Spiked eigenvalues of noncentral Fisher matrix with applications††thanks: The first two authors contributed equally to this work. For correspondence, please contact Zhidong Bai and Jiang Hu.
Abstract
In this paper, we investigate the asymptotic behavior of spiked eigenvalues of the noncentral Fisher matrix defined by , where is a noncentral sample covariance matrix defined by and . The matrices and are two independent Gaussian arrays, with respective and and the Gaussian entries of them are independent and identically distributed (i.i.d.) with mean and variance . When , , and grow to infinity proportionally, we establish a phase transition of the spiked eigenvalues of . Furthermore, we derive the central limiting theorem (CLT) for the spiked eigenvalues of . As an accessory to the proof of the above results, the fluctuations of the spiked eigenvalues of are studied, which should have its own interests. Besides, we develop the limits and CLT for the sample canonical correlation coefficients by the results of the spiked noncentral Fisher matrix and give three consistent estimators, including the population spiked eigenvalues and the population canonical correlation coefficients.
keywords:
[class=MSC2020]keywords:
, , and
1 Introduction
Fisher matrix is one of the most classical and important tools in multivariate statistic analysis (for details see [1], [29], and [30]). [22] provided a remarked five-way classification of the distribution theory and introduced some representative applications, such as signal detection in noise and testing equality of group means under unknown covariance matrix and so on. Among these applications, some statistics can be transformed into a Fisher matrix while others can be studied by a noncentral Fisher matrix. So it is natural to study the spectral properties of the Fisher matrix and noncentral Fisher matrix.
There have been many works focusing on the Fisher matrix, [34] derived the limiting spectral distribution (LSD) of Fisher matrix, which is the celebrated Wachter distribution. [19] proved the largest eigenvalue of Fisher matrix follows Tracy-Widom (T-W) law, see [33]. [38] was devoted to the CLT for linear spectral statistics (LSS) of the Fisher matrix. [40] studied the LSD and CLT of LSS of the so-called general Fisher matrix. In fact, these above works all focus on the central Fisher matrix. Before introducing the concept of the noncentral Fisher matrix, it is necessary to know the large dimensional information-plus-noise-type matrix,
| (1) |
where is a matrix containing i.i.d. entries with mean and variance . is a deterministic and it is assumed to have a LSD. Here and subsequently, denotes conjugate transpose, and stands for transpose on real matrix and vector. In [17, 18, 14, 5], a lot of spectral properties of have been researched. Actually, the matrix is a noncentral sample covariance matrix and is called the noncentral parameter matrix, whose eigenvalues are arranged as a descending order:
| (2) |
However, many problems, such as signal detection in noise and testing equality of group means under unknown covariance matrix always involve the noncentral Fisher matrix, which is constructed based on the matrix ,
| (3) |
where and is independent of . The entries are i.i.d. with mean and variance . To the best of our knowledge, there are only a handful of works devoted to the noncentral Fisher matrices. Under the Gaussian assumption, [27] developed an approximation to the distribution of the largest eigenvalue of the noncentral Fisher matrix and [12] derived the CLT for the LSS of the large dimensional noncentral Fisher matrix. In this paper, we concentrate on the outlier eigenvalues of the noncentral Fisher matrix defined in (3). Specially, we will work with the following assumption,
Assumption a: Assume that is a nonrandom matrix and the empirical spectral distribution (ESD) of satisfies , ( denoting weakly convergence), where is a non-random probability measure. In addition, the eigenvalues of are subject to the condition
| (4) |
and satisfies the separation condition, that is,
| (5) |
where is positive constant and independent of and is allowed to grow at an order . In addition, denotes the set of ranks of , where is the multiplicities of satisfying , a fixed integer.
Remark 1.1.
Note that can be located in any gap between the supports of , which means that is not just the extreme eigenvalues of .
The eigenvalues are called as population spiked eigenvalues of the noncentral sample covariance matrix (1) and the noncentral Fisher matrix (3). We call these two matrices satisfying (4) the spiked noncentral sample covariance matrix and the spiked noncentral Fisher matrix, respectively. In fact, the spiked eigenvalues should have allowed to diverge at any rate, but under the restriction of our studying method, we have to assume them at a rate of . In this paper, we are devoted to exploring the properties of the limits of the sample spiked eigenvalues (corresponding to ) of the noncentral Fisher matrix. From now on, we call the sample spiked eigenvalues simply spiked eigenvalues when no confusion can arise.
To study the principal component analysis (PCA), [26] proposed the spiked model based on the covariance matrix. The spiked model has been studied much further and extended in various random matrices such as Fisher matrix, sample canonical correlation matrix, separable covariance matrix, see [11, 16] for more details. The main emphasis of the research of the spiked model is on the limits and the fluctuations of the spiked eigenvalues of these kinds of random matrices. [8, 31, 6, 7, 2, 13, 23] focused on the spiked sample covariance matrix and [35, 25, 24] concentrated on the central spiked Fisher matrices.
The main contribution of the paper is the establishment of the limits and fluctuations of the spiked eigenvalues of the noncentral Fisher matrix under the Gaussian population assumption. Even better, we apply the above theoretical results to the canonical correlation analysis (CCA) and derive the limits and fluctuations of sample canonical correlation coefficients and give three consistent estimators, including the population spiked eigenvalues and the population canonical correlation coefficients. In addition, we study the properties of sample spiked eigenvalues of the noncentral sample covariance matrix, which should have its own interest.
The rest of the paper is organized as follows. In Section , we define some notations and we present the LSD of some random matrices. In Section , we study the limits and fluctuations of spiked eigenvalues of the noncentral sample covariance matrix and noncentral Fisher matrix. In Section , we present the limits and fluctuations of spiked eigenvalues of sample canonical correlation matrix are investigated, give three estimators of the population spiked eigenvalues, and conduct the actual data analysis about climate and geography by CCA. To show the correctness and rationality of theorems intuitively, we design a series of simulations in Section . In Section , we summarize the main conclusions and the outlook. Section presents technical proof.
2 Preliminaries
In this section, we collect some notations and preliminary results or assumptions, which will be throughout the paper. Although some notations have been mentioned above, we still provide the precise definitions here.
2.1 Basic notions
For any matrix with only real eigenvalues, let be the empirical spectral distribution (ESD) function of , that is,
where denotes the -th largest eigenvalue of . If has a limiting distribution , then we call it the limiting spectral distribution (LSD) of sequence . For any function of bounded variation on the real line, its Stieltjes transform (ST) is defined by
2.2 Symbols and Assumptions
In this paper, we study the spiked eigenvalues of the noncentral spiked sample covariance matrix defined in (1) and the noncentral spiked Fisher matrix defined in (3) with the matrix satisfying (4). In order to distinguish the symbols of these three matrices clearly, we show the notations of eigenvalues and ST of the matrices in Table 1.
| Matrix | |||
|---|---|---|---|
| LSD | |||
| ST | |||
| Population spiked eigenvalue | |||
| Sample eigenvalue | - | ||
| Limit | - |
Throughout the paper, we consider the following assumptions about the high-dimensional setting and the moment conditions.
Assumption b: Assume that , with , as .
Assumption c: Assume that the matrix and are two independent arrays of independent standard Gaussian distribution variables and , respectively. If and are complex,
, , and are required.
2.3 LSD for and
To introduce the necessary conclusions and symbols in the following sections, we provide the LSD for and by the results in [17, 39]. Note that similar results are obtained in [12]. According to Theorem of [17], the ST of the LSD of is the unique solution to the equation
| (6) | |||||
where is the ST of . For simplicity, we write as in (6). By Theorem of [39], the ST of the LSD of satisfies the following equation:
| (7) |
From (6.12) in [4], we have
| (8) |
3 Main Results
In this section, we state our main results and briefly summarize our proof strategy. Our main results include the limits and the CLT of the spiked eigenvalues of the noncentral sample covariance matrix and the noncentral Fisher matrix .
3.1 Limits and fluctuations for the matrix
The noncentral sample covariance matrix and its eigenvalues are arranged as a descending order as
| (9) |
Theorem 3.1.
If Assumption hold and the population spiked eigenvalues satisfies , for . Then we have
| (10) |
where
| (11) |
Remark 3.1.
Considering that the convergence may be slow, in , we use and instead of and , respectively. In following theorems related to the limits of spiked eigenvalues, we will take the same treatment.
Having disposed of the limits of the sample spiked eigenvalues, we are now in a position to show the CLT for the sample spiked eigenvalues.
Theorem 3.2.
Suppose the Assumption hold, the -dimensional random vector
converges weakly to the joint distribution of the eigenvalues of Gaussian random matrix , where is a -dimensional standard GOE (GUE) matrix. If the samples are either real, ; or complex, , and
where and are the derivatives of and at the point , respectively, and
| (12) |
Remark 3.2.
It is worth pointing out that is equal to the (half of) variance of when is a single eigenvalue. When is multiple, the limiting distribution of is related to that of the eigenvalues of a GOE (GUE) matrix, the variance of whose diagonal elements is equal to (). In what follows, we also call as the scale parameter of the GOE (GUE) matrix.
Remark 3.3.
[15] and [10] focused on the noncentral spiked sample covariance matrix. [15] studied the limits and rates for the spiked eigenvalues and vectors of the noncentral sample covariance matrix. [10] was devoted to the fluctuation of the spiked vectors of the noncentral sample covariance matrix. Note that both of the works are under the condition of finite rank, specially, the rank of the is finite. Compared with [15] and [10], our assumptions about is more general.
3.2 Limits and fluctuations for the noncentral Fisher matrix
Having disposed of the noncentral spiked sample covariance matrix , we can now return to the noncentral Fisher matrix . The eigenvalues of noncentral Fisher matrix are sorted in descending order as
| (13) |
Theorem 3.3.
Let the Assumption hold, the noncentral Fisher matrix is defined in (3). If satisfies and , for , then we have
where
| (14) |
is the derivative of , and are same, but , and replaced by , and , respectively.
The task is now to show the CLT for the sample spiked eigenvalues of the noncentral Fisher matrix .
Theorem 3.4.
Suppose that the Assumption hold, the dimensional random vector
converges weakly to the joint distribution of the eigenvalues of Gaussian random matrix where
| (15) |
is defined in Theorem 3.2 and satisfies
| (16) |
4 Applications
In this section, we discuss some applications of our results in limiting properties of sample canonical correlations coeffcients, estimators of the population spiked eigenvalues and the population canonical correlations coeffcients. At the end, we present an experiment on a real environmental variables for world countries data.
4.1 Limits and fluctuations for the sample canonical correlation matrix
The CCA is the general and favorable method to investigate the relationship between two random vectors. Under the high-dimensional setting and the Gaussian assumption, [11] studied the limiting properties of sample canonical correlation coefficients. Under the sharp moment condition, [36, 28] prove the largest eigenvalue of sample canonical correlation matrix converges to T-W law to test the independence of random vectors with two different structures. Moreover, [37] shows the limiting distribution of the spiked eigenvalues depends on the fourth cumulants of the population distribution. Note that [3, 36, 28, 37] only focused on the finite rank case, where the number of the positive population canonical correlation coefficients of two groups of high-dimensional Gaussian vectors are finite. However, we popularize finite rank case to infinite rank case, in other words, we get the limits and fluctuations of the sample canonical correlation coefficients under the infinite rank case. In the following, we will introduce the application about limiting properties of sample canonical correlations coeffcients in great detail.
Let , be independent observations from a -dimensional Gaussian distribution with mean zero and covariance matrix
where and are -dimensional and -dimensional vectors with the population covariance matrices and , respectively. Without loss of generality, we assume that . Define the corresponding sample covariance matrix as
| (17) |
which can be formed as
with
In the sequel, is called as the population canonical correlation matrix and its eigenvalues are denoted by
| (18) |
By the singular value decomposition, we have that
| (19) |
where
| (21) |
, is a zero matrix, and are orthogonal matrix with size and , respectively. It follows that are also the eigenvalues of the diagonal matrix . According to Theorem 12.2.1 of [1], the nonnegative square roots are the population canonical correlation coefficients. Correspondingly, is called as the sample canonical correlation matrix and its eigenvalues are denoted by
| (22) |
The following theorem describes the function relation between sample canonical correlation coefficients and the eigenvalues of a special noncentral Fisher matrix.
Theorem 4.1.
[Theorem 1 in [3]] Suppose that , is the ordered eigenvalue of the sample canonical correlation matrix . Then, there exists a noncentral Fisher matrix whose eigenvalue satisfies and is the noncentral parameter matrix,
| (23) |
where and is a matrix and contains i.i.d. elements with standard Gaussian distribution.
Combining Theorem 4.1 with the properties of the noncentral Fisher matrix, we obtain the limits and fluctuations of the sample canonical correlation coefficients under the following assumption.
Assumption d: The empirical spectral distribution (ESD) of , , tends to proper probability measure , if . Assume that is subject to the condition
| (24) |
where is out of the support of and satisfies the separation condition defined in (5). is a fixed positive integer with convention . In addition, is allowed to be with the order .
Remark 4.1.
Note that the noncentral parameter matrix (23) is random, so the assumption about multiple roots in (24) is not reasonable. In the following Assumption d′, we replace the comndition of multiple roots by single root. However, we think the results of the limits and fluctuations for the multiple roots case are correct and our guess will be verifed by some simulations in the following section.
Assumption d′:The assumptions are same as Assumption d, the additional assumption .
Theorem 4.2.
It is worth noting that we can conclude the results in Theorem 1.8 of [11] by Theorem 4.2 or Theorem 3.1 in [35], when the LSD of degenerates to .
Corollary 4.2.
Let the Assumption [] and [] hold, furthermore, the LSD degenerates to and satisfies then we have
| (26) |
where
Having disposed of the results of limits of the square of sample canonical correlation coefficients associated to the , we can now return to show the CLT for them.
Theorem 4.3.
Let the Assumption and hold, and is the square of eigenvalues of sample canonical correlation matrix. We set and as tends to infinity, then the -dimensional random vector
converges weakly to the joint distribution of the eigenvalues of Gaussian random matrix , and
where and denote the value and derivative at the point , respectively, stands for the unique solution (7) with , , replaced by , , , respectively.
4.2 Estimators of the population spiked eigenvalues
In this section, we develop two consistent estimators of population spiked eigenvalues defined in (24), which are derived by the results of the noncentral sample covariance matrix and the noncentral Fisher matrix, respectively. At first, we proceed to show the estimator of population spiked eigenvalues for the noncentral sample covariance matrix. From the conclusion of Theorem 3.3, we have
and
It is sufficient to consider the estimators of and , which are denoted by and , respectively. We adopt an approach similar to that in [23] to estimate . Define and the set and ; then,
| (27) |
is a good estimator of , where the set is selected to avoid the effect of multiple roots and to make the estimator more accurate. Then we have
| (28) |
We now turn to give the other estimator for the population spiked eigenvalues by the results of the noncentral Fisher matrix. From the conclusion of Theorem 3.3, we have
then,
| (29) |
According to Theorem 3.1, we know
then,
Note that (29) and is the natural estimator of , we set as the estimator of and have
where are the estimators of . Similar considerations in (27) are applied here, we have and the set and ; then,
| (30) |
is a good estimator of . Then we have,
| (31) |
where is the estimator of at , by (8) we have
| (32) |
4.3 The environmental variables for world countries data
To illustrate the application of canonical correlation, we apply our result to the environmental variables for world countries data111The data can be download from: https://www.kaggle.com/zanderventer/environmental-variables-for-world-countries.. Deleting the samples missing value and the variables related to others, then, we get samples with variables. We divide the variables into two groups, one (, ) contains the elevation above sea level, percentage of country covered by cropland, percentage cover by trees m in height and so on, the other one (, ) contains annual precipitation, temperature mean annual, mean wind speed, average cloudy days per year and so on. We want to explore the relationship between the geographical conditions and climatic conditions , so we test their first canonical correlation coefficient being zero or not, i.e.,
Therefore, we take the largest eigenvalue of the sample canonical correlation matrix as the test statistic. By the formula (2.1) in [11], the normalized largest eigenvalues of the sample CCA matrix tends to the T-W law under the null hypothesis. The eigenvalues of are as follows:
| 0.9152 | 0.7755 | 0.4560 | 0.4034 | 0.2548 | 0.2247 | 0.0492 |
According to the data, we obtain that -value approaches zero. Thus we have strong evidence to reject the null hypothesis and conclude that the geographical conditions relate to climatic conditions. Moreover, we use Algorithm 1 to give an estimator of the population canonical correlation coefficients,
| (33) |
By (33), we get the population canonical correlation coefficients , which implies that the correlation between geographical conditions and climatic conditions is strong.
Input: the samples
Output:
5 Simulation
We conduct simulations that support the theoretical results and illustrate the accuracy of the estimators. The simulations are divided into two sections, one is to verify the accuracy of Theorem 3.2, 3.4 and 4.3, and another is confirm the performance of the estimators in (28), (31) and (33).
5.1 Simulations for the asymptotic normality
In this section, we assume the eigenvalues of satisfy
| (34) |
in this situation, we set defined in (21) satisfying
| (35) |
In Figure 1-6, we compare the empirical density (the blue histogram) of the two of largest eigenvalues of , and the CCA matrix with the standard normal density curve (the red line) with 2000 repetitions. To be more convincing, we put the Q-Q plots together with the histograms. According to the histograms and Q-Q plots, we can conclude that the Theorem 3.2, 3.4 and 4.3 are reasonable.
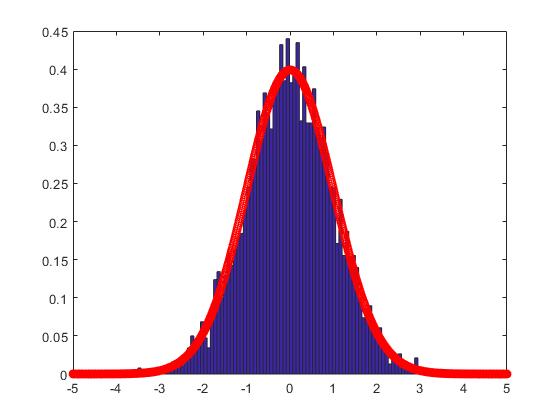
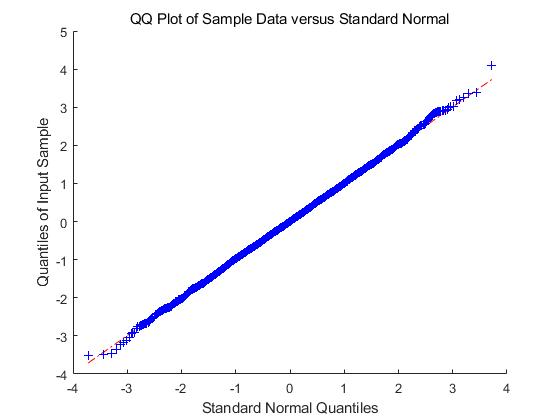
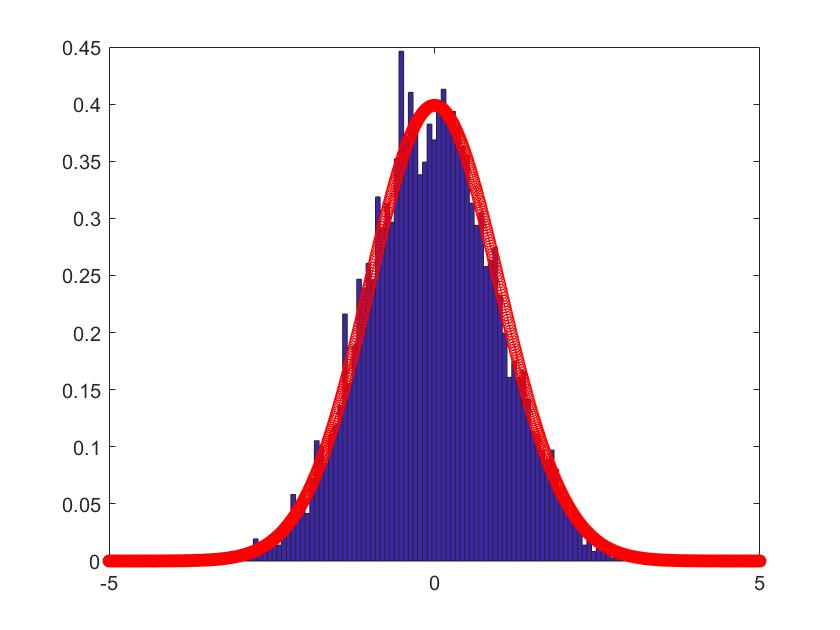
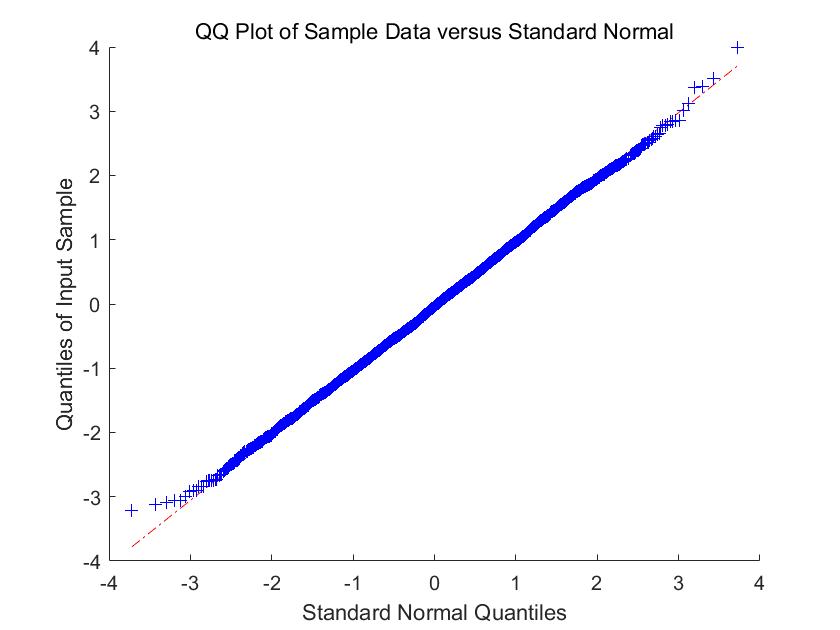
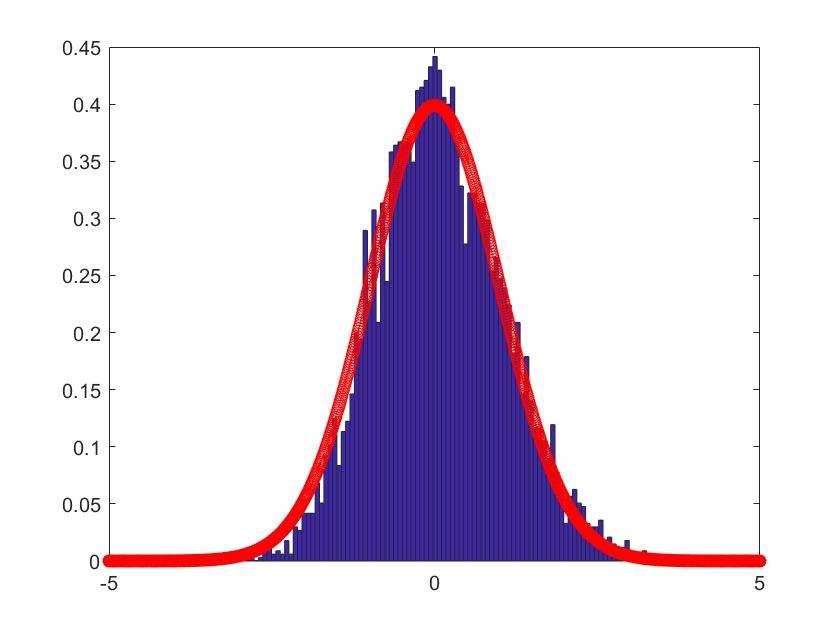
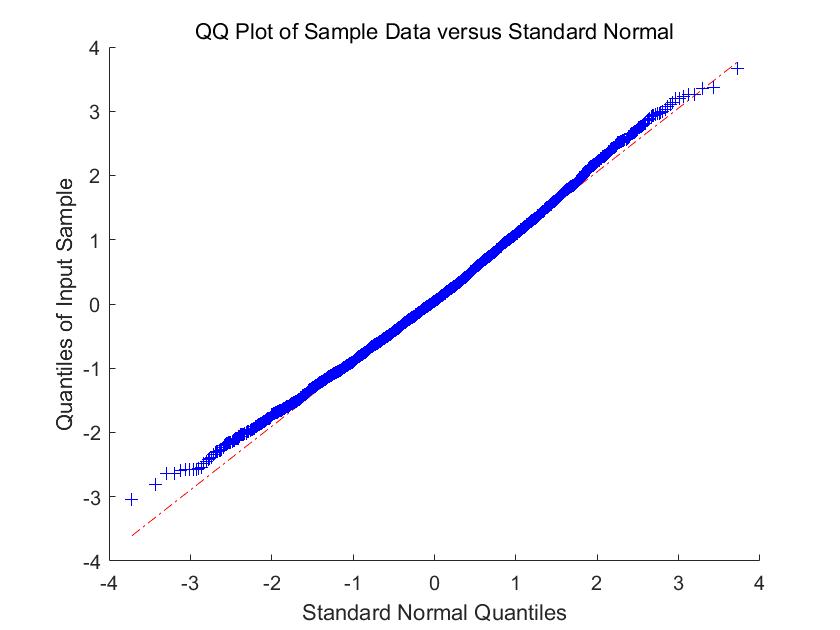
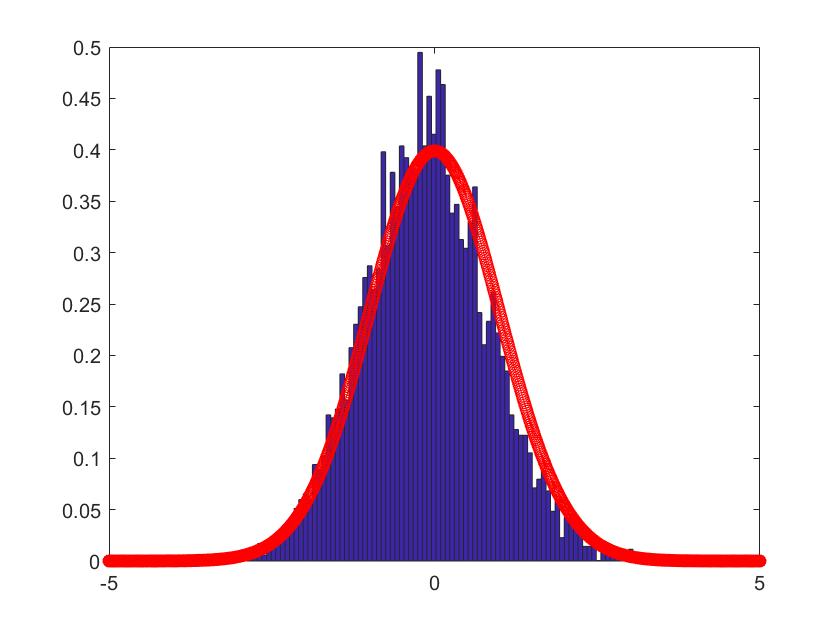
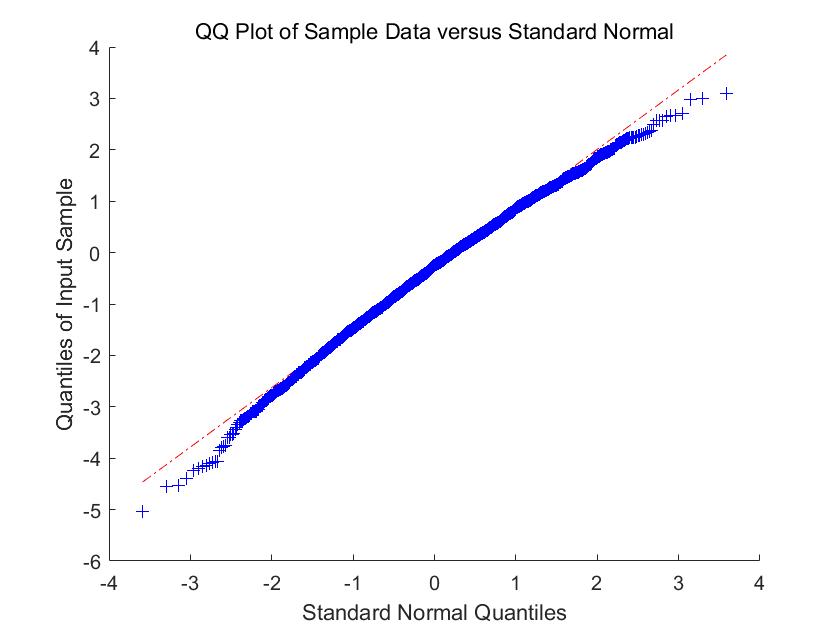
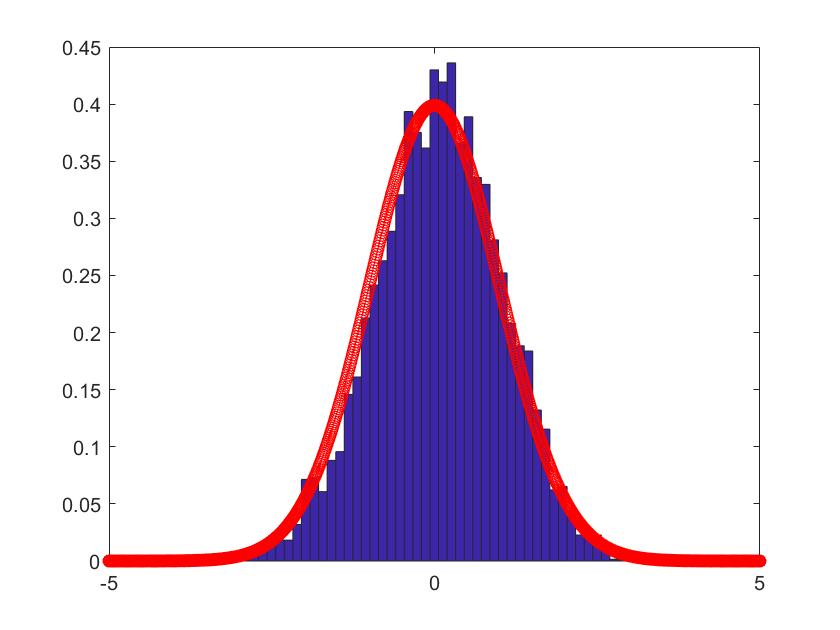
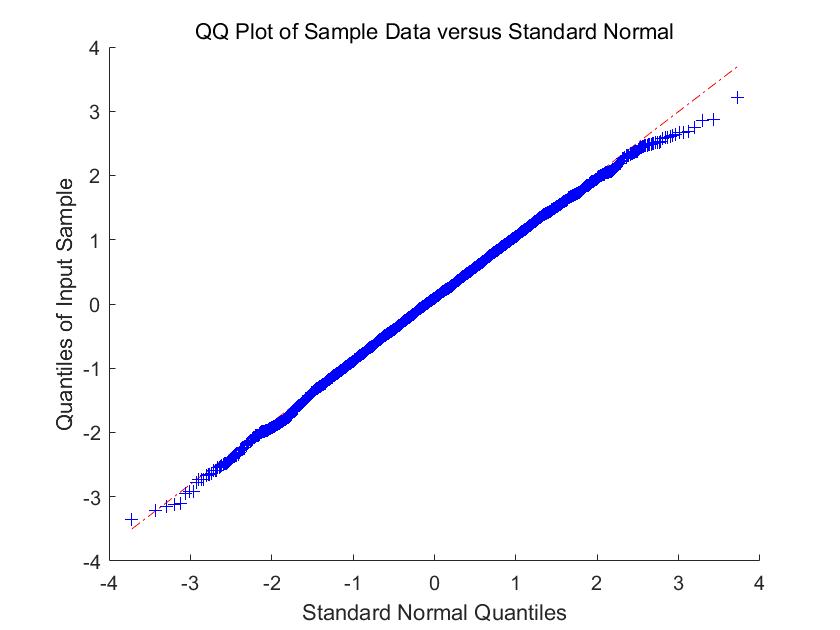
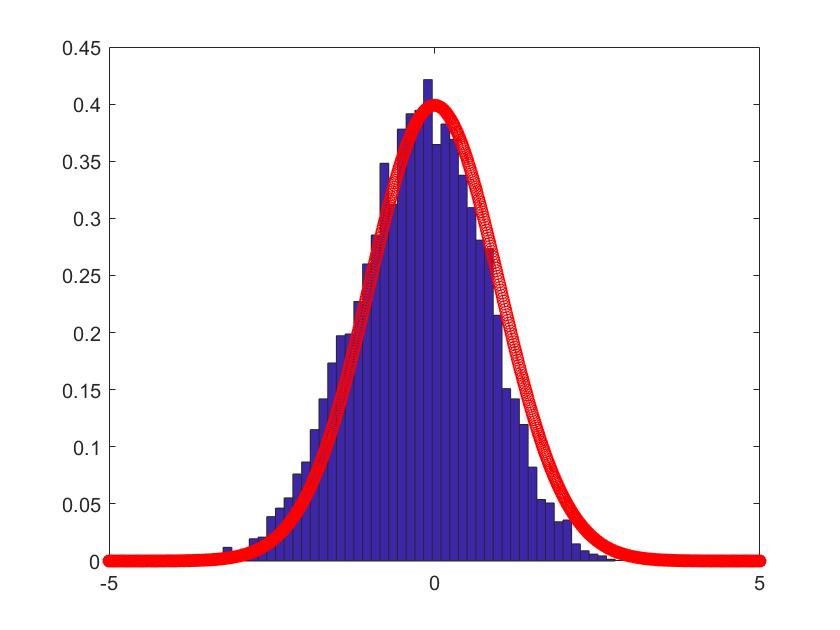
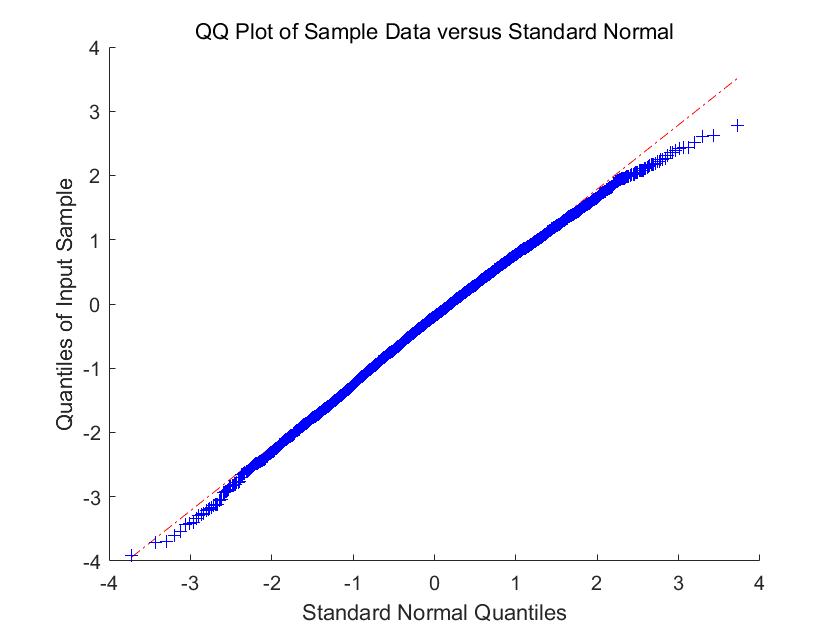
5.2 Simulations for the estimators
We conduct the following simulations to verify the accuracy of the estimators in (28), (31) and (33). Unlike (34), in this subsection, the eigenvalues of are set as
| (36) |
where , , and . Note that we set the second eigenvalue as a multiple eigenvalue. According to the single root condition in Assumption d′, we set the eigenvalues of satisfying the model (35).
Remark 5.1.
We consider the estimator and with and , respectively. Then the frequency histograms of the estimators are present in Figure 7-10 with repetitions. In Figure 11-12, we show the accuracy of the estimator for the two of largest population canonical correlation coefficients. We conclude that the estimators become accurate with increasing as the horizontal axis is more concentrated among three estimators.
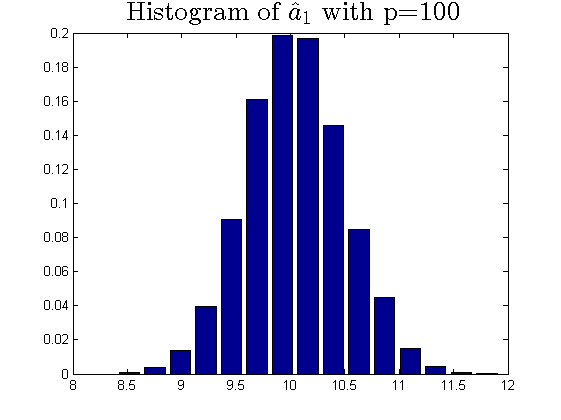
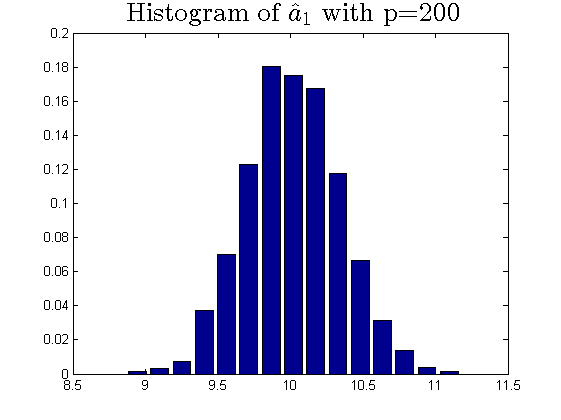
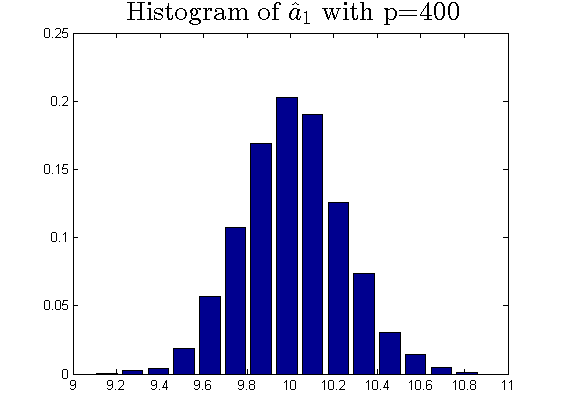
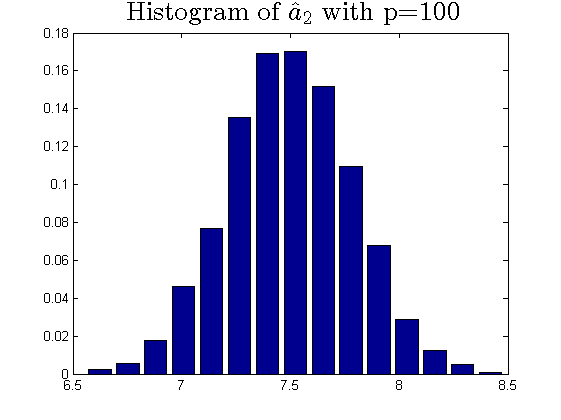
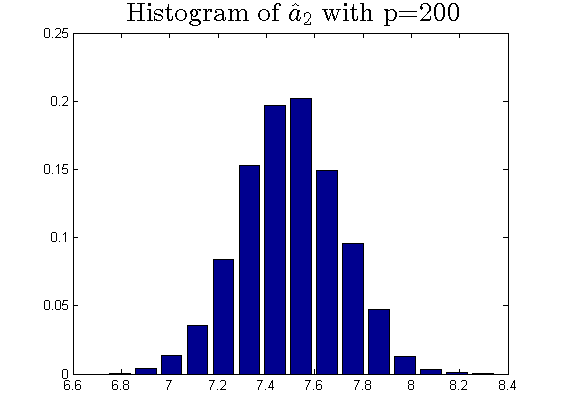
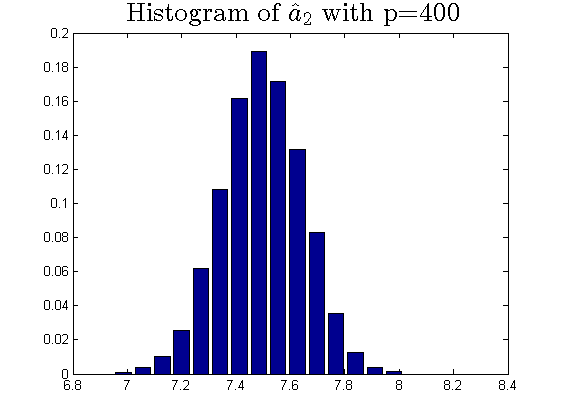
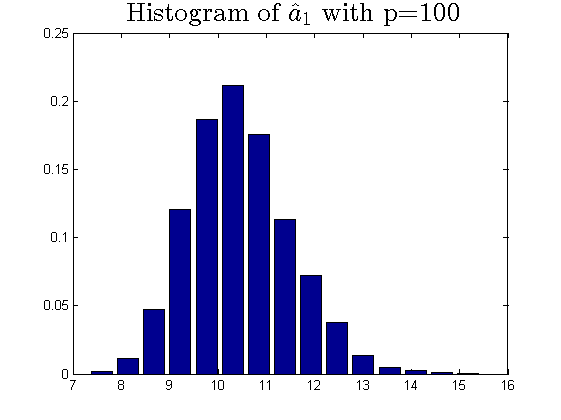
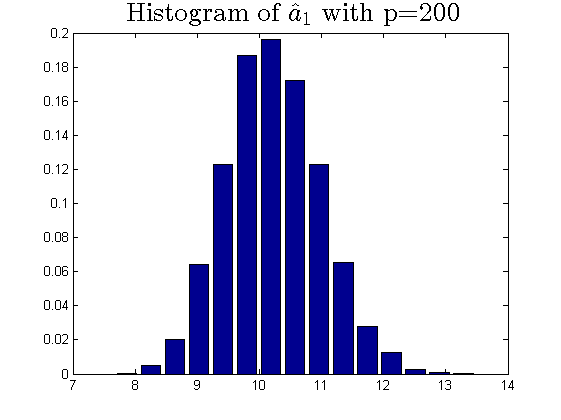
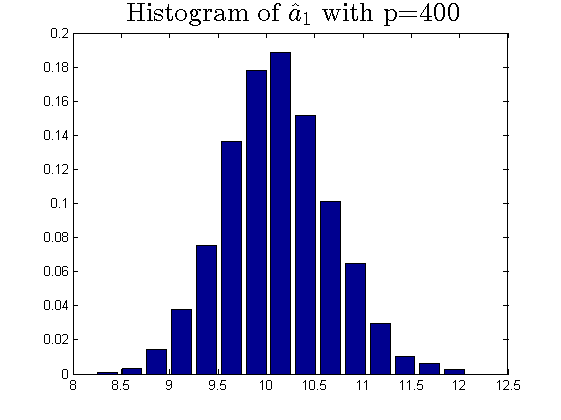
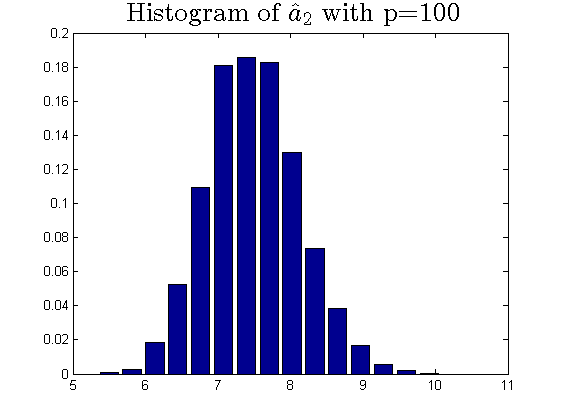
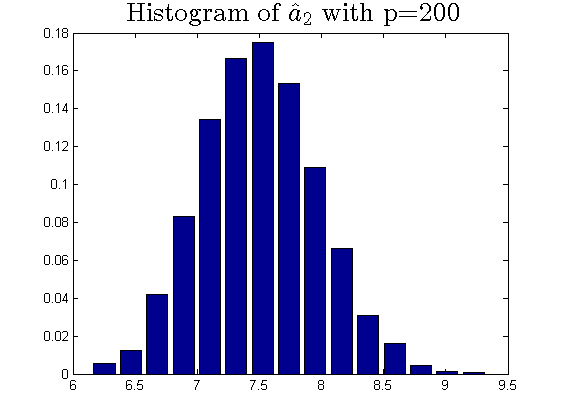
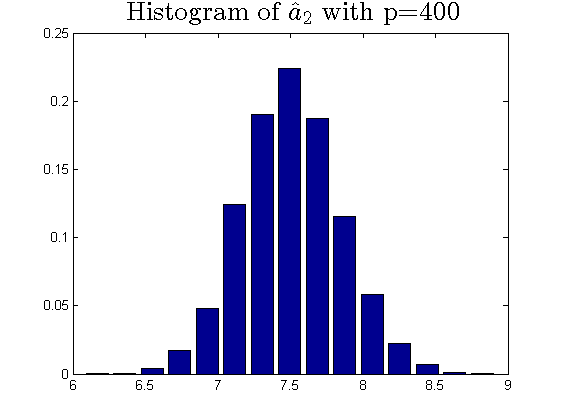
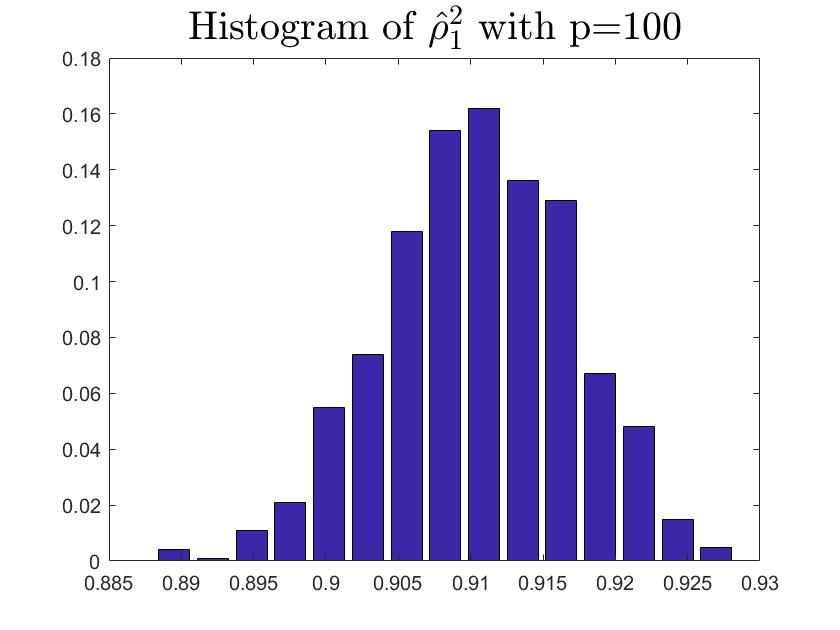
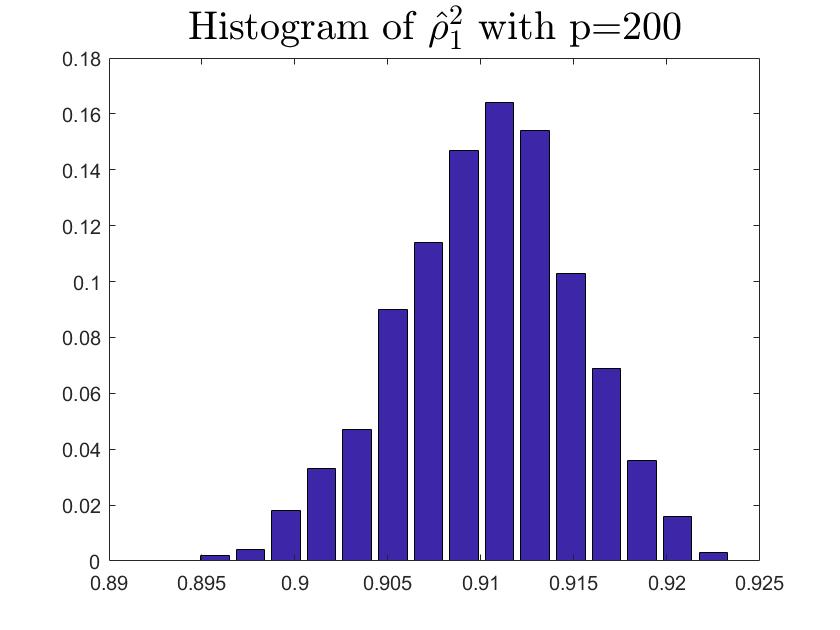
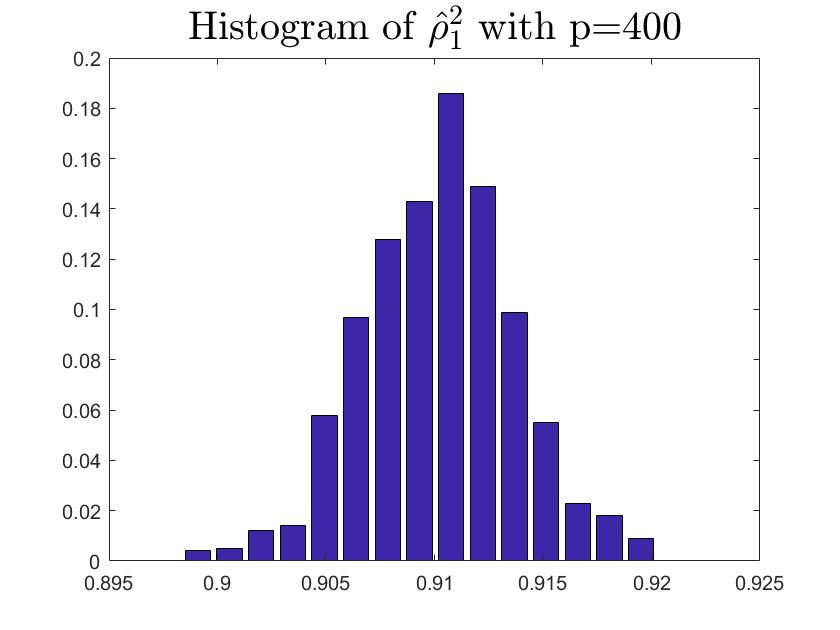
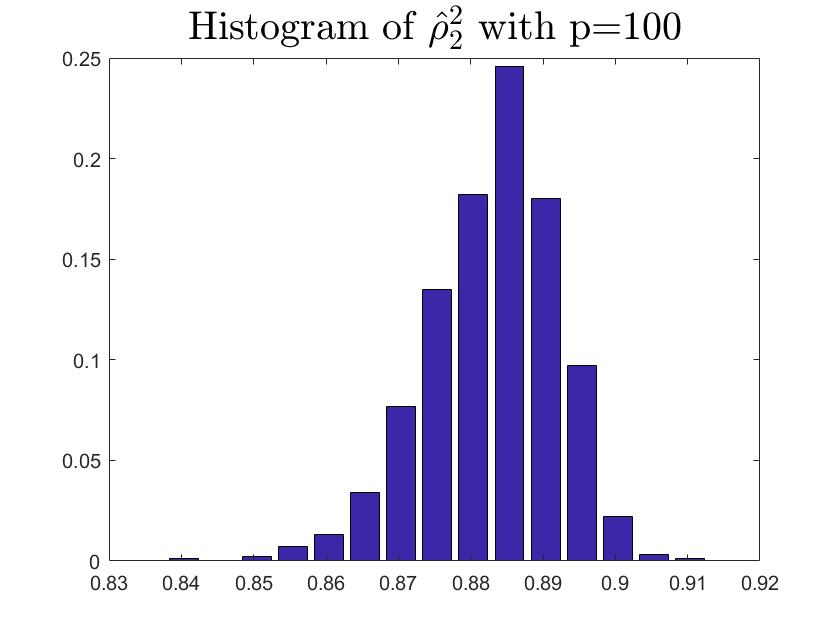
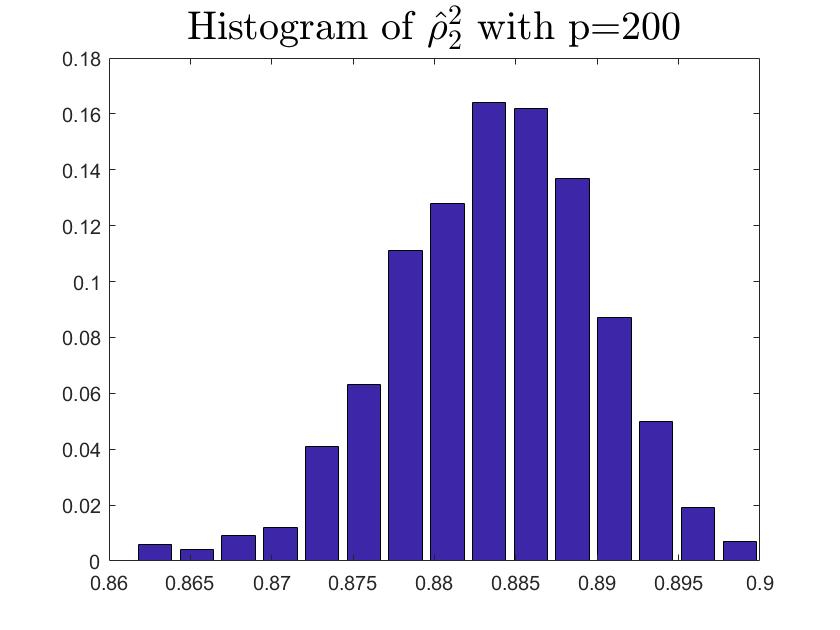
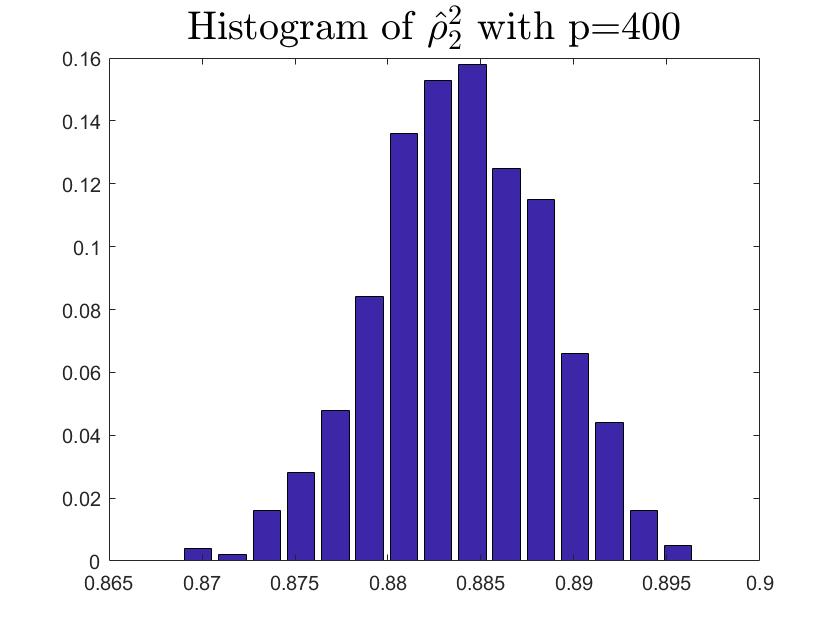
To a certain extent, the histograms present the accuracy of estimates of the spiked eigenvalues, however, which is not convincing enough. So we use the Mean Square Errors (MSE) criteria to show the accuracy of estimates in Table 3.
| 100 | 200 | 400 | 100 | 200 | 400 | |
|---|---|---|---|---|---|---|
| 1.2928 | 0.6183 | 0.3176 | 0.4017 | 0.2194 | 0.1144 | |
| 0.2077 | 0.1064 | 0.0540 | 0.0821 | 0.0421 | 0.0222 | |
| 4.8001e-05 | 2.5296e-05 | 1.2784e-05 | 7.7782e-05 | 4.4870e-05 | 2.3276e-05 | |
The notation , and in Table 3 are short for the noncentral sample covariance matrix, the noncentral Fisher matrix and CCA matrix, respectively. According to Table 3, we find that the MSE decreases as the dimensionality increases, which is consistent with the above mentioned simulation results. Compared with the MSE of the two estimators in Table 3, the estimator derived by the noncentral Fisher matrix is more consistent than the noncentral sample covariance matrix.
5.3 Simulation for multiple roots case
Both Theorem (4.2) and Theorem (4.3) need satisfy the Assumption d′, specially, the spiked eigenvalue is a single root. So we set meet (35) in subsection 5.1. However, we guess our theories and estimator for the single root are effective under the multiple roots condition. In this subsection, we will present some simulations to show the correctness and rationality estimating population canonical correlation coefficient under the multiple roots condition. We assume
| (37) |
set the ratio among as and 1000 repetitions. According to Fig 13 and Table 4, the performance looks good.
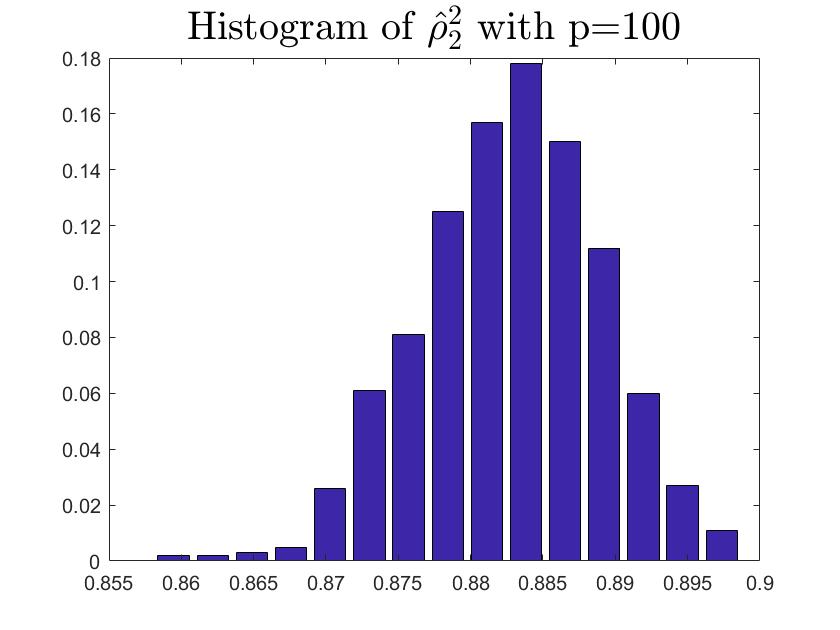
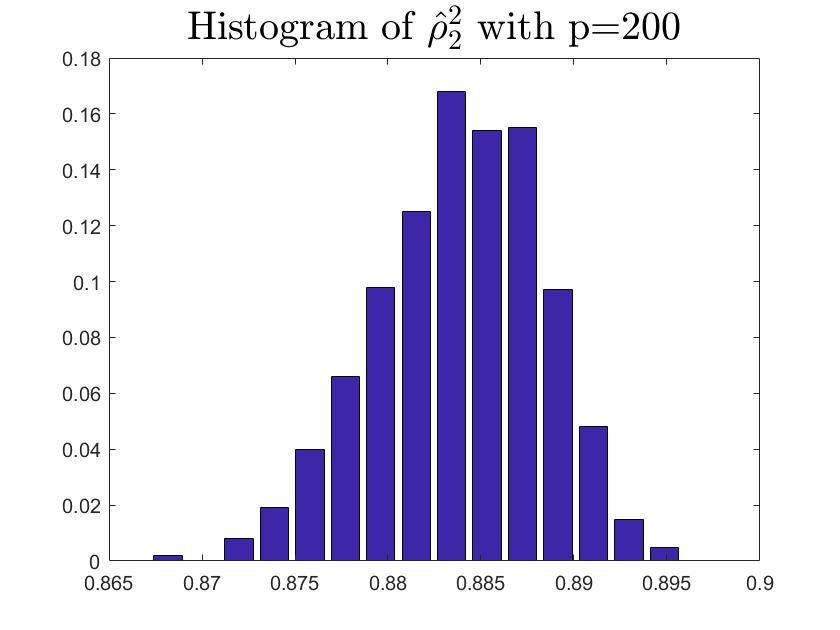
| 100 | 200 | 400 | |
| 3.7055e-05 | 2.2209e-05 | 1.2577e-05 | |
6 Conclusion and discussion
In this work, we study the limiting properties of the sample spiked eigenvalues of the noncentral Fisher matrix under high-dimensional setting and Gaussian assumptions. Similar to the spiked model work, we find a phase transition for the limiting properties of the sample spiked eigenvalues of the noncentral Fisher matrix. In addition, we present the CLT for the sample spiked eigenvalues. As an accessory to the proof of the results of the limiting properties of the sample spiked eigenvlaues of the noncentral Fisher matrix, the fluctuations of the spiked eigenvalues of noncentral sample covariance matrix are studied, which should have its own interests.
General distribution. It would be natural to ask if our results in the current work can be extended from Gaussian to more general distribution of the matrix entries. Our future work will focus on the limiting properties of the sample spiked eigenvalues of the noncentral Fisher matrix under general distribution of the matrix entries.
7 Appendix
7.1 Proof of Theorem 3.1
There is no loss of generality in assuming
| (44) |
where is the first rows of , the diagonal of is composed of the spiked eigenvalues while the diagonal of is composed of the non-spiked bounded eigenvalues, and . According to the structure of in (44), we decompose as following,
where denotes the first rows of , and stands for the remaining rows of . Then the sample eigenvalues of noncentral sample covariance matrix are sorted in descending order as
If we only consider the sample spiked eigenvalues of , , , , then the eigen-equation is
| (48) | ||||
| (51) |
Because is fixed, and share the same the LSD, then is an outlier for large , i.e. . Rewrite (7.1) by the inverse of a partitioned matrix ([20], Section 0.7.3) and the in-out exchange formula, we have
if . For simplicity, we denote briefly by . When there is no ambiguity, we also rewrite it as . Then
| (52) |
where
| (53) | ||||
| (54) |
, and is the first major diagonal submatrix of .
Here we announce that the following results of almost sure convergence are ture without proofs and the detailed proofs are postponed in Subsection 7.1.1.
| (55) | |||
| (56) | |||
| (57) |
According to (52), we have . By the formula (1.3) in [17], we arrive at
From
| (58) |
we can obtain
| (59) |
For arbitrary , let
| (60) |
where , and denotes the ST of ESD of bulk eigenvalues of . An easy calculation shows that
where is the ST of LSD of with and replaced by and ESD of bulk eigenvalues of . Combining (59) and the fact that the dimension of matrix is finite, there exists ‘’ (assume ) such that the -th diagonal element convergence almost surely to zero. For this ‘’ we have
Then subtracting the -th one from all the diagonal elements of the matrix in the above determinant, we find the difference has a lower bound except the -th block containing -th location, i.e.
is with the lower bound as a result of (5) in Assumption A. So for the diagonal elements of -th block, we have
By the factor
has lower bound, we get . If is bounded, the limit of satisfies
where is the Stieltjes transform of the LSD of . The second equivalence relation is a consequence of (6). The proof of Theorem 3.1 is completed.
Remark 7.1.
If tends to infinite as stated in Assumption A, we only need to multiply by from both side of (52), and similar arguments above applying to the infinite case, we can get the same conclusion with only describing as: . Therefore, we will not repeat the situation that tending infinite in following proof.
7.1.1 Proofs of (55), (56) and (57)
(57) can be obtain by Kolmogorov’s law of large numbers straightly. The proof of (55) and (56) are similar, so we take the proof of (56) as example. We consider the following series for any ,
where the event means the spectral norm of is bounded, i.e., and means Kolmogorov norm, defined as the largest absolute value of all the entries. Then we have
where the last equation is a consequence of the exact separation result of information-plus-noise type matrices in [5]. For the first term, we have
| (61) |
In fact, there exists a constant , independent with , such that
which implies (7.1.1) is summable when . By the Borel-Cantelli lemma, we have
7.2 Proof of Theorem 3.2
In this section, we will consider the random vector
where is defined as (60), The reason of using rather than its limit lies in the fact that the convergence may be very slow. The following proof is based on (52) and (7.1), then
where is the Stieltjes transform of with parameter and replaced by and , and
| (62) | |||||
| (63) | |||||
| (64) |
Here we give the estimators of , , and and the detailed proof is postponed in the following part,
| (65) | |||||
| (66) | |||||
| (67) |
According to the definition (60), if , then we obtain
| (68) |
We rewrite the -th block matrix of as
By the discussion of the limiting distribution of and Skorokhod strong representation theorem, for more details, see [32] or [21], on an appropriate probability space, one may redefine the random variables such that tends to the normal variables with probability one. Then, the eigen-equation of (52) becomes
where and is -th diagonal block of . Then multiplying to the -th block row and column of the determinant of the eigen-equation above, and making . Then we have
Simplifying the above, we have the random vector tends to a random vector consists of the ordered eigenvalues of GOE (GUE) matrix under real (complex) case with the scale parameter
| (69) |
where and are defined in (6) and (12), and stand for their derivatives at , respectively. We shall have establish the proof of theorem 3.2 if we prove the limiting distribution of and the limits of , and . In the following, we will put these proofs.
7.2.1 Limiting distribution of
In this section, we proceed to show the limiting distribution of . According to the definition of in (7.1), the proof will be divided into three parts, where are , and
| (70) |
By Theorem 7.1 in [6], it is easy to obtain that the -th block of matrix tends to -dimensional GOE (GUE) matrix with scale parameter under real (complex) case.
Having disposed of , we can now turn to the proof of (70). To complete the proof of (70), we consider the limiting distribution of
Rewrite as and similar considerations apply to , . Then, we have
| (71) |
Then, the first major diagonal submatrix is
where
We emphasize that both and are noncentral sample covariance matrices with the same limiting noncentral parameter matrix. So the Stieltjes transform of LSD of is . Similar arguments apply to , we conclude that tends to with probability one. By the CLT of the quadratic form, we have
and the -th block of tends to -dimensional GOE (GUE) matrix with scale parameter under real (complex) case. Moreover,
| (72) |
where
By (7.2.1) and classical CLT, it is easy to see that the corresponding block of tends to the GOE (GUE) matrix under real (complex) case with scale parameter
We shall have established the limiting distribution of if we give the limiting distribution of
| (73) |
It is easily seen that the elements () of (73) is , where is the -th row of and is the -th column of . Since is independent of , the limiting distribution of is Gaussian under given . The mean of the Gaussian is zero and its variance is present under two different situations. Under the real samples situation, the variance is equal to
| (74) |
and under the complex samples situation, the variance is equal to
| (75) |
What is left is to compute the limits of (74) and (75). By the inverse blockwise matrix formula, we know that the vector consisted of the first components of is equal to the -th column of and the vector consisted of next components is equal to the -th column of . By (71), we have
where
Then applying (7.2.1), we have
| (76) |
In the same manner we can see that
| (77) |
which implies the variables in asymmetric positions are asymptotic independent. From the above analysis, we obtain the corresponding block of tends to a GOE (GUE) matrix under real (complex) case with scale parameter
The third moment of normal population is zero so that the limiting distribution of , and (70) are independent among them. We conclude that the limiting distribution of the -th block of equals the GOE (GUE) matrix under real (complex) matrix with the scale parameter
| (78) |
7.2.2 Limits of , and
In this section, we proceed to show the limits of , and defined in (62)-(64). To deal with , we note that
where the last equality is the consequence of Theorem 1 in [9]. As is bounded a.s. and Theorem 3.1, we have
The task is now to consider the limit of ,
the last equality being a consequence of
It remains to show the limit of . Here, we focus on and other terms can be handle in a similar way. According to , we have
Note that the assumption the rate of diverging to infinity in Assumption A is used here. To be specific, We find that if the rate of diverging to infinity is more than , will tend infinity.
Combining the limiting distribution of , we obtain the limiting distribution of the random vector and its key scale parameter is defined in (7.2).
7.3 Proof of Theorem 3.3
At first, we consider the first order limit of the spiked eigenvalues of under given the matrix sequence . Recall
where is an diagonal matrix and denotes the first rows of . The matrix can be seen as a general non-negative definite matrix with the eigenvalues formed in descending order,
| (81) |
We consider the eigen-equation
We denote as . The entries of are the standard normal so that both and have the same distribution. If there is no confusion, we will still write the notation . Then the eigen-equation becomes
According to the sample spiked eigenvalues , , of , we have almost surely, then
where
| (83) | |||||
Similar to Subsection 7.1.1, by the assumption on , the strong law of large numbers and the Stietjes transformation equation of - law, we have as , and
| (84) |
where is the Stieltjes transform of . Taking limit on the eigen-equation, there exists a diagonal block being , then we have , where and are the almost surely limit of and respectively. According to (8), we have
i.e.,
| (85) | |||||
| (86) |
From what has already been proved, we conclude that the first order limit of is independent of , only related to the limit of their spiked eigenvalues. An easy computation shows the relationship between and :
7.4 Proof of Theorem 3.4
We are now in a position to study the asymptotic distribution of the random vector
| (87) |
where with the parameters in function replaced by the corresponding empirical parameters, and which will be divided into two steps. At first, we give the conditional limiting distribution of , then we will find the limiting distribution are independent with the choice of conditioning . Secondly, combining the above theorems and the following subsection, we can complete the proof of Theorem 3.4.
7.4.1 The conditional limiting distribution of
In this section, we consider the CLT of the random vector . Recall the eigen-equation
where
By simple calculation, we set and have
i.e.
| (88) |
By (86), we have
We recall
becomes
| (89) |
where is -th diagonal block of .
By Skorokhod strong representation theorem (for more detais, see [32] or [21]), on an appropriate probability space, one may redefine the random variables such that tends to the Gaussian variables with probability one. Multiplying to the -th block row and column of the determinant in (89), and . It is easily seen that all non-diagonal elements tend to zero and and all the diagonal entries except the -th are bounded away from zero as or . Therefore,
where
| (90) |
By classical CLT, we have tends to an -dimensional GOE (GUE) matrix under real (complex) case with the scale parameter . In fact, the scale parameter is the limit of
Then we conclude that the conditional limiting distribution of equals the joint distribution of the eigenvalues of GOE (GUE) matrix with the scale parameter .
7.4.2 The limiting distribution of
In this part, we will give the asymptotic distribution of . It is worth pointing out that the asymptotic distribution of is without the condition . According to (87), we have
| (91) | ||||
where the condition limiting distribution of
is independent with the condition, so the asymptotic distribution of the first term of (91) is the joint distribution of the order eigenvalues of a GOE (GUE) matrix with parameter . According to Subsection 7.2, it follows that the limiting distribution of
equals the joint distribution of the order eigenvalues of a GOE (GUE) matrix with parameter defined in (7.2). Combining (85) with (86), we obtain
and
Then the asymptotic distribution of the second term of (91) is the same as the eigenvalues of a GOE (GUE) matrix with parameter
In summary, the limiting distribution of is related to that of eigenvalues of the GOE (GUE) matrix with parameter
7.5 Proof of Theorem 4.3
According to Theorem 4.1, we know that there exsits a function relation between sample canonical correlation coefficients and the eigenvalues of a special noncentral Fisher matrix. The noncentral parameter matrix defined in (23) is a random matrix, so the proof of Theorem 4.3 cannot be obtained directly be Theorem 3.4 and 4.1. Now we will present the details of the proof.
Consider the random variable
we have
Under the Assumption d′ and given , the limiting distribution of first term in can be obtained by Theorem 3.4 and its covariance satisfies (15), which is independent of selection . We apply the Mean value theorem to the second term in , i.e.,
where or , and or . By Theorem 3.1 and 3.3, we have
where
And
where
Then the covariance function of satisfies
| (92) |
where
According to Delta method, we rewrite
then the covariance function of will be
References
- [1] {bbook}[author] \bauthor\bsnmTheodore W. Anderson (\byear2003). \btitleAn Introduction to Multivariate Statistical Analysis, \beditionThird edition ed. \bpublisherWiley. \endbibitem
- [2] {barticle}[author] \bauthor\bsnmBai, \bfnmZhidong\binitsZ. and \bauthor\bsnmDing, \bfnmXue\binitsX. (\byear2012). \btitleEstimation of spiked eigenvalues in spiked models. \bjournalRandom Matrices: Theory and Applications \bvolume01 \bpages1150011. \bdoi10.1142/S2010326311500110 \bmrnumber2934717 \endbibitem
- [3] {barticle}[author] \bauthor\bsnmBai, \bfnmZhidong\binitsZ., \bauthor\bsnmHou, \bfnmZhiqiang\binitsZ., \bauthor\bsnmHu, \bfnmJiang\binitsJ., \bauthor\bsnmJiang, \bfnmDandan\binitsD. and \bauthor\bsnmZhang, \bfnmXiaozhuo\binitsX. (\byear2021). \btitleLimiting canonical distribution of two large dimensional random vectors. \bjournalIn Advances on Methodology and Applications of Statistics - A Volume in Honor of C.R. Rao on the Occasion of his 100th Birthday. Edited by Carlos A. Coelho, N. Balakrishnan and Barry C. Arnold. \endbibitem
- [4] {bbook}[author] \bauthor\bsnmBai, \bfnmZhidong\binitsZ. and \bauthor\bsnmSilverstein, \bfnmJack W.\binitsJ. W. (\byear2010). \btitleSpectral Analysis of Large Dimensional Random Matrices, \beditionsecond ed. \bseriesSpringer Series in Statistics. \bpublisherSpringer, New York. \bdoi10.1007/978-1-4419-0661-8 \bmrnumber2567175 \endbibitem
- [5] {barticle}[author] \bauthor\bsnmBai, \bfnmZhidong\binitsZ. and \bauthor\bsnmSilverstein, \bfnmJack W.\binitsJ. W. (\byear2012). \btitleNo eigenvalues outside the support of the limiting spectral distribution of Information-plus-Noise type matrices. \bjournalRandom Matrices: Theory and Applications \bvolume01 \bpages1150004. \bdoi10.1142/S2010326311500043 \bmrnumber2930382 \endbibitem
- [6] {barticle}[author] \bauthor\bsnmBai, \bfnmZhidong\binitsZ. and \bauthor\bsnmYao, \bfnmJianfeng\binitsJ. (\byear2008). \btitleCentral limit theorems for eigenvalues in a spiked population model. \bjournalAnnales de l’Institut Henri Poincaré, Probabilités et Statistiques \bvolume44 \bpages447–474. \bdoi10.1214/07-AIHP118 \bmrnumber2451053 \endbibitem
- [7] {barticle}[author] \bauthor\bsnmBai, \bfnmZhidong\binitsZ. and \bauthor\bsnmYao, \bfnmJianfeng\binitsJ. (\byear2012). \btitleOn sample eigenvalues in a generalized spiked population model. \bjournalJournal of Multivariate Analysis \bvolume106 \bpages167–177. \bdoi10.1016/j.jmva.2011.10.009 \bmrnumber2887686 \endbibitem
- [8] {barticle}[author] \bauthor\bsnmBaik, \bfnmJinho\binitsJ., \bauthor\bsnmArous, \bfnmGérard Ben\binitsG. B. and \bauthor\bsnmPéché, \bfnmSandrine\binitsS. (\byear2005). \btitlePhase transition of the largest eigenvalue for nonnull complex sample covariance matrices. \bjournalAnnals of Probability \bvolume33 \bpages1643–1697. \bdoi10.1214/009117905000000233 \bmrnumberMR2165575 \endbibitem
- [9] {barticle}[author] \bauthor\bsnmBanna, \bfnmMarwa\binitsM., \bauthor\bsnmNajim, \bfnmJamal\binitsJ. and \bauthor\bsnmYao, \bfnmJianfeng\binitsJ. (\byear2020). \btitleA CLT for linear spectral statistics of large random Information-plus-Noise matrices. \bjournalStochastic Processes and their Applications \bvolume130 \bpages2250–2281. \bdoi10.1016/j.spa.2019.06.017 \endbibitem
- [10] {barticle}[author] \bauthor\bsnmBao, \bfnmZhigang\binitsZ., \bauthor\bsnmDing, \bfnmXiucai\binitsX. and \bauthor\bsnmWang, \bfnmKe\binitsK. (\byear2021). \btitleSingular vector and singular subspace distribution for the matrix denoising model. \bjournalThe Annals of Statistics \bvolume49 \bpages370-392. \endbibitem
- [11] {barticle}[author] \bauthor\bsnmBao, \bfnmZhigang\binitsZ., \bauthor\bsnmHu, \bfnmJiang\binitsJ., \bauthor\bsnmPan, \bfnmGuangming\binitsG. and \bauthor\bsnmZhou, \bfnmWang\binitsW. (\byear2019). \btitleCanonical correlation coefficients of high-dimensional Gaussian vectors: finite rank case. \bjournalThe Annals of Statistics \bvolume47 \bpages612–640. \bdoi10.1214/18-AOS1704 \bmrnumber3909944 \endbibitem
- [12] {barticle}[author] \bauthor\bsnmBodnar, \bfnmTaras\binitsT., \bauthor\bsnmDette, \bfnmHolger\binitsH. and \bauthor\bsnmParolya, \bfnmNestor\binitsN. (\byear2019). \btitleTesting for independence of large dimensional vectors. \bjournalThe Annals of Statistics \bvolume47 \bpages2977–3008. \bdoi10.1214/18-AOS1771 \bmrnumberMR3988779 \endbibitem
- [13] {barticle}[author] \bauthor\bsnmCai, \bfnmT. Tony\binitsT. T., \bauthor\bsnmHan, \bfnmXiao\binitsX. and \bauthor\bsnmPan, \bfnmGuangming\binitsG. (\byear2020). \btitleLimiting laws for divergent spiked eigenvalues and largest nonspiked eigenvalue of sample covariance matrices. \bjournalAnnals of Statistics \bvolume48 \bpages1255–1280. \bdoi10.1214/18-AOS1798 \bmrnumberMR4124322 \endbibitem
- [14] {barticle}[author] \bauthor\bsnmCapitaine, \bfnmMireille\binitsM. (\byear2014). \btitleExact separation phenomenon for the eigenvalues of large Information-plus-Noise type matrices. application to spiked models. \bjournalIndiana University Mathematics Journal \bvolume63 \bpages1875–1910. \bdoi10.1512/iumj.2014.63.5432 \endbibitem
- [15] {barticle}[author] \bauthor\bsnmDing, \bfnmXiucai\binitsX. (\byear2020). \btitleHigh dimensional deformed rectangular matrices with applications in matrix denoising. \bjournalBernoulli \bvolume17 \bpages387-417. \endbibitem
- [16] {barticle}[author] \bauthor\bsnmDing, \bfnmXiucai\binitsX. and \bauthor\bsnmYang, \bfnmFan\binitsF. (\byear2019). \btitleSpiked separable covariance matrices and principal components. \bjournalarXiv:1905.13060. \endbibitem
- [17] {barticle}[author] \bauthor\bsnmDozier, \bfnmR Brent\binitsR. B. and \bauthor\bsnmSilverstein, \bfnmJack W\binitsJ. W. (\byear2007). \btitleOn the empirical distribution of eigenvalues of large dimensional Information-plus-Noise-type matrices. \bjournalJournal of Multivariate Analysis \bvolume98 \bpages678–694. \endbibitem
- [18] {barticle}[author] \bauthor\bsnmDozier, \bfnmR. Brent\binitsR. B. and \bauthor\bsnmSilverstein, \bfnmJack W.\binitsJ. W. (\byear2007). \btitleAnalysis of the limiting spectral distribution of large dimensional Information-plus-Noise type matrices. \bjournalJournal of Multivariate Analysis \bvolume98 \bpages1099–1122. \bdoi10.1016/j.jmva.2006.12.005 \endbibitem
- [19] {barticle}[author] \bauthor\bsnmHan, \bfnmXiao\binitsX., \bauthor\bsnmPan, \bfnmGuangming\binitsG. and \bauthor\bsnmZhang, \bfnmBo\binitsB. (\byear2016). \btitleThe Tracy-Widom law for the largest eigenvalue of F type matrices. \bjournalThe Annals of Statistics \bvolume44 \bpages1564–1592. \bdoi10.1214/15-AOS1427 \bmrnumberMR3519933 \endbibitem
- [20] {bbook}[author] \bauthor\bsnmHorn, \bfnmRoger A.\binitsR. A. and \bauthor\bsnmJohnson, \bfnmCharles R.\binitsC. R. (\byear2012). \btitleMatrix Analysis. \bpublisherCambridge university press. \endbibitem
- [21] {barticle}[author] \bauthor\bsnmHu, \bfnmJiang\binitsJ. and \bauthor\bsnmBai, \bfnmZhiDong\binitsZ. (\byear2014). \btitleStrong representation of weak convergence. \bjournalScience China Mathematics \bvolume57 \bpages2399–2406. \bdoi10.1007/s11425-014-4855-6 \bmrnumber3266500 \endbibitem
- [22] {barticle}[author] \bauthor\bsnmJames, \bfnmAlan T.\binitsA. T. (\byear1964). \btitleDistributions of matrix variates and latent roots derived from normal samples. \bjournalAnnals of Mathematical Statistics \bvolume35 \bpages475–501. \bdoi10.1214/aoms/1177703550 \bmrnumberMR181057 \endbibitem
- [23] {barticle}[author] \bauthor\bsnmJiang, \bfnmDandan\binitsD. and \bauthor\bsnmBai, \bfnmZhidong\binitsZ. (\byear2021). \btitleGeneralized four moment theorem and an npplication to CLT for spiked eigenvalues of high-dimensional covariance matrices. \bjournalBernoulli \bvolume27 \bpages274–294. \bdoi10.3150/20-BEJ1237 \bmrnumberMR4177370 \endbibitem
- [24] {barticle}[author] \bauthor\bsnmJiang, \bfnmDandan\binitsD., \bauthor\bsnmHou, \bfnmZhiqiang\binitsZ. and \bauthor\bsnmBai, \bfnmZhidong\binitsZ. (\byear2019). \btitleGeneralized Four Moment Theorem with an application to the CLT for the spiked eigenvalues of high-dimensional general Fisher-matrices. \bjournalarXiv:1904.09236. \endbibitem
- [25] {barticle}[author] \bauthor\bsnmJiang, \bfnmDandan\binitsD., \bauthor\bsnmHou, \bfnmZhiqiang\binitsZ. and \bauthor\bsnmHu, \bfnmJiang\binitsJ. (\byear2021). \btitleThe limits of the sample spiked eigenvalues for a high-dimensional generalized Fisher matrix and its applications. \bjournalJournal of Statistical Planning and Inference. Accept. \endbibitem
- [26] {barticle}[author] \bauthor\bsnmJohnstone, \bfnmIain M.\binitsI. M. (\byear2001). \btitleOn the distribution of the largest eigenvalue in principal components analysis. \bjournalThe Annals of Statistics \bvolume29 \bpages295–327. \bdoi10.1214/aos/1009210544 \bmrnumberMR1863961 \endbibitem
- [27] {barticle}[author] \bauthor\bsnmJohnstone, \bfnmI. M.\binitsI. M. and \bauthor\bsnmNadler, \bfnmB.\binitsB. (\byear2017). \btitleRoy’s largest root test under rank-one alternatives. \bjournalBiometrika \bvolume104 \bpages181–193. \endbibitem
- [28] {barticle}[author] \bauthor\bsnmMa, \bfnmZongming\binitsZ. and \bauthor\bsnmYang, \bfnmFan\binitsF. (\byear2021). \btitleSample canonical correlation coefficients of high-dimensional random vectors with finite rank correlations. \bjournalarXiv:2102.03297. \endbibitem
- [29] {bbook}[author] \bauthor\bsnmMardia, \bfnmKantilal Varichand\binitsK. V., \bauthor\bsnmKent, \bfnmJohn T\binitsJ. T. and \bauthor\bsnmBibby, \bfnmJohn M\binitsJ. M. (\byear1979). \btitleMultivariate analysis. \bpublisherAcademic press London. \endbibitem
- [30] {bbook}[author] \bauthor\bsnmRobb J. Muirhead (\byear1982). \btitleAspects of Multivariate Statistical Theory. \bpublisherWiley. \endbibitem
- [31] {barticle}[author] \bauthor\bsnmPaul, \bfnmDebashis\binitsD. (\byear2007). \btitleAsymptotics of sample eigenstructure for a large dimensional spiked covariance model. \bjournalStatistica Sinica \bvolume17 \bpages1617–1642. \endbibitem
- [32] {barticle}[author] \bauthor\bsnmSkorokhod, \bfnmAnatoly V\binitsA. V. (\byear1956). \btitleLimit theorems for stochastic processes. \bjournalTheory of Probability & Its Applications \bvolume1 \bpages261–290. \endbibitem
- [33] {barticle}[author] \bauthor\bsnmTracy, \bfnmCraig A\binitsC. A. and \bauthor\bsnmWidom, \bfnmHarold\binitsH. (\byear1996). \btitleOn orthogonal and symplectic matrix ensembles. \bjournalCommunications in Mathematical Physics \bvolume177 \bpages727–754. \endbibitem
- [34] {barticle}[author] \bauthor\bsnmWachter, \bfnmKenneth W\binitsK. W. (\byear1980). \btitleThe limiting empirical measure of multiple discriminant ratios. \bjournalThe Annals of Statistics \bpages937–957. \endbibitem
- [35] {barticle}[author] \bauthor\bsnmWang, \bfnmQinwen\binitsQ. and \bauthor\bsnmYao, \bfnmJianfeng\binitsJ. (\byear2017). \btitleExtreme eigenvalues of large-dimensional spiked Fisher matrices with application. \bjournalThe Annals of Statistics \bvolume45 \bpages415–460. \bdoi10.1214/16-AOS1463 \bmrnumberMR3611497 \endbibitem
- [36] {barticle}[author] \bauthor\bsnmYang, \bfnmFan\binitsF. (\byear2020). \btitleSample canonical correlation coefficients of high-dimensional random vectors: local law and Tracy-Widom limit. \bjournalarXiv:2002.09643. \endbibitem
- [37] {barticle}[author] \bauthor\bsnmYang, \bfnmFan\binitsF. (\byear2021). \btitleLimiting Distribution of the Sample Canonical Correlation Coefficients of High-Dimensional Random Vectors. \bjournalarXiv:2103.08014. \endbibitem
- [38] {barticle}[author] \bauthor\bsnmZheng, \bfnmShurong\binitsS. (\byear2012). \btitleCentral limit theorems for linear spectral statistics of large dimensional F-matrices. \bjournalAnnales de l’I.H.P. Probabilités et statistiques \bvolume48 \bpages444–476. \bdoi10.1214/11-AIHP414 \endbibitem
- [39] {barticle}[author] \bauthor\bsnmZheng, \bfnmShurong\binitsS., \bauthor\bsnmBai, \bfnmZhidong\binitsZ. and \bauthor\bsnmYao, \bfnmJianfeng\binitsJ. (\byear2015). \btitleCLT for linear spectral statistics of a rescaled sample precision matrix. \bjournalRandom Matrices: Theory and Applications \bvolume04 \bpages1550014. \bdoi10.1142/S2010326315500148 \bmrnumber3418843 \endbibitem
- [40] {barticle}[author] \bauthor\bsnmZheng, \bfnmShurong\binitsS., \bauthor\bsnmBai, \bfnmZhidong\binitsZ. and \bauthor\bsnmYao, \bfnmJianfeng\binitsJ. (\byear2017). \btitleCLT for eigenvalue statistics of large-dimensional general Fisher matrices with applications. \bjournalBernoulli \bvolume23 \bpages1130–1178. \bdoi10.3150/15-BEJ772 \bmrnumberMR3606762 \endbibitem