SReferences
Soft Multicopter Control Using
Neural Dynamics Identification
Abstract
We propose a data-driven method to automatically generate feedback controllers for soft multicopters featuring deformable materials, non-conventional geometries, and asymmetric rotor layouts, to deliver compliant deformation and agile locomotion. Our approach coordinates two sub-systems: a physics-inspired network ensemble that simulates the soft drone dynamics and a custom LQR control loop enhanced by a novel online-relinearization scheme to control the neural dynamics. Harnessing the insights from deformation mechanics, we design a decomposed state formulation whose modularity and compactness facilitate the dynamics learning while its measurability readies it for real-world adaptation. Our method is painless to implement, and requires only conventional, low-cost gadgets for fabrication. In a high-fidelity simulation environment, we demonstrate the efficacy of our approach by controlling a variety of customized soft multicopters to perform hovering, target reaching, velocity tracking, and active deformation.
Keywords: Soft Robotics, Deformation Mechanics, Data-driven control, LQR, Physics-informed Machine Learning
Video: https://youtu.be/xYWp5jzOwkc
1 Introduction
Making a drone’s body soft opens up brand new horizons to advance its maneuverability, safety, and functionalities. The intrinsic property of soft materials to deform and absorb energy during collision allows safe human-machine interactions [1, 2, 3]. In circumscribed environments, soft drones can naturally deform their bodies to travel through gaps and holes, making them effective for emergency rescues. Moreover, the ability to perform controlled deformation enables soft drones to perform secondary functionalities apart from aerial locomotion, such as flapping wings, grasping objects, and even operating machines, any additional mechanical parts.
Despite the various advantages that this promises, to date a reliable and practical algorithm that controls soft drones to fly and deform has been lacking, due to multifaceted challenges. Unlike how it is for rigid drones, which are fully defined by 12-dimensional state vectors, describing the state of soft drones is far from trivial. Since a continuum body deforms in infinite DOFs, one needs to design discrete representations both compact —— so that the underactuated control problem is feasible, and measurable —— so that the controller can adjust to unmodelled errors. Even if such discretizations are obtained, the dynamic interplay of these state variables cannot be derived analytically in closed-form, as the dynamics in the full space is governed by complex PDEs. Finally, if one is to adopt machine-learning methods to model the dynamics, a problem is posed by the complexity of soft body simulation, which inevitably leads to scarce data, making brute-force learning an ill-fated avenue.
Bridging the deformation mechanics, deep learning, and optimal control, our method is so designed to successfully overcome the abovementioned challenges. First, we adopt the polar decomposition theorem to build a low-dimensional decomposed state space consisting of three geometric, latent variables each representing rotation, translation, and deformation, which can be synthesized from the readings of a set of onboard Inertial Measurement Units (IMUs). We define the interdependencies of these three variables and learn them with lightweight neural networks, thereby learning a neural simulator in a latent space on which the controller will be based. With automatic differentiation, we then extract the numeric gradients of the learned system to be controlled with a Linear Quadratic Regulator (LQR). Due to the fact that LQR requires the system to be linearized around fixed points that are inaccessible, we extend it with a novel online-relinearization scheme that iteratively converges to the desired target, bringing robustness and convenience for human piloting.
As shown in Figure. 1, our system takes soft drone geometries as input, and returns functionals that compute control matrices based on the drone’s current state. To the best of our knowledge, the proposed approach is the first to control soft drones that are meant to deform significantly in flight; we show that we can not only regulate such deformation for balanced locomotion, but also capitalize on the deforming ability to perform various feats in the air.

2 Related Work
Multicopter Over the last few years, quadcopters have virtually dominated the commercial UAV industry, thanks to their simple mechanical structures, optimized efficiency for hovering, and easy-to-control dynamics that has been extensively studied by [4, 5] and many more. Various methods have been successfully developed to control quadcopters, including PD/PID [6], LQR [7, 8], differential flatness [9], sliding mode [10], and MPC [11] methods. Recent research explores the control of non-conventional multicopter designs, including ones with extra rotors [12], asymmetric structures [7], articulated linkage [13], or with gliding wings [14]. The problem of controlling drones fabricated with soft materials is still understudied.
Aerial Deformation Recent works have explored the potential of drones to actively deform in flight [15]. [13, 16] achieve impressive results with their multi-linked drones in passing through small openings or grasping objects, but the added mechanical components in their designs imply additional cost, fabrication complexity, energy consumption, and maladroitness. [17] proposes a lightweight, planar folding mechanism actuated by servo motors that is effective in controlling the drones to travel through confined spaces, but the simplified mechanism limits the ability to perform extra functionalities such as grasping. [18] propose the incorporation of a cable-actuated soft gripper with a rigid quadcopter to achieve load manipulation. While previous works add additional actuators to control deformation, we control deformation jointly with locomotion using rotors only.
Data-driven Soft Robot Control The modeling and control of soft robots is a challenging problem due to the high DOFs and the non-linear dynamics [1], which together make closed-form solutions unfeasible to be derived [19], and therefore making data-driven approaches favorable. [20, 21, 22], and many more, use deep reinforcement learning to train neural network controllers for soft robots. [23, 24] marries machine learning with control theory, applying MPC or PD control methods on models learned from data. [19] propose the possibility of end-to-end supervised learning with a differentiable soft-body simulator, although their current design does not facilitate feedback mechanism in real-life due to the assumption of full state measurement.
3 Methodology
Overview The workflow of our proposed system is given in Figure. 2. We start with the IMU sensor readings, which are position, orientation and their rates of change at multiple locations of the drone’s body, which will be processed to form the current state vector as the concatenation of the three decomposed latent variables , , and . This vector, along with the previously applied
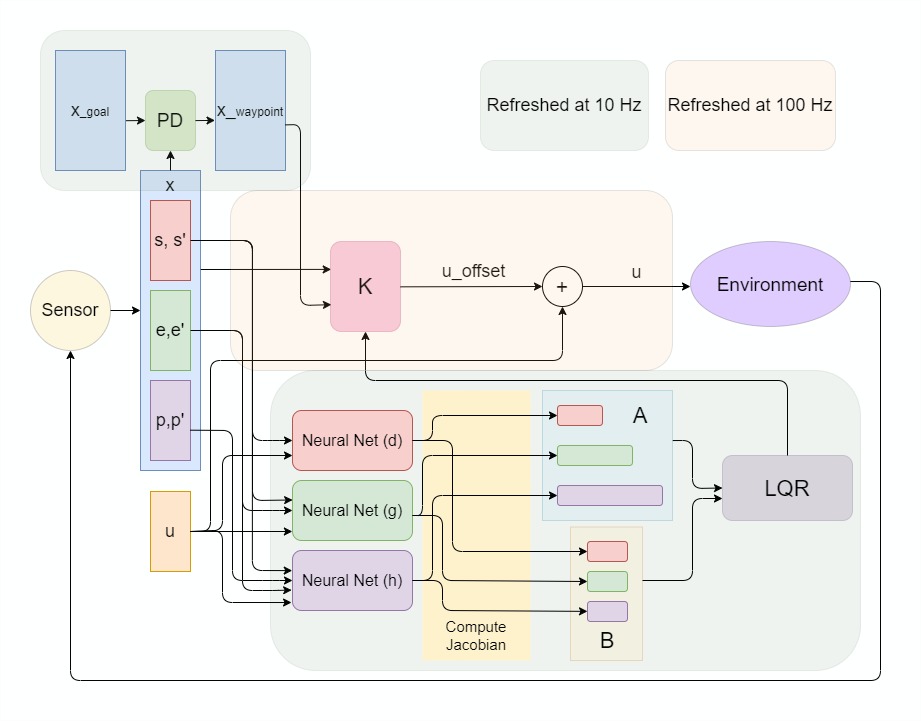
actuation will be passed into the three trained network modules as inputs. Then we extract the numeric gradients to form the Jacobian matrices, which will be used to assemble the matrices and representing the linearized dynamics. Then, and will be passed into the LQR algorithm to form the control matrix , given which we simply need to pass in our current state , our next waypoint state , and the current actuation , to obtain the new actuation , which will be applied to the drone’s rotors to complete the control loop. The will be computed by a Proportional-Derivative (PD) controller given final goal state . The control loop will operate at while the recomputation of takes place at .
Geometric State Decomposition Let , denote the volume of the drone’s undeformed and deformed geometry, and let , be their respective finite discretizations as particles forming the solid body, with . We can always write:
| (1) |
for some rotation matrix , some position , and some non-linear function which reduces to when and . In other words, we first define a local reference frame by the transformation resulting from and , and express the deformation in such a frame with , thereby decomposing the total transformation into a rigid component and a deformable component. In this way, the rigid, component can be simulated side by side with the deformable component , an approach proposed by [25] and adopted by various works in the deformation simulation community [26, 27, 28], taking advantage of the fact that the local-frame deformation is much nicer to work with than the world-frame deformation . In this work, we adopt the same philosophy and learn evolution rules for , , and in juxtaposition.
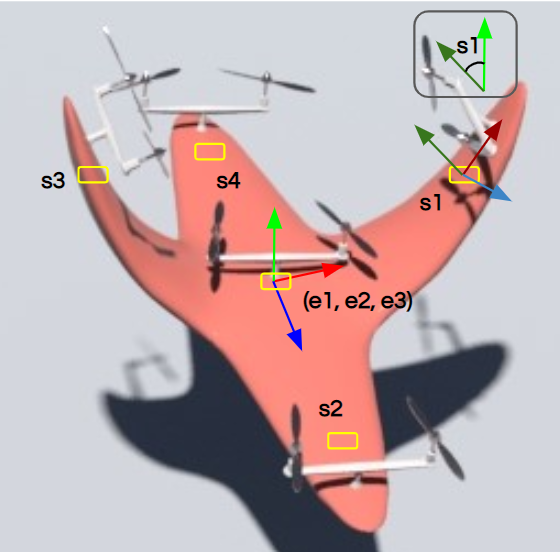
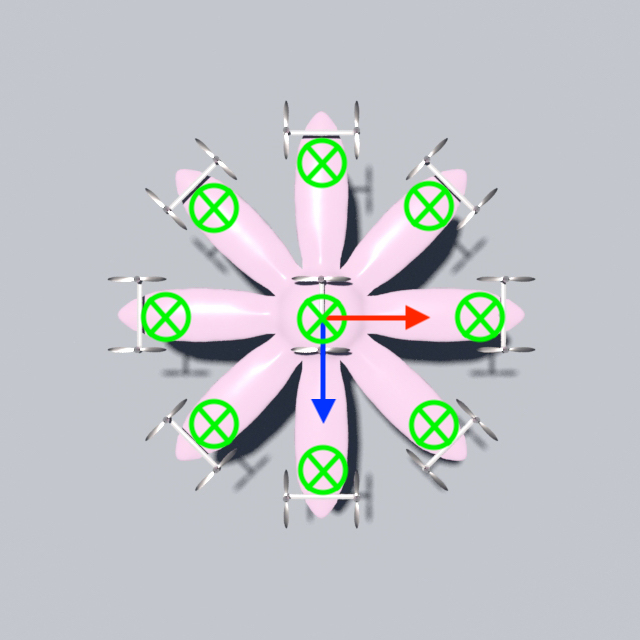
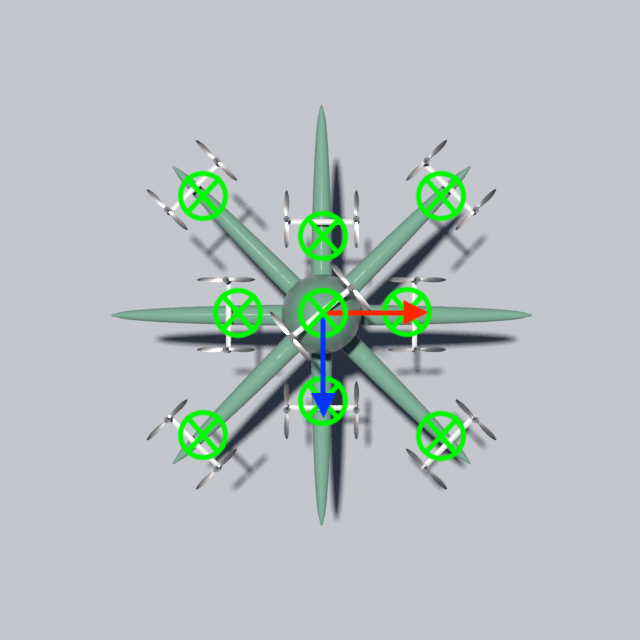
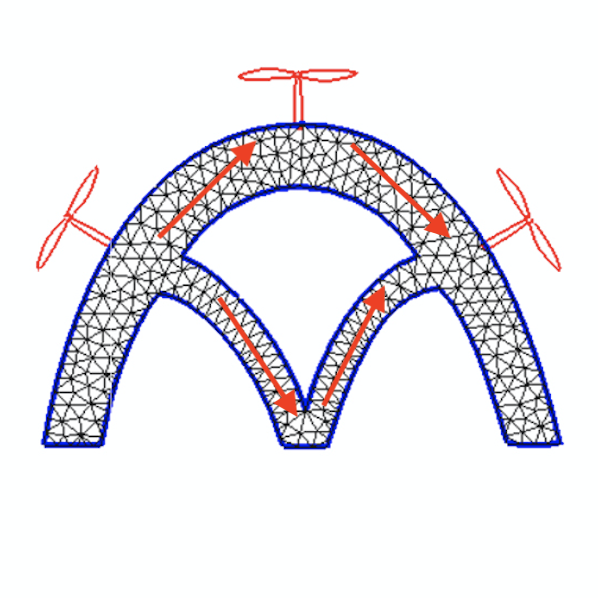
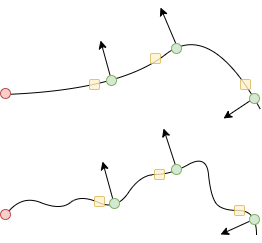
Measurability Since our goal is to build feedback controllers for , i.e, , we would need to define , , and in such a way that they can be measured by sensors. In this work, we adopt the following strategy. As shown in Figure. 3 we plant Inertial Measuring Units (IMUs), which are compact, low-cost MEMS outputting rotational and translational status, at the drone’s geometric center and around its periphery, next to the propellers. For the local frame rotation , we use the Euler angles measured at the geometric center. For local frame origin , we average the positional measurements of all the IMUs to approximate the center of mass. For the local frame deformation , we obtain an approximate representation by computing a scalar angle difference between the -axis measured by each peripheral IMU and the -axis defined by , and concatenate these scalars together. In the shown case, each entry of represents how its associated wing is folded, where the sign indicates inward or outward and the magnitude indicates the angle. Such a design of facilitates interactive piloting since it is intuitive to describe one’s desired deformation in terms of the bent angles. Since we have parameterized with , and , controlling the dynamics of now relegates to controlling the dynamics of .
Dynamic Coupling The drone’s body will be actuated by a set of propellers, each providing a scalar thrust along the normal of the surface it is planted on. Let denote the thrusts. The second-order dynamics of is given by the momentum conservation:
| (2) |
where represents the particle mass. We note here the translational and rotational symmetries of the experienced forces. Since depends on the rotors’ normal directions which are computed locally with neighboring particles, it is unchanged when the whole of is rotated or translated. The translational and rotational invariance of and is based on the principle of material frame-indifference in continuum mechanics, which states that the behavior of a material is independent of the reference frame [29]. Combining the symmetry with the equality , and ignoring the Coriolis forces resulting from the evolving , we get that:
| (3) |
Since is constant, is a function of , and we know is a function of , then the dynamics coupling of , , and are as follows. Since is the average of , it depends on , , , and . Since is measured in the local geometric center of , depends on , , , and as well. For , since it is measured by projecting onto the local frame by left-multiplying , the component in cancels out for and depends on , and only.
These interdependencies will be modelled by learned neural networks, in particular, we train networks such that , , and .
Learning the Dynamics Training the networks , and can be done in a relatively straightforward fashion. The three networks share the same lightweight architecture consisting of four residual blocks [30] featuring linear layers as previously explored by [31, 32]. The three networks will be trained separately using the same reservoir of data samples of the form {} generated from Finite Element Method (FEM) simulation. We use Adam optimizer and L1 loss for optimization, with hyperparameter details given in the supplement. There are two techniques that we adopt that are worth reporting. First, for data generation, we would apply a constant random thrust uniformly sampled in the range , where denotes a rotor’s max output thrust, to the drone’s rotors for , before a new random thrust is applied. The soft drone would be dancing and twisting in the air, but despite that, this method leads to successful trainings, while generating data from a guiding controller, or switching random control signals at every instant, would fail. Secondly, we’ve found that trainings converge much better when we predict the next frame’s velocity using the current one, instead of directly predicting the acceleration. Although this approach can lead to local minima for settling at the input, current velocity, that does not happen in our experiments and the acceleration can be convincingly reconstructed from the two velocities, as we shall elaborate in the results section.
Controlling the Learned Dynamics Once the networks , and are trained, the dynamics can be expressed as
| (4) |
To control such learned dynamics, we summon the Linear Quadratic Regulator (LQR), a well-proven method for controlling rigid drones. Since LQR requires a linear system, we will perform first-order Taylor expansion around an operating point with Jacobian matrices from automatic differentiation which can be done with PyTorch. In particular, we write:
| (5) |
where , and , as shown in Equation 6:
| (6) |
If we make the assumption that for and close enough to each other, , then we have:
| (7) |
Once the linear system is obtained, LQR outputs the control matrix and the control policy that drives to while keeping close to by minimizing the cost function . The and matrices are cost matrices used to manage the tradeoff between the two objectives. The optimization is done by solving the Continuous-time Algebraic Riccati Equation with SciPy.
Online Relinearization
Traditionally, the operating point, which is the state-actuation pair is chosen to be a fixed point such that . For typical rigid drones, such fixed points can be obtained trivially, and yet, for deformable drones, without iteratively testing and optimizing with the neural dynamic system, it is generally not possible to know beforehand which set of rotor input would exactly balance the internal stress, viscous damping, and external gravity, or if such a balance exists. We see the fixed-point assumption as being overly strict and seek to circumvent it. The purpose of assuming is to turn the affine Equation. 5 into a linear one which LQR recognizes. In that case, is time-invariant and indeed . Since in our case we cannot guarantee , then so directly running LQR with and would typically fail. However, by making the proximity assumption as in Equation. 7, we can obtain the linear form locally. In other words, with not being fixed points, we can still regulate close-enough neighbor states to it.
Input: , , , , , ,
As in Algorithm. 1, our solution is built upon this observation. We initialize our drone with arbitrary , and . At each instant, we will linearize around the current . We run LQR with the linear system to obtain . In practice, we don’t want to attract neighboring state to current state, but rather drive the current state to our goal state. Our strategy is that if we want to reach a state from , then we will pretent to be at trying to reach , and compute . Given the current state and the goal state , we calculate using a PD control: . The control matrix will be used for timesteps before updated again.
4 Experiments and Evaluation

To test the efficacy of our method, we design a number of soft drone models in 2D and 3D featuring asymmetrical structures and odd numbers of rotors, as depicted in Figure. 4. We conduct training on each model individually and use the generated controllers to direct the models to perform hovering, target reaching, velocity tracking, and active deformation.
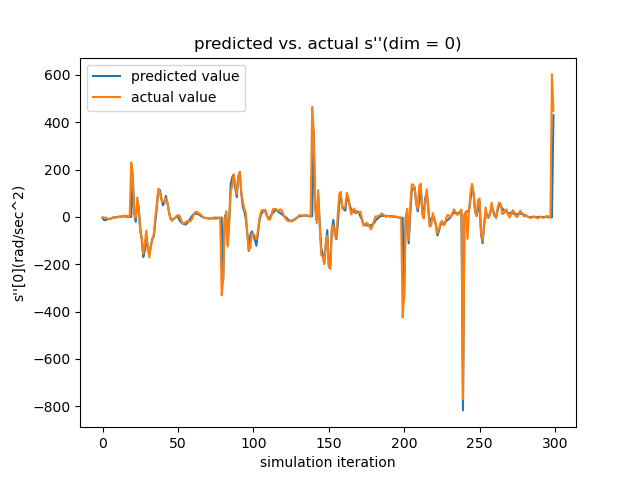
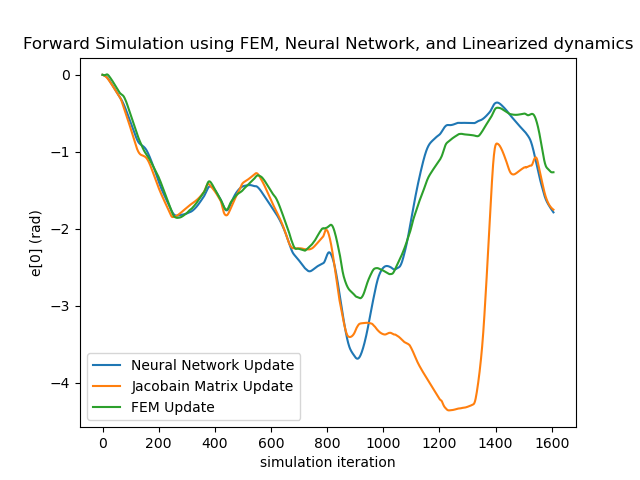
Testing the Linearized Networks To verify the quality of our learned dynamics, we focus on two aspects. First, since our model predicts the next frame’s velocity with the current velocity, rather than the acceleration (which is what we ultimately want), we need to make sure that the network actually learns how the velocity evolves, instead of reproducing the current velocity. As seen in the left subfigure of Figure. 17, which overlays the actual acceleration and the predicted acceleration reconstructed from the predicted velocity, the networks learn the evolution rules of velocity successfully.
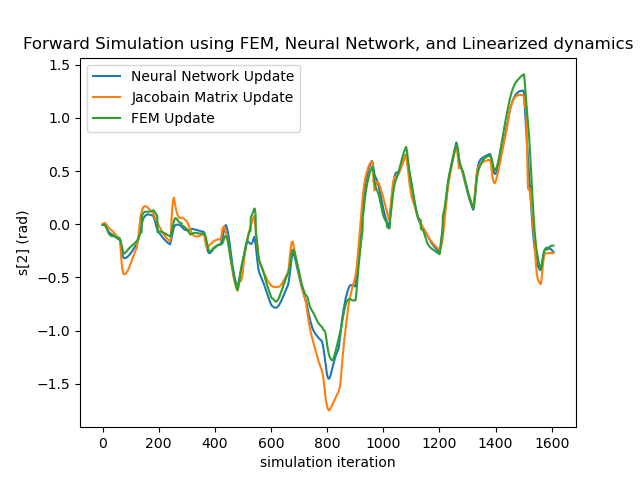
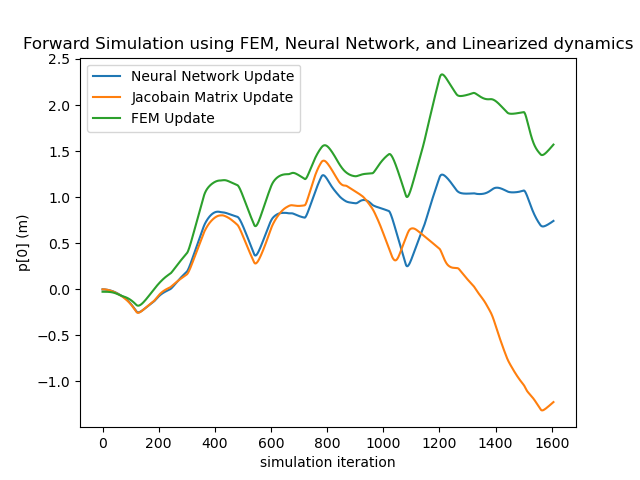
Secondly, since the LQR controller relies on the Taylor-expanded version of the learned networks, it is necessary to verify how well the networks’ gradient matches that of the actual dynamics. Since the ground-truth gradient is difficult to obtain, we test this by reproducing temporal sequences using the linearized version as in Equation. 5 relinearized at . As shown in the right subfigure, even with error accumulation, the linearized evolution sequence (Jacobian Matrix Update) keeps up with the ground truth for over a minute, showing the linearized neural network can reliably approximate the real dynamics locally.
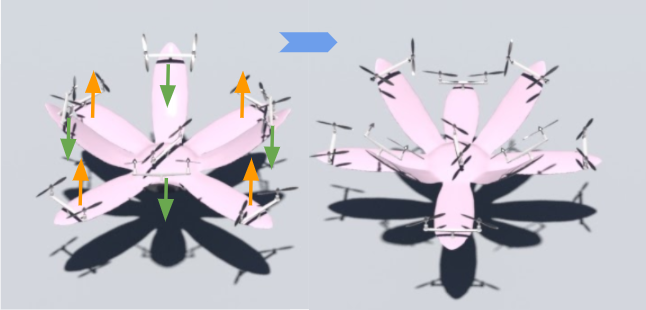
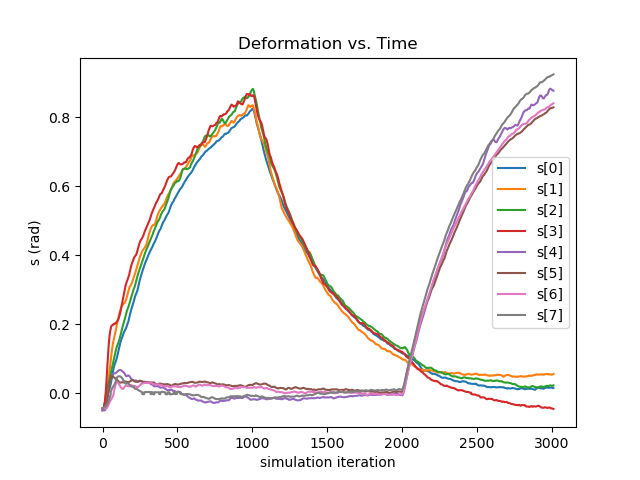
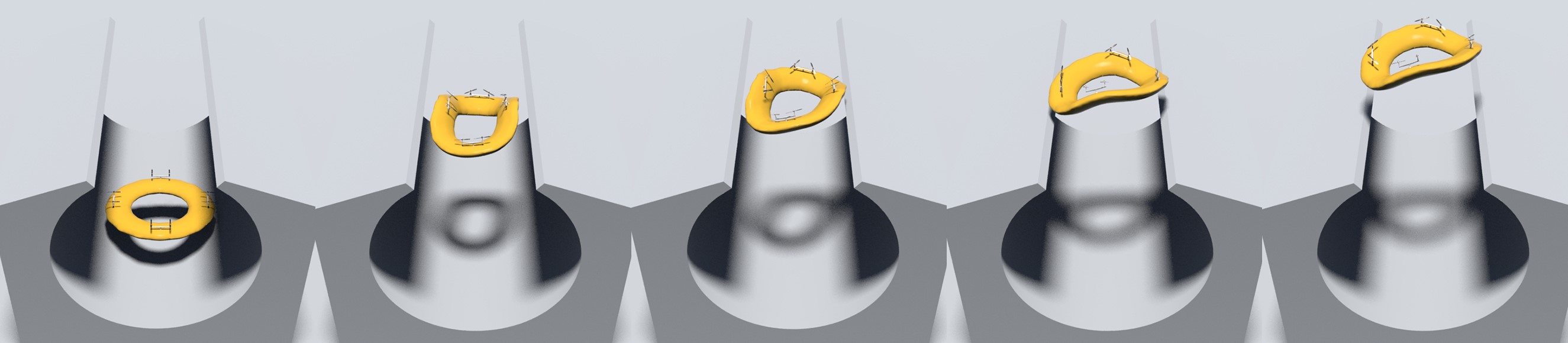
Aerial Deformation Our method successfully controls the drones to deform into specified configurations while hovering or tracking a velocity. The first experiment instructs the flower drone to maintain its location and orientation while deforming into two different configurations: first with lateral petals raised and axial petals flat, then with lateral petals flat and axial petals raised, as shown in Figure. 6. In the middle subfigure, the pitch of all eight petals are controlled as expected in a smooth manner: petals will rise first while petals stay still, before the roles are gradually switched. The right subfigure shows that this is done while maintaining precise control of balance and position. Ever since the initial drop in the direction immediately after release, other rotational and translational movements are contained within and .


The second experiment combines velocity tracking with aerial deformation in an obstacle avoidance scenario. As shown in the top of Figure. 7, three concrete blocks form a gap that is narrower than the star drone’s body along the direction. Here, we instruct the drone to fold up two wings by increasing their associated angles, and at the same time maintaining a forward and upward velocity in the direction. It is also crucial to limit the deviation along the direction in order to not crush into the blocks. As one sees in the first subfigure
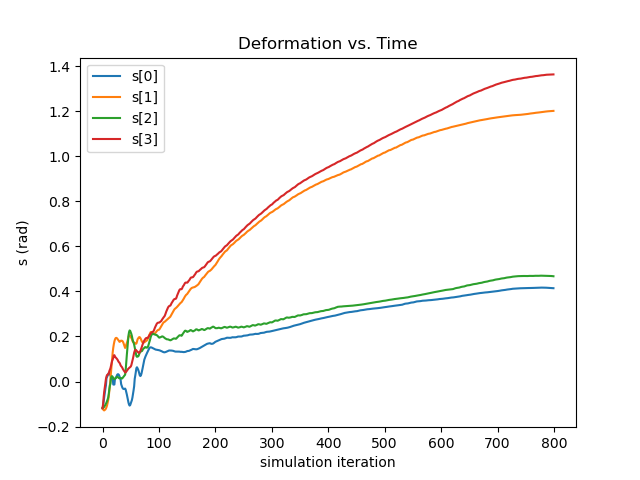
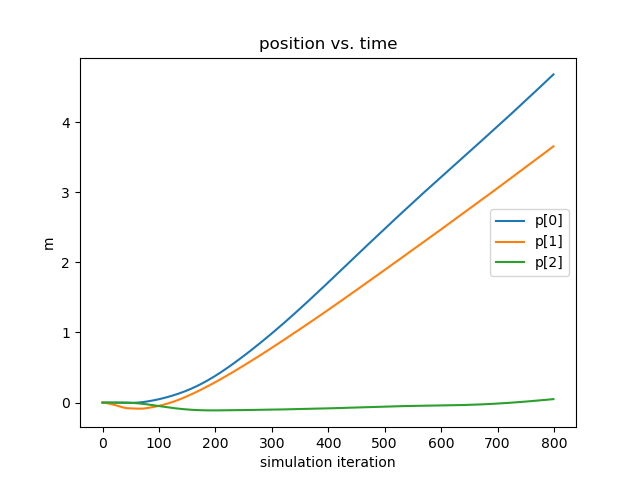
of Figure. 8, our controller increases the wing pitch by over , reducing its width for over 30%. As seen in the second subfigure, it does so while maintaining a steady velocity in the direction, and deviating for less than in the -axis throughout the entire sequence, thus leading to the successful object avoidance as depicted in the bottom of Figure. 7.
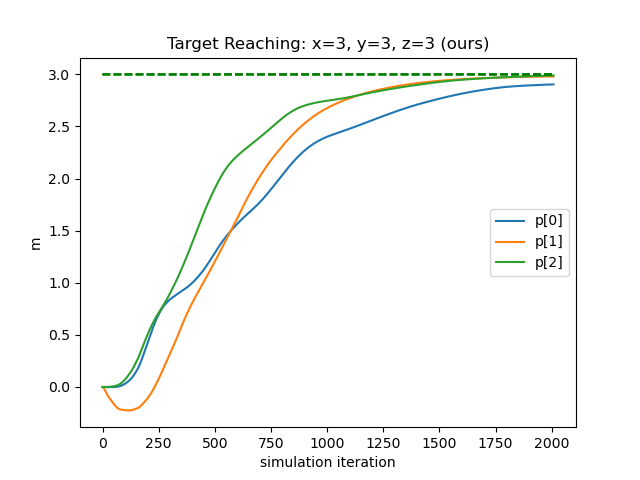
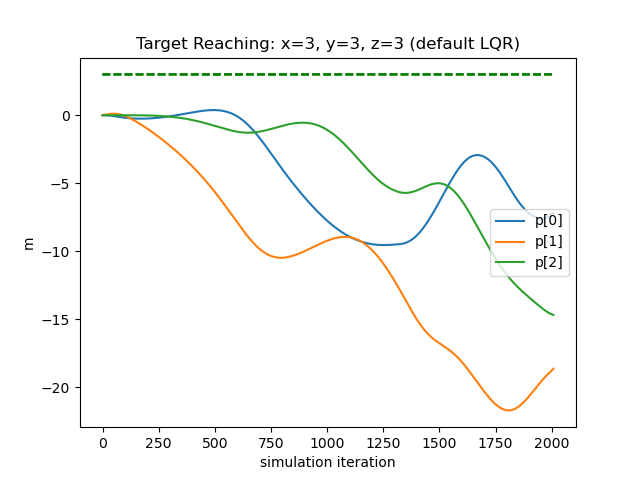
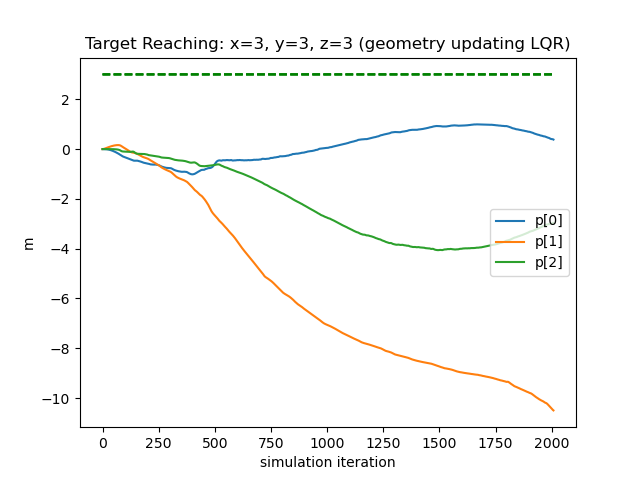
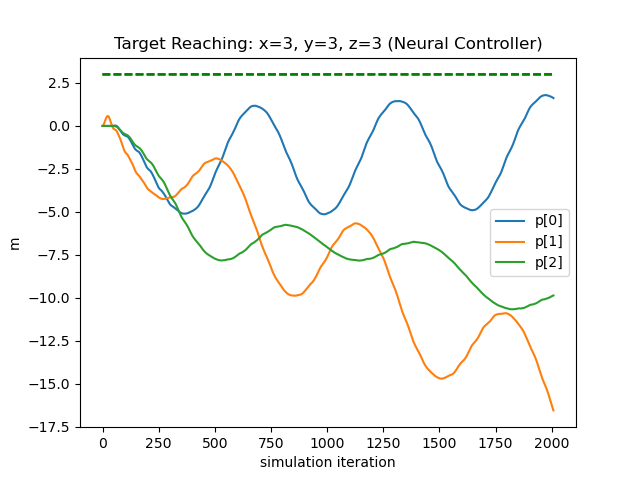
SOTA Comparison We compare our method with three different controllers: traditional LQR, geometry-updating LQR, and a neural network controller trained end-to-end using the strategy proposed by [19]. Our metrics will base on locomotion, since existing controllers for soft drone deformation is unavailable. The first candidate computes an LQR control matrix using the relevant quantities —— fixed point, rotor position, rotor orientation, and rotational inertia, calculated from the drone’s rest shape. The second recomputes the control matrix at every timestep with the relevant quantities updated based on the deformation, with further details given in the supplement. The third takes our trained network dynamic system as a differentiable simulator to train another network controller. We instruct all controllers to direct the flower drone to travel from position to . As depicted in Figure. 9, our method (left) successfully drives the coordinates of the drone to the target within 7% error, while the other controllers fail due to the fragility of the soft drone dynamics. As shown in the table below, we compare their performance numerically with three metrics: final error, thrust usage, and the survival time before illegal configurations are encountered, which shows that our method excels the other candidates by far.
| Target Reaching | ||||
| metrics | ours | LQR | Geometry-updating LQR | Neural Controller |
| survival time (s) | 20.0 | 0.67 | 0.69 | 0.19 |
| final error (m) | 0.099 | 29.744 | 14.989 | 23.454 |
| thrust usage (N) | 26740 | 90596 | 61947 | 179996 |
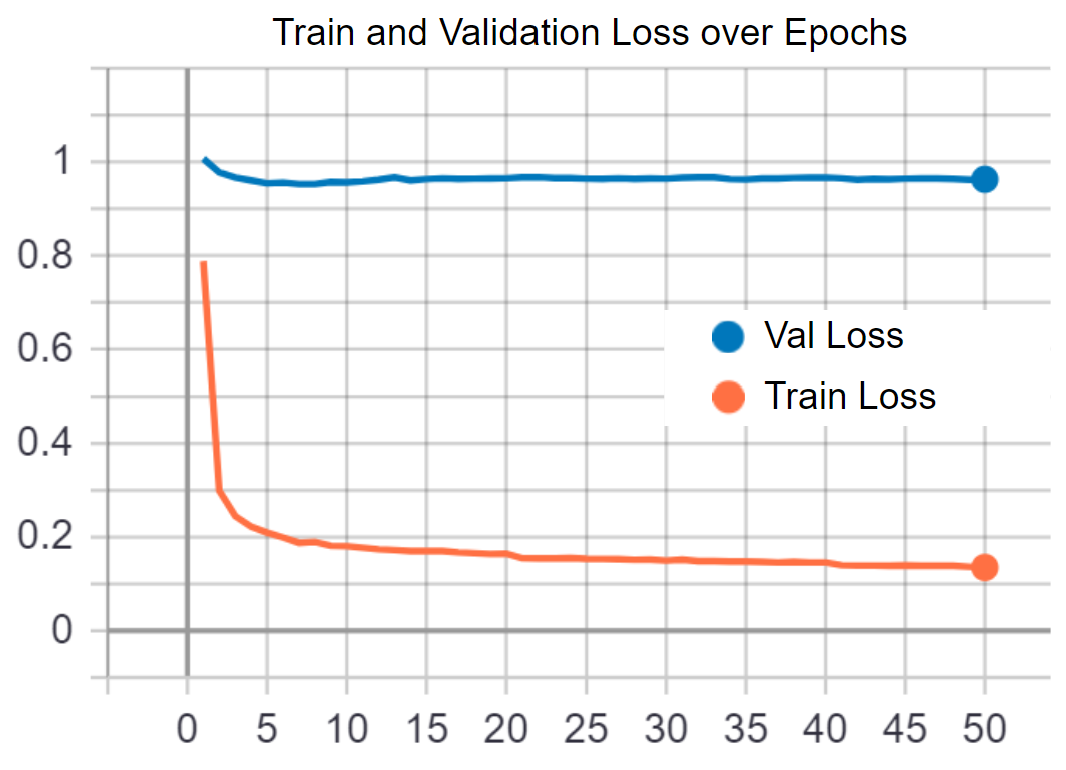
Ablation Testing: State Decomposition The state decomposition is helpful for defining a local frame in which deformation can be expressed compactly as scalars. In this experiment, we train without decomposing and feed the network with the concatenated vector of the position, center orientation, and peripheral orientations. As displayed in Figure. 10, the validation loss is unable to converge successfully, signifying that the network fails to learn the correct patterns. This can be due to the fact that such unprocessed states double the size of the decomposed version, and also that the evolution rules of the position and orientation are highly unalike, thus demanding the network to evolve into multi-modal behaviors.
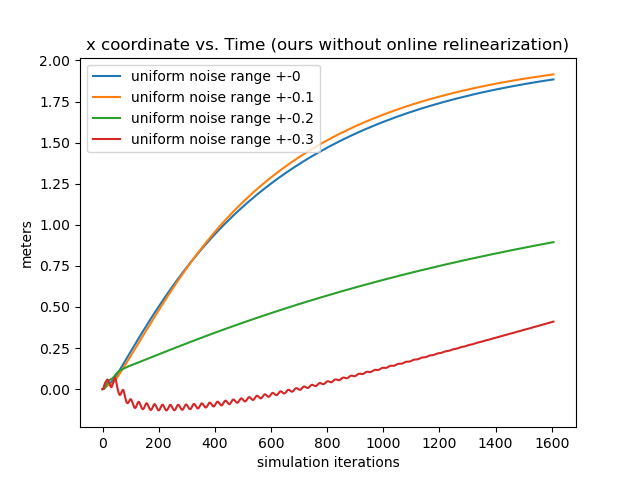
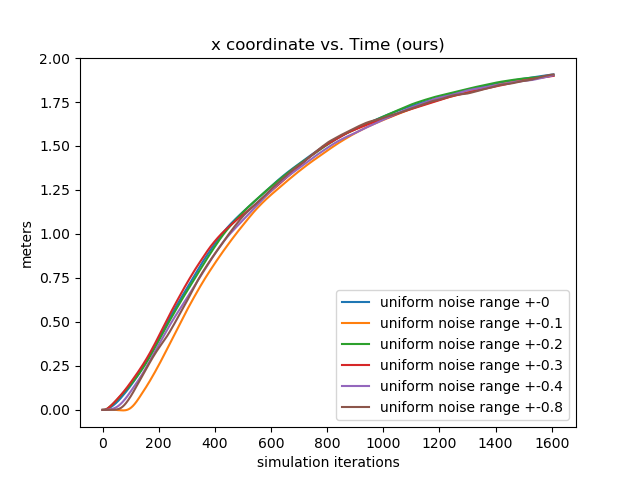
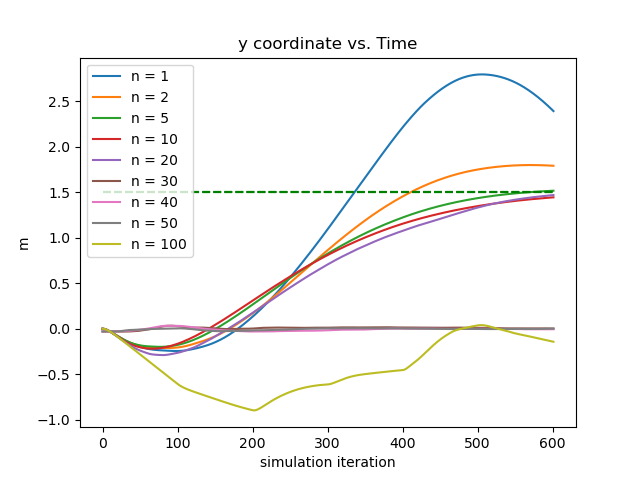
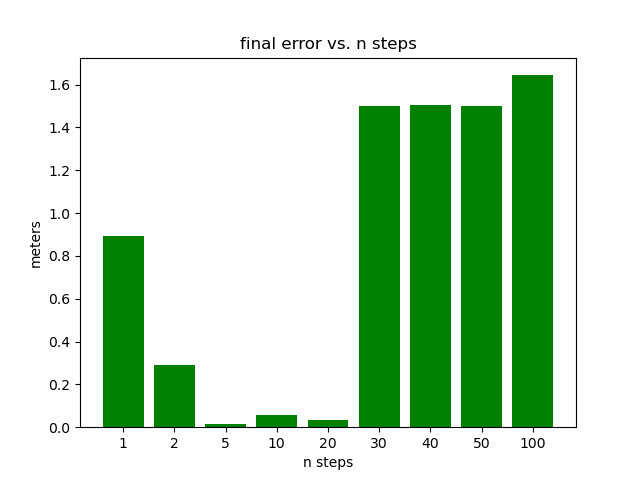
Ablation Testing: Online Relinearization We show the importance of the online relinearing mechanism by testing the controller performance where the input targets deviates from a fixed point by different margins. We first obtain a fixed point by trial-and-error and then fine-tune it with gradient descent using our learned networks. Then, we keep the goal location untouched, and pollute the rest of the fixed point by adding uniform random noise proportional to each state variable by 10%, 20%, 30%, 40%, and 80%. We direct the rod drone to translate for 2 units along the direction. The results are depicted in the left 2 subfigures of Figure. 11. The first subfigure shows the results without online relinearization, where the control quality deteriorates significantly when over 20% noise is added, and start to generate NANs after 40% noise is added. The second subfigure shows the results with online relinearization, in which the controller performs steadily even with 80% noise added. The significance is that during deployment the pilot only needs to input the target configuration without worrying about the hard-to-compute fixedness of such configuration, thereby making our control system feasible for human piloting.
Effect of Relinearization Frequency The parameter controls the relinearization frequency . The more often the system is linearized the more accurate the linear approximation is. And also, since we set a new waypoint at each linearization, whose distance away is inversely proportional to , frequent linearzation sets many adjacent waypoints while infrequent linearization sets long-term, sparse waypoints. In this experiment, we test the performance of 9 different values of : , and show that it is not the case that larger implies better performance. As shown in the right two subfigures of Figure. 11, is clearly the sweet-spot of this parameter, where smaller leads to overshoots, and larger insufficient actuation.
5 Discussion and Conclusion
We propose a computational system to generate controllers for soft multicopters that jointly controls the locomotion and active deformation, without relying on extra mechanical parts. Our method takes advantage of a physics-inspired decomposed state space, and train neural networks to represent the dynamics. We control the neural dynamics system using an LQR controller enhanced with a novel online relinearization scheme. We use our method to successfully generate controllers for a variety of soft multicopters to perform hovering, target reaching, velocity tracking, and active deformation.
Sim2Real Transfer Our method is well-suited for real-world adaptations. First, we limit the interfacing between the simulator and the learning system strictly to sensor readings, so we make sure that no unrealistic benefit is gained from experimenting virtually. Secondly, we form a straightforward guideline for sensor deployment, featuring accessible gadgets with easy installation. Thirdly, the computation of LQR optimization and neural network evaluation can be realistically carried out in real-time by onboard computers, as previously explored by [33, 34]. Finally, being data-driven, our method betters the analytic approaches for Sim2Real adaptation, since it learns from data which contain the unmodelled nuances of the real world. The main challenge for Sim2Real transfer would be the experimental designs to generate meaningful data using the fabricated drones.
Limitations With our approach there are several limitations. First, the sensor placement requires human design, and there lacks a mechanism to tell, before training, if a sensing scheme would work. Secondly, every drone requires a separate training with no knowledge transfer. Thirdly, we use dual rotors with counter-rotation to cancel the spinning torque effects, which complicates the manufacturing process. Finally, the current control scheme is ineffective for aggressive maneuvers.
In the future, we plan to build an automated system for optimizing sensor locations as well as a unified neural dynamics platform that facilitates knowledge transfer, and to evaluate our approach on real-world soft multicopters.
Acknowledgments
We thank all the reviewers for their valuable comments. We acknowledges the funding support from Neukom Institute CompX Faculty Grant and Neukom Scholar Program, Burke Research Initiation Award, Toyota TEMA North America Inc, and NSF 1919647. We credit the Houdini Education licenses for the video generations.
References
- Rus and Tolley [2015] D. Rus and M. T. Tolley. Design, fabrication and control of soft robots. Nature, 521(7553):467–475, 2015.
- Lee et al. [2017] C. Lee, M. Kim, Y. J. Kim, N. Hong, S. Ryu, H. J. Kim, and S. Kim. Soft robot review. International Journal of Control, Automation and Systems, 15(1):3–15, 2017.
- Best et al. [2016] C. M. Best, M. T. Gillespie, P. Hyatt, L. Rupert, V. Sherrod, and M. D. Killpack. A new soft robot control method: Using model predictive control for a pneumatically actuated humanoid. IEEE Robotics Automation Magazine, 23(3):75–84, 2016.
- [4] R. Tedrake. Underactuated robotics: Algorithms for walking, running, swimming, flying, and manipulation (course notes for mit 6.832), downloaded on 7, 19, 2020 from http://underactuated.mit.edu/.
- Hoffmann et al. [2007] G. Hoffmann, H. Huang, S. Waslander, and C. Tomlin. Quadrotor helicopter flight dynamics and control: Theory and experiment. In AIAA guidance, navigation and control conference and exhibit, page 6461, 2007.
- Tayebi and McGilvray [2004] A. Tayebi and S. McGilvray. Attitude stabilization of a four-rotor aerial robot. In 2004 43rd IEEE Conference on Decision and Control (CDC)(IEEE Cat. No. 04CH37601), volume 2, pages 1216–1221. Ieee, 2004.
- Du et al. [2016] T. Du, A. Schulz, B. Zhu, B. Bickel, and W. Matusik. Computational multicopter design. 2016.
- Bouabdallah et al. [2004] S. Bouabdallah, A. Noth, and R. Siegwart. Pid vs lq control techniques applied to an indoor micro quadrotor. In 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)(IEEE Cat. No. 04CH37566), volume 3, pages 2451–2456. IEEE, 2004.
- Mellinger and Kumar [2011] D. Mellinger and V. Kumar. Minimum snap trajectory generation and control for quadrotors. In 2011 IEEE international conference on robotics and automation, pages 2520–2525. IEEE, 2011.
- Waslander et al. [2005] S. L. Waslander, G. M. Hoffmann, J. S. Jang, and C. J. Tomlin. Multi-agent quadrotor testbed control design: Integral sliding mode vs. reinforcement learning. In 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3712–3717. IEEE, 2005.
- Wang et al. [2015] Z. Wang, K. Akiyama, K. Nonaka, and K. Sekiguchi. Experimental verification of the model predictive control with disturbance rejection for quadrotors. In 2015 54th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), pages 778–783. IEEE, 2015.
- Baranek and Šolc [2012] R. Baranek and F. Šolc. Modelling and control of a hexa-copter. In Proceedings of the 13th International Carpathian Control Conference (ICCC), pages 19–23. IEEE, 2012.
- Zhao et al. [2018] M. Zhao, F. Shi, T. Anzai, K. Chaudhary, X. Chen, K. Okada, and M. Inaba. Flight motion of passing through small opening by dragon: Transformable multilinked aerial robot. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4735–4742. IEEE, 2018.
- Xu et al. [2019] J. Xu, T. Du, M. Foshey, B. Li, B. Zhu, A. Schulz, and W. Matusik. Learning to fly: computational controller design for hybrid uavs with reinforcement learning. ACM Transactions on Graphics (TOG), 38(4):1–12, 2019.
- Floreano et al. [2017] D. Floreano, S. Mintchev, and J. Shintake. Foldable drones: from biology to technology. In Bioinspiration, Biomimetics, and Bioreplication 2017, volume 10162, page 1016203. International Society for Optics and Photonics, 2017.
- Anzai et al. [2018] T. Anzai, M. Zhao, S. Nozawa, F. Shi, K. Okada, and M. Inaba. Aerial grasping based on shape adaptive transformation by halo: Horizontal plane transformable aerial robot with closed-loop multilinks structure. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 6990–6996. IEEE, 2018.
- Falanga et al. [2018] D. Falanga, K. Kleber, S. Mintchev, D. Floreano, and D. Scaramuzza. The foldable drone: A morphing quadrotor that can squeeze and fly. IEEE Robotics and Automation Letters, 4(2):209–216, 2018.
- Fishman and Carlone [2020] J. Fishman and L. Carlone. Control and trajectory optimization for soft aerial manipulation. arXiv preprint arXiv:2004.04238, 2020.
- Spielberg et al. [2019] A. Spielberg, A. Zhao, Y. Hu, T. Du, W. Matusik, and D. Rus. Learning-in-the-loop optimization: End-to-end control and co-design of soft robots through learned deep latent representations. In Advances in Neural Information Processing Systems, pages 8284–8294, 2019.
- Thuruthel et al. [2018] T. G. Thuruthel, E. Falotico, F. Renda, and C. Laschi. Model-based reinforcement learning for closed-loop dynamic control of soft robotic manipulators. IEEE Transactions on Robotics, 35(1):124–134, 2018.
- Satheeshbabu et al. [2020] S. Satheeshbabu, N. K. Uppalapati, T. Fu, and G. Krishnan. Continuous control of a soft continuum arm using deep reinforcement learning. In 2020 3rd IEEE International Conference on Soft Robotics (RoboSoft), pages 497–503. IEEE, 2020.
- You et al. [2017] X. You, Y. Zhang, X. Chen, X. Liu, Z. Wang, H. Jiang, and X. Chen. Model-free control for soft manipulators based on reinforcement learning. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2909–2915. IEEE, 2017.
- Zheng et al. [2020] G. Zheng, Y. Zhou, and M. Ju. Robust control of a silicone soft robot using neural networks. ISA transactions, 100:38–45, 2020.
- Bruder et al. [2019] D. Bruder, B. Gillespie, C. D. Remy, and R. Vasudevan. Modeling and control of soft robots using the koopman operator and model predictive control. arXiv preprint arXiv:1902.02827, 2019.
- Terzopoulos and Witkin [1988] D. Terzopoulos and A. Witkin. Physically based models with rigid and deformable components. IEEE Computer Graphics and Applications, 8(6):41–51, 1988.
- Pentland and Williams [1989] A. Pentland and J. Williams. Good vibrations: Modal dynamics for graphics and animation. In Proceedings of the 16th annual conference on Computer graphics and interactive techniques, pages 215–222, 1989.
- Sorkine and Alexa [2007] O. Sorkine and M. Alexa. As-rigid-as-possible surface modeling. In Proceedings of the fifth Eurographics symposium on Geometry processing, pages 109–116, 2007.
- Lu et al. [2016] W. Lu, N. Jin, and R. Fedkiw. Two-way coupling of fluids to reduced deformable bodies. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, pages 67–76, 2016.
- Speziale [1998] C. G. Speziale. A review of material frame-indifference in mechanics. 1998.
- He et al. [2016] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- Weinan [2017] E. Weinan. A proposal on machine learning via dynamical systems. Communications in Mathematics and Statistics, 5(1):1–11, 2017.
- Lu et al. [2018] Y. Lu, A. Zhong, Q. Li, and B. Dong. Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. In International Conference on Machine Learning, pages 3276–3285, 2018.
- Kaufmann et al. [2018] E. Kaufmann, A. Loquercio, R. Ranftl, A. Dosovitskiy, V. Koltun, and D. Scaramuzza. Deep drone racing: Learning agile flight in dynamic environments. arXiv preprint arXiv:1806.08548, 2018.
- Foehn and Scaramuzza [2018] P. Foehn and D. Scaramuzza. Onboard state dependent lqr for agile quadrotors. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 6566–6572. IEEE, 2018.
Soft Multicopter Control using
Neural Dynamics Identification
Supplementary
A Overview
In this document, we present the supplementary materials to our published paper. In Section B, we describe the specifications of the 2D and 3D drone models used in our training and testing, including the soft material properties, the rotor designs, and the sensor placements. In Section C we introduce the details of how the state vector and are obtained from sensor readings. In Section D we propose a general guideline for deploying IMU sensors for arbitrary drone shapes. In Section E we describe the simulation environment, the simulation model used, and the noise treatment. In Section F, we specify the details of the learning module, including the network structure used, the data generation scheme, as well as the techniques and hyperparameters used along the training procedure. In Section G, we specify the parameters used in our control module and the mathematical derivation of the benchmark LQR controller. In Section H, we present a discussion about the system design choices, the assumptions we have made, and the potential challenges for the fabrication and control of real-world soft multicopters.
B Drone Designs
Sensor Layouts
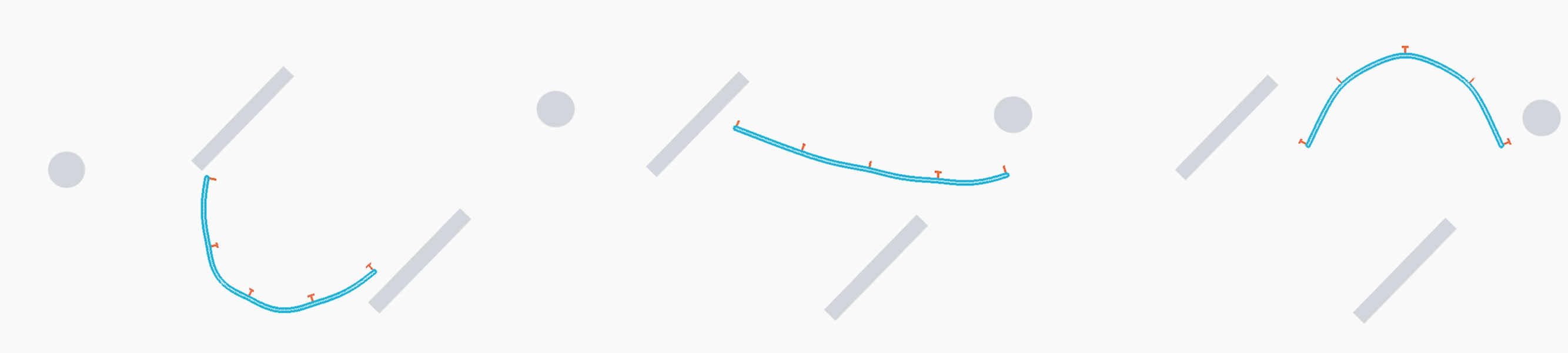
For the 3D examples, the sensing scheme is depicted in Figure. 12. Each IMU measures the local , , and axes, which are coded by Red, Green, and Blue respectively. The axis will point out of the plane. For the peripheral measurements, we will only make use of the measured axis. Since rotation in 2D can be represented by one scalar only, for 2D drones the IMU will only output the angle between the measured vector and the horizontal. The measured vectors are depicted in Figure. 13. Please also refer to Figure. 12 and Figure. 13 for the nicknames of these drone models. For 2D drones, we only train controllers of the rod model since it is the most deformable 2D geometry among all and therefore the one that displays the most interesting behaviors.
Drone Specifications
The specifications of our tested models’ size and material properties are presented in Table. 1.
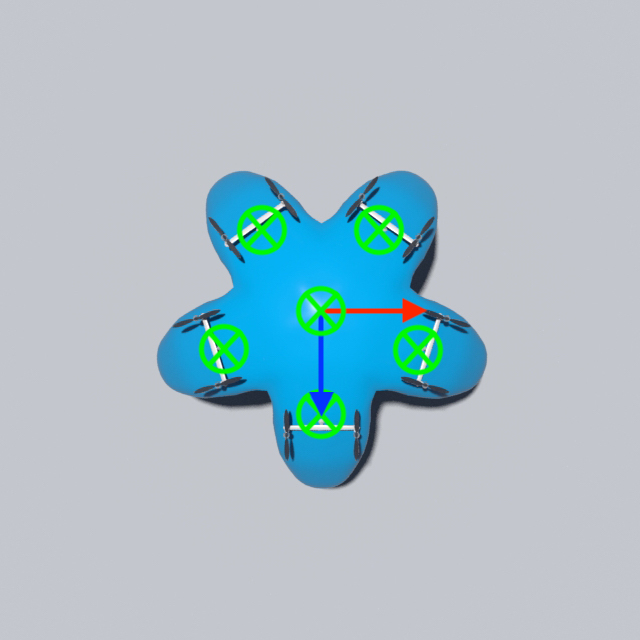
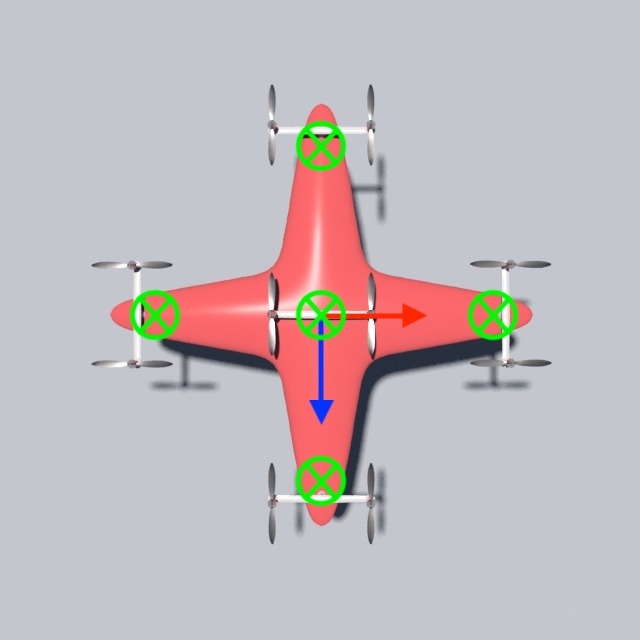
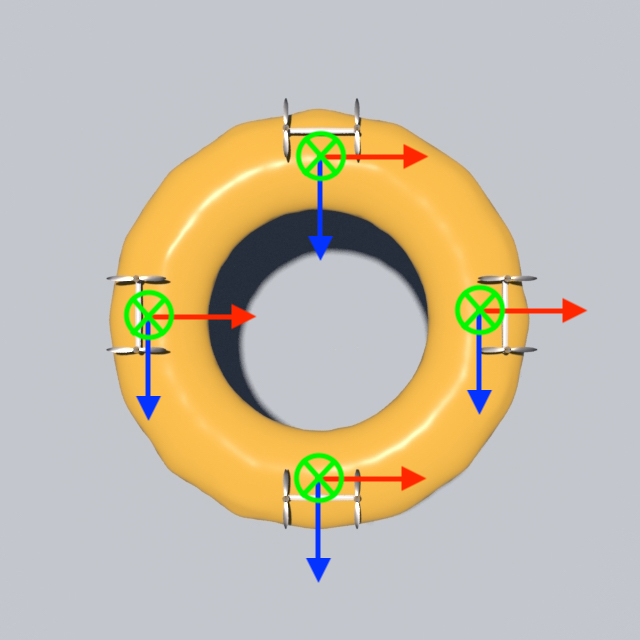
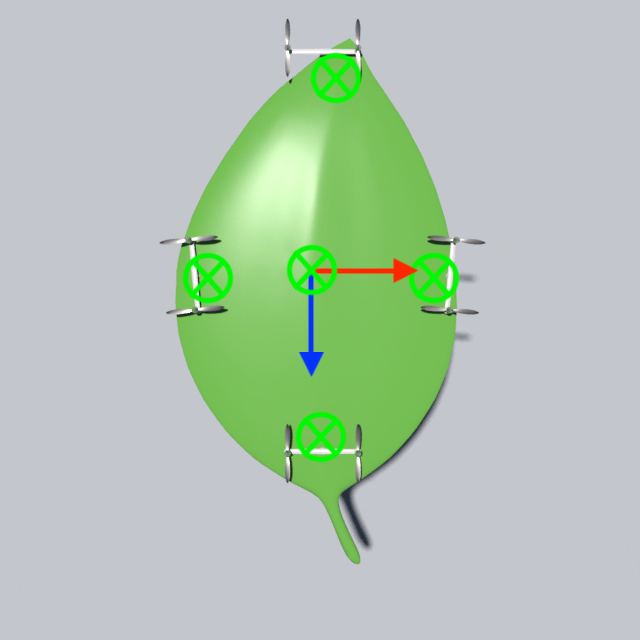
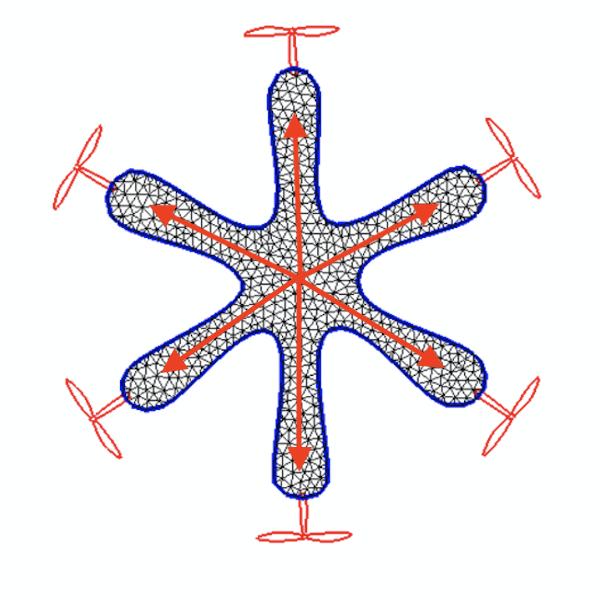
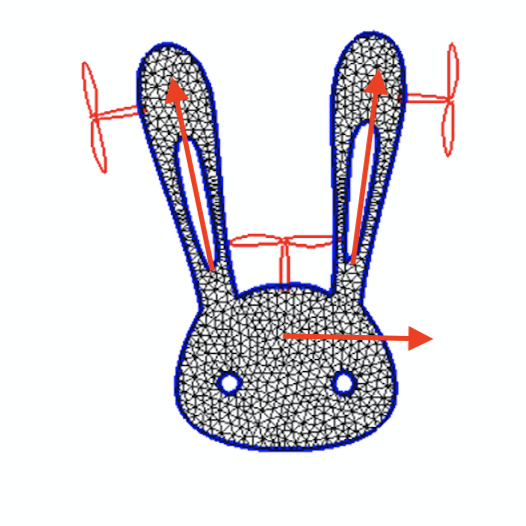
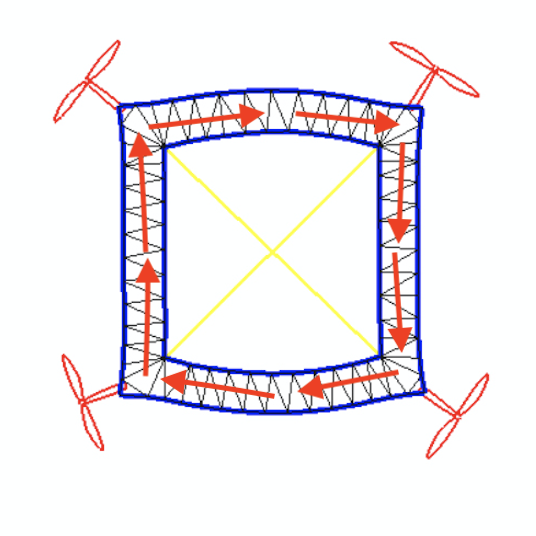
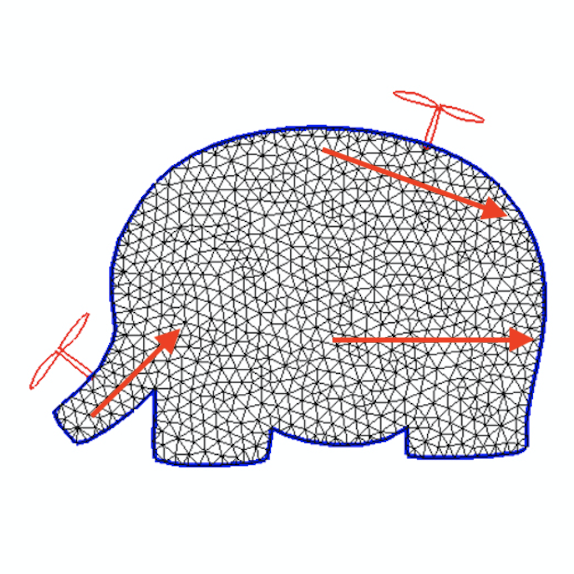

Drone Design Procedure
To customize 2D drones, we develop a web-based painting tool , as shown in Figure. 14, to sketch the contours, and use TetGen\citeStetgen to create triangle meshes from the contours. The interface also allows users to set rotor positions and assign materials to triangle elements of the mesh interactively. 3D drones are modeled in Maya and then converted to tetrahedron meshes using TetGen.
Dual-Propeller Rotor
A rotor mounted on a soft drone will influence the drones’ body with
-
1.
the thrust from accelerating the air and creating a low-pressure region in front of it, a force which will act in the normal direction of the surface on which the rotor is mounted;
-
2.
the torque that acts on the drone’s body in the opposite direction of the rotor’s rotation to conserve angular momentum;
-
3.
the gyroscopic torque that will act in the direction perpendicular to the gravity and the rotor’s spinning direction, which happens when the rotor is tilted.
In this work, each of the actuators will be implemented by a dual-rotor with counter-rotation, and the actuation will be split in half for each of the two rotors. With the two sub-rotors spinning in countering directions, the second term will be canceled out. The two sub-rotors will cancel the gyroscopic moments of their counterparts as well. Under this setting, in our simulation, only the normal force is modeled.
| 3D models | ||||||
| specs | Donut | Starfish | Flower | Leaf | Octopus | Orange peel |
| mass() | 1 | 1 | 1 | 1 | 1 | 1 |
| modulus() | 1e4 | 3e3 | 6e3 | 3e3 | 1e4 | 5e2 |
| length-x() | 3.5 | 3.6 | 3.6 | 2.4 | 3.6 | 3 |
| length-y() | 0.36 | 0.375 | 0.225 | 0.075 | 1.5 | 1.3 |
| length-z() | 3.5 | 3.6 | 3.6 | 4.5 | 3.6 | 2.9 |
| num sensors | 4 | 4 | 8 | 4 | 8 | 5 |
| num rotors | 4 | 5 | 9 | 4 | 9 | 5 |
| max thrust() | 10 | 10 | 10 | 10 | 10 | 10 |
| 2D models | ||||||
| specs | Engine | Bunny | Diamond | Elephant | Rainbow | Long Rod |
| mass() | 1 | 1 | 1 | 1 | 1 | 1 |
| modulus() | 6e3 | 6e3 | 6e3 | 6e3 | 6e3 | 6e3 |
| length-x() | 1.90 | 1.12 | 1.47 | 2.46 | 2.08 | 0.1 |
| length-y() | 2.16 | 1.75 | 1.42 | 1.69 | 1.30 | 8.0 |
| num sensors() | 6 | 3 | 8 | 3 | 4 | 8 |
| num rotors() | 6 | 3 | 4 | 2 | 2 | 5 |
| max thrust() | 10 | 10 | 10 | 10 | 10 | 10 |
C Computation of the State Vectors
Computation of e
In the common case where the drone’s body contains no hole in the middle, an IMU will be placed at the geometric center, and the measured rotation of the IMU’s rigid frame will be used as the definition of the drone’s body frame. For cases like the donut, where there is a hole in the middle, the strategy is to insert a few IMU at the circumferential locations, and average these obtained rotations. In our case where the 4 inserted IMUs are center-symmetric, the average rotation is obtained by averaging the body-frame -direction of IMU 1, 3, the body-frame -direction of IMU 2, 4, and use cross products to obtain the combined body frame. For the general case, this operation can be done by converting these measurements into quaternions and apply the averaging methods described in \citeS2markley2007averaging to obtain the body frame.
Computation of s
The deformation vector will constitute measurements from IMUs inserted at peripheral points. For measuring these local deformations, we will measure the normal vector of the local body surface, which is the direction of the -axis of IMU’s body frame. Given the IMU’s measured rotation matrix (body-to-world) , we will first calculate its -axis in the world frame by
| (8) |
Then given the body-to-world rotation matrix defined by , we will map the on to the drone’s body frame:
| (9) |
Then, an axis-angle will be calculated for how to rotate the Y-axis in the drone’s body frame to . The axis will be calculated by:
| (10) |
| (11) |
The angle will be calculated by:
| (12) |
where
| (13) |
with representing the body frame location of the inserted IMU when undeformed.
In this way, the deformation is converted into a scalar, and by the construction of , the magnitude of the scalar will represent the magnitude of the deformation, while the sign represents whether the deformation is inward (positive) or outward (negative).
D Guidelines for Sensor Placement
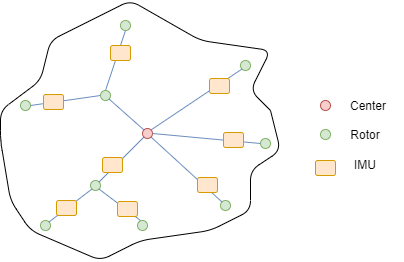
We present a general guideline for selecting where IMUs are deployed in the left part of Figure. 15. Given an arbitrary drone shape in 3D (pressed onto the X-Z plane), we build a tree with the root node being the geometric center of the drone, and the child nodes being the rotors. The IMUs will be inserted at the edges of the tree near the outer rotor. The effectiveness of this approach is contingent on the simple modality of the soft drone’s deformation. For instance, if you take a look at the right part of Figure. 15, for the above case, the deformed shape of the drone’s arm can be approximately reconstructed from the three measurements, whereas in the lower case, the three measurements are far from enough to describe the deformed shape, as the deformation is highly multi-modal, while these higher-order deformation modes are effectively beyond the controlling capacity of the drone’s rotors. As a result, it is the task in the design of these drones (mostly selecting the modulus and thickness) so that the drone is soft enough to perform significant deformation, while the deformation mode of the drone is simple. In practice, this IMU insertion guideline works for our various examples.
E Simulation Description
Soft Body Model
In our simulation environment, the deformation of a soft body is simulated using an explicit co-rotated elastic finite element model \citeS2muller2004interactive. A mass-proportional damping term is used to model the damped elastic behavior. We use tetrahedron (3D) and triangle (2D) meshes for discretization. An OpenMP-based parallel implementation of the elastic solver was employed to boost the simulation performance. Each rotor is rigidly bound to a local set of surface vertices on the finite element mesh in the course of the simulation, with the rotor direction aligned to the averaged normal direction of the local surface triangle primitives in 3D (surface segments in 2D).
In our simulation environment, an IMU is implemented by binding a number of nearby vertices and use their positions to define a reference frame via cross products.
Noise Treatment
In the simulation environment, in order to emulate the perturbations and uncertainties in the real world, noise is added to the sensor readings, and a time delay is added to the rotor output. The details of these noises are given in the table below.
| Category | Noise type | Level |
|---|---|---|
| angle measurements | Gaussian | , |
| position measurements | Gaussian | , |
| rotor perturbation | Gaussian | , |
| output delay | constant |
F Learning of Neural Networks
Dataset Generation
The training data are generated with our implementation of a Finite Element simulator. Given a drone geometry, we initialize the drone as undeformed, lying at the origin, and apply a random thrust to each rotor and observe the drone’s position, rotation, and deformation at . Each set of random thrust is applied for . Other data generation schemes we tried also consist of using a rigid LQR controller to generate the thrusts, or apply a different random thrust each frame, but the former yields poor test loss due to the confined distribution of LQR control outputs, while the latter generates data too noisy to train on. The insight is that we need to give the system enough time to respond to a signal and display meaningful behaviors.
Network Architecture and Training
As shown in Figure. 16, All the three neural networks to learn adopts the same architecture. The architecture is similar to ResNet except that the convolution layers are replaced by fully connected layers. Note that there are no normalization techniques used in our networks.

We use Adam optimizer with initial learning rate 0.001 and decay rate 0.8 for each 20 steps. The batch size is 512. We train for 50 epoches. For loss function we found out L1 loss provides superior result to L2 loss due to the robustness of the L1 loss.
Testing of the Networks
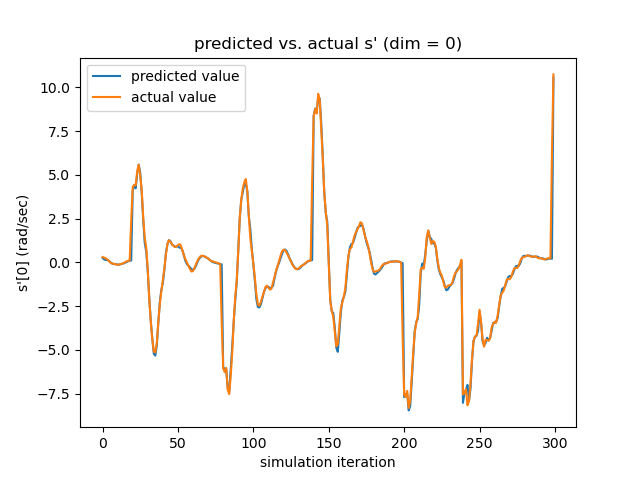
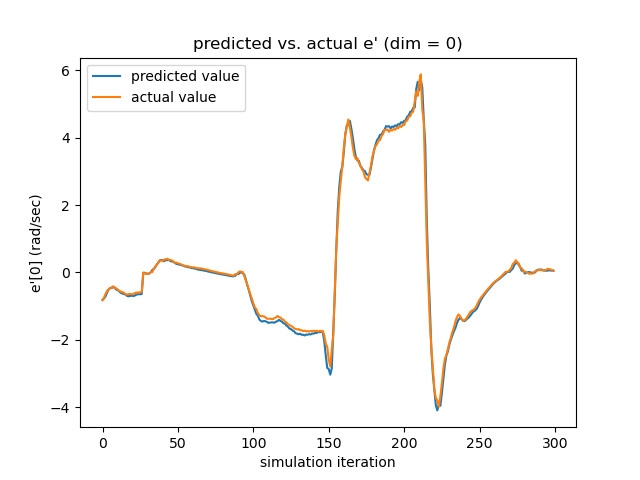
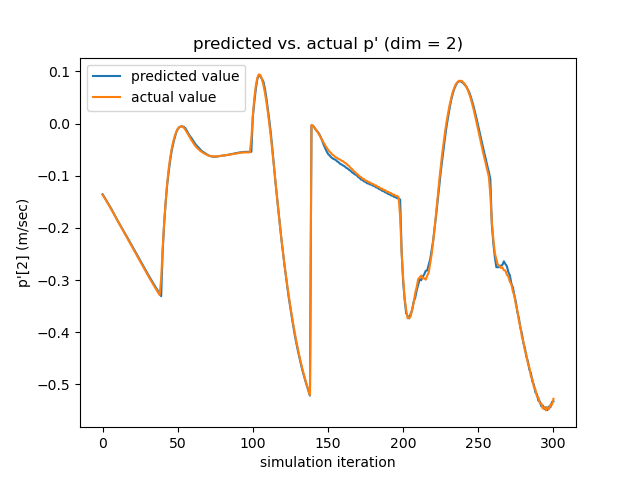
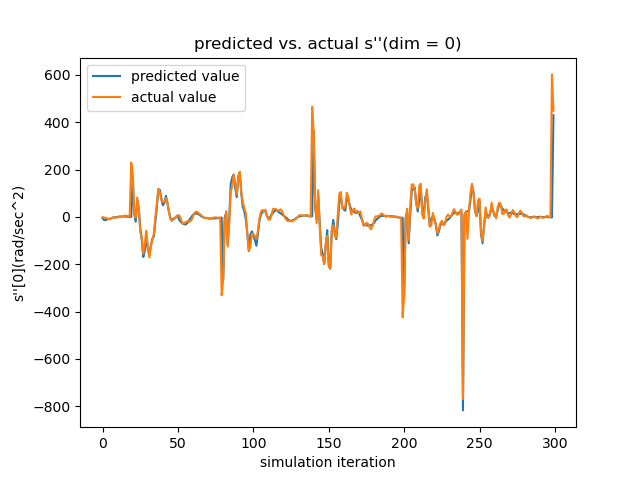
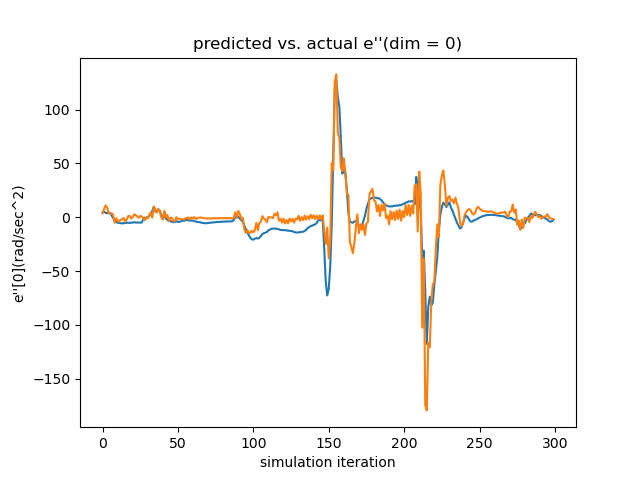
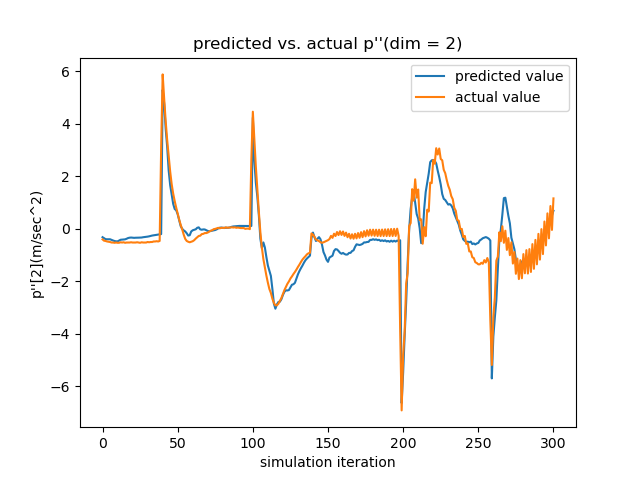
Section 4 of the paper presents the testing results of our trained neural dynamic systems. More testings are depicted in Figure. 17 and Figure. 18 with the same experimental setups.
G Control
LQR Overview
The Linear Quadratic Controller is a kind of full-state feedback controller, where the control of the system is based on the current state. Given a linear system in state-space form:
| (14) |
where x is the state vector, u is the control vector (in our case the thrusts for individual propellers), and A and B are matrices, we compute a control matrix K and combine that with the state by:
| (15) |
The way we obtain is as follows: suppose we want to set both the state and the control to be 0. We define cost matrices and that penalizes squared and squared respectively, we desire to minimize the infinite horizon cost:
| (16) |
which means our goal is to find the optimal cost-to-go function that satisfies the Hamilton–Jacobi–Bellman (HJB) equation. Utilizing the convex nature of the problem, we know that the minimum occurs when the gradient is zero, so we have:
| (17) |
which yields the control policy:
| (18) |
After transformation, we can find the value of by solving the equation:
| (19) |
This is known as the Algebraic Riccati Equation, which can be solved by iterating backward in time.
Online Reinitialization Parameters
Although our network eliminates the necessity for the extensive, empirical parameter tuning process, there are a few hyper-parameters that needs to be tuned for effective performance. We will present the exact value or the value range for these parameters in the table below.
| Parameter type | Value/Value range |
|---|---|
| gain (related to ) | 100 to 200 |
| gain (related to ) | 50 to 200 |
| gain (related to ) | 100 to 200 |
| gain | 2 |
Rigid LQR State Definition
The state of a rigid object can be described by its position and rotation. Let be the vector describing position, and let be the vector describing rotation. And let . Since the dynamics is second order, the state will be defined as . For the 3D case, , e = , where , , are the spacial coordinates, , , are the Euler angles. For the 2D case, , , as the rotation in 2D can be described by a sole parameter.
| SO(3) | Body-to-world rotation matrix | |
| Motor position in body frame | ||
| unit sphere | Motor orientation in body frame | |
| Mapping from thrusts to net force. The i-th column is . | ||
| Mapping from thrusts to net torque. The i-th column is | ||
| Inertia Tensor in Body Frame. Value is | ||
| Ixx | R | |
| Iyy | R | |
| Izz | R | |
| Ixy | R | |
| Ixz | R | |
| Iyz | R | |
| Mapping from world frame angular velocity to body frame angular velocity, such that . Value is | ||
| Derivative of . Value is |
Dynamic Model
Let denote the drone’s actuation, and , where is the number of propellers and represents the thrust provided by each propeller. The dynamic model is a function f such that . In 3D, the dynamics of the drone will be directly derived from the Newton-Euler equations:
| (20) |
| (21) |
with the variable definitions given in the table below. For the 2D case, these equations simplify to
| (22) |
| (23) |
Manipulator Form
Follow the formulation purposed in \citeS2russnote, we will reorganize these equations into the Manipulator Form, whose template is as follows:
| (24) |
Consequently,
| (25) |
This allows us to write:
| (26) |
For the 3D case, reorganizing the dynamics equations yields
,
,
,
.
For the 2D case, we have
,
,
,
.
Linearization via Taylor Expansion
Since the function described above is a non-linear model, we will linearize it by taking the first order Taylor Expansion around an operating point () such that . For close enough to , we have:
| (27) |
Since we know that:
| (28) |
can be represented by the block matrix:
| (29) |
It can be seen trivially that and .
For , by the Product Rule we know,
| (30) |
Since we defined to be such that , then at . Since we know is non-zero, then . Besides, since we have , we have , then Also, since , and has nothing to do with , . So we can conclude that:
| (31) |
Since
| (32) |
| (33) |
So,
| (34) |
where:
| (35) |
Finally,
since and with , .
So to sum up:
| (36) |
For , we have:
| (37) |
.
It is clear to see that , and , (remember than none of G, B, C, H is related to u). So we have
| (38) |
For the 2D case and are simplified to become:
| (39) |
| (40) |
The matrices and will then be optimized by the LQR to yield the control matrix . For the geometry-updating LQR, the quantities that are updated each time are , and , which are all the time-varying values in the above derivation. Besides, the fixed-point is also recalculated.
Fixed Point
Assuming satisfies , we have:
| (41) |
| (42) |
for torque and force balance respectively. Given certain , , we will first solve the equation:
| (43) |
to satisfy the torque balance. Then we will rotate the reference frame so that the direction of the combined thrust aligns with the -axis. The rotation axis is calculated by:
| (44) |
| (45) |
The angle is calculated by:
| (46) |
After the rotation in axis-angle form is calculated, the fixed-point Euler angles would be extracted to form the part of .





H Toward a Real Soft Drone
Although we carried out the experiments purely in numerical simulation environments, we designed our approach with its real-life feasibility in mind, and our method is intrinsically suitable for real-world deployment. First, our perception of the soft drone is explicitly sensor-based. Unlike many other works that deal with soft-robot controls like \citeS2barbivc2008reallqrsoft \citeS2spielberg2019learning which observe the full state (particle positions) and apply model reduction techniques to synthesize the state, we resist this unrealistic assumption, and throughout our pipeline, the interfacing between the simulator and the training/controlling modules is strictly limited to the sensor measurements. In this sense, we observe the simulation environment in the same limited fashion as we observe the real world, so that no unfair advantage is taken. We expect the rest of the pipeline to work exactly the same if we swap the simulator with the real-world environment, since the interfacing will not be changed. Secondly, as we have mentioned in the paper, in designing the sensing scheme, the only sensors we used are Inertial Measurement Units (IMU), which are basic and accessible tools used everywhere for rigid drones. No other sensor types, such as bending, thermal or fluidic sensors are used. This simplistic approach allows us to conveniently fabricate these soft drones by implanting the IMU microprocessors at the surface, without having to cut open the drone’s body or insert extra measurement devices. Basically, to fabricate an actual soft drone, we just need to cut out the desired shape from solid materials (if not with 3D printing techniques), implant the IMUs at the surface, set up their connection to a central onboard processor using WIFI, and flash the trained neural network and controlling script onto the hardware. Thirdly, the computational efficiency of our algorithm allows it to be handled by on-board processors. In the testing case, our relinearization is done at , and can be relaxed to for the more stable geometries. There have been previous works conducted that performs LQR recalculation \citeS2foehn2018onboardLQR and network-based control loop \citeS2kaufmann2018deep at using onboard computers. With further code optimization, we believe that our current system can be implemented fully onboard. Lastly, we simulate the soft body using a co-rotated elastic Finite Element simulator, which is known for providing physically realistic behaviors and is commonly used in engineering design, with noise and time delay applied. As a result, our success in this simulation testing environment is meaningful for its future adaptation to real-world scenarios.
plain \bibliographySexample
Soft Drones Flying: Control of Deformable Multicopters via Dynamics Identification
Soft Multicopter Control using
Neural Dynamics Identification
Supplementary