Solution of physics-based inverse problems using conditional generative adversarial networks with full gradient penalty
Abstract
The solution of probabilistic inverse problems for which the corresponding forward problem is constrained by physical principles is challenging. This is especially true if the dimension of the inferred vector is large and the prior information about it is in the form of a collection of samples. In this work, a novel deep learning based approach is developed and applied to solving these types of problems. The approach utilizes samples of the inferred vector drawn from the prior distribution and a physics-based forward model to generate training data for a conditional Wasserstein generative adversarial network (cWGAN). The cWGAN learns the probability distribution for the inferred vector conditioned on the measurement and produces samples from this distribution. The cWGAN developed in this work differs from earlier versions in that its critic is required to be 1-Lipschitz with respect to both the inferred and the measurement vectors and not just the former. This leads to a loss term with the full (and not partial) gradient penalty. It is shown that this rather simple change leads to a stronger notion of convergence for the conditional density learned by the cWGAN and a more robust and accurate sampling strategy. Through numerical examples it is shown that this change also translates to better accuracy when solving inverse problems. The numerical examples considered include illustrative problems where the true distribution and/or statistics are known, and a more complex inverse problem motivated by applications in biomechanics.
keywords:
PDE-based inverse problems , Bayesian inference , conditional generative adversarial networks , generative models , deep learning , uncertainty quantification[label1]organization=Department of Mathematics, University of Maryland, city=College Park, postcode=20742, state=Maryland, country=USA \affiliation[label2]organization=Aerospace and Mechanical Engineering Department, University of Southern California, city=Los Angeles, postcode=90089, state=California, country=USA
1 Introduction
Inverse problems arise in many fields of engineering and science. Typically, they involve recovering the input fields or parameters in a system given noisy measurements of its response. In contrast to direct problems, where one wishes to determine the response given the input parameters, inverse problems are notoriously hard to solve. This is because they are often ill-posed in the sense of Hadamard [1] and involve measurements that are corrupted by noise, while their solution often requires injecting some prior information or beliefs regarding the inferred parameters or fields.
The challenges described above can be addressed by working with a probabilistic version of the inverse problem where the input and response vectors/fields are treated as random vectors /processes. In this manuscript, we refer to the input vector as the vector of the parameters to be inferred, or the inferred vector for short. In the probabilistic framework, the solution of an inverse problem transforms to characterizing the conditional probability distribution of the inferred vector conditioned on a measurement of the response; this distribution is known as the posterior distribution. Using Bayes’ rule, the posterior distribution can be expressed (up to a multiplicative constant) as the product of a marginal distribution for the inferred vector with the conditional distribution for the measurement given the inferred parameters [2]. The former is replaced by a prior distribution for the parameters to be inferred, and the latter leads to the likelihood term, which is determined by the model for the noise in the measurement and the forward map that links the parameters to the response. Once the probabilistic inverse problem has been framed, a method like Markov Chain Monte Carlo (MCMC) [3, 4] may be applied to sample from the posterior distribution; these samples help approximate the posterior distribution that may otherwise be analytically intractable [5]. The steady state of the Markov chain leads to samples that are drawn from the desired conditional distribution for the input parameters.
While the MCMC method and its variants can be used to solve some probabilistic inverse problems, their efficacy diminishes under several conditions. These include problems where the dimension of the inferred vector becomes large (greater than 50, for example) — the so-called curse of dimensionality [6, 7, 8]. It also includes problems where prior information about the parameters to be inferred cannot be expressed in terms of a simple probability distribution and is determined through samples. Finally, some variants of the MCMC method with improved convergence properties, like the Hamiltonian Monte Carlo (HMC) method [9, 10], rely on computing the derivative of the forward map with respect to the parameters. In cases where the forward map is implemented through a complex legacy code, computing this derivative is not feasible and these methods cannot be used.
Recently, there has been a growing interest in utilizing novel machine and deep learning algorithms to address the challenges described above. Most of these methods first consider samples of the parameters to be inferred derived from a prior distribution and utilize the forward map and a model for noise to generate corresponding samples of the measurement vector. Thereafter, they use this dataset to train algorithms for sampling the conditional distribution for the parameters given the measured response. One such class of methods that utilize deep neural networks to map the response vector to the vector of parameters, is referred to as Bayesian Neural Networks (BNNs) [11, 12, 13, 14]. In these networks, in addition to the input and output vectors, the network weights are also treated as random variables. Thereafter, Bayes’ rule is applied to derive an expression for the posterior distribution of the network parameters (weights and biases) given the training data. Then, variational inference is used to derive an approximation for the posterior density of the network parameters. Once this density is known, multiple realizations of the network parameters are sampled and the resulting networks are applied to the same measured response to yield an ensemble of inferred vectors. The performance of BNNs is limited by the approximations that are typically incurred to make variational inference tractable, which include assuming mixture models for the weights and selecting a small subset of the network weights as stochastic [15, 16].
Another class of deep learning algorithms utilize Generative Adversarial Networks (GANs) [17] to learn and then sample from the posterior distribution. GANs are generative models that learn a reduced-order representation of a probability distribution from its samples and then efficiently generate samples from it. GANs comprise of two networks: a generator and a critic. The generator network maps low-dimensional vectors drawn from a simple probability distribution to the output domain, while the critic maps samples from the output domain to a scalar. For the Wasserstein GAN [18, 19], under suitable assumptions, it can be shown that the probability distribution of the samples produced by the trained generator converges to the true distribution (from which the training samples are drawn) in the Wasserstein-1 distance. This is achieved by imposing a 1-Lipschitz constraint on the critic. In [20], a WGAN was used to learn the prior distribution of the inferred vector, and then used in conjunction with the HMC method to learn the posterior conditional distribution. While this approach reduced the dimension of the underlying inverse problem by mapping it to the low-dimensional latent space of the WGAN, it still required the use of an HMC method to sample from the posterior distribution.
In contrast to the approach described above, conditional GANs [21] can be used to approximate the posterior distribution directly. Adler and Öktem [22] proposed a conditional WGAN (cWGAN) that aims to directly learn the posterior distribution, and used it to improve the results of an inverse problem in medical imaging. Ray et al. [23] improved the architecture of cWGAN and applied it to solve complex inverse problems motivated by physics-driven applications. Kovachki et al. [24] proposed the Monotone GAN (MGAN) to solve inverse problems. This method differs from the cWGAN in several ways. First, it uses a latent space whose dimension is the same as that of the inferred vector, whereas the cWGAN typically uses a latent space of reduced dimension. Second, it relies on block triangular transformations to map the latent space to the space of the inferred vector, whereas a cWGAN uses a U-NET [25] architecture. Finally, it requires the generator that transforms the latent space to the space of inferred parameters to be monotonic, whereas the cWGAN imposes a 1-Lipschitz condition on the critic and not the generator.
The cWGAN proposed by Adler and Öktem [22] uses a critic network that is 1-Lipschitz with respect to the inferred vector only. The 1-Lipschitz constraint is implemented weakly through a gradient penalty term, and the gradient is computed with respect to the inferred vector. Herein, we refer to this as Partial-GP. As a result of the partial 1-Lipschitz constraint being imposed on the critic, the Kantorovich-Rubinstein duality (see [26] for example) can be invoked to show that the critic for the cWGAN with Partial-GP belongs to the space of functions that can only be optimized to approximate the Wassertstein-1 distance between distributions of the inferred vector. Based on this, Adler and Öktem [22] develop a training objective function for the cWGAN that aims to reduce the averaged Wasserstein-1 distance between the true posterior distribution and the one induced by the cWGAN; the average is taken over all possible values of the measurement vector. This does not necessarily mean that the distribution of the inferred vector conditioned on any one particular value of the measurement vector will converge to the true posterior distribution even if the critic and generator networks are sufficiently expressive, and are perfectly trained.
In this work we improve upon the cWGAN with Partial-GP [22], with a novel cWGAN formulation which differs from the original formulation in one critical aspect. In our approach, we require the critic network to be a 1-Lipschitz function of all its inputs — the inferred and measurement vector. Therefore, the crucial algorithmic difference that arises is that the gradient must be computed with respect to both arguments of the critic as opposed to just the inferred vector for Partial-GP. Remarkably, this small change in the implementation has a significant effect on the properties of the final network. Due to the critic being 1-Lipschitz with respect to its entire input argument, we can show, via the Kantorovich-Rubinstein duality, that the critic in the cWGAN belongs to the space of functions that can minimize the Wasserstein-1 between distributions of the joint random vector containing both the inferred variable and the measurements. As a result, we show that the generator of a cWGAN that is perfectly trained with the same training objective as [22] will converge to the true conditional distribution for the inferred vector for any measurement vector.
Additionally, the convergence guarantees of the proposed cWGAN with Full-GP allow us to develop a new evaluation strategy where the cWGAN is evaluated at measurement values obtained by perturbing the actual measurement vector with samples from a zero-mean Gaussian distribution that has a minute variance. We show that this new evaluation strategy may lead to improved performance of cWGANs. Further, we study the behavior of the proposed cWGAN with Full-GP on a suite of illustrative examples and its ability to approximate the joint distribution and the posterior distribution. We also apply the proposed cWGANs to two challenging inverse problems arising in inverse heat conduction and elastography [27] that help establish its efficacy in solving physics-based inverse problems.
The format of the remainder of this manuscript is as follows. In the following section we introduce the mathematical background required to develop and analyze the new cWGAN with Full-GP. In Section 3, we describe how the Full-GP cWGAN is trained and then used to solve a probabilistic inverse problem. In Section Section 4, we perform a detailed analysis of the convergence of the conditional density generated by Full-GP cWGAN with increasing number of trainable generator parameters. We also compare it with the corresponding analysis for the cWGAN with Partial-GP. In Section Section 5, we apply the Full-GP and Partial-GP cWGAN networks to inverse problems with increasing complexity, and evaluate their ability to recover the true posterior distribution for cases where it is known. We observe that the Full-GP cWGAN performs better. We end with conclusions in Section 6.
2 Background
2.1 Problem setup
Consider the following measurement model
| (1) |
where is the forward model/process, is some input field to the forward model, while is the corresponding output/measured field of the model corrupted by some measurement noise . Then our goal is to solve the inverse problem of reconstructing/inferring given some noisy measurement . In the probabilistic setting, necessary for carrying out Bayesian inference, the inferred field and the measured field are modeled as random variables and , respectively. Let be the joint probability measure corresponding to the pair of random variable , with marginal measures , . Then, given a realization , we wish to approximate the conditional measure and efficiently draw samples from it in order to evaluate useful conditional statistics.
2.2 Conditional GANs
Conditional generative adversarial networks (cGANs) [21] can be used to learn conditional probability measures. Typically, cGANs comprise two deep neural networks, a generator and a critic . The generator is a mapping given by
| (2) |
where is a realization of the latent random variable with the measure . The latent measure is chosen to be simple, such as a multidimensional Gaussian, to make it easy to sample from. The generator can be interpreted as a mapping that, given a , can generate ‘fake’ samples of the inferred field from the push-forward measure . The critic, on the other hand, is given by the mapping
| (3) |
whose role is to distinguish between paired samples drawn from the true joint measure and the fake/generated joint measure .
In a conditional Wasserstein GAN (cWGAN) [22], a variant of cGAN, both the generator and critic networks are trained in an adversarial manner using the objective ‘loss’ function
| (4) | ||||
and solving the minmax problem
| (5) |
3 Conditional WGAN with Full-GP
In this work, we propose a cWGAN model with Full-GP which, unlike the original cWGAN proposed by Adler and Öktem [22], imposes a 1-Lipschitz constraint on the critic with respect to its entire argument . Let us denote by Lip the 1-Lipschitz functions on . If we assume that the maximization in (5) is over , then we can show by the Kantorovich–Rubinstein duality argument [26] that
| (6) | ||||
where is the Wasserstein-1 distance defined on the space of joint probability measures on . In practice, the 1-Lipschitz constraint on the critic can be imposed by augmenting the loss function by a gradient penalty term [19] when training the critic, i.e., by solving
| (7) |
where is a hyper-parameter which appropriately weights the penalty term. We use the following penalty term:
| (8) |
where denotes the uniform distribution on , denotes the gradient with respect to both its arguments, and
| (9) |
The gradient penalty term in Eq. 8 imposes a 1-Lipschitz constraint on the critic with respect to both its arguments and . Using this modified penalty term is crucial to ensure that solving minmax problem is equivalent to minimizing the distance between the true joint measure and the generated joint . This in turn leads to an alternative analysis of (weak) convergence to the true conditional measure which is described in Section 4.
Remark 3.1.
In the original cWGAN model [22], the penalty term was chosen to constrain the critic to be 1-Lipschitz only with respect to the first argument . More precisely, Adler and Öktem [22] use the following penalty term:
| (10) |
where denotes the derivative with respect to the first argument of the critic. Note that, the derivative operator in Eq. 8 has been replace with in Eq. 10.
3.1 Training
To train the proposed cWGAN with Full-GP, we assume access to a dataset of paired samples from the true joint measure . In practice, this can be constructed by first generating samples sampled from a measure (based on prior knowledge about the inferred field), and then generating the corresponding ’s using the forward (noisy) model from Eq. 1. Alternatively, such paired data might be available from experiments.
Next, by replacing the expectations in the objective function Eq. 4 by empirical averages, and choosing suitable architectures for the generator and critic (along with other hyper-parameters), the minmax problem Eq. 6 is solved to find the optimal critic and generator . This involves using a gradient-based optimizer, such as Adam [28], to optimize the trainable parameters of the two networks. A computationally tractable strategy to solve the minmax problem is to use an iterative approach to train the networks. Typically, maximization steps are taken to update the trainable parameters of the critic, followed by a single minimization update step for the generator. The training is terminated after a certain number of epochs (loops over the training dataset) are completed.
3.2 Evaluation
Consider the expectation of a continuous and bounded functional with respect to the true posterior conditional measure
| (11) |
for a given . For instance, choosing and in Eq. 11 for leads to the evaluation of the component-wise mean and variance of each component of . The conditional expectation in Eq. 11 can be approximated using the trained generator of the cWGAN using the following algorithm: Given , , sample size and
-
1.
Draw random samples from , i.e., the Gaussian measure centered at with covariance .
-
2.
Generate samples from .
-
3.
Approximate the conditional expectation (11) using the empirical average
(12)
The motivation behind using Eq. 12 to approximate the conditional expectations (and the choice of ) is given by Theorem 4.2 in Section 4 (see the discussion following its proof).
4 Convergence analysis of the cWGAN with Full-GP
In this section, we analyze the convergence of the cWGAN with Full-GP and show how the optimal generator can be used to approximate the posterior statistics from Eq. 11 in accordance to Eq. 12. This proof, which forms the main result of this section, is contained in Theorem 4.1 for and in Theorem 4.2 for . The proofs of these theorems rely on three distinct assumptions. The first (Assumption 4.1) is a statement of the convergence of a standard (not conditional) WGAN with increasing number of learnable parameters. This is also implicitly assumed in the original WGAN papers [18, 19]. The second assumption (Assumption 4.2) assumes that the true and learned conditional expectations are bounded. Finally, the third (Assumption 4.3) invokes the absolutely continuity of the marginal measure of measurement vector and ensuring the existence of a bounded marginal density.
Let be the family of generator networks such that any network has trainable parameters. We begin with our first assumption about the convergence of a standard WGAN with increasing capacity of the networks.
Assumption 4.1 (WGAN convergence).
We assume that for every , we can find a minimizing generator and a critic such that solves the maximization problem in Eq. 6. In other words, by defining
for any other , we have
Further, the sequence of minimizing generators leads to the following convergence
Under Assumption 4.1, the sequence of measures will converge to in the metric, and hence weakly [26], i.e.,
| (13) |
Next, we show how an appropriate choice of leads to approximating the conditional expectation (11). Given a generator , we define the generated conditional expectations for any as
| (14) |
We require the conditional expectations to be finite and computable.
Assumption 4.2 (Bounded conditional expectation).
For any , we assume that:
-
1.
; and that
-
2.
there exists a positive integer (which may depend on ) such that
for all optimized generators with . In other words, we assume a uniform bound (over ) for optimal generators beyond a certain network size.
We also make the following assumption about the true marginal to simplify the exposition.
Assumption 4.3 (Absolute continuity).
We assume that is absolutely continuous with respect to the Lebesgue measure on , which ensures the existence of density satisfying
Furthermore, we assume that .
Now, let be given for which . Let be the Gaussian measure on with density
| (15) |
The following standard result shows how the Dirac measure can be approximated using a Gaussian.
Lemma 4.1.
Let and . Then
| (16) |
Proof.
Note that
Applying a change of variables , we get
Since the integrand converges a.e. to as and
we get (16) by an application of the dominated convergence theorem. ∎
For the rest of the theoretic discussion, we omit the superscript and it is understood that denotes the optimal generator in accordance to Assumption 4.1. We are now ready to state and prove the main results about approximating Eq. 11.
Theorem 4.1.
Proof.
Consider the Gaussian measure whose density is given by Eq. 15. Let , which clearly belongs to . By Assumption 4.3, we have
| (18) | |||||
Then using Assumptions 4.2, 4.3, and Lemma 4.1 in Eq. 18 leads to
| (19) |
Thus, there exists such that
| (20) |
Similarly, we can show that
and for any optimal generator with
| (21) |
In other words there exists such that for
| (22) |
Note that will be independent on because of the uniform bound assumption in Assumption 4.2 for .
We note that by choosing both inequalities 20 and 22 hold simultaneously. For this and the corresponding , we have the weak convergence estimate Eq. 13 due to Assumption 4.1. Thus, there exists a positive integer such that
| (23) |
Further, by setting , we have using inequalities 20, 22 and 23 that for all
∎
We construct a sequence of joint measures with elements
| (24) |
which is different from or . We now prove a robustness result which shows that we can obtain error estimates similar to Theorem 4.1 even if we inject a controlled amount of noise into the given measurement in accordance to .
Theorem 4.2.
Proof.
We set and consider the corresponding . Thus, by Eq. 13 there exists a positive integer such that
| (30) |
Note that
| (31) | |||||
Taking the Monte Carlo approximation of Eq. 31 leads to the approximation formula Eq. 12 in our algorithm, with the choice of motivated by the proof of Theorem 4.2. In particular, to get a reasonable approximation of the conditional expectation, we need to pick a small enough to ensure that inequalities 26, 27 and 29 are satisfied and a generator large (expressive) enough to ensure the inequality 30 is satisfied.
4.1 Comparison with the Partial-GP approach of [22]
We briefly discuss the theoretical inferences of the Partial-GP approach considered for cWGANs in [22], and how it differs from the Full-GP approach. Let us define by the space of 1-Lipschitz function in , and by the space of functions measurable in that are 1-Lipschitz in for all . Clearly, and implies for any . The authors of [22] solve the maximization problem (7) with (10) but over the larger space
| (32) | |||||
The authors then proceed to prove that the and operators in Eq. 32 may be interchanged under the following technical assumption
Assumption 4.4.
Given a generator and , there exists a measurable mapping such that for all it holds that and
We note that the Assumption 4.4 may not be easy to verify, nor is it easy to interpret the mapping .
Thereafter, by an application of the Kantorovich–Rubinstein duality argument, they obtain
| (33) | |||||
which is the ‘expected’ (mean) metric with respect to between the true conditional measure and the learned conditional measure. Thus, finding the optimal generator corresponds to minimizing this ‘expected’ (mean) metric between the conditionals with respect to the true measure . However, finding a sequence of generators such that
| (34) |
does not guarantee weak convergence of the measures to . In fact, by the properties of convergence in , eq. 34 would only guarantee the existence of a sub-sequence of measures such that , which in turn would lead to the weak-convergence result
In contrast to Partial-GP, Full-GP is able to provide an alternate route to prove weak convergence. The primary difference stems from formulating the maximization Eq. 7 over . First, this allows us to consider the weak convergence of the learnt joint measures to the true joint measure without requiring a a technical assumption like Assumption 4.4 or a sub-sequential argument. Then, by using the fact that a Gaussian measure closely resembles a Dirac measure in the asymptotic limit of diminishing variance (Lemma 4.1), we are able to derive error estimates for approximating the conditional expectation in Eq. 11 by sampling using the trained generator (Theorems 4.1 and 4.2).
5 Numerical experiments
In this section, several numerical experiments are presented to analyze the performance of the proposed cWGANs with Full-GP. The experiments include: one-dimensional problems where the target measure is known; an inverse heat conduction problem where the reference statistics of the target measure are available [23]; and a complex inverse problem in elastography where the target measure is unknown. For the first two problems, where the target statistics are available and we have a reliable reference to estimate error, we use both the Partial-GP [22] (see Eq. 10), and Full-GP (see Eq. 8) approaches to perform a comparison of the two methods.
5.1 Illustrative examples
We first analyze the performance of the proposed methodology using one-dimensional random variables and (the paired random variable, , being two-dimensional) where the target probability measures are available. These are defined as follows:
| (35) | ||||
| (36) | ||||
| (37) | ||||
Here and refer to the Normal, Uniform, and Gamma distributions, respectively. Column 1 of Fig. 1 shows the true joint distribution corresponding to Eqs. 35, 36 and 37. We consider the problem of learning the distribution of conditioned on . For all three problems, we construct a training dataset that is composed of 2,000 samples of and . For this set of problems, we compare the performance of cWGANs with Partial-GP and Full-GP. For the cWGAN with Full-GP we consider two cases: (i.e., is estimated as for a given ), and an optimally chosen (i.e., estimated using Eq. 12). The optimal value of is chosen such that the batch Wasserstein-1 distance, , between and attains a minimum; we estimate the distance using the open source POT package [29] and 104 realizations. Moreover, is scaled by such that , where is the standard deviation of the random variable . In practice, it is easier to work with rather than since the former is dimensionless and a scaled quantity and can be compared across different examples.
In the cWGANs, for both Full-GP and Partial-GP, we use multilayer perceptrons (MLPs) for the critic and generator networks and perform a hyper-parameter search (including for the gradient penalty weight ) to determine the optimal configuration for each method. We provide further description of the problem set-up and additional details necessary to reproduce the results in Section A1.

Fig. 1 shows the results when a cWGAN with Full-GP and Partial-GP attempts to learn the conditional measure for the problems defined in Eqs. 35, 36 and 37 corresponding to two separate values of . Columns 2-7 show histograms of the samples drawn from and, in red, the outline of the histogram of samples drawn from the true conditional distribution . Columns 2 and 3 correspond to the cWGAN with Partial-GP, columns 4 and 5 correspond to Full-GP with , and columns 6 and 7 correspond to Full-GP with optimally chosen . Although the difference between the histograms for the distribution of conditioned on obtained using the various approaches is minor, we observe that in all three cases the Full GP approach yields histograms of the conditional distribution that are closer to their corresponding reference. The histograms obtained using cWGANs with Full-GP where appear to be the best match to the reference. This improvement in performance may be attributed to the smoothing that occurs as a consequence of adding noise to the input . Also note that, due to the limited quantity of training data (2,000 training samples), it is not possible to approximate the target measure too well.
We quantify the performance of each method using the following two metrics: the batch Wasserstein-1 distance , which is the same metric that is employed to choose , and the relative error between samples from the target and generated random variables. We define relative error as follows:
where and denote the true and generated joint distributions, respectively. We estimate the relative errors using 106 realizations.
Table 1 shows the minimum error achieved from four independent runs for each method and joint measure. For all three problems, cWGANs with Full-GP outperform cWGANs with Partial-GP on both metrics. Another observation that can be made from Table 1 is that the joint distribution induced by cWGANs with Full-GP when have smaller distances as compared to the case where , which is expected since this is the same metric that we use to choose , but the influence of on the relative error is negligible.
| Example | Partial-GP | Full-GP () | Full-GP () | |||
| dist. | rel. L2 error | dist. | rel. L2 error | dist. | rel. L2 error | |
| Tanh+ | 0.0429 | 0.192 | 0.0427 | 0.131 | 0.0390 | 0.134 |
| Bimodal | 0.0509 | 0.201 | 0.0509 | 0.161 | 0.0471 | 0.163 |
| Swissroll | 0.0477 | 0.360 | 0.0483 | 0.284 | 0.0399 | 0.281 |
Fig. 2 shows the variation in the distance between and (for the same instances of as shown in Figure 1) as the non-dimensional quantity is varied. The blue curve corresponds to Full-GP with and the red curve corresponds to Partial-GP. Fig. 2 shows that the change in the distance is negligible for , which may explain the limited influence of . Therefore, in a practical problem where the true condition density is not known, need not be optimized as long as a small value is chosen. Further, we observe that the distance between and using the Partial-GP method is greater or similar to Full-GP for all problems at both instances of considered here.

5.2 Inverse heat conduction
We consider the following two-dimensional heat conduction problem
| (38) | |||||
| (39) | |||||
| (40) |
where denotes the temperature field, denotes the conductivity field (which is set to 0.64), and denotes the initial temperature field. Given a noisy temperature field at final time , we wish to infer the initial condition . We remark that this inverse problem is very ill-posed problem due to the significant loss of information via diffusion [30].
For the Bayesian framework, we assume the following prior on the initial data
| (41) |
with sampled from the uniform distribution on , and sampled uniformly from . The prior distribution defined by Eq. 41 corresponds to a linearly varying temperature field in a rectangular region of random shape/size with a zero background outside the rectangle. For the present inverse problem, we represent the discrete initial temperature field (to be inferred) on a Cartesian grid by the random variable . The final temperature field is recovered by solving Eqs. (38), (39) and (40) using a central-space-backward-time finite difference scheme on the same gird. We then add noise sampled from to generate a realization of the noisy measurement variable . Figure 3 depicts a few of the paired samples that form the dataset.
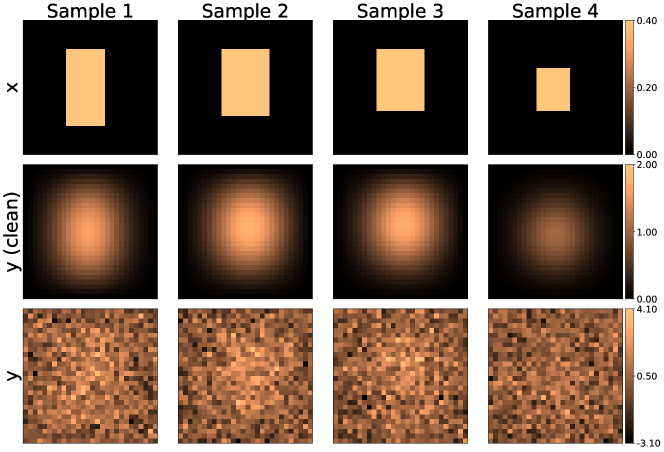


| Posterior Statistics | Partial-GP | Full-GP | |
| Mean | 0.441 | 0.420 | 0.406 |
| SD | 0.460 | 0.454 | 0.435 |
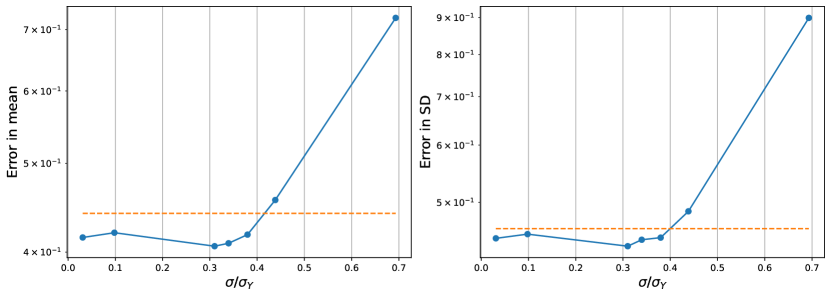
Based on the experiments performed in [23], we consider cWGAN models for the Partial-GP and Full-GP approaches with . The details about the GAN architectures are available in Appendix A2. Both cWGANs are trained on a dataset with 10,000 training sample pairs. After a thorough sweep over the the gradient-penalty parameter , we found for the Partial-GP approach and for the Full-GP approach to be optimal. Both cWGANs are tested on an unseen pair shown in Figure 4. Following [23], the reference posterior pixel-wise mean and standard deviation (SD) of given for this test sample (depicted in the first column of Figure 5) is calculated using Monte Carlo sampling of the random variables . As can be seen in Figure 5 the pixel-wise statistics are captured better with the Full-GP approach compared to the Partial-GP approach. This is corroborated by the error of these statistics listed in Table 2, with the smallest errors observed for , where is the sampling parameter for and is the mean pixel-wise standard deviation over the samples in the training set. Note that the error here is evaluated as
and similarly for the standard deviation. We also perform a sweep over to see how this sampling parameter influences the errors. As shown in Figure 6, the errors are comparable for while being smaller than those observed with the Partial-GP approach. As expected, the errors increase significantly for larger values of the sampling parameter.
5.3 Inverse Helmholtz equation
Lastly, we use cWGANs with Full-GP to solve the inverse Helmholtz equation, which is extensively used to model the propagation of waves in elastography applications [31, 32]. In such applications, wave fields are measured and used to infer the mechanical properties of the propagation medium. This relation is given by the Helmholtz equation:
| (42) |
where denotes the wave propagation frequency, and denote the real and imaginary components of the wave amplitude field at frequency , denotes the shear modulus field, is the wave dissipation coefficient and denotes the density. The physical domain of interest is 1.75 mm 1.75 mm. However, we model a larger domain that includes the domain of interest to allow for wave dissipation and avoid reflections: the left edge is padded by 2.6 mm, 1.75 mm is added on the top and bottom edges, but the right edge is not padded. We impose the following boundary condition on the right boundary: mm and . The boundary conditions on all other boundaries of the expanded domain are . Further, we assume that and kg/m3 are constant over the entire physical domain of this problem. Now, the inverse problem we wish to solve here consists of inferring the shear modulus from the wave amplitude fields and .

In this particular example, we simulate the case when the tissue displacement within a human optic nerve head (ONH) is measured using ultrasound waves. Fig. 7 shows the typical geometry of an ONH considered in this example and delineates its various parts. The prior distribution controls the geometry of the optic nerve head (ONH) and its shear modulus field . Table 3 lists the 16 random variables that make up the prior distribution; these are adapted from the literature [33, 34, 35, 36].
| Parameter | Definition |
| Width of lamina cribrosa (mm) | |
| Thickness of lamina cribrosa (mm) | |
| Radius of lamina cribrosa (mm) | |
| Thickness of the sclera (mm) | |
| Radius of the sclera and retina (mm) | |
| Thickness of retina (mm) | |
| Width of optic nerve (mm) | |
| Radius of optic nerve (mm) | |
| Thickness of pia matter (mm) | |
| Optic nerve shear modulus (kPa) | |
| Sclera shear modulus (kPa) | |
| Pia matter shear modulus (kPa) | |
| Retina shear modulus (kPa) | |
| Lamina cribrosa shear modulus (kPa) | |
| Background shear modulus (kPa) | |
| Rotation of the geometry (rad) | |
| In this example, the normal distributions are truncated to have support between | |
Similar to the previous example, we discretize the shear modulus field over a Cartesian grid and denote it by . The real and imaginary wave amplitude fields, and , respectively, are also represented on Cartesian grids. We solve the Helmholtz equation in Eq. 42 using FEniCS [37] and add isotropic Gaussian noise to the measurements; the added noise has standard deviation equal to 4% of the maximum of and across all training samples. We denote the noisy and as and , respectively; the random variable consists of and . Finally, we construct a training dataset that consists of 12,000 samples of and pairs; three such pairs are shown in Fig. 8. Reference posterior statistics, which allow for the fair comparison of cWGANs, are not available for this problem, so we perform a qualitative study of the performance of the cWGAN with Full-GP. We use the same hyper-parameters for the cWGANs in this example as the inverse heat conduction example; see A for more details.

Figure 9 shows the predictions of the cWGAN for the three test samples shown in Figure 8. For each test sample, columns 1 and 2 show the noisy and measurements, respectively; column 3 shows the ground truth shear modulus ; columns 4 and 5 show the corresponding posterior mean; and, columns 6 and 7 show the posterior standard deviation. Results are reported for two values of the sampling parameter for : (columns 4 and 6 of Fig. 9) and (columns 5 and 7 of Fig. 9); the latter value of is reused from the inverse heat conduction problem and is the mean pixel-wise standard deviation over the samples in the training set. The posterior statistics are estimated using samples. The posterior mean estimated using cWGANs with Full-GP is similar to the ground truth for all three test samples and for both values of considered here. Moreover, we observe large standard deviations in the posterior distribution in areas where we expect the predictions to be uncertain, such as the edges of the ONH. However, the predicted posterior standard deviation when is comparatively larger than the predicted posterior standard deviation when . This may be attributed to the additional sampling variance injected into when .

6 Conclusions and Outlook
In this manuscript a novel version of the cWGAN is developed for solving probabilistic inverse problems where the forward operator is constrained by a physics-based model. The approach is particularly useful for problems where the prior information for the inferred vector is known through samples, and the forward operator is known only as a black-box. The cWGAN developed in this work differs from earlier versions in that its critic is required to be 1-Lipschitz with respect to both the inferred and the measurement vectors and not just the former. This leads to a loss term with a gradient penalty for the critic which is computed using all of its arguments. This simple change has a significant impact on the cWGAN. It allows us to prove that the conditional distribution learned by the cWGAN weakly converges to the true conditional distribution. It also leads to a new sampling strategy, wherein the output of the generator is computed for measurements sampled from a Gaussian distribution tightly centered around the true measurement. Through numerical examples it is demonstrated that the new cWGAN is more accurate than its predecessor, and the that new sampling strategy helps in further improving its performance. The application of this approach to a challenging inverse problem that is by applications motivated in biomechanics is also described.
The ideas described in this manuscript may be extended in several interesting directions. These include, (i) their application to more challenging and complex inference problems; (ii) their application to probabilistic operator networks [38, 39, 40] that map functions of one class to another (initial state to final state, or vice-versa); (iii) the use of more complex network architectures like transformers and self-attention networks [41] in the generator and critic networks of the cWGAN.
7 Acknowledgments
The authors acknowledge support from ARO, USA grant W911NF2010050 and from the Airbus Institute for Engineering Research at USC. The authors acknowledge the Center for Advanced Research Computing (CARC) at the University of Southern California, USA for providing computing resources that have contributed to the research results reported within this publication.
References
- Hadamard [1902] J. Hadamard, Sur les problèmes aux dérivées partielles et leur signification physique, Princeton University Bulletin (1902) 49–52.
- Dashti and Stuart [2017] M. Dashti, A. M. Stuart, The Bayesian approach to inverse problems, in: Handbook of Uncertainty Quantification, Springer, 2017, pp. 311–428.
- Chib [2001] S. Chib, Markov chain Monte Carlo methods: computation and inference, Handbook of econometrics 5 (2001) 3569–3649.
- Brooks et al. [2011] S. Brooks, A. Gelman, G. Jones, X.-L. Meng, Handbook of Markov chain Monte Carlo, CRC press, 2011.
- Liu [2001] J. S. Liu, Monte Carlo strategies in scientific computing, volume 75, Springer, 2001.
- Gelman et al. [1997] A. Gelman, W. R. Gilks, G. O. Roberts, Weak convergence and optimal scaling of random walk Metropolis algorithms, The Annals of Applied Probability 7 (1997) 110–120.
- Cui et al. [2016] T. Cui, K. J. Law, Y. M. Marzouk, Dimension-independent likelihood-informed mcmc, Journal of Computational Physics 304 (2016) 109–137.
- Huijser et al. [2015] D. Huijser, J. Goodman, B. J. Brewer, Properties of the affine invariant ensemble sampler in high dimensions, arXiv preprint arXiv:1509.02230 (2015).
- Neal et al. [2011] R. M. Neal, et al., MCMC using Hamiltonian dynamics, Handbook of Markov chain Monte Carlo 2 (2011) 2.
- Betancourt [2017] M. Betancourt, A conceptual introduction to Hamiltonian Monte Carlo, arXiv preprint arXiv:1701.02434 (2017).
- Murphy [2023] K. P. Murphy, Probabilistic Machine Learning: Advanced Topics, MIT Press, 2023. URL: http://probml.github.io/book2.
- Blundell et al. [2015] C. Blundell, J. Cornebise, K. Kavukcuoglu, D. Wierstra, Weight uncertainty in neural network, in: International Conference on Machine Learning, PMLR, 2015, pp. 1613–1622.
- Jospin et al. [2022] L. V. Jospin, H. Laga, F. Boussaid, W. Buntine, M. Bennamoun, Hands-on Bayesian neural networks—A tutorial for deep learning users, IEEE Computational Intelligence Magazine 17 (2022) 29–48.
- Lampinen and Vehtari [2001] J. Lampinen, A. Vehtari, Bayesian approach for neural networks—review and case studies, Neural Networks 14 (2001) 257–274.
- Fortuin [2022] V. Fortuin, Priors in Bayesian deep learning: A review, International Statistical Review 90 (2022) 563–591.
- Tran et al. [2022] B.-H. Tran, S. Rossi, D. Milios, M. Filippone, All you need is a good functional prior for Bayesian deep learning, Journal of Machine Learning Research 23 (2022) 1–56.
- Goodfellow et al. [2014] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio, Generative adversarial nets, in: Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, K. Weinberger (Eds.), Advances in Neural Information Processing Systems, volume 27, Curran Associates, Inc., 2014. URL: https://proceedings.neurips.cc/paper_files/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf.
- Martin Arjovsky [2017] L. B. Martin Arjovsky, Soumith Chintala, Wasserstein Generative Adversarial Networks, in: Proceedings of the 34th International Conference on Machine Learning, PMLR, 2017, pp. 214–223.
- Gulrajani et al. [2017] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, A. C. Courville, Improved training of wasserstein gans, in: Advances in Neural Information Processing Systems, 2017, pp. 5767–5777.
- Patel et al. [2022] D. V. Patel, D. Ray, A. A. Oberai, Solution of physics-based bayesian inverse problems with deep generative priors, 2022.
- Mirza and Osindero [2014] M. Mirza, S. Osindero, Conditional generative adversarial nets, 2014. URL: https://arxiv.org/abs/1411.1784. arXiv:1411.1784.
- Adler and Öktem [2018] J. Adler, O. Öktem, Deep Bayesian inversion, arXiv preprint arXiv:1811.05910 (2018). URL: https://arxiv.org/abs/1811.05910.
- Ray et al. [2022] D. Ray, H. Ramaswamy, D. V. Patel, A. A. Oberai, The efficacy and generalizability of conditional GANs for posterior inference in physics-based inverse problems, Numerical Algebra, Control and Optimization (2022). URL: https://doi.org/10.3934/naco.2022038. doi:10.3934/naco.2022038.
- Kovachki et al. [2020] N. Kovachki, R. Baptista, B. Hosseini, Y. Marzouk, Conditional sampling with monotone GANs, arXiv preprint arXiv:2006.06755 (2020).
- Ronneberger et al. [2015] O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, Springer, 2015, pp. 234–241.
- Villani [2008] C. Villani, Optimal Transport: Old and New, Grundlehren der mathematischen Wissenschaften, Springer Berlin Heidelberg, 2008.
- Barbone and Oberai [2010] P. E. Barbone, A. A. Oberai, A review of the mathematical and computational foundations of biomechanical imaging, Computational Modeling in Biomechanics (2010) 375–408.
- Kingma and Ba [2017] D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, 2017. URL: https://arxiv.org/abs/1412.6980. arXiv:1412.6980.
- Flamary et al. [2021] R. Flamary, N. Courty, A. Gramfort, M. Z. Alaya, A. Boisbunon, S. Chambon, L. Chapel, A. Corenflos, K. Fatras, N. Fournier, L. Gautheron, N. T. Gayraud, H. Janati, A. Rakotomamonjy, I. Redko, A. Rolet, A. Schutz, V. Seguy, D. J. Sutherland, R. Tavenard, A. Tong, T. Vayer, POT: Python optimal transport, Journal of Machine Learning Research 22 (2021) 1–8. URL: http://jmlr.org/papers/v22/20-451.html.
- Heinz Werner Engl [2000] A. N. Heinz Werner Engl, Martin Hanke, Regularization of Inverse Problems, Springer Dordrecht, 2000.
- McLaughlin and Renzi [2006] J. McLaughlin, D. Renzi, Shear wave speed recovery in transient elastography and supersonic imaging using propagating fronts, Inverse Problems 22 (2006) 681.
- Zhang et al. [2012] Y. Zhang, A. A. Oberai, P. E. Barbone, I. Harari, Solution of the time-harmonic viscoelastic inverse problem with interior data in two dimensions, International Journal for Numerical Methods in Engineering 92 (2012) 1100–1116.
- Sigal [2009] I. A. Sigal, Interactions between geometry and mechanical properties on the optic nerve head, Investigative ophthalmology & visual science 50 (2009) 2785–2795.
- Şahan et al. [2019] M. H. Şahan, A. Doğan, M. İnal, M. Alpua, N. Asal, Evaluation of the optic nerve by strain and shear wave elastography in patients with migraine, Journal of Ultrasound in Medicine 38 (2019) 1153–1161.
- Qian et al. [2021] X. Qian, R. Li, G. Lu, L. Jiang, H. Kang, K. K. Shung, M. S. Humayun, Q. Zhou, Ultrasonic elastography to assess biomechanical properties of the optic nerve head and peripapillary sclera of the eye, Ultrasonics 110 (2021) 106263.
- Zhang et al. [2020] L. Zhang, M. R. Beotra, M. Baskaran, T. A. Tun, X. Wang, S. A. Perera, N. G. Strouthidis, T. Aung, C. Boote, M. J. Girard, In vivo measurements of prelamina and lamina cribrosa biomechanical properties in humans, Investigative Ophthalmology & Visual Science 61 (2020) 27–27.
- Alnæs et al. [2015] M. Alnæs, J. Blechta, J. Hake, A. Johansson, B. Kehlet, A. Logg, C. Richardson, J. Ring, M. E. Rognes, G. N. Wells, The FEniCS project version 1.5, Archive of Numerical Software 3 (2015).
- Lu et al. [2021] L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nature machine intelligence 3 (2021) 218–229.
- Li et al. [2020] Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, arXiv preprint arXiv:2010.08895 (2020).
- Patel et al. [2022] D. V. Patel, D. Ray, M. R. Abdelmalik, T. J. Hughes, A. A. Oberai, Variationally mimetic operator networks, arXiv preprint arXiv:2209.12871 (2022).
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in Neural Information Processing Systems 30 (2017).
Appendix A GAN architectures and experimental setup
The generator and critic architectures for the experiments considered in Section 5 are described in this section. Other key hyper-parameters are listed in Table 1. All networks were trained using Adam optimizer with parameters , .
| Hyperparameter | Experiment | ||||
| Illustrative examples | Inverse heat conduction | Inverse Helmholtz equation | |||
| Tanh+ | Bimodal | Swissroll | |||
| Training samples | 2,000 | 2,000 | 2,000 | 10,000 | 12,000 |
| 1 | 1 | 1 | |||
| 1 | 1 | 1 | |||
| 1 | 1 | 1 | 3 | 50 | |
| Batch size | 2,000 | 2,000 | 2,000 | 50 | 50 |
| Activation func | tanh | tanh | tanh | LReLU(0.1) | ELU |
| 20 | 20 | 20 | 4 | 4 | |
| Max epochs | 600,000 | 600,000 | 600,000 | 500 | 4,000 |
| Learning rate | |||||
A1 Illustrative examples
The generator and critic architectures chosen to solve this problem are multilayer perceptrons (MLPs) with 4 hidden layers with units, respectively.
A2 Inverse heat conduction
The generator and critic architectures are identical to those considered for the inverse heat conduction problem in [23]. In particular, a residual block based U-Net architecture is used for the generator, with the latent information injected at every level of the U-Net through conditional instance normalization. The critic comprises residual block based convolution layers followed by a couple of fully connected layers. See [23] for precise details of the architectures, and the benefits of using conditional instance normalization, especially when the generator input is an image while the latent variable is a vector.
A3 Inverse Helmholtz problem
For this problem, we used the same generator and critic architectures as for the inverse heat conduction problem. The only differences are regarding the different size of the inputs and using the ELU activation function instead of LReLU(0.1). We used the same hyper-parameters as in the inverse heat equation problem (see Table 1).