SplitMixer: Fat Trimmed From MLP-like Models
Abstract
We present SplitMixer, a simple and lightweight isotropic MLP-like architecture, for visual recognition. It contains two types of interleaving convolutional operations to mix information across spatial locations (spatial mixing) and channels (channel mixing). The first one includes sequentially applying two depthwise 1D kernels, instead of a 2D kernel, to mix spatial information. The second one is splitting the channels into overlapping or non-overlapping segments, with or without shared parameters, and applying our proposed channel mixing approaches or 3D convolution to mix channel information. Depending on design choices, a number of SplitMixer variants can be constructed to balance accuracy, the number of parameters, and speed. We show, both theoretically and experimentally, that SplitMixer performs on par with the state-of-the-art MLP-like models while having a significantly lower number of parameters and FLOPS. For example, without strong data augmentation and optimization, SplitMixer achieves around 94% accuracy on CIFAR-10 with only 0.28M parameters, while ConvMixer achieves the same accuracy with about 0.6M parameters. The well-known MLP-Mixer achieves 85.45% with 17.1M parameters. On CIFAR-100 dataset, SplitMixer achieves around 73% accuracy, on par with ConvMixer, but with about 52% fewer parameters and FLOPS. We hope that our results spark further research towards finding more efficient vision architectures and facilitate the development of MLP-like models. Code is available at https://github.com/aliborji/splitmixer.
1 Introduction
Architectures based exclusively on multi-layer perceptrons (MLPs)222The MLPs used in the MLP-Mixer, in particular those applied to the image patches, are in essence convolutions. But since each convolution is in fact an MLP, one can argue that MLP-Mixer only uses MLPs. The fact that matters is that parameters are shared across MLPs that are applied to image patches. [29] have emerged as strong competitors to Vision Transformers (VIT) [9] and Convolutional Neural Networks (CNNs) [17, 11]. They achieve compelling performance on several computer vision problems, in particular large-scale object classification. Further, they are very simple and efficient and perform on par with more complicated architectures. MLP-like models contain two types of layers to mix information across spatial locations (spatial mixing) and channels (channel mixing). These operations can be implemented via MLPs as in [29], or convolutions as in [33].


We propose the SplitMixer, a conceptually and technically simple, yet very efficient architecture in terms of accuracy, the number of required parameters, and computation. Our model is similar in spirit to the ConvMixer [33] and MLP-Mixer [29] models333MLPMixer generalizes the ConvMixer. in that it accepts image patches as input, dissociates spatial mixing from channel mixing, and maintains equal size and resolution throughout the network, hence an isotropic architecture. Similar to ConvMixer, it uses standard convolutions to achieve the mixing steps. Unlike ConvMixer, however, it uses 1D convolutions to mix spatial information. This modification maintains the accuracy but does not lower the number of parameters significantly. The biggest reduction in the number of parameters is achieved by how we modify channel mixing. Instead of applying convolutions across all channels, we apply them to channel segments that may or may not overlap each other. We implement this part with our ad-hoc solutions or with 3D convolution. This way, we find some architectures that are very frugal in terms of model size and computational needs, and at the same time exhibit high accuracy. To illustrate the efficiency of the proposed modifications, in Figure 1 we plot accuracy vs. number of parameters for our models and state-of-the-art models that do not use external data for training. Over CIFAR-{10,100} datasets, in the low-parameter regime, our models push the envelope towards the top-left corner, which means a better trade-off between accuracy and model size (also speed). Our models even outperform some very well-known architectures such as MobileNet [14].
Despite its simplicity, SplitMixer achieves excellent performance. Without strong data augmentations, it attains around 94% Top-1 accuracy on CIFAR10 with only 0.27M parameters and 71M FLOPS. ConvMixer achieves the same accuracy but with 0.59M parameters and 152M FLOPS (almost twice more expensive). MLP-Mixer can only achieve 85.45% with 17.1M parameters and 1.21G FLOPS. ResNet50 [11] achieves 80.76% using 23.84M parameters and, MobileNet [14] attains 89.81% accuracy using 0.24M parameters.
In summary, our main contributions are as follows:
-
•
Applying 1D depthwise convolution sequentially across width and height for spatial mixing. We are inspired by the extensive use of spatial separable convolutions and depthwise separable convolutions in the literature (e.g. [14]),
-
•
Splitting the channels into overlapping or non-overlapping segments and applying pointwise convolution to segments for channel mixing,
-
•
Theoretical analyses and empirical support for computational efficiency of the proposed solution, as well as measuring model throughput, and
-
•
Ablation analyses to determine the contribution of different model components.
2 SplitMixer
The overall architecture of SplitMixer is depicted in Figure 2. It consists of a patch embedding layer followed by repeated applications of fully convolutional SplitMixer blocks. Patch embeddings with patch size and embedding dimension are implemented as 2D convolution with input channels (3 for RGB images), output channels, kernel size , and stride :
| (1) |
where is a normalization technique (e.g. BatchNorm [16]), is an element-wise nonlinearity (e.g. GELU [12]), and is the input image. The SplitMixer block itself consists of two 1D depthwise convolutions (i.e. grouped convolution with groups equal to the number of channels ) followed by several pointwise convolutions with kernel size . Each convolution is followed by nonlinearity and normalization 444We use GELU and BatchNorm throughout the paper, except in ablation experiments.. Therefore, each block can be written as:
| (2) | ||||
| (3) | ||||
| (4) |
The SplitMixer block is applied times (indexed by l), after which global pooling is applied to obtain a feature vector of size . Finally, a softmax classifier maps this vector to the class label. Please see Appendix B for PyTorch implementations. In what follows, we describe the spatial and channel mixing layers of the architecture.

2.1 Spatial mixing
We replace the kernels555Throughout the paper, a tensor or a kernel is represented as width height channels. in ConvMixer by two 1D kernels: 1) a kernel across width, and 2) a kernel across height. This reduces parameters to in each SplitMixer block. Similarly the FLOPS is reduced to , where and are width and height of the input tensor , respectively. Therefore, separating the 2D kernel into two 1D kernels results in times savings in parameters and FLOPS. The two 1D convolutions are applied sequentially and each one is followed by a GELU activation and BatchNorm (denoted as “Act + Norm” in Figure 2).
2.2 Channel mixing

We notice that most of the parameters in ConvMixer reside in the channel mixing layer. For channels and kernel size (), in each block there are parameters in the spatial mixing part and parameters in the channel mixing part. Thus, the fraction of parameters in the two parts is which is much smaller than 1 (e.g. ). Therefore, most of the parameters are used for channel mixing.
Implementation using 3D convolution. The basic idea here is to utilize 3D convolutions with certain strides. The output will be a set of interleaved maps coming from different segments. The same 3D kernel (with shared parameters) is applied to all segments. A certain number of 3D kernels will be needed to obtain an output tensor with the same number of channels as the input. Applying 3D kernels of size and stride (assume is divisible by ), will require parameters. Hence, more parameters and computation will be saved by increasing the number of segments (i.e. smaller 3D kernels). While being easy to implement, using 3D convolution has some restrictions. For example, kernel parameters have to be shared across segments, and all segments have to be convolved. Further, we find that channel mixing using 3D convolution is much slower than our other approaches (mentioned next). Please see Appendix E for the implementation of the channel mixing layer using 3D convolution.
Other channel mixing approaches. A number of approaches are proposed that differ depending on whether they allow overlap or parameter sharing among segments. They offer different degrees of trade-off in accuracy, number of parameters, and FLOPS. Notice that both of our spatial and channel mixing modifications can be used in tandem or separately. In other words, they are independent of each other. The channel mixing approaches are shown in Figure 3 and are explained below.
2.2.1 SplitMixer-I: Overlapping segments, no parameter sharing, update one segment per block
The input tensor is split into two overlapping segments along the channel dimension. The intuition here is that the overlapped channels allow efficient propagation of information from the first segment to the second. Let be the size of each segment and a fraction of , i.e. . The two segments can be represented as and in PyTorch. For instance, for , one-third of the middle channels are shared between the two segments. We choose to apply convolution to only one segment in each block, e.g. the left segment in odd blocks and the right segment in even blocks. number of convolutions are applied to the segment that should be updated. Therefore, the output has the same number of channels as the original segment, which is then concatenated to the other (unaltered) segment. The final output is a tensor with channels to be processed in the next block. In the experiments, we choose . The reduction in parameters per block can be approximated as666For simplicity, here we discard bias, BatchNorm, and optimizer parameters.:
| (5) |
which means fraction of parameters are reduced (e.g. 56% parameter reduction for ). Notice that the bigger the , the less saving in parameters. Similarly, the reduction in FLOPS can be approximated as:
| (6) |
These equations show the saving in FLOPS is the same as the saving in parameters. We also tried a variation of this design which is updating both segments in the same block. This new variation has fewer parameters and FLOPS than ConvMixer. It saves less parameters compared to SplitMixers (ratio equal to ) but achieves slightly higher accuracy (i.e. trade-off in favor of accuracy). Results are shown in Appendix D.
2.2.2 SplitMixer-II: Non-overlapping segments, no parameter sharing, update one segment per block
We first split the channels into non-overlapping segments, each with size , along the channel dimension777Notice that when is not divisible by the number of segments, the last segment will be longer (e.g. dividing into 3 segments means the segments would have dimension [85, 85, 86], in order).. In each block, only one segment is convolved and updated. Parameters are not shared across the segments. Following the above calculation, saving in parameters and FLOPS is . For example, for , roughly 75% of the parameters are reduced. The same argument holds for FLOPS.
2.2.3 SplitMixer-III: Non-overlapping segments, parameter sharing, update all segments per block
Here, channels are split into non-overlapping segments with shared parameters. Notice that under this setting, must be divisible by in order to get all the channels convolved. All segments are convolved and updated simultaneously in each block. Due to parameter sharing, the reduction in parameters is the same as SplitMixer-II, i.e. the two SplitMixers have the same number of parameters for the same number of segments. The number of FLOPS, however, is higher now since computation is done over all segments. The number of FLOPS is the same as SplitMixer-IV, which will be calculated in the following subsection.
2.2.4 SplitMixer-IV: Non-overlapping segments, no parameter sharing, update all segments per block
This approach is similar to SplitMixer-III with the difference that here parameters are not shared across the segments. All segments are convolved and updated, and the results are concatenated. The reduction in parameters per block is:
| (7) |
which results in parameter saving. For example, 66.6% of the parameters are reduced for . More savings can be achieved with more segments. The reduction in FLOPS is:
| (8) |
which means the same saving in FLOPS as in parameters.
Comparison of channel mixing approaches. Among the mixing approaches, the SplitMixer-II saves the most parameters and computation but achieves lower accuracy. SplitMixer-I strikes a good balance between accuracy and model size (and FLOPS) thanks to its partial channel sharing. We assumed the same number of blocks in all mixing approaches. In practice, a smaller number of blocks might be required when all segments are updated simultaneously in each block. Notice that apart from these approaches, there may be some other ways to perform channel mixing. For example, in SplitMixer-I, parameters can be shared across the overlapped segments, or multiple segments can overlap. We leave these explorations to future research (See Appendix D). We have also empirically measured the amount of potential saving in parameters and FLOPS over CIFAR-10 and ImageNet datasets, for model specifications mentioned in the next section. Results are shown in Appendix A.
Naming convention. We name SplitMixers after their hidden dimension and number of blocks like SplitMixer-A-h/b, where A is a specific model type (I, II, ).
3 Experiments and Results
We conducted several experiments to evaluate the performance of SplitMixer in terms of accuracy, the number of parameters, and FLOPS. Our goal was not to obtain the best possible accuracy. Rather, we were interested in knowing whether and how much parameters and computation can be reduced relative to ConvMixer. To this end, we used the exact same code, parameters, and machines to run the models. A thorough comparison of ConvMixer with other models is made in [33]. We used PyTorch to implement our model and a Tesla V100 GPU with 32GB RAM to run it.
3.1 Experimental setup
We used RandAugment [6], random horizontal flip, and gradient clipping. Due to limited computational resources, we did no perform extensive hyperparameter tuning, so better results than those reported here may be possible888Unlike ConvMixer, we are not using the timm framework. This framework offers a wider range of data augmentations, such as Mixup and Cutmix, which are not provided by PyTorch (torchvision.transforms). We expect better results using timm.. All models were trained for 100 epochs with batch size 512 over CIFAR-{10,100} and 64 over Flowers102 and Food101 datasets. Across all datasets, and were set to 256 and 8.
We used AdamW [22] as the optimizer, with weight decay set to 0.005 (0.1 for Flowers102). The learning rate (lr) was adjusted with the OneCycleLR scheduler (max-lr was set to 0.05 for CIFAR-{10,100}, 0.03 for Flowers102, and 0.01 for Food101). We utilized the ithop library999https://github.com/Lyken17/pytorch-OpCounter for measuring the number of parameters and FLOPS.
3.2 Results on CIFAR-{10,100} dasasets
Both datasets contain 50,000 training images and 10,000 test images (resolution is 32 32); each class has the same number of samples. We set and over both datasets.
Shown in the top panel of Figure 4, ConvMixer scores slightly above 94% on CIFAR-10101010The original ConvMixer paper [33] has reported 96% accuracy on CIFAR-10 with Mixup and Cutmix data augmentation with 0.7M parameters. We, thus, expect even better results for SplitMixer with stronger data augmentation.. SplitMixer-I has about the same accuracy as ConvMixer but with less than 0.3M parameters which are almost half of the ConvMixer parameters. The same statement holds for FLOPS as shown in the right panels of Figure 4. SplitMixer with 1D spatial mixing and regular channel mixing as in ConvMixer (denoted as “SplitMixer 1D S + ConvMixer C” in the Figure) attains about the same accuracy as ConvMixer with slightly lower parameters and FLOPS. SplitMixer-I with 2D spatial kernels and segmented channel mixing (denoted as “SplitMixer 2D S + C”) performs on par with SplitMixer-I. Performance of the SplitMixer-II quickly drops with more segments (and subsequently fewer parameters). SplitMixers III and IV also perform well (above 90%). Interestingly, with only about 76K parameters, SplitMixer-III reaches about 91% accuracy. SplitMixer-V (Appendix D), performs close to ConvMixer, but it does not save many parameters or FLOPS.
Qualitatively similar results are obtained over the CIFAR-100 dataset. Here, ConvMixer scores 73.9% accuracy, above the 72.5% by SplitMixer-I, but with twice more parameters and FLOPS.
On both datasets, increasing the number of segments saves more parameters and FLOPS but at the expense of accuracy. Interestingly, SplitMixer-I with only channel mixing does very well. Our channel mixing approaches are much more effective than 1D spatial mixing in terms of lowering the number of parameters and FLOPS.
Results using 3D convolution. We experimented with a model that uses kernels of size and stride along the channel dimension (i.e. channels are partitioned into two non-overlapping segments each of size ) for channel mixing. This model scores 93.09% and 71.99% on CIFAR-10 and CIFAR-100, respectively. While having similar accuracy, the number of parameters (about 0.2 M), and FLOPS (about 0.08 G) as SplitMixer models, this model is much slower to train (each epoch takes twice more time). Notice that, among the channel mixing approaches, only SplitMixer-III can be considered as 3D convolution. Thus, performing channel mixing through strided 3D convolution is a subset of our proposed solutions.







3.3 Results on Flowers102 and Food101 datasets
Flowers102 contains 1020 training images (10 per class) and 6149 test images. Food101 contains 750 training images and 250 test images for each of its 101 classes. We used larger patch () and kernel sizes () since image size is bigger in these datasets (both resized to 224 224).
Results are shown in Figures 4. The patterns are consistent with what we observed over CIFAR datasets. SplitMixer variants, with small number of segments, perform close to the ConvMixer. Over the Flowers102 dataset, SplitMixer-I scores 62.03%, higher than the 60.47% by ConvMixer. Similarly, over Food101, SplitMixer-I scores 1% lower than ConvMixer, but with less than half of ConvMixer’s parameters and FLOPS. In general, increasing the overlap between segments (by raising in SplitMixer-I) or reducing the number of segments enhances the accuracy but also increases the number of parameters across datasets (not conclusive on Food101 dataset). Further, SplitMixer is effective over both small and large datasets.
3.4 Comparison with state of the art
Table 1 shows a comparison of SplitMixer with models from MLP, Transformer, and CNN families. Some results are borrowed from [23] where they trained the models for 200 epochs, whereas here we trained our models for 100 epochs. While the experimental conditions in [23] might not be exactly the same as ours, cross-examination still provides insights into how our models fare compared to others, in particular the MLP-based models. We have also provided additional comparative results in Figure 1. Our models outperform other models while having significantly smaller sizes and computational needs. For example, SplitMixer-I has about the same number of parameters as ResNet20, but is about 2% better on CIFAR-10 and 5% better on CIFAR-100. Over Flowers102, SplitMixer drastically outperforms other models in all three aspects, including accuracy, number of parameters, and FLOPS. Both SplitMixer and ConvMixer are on par with other models on the Food101 dataset, with ConvMixer performing slightly better.
| Model Family | Model | Params (M) | FLOPS (G) | Top-1 ACC (%) | |
| CIFAR10 | CIFAR100 | ||||
| CNN | ResNet20 [11] | 0.27 | 0.04 | 91.99 | 67.39 |
| Transformer | ViT [9] | 2.69 | 0.19 | 86.57 | 60.43 |
| MLP | AS-MLP [19] | 26.20 | 0.33 | 87.30 | 65.16 |
| ” | gMLP [20] | 4.61 | 0.34 | 86.79 | 61.60 |
| ” | ResMLP [30] | 14.30 | 0.93 | 86.52 | 61.40 |
| ” | ViP [13] | 29.30 | 1.17 | 88.97 | 70.51 |
| ” | MLP-Mixer [29] | 17.10 | 1.21 | 85.45 | 55.06 |
| ” | S-FC (-LASSO) [25] | - | - | 85.19 | 59.56 |
| ” | MDMLP [23] | 0.30 | 0.28 | 90.90 | 64.22 |
| ” | ConvMixer [34] | 0.60 | 0.15 | 94.17 | 73.92 |
| ” | SplitMixer-I (ours) | 0.28 | 0.07 | 93.91 | 72.44 |
| Model Family | Model | Params (M) | FLOPS (G) | ACC (%) | |
| Flowers102 | Food101 | ||||
| CNN | ResNet20 [11] | 0.28 | 2.03 | 57.94 | 74.91 |
| Transformer | ViT [9] | 2.85 | 0.94 | 50.69 | 66.41 |
| MLP | AS-MLP [19] | 26.30 | 1.33 | 48.92 | 74.92 |
| ” | gMLP [20] | 6.54 | 1.93 | 47.35 | 73.56 |
| ” | ResMLP [30] | 14.99 | 1.23 | 45.00 | 68.40 |
| ” | ViP [13] | 30.22 | 1.76 | 42.16 | 69.91 |
| ” | MLP-Mixer [29] | 18.20 | 4.92 | 49.41 | 61.86 |
| ” | MDMLP [25] | 0.41 | 1.59 | 60.39 | 77.85 |
| ” | ConvMixer [34] | 0.70 | 0.70 | 60.47 | 74.59 |
| ” | SplitMixer-I (ours) | 0.34 | 0.33 | 62.03 | 73.56 |
3.5 Ablation experiments
We conducted a series of ablation experiments to study the role of different design choices and model components. Results are shown in Table 2 over CIFAR-{10,100} datasets. We took the SplitMixer-I as the baseline and discarded or added pieces to it. Our findings are summarized below:
| Ablation of SplitMixer-I-256/8 on CIFAR- | ||
| Ablation | CIFAR-10 Acc. (%) | CIFAR-100 Acc. (%) |
|---|---|---|
| SplitMixer-I (baseline) | 93.91 | 72.88 |
| – Residual in Eq. 3 | 92.24 | 71.34 |
| + Residual in Eq. 4 | 92.35 | 70.44 |
| BatchNorm LayerNorm | 88.28 | 66.60 |
| GELU ReLU | 93.39 | 72.56 |
| – RandAug | 90.87 | 66.54 |
| – Gradient Norm Clipping | 93.38 | 71.95 |
| SplitMixer-I (Spatial only) | 76.24 | 53.25 |
| SplitMixer-I (Channel only) | 64.21 | 40.46 |
| One segment with size | 76.28 | 51.28 |
-
•
Completely removing the residual connections does not hurt the performance much. These connections, however, might be important for very deep SplitMixers.
-
•
Moving the residual connection to after channel mixing seems to hurt the performance. We find that the best place for the residual connections is right after spatial mixing.
-
•
Switching to LayerNorm, instead of BatchNorm, leads to drastic performance drop.
-
•
The choice of activation function, GELU vs. ReLU, is not very important. In fact, we found that using ReLU sometimes helps.
-
•
Gradient norm clipping hinders the performance slightly, thus it is not very important.
-
•
Data augmentation, here as RandAug111111Unlike ConvMixer, we do not have Mixup and CutMix, is critical to gaining high performance.
-
•
SplitMixer-I with only 1D spatial mixing, and no channel mixing, performs very poorly. The same is true for ablating the spatial mixing i.e. having only channel mixing. We find that spatial mixing is more important than channel mixing in our models.
-
•
Keeping only one of the segments in channel mixing, hence 1D spatial mixing plus channel mixing using channels (), lowers the accuracy by a large margin. This indicates that there is a substantial benefit in having a larger and splitting it into segments (and having overlaps between them). Notice that in each block, only one segment is updated. In other words, simply lowering the number of channels does not lead to the gains that we achieve with our models. Any ConvMixer, small or large, can be optimized using our techniques.



3.6 The role of the number of blocks
We wondered about the utility of the proposed modifications over deeper networks. To this end, we varied the number of blocks of ConvMixer and SplitMixer-I in the range 2 to 10 in steps of 2, and trained the models. Other parameters were kept the same as above. As the results in Figure 5 show, increasing the number of blocks improves the accuracy of both models on CIFAR{10,100}. SplitMixer-I performs slightly below the ConvMixer, but it has a huge advantage in terms of the number of parameters and FLOPS, in particular over deeper networks. The model size and computation grow slower for SplitMixer compared to ConvMixer.
3.7 Model throughput
We measured throughput using batches of 64 images on a single Tesla v100 GPU with 32GB RAM [26], averaging over 100 such batches. Similar to ConvMixer, we considered CUDA execution time rather than “wall-clock” time. Here, we used the network built for the FLOWER102 classification (, , , , and image size ). We measured throughput when our model was the only process running on the GPU. Results are shown in Table 3. The throughput of our model is almost three times higher than ConvMixer. As expected, the throughput is higher with more segments in the channels because the number of FLOPS is lower. We also measured throughput using a Tesla v100 GPU with 16GB RAM. Results are presented in Appendix C.
| Network | Throughput (img/sec) | ||||||
| ConvMixer | 815.84 | ||||||
| Overlap ratio | |||||||
| 2/3 | 3/5 | 4/7 | 5/9 | 6/11 | - | - | |
| SplitMixer-I | 2097.55 | 2208.40 | 2210.06 | 2220.09 | 2231.42 | - | - |
| Number of segments | |||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| SplitMixer-II | 2322.02 | 2291.44 | 2440.16 | 2464.33 | 2474.318 | - | - |
| SplitMixer-III | 2112.290 | - | 2171.70 | - | - | - | 2185.61 |
| SplitMixer-IV | 2110.92 | 2084.55 | 2170.57 | 2146.76 | - | - | - |
3.8 Feature visualization
In Appendix F, we plot the learned feature maps at successive layers of SplitMixer-I-256/8 model trained over CIFAR-10 with , , and . Notice that in each block, 170 channels are convolved (the first 170 channels in even blocks and the second 170 channels in odd blocks, with overlap). Some maps seem to be the output of convolution with oriented edge filters. Few others seem to be dead with no activation. We also found similar maps for the ConvMixer model (not shown).
3.9 Negative results
Here, we report some configurations that we tried but did not work. Initially, we attempted to use a number of fully connected layers to perform spatial and channel mixing, hoping the network would implicitly learn how to mix information. This model did not converge, indicating that perhaps inductive biases pertaining to spatial and channel mixing matter in these architectures. Also, sequentially applying convolutions across the width, height and channels, with shared parameters across each, did not result in good accuracy, although some works (e.g. [13]) have been able to make similar, but more complicated, designs to work.
4 Related Work
For about a decade, CNNs have been the de-facto standard in computer vision [11]. Recently, the Vision Transformers (ViT) [9] by Dosovitskiy et al. and its variants [32, 8, 21, 31, 1, 36], and the multi-layer perceptron mixer (MLP-Mixer) by Tolstikhin et al. [29] and its variants [30, 18] have challenged CNNs. These models have shown impressive results, even better than CNNs, in large-scale image classification. Unlike CNNs that exploit local convolutions to encode spatial information, vision transformers take advantage of the self-attention mechanism to capture global information. MLP-based models, on the other hand, capture global information through a series of spatial and channel mixing operations.
MLP-Mixer borrows some design choices from recent transformer-based architectures [35]. Following ViT, it converts an image to a set of patches and linearly embeds them to a set of tokens. These tokens are processed by a number of “isotropic” blocks, which are in essence similar to the repeated transformer-encoder blocks [35]. For example, MLP-Mixer [29] replaces self-attention with MLPs applied across different dimensions (i.e. spatial and channel location mixing). ResMLP [30] is a data-efficient variation on this scheme. CycleMLP [4], gMLP [20], and vision permutator [13], conduct different approaches to perform spatial and channel mixing. For example, vision permutator [13] permutes a tensor along the height, width, and channel to apply MLPs. Some works attempt to bridge convolutional networks and vision transformers and use one to improve the other [5, 8, 7, 10, 36, 3, 28, 2].
We are primarily inspired by the ConvMixer [33]. This model introduces a simpler version of MLP-Mixer but is essentially the same. It replaces the MLPs in MLP-Mixer with convolutions. In general, Convolution-based MLP models are smaller than their heavy Transformer-, CNN-, and MLP-based counterparts. Here, we show that it is possible to trim these models even more. Perhaps the biggest advantage of the MLP-based models is that they are easy to understand and implement, which in turn helps replicate results and compare models. To this end, we share our code publicly (https://github.com/aliborji/splitmixer).
5 Discussion and Conclusion
We proposed SplitMixer, an extremely simple yet very efficient model, that is similar in spirit to ConvMixer, ViT, and MLP-Mixer models. SplitMixer uses 1D convolutions for spatial mixing and splits the channels into several segments for channel mixing. It performs convolution on each segment. Our experiments, even without extensive hyperparameter tuning, demonstrate that these modifications result in models that are very efficient in terms of the number of parameters and computation. In terms of accuracy, they outperform several MLP-based models and some other model types with similar size constraints. Our main point is that SplitMixer allows sacrificing a small amount of accuracy to achieve big gains in reducing parameters and FLOPS.
The proposed solution based on separable filters, depthwise convolution, and channel splitting is quite efficient in terms of parameters and computation. However, if a network is already small, reducing the parameters too much may cause the network not to learn properly during training. Thus, a balance is required to enhance efficiency without significantly reducing effectiveness.
We propose the following directions for future research in this area:
-
•
We suggest trying a wider range of hyperparameters and design choices for SplitMixer, such as strong data augmentation (e.g. Mixup, Cutmix), deeper models, larger patch sizes, overlapped image patches, label smoothing [24], and stochastic depth [15]. Previous research has shown that some classic models can achieve state-of-the-art performance through carefully-designed training regimes [37],
-
•
We tried a number of ways to split and mix the channels and learned that some perform better than the others. There might be even better approaches to do this,
-
•
Incorporating techniques similar to the ones proposed here to optimize other MLP-like models is also a promising direction,
-
•
MLP-like models, including SplitMixer, lack effective means of explanation and visualization, which need to be addressed in the future (See Appendix F),
-
•
Our results entertain the idea that it may be possible to find model classes that have fewer parameters than the number of data points. This may challenge the current belief that deep networks have to be overparameterized to perform well,
- •
-
•
Lastly, it is essential to a) understand the basic principles underlying CNNs, Transformers, and MLP-based models, b) explain why some design choices work while some others do not (e.g. [27]), and c) enumerate the key must-have building blocks (e.g. convolution, pooling, residual connection, normalization, data augmentation, and patch embeddings). This will help unify existing architectures, improve them, and invent even more efficient ones.
Note: We are currently running the experiments on ImageNet-1K dataset.
References
- [1] Hangbo Bao, Li Dong, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
- [2] Irwan Bello. Lambdanetworks: Modeling long-range interactions without attention. arXiv preprint arXiv:2102.08602, 2021.
- [3] Irwan Bello, Barret Zoph, Ashish Vaswani, Jonathon Shlens, and Quoc V Le. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3286–3295, 2019.
- [4] Shoufa Chen, Enze Xie, Chongjian Ge, Ding Liang, and Ping Luo. Cyclemlp: A mlp-like architecture for dense prediction. arXiv preprint arXiv:2107.10224, 2021.
- [5] Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self-attention and convolutional layers. arXiv preprint arXiv:1911.03584, 2019.
- [6] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 702–703, 2020.
- [7] Zihang Dai, Hanxiao Liu, Quoc V Le, and Mingxing Tan. Coatnet: Marrying convolution and attention for all data sizes. arXiv preprint arXiv:2106.04803, 2021.
- [8] Stéphane d’Ascoli, Hugo Touvron, Matthew Leavitt, Ari Morcos, Giulio Biroli, and Levent Sagun. Convit: Improving vision transformers with soft convolutional inductive biases. arXiv preprint arXiv:2103.10697, 2021.
- [9] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [10] Jianyuan Guo, Kai Han, Han Wu, Chang Xu, Yehui Tang, Chunjing Xu, and Yunhe Wang. Cmt: Convolutional neural networks meet vision transformers. arXiv preprint arXiv:2107.06263, 2021.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [12] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- [13] Qibin Hou, Zihang Jiang, Li Yuan, Ming-Ming Cheng, Shuicheng Yan, and Jiashi Feng. Vision permutator: A permutable mlp-like architecture for visual recognition, 2021.
- [14] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [15] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In European conference on computer vision, pages 646–661. Springer, 2016.
- [16] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. PMLR, 2015.
- [17] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
- [18] Jiachen Li, Ali Hassani, Steven Walton, and Humphrey Shi. Convmlp: Hierarchical convolutional mlps for vision. arXiv preprint arXiv:2109.04454, 2021.
- [19] Dongze Lian, Zehao Yu, Xing Sun, and Shenghua Gao. As-mlp: An axial shifted mlp architecture for vision. arXiv preprint arXiv:2107.08391, 2021.
- [20] Hanxiao Liu, Zihang Dai, David R So, and Quoc V Le. Pay attention to mlps. arXiv preprint arXiv:2105.08050, 2021.
- [21] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows, 2021.
- [22] Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam. 2018.
- [23] Tian Lv, Chongyang Bai, and Chaojie Wang. Mdmlp: Image classification from scratch on small datasets with mlp. arXiv preprint arXiv:2205.14477, 2022.
- [24] Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? Advances in neural information processing systems, 32, 2019.
- [25] Behnam Neyshabur. Towards learning convolutions from scratch. Advances in Neural Information Processing Systems, 33:8078–8088, 2020.
- [26] Tesla NVIDIA. Nvidia tesla v100 gpu architecture, 2017.
- [27] Namuk Park and Songkuk Kim. How do vision transformers work? arXiv preprint arXiv:2202.06709, 2022.
- [28] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jonathon Shlens. Stand-alone self-attention in vision models. arXiv preprint arXiv:1906.05909, 2019.
- [29] Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, et al. Mlp-mixer: An all-mlp architecture for vision. arXiv preprint arXiv:2105.01601, 2021.
- [30] Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, and Hervé Jégou. Resmlp: Feedforward networks for image classification with data-efficient training. arXiv preprint arXiv:2105.03404, 2021.
- [31] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021.
- [32] Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. arXiv preprint arXiv:2103.17239, 2021.
- [33] Asher Trockman and J Zico Kolter. Orthogonalizing convolutional layers with the cayley transform. arXiv preprint arXiv:2104.07167, 2021.
- [34] Asher Trockman and J Zico Kolter. Patches are all you need? arXiv preprint arXiv:2201.09792, 2022.
- [35] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [36] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv preprint arXiv:2102.12122, 2021.
- [37] Ross Wightman, Hugo Touvron, and Hervé Jégou. Resnet strikes back: An improved training procedure in timm, 2021.
Appendix A Parameter and FLOPS Saving
Here, we empirically show how much parameters and FLOPS can be reduced by SplitMixer. Experiments are conducted on CIFAR-10 and ImageNet datasets using model specifications mentioned in the main text.




Appendix B PyTorch Implementations
Appendix C Model Throughput
| Network | Throughput (img/sec) | ||||||
| ConvMixer | 483.37 | ||||||
| Overlap ratio | |||||||
| 2/3 | 3/5 | 4/7 | 5/9 | 6/11 | - | - | |
| SplitMixer-I | 733.57 | 742.80 | 746.88 | 734.04 | 734.07 | - | - |
| Number of segments | |||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| SplitMixer-II | 770.18 | 790.13 | 815.27 | 821.58 | 825.91 | - | - |
| SplitMixer-III | 699.80 | - | 718.14 | - | - | - | 718.25 |
| SplitMixer-IV | 696.39 | 681.12 | 715.64 | 714.95 | - | - | - |
Appendix D Other Variants of SplitMixer
Here, we introduce another variant of SplitMixer, called SplitMixer-V, which is similar to SplitMixer-I with the difference that in each block both overlapped segmented are updated. The approximate reduction in parameters per block is:
| (9) |
which means fraction of parameters are reduced (e.g. 11% parameter reduction for , much lower than 56% obtained using SplitMixer-I with the same ). The saving in FLOPS is the same.
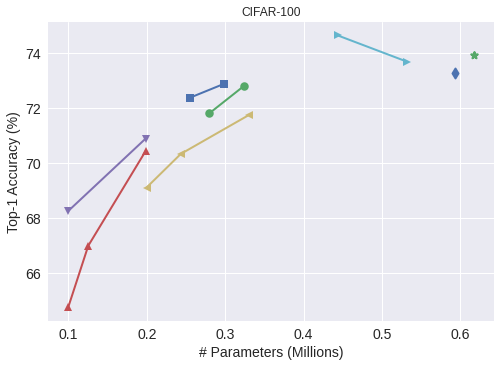
We tested SplitMixer-V over CIFAR-{10,100} datasets with the same parameters used for other SplitMixers on these datasets. Results are shown in Table below. This model performs close to ConvMixer and is sometimes even better than it. It, however, does not save much of the parameters and FLOPS, compared to the other SplitMixers. As was mentioned in the main text, SplitMixer variants offer different degrees of trade-off between accuracy and the number of parameters (and FLOPS).
| CIFAR-10 | CIFAR-100 | |||||
| Accuracy (%) | Params (M) | FLOPS (M) | Accuracy (%) | Params (M) | FLOPS (M) | |
| ConvMixer | 94.17 | 0.59 | 152 | 73.92 | 0.62 | 152 |
| SplitMixer-V-256/8 | ||||||
| 93.88 | 0.51 | 131 | 73.68 | 0.53 | 131 | |
| 93.96 | 0.42 | 108 | 74.63 | 0.44 | 108 | |
The code for this design is given below.
Appendix E Channel Mixing Using 3D Convolution
Appendix F Visualization of Feature Maps
Here, we visualize the output maps of the SplitMixer-I-256/8 model trained over CIFAR-10 with , , and . Notice that in each block 170 channels are convolved (first 170 channels in even blocks and the second 170 channels in odd blocks; with overlap). Notice that the learned kernels for patch embedding are too small to plot here.





