Solutions of the Multivariate Inverse Frobenius–Perron Problem
Abstract
We address the inverse Frobenius–Perron problem: given a prescribed target distribution , find a deterministic map such that iterations of tend to in distribution. We show that all solutions may be written in terms of a factorization that combines the forward and inverse Rosenblatt transformations with a uniform map, that is, a map under which the uniform distribution on the -dimensional hypercube as invariant. Indeed, every solution is equivalent to the choice of a uniform map. We motivate this factorization via -dimensional examples, and then use the factorization to present solutions in and dimensions induced by a range of uniform maps.
I Introduction
A basic question in the theory of discrete dynamical systems, and in statistical mechanics, is whether a chaotic iterated function , that maps a space back onto , has an equilibrium distribution, with probability density function (PDF) 111The density function is with respect to some underlying measure, typically Lebesgue. Throughout this paper we will use the same symbol for the distribution and associated PDF, with meaning taken from context.. A necessary condition is that the distribution is invariant under , i.e. if ( is distributed as ) then so is , and further that the orbit of almost all points defined as tends in distribution to . Then, under mild conditions, the map is ergodic for , that is, expectations with respect to may be replaced by averages over the orbit dorfman1999introduction ; LasotaMackey .
For example, it is well known UlamvonNeumann1947 ; may1976simple ; dorfman1999introduction ; LasotaMackey that the logistic map , for , is chaotic with the equilibrium distribution having PDF
implying that is ergodic for .
Our motivating interest is in using this ergodic property to implement sample-based inference for Bayesian analysis or machine learning. In those settings, the target distribution is defined by the application. Generating a sequence that is ergodic for is useful because then expectations of any quantity of interest can be computed as averages over the sequence, i.e.,
| (1) |
Commonly in statistics, such ergodic sequences are generated using a stochastic iteration that simulates a Markov chain targeting mcmc_liu ; here we explore deterministic iterations that generate an orbit that is ergodic for .
The equilibrium distribution for a given iterated function, if it exists, can be approximated by computing the orbit of the map for some starting point then performing kernel density estimation, or theoretically by seeking the stationary distribution of the Frobenius–Perron (FP) operator that is the transfer KlusKoltaiSchutte2016 , aka push-forward, operator induced by a deterministic map dorfman1999introduction ; LasotaMackey ; we present the FP equation in Section II.
The inverse problem that we consider here, of determining a map that gives a prescribed equilibrium distribution, is the inverse Frobenius–Perron problem (IFPP) and has been studied extensively grossmann1977invariant ; ershov1988solution ; diakonos1996construction ; diakonos1999stochastic ; pingel1999theory ; bollt2000controlling ; nie2013new ; nie2018matrix . Summaries of previous approaches to the IFPP are presented in bollt2000controlling ; rogers2008synthesis that characterize approaches as based on conjugate functions (see grossmann1977invariant for details) or the matrix method (see rogers2008synthesis for details), and wei2015solutions that also lists the differential equation approach. Existing work almost solely considers the IFPP in one-variable, , the exception being the development of a two-dimensional solution in bollt2000controlling that is also presented in rogers2008synthesis .
The matrix method, first suggested by Ulam Ulam1960 , solves the IFPP for a piecewise-constant approximation to the target density, using a transition matrix representation of the approximated FP operator. Convergence of the discrete approximation is related to Ulam’s conjecture, and has been proved for the multidimensional problem; see wei2015solutions and references therein. While the matrix method allows construction of solutions, at least in the limit, existing methods only offer a limited class of very non-smooth solutions, so are not clearly useful for characterizing all solutions, as we do here. We do not further consider the matrix methods.
The development in this paper starts with the differential equation approach in which the IFPP for restricted forms of distributions and maps is written as a differential equation that may be solved. We re-derive some existing solutions to the IFPP this way in Sec. III. The main contribution of this paper is to show that the form of these solutions may be generalized to give the general solution of the IFPP for any probability distribution in any dimension , as presented in the factorization theorem of Sec. IV. This novel factorization represents solutions of the IFPP in terms of the Rosenblatt transformation rosenblatt-1952 and a uniform map, that is a map on that leaves the uniform distribution invariant. In particular, we show that the conjugating functions in grossmann1977invariant are exactly the inverse Rosenblatt transformations. For a given Rosenblatt transformation, there is a one-to-one correspondence between solution of the IFPP and choice of a uniform map.
This reformulation of the IFPP in terms of two well-studied constructs leads to practical analytic and numerical solutions by exploiting existing, well-developed methods for Rosenblatt transformations, and for deterministic iterations that target the uniform distribution. The factorization also allows us to establish equivalence of solutions of the IFPP and other methods that employ a deterministic map within the generation of ergodic sequences. This standardizes and simplifies existing solution methods by showing that they are special cases of constructing the Rosenblatt transformation (or its inverse), and selection of a uniform map.
This paper starts with definitions of the IFPP and the Lyuapunov exponent in Sec. II. Solutions of the IFPP in one-dimension, , are developed in Sec. III. These solutions for motivate the factorization theorem in Sec. IV that presents a general solution to the IFPP for probability distributions with domains in for any . Sec. V presents further examples of univariate, , solutions to the IFPP based on the factorization theorem in Sec. IV. Two 2-dimensional numerical examples are presented in Section VI.3 to demonstrate that the theoretical constructs may be implemented in practice. A summary and discussion of results is presented in Section VII, including a discussion of some existing computational methods that can be viewed as implicitly implementing the factorization solution of the IFPP presented here.
II Inverse Frobenius–Perron Problem and Lyapunov Exponent
In this section we define the forward and inverse Frobenius–Perron problems, and also the Lyuapunov exponent that measures chaotic behaviour.
II.1 Frobenius–Perron Operator
A deterministic map defines a map on probability distributions over state, called the transfer operator KlusKoltaiSchutte2016 . Consider the case where the initial state ( is distributed as ) for some distribution and let denote the -step distribution, i.e., the distribution over at iteration . The transfer operator that maps induced by is given by the Frobenius–Perron operator associated with dorfman1999introduction ; LasotaMackey ; Gaspard1998
| (2) |
where denotes the Jacobian determinant 222We have used the language of differential maps, as all the maps that we display in this paper are differentiable almost everywhere varberg1971change. More generally, denotes the density of with respect to , see, e.g., (LasotaMackey, , Remark 3.2.4.). of at , and the sum is over inverse images of .
The equilibrium distribution of satisfies
| (3) |
and we say that is invariant under .
II.2 Inverse Frobenius–Perron Problem
The inverse problem that we address is finding an iterative map that has a given distribution as its equilibrium distribution. We do this by performing the inverse Frobenius–Perron problem (IFPP) of finding that satisfies (3) to ensure that is an invariant distribution of . Establishing chaotic hence ergodic behaviour is a separate calculation.
We will assume throughout that is absolutely continuous with respect to the underlying measure so that a probability density function exists, and, furthermore, that , .
II.3 Lyapunov Exponent
The Lyapunov exponent of an iterative map gives the average exponential rate of divergence of trajectories. We define the (maximal) Lyapunov exponent as dorfman1999introduction ; LasotaMackey
| (4) |
that features the starting value . For ergodic maps the dependency on is lost as and the Lyapunov exponent may be written
| (5) |
where is the invariant density. A positive Lyapunov exponent indicates that the map is chaotic.
The theoretical value for the Lyapunov exponent may be obtained using (5), while (4) provides an empirical value obtained by iterating the map . For example, the Lyapunov exponent of the logistic map evaluated by (5) is while (4) evaluated over an orbit with iterations gave .
For chaotic maps, any uncertainty in initial value means that an orbit cannot be precisely predicted, since initial states with any separation become arbitrarily far apart, within , as iterations increase. Hence it is useful to characterize the orbit statistically, in terms of the equilibrium distribution over states in the orbit.
It is interesting to note that theoretical chaotic and ergodic behaviour does not necessarily occur when iterations of a map are implemented on a finite-precision computer. For example, when the logistic map, above, on is iterated on a binary computer the multiplication by corresponds to a shift left by two bits and all subsequent operations maintain lowest order bits that are zero. Repeated iterations eventually produce the number zero, no matter the starting value. While it is simple to correct this non-ideal behaviour, as was done to give the numerical Lyapunov exponent, above, it is important to note that computer implementation can have very different dynamics to the mathematical model.
III Solution of the IFPP in -dimension
In this Section we develop solutions of the IFPP in one-dimension, . Without loss of generality we consider distributions on the unit interval , as the domain of any univariate distribution may be transformed by a change of variable to , including when the domain is the whole real line .
For distributions over a scalar random variable, the FP equation for the invariant density (3) simplifies to
| (6) |
III.1 The Simplest Solution
We first note, almost trivially, that the identity map , where , has as an invariant distribution, so solves the IFPP for any . Somewhat less trivial is to derive this simplest solution by assuming that is monotonic increasing and , so that there is just one inverse image in (6). Writing gives the differential equation with separated variables
| (7) |
that has solution
where is the cumulative distribution function (CDF) for . If is invertible denote the inverse by , called the the inverse distribution function (IDF), otherwise let denote the generalized inverse distribution function, . Then, , or , almost everywhere. Hence the identity map is the unique monotonic increasing map that has as its invariant distribution. Clearly, the identity map is not ergodic for .
We may generalize this solution by setting , for some , and also only requiring to be piecewise continuous. Allowing one discontinuity in we write the integral of the separated differential equation (7) as
giving the solution to the IFPP
| (8) |
where . Here denotes the operator that translates by with wrap-around on 333Hence is the translation operator on the unit circle
| (9) |
where denotes the floor function; see Figure 1 (left). The identity map is recovered when .


It is easily seen that the Lyapunov exponent of the map in (8) is , so the map is not chaotic. However, interestingly, this map can generate a sequence of states that produce a numerical integration rule with respect to , since appropriate choices of and number of iterations can produce a rectangle rule quadrature or a quasi Monte Carlo lattice rule; see Sec. IV.3.
III.2 Exploiting Symmetry in
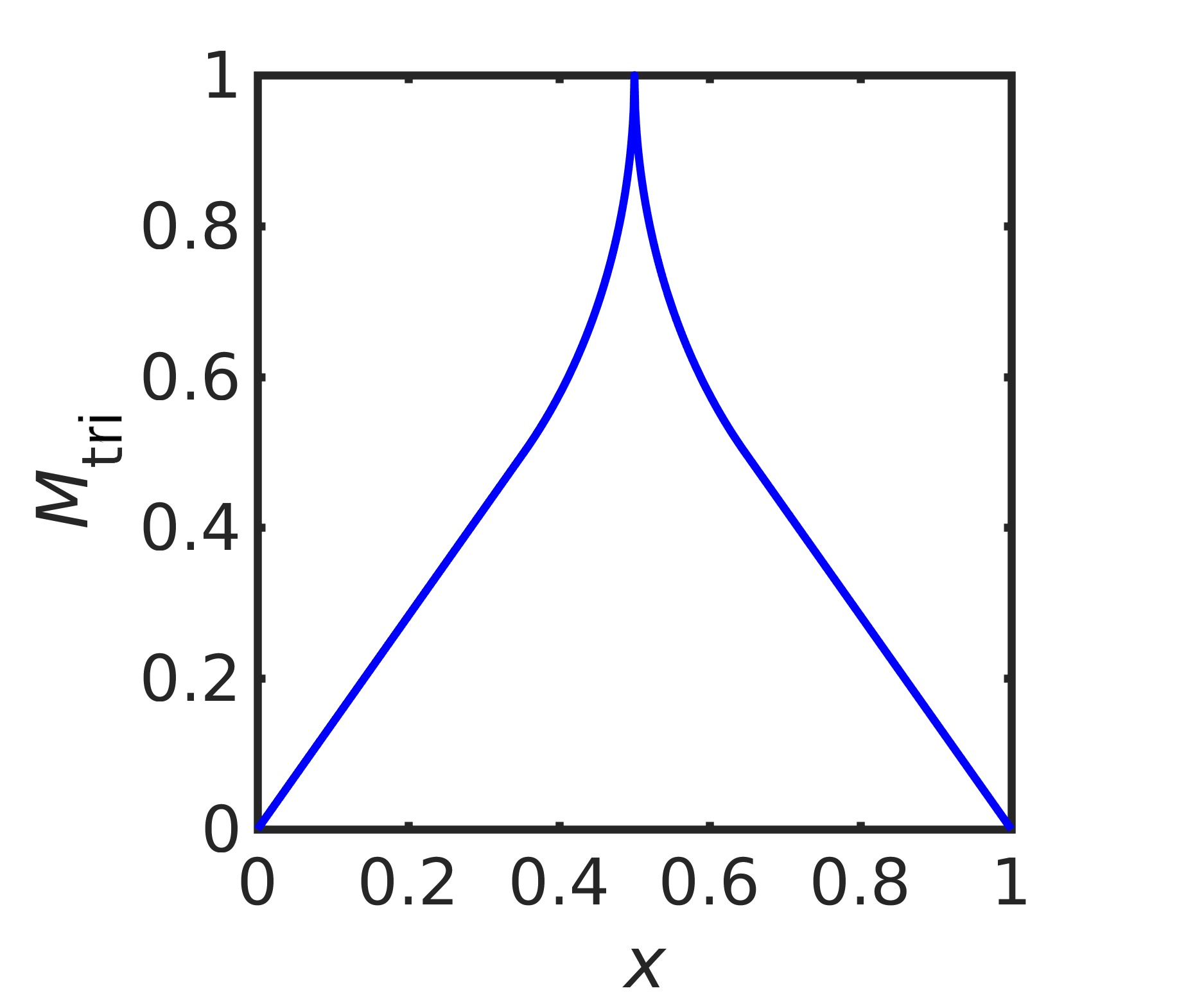
When the PDF has reflexive symmetry about , i.e. , we can simplify the FP equation (6) by assuming that the map has the same symmetry. Specifically, we write the triangle map (see Figure 1 (right))
| (10) |
that has reflexive symmetry about , and write
| (11) |
where is a monotonic increasing map with (and, it will turn out, ). Hence the FP equation simplifies to
| (12) |
that we can write as the separated equations
that has the continuous solution
giving the continuous solution to the IFPP
| (13) |
One can solve for , though we do not further consider the function .
The approach we have used here simplifies the approach in diakonos1996construction , while ‘doubly symmetric’ maps of the form (11) were considered in gyorgyi1984fully , and again in pingel1999theory ; diakonos1999stochastic .
III.3 Symmetric Triangular Distribution
To give a concrete example of the solution in (13), we consider the symmetric triangular distribution on with PDF
| (14) |
that has reflexive symmetry about . The CDF is
giving the unimodal map, after substituting into (13),
| (15) |
shown in Figure 2 (left). The same map was derived in grossmann1977invariant . Figure 2 (right) shows a normalized histogram of iterates of starting at , confirming that the orbit of converges to the desired triangular distribution. The numerical implementation avoids finite-precision effects, as discussed later.
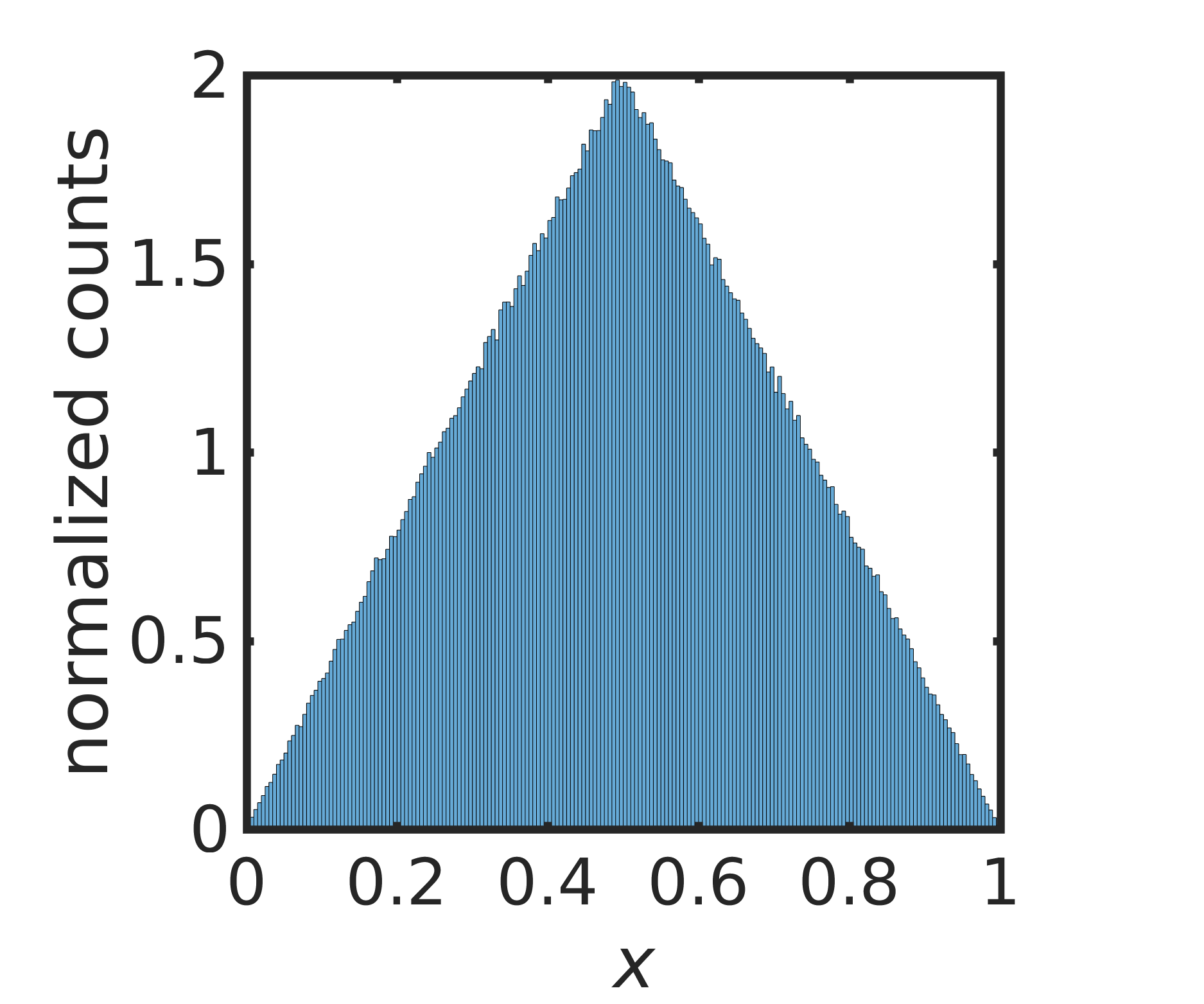
The theoretical Lyapunov exponent for is while (4) evaluated over an orbit with iterations gave .
IV Solutions of the IFPP for General Multi-Variate Target Distributions
The solutions to the -dimensional IFPP with special structure in Eqs (8) and (13) are actually examples of a general solution to the IFPP for multi-variate probability distributions with no special structure. We state that connection via a theorem that establishes a factorization of all possible solutions to the IFPP, and that also provides a practical means of solving the IFPP.
We first introduce the forward and inverse Rosenblatt transformations, that is the multi-variate generalization the CDF and IDF for univariate distributions.
IV.1 Forward and Inverse Rosenblatt Transformations
A simple transformation of an absolutely continuous -variate distribution into the uniform distribution on the -dimensional hypercube was introduced by Rosenblatt rosenblatt-1952 , as follows. The joint PDF can be written as a product of conditional densities,
where is a conditional density given by
| (16) |
in terms of the marginal densities,
| (17) |
where .
Let where is the Rosenblatt transformation rosenblatt-1952 from the state-space of to the -dimensional unit cube , defined in terms of the (cumulative) distribution function by
As noted in rosenblatt-1952 , there are transformations of this type, corresponding to the ways of ordering the coordinates. Further multiplicity is introduced by considering coordinate transformations, such as rotations.
Notice that in -dimension, the Rosenblatt transformation is simply the CDF .
It follows that if then , i.e., is uniformly distributed on the -dimensional unit cube rosenblatt-1952 . When , the distribution functions are strictly monotonic increasing and the inverse of the Rosenblatt transformation is well defined, otherwise let denote the generalized inverse as in Sec. III.1. Then, if it follows that , i.e., is distributed as the desired target distribution johnson1987multivariate ; this is the basis of the conditional distribution method for generating multi-variate random variables, that generalizes the inverse cumulative transformation method for univariate distributions devroye-rvgen-1986 ; johnson1987multivariate ; hormann-rvgen-2004 ; dolgov2020approximation . These results may also be established by substituting or into the the FP equation (2), noting that there is a single inverse image and that the Jacobian determinant of equals the target PDF .
In the remainder of this paper, we refer to any map satisfying as a Rosenblatt transformation, with (generalized) inverse as defined above.
IV.2 Factorization Theorem
The following theorem characterizes solutions to the IFPP.
Theorem 1.
Given a probability distribution in -dimensions, a map is a solution of the IFPP, that is, satisfies the FP equation (3), if and only if
| (18) |
where is a Rosenblatt transformation and is a ‘uniform map’ on the unit -dimensional hypercube, i.e. a map that has as invariant distribution 444When satisfies the stronger condition that is the equilibrium distribution, is called an exact map LasotaMackey ..
Proof: We will show that is an invariant distribution of iff has the form (18). () Assume has the form (18). If then hence , as in invariant under , hence , as desired. () If is invariant under then is a uniform map, since if then , , and . Inserting this into (18) gives the desired factorization. ∎
The first part of the proof shows that any uniform map induces a solution to the IFPP, though the particular solution depends on the particular Rosenblatt transformation. The second part of the proof shows that different solutions to the IFPP effectively differ only by the choice of the uniform map , once the Rosenblatt transformation is determined, that is, a coordinate system is chosen with an ordering of those coordinates.
Grossmann and Thomae grossmann1977invariant called dynamical systems and related by a formula of the form (18) as ‘related by conjugation’, or just ‘conjugate’, and the map in (18) is a ‘conjugating function’. Thus, in the language of grossmann1977invariant , Theorem 1 shows that the IFPP for any distribution has a solution (actually, it shows that there are infinitely many solutions), every solution map is conjugate to a uniform map, and the conjugating function is precisely the inverse Rosenblatt transformation.
Notice that both the translation operator in (9) and the triangle map in (10) are uniform maps on the unit interval . Thus, the solutions to the IFPP given in Eqs (8) and (13) are examples of the general solution form in (18). In particular, while the solution to the IFPP in (13) was derived assuming symmetry of the target density , (13) actually gives a solution of the IFPP for any density . Unimodal maps of this form were derived in ershov1988solution .
IV.3 Properties of from
Many properties of the map are inherited from the uniform map .
When and are continuous, is continuous iff is continuous. In one dimension, monotonicity of the CDF and IDF imply that the number of modes of equals the number of modes of ; in particular, is unimodal iff is unimodal.
Constructing iterative maps with specific periodicity of the orbit is possible through the use of translation operators as uniform maps, defined in Eq. (9). Consider, first, maps in one dimension on . If the shift and , the map is aperiodic. However, in the case that and such that
| (19) |
with and , then the map is periodic with periodicity , and iterative maps constructed with exhibit the same periodicity. These properties may be extended to multi-dimensional settings when the translation constant is a vector of shifts in each coordinate direction, as used in rank-one lattice rules for quasi-Monte Carlo integration dick2013high .
The factorization in Theorem 1 also shows that performing an iteration with an iterative map on the space is equivalent to applying the corresponding uniform map on the space through the transformations and , as indicated in the following (commuting) diagram.
Using this commuting property, it is straightforward to prove the following lemma.
Lemma 1.
For given distribution , let be a Rosenblatt transformation for . Let be a solution of the IFFP, as guaranteed by Theorem 1, where is a uniform map. Then
| (20) |
Hence, instead of iterating on the space to produce the sequence , Eq. (20) shows that one can iterate the map on the space to produce the sequence and then evaluate , , to produce exactly the same sequence on . Since the map is mixing or ergodic iff the uniform map is mixing or ergodic, respectively, in this sense mixing and ergodicity of is inherited from .
Using the expansion in Eq. (20), we see that is deterministic or stochastic iff is deterministic or stochastic, respectively. Even though we are not considering stochastic maps here, we note that, for stochastic maps, iterations of are correlated or independent iff iterations of are correlated or independent, respectively.
Some other properties that are, and are not, preserved by the transformation from to are discussed in grossmann1977invariant .
V Examples in One Dimension
V.1 Uniform Maps on
We have already encountered three uniform maps on the interval , namely the identity map (Figure 3 (top, left)) and the translation operator (9) (Figure 1 (left)), that have Lyapunov exponent , and the triangle map (Figure 1 (right)) with Lyapunov exponent .
Some further elementary uniform maps on , and associated Lyapunov exponents, are:
-
•
periods of a sawtooth function on (Figure 3, top-right, for periods) 555The two period sawtooth map is also called the Bernoulli map, and its orbit is the dyadic transformation.
(21) with Lyapunov exponent ,
-
•
periods of a triangle function on (Figure 3 (bottom, left) for periods) 666This is the ‘broken linear transformation’ in grossmann1977invariant of order .
(22) with Lyapunov exponent ,
- •




Obviously, many more uniform maps are possible. Further examples can be formed by partitioning the domain and range of any uniform map, and then permuting the subintervals. Many existing ‘matrix-based’ methods for constructing solutions to the IFPP, can be viewed as examples of such a partition-and-permute of an elementary uniform map rogers2004synthesizing . Uniform maps of other forms are developed in huang2005characterizing from two-segmental Lebesgue processes, producing uniform maps that are curiously non-linear.
Lemma 2.
The composition of uniform maps is also a uniform map, i.e., if and are uniform maps then so is .
An example is , that can be constructed as the composition .
We mentioned the numerical artifacts that can occur with finite-precision arithmetic, particularly when implementing maps on a binary computer and when the endpoints of the interval and constants in the maps have exact binary representations. We avoided these artifacts by composing the stated uniform map with the translation for that does not have finite binary representation 777Computation was performed in MatLab that implements IEEE Standard 754 for double-precision binary floating-point format.. This small shift is indiscernible in the graphs of the maps.
V.2 Ramp Distribution
To give a concrete example of the solution in (13) for a distribution without reflexive symmetry, we consider the ramp distribution with PDF
| (24) |
that has CDF
We produce a unimodal, continuous map by choosing the uniform map , as in (13), to give
| (25) |
shown in Figure 4 (left). Figure 2 (right) shows a normalized histogram of iterates of starting at , confirming that the orbit of converges to the desired ramp distribution, as guaranteed by Theorem 1. The numerical implementation avoids finite-precision effects, as discussed earlier.

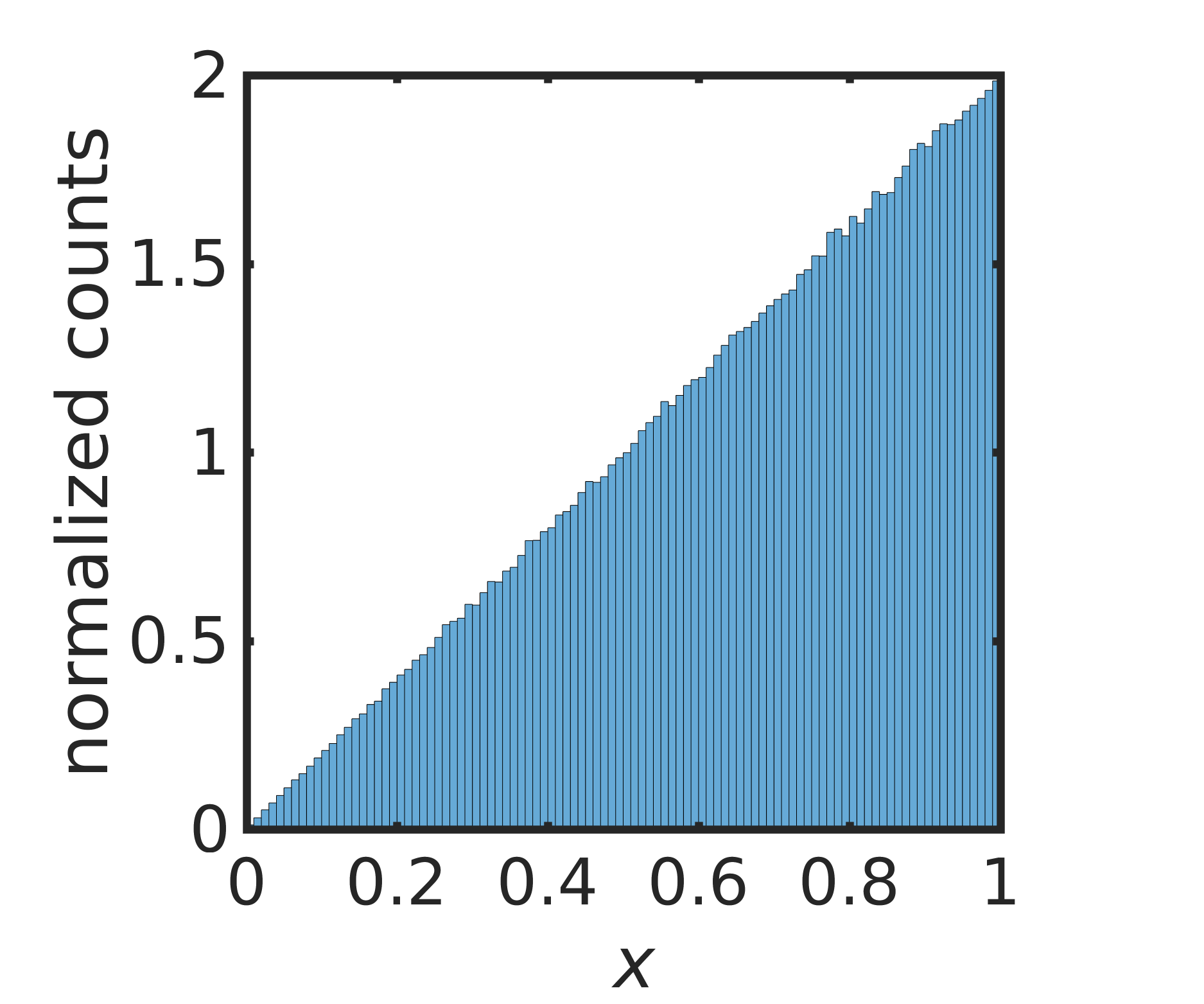
The estimated Lyapunov exponent for this map is , which is greater than the Lyapunov exponent for the inducing triangular map which is .
Using a different uniform map gives a different solution to the IFPP. For example, choosing gives the map shown in Figure 5 (left). A normalized histogram over an orbit of iterations is shown in Figure 5 (right), confirming that this map is also ergodic for .


The estimated Lyapunov exponent for this map is , which is the same numerical value as the Lyapunov exponent for the sawtooth map which is . Comparing with the result for the map induced by , this shows that the Lyapunov exponent of a map is not generally equal to the Lyapunov exponent of the inducing uniform map.
V.3 The Logistic Map and Alternatives
The logistic map, mentioned in the introduction, is
| (26) |
The equilibrium distribution of this map
| (27) |
can be easily verified by substituting into the FP equation (6). The CDF of is
| (28) |
and the IDF is
| (29) |
The logistic map (26) is induced by the factorization (18) by choosing the triangle map as uniform map, i.e., substituting the CDF (28) and IDF (29) into (13); see Figure 6 (left). Equivalently, one may note that the logistic map (26) is transformed into the triangle map by the change of variables ; in the language of grossmann1977invariant , and are conjugate dynamical laws.
Other iterative maps which preserves the same equilibrium distribution (27) can be constructed by choosing another uniform map, such as periods of a triangle function (22). This gives the iterative maps
| (30) |
that coincide with the power of the logistic map (26) for . Figure 6 (right) shows the map which preserves the same equilibrium distribution as the logistic map but induced by the uniform map . Since is not of the form , this map is not simply a power of the logistic map.


The theoretical value of the Lyapunov exponent of the map in (30) is , using (5). Table 1 gives the theoretical values of the Lyapunov exponent and experimentally calculated values using iterations, as in (4), for some values of .
VI Two Examples in Two Dimensions
VI.1 Uniform Maps on
Two well-known examples of uniform maps in the two-dimensional unit square, , are the baker’s map
| (31) |
where is the unit step function, and the Arnold cat map
| (32) |
Other uniform maps in dimensions may be formed by -dimensional uniform maps acting on each coordinate, giving the coordinate-wise uniform map
| (33) |
where , , are uniform maps in one dimension. We will use the baker’s map (31) and a coordinate-wise uniform map in the -dimensional examples that follow.
VI.2 Checker-Board Distribution
This example demonstrates construction of a map in two-dimensions that targets the checker board distribution, shown in Figure 8 (bottom-left) and Figure 9 (bottom-left), using the factorization (18).
The first step in constructing a solution to the IFPP for this distribution is to construct the forward and inverse Rosenblatt transformations, which requires the marginal density functions (17) that may be evaluated analytically in this case. A plot of the two components of the functions and is shown in Figure 7.

We construct two solutions to the IFPP, each induced by choosing a particular uniform map: the first is the baker’s map (31); the second is a component-wise uniform map (33) with an asymmetric triangle map (23) acting on each component,
| (34) |
where for and with .
Figure 8 (top row) shows the two components of the map induced by the baker’s map, the checker-board distribution (bottom-left), and a histogram of iterates (bottom-right) showing that the map does indeed converge in distribution to the desired distribution.

Figure 9 (top row) shows the two components of the map constructed using the two component-wise asymmetric triangular maps, the checker-board distribution (bottom-left), and a histogram of iterates (bottom-right) showing that the map also converges in distribution to the desired distribution, and hence is also a solution to the IFPP.

VI.3 A Numerical Construction
Numerical implementation of the factorized solution (18) is not difficult in few dimensions. In this section we present an example of numerical implementation using a normalized greyscale image of a coin 888A pre-2006 New Zealand cent coin., piecewise constant over pixels, as the target distribution; see Figure 10 (left). The marginal distributions (17) are evaluated as linear interpolation of cumulative sums over pixel values, and hence the CDF and then forward and inverse Rosenblatt transformations follow as in section IV.1. The uniform map was produced as component-wise univariate translation maps, specifically
where for and with . The resulting map is given by Eq. (18).


Figure 10 (right) shows a normalized histogram, binned to pixels, of iterations of this map. As can be seen, the estimated PDF from the orbit of this map does reproduce the image of the coin. However, there are also obvious artifacts near the edge of the image showing that mixing could be better. We conjecture that a chaotic uniform map would produce better mixing and fewer numerical artifacts.
VII Summary and Discussion
We have shown how the solution of the IFPP, of finding an iterative map with a given invariant distribution, can be constructed from uniform maps through the factorization established in Theorem 1,
where denotes the Rosenblatt transformation that has Jacobian determinant equal to density function of the invariant distribution. In one-dimension, is exactly the CDF of the given distribution, so the factorization generalizes existing one-dimensional solutions to the setting of arbitrary multi-variate distributions. The factorization also shows the relationship between arbitrary iterative maps and uniform maps, i.e., given a Rosenblatt transformation the solution of the IFPP is equivalent to the choice of a uniform map that has as invariant distribution.
We find the factorization (18) appealing as it shows that solution of the IFPP for arbitrary distributions, and in multi dimensions, is reduced to two standard and well-studied problems, i.e., constructing the Rosenblatt transformation (or CDF in one dimension) and designing a uniform map. It is therefore surprising, to us, that the factorization (18), and more generally the Rosenblatt transformation, appears to not be widely used in the study of chaotic iterated functions and the IFPP. Grossmann and Thomae grossmann1977invariant , in one of the earliest studies of the IFPP, essentially derived the factorization (18) by introducing conjugate maps and establishing the relation (in their notation) that where is the invariant distribution and is the conjugating function; see (grossmann1977invariant, , Figure 3). It is a small step to identify that is the IDF, generalized in multi-dimensions by the inverse Rosenblatt transformation. However, the connection was not made in grossmann1977invariant , despite the Rosenblatt transformation having been already known, in statistics, for some decades rosenblatt-1952 .
We constructed solutions to the IFPP for distributions with special reflexive symmetry structure, and then with no special structure, by constructing the Rosenblatt transformation, and its inverse, for some examples in one and two dimensions. For simple distributions with analytic form the Rosenblatt transformation may be constructed analytically, while numerically-defined distributions required calculation of the marginal distributions (17) using numerical techniques.
Although this factorization and construction is applicable to high-dimensional problems, the main difficulty is obtaining all necessary marginal densities, which requires the high-dimensional integral over in (17). In general, this calculation can be extremely costly. Even a simple discretization of the PDF , or of the argument of the marginal densities (17), leads to exponential cost with dimension.
To overcome this cost, Dolgov et al. dolgov2020approximation precomputed an approximation of in a compressed tensor train representation that allows fast computation of integrals in (17), and subsequent simulation of the inverse Rosenblatt transformation from the conditionals in (17), and showed that computational cost scales linearly with dimension . Practical examples presented in dolgov2020approximation , in dimension , demonstrate that operation by the forward and inverse Rosenblatt transformations is computationally feasible for multivariate problems with no special structure.
Finding a solution of the IFPP with desired properties is reduced to a standard problem of designing a uniform map on , for which there are many existing efficient options. For example, standard computational uniform random number generators, that produce pseudo-random sequences of numbers, are one such existing uniform map, as are the quasi-Monte Carlo rules that we mentioned earlier dick2013high . These induce pseudo-random and quasi-Monte Carlo sequences, respectively, on the space via the inverse Rosenblatt transformation gentle2003random . Both these schemes were demonstrated in practical high-dimensional settings in dolgov2020approximation .
The RHS of Eq. (20) in dimension is exactly the standard computational route for implementing inverse cumulative transformation sampling from , since computational uniform pseudo-random number generators perform a deterministic iteration on to implement a uniform map gentle2003random . For , the RHS of Eq. (20) is the conditional distribution method that generalizes the inverse cumulative transformation method, as mentioned above devroye-rvgen-1986 ; johnson1987multivariate ; hormann-rvgen-2004 ; dolgov2020approximation . Hence Lemma 1 shows that standard computational implementation of both the inverse cumulative transformation method in and the conditional distribution method in is equivalent to implementing a solution to the IFFP. In this sense, computational inverse cumulative transformation sampling from can be viewed as the prototype for all iterative maps that target the distribution , with each ergodic sequence corresponding to a particular choice of uniform map.
We mentioned that the Rosenblatt transformation associated with a given distribution is not unique. Actually, any two Rosenblatt transformations for are related by a uniform map, as shown in the following Lemma.
Lemma 3.
If is a Rosenblatt transformation for then is a Rosenblatt transformation for if and only if
for some uniform map .
Proof: () Since and are Rosenblatt transformations for , then is a uniform map and . () If then if , and so is a Rosenblatt transformation. ∎
Hence, any Rosenblatt transformation may be written as for some uniform map and a fixed Rosenblatt transformation .
The Rosenblatt transformations that map any distribution to the uniform distribution on the hypercube may also be used to understand mappings between spaces that are designed to transform one distribution to another, such as the ‘transport maps’ developed in parno2018transport . Consider distributions and , with Rosenblatt transformations and , respectively, that may be related as in the following diagram.
The diagram suggests a proof of the following lemma, that generalizes the factorization Theorem 1.
Lemma 4.
A map satisfies iff it can be written as , where and are Rosenblatt transformations for and , respectively, and is a uniform map.
Hence, for given Rosenblatt transformations, the choice of a map, that maps samples from to samples from , is equivalent to the choice of a uniform map. Alternatively, if a fixed uniform map is selected, such as the identity map, the choice of map is completely equivalent to the choice of Rosenblatt transformations. This factorization also shows that the equivalence class of conjugate maps, noted in grossmann1977invariant , for each dimension , is generated by the uniform maps, and each member of the equivalence class contains maps that target each distribution, when the associated Rosenblatt transformation satisfies the mild conditions to be a conjugating function as defined in grossmann1977invariant .
References
- [1] The density function is with respect to some underlying measure, typically Lebesgue. Throughout this paper we will use the same symbol for the distribution and associated PDF, with meaning taken from context.
- [2] J.R. Dorfman. Cambridge Lecture Notes in Physics: An introduction to chaos in nonequilibrium statistical mechanics, volume 14. Cambridge University Press, 1999.
- [3] Andrzej Lasota and Michael C. Mackey. Chaos, fractals, and noise. Springer-Verlag, New York, second edition, 1994.
- [4] S. Ulam and J. von Neumann. On combination of stochastic and deterministic processes. Bulletin of the American Mathematical Society, 53(11):1120, 1947.
- [5] R.M. May. Simple mathematical models with very complicated dynamics. Nature, 261(5560):459–467, 1976.
- [6] J. S. Liu. Monte Carlo Strategies in Scientific Computing. Springer-Verlag, 2001.
- [7] Stefan Klus, Péter Koltai, and Christof Schütte. On the numerical approximation of the Perron–Frobenius and Koopman operator. Journal of Computational Dynamics, 3(1):51–79, 2016.
- [8] Siegfried Grossmann and Stefan Thomae. Invariant distributions and stationary correlation functions of one-dimensional discrete processes. Zeitschrift für Naturforschung a, 32(12):1353–1363, 1977.
- [9] S. V. Ershov and Georgii Gennad’evich Malinetskii. The solution of the inverse problem for the Perron–Frobenius equation. USSR Computational Mathematics and Mathematical Physics, 28(5):136–141, 1988.
- [10] F.K. Diakonos and P. Schmelcher. On the construction of one-dimensional iterative maps from the invariant density: The dynamical route to the beta distribution. Physics Letters A, 211(4):199–203, 1996.
- [11] FK Diakonos, D. Pingel, and P. Schmelcher. A stochastic approach to the construction of one-dimensional chaotic maps with prescribed statistical properties. Physics Letters A, 264(2-3):162–170, 1999.
- [12] D. Pingel, P. Schmelcher, and F.K. Diakonos. Theory and examples of the inverse Frobenius–Perron problem for complete chaotic maps. Chaos, 9(2):357–366, 1999.
- [13] Erik M Bollt. Controlling chaos and the inverse Frobenius–Perron problem: global stabilization of arbitrary invariant measures. International Journal of Bifurcation and Chaos, 10(05):1033–1050, 2000.
- [14] Xiaokai Nie and Daniel Coca. A new approach to solving the inverse Frobenius–Perron problem. In 2013 European Control Conference (ECC), pages 2916–2920. IEEE, 2013.
- [15] Xiaokai Nie and Daniel Coca. A matrix-based approach to solving the inverse Frobenius–Perron problem using sequences of density functions of stochastically perturbed dynamical systems. Communications in Nonlinear Science and Numerical Simulation, 54:248–266, 2018.
- [16] A. Rogers, R. Shorten, D.M. Heffernan, and D. Naughton. Synthesis of piecewise-linear chaotic maps: Invariant densities, autocorrelations, and switching. International Journal of Bifurcation and Chaos, 18(8):2169–2189, 2008.
- [17] Nijun Wei. Solutions of the inverse Frobenius–Perron problem. Master’s thesis, Concordia University, 2015.
- [18] Stanisław Marcin Ulam. A Collection of Mathematical Problems. Interscience Publishers, 1960.
- [19] M. Rosenblatt. Remarks on a multivariate transformation. Ann. Math. Stat., 23(3):470–472, 1952.
- [20] Pierre Gaspard. Chaos, scattering and statistical mechanics. Cambridge University Press, 1998.
- [21] We have used the language of differential maps, as all the maps that we display in this paper are differentiable almost everywhere [varberg1971change]. More generally, denotes the density of with respect to , see, e.g., [3, Remark 3.2.4.].
- [22] Hence is the translation operator on the unit circle .
- [23] G Györgyi and P Szépfalusy. Fully developed chaotic 1-d maps. Zeitschrift für Physik B Condensed Matter, 55(2):179–186, 1984.
- [24] M.E. Johnson. Multivariate Statistical Simulation. John Wiley & Sons, 1987.
- [25] L. Devroye. Non-Uniform Random Variate Generation. Springer-Verlag, 1986.
- [26] W. Hörmann, J. Leydold, and G. Derflinger. Automatic Nonuniform Random Variate Generation. Springer-Verlag, 2004.
- [27] Sergey Dolgov, Karim Anaya-Izquierdo, Colin Fox, and Robert Scheichl. Approximation and sampling of multivariate probability distributions in the tensor train decomposition. Statistics and Computing, 30(3):603–625, 2020.
- [28] When satisfies the stronger condition that is the equilibrium distribution, is called an exact map [3].
- [29] Josef Dick, Frances Y Kuo, and Ian H Sloan. High-dimensional integration: the quasi-Monte Carlo way. Acta Numerica, 22:133, 2013.
- [30] The two period sawtooth map is also called the Bernoulli map, and its orbit is the dyadic transformation.
- [31] This is the ‘broken linear transformation’ in [8] of order .
- [32] Alan Rogers, Robert Shorten, and Daniel M Heffernan. Synthesizing chaotic maps with prescribed invariant densities. Physics Letters A, 330(6):435–441, 2004.
- [33] W. Huang. Characterizing chaotic processes that generate uniform invariant density. Chaos, Solitons & Fractals, 25(2):449–460, 2005.
- [34] Computation was performed in MatLab that implements IEEE Standard 754 for double-precision binary floating-point format.
- [35] A pre-2006 New Zealand cent coin.
- [36] James E Gentle. Random number generation and Monte Carlo methods, volume 381. Springer, 2003.
- [37] Matthew D Parno and Youssef M Marzouk. Transport map accelerated Markov chain Monte Carlo. SIAM/ASA Journal on Uncertainty Quantification, 6(2):645–682, 2018.