Speaker Recognition in Realistic Scenario
Using Multimodal Data
Abstract
In recent years, an association is established between faces and voices of celebrities leveraging large scale audio-visual information from YouTube. The availability of large scale audio-visual datasets is instrumental in developing speaker recognition methods based on standard Convolutional Neural Networks. Thus, the aim of this paper is to leverage large scale audio-visual information to improve speaker recognition task. To achieve this task, we proposed a two-branch network to learn joint representations of faces and voices in a multimodal system. Afterwards, features are extracted from the two-branch network to train a classifier for speaker recognition. We evaluated our proposed framework on a large scale audio-visual dataset named VoxCeleb. Our results show that addition of facial information improved the performance of speaker recognition. Moreover, our results indicate that there is an overlap between face and voice.
Index Terms:
Speaker identification, Multimodal, Face-voice associationI Introduction
Speaker recognition is a fundamental task of speech processing with applications in a variety of real world domains. However,speaker recognition task is challenging under real world scenarios due to intrinsic and extrinsic variations. Intrinsic variations are associated with the speaker attributes namely gender, age and manner of speaking while extrinsic variations include factors outside the speaker personality such as background noise, microphone noise etc. [1]. This makes speech signals prone to a large degree of variability. In recent years, Convolutional Neural Networks (CNNs) have opened new paths for speaker recognition task where speech signal is converted to spectrograms to be classified with these networks [2, 3]. Though, speaker recognition methods based on CNNs have surpassed the traditional methodologies [2]. However these methods suffered deterioration under real world scenarios.

Recently, large scale datasets namely VoxCeleb and VoxCeleb are curated for speaker recognition task. These datasets are instrumental in developing CNN methods for speaker recognition task. For example, the work in [2, 3] modified standard CNN such as VGG-M [4] and ResNet [5] to perform speaker recognition task. Moreover, both VoxCeleb and VoxCeleb datasets contain visual information which is instrumental for developing various multimodal applications such as cross modal transfer between face and voice [6, 7, 8, 9, 10], emotion recognition [11], speech separation [12] and face generation [13]. These applications are instrumental in establishing a correlation between faces and voices of speakers. Moreover, it is a well studied fact that humans end up associating voices and faces of people due to the fact that neuro-cognitive pathways for voices and faces share the same structure [14]. Due to the availability of large scale audio-visual datasets such as VoxCeleb and association between faces and voices of speakers, a fundamental question arises: can audio-visual information can be used to improve speaker recognition task? To investigate it, we proposed a two-branch network to establish association between faces and voices. The proposed two-branch consists of the following three components: 1) feature extraction of faces and voices with task-specific pre-trained subnetworks, 2) a series of fully connected layers for faces and voices to learn joint multimodal representations, and 3) loss formulations. Afterwards, we extracted the features of audio segments to train a classifier for speaker identification task. Our results indicate that the facial information along with speech segments is instrumental in improve speaker recognition task. Fig. 1 shows the training and testing strategy of the proposed framework.
We summarize our key contributions as follows: 1) We propose a two-branch network to learn multimodal discriminative joint representations of faces and voices of speakers. 2) We present a comparisons of speaker recognition task with only speech segments and multimodal information. 3) Our results indicate that multimodal information considerable improves speaker recognition task.
II Related Work
We summarize previous work relevant to the speaker recognition and face-voice association tasks.
II-A Speaker Recongition
Sandra et al. [15] laid the groundwork for speaker recognition systems attempting to find a similarity measure between two speech signals by using filter banks and digital spectrograms. We provided a brief overview of speaker recognition methods as clustered in two main categorizes: Traditional and neural network based methods.
Traditional methods. There have been many advancements in the speaker recognition task due to the availability of data and computing resources. However, noisy environment presents a challenging scenario. For several years, the standard speaker recognition task relied on ways that are dependant on features that required manual intervention and domain knowledge. This includes features extracted from low dimensional short term representation of the speech signals such as MEL Frequency Cepstrum Coefficients [16].
The performance of these systems
degrade in real world conditions [17, 18].
These systems are dependent on Human ability to extract useful features which is a limitation for the system.
Joint Factor Analysis captures both speaker-specific and session-specific variability in speech signals by decomposing the speech signal into a set of latent factors [19].
Support Vector Machine (SVM) classifier has been very successful for robust recognition tasks. However, such methods are very slow, complex and prone to degradation when applied to various real world scenarios.
Despite of these advancements, the performance of traditional approaches drop in the presence of noise. Moreover, the performance degraded as the size of data increases. In real world applications there is often no knowledge of environmental noise, transmission channel used and number of speakers in the background. In such cases the traditional methods may degrade in performance.
Deep Learning Methods. Over the last few years, advances in computing resources and neural networks has led to more efficient methods. With these advancement, CNN are extensively used in tasks such as speaker recognition.
For example, the work in [2, 3] propose a CNN based method to transform speech segments into spectrograms for speaker recognition task.
With this advancement, speaker recognition task is moved from manually extracted features to data driven methods.
Specifically, the work in [2] train a modified VGG-M on spectrogram extracted directly from speech segment.
II-B Face-voice Association
Recently, an association between faces and voices of speakers are established by leveraging cross-modal verification and matching tasks [7, 10, 6, 9, 20, 21]. The work in [7] used a triplet network to learn joint representation for face-voice association task. Similarly, the work in [22] used a triplet network [23] to minimize the distance between faces and voices by extracting features from face subnetwork [24] and voice subnetwork [25]. Nawaz et. al [6] learns shared latent space by taking advantage from class centers with a single stream network which eliminate the need of pair or triplet samples. On similar grounds, Saeed et. al [20, 21] proposed a light-weight, plug-and-play mechanism that exploits the complementary cues from faces and voices to form enriched fused embeddings and clusters them based on their identity labels via orthogonality constraints.
In contrast to existing methods, our goal is to extract robust features from a multimodal system trained on faces and voices for speaker recognition task.
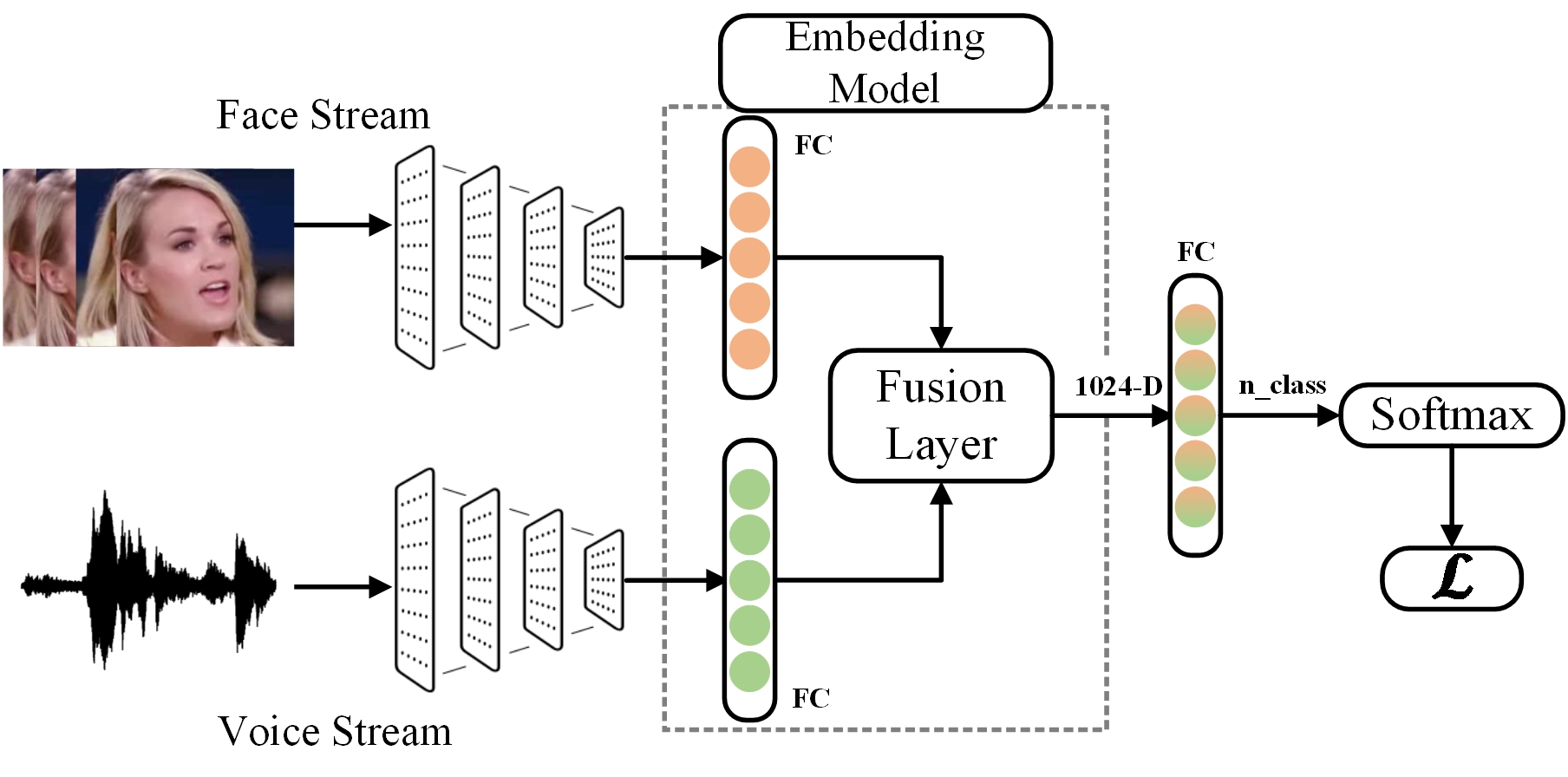

III Overall Framework
III-A Baseline
We extracted -D features of VoxCeleb dataset with VGGVox subnetwork to establish a baseline. SVM classifier is trained on these features for speaker recognition task. Decision function shape is set to one vs one for multi class classification using SVM, kernel parameter was set to poly while degree of polynomial kernel function was set to 3. After training SVM on the features extracted using VGGVox, accuracy of identification is 91%.
III-B Two Branch Network
Our proposed method consists of training a multimodal system using a two-branch network with face and voice information. Afterwards, the multimodal is used to extract features to train a classifier for speaker recognition task. Face and audio features are extracted from VGGFace [26] and VGGVox [2] subnetworks respectively. Afterwards, face and voice features are input to two independent branches, with each modality specific branch respectively. Features from both subnetworks are fused after passing from fully connected and normalization layers. Fig.2 shows the proposed framework.
III-C Multimodal Fusion
We extracted features from face and voice information. These features are then fused and passed to fully connected layer to learn joint representations from both face and voices signals. After fusion a softmax layer is used to learn for the output classes. Softmax function is used as the activation function to predict a multinomial probability distribution where probability is required for multi class classification problems. Features extracted from this two branch network are then used to train a classifier.
III-D Loss Formulation
We want the fused feature to capture the semantics of the speaker or identity. In other words, these features should be able to predict the identity labels with good accuracy. It is possible if the samples belonging to the same class are placed nearby whereas the ones with different classes are far away. A popular choice to achieve this is softmax cross entropy (CE) loss, which also allows stable and efficient training. Now, the loss with fused embeddings is computed as
| (1) |
Categorical cross entropy is a very good measure of how distinguishable two discrete probability distributions are from each other [27]. Adam was used as optimizer with learning rate ranging from to . Network was trained using batch size of , , and . Maximum results were achieved with as learning rate and as batch size.
IV Experiments and Results Discussions
IV-A Training Detail and Dataset
Dataset. VoxCeleb is a large-scale dataset of audio-visual human speech videos extracted ‘in the wild’ from YouTube. These videos contain real world noise with background chatter, overlapping speech, laughter and recording equipment noise. Table I provides shows statistics of the dataset.
| Train | Test | Total | |
|---|---|---|---|
| # of speakers | 1,251 | 1,251 | 1,251 |
| # of videos | 21,245 | 1,251 | 22,496 |
| # of utterances | 145,265 | 8,251 | 153,516 |



Training. Inspired by [20], we propose a two-branch network to analyze the effect of multimodal information on speaker recognition task.
Face embeddings were extracted from pretrained VGGFace [26] while audio embeddings are extracted from VGGVox [2].
Face and voice embeddings were passed as input to two-branch network with subnetworks containing multiple dense layers followed by dropout and normalization layers. Dropout of 10% and 20% was used during training.
Normalized embeddings from two subnetworks are then fused and passed through dense and normalization layers to softmax layer containing hidden units for the classes in dataset. Training is performed with multiple margin values, dropout, batch size, loss functions and learning rates.
Testing
Features are extracted from the two branch network to train and test support vector machine classifier. We extracted feature with -D size form the fusion layer of the model.
Feature extraction is performed in two ways:
-
•
Aiding with face signals: During this phase face and speech signals were provided as input to trained two branch network and speech features were extracted from it.
-
•
Aiding without face signals: During this phase only speech signals were provided as input to trained two branch network and speech features were extracted from it. For face subnetwork input vector was set to zero.
Speaker identification. Features extracted are normalized and used to train and test a SVM classifier. Kernel parameter of support vector machine is set to poly while decision function shape was set to ovo. Remaining parameters are set to default during training.
IV-B Results from Voice Only Features
We extracted the feature from VGGVox subsnetwork and trained a classifier to establish a baseline, resulting in 91% identification performance. Fig. 3(a) shows confusion matrix of the baseline results. Moreover, stochastic neighbor embedding for a sample test set in Fig. 4(a) shows that the network has distributed the features for multiple classes far apart which has reduced the accuracy of classifier on those features.
IV-C Results from Aided Facial Information
Table II shows results of a classifer trained on features extracted from the two-branch network. Confusion matrix of two branch fused features can be seen in Fig.3(b). Moreover, T-SNE plot for a sample test set in Fig.4(b) shows that the network has distributed the features more efficiently where same class features are close to each other that has resulted in better learning of SVM for speaker recognition task.
Experiments show that when speech signals are aided by faces during feature extraction, speaker recognition is improved significantly. Without facial information, the system is likely to be effected with noise. When we have face information aiding the voice information degraded in one mode can be recovered by the other.
V Conclusion
In this work we proposed that presence of multimodal information improve the performance of speaker recognition task. We propose the two-branch network to extract features from both face and voice signals. SVM was used to classify speaker based on features from single domain and multi domain. We obtained promising results when we used both face and speech information as input to our model. The identification performance achieved using our approach is higher compared to VGGVox which only exploit single modality. Also the results using both speech and face signals while extracting features from our model are better as compared to inputting only speaker information which clearly indicates that face information can aid in speaker recognition. Also, this increase in speaker recognition performance with the aid of facial information gives us clue that though there is some association between face and voice of a person.
Another very important contribution is that this work opens the research path for classification and retrieval tasks of other modalities.
Acknowledgements.
Authors gratefully acknowledge the support of Swarm Robotics Lab, NCRA for providing the necessary equipment and resources for our experiments.
References
- [1] Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and Andrew Y Ng, “Multimodal deep learning,” in Proceedings of the 28th international conference on machine learning (ICML-11), 2011, pp. 689–696.
- [2] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: a large-scale speaker identification dataset,” in INTERSPEECH, 2017.
- [3] Joon Son Chung, Arsha Nagrani, and Andrew Zisserman, “Voxceleb2: Deep speaker recognition,” arXiv preprint arXiv:1806.05622, 2018.
- [4] Ken Chatfield, Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman, “Return of the devil in the details: Delving deep into convolutional nets,” arXiv preprint arXiv:1405.3531, 2014.
- [5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [6] Shah Nawaz, Muhammad Kamran Janjua, Ignazio Gallo, Arif Mahmood, and Alessandro Calefati, “Deep latent space learning for cross-modal mapping of audio and visual signals,” in 2019 Digital Image Computing: Techniques and Applications (DICTA). IEEE, 2019, pp. 1–7.
- [7] Arsha Nagrani, Samuel Albanie, and Andrew Zisserman, “Seeing voices and hearing faces: Cross-modal biometric matching,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8427–8436.
- [8] Yandong Wen, Mahmoud Al Ismail, Weiyang Liu, Bhiksha Raj, and Rita Singh, “Disjoint mapping network for cross-modal matching of voices and faces,” in 7th International Conference on Learning Representations, ICLR 2019, USA, May 6-9, 2019, 2019.
- [9] Shah Nawaz, Muhammad Saad Saeed, Pietro Morerio, Arif Mahmood, Ignazio Gallo, Muhammad Haroon Yousaf, and Alessio Del Bue, “Cross-modal speaker verification and recognition: A multilingual perspective,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1682–1691.
- [10] Arsha Nagrani, Samuel Albanie, and Andrew Zisserman, “Learnable pins: Cross-modal embeddings for person identity,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 71–88.
- [11] Samuel Albanie, Arsha Nagrani, Andrea Vedaldi, and Andrew Zisserman, “Emotion recognition in speech using cross-modal transfer in the wild,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 292–301.
- [12] Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman, “The conversation: Deep audio-visual speech enhancement,” arXiv preprint arXiv:1804.04121, 2018.
- [13] O. Wiles, A.S. Koepke, and A. Zisserman, “Self-supervised learning of a facial attribute embedding from video,” in British Machine Vision Conference, 2018.
- [14] Miyuki Kamachi, Harold Hill, Karen Lander, and Eric Vatikiotis-Bateson, “Putting the face to the voice’: Matching identity across modality,” Current Biology, vol. 13, no. 19, pp. 1709–1714, 2003.
- [15] Sandra Pruzansky, “Pattern-matching procedure for automatic talker recognition,” The Journal of the Acoustical Society of America, vol. 35, no. 3, pp. 354–358, 1963.
- [16] Richard J Mammone, Xiaoyu Zhang, and Ravi P Ramachandran, “Robust speaker recognition: A feature-based approach,” IEEE signal processing magazine, vol. 13, no. 5, pp. 58, 1996.
- [17] Umit Yapanel, Xianxian Zhang, and John HL Hansen, “High performance digit recognition in real car environments,” in Seventh International Conference on Spoken Language Processing, 2002.
- [18] John HL Hansen, Ruhi Sarikaya, Umit Yapanel, and Bryan Pellom, “Robust speech recognition in noise: an evaluation using the spine corpus,” in Seventh European Conference on Speech Communication and Technology, 2001.
- [19] Patrick Kenny, “Joint factor analysis of speaker and session variability: Theory and algorithms,” CRIM, Montreal,(Report) CRIM-06/08-13, vol. 14, no. 28-29, pp. 2, 2005.
- [20] Muhammad Saad Saeed, Muhammad Haris Khan, Shah Nawaz, Muhammad Haroon Yousaf, and Alessio Del Bue, “Fusion and orthogonal projection for improved face-voice association,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7057–7061.
- [21] Muhammad Saad Saeed, Shah Nawaz, Muhammad Haris Khan, Sajid Javed, Muhammad Haroon Yousaf, and Alessio Del Bue, “Learning branched fusion and orthogonal projection for face-voice association,” arXiv preprint arXiv:2208.10238, 2022.
- [22] Changil Kim, Hijung Valentina Shin, Tae-Hyun Oh, Alexandre Kaspar, Mohamed Elgharib, and Wojciech Matusik, “On learning associations of faces and voices,” in Asian Conference on Computer Vision. Springer, 2018, pp. 276–292.
- [23] Elad Hoffer and Nir Ailon, “Deep metric learning using triplet network,” in Similarity-Based Pattern Recognition: Third International Workshop, SIMBAD 2015, Copenhagen, Denmark, October 12-14, 2015. Proceedings 3. Springer, 2015, pp. 84–92.
- [24] Karen Simonyan and Andrew Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [25] Yusuf Aytar, Carl Vondrick, and Antonio Torralba, “Soundnet: Learning sound representations from unlabeled video,” Advances in neural information processing systems, vol. 29, 2016.
- [26] Omkar M Parkhi, Andrea Vedaldi, and Andrew Zisserman, “Deep face recognition,” 2015.
- [27] Zhilu Zhang and Mert Sabuncu, “Generalized cross entropy loss for training deep neural networks with noisy labels,” Advances in neural information processing systems, vol. 31, 2018.
- [28] Sarthak Yadav and Atul Rai, “Learning discriminative features for speaker identification and verification.,” in Interspeech, 2018, pp. 2237–2241.