Space-Time Smoothing of Survey Outcomes using the R Package SUMMER
Abstract
The increasing availability of complex survey data, and the continued need for estimates of demographic and health indicators at a fine spatial and temporal scale, has led to the need for spatio-temporal smoothing methods that acknowledge the manner in which the data were collected. The open source R package SUMMER implements a variety of methods for spatial or spatio-temporal smoothing of survey outcomes. In this paper, we focus primarily on demographic and health indicators. Our methods are particularly useful for data from Demographic Health Surveys (DHS) and Multiple Indicator Cluster Surveys (MICS). We build upon functions within the survey package, and use INLA for fast Bayesian computation. This paper includes a brief overview of these methods and illustrates the workflow of processing surveys, fitting space-time smoothing models for both binary and composite indicators, and visualizing results with both simulated data and DHS surveys.
Introduction
A wealth of health and demographic indicators are now collected across the world, and interest often focuses on patterns in space and time. Spatial patterns indicate potential disparities while temporal trends are important for determining the impact of interventions and to assess whether targets, such as the sustainable development goals (SDGs) are being met (MacFeely 2020). In low- and middle-income countries (LMIC) the most reliable data with sufficient spatial resolution are often collected under complex sampling designs. Common sources of data include the Demographic Health Surveys (DHS) and Multiple Indicator Cluster Surveys (MICS), both of which use multi-stage cluster sampling. A two-stage cluster design is most common for these surveys. A sampling frame of clusters (for example, enumeration areas) is constructed, often from a census, and then strata are formed. The strata consist of some administrative geographical partition crossed with urban/rural (with countries having their own definitions of this dichotomy). Then a pre-specified number of clusters are sampled from these strata under some probabilistic scheme, for example, with probability proportional to size (PPS). Different surveys are powered to different geographical levels. Then, within the selected clusters, households are randomly sampled and individuals are sampled within these households, and asked questions on a range of health and demographic variables. This data collection process that must be acknowledged in the analysis to reduce bias and obtain proper uncertainty measures in the prevalence estimates.
Various packages are available for within R for small area estimation (SAE) of prevalence, including the sae package (Molina and Marhuenda 2015) that supports the popular book of Rao and Molina (2015) and includes the famous Fay and Herriot (1979) model and spatial smoothing options. Other packages include rsae (Schoch 2014), hbsae (Boonstra 2012), BayesSAE (Shi 2018) and msae (Permatasari and Ubaidillah 2021). A more comprehensive list of related packages are described at OfficialStatistics. Most of the existing packages focus on classical SAE models and provide very limited options for fitting spatial and space-time smoothing models.
In this paper we introduce the R package, SUMMER111The name originally arises from ‘Spatio-temporal Under-five Mortality Methods for Estimation in R’. As the package becomes a more general toolkit, it now stands for ‘Sae Unit/area Models and Methods for Estimation in R’. This package and its details are available on CRAN. SUMMER provides a computational framework and a collection of tools for smoothing and mapping the prevalence of indicators with complex survey data over space and time, with a special focus on estimating mortality rates. Smoothing is important to avoid unstable estimates and combine information from multiple surveys over time. Originally developed for small area estimation of the under-5 child mortality rate (U5MR), the SUMMER package has been extended to broader mortality rate estimation and more general tasks in SAE. The implemented methods have already been successfully applied to a range of data, e.g., subnational estimates of mortality rates (Mercer et al. 2015; Li et al. 2019; Schlüter and Masquelier 2021; Fuglstad, Li, and Wakefield 2021), HIV prevalence (Wakefield, Okonek, and Pedersen 2020) and vaccination coverage (T. Q. Dong and Wakefield 2021). Recently, the SUMMER package was used to obtain the official United Nations Inter-Agency Group for Mortality Estimation (UN IGME) yearly estimates (1990–2021) of U5MR at administrative level below the national level (admin-2 estimates) for countries in Africa and Asia (United Nations Inter-agency Group for Child Mortality Estimation 2023). Previously, the UN IGME only produced national estimates using the B3 model (Alkema and New 2014). The results of these endeavors are available online at https://childmortality.org.
The main focus of this paper is to provide an overview of the different prevalence models using survey data and how they can be implemented in SUMMER. The rest of the paper is organized as follows. We first briefly describe different methods to estimate prevalence using survey data. We start with a generic binary indicator and proceed with estimating mortality rates. We then provide an overview of the SUMMER package and the workflows of using SUMMER for prevalence mapping. We then discuss three examples for spatial and space-time smoothing of binary and composite indicators with increasing complexity. The first two examples uses simulated data that are included in the SUMMER package. The last example uses the most recent DHS survey from Malawi. Then we illustrate various visualization and model checking tools in the SUMMER package. Finally we conclude with future work.
Space-time smoothing using complex survey data
In this section we review different methods to estimate the prevalence of a health outcome from complex survey data. We begin by discussing design-based, direct estimates (Rao and Molina 2015) which are based on response data from that area only. Next, we describe space-time smoothing of the direct estimates using a Fay-Herriot model (Fay and Herriot 1979). We discuss both estimating the prevalence of a single binary indicator and the composite indicators such as U5MR. We then describe a cluster-level model to estimate prevalence at finer spatial and temporal resolutions.
Estimating the prevalence of a generic binary indicator
Consider a study region that is partitioned into areas, with interest focusing on estimating the prevalence of a binary indicator in each area, possibly over time. The data are collected via some complex survey design. For each individual , let denote the individual’s outcome, and denote the design weight associated with this individual. Further, let represent the indexes of individuals sampled in area and in time period . The design-based estimator (Horvitz and Thompson 1952; Hájek 1971) is
| (1) |
This is an example of a direct estimate. The variance of can be calculated using standard methods (Wolter 2007) and can be easily computed using the survey package. Let denote the design-based variance of , obtained from the design-based variance of via linearization (the delta method). We take the logit transformed direct estimates as input data and estimate the true prevalence with the random effects model,
| (2) | ||||
| (3) |
In this model, which is a space-time smoothing extension of the Fay and Herriot (1979) model, is the true prevalence we aim to estimate, and are area-level covariates. The rest of the terms are normally distributed random effects including structured time trends , unstructured, independent and identically distributed (iid), temporal terms , structured spatial trends , unstructured spatial terms , and space-time interaction terms . The terms are implemented via the BYM2 parameterization (Riebler et al. 2016), a reparameterization of the classical BYM model (Besag, York, and Mollié 1991) that combines iid error terms with intrinsic conditional autoregressive (ICAR) random effects. Several different temporal models are implemented in SUMMER for the structured temporal trends and space-time interaction effects, including random walks of order 1 and 2, and autoregressive models (Håvard Rue and Held 2005) with additional linear trends. The interaction term can be one of the type I to IV interactions of the chosen temporal model and the ICAR model in space, as described in Knorr-Held (2000). In order for the model to be identifiable, we impose sum-to-zero constraints on each group of random effects. More details on the prior choices are provided in the supplementary materials.
Estimating mortality rates using area-level models
For composite indicators such as mortality rates, the direct estimates require additional modeling. Here we focus on the estimation of the U5MR, one of the most critical and widely available population health indicator. The methodology and the functions in SUMMER are readily applicable to mortality rates of other age groups as well, but we note that modeling mortality beyond age 5 is usually more challenging in practice because death becomes rarer, and survey data alone are not sufficient for reliable inference.
The SUMMER package implements the discrete hazards model described in Mercer et al. (2015). We use discrete time survival analysis to estimate age-specific monthly probabilities of dying in user-defined age groups. We assume constant hazards within the age bands. The default choice uses the monthly age bands
for U5MR and they can be easily specified by the user. The U5MR for area and time can be calculated as,
| (4) |
where and are the start and end of the -th age group, and is the probability of death in age group in area and time , with the estimate of this quantity. This calculation follows the synthetic cohort life table approach in which mortality probabilities for each age segments based on real cohort mortality experience are combined. This allows the full use of the most recent data, which is especially useful when survey data are sparse and is the default approach that The DHS Program (2020) uses.
The constant one-month hazards in each age band can be estimated by a weighted logistic regression model (Binder 1983):
| (5) |
where is the age band indicator for the -th month, i.e.
| (6) |
The design-based variance of may then be estimated using the delta method or resampling methods such as the jackknife (J. Pedersen and Liu 2012). The smoothing of the direct estimates can then proceed using the model described in equations (2) – (3). When multiple surveys exist, one may choose to either model the survey-specific effects as fixed or random (Mercer et al. 2015) or first aggregate the direct estimates from multiple surveys to obtain a “meta-analysis” estimate in each area and time period (Li et al. 2019), i.e., at each time , we combine the available direct estimates from multiple surveys to form the estimate
and the associated design-based variance on the logit scale is . To mitigate the sparsity of available data in each year, Li et al. (2019) also considers a temporal model defined at the yearly level while the direct estimates are calculated at multi-year periods. All these variations can be fit using the SUMMER package.
Estimating mortality rates with cluster-level models
The space-time Fay-Herriot estimates are useful when there are enough observations at the spatial and temporal unit of the analysis. When the target of inference is at finer resolution, e.g., on a yearly time scale with admin-2 areas and surveys stratified at admin-1 levels, the direct estimates may contain many s or s and the design-based variance cannot be calculated reliably. In this case, we can consider unit-level models where the individual survey responses are modeled. In the rest of this section, we describe a model for the cluster-level risk, where we account for the additional within-cluster variation by allowing overdispersion in the likelihood. More detailed comparisons of this modeling choice was examined in (T. Q. Dong and Wakefield 2021). In a two-stage cluster design, the clusters are referred to as primary sampling units (PSUs) and the households are referred to as secondary sampling units (SSUs). Thus we refer to such models as cluster-level model to avoid confusion. We describe the model for the mortality estimation problem below, while the same formulation applies to the case of any generic binary indicators as well.
In the most general setting, we consider multiple surveys over time, indexed by . The sampling frame that was used for survey , will be denoted by . We assume a discrete hazards model as before. We consider a beta-binomial model for the probability (hazard) of death from month to in survey and at cluster in year . This model allows for overdispersion relative to the binomial model. Assuming constant hazards within age bands, we assume the number of deaths occurring within age band , in cluster , time , and survey follow the beta-binomial distribution,
| (7) |
where is the monthly hazard at -th month of age, in cluster , time , and survey and is the overdispersion parameter. The latent logistic model we use is,
| (8) | ||||
| (9) |
This form consists of a collection of terms that are used for prediction and a number that are not, as we now describe. We include a survey fixed effect with the constraint for each sampling frame , so that the main temporal trends are identifiable for each sampling frame. The terms are not included in the prediction, i.e., they are set to zero. The are unstructured temporal effects that allow for perturbations over time. It is a contextual choice whether they are used in predictions. We include terms in (9) that are analogous to those in equations (2)–(3), in particular the spatial main effects and and the space-time interactions .
For the temporal main effects and , we have stratum-specific distinct trends for each age group in surveys from each sampling frame. We include separate urban and rural temporal terms to acknowledge the sampling design, often urban clusters are oversampled and have different risk to rural clusters, and so it is important to acknowledge this aspect in the model (Paige et al. 2020). The urban-rural stratification effects may also be parameterized as time-invariant fixed effects, i.e., restricting . For a detailed discussion of the parameterization of stratification effects, we refer readers to Wu et al. (2021). In addition, it is usually reasonable to assume shared temporal trends up to a constant shift across some age groups. For example, we may let
where is a collection of temporal random effects with sum-to-zero constraint , and is a reduced set of age bands. The default choice for U5MR in the package is
| (10) |
That is, we assume the temporal trends for logit hazards in the last four age groups are parallel and only differ by the intercept term .
In situations where biases are known for particular surveys and/or years, we can adjust for bias following Wakefield et al. (2019) by including the bias ratio term, , where is the expected U5MR in year and is the biased version. This approach has been used to adjust for mothers who have died from AIDS (Walker, Hill, and Zhao 2012); such mothers cannot be surveyed, and their children are more likely to have died, so the missingness is informative.
The predicted U5MRs in urban and rural regions of area and at time according to sampling frame are,
| (11) | |||||
| (12) |
where , for the default choice of age bands. The aggregate risk in area and in year according to sampling frame is
| (13) |
where and are the proportions of the under-5 population in area that are urban and rural in year according to the classification of sampling frame . The final aggregation over different sampling frames can be done using meta-analysis combination, so that,
where is the scaled inverse of , which is the posterior variance of . Beyond point estimates, we obtain the full posterior of , and various summaries can be reported or mapped. The estimate constructed for U5MR is not relevant to any child, because that child would have to experience the hazards for each age group simultaneously in time period , rather than moving through age groups over multiple time periods. Nevertheless, the resultant U5MR is a useful summary and the conventional measure that is used to inform on child mortality.
Overview of SUMMER
The SUMMER package provides a collection of functions for SAE with complex survey data. The package can be installed in R directly by
install.packages("SUMMER")
The SUMMER package requires the INLA package (H. Rue, Martino, and Chopin 2009) to be installed. All analysis in this package are conducted with SUMMER package version and INLA version . INLA can be installed with
install.packages("INLA", repos=c(getOption("repos"),
INLA="https://inla.r-inla-download.org/R/stable"), dep=TRUE)
The SUMMER package implements a variety of space-time smoothing models using survey data. There are three main functions to implement these models, discussed below and in the three examples in the following sections.
-
•
smoothSurvey() produces direct and Fay-Herriot estimates for a generic binary indicator from raw survey data.
-
•
smoothDirect() takes direct estimates as input and produces the Fay-Herriot estimates for mortality estimation discussed in Li et al. (2019).
-
•
smoothCluster() performs cluster-level smoothing using the Beta-Binomial model discussed in the previous section, and with more details discussed in Wu et al. (2021) and Fuglstad, Li, and Wakefield (2021).
We note that smoothDirect() and smoothCluster() includes many more features in modeling composite indicators such as child mortality. In comparison, smoothSurvey() can only model generic binary indicators, but it has a simpler interface and workflow, which is appealing for broader communities of practitioners.
The main source of data required for these methods are the survey data and the corresponding spatial adjacency matrix, which can be derived from spatial polygons data describing region boundaries. For cluster-level modeling, we also need to know which region each cluster belongs to. In the context of modeling DHS data, the survey data and cluster locations are usually recorded in separate files. Figure 1 shows schematically the workflow of data processing and smoothing for generic binary indicators and mortality estimates using the SUMMER package. In this paper, our workflow starts with the birth records and GPS files in .dta files as an example. Such files can be directly downloaded from the DHS data portal. It is also straightforward to load data in other formats and supply the R objects into the functions. The entire pipeline of analysis can be carried out using functions in SUMMER. The analysis of the main paper can be reproduced without registering for data access. We include a more extensive analysis of DHS data in the supplementary materials, which requires registration with DHS program for data access.

Before demonstrating the utilities of these functions in the following examples, we first load the packages for the analysis, data processing and visualization. For the analysis presented in this paper, we use the ggplot2 package (Wickham 2016) and patchwork package (T. L. Pedersen 2019) to make further customize the visualization produced by SUMMER.
library(SUMMER) library(ggplot2) library(patchwork)
Example 1: prevalence estimation for a binary indicator
We start by considering the simplest scenario of estimating the prevalence of a binary indicator using a dataset from the Behavioral Risk Factor Surveillance System (BRFSS) survey. BRFSS is an annual telephone health survey conducted by the Centers for Disease Control and Prevention (CDC) that tracks health conditions and risk behaviors in the United States and its territories since 1984. The BRFSS sampling scheme is complex with high variability in the sampling weights. In this example, we estimate the prevalence of Type II diabetes in health reporting areas (HRAs) in the King County of Washington using BRFSS data. We will compare the direct estimates and the Fay-Herriot estimates.
The BRFSS dataset in SUMMER contains the full BRFSS dataset with observations. The diab2 variable is the binary indicator of Type II diabetes, strata is the strata indicator and rwt_llcp is the final design weight. For the purpose of this analysis, we first remove records with missing HRA code or diabetes status from this dataset.
data(BRFSS) data <- subset(BRFSS, !is.na(diab2) & !is.na(hracode))
The KingCounty dataset in SUMMER contains the map of the HRAs in the King County. We first extract the spatial adjacency matrix for the HRAs using the getAmat() function.
data(KingCounty) KingGraph <- getAmat(KingCounty, KingCounty$HRA2010v2_)
We then use the smoothSurvey() function to obtain both the direct and Fay-Herriot estimates by HRA. The function requires specifications of the variables that determines the survey design, including sampling weights (weightVar), strata indicator (strataVar), and cluster identifiers (clusterVar). In this dataset, there are no clusters so we use the formula ~1 in this situation (Lumley 2004). We also need to specify region indicators (regionVar) in the data frame that match the column and row names of the spatial adjacency matrix.
fit.BRFSS <- smoothSurvey(data = data, Amat = KingGraph,
response.type = "binary", responseVar = "diab2",
strataVar="strata", weightVar="rwt_llcp",
regionVar="hracode", clusterVar = "~1")
head(fit.BRFSS$direct, n = 3)
#> region direct.est direct.var direct.logit.est direct.logit.var direct.logit.prec #> 1 Auburn-North 0.10 0.00046 -2.2 0.053 18.8 #> 2 Auburn-South 0.23 0.00240 -1.2 0.075 13.3 #> 3 Ballard 0.07 0.00050 -2.6 0.115 8.7
head(fit.BRFSS$smooth, n = 3)
#> region mean var median lower upper logit.mean logit.var logit.median #> 1 Auburn-North 0.102 0.00026 0.101 0.074 0.137 -2.2 0.030 -2.2 #> 2 Auburn-South 0.160 0.00093 0.157 0.108 0.228 -1.7 0.051 -1.7 #> 3 Ballard 0.059 0.00018 0.057 0.037 0.089 -2.8 0.057 -2.8 #> logit.lower logit.upper #> 1 -2.5 -2.5 #> 2 -2.1 -2.1 #> 3 -3.3 -3.3
The fitted object is of class SUMMERmodel.svy, and the direct ($direct) and Fay-Herriot estimates ($smooth) are saved as data frames in the fitted objects. Notice that since the analysis is performed on the logit of the prevalence, estimates on both the logit and the probability scales are returned in the output. We use the mapPlot() function in SUMMER to show the estimates on a map. In essence, the mapPlot() function takes a data frame, a SpatialPolygonsDataFrame object, the column names indexing regions in both the data frame and the polygons, and returns a ggplot object. Additional function arguments are available to more easily customize the visualizations. Figure 2 compares the point estimates on the map and the effect of spatial smoothing can be easily seen.
g1 <- mapPlot(fit.BRFSS$direct, geo = KingCounty,
by.data = "region", by.geo = "HRA2010v2_",
variables = "direct.est", label = "Direct Estimates",
legend.label = "Prevalence", ylim = c(0, 0.24))
g2 <- mapPlot(fit.BRFSS$smooth, geo = KingCounty,
by.data = "region", by.geo = "HRA2010v2_",
variables = "median", label = "Fay Herriot Estimates",
legend.label = "Prevalence", ylim = c(0, 0.24))
g1 + g2

Similar analysis can be implemented for Gaussian observations, and can include temporal smoothing or covariates in the smoothing model. The hyperpriors can also be further customized. For more details and examples, we refer the readers to the package documentation under the smoothSurvey() section.
Example 2: area-level model of NMR and U5MR using simulated data
In the second example, we consider estimating mortality rates using multiple surveys. We use the NMR and U5MR as two examples, but the implementation in the SUMMER package allows straightforward extensions to other age groups. We use a simulated survey dataset in this example. A more detailed case study using cluster-level model is provided in the supplementary materials.
We load the DemoData dataset from the SUMMER package. The DemoData is a list that contains full birth history data from simulated surveys with stratified cluster sampling design, similar to most of the DHS surveys. It has been pre-processed into the person-month format, where for each list entry, each row represents one person-month record. Each record contains columns for the cluster ID (clustid), household ID (id), strata membership (strata) and survey weights (weights). The region and time period associated with each person-month record has also been pre-computed. The age variable in this data frame are in the form of -, i.e., - corresponds to age group with 1 to 11 completed months, whereas age groups with only one month are stored using a single number representation, e.g., age group . This is also the data structure in the output of the getBirths function in the SUMMER package. In all the analysis of this paper, we use the default age bands as described before. If a different set of age band is desired, they can be specified by the month.cut argument in the getBirths function.
data(DemoData) head(DemoData[[1]])
#> clustid id region time age weights strata died #> 1 1 1 eastern 00-04 0 1.1 eastern.rural 0 #> 2 1 1 eastern 00-04 1-11 1.1 eastern.rural 0 #> 3 1 1 eastern 00-04 1-11 1.1 eastern.rural 0 #> 4 1 1 eastern 00-04 1-11 1.1 eastern.rural 0 #> 5 1 1 eastern 00-04 1-11 1.1 eastern.rural 0 #> 6 1 1 eastern 00-04 1-11 1.1 eastern.rural 0
In order to compute NMR, we create a new list of surveys with only deaths within age group .
DemoDataNMR <- DemoData
for(i in 1:length(DemoData)){
DemoDataNMR[[i]] <- subset(DemoData[[i]], age == "0")
}
We now turn to the estimation of NMR and U5MR using four simulated surveys in DemoData. For multiple surveys, we combine the person-month records into a list and use the getDirectList() function to obtain the survey specific direct estimates. When there are no deaths in a given area and time period, or when more than half of the age groups do not exist in the person-month data, the direct estimates cannot be reliably computed and are set to NA. When only a small fraction of the age groups are not observed, they will be combined with the previous age groups when fitting the discrete hazard model.
periods <- c("85-89", "90-94", "95-99", "00-04", "05-09", "10-14")
directNMR <- getDirectList(births = DemoDataNMR, years = periods,
regionVar = "region", timeVar = "time",
clusterVar = "~clustid + id", ageVar = "age",
weightsVar = "weights")
directU5 <- getDirectList(births = DemoData, years = periods,
regionVar = "region", timeVar = "time",
clusterVar = "~clustid + id", ageVar = "age",
weightsVar = "weights")
The direct estimates from multiple surveys can be combined to produce a “meta-analysis” estimator using the aggregateSurvey() function.
directNMR.comb <- aggregateSurvey(directNMR) directU5.comb <- aggregateSurvey(directU5)
Once the direct estimates are calculated, we fit the space-time Fay-Herriot model in the same fashion as in the previous example. The argument year.label specifies the order of the years column in the direct estimates, so that it does not have to be integer valued, and can easily allow extensions to future and past time periods not in the data. We can also fit the temporal model at the yearly level even though the direct estimates are in five year periods (Li et al. 2019). In this case we need to specify the proper range of the time periods (year_range) encoded by the time periods in year.label, and the number of years in each period (m). Unequal periods are not supported at this time. The smoothDirect() function returns a fitted object of class SUMMERmodel.
fhNMR <- smoothDirect(data = directNMR.comb, Amat = DemoMap$Amat,
year.label = c(periods, "15-19"), year.range = c(1985, 2019),
time.model = "rw2", type.st = 4, is.yearly = TRUE, m = 5)
fhU5 <- smoothDirect(data = directU5.comb, Amat = DemoMap$Amat,
year.label = c(periods, "15-19"), year.range = c(1985, 2019),
time.model = "rw2", type.st = 4, is.yearly = TRUE, m = 5)
The Fay-Herriot estimates can be summarized by the getSmoothed() function. The desired posterior credible intervals are specified by the CI argument. It organizes the estimates into a data frame of class SUMMERproj, which can be directly viewed or plotted using the plot method. Additional customization can be added using the syntax of ggplot2, as shown in Figure 3.
est.NMR <- getSmoothed(fhNMR, CI = 0.95)
est.U5 <- getSmoothed(fhU5, CI = 0.95)
g3 <- plot(est.NMR, per1000 = TRUE) + ggtitle("NMR")
g4 <- plot(est.NMR, per1000 = TRUE, plot.CI=TRUE) + facet_wrap(~region)
g5 <- plot(est.U5, per1000 = TRUE) + ggtitle("U5MR")
g6 <- plot(est.U5, per1000 = TRUE, plot.CI=TRUE) + facet_wrap(~region)
(g3 + g4) / (g5 + g6)

Example 3: cluster-level model of U5MR using Malawi DHS data
We now consider a more realistic example of estimating U5MR at admin-2 level using the 2015–2016 Malawi DHS survey. The full dataset is available on the DHS website at https://dhsprogram.com/data/available-datasets.cfm?ctryid=24. Access to the full micro-level data requires registration with the DHS. Once access is approved, the rdhs (Watson and Eaton 2019) package can be used to load data directly from the DHS API in R. We document the process to read the raw DHS files and process the birth records in the supplementary materials.
For reproducibility of the examples in this paper, we start with the aggregated count data from the 2015 Malawi DHS. The pre-processed count data is available in the supplementary materials. This aggregated dataset consists of the counts of deaths occurred within each age band and the total number of person-months by cluster and year. This aggregated dataset and the full data acquisition and cleaning steps to obtain this dataset are described in the supplementary materials. The processing steps involves primarily the getBirths() and getCounts() functions and some data cleaning in region names. The supplementary materials also includes workflows and results on fitting several other smoothing models on the Malawi DHS data.
Subnational spatial polygon files can usually be found on the DHS spatial data repository (The DHS Program 2020) or the GADM database of global administrative areas (Global Administrative Areas 2012). The admin-2 region polygon of Malawi is included in the SUMMER package already and can be directly loaded.
data(MalawiMap) MalawiGraph = getAmat(MalawiMap, names=MalawiMap$ADM2_EN)
We then load the pre-processed count data and fit the cluster-level model using the smoothCluster() function. We consider the observations from 2007 to 2015 and project the mortality rates to 2019. To simplify results, we fit the unstratified model in this example by removing the strata variable from the data frame or setting it to NA. The supplementary materials contains additional details to fit stratified cluster-level models.
load("Data/DHS_counts.rda")
agg.counts$strata <- NA
head(agg.counts)
#> v001 v025 admin2 time age v005 died total survey cluster strata region years Y #> 55427 696 urban Likoma 2000 0 12778 0 3 DHS2015 696 NA Likoma 2000 0 #> 55428 696 urban Likoma 2001 0 12778 0 4 DHS2015 696 NA Likoma 2001 0 #> 55429 696 urban Likoma 2002 0 12778 0 2 DHS2015 696 NA Likoma 2002 0 #> 55430 696 urban Likoma 2003 0 12778 0 4 DHS2015 696 NA Likoma 2003 0 #> 55431 696 urban Likoma 2004 0 12778 0 3 DHS2015 696 NA Likoma 2004 0 #> 55432 696 urban Likoma 2005 0 12778 0 2 DHS2015 696 NA Likoma 2005 0
Sometimes additional information is available to adjust the estimates from the surveys. For example, in countries with high prevalence of HIV, estimates of U5MR can be biased, particularly before ART treatment became widely available. Pre-treatment, HIV positive women had a high risk of dying, and such women who had given birth were therefore less likely to appear in surveys. The children of HIV positive women are also more likely to have a higher probability of dying compared to those born to HIV negative women. Hence, we expect that the U5MR is underestimated if we do not adjust for the missing women. For the two surveys in Malawi, the calculated HIV adjustment ratios as described in Walker, Hill, and Zhao (2012) are stored in the SUMMER as MalawiData$HIV.yearly. The unstratified cluster-level model can be fitted using the smoothCluster() function.
fit.bb <- smoothCluster(data = agg.counts, Amat = MalawiGraph,
family = "betabinomial", year.label = 2000:2019,
time.model = "rw2", st.time.model = "ar1",
age.group = c("0", "1-11", "12-23", "24-35", "36-47", "48-59"),
age.n = c(1, 11, 12, 12, 12, 12),
age.time.group = c(1, 2, 3, 3, 3, 3),
pc.st.slope.u = 2, pc.st.slope.alpha = 0.1,
bias.adj = MalawiData$HIV.yearly,
bias.adj.by = c("years", "survey"),
survey.effect = FALSE)
When not specified explicitly, the space-time interaction term inherits the same temporal dependency structure defined by time.model. We can use different models for the interaction term by specifying st.time.model argument. For example, in the model above, we can model the main temporal trends using random walks of order 2, and model the space-time interaction using the interaction of a temporal AR(1) process and an ICAR process in space. To allow each region to have more flexible temporal trends, we add region-specific random slopes to the interaction terms by specifying the priors pc.st.slope.u and pc.st.slope.alpha. These arguments specifies that the probability of the absolute temporal change from the shared temporal trend (on the logit scale) over the entire time period exceeding pc.st.slope.u is pc.st.slope.alpha. The age.group, age.n and age.time.group specify the age groups, their corresponding length (in months), and how they are grouped when modeling the temporal trends, i.e., the term defined before.
After we fit the model, we use the getSmoothed() function to obtain the posterior summaries of the prevalence by taking nsim draws from the posterior distribution. Since for the cluster-level models, the estimates may not be a linear combination of the random effect terms in the case of a composite indicator, the posterior summaries are obtained via posterior samples. For the cluster-level model, the getSmoothed() function returns a few an object of class SUMMERprojlist, which includes potentially multiple projections for each stratum ($stratified), sampling frame ($overall), and aggregated over different sampling frames ($final) if applicable. In this example, since we fit an unstratified model with only one sampling frame, the estimates stored in est.bb$stratified and est.bb$overall are the same. In addition, by specifying save.draws = TRUE, the full posterior draws are stored, which can be re-used to speed up other functions that require access to posterior samples of internal model parameters.
est.bb <- getSmoothed(fit.bb, nsim = 1000, save.draws = TRUE)
Visualization and model checking
In addition to the plots shown in the previous sections, the SUMMER package provides a collection of visualization tools to assess model fit and uncertainty in the estimates. Assessment of uncertainty is a key step in analysis as maps of point estimates can be intoxicating, but often hide huge uncertainty, which should temper initial enthusiasm. Most of the visualization options return a ggplot2 object, which can be further customized. In this section, we use the fitted models for Malawi 2015 – 2016 DHS as an example.
The first set of visualizations are the line plots that we have shown before. Figure 4 shows subnational posterior median U5MR estimates over time for the five northern regions. We also scale the estimates to be deaths per live births using the per1000 argument.
select <- c("Chitipa", "Karonga", "Rumphi", "Mzimba")
plot(subset(est.bb$overall, region %in% select), per1000 = TRUE, year.proj = 2016)
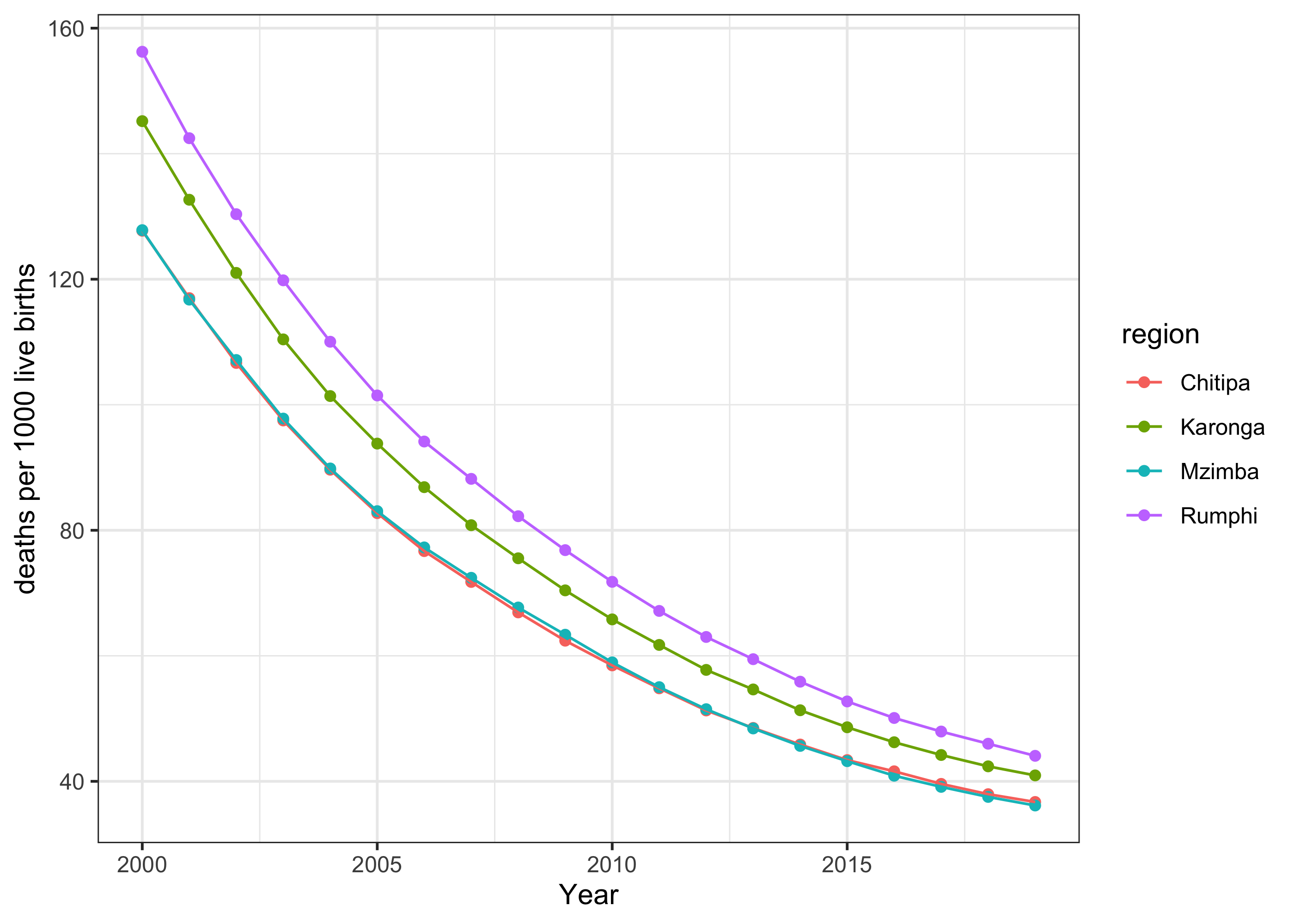
By default, subnational estimates do not show the intervals to avoid many overlapping vertical bars, but they can be added back with the plot.CI option as illustrated in previous examples. We also compare the smoothed estimates with the pre-computed direct estimates in Figure 5, where the shrinkage in point estimates and the reduction in uncertainty intervals can be easily seen. The direct estimate computation are detailed in the supplementary materials.
load("Data/DHS_direct_hiv_adj.rda")
plot(subset(est.bb$overall, region %in% select), per1000 = TRUE,
year.proj = 2016, plot.CI = TRUE,
data.add = direct.2015.hiv, label.add = "Direct Estimates",
option.add = list(point = "mean", lower = "lower", upper = "upper")) +
facet_wrap(~region, ncol = 4)

The mapPlot() function visualizes the estimates on a map. The estimates, est.bb$overall, are in the long format where estimates of each year and period are stacked. This is specified with the is.long argument. Figure 6 maps the changes over time. The drops in U5MR in all regions is apparent, though there is great spatial heterogeneity.
year.plot <- c("2007", "2010", "2013", "2016", "2019")
mapPlot(subset(est.bb$overall, years %in% year.plot),
geo = MalawiMap, by.data = "region", by.geo = "ADM2_EN",
is.long = TRUE, variables = "years", values = "median",
ncol = 5, direction = -1, per1000 = TRUE, legend.label = "U5MR")

The hatchPlot() function plots additional hatching lines on the map indicating the width of the uncertainty intervals. Denser hatching lines represent higher uncertainty. Usually estimates of the early years have higher uncertainty as shown in Figure 7. It also clearly shows the increase in uncertainty in the projections. We also note that both mapPlot() and hatchPlot() function can be used in broader cases as they provide a general tool to visualize rectangular data on a map.
hatchPlot(subset(est.bb$overall, years %in% year.plot),
geo = MalawiMap, by.data = "region", by.geo = "ADM2_EN",
is.long = TRUE, variables = "years", values = "median",
lower = "lower", upper = "upper", hatch = "red",
ncol = 5, direction = -1, per1000 = TRUE, legend.label = "U5MR")

The ridgePlot() function provides another visual comparison of the estimates and their associated uncertainty. Figure 8 shows one such example where the marginal posterior densities of the estimates in the selected years are plotted with regions sorted by their posterior medians in the last plotted period. The posterior densities can also be grouped with all estimates in each region plotted in the same panel using by.year = FALSE argument in the ridgePlot() function. These plots are particularly useful to quickly identify regions with high and low estimates, while also showing the uncertainties associated with the rankings as well. The ranking of areas is often an important endeavor, since it can inform interventions in areas that are performing poorly or, more optimistically, allow areas with better outcomes to be examined to see if covariates (for example) are explaining their more positive performance.
ridgePlot(draws = est.bb, Amat = MalawiGraph, year.plot = year.plot,
ncol = 5, per1000 = TRUE, order = -1, direction = -1) + xlim(c(0, 200))

Finally, as models get more complicated, it becomes increasingly important to examine the estimated random effects for idiosyncratic behavior that may be evidence of model misspecification. The SUMMER package provides tools to easily extract and plot posterior marginal distributions for each of the random effect components. We can use the getDiag() function to extract the posterior marginal distributions of the spatial, temporal, and space-time interaction terms from the fitted models, which can then be plotted in the similar fashion as the estimates. The space-time interaction term in the fitted model contains a sum of a region-specific linear trend and an AR(1) random effect. Thus we need posterior samples to compute their marginal distributions. We can feed the saved posterior draws from the est.bb here to speed up the computation.
r.time <- getDiag(fit.bb, field = "time") r.space <- getDiag(fit.bb, field = "space") r.interact <- getDiag(fit.bb, field = "spacetime", draws = est.bb$draws)
The extracted posterior summaries of the random effects can then be examined and visualized. Figure 9 shows the posterior summaries of the temporal, spatial, and interaction terms in the model.
g.time <- ggplot(r.time, aes(x = years, y = median, ymin=lower, ymax=upper)) +
geom_line() +
geom_ribbon(color=NA, aes(fill = label), alpha = 0.3) +
facet_wrap(~group, ncol = 3) +
theme_bw() +
ggtitle("Age-specific Temporal effects")
g.space <- mapPlot(subset(r.space, label = "Total"),
geo=MalawiMap, by.data="region", by.geo = "ADM2_EN",
direction = -1, variables="median",
removetab=TRUE, legend.label = "Effect") +
ggtitle("Spatial effects")
g.interact <- ggplot(r.interact, aes(x = years, y = median, group=region)) +
geom_line() + ggtitle("Interaction effects")
g.time + g.space + g.interact + plot_layout(widths = c(3, 2, 3))

Discussion
The present paper aims to provide a general overview of the R package SUMMER for space-time smoothing of demographic and health indicators. The particular focus of this paper is on mortality estimation and the demonstration of the workflow for practitioners to fit flexible Bayesian smoothing models with DHS data. The implementation using INLA allows fast computation of these smoothing models. The Fay-Herriot estimates can usually be fit within seconds to minutes depending on the number of regions and time period. The cluster-level model may require longer computation time, especially with surveys containing many samples. We leave the fitting of more time-consuming models in the supplementary materials.
The SUMMER package is in constant development. This paper introduced the core functionalities of the package. There are many more functionalities to tackle application-specific issues, such as different age-time interactions, aggregation over urban/rural strata, benchmarking to external national estimates, etc. We are also expanding the package to include more options for the traditional SAE models with fast implementations built on our current computational framework. Recent extensions built on SUMMER functionalities include the recent addition of SAE methods in the survey package (Lumley 2024) and the surveyPrev package (Q. Dong et al. 2024) which provides a general pipeline to download, process, and map a broad variety of DHS indicators.
In the future, we have several plans to improve the functionality of SUMMER. In the cluster-level model, we would like to allow different overdispersion parameters for different age groups. We plan to incorporate methods for child mortality estimation using summary birth history data (Hill et al. 2015; Wilson and Wakefield 2021) in which women provide only information on the number of children born, and number died, without the dates of these events. We also expect to extend the core functionalities to model other demographic and health indicators such as fertility. In our examples in this paper, we did not include covariates. In both the area-level and the cluster-level models, covariates can be included, see Wakefield, Okonek, and Pedersen (2020) for an example in the context of HIV prevalence mapping in Malawi. Finally, in the long term, we would like to incorporate continuous spatial models as well.
References
reAlkema, Leontine, and Jin Rou New. 2014. “Global Estimation of Child Mortality Using a Bayesian B-Spline Bias-Reduction Model.” The Annals of Applied Statistics 8: 2122–49.
preBesag, Julian, Jeremy York, and Annie Mollié. 1991. “Bayesian Image Restoration, with Two Applications in Spatial Statistics (with Discussion).” Annals of the Institute of Statistical Mathematics 43: 1–59.
preBinder, David A. 1983. “On the Variances of Asymptotically Normal Estimators from Complex Surveys.” International Statistical Review 51: 279–92.
preBoonstra, Harm Jan. 2012. Hbsae: Hierarchical Bayesian Small Area Estimation.
preDong, Qianyu, Zehang R Li, Yunhan Wu, Andrea Boskovic, and Jon Wakefield. 2024. surveyPrev: Mapping the Prevalence of Binary Indicators Using Survey Data in Small Areas. https://CRAN.R-project.org/package=surveyPrev.
preDong, Tracy Qi, and Jon Wakefield. 2021. “Modeling and Presentation of Vaccination Coverage Estimates Using Data from Household Surveys.” Vaccine 39 (18): 2584–94.
preFay, Robert E., and Roger A. Herriot. 1979. “Estimates of Income for Small Places: An Application of James–Stein Procedure to Census Data.” Journal of the American Statistical Association 74: 269–77.
preFuglstad, Geir-Arne, Zehang Richard Li, and Jon Wakefield. 2021. “The Two Cultures for Prevalence Mapping: Small Area Estimation and Spatial Statistics.” arXiv Preprint arXiv:2110.09576.
preGlobal Administrative Areas. 2012. “GADM Database of Global Administrative Areas.”
preHájek, Jaroslav. 1971. “Discussion of, ‘An Essay on the Logical Foundations of Survey Sampling, Part I,’ by D. Basu.” In Foundations of Statistical Inference, edited by V. P. Godambe and D. A. Sprott. Toronto: Holt, Rinehart; Winston.
preHill, Kenneth, Eoghan Brady, Linnea Zimmerman, Livia Montana, Romesh Silva, and Agbessi Amouzou. 2015. “Monitoring Change in Child Mortality Through Household Surveys.” PloS One 10: e0137713.
preHorvitz, Daniel G, and Donovan J Thompson. 1952. “A Generalization of Sampling Without Replacement from a Finite Universe.” Journal of the American Statistical Association 47: 663–85.
preKnorr-Held, Leonhard. 2000. “Bayesian Modelling of Inseparable Space-Time Variation in Disease Risk.” Statistics in Medicine 19: 2555–67.
preLi, Zehang R, Yuan Hsiao, Jessica Godwin, Bryan D Martin, Jon Wakefield, and Samuel J Clark. 2019. “Changes in the Spatial Distribution of the Under Five Mortality Rate: Small-Area Analysis of 122 DHS Surveys in 262 Subregions of 35 Countries in Africa.” PLoS One.
preLumley, Thomas. 2004. “Analysis of Complex Survey Samples.” Journal of Statistical Software 9 (1): 1–19.
pre———. 2024. “Survey: Analysis of Complex Survey Samples.”
preMacFeely, Steve. 2020. “Measuring the Sustainable Development Goal Indicators: An Unprecedented Statistical Challenge.” Journal of Official Statistics 36 (2): 361–78.
preMercer, Laina D, Jon Wakefield, Athena Pantazis, Angelina M Lutambi, Honorati Masanja, and Samuel Clark. 2015. “Small Area Estimation of Childhood Mortality in the Absence of Vital Registration.” Annals of Applied Statistics 9: 1889–1905.
preMolina, Isabel, and Yolanda Marhuenda. 2015. “sae: An R Package for Small Area Estimation.” The R Journal 7: 81–98.
prePaige, John, Geir-Arne Fuglstad, Andrea Riebler, and Jon Wakefield. 2020. “Model-Based Approaches to Analysing Spatial Data from Complex Surveys.” Journal of Survey Statistics and Methodology.
prePedersen, Jon, and Jing Liu. 2012. “Child Mortality Estimation: Appropriate Time Periods for Child Mortality Estimates from Full Birth Histories.” PLoS Med 9 (8): e1001289.
prePedersen, Thomas Lin. 2019. patchwork: The Composer of Plots. https://CRAN.R-project.org/package=patchwork.
prePermatasari, Novia, and Azka Ubaidillah. 2021. “msae: An R Package of Multivariate Fay Herriot Models for Small Area Estimation.” The R Journal.
preRao, John NK, and Isabel Molina. 2015. Small Area Estimation, Second Edition. New York: John Wiley.
preRiebler, Andrea, Sigrunn H Sørbye, Daniel Simpson, and Håvard Rue. 2016. “An Intuitive Bayesian Spatial Model for Disease Mapping That Accounts for Scaling.” Statistical Methods in Medical Research 25: 1145–65.
preRue, Håvard, and Leonhard Held. 2005. Gaussian Markov Random Fields: Theory and Application. Boca Raton: Chapman; Hall/CRC Press.
preRue, H., S. Martino, and N. Chopin. 2009. “Approximate Bayesian Inference for Latent Gaussian Models Using Integrated Nested Laplace Approximations (with Discussion).” Journal of the Royal Statistical Society, Series B 71: 319–92.
preSchlüter, Benjamin-Samuel, and Bruno Masquelier. 2021. “Space-Time Smoothing of Mortality Estimates in Children Aged 5-14 in Sub-Saharan Africa.” Plos One 16 (1): e0245596.
preSchoch, Tobias. 2014. Rsae: Robust Small Area Estimation.
preShi, Chengchun. 2018. BayesSAE: Bayesian Analysis of Small Area Estimation.
preThe DHS Program. 2020. “Spatial Data Repository.” https://spatialdata.dhsprogram.com/home/.
preUnited Nations Inter-agency Group for Child Mortality Estimation. 2023. “Subnational Under-Five and Neonatal Mortality Estimates, 2000–2021 Estimates Developed by the United Nations Inter-agency Group for Child Mortality Estimation.” United Nations Children’s Fund, New York.
preWakefield, Jon, Geir-Arne Fuglstad, Andrea Riebler, Jessica Godwin, Katie Wilson, and Samuel Clark. 2019. “Estimating Under Five Mortality in Space and Time in a Developing World Context.” Statistical Methods in Medical Research 28: 2614–34.
preWakefield, Jon, Taylor Okonek, and Jon Pedersen. 2020. “Small Area Estimation of Health Outcomes.” International Statistical Review.
preWalker, Neff, Kenneth Hill, and Fengmin Zhao. 2012. “Child Mortality Estimation: Methods Used to Adjust for Bias Due to AIDS in Estimating Trends in Under-Five Mortality.” PLoS Med 9: e1001298.
preWatson, OJ, and Jeff Eaton. 2019. rdhs: API Client and Dataset Management for the Demographic and Health Survey (DHS) Data. https://CRAN.R-project.org/package=rdhs.
preWickham, Hadley. 2016. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. https://ggplot2.tidyverse.org.
preWilson, Katie, and Jon Wakefield. 2021. “Child Mortality Estimation Incorporating Summary Birth History Data.” Biometrics 77 (4): 1456–66.
preWolter, Kirk. 2007. Introduction to Variance Estimation. Springer Science & Business Media.
preWu, Yunhan, Zehang Richard Li, Benjamin K. Mayala, Houjie Wang, Peter Gao, Johnny Paige, Geir-Arne Fuglstad, et al. 2021. “Spatial Modeling for Subnational Administrative Level 2 Small-Area Estimation.” DHS Spatial Analysis Reports No. 21. Rockville, Maryland, USA: ICF.
p
Zehang Richard Li
University of California, Santa Cruz
Santa Cruz CA, USA
ORCiD: 0000-0002-9079-593X
[email protected]
Bryan D Martin
University of Washington
Seattle, WA, USA
[email protected]
Tracy Qi Dong
Fred Hutchinson Cancer Research Center
Seattle, WA, USA
[email protected]
Geir-Arne Fuglstad
Norwegian University of Science and Technology
Trondheim, Norway
[email protected]
Jessica Godwin
University of Washington
Seattle, WA, USA
[email protected]
John Paige
Norwegian University of Science and Technology
Trondheim, Norway
[email protected]
Andrea Riebler
Norwegian University of Science and Technology
Trondheim, Norway
[email protected]
Samuel J Clark
The Ohio State University
Columbus, OH, USA
[email protected]
Jon Wakefield
University of Washington
Seattle, WA, USA
[email protected]
Appendix
Prior specification
In all the model implementations, we apply penalised complexity (PC) priors to model the random effects (Simpson et al., 2017). These priors are proper and parameterization invariant. The basis of PC priors is to regard each model component as a flexible extension of a so-called base model. Considering an unstructured iid model component, the base model would be to remove this component from the linear predictor by letting its variance parameter go to zero. This is also the base model for any simple Gaussian model component with mean zero. The main idea is to follow Occam’s razor and favor less complex, or more intuitive, models unless the data suggest otherwise. Of note, state-of-the-art priors, such as the inverse gamma prior for a variance parameter, put zero density mass at the base model and as such do not allow the recovery of this model. The PC prior is specified by following a number of desirable principles and is derived based on the Kullback-Leibler distance of the flexible model from the base model. For details we refer to Simpson et al. (2017). Here, we will shortly comment on the PC priors relevant for the parameters used in our models and their default hyperparameters. All the PC priors can be specified by the user in the function calls using arguments such as pc.u and pc.alpha.
Considering a simple Gaussian model component with standard deviation parameter , the PC prior results in an exponential distribution for . The rate parameter can be informed using a probability contrast of the form , which leads to (Simpson et al., 2017). The SUMMER package uses as default and , which means that the 99th percentile of the prior is at 1.
For the structured spatial random effects, we use the BYM2 model (Riebler et al., 2016; Simpson et al., 2017). It has a structured and unstructured term, and uses a single variance, , that represents the marginal spatial variance and a mixing parameter specifying the proportion of spatial variation. To interpret as a marginal standard deviation, the spatial component needs to be scaled, so that . This leads to:
where is iid normally distributed with fixed variance equal to 1 and is the scaled ICAR model. We follow Riebler et al. (2016) and scale the ICAR component so that the geometric mean of the marginal variances of is equal to 1. Note that we also apply this scaling procedure to all intrinsic model components, such as random walk of order 1 or 2 components (Sørbye and Rue, 2014), to ensure interpretability of the prior distributions assigned to their flexibility parameters. The BYM2 model has a two-stage base model, with the first implying the absence of any spatial effect by setting equal to zero, and the second by assuming and therefore only unstructured spatial variation. For we use an exponential prior as outlined before. The prior for depends on the study-specific neighborhood graph and is not available in closed form, see Riebler et al. (2016) for details. Its hyperparameter can be derived from . The SUMMER package uses as default and , which means that the 66.6th percentile of the prior is at 0.5, so that values of less than are preferred a little more, a priori.
For the autoregressive model for time effects, we again use an exponential prior for the marginal standard deviation. For the autocorrelation correlation coefficient , we assume as base model . This represents a limiting random walk which assumes that the process does not change in time. The prior for is again not available in closed form, see Sørbye and Rue (2017) for details. Its hyperparameter can be found from . The SUMMER package uses as default and , which means that the 10th percentile of the prior is at 0.7, and therefore preferring values of that are close to 1.
The space-time interaction terms, , are modeled with the Type I, II, III, IV models of Knorr-Held (2000). The Type I model assumes iid interaction terms, the Type II model that the interactions are temporally structured but independent in space and the Type III model that the interactions are iid in time but spatially structured via an ICAR model. For the default Type IV interaction, we assume the specified temporal model and spatial (ICAR) structured effects interact. When the temporal component in the space-time interaction terms are modeled with a random walk of order 1 or an autoregressive model of order 1, we may also allow area-specific deviations from the main temporal trends by letting , where follows the specified interaction model and are random slopes. This allows us to capture more flexible temporal dynamics, and may aid in area-specific predictions. The random slopes are modeled with a Gaussian prior. To facilitate interpretation, we scale the time index to be from to , so that the random slope can be interpreted as the total deviation from the main time trend from the first and last years to be projected, on the logit scale. Users can specify priors for the random slopes with the PC prior so that using arguments pc.st.slope.u and pc.st.slope.alpha.
Additional analysis of the simulated dataset
Unstratified cluster-level model
In this section, we present additional analysis for the simulated dataset in Example 2 of the main paper. We first load the package, data, and compute the direct estimates of U5MR following the example in the main paper.
library(SUMMER)library(stringr)library(dplyr)library(ggplot2)library(patchwork)data(DemoData)periods <- c("85-89", "90-94", "95-99", "00-04", "05-09", "10-14")directU5 <- getDirectList(births = DemoData, years = periods, regionVar = "region", timeVar = "time", clusterVar = "~clustid + id", ageVar = "age", weightsVar = "weights")
We now describe the fitting of the cluster level model. For simplicity, we first assume the survey was designed so that each of the four regions was a strata (thus no additional stratification within regions). The stratified analysis is left to the next section.
First, we calculate the number of person-months and number of deaths for each cluster, time period, and age group. Notice that we do not need to impute all the 0’s for combinations that do not exist in the data. We first create the data frame using the getCounts() function. The getCounts() function prepares the aggregated count dataset without modifying the original column names. For the model fitting functions to correctly identify the data columns, we rename the cluster ID and time period columns to be ‘cluster’ and ‘years’. The response variable is ‘Y’ and the binomial total is ‘total’.
counts.all <- NULLfor(i in 1:length(DemoData)){ vars <- c("clustid", "region", "time", "age") counts <- getCounts(DemoData[[i]][, c(vars, "died")], variables = 'died', by = vars, drop=TRUE) counts <- counts %>% mutate(cluster = clustid, years = time, Y=died) counts$survey <- names(DemoData)[i] counts.all <- rbind(counts.all, counts)}head(counts.all)
## clustid region time age died total cluster years Y survey ## 1 36 central 85-89 0 0 1 36 85-89 0 1999 ## 2 38 central 85-89 0 0 1 38 85-89 0 1999 ## 3 91 central 85-89 0 0 1 91 85-89 0 1999 ## 4 101 central 85-89 0 0 1 101 85-89 0 1999 ## 5 128 central 85-89 0 0 1 128 85-89 0 1999 ## 6 129 central 85-89 0 0 1 129 85-89 0 1999
With the created data frame, we fit the cluster-level model using the smoothCluster() function and obtain the estimates with the getSmoothed() function. Notice that here we need to specify the age groups (age.groups), the length of each age group (age.n) in months, and how the age groups are mapped to the temporal random effects (age.rw.group). In the default case, age.rw.group = c(1, 2, 3, 3, 3, 3) means the first two age groups each has its own temporal trend, the the following four age groups share the same temporal trend. We start with the default temporal model of random walk or order 2 on the 5-year periods in this dataset (with real data, we can use a finer temporal resolution). We add survey iid effects to the model as well using survey.effect = TRUE argument.
fit.bb.sim <- smoothCluster(data = counts.all, Amat = DemoMap$Amat, family = "betabinomial", year.label = c(periods, "15-19"), age.group = c("0", "1-11", "12-23", "24-35", "36-47", "48-59"), age.n = c(1, 11, 12, 12, 12, 12), age.time.group = c(1, 2, 3, 3, 3, 3), time.model = "rw2", st.time.model = "ar1", pc.st.slope.u = 2, pc.st.slope.alpha = 0.1, survey.effect = TRUE)est.bb.sim <- getSmoothed(fit.bb.sim, nsim = 1000)
We visualize the results from the cluster level model in Figure 10. We also overlay the survey-specific direct estimates using the data.add argument.
plot(est.bb.sim$overall, plot.CI=TRUE, data.add = directU5, option.add = list(point = "mean", by = "surveyYears"), color.add="steelblue") + facet_wrap(~region, ncol = 4)

Stratified cluster-level model
We now describe the fitting of the cluster-level model for U5MR taking into account the urban/rural stratification. For this simulated dataset, the strata variable is coded as region crossed by urban/rural status. For our analysis with urban/rural stratified model, we first construct a new strata variable that contains only the urban/rural status, i.e., the additional stratification within each region and computes the counts of person-months annd death similar to the previous case.
for(i in 1:length(DemoData)){ strata <- DemoData[[i]]$strata DemoData[[i]]$strata[grep("urban", strata)] <- "urban" DemoData[[i]]$strata[grep("rural", strata)] <- "rural"}counts.all <- NULLfor(i in 1:length(DemoData)){ vars <- c("clustid", "region", "strata", "time", "age") counts <- getCounts(DemoData[[i]][, c(vars, "died")], variables = 'died', by = vars, drop=TRUE) counts <- counts %>% mutate(cluster = clustid, years = time, Y=died) counts$survey <- names(DemoData)[i] counts.all <- rbind(counts.all, counts)}
With the created data frame, we fit the cluster-level model using the smoothCluster function. The temporal main effects are defined for each stratum separately (specified by strata.time.effect = TRUE, so in total six random walks are used to model the main temporal effect.
fit.bb <- smoothCluster(data = counts.all, Amat = DemoMap$Amat, family = "betabinomial", year.label = c(periods, "15-19"), age.group = c("0", "1-11", "12-23", "24-35", "36-47", "48-59"), age.n = c(1, 11, 12, 12, 12, 12), age.time.group = c(1, 2, 3, 3, 3, 3), time.model = "rw2", st.time.model = "ar1", pc.st.slope.u = 2, pc.st.slope.alpha = 0.1, survey.effect = TRUE, strata.time.effect = TRUE)
## ---------------------------------- ## Cluster-level model ## Main temporal model: rw2 ## Number of time periods: 7 ## Spatial effect: bym2 ## Number of regions: 4 ## Interaction temporal model: ar1 ## Interaction type: 4 ## Interaction random slopes: yes ## Number of age groups: 6 ## Stratification: yes ## Number of age-specific fixed effect intercept per stratum: 6 ## Number of age-specific trends per stratum: 3 ## Strata-specific temporal trends: yes ## Survey effect: yes ## ----------------------------------
est.bb <- getSmoothed(fit.bb, nsim = 1000, CI = 0.95, save.draws=TRUE)
## Starting posterior sampling... ## Cleaning up results... ## No strata weights has been supplied. Overall estimates are not calculated.
summary(fit.bb)
## ---------------------------------- ## Cluster-level model ## Main temporal model: rw2 ## Number of time periods: 7 ## Spatial effect: bym2 ## Number of regions: 4 ## Interaction temporal model: ar1 ## Interaction type: 4 ## Interaction random slopes: yes ## Number of age groups: 6 ## Stratification: yes ## Number of age group fixed effect intercept per stratum: 6 ## Number of age-specific trends per stratum: 3 ## Strata-specific temporal trends: yes ## Survey effect: yes ## ---------------------------------- ## Fixed Effects ## mean sd 0.025quant 0.5quant 0.97quant mode kld ## age.intercept0:rural -3.0 0.14 -3.3 -3.0 -2.7 -3.0 0 ## age.intercept1-11:rural -4.7 0.11 -4.9 -4.7 -4.5 -4.7 0 ## age.intercept12-23:rural -5.8 0.14 -6.1 -5.8 -5.5 -5.8 0 ## age.intercept24-35:rural -6.6 0.20 -6.9 -6.6 -6.2 -6.6 0 ## age.intercept36-47:rural -6.9 0.23 -7.3 -6.9 -6.4 -6.9 0 ## age.intercept48-59:rural -7.3 0.29 -7.9 -7.3 -6.8 -7.3 0 ## age.intercept0:urban -2.7 0.13 -3.0 -2.7 -2.5 -2.7 0 ## age.intercept1-11:urban -5.0 0.13 -5.2 -5.0 -4.7 -5.0 0 ## age.intercept12-23:urban -5.7 0.17 -6.1 -5.7 -5.4 -5.7 0 ## age.intercept24-35:urban -7.1 0.29 -7.6 -7.1 -6.5 -7.1 0 ## age.intercept36-47:urban -7.6 0.37 -8.3 -7.6 -6.9 -7.6 0 ## age.intercept48-59:urban -8.0 0.46 -8.9 -8.0 -7.1 -8.0 0 ## ## Slope fixed effect index: ## time.slope.group1: 0:rural ## time.slope.group2: 1-11:rural ## time.slope.group3: 12-23:rural, 24-35:rural, 36-47:rural, 48-59:rural ## time.slope.group4: 0:urban ## time.slope.group5: 1-11:urban ## time.slope.group6: 12-23:urban, 24-35:urban, 36-47:urban, 48-59:urban ## ---------------------------------- ## Random Effects ## Name Model ## 1 time.struct RW2 model ## 2 time.unstruct IID model ## 3 region.struct BYM2 model ## 4 region.int Besags ICAR model ## 5 st.slope.id IID model ## 6 survey.id IID model ## ---------------------------------- ## Model hyperparameters ## mean sd 0.025quant 0.5quant ## overdispersion for the betabinomial observations 0.002 0.001 0.001 0.002 ## Precision for time.struct 91.454 111.521 11.674 58.458 ## Precision for time.unstruct 831.467 3076.794 15.769 225.650 ## Precision for region.struct 252.997 671.939 5.264 88.691 ## Phi for region.struct 0.346 0.240 0.027 0.297 ## Precision for region.int 771.901 3485.913 7.931 168.610 ## Group PACF1 for region.int 0.893 0.203 0.253 0.970 ## Precision for st.slope.id 24.590 63.442 0.801 9.168 ## 0.97quant mode ## overdispersion for the betabinomial observations 0.005 0.002 ## Precision for time.struct 349.819 27.909 ## Precision for time.unstruct 4750.233 35.610 ## Precision for region.struct 1367.096 11.338 ## Phi for region.struct 0.849 0.077 ## Precision for region.int 4531.658 15.399 ## Group PACF1 for region.int 0.999 1.000 ## Precision for st.slope.id 130.531 1.920 ## [,1] ## log marginal-likelihood (integration) -3455 ## log marginal-likelihood (Gaussian) -3449
The est.bb object above computes the U5MR estimates by urban/rural strata. In order to obtain the overall region-specific U5MR, we need additional information on the population fractions of each stratum within regions. For illustration purpose, here we simulate the population totals over the years and use these population totals to compute the population fractions later.
pop.base <- expand.grid(region = c("central", "eastern", "northern", "western"), strata = c("urban", "rural"))pop.base$population <- round(runif(dim(pop.base)[1], 1000, 20000))periods.all <- c(periods, "15-19")pop <- NULLfor(i in 1:length(periods.all)){ tmp <- pop.base tmp$population <- pop.base$population + round(rnorm(dim(pop.base)[1], mean = 0, sd = 200)) tmp$years <- periods.all[i] pop <- rbind(pop, tmp)}head(pop)
## region strata population years ## 1 central urban 16529 85-89 ## 2 eastern urban 10630 85-89 ## 3 northern urban 14664 85-89 ## 4 western urban 11470 85-89 ## 5 central rural 5836 85-89 ## 6 eastern rural 5479 85-89
In order to compute the aggregated estimates, we need the proportion of urban/rural populations within each region in each time period, as computed below in the weight.strata object.
weight.strata <- expand.grid(region = c("central", "eastern", "northern", "western"), years = periods.all)weight.strata$urban <- weight.strata$rural <- NAfor(i in 1:dim(weight.strata)[1]){ which.u <- which(pop$region == weight.strata$region[i] & pop$years == weight.strata$years[i] & pop$strata == "urban") which.r <- which(pop$region == weight.strata$region[i] & pop$years == weight.strata$years[i] & pop$strata == "rural") weight.strata[i, "urban"] <- pop$population[which.u] / (pop$population[which.u] + pop$population[which.r]) weight.strata[i, "rural"] <- 1 - weight.strata[i, "urban"]}head(weight.strata)
## region years rural urban ## 1 central 85-89 0.26 0.74 ## 2 eastern 85-89 0.34 0.66 ## 3 northern 85-89 0.53 0.47 ## 4 western 85-89 0.34 0.66 ## 5 central 90-94 0.26 0.74 ## 6 eastern 90-94 0.36 0.64
Now we can recompute the smoothed estimates with the population fractions.
est.bb <- getSmoothed(fit.bb, nsim = 1000, CI = 0.95, save.draws = TRUE, weight.strata = weight.strata)head(est.bb$overall)
## region years time area variance median mean upper lower rural urban is.yearly ## 5 central 85-89 1 1 0.00149 0.22 0.22 0.30 0.16 0.26 0.74 FALSE ## 6 central 90-94 2 1 0.00060 0.20 0.20 0.25 0.15 0.26 0.74 FALSE ## 7 central 95-99 3 1 0.00033 0.18 0.18 0.22 0.15 0.25 0.75 FALSE ## 1 central 00-04 4 1 0.00026 0.17 0.17 0.21 0.14 0.25 0.75 FALSE ## 2 central 05-09 5 1 0.00027 0.16 0.16 0.20 0.13 0.26 0.74 FALSE ## 3 central 10-14 6 1 0.00043 0.15 0.15 0.19 0.11 0.26 0.74 FALSE ## years.num ## 5 NA ## 6 NA ## 7 NA ## 1 NA ## 2 NA ## 3 NA
We can compare the stratum-specific and aggregated U5MR estimates now.
g1 <- plot(est.bb$stratified, plot.CI = TRUE) + facet_wrap(~strata) + ylim(0, 0.5)g2 <- plot(est.bb$overall, plot.CI = TRUE) + ylim(0, 0.5) + ggtitle("Aggregated estimates")g1 + g2

Obtaining and pre-processing Malawi DHS data
In this section, we present the full workflow of downloading and pre-processing the two most recent Malawi DHS datasets, the 2010 and 2015 – 2016 DHS. We also describe how the count data used in the main paper is produced. First, we load and process the spatial polygon data.
data(MalawiMap)MalawiGraph <- getAmat(MalawiMap, names=MalawiMap$ADM2_EN)mapPlot(geo=MalawiMap, by.geo = "ADM2_EN")

Loading DHS data using the rdhs package
In this example, we use the 2010 and 2015–2016 Malawi DHS surveys. The DHS website (https://dhsprogram.com/data/available-datasets.cfm?ctryid=24) provides links to download all the surveys with registration. Once access is approved, we can use the rdhs package to load data directly from the DHS API (Watson and Eaton, 2019). We first download both the birth records (BR) and GPS data (GE) for these two surveys. Notice the following codes can only be run after registration with DHS and set up the credentials using the rdhs package. Additional information on this step can be found in the documentation of the rdhs package.
library(rdhs)sv <- dhs_surveys(countryIds = "MW", surveyType = "DHS", surveyYearStart = 2010)BR <- dhs_datasets(surveyIds = sv$SurveyId, fileFormat = "Flat", fileType = "BR")BRfiles <- get_datasets(BR$FileName, reformat=TRUE)GPS <- dhs_datasets(surveyIds = sv$SurveyId, fileFormat = "Flat", fileType = "GE")GPSfiles <- get_datasets(GPS$FileName, reformat=TRUE)
The downloaded data can then be loaded by the returned file paths.
Surv2010 <- readRDS(BRfiles[[1]])Surv2015 <- readRDS(BRfiles[[2]])DHS2010.geo <- readRDS(GPSfiles[[1]])DHS2015.geo <- readRDS(GPSfiles[[2]])
load("data/downloaded.rda")
Cleaning the DHS data
We then use the getBirths() function to process the raw birth history into person-month format. We label the person-month records with 6 age groups specified by month.cut. In this example, instead of using 5 year periods, we work directly with yearly estimates specified by year.cut.
DHS2010 <- getBirths(data = Surv2010, month.cut = c(1, 12, 24, 36, 48, 60), year.cut = seq(2000, 2020, by = 1), strata = "v022")DHS2015 <- getBirths(data = Surv2015, month.cut = c(1, 12, 24, 36, 48, 60), year.cut = seq(2000, 2020, by = 1), strata = "v022")
We perform similar processing steps for the 2015–2016 DHS survey birth records. Since only a small fraction of observations are available in 2016, we remove the partial year observations in this survey.
DHS2015 <- subset(DHS2015, time != 2016)
The DHS dataset does not usually have sufficient spatial resolution information in the birth records file, so we need to use the GPS datasets of cluster locations to assign records to the admin-2 areas. This process can be highly survey-specific and require more extensive data manipulation. In the 2010 DHS dataset, the GPS file contains the cluster ID (DHSCLUST), urbanicity indicator (URBAN_RURA), and DHSCLUST variable in the format of “admin-2_urbanrural”, with some spelling and capitalization differences as in the polygon file. From the GPS dataset, we processed a list of clusters and their corresponding admin-2 areas.
cluster.list <- data.frame(DHS2010.geo) %>% distinct(DHSCLUST, DHSREGNA, URBAN_RURA) %>% mutate(admin2 = gsub(" - rural", "", DHSREGNA)) %>% mutate(admin2 = gsub(" - urban", "", admin2)) %>% mutate(admin2 = recode(admin2, "nkhatabay" = "nkhata bay")) %>% mutate(admin2 = recode(admin2, "nkhota kota" = "nkhotakota")) %>% mutate(admin2 = str_to_title(admin2)) %>% mutate(urban = ifelse(URBAN_RURA=="U", 1, 0)) %>% select(v001 = DHSCLUST, admin2, urban) head(cluster.list, n=3)
## v001 admin2 urban ## 1 1 Dedza 0 ## 2 2 Balaka 0 ## 3 3 Mchinji 0
We then merge this list to the main person-month file, which adds the admin2 and urban columns to the data frame.
DHS2010 <- DHS2010 %>% left_join(cluster.list)head(DHS2010)
## dob survey_year died id.new caseid v001 v002 v004 v005 v021 v022 v023 ## 1 1316 NA 0 1 1 1 2 1 1 1 1902867 1 12 central ## 2 1316 NA 0 1 1 1 2 1 1 1 1902867 1 12 central ## 3 1316 NA 0 1 1 1 2 1 1 1 1902867 1 12 central ## 4 1316 NA 0 1 1 1 2 1 1 1 1902867 1 12 central ## 5 1316 NA 0 1 1 1 2 1 1 1 1902867 1 12 central ## 6 1316 NA 0 1 1 1 2 1 1 1 1902867 1 12 central ## v024 v025 v139 bidx agemonth obsStart obsStop obsmonth year age time strata ## 1 central rural central 1 0 1316 1316 1316 109 0 2009 12 ## 2 central rural central 1 1 1317 1317 1317 109 1-11 2009 12 ## 3 central rural central 1 2 1318 1318 1318 109 1-11 2009 12 ## 4 central rural central 1 3 1319 1319 1319 109 1-11 2009 12 ## 5 central rural central 1 4 1320 1320 1320 109 1-11 2009 12 ## 6 central rural central 1 5 1321 1321 1321 110 1-11 2010 12 ## admin2 urban ## 1 Dedza 0 ## 2 Dedza 0 ## 3 Dedza 0 ## 4 Dedza 0 ## 5 Dedza 0 ## 6 Dedza 0
We perform similar processing steps for the 2015–2016 DHS GPS data. To illustrate the idiosyncratic data processing steps required for each survey, the DHSCLUST variable in this dataset is in the form of “admin-1_urbanrural” and does not allow us to parse the admin-2 area names. The strata variable v022 in the birth records, however, is in the “admin-2_urbanrural” format. Therefore, we first merge the v022 variables to the GPS data and proceed in a similar fashion to the previous example.
cluster.list <- data.frame(DHS2015.geo) %>% mutate(v001 = DHSCLUST) %>% left_join(DHS2015, by = "v001") %>% distinct(v001, v022, URBAN_RURA) %>% mutate(admin2 = gsub(" - rural", "", v022)) %>% mutate(admin2 = gsub(" - urban", "", admin2)) %>% mutate(admin2 = recode(admin2, "nkhatabay" = "nkhata bay")) %>% mutate(admin2 = recode(admin2, "nkhota kota" = "nkhotakota")) %>% mutate(admin2 = str_to_title(admin2)) %>% mutate(urban = ifelse(URBAN_RURA=="U", 1, 0)) %>% select(v001, admin2, urban) DHS2015 <- DHS2015 %>% left_join(cluster.list)head(DHS2015)
## dob survey_year died id.new caseid v001 v002 v004 v005 v021 v022 ## 1 1334 NA 0 1 1 12 2 1 12 1 118748 1 ntchisi - urban ## 2 1334 NA 0 1 1 12 2 1 12 1 118748 1 ntchisi - urban ## 3 1334 NA 0 1 1 12 2 1 12 1 118748 1 ntchisi - urban ## 4 1334 NA 0 1 1 12 2 1 12 1 118748 1 ntchisi - urban ## 5 1334 NA 0 1 1 12 2 1 12 1 118748 1 ntchisi - urban ## 6 1334 NA 0 1 1 12 2 1 12 1 118748 1 ntchisi - urban ## v023 v024 v025 v139 bidx agemonth obsStart obsStop ## 1 ntchisi - urban central region urban central region 1 0 1334 1334 ## 2 ntchisi - urban central region urban central region 1 1 1335 1335 ## 3 ntchisi - urban central region urban central region 1 2 1336 1336 ## 4 ntchisi - urban central region urban central region 1 3 1337 1337 ## 5 ntchisi - urban central region urban central region 1 4 1338 1338 ## 6 ntchisi - urban central region urban central region 1 5 1339 1339 ## obsmonth year age time strata admin2 urban ## 1 1334 111 0 2011 ntchisi - urban Ntchisi 1 ## 2 1335 111 1-11 2011 ntchisi - urban Ntchisi 1 ## 3 1336 111 1-11 2011 ntchisi - urban Ntchisi 1 ## 4 1337 111 1-11 2011 ntchisi - urban Ntchisi 1 ## 5 1338 111 1-11 2011 ntchisi - urban Ntchisi 1 ## 6 1339 111 1-11 2011 ntchisi - urban Ntchisi 1
Then we use the getCounts() function to obtain the count data format input and stack the two DHS survey data into a single data frame.
vars <- c("v001", "v025", "admin2", "time", "age", "v005")dat1 <- getCounts(DHS2010[, c(vars, "died")], variables = 'died', by = vars, drop=TRUE)dat1$survey = "DHS2010"dat2 <- getCounts(DHS2015[, c(vars, "died")], variables = 'died', by = vars, drop=TRUE)dat2$survey = "DHS2015"DHS.counts <- rbind(dat1, dat2) %>% mutate(cluster = v001, strata = v025, region = admin2, years = time, Y = died)
The analysis in the main paper is carried out only on the 2015–2016 dataset, which is obtained using the same procedure.
Additional analysis of the 2010 and 2015 – 2016 Malawi DHS
In this section, we provide additional workflow of estimating U5MR from 2000 to 2019 using the two DHS surveys. The focus of this section is on the models not discussed in details in Example 3 of the main paper.
Direct estimates
We use getDirectList to obtain direct estimates from both surveys and combine into the ‘meta-analysis’ estimator using aggregateSurvey. Notice that the survey variable in the returned data frame contains a numeric index of each survey in the list, and the surveyYears contains the survey names we assigned in the input list.
direct <- getDirectList(births = list(DHS2010=DHS2010, DHS2015=DHS2015), years = 2000:2019, regionVar = "admin2", timeVar = "time", clusterVar = "~v001 + v002", ageVar = "age", weightsVar = "v005")direct.comb <- aggregateSurvey(direct)
When additional information is available to adjust the direct estimates from the surveys, we use the methods described in Li et al. (2019). We can perform the ratio adjustment to the direct estimates using the getAdjusted() function. For the two surveys in Malawi, the calculated HIV adjustment ratios as described in Walker et al. (2012) are stored in MalawiData$HIV.yearly. In order to get the correct uncertainty bounds, we also need to specify the columns corresponding to the unadjusted uncertainty bounds, the lower and upper columns, which are on the probability scale in this case.
data(MalawiData)direct.2010 <- subset(direct, survey == 1)direct.2010.hiv <- getAdjusted(data = direct.2010, ratio = subset(MalawiData$HIV.yearly, survey == "DHS2010"), logit.lower = NA, logit.upper = NA, prob.lower = "lower", prob.upper = "upper")direct.2015 <- subset(direct, survey == 2)direct.2015.hiv <- getAdjusted(data = direct.2015, ratio = subset(MalawiData$HIV.yearly, survey == "DHS2015"), logit.lower = NA, logit.upper = NA, prob.lower = "lower", prob.upper = "upper")
Finally, we combine the direct estimates into direct.comb.hiv.
direct.hiv <- rbind(direct.2010.hiv, direct.2015.hiv)direct.comb.hiv <- aggregateSurvey(direct.hiv)
Space-time Fay-Harriot estimates
We now fit a national Fay-Harriot model with the calculated direct estimates using smoothDirect() and getSmoothed() functions.
fit.national.unadj <- smoothDirect(data = direct.comb, Amat = NULL, year.label = 2000:2019, year.range = c(2000, 2019), time.model = "rw2", m = 1)est.unadj <- getSmoothed(fit.national.unadj)
For comparison, we smooth both the unadjusted direct estimates and the direct estimates with HIV adjustments.
fit.national.hiv <- smoothDirect(data = direct.comb.hiv, Amat = NULL, year.label = 2000:2019, year.range = c(2000, 2019), time.model = "rw2", m = 1)est.hiv <- getSmoothed(fit.national.hiv)
In addition, we also demonstrate the benchmarking procedure described in Li et al. (2019), where we first fit a smoothing model and then benchmark the results with the UN IGME estimates – the latter are based on more extensive data (Alkema and New, 2014) . We first calculate the adjustment ratio compared to the 2019 UN IGME estimates.
UN <- MalawiData$IGME2019UN.est <- UN$mean[match(2000:2019, UN$years)]Smooth.est <- est.hiv$median[match(2000:2019, est.hiv$years)]UN.adj <- data.frame(years = 2000:2019, ratio = Smooth.est / UN.est)head(UN.adj, n = 3)
## years ratio ## 1 2000 1.1 ## 2 2001 1.2 ## 3 2002 1.1
We then fit the smoothing model on the benchmarked direct estimates.
direct.comb.benchmark <- getAdjusted(data = direct.comb.hiv, ratio = UN.adj, logit.lower = NA, logit.upper = NA, prob.lower = "lower", prob.upper = "upper")fit.benchmark <- smoothDirect(data = direct.comb.benchmark, Amat = NULL, year.label = 2000:2019, year.range = c(2000, 2019), time.model = "rw2", m = 1)est.benchmark <- getSmoothed(fit.benchmark)
We compare the different Fay-Harriot estimates in Figure 13. Compared to the raw estimates, HIV adjustments lead to higher estimates in the earlier years. The benchmarking step produces a national trend that follows the same trajectory as the UN IGME estimates.
g1 <- plot(est.unadj, is.subnational=FALSE, proj.year = 2016) + ggtitle("Unadjusted") + ylim(c(0, 0.22))g2 <- plot(est.hiv, is.subnational=FALSE, proj.year = 2016) + ggtitle("With HIV adjustment") + ylim(c(0, 0.22))g3 <- plot(est.benchmark, is.subnational=FALSE, proj.year = 2016, data.add = UN, option.add = list(point = "mean"), label.add = "UN", color.add = "red") + ggtitle("Benchmarked to UN IGME") + ylim(c(0, 0.22))g1 + g2 + g3

Finally, the subnational models can be fit in the same manner. Since the direct estimates are already on the yearly scale, we do not need to perform the transformation from periods to years. So we set is.yearly to FALSE to fit the period model directly.
fit.smooth.direct <- smoothDirect(data = direct.comb.benchmark, Amat = MalawiGraph, year.label = 2000:2019, year.range = c(2000, 2019), time.model = "rw2", m = 1, type.st = 4, pc.alpha = 0.05, pc.u = 1)est.smooth.direct <- getSmoothed(fit.smooth.direct)
Cluster-level model estimation
We now describe the fitting of the cluster level model using the two DHS surveys. With the created data frame, we first fit the national model with survey-year-specific HIV adjustment factors specified using bias.adj and bias.adj.by arguments. The adjustments are performed as offsets in the likelihood as described before. We also add a sum-to-zero survey effect term.
fit.bb.nat <- smoothCluster(data = DHS.counts, Amat = NULL, family = "betabinomial", year.label = 2000:2019, time.model = "rw2", bias.adj = MalawiData$HIV.yearly, bias.adj.by = c("years", "survey"), survey.effect = TRUE)
The getSmoothed function then produces estimates from the fitted cluster-level model. Similar to before, we take nsim draws of the posterior distribution to calculate the summaries of the U5MR estimates.
est.bb.nat <- getSmoothed(fit.bb.nat, nsim = 1000, save.draws = TRUE)
In this example, no strata weights are provided and thus the overall estimates are empty. Given a data frame of strata proportions, we can rerun the getSmoothed function to re-aggregate the stratified estimates. The save.draws argument in the getSmoothed call allows the raw posterior draws to be returned as part of the output object. This can be helpful in such situations, as posterior draws already computed can be inserted into new getSmoothed calls using the draws argument to avoid resampling again.
Figure 14 shows the national estimates of U5MR in Malawi for urban and rural stratum respectively using the cluster-level model.
plot(est.bb.nat$stratified, is.subnational=FALSE, proj.year = 2016) + facet_wrap(~strata)
We can also fit the subnational model in the same fashion. Additional analysis can be similarly carried out as in the previous example with simulated data. For the cluster-level model, benchmarking to national estimates is also implemented in the package using the procedure described in [@okonek2022computationally] with additional information on population fractions by region. We refer readers to the package vignette for more details.
fit.bb <- smoothCluster(data = DHS.counts, Amat = MalawiGraph, family = "betabinomial", year.label = 2000:2019, time.model = "rw2", st.time.model = "ar1", pc.st.slope.u = 2, pc.st.slope.alpha = 0.1, bias.adj = MalawiData$HIV.yearly, bias.adj.by = c("years", "survey"), survey.effect = TRUE, strata.time.effect = TRUE)est.bb <- getSmoothed(fit.bb, nsim = 1000, save.draws = TRUE)
The U5MR by strata can be visualized directly. Notice that in order to produce the overall estimates by region and time, additional information on population fractions in urban/rural is necessary, similar to the analysis conducted in the main paper using simulated data. For more details on obtaining such factions, we refer readers to [@fuglstad2021two] and [@wu2021spatial].
plot(est.bb$stratified) + facet_wrap(~strata)

References
- Alkema and New (2014) L. Alkema and J. R. New. Global estimation of child mortality using a Bayesian B-spline bias-reduction model. The Annals of Applied Statistics, 8:2122–2149, 2014.
- Knorr-Held (2000) L. Knorr-Held. Bayesian modelling of inseparable space-time variation in disease risk. Statistics in Medicine, 19:2555–2567, 2000.
- Li et al. (2019) Z. R. Li, Y. Hsiao, J. Godwin, B. D. Martin, J. Wakefield, and S. J. Clark. Changes in the spatial distribution of the under five mortality rate: small-area analysis of 122 DHS surveys in 262 subregions of 35 countries in Africa. PLoS One, 2019. Published January 22, 2019.
- Riebler et al. (2016) A. Riebler, S. H. Sørbye, D. Simpson, and H. Rue. An intuitive Bayesian spatial model for disease mapping that accounts for scaling. Statistical Methods in Medical Research, 25:1145–1165, 2016.
- Simpson et al. (2017) D. Simpson, H. Rue, A. Riebler, T. Martins, and S. Sørbye. Penalising model component complexity: A principled, practical approach to constructing priors (with discussion). Statistical Science, 32:1–28, 2017.
- Sørbye and Rue (2014) S. H. Sørbye and H. Rue. Scaling intrinsic gaussian markov random field priors in spatial modelling. Spatial Statistics, 8:39–51, 2014.
- Sørbye and Rue (2017) S. H. Sørbye and H. Rue. Penalised complexity priors for stationary autoregressive processes. Journal of Time Series Analysis, 38(6):923–935, 2017.
- Walker et al. (2012) N. Walker, K. Hill, and F. Zhao. Child mortality estimation: methods used to adjust for bias due to AIDS in estimating trends in under-five mortality. PLoS Med, 9:e1001298, 2012.
- Watson and Eaton (2019) O. Watson and J. Eaton. rdhs: API client and dataset management for the Demographic and Health Survey (DHS) data, 2019. URL https://CRAN.R-project.org/package=rdhs. R package version 0.6.3.