRIL (CNN) | ||||
4.1 Experimental Setup
Dataset and protocol. We evaluate our method on CIFAR-100 [22], ImageNet-Subset [6, 15, 8] and ImageNet-Full [6]. CIFAR-100 consists of 60,000 images of pixels with 100 classes. It contains 500 training data and 100 test data for each class. ImageNet is a large-scale classification dataset, including 1.28 million images and 50k test set, and consists of 1,000 classes. ImageNet-Full uses all classes of ImageNet, and ImageNet-Subset refers to a dataset that randomly extracts 100 classes out of 1,000 classes. We use the same random seed and class order as the previous methods [8, 19] for fair comparison. After learning a part of the entire class for CIL setting, we gradually learn a certain number of classes. Feature-based distillation methods transfer representation directly, so representation of previously learned models is important. Therefore, it shows better performance than response-based distillation in small task incremental learning settings, where it learns about half of the total class in advance and then gradually learns a small number of classes [15, 8, 19].
Implementation details. For reproducibility, we conducted an experiment based on the PODNet [8] code. All experiments are conducted on TITAN-Xp GPU and two GPUs are used for ImageNet-Full. We follow the experimental setup of PODNet [8]. In the CIFAR-100 experiment, we use the ResNet-32 [13] architecture. We trained the model for 160 epochs with SGD with momentum of 0.9 and used a batch size of 128 and a weight decay of 0.0005. We use a cosine annealing learning rate scheduler with an initial learning rate of 0.1. The hyperparameters are , and . For ImageNet-Subset and ImageNet-Full, we use the ResNet-18 [13] architecture. We trained the model for 90 epochs with SGD with momentum of 0.9 and used a cosine annealing learning rate scheduler with an initial learning rate of 0.1 and 0.05, respectively. We use a batch size of 64 and a weight decay of 0.0001. and use 0.999 and 0.1. uses 5 and 7 for ImageNet-Subset and ImageNet-Full, respectively.
4.2 Main Results
CIFAR-100. We compare the average accuracy with the state-of-the-art methods that use the exemplar and KD [31, 42, 15, 8, 35, 16, 24, 19, 2] in Table 1. For a method based on other framework, GeoDL [35], DDE [16], AANet [24] and CSCCT [2] are a performance result based on PODNet (CNN) [8]. We learn 50 classes in -th task and increase the classes of fixed numbers for each task. As a result of the experiment using the NME classifier, the performance improvement of 0.81–1.96 percent points in all experimental environments. Experiments using a CNN classifier show that 5 tasks had lower performance of 0.28 percent points than closest state-of-the-art, but 10 tasks, 25 tasks and 50 tasks show performance improvements of 0.13–1.46 percent points compared to the state-of-the-art method.
ImageNet-Subset/Full. Unlike CIFAR-100, ImageNet uses only the CNN classifier for all experimental results based on the empirical fact that the performance of the knn-based NME classifier is poor due to the large number of classes. For the same reason, previous studies also only report CNN results for ImageNet experiments [8, 19]. Also, for methods that are additionally applied to other frameworks, results based on frameworks recorded with best performance. Table 2 shows the results of our ImageNet experiment. In the ImageNet-Subset, our method achieves state-of-the-art in all experiments, with performance 0.78–1.73 percent points higher than the nearest best performance. Experiments on ImageNet-Full achieved state-of-the-art by a difference of 0.07 percent point in experiments on 5 tasks, and 0.15 percent point lower than the state-of-the-art in experiments on 10 tasks.
| ImageNet-Subset | ImageNet-Full | |||||
| 50 tasks | 25 tasks | 10 tasks | 5 tasks | 10 tasks | 5 tasks | |
| Class per tasks | 1 | 2 | 5 | 10 | 50 | 100 |
| iCaRL [31] | ||||||
| BiC [42] | ||||||
| LUCIR [15] | ||||||
| Mnemonics [26] | ||||||
| PODNet [8] | ||||||
| DDE [16] | ||||||
| GeoDL [35] | ||||||
| AANet [24] | 76.96 | |||||
| CSCCT [2] | ||||||
| AFC [19] | 72.08 | 73.34 | 75.75 | 76.84 | 68.90 | |
| SRIL (Ours) | 66.87 | |||||
4.3 Ablation studies

Representation similarity analysis. Figure 4 shows centered kernel alignment (CKA) [21] similarity for the intermediate feature between -th task model and -th task model trained on CIFAR-100. Both axis refers to the output of the middle layer, which applies feature distillation of the -th task model and -th task model. The diagonal of the heatmap is CKA similarity for the output of the same layer. Therefore, the closer the diagonal component is to 1, the higher representation similarity of the two models. As a method of using feature distillation, we compare PODNet [8] and AFC [19] with our proposed method, SRIL. As a result, SRIL has higher CKA similarity than the existing methods. In particular, for the last intermediate feature closest to the embedding, the CKA similarities of PODNet, AFC and SRIL are 0.715, 0.885 and 0.992, respectively. T0 Acc at the top of Figure 4 denotes the accuracy of the -th task data of the -th task model. T0 Acc are , , and , respectively, and SRIL achieves the best accuracy. Through this, we confirm that SRIL maintains performance for old classes and has high stability by preserving the representation.
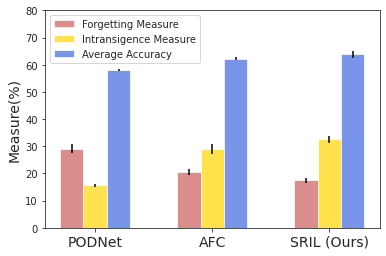
Stability-Plasticity analysis. We analyze Forgetting Measure () [5] and Intransigence Measure () [5] to determine how the stability and plasticity of SRIL differ from other feature distillation methods in Figure 5. is a measure of stability and is defined as the average difference between the maximum accuracy of the previous model and the accuracy of the current model for all tasks. A lower value indicates higher stability. is a measure of plasticity and is defined as an average difference in accuracy for new data between models learned without regularization and models with regularization of all tasks. A lower value indicates higher plasticity. As a result, PODNet [8] has strengths in plasticity, and AFC [19] and SRIL have strengths in stability. Due to the stability-plasticity dilemma, no method is good for both and , and our method strikes a good balance between stability and plasticity and achieves the best average accuracy. We explain the results of the main experiment through the results of stability-plasticity analysis. Our method has high stability by using two selective regularization methods, feature distillation and weight interpolation, and improves overall performance by maintaining performance on the old task. As a result, there was a large performance gain in small task setting, where the class increased by a small number. On ImageNet-Full, we achieved a similar level of performance to the existing method.
Effect of each component. We perform an ablation study to examine the effectiveness of each component of our methods in Table 3. The separated feature distillation (SFD) is a general feature distillation applied to each of old and new classes, and is the same as the form without a mask in GFD. As a result of the experiment, in the case of GFD, there was an overall performance improvement when using the mask, and when using CWI, it shows a large performance improvement for the experiment learning 50 tasks, which are small tasks. In addition, it can be confirmed that the highest performance is obtained when the two methods are used together. Especially, in the case of the second column, stability and plasticity are not balanced due to lack of stability why only using feature distillation. However, by balancing stability and plasticity through CWI, we achieve a significant performance gain of 4.43 percent point.
| 50 tasks | 5 tasks | |||||
|---|---|---|---|---|---|---|
| SFD | GFD | CWI | NME | CNN | NME | CNN |
| ✓ | ||||||
| ✓ | ||||||
| ✓ | ✓ | |||||
| ✓ | ✓ | |||||

Hyperparameter sensitivity analysis. In Figure 6, we investigate our hyperparameters for the gradient-based feature distillation, and and for the confidence-aware weight interpolation on CIFAR-100. As increases, the forgetting measure decreases, and the average accuracy remains similar. increases as and increase. This means that stability decreases and plasticity increases as the hyperparameters of the two values increase. When the two values are infinity and 1, weight interpolation is not used at all, and at this time, the performance deteriorates the most. Our method can control the balance between plasticity and stability through these three parameters. Based on these results, we determine the final hyperparameters.

Effect of memory budget. We conduct an experiment on exemplar that stores 5, 10, 20, and 50 samples for each class to check the dependence by memory budget in Table 4. Although our method adopts an asymmetric learning strategy for current task data and exemplar, our method achieves state-of-the-art for all memory sizes and shows robust performance even for small exemplar sizes. For the most challenging experiment with a memory size of 5 per class, we achieve significant performance improvements of 5.72 and 5.57 percent points for NME and CNN, respectively.
Feature visualization. We visualize the embedded features of 0-th task data for model trained up to the -th task on CIFAR-100 using t-SNE [38] in Figure 7. Compared to previous work [8], our method achieves to construct more cohesive clusters for each class. These results show that our method works successfully on knn based NME classifier and small exemplar size.
Effect of initial task size. To investigate the effect on the initial representation, we experiment by reducing the initial task size, the number of classes for the -th task, from 50 to 20 by 10 in Table 5. For all experiments, our method achieves state-of-the-art. Confirming good performance even in the case of lack of diversity in the initial representation demonstrates that our method is robust to the initial representation of the model.
5 Conclusion
In this paper, we proposed a selective regularization method to accept new knowledge while preserving previous knowledge. We introduced an asymmetric feature distillation approach using the gradients of classification and knowledge distillation losses to decide whether to perform pattern completion and separation. Furthermore, we proposed a confidence-aware weight interpolation method to improve the balance between stability and plasticity in class-incremental learning. We achieved competitive performance to the state-of-the-art methods, and extensive experiments demonstrate the effectiveness of our method in a variety of scenarios.
References
- [1] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. Memory aware synapses: Learning what (not) to forget. In Proceedings of the European conference on computer vision (ECCV), pages 139–154, 2018.
- [2] Arjun Ashok, KJ Joseph, and Vineeth N Balasubramanian. Class-incremental learning with cross-space clustering and controlled transfer. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVII, pages 105–122. Springer, 2022.
- [3] Lucas Caccia, Rahaf Aljundi, Nader Asadi, Tinne Tuytelaars, Joelle Pineau, and Eugene Belilovsky. New insights on reducing abrupt representation change in online continual learning. In International Conference on Learning Representations, 2022.
- [4] Francisco M Castro, Manuel J Marin-Jimenez, Nicolas Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. In Proceedings of the European Conference on Computer Vision (ECCV), pages 233–248, 2018.
- [5] Arslan Chaudhry, Puneet K Dokania, Thalaiyasingam Ajanthan, and Philip HS Torr. Riemannian walk for incremental learning: Understanding forgetting and intransigence. In ECCV, 2018.
- [6] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [7] Songlin Dong, Xiaopeng Hong, Xiaoyu Tao, Xinyuan Chang, Xing Wei, and Yihong Gong. Few-shot class-incremental learning via relation knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 1255–1263, 2021.
- [8] Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled outputs distillation for small-tasks incremental learning. In Proceedings of the IEEE European Conference on Computer Vision (ECCV), 2020.
- [9] Yunshu Du, Wojciech M Czarnecki, Siddhant M Jayakumar, Mehrdad Farajtabar, Razvan Pascanu, and Balaji Lakshminarayanan. Adapting auxiliary losses using gradient similarity. arXiv preprint arXiv:1812.02224, 2018.
- [10] Steven Vander Eeckt et al. Weight averaging: A simple yet effective method to overcome catastrophic forgetting in automatic speech recognition. ICASSP, 2023.
- [11] I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y. Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks. ArXiv e-prints, dec 2013.
- [12] Yiduo Guo, Bing Liu, and Dongyan Zhao. Online continual learning through mutual information maximization. In International Conference on Machine Learning, pages 8109–8126. PMLR, 2022.
- [13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [14] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- [15] Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a unified classifier incrementally via rebalancing. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [16] Xinting Hu, Kaihua Tang, Chunyan Miao, Xian-Sheng Hua, and Hanwang Zhang. Distilling causal effect of data in class-incremental learning. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 3957–3966, 2021.
- [17] Ching-Yi Hung, Cheng-Hao Tu, Cheng-En Wu, Chien-Hung Chen, Yi-Ming Chan, and Chu-Song Chen. Compacting, picking and growing for unforgetting continual learning. In Advances in Neural Information Processing Systems, pages 13647–13657, 2019.
- [18] P Izmailov, AG Wilson, D Podoprikhin, D Vetrov, and T Garipov. Averaging weights leads to wider optima and better generalization. In 34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, pages 876–885, 2018.
- [19] Minsoo Kang, Jaeyoo Park, and Bohyung Han. Class-incremental learning by knowledge distillation with adaptive feature consolidation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16071–16080, 2022.
- [20] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proc. of the national academy of sciences, 2017.
- [21] Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. In International Conference on Machine Learning, pages 3519–3529. PMLR, 2019.
- [22] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [23] Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
- [24] Yaoyao Liu, Bernt Schiele, and Qianru Sun. Adaptive aggregation networks for class-incremental learning. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 2544–2553, 2021.
- [25] Yaoyao Liu, Bernt Schiele, and Qianru Sun. Rmm: Reinforced memory management for class-incremental learning. Advances in Neural Information Processing Systems, 34:3478–3490, 2021.
- [26] Yaoyao Liu, Yuting Su, An-An Liu, Bernt Schiele, and Qianru Sun. Mnemonics training: Multi-class incremental learning without forgetting. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 12245–12254, 2020.
- [27] Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989.
- [28] Martial Mermillod, Aurélia Bugaiska, and Patrick Bonin. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects, 2013.
- [29] Yair Movshovitz-Attias, Alexander Toshev, Thomas K Leung, Sergey Ioffe, and Saurabh Singh. No fuss distance metric learning using proxies. In Proceedings of the IEEE international conference on computer vision, pages 360–368, 2017.
- [30] Randall C O’Reilly and James L McClelland. Hippocampal conjunctive encoding, storage, and recall: Avoiding a trade-off. Hippocampus, 4(6):661–682, 1994.
- [31] Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017.
- [32] A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell. Progressive neural networks. ArXiv e-prints, jun 2016.
- [33] Adam Santoro. Reassessing pattern separation in the dentate gyrus, 2013.
- [34] Khadija Shaheen, Muhammad Abdullah Hanif, Osman Hasan, and Muhammad Shafique. Continual learning for real-world autonomous systems: Algorithms, challenges and frameworks. Journal of Intelligent & Robotic Systems, 105(1):9, 2022.
- [35] Christian Simon, Piotr Koniusz, and Mehrtash Harandi. On learning the geodesic path for incremental learning. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 1591–1600, 2021.
- [36] Zafir Stojanovski, Karsten Roth, and Zeynep Akata. Momentum-based weight interpolation of strong zero-shot models for continual learning. In NeurIPS 2022 Workshop on Distribution Shifts: Connecting Methods and Applications, 2022.
- [37] Xiaoyu Tao, Xinyuan Chang, Xiaopeng Hong, Xing Wei, and Yihong Gong. Topology-preserving class-incremental learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIX 16, pages 254–270. Springer, 2020.
- [38] Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(11), 2008.
- [39] Pieter Verbeke and Tom Verguts. Learning to synchronize: How biological agents can couple neural task modules for dealing with the stability-plasticity dilemma. PLoS computational biology, 15(8):e1006604, 2019.
- [40] Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International Conference on Machine Learning, pages 23965–23998. PMLR, 2022.
- [41] Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. Robust fine-tuning of zero-shot models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7959–7971, 2022.
- [42] Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, and Yun Fu. Large scale incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 374–382, 2019.
- [43] J Yoon, E Yang, J Lee, and SJ Hwang. Lifelong learning with dynamically expandable networks. In International Conference on Learning Representations, ICLR, 2018.
- [44] Yichen Zhu and Yi Wang. Student customized knowledge distillation: Bridging the gap between student and teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5057–5066, 2021.