Sparse Autoencoders Enable Scalable and Reliable Circuit Identification in Language Models
Abstract
This paper introduces an efficient and robust method for discovering interpretable circuits in large language models using discrete sparse autoencoders. Our approach addresses key limitations of existing techniques, namely computational complexity and sensitivity to hyperparameters. We propose training sparse autoencoders on carefully designed positive and negative examples, where the model can only correctly predict the next token for the positive examples. We hypothesise that learned representations of attention head outputs will signal when a head is engaged in specific computations. By discretising the learned representations into integer codes and measuring the overlap between codes unique to positive examples for each head, we enable direct identification of attention heads involved in circuits without the need for expensive ablations or architectural modifications. On three well-studied tasks - indirect object identification, greater-than comparisons, and docstring completion - the proposed method achieves higher precision and recall in recovering ground-truth circuits compared to state-of-the-art baselines, while reducing runtime from hours to seconds. Notably, we require only 5-10 text examples for each task to learn robust representations. Our findings highlight the promise of discrete sparse autoencoders for scalable and efficient mechanistic interpretability, offering a new direction for analysing the inner workings of large language models.
1 Introduction
The rapid advancement of large language models (LLMs) based on transformers [44] has spurred interest in mechanistic interpretability [32], which aims to break down model components into human-understandable circuits. Circuits are defined as subgraphs of a model’s computation graph that implement a task-specific behaviour [31]. While progress has been made in automating the isolation of certain circuits [6, 5, 28], automatic circuit discovery remains too brittle and complex to replace manual inspection. As model sizes grow [18, 22], manual inspection becomes increasingly impractical, hence the need for more robust and efficient methods.
Automated circuit identification algorithms suffer from several drawbacks, such as sensitivity to the choice of metric, the type of intervention used to identify important components, and computational intensity [6, 34, 46, 11]. Whilst faster variants of automated algorithms have been leveraged with some success [42, 15], they retain many of the same failure modes and performance is heavily dependent on metric choice. All variants of automated circuit-identification have been shown to perform poorly at recovering ground-truth circuits in specific situations [6], meaning researchers cannot know a priori whether the circuit found is accurate or not. Without simpler and more robust algorithms, researchers will be limited to using painstakingly slow manual circuit identification [38].
Our main contribution is the introduction of a highly performant yet remarkably simple circuit-identification method based on the presence of features in sparse autoencoders (SAEs) trained on transformer attention head outputs. SAEs have been shown to learn interpretable compressed features of the model’s internal states [7, 40, 4]. We hypothesise that these representations of attention head outputs should contain signal about when a head is engaged in a particular type of computation as part of a circuit. The key insight behind our approach is that by training SAEs on carefully designed examples of a task that requires the language model to use a specific circuit (and examples where it doesn’t), the learned representations should capture circuit-specific behaviour.
We demonstrate that by simply looking for the codes unique to positive examples within as few as 5-10 text examples of a task, we can directly identify the attention heads in the ground-truth circuit with better or equal precision and recall than existing methods, while being significantly faster and less complex. Specifically, our method allows us to do away with choosing a metric to measure the importance of a model component, which we see as a fundamental advantage of our method over previous approaches. We evaluate the proposed method on three well-studied circuits and demonstrate its robustness to hyperparameter choice. Our findings highlight the potential of using discrete sparse autoencoders for efficient and effective circuit identification in large language models.

2 Background
2.1 Attention Heads and Circuits in Autoregressive Transformers
Autoregressive, decoder-only transformers rely on self-attention to weigh the importance of different parts of the input sequence [44], with a goal to predict the next token. In the multi-head attention mechanism, each attention head operates on a unique set of query, key, and value matrices, allowing the model to capture diverse relationships between elements of the input. The output of the -th attention head can be formally described as:
where is the input sequence, are the query, key, and value matrices for the -th head, and is the dimensionality of the key vectors. The outputs of the individual attention heads are then concatenated and linearly transformed to produce the overall output of the multi-head attention layer:
where is the projection matrix. Each attention head output resides in the residual stream space , contributing independently to total attention at that layer [8].
The residual stream refers to the sequence of token embeddings, with each layer’s output being added back into this stream. Attention heads read from the residual stream by extracting information from specific tokens and write back their outputs, modifying the embeddings for subsequent layers. This additive form allows us to analyse each head’s contribution to the model’s behaviour by examining them independently. By tracing the flow of information across layers, we can identify computational circuits composed of multiple attention heads.
2.2 Learning Sparse Representations of Attention Heads with Autoencoders
Sparse autoencoders provide a promising approach to learn useful representations of attention head outputs that are amenable to circuit analysis. Given a set of attention head outputs , where , we train an autoencoder with a single hidden layer and tied weights for the encoder and decoder . The autoencoder learns a dictionary of basis vectors such that each can be approximated as a sparse linear combination of the dictionary elements: where are the sparse activations and is the dimensionality of the bottleneck layer. The autoencoder is trained to minimise a loss function that includes a reconstruction term and a sparsity penalty, controlled by the hyperparameter :
The dimensionality of the bottleneck layer can be either larger (projecting up) or smaller (projecting down) than the input dimensionality . While projecting up allows for an overcomplete representation and can capture more nuanced features, projecting down can also be effective in learning a compressed representation that captures the most essential aspects of the attention head outputs [33, 21, 48]. We propose a subtle but significant shift in perspective by treating sparse autoencoding as a compression problem rather than a problem of learning higher-dimensional sparse bases in the context of transformers. We hypothesise that compression is likely a key mechanism in identifying features which represent circuit-related computation, and in contrast which computation is shared between positive and negative examples.
To further simplify the representation and facilitate the identification of distinct behaviours within the attention heads, we discretise the sparse activations obtained from the autoencoder using an argmax operation over the feature dimension, , where is the discrete code assigned to the -th attention head output. This yields a discrete bottleneck representation analogous to vector quantization [35]. We will next discuss how to leverage the resulting discrete representations to identify important task-specific circuits in the transformer.
3 Methodology
Our approach centers on training a sparse autoencoder with carefully designed positive and negative examples, where the model only successfully predicts the next token for positive examples. The critical insight is that the compressed representation must capture the difference between the two sets of examples to achieve a low reconstruction loss. This differentiation enables us to isolate circuit-specific behaviours and identify the attention heads involved in the circuit of interest.
3.1 Datasets
We compile datasets of 250 “positive” and 250 “negative” examples for each task. Positive examples are text sequences where the model must use the circuit of interest to correctly predict the next token. In contrast, negative examples are semantically similar to positive examples but corrupted such that there is no correct “next token.” This dataset design ensures that the learned representations are common between positive and negative examples for attention heads processing semantic similarities but different for heads involved in circuit-specific computations. Table 3.1 shows task examples, and Appendix B contains details of each dataset.
| Task | Positive Example | Negative Example | Answer |
|---|---|---|---|
| IOI | “When Elon and Sam finished their meeting, Elon gave the model to ” | “When Elon and Sam finished their meeting, Andrej gave the model to ” | “Sam” |
| Greater-than | “The AI war lasted from 2024 to 20” | “The AI war lasted from 2024 to 19” | Any two digit number |
| Docstring | ⬇ def old(self, page, names, size): """sector␣gap""" :param page: message tree :param names: detail mine :param | ⬇ def old(self, page, names, size): """sector␣gap""" :param image: message tree :param update: detail mine :param | size |
The Indirect Object Identification (IOI) task involves sentences such as “When Elon and Sam finished their meeting, Elon gave the model to” with the aim being to predict “Sam”, the indirect object [46]. Negative examples introduce a third name, eliminating any bias towards completing either of the two original names.
The Greater-than task involves sentences of the form “The <noun> lasted from XXYY to XX”, where the aim is give all non-zero probability to years > YY [14]. Negative examples consist of impossible completions, with the ending year preceding the starting century.
The Docstring task assesses the model’s ability to predict argument names in Python docstrings based on the function’s argument list [17]. Docstrings follow a format with :param followed by an argument name. The model predicts the next argument name after the :param tag. Negative examples employ random argument names.
3.2 Model and circuit identification with learned features
Our methodology consists of two stages: training the sparse autoencoder to conduct dictionary learning on the cached model activations, and using these learned representations to identify model components involved in the circuit (Figure 1).
Training the autoencoder to get learned features
We first take all positive and negative input prompts for a dataset and tokenize them. Since each prompt is curated to have the same number of tokens for all positive and negative examples across all datasets, we concatenate the prompts into a single tensor . We found that using only 10 examples (with an equal number of positive and negative examples) led to the most robust representations learned by the SAE (see Figure 24). The remaining examples are used as an evaluation set.
Node-Level and Edge-Level Circuit Identification
Node-level circuit discovery predicts model components (i.e., attention heads) as part of the circuit based on individual outputs in isolation. In contrast, edge-level circuit discovery predicts whether the information flow (i.e., the edge) is important by considering how certain components act together, specifically the frequency of co-activation of specific codes in different heads. For a full discussion of the details and semantics of node-level and edge-level discovery, see Appendix C.
After training the SAE, we perform a forward pass of all examples through the encoder to obtain the learned activations . We then apply an argmax operation across the feature (bottleneck) dimension of , which yields a matrix of discrete codes , where each code represents the most activated feature for a particular attention head.
Node-level identification: Let be a matrix of one-hot vectors indicating which codes are activated for each head in the positive examples, and let be the corresponding matrix for the negative examples.
We next compute a vector , where each element represents the number of unique codes that appear only in the positive examples, optionally normalised by the total number of codes across all examples, for the -th attention head: . Intuitively, a high value of indicates that the -th head activates a large proportion of codes that are unique to positive examples. We then apply a softmax function to and select a threshold to determine if a head is part of the ground-truth circuit (Figure 1). Whilst we vary to construct analyses such as ROC curves, in practice a single should be selected to predict a circuit.
Edge-level identification: Let us construct co-occurrence matrices and for the positive and negative examples, respectively. Each entry represents the frequency of co-occurrence between codes and in heads and :
We then compute a matrix , where each entry represents the number of co-occurrences that appear in the positive examples but not in the negative examples for the head pair : where . Once the head pairs are sorted in descending order of their corresponding values in , we introduce a hyperparameter to determine the number of top-ranked head pairs to include in the predicted circuit. We set to be half the total number of head pairs for all analyses, and show that this is a robust choice in Appendix L.2.
The next step is to initialise as a zero vector. For each of the top head pairs , the corresponding entries in are incremented: and . We then apply softmax across and choose a threshold to predict whether a particular head is part of the circuit (Figure 6).
4 Results
We tokenise positive and negative input prompts with the GPT-2 tokeniser [37], pass them through GPT-2 Small, and cache the outputs of each attention head. We concatenate all prompts into a single tensor , aggregating across the position dimension by taking the mean. We train the SAE on 10 examples from this tensor and use the rest for validation. The SAE is trained until convergence on the evaluation set, using a combination of reconstruction and sparsity losses, optimised with the Adam algorithm. For the main results, we set the number of learned features to be 200 and to be 0.02 across all datasets. For edge-level identification, we choose to be half of the total number of co-occurrences.
We compare our method to the three state-of-the-art approaches to circuit discovery in language models: automatic circuit discovery (ACDC) [6], head importance score pruning (HISP) [28], and subnetwork probing (SP) [5]. Appendix C.4 contains details of these algorithms. Additionally, we provide an unsupervised evaluation comparison of our method with edge attribution patching [42], which uses linear approximations to the patches performed in ACDC above (see 5). This makes EAP comparable to our method in terms of speed and efficiency; see Appendix C.5.
The whole process, from training the SAE to sweeping over all thresholds in a circuit, typically takes less than 15 seconds on GPT2-Small, and less than a minute on GPT2-XL. See Figure 7 for a detailed indication of wall-times for our method at various scales.

4.1 Discrete SAE features excel in node-level and edge-level circuit discovery
Our circuit-identification method outperforms ACDC, HISP, and SP in terms of ROC AUC across all datasets, regardless of ablation type used for these methods (Figure 2), with the exception of ACDC, which achieves a higher ROC AUC on edge-level circuit identification on the docstring task. We find a strong correlation between the number of unique positive codes per head and the presence of that head in the ground-truth circuit (Figure 8, Appendix B). ROC curves are constructed by sweeping over thresholds (Figure 9): for our method, we sweep over the threshold required for a softmaxed head’s number of unique positive codes to be included in the circuit, while for ACDC, we sweep over the threshold , which determines the difference in the chosen metric between an ablated and clean model required to remove a node from the circuit. Notably, we identify negative name-mover heads in the IOI circuit [46] (heads that calibrate probability by downweighting the logit of the IO name), which other algorithms struggled to do [6] (see Appendix B.1).
4.2 Performance is robust to hyperparameter choice
To demonstrate the robustness of our method to its hyperparameters, we consider two distinct groups: (1) those controlling the capacity and expressiveness of the sparse autoencoder (SAE), namely the size of the bottleneck and the sparsity penalty , and (2) the threshold for selecting a head after softmax. We trained 100 autoencoders with varying numbers of features in the hidden layer and different values of . We observed no significant drop-off in ROC AUC for IOI and Docstring tasks, and a slight drop-off for Greater-than, as we increase both hyperparameters (Figure 4). Finally, we examine the robustness of the value of on the pointwise F1 score (node-level) for both the IOI and GT datasets (Figure 4). The optimal threshold is approximately the same for both tasks, suggesting we may be able to set this threshold for any arbitrary circuit. For edge-level discovery, we also find that performance is robust to (Appendix L.2).


4.3 Identified circuits outperform or match the full model
Standalone metrics of circuit performance
We evaluate the effectiveness of our circuit relative to the full GPT-2 model, a fully corrupted counterpart, and a random complement circuit of equivalent size across two distinct tasks. The corrupted activations are created by caching activations on corrupted prompts, similar to our negative examples (see Appendix B). To measure a given circuit, we replace the activations of all attention heads not in the circuit with their corrupted activation. We use metrics specifically designed for each task, and our circuit is chosen by using the maximum F1 score across thresholds.
For the IOI task, the primary metric is logit difference, calculated as the difference in logits between the indirect object’s name and the subject’s name. Our circuit achieves a logit difference of 3.62, surpassing the full GPT-2 model’s average of 3.55, indicating that the correct name is approximately times more likely than the incorrect name. However, our circuit performs slightly worse than the ground-truth circuit identified by [46]; full results are in Table 2 (see Appendix B.1 for details).
For the Greater-than task, we focus on probability difference (PD) and cutoff sharpness (CS), as defined by [14]. These metrics evaluate the model’s effectiveness in distinguishing years greater than the start year and the sharpness of the transition between valid and invalid years (see Appendix B.2 for formal details). Despite having fewer attention heads, our circuit achieves a PD of 76.54% and a CS of 5.76%, slightly outperforming the ground-truth circuit and significantly surpassing the clean GPT-2 model. The corrupted model and random complements exhibit negative PDs and negligible CS values; see Table 2.
| Model/Circuit | No. Heads | IOI | Greater-than | ||
|---|---|---|---|---|---|
| Probability mult. | Logit Diff. | Probability Diff. | Sharpness | ||
| GPT-2 (Clean) | 144 | 34.88 | 3.55 | 76.96% | 5.57% |
| GPT-2 (Corrupt) | 144 | 0.03 | -3.55 | -40.32% | -0.06% |
| Ground-truth | 26 | 61.14 | 4.11 | 71.30% | 5.50% |
| Ours | 40 | 37.48 | 3.62 | 76.54% | 5.76% |
| Random comp. | 40 | 0.23 | -2.23 | -37.91% | -0.04% |
Faithfulness of IOI and Greater-than circuits
In the absence of a ground-truth circuit, evaluating whether our learned circuit reflects the true circuit used by the model is challenging. To this end, we employ the concept of faithfulness introduced by [25]. Faithfulness represents the proportion of the model’s performance that our identified circuit explains, relative to the baseline performance when no specific input information is provided. We measure faithfulness by selecting a threshold to determine which heads to include in the circuit and ablating all other heads by replacing them with corrupted activations. Faithfulness is computed as , where , , and are the average performance metrics over the dataset for the identified circuit, all heads ablated, and the full model, respectively. By sweeping over all , we track performance improvement as we add circuit components. For comparison, we randomly select heads to use clean ablations for at each , repeat this sampling 10 times, and average the metrics.


Our results are shown in Figure 5. We also show the same faithfulness and metric curves applied to edge attribution patching (EAP) [42]. As we add attention heads from our circuit in order of threshold, performance quickly approaches that of the full model across all metrics and, in some cases, even outperforms the full model with considerably fewer heads. Importantly, our predicted circuit performs better or equal in all metrics than EAP.
5 Related Work
5.1 Sparse and Discrete Representations for Circuit Discovery
Sparse and discrete representations of transformer activations have gained attention for their potential to enhance model interpretability. [40] and [4] are generally considered the first groups to explore sparse dictionary learning to untangle features conflated by superposition, where multiple features are distributed across fewer neurons in transformer MLPs. Their work highlighted the utility of sparse representations but does not fully address the identification of computational circuits. [20] were the first to show that SAEs also learn useful representations when applied to attention heads rather than MLPs, and scaled this to GPT-2 [19, 37].
[43] integrated a vector-quantized codebook into the transformer architecture. This technique demonstrates that incorporating discrete, interpretable features incurs only modest performance degradation and facilitates causal interventions. However, it necessitates architectural modifications, rendering it redundant for interpreting existing large-scale language models. [7] used recursive analysis to trace the activation lineage of target dictionary features across layers. While this offers insights into layer-wise contributions, it falls short of mapping these activations to specific model components or elucidating their role within the residual stream.
Most closely related to our work and conducted in parallel is that of [25], who employed a large SAE trained on diverse components, defining a framework for explicitly finding circuits. Their method relies on attribution patching (see below), which introduces practical difficulties at scale and again relies on a choice of metric. Additionally, their approach requires an SAE trained on millions of activations with significant upward projection to the dictionary, making it impractical for identifying specific circuits. Similarly, [16] used SAE-learned features to map attention head contributions to identified circuits. However, their approach still uses a form of attribution patching and suggests a tendency for identified features to be polysemantic.
5.2 Ablation and Attribution-Based Circuit Discovery Methods
Ablation-based methods are fundamental in identifying critical components within models. [6] introduced the ACDC algorithm, which automatically determines a component’s importance by looking at the model’s performance on a chosen metric with and without that component ablated. ACDC explores different ablation methods, such as replacing activations with zeros [34], using mean activations across a dataset [46], or activations from another data point [11]. Despite its effectiveness, ACDC is computationally intensive and sensitive to the choice of metric and type of intervention. The method often fails to identify certain critical model components even when minimising KL divergence between the subgraph and full model.
Subnetwork Probing (SP) and Head Importance Score for Pruning (HISP) are similar methods. SP identifies important components by learning a mask over internal components, optimising an objective that balances accuracy and sparsity [5]. HISP ranks attention heads based on the expected sensitivity of the model to changes in each head’s output, using gradient-based importance scores [28]. Both methods, however, are computationally expensive and sensitive to hyperparameters.
Recent advancements have addressed limitations of traditional circuit discovery methods. [42] introduced Edge Attribution Patching (EAP), using linear approximations to estimate the importance of altering an edge in the computational graph from normal to corrupted states [29], reducing the need for extensive ablations. However, EAP’s reliance on linear approximations can lead to overestimation of edge importance and weak correlation with true causal effects. Additionally, EAP fails when the gradient of the metric is zero, necessitating task-specific metrics for each new circuit. [15] recently proposed Edge Attribution Patching with Integrated Gradients (EAP-IG) to address these issues, evaluating gradients at multiple points along the path from corrupted to clean activations for more accurate attribution scores. Future work will benchmark our method against EAP and EAP-IG to understand the tradeoffs of each.
6 Discussion
The alignment of SAE-produced representations with language model circuits has significant implications for the scalability and interpretability of circuit discovery methods. If the level of granularity required for feature components in the circuit is coarser than the original head output dimension, it suggests that SAEs can efficiently project down rather than up, corresponding to a low level of feature-splitting and a high level of abstraction in the terminology of [4]. This finding is promising for the scalability of SAEs as circuit finders, especially when dealing with small datasets where the SAE is trained directly on positive/negative examples, eliminating the need for expensive training on millions of activations across all layers, heads, and components. The fact that we can learn sufficient representations by training the SAE on only 5-10 examples speaks to the scalability of our method. We will release the code upon acceptance.
Moreover, using SAEs for circuit discovery also eliminates the need for ablation, which all prior approaches rely on [45, 9] to assess a component’s indirect effect on performance as a proxy for importance [36]. By directly examining features, we bypass the computational complexities and difficulties in choosing a metric for each different circuit. Further, using features themselves as circuit components makes them inherently interpretable, opening up the possibility of applying auto-interpretability techniques to features in circuits [3]. The combination of automatic circuit identification and interpretable by-products represents a significant step towards the ultimate goal of mechanistic interpretability: the automatic identification and interpretation of circuits, at scale, in language models.
6.1 Limitations
Our method has several limitations that will be addressed in future work. First, although we learn discrete representations of attention head outputs, the interpretability of these learned codes may still be limited. Further work is needed to map these codes to human-interpretable concepts and behaviours. Second, we require the generation of a dataset of positive and negative examples for a circuit. This means we cannot do unsupervised circuit discovery and must carefully craft negative examples that are semantically similar to the positive ones, but are still corrupted enough to switch off the target circuit. To address this limitation, we plan to apply techniques such as quanta discovery from gradients [27] to automatically curate our positive and negative token inputs.
In addition to these method-specific limitations, any circuit discovery method faces the fundamental limitation of relying on human-annotated ground truth. The circuits found by previous researchers through manual inspection may be incomplete [46] or include edges that are correlated with model behaviour but not causally active [49]. Further, SAEs have been shown to make pathological errors [13]; until these are resolved, we may need to include these errors in the circuit discovery process itself (much like [25]).
6.2 Future Directions
One promising direction for future exploration is investigating the compositionality of the identified circuits and how they interact to give rise to complex model behaviours. Developing methods to analyse the hierarchical organisation of circuits and their joint contributions to various tasks could provide a more comprehensive understanding of the inner workings of large language models. A key aspect of this research could involve applying autointerpretability methods [3] to our learned features in discovered circuits.
Finally, extending our approach to other model components, such as feedforward layers and embeddings, could offer a more complete picture of the computational mechanisms underlying transformer-based models. By combining insights from different levels of abstraction, we can work towards developing a more unified and coherent framework for mechanistic interpretability, thus advancing our understanding of how transformer models process and generate language.
References
- [1] Collin F Baker, Charles J Fillmore and John B Lowe “The Berkeley framenet project” In COLING 1998 Volume 1: The 17th International Conference on Computational Linguistics, 1998
- [2] Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth and Edward Raff “Pythia: A suite for analyzing large language models across training and scaling” In International Conference on Machine Learning, 2023, pp. 2397–2430
- [3] Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu and William Saunders “Language models can explain neurons in language models”, 2023
- [4] Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison and Amanda Askell “Towards monosemanticity: Decomposing language models with dictionary learning” In Transformer Circuits Thread, 2023, pp. 2
- [5] Steven Cao, Victor Sanh and Alexander M Rush “Low-complexity probing via finding subnetworks” In arXiv preprint arXiv:2104.03514, 2021
- [6] Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim and Adrià Garriga-Alonso “Towards automated circuit discovery for mechanistic interpretability” In Advances in Neural Information Processing Systems 36, 2024
- [7] Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben and Lee Sharkey “Sparse autoencoders find highly interpretable features in language models” In arXiv preprint arXiv:2309.08600, 2023
- [8] Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen and Tom Conerly “A mathematical framework for transformer circuits” In Transformer Circuits Thread 1, 2021, pp. 1
- [9] Matthew Finlayson, Aaron Mueller, Sebastian Gehrmann, Stuart Shieber, Tal Linzen and Yonatan Belinkov “Causal analysis of syntactic agreement mechanisms in neural language models” In arXiv preprint arXiv:2106.06087, 2021
- [10] Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser and Connor Leahy “The Pile: An 800GB Dataset of Diverse Text for Language Modeling” In arXiv preprint arXiv:2101.00027, 2021
- [11] Atticus Geiger, Hanson Lu, Thomas Icard and Christopher Potts “Causal abstractions of neural networks” In Advances in Neural Information Processing Systems 34, 2021, pp. 9574–9586
- [12] Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato and Aryaman Arora “Localizing model behavior with path patching” In arXiv preprint arXiv:2304.05969, 2023
- [13] Wes Gurnee “SAE reconstruction errors are (empirically) pathological”, 2024
- [14] Michael Hanna, Ollie Liu and Alexandre Variengien “How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model” In Advances in Neural Information Processing Systems 36, 2024
- [15] Michael Hanna, Sandro Pezzelle and Yonatan Belinkov “Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms” In arXiv preprint arXiv:2403.17806, 2024
- [16] Zhengfu He, Xuyang Ge, Qiong Tang, Tianxiang Sun, Qinyuan Cheng and Xipeng Qiu “Dictionary Learning Improves Patch-Free Circuit Discovery in Mechanistic Interpretability: A Case Study on Othello-GPT” In arXiv preprint arXiv:2402.12201, 2024
- [17] Stefan Heimersheim and Jett Janiak “A circuit for Python docstrings in a 4-layer attention-only transformer”, 2023
- [18] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu and Dario Amodei “Scaling laws for neural language models” In arXiv preprint arXiv:2001.08361, 2020
- [19] C Kissane, R Krzyzanowski, A Conmy and N Nanda “Attention SAEs scale to GPT-2 small” In Alignment Forum, 2024
- [20] Connor Kissane, Robert Krzyzanowski, Arthur Conmy and Neel Nanda “Sparse Autoencoders Work on Attention Layer Outputs”, Alignment Forum, 2024
- [21] Honglak Lee, Alexis Battle, Rajat Raina and Andrew Ng “Efficient sparse coding algorithms” In Advances in Neural Information Processing Systems 19, 2006
- [22] Tom Lieberum, Matthew Rahtz, János Kramár, Geoffrey Irving, Rohin Shah and Vladimir Mikulik “Does circuit analysis interpretability scale? evidence from multiple choice capabilities in chinchilla” In arXiv preprint arXiv:2307.09458, 2023
- [23] David Lindner, János Kramár, Sebastian Farquhar, Matthew Rahtz, Tom McGrath and Vladimir Mikulik “Tracr: Compiled transformers as a laboratory for interpretability” In Advances in Neural Information Processing Systems 36, 2024
- [24] Laurens Maaten and Geoffrey Hinton “Visualizing data using t-SNE.” In Journal of Machine Learning Research 9.11, 2008
- [25] Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau and Aaron Mueller “Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models” In arXiv preprint arXiv:2403.19647, 2024
- [26] Callum McDougall, Arthur Conmy, Cody Rushing, Thomas McGrath and Neel Nanda “Copy suppression: Comprehensively understanding an attention head” In arXiv preprint arXiv:2310.04625, 2023
- [27] Eric Michaud, Ziming Liu, Uzay Girit and Max Tegmark “The quantization model of neural scaling” In Advances in Neural Information Processing Systems 36, 2024
- [28] Paul Michel, Omer Levy and Graham Neubig “Are sixteen heads really better than one?” In Advances in Neural Information Processing Systems 32, 2019
- [29] Neel Nanda “Attribution Patching: Activation Patching At Industrial Scale”, 2022
- [30] Neel Nanda “TransformerLens: A library for mechanistic interpretability of GPT-style language models”, https://github.com/neelnanda-io/TransformerLens, 2024
- [31] Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov and Shan Carter “Zoom in: An introduction to circuits” In Distill 5.3, 2020, pp. e00024–001
- [32] Chris Olah, Arvind Satyanarayan, Ian Johnson, Shan Carter, Ludwig Schubert, Katherine Ye and Alexander Mordvintsev “The building blocks of interpretability” In Distill 3.3, 2018, pp. e10
- [33] Bruno A Olshausen and David J Field “Sparse coding with an overcomplete basis set: A strategy employed by V1?” In Vision research 37.23 Elsevier, 1997, pp. 3311–3325
- [34] Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai and Anna Chen “In-context learning and induction heads” In arXiv preprint arXiv:2209.11895, 2022
- [35] Aaron Oord and Oriol Vinyals “Neural discrete representation learning” In Advances in Neural Information Processing Systems 30, 2017
- [36] Judea Pearl “Direct and indirect effects” In Probabilistic and causal inference: the works of Judea Pearl, 2022, pp. 373–392
- [37] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever “Language models are unsupervised multitask learners” In OpenAI blog 1.8, 2019, pp. 9
- [38] Tilman Räuker, Anson Ho, Stephen Casper and Dylan Hadfield-Menell “Toward transparent ai: A survey on interpreting the inner structures of deep neural networks” In 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), 2023, pp. 464–483 IEEE
- [39] Rico Sennrich, Barry Haddow and Alexandra Birch “Neural machine translation of rare words with subword units” In arXiv preprint arXiv:1508.07909, 2015
- [40] Lee Sharkey, Dan Braun and Beren Millidge “Taking features out of superposition with sparse autoencoders” In AI Alignment Forum, 2022
- [41] Dinghan Shen, Mingzhi Zheng, Yelong Shen, Yanru Qu and Weizhu Chen “A simple but tough-to-beat data augmentation approach for natural language understanding and generation” In arXiv preprint arXiv:2009.13818, 2020
- [42] Aaquib Syed, Can Rager and Arthur Conmy “Attribution Patching Outperforms Automated Circuit Discovery” In arXiv preprint arXiv:2310.10348, 2023
- [43] Alex Tamkin, Mohammad Taufeeque and Noah D Goodman “Codebook features: Sparse and discrete interpretability for neural networks” In arXiv preprint arXiv:2310.17230, 2023
- [44] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser and Illia Polosukhin “Attention is all you need” In Advances in Neural Information Processing Systems 30, 2017
- [45] Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer and Stuart Shieber “Investigating gender bias in language models using causal mediation analysis” In Advances in Neural Information Processing Systems 33, 2020, pp. 12388–12401
- [46] Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris and Jacob Steinhardt “Interpretability in the wild: a circuit for indirect object identification in GPT-2 small” In arXiv preprint arXiv:2211.00593, 2022
- [47] Gail Weiss, Yoav Goldberg and Eran Yahav “Thinking Like Transformers” In arXiv preprint arXiv:2106.06981, 2021
- [48] John Wright and Yi Ma “High-dimensional data analysis with low-dimensional models: Principles, computation, and applications” Cambridge University Press, 2022
- [49] Fred Zhang and Neel Nanda “Towards Best Practices of Activation Patching in Language Models: Metrics and Methods” In arXiv preprint arXiv:2309.16042, 2024
- [50] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang and Luke Zettlemoyer “OPT: Open Pre-trained Transformer Language Models” In arXiv preprint arXiv:2205.01068, 2022
Appendix A Methodology details
A.1 Sparse autoencoder architecture
Much like [4], our sparse autoencoders (SAEs) consist of a single hidden layer with tied weights for the encoder and decoder . The SAE learns a dictionary of basis vectors such that each attention head output can be approximated as a sparse linear combination of the dictionary elements:
where are the sparse activations and is the dimensionality of the bottleneck layer. Our SAEs use the following parameters:
The columns of are constrained to be unit vectors, representing the dictionary elements . Given an input attention head output , the activations of the bottleneck layer are computed as:
and the reconstructed output is obtained via:
where the tied bias is subtracted before encoding and added after decoding. The dimensionality of the bottleneck layer can be either larger (projecting up) or smaller (projecting down) than the input dimensionality . Hyperparameter sweeps found that projecting down (using fewer dimensions in the bottleneck layer than the dimension of the input) worked best for circuit identification. Additionally, we use a custom backward hook to ensure the dictionary vectors maintain unit norm by removing the gradient information parallel to these vectors before applying the gradient step.
A.2 Training the sparse autoencoder
We collate 250 and 250 positive examples for each dataset. We randomly sample 10 examples for training the SAE from this collection of examples, unless otherwise specified. We tokenise these examples and stack them into a single tensor of shape , which can easily be passed through the SAE in a single forward pass. We then cache all attention head results in all layers - these are the inputs to our sparse autoencoder.
The SAE is trained to minimise a loss function that includes a reconstruction term and a sparsity penalty, controlled by the hyperparameter :
L = ∑_i=1^n_heads ∥h_i - ∑_j=1^d_bottleneck z_i,j v_j ∥_2^2 + λ∑_i=1^n_heads ∑_j=1^d_bottleneck |z_i,j|.
where is typically about 0.01, our learning rate is 1e-3, and we train for 500 epochs using the Adam optimiser. We use a single NVIDIA Tesla V100 Tensor Core with 32GB of VRAM for all experiments.
A.3 Counting the unique positive occurrences and co-occurrences
Edge-level: co-occurrences
Edge-level circuit identification aims to predict which attention heads are part of a circuit by analysing patterns in how the heads perform similar computation in tandem, rather than in isolation.
The first step is to construct two co-occurrence matrices, and , which capture how often different token codes co-occur between each pair of heads in the positive and negative examples, respectively. For instance, counts the number of times code c1 in head h1 occurs together with code in head across the positive examples. does the same for the negative examples.
Next, we compute a matrix that identifies code co-occurrences that are unique to the positive examples for each head pair. An entry sums up the number of positive-only co-occurrences between heads and - that is, cases where a code pair has a positive count in but a zero count in for that head pair.
Intuitively, captures which head pairs tend to jointly attend to particular token patterns more often in positive examples compared to negative examples. Head pairs with high values in are stronger candidates for being part of the relevant circuit.
The head pairs are then sorted in descending order by their values. To build the predicted circuit, we take the top head pairs from this sorted list, where is a hyperparameter. For each of these top pairs , we increment the entries for and in a vector . This vector keeps track of how many times each head appears in the top head pairs. The reason for using only the top pairs is that including all pairs would make each head co-occur with every other head once, leading to a uniform that would not distinguish between heads.

Applying softmax to normalises it into a probability distribution, allowing us to set a threshold to make the final predictions, with being the same scale for any arbitrary circuit (i.e. between 0 and 1). Heads that have a value exceeding are predicted to be part of the circuit. This whole process is outlined in Figure 6, where we step through an example of the process on a 1-layer transformer with 6 attention heads and using 6 text examples (3 positive, and 3 negative).
A.4 Indication of wall-time as the underlying language models scale
A key benefit of our method over existing approaches is its efficiency. Whilst ACDC takes upwards of several hours to run on a V100 or A100 GPU for IOI on GPT2-Small [6], our method completes in under 3 seconds for GPT2-Small, and under 45 seconds for GPT2-XL. In fact, as we previously showed that one may be able to use only 10 examples when training the SAE, if this trend holds across model scales we can reduce time to less than 10 seconds for GPT2-XL.

We show the specific model specifications in Table 3. If the number of text examples for both the SAE and counting positive codes remains constant, the main contribution to increased time for our method is and , as each example is in . Since the counting of unique positive codes involves elementary set operations over only a few hundred arrays of integer codes, it is only training the SAE that takes perceptibly longer as we increase the size of the underlying language model.
| Model | act_fn | |||||||
|---|---|---|---|---|---|---|---|---|
| GPT-2 Small | 85M | 12 | 768 | 12 | gelu | 1024 | 50257 | 3072 |
| GPT-2 Medium | 302M | 24 | 1024 | 16 | gelu | 1024 | 50257 | 4096 |
| GPT-2 Large | 708M | 36 | 1280 | 20 | gelu | 1024 | 50257 | 5120 |
| GPT-2 XL | 1.5B | 48 | 1600 | 25 | gelu | 1024 | 50257 | 6400 |
Appendix B Circuit visualisation and analysis
Clearly, the number of unique positive codes per head is highly positively correlated with the presence of that head in the ground-truth circuit, as seen in Figure 8. In this section, we provide further details on the predicted circuits and provide some further analysis.

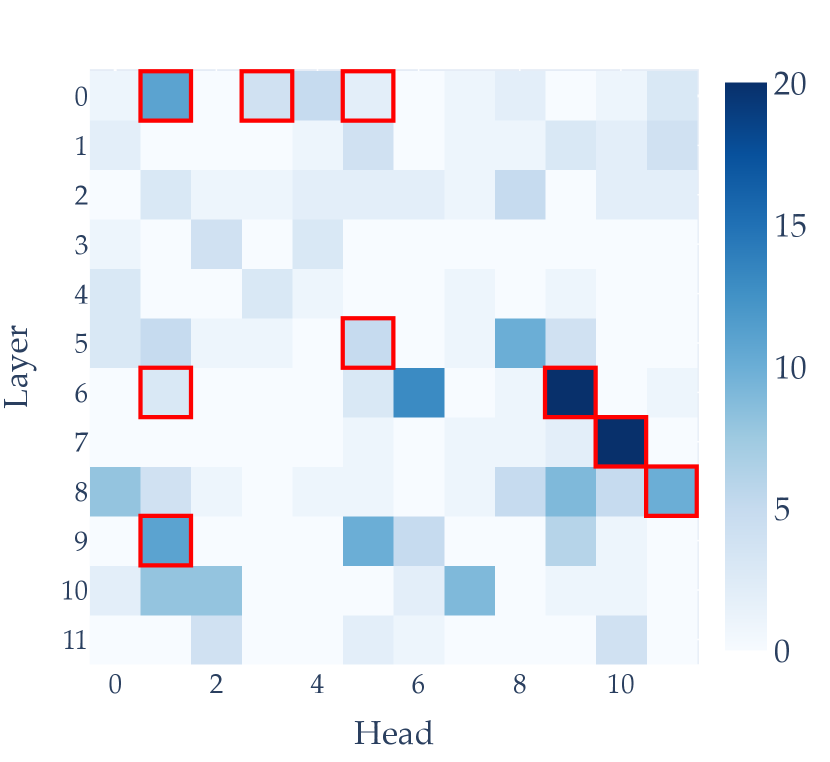


B.1 Indirect Object Identification
Predicted circuit
We compare the performance of our circuit to the full model, a fully corrupted model, and a random complement circuit of the same size. The metric is logit difference: the difference in logit between the indirect object’s name and the subject’s name. The full model’s average logit difference is 3.55, meaning the correct name is times more likely than the incorrect name.
To create a corrupted cache of activations, we run the model on the same prompts with the subject’s name swapped. Replacing all attention heads’ activations with these corrupted activations gives an average logit difference of -3.55. When testing our circuit, we replace activations for heads not in the circuit with their corrupted activations.
Our circuit has a higher logit difference (3.62) than the full GPT-2 model. The ground-truth circuit from [46] has a logit difference of 4.11. We compare this to the average logit difference (-1.97) of 100 randomly sampled complement circuits with the same number of heads as our circuit. These results are shown in Table 4.
We also provide the normalised logit difference: the logit difference minus the corrupted logit difference, divided by the signed difference between clean and corrupted logit differences. A value of 0 indicates no change from corrupted, 1 matches clean performance, less than 0 means the circuit performs worse than corrupted, and greater than 1 means the circuit improves on clean performance.
| Model/circuit | Attn. heads | Logit Diff. | Normalised Logit Diff. | Probability Diff. |
|---|---|---|---|---|
| GPT-2 (Clean) | 144 | 3.55 | 1.0 | 34.88 |
| GPT-2 (Corrupted) | 144 | -3.55 | 0.0 | 0.03 |
| Ground-truth | 26 | 4.11 | 1.08 | 61.14 |
| Ours | 40 | 3.62 | 1.01 | 37.48 |
| Random complement | 40 | -2.23 | 0.19 | 0.23 |


Negative name mover heads and previous token heads
What seems to be a key advantage of our method over ACDC is our ability to detect both negative name mover heads and one of the previous token heads. [46] found that there exist attention heads in GPT-2 that actually write to the residual stream in the opposite direction of the heads that output the remaining name in the sentence, called negative name-mover heads. These likely “hedge” a model’s predictions in order to avoid high cross-entropy loss when the sentence has a different structure, like a new person being introduced or a pronoun being used instead of the repeated name [46]. Previous token heads copy information from the second name to the word after and have been found to have a minor role in the circuit.
[6] found that they were unable to identify either of these types of heads as part of the circuit unless using a very low threshold , which led to many extraneous heads being included in their prediction. This is despite the fact that negative name mover heads in particular are highly important in calibrating the confidence of name prediction in the circuit [26]. The fact that we find both negative name mover heads (L10H7 and L11H10) and one of the previous token heads (L2H2) is highly promising evidence that our the distribution of our SAE activations provide a robust representation of the on-off nature of any given head in a circuit. Being able to identify negative components (that actively decrease confidence in predictions) in circuits is really important, because many circuits involve this general behaviour, known as copy suppression [26].
B.2 Greater-than
Setup details
The Greater-than task focuses on a simple mathematical operation in the form it appears in text i.e. a sentence of the form “The <noun> lasted from the year XXYY to the year XX”, where the aim is to give all non-zero probabilities to completions YY. We use the same setup as [14]. We use nouns which imply some form of duration, for example war, found used FrameNet [1]. The century XX is sampled from and the start year YY from . Because of GPT-2’s byte-pair encoding [39], more frequent years are tokenised as single tokens (e.g. “[1800]” instead of “[18][00]”) and so these are removed from the pool. Years ending in “01” and “99” are removed so as to ensure that there is at least one correct and incorrect valid tokenised answer.111Code to generate similar datasets can be found at [14]’s Github repository.
Predicted circuit
Figure 11 shows our predicted circuit and the canonical ground-truth circuit from [14]. We have a high similarity, although we predict several heads from layers 10 and 11 that [14] attribute to MLP layers instead. It is possible that by only looking at attention head outputs and not MLP layers that these later layer heads appear to be doing the role that in actual fact is largely done by MLP layers. An interesting follow-up is examining why these later layer heads appear in our predicted circuit if they’re not actually doing any useful computation for the task, or whether they might actually be doing some sort of relevant manipulation of the residual stream.


We again examine the performance of the predicted circuit in the context of the clean model and the ground-truth circuit from [14]. We produce a dataset of 100 examples according to the same process outlined above. The corrupted examples are the same prompts but the YY is replaced with “01”. We define two metrics measuring the performance of the model, introduced by [14].
Let be the start year of the sentence, and be the probability assigned by the model to a two-digit output year . The first metric, probability difference (), measures the extent to which the model assigns higher probability to years greater than the start year. It is calculated as:
| (1) |
Probability difference ranges from -1 to 1, with higher values indicating better performance in reflecting the greater-than operation. A positive value of indicates that the model assigns higher probabilities to years greater than the start year, while a negative value suggests the opposite.
The second metric, cutoff sharpness (), quantifies the model’s behaviour of producing a sharp cutoff between valid and invalid years. It is calculated as:
| (2) |
where is the probability assigned to the year immediately following the start year, and is the probability assigned to the year immediately preceding the start year. Cutoff sharpness also ranges from -1 to 1, with larger values indicating a sharper cutoff. Although not directly related to the greater-than operation, this metric ensures that the model’s output depends on the start year and does not produce constant but valid output. A high value of suggests that the model exhibits a sharp transition in probabilities between the years adjacent to the start year.
| Model/circuit | Attention heads | Probability Difference | Cutoff Sharpness |
|---|---|---|---|
| GPT-2 (Clean) | 144 | 76.96% ( 26.82%) | 5.57% ( 8.08%) |
| GPT-2 (Corrupted) | 144 | -40.32% ( 55.28%) | -0.06% ( 0.08%) |
| Ground-truth | 9 | 71.30% ( 28.71%) | 5.50% ( 6.89%) |
| Ours | 29 | 76.54% ( 27.51%) | 5.76% ( 7.42%) |
| Random complement | 29 | -37.91% ( 55.76%) | -0.04% ( 0.78%) |
Table 5 presents the performance of our predicted circuit in comparison to the clean GPT-2 model, the corrupted GPT-2 model, the ground-truth circuit from [Hanna et al., 2024], and random complement circuits. The performance is measured using probability difference (PD) and cutoff sharpness (CS). Our predicted circuit, consisting of 29 attention heads, achieves a PD of 76.54% and a CS of 5.76%, slightly outperforming the ground-truth circuit (PD: 71.30%, CS: 5.50%), albeit having more heads. Notably, our circuit also surpasses the performance of the clean GPT-2 model (144 heads) in CS, and is essentially the same in PD. In contrast, the corrupted GPT-2 model and the average of 100 random complement circuits of the same size as our predicted circuit show negative PD and near-zero CS, indicating poor performance in capturing the greater-than operation and producing a sharp cutoff between valid and invalid years. These results demonstrate that our predicted circuit effectively captures the relevant information for the task while being significantly smaller than the full GPT-2 model.
Exploratory analysis of relationship between codes and year
We also did some exploratory analysis of whether the learned activations from the encoder, and their corresponding codes, were associated at all with the starting year of the completion. For instance, were there codes that only activated for high year numbers, such as <CENTURY>90 and above? If we only use 100 codes, do these codes roughly get distributed to particular years, so there is a soft bijection between codes and two-digit years?
To answer some of these questions, we created a new dataset consisting of prompts of the form “The war lasted from the year <century><year> to <century>”, and trained a sparse autoencoder on the attention head outputs of GPT2-Small on these prompts, with 100 learned features.


We initially examined the t-SNE dimensionality reduction [24] of embeddings for all examples across all heads, shown in Figure 12. We colour the points by the year in the example (e.g. the 14 in “The war lasted from 1914 to 19”). Interestingly, we notice two distinct clusters of activations. The first, on the upper right in Figure 12(a), seems to have a fairly well-defined transition between examples with low year numbers to examples with high year numbers. However, the other cluster (the lower left in both plots) appears to have no discernible order. This suggests that the SAE may be learning degenerate latent representations for examples that differ only in the century used.

We then show the same plot, except colouring each example by the century of the example (e.g. the 19 in “The war lasted from 1914 to 19”). Incredibly, there is almost perfect linear separation between the classes (where the classes pertain to centuries). If we instead produce the same plot with the background being the century of the 10 nearest neighbouring points, some structure with regards to year of the example begins to emerge (Figure 13). There seems to be a stronger gradient within groups, with the year number increasing linearly in a certain direction. However, there is still a significant amount of noise, and future research should examine why the SAE learns representations that focus more on the century than the year, when the year is evidently more important for successful completion of the Greater-than task.
We also examined the top 2 principal components of the encoder activations on individual attention heads across examples to determine if they had some relationship to the year number in the example. This is shown in Figure 14. These four individual heads are selected to show a variety of behaviours. For some, like 14(a) and 14(b), the principal components seem to directly correspond to “low” years and “high” years, with many examples in the approximately the same decade being mapped to almost exactly the same PCA-reduced point. Other heads, such as 14(c) and 14(d), have significantly more variability, but seem to follow some gradient of transitioning from lower years to higher years as we move across the space.




B.3 Docstring


Our predicted Docstring circuit is shown in Figure 15. Interestingly, our circuit identification method does not predict L0H2 and L0H4 as being part of the circuit, whereas [17] does. However, after running the ACDC algorithm (as well as HISP and HP, and manual interpretation) on the docstring circuit, [6] concluded that these two heads are not relevant under the docstring distribution. The agreement between ACDC and our method with regard to these heads that are manually confirmed to not be part of the circuit is promising for the reliability of our approach.
Appendix C Detailed comparison to ACDC and other circuit identification methods
It is important to clarify the distinctions and similarities between [6]’s ACDC method and our approach. Our work builds upon ACDC, adapting its code, results, and experiments from their MIT-licensed GitHub repository.222https://github.com/ArthurConmy/Automatic-Circuit-Discovery The primary workflow for ACDC begins by specifying the computational graph of the full model for the task or circuit under examination, alongside a threshold for the acceptable difference in a metric between the predicted circuit and the full model. This computational graph, represented using a correspondence class, includes nodes and edges that connect these nodes, typically representing components like attention heads, query/key/value projections, and MLP layers, with edges indicating the connections between these components.
ACDC then iterates backwards over the topologically sorted nodes in the computational graph, starting from the output and moving towards the input. During this process, it ablates activations of connections between a node and its children by replacing the activations with corrupted or zero values, measuring the impact on the output metric. The ablation is performed using a receiver hook function, which modifies the input activations to a node based on the presence or absence of edges connecting it to its parents. If the change in the metric is less than the specified threshold, the connection is pruned, updating the graph structure and altering the parent-child relationships between nodes. This is shown in Figure 16.
This pruning step is recursively applied to the remaining nodes. If a node becomes disconnected from the output node, it is removed from the graph. The resulting subgraph contains the critical components and connections necessary for the given task. An important hyperparameter in ACDC is the order in which the algorithm iterates over the parent nodes. This order, whether reverse, random, or based on their indices, significantly affects the performance in circuit identification.



C.1 Nodes vs. edges
ACDC operates primarily on edges rather than nodes, even though the procedure is agnostic to whether we corrupt nodes or edges in the computational graph. The reason for this is that operating on edges allows ACDC to capture the compositional nature of reasoning in transformer models, particularly in how attention heads in subsequent layers build upon the computations of previous layers.
By replacing the activation of the connection between two nodes (e.g., Layer 0 and Layer 1) while maintaining the original activations between other nodes (e.g., Layer 1 and Layer 2), ACDC can distinguish the effect of model components in different layers independently. This is crucial for understanding the role of each component in the compositionality of computation between attention heads in subsequent layers [8].
Although ACDC can split the computational graph into query, key, and value calculations for each attention head, the authors focus primarily on attention heads and MLP layers to complete their circuit identification within a reasonable amount of time. This is similar to the approach taken in our method, where we also focus on attention heads, as the canonical circuits for each task are largely defined in terms of this level of granularity.
C.2 Final output
The final output of an ACDC circuit prediction is a subgraph of the original computational graph, which contains the critical nodes and edges for the given task. The nodes in this subgraph represent the components specified in the original computational graph, such as attention heads, query/key/value projections, and MLP layers. The edges represent the connections between these components that are essential for the model’s performance on the task.
For most of the circuits examined in the ACDC paper, including the IOI task, the authors focus on attention heads, as these have canonical ground-truths from previous works. This allows for a direct comparison between the ACDC-discovered circuits and the manually identified circuits, providing a way to validate the effectiveness of the ACDC algorithm in recovering known circuits. This means we can also provide a direct comparison to ACDC on both a node-level and edge-level. Regardless of the approach in finding the circuit components, the final output of both methods is a predicted circuit of attention heads we can compare to the ground-truth for the relevant task.
C.3 On why we can compare ACDC to our method
So why do we believe it makes sense to compare our node-level and edge-level circuit discovery with ACDC’s node- and edge-level discovery, when the methods of determining the importance of a node or an edge are fundamentally difference in either case? For instance, we determine the importance of an “edge” between two heads by examining the number of unique co-occurrence code-pairs for that pair of heads. ACDC instead ablates the activation of the connection between these two heads. However, we note that the result of both of these methods (that is, a binary classification of a head as being in the circuit or not being in the circuit) is the same. We simply group the edge-level and node-level methods together for comparison because edge-level focuses on the information moving between nodes (via the residual stream), whereas node-level looks at the output of an individual head (to the residual stream) in isolation.
C.4 HISP and SP
Subnetwork probing [5] and head importance score for pruning [28] are both predecessors of ACDC used to examine which transformer components are important for certain inputs, and thus which components might be part of the circuit for a specific type of task. Whilst they are not the focal comparison of our results, we include the methodology used here largely as a supplement to Figure 2. We follow the exact same setup as [6], and direct the reader to the ACDC repository for implementation details 333https://github.com/ArthurConmy/Automatic-Circuit-Discovery.
Subnetwork probing (SP)
To compare our circuit discovery approach with Subnetwork Probing (SP) [5], we adopt a similar setup to ACDC [6]. SP learns a mask over the internal model components, such as attention heads and MLP layers, using an objective function that balances accuracy and sparsity. This function includes a regularisation parameter , which we do not refer to in the main text to avoid confusion with the sparsity penalty used in training our sparse autoencoder (SAE). Unlike the original SP method, which trains a linear probe after learning a mask for every component, we omit this step to maintain alignment with ACDC’s methodology.
We made three key modifications to the original SP method. First, we adjusted the objective function to match ACDC’s, using either KL divergence or a task-specific metric instead of the negative log probability loss originally used by [5]. Second, we generalised the masking technique to replace activations with both zero and corrupted activations. This change reflects the more common use of corrupted activations in mechanistic interpretability and is achieved by linearly interpolating between a clean activation (when the mask weight is 1) and a corrupted activation (when the mask weight is 0), editing activations rather than model weights. Third, we employed a constant learning rate instead of the learning rate scheduling used in the original SP method.
To determine the number of edges in subgraphs identified by SP, we count the edges between pairs of unmasked nodes. For further implementation details, please refer to the ACDC repository [6].
Head importance score for pruning (HISP)
To compare our approach with Head Importance Score for Pruning (HISP) [28], we adopt the same setup as ACDC [6]. HISP ranks attention heads based on an importance score and retains only the top heads to predict the circuit, with being a hyperparameter used to generate the ROC curve. We made two modifications to the original HISP setup. First, instead of using the derivative of a loss function, we use the derivative of a metric . Second, we account for corrupted activations as well as zero activations by generalizing the interpolation factor between the clean head output (when ) and the corrupted head output (when ).
The importance scores for components are computed as follows: I_C := 1n ∑_i=1^n |(C(x_i) - C(x_i^′))^T ∂F(xi)∂C(xi)|, where is the output of an internal component of the transformer. For zero activations, the equation is adjusted to exclude the term. All scores are normalized across different layers as described by [28]. The number of edges in subgraphs identified by HISP is determined by counting the edges between pairs of unmasked nodes, similar to the approach used in Subnetwork Probing. For more details on the implementation, please refer to the ACDC repository [6].
C.5 Edge attribution patching (EAP)
Edge Attribution Patching (EAP) is designed to efficiently identify relevant model components for solving specific tasks by estimating the importance of each edge in the computational graph using a linear approximation [42]. Implemented in PyTorch, EAP computes attribution scores for all edges using only two forward passes and one backward pass. This method leverages a Taylor series expansion to approximate the change in a task-specific metric, such as logit difference or probability difference, after corrupting an edge. For the IOI and Greater-than tasks, EAP used edge-based attribution patching with absolute value attribution. Both tasks employed the negative absolute metric for computing attributions. EAP pruned nodes using a single iteration, with the pruning mode set to “edge”. This approach avoids issues with zero gradients in KL divergence by using task-specific metrics, making it a robust and scalable solution for mechanistic interpretability. We adapted the code from [42]’s original paper, available here.
We noted above that EAP is limited in the metrics we can apply for discovery because the gradient of the metric cannot be zero; we elaborate here. For instance, this means we cannot use the KL divergence metric to find importance components. The KL divergence is equal to 0 when comparing a clean model to a clean model (i.e. without ablations) and is non-negative, so the zero point is a global minimum and all gradients are zero here.
C.6 Head activation norm difference
The effectiveness of using SAE-learned features for identifying circuit components raises an important question: why is it necessary to project raw head activations into the SAE latent space to distinguish between positive and negative circuit computations? To investigate whether this projection aids in reducing noise or interference, we analysed the mean per-head activation averaged across positive and negative examples and computed the difference. We then calculated the norm of this difference for each head, applied a softmax function over all heads, and evaluated the ROC AUC against the ground-truth circuit. This analysis was conducted using the same number of examples (10) that the SAE was trained on.

As shown in Figure 17, head activations do contain some signal regarding the heads involved in circuit-specific computation. However, they are not as effective as our method in distinguishing these computations. This may be due to the variation in particular dimensions within the residual stream across all heads (corresponding to the vertical stripes in Figure 18), which likely requires non-linear computation to disentangle positive and negative examples, a task the SAE likely performs effectively.

We observed that performance for the IOI and Greater-than tasks improved as the number of activations over which we computed the mean difference increased. Specifically, both tasks reached a ROC AUC of approximately 0.80-0.85 around 500 examples. However, for the docstring task, performance actually worsened with an increased number of examples. This suggests that while the mean difference method can serve as an initial sanity check, it lacks robustness for reliable circuit identification.
Appendix D How does the formulation of positive and negative examples affect performance?
D.1 Alternative negative examples for the Greater-than task
The choice of negative examples is a crucial factor in the performance of the circuit identification method. In this study, we selected negative examples that were semantically similar to the positive examples but corrupted enough to prevent the model from using the current circuit to generate a correct answer.
To investigate the sensitivity of our method to the choice of negative examples, we conducted experiments with five different types of negative examples for the greater-than task:
-
1.
Range: The completion year starts with the preceding century. For example, “The competition lasted from the year 1523 to the year 14”. These are the negative examples used throughout this paper.
-
2.
Year: The original negative examples from the previous paper, where the year starts with “01”. For example, “The competition lasted from the year 1501 to the year 15”.
-
3.
Random: The numeric completion of the century is replaced with random uppercase letters. For example, “The competition lasted from the year 19AB to the year 19”.
-
4.
Unrelated: Examples unrelated to the task, similar to the easy negatives, in the form of “I’ve got a lovely bunch of <NOUN>”.
-
5.
Copy: Negative examples with the same form as the positive examples but with different randomized years and centuries.
The results of these experiments are presented in Figure 19. The findings clearly demonstrate that our heuristic of selecting semantically similar examples that switch off the circuit is an effective approach to maximising performance. This is evident from the drop in performance when using Year types compared to Range. When using Year types, the circuit likely remains active when detecting the need to find a two-digit completion greater than “01". In contrast, the Range type makes the negative examples nonsensical by setting the completion century in the past, which likely switches off the circuit.

Interestingly, Unrelated negative examples lead to a considerable drop in performance, which we explore further below.
D.2 Including “easy negatives” in the training data
Various studies suggest that hard negative samples, which have different labels from the anchor samples (in this case, our positive examples) but with very similar embedding features, allow contrastive-loss trained autoencoders to learn better representations to distinguish between the two [41]. However, in our case, our negative samples are specifically designed to all be hard negatives.
Currently, there is no reason to believe that the most important codes for differentiating between positive and negative examples should capture all the codes in the IOI task. This is because the IOI negative examples are actually almost positive examples. For instance, we would expect previous token heads to be exactly the same in both the negative and positive examples (since both involve two names at least). So, we actually need to give the model data such that some of the codes are forced to be assigned to non-IOI related behaviour. This will hopefully make the remaining codes more relevant for finding the right attention heads in the right layer. This suggests that we should include some non-IOI related data, such as samples from the Pile dataset, in the training data.
We experimented with whether inclusion of “easy negatives”, defined as random pieces of text sampled from the Pile [10], would allow the autoencoder to produce representations that were better for us to pick out the important model components for implementing the task. For example, if the positive samples and hard negative samples shared heads for the IOI task, such as detecting names, we would not identify those heads as important because importance is defined by whether the discrete representation helps distinguish a positive sample from a negative one. Thus, including easy negatives could make those particular heads important.

However, as seen in Figure 20, inclusion of easy negatives actually leads to a decrease in performance on the IOI task. It’s possible that the model is forced to assign codes to expressing concepts and behaviours unrelated to the IOI task, and thus cannot as meaningfully distinguish between the semantically-similar positive and negative examples.
Appendix E Normalisation and design choices
E.1 Softmax across head or layer
A key design choice is whether to take the softmax across the vector of individual head counts or whether to take it across individual layers; that is, first reshape the vector into a matrix of shape . A valid concern is that taking the softmax across layers will make unimportant heads seem important. For instance, if there is a layer with a head that has 1 unique positive code, and all other heads in that layer have 0, this head will have a value of 1.0 and thus be selected no matter what the threshold is. However, it possible that the law of large numbers will cause the number of unique positive codes to be approximately uniform in unimportant layers, so this may not be an issue.
We show the effects of taking the softmax across layer and across individual heads on the node-level ROC AUC in Figure 22. Softmax across heads performs best in all three tasks, with significant improvement compared with softmax across layers in the IOI and Docstring tasks.


E.2 Normalising unique positive codes by overall number of unique codes
We also hypothesised that we may be able to improve performance by normalising by the overall number of unique codes per head. The reasoning is as follows: if a head has a large number of unique positive codes, our current method is likely to include it in the circuit. However, if the head also has a large number of unique negative codes, then clearly it has a large range of outputs and the autoencoder deemed it necessary to assign many codes to this head, regardless of whether the example is positive or negative. In essence, the head is important regardless of if we’re in the IOI task or not; including the head in our circuit prediction may be erroneous. Normalising by the overall number of unique codes should correct this.
As shown in Figure 22, normalising seems to have a relatively minor effect. It decreases node-level ROC AUC in the Docstring and IOI tasks, and slightly increases performance in the Greater-than task.
E.3 Number of examples used
Finally, we show in Figure 24 how node-level performance varies with the number of positive and negative examples used to calculate the head importance score (i.e. the softmaxed number of unique positive codes per head). We find that we can use as little as 10 examples for the IOI and Docstring tasks, but require the full 250 positive and 250 negative for the Greater-than task. We suspect this is to do with the numerical nature of the Greater-than task and the fact that there are 100 two digit numbers specifying appropriate completions, and so a larger sample size may be required to represent what each of these different attention head outputs look like.


Additionally, we note that the number of examples the SAE requires during training to learn robust representations is actually only about 5-10. Figure 24 shows that node-level performance actually decreases for IOI and Greater-than (both GPT-2 tasks) as we increase the number of training examples for the sparse autoencoder. Whilst the Docstring task does not see a decrease as we increase the training example set, it still achieves near-maximal performance around 10 examples. For Docstring and IOI, we can also achieve near-maximal performance with just 10 examples for both steps (training the SAE and counting unique positive codes). However, Greater-than requires a significant number of examples for the latter step.
Appendix F Further comparisons to previous methods
In an extension to Figure 2, we record the actual values for each method with both random and zero ablations in Table 6. This allows us to compare previous methods with ours, with both the optimal hyperparameters for each dataset, and set hyperparameters across datasets.
| Task | ACDC | HISP | SP | Ours | Ours (set params) |
|---|---|---|---|---|---|
| Node-level | |||||
| Docstring | 0.938 / 0.825 | 0.889 / 0.889 | 0.941 / 0.398 | 0.945 | 0.915 |
| Greater-than | 0.766 / 0.783 | 0.631 / 0.631 | 0.811 / 0.522 | 0.821 | 0.832 |
| IOI | 0.777 / 0.424 | 0.728 / 0.728 | 0.797 / 0.479 | 0.854 | 0.853 |
| Edge-level | |||||
| Docstring | 0.972 / 0.929 | 0.821 / 0.821 | 0.942 / 0.482 | 0.974 | 0.914 |
| Greater-than | 0.461 / 0.491 | 0.706 / 0.706 | 0.812 / 0.639 | 0.963 | 0.856 |
| IOI | 0.589 / 0.447 | 0.836 / 0.836 | 0.707 / 0.393 | 0.863 | 0.840 |
Appendix G tracr-tasks
tracr is a compiler that converts human-readable programs into transformer weights [47, 23]. This allows us to automatically determine the attention heads responsible for implementing a certain behaviour, as we have access to the underlying assignation of components to layers.
G.1 Compiled models
We compile tracr transformers for four different tasks: reversing a list (tracr-reverse), counting the fraction of previous tokens in a position equal to a certain token (tracr-fracprev), sorting a list (tracr-sort), and sorting a list by the frequency of the tokens in the list (tracr-sortfreq). All code required to compile these models is available in the Tracr repository. Note that all of these transformers output a vector of tokens rather than a single token, and each of the compiled transformers has a maximum sequence length, which we set to 6 for all examples.
We then simulate our circuit-discovery methodology as follows. For each vocabulary of inputs to each task, we generate 250 permutations with replacement for our positive examples. Because tracr transformers have compiled weights that only implement a single task, there is no way to “turn off” a circuit with negative examples. Due to this, we corrupt the residual stream directly to create our negative examples. To do this for each example, we add Gaussian noise to attention head vectors or if the respective actual weight matrices , or in the transformer contain all zeros; simultaneously, we zero out the attention head vectors and if the respective weight matrices or contain a non-zero element. We define an attention head component (, or ) as being in the ground-truth circuit if it makes a non-trivial write the to residual stream (i.e. the output to the residual stream is non-zero). Finally, we train our SAE on 10 randomly sampled positive and negative examples and use the full 500 examples to calculate the number of unique positive codes.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b2c911e8-5587-4799-85e9-44cc0d3f76b8/x33.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b2c911e8-5587-4799-85e9-44cc0d3f76b8/x34.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b2c911e8-5587-4799-85e9-44cc0d3f76b8/x35.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b2c911e8-5587-4799-85e9-44cc0d3f76b8/x36.png)
Our method achieves a perfect ROC AUC of 1.0 on all tracr-tasks (Figure 3.1). Whilst we should expect good performance on what amounts to a relatively simple task (since the residual streams are corrupted directly), this does provide further evidence of the mechanism that makes our approach successful. Clearly, circuit identification really does boil down to heads that are active on positive examples but inactive on negative. It appears that the SAE then assigns a high number of codes to active attention heads. Active heads are then obviously more likely to be involved in the circuit. We are currently investigating how to collect further evidence in support of this hypothesis.
Appendix H Induction circuit
Another “circuit” commonly studied in the literature is induction, which is implemented by heads that complete token sequences in the form [A][B] ... [A] -> [B] [34]. We include induction here as a study in how our method may be evaluated without a ground-truth circuit, and how these evaluations may demonstrate model agnosticity.
We generate our positive and negative examples (25 of each) for the task by randomly sampling examples of 10 integers, representing tokens, and then repeating this pattern of 10 integers for each example for the positive examples, and generating 10 more non-repeating tokens for the negative examples. The process for identifying the circuit is then exactly the same as above. We use 10 tokenised examples for training the SAE.
Our initial induction experiment was performed on a pre-trained 2-layer, 8-head attention only transformer from [12]. We compared how the KL divergence between the clean model and our circuit (with all other components ablated to zero) changed as we altered our threshold . For edge-level circuit identification, we compared the same KL on the same model with ACDC, with both zero and random ablation. Figure 26(a) shows that the KL divergence drops at approximately the same rate for our method as that of ACDC. This is promising and perhaps surprising, as our method is not set up to minimise KL divergence between clean model and circuit, whereas ACDC is. For node-level, we reach near-zero KL divergence around 12-15 nodes (i.e. 12-15 attention heads), showing our method is good at not identifying unimportant heads in the circuit (Figure 26(b)).


We also experimented with how our method performed in terms of faithfulness across different language models, this time using the mean loss on the repeated tokens as our metric. We repeated the above process for node and edge-level circuit identification on GPT2-Small, Pythia-160M [2], and Opt-125M [50]. It appears that, at least for the induction task, recovery of performance occurs at the same rate across different models. Note that we can directly compare the number of nodes and edges across these models here as they each have 12 layers with 12 attention heads in each layer.


Appendix I Visualising the distribution of codes and their relation to the circuit
I.1 Correlation between occurrences/co-occurrences and presence in the circuit
We provide two visualisations of the correlation between the number of unique positive codes and the presence of a head in the circuit. First, we show how the number of unique positive codes per head alongside the ground-truth circuit, arranged by layer and head, in Figure 8. Clearly, heads with a high number of positive layers are much more likely to be in the circuit.
We show the high correlation between number of unique positive codes per head and its presence in the circuit in Figure 8. This corresponds to the node-level circuit identification, where (after softmax) we predict a head’s presence in the circuit if it exceeds the pre-defined threshold .
Similarly, we show matrices of the co-occurrence of codes in Figure 3.1, alongside the ground-truth circuit. However, because we have an array of size , this time we colour the ground-truth circuit as follows: a (head, head) array entry is dark blue if both heads are in the circuit, light blue if only one is, and white if neither are. Again, we see a very strong similarity between the number of co-occurrences of codes in (head, head) pairs and the presence of one or both heads in the circuit.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b2c911e8-5587-4799-85e9-44cc0d3f76b8/x41.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b2c911e8-5587-4799-85e9-44cc0d3f76b8/x42.png)
I.2 Distribution and sparsity of codes
We also visualise the difference between the number of unique positive codes and unique negative codes per head (Figure 29). Again, we see a strong pattern where heads with a high difference (many more unique positive codes than unique negative) are very likely to be in the ground-truth circuit.

We also examine the sparsity of our learned representations, and whether there is any different between positive and negative representations. We plot the histogram of average non-zero activations across all heads for the positive and negative examples in Figure 30. Whilst there doesn’t appear to be any significant difference, the average non-zero activations were slightly higher per positive example (0.56) compared to negative examples (0.42).

Finally, we investigate the relationship between the most common positive codes and their activations in the ground truth heads. Figure 31 presents activation histograms for the most frequently occurring positive code in each of the three identified heads (141, 127, and 93) for the IOI task. By comparing the activation distributions of these codes for positive and negative examples, we observe a consistent pattern of separated activations between positive and negative examples. The relatively clear separation between the positive and negative activation distributions further highlights the importance of these codes in the functioning of the identified circuit. This analysis provides valuable insights into the fine-grained workings of the learned representations and their role in capturing task-specific patterns.

Appendix J What didn’t work: contrastive loss experiments
In addition to the completely unsupervised setting discussed above, we hypothesised that injecting some information about the task into the autoencoder might assist it in constructing representations of residual streams that better allowed us to distinguish between positive and negative examples. As such, we trained the sparse autoencoder with an additional loss component that penalised the cosine similarity between positive and negative vectors at the same sequence position, whilst penalising dissimilarity between vectors with the same label at the same sequence position.
In the abstract setting, suppose we wish to compute the average cosine similarity between vectors at the same sequence position in both tensors and , while maintaining the sequence length as the same for both. Given and , we calculate the average cosine similarity for vectors at each sequence position across all vectors at the same position in the other tensor. Specifically, for every vector at sequence position in , compute its average cosine similarity with all vectors at position in , and vice versa.
The process is as follows:
-
1.
Cosine Similarity Calculation for Position : For each position in the sequence , and for each dimension , calculate the cosine similarity between vector and every vector , where is fixed for this operation indicating the sequence position. Specifically, for vectors at sequence position , the similarity between and all is calculated as:
-
2.
Average Across All Sequence Positions: After computing for every vector at sequence position in against all vectors at position in , average these similarities across all sequence positions :
-
3.
Final loss: Finally, we take our tensor of positive examples , where is the number of learned features in the sparse autoencoder, is our sequence length (for the individual attention heads data , 12 heads in 12 layers) and is the number of positive examples in the batch. Similarly, we take our tensor of negative examples , where is the number of negative examples in the batch. We then calculate the additional loss component using a typical contrastive loss structure:
This is simply added to the overall loss, in addition to the reconstruction loss and sparsity loss (note the concatenation of and along the batch dimension yields ): L(x)=⏟∥x-^x∥_2^2_Reconstruction loss + ⏟λ∥c∥_1_Sparsity loss + ⏟αL_cont(P, N)_Contrastive loss
We do 10 runs at varying levels for the IOI task and show the results in Figure 32. Unfortunately, contrastive loss seemed to decrease the quality of the final predictions. This holds both with and without normalisation.

Appendix K Entropy vs. Co-occurrence for Edge-Level Circuit Identification
In addition to the edge-level circuit identification methodology described in the main text, we explored an alternative approach based on the entropy of positive code co-occurrences in head pairs. This method again involves constructing a co-occurrence matrix , where each entry represents the frequency of co-occurrence of feature in head with feature in head across all examples. The matrix is populated by analysing the model’s activations for each input example, identifying the “active” feature (argmax across the feature dimension) for each head in every example, and incrementally building the co-occurrence counts for each observed pair of active features across all head pairs.
To distill meaningful relationships from the co-occurrence matrix, we calculate the entropy for each head pair as follows:
where represents the normalised probability of co-occurrence of features and between heads and , derived from . Prior to entropy calculation, is normalised such that for each head pair, the sum of all co-occurrence probabilities equals one.
We apply a softmax function row-wise across the entropy matrix to normalise the entropy values and calculate the entropy matrices for the positive example set, denoted as . From , we select the top head pairs based on their normalised entropy difference, indicating the most significant edges in the circuit. These head pairs are then mapped back to their corresponding layers and heads within the model architecture.
To evaluate the robustness and predictive power of the identified circuit components (edges), we generate a binary prediction array for the ground truth head pairs, applying a threshold to the softmax-normalised values from . However, we found entropy to be a worse signal for predicting the presence of a head in a circuit. As shown in Figure 33, the entropy values do not align well with the ground truth edges in the IOI task. Furthermore, even when selecting the best hyperparameter, the ROC AUC does not exceed 0.50 (see Figure 34), indicating that the entropy-based approach does not reach the performance level of the original co-occurrence-based method described in the main text.


Appendix L Full hyperparameter sweeps
L.1 Best hyperparameters for each task
The best hyperparameters for each task are given in Table 7. Importantly, all optimal hyperparameters are approximately the same between the Greater-than and IOI tasks, with some differences to Docstring. We hypothesise that this makes sense because Docstring has a smaller number of heads in the model and thus may need higher regularisation i.e. a higher sparsity penalty .
| Task | Learned Features | Threshold | |
|---|---|---|---|
| Docstring | 270 | 0.067 | 1.12e-07 |
| Greater-than | 246 | 0.011 | 1.71e-15 |
| IOI | 379 | 0.022 | 6.26e-16 |
L.2 Effect of in edge-selection
Another hyperparameter introduced by edge-level detection is the number of (head, head) co-occurrence pairs to add to keep from the sorted list of positive co-occurrence counts before taking the set and only keeping heads existing in the remaining tuples in that set. Figure 35 illustrates that ROC AUC is relatively robust to the selection of ; most of the values of lead to essentially the same performance, except for at the very start and very end. In fact, it seems that selecting to be half of the number of overall co-occurrence pairs of codes in heads is a robust heuristic for optimising performance across datasets.



L.3 Contour plots
We show contour plots from the Optuna optimisation in Figure 36. It seems that a lower across datasets is beneficial. However, the number of learned features does not seem to be that important for Docstring or IOI, whilst a low number of learned features leads to lower AUC for the Greater-than task.



Appendix M Comparison to Vector-Quantised Variational Autoencoders (VQ-VAEs)
Our work on using sparse autoencoders for circuit discovery shares some key similarities with Vector-Quantized Variational Autoencoders (VQ-VAEs) [35]. Both methods aim to learn discrete representations of input data that capture the most salient information while discarding noise and irrelevant details.
In a VQ-VAE, the encoder network maps the input data to a continuous latent space, which is then quantised using a learned codebook of discrete vectors. The quantisation step involves finding the nearest codebook vector to each latent vector and replacing it with the corresponding discrete code. This process is analogous to our approach of taking the argmax of the learned features to obtain discrete codes representing the most activated feature for each attention head.
However, there are some important differences between our method and VQ-VAEs. First, our approach uses a sparse autoencoder with a sparsity penalty in the loss function to encourage the learning of a sparse representation. This sparsity constraint helps to identify the most important features and reduces the influence of noise and irrelevant information. In contrast, VQ-VAEs essentially enforce the maximum amount of sparsity by default, as they assign a single vector to each bottleneck representation, which is bijective to a set of integer codes. This is equivalent to having a sparse autoencoder with only one activating feature at any time, and this feature can only take on a single value (i.e. 1).
Second, in a VQ-VAE, the codebook vectors are learned jointly with the encoder and decoder networks using a vector quantisation objective. The codebook is updated during training to better represent the latent space. In our approach, we do not explicitly learn a codebook; instead, we rely on the sparsity constraint to encourage the autoencoder to learn a set of meaningful features that can be discretised using the argmax operation. However, the hidden dimension of our autoencoder is analogous to the codebook size when we apply our discretisation.
Third, VQ-VAEs use a straight-through gradient estimator to propagate gradients through the quantisation step, allowing for end-to-end training of the encoder, codebook, and decoder [35]. In our method, we train the sparse autoencoder using standard backpropagation without the need for a specialised gradient estimator, because the discretisation comes after.
Despite these differences, both our method and VQ-VAEs share the goal of learning a meaningful discrete representation of the input data. It would be interesting to substitue VQ-VAEs into our method and determine if a similar or better performance can be achieved.