SR-LIVO: LiDAR-Inertial-Visual Odometry and Mapping with Sweep Reconstruction
Abstract
Existing LiDAR-inertial-visual odometry and mapping (LIV-SLAM) systems mainly utilize the LiDAR-inertial odometry (LIO) module for structure reconstruction and the visual-inertial odometry (VIO) module for color rendering. However, the accuracy of VIO is often compromised by photometric changes, weak textures and motion blur, unlike the more robust LIO. This paper introduces SR-LIVO, an advanced and novel LIV-SLAM system employing sweep reconstruction to align reconstructed sweeps with image timestamps. This allows the LIO module to accurately determine states at all imaging moments, enhancing pose accuracy and processing efficiency. Experimental results on two public datasets demonstrate that: 1) our SR-LIVO outperforms existing state-of-the-art LIV-SLAM systems in both pose accuracy and time efficiency; 2) our LIO-based pose estimation prove more accurate than VIO-based ones in several mainstream LIV-SLAM systems (including ours). We have released our source code to contribute to the community development in this field.
Index Terms:
SLAM, localization, sensor fusion.I Introduction
In robotic applications like autonomous vehicles [4] and drones [2, 3], cameras, 3D light detection and ranging (LiDAR) and inertial measurement unit (IMU) are key sensors. The integration of IMU measurements can provide motion prior to ensure accurate and quick state estimation. While LiDAR excels in capturing 3D structures, it lacks color information which cameras compensate for. This synergy has led to the rise of LiDAR-inertial-visual odometry and mapping (LIV-SLAM) as a leading method for accurate state estimation and dense color map reconstruction.
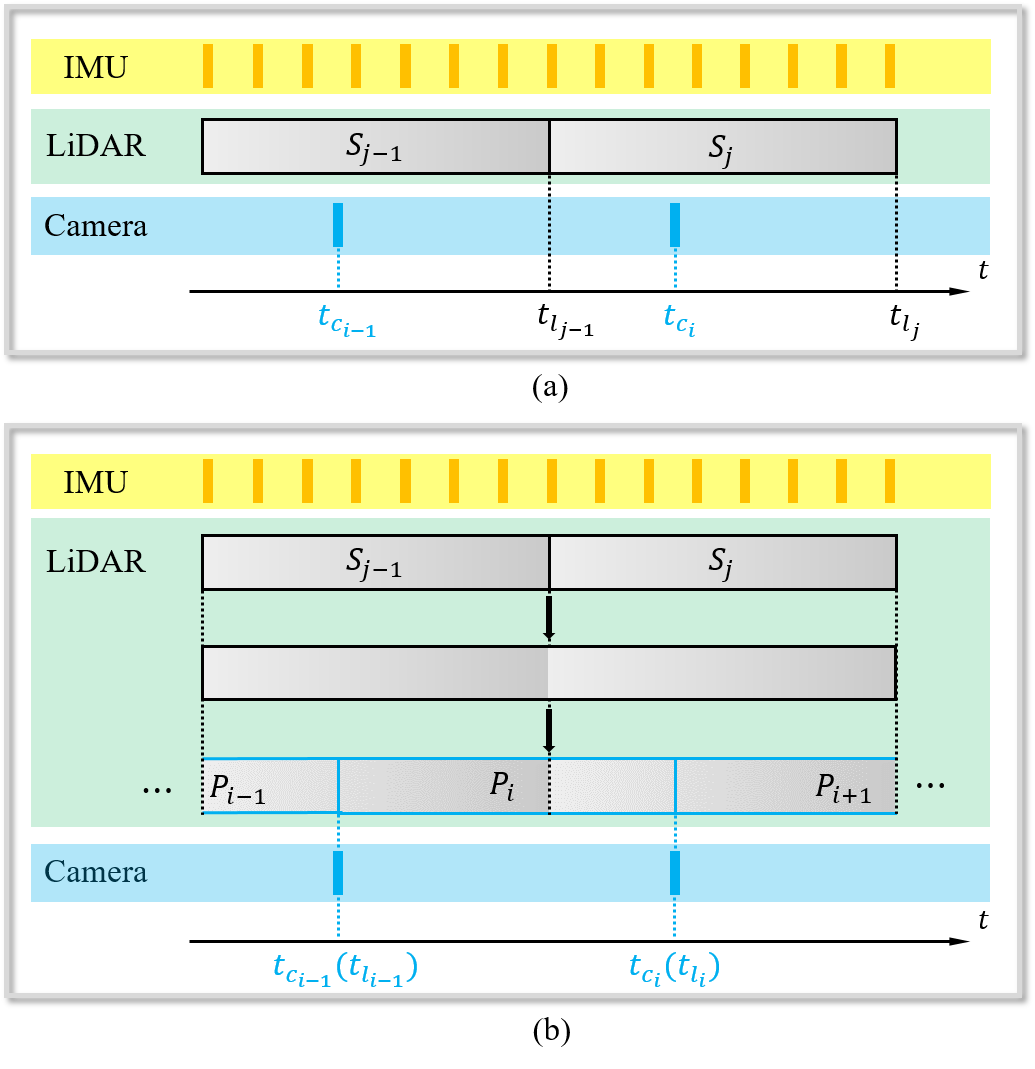
Existing state-of-the-art LIV-SLAM systems [6, 5, 18] mainly consist of a LIO module and a VIO module. The LIO module reconstructs 3D structures while the VIO module colors them. Both LIO and VIO modules perform state estimation. The LIO module obtains the estimated state at the end timestamp of a LiDAR sweep (e.g., and in Fig. 1 (a)), and the VIO module solves the state at the timestamp of each captured image (e.g., and in Fig. 1 (a)). Compared to LIO, VIO is less reliable to photometric changes, weak textures and motion blur, and thus suffers less accurate pose results and in turn degrade colored reconstruction.
In this paper, we propose SR-LIVO, a novel and advanced LVI-SLAM framework that enhances both accuracy and reliability. We shift state estimation entirely to the LIO module, known for its better precision. A key challenge brought by this design is that: the timestamp of the captured images and the end timestamp of LiDAR sweeps are often not aligned. Without the state of the image acquisition moment, we can hardly use image data to render color for the restored 3D structures. To address this issue, we adopt the sweep reconstruction method proposed in our previous work [16] for data synchronization (e.g., and in Fig. 1 (b)) with the timestamp of captured images (e.g., and in Fig. 1 (b)). In this way, the LIO module can directly estimate states at image capture moments. Consequently, the vision module’s role is simplified to optimizing camera parameters (e.g., camera intrinsics, extrinsics and time-offset) and completing the color rendering task.
Experimental results on the public datasets [7], [5] demonstrate the following key findings: 1) Our system outperforms existing state-of-the-art LIO systems (i.e., [6, 5]) in terms of the smaller absolute trajectory error (ATE), and is much more efficient than [5]; 2) The estimated pose from the LIO module is more accurate than that from the VIO modules of several mainstream LIV-SLAM systems. Meanwhile, the visualization results demonstrate that our SR-LIVO can achieve comparable reconstruction results to [5] on their self-collected dataset (i.e., ), and can achieve much superior results to [5] on the dataset.
To summarize, the main contributions of this work are three folds: 1) We identify an important function of sweep reconstruction, i.e., aligning LiDAR sweep and image timestamps; 2) We design a new LIV-SLAM system based on sweep reconstruction, where the vision module is no longer needed to perform state estimation but only for coloring the reconstructed map; 3) We have released the source code of our system to benefit the development of the community111https://github.com/ZikangYuan/sr_livo.
II Related Work
In recent years, various LiDAR-visual and LiDAR-inertial-visual fusion frameworks have been proposed. V-LOAM [17] is the first cascaded LIV-SLAM framework that provides motion priori for LiDAR odometry via a loosely coupled VIO. [11] cascades a tightly-coupled stereo VIO, a LiDAR odometry and a LiDAR-based loop closing module together. Compared with [17] and [11], the vision module of DV-LOAM [12] utilizes the direct method to perform pose estimation and multi-frame joint optimization in turn to make the vision module provide more accurate motion priori for the subsequent LiDAR module. Lic-Fusion [19] combines the IMU measurements, sparse visual features, LiDAR features with online spatial and temporal calibration within the multi state constrained Kalman filter (MSCKF) framework. To further enhance the accuracy and the robustness of the LiDAR points registration, LIC-Fusion 2.0 [20] proposes a plane-feature tracking algorithm across multiple LiDAR sweeps in a sliding-window and refines the pose of sweep within the window. LVI-SAM [10] integrates the data from camera, LiDAR and IMU into a tightly-coupled graph-based optimization framework. The vision and LiDAR module of LVI-SAM can run independently when each other fails, or jointly when both visual and LiDAR features are sufficient. R2Live [6] firstly proposes to run a LIO module and a VIO module in parallel, where the LIO module provides geometric structure information for the VIO module. The back end utilizes the visual landmarks to perform graph-based optimization. Based on R2Live, R3Live [5] omits the graph-based optimization module and adds a color rendering module for dense color map reconstruction. Compared to R3Live, Fast-LIVO [18] combines LiDAR, camera and IMU measurements into a single error state iterated Kalman filter (ESIKF), which can be updated by both LiDAR and visual observations. mVIL-Fusion [13] proposes a three-staged cascading LVI-SLAM framework, which consists of a LiDAR-assisted VIO module, a multi sweep-to-sweep joint optimization module, a sweep-to-map optimization module and a loop closing module. VILO-SLAM [8] fuses 2D LiDAR residual factor, IMU residual factor and visual reprojection residual factor into an optimization-based framework. In [14], a weight function is designed based on geometric structure and reflectivity to improve the performance of solid-state LIO under severe linear acceleration and angular velocity changes.
III Preliminary
III-A Coordinate Systems
We denote , , and as a 3D point in the world coordinate, the LiDAR coordinate, the IMU coordinate and the camera coordinate respectively. The world coordinate is coinciding with at the starting position.
We denote the IMU coordinate for taking the IMU measurement at time as and the corresponding camera coordinate at as . The transformation matrix (i.e., extrinsics) from to is denoted as , where consists of a rotation matrix and a translation vector . Similarly, we can also obtain the extrinsics form LiDAR to IMU, i.e., . For the datasets involved in this work, we use the internal IMU of LiDAR, therefore, we treat as absolutely accurate and do not require online correction. For , we optimize it online because the camera is a separate external sensor.
III-B Distortion Correction
For each camera image, we utilized the offline-calibrated distortion parameters to correct the image distortion. For LiDAR points, we utilize the IMU-integrated pose to compensate the motion distortion.
IV System Overview
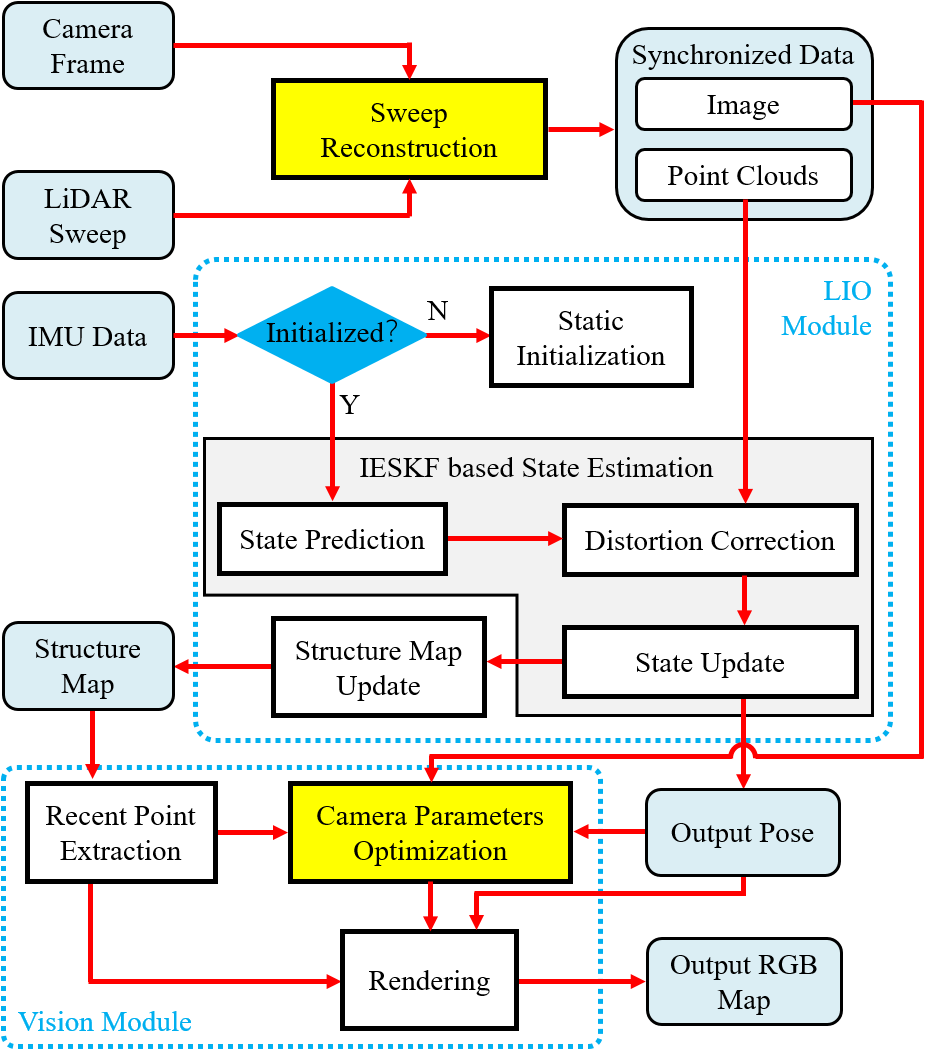
Fig. 2 illustrates the framework of our system which consists of three main modules: a sweep reconstruction module, a LIO state estimation module and a vision module. The sweep reconstruction module aligns the end timestamp of reconstructed sweep with the timestamp of captured image. The LIO module estimates the state of the hardware platform, and restores the structure in real time. The vision module optimizes the camera parameters including camera intrinsics, extrinsics, time-offset, and renders color to the restored structure map in real time. For map management, we utilized the Hash voxel map, which is the same as CT-ICP [1]. The implementation details of various parts of the LIO module are exactly the same as our previous work SR-LIO [15], therefore, we omit the introduction of this module, and only introduce the details of sweep reconstruction and our vision module in Sec. V.
V System Details
V-A Sweep Reconstruction
In our previous work SDV-LOAM [16], we firstly propose the sweep reconstruction idea, which increases the frequency of LiDAR sweeps to the same frequency as camera images. In this work, we point out another important function of this idea: aligning the end timestamp of reconstructed sweep to the timestamp of captured image. According to the frequency of LiDAR sweeps and camera images, the processing method is also different in practice. There are three specific cases as following:
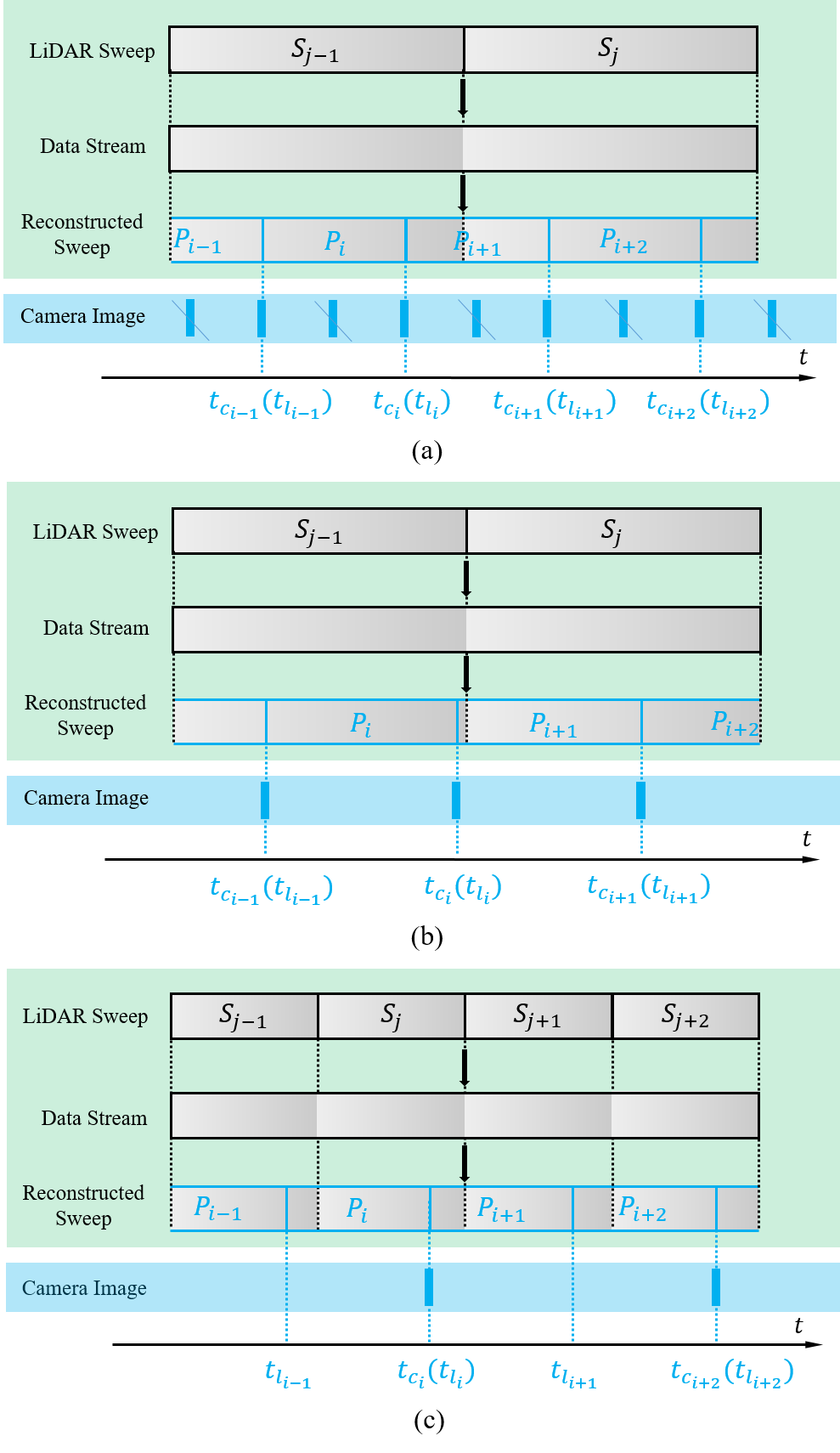
The frequency of captured images is more than twice that of raw LiDAR sweeps (as shown in Fig. 3 (a)). In this case, we firstly down-sample the frequency of camera images to twice the frequency of raw LiDAR sweeps. Then we disassemble the raw LiDAR sweep (i.e., and in Fig. 3 (a)) into continuous point cloud data stream, and recombine the point cloud data stream with aligning the end timestamp (e.g., in Fig. 3 (a)) of reconstructed sweep (i.e., in Fig. 3 (a)) to the timestamp of down-sampled captured image (e.g., in Fig. 3 (a)). In this way, the number of LiDAR points in reconstructed sweep is only half that in raw input sweep. For spinning LiDAR, not only the number, but also the horizontal distribution range is reduced from to . If the frequency of reconstructed sweeps is more than twice that of raw sweeps, the number and horizontal distribution range of points will decrease further, and eventually the LIO module may fail to perform properly. Therefore, we need to down-sample the frequency of camera images to at most twice the frequency of raw LiDAR sweeps.
The frequency of captured images is less than twice but more than that of raw LiDAR sweeps (as shown in Fig. 3 (b)). In this case, we directly disassemble the raw LiDAR sweep (i.e., and in Fig. 3 (b)) into continuous point cloud data stream, and recombine the point cloud data stream with aligning the end timestamp (e.g., in Fig. 3 (b)) of reconstructed sweep (e.g., in Fig. 3 (b)) to the timestamp of captured image (e.g., in Fig. 3 (b)). In this way, the point cloud number and the horizontal distribution range of reconstructed sweeps are less than that of raw LiDAR sweeps, but also enough to support the LIO module run properly.
The frequency of captured images is less than that of raw LiDAR sweeps (as shown in Fig. 3 (c)). In this case, we directly disassemble the raw LiDAR sweep (i.e., , , and in Fig. 3 (c)) into continuous point cloud data stream, and recombine the point cloud data stream according to the following two situations: 1) We assume the current reconstructed sweep begins at but the end timestamp is not yet determined. When the time interval from current moment to reaches the time period of a raw LiDAR sweep and there are no images around current moment, we set the current moment as the end timestamp (e.g., in Fig. 3 (c)) of this reconstructed sweep (e.g., in Fig. 3 (c)). 2) We assume the current reconstructed sweep begins at but the end timestamp is not yet determined. When the current moment reaches the timestamp of captured image (e.g., in Fig. 3 (c)) and there is a sufficient time interval from to , we set the current moment as the end timestamp (e.g., () in Fig. 3 (c)) of reconstructed sweep (e.g., in Fig. 3 (c)). Under the situation 2), not all synchronized data includes image data (i.e., and in Fig. 3 (c)). For synchronized data without camera images, we just utilize the LIO module to estimate state without the vision module running. For synchronized data with both point cloud and image data, the LIO module and the vision module execute in turn.
V-B Vision Module
V-B1 Recent Point Extraction
Similar as R3Live [5], firstly we record all recently visited voxels when performing structure map update. Then, we select the newest added point from each visited voxel , to obtain the recent point set .
V-B2 Camera Parameters Optimization
Different from existing state-of-the-art frameworks (e.g., R3Live and Fast-LIVO), we have estimated the state at the timestamp (e.g., ) of captured images (e.g., ) in the LIO module. Therefore, we no longer need to solve state (i.e., pose, velocity and IMU bias) in the vision module, but only need to utilize the image data to optimize some camera parameters:
| (1) |
where is the time-offset between IMU and camera while LiDAR is assumed to be synced with the IMU already. and are the extrinsics between camera and IMU. are the camera intrinsics, where denote the camera focal length, denote the offsets of the principal point from the top-left corner of the image plane.
To balance the effects of previous estimates and the current image observation on camera parameters, we utilize an ESIKF to optimize the camera parameters , where the error state is defined as:
| (2) |
For the state prediction, the error state and covariance is propagated as:
| (3) |
For the state update, the minimizing PnP projection error and the minimizing photometric error are used to update in turn.
The minimizing PnP projection error. Assuming that we have tracked map points , and their projection on image is , we leverage the Lucas-Kanade optical flow to find out their locations in the current image : . For the exemplar point , we calculate the re-projection error by:
| (4) |
where is computed as below:
| (5) | ||||
where is the time interval between the last image and the current image . In Eq. 5, the first item is the pin-hole projection function and the second one is the online-temporal correction factor [9]. We can express the observation matrix as:
| (6) |
The corresponding Jacobian matrix of observation constraint is calculated as:
| (7) | ||||
The minimizing photometric error. For the exemplar point , if has been rendered the color intensity , we firstly project to by Eq. 4 and 5, and then calculate the photometric error by:
| (8) |
where represents the color intensity of image pixel. The observation matrix and the corresponding Jacobin matrix have the similar formula as Eq. 6-7.
The same as R3Live [5], for each image , we firstly utilize the minimizing PnP projection error to update the ESIKF, and then utilize the minimizing photometric error to update the ESIKF. The difference is that the ESIKF of R3Live’s vision module estimates both state and camera parameters of , but we only optimize camera parameters of , while the state of has been solved in our LIO module.
V-B3 Rendering
After the camera parameters have been optimized, we perform the rendering function to update the color of map points. To ensure the density of colored point cloud map, we not only render points in the recent point set , but also render all points in recently visited voxels . The rendering function we utilize is the same as R3Live [5].
VI Experiments
We evaluate our system on the drone-collected dataset [7] and the handheld device-collected dataset [5]. The sensors used in dataset are the left camera, the horizontal 16-channel OS1 gen14 LiDAR and its internal IMU, while the high-accuracy laser tracking methods are employed to provide position ground truth. The sensors used in dataset are the camera, the LiVOX AVAI LiDAR and its internal IMU, while no position ground truth data are provided. We utilize all sequences of [7] and 6 sequences (i.e., : , : , : , : , : and : ) of for evaluation. A consumer-level computer equipped with an Intel Core i7-11700 and 32 GB RAM is used for all experiments.
VI-A Comparison of the State-of-the-Arts
We compare our system with two state-of-the-art LIV-SLAM systems, i.e., R3Live [5] and Fast-LIVO [18], on dataset [7] and dataset [5]. For the dataset, we utilize the universal evaluation metrics - absolute translational error (ATE) as the evaluation metrics. The dataset does not provide the position groundtruth, however, they return to their starting point at the end of most sequences. Therefore, we utilize the end-to-end error instead. For a fair comparison, we obtain the results of above systems based on the source code provided by the authors.
| R3Live [5] | Fast-LIVO [18] | Ours | |
| 1.69 | 0.28 | 0.21 | |
| 0.18 | 0.23 | ||
| 0.64 | 0.26 | 0.22 | |
| 0.63 | 0.34 | 0.18 | |
| 0.35 | 0.29 | 0.19 | |
| 0.23 | 0.29 | 0.20 | |
| 0.40 | 0.73 | 0.12 | |
| 0.27 | 0.25 | 0.22 | |
| 0.21 | 0.24 | 0.21 |
| R3Live [5] | Fast-LIVO [18] | Ours | |
| 0.097 | 0.070 | 0.021 | |
| 0.115 | 0.090 | 0.053 | |
| 0.071 | 0.050 | 0.120 | |
| 0.603 | 0.546 | 0.546 | |
| 0.036 | 13.463 | 0.024 |
Results in Table I demonstrate that our system outperforms R3Live and Fast-LIVO for almost all sequences in terms of smaller ATE. ”” means the system drifts halfway through the run, where our SR-LIVO has better robustness than R3Live on dataset. The end-to-end errors are reported in Table II, whose overall trend is similar to the RMSE of ATE results. Our SR-LIVO achieves the lowest drift in four of the total five sequences. Fast-LIVO achieves large end-to-end error on sequence because Fast-LIVO updates a single ESIKF with LiDAR and visual observations, while the low-quality visual observations would diverge the results of the filter.
VI-B Comparison of LIO module and VIO module
Our system is designed based on the logic that: the state estimation performance of LIO module is more accurate than that of VIO module. Therefore, we provide quantitative data in this section to prove that our logical base is correct. We compare the ATE results of the VIO module with the LiDAR module on R3Live, Fast-LIVO and our SR-LIVO. Our proposed SR-LIVO does not include the VIO module, and we implement a VIO module modeled similar as R3Live to complete this ablation study.
| R3Live | R3Live (V) |
|
|
|
|
|||||||||
| 1.69 | 1.71 | 0.28 | 0.30 | 0.21 | 0.24 | |||||||||
| 0.18 | 0.26 | 0.23 | 0.23 | |||||||||||
| 0.64 | 0.81 | 0.26 | 0.27 | 0.22 | 0.27 | |||||||||
| 0.63 | 0.63 | 0.33 | 0.33 | 0.18 | 0.19 | |||||||||
| 0.35 | 0.41 | 0.29 | 0.30 | 0.19 | 0.20 | |||||||||
| 0.23 | 0.32 | 0.22 | 0.29 | 0.20 | 0.24 | |||||||||
| 0.40 | 0.70 | 0.73 | 0.42 | 0.12 | 0.38 | |||||||||
| 0.27 | 0.33 | 0.25 | 0.31 | 0.22 | 0.22 | |||||||||
| 0.21 | 0.23 | 0.24 | 0.27 | 0.21 | 0.22 |
The results in Table III demonstrate that: the accuracy of LIO modules is superior to that of VIO modules whether the framework is based on R3Live, Fast-LIVO or our SR-LIVO. This supports the conclusion that LIO is better at state estimation than VIO.
VI-C Time Consumption
| Vision | LiDAR | Total | ||||
| R3Live | Ours | R3Live | Ours | R3Live | Ours | |
| 38.90 | 20.86 | 17.51 | 9.67 | 50.57 | 30.53 | |
| 33.80 | 19.95 | 24.23 | 10.83 | 49.95 | 30.78 | |
| 37.16 | 21.51 | 18.16 | 9.55 | 49.27 | 31.06 | |
| 43.25 | 20.33 | 19.33 | 10.54 | 56.14 | 30.87 | |
| 40.23 | 19.64 | 20.95 | 11.78 | 54.20 | 31.42 | |
| 38.82 | 20.80 | 27.92 | 13.08 | 57.43 | 33.88 | |
| 5.23 | 5.43 | 38.66 | 11.15 | 31.02 | 16.58 | |
| 5.41 | 30.04 | 9.69 | 24.60 | 15.10 | ||
| 5.00 | 6.93 | 27.43 | 10.00 | 23.29 | 16.93 | |
| 6.58 | 6.02 | 19.62 | 7.94 | 19.67 | 13.96 | |
| 6.49 | 8.68 | 20.07 | 7.81 | 19.87 | 16.49 | |
| 6.98 | 7.22 | 20.04 | 8.02 | 20.34 | 15.24 | |
| 5.10 | 5.69 | 24.30 | 8.97 | 21.31 | 14.66 | |
| 5.52 | 5.48 | 26.74 | 9.31 | 23.36 | 14.79 | |
| 5.26 | 5.11 | 26.47 | 10.24 | 22.92 | 15.35 | |
We evaluate the runtime breakdown (unit: ms) of our system and R3Live for all testing sequences. In general, the whole system framework consists of the VIO module and the LIO module. For each sequence, we test the time consumption of the above two modules, and the total time for handling a sweep. Results in Table IV show that our system takes 3034ms to handle a sweep on dataset and 1417ms to handle a sweep on dataset, while R3Live takes 4958ms to handle a sweep on dataset and 1031ms to handle a sweep on dataset. That means our system can run around 1.6X faster than R3Live.
VI-D Real-Time Performance Evaluation
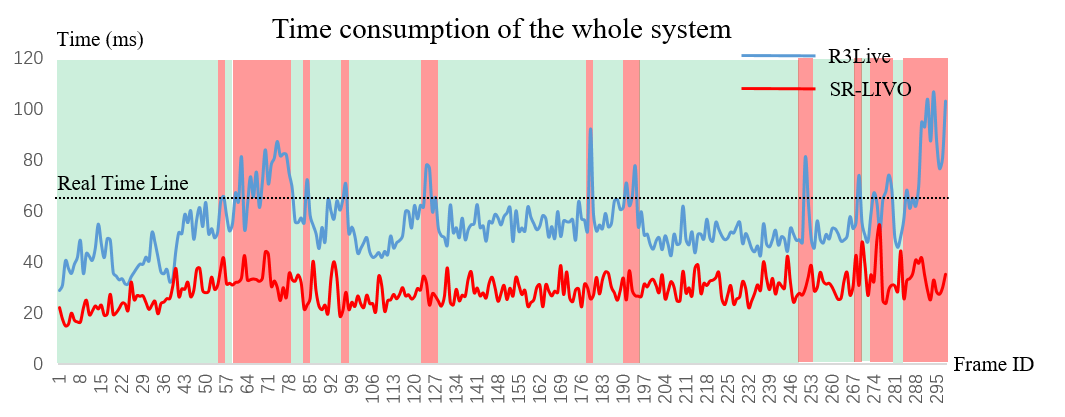
We take as the exemplar sequence, and plot the curve of time consumption as the frame ID changes. Fig. 4 demonstrates that R3Live cannot ensure the real-time performance for a considerable amount of time, while our SR-LIVO can run in real time stably.
VI-E Visualization for Map


Fig. 5 shows the ability of our SR-LIVO to reconstruct a dense, 3D, RGB-colored point cloud map on the exemplar sequence (e.g., ), which is comparable to the reconstruction result of R3Live (Fig. 1 in [5]). Under the premise that the reconstruction result is equal, our method can run stably in real time while R3Live cannot, demonstrating the strength of our approach.
The camera images of dataset are grayscale images, leading to the grayscale map. Fig. 6 compares the visualizations of our reconstructed grayscale map with R3Live on the exemplar sequence (e.g., ) of dataset, on which our system achieves significantly better reconstruction result.
VII Conclusion
This paper proposes a novel LIV-SLAM system, named SR-LIVO, which adapts the sweep reconstruction method to align the end timestamp of reconstructed sweep to the timestamp of captured image. Thus, the state of all image-captured moments can be solved by the more reliable LIO module instead of the hypersensitive VIO module. In SR-LIVO, we utilize an ESIKF to solve state in LIO module, and utilize an ESIKF to optimize camera parameters in vision module respectively for optimal state estimation and colored point cloud map reconstruction.
Our system achieves state-of-the-art pose accuracy on two public datasets, and achieves much lower time consumption than R3Live while keeping the reconstruction result comparable or better. Future work includes adding loop closing module to this framework.
References
- [1] P. Dellenbach, J.-E. Deschaud, B. Jacquet, and F. Goulette, “Ct-icp: Real-time elastic lidar odometry with loop closure,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 5580–5586.
- [2] F. Gao, W. Wu, W. Gao, and S. Shen, “Flying on point clouds: Online trajectory generation and autonomous navigation for quadrotors in cluttered environments,” Journal of Field Robotics, vol. 36, no. 4, pp. 710–733, 2019.
- [3] F. Kong, W. Xu, Y. Cai, and F. Zhang, “Avoiding dynamic small obstacles with onboard sensing and computation on aerial robots,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7869–7876, 2021.
- [4] J. Levinson, J. Askeland, J. Becker, J. Dolson, D. Held, S. Kammel, J. Z. Kolter, D. Langer, O. Pink, V. Pratt et al., “Towards fully autonomous driving: Systems and algorithms,” in 2011 IEEE intelligent vehicles symposium (IV). IEEE, 2011, pp. 163–168.
- [5] J. Lin and F. Zhang, “R 3 live: A robust, real-time, rgb-colored, lidar-inertial-visual tightly-coupled state estimation and mapping package,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 10 672–10 678.
- [6] J. Lin, C. Zheng, W. Xu, and F. Zhang, “R 2 live: A robust, real-time, lidar-inertial-visual tightly-coupled state estimator and mapping,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7469–7476, 2021.
- [7] T.-M. Nguyen, S. Yuan, M. Cao, Y. Lyu, T. H. Nguyen, and L. Xie, “Ntu viral: A visual-inertial-ranging-lidar dataset, from an aerial vehicle viewpoint,” The International Journal of Robotics Research, vol. 41, no. 3, pp. 270–280, 2022.
- [8] G. Peng, Y. Zhou, L. Hu, L. Xiao, Z. Sun, Z. Wu, and X. Zhu, “Vilo slam: Tightly coupled binocular vision–inertia slam combined with lidar,” Sensors, vol. 23, no. 10, p. 4588, 2023.
- [9] T. Qin and S. Shen, “Online temporal calibration for monocular visual-inertial systems. in 2018 ieee,” in RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3662–3669.
- [10] T. Shan, B. Englot, C. Ratti, and D. Rus, “Lvi-sam: Tightly-coupled lidar-visual-inertial odometry via smoothing and mapping,” in 2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021, pp. 5692–5698.
- [11] W. Shao, S. Vijayarangan, C. Li, and G. Kantor, “Stereo visual inertial lidar simultaneous localization and mapping,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 370–377.
- [12] W. Wang, J. Liu, C. Wang, B. Luo, and C. Zhang, “Dv-loam: Direct visual lidar odometry and mapping,” Remote Sensing, vol. 13, no. 16, p. 3340, 2021.
- [13] Y. Wang and H. Ma, “mvil-fusion: Monocular visual-inertial-lidar simultaneous localization and mapping in challenging environments,” IEEE Robotics and Automation Letters, vol. 8, no. 2, pp. 504–511, 2022.
- [14] T. Yin, J. Yao, Y. Lu, and C. Na, “Solid-state-lidar-inertial-visual odometry and mapping via quadratic motion model and reflectivity information,” Electronics, vol. 12, no. 17, p. 3633, 2023.
- [15] Z. Yuan, F. Lang, T. Xu, and X. Yang, “Sr-lio: Lidar-inertial odometry with sweep reconstruction,” arXiv preprint arXiv:2210.10424, 2022.
- [16] Z. Yuan, Q. Wang, K. Cheng, T. Hao, and X. Yang, “Sdv-loam: Semi-direct visual-lidar odometry and mapping,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [17] J. Zhang and S. Singh, “Laser–visual–inertial odometry and mapping with high robustness and low drift,” Journal of field robotics, vol. 35, no. 8, pp. 1242–1264, 2018.
- [18] C. Zheng, Q. Zhu, W. Xu, X. Liu, Q. Guo, and F. Zhang, “Fast-livo: Fast and tightly-coupled sparse-direct lidar-inertial-visual odometry,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 4003–4009.
- [19] X. Zuo, P. Geneva, W. Lee, Y. Liu, and G. Huang, “Lic-fusion: Lidar-inertial-camera odometry,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 5848–5854.
- [20] X. Zuo, Y. Yang, P. Geneva, J. Lv, Y. Liu, G. Huang, and M. Pollefeys, “Lic-fusion 2.0: Lidar-inertial-camera odometry with sliding-window plane-feature tracking,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 5112–5119.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fd0f9fe1-6894-4b04-860c-8459bbf1c908/zikangyuan.jpg) |
Zikang Yuan received the B.E. degree from Huazhong University of Science and Technology (HUST), Wuhan, China, in 2018. He is currently a 4th year PhD student of HUST, School of Institute of Artificial Intelligence. He has published two papers on ACM MM, three papers on TMM, one paper on TPAMI and one paper on IROS. His research interests include monocular dense mapping, RGB-D simultaneous localization and mapping, visual-inertial state estimation, LiDAR-inertial state estimation, LiDAR-inertial-wheel state estimation and visual-LiDAR pose estimation and mapping. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fd0f9fe1-6894-4b04-860c-8459bbf1c908/jiedeng.png) |
Jie Deng is currently a 4th year B.E. student of HUST, School of Electronic Information and Communications. Her research interests include LiDAR-inertial state estimation, LiDAR-inertial-wheel state estimation and visual-LiDAR pose estimation and mapping. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fd0f9fe1-6894-4b04-860c-8459bbf1c908/ruiyeming.png) |
Ruiye Ming received the B.E. degree from Zhengzhou University(ZZU), Zhengzhou, China, in 2022. He is currently a 2nd year graduate student of HUST, School of Electronic Information and Communications. His research interests include visual-LiDAR odometry, LiDAR point based loop closing, object reconstruction and deep-learning based depth estimation. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fd0f9fe1-6894-4b04-860c-8459bbf1c908/fengtianlang.jpg) |
Fengtian Lang received the B.E. degree from Huazhong University of Science and Technology (HUST), Wuhan, China, in 2023. He is currently a 1st year graduate student of HUST, School of Electronic Information and Communications. He has published one paper on IROS. His research interests include LiDAR-inertial state estimation, LiDAR-inertial-wheel state estimation and LiDAR point based loop closing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fd0f9fe1-6894-4b04-860c-8459bbf1c908/xinyang.jpg) |
Xin Yang received her PhD degree in University of California, Santa Barbara in 2013. She worked as a Post-doc in Learning-based Multimedia Lab at UCSB (2013-2014). She is current Professor of Huazhong University of Science and Technology School of Electronic Information and Communications. Her research interests include simultaneous localization and mapping, augmented reality, and medical image analysis. She has published over 90 technical papers, including TPAMI, IJCV, TMI, MedIA, CVPR, ECCV, MM, etc., co-authored two books and holds 3 U.S. Patents. Prof. Yang is a member of IEEE and a member of ACM. |