Soft Actor-Critic with Beta Policy via Implicit Reparameterization Gradients
Abstract
Recent advances in deep reinforcement learning have achieved impressive results in a wide range of complex tasks, but poor sample efficiency remains a major obstacle to real-world deployment. Soft actor-critic (SAC) mitigates this problem by combining stochastic policy optimization and off-policy learning, but its applicability is restricted to distributions whose gradients can be computed through the reparameterization trick. This limitation excludes several important examples such as the beta distribution, which was shown to improve the convergence rate of actor-critic algorithms in high-dimensional continuous control problems thanks to its bounded support. To address this issue, we investigate the use of implicit reparameterization, a powerful technique that extends the class of reparameterizable distributions. In particular, we use implicit reparameterization gradients to train SAC with the beta policy on simulated robot locomotion environments and compare its performance with common baselines. Experimental results show that the beta policy is a viable alternative, as it outperforms the normal policy and is on par with the squashed normal policy, which is the go-to choice for SAC. The code is available at https://github.com/lucadellalib/sac-beta.
1 Introduction
In recent years, we have witnessed impressive advances in deep reinforcement learning, with successful applications on a wide range of complex tasks, from playing games Mnih et al. (2013); Silver et al. (2016) to high-dimensional continuous control Schulman et al. (2016). However, the poor sample efficiency of deep reinforcement learning is a major obstacle to its use in real-world domains, especially in tasks such as robotic manipulation that require interaction without the safety net of simulation. The high risk of damaging and the costs associated with physical robot experimentation make it crucial for the learning process to be sample efficient. As a result, it is of paramount importance to develop algorithms that can learn from limited data and generalize effectively to new situations. To address this issue, Haarnoja et al. (2018) introduced soft actor-critic (SAC), an off-policy model-free algorithm that bridges the gap between stochastic policy optimization and off-policy learning, achieving state-of-the-art on the popular multi-joint dynamics with contact (MuJoCo) Todorov et al. (2012) benchmark suite. Based on the maximum entropy framework, SAC aims to maximize a trade-off between the expected return and the entropy of the policy, i.e. to accomplish the task while acting as randomly as possible. As a consequence, the agent is encouraged to explore more widely, and to assign identical probability mass to actions that are equally attractive. A key step of the algorithm, necessary for computing the entropy-augmented objective function, is sampling an action from the current policy in a differentiable manner, which is accomplished through the use of the reparameterization trick. However, certain distributions such as gamma, beta, Dirichlet and von Mises cannot be used with the reparameterization trick. Hence, the applicability of SAC to practical problems that could benefit from the injection of prior knowledge through an appropriate distribution family is limited. This restriction is particularly relevant for domains where the choice of the distribution is critical to achieving good performance, such as tasks involving actions with specific bounds or constraints.
Normalizing flows Rezende and Mohamed (2015); Dinh et al. (2017) are an attractive solution to this problem. By using a series of invertible transformations to map a simple density to a more complex one via the change of variable formula, normalizing flows improve the expressiveness of the policy while retaining desirable properties such as the ease of reparameterization. For example, the squashing function originally used in SAC Haarnoja et al. (2018) to enforce action bounds can be interpreted as a single layer normalizing flow with no learnable parameters. Mazoure et al. (2020) further extend it by incorporating radial, planar and autoregressive flows to allow for a broader range of distributions (e.g. multimodal), resulting in improved performance on variety of tasks. A similar study by Ward et al. (2019) shows that combining SAC with modified Real NVP flows Dinh et al. (2017) leads to better stability and increased exploration capabilities in sparse reward environments. While normalizing flows have many useful properties, there are also some drawbacks to their use in deep reinforcement learning. One issue is that they can be computationally demanding for large-scale problems or when dealing with high-dimensional inputs. Additionally, they can be difficult to train, especially when using complex flow architectures.
An orthogonal approach to normalizing flows that addresses the problem of differentiating through stochastic nodes is implicit reparameterization Figurnov et al. (2018); Jankowiak and Obermeyer (2018), which enables the computation of gradients for a broader class of distribution families for which the reparameterization trick is not applicable. In this work, we use implicit reparameterization gradients to train SAC with the beta policy, which is bounded to the unit interval and was shown to substantially improve the convergence rate of actor-critic algorithms such as TRPO Schulman et al. (2015) and ACER Wang et al. (2017) (which do not require differentiating through random variables) Chou et al. (2017) on continuous control problems. In particular, we explore two variants of implicit reparameterization and we evaluate their performance on four MuJoCo Todorov et al. (2012) environments. Experiments demonstrate that the beta policy outperforms the normal policy and yields similar results to the squashed normal policy Haarnoja et al. (2018), which is the go-to choice for SAC.
2 Background
2.1 Markov Decision Process
A reinforcement learning problem Sutton and Barto (1998) can be formalized as a Markov decision process, defined by a tuple , where denotes the state space, the action space, the reward function and the transition probability density function. At each time step , the agent observes a state and performs an action according to a policy , which results in a reward and a next state . The return associated with a trajectory (a.k.a. episode or rollout) is defined as
| (1) |
i.e. the infinite-horizon cumulative discounted reward with discount factor . The agent aims to maximize the expected return
| (2) |
i.e. to learn an optimal policy . The state value function (a.k.a. state value) of a state is defined as
| (3) |
i.e. the expected return obtained by the agent if it starts in state and always acts according to policy . Similarly, the state-action value function (a.k.a. action value or Q-value) of a state-action pair is defined as
| (4) |
i.e. the expected return obtained by the agent if it starts in state , performs action and always acts according to policy .
2.2 Soft Actor-Critic
SAC Haarnoja et al. (2018) redefines the expected return in Eq. 2 to be maximized by policy as
| (5) |
where is a trajectory of state-action-reward triplets sampled from the environment, the discount factor, the entropy of in state , and a temperature parameter that controls the relative strength of the entropy regularization term. Since now includes a state-dependent entropy bonus, the definitions of and need to be updated accordingly as
| (6) |
| (7) |
Note that the modified does not include the entropy bonus from the first time step. Let be the action value function approximated by a neural network with weights and a stochastic policy parameterized by a neural network with weights . The action value network is trained to minimize the squared difference between and the soft temporal difference estimate of , defined as
| (8) |
which is the standard temporal difference estimate Sutton (1988) augmented with the entropy bonus, where and are sampled from a replay buffer storing past experiences and is sampled from the current policy . In practice, the approximation is computed by a target network Mnih et al. (2015), whose weights are periodically updated as , with smoothing coefficient . Not only does this help to stabilize the training process, but it also turns the ill-posed problem of learning via bootstrapping into a supervised learning one that can be solved via gradient descent. Furthermore, double Q-learning is used to reduce the overestimation bias and speed up convergence Hasselt et al. (2016). This means that is computed as the minimum between two action value function approximations and , parameterized by neural networks with weights and , respectively.
While the action value network learns to minimize the error in the Q-value approximation, is updated via gradient ascent to maximize
| (9) |
where is the transition probability function, , and is drawn from in a differentiable way through the reparameterization trick. The temperature parameter , which explicitly handles the exploration-exploitation trade-off, is particularly sensitive to the magnitude of the reward, and needs to be tuned manually for each task. The final algorithm, which alternates between sampling transitions from the environment and updating the neural networks using the experiences retrieved from a replay buffer, is shown in Algorithm 1. Note that, although in theory the replay buffer can store an arbitrary number of transitions, in practice a maximum size should be specified based on the available memory. When the replay buffer overflows, past experiences are removed according to the First-In First-Out (FIFO) rule. It is also advisable to collect a minimum number of transitions prior to the start of the training process to provide the neural networks with a sufficient amount of uncorrelated experiences to learn from.
2.3 Implicit Reparameterization Gradients
Implicit reparameterization Figurnov et al. (2018); Jankowiak and Obermeyer (2018) is an alternative to the reparameterization trick (a.k.a. explicit reparameterization) that enables the computation of gradients of stochastic computations for a broader class of distribution families. Explicit reparameterization requires an invertible and continuously differentiable standardization function that, when applied to a sample from distribution , removes its dependency on the distribution parameters :
| (10) |
For instance, in the case of a normal distribution a valid standardization function is . Let denote an objective function whose expected value over is to be optimized with respect to . Then
| (11) |
and the gradient of the expectation can be computed via chain rule as
| (12) |
Although many continuous distributions admit a standardization function, it is often non-invertible or prohibitively expensive to invert, hence the reparameterization trick is not applicable. This is the case for distributions such as gamma, beta, Dirichlet and von Mises. Fortunately, implicit reparameterization relaxes this constraint, allowing for gradient computations without . Using the change of variable , Eq. 12 can be rewritten as:
| (13) |
At this point, can be obtained via implicit differentiation by applying the total gradient operator to the equation :
| (14) |
Remarkably, this expression for the gradient does not require inverting the standardization function but only differentiating it.
3 Method
The main goal of this work is to explore the use of SAC in combination with the beta policy. To do so, we employ implicit reparameterization to enable differentiation through the sampling process. As explained in Section 2.3, this approach only requires backpropagating through the standardization function without inverting it. Hence, we need to define an appropriate for the beta distribution and derive an expression for . Following Figurnov et al. (2018), can also be obtained as , where and . Then the problem reduces to calculating implicit reparameterization gradients for the gamma distribution . Being its density closed under scaling transforms, a valid standardization function for is simply . However, for , is the regularized incomplete gamma function, which cannot be expressed analytically. Therefore, it is necessary to resort to approximations. A possible solution is the one proposed by Figurnov et al. (2018), who apply forward-mode automatic differentiation to algorithm AS 32 Bhattacharjee (1970), a numerical method that approximates its value. An alternative approach by Jankowiak and Obermeyer (2018), inspired by the theory of optimal mass transport, derives instead a minimax closed-form approximation based on Taylor expansion of the derivative of the beta cumulative distribution function, which is also a valid standardization function. Nevertheless, as reported by Figurnov et al. (2018), it is slower and less accurate than the automatic differentiation strategy. In this study, we experiment with both techniques and we compare the resulting implicitly reparameterized beta policy to more frequently used ones such as normal and squashed normal. In summary, we consider the following four SAC variants:
-
•
SAC-Beta-AD: SAC with a beta policy whose gradient is computed via automatic differentiation implicit reparameterization Figurnov et al. (2018).
-
•
SAC-Beta-OMT: SAC with a beta policy whose gradient is computed via optimal mass transport implicit reparameterization Jankowiak and Obermeyer (2018).
-
•
SAC-Normal: SAC with a normal policy whose gradient is computed via reparameterization trick.
-
•
SAC-TanhNormal: SAC with a squashed normal policy, obtained by applying to samples drawn from a normal distribution Haarnoja et al. (2018), whose gradient is computed via reparameterization trick.
4 Experiments
4.1 MuJoCo Environments
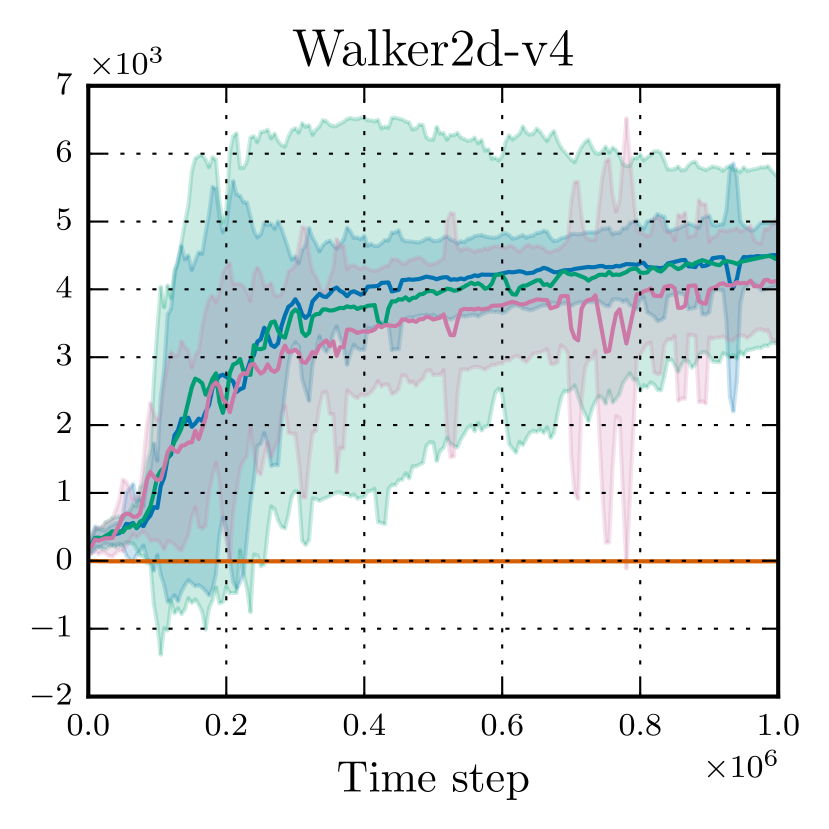
We evaluate the proposed methods on four of the eleven MuJoCo environments, namely Ant-v4, HalfCheetah-v4, Hopper-v4 and Walker2d-v4 (see Fig. 1). The goal is to walk as fast as possible without falling while at the same time minimizing the number of actions and reducing the impact on each joint. Observations consist of coordinate values of different robot’s body parts, followed by the velocities of each of those individual parts. Actions, bounded to , represent the torques applied at the joints. The dimensionality of both the observation and the action space varies across the environments, depending on the complexity of the task (see Table 1).
4.2 Training Setup and Hyperparameters
Hyperparameter values are reported in Table 2. We use the same architecture for both the policy and the action value network, consisting of fully connected hidden layers with ReLU nonlinearities. The action value network receives as an input the concatenation of the flattened observation and action and returns a Q-value. The policy network receives as an input the flattened observation and returns the parameters of the corresponding action distribution. In particular, for SAC-Beta-AD and SAC-Beta-OMT, it returns the logarithm of the concentration parameters shifted by to ensure that the distribution is both concave and unimodal Chou et al. (2017). For SAC-Normal and SAC-TanhNormal, it returns the mean and the logarithm of the standard deviation. For all distributions, we assume the action dimensions are independent. To improve training stability, we clip the log shifted concentrations and log standard deviation to the interval . Furthermore, we clip the samples drawn from the beta distribution to the interval to avoid underflow and we linearly map them from to the environment’s action interval . We train the policy for time steps using Adam optimizer Kingma and Ba (2015) with a learning rate of and a batch size of . We perform gradient update per time step and synchronize the target networks after each update with smoothing coefficient . We use a discount factor of , a temperature of and a replay buffer of size , which is filled with initial transitions collected by sampling actions uniformly at random. We test the policy every time steps for episodes using the distribution mean as the predicted action and we report the average return.
| Environment | Observation dimensions | Action dimensions |
|---|---|---|
| Ant-v4 | ||
| HalfCheetah-v4 | ||
| Hopper-v4 | ||
| Walker2d-v4 |
| Parameter | Value |
|---|---|
| Number of hidden layers (all networks) | |
| Number of neurons per hidden layer | |
| Nonlinearity | ReLU |
| Optimizer | Adam Kingma and Ba (2015) |
| Learning rate | |
| Batch size | |
| Replay buffer size | |
| Discount factor | |
| Target smoothing coefficient | |
| Target update frequency | |
| Temperature | |
| Log standard deviation interval | |
| Log shifted concentration interval | |
| Beta sample interval | |
| Number of gradient updates per time step | |
| Number of initial time steps | |
| Total number of time steps | |
| Test frequency | |
| Number of test episodes |
4.3 Implementation and Hardware
Software for the experimental evaluation was implemented in Python 3.10.2 using Gymnasium 0.28.1111https://github.com/Farama-Foundation/Gymnasium/tree/v0.28.1 Brockman et al. (2016) + EnvPool 0.8.1222https://github.com/sail-sg/envpool/tree/v0.8.1 Weng et al. (2022b) for the MuJoCo environments, Tianshou 0.5.0333https://github.com/thu-ml/tianshou/tree/v0.5.0 Weng et al. (2022a) for SAC, PyTorch 1.13.1444https://github.com/pytorch/pytorch/tree/v1.13.1 Paszke et al. (2019) for the neural network architectures, probability distributions and reference implementation of optimal mass transport implicit reparameterization, TensorFlow 2.11.0555https://github.com/tensorflow/tensorflow/tree/v2.11.0 Abadi et al. (2015) + TensorFlow Probability 0.19.0666https://github.com/tensorflow/probability/tree/v0.19.0 Dillon et al. (2017) for the reference implementation of automatic differentation implicit reparameterization and Matplotlib 3.7.0777https://github.com/matplotlib/matplotlib/tree/v3.7.0 Hunter (2007) for plotting. All the experiments were run on a CentOS Linux 7 machine with an Intel Xeon Gold 6148 Skylake CPU with cores @ GHz, GB RAM and an NVIDIA Tesla V100 SXM2 @ GB with CUDA Toolkit 11.4.2.
4.4 Results and Discussion
A comparison between the proposed SAC variants is presented in Fig. 1, with the final performance reported in Table 3. We observe that SAC-Normal struggles to learn anything useful, as the average return remains close to zero in all the environments. This could be ascribed to a poor initialization, as the training process immediately diverges and the policy gets stuck in a region of the search space from which it cannot recover. Further investigations are needed to understand why the normal policy performs poorly with SAC while it does not exhibit the same flawed behavior with other non-entropy-based algorithms such as TRPO Schulman et al. (2015); Chou et al. (2017). Overall, SAC-Beta-AD and SAC-Beta-OMT perform similarly to SAC-TanhNormal, with slightly higher final return in Ant-v4 and Walker2d-v4 but worse in HalfCheetah-v4 and Hopper-v4. However, the large standard deviation values indicate that more experiments might be necessary to obtain more accurate estimates. Regarding the comparison between SAC-Beta-AD and SAC-Beta-OMT, we only observe little differences mostly due to random fluctuations. This is surprising, since we were expecting faster convergence with SAC-Beta-AD, given the fact that it provides more accurate gradient estimates Figurnov et al. (2018). This suggests that highly accurate gradients may not be critical to the algorithm’s success. Therefore, a simpler gradient estimator such as the score function estimator Mohamed et al. (2020), which does not rely on assumptions about the distribution family, could be a promising alternative to explore.







| Environment | SAC-Beta-AD | SAC-Beta-OMT | SAC-Normal | SAC-TanhNormal |
|---|---|---|---|---|
| Ant-v4 | ||||
| HalfCheetah-v4 | ||||
| Hopper-v4 | ||||
| Walker2d-v4 |
We also conduct an ablation study for SAC-Beta-OMT on Ant-v4 to gain more insights on the impact of our design choices. In particular, we consider the following three ablations:
-
•
SAC-Beta-OMT-no_clip: we do not clip the log shifted concentrations.
-
•
SAC-Beta-OMT-non_concave: we do not shift the concentrations, allowing for non-concave beta distributions.
-
•
SAC-Beta-OMT-softplus: following Chou et al. (2017), we model the concentrations using instead of , meaning that the policy network effectively returns inverse softplus shifted concentrations.
As depicted in Fig. 2, SAC-Beta-OMT performs the best, demonstrating the effectiveness of our training setup. Note that SAC-Beta-OMT-no_clip terminates prematurely after k time steps due to exploding or vanishing concentrations, leading us to the conclusion that clipping is crucial to avoid instabilities in the optimization process.

5 Conclusion
In this work, we utilized implicit reparameterization gradients Figurnov et al. (2018); Jankowiak and Obermeyer (2018) to train SAC with the beta policy, which is an alternative to normalizing flows in addressing the bias issue resulting from the mismatch between the infinite support of the normal distribution and the bounded action space typically present in real-world settings. Experiments on four MuJoCo environments show that the beta policy is a viable alternative, as it outperforms the normal policy and yields similar results to the squashed normal policy, frequently used together with SAC. Future research includes analyzing the qualitative behavior of the learned policies, extending the evaluation to more diverse tasks and exploring other non-explicitly reparameterizable distributions that could potentially be beneficial for injecting domain knowledge into the problem at hand. Additionally, more generic gradient estimators such as the score function estimator Mohamed et al. (2020) could be investigated.
References
- Abadi et al. [2015] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org.
- Bhattacharjee [1970] G. P. Bhattacharjee. Algorithm AS 32: The incomplete gamma integral. Journal of the Royal Statistical Society. Series C (Applied Statistics), 19(3):285–287, 1970. URL https://www.jstor.org/stable/2346339.
- Brockman et al. [2016] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. OpenAI Gym. arXiv preprint arXiv:1606.01540v1, 2016. URL http://arxiv.org/abs/1606.01540v1.
- Chou et al. [2017] P.-W. Chou, D. Maturana, and S. Scherer. Improving stochastic policy gradients in continuous control with deep reinforcement learning using the beta distribution. In International Conference on Machine Learning (ICML), volume 70, pages 834–843, 2017. URL https://proceedings.mlr.press/v70/chou17a.html.
- Dillon et al. [2017] J. V. Dillon, I. Langmore, D. Tran, E. Brevdo, S. Vasudevan, D. Moore, B. Patton, A. Alemi, M. D. Hoffman, and R. A. Saurous. TensorFlow Distributions. arXiv preprint arXiv:1711.10604v1, 2017. URL https://arxiv.org/abs/1711.10604v1.
- Dinh et al. [2017] L. Dinh, J. Sohl-Dickstein, and S. Bengio. Density estimation using Real NVP. In International Conference on Learning Representations, (ICLR), 2017. URL https://arxiv.org/abs/1605.08803v3.
- Figurnov et al. [2018] M. Figurnov, S. Mohamed, and A. Mnih. Implicit reparameterization gradients. In International Conference on Neural Information Processing Systems (NeurIPS), volume 31, 2018. URL https://arxiv.org/abs/1805.08498v4.
- Haarnoja et al. [2018] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning (ICML), pages 1861–1870, 2018. URL https://arxiv.org/abs/1801.01290v2.
- Hasselt et al. [2016] H. V. Hasselt, A. Guez, and D. Silver. Deep reinforcement learning with double Q-learning. In AAAI Conference on Artificial Intelligence, pages 2094–2100, 2016. URL https://arxiv.org/abs/1509.06461v3.
- Hunter [2007] J. D. Hunter. Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3):90–95, 2007. URL https://doi.org/10.1109/MCSE.2007.55.
- Jankowiak and Obermeyer [2018] M. Jankowiak and F. Obermeyer. Pathwise derivatives beyond the reparameterization trick. In International Conference on Machine Learning (ICML), volume 80, pages 2240–2249, 2018. URL https://arxiv.org/abs/1806.01851v2.
- Kingma and Ba [2015] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015. URL https://arxiv.org/abs/1412.6980v9.
- Mazoure et al. [2020] B. Mazoure, T. Doan, A. Durand, J. Pineau, and R. D. Hjelm. Leveraging exploration in off-policy algorithms via normalizing flows. In Conference on Robot Learning (CoRL), pages 430–444, 2020. URL https://arxiv.org/abs/1905.06893v3.
- Mnih et al. [2013] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller. Playing atari with deep reinforcement learning. In International Conference on Neural Information Processing Systems (NeurIPS), 2013. URL https://arxiv.org/abs/1312.5602v1.
- Mnih et al. [2015] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. A. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis. Human-level control through deep reinforcement learning. Nature, pages 529–533, 2015. URL https://doi.org/10.1038/nature14236.
- Mohamed et al. [2020] S. Mohamed, M. Rosca, M. Figurnov, and A. Mnih. Monte carlo gradient estimation in machine learning. Journal of Machine Learning Research (JMLR), 21(1), 2020. URL https://arxiv.org/abs/1906.10652v2.
- Paszke et al. [2019] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An imperative style, high-performance deep learning library. In International Conference on Neural Information Processing Systems (NeurIPS), volume 32, 2019. URL https://arxiv.org/abs/1912.01703v1.
- Rezende and Mohamed [2015] D. Rezende and S. Mohamed. Variational inference with normalizing flows. In International Conference on Machine Learning (ICML), volume 37, pages 1530–1538, 2015. URL https://arxiv.org/abs/1505.05770v6.
- Schulman et al. [2015] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz. Trust region policy optimization. In International Conference on Machine Learning (ICML), pages 1889–1897, 2015. URL https://arxiv.org/abs/1502.05477v5.
- Schulman et al. [2016] J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel. High-dimensional continuous control using generalized advantage estimation. In International Conference on Learning Representations (ICLR), 2016. URL https://arxiv.org/abs/1506.02438v6.
- Silver et al. [2016] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis. Mastering the game of Go with deep neural networks and tree search. Nature, 529:484–489, 2016. URL https://doi.org/10.1038/nature16961.
- Sutton [1988] R. S. Sutton. Learning to predict by the methods of temporal differences. Machine Learning, pages 9–44, 1988. URL https://doi.org/10.1023/A:1022633531479.
- Sutton and Barto [1998] R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction. MIT Press, 1998.
- Todorov et al. [2012] E. Todorov, T. Erez, and Y. Tassa. MuJoCo: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033, 2012. URL https://doi.org/10.1109/IROS.2012.6386109.
- Wang et al. [2017] Z. Wang, V. Bapst, N. Heess, V. Mnih, R. Munos, K. Kavukcuoglu, and N. de Freitas. Sample efficient actor-critic with experience replay. In International Conference on Learning Representations (ICLR), 2017. URL https://arxiv.org/abs/1611.01224v2.
- Ward et al. [2019] P. Ward, A. Smofsky, and A. Bose. Improving exploration in soft-actor-critic with normalizing flows policies. In International Conference on Machine Learning (ICML), 2019. URL https://arxiv.org/abs/1906.02771v1.
- Weng et al. [2022a] J. Weng, H. Chen, D. Yan, K. You, A. Duburcq, M. Zhang, Y. Su, H. Su, and J. Zhu. Tianshou: A highly modularized deep reinforcement learning library. Journal of Machine Learning Research (JMLR), 23(267):1–6, 2022a. URL https://arxiv.org/abs/2107.14171v3.
- Weng et al. [2022b] J. Weng, M. Lin, S. Huang, B. Liu, D. Makoviichuk, V. Makoviychuk, Z. Liu, Y. Song, T. Luo, Y. Jiang, Z. Xu, and S. Yan. EnvPool: A highly parallel reinforcement learning environment execution engine. In International Conference on Neural Information Processing Systems (NeurIPS), volume 35, pages 22409–22421, 2022b. URL https://arxiv.org/abs/2206.10558v2.