SOLVER: Scene-Object Interrelated Visual
Emotion Reasoning Network
Abstract
Visual Emotion Analysis (VEA) aims at finding out how people feel emotionally towards different visual stimuli, which has attracted great attention recently with the prevalence of sharing images on social networks. Since human emotion involves a highly complex and abstract cognitive process, it is difficult to infer visual emotions directly from holistic or regional features in affective images. It has been demonstrated in psychology that visual emotions are evoked by the interactions between objects as well as the interactions between objects and scenes within an image. Inspired by this, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER) to predict emotions from images. To mine the emotional relationships between distinct objects, we first build up an Emotion Graph based on semantic concepts and visual features. Then, we conduct reasoning on the Emotion Graph using Graph Convolutional Network (GCN), yielding emotion-enhanced object features. We also design a Scene-Object Fusion Module to integrate scenes and objects, which exploits scene features to guide the fusion process of object features with the proposed scene-based attention mechanism. Extensive experiments and comparisons are conducted on eight public visual emotion datasets, and the results demonstrate that the proposed SOLVER consistently outperforms the state-of-the-art methods by a large margin. Ablation studies verify the effectiveness of our method and visualizations prove its interpretability, which also bring new insight to explore the mysteries in VEA. Notably, we further discuss SOLVER on three other potential datasets with extended experiments, where we validate the robustness of our method and notice some limitations of it.
Index Terms:
Visual Emotion Analysis, Emotion Graph, Graph Convolutional Network, Attention MechanismI Introduction
Human beings are born with one of the greatest power — emotion [1], which is invisible yet indispensable in our daily lives. With the prevalence of social networks, images have become a major medium for people to express emotions and to understand others as well. Nowadays, computer vision algorithms mostly teach networks how to “see” like a human while scarcely tell them how to “feel” like a human, which has been considered as a crucial step towards the understanding of human cognition [2]. As shown in Fig. 1, when encountering an image, not only do we see objects and scenes, but we are also evoked by a certain emotion behind them involuntarily. Therefore, aiming at finding out how people feel emotionally towards different visual stimuli, Visual Emotion Analysis (VEA) has become an important research topic with increasing attention recently. Progress in VEA may benefit other related tasks (e.g., image aesthetic assessment [3, 4], stylized image captioning [5, 6], and social relation inference [7]), and will have a great impact on many applications, including decision making [8], smart advertising [9], opinion mining [10], and mental disease treatment [11].


Researchers have been engaged in VEA for more than two decades [12], during which methods have varied from the early traditional ones to the recent deep learning ones. In the early years, researchers designed hand-crafted features (e.g., color, texture, shape, composition, balance, and emphasis) based on art and psychological theories [13, 14, 15, 16, 17], attempting to find out the potential impact factors on human visual emotions. However, it was hard to cover all the important factors by implementing manually designed features, which led to sub-optimal results. With the prevalence of deep learning networks, more and more researchers in VEA employed Convolutional Neural Networks (CNNs) in an end-to-end manner to predict emotions [18, 19, 20, 21, 22, 23, 24, 25]. Earlier attempts directly implemented a general CNN to extract holistic features from affective images [18, 24], which neglected the fact that visual emotions can also be evoked by local regions. Recently, in order to trace emotions more concretely, researchers in VEA adopted detection methods and attention mechanisms to focus on local regions [25, 20, 21]. Most of the aforementioned methods mapped holistic or regional features to emotion labels directly. However, since human emotions involves a highly complex and abstract cognitive process, we argue that a direct mapping may underestimate the wide affective gap [20] between low-level pixels and high-level emotions.
In addition to computer vision, researchers in other fields also devoted themselves to exploring the mysteries of visual emotions, including psychology [26], neuroscience [27] and sociology [28]. It has been demonstrated in psychology that scenes and objects can be regarded as emotional stimuli in affective images [29]. In [30], psychologist Frijda suggested that emotional state is not about a specific object, but the perception of multiple emotionally meaningful objects. Neuroscientist Moshe suggested that visual objects occur in rich surroundings are often embedded with other related objects, which serves as a key cognitive process in the human brain [31].
Based on the above studies, we believe that visual emotions are evoked by the interactions between objects as well as the interactions between objects and scenes within an image. To be specific, we argue that rather than an isolated object, multiple objects in an image interact with each other and jointly contribute to the final emotion. Besides, as scenes affect the emotional tone of an image, we further take scenes into account by mining the scene-object interactions, assuming that it is scenes that guide objects to evoke distinct emotions. As shown in Fig. 2(a), there are red roses in both left images and red tulips in the ones on the right, but we have different emotions towards them. Take red roses as an example, when red roses appear with a bride and a groom, it can be inferred as a wedding ceremony, which brings people a positive emotion, i.e., contentment. Oppositely, when red roses and a deadee comes together, people may feel sad with a negative emotion. Therefore, it is not the red roses alone that evoke a specific emotion, but the interactions between red roses and other objects jointly determine the final result. Fig. 2(b) shows that under the same scene of lawn, different objects may evoke different emotions as well. In particular, running kids on the lawn may bring us excitement while a sly crocodile lying on the lawn makes us fear. It is obvious that different interactions between objects and scenes may evoke distinct emotions, from which we attach importance to both objects and scenes when analyzing visual emotions.
Motivated by the above facts, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER), aiming at predicting visual emotions from the interactions between objects and objects as well as objects and scenes. In order to mine the emotional relationships between different objects within an image, we construct an Emotion Graph and conduct reasoning on it. To be specific, by transforming and filtering detected object features, we construct the Emotion Graph with objects as nodes and emotional relationships as edges. Subsequently, we adopt Graph Convolutional Network (GCN) to perform reasoning on the Emotion Graph, which correlates objects with their emotional relationships and eventually yields emotion-enhanced object features. Furthermore, we propose a Scene-Object Fusion Module to interrelate scenes and objects with each other. Specifically, a novel scene-based attention mechanism is designed by exploiting scene features as guidance in object fusion process, which not only fuses multiple object features into a single one, but also serves as a pivot to interact between objects and scenes.
Our contributions can be summarized as follows:
-
•
We propose a novel framework, namely SOLVER, to predict visual emotions from the interactions between objects and objects as well as objects and scenes within an image, which outperforms the state-of-the-art methods on eight public visual emotion datasets. To the best of our knowledge, it is the first work that reasons between objects and scenes to infer emotions.
-
•
We construct an Emotion Graph to depict emotional relationships between different objects, and subsequently conduct GCN reasoning on it, aiming to interrelate objects with their emotional relationships.
-
•
We propose a Scene-Object Fusion Module by exploiting scene features to guide object fusion process with a designed scene-based attention mechanism, which serves as a pivot to mine the emotional relationships between objects and scenes.
The rest of the paper is organized as follows. Section II overviews the existing methods on visual emotion analysis, object detection, and graph reasoning. In Section III, we introduce the proposed SOLVER by constructing an Emotion Graph and a Scene-based Fusion Module. Extensive experiments, including comparisons, ablation studies, visualizations, and further discussions are conducted on visual emotion datasets and other potential datasets given in Section IV. Finally, we conclude our work in Section V.
II Related work
This work addresses the problem of visual emotion analysis, which is also closely related to object detection and graph reasoning. In this section, we review the existing methods from the above three aspects.
II-A Visual Emotion Analysis
In Visual Emotion Analysis (VEA), related work can be divided into several aspects according to different criteria. Based on different psychological models, i.e., Categorical Emotion States (CES) and Dimensional Emotion Space (DES), VEA can be grouped into classification task [18, 19, 20, 21, 22, 23, 24, 25, 32] and distribution learning task [33, 34, 35, 36, 37, 38]. Oriented to distinct objects, VEA can be divided into personalized VEA [39, 40] and dominant VEA [18, 19, 20, 21, 22, 23, 24, 25], which concentrate on one individual’s emotion or the averaged one of the public. Besides, there are also some surveys concerning this topic [41, 42, 43, 44]. Our work focuses on dominant emotion classification problem.
II-A1 Traditional Methods
Earlier works on VEA mainly focused on designing hand-crafted features to mine emotions from affective images. Inspired by psychology and art theory, Machajdik et al. [13] extracted specific image features and combined them to predict emotions, which consisted of color, texture, composition and content. Borth et al. [17] introduced Adjective Noun Pairs (ANPs) and proposed a visual concept detector, i.e., Sentibank, to filter out visual concepts strongly related to emotions from a semantic level. Considering both bag-of-visual word representations and color distributions, Siersdorfer et al. [15] proposed an emotion analysis method based on information theory. By leveraging object detection and concept modeling methods, Chen et al. [45] first recognized the top six frequent objects, i.e., car, dog, dress, face, flower, food, and then modeled the concept similarity between those ANPs. In order to understand the relationship between artistic principles and emotions, Zhao et al. [14] proposed a method for both classification and regression tasks in VEA by extracting principle-of-art-based emotional features, including balance, emphasis, harmony, variety, gradation, and movement. Besides, Zhao et al. [16] extracted low-level generic and elements-of-art features, mid-level attributes and principles-of-art features, high-level semantic and facial features, followed by a multi-graph learning framework. While these methods have been proven to be effective on several small-scale datasets, the hand-crafted features are still limited in covering all important factors in visual emotions.

II-A2 Deep Learning Methods
Recently, with the great success of deep learning networks, researchers in VEA have adopted Convolutional Neural Network (CNN) to predict emotions and have achieved significant progress. Based on their previous SentiBank [17], Chen et al. [18] implemented deep networks to construct a visual sentiment concept classification method named DeepSentiBank. Leveraging half a million images labeled with website meta data, You et al. [24] proposed a novel progressive CNN architecture (PCNN) to predict emotions. Rao et al. [19] constructed a multi-level deep representation network (MldrNet), which extracted emotional features from image semantics, aesthetics and low-level visual features simultaneously through multiple instance learning framework. Earlier attempts simply implemented a general CNN to extract holistic features from affective images, neglecting the fact that visual emotions can also be evoked by local regions. Different from previous methods, You et al. [46] utilized attention mechanism to discover emotion-relevant regions, which serves as a prior attempt to focus on local regions in VEA. Similarly, Yang et al. [20] constructed a local branch to discover affective regions by implementing the off-the-shelf detection tools. A weakly supervised coupled network (WSCNet) [21] was further proposed by Yang et al., which discovers emotion regions through attention mechanism and leverages both holistic and regional features to predict emotions in an end-to-end manner. Besides, by employing deep metric learning, Yang et al. [22] proposed a multi-task deep framework for tackling both retrieval and classification tasks in VEA. Zhang et al. [47] proposed a novel CNN model to extract and integrate content information as well as style information to infer visual emotions. Considering different kinds of emotional stimuli, Yang et al. [32] proposed a stimuli-aware VEA network together with a hierarchical cross-entropy loss. Most of the existing deep learning methods directly used holistic feature or regional features to predict visual emotions. However, considering the complexity and abstractness involved in the cognitive process of human emotions, we argue that a direct mapping may underestimate the wide affective gap between low-level pixels and high-level emotions.
Psychological studies have demonstrated that visual emotions are evoked by the interactions between objects and objects as well as objects and scenes [29, 30, 31]. Based on these observations, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER) to predict visual emotions. To mine the emotional relationships between different objects, we first construct an Emotion Graph and then conduct GCN reasoning on it to yield emotion-enhanced object features. Besides, a Scene-Object Fusion Module is further proposed to effectively interrelate objects and scenes with a novel scene-based attention mechanism.
II-B Object Detection
Object detection serves as a core problem in computer vision, which has shown dramatic progress recently. Further, object detection methods have been implemented into various related tasks as a pre-processing step, including image captioning [48, 49], scene graph [50, 51], visual reasoning [52, 53], person re-identification [54, 55], etc. Object detection methods can be roughly divided into one-stage methods (e.g., YOLO [56], SSD [57]) and two-stage methods (e.g., R-CNN [58], Fast R-CNN [59], Faster R-CNN [60]) according to whether region proposals are generated. R-CNN was a pioneer work in two-stage detection methods, which boosted detection accuracy exceedingly by implementing deep networks for the first time. Based on their previous work, Girshick proposed Fast R-CNN to reduce the redundant computation of feature extraction in R-CNN and further improve its accuracy and speed. Region Proposal Network (RPN) was introduced by Faster R-CNN to replace the original time-consuming Selective Search, which not only unified object detection in an end-to-end network, but also improved its efficiency simultaneously. Since Faster R-CNN is widely used for its great performance on both accuracy and speed [61, 62, 63, 64, 65], we adopt Faster R-CNN to extract object features and then construct an Emotion Graph based on them.
II-C Graph-based Reasoning
Recently, Graph Neural Networks (GNNs) have been proved to be an effective framework to exchange and propagate information through structured graphs, which have been widely used in various computer vision tasks [66, 67, 68]. In Gated Graph Neural Network (GGNN) [69], Li et al. adopted Gate Recurrent Units (GRUs) to update hidden states of graph nodes and implemented modern optimization techniques to yield output sequences. Aiming to learn the graph-structured data via convolutional operations, Graph Convolutional Network (GCN) [70] was proposed as a scalable approach for semi-supervised classification. In Graph Attention Networks (GAT) [71], self-attention mechanism was introduced to update node features by attending over its neighbors, which was often used in bidirectional graph. In this paper, we apply GCN to conduct reasoning on the Emotion Graph, which correlates objects with their emotional relationships and yields emotion-enhanced object features.
III Methodology
In this section, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER) to predict visual emotions through mining the interrelationships between objects and objects as well as objects and scenes. Rather than adopting scene and object features directly, we develop a reasoning mechanism to infer deep emotional relationships between objects and scenes, which is helpful to bridge the existing affective gap. Fig. 3 shows the architecture of the proposed network. We first employ an object detector, i.e., Faster R-CNN, to extract semantic concepts and visual features of distinct objects (Sec. III-A). After transforming and filtering those object features, we construct an Emotion Graph to depict emotional relationships between different objects (Sec. III-B1) and subsequently conduct GCN reasoning on it to correlate different objects with their pairwise relationships, yielding emotion-enhanced object features (Sec. III-B2). Finally, we design a Scene-Object Fusion Module by exploiting scene features as guidance to fuse object features with scene-based attention mechanism, from which scene-object interrelationships are built simultaneously (Sec. III-C).
III-A Object Detector
We adopt Faster R-CNN [60] as the object detector to select a set of candidate regions using ResNet-101 [72] as backbone. Our Faster R-CNN model is pre-trained on Visual Genome dataset [73], which outputs attribute classes in addition to general object classes, providing more detailed information. For example, object classes include: dog, building, mountains, woman, etc., while attribute classes include: white, large, rocky, beautiful, etc. In the following process, we employ object classes alone, aiming to build up connections between emotions and objects. For simplicity, we only use the top-10 RoIs and further prove its effectiveness in Sec. IV-D2. After applying Faster R-CNN, each image can be represented as a set of object semantic concepts with corresponding confidence scores , and a set of object visual features , in which , , and . Object semantic concepts are prediction results of the top-10 RoIs, which can be regarded as pseudo object-level labels since the involved visual emotion datasets only contain image-level labels. Each confidence score indicates the degree of confidence towards its corresponding prediction result . For each selected region , we extract the feature after the average pooling layer to serve as object visual feature .
III-B Emotion Graph
In this section, we build up an Emotion Graph and perform reasoning on it to mine the emotional relationships between different objects. Based on the detection results of Faster R-CNN, we construct the Emotion Graph with objects as nodes and emotional relationships as edges, by transforming and filtering those detected object features in Sec. III-A. Subsequently, we conduct GCN reasoning on the Emotion Graph, which propagates object information under different emotional relationships and eventually yields emotion-enhanced object features.
III-B1 Emotion Graph Construction

We construct our Emotion Graph by setting objects as nodes and building up emotional relationships between them based on previous detection results as shown in Fig. 4. For word embedding, following the recent work [67, 64], we employ Global Vectors for Word Representation (GloVe) [74], an unsupervised learning algorithm to obtain vector representations for words. Thus, semantic concepts are embedded to semantic features , where and . Notably, towards a specific object (e.g., cat, tree, balloon), visual features may vary from instance to instance while semantic features always remain unchanged. Thus, instead of visual features , we adopt semantic features as nodes to construct the Emotion Graph, aiming to map objects to emotions with one-to-one relationships. Oppositely, we build up edges based on visual features , so as to depict diverse emotional relationships between distinct objects. Considering the existing gap between semantics and emotions, we first embed visual features from semantic space to emotional space using a linear function followed by a non-linear -norm function:
| (1) |
which may bring a richer description towards emotional space. In Eq. (1), , is a learnable embedding matrix, and is a learnable embedding bias.
Therefore, the emotional visual features are denoted as , in which . Following [63, 75], we build up adjacency matrix by calculating affinity matrix to construct pairwise emotional relationships between objects for the Emotion Graph:
| (2) |
where , , represents two emotional visual features, and denotes the emotional relationships between them. Notably, and are two embedding functions with different parameters. Since visual features may vary greatly under the same emotion, we further embed them with different parameters to eliminate the bias of distinct features, hoping that they would be more comparable in the emotional space. The settings in Eq. (2), i.e., two functions with different parameters, is further ablated in Section IV-D1.
Our Emotion Graph is eventually constructed as where nodes denote the objects with their semantic features:
| (3) |
and edges represent the emotional relationships between different objects, which are described by affinity matrix:
| (4) |
which means there will be an edge with high affinity score connecting two objects if they have strong emotional relationships and are thus highly correlated. In order to remove redundancy of object nodes, we set a confidence threshold of 0.3 for to filter out less confident ones from the nodes, resulting in filtered nodes:
| (5) |
| (6) |
where and . Notably, not only do we remove redundant nodes, but we also delete adjacent edges of these nodes through masking operations as shown in Eq. (8), where denotes sign function and denotes absolute value function. After applying the above two functions, outputs either 1 or 0, suggesting whether or not edge still exists after the masking operation:
| (7) |
| (8) |
where and takes the maximum element of and . We then apply mask matrix to affinity matrix and obtain the masked affinity matrix as
| (9) |
where denotes the element-wise multiplication. The validity of mask operation is further proved in Sec. IV-D1. In order to depict emotional relationships between objects, the Emotion Graph is eventually built up with as nodes and as edges and further propagates information to yield emotion-enhanced features in Sec. III-B2.
III-B2 Emotion Graph Reasoning
In order to mine the emotional relationships between different objects, we apply Graph Convolutional Network (GCN) [70] to perform reasoning on the Emotion Graph, which is capable of exchanging and propagating information through structured graph. In traditional GCN, as shown in Eq. (10), adjacency matrix is denoted as while degree matrix is denoted as , where symmetric normalized Laplacian matrix depicts the relationships between different nodes:
| (10) |
where denotes the node features of the l-th layer and denotes a nonlinear activation function. Different from the supervised graph learning tasks, we need to establish a set of rules to calculate edges of the Emotion Graph, which is described in Eqs. (1) (2) (9). Following similar update mechanism with Eq. (10), our GCN layer is defined as
| (11) |
where denotes the input node features of the l-th layer and denotes the input edge features. Notably, we add a residual block in our GCN following [63] to better maintain the original node features, drawing lessons from residual block in ResNet. For the l-th layer, is the weight matrix of GCN and is the weight matrix of the residual block. It can be inferred from Eq. (11) that each node is updated based on both its neighbors and itself, from which object features propagate throughout the whole Emotion Graph under their emotional relationships. We conduct reasoning on our Emotion Graph by applying several GCN layers to update object features iteratively:
| (12) |
where . The output of the final GCN layer is regarded as emotion-enhanced object features, as object features are iteratively updated under their emotional relationships. In our experiment, L is set to 4, which is further ablated in Sec. IV-D2. Therefore, we successfully construct the Emotion Graph and conduct reasoning on it to correlate objects with their emotional relationships.
III-C Scene-Object Fusion Module

In previous sections, we model the emotional relationships between distinct objects and yield emotion-enhanced object features. Besides salient objects, scenes are regarded as another major stimulus in emotion evocation process, which largely affect the emotional tone of an image and thus cannot be ignored in VEA. In this section, assuming that it is scenes that guide objects to evoke distinct emotions, we propose a novel scene-based attention mechanism to mine the scene-object interrelationships. By implementing ResNet-50 [72] as backbone, scene feature extractor takes an affective image as input and outputs with its corresponding scene feature, which is denoted as with . In order to mine the deep interrelationships between scenes and objects, we propose a scene-based attention mechanism by exploiting scene features as guidance to fuse object features under different scene-object emotional relationships. To be specific, we first project the scene feature and emotion-enhanced object features into an embedding space to narrow the gap between scenes and objects, and calculate object attention weights by mining the emotional relationships between them:
| (13) |
| (14) |
where embedding functions are constructed by two learnable matrices , followed by an -norm function. Besides, so as to normalize each attention weight to , we apply Sigmoid function as the nonlinear activation function . The closer relationship a specific object is to a scene , the greater attention weight it will gain. Considering that different interactions between objects and scenes may evoke different emotions, we employ their interrelationships, i.e., the attention weights , as guidance to fuse object features:
| (15) |
After applying attention weights to all object features, we obtain the attended object feature with . The overall process of the scene-based attention mechanism is shown in Fig. 5. Since both scenes and objects are indispensable in emotion evocation process, we further concatenate the scene feature with the object feature as
| (16) |
The concatenated emotion feature is then fed into the emotion classifier and a Softmax function successively:
| (17) |
| (18) |
where denotes the number of emotion categories and denotes the number of affective images in a specific visual emotion dataset. Moreover, represents emotion labels in the dataset while represents emotion prediction results of the proposed SOLVER. is a learnable weight matrix in the emotion classifier, which is further optimized by the cross-entropy (CE) loss together with the whole network in an end-to-end manner.
IV Experimental results
IV-A Datasets
| Dataset | # Images | # Classes | Type |
|---|---|---|---|
| FI [76] | 23,164 | 8 | Social |
| Flickr [77] | 60,730 | 2 | Social |
| Instagram [77] | 42,848 | 2 | Social |
| EmotionROI [25] | 1,980 | 6 | Social |
| Twitter I [24] | 1,269 | 2 | Social |
| Twitter II [17] | 603 | 2 | Social |
| ArtPhoto [13] | 806 | 8 | Artistic |
| IAPSa [78, 79] | 395 | 8 | Natural |
Results are reported in classification accuracy (%) on six visual emotion datasets.
| Method | FI | Flickr | EmotionROI | Twitter I | Twitter II | |
|---|---|---|---|---|---|---|
| Sentibank [17] | 49.23 | 69.26 | 66.53 | 35.24 | 66.63 | 65.93 |
| Zhao et al. [14] | 46.13 | 66.61 | 64.17 | 34.84 | 67.92 | 67.51 |
| DeepSentibank [18] | 51.54 | 70.16 | 67.13 | 42.53 | 71.25 | 70.23 |
| Fine-tuned AlexNet [80] | 59.85 | 79.73 | 77.29 | 44.19 | 75.20 | 75.63 |
| Fine-tuned VGG-16 [81] | 65.52 | 80.75 | 78.72 | 49.75 | 78.35 | 77.31 |
| Fine-tuned ResNet-50 [72] | 67.53 | 82.73 | 81.45 | 52.27 | 79.53 | 78.15 |
| MldrNet [19] | 65.23 | – | – | – | – | – |
| Sun et al. [82] | – | 79.85 | 78.67 | – | 80.33 | 78.97 |
| Yang et al. [23] | 67.48 | – | – | 52.40 | – | – |
| Yang et al. [22] | 67.64 | – | – | – | – | – |
| WSCNet [21] | 70.07 | 81.36 | 81.81 | 58.25 | 84.25 | 81.35 |
| Zhang et al. [47] | 71.77 | – | – | – | – | – |
| SOLVER (Ours) | 72.33 | 86.20 | 85.60 | 62.12 | 85.43 | 83.19 |
We evaluate the proposed SOLVER on eight public visual emotion datasets, including the Flickr and Instagram (FI) [76], Flickr, Instagram [77], EmotionROI [25], Twitter I [24], Twitter II [17], ArtPhoto [13] and IAPSa [78, 79]. The involved datasets can be roughly divided into large-scale datasets (i.e., FI, Flickr, Instagram) and small-scale datasets (i.e., EmotionROI, Twitter I, Twitter II, Artphoto, IAPSa), for which more details are shown in TABLE I.
FI. The FI dataset, with 23,164 images, is one of the largest well-labeled datasets, which is collected from the Flickr and Instagram by searching eight emotion categories as keywords, i.e., Amusement, Anger, Awe, Contentment, Disgust, Excitement, Fear and Sad. The collected images are then well-labeled by 225 Amazon Mechanical Turk (AMT) workers through keeping the weakly labels and their corresponding images with at least three of the five are agreed.
Flickr and Instagram. Using image ID or emotional words as query keywords, the Flickr and Instagram datasets are crawled from the internet, containing 60,730 and 42,848 affective images respectively. Labeled by crowed-sourcing human annotation, these datasets provide sentiment labels with two emotion categories, i.e., positive, negative. With approximately 100 thousand images in total, the Flickr and Instagram datasets provide us with a large dataset to train with deep learning methods.
EmotionROI. The EmotionROI dataset contains 1,980 images with six emotion categories (i.e., anger, disgust, fear, joy, sad, surprise), which is a widely-used emotion prediction benchmark collected from Flickr. Besides, each image is also annotated with 15 bounding boxes as emotional regions, which act as pixel-level supervisions besides image-level labels.
Twitter I. Collected from social websites, Twitter I contains 1,269 affective images in total. Five AMT workers are recruited to generate sentiment labels for each candidate image in Twitter I.
Twitter II. Twitter II consists of 603 images downloaded from Twitter website, which is also labeled by AMT participants. With sentiment labels, there are 470 positive images and 133 negative images in total.
ArtPhoto. Rather than collecting images from social networks, ArtPhoto dataset are taken by professional artists, aiming to deliberately evoke certain emotions in their photos. Labeled with eight emotion categories, Artphoto dataset contains 806 images in total.
IV-B Implementation Details
Based on ResNet-50, our scene feature extractor is pre-trained on a large-scale visual recognition dataset, ImageNet [83]. We adopt Faster R-CNN as our object detector based on ResNet-101, which is pre-trained on Visual Genome dataset [73]. The whole network, including the scene branch and the object branch, is then jointly trained in an end-to-end manner with affective datasets. Following the same setting in [76], FI dataset is randomly split into training set (80%), validation set (5%) and testing set (15%). Flickr and Instagram datasets are randomly split into training set (90%) and testing set (10%), which follows the same configuration in [77]. Most of the small-scale datasets are split into training set (80%) and testing set (20%) randomly, except for those with specified training/testing separations [17][25]. For training/validation/testing sets, we first resize each image to 480 on its shorter side and then crop it to 448448 randomly followed by a horizontal flip [72]. Our SOLVER is trained by the adaptive optimizer Adam [84]. With a weight decay of 5e-5, the learning rate starts from 5e-5 and is decayed by 0.1 every 5 epochs, and the total epoch number is set to 50. Our framework is implemented using PyTorch [85] and our experiments are performed on an NVIDIA GTX 1080Ti GPU.
IV-C Comparison with the State-of-the-art Methods
To evaluate the effectiveness of the proposed SOLVER, we conduct experiments compared with the state-of-the-art methods on eight visual emotion datasets, which are shown in TABLE II and Fig. 6.
In TABLE II, we first compare our SOLVER with the state-of-the-art methods in classification accuracy on six visual emotion datasets, including FI, Flickr, Instagram, EmotionROI, Twitter I and Twitter II. which can be divided into traditional methods and deep learning ones. For traditional methods, Sentibank [17] and Zhao et al. [14] adopted a set of emotion-related hand-crafted features, which were early attempts to explore the mysteries in VEA. We also conduct experiments on several typical CNN backbones by fine-tuning the network parameters with visual emotion datasets, including AlexNet [80], VGG-16 [81] and ResNet-50 [72]. Benefiting from its powerful representation ability, deep learning methods gained significant performance boosts compared with those traditional ones. With coupled global-local branches, Yang et al. [21] proposed WSCNet and greatly improved the classification performance in VEA. Zhang et al. [47] further boosted the classification performance by exploring content as well as style information to predict visual emotions. Notably, the missing data in TABLE II is due to the lack of both classification results and open source codes. We can infer from TABLE II that our SOLVER achieves greater performance boosts on large-scale datasets compared with those small-scale ones, as deep scene-object interrelationships can be better mined with larger datasets. Overall, the proposed SOLVER outperforms the state-of-the-art methods by a large margin on six visual emotion datasets.
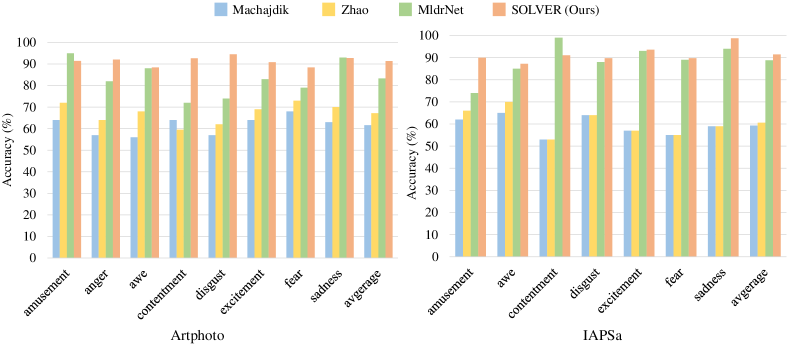
We further conduct detailed comparisons with the-state-of-the-art methods on Artphoto [13] and IAPSa [78, 79], as shown in Fig. 6. Considering the limited and imbalanced data in the above datasets, we employ the “one against all” strategy to train our network following the previous method [13] for fair comparison. Moreover, images in each category are randomly split into five batches and a 5-fold cross-validation is further implemented for emotion classification. We further remove the category of anger from IAPSa dataset following [13, 14, 19], as there are only eight samples in this category, where our SOLVER outperforms the state-of-the-art methods, including Machajdik[13], Zhao et al.[14] and MldrNet [19]. In addition to the optimal overall accuracy, our method is generally robust and applicable to each emotion with smaller accuracy deviation between categories. The above analysis proves that our SOLVER is applicable on Artphoto and IAPSa datasets as well.
The proposed SOLVER consistently outperforms the state-of-the-art methods on eight visual emotion datasets, which proves the effectiveness and robustness of our method.
IV-D Ablation Study
Our SOLVER is further ablated to verify the validity of its network structure and the involved hyper-parameters.
| Module | Ablated Combinations | Acc (%) |
| Emotion Graph | single object | 34.98 |
| multiple objects | 47.60 | |
| multiple objects + GCN + one embedding | 62.40 | |
| multiple objects + GCN + two embeddings | 64.47 | |
| multiple objects + GCN + mask + one embedding | 63.86 | |
| multiple objects + GCN + mask + two embeddings | 66.28 | |
| Scene-Object Fusion Module | scene | 67.53 |
| scene + single object | 68.13 | |
| scene + multiple objects | 70.20 | |
| scene + multiple objects + scene-based attention | 70.66 | |
| scene + multiple objects + GCN + one embedding + scene-based attention | 71.06 | |
| scene + multiple objects + GCN + two embedding + scene-based attention | 71.67 | |
| scene + multiple objects + GCN + mask + one embedding + scene-based attention | 71.93 | |
| scene + multiple objects + GCN + mask + two embeddings + scene-based attention | 72.33 |
IV-D1 Network Architecture Analysis
As shown in TABLE III, we conduct ablation study on FI dataset, aiming to verify the effectiveness of each proposed module. Our SOLVER mainly consists of two modules: Emotion Graph (i.e., object-object interaction) and Scene-Object Fusion Module (i.e., scene-object interaction), as shown in the first column. In each module, there are some detailed network designs, which are depicted as ablated combinations in the second column in TABLE III. In the Emotion Graph, we first conduct ablation studies concerning a single object and multiple objects, which indicates that multiple objects bring a performance boost compared with a single one. After that, we introduce our GCN reasoning mechanism with detailed designs into comparisons, i.e., one/two embedding(s), w/wo mask, suggesting that the object-object interactions indeed improve the performance in predicting emotions. From the above experiments, it is obvious that two embedding functions with different parameters achieve better performance than one embedding function and mask operation can further bring a performance boost. In the Scene-Object Fusion Module, it is obvious that both scene branch and scene-based attention mechanism make a great contribution to emotion classification, which suggests that it is the scene that guide object fusion process. From the above ablation studies, we can conclude that each detailed design of the proposed method is complementary and indispensable, which jointly contributes to the final result.
| L | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Acc (%) | 71.03 | 71.49 | 72.04 | 72.33 | 72.36 | 72.01 | 72.13 | 71.58 |

IV-D2 Hyper-Parameter Analysis
We conduct experiments to validate the choice of node number and the layer number in our Emotion Graph, as shown in Fig. 7 and TABLE IV. In general settings of Visual Genome dataset [73], top-36 RoIs are selected from the pre-trained object detector. However, we believe that such a large number of nodes can be redundant in our Emotion Graph and thus further conduct experiments to figure out the optimal , balancing both accuracy and computational cost. To be specific, we design experiments on both scene-based attention mechanism and the GAP layer, aiming to reduce the randomness in a single experiment. Setting as the step value, is varied from 0 to 20. We find that the accuracy constantly grows as varies from 0 to 10, while it slightly drops after , due to the redundancy of RoIs in object detection. It is worth mentioning that the growth of accuracy from 0 to 10 further proves that visual emotion analysis is not about a single object, but the interactions between multiple objects. From the above analysis, we choose as the node number in our Emotion Graph. For GCN layers, we ablate the number of GCN layers for better illustration. Setting as the step value, L is varied from 1 to 8. It is obvious that the accuracy consistently grows as the GCN layers increase, contributing to the excellent reasoning ability GCN owns. However, the performance meets a bottleneck when the number of GCN layers is too large, which may be caused by over fitting of too many parameters.
IV-E Visualization
The effectiveness of the proposed SOLVER has been quantitatively evaluated by comparing to the state-of-the-art methods and performing detailed ablation studies. As we are motivated by the psychological evidences that emotions are evoked by the two categories of interactions, in this section, we try to figure out how objects and objects, objects and scenes are interrelated with each other by visualizing the intermediate process of the SOLVER. To be specific, we visualize the emotional object concepts (Sec. IV-E1) and emotional object regions (Sec. IV-E2) for each category (i.e., Amusement, Awe, Contentment, Excitement, Anger, Disgust, Fear and Sad), which further validates the interpretability of our method and explores the mysteries of visual emotions.
IV-E1 Emotional Object Concepts
Considering that there exist relationships between objects, scenes and emotions, we visualize the top-10 emotional object concepts for each category. After implementing Faster R-CNN on FI dataset, we first calculate the frequency for each object in each emotion category , where denotes the overall object number and denotes the emotion categories in the whole dataset:
| (19) |
where and represents the count of object in category . Subsequently, we derive the scene-based attention coefficient from the trained model and calculate the averaged attention coefficient for each object in each emotion category :
| (20) |
where denotes the j-th instance of object in category . While object frequency represents the objects distribution of each emotion in the dataset, scene-based attention coefficient represents the correlations between objects and emotions learned by our SOLVER. Taking both object frequency and scene-based attention coefficient into account, we obtain the weighted frequency for each object in each emotion category :
| (21) |
It is obvious that not all the objects are emotional, some non-emotional objects appear in every emotion category, e.g., man, woman, people, etc. Thus, we adopt the TF-IDF [86] technique to separate the emotion-specific objects from the non-emotional ones, where the importance of an object increases as it appears in a specific emotion category and decreases inversely with its appearance in the whole dataset. As shown in Fig. 8, we list the top-10 emotional object concepts for each emotion category with their corresponding weighted frequencies. Besides, we present three typical images for each emotion to further illustrate these emotional object concepts in a concrete and vivid form. Taking awe as an example, there are mountains, castle, ocean in the first image, cliff, horizon, sunset in the second one, and ocean, wave, shore in the third one, which indicates that interactions between these emotional objects may evoke awe to a large extent. The most relevant concepts towards excitement include raft, surfboard, plane, microphone, player, etc., which implies sports events or entertainments and consequently evokes excitement.


IV-E2 Emotional Object Regions
Besides emotional object concepts, we also visualize emotional object regions by presenting one image for each emotion category as a representative. As shown in Fig. 9, after implemented the proposed SOLVER, an affective image (i.e., the upper one) is turned into a set of emotional object regions (i.e., the lower one) with corresponding semantic concepts and attention weights. Notably, we first adopt object detectors to refine emotions to object level and then mine the interrelationships between objects and emotions with scene-based attention mechanism, which takes the scene feature as a guidance to fuse objects. Attention weights reflect the relevance between objects, scenes and emotions. The more an object is related to a specific emotion, the higher the attention weight will gain. For example, in amusement, tower (0.957), building (0.938) get higher attention scores while cloud (0.764) gets a lower score, as when tower and building comes together, they often indicate castle and amusement park, which surely bring people joy. When people or other animals are angry, the most striking part of their facial expression is an opened mouth. Thus, angry is represented by an furious leopard with a distinguished opened mouth, and accordingly our SOLVER focuses more on its mouth (0.851) than its head (0.684), eyes (0.654).
IV-F Further Discussions
To validate the robustness of our method, we further extend experiments on three other potential datasets, i.e., LUCFER [87], EMOTIC [88], and Flickr CC [17], with more diverse emotional settings. Meanwhile, we also notice some limitations of our method and discuss them for future work.
IV-F1 Potential Datasets
LUCFER [87] contains over 3.6M images with 3-dimensional labels including emotion, context, and valence, which is currently the largest emotion recognition dataset. With a sum of 18,316 images, EMOTIC [88] serves as a pioneer dataset in emotion state recognition (ESR) field, which is labeled with both discrete categories (i.e., 26 defined emotions) and continuous dimensions (i.e., valence, arousal, and dominance (VAD)). Containing 500,000 images in total, Flickr CC [17] is one of the largest visual sentiment datasets labeled with 1,553 fine-grained ANPs (Adjective Noun Pairs).
IV-F2 Data Preprocessing
Since SOLVER is oriented to single-label emotion classification tasks, we preprocess the three potential datasets in distinct and reasonable ways to fit our task. According to the rules in LUCFER, we degenerate the 275 fine-grained emotion-context pairs into eight basic emotions (i.e., Anger, Anticipation, Disgust, Fear, Joy, Sadness, Surprise, and Trust) in Plutchik’s wheel. Besides, we group the eight emotions into two sentiments (i.e., positive, and negative) according to their polarities. Following the same setting in [87], LUCFER is split into training set (80%) and testing set (20%). Each image in EMOTIC is annotated with multiple emotion labels, which is different from our single-label classification task. Besides, it is irrational to degrade a multi-label task to a single-label one. Fortunately, valence in VAD measures the positive degree of an emotion, where corresponds to positive and negative. Thus, we degenerate valence to sentiment labels (i.e., positive, and negative) according to psychological model. EMOTIC is split into training set (70%), validation set (10%), and testing set (20%) [88]. Based on Visual Sentiment Ontology (VSO) [17], we degenerate its 1,553 ANPs into sentiment labels (i.e., positive, and negative). The Flickr CC dataset is split into training set (80%) and testing set (20%), which follows the same setting in [17].
IV-F3 Classification Accuracy
We conduct experiments in classification accuracy on three potential datasets in TABLE V and TABLE VI. Specifically, results using models trained on FI dataset are reported in TABLE V, and results using models trained on different datasets themselves are shown in TABLE VI. In particular, LUCFER is conducted with two experimental settings, eight emotions (i.e., LUCFER-8) and two sentiments (i.e., LUCFER-2), for richer comparisons and analyses. In order to validate the effectiveness of our method and to explore the emotional diversity in different datasets, we ablated our experiments to three settings including Scene branch, Object branch, and SOLVER.

In TABLE V, it can be noticed that the FI trained model achieves relatively good results on LUCFER-2 (69.38%), while meets unsatisfactory results on LUCFER-8, EMOTIC-2 and Flickr CC-2 (14.69%, 36.13%, and 36.86%). Dataset shift is a common problem in machine learning. Since emotions are complex and ambiguous to be described and labeled, this gap becomes even larger. Besides, VEA aims at finding out how people feel emotionally towards different visual stimuli, while ESR focuses on recognizing peoples’ emotional states from their frames. The mismatches between these two areas may lead to a performance degradation in TABLE V. Compared with the other 2-sentiment tasks, LUCFER-2 achieves quite a good result, which attributes to the well-constructed dataset with more emotional stimuli and less noise. It is obvious that Object branch performs generally better than Scene branch on LUCFER. The possible reason may be that there are distinct and obvious objects conveying emotions, while scene features are not clearly distinguishable to separate different emotions apart. The three results on EMOTIC dataset are close to each other, which indicates that our SOLVER failed to find key features related to ESR. Moreover, we guess that the key features concerning ESR may be facial expressions or body language, which our method does not involve. Similarly, SOLVER performs poorly on Flickr CC, resulting from its very large data scale compared with FI. Besides, most images in Flickr CC contain a distinct object or a simple scene, which our SOLVER may fail to match with.
For fair comparisons with datasets in Sec IV-C, we also report the results using models trained on three potential datasets and tested on themselves in TABLE VI. Compared with TABLE V, it is obvious that the corresponding results in TABLE VI have significant performance improvements, which are comparable to the results in TABLE II. In TABLE VI, it is undoubted that LUCFER is a well-labeled dataset, whose 8-emotion accuracy (75.59%) is higher than others’ 2-sentiment ones (65.07%, and 71.68%). TABLE VI shows that SOLVER constantly outperforms the other ablated branches on all experimental settings, which further validates the effectiveness and the robustness of each proposed branch.
From TABLE V and TABLE VI, we can conclude that SOLVER achieves competitive results on three potential datasets. Meanwhile, we also noticed some limitations of our method. Firstly, when facing ESR tasks, SOLVER fails to leverage the facial expressions as well as body language of people within the images, resulting in degraded performance. Secondly, SOLVER is proposed to mine the emotional correlations between objects and scenes, which fails to deal with the situation of a single object or a simple scene.

IV-F4 Visualizations
In addition to classification accuracy, we also visualize emotional object regions on potential datasets from different trained models (i.e., FI and themselves). In Fig. 10, we present the visualizations of emotional object regions on LUCFER. While the first row represents the input images, the second row uses model trained on FI and the third row is trained on LUCFER itself. By analyzing the difference in attention weights, we discover some possible reasons for the performance improvements in TABLE VI compared with TABLE V. Take the first image as an example, while the second row focuses more on grass, tree, and other objects, the third row attends more weights on man, shirt, and hair. It is obvious that FI trained model concentrate more on objects unrelated to people while LUCFER trained model emphasizes more on human-centered ones, which further shows the robustness of our method. As ESR datasets are constructed by images all containing people, it is understandable that increased attention weights on people and their related objects may bring a performance boost in such datasets. As is mentioned above, there are some similarities in VEA and ESR tasks yet much more differences in details. The visualizations also prove that emotions are always evoked by people within the images in ESR datasets, especially their facial expressions and body language, which is different from our VEA task.
IV-F5 Failure Cases
Fig. 11 shows three types of failure cases on LUCFER. In Fig. 11 (a), two images in the first column share the same scene (i.e., stadium), and two images in the second column share the same object (i.e., tennis). However, under the same scene/object, emotions are varying according to different facial expressions and body language. Take first row as an example, by observing the waving fists and the confident smile, the coach is angry with his players while the player is satisfied with herself Since SOLVER mines emotions from the interactions between objects and scenes, facial expressions and body language are not considered in our method. This failure is mainly caused by the mismatch between VEA and ESR, which will be considered in our future work. In Fig. 11 (b), we can see that people in an image do not necessarily share the same emotion. Take the second row as an example, the woman seems happy while the man is angry. While ESR concentrates on the emotions of characters within the image, our VEA focuses on the emotions of viewers outside the image. This failure also results from the mismatch between two tasks. Besides, there are also some images where emotions may be weak and obscure as in Fig. 11 (c). In other words, these images hardly arouse any of our emotions. This failure is universal in both tasks. We may find a reasonable way to separate emotional images and emotionless images in our future work.
V Conclusion
We have proposed a Scene-Object interreLated Visual Reasoning network (SOLVER) to mine emotions from the interactions between objects and objects as well as objects and scenes. We first constructed an Emotion Graph based on detected features and conducted GCN reasoning on it, aiming to extract the emotional relationships between different objects. Besides, we proposed a Scene-Object Fusion Module to fuse objects with the guidance of scene-based attention mechanism. Extensive experiments and comparisons have shown that the proposed SOLVER consistently outperforms the state-of-the-art methods on eight public visual emotion datasets. Notably, visualization results on emotional object concepts and regions not only proved the interpretability of our network, but also offered new insight to explore the mysteries in visual emotion analysis. We further extended our experiments on three other potential datasets, where we validated the effectiveness and robustness of our method with more diverse emotional settings. Additionally, we also noticed some limitations of our method. Since SOLVER aims at mining emotions from the interactions between objects and scenes, it may fail to deal with situations including images with a single object/scene and drawings without objects/scenes. In ESR datasets, though scenes and objects are still important in predicting emotions, human-centered attributes, i.e., facial expressions and body language, play a leading role that cannot be ignored. These limitations will be considered in a unified network for a better performance in our future work.
References
- [1] E. R. Gerber, “Rage and obligation: Samoan emotion in conflict,” Person, self, and experience: Exploring Pacific ethnopsychologies, vol. 121, p. 167, 1985.
- [2] E. A. Phelps, “Emotion and cognition: insights from studies of the human amygdala,” Annual Review of Psychology, vol. 57, pp. 27–53, 2006.
- [3] L. Li, H. Zhu, S. Zhao, G. Ding, and W. Lin, “Personality-assisted multi-task learning for generic and personalized image aesthetics assessment,” IEEE Transactions on Image Processing, vol. 29, pp. 3898–3910, 2020.
- [4] H. Zeng, Z. Cao, L. Zhang, and A. C. Bovik, “A unified probabilistic formulation of image aesthetic assessment,” IEEE Transactions on Image Processing, vol. 29, pp. 1548–1561, 2019.
- [5] T. Chen, Z. Zhang, Q. You, C. Fang, Z. Wang, H. Jin, and J. Luo, ““factual”or“emotional”: Stylized image captioning with adaptive learning and attention,” in ECCV, 2018, pp. 519–535.
- [6] L. Guo, J. Liu, P. Yao, J. Li, and H. Lu, “Mscap: Multi-style image captioning with unpaired stylized text,” in CVPR, 2019, pp. 4204–4213.
- [7] Z. Zhang, P. Luo, C.-C. Loy, and X. Tang, “Learning social relation traits from face images,” in ICCV, 2015, pp. 3631–3639.
- [8] R. Szczepanowski, J. Traczyk, M. Wierzchoń, and A. Cleeremans, “The perception of visual emotion: comparing different measures of awareness,” Consciousness and Cognition, vol. 22, no. 1, pp. 212–220, 2013.
- [9] A. A. Mitchell, “The effect of verbal and visual components of advertisements on brand attitudes and attitude toward the advertisement,” Journal of Consumer Research, vol. 13, no. 1, pp. 12–24, 1986.
- [10] Z. Li, Y. Fan, B. Jiang, T. Lei, and W. Liu, “A survey on sentiment analysis and opinion mining for social multimedia,” Multimedia Tools and Applications, vol. 78, no. 6, pp. 6939–6967, 2019.
- [11] M. J. Wieser, E. Klupp, P. Weyers, P. Pauli, D. Weise, D. Zeller, J. Classen, and A. Mühlberger, “Reduced early visual emotion discrimination as an index of diminished emotion processing in parkinson’s disease?–evidence from event-related brain potentials,” Cortex, vol. 48, no. 9, pp. 1207–1217, 2012.
- [12] P. J. Lang, M. M. Bradley, B. N. Cuthbert et al., “International affective picture system (iaps): Technical manual and affective ratings,” NIMH Center for the Study of Emotion and Attention, vol. 1, pp. 39–58, 1997.
- [13] J. Machajdik and A. Hanbury, “Affective image classification using features inspired by psychology and art theory,” in ACMMM, 2010, pp. 83–92.
- [14] S. Zhao, Y. Gao, X. Jiang, H. Yao, T.-S. Chua, and X. Sun, “Exploring principles-of-art features for image emotion recognition,” in ACMMM, 2014, pp. 47–56.
- [15] S. Siersdorfer, E. Minack, F. Deng, and J. Hare, “Analyzing and predicting sentiment of images on the social web,” in ACMMM, 2010, pp. 715–718.
- [16] S. Zhao, H. Yao, Y. Yang, and Y. Zhang, “Affective image retrieval via multi-graph learning,” in ACMMM, 2014, pp. 1025–1028.
- [17] D. Borth, R. Ji, T. Chen, T. Breuel, and S.-F. Chang, “Large-scale visual sentiment ontology and detectors using adjective noun pairs,” in ACMMM, 2013, pp. 223–232.
- [18] T. Chen, D. Borth, T. Darrell, and S.-F. Chang, “Deepsentibank: Visual sentiment concept classification with deep convolutional neural networks,” arXiv preprint arXiv:1410.8586, 2014.
- [19] T. Rao, X. Li, and M. Xu, “Learning multi-level deep representations for image emotion classification,” Neural Processing Letters, pp. 1–19, 2016.
- [20] J. Yang, D. She, M. Sun, M.-M. Cheng, P. L. Rosin, and L. Wang, “Visual sentiment prediction based on automatic discovery of affective regions,” IEEE Transactions on Multimedia, vol. 20, no. 9, pp. 2513–2525, 2018.
- [21] J. Yang, D. She, Y.-K. Lai, P. L. Rosin, and M.-H. Yang, “Weakly supervised coupled networks for visual sentiment analysis,” in CVPR, 2018, pp. 7584–7592.
- [22] J. Yang, D. She, Y.-K. Lai, and M.-H. Yang, “Retrieving and classifying affective images via deep metric learning,” in AAAI, 2018.
- [23] J. Yang, D. She, and M. Sun, “Joint image emotion classification and distribution learning via deep convolutional neural network.” in IJCAI, 2017, pp. 3266–3272.
- [24] Q. You, J. Luo, H. Jin, and J. Yang, “Robust image sentiment analysis using progressively trained and domain transferred deep networks,” in AAAI, 2015.
- [25] K.-C. Peng, A. Sadovnik, A. Gallagher, and T. Chen, “Where do emotions come from? predicting the emotion stimuli map,” in ICIP, 2016, pp. 614–618.
- [26] K. T. Strongman, The psychology of emotion: Theories of emotion in perspective. John Wiley & Sons, 1996.
- [27] R. D. Lane and L. Nadel, Cognitive neuroscience of emotion. Oxford University Press, 2002.
- [28] A. R. Hochschild, “The sociology of emotion as a way of seeing,” Emotions in social life: Critical themes and contemporary issues, pp. 3–15, 1998.
- [29] T. Brosch, G. Pourtois, and D. Sander, “The perception and categorisation of emotional stimuli: A review,” Cognition and emotion, vol. 24, no. 3, pp. 377–400, 2010.
- [30] N. H. Frijda, “Emotion experience and its varieties,” Emotion Review, vol. 1, no. 3, pp. 264–271, 2009.
- [31] M. Bar, “Visual objects in context,” Nature Reviews Neuroscience, vol. 5, no. 8, pp. 617–629, 2004.
- [32] J. Yang, J. Li, X. Wang, Y. Ding, and X. Gao, “Stimuli-aware visual emotion analysis,” IEEE Transactions on Image Processing, 2021.
- [33] J. Yang, M. Sun, and X. Sun, “Learning visual sentiment distributions via augmented conditional probability neural network,” in AAAI, vol. 31, no. 1, 2017.
- [34] S. Zhao, G. Ding, Y. Gao, X. Zhao, Y. Tang, J. Han, H. Yao, and Q. Huang, “Discrete probability distribution prediction of image emotions with shared sparse learning,” IEEE Transactions on Affective Computing, vol. 11, no. 4, pp. 574–587, 2018.
- [35] S. Zhao, X. Zhao, G. Ding, and K. Keutzer, “Emotiongan: Unsupervised domain adaptation for learning discrete probability distributions of image emotions,” in ACMMM, 2018, pp. 1319–1327.
- [36] S. Zhao, H. Yao, Y. Gao, R. Ji, and G. Ding, “Continuous probability distribution prediction of image emotions via multitask shared sparse regression,” IEEE transactions on multimedia, vol. 19, no. 3, pp. 632–645, 2016.
- [37] S. Zhao, G. Ding, Y. Gao, and J. Han, “Learning visual emotion distributions via multi-modal features fusion,” in ACMMM, 2017, pp. 369–377.
- [38] J. Yang, J. Li, L. Li, X. Wang, and X. Gao, “A circular-structured representation for visual emotion distribution learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4237–4246.
- [39] S. Zhao, H. Yao, Y. Gao, G. Ding, and T.-S. Chua, “Predicting personalized image emotion perceptions in social networks,” IEEE transactions on affective computing, vol. 9, no. 4, pp. 526–540, 2016.
- [40] S. Zhao, G. Ding, J. Han, and Y. Gao, “Personality-aware personalized emotion recognition from physiological signals,” in IJCAI, 2018, pp. 1660–1667.
- [41] D. Joshi, R. Datta, E. Fedorovskaya, Q.-T. Luong, J. Z. Wang, J. Li, and J. Luo, “Aesthetics and emotions in images,” IEEE Signal Processing Magazine, vol. 28, no. 5, pp. 94–115, 2011.
- [42] S. Zhao, G. Ding, Q. Huang, T.-S. Chua, B. W. Schuller, and K. Keutzer, “Affective image content analysis: A comprehensive survey,” in IJCAI, 2018, pp. 5534–5541.
- [43] S. Zhao, S. Wang, M. Soleymani, D. Joshi, and Q. Ji, “Affective computing for large-scale heterogeneous multimedia data: A survey,” ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol. 15, no. 3s, pp. 1–32, 2019.
- [44] S. Zhao, X. Yao, J. Yang, G. Jia, G. Ding, T.-S. Chua, B. W. Schuller, and K. Keutzer, “Affective image content analysis: Two decades review and new perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [45] T. Chen, F. X. Yu, J. Chen, Y. Cui, Y.-Y. Chen, and S.-F. Chang, “Object-based visual sentiment concept analysis and application,” in ACMMM, 2014, pp. 367–376.
- [46] Q. You, H. Jin, and J. Luo, “Visual sentiment analysis by attending on local image regions,” in AAAI, 2017.
- [47] W. Zhang, X. He, and W. Lu, “Exploring discriminative representations for image emotion recognition with cnns,” IEEE Transactions on Multimedia, vol. 22, no. 2, pp. 515–523, 2019.
- [48] N. Yu, X. Hu, B. Song, J. Yang, and J. Zhang, “Topic-oriented image captioning based on order-embedding,” IEEE Transactions on Image Processing, vol. 28, no. 6, pp. 2743–2754, 2018.
- [49] L. Zhou, Y. Zhang, Y.-G. Jiang, T. Zhang, and W. Fan, “Re-caption: Saliency-enhanced image captioning through two-phase learning,” IEEE Transactions on Image Processing, vol. 29, pp. 694–709, 2019.
- [50] D. Xu, Y. Zhu, C. B. Choy, and L. Fei-Fei, “Scene graph generation by iterative message passing,” in CVPR, 2017, pp. 5410–5419.
- [51] J. Yang, J. Lu, S. Lee, D. Batra, and D. Parikh, “Graph r-cnn for scene graph generation,” in ECCV, 2018, pp. 670–685.
- [52] H. Xu, C. Jiang, X. Liang, L. Lin, and Z. Li, “Reasoning-rcnn: Unifying adaptive global reasoning into large-scale object detection,” in CVPR, 2019, pp. 6419–6428.
- [53] J. Zhang, F. Shen, X. Xu, and H. T. Shen, “Temporal reasoning graph for activity recognition,” IEEE Transactions on Image Processing, vol. 29, pp. 5491–5506, 2020.
- [54] W. Zhang, X. He, X. Yu, W. Lu, Z. Zha, and Q. Tian, “A multi-scale spatial-temporal attention model for person re-identification in videos,” IEEE Transactions on Image Processing, vol. 29, pp. 3365–3373, 2019.
- [55] Y. Hao, N. Wang, J. Li, and X. Gao, “Hsme: hypersphere manifold embedding for visible thermal person re-identification,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 8385–8392.
- [56] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in CVPR, 2016, pp. 779–788.
- [57] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in ECCV, 2016, pp. 21–37.
- [58] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in CVPR, 2014, pp. 580–587.
- [59] R. Girshick, “Fast r-cnn,” in ICCV, 2015, pp. 1440–1448.
- [60] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in NeurIPS, 2015, pp. 91–99.
- [61] Y.-L. Li, S. Zhou, X. Huang, L. Xu, Z. Ma, H.-S. Fang, Y. Wang, and C. Lu, “Transferable interactiveness knowledge for human-object interaction detection,” in CVPR, 2019, pp. 3585–3594.
- [62] H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei, “Relation networks for object detection,” in CVPR, 2018, pp. 3588–3597.
- [63] K. Li, Y. Zhang, K. Li, Y. Li, and Y. Fu, “Visual semantic reasoning for image-text matching,” in ICCV, 2019, pp. 4654–4662.
- [64] Y. Huang, J. Chen, W. Ouyang, W. Wan, and Y. Xue, “Image captioning with end-to-end attribute detection and subsequent attributes prediction,” IEEE Transactions on Image Processing, vol. 29, pp. 4013–4026, 2020.
- [65] J. Ji, C. Xu, X. Zhang, B. Wang, and X. Song, “Spatio-temporal memory attention for image captioning,” IEEE Transactions on Image Processing, 2020.
- [66] X. He, Q. Liu, and Y. Yang, “Mv-gnn: Multi-view graph neural network for compression artifacts reduction,” IEEE Transactions on Image Processing, 2020.
- [67] Z.-M. Chen, X.-S. Wei, P. Wang, and Y. Guo, “Multi-label image recognition with graph convolutional networks,” in CVPR, 2019, pp. 5177–5186.
- [68] Y. Chen, M. Rohrbach, Z. Yan, Y. Shuicheng, J. Feng, and Y. Kalantidis, “Graph-based global reasoning networks,” in CVPR, 2019, pp. 433–442.
- [69] Y. Li, D. Tarlow, M. Brockschmidt, and R. Zemel, “Gated graph sequence neural networks,” arXiv preprint arXiv:1511.05493, 2015.
- [70] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [71] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” arXiv preprint arXiv:1710.10903, 2017.
- [72] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
- [73] R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma et al., “Visual genome: Connecting language and vision using crowdsourced dense image annotations,” International journal of computer vision, vol. 123, no. 1, pp. 32–73, 2017.
- [74] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in EMNLP, 2014, pp. 1532–1543.
- [75] H. Xu, C. Jiang, X. Liang, and Z. Li, “Spatial-aware graph relation network for large-scale object detection,” in CVPR, 2019, pp. 9298–9307.
- [76] Q. You, J. Luo, H. Jin, and J. Yang, “Building a large scale dataset for image emotion recognition: The fine print and the benchmark,” in AAAI, 2016.
- [77] M. Katsurai and S. Satoh, “Image sentiment analysis using latent correlations among visual, textual, and sentiment views,” in ICASSP, 2016, pp. 2837–2841.
- [78] P. J. Lang, M. M. Bradley, B. N. Cuthbert et al., “International affective picture system (iaps): Instruction manual and affective ratings,” The center for research in psychophysiology, University of Florida, 1999.
- [79] J. A. Mikels, B. L. Fredrickson, G. R. Larkin, C. M. Lindberg, S. J. Maglio, and P. A. Reuter-Lorenz, “Emotional category data on images from the international affective picture system,” Behavior research methods, vol. 37, no. 4, pp. 626–630, 2005.
- [80] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in NeurIPS, 2012, pp. 1097–1105.
- [81] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [82] M. Sun, J. Yang, K. Wang, and H. Shen, “Discovering affective regions in deep convolutional neural networks for visual sentiment prediction,” in ICME, 2016, pp. 1–6.
- [83] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in CVPR, 2009, pp. 248–255.
- [84] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [85] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” 2017.
- [86] G. Salton and C. T. Yu, “On the construction of effective vocabularies for information retrieval,” Acm Sigplan Notices, vol. 10, no. 1, pp. 48–60, 1973.
- [87] P. Balouchian, M. Safaei, and H. Foroosh, “Lucfer: A large-scale context-sensitive image dataset for deep learning of visual emotions,” in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2019, pp. 1645–1654.
- [88] R. Kosti, J. M. Alvarez, A. Recasens, and A. Lapedriza, “Emotion recognition in context,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1667–1675.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cdf4b49-95d4-4572-af20-cd2aba09f441/JingyuanYang.jpg) |
Jingyuan Yang received the B.Eng. degree in Electronic and Information Engineering from Xidian University, Xi’an, China, in 2017. She is currently a Ph. D. Candidate at the School of Electronic Engineering, Xidian University. Her current research interest is visual emotion analysis in deep learning and its applications. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cdf4b49-95d4-4572-af20-cd2aba09f441/XinboGao.jpg) |
Xinbo Gao (Senior Member, IEEE) received the B.Eng., M.Sc. and Ph.D. degrees in electronic engineering, signal and information processing from Xidian University, Xi’an, China, in 1994, 1997, and 1999, respectively. From 1997 to 1998, he was a research fellow at the Department of Computer Science, Shizuoka University, Shizuoka, Japan. From 2000 to 2001, he was a post-doctoral research fellow at the Department of Information Engineering, the Chinese University of Hong Kong, Hong Kong. Since 2001, he has been at the School of Electronic Engineering, Xidian University. He is a Cheung Kong Professor of Ministry of Education of P. R. China, a Professor of Pattern Recognition and Intelligent System of Xidian University. Since 2020, he is also a Professor of Computer Science and Technology of Chongqing University of Posts and Telecommunications. His current research interests include Image processing, computer vision, multimedia analysis, machine learning and pattern recognition. He has published six books and around 300 technical articles in refereed journals and proceedings. Prof. Gao is on the Editorial Boards of several journals, including Signal Processing (Elsevier) and Neurocomputing (Elsevier). He served as the General Chair/Co-Chair, Program Committee Chair/Co-Chair, or PC Member for around 30 major international conferences. He is a Fellow of the Institute of Engineering and Technology and a Fellow of the Chinese Institute of Electronics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cdf4b49-95d4-4572-af20-cd2aba09f441/LeidaLi.jpg) |
Leida Li (Member, IEEE) received the B.S. and Ph.D. degrees from Xidian University, Xi’an, China, in 2004 and 2009, respectively. In 2008, he was a Research Assistant with the Department of Electronic Engineering, National Kaohsiung University of Science and Technology, Kaohsiung, Taiwan. From 2014 to 2015, he was a Visiting Research Fellow with the Rapid-Rich Object Search (ROSE) Lab, School of Electrical and Electronic Engineering, Nanyang Technological University, Singapore, where he was a Senior Research Fellow, from 2016 to 2017. He is currently a Professor with the School of Artificial Intelligence, Xidian University, China. His research interests include multimedia quality assessment, affective computing, information hiding, and image forensics. He has served as an SPC for IJCAI 2019-2021, the Session Chair for ICMR 2019 and PCM 2015, and TPC for CVPR 2021, ICCV 2021, AAAI 2019-2021, ACM MM 2019-2020, ACM MM-Asia 2019, and ACII 2019. He is currently an Associate Editor of the Journal of Visual Communication and Image Representation and the EURASIP Journal on Image and Video Processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cdf4b49-95d4-4572-af20-cd2aba09f441/XiumeiWang.jpg) |
Xiumei Wang received the Ph.D. degree from Xidian University, Xi’an, China, in 2010. She is currently a Lecturer with the School of Electronic Engineering, Xidian University. Her current research interests include nonparametric statistical models and machine learning. She has published several scientific articles, including the IEEE Trans. Cybernetics, Pattern Recognition, and Neurocomputing in the above areas. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/8cdf4b49-95d4-4572-af20-cd2aba09f441/JinshanDing.jpg) |
Jinshan Ding is a Professor with the School of Electronic Engineering, Xidian University, Xi’an, China. He founded the Millimeter-Wave and THz Research Group, Xidian University, after his return from Germany. His research interests include millimeter-wave and THz radar, video SAR, and machine learning in radar. |