Sparse Attention Decomposition
Applied to Circuit Tracing
Abstract
Many papers have shown that attention heads work in conjunction with each other to perform complex tasks. It’s frequently assumed that communication between attention heads is via the addition of specific features to token residuals. In this work we seek to isolate and identify the features used to effect communication and coordination among attention heads in GPT-2 small. Our key leverage on the problem is to show that these features are very often sparsely coded in the singular vectors of attention head matrices. We characterize the dimensionality and occurrence of these signals across the attention heads in GPT-2 small when used for the Indirect Object Identification (IOI) task. The sparse encoding of signals, as provided by attention head singular vectors, allows for efficient separation of signals from the residual background and straightforward identification of communication paths between attention heads. We explore the effectiveness of this approach by tracing portions of the circuits used in the IOI task. Our traces reveal considerable detail not present in previous studies, shedding light on the nature of redundant paths present in GPT-2. And our traces go beyond previous work by identifying features used to communicate between attention heads when performing IOI.
1 Introduction
Recent work has made progress interpreting emergent algorithms used by language models in terms of circuits [22]. Much work in model interpretability views a model as a computational graph [6], and a circuit as a subgraph having a distinct function [2, 27, 14]. In language models, the computation graph is typically realized through communication between model components via the residual stream [4].
In this context, an important subtask is tracing a circuit [27, 12, 2] – identifying causal communication paths between model components that are significant for model function. Focusing on just communication between attention heads, one approach to circuit tracing might be to track information flow. For example, given an attention head computing a score for a particular pair of tokens, one might ask which upstream heads modify those tokens in a way that functionally changes the downstream attention head’s output. A straightforward attack on this question would involve direct inspection of residuals and model component inputs and outputs at various places within the model. Unfortunately and not surprisingly, direct inspection reveals that the great majority of upstream attention heads meet this criterion. Each downstream attention head examines a pair of query and key subspaces, and most upstream heads write at least some component into each downstream head’s query or key subspace. The problem this causes is that, absent interventions using counterfactual inputs, it is not clear which of those contributions are making changes that are significant in terms of model function.
Many previous studies have approached this problem by averaging over a large set of inputs, comparing test cases with counterfactual examples, and by using interventions such as patching [30, 8]. This approach has many successes, but it can be hard to isolate specific communicating pairs of attention heads and hard to identify exactly what components of the residual are mediating the communication.
In this paper we explore a different strategy. We ask whether leverage can be gained on this problem by looking for low dimensional components of each upstream head’s contributions. To do so, we ask: is there a change of basis associated with any given attention head, such that components of its input in the new basis make sparse contributions to the attention head’s output? If so, those components may represent the most significant parts of the input in terms of model function. Our main result is to find a change of basis for the attention head’s inputs, such that attention scores are sparsely constructed in the new basis. We show that this basis comes from the singular value decomposition of the QK matrix of the attention head.
Our testbed is GPT-2 small applied to the Indirection Object Identification (IOI) task [27]. In this setting we show that in the new basis, tracing inputs to attention heads back to sources serves generally identifies a small set of upstream attention heads whose outputs are sufficient to explain the downstream attention head’s output. Further, the small set identified generally includes upstream heads that are known to be functionally associated with the downstream head. We also show that, in the new basis, the representations of tokens can be correlated with semantic features. We exploit these properties to build a communication graph of the attention heads of GPT-2 for the IOI task. By construction, each edge represents a causal direct effect between an upstream head and the attention score output from the downstream head; more interestingly, we demonstrate that the edges in this graph generally identify a communication path that has causal effect on the ability of GPT-2 to perform the IOI task.
In sum, our contributions are twofold. First, we draw attention to the fact that attention scores are typically sparsely decomposable given the right basis. This has significant implications for interpretability of model activations. Note that this is very different from the uses of SVD to analyze model matrices in previous work; we are not concerned with static analysis of model matrices themselves. Second, we demonstrate that by leveraging the sparse decomposition to denoise inputs to heads, we can effectively and efficiently trace functionally significant causal communication paths between attention heads.
2 Related Work
The dominant style of circuit tracing is via patching [30, 8]. That strategy has shown considerable success [27, 2, 11, 12] but is time-consuming, generally requires the creation of a counterfactual dataset to provide task-neutral activation patches, may miss alternative pathways [13, 19], and has been shown to produce indirect downstream effects that can even result in compensatory self-repair [15, 24].
In this work, we trace circuits using only a single forward pass, eliminating the need for counterfactuals and avoiding the problems of self-repair after patching. The authors in [5] trace circuits in a single forward pass, and argue that the approach is much faster than patching, and avoids dependence on counterfactual examples and the risk of self-repair. We derive the same benefits, but unlike that paper we leverage spectral decomposition of attention head matrices to identify the signals flowing between heads.
Like distributed alignment search [7] we adopt the view that placing a neural representation in an alternative basis can reveal interpretable dimensions [26]. However, unlike that work, we do not require a gradient descent process to find the new basis, but rather extract it directly from attention head matrices. Likewise, using sparse autoencoders (SAEs) the authors in [9, 14] construct interpretable dimensions from internal representations; our approach is complementary to the use of SAEs and the relationship between the representations we extract and those obtained from SAEs is a valuable direction for further study.
We demonstrate circuit tracing for the IOI task in GPT-2 small, which has become a ‘model organism’ for tracing studies [27, 2, 5]. Like previous studies, one portion of our validation consists of recovering known circuits; however we go beyond recovery of those known circuits in a number of ways, most importantly by identifying signals used for communication between heads.
The use of SVD in our study is quite different from its previous application to transformers. SVD of attention matrices has been used to reduce the time and space complexity of the attention mechanism [29, 28] and improve reasoning performance [25], often leveraging a low-rank property of attention matrices. Our work does not rely on attention matrices showing low-rank properties. We use SVD as a tool to decompose the computation of attention; the leverage we obtain comes from the resulting sparsity of the terms in the attention score computation. Likewise, previous work has shown interpretability of the singular vectors of OV matrices and MLP weights — though not of QK matrices [18]. We show here evidence that it is the representations of tokens in the bases provided by the singular vectors of QK matrices that show interpretability.
After completion of this work, we became aware of [16]. That paper shares with this one the idea that SVD of attention matrices can be used to denoise and thereby infer communication between attention heads. This paper differs in a number of ways. This paper develops and demonstrates a general methodology for circuit tracing (§4.2), including a noise separation rule that can be used to automatically identify which singular vectors of an attention head should be used to identify communication signals for any given input (§4.1 and §5.1). In contrast, the authors in [16] manually select one or two singular vectors in each case. Importantly, we find that the singular vectors that are relevant for any task depend on the model input; in contrast, most of the analyses in [16] focus on Composition Score, which is a static, data-independent measure applied only to model weights. By using our general, data-dependent methodology, this paper presents a trace of the IOI circuit across all attention heads and layers (§5.3 and Figure 5), something that is not done in [16].
3 Background
Notation.
In this paper, vectors are column vectors and are shown in boldface, eg, . Note though that GPT-2 uses row vectors for token embeddings; so when treating an individual embedding as a vector it will appear as .
In the model, token embeddings are -dimensional, there are attention heads in each layer, and there are layers. We define , which is the dimension of the spaces used for keys and queries in the attention mechanism. In GPT-2 small, , , , and .
Attention Mechanism.
The attention mechanism operates on a set of tokens in -dimensional embeddings: . Each token is passed through two affine transforms given by , , using weight matrices and offsets . Then the inner product is taken for all pairs of transformed tokens to yield attention scores. More precisely:
| (1) | |||||
We can capture (1) in a single bilinear form by making the following definitions:
| (2) |
Then we can rewrite the score computation (1) as
| (3) |
in which is the destination token and is the source token of the attention computation. To enforce masked self-attention, is set to for . Attention scores are then normalized, for each destination (corresponding to a row in ), yielding attention weights , in which the Softmax operation is performed for each row of . The resulting attention weight is the amount of attention that destination is placing on source .
To compute the output of the attention head each input token is first passed through an affine transformation: with . Attention weights are then used to combine rows of to construct the attention head’s outputs: . Finally each combined output is passed through another affine transformation which transforms it back into the -dimensional embedding space. Putting it all together we have
| (4) |
4 Circuit Tracing
4.1 Approach
The approach used in this paper to trace circuits starts by decomposing the attention score in terms of the SVD of The matrix has size , but due to its construction it has maximum rank . We therefore work with the SVD of in which , and . and are orthonormal matrices with and , and with . Important to our work is that the SVD of can equivalently be written as
| (5) |
in which and are orthonormal sets and each term in the sum is a rank-1 matrix having Frobenius norm . We refer to each term as an orthogonal slice of , since we have whenever .
The following hypothesis drives our approach:
Hypothesis (Sparse Decomposition) When an attention head performs a task that requires detecting components in a pair of low-dimensional subspaces in its inputs and , and its inputs have significant components in those subspaces, it will show large values of for a distinct subset of values of .
In the remainder of this paper we show a variety of evidence that is consistent with the sparse decomposition hypothesis in the case of GPT-2 small. In §6 we will discuss reasons why this phenomenon may arise.
When the sparse decomposition hypothesis holds, we can approximate the score computed by the attention head as follows:
| (6) |
where the number of terms in the sum (i.e., ) is small.
We use to denote the subset of values of for the token pair . Besides being specific to an attention head and token pair, also depends on the task. In this paper we do not define ‘task’ precisely; in what follows, we study only a limited set of attention head functions that are performed when generating outputs for IOI prompts in GPT-2 small. We leave the association between and precisely-defined tasks as a fascinating direction for future work.
Our tracing strategy constructs using (6), i.e., using in place of all of the singular vectors of . This is akin to denoising in signal processing. When a signal has an approximately-sparse representation in a particular orthonormal basis (e.g., the Fourier basis or a wavelet basis) then removing the signal components that correspond to small coefficients is useful to suppress noise. Likewise, we find that in the orthonormal bases provided by and , contributions of the inputs and are typically approximately-sparse. Hence removing the dimensions with contributions summing to zero allows us to identify low-dimensional components of the inputs that are responsible for most of the attention head’s output (score). We illustrate the benefits of denoising in §5.2.
Hence, to fix , we consider the individual contributions made by each orthogonal slice to : . Empirically we typically find a few large, positive terms and many others that may be positive or negative. We seek to separate terms into ‘signal’ and ‘noise.’ To do so we adopt a simple heuristic, treating noise terms as a set that, in sum, has little or no effect on the attention head score. Accordingly, we define the noise terms to be the largest set of terms whose sum is less than or equal to zero. The indices of the remaining terms constitute . Terms denoted by are strictly positive, and are the largest positive terms. Typically the number of those terms, ie, , is 20 or less, often just 2 or 3. We refer to this condition where is small as the sparse decomposition of attention head scores in terms of the orthogonal slices of .
Given , we can decompose model residuals into ‘signal’ and ‘noise’ in terms of their impact on Define subspaces and and associated projectors and . The denoising step separates the inputs and into:
| (7) |
where and . Then we have and
where is as small as possible.111To go from to we simply drop the last component; this is explained in the Appendix. Intuitively, we interpret a signal to approximately represent a feature that is used for communication between attention heads; we present evidence in support of this interpretation below.
4.2 Singular Vector Tracing
We use this framework to trace circuits in GPT-2 small as follows. A prompt corresponding to the IOI task is input to GPT-2. Consider th -th attention head at layer generating attention score for source token and destination token . Then defines a set of orthogonal slices that the attention head is using. Hence we can approximately construct as in (6), where we are using the SVD of .
We will trace circuits causally with respect to the singular vectors of each attention head. For attention head generating output on tokens , we identify the subspaces and . We then look at each attention head ‘upstream’ of , to determine how much each contributes in the subspace to destination token and in the subspace to source token Specifically, for attention head with denote the output according to (4) that it adds to token as (likewise for ). We then compute
| (8) |
Conceptually, is an estimate of how much attention head , by writing to token , has changed the output (score) of attention head on token pair . We use to incorporate the magnitude of each singular vector’s contribution to the attention head output, dividing the contribution equally between the source and destination tokens. We refer to as the contribution of attention head to attention head on token pair through token .
A singular vector trace of a model on a given input is a weighted, directed acyclic graph involving attention head pairs and token pairs and having edge weights . It includes nodes that correspond to attention heads, and we add dummy nodes to allow for the separate contributions made through each token to be captured. Hence the graph consists of weighted edges of the type that capture the contributions, and edges of the type that capture which tokens are being attended by the attention head .
4.3 Experiments
To demonstrate the utility of singular vector tracing we apply it to a specific setting: the behavior of GPT-2 small when performing indirect object recognition (IOI). The IOI problem was introduced in [27] and that paper identified circuits that GPT-2 uses to perform the IOI task. As described in [27]: In IOI, sentences such as “When Mary and John went to the store, John gave a drink to” should be completed with “Mary.” To be successful, the model must identify the indirect object (IO, ‘Mary’) and distinguish it from the subject (S, ‘John’) in a prompt that mentions both. Thus, a succinct measure of model performance can be obtained by comparing the output logits of the IO and S tokens. The authors identified a collection of attention heads and the token positions they attend to when performing the IOI task. We refer the reader to [27] for additional details.
The IOI dataset that we use consists of 256 example prompts with 106 different names. We are using the same 15 templates used in [27], with two patterns (‘ABBA’ and ‘BABA’), which refers to the order of the names appearing in the sentence (the IO name is A, and the S name is B). Prompt sizes range from 14 to 20 tokens.
As in [27], we focus on understanding the interaction between attention heads. We believe that extending our framework to include the contributions of MLPs is an important direction for future work. Furthermore, in the analyses in this paper we do not consider cases in which heads attend to the first token – that is, when attention head has a large value of for . Because the attention weights for each target token form a probability distribution, when a destination token should not be meaningfully modified, attention heads normally put their weight on the first token. This role for token 0 has been noted in previous work [20].222GPT-2 does not use a ‘bos’ token.
Singular vector tracing as described in §4.2 can be applied at every attention head with respect to every token pair. However in our experiments we limit our analysis to cases where the attention head is primarily attending to a single source token for a given destination token. This strategy is similar to analyses in prior work [27, 2, 5]; it reduces complexity in the tracing analysis, but could be relaxed in future work. Specifically we say that an attention head is ‘firing’ if it places more than 50% weight on a particular source token for any given destination. This rule implies that a head can only ‘fire’ on one source token for each destination token. In general, we only trace upstream from attention heads that are firing on specific token pairs.
Note that interpreting (8) as giving the actual magnitude of the change in downstream attention score overlooks processing that may affect the signal in between the upstream head and the downstream head. Previous work has shown that downstream processing can compensate for upstream ablations [15] and that some layers may remove features added by previous layers [24]. We show results in §5.4 that confirm the direct causality of signals on downstream attention head outputs, but also illustrate that downstream processing can at times have a noticeable effect on model performance after signal interventions. Further, (8) ignores the impact of the layer norm. Attention head adds its output to the residual , but will be subjected to the layer norm before being input to attention head . We account for the effect of the layer norm using three techniques: weights and biases are folded into the downstream affine transformations, output matrices are zero centered,333These operations are provided by the TransformerLens library; see [20]. and the scaling applied to each token is factored into the contribution calculation. More details on tracing are provided in the Appendix444Code available at https://github.com/gaabrielfranco/sparse-attention-decomposition.
5 Results
5.1 Characterizing Attention Head Behavior via SVD
Throughout this and the next section, we use as our examples attention heads that figured prominently in the results of [27]. This aids interpretation and ensures we are paying attention to important components of the model.


(a) (b)
We start by demonstrating the approximately-sparse nature of attention scores when decomposed via SVD. Figure 1 shows typical cases. Each plot in the figure shows results for attention head and a single source token, destination token, and prompt. The 64 contributions made by each orthogonal slice to the attention score are shown. Red bars correspond to sets ; the sum of the red bars is approximately equal to the sum of all bars, which is the attention score for this head on these inputs. Figure 1(a) corresponds to the case in which the attention score is negative (and so the attention weight would be nearly zero); Figure 1(b) corresponds to a case in which the attention score is positive (28.1), and the attention weight is large ( 0.83). Note that orthogonal slices are shown in order of decreasing singular value; the effect shown is not due to a low-rank property of itself. Rather, the effect shown corresponds to sparse construction of the attention score when the inputs are encoded in the bases given by the SVD of .




(a) (b) (c) (d)
We see considerable evidence in our experiments that the orthogonal slices used by an attention head are similar to each other when the attention head is firing. Figure 2 shows examples of the sets for four attention heads: (3, 0), (4, 11), (8, 6), and (9, 9) across 256 prompt inputs. Furthermore, the nature of these attention head’s functions are evident in the sets of slices that they use. In the case of (8, 6) (an S-inhibition head), there is a set of about 6 slices that are consistently used; these are the same as the red bars in Figure 1(b). Attention head (9, 9) (a name mover head) uses a larger set, but there is still clearly a specific set of slices that frequently appear. Attention head (3, 0) (a duplicate-token head) uses a broad set of slices; this is consistent with its need to look at all the token’s dimensions, since its role is to detect identical tokens. And attention head (4, 11) (a previous token head) primarily uses a single slice; this also is consistent with its role of detecting adjacent tokens, which appears to only require detecting a feature in a one-dimensional subspace. Finally, we show in the Appendix corresponding plots for when these attention heads are not firing; there too, a consistent set of slices is used, but the slices are completely different from those used when the head is firing.


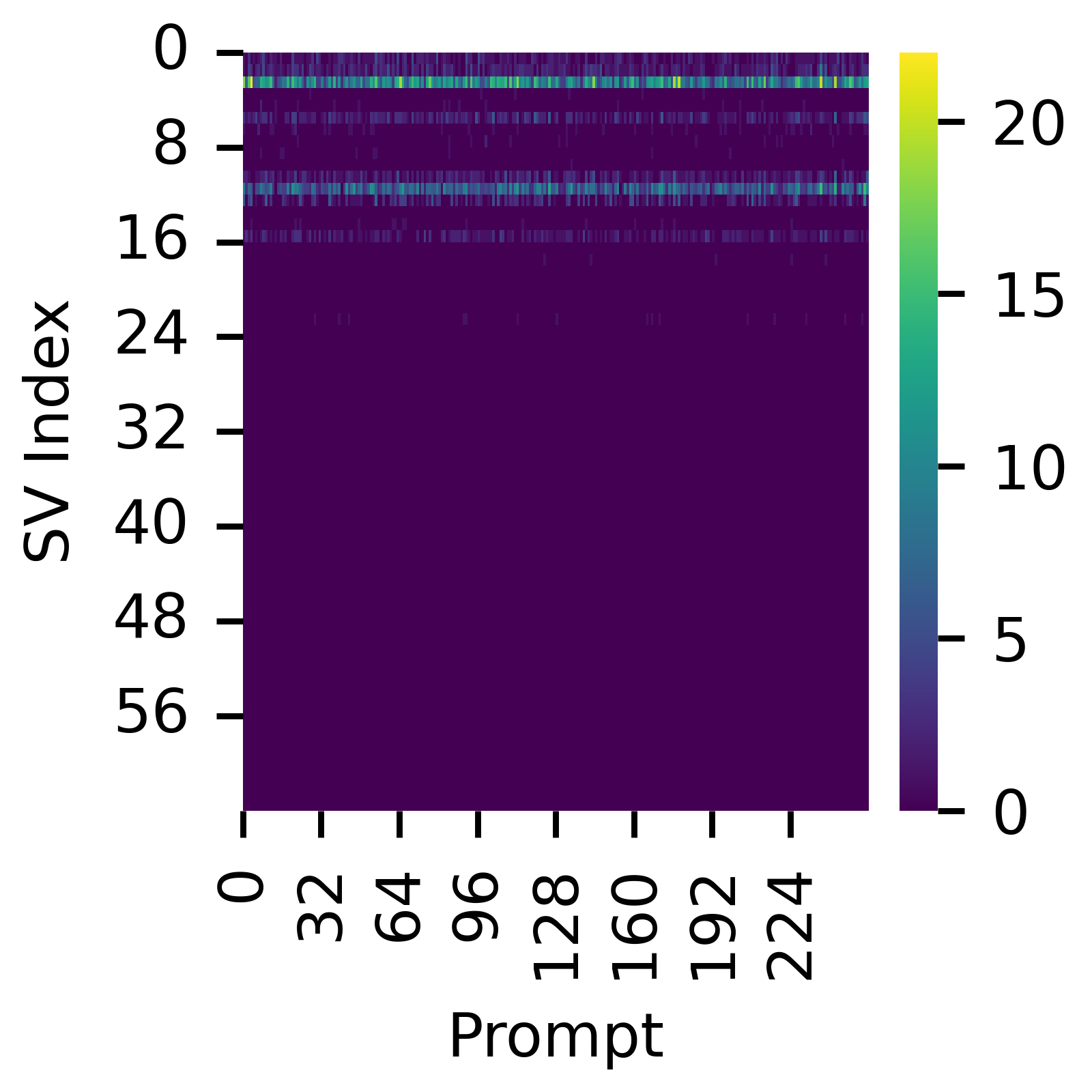
The sparsity of the contributions of the slices of to attention scores is summarized in Figure 3. In Figure 3(a) we show the distribution of the number of orthogonal slices used, ie, , across all the prompts in our dataset. The figure shows that the number of slices used is consistently small, much smaller than the number of available dimensions (64). We also ask whether the sparsity observed is an artifact of the input data used in our experiments. To assess this, we run GPT-2 on a dataset consisting of non-specific inputs, having no relationship to the IOI task. We use the first 256 elements of The Pile [21] selecting the first 21 tokens from each element to match the IOI dataset size. The corresponding plot is shown in Figure 3(b). This comparison suggests that sparse decompositions of attention scores is not limited to the IOI setting.
5.2 Do We Need Singular Vectors?
Next we show that it is possible to leverage the sparsity of attention score decomposition. To illustrate this, we ask the following question: given a token that is input to a particular attention head, what similarity does it show to the outputs of upstream attention heads? In other words, could we trace some part of a circuit by simply looking upstream to see who has ‘contributed’ to the token?
We take as our examples heads (9, 9) and (10, 0), which are name mover heads. The authors in [27] find that functionally important contributors to the ‘end’ tokens of these heads are (7, 3), (7, 9), (8, 6), and (8, 10). The heatmaps in Figure 4 show contribution scores (computed via (8)) for two cases: the case where the signal is taken to be the entire residual , and the case where the signal is taken to be just its low-dimensional component as described in §4.1.
The figure shows the strong filtering and correcting effect that results from exploiting the sparsity of attention decomposition. Figures 4(a) and (c) show that if we simply ask how much each upstream head contributes to the attention score of the downstream head, we get a very noisy answer with two problems. First, a large set of attention heads have high scores; and second, the known functional relationships from [27] are not evident. On the other hand, when we focus on Figures 4(b) and (d), we see considerable noise suppression; many heads in middle layers of the model are no longer shown as being significant. Furthermore, we see that one attention head (8, 6) stands out, and it is one of those previously identified as functionally important. And in the case of Figure 4(d), we see that other attention heads with known functional relationship (7, 3) and (7, 9), are also highlighted. In §5.3 we will show many other attention head pairs with functional relationships from [27] that are recovered using the singular vector tracing strategy. In the Appendix we show a hypothetical network trace performed without using singular vectors; the resulting trace is not usable and shows little evidence of known functional relationships in the IOI circuit.


(a) (b) (c) (d)
Interpreting Signals.
Detailed investigation of the interpretability of signals is beyond the scope of this paper. However we observe that in some cases signals show interpretability. As an example, we consider the name mover attention head (9, 9). For each tokens in the input to layer 9, we compute the magnitude of its residual in the subspace of (9, 9). This measures the strength of the signal that (9, 9) uses to identify the IO token. We find that this measure cleanly separates the names in our data from the non-names. Details are in the Appendix.

5.3 Singular Vector Trace of GPT-2 on IOI
Next we construct a singular vector trace using the concepts from §4.2. We start at a particular attention head and token pair. If the head is firing on the token pair (as discussed in §4.3) we obtain the subspaces and and associated projectors and . We then look at each upstream attention head’s output, and separate from it the signal it contains for the downstream head. The properly adjusted magnitude of this signal constitutes the upstream head’s contribution to the downstream head’s attention score via the corresponding token, as computed via (8).
Empirically we find that the contributions from most upstream heads are small, with only a few upstream heads making large contributions to the downstream attention score. We filter out the small contributions, which are unlikely to have significant impact on model performance. To do this for a given downstream firing, we adopt the simple rule of choosing the smallest set of upstream heads whose contributions sum to at least 70% of the sum of all contributions.
Using this rule, for each token we identify the upstream heads with significant contribution through that token. An edge in the resulting trace graph is defined by the upstream head, the downstream head, the two tokens on which the downstream head is firing, and the choice of which token is being written into by the upstream head. For each upstream head we then ask whether it is firing on that token as a destination. If so, the process repeats from that head and token pair. The process is presented in detail as Algorithm 1 in the Appendix.
We ran singular vector tracing on GPT-2 small using 256 prompts from the IOI dataset described in §4.3. We started the trace at the three name mover heads (9, 6), (9, 9) and (10, 0), as they were identified as having direct effect on model performance in [27]. The resulting trace is shown in Figure 5; we refer to the graph in the figure as . There are two kinds of edges in : communication edges from heads to tokens, and attention edges from tokens to heads. In the figure, blue edges are toward tokens that are source tokens downstream, and red edges likewise are destinations. The width of the edge is the accumulated contribution of the edge over the 256 prompts. Darker nodes fired more often in our traces, and we have placed green borders around nodes that appeared in [27]. Edges that appear very few times (less than 65 times over the 256 prompts) are omitted.
We make a number of observations. First, the trace shows broad agreement with results in [27], although not all nodes in that paper appear in our graph; this may reflect differences of effect size, or differences between the input datasets. The trace shows agreement with previous results on head-to-head connections and also on the tokens through which the communication is effected. Note that in the appendix we show that further filtering this graph to just its most frequent edges yields a set of attention heads in agreement with [27] to a precision of 0.52 and recall of 0.69.
The trace also goes beyond previous results in a number of ways. Whereas in previous work, the upstream contributors to name mover source tokens were not identified, this trace shows where important features for the that (IO) token are added and that this happens very early in the model’s processing. Previous work also proposed that redundant paths were present in GPT-2’s processing for the IOI task; this trace confirms their existence and elucidates the nature of their interconnection pattern. For example, there is distinct lattice structure among nodes at layers 7, 8, and 9. (In the Appendix we isolate this lattice structure for better inspection.) We also identify highly active heads that were not discussed in previous work, including (2, 8) which attends to the ditransitive verb of the prompt and feeds into (4, 11) (a previous token head) as well as (8, 6) (a S-inhibition head); and (4, 3) which attends to the last token (which is always a preposition in our prompts) and its predecessor.
We note as well that singular value tracing itself requires only a single pass over the data, and as used here, doesn’t make use of counterfactual inputs. Most importantly, it identifies specific features that are present in the communication from one head to another, and which can be further investigated as to meaning and role.
5.4 Validation
We adopt a variety of strategies to validate the graph in Figure 5. To demonstrate the causal effect of each edge’s communication on model performance, we intervene on individual edges; and to demonstrate that the structure of the graph itself is functionally significant, we intervene on various collections of edges simultaneously.
Edge Validation.
A communication edge in represents the contribution , which is a measure of the amount that head would change the attention score of head via if there were no downstream modifications. Validating an edge in involves intervening in the output of the upstream attention head by modifying the signals (as defined in (7)) used by the downstream attention head . We define two types of interventions: global interventions, and local interventions. In a global intervention, we simply modify the signal in the output of the upstream attention head; in a local intervention, we modify the signal only at the input to the downstream attention head. Global interventions have the potential to directly affect all downstream heads, while local interventions are limited in their direct effect to only the downstream head.
Specifically, we define as the projection of the upstream head’s output onto the associated subspace defined by . An edge ablation consists of subtracting from the residual; and edge boosting consists of adding to the residual. Additionally, for comparison purposes we define which consists of constructing the projection of the residual using a set of ’s singular vectors chosen at random from those not in ; the size of the chosen set is the same as . Performing the same interventions using allows us to assess whether intervening in the subspaces and is more effective than a random strategy. Implementation details of these interventions are in the Appendix.
We measure the effects of interventions using the same metric as [27]. Let be the logit difference between the IO and S tokens when the model is run on input . Then define for a particular intervention on a particular edge corresponding to residual . A negative value of indicates that the model’s performance on the IOI task has gotten worse; while a positive value of indicates that the model’s performance has improved.
Our results show, with some interesting exceptions, that almost all of the edges from that we test cause model performance to degrade when ablated. Importantly, we also show that model performance shows corresponding increases when an edge is boosted. Generally speaking, intervening on an edge with higher weight (shown as thicker) in Figure 5 has stronger impact on model performance. We conclude that tracing via singular vectors generally identifies functionally causal communication paths for IOI in GPT-2.
It is important to note that the magnitudes of the interventions performed here are small. We are intervening in a subspace of dimension less than 20 (typically) on a vector with 768 dimensions. The vast majority of dimensions of the residual are unaffected. To illustrate, we find that the cosine similarity between residuals before and after a local intervention in our experiments is generally higher than 0.999; and the relative change in vector norm before and after intervention is typically less than 1%. Details are in the Appendix.
As an example of our results, we show in Figure 7 interventions on edges into (10, 0, end). Both local and global interventions show causal impact on model performance, with more significant edges having larger impact. We note that in a number of cases (shown in the Appendix) local interventions can have greater impact than global interventions, presumably due to downstream modification of signals by other components; we also show cases where global interventions have greater impact than local interventions, presumably because signals are being shared between multiple communication paths in the model.



Structural Validation.
The results in [27] suggest that there are alternative paths that can be used by the model to perform the IOI task. An advantage of the trace shown in Figure 5 is that those alternate paths are made explicit. To demonstrate that the structure of is informative, we show that intervening on parallel edges is frequently additive, while intervening on serial edges is frequently not.
Figure 7 shows a multi-edge intervention in a large set edges on parallel paths: all outgoing edges from attention heads (0, 11) and (0, 9). Global interventions of these edges have significant impact in the performance of the model, and this effect is amplified when we intervene on both (0, 11) and (0, 9) at the same time, showing intervention on parallel paths that is additive. On the other hand, local intervention in the downstream nodes of these edges has a smaller effect, suggesting that the model has redundant paths for the same task (eg, backup name movers as discussed in [27]). Results showing intervention on serial edges are in the Appendix.
6 Discussion
6.1 Possible Mechanisms
The results in §§5.1 and 5.2 support the sparse decomposition hypothesis. In this section we discuss some possible mechanisms behind this phenomenon. First, a motivation for decomposing attention matrices using SVD comes from the following fact:
Lemma 1 Given vectors and , among all rank-1 matrices having unit Frobenius norm, the matrix that maximizes is
The proof is straightforward and provided in the Appendix. This suggests that model training could have the following effect. If an attention head needs to attend to particular vectors and , it needs to output a large value for . In that case, model training could result in construction of in which one term of the SVD, say , has , , and with reflecting the importance of this term in the overall computation of the attention score. As an illustration, we note that the results in §5.2 and the Appendix show that in GPT-2 the singular vectors of some matrices are correlated with word features that are relevant for the IOI task.
Consider a hypothetical case in which the sets of vectors to which the attention head needs to attend, say and , happen to each form orthogonal sets. Then to achieve maximum discrimination power in distinguishing corresponding pairs, the singular vectors of , that is and respectively, should be aligned with the corresponding vectors in and . To move from vectors to features, we refer to the linear representation hypothesis [17, 10, 23] which suggests that concepts, including high-level concepts, are represented linearly in the model.
To move closer to realistic cases, we note that the authors in [3] make observations, based on experimental evidence and geometric considerations, about features constructed by neural models. They argue that models will tend to represent correlated feature sets in a manner such that, considered in isolation, the sets are nearly orthogonal. They term this the use of “local, almost-orthogonal bases.” In our case, if an attention head is attending to vector sets and that are important when performing a specific task, then we may hypothesize that training will construct the sets to be “nearly-orthogonal,” meaning that cosine similarities among the vectors in each set would typically be small.555In the language of [3] we are making a “local non-superposition assumption.” In this case, the resulting sets of singular vectors , are more likely to sparsely encode the and than exist in one-to-one correspondence.
Given the above argument, for cases where the linear representation hypothesis holds, we expect that an attention head is testing for a pair of low-dimensional subspaces in the inputs and . In that case, we expect that subsets of the singular vectors of will be constructed during training so as to ‘match’ those subspaces. In this context, a sparse encoding allows the attention head to attend to more than different subspaces, expanding the number of concepts that the attention head can recognize.
Note however that attention heads have been shown to have a variety of functions, not all of which correspond to testing low-dimensional subspaces. For example, some attention heads have the role of detecting when tokens and are identical [4, 27]. In that case, we expect that and will have non-negligible inner products with most or all of the singular vectors of . In fact, we see exactly this phenomenon in the case of the duplicate-token head (3, 0) as shown in Figure 2(a).
6.2 Limitations and Future Work
There are a number of limitations of our study and directions for future work. First, the method as used here does not explore alternative pathways that may affect model output [13]. It also does not directly assess adaptive computations in the model [14, 24] nor does it construct minimal circuits in the sense of [27]. However, we believe that it offers an alternative toolbox that can be extended to help investigate those issues, in part by exposing the signals passing between specific pairs of attention heads.
Next, the noise separation strategy we use is not perfect, and is perhaps too permissive. We believe that an approach that determines sets differently may yield more precise results. For example, Figure 2 shows that certain orthogonal slices are frequently reused by certain attention heads, and a better identification strategy might use this observation.
Next, the tracing strategy used herein only considers edges that make positive contributions to attention scores. However, as Figure 1 shows, certain orthogonal slices contribute strongly negative terms to the attention computation. We have observed that these negative terms are important for determining when an attention head does not fire. The output of an attention head in general seems to depend on the balance between the few strongly positive terms and the few strongly negative terms. This is a fertile area for for investigation that could lead to deeper understanding of control signals in the model.
In this paper, we have restricted attention to heads that are firing (putting 50% or more attention weight on one source token). Not all attention heads work by firing on a pair of inputs. Conceptually there is no difficulty applying singular vector tracing to non-firing situations, but identifying likely causal paths and functions becomes more challenging.
Finally, we have not explored in depth the nature of the signals themselves. Indirect evidence, such as the difference in effect between local and global ablations, suggests that there are some similarities between signals used on different edges of the network. Exploration of the nature of signals and their relationships is an intriguing direction for future work.
7 Conclusions
Transformer-based models are largely considered closed boxes whose internals are difficult to interpret in domain-level terms [1]. By helping elucidate the circuits used by a language model in performing a given task, we hope to improve our ability to assess, validate, control, and improve model functions. In this paper we draw attention to a powerful tool for analyzing circuits: the fact that attention scores are typically sparsely constructed. This effect leads directly to the ability to identify signals used by attention heads to effect inter-head communication. We show that these low-dimensional signals have causal effect on attention head computations, and generally on the ability of GPT-2 to perform the IOI task. We believe that further exploration of signals holds promise for even deeper understanding of the internals of language models.
References
- [1] Afra Alishahi, Grzegorz Chrupała, and Tal Linzen. Analyzing and interpreting neural networks for nlp: A report on the first blackboxnlp workshop. Natural Language Engineering, 25(4):543–557, 2019.
- [2] Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 16318–16352. Curran Associates, Inc., 2023.
- [3] Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy Models of Superposition. Transformer Circuits Thread, 2022.
- [4] Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread, 2021.
- [5] Javier Ferrando and Elena Voita. Information flow routes: Automatically interpreting language models at scale, 2024.
- [6] Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. Causal abstractions of neural networks. arXiv, 2021.
- [7] Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah D. Goodman. Finding alignments between interpretable causal variables and distributed neural representations, 2024.
- [8] Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching, 2023.
- [9] Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. Finding neurons in a haystack: Case studies with sparse probing. arXiv, 2023.
- [10] Wes Gurnee and Max Tegmark. Language models represent space and time. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024.
- [11] Michael Hanna, Ollie Liu, and Alexandre Variengien. How does gpt-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model. arXiv, 2023.
- [12] Tom Lieberum, Matthew Rahtz, János Kramár, Neel Nanda, Geoffrey Irving, Rohin Shah, and Vladimir Mikulik. Does circuit analysis interpretability scale? evidence from multiple choice capabilities in chinchilla. arXiv, 2023.
- [13] Aleksandar Makelov, Georg Lange, and Neel Nanda. Is this the subspace you are looking for? an interpretability illusion for subspace activation patching. arXiv, 2023.
- [14] Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv, 2024.
- [15] Thomas McGrath, Matthew Rahtz, Janos Kramar, Vladimir Mikulik, and Shane Legg. The hydra effect: Emergent self-repair in language model computations. arXiv, 2023.
- [16] Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Talking heads: Understanding inter-layer communication in transformer language models, 2024.
- [17] Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. In Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff, editors, Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 746–751, Atlanta, Georgia, June 2013. Association for Computational Linguistics.
- [18] Beren Millidge and Sid Black. The singular value decompositions of transformer weight matrices are highly interpretable. https://www.alignmentforum.org/posts/mkbGjzxD8d8XqKHzA/the-singular-value-decompositions-of-transformer-weight.
- [19] Aaron Mueller. Missed causes and ambiguous effects: Counterfactuals pose challenges for interpreting neural networks. arXiv, 2024.
- [20] Neel Nanda. Transformer lens main demo notebook. https://colab.research.google.com/github/neelnanda-io/TransformerLens/blob/main/demos/Main_Demo.ipynb.
- [21] Neel Nanda. The first 10,000 elements of the pile. https://huggingface.co/datasets/NeelNanda/pile-10k, 2024.
- [22] Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits. Distill, 5(3):e00024–001, 2020.
- [23] Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. In Causal Representation Learning Workshop at NeurIPS 2023, 2023.
- [24] Cody Rushing and Neel Nanda. Explorations of self-repair in language models. arXiv, 2024.
- [25] Pratyusha Sharma, Jordan T. Ash, and Dipendra Misra. The truth is in there: Improving reasoning in language models with layer-selective rank reduction. In The Twelfth International Conference on Learning Representations, 2024.
- [26] P. Smolensky. Neural and conceptual interpretation of PDP models, page 390–431. MIT Press, Cambridge, MA, USA, 1986.
- [27] Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
- [28] Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. Svd-llm: Truncation-aware singular value decomposition for large language model compression. arXiv, 2024.
- [29] Yifan Wu, Shichao Kan, Min Zeng, and Min Li. Singularformer: Learning to decompose self-attention to linearize the complexity of transformer. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, page 4433–4441, 2023.
- [30] Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods, 2024.
Appendix A Appendix
Handling Homogeneous Coordinates.
The matrix as defined in (2) expects inputs in homogeneous coordinates in which the last component of the input vector is 1. This allows the bilinear form (3) to incorporate the linear and constant terms in (1). When projecting a residual to isolate a signal component, we are only concerned with the dimensions represented in the residual. We are not concerned with the additional th dimension, as that dimension represents the linear and constant terms that will be added by the downstream attention head. Hence, to compute the projection of a residual in the subspace associated with , we first form by extending with a th component having value 1, then compute , then drop the th component of leaving .



(a) (b) (c) (d)
Slices Used When a Head is Not Firing.
In Figure 8 we show analogous plots to Figure 2, except that we choose cases where the attention heads are not firing. Interestingly, a consistent and small set of orthogonal slices is used in each head when it is not firing. However, comparing to Figure 2, we see that an entirely different set of orthogonal slices are in use when the head is not firing. We note that across our measurements we find a very small number of slices are responsible for an attention head’s score when it is not firing.
Interpretability of Signals.
As described in §5.2, we find that signals can show interpretability. As a simple illustration, we consider the (9, 9) attention head, a name mover. The projection of a token’s residual into the subspace of this attention head isolates the signal used by the head to recognize the IO token.
To make this a uniform measure we can apply across multiple tokens, we create a consensus estimate of a single subspace across all firings of (9, 9). We do this by selecting only the orthogonal slices that appear in at least 100 firings. This yields 12 sets of singular vectors which we can use to construct . We then measure for all token residuals at the input of layer 9. The average of the norms for each token is plotted in Figure 9. Tokens are sorted by the magnitude of the signal and colored according to whether they are names (in red) or not (in blue). We see that magnitude of the signal in is a clear measure of whether that token is a name, ie, a potential IO.











and across multi-edge ablations.


Tracing Details: Sign Ambiguity and Layer Norm.
Here we discuss some of the fine points of our tracing method.
First, note that for each term in (6), we get the same value if we replace with . For consistency of interpretation, we adopt the convention of defining to lie in the direction that creates a positive inner product with . This determines the direction for (and if then will lie in the direction of positive inner product with ). The result is that we can treat the set of vectors as rays defining a cone of positive influence on , and similarly for .
Second, as noted in §4.3, to properly attribute contributions of upstream heads to downstream inputs, we need to take into account the effect of the (downstream) layer norm. The layer norm operation can be decomposed into four steps: centering, normalizing, scaling, and translation. Centering, scaling, and translation are affine maps, which means that they can be folded into different parts of the model with mathematical equivalence. The TransformerLens library handles the centering step by setting each weight matrix that writes into the residual stream to have zero mean. Moreover, it folds the scaling and translation operations into the weights of the next downstream layer.666See https://github.com/TransformerLensOrg/TransformerLens/blob/main/further_comments.md for more details. The result is that centering, scaling, and translation make changes to the matrices used to compute as shown in (2). The remaining step is the normalizing step. This step does not change the direction of the residual; it only affects the magnitude of the contribution calculation (8). Since for any contribution calculation, we are considering a specific addition to the residual , we can simply scale its contribution by the same scaling factor used for the corresponding token when it is input to the downstream layer.
Algorithm for Singular Vector Tracing.
Singular vector tracing starts from a given head, token pair, and prompt and works upstream in the model to identify causal contributions to that attention head’s output. If the upstream attention heads are themselves firing (attending mainly to a pair of tokens), then the process proceeds recursively for each token. We present singular vector tracing as Algorithm 1.
Alternative Paths in the IOI Circuit
Previous work has noted that interventional studies are complicated by the presence of alternative causal paths in the IOI circuit. In Figure 14 we isolate nodes from the top layers of our network trace. The figure illustrates the lattice-like structure existing between the attention heads responsible for the higher-level processing in the circuit. The heads that take part in alternate pathways include the three name mover head (9, 6), (9, 9), and (10, 0), and the three S-inhibition heads (7, 3), (7, 9), and (8. 6).

Skeleton of SVT Graph.
In Figure 15 we show a version of singular vector trace shown in Figure 5. In this figure we have shown only edges that appear very frequently in our traces. Specifically, we show edges and (the nodes they connect to) that occur more than 170 times in our trace of 256 prompts. Because our trace strategy starts from (9, 6), (9, 9), and (10, 0), only 16 of the heads identified in [27] can appear in the trace. The figure shows that this ‘skeleton’ contains 11 of the 16 possible attention heads previously identified, out of a total of 21 attention heads in the trace (precision 0.52, recall 0.69).

Tracing Without Singular Vectors.
In §5.2 we show the noise suppression effect of filtering signals using the orthogonal slices of . That section shows that using all the orthogonal slices of , ie, simply looking at the residuals directly, without extracting their signals, is very noisy and leads to incorrect conclusions. As a further illustration, in Figure 16 we demonstrate a attempted circuit trace in which residuals are directly used for tracing, instead of using signals as in all other traces in this paper. The figure shows that the resulting trace is not useful. It does not contain most of the nodes that were identified as functionally important in [27]. Further, it seems that contributions to source tokens are almost completely missed. The figure also shows that the most noisy and incorrect parts of the graph concern the longer-range connections between early and late layers of the model.

Intervention Details.
Here we provide precise descriptions of the intervention strategies used in §5.4. Assume that, for a given instance, we are intervening in an edge of type (either source or destination), with destination token , source token .
Global interventions are performed at the upstream head while local interventions are done at the downstream head . We denote the the token position that will be intervened. Specifically, if head has output on token , we define a global ablation intervention as the modification ; and if head has input (after layer norm), a local ablation intervention is the modification . For boosting interventions, we implement and .
Implementing the intervention depends on whether the token is a source or destination token in the downstream head. When the edge is a source edge ( = source), we intervene in the source token (), and we set equal to the signal . In this case, is the projector onto the subspace defined by . When the edge is a destination type edge, we intervene in the destination token (), and we set equal to the signal , where is the projector onto the subspace defined by . In the case of local interventions, to make their encoding consistent with the assumptions imposed by layer norm folding, we center and scale them before adding them to the downstream input vector.
Magnitudes of Interventions.
Here we provide more detailed evidence of the magnitudes of the interventions we perform in §5.4. Given the intervened residual and the original residual , we use two metrics: the cosine similarity between and and the ratio of the residual norms before and after the intervention .
For the single-edge interventions, we show the distribution across prompts that were intervened. In the case of the multi-edge interventions, different prompts can have different numbers of interventions. In that case, for each multi-edge intervention, we compute the metric per prompt, and the plots show the distribution of the average values across multiple multi-edge interventions. As expected, single edge interventions have smaller effects in the residual than multi-edge interventions. However, both are very peaked in the value 1.0, showing that most of these interventions have very small effects in the residual. See Figures 10, 11, 13, and 13 for more details.


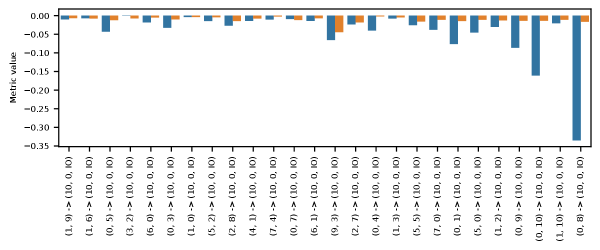

Effect of an Edge.
An edge in Figure 5 corresponds to a signal that has direct effect on a downstream attention head, and the weight of the edge corresponds to the strength of this signal. We expect that when we ablate an edge (for example), the attention score of the intervened token pair in the downstream head is decreased, especially for local interventions. In general this does not guarantee a particular indirect effect on model performance, due to indirect effects including self-repair and redundant paths in the circuit.
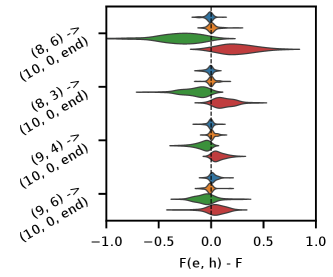
In Figures 17, 18, 19, and 20 we present examples showing the range of effects that edge ablation can have on both downstream attention scores, and on model performance. Edges in the figures are ordered by increasing weight (magnitude of the contribution (8) of the edge).
In all cases, edge ablations decrease attention scores as expected, with the effect varying depending on the weight of the edge. Further, in Figures 17, 19, and 20 edge ablations generally decrease model performance, again as expected. For the local ablations in Figure 20, the impact on model performance is proportionate to the decrease in attention score caused by the ablation. However in the case of global interventions, impact on model performance is not generally proportionate to the decrease in attention score.
Figure 18, corresponding to local ablations of edges into (9, 6) is a special case that we discuss in more detail below.
Additional Intervention Results.
Here we show more extensive results of the intervention based validation experiments. First, we show that ablations generally decrease the IO logit, and boosting generally increases the IO logit. Figure 22, Figure 23, and Figure 24.
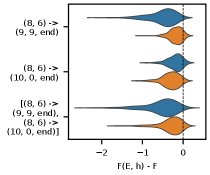
We also examine a wide range of multi-edge ablations to illustrate the impact of multiple paths in the traced circuit. First, note that Figure 14 gives a detailed look at the many redundant paths through the top layers of the traced circuit. In Figure 25 we show a variety of cases in which edges that are parts of parallel paths are ablated, both separately and together. In many cases we see evidence that the effect of ablating parallel paths has an additive nature. Then in Figure 26 we show a variety of cases in which edges that are parts of serial paths are ablated, both separately and together. In many of these cases, we see what is closer to a superposition effect, in which the effects of each edge are separately felt and not generally additive.
On a different point, in Figure 28 we show the effects of ablating edges outgoing from (2, 8). This shows that (2, 8) – which we identify as an important part of the IOI network in this paper, attending to the verb of the sentence – also has a causal effect on model performance.
Ablation Results for (9, 6) Edges.
In §5.4 we show that ablating edges that feed into most components of the model decreases the value of , measured as . Here we show that (9, 6) (a name mover head) exhibits the opposite behavior, but only for local interventions. Figure 21 shows the intervention results for the four most significant edges into (9, 6), and Figure 28 shows results for ablating all incoming edges of (9, 6). Note that global ablation of the (9, 6) signal decreases the logit of the IO token as expected. However, when the intervention is applied locally so that it only affects the (9, 6) head, ablation increases the logit of the IO token and boosting decreases the IO logit. More detail on ablations is provided in Figure 18. This figure shows that after ablation, the attention scores of the (9, 6) are indeed decreasing; it is only the downstream impact on the IO logit that is increasing. Further, the amount of increase of the IO logit is proportionate to the amount of decrease of the (9, 6) attention score. This suggests a different role for the (9, 6) compared to the other name mover heads. This effect is borne out across all local edge interventions in the (9, 6) and is suggestive of the need for further study.


(a) (b)
Proof of Lemma 1.
Given vectors and , among all rank-1 matrices having unit Frobenius norm, the matrix that maximizes is
First we show that any rank-1 matrix having unit Frobenius norm can be expressed as the outer product of two unit-norm vectors. Consider a rank-1 matrix having unit Frobenius norm. Since is rank-1, we can write . Now construct By construction is both rank-1 and unit norm. Matrices and differ by a constant factor . However, since they have the same norm, we must have , and so can be expressed as the outer product of two unit vectors.
Next consider a unit-norm, rank-1 matrix for unit vectors and . By way of contradiction, suppose . Then The right hand side is the positive quantity . The left hand side is the product of the projections of onto , and onto . The product is maximized when , or . In either case, , proving the lemma.


(a) (b)


(c) (d)


(a) (b)


(c) (d)

(a) (b)


(c) (b)


(a) (b) (c)



(d) (e) (f)

(g)


(a) (b)


(c) (d)

