tlcyan \addauthoradolive \addauthorjbmagenta
Social Learning with Bounded Rationality:
Negative Reviews Persist under Newest First
Current version: August 2024111An extended abstract appeared at the ACM Conference on Economics and Computation (EC) 2024.)
Abstract
We study a model of social learning from reviews where customers are computationally limited and make purchases based on reading only the first few reviews displayed by the platform. Under this bounded rationality, we establish that the review ordering policy can have a significant impact. In particular, the popular Newest First ordering induces a negative review to persist as the most recent review longer than a positive review. This phenomenon, which we term the Cost of Newest First, can make the long-term revenue unboundedly lower than a counterpart where reviews are exogenously drawn for each customer.
We show that the impact of the Cost of Newest First can be mitigated under dynamic pricing, which allows the price to depend on the set of displayed reviews. Under the optimal dynamic pricing policy, the revenue loss is at most a factor of 2. On the way, we identify a structural property for this optimal dynamic pricing: the prices should ensure that the probability of a purchase is always the same, regardless of the state of reviews. We also study an extension of the model where customers put more weight on more recent reviews (and discount older reviews based on their time of posting), and we show that Newest First is still not the optimal ordering policy if customers discount slowly.
Lastly, we corroborate our theoretical findings using a real-world review dataset. We find that the average rating of the first page of reviews is statistically significantly smaller than the overall average rating, which is in line with our theoretical results.
1 Introduction
The use of product reviews to inform customer purchase decisions has become ubiquitous in a variety of online platforms, ranging from electronic commerce to accommodation and recommendation platforms. While the online nature of such platforms may hinder the ability of customers to confidently evaluate the product compared to an in-person experience, reviews written by previous customers can shed light on the product’s quality. It is well established that product reviews play a significant role on customer purchase decisions [CM06, ZZ10, Luc16].
The process in which reviews impact product purchases can be seen as a problem of social learning, which generically studies how agents update their beliefs for an unknown quantity of interest (e.g., product quality) based on observing actions of past agents (e.g., reading reviews written by past customers). The typical assumption in the literature of social learning with reviews is that, when deciding whether to purchase a product, customers consider either all reviews provided by previous customers [CIMS17, IMSZ19, GHKV23] or a summary statistic such as their average rating [BS18, CLT21, AMMO22]. The motivation for the latter assumption is that customers have limited time and computational power and thus rely on a summary statistic, often provided by the platform (see Section 1.2 for a further discussion on these lines of work).
However, in practice, a common scenario may be somewhere “in between” the above two assumptions: customers read a small number of reviews in detail. Existing works have found that the textual content of a review contains important information that goes beyond its numeric score and such information can heavily influence purchase decisions [GI10, AGI11, LDRF+13, LLS19, LYMZ22]. Therefore, customers look beyond the average review rating and read a small number of reviews in detail. In particular, [Kav21] find that 76% of customers read between 1 and 9 reviews before making a purchase. This motivates the main questions of our work:
When customers read a limited number of reviews, how does this impact social learning?
Are there operational decisions that should be reconsidered due to this bounded rationality?
To answer these questions, we study a model for a single product (formalized in Section 2), where a platform makes decisions regarding how reviews are ordered and how the product is priced. Customers arrive sequentially and each customer takes only the first reviews into account to inform their purchase decision, where is a small constant. We assume that the ’th customer’s valuation can be decomposed as the sum of a) an idiosyncratic valuation that is known to them and b) a product quality that has a fixed mean ; the latter quantity is unknown to the customer and can only be inferred via the reviews. We assume that when a customer reads a review written by customer , they observe (see Section 1.2 for a discussion of this assumption). Each customer uses reviews to update their belief about , and makes a purchase if their estimate of their valuation is higher than the price. In the event of a purchase, they leave a review that future customers can read.
1.1 Our contribution
A popular review ordering policy is to display reviews in reverse chronological order (newest to oldest); we refer to this policy as . This is the default option in platforms such as Airbnb, Tripadvisor and Macy’s222This statement is based on access on Feb 7, 2024. Many other platforms such as Amazon and Yelp list newest as the second default and have their own ordering mechanism as the default option. as it allows customers to get access to the most up-to-date reviews. In the context of our model, under the ordering, a customer considers the most recent reviews. The set of these reviews evolves as a stochastic process over customer arrivals: when a new purchase happens and thus a new review is provided, this review replaces the -th most recent review.
Cost of Newest First.
By analyzing the steady state of the aforementioned stochastic process, we observe that the ordering policy induces an undesirable behavior where negative reviews are read more than positive reviews, leading to a significant loss in overall revenue (Section 3).
To illustrate this phenomenon, consider a simple setting where customers only read the first review () and the probability of a purchase is higher when the review is positive. When the ’th customer arrives, if the first review is positive, this customer is likely to buy the product and subsequently leave a review; the new review from the ’th customer then becomes the “first review” for the ’th customer. On the other hand, if the first review is negative for the ’th customer, they are less likely to buy the product, and hence the same negative review remains as the “first review” for the ’th customer. Therefore, negative reviews persist under the newest first ordering: a review will stay longer as the first review if it is negative compared to if it is positive.
We show that this arises due to the endogeneity of the stochastic process that induces and results in a loss of long-term revenue. To formalize this notion, we compare to an exogenous process where each arriving customer sees an independently drawn random set of reviews; we refer to this ordering policy as . We establish that the long-term revenue under is strictly smaller than that of under any non-degenerate instance (Theorem 3.1) and that the revenue under can be arbitrarily smaller, in a multiplicative sense, compared to (Theorem 3.2). We refer to this phenomenon as the Cost of Newest First (CoNF).
Dynamic pricing mitigates CoNF.
Seeking to mitigate this phenomenon, we consider the impact of optimizing the product’s price (Section 4). We show that even under the optimal static price, the CoNF remains arbitrarily large (Theorem 4.1). However, if we allow for dynamic pricing, where the price can depend on the state of the reviews, we show that the CoNF is upper bounded by a factor of when the idiosyncratic valuation distribution is non-negative and gracefully decays with its negative mass otherwise (Theorem 4.2).
This improvement stems from the fact that dynamic pricing allows us to change the steady state distribution of the stochastic process. Recall that, under , the stochastic process spends more time on states with negative reviews than states with positive reviews. The optimal dynamic pricing policy sets prices so that the purchase probability is equal across all states (Theorem 4.4) — this ensures that the steady state distribution under is the same as that of .
A broader implication of this result is that, when purchase decisions depend on the state of the first reviews, platforms that offer state-dependent prices can be arbitrarily better off than platforms that are unaware of this phenomenon and statically optimize prices (Theorem 4.6).
Time-discounting customers.
Having identified the potential inefficiency of the ordering policy, we extend our model to incorporate the main reason behind its popularity: customers often prefer to read more recent reviews as they contain more up-to-date content. A recent survey [Mur19] shows that of the participants only look at reviews within the last two weeks and over of the participants disregard any review that was not posted in the past three months.
To capture this recency-awareness, we extend our model to allow for customers to place more weight on more recent reviews when they update their beliefs (Section 5). Despite the presence of CoNF, when customers severely time-discount, we show that yields the highest revenue (Theorem 5.1); in the other extreme where customers do not discount at all, maximizes revenue (Theorem 5.2). Interestingly, when customers discount slightly, neither of or maximizes revenue; it is better to consider a finite window of the most recent reviews, and select reviews at random from this set (Theorem 5.3). Finally, we show that the CoNF interacts with the discount factor in a non-trivial way. For a random set of reviews, if higher weights imply a higher purchase probability, then one would expect that non-discounting customers purchase more than discounting customers. However, due to the CoNF, we show that there are cases in which discounting customers yield a higher purchase rate than non-discounting customers (Theorem 5.4).
Empirical evidence from Tripadvisor data.
Finally in Section 6, we corroborate our theoretical findings using real-world review data from Tripadvisor, an online platform where the default review ordering policy is newest first. We evaluate 109 hotel pages, and we find that for 79 of them, the average review rating of the first 10 reviews is lower than the average review rating of all reviews. These empirical findings support our main theoretical results with statistical significance.
1.2 Related Work and Comparison of Key Modeling Assumptions
Social learning and incentivized exploration.
Classical models of social learning from [Ban92] and [BHW92] study a setting in which there is an unknown state of the world and each agent observes an independent, noisy signal about the state as well as the actions of past agents. The agent uses this information to update their beliefs and then takes an action. In this setting, undesirable “herding” behavior can arise: agents may converge to taking the wrong action. Conceptually closer to our work, [Say18] shows that dynamic pricing can mitigate the aforementioned herding behavior. Subsequent works study how social learning is affected by the agent’s signal distribution [SS00], prior for the state [CDO22], heterogeneous preferences [GPR06, LS16], as well as the structure of their observations [AMMO22]. From a different perspective, there is a stream of literature that aim to design mechanisms to help the learning process, either by modifying the information structure [KMP14, MSS20, BPS18] or by incentivizing exploration through payments [FKKK14, KKM+17].
Social learning with reviews.
Closer to our work, several papers focus on the setting where customers learn about a product’s quality through reviews [HPZ17, CIMS17, BS18, SR18, IMSZ19, CLT21, AMMO22, GHKV23, Bon23, CSS24]. This literature induces several modeling differences compared to classical social learning. First, agents do not receive independent signals of the unknown state (the product quality). Second, agents not only observe the binary purchase decision of previous agents, but also the reviews of previous agents who purchased the product. We highlight the key modeling assumptions of our work and how they relate to existing works.
No self-selection bias.
In prior works of social learning with reviews, the main difficulty stems from the self-selection bias, the idea that only customers who value the product highly will buy the product and hence these customers leave reviews with higher ratings. In the presence of self-selection bias, [CIMS17] and [IMSZ19] study conditions in which customer beliefs eventually successfully learn the quality of a product, where customers update their beliefs based on the entire history of reviews. [AMMO22, BS18, SR18, CLT21] consider models in which customers only incorporate summary statistics of prior reviews (e.g., average rating) into their beliefs. [Bon23] analyzes how the magnitude of the self-selection bias depends on the product’s quality and polarization. [CSS24] consider a model where the platform’s pricing decision affect the review ratings and characterizes the impact of the price on the average rating. This is also empirically supported by [BMZ12] which shows that Groupon discounts lead to lower ratings. [HPZ17] study a two-stage model which quantifies both self-selection bias and under-reporting bias (reviews are provided only by customers with extreme experiences); see references within for further related work.
In contrast, our work studies a model where self-selection bias does not arise. Specifically, we assume that customer ’s valuation can be decomposed as , where is customer-specific, and has a fixed mean shared across customers. The quantity is the unknown quantity of interest for all customers. Our model assumes that a review reveals . In contrast, prior works assume that a review reveals and one cannot separate the contribution from each term. This means that, in our model, the customer-specific valuation and the pricing decision affect the purchase probability but do not affect the review itself conditioning on a purchase. Although our assumption makes it “easier” for customers to learn , we study a new phenomenon that arises due to the fact that customers only read a small number of reviews.
The practical motivation for our modeling assumption is the following. On most online platforms, a review is composed by both a numeric score (e.g., 4 out of 5) and a textual description that further explains the reviewer’s thoughts. Within our model, one interpretation is that the numeric score reveals , but one can use the textual content of the review to separate from . Therefore, we assume that reading the text of the review reveals , but we also assume that each customer only reads a small number of reviews since reading the text takes time. Even though most platforms provide the average score of the numeric ratings, this will suffer from self-selection bias (as shown in [BS18, CLT21]) and hence customers must read reviews in detail to learn .
[GHKV23] also study a setting with no self-selection bias (without bounded rationality), focusing on dynamic pricing. Their model assumes that customers are partitioned into a finite number of types and only read reviews written by customers of the same type. This overcomes self-selection bias as customers of the same type can be thought of as having the same value of in our model.
Belief convergence vs. stochastic process.
In the existing literature, social learning is deemed “successful” if the customer’s estimate of product quality converges to the true quality. This convergence can either be that their belief distribution converges to a single point [IMSZ19, AMMO22], or that the customer’s scalar estimate of the product quality (e.g., average rating) converges to the true quality [CIMS17, BS18]. In our setting, customers update their beliefs based on the first reviews and, as discussed above, these reviews evolve across customers as a stochastic process. Therefore, customer beliefs do not converge but rather oscillate based on the state of those reviews, even as the number of customers goes to infinity.
Closer to our work, [PSX21] study a similar model (without bounded rationality) and show that the initial review can have an effect on the proclivity of customer purchases and the number of reviews. This bias introduced by initial reviews is also empirically observed by the work of [LKAK18]. Unlike our model, this effect diminishes over time as the product acquires more reviews and the initial review becomes less salient. Our results on the Cost of Newest First can thus be viewed as a stronger version of the result in [PSX21] as we show that, in the presence of bounded rationality, the effect of negative reviews persists even in the steady-state of the system.
Fully Bayesian vs. non-Bayesian.
Existing papers differ in whether customers incorporate information from reviews in a fully Bayesian or non-Bayesian manner. For example, [IMSZ19] and [AMMO22] study a fully Bayesian setting where all distributions (prior on , distribution of ) and purchasing behaviors are common knowledge and each customer forms a posterior belief on using the information given to them. In contrast, [CIMS17] and [CLT21] assume that customers use a simple non-Bayesian rule when making their purchase decision. Moreover, [BS18] study both Bayesian and non-Bayesian update rules and compare them.
In our paper, customers use a Bayesian framework but their update rule is not fully Bayesian. Specifically, customers start with a Beta prior on . This prior need not be correct as we assume that is a fixed number. We assume reviews are binary (0 or 1), and customers read of them and update their beliefs assuming that these reviews are independent draws from . However, this is not necessarily the “correct” Bayesian update rule for the customers, due to the endogeneity of the stochastic process of the first reviews. That is, under the ordering rule, negative reviews are more likely to persist as the most recent review — hence even if , the most recent review is more likely to be negative than positive. Therefore, a fully Bayesian customer should take this phenomenon into account when updating their beliefs. We assume that customers do not account for this (and hence are not fully Bayesian), and we study the impact of how this endogeneity impacts the steady state of the process. Our model also implicitly assumes that customers do not use additional information about previous customers’ non-purchase decisions (which are typically non-observable) and the platform’s pricing policy (which is often opaque).
Finally, our model is flexible in that it allows customers to map their belief distribution to a scalar estimate of in an arbitrary manner, e.g, the mean of the belief distribution (which is considered in most prior work) as well as a pessimistic estimate thereof (as studied in [GHKV23]).
Other work on social learning with reviews.
[HC24] study the design of rating systems motivated by the idea that older reviews become less relevant. In a setting where the product’s quality changes, they show that a moving average rating system is optimal in reflecting the true quality. Social learning with reviews has also been studied for ranking [MSSV23], incorporating quality variability [DLT21], dealing with non-stationary environments [BPS22], and has been applied to green technology adoption [RHP23].
2 Model
We consider a platform that repeatedly offers a product to customers that arrive in consecutive rounds . The customer makes a purchase decision based on a finite number of reviews and the price; if a purchase occurs, they leave a new review for the product. We consider the platform’s decisions regarding the ordering of reviews as well as the price.
Customer valuation. The customer at round has a realized valuation for the product, where and represent the contribution from the product’s unobservable and observable parts respectively. Specifically, is drawn independently from for each customer , where is the same across all customers and is unknown to them. Contrastingly, the quantity is customer-specific and is known to customer before they purchase. We assume that, at every round , is drawn independently from a distribution with bounded support. The platform knows the distribution but not .
If the customer at round knew their exact valuation , then they would purchase the product if and only if , where is the price of the product at time . However, is unknown and hence so is . We assume that the customers read reviews to learn about , and their purchase decision depends on their belief about after reading the reviews. Note that customers cannot aim to estimate beyond estimating , since is drawn independently for each customer.
Review generation. If the customer at round purchases the product, they write a review that future customers may read. The review rating given by customer is (see Section 1.2 for a discussion of this assumption). We often refer to a review with as positive and to a review with as negative. We denote by the rating of customer ’s review, where if customer did not purchase the product.
2.1 Customer Purchase Behavior
We describe the customer purchase behavior at one round, taking the price and the review ordering as fixed. Customers have a prior for the value of , for some fixed . This prior need not be correct and could be based on information about the features of the product or summary statistics of all reviews which are subject to self-selection bias (see discussion in Section 1.2). Customers read the first reviews that are shown to them to update their prior. Formally, letting denote the ratings of the first reviews shown, the customer creates the following posterior for the unobservable quality :
This corresponds to the natural posterior update for if each is an independent draw from .333The reviews are not necessarily independent draws from , hence the customers are not completely Bayesian. See the last point in Section 1.2 for a detailed discussion. Note that the customer places equal weight on the first reviews (we also consider time-discounted weights in Section 5). Based on this posterior, the customer creates an estimate for their valuation. We assume that there is a mapping from their posterior to a real number that represents an estimate of the fixed valuation . For example, the mapping represents risk-neutral customers, while if corresponds to the -quantile of for , this represents pessimistic customers (see Section 5.1). The customer then forms their estimated valuation and buys the product at price if and only if . Finally, the customer leaves a review if they bought the product, otherwise .
To ease exposition, we often use to denote the number of positive ratings (i.e., ), and we overload notation to denote by to refer to . We make the natural assumption that higher number of positive ratings leads to a higher purchase probability.
Assumption 2.1.
The estimate is strictly increasing in the number of positive reviews .
We also assume that the idiosyncratic valuation has positive mass on non-negative values.
Assumption 2.2.
The distribution has positive mass on non-negative values: .
We denote the above problem instance as for product quality , prior parameters , idiosyncratic distribution , customers’ attention budget , and an estimate mapping .
2.2 Platform Decisions
We consider two platform decisions, review ordering and pricing.
Review ordering. With respect to ordering, since customers only take the first reviews into account, choosing an ordering is equivalent to selecting a set of reviews to show. Let be the set of previous rounds in which a review was submitted and let be the observed history before round . At round , the platform maps (possibly in a randomized way) its observed history to the set of review ratings corresponding to the reviews shown. We study the steady-state distribution of the system; to avoid initialization corner cases, we assume that at time , there is an infinite pool of reviews where . We consider the following review ordering policies:
-
•
selects the newest reviews. This is formally defined as where is the rating of the -th most recent review.
-
•
selects reviews uniformly at random (without replacement) from the most recent reviews, independently at each round . Note that .
-
•
shows random reviews. This corresponds to ratings being drawn independently from at each round ; i.e., where .
Formally, is defined as the limit of as (see Appendix A for details). Note that, under , the customers’ and platform’s actions at the current round do not influence the reviews shown in future rounds (i.e. the reviews are exogenous). In contrast, under and for any , the customers’ and platform’s actions influence what reviews are shown in future rounds (i.e. the reviews are endogenous to the underlying stochastic process).
Pricing. The platform also decides on the pricing policy, where the price at each round can depend on the set of displayed reviews. We denote a pricing policy by a function , which maps the set of displayed review ratings to a price. We study two classes of pricing policies: static and dynamic. We let be the set of pricing policies that assign a fixed price , i.e., for any . Similarly, includes the set of pricing policies where can depend on the review ratings .
2.3 Revenue and the Cost of Newest First
For an ordering policy and pricing policy , we define the revenue as the steady-state revenue:444The policies we consider have a stationary distribution so, in our analysis, we replace the with a .
| (1) |
Our main focus lies in understanding the effect of the ordering policy on the revenue. Specifically, we compare the revenues of the ordering policies and . For a pricing policy , we define the Cost of Newest First (CoNF) as follows:555For all the policies we consider, . This is formalized for in Definition 3.1.
If , i.e., for any we use and as shorthand for the corresponding steady-state revenue and CoNF.
In Section 4, we study the CoNF when the platform can optimize its pricing policy over a class of policies. For a class of pricing policies , we define similarly the optimal revenue within-class with respect to an ordering policy and the corresponding CoNF as:
To ease exposition, we make the mild assumption that .666For the policies we consider, by Assumption 2.2 and the fact that ; is satisfied if the maximum revenue from a customer’s idiosyncratic valuation is finite, i.e., .
Finally, we note that, unlike classical revenue maximization works, our focus is not on identifying policies that maximize revenue but rather in comparing the performance of different ordering policies ( vs ) and different pricing policies ( vs ).
Remark 2.1.
Our assumption of Bernoulli reviews and Beta prior is made for ease of exposition. Our results extend to a more general model where reviews come from an arbitrary distribution with finite support (not only ) and the estimator arbitrarily maps reviews to an estimate for the fixed valuation ; see Appendix B for details.
3 Cost of Newest First with a Fixed Static Price
Throughout this section, we assume a static pricing policy where the price is fixed and given. We establish the main phenomenon of the Cost of Newest First by showing that under very mild conditions on the price . We then show that can be arbitrarily large.
Recall that refers to , where refers to the number of positive reviews. We first introduce two natural conditions that the price should satisfy.
Definition 3.1 (Non-absorbing price).
A price is non-absorbing if the purchase probability is positive for any displayed review ratings; i.e., for all ,
A non-absorbing price is required to guarantee that does not get “stuck” in a zero-revenue state. Specifically, under an absorbing price, there exists a set of review ratings such that the purchase probability is zero. In such a state, there will be no new subsequent review, and the set of most recent reviews will never be updated, resulting in zero revenue for . This is formalized in the following proposition (whose proof is provided in Appendix C.1).
Proposition 3.1.
Any absorbing price yields revenue under , i.e., .
Definition 3.2 (Non-degenerate price).
A price is non-degenerate if there exist , such that the purchase probability is different given and positive review ratings:
A non-degenerate price implies that the review ratings “matter”, since there exist distinct review ratings where the purchase probability differs. In contrast, under a degenerate price, the review ratings have no impact on the purchase probability, hence the review ordering policy has no impact on revenue under such prices. Note that there exist prices which are absorbing and non-degenerate and there also exist prices which are degenerate and non-absorbing.777E.g. if , , and (mean). Then the price is non-degenerate but absorbing, while the price is degenerate but non-absorbing.
3.1 Existence of Cost of Newest First
Our main result is that the revenue under is strictly higher than that of ; that is, . As a building block towards this result, we first provide simple and interpretable closed form expressions for and for a static price , which are given in Propositions 3.2 and 3.3 respectively. Let denote the Bernoulli distribution with success probability and denote the Binomial distribution with i.i.d. trials.
Proposition 3.2 (Revenue of ).
For any fixed price ,
Proof.
By definition, displays i.i.d. reviews at every round . As a result, the number of positive reviews is distributed as , yielding expected revenue, at every round , equal to the right hand side of the theorem. Given that this quantity does not depend on , recalling Eq.(1), it equals the steady-state revenue. ∎
Unlike which displays i.i.d. reviews at every round, the reviews displayed by are an endogenous function of the history. The proof of the next result underlies the technical crux of this section and is presented in Section 3.2.
Proposition 3.3 (Revenue of ).
For any non-absorbing fixed price ,
Intuitively, when the newest reviews are positive, the customer is more likely to buy the product and leave a new review, which then updates the set of newest reviews. On the other hand, when the newest reviews are negative, the customer is less likely to buy, and hence the set of newest reviews is less likely to be updated. This implies that spends more time in a state with negative reviews (which yield lower revenue) compared to . This phenomenon is the driver of our main result and we refer to it as the Cost of Newest First (CoNF).
Theorem 3.1 (Cost of Newest First).
For any non-degenerate price , the revenue of is strictly smaller than that of , i.e., .
Proof.
If is absorbing (Definition 3.1), by Proposition 3.1, as there is a state of reviews in which there will never be another purchase. However, as is non-degenerate and hence there is a state of reviews with a positive purchase probability.
If is non-absorbing, we next show that the expression of Proposition 3.2 is higher than the one of Proposition 3.3. By Jensen’s inequality, for any non-negative random variable and equality is achieved if and only if is a constant. Letting be the purchase probability in a state with positive reviews, we apply the inequality for ,
Multiplying with on both sides we obtain that . It remains to show that when is non-degenerate, the inequality is strict. Note that since is non-degenerate, we have that and thus is not a constant random variable when . Therefore, the inequality is strict. ∎
We describe a simple example that provides intuition on the CoNF established in Theorem 3.1, which is also illustrated in Figure 1.
Example 3.1.
Suppose , , , , and . Under the probability that the review shown is positive is (see Figure 1(a)). Under the purchase probability is when the review is positive and when it is negative. Thus, under , transitioning from a positive to a negative review is twice as likely as transitioning from a negative to a positive review (see Figure 1(b)). Hence, a negative rating is twice as likely as positive rating. This leads to lower revenue in steady state for compared to .
3.2 Characterization of Revenue under Newest (Proof of Proposition 3.3)
We provide the proof of Proposition 3.3, which contains the main technical crux of this section. We first introduce some notation. Recalling that denotes the rating of the -th most recent review at round , we refer to the most recent reviews by the vector . We note that is a time-homogeneous Markov chain with a finite state space . Given that we assume an infinite pool of initial reviews, where for .
With respect to its transition dynamics of this Markov chain, for the state , the purchase probability is . If there is no purchase, no review is given and the state remains . If there is a purchase, transitions to the state if the review is positive (with probability ) and to the state if the review is negative (with probability ).
Because the price is non-absorbing, for every state of reviews , the purchase probability is positive, and the probability that a new review is positive is strictly greater than zero (since ). Then, can reach every state from every other state with positive probability (i.e. it is a single-recurrence-class Markov Chain with no transient states), and hence has a unique stationary distribution, which we denote by . Our next lemma exactly characterizes the form of this stationary distribution.
Lemma 3.1.
The stationary distribution of under any non-absorbing price is
where is a normalizing constant.
Proof sketch.
If the reviews were drawn i.i.d. at each round, the probability of state would be exactly , which is the numerator. However, the set of newest reviews is only updated when there is a purchase, which occurs with probability . Therefore, we multiply the numerator by , which is the expected number of rounds until there is a new review under state ; in fact, we show such a property holds for general Markov chains (Lemma C.3). A formal proof is provided in Appendix C.2. ∎
Equipped with Lemma 3.1, we now prove Proposition 3.3.
Proof of Proposition 3.3.
Using Eq. (1), the revenue of can be written as
where the second step expresses the revenue of the stationary distribution via the Ergodic theorem. Expanding based on Lemma 3.1, the term cancels out and:
Note that the term in the parenthesis equals 1, since it is a sum over all probabilities of . This yields , which gives the expression in the theorem. ∎
3.3 Cost of Newest First can be arbitrarily bad
Theorem 3.1 implies that, for any non-absorbing price , the CoNF is strictly greater than , i.e. .888For a non-absorbing price the denominator of is strictly positive. We now show that it can be arbitrarily large. We first provide a closed-form expression for by dividing the expressions in Propositions 3.2 and 3.3 (see Appendix C.3 for proof details).
Lemma 3.2.
For any non-absorbing price , the CoNF is given by:
Theorem 3.2.
For any continuous value distribution with positive mass on a bounded support, and any , there exists a non-degenerate and non-absorbing price such that .
Proof.
One summand in the right hand side of Lemma 3.2 has a term corresponding to the ratio of the purchase probability of all reviews being positive compared to all reviews being negative:
which quantifies how much the reviews affect the purchase probability. Since all other terms are non-negative, the CoNF is lower bounded by this summand, i.e., .
Since is bounded, suppose that its support is . When all reviews are negative, selecting a price of results in a purchase probability of . Combined with the continuity of , this implies that, when , the purchase probability goes to 0. If, on the other hand, all reviews were positive, then using and that is continuous and has positive mass on its support, the purchase probability is positive; i.e., . Therefore , which implies that since .
Lastly, any price is non-absorbing and non-degenerate because for such prices, Hence, for every there exists such that is non-absorbing, non-degenerate, and . ∎
Remark 3.1.
In Appendix C.4, we complement Theorem 3.2 by showing that, if has monotone hazard rate, is monotonically increasing in . In Appendix C.5, we present an explicit expression when and is uniform on ; in particular, for .
Remark 3.2.
In Appendix C.6, we show that . This suggests that, when is small, the Cost of Newest First is also small. The former occurs when review ratings have small impact on purchases. For example, when and , the idiosyncratic variability dominates the variability from estimating through reviews, yielding and thus .
3.4 Generalizing the insight beyond revenue
We generalize our main insights beyond revenue loss by analyzing the distribution of the number of positive reviews among the reviews. We prove a structural result on this distribution (Proposition 3.4) and show that its expectation is smaller under compared to (Theorem 3.3). These theoretical results are used as a basis for comparison in Section 6, where we analyze a real-world review dataset. We first strengthen the non-degeneracy condition (Definition 3.2) to hold for each pair of review ratings.
Definition 3.3 (Strongly non-degenerate price).
A price is strongly non-degenerate if the purchase probability is different for all positive review ratings with :
Lemma 3.1 implies that the stationary distribution of seeing positive reviews under is
By Proposition 3.3, , so can be interpreted as the rate at which customers purchase under . In contrast, the corresponding stationary distribution under is
To compare and , we show that there is critical threshold such that the steady-state probability of having positive reviews is higher under than if , and smaller if . This phenomenon is illustrated in Figure 2. Formally, is the largest number of positive review ratings where the purchase probability is at most the average purchase rate , i.e., .
Proposition 3.4.
For any strongly non-degenerate and non-absorbing price , if and if .
Proof.
Observe that . As is strongly non-degenerate, the purchase probability is strictly increasing in . By the definition of , if , and thus . The other case is analogous. ∎

Next, we use Proposition 3.4 to show that the mean of is strictly smaller than that of ; the proof of the this result is in Appendix C.7.
Theorem 3.3.
For any non-degenerate and non-absorbing price , the average number of positive reviews under is smaller than under . Formally, .
In Section 6, we track the distribution of review ratings for a set of hotels from Tripadvisor (which uses as its default ordering policy). The results from this data analysis support our theoretical findings (Proposition 3.4 and Theorem 3.3).
4 Dynamic Pricing Mitigates the Cost of Newest First
In this section, we allow the platform to optimize the pricing policy , while the review ordering policy is either or . We assume that the platform knows the true underlying quality .999We assume is fixed over time and the platform has access to enough reviews to estimate arbitrarily well. Recall that and are the classes of static and dynamic pricing policies respectively, and that the revenue and CoNF for a class are defined respectively as
The main results of this section (Section 4.1) establish that the CoNF can be arbitrarily large for the optimal static pricing policy (Theorem 4.1) but that it is bounded by a small constant for the optimal dynamic pricing policy (Theorem 4.2). The main technical challenge of this section is in proving Theorem 4.2. To do this, we first characterize the optimal dynamic pricing policies under both and and derive exact expressions for their long-term revenue (Section 4.2). In doing so, we derive a structural property of the optimal dynamic pricing policy under : the prices ensure that the purchase probability is always equal regardless of the state of reviews.
4.1 Cost of Newest First under Optimal Static and Dynamic Pricing
We first establish that when optimizing over static prices, the CoNF can be arbitrarily large for any number of reviews . Note that this is not implied by Theorem 3.2, since here we assume the platform always chooses the optimal static price for a given instance.
Theorem 4.1.
For any instance where the support of is , it holds that .
This implies that if is held constant and and . Intuitively, this means that when the variability in the customer’s idiosyncratic valuation is negligible compared to the variability in review-inferred quality estimates, spends a disproportionate time in the state with no positive reviews, which leads to unbounded CoNF.
Proof of Theorem 4.1.
Observe that any price is absorbing since . By Proposition 3.1, such prices induce . For any non-absorbing price , its revenue is at most . As a result, .
Under , if all reviews are positive, the non-negativity of the value distribution implies that a price induces a purchase with probability one. The probability of this event is , which implies that . Combining the two inequalities we obtain
∎
Next, we show an upper bound under dynamic pricing, which is the main result of this section.
Theorem 4.2.
For any instance, it holds that .
In contrast to static pricing where the CoNF can be arbitrarily bad, Theorem 4.2 shows that its negative impact can be mitigated via dynamic pricing. If the idiosyncratic valuation is always non-negative, the upper bound on is 2. Even when can be negative, for example if it is non-negative at least with probability 1/2, then Theorem 4.2 implies that .
The proof of Theorem 4.2 (Section 4.3) relies on characterizing the optimal dynamic pricing policies under both and and their corresponding revenues (Section 4.2). Recall that with static pricing, spends a disproportionate amount of time in a negative review state compared to . In contrast, the optimal dynamic pricing sets prices so that the purchase probability is equal across all review states, leading to and spending the same amount of time in each review state (Section 4.2). This allows us to bound the ratio of demands under and by a factor of . Finally, we bound the ratio of the optimal prices under and , which we decompose in two terms stemming from the customer’s belief about and customer specific valuation; each term is bounded by 1 (Section 4.3).
We complement this result by a lower bound (proof in Appendix D.1) which shows that the Cost of Newest First still exists even under optimal dynamic pricing.
Proposition 4.1.
For any , there exists an instance such that .
Remark 4.1.
Even under optimal dynamic pricing, it is still the case that induces no smaller revenue than , i.e., (see Appendix D.2).
Remark 4.2.
If we have the additional knowledge of for some , then we can improve the result of Theorem 4.2 to (see Appendix D.3).
4.2 Characterization of Optimal Dynamic Pricing
A useful quantity in our characterization results is the optimal revenue for a given valuation distribution represented by a random variable ; in particular, the optimal revenue is101010We note that for our valuations distributions as has bounded support and .
First, we derive the optimal pricing policy for . Specifically, for every state of reviews, the optimal price is the revenue-maximizing price for that state. For a state of reviews , we denote by the number of positive review ratings.
Theorem 4.3.
For every review state , any optimal pricing policy under sets . This implies that
Proof.
By definition, displays i.i.d. reviews at every round . If the displayed reviews are , the revenue obtained by offering price is equal to
Thus the optimal price is any revenue-maximizing price . Since the number of positive reviews is distributed as , the optimal revenue is equal to . ∎
Next, we characterize the optimal dynamic pricing policy under . We show that it satisfies a structural property: the purchase probability is equal regardless of the review state. We define the policies that satisfy this property as review-offsetting policies.
Definition 4.1.
A dynamic pricing policy is review-offsetting if there exists an offset such that for all .
Note that for a review-offsetting policy , the purchase probability at any state is , where the last term does not depend on . Hence, review-offsetting policies induce equal purchase probability regardless of the state of reviews.
The main result of this section establishes that under , there is a review-offsetting dynamic pricing policy that maximizes revenue and characterizes the corresponding offset.111111We note that this characterization is the only place where we require the platform to know the true quality .
Theorem 4.4.
Let . Under , the review-offsetting policy with offset is an optimal dynamic pricing policy.
Intuitively, the term is the optimal price when facing a single customer with a random valuation for . The selected offset makes the purchase probability equal to the purchase probability under the “single customer” setting with the optimal price . This intuition enables us to characterize the optimal revenue of dynamic policies (proof in Appendix D.4).
Theorem 4.5.
The revenue of the optimal dynamic pricing policy under equals the optimal revenue from selling to a single customer with valuation . That is,
Remark 4.3.
To prove Theorem 4.4, for any dynamic pricing policy and any state , we define a corresponding policy to be the review-offsetting policy with offset . The policy has the same purchase probability as at state , i.e., . We show that (1) can be improved by one of for (Lemma 4.1) and (2) using such a review-offsetting policy reduces the problem to facing a single customer with valuation (Lemma 4.2).
Lemma 4.1.
The revenue of is at most the highest revenue of over , i.e.,
Equality holds if and only if for all .
Lemma 4.2.
Let . For a review-offsetting policy with offset :
Proof of Theorem 4.4.
By Lemma 4.2, a review-offsetting policy with offset has revenue
This is the revenue of selecting a price when facing a single customer with valuation . The revenue-maximizing price against such a customer is . By Lemma 4.2, the review-offsetting policy (of the theorem) with offset attains this optimal revenue and is thus the revenue-maximizing review-offsetting policy. What remains is to show that dynamic pricing policies that are not review-offsetting do not obtain higher revenue; this follows from Lemma 4.1. ∎
To prove Lemmas 4.1 and 4.2, we provide a closed-form expression for the revenue of any dynamic pricing policy (proof in Appendix D.7), which is an analogue of Proposition 3.3. Similar to Definition 3.1, we define a non-absorbing dynamic pricing policy as one where the purchase probability for every state of reviews is positive, i.e., for all .
Proposition 4.2.
For a non-absorbing dynamic pricing policy ,121212In this proposition and the following proofs we again use the notation and .
Proof of Lemma 4.2.
Since , its expected price is . The purchase probability in every state is the same and equal to . As a result, by Proposition 4.2, . ∎
To prove Lemma 4.1 we use the following natural convexity property (proof in Section D.8).
Lemma 4.3.
Let be such that for all . Then . Equality is achieved if and only if for all .
Proof of Lemma 4.1.
Given that is review-offsetting policy with offset , by Lemma 4.2,
where . Given that and thus , Proposition 4.2 implies that the revenue of can be expressed as:
Letting and be the probability that i.i.d. trials result in , Lemma 4.3 implies that the maximum revenue among is no smaller than that of :
By Lemma 4.3 equality holds if and only if is the same for all . ∎
Remark 4.4.
In Section D.9, we compare the optimal dynamic pricing policies under and . We show that, under mild regularity conditions, states with result in higher price under , while states which result in lower price under .
4.3 Cost of Newest First is Bounded under Dynamic Pricing (Theorem 4.2)
We now prove Theorem 4.2, leveraging the results of Section 4.2 that characterize the optimal dynamic pricing policies. For convenience, we denote by and . By Theorem 4.3 and Theorem 4.5, we can express the Cost of Newest First as:
| (2) |
where the denominator does not depend on and can thus move inside the expectation. We now focus on the quantity inside the expectation for a particular realization of . For any price ,
| (3) |
The inequality replaces the revenue-maximizing price by another price , which can only increase the ratio. Given that we operate with dynamic prices, we are allowed to select a different price for any number of positive reviews .
In particular, a price of ensures that the demand ratio is one. However, if , the denominator in the price ratio can be unboundedly small. To simultaneously bound the expected price and demand ratios, we select .
Lemma 4.4.
The expected price ratio is at most .
Lemma 4.5.
For any , the demand ratio is .
What is left is to prove the lemmas that bound the expected price ratio and the demand ratio.
Proof of Lemma 4.4.
Given that customer valuations are additive with a belief and an idiosyncratic component, the optimal price (numerator of price ratio) can be similarly decomposed as:
The expected price ratio for is:
Given that the denominators in both terms are positive and , each of those terms can be upper bounded by , concluding the proof. ∎
Proof of Lemma 4.5.
For every number of positive reviews , we distinguish two cases based on where the maximum in lies. If the demand ratio is equal to . Otherwise,
∎
4.4 Broader Implication: Cost of Ignoring State-dependent Customer Behavior
Suppose a platform uses , and they are not aware of the phenomenon that customer’s purchase decisions depend on the state of reviews — they instead assume the purchase behavior is constant (i.e., purchase probability does not depend on the state of the newest reviews). Then, if the platform uses a standard data-driven approach to optimize prices (e.g., do price experimentation and estimate demand from data), the optimal revenue is . In contrast, a platform can estimate separate demands for each state of reviews and employ a dynamic pricing policy to earn . We show, by comparing with , that the revenue loss from not accounting for this state-dependent behavior can be arbitrarily large. The proof of the following result is provided in Appendix D.10.
Theorem 4.6.
For any , there exists an instance such that .
5 Cost of Newest First under Time-Discounting Customers
As discussed in the introduction, customers prefer to read more recent reviews; this explains the practical popularity of . We thus extend the customer model to account for this behavior of preferring newer reviews and analyze the revenue of review ordering policies under this model.
5.1 Model of Time-Discounting Customers
We first define the new behavioral model. For , -time-discounting customers have the following purchase behavior. At round , when presented with reviews which appeared at rounds in the past , the posterior they form is
Comparing to the model in Section 2, customers’ weight on the -th review depends on the number of rounds since the posting of this review . Intuitively, this means that a significance of a review compared to the prior decreases as the review becomes more stale. Formally, a review from rounds ago is discounted by . Note that corresponds to our original model while corresponds to customers who only consider the review from the immediately previous round.
Customers map this posterior to an estimate of the fixed valuation . Using their personal preference and their estimate for the fixed valuation, they form their estimated valuation and purchase the product if and only if where is the price offered by the platform. We assume that is a continuous distribution and is continuous in .
We now discuss how the random ordering policy behaves when . Recall (Section 2.2) that we start with an infinite pool of reviews: where . Then, a review chosen at random from this pool will be “infinitely stale” (i.e., almost surely), and such a review will have a weight of 0 almost surely. Therefore, is equivalent to showing no reviews; i.e., .
We also analyze the policy, which selects reviews uniformly at random from the newest reviews for a window . Intuitively, a higher window corresponds to more randomness in the displayed reviews and interpolates between and .
We denote by the steady-state revenue under -time-discounting customers, review ordering policy , and pricing policy , defined in Eq. (1).131313We note that the discount factor only affects the customer’s belief and the revenue itself is not time-discounted. Since reviews do not affect the customer’s belief under when ,
| (4) |
and we can show that (see Appendix E.1).
Lastly, we define a “review-benefiting” condition where customers are more likely to buy when the weights placed on reviews are higher (Definition 5.1). Without this, it could be better for the platform to intentionally show no reviews; hence this condition effectively states that reviews “help” on average.
Definition 5.1 (Review-benefiting price for an instance).
A price is review-benefiting for an instance if for any set of weights where ,141414 refers to for all , and the inequality is strict for at least one element.
Each term refers to the expected purchase probability given the weight vector for the reviews, where the expectation is over the review ratings . Definition 5.1 states that when the weights are larger, the expected purchase probability should also be larger.
To provide intuition, we discuss two instances that induce review-benefiting prices. The first is when the prior mean is correct () but customers are pessimistic, i.e., their estimate for the fixed valuation is the -quantile of for . In this case, incorporating reviews reduces the variance of the customer’s posterior and hence a higher weight on reviews increases on average. The second example is when customers are risk-neutral, i.e., is the mean of , but the prior mean is negatively biased (). Incorporating more reviews drawn from , on average, increases the mean of the posterior . We formalize these instances in Appendix E.2.
5.2 (Non-)Monotonicity in Revenue with Respect to
We analyze how depends on the window size for different values of the discount factor . We first consider customers who discount extremely: ; i.e., only the previous round’s review is incorporated in the customer’s belief. In Theorem 5.1 (proof in Section E.3), we establish that the revenue of is monotonic in . Since , this implies that for any . Therefore, if customers heavily discount, is indeed the best ordering policy. To ensure that the process of the newest reviews does not get absorbed into any state of reviews, we say that a price is strongly non-absorbing if the purchase probability for any state of reviews and any discount factor lies in (see Definition E.1 for a formal statement).
Theorem 5.1.
For a review-benefiting and strongly non-absorbing price , is strictly decreasing in .
Next, we consider the other extreme of ; this is equivalent to our original model where all reviews are weighted equally. By Theorem 3.1 we have already established that . The following theorem (proof in Section E.4) extends this result by showing that is strictly increasing in the window .
Theorem 5.2.
For any non-degenerate and non-absorbing static price , is strictly increasing in .
Slightly discounting customers.
We have established that the revenue has an opposite relationship in under and . It is natural to ask what happens when . We consider the case when customers employ a discount factor close to 1; i.e., where is small. In the following theorem (proof in Section E.5), we establish that the revenue is no longer monotonic in ; the maximum revenue is achieved by a finite .
Theorem 5.3.
For any problem instance and any non-degenerate, non-absorbing, review-benefiting, and strongly non-absorbing price , there exists such that, for all discount factors , there exist finite with
5.3 Interaction between CoNF and the Discount Factor
Recall that a review-benefiting price for an instance implies that when the review ratings are drawn independently (), higher weights result in a higher purchase probability. Therefore, one may expect that the revenue would be higher for non-discounting customers () than for those that discount (). However, we show below that, under , this intuition does not always hold due to the interaction with the Cost of Newest First.
We focus on a class of instances where a single review is shown (), the customer-specific valuation is uniform ( with ), the fixed valuation is , the prior parameters are (correct prior mean), and is the -quantile of the customer’s belief for , i.e., the customer’s estimate for fixed valuation is pessimistic.
Theorem 5.4.
For any instance in the class and any , there exists a non-absorbing and review-benefiting price such that .
The high-level idea behind this result (proof in Section E.9) is that the impact of the Cost of Newest First is higher when the weights are larger. To see this, suppose a negative review is posted at time , which decreases the purchase probability for the future customers who see this review as the first review. If customers are time-discounting (), then even if this review is the newest review, the weight of this negative review eventually vanishes. On the other hand, if customers do not discount () then the weight of this review stays at 1 as long as this is remains as the newest review. As a result, the negative impact of the Cost of Newest First can outweigh the positive impact of higher weights that a review-benefiting instance offers.
6 Evidence supporting CoNF from Tripadvisor
Tripadvisor is an online platform whose default review ordering policy is . We focused on 109 hotels in the region of Times Square, New York, where we retrieved the newest 1000 reviews for each of these hotels. We searched “Times Square” on Tripadvisor (March 20, 2024) and collected data from the first 21 hotels with more than 1000 reviews.151515We initially retrieved 3 more hotels that had less than 1000 reviews (respectively 394, 770, and 957) but later removed them to have a consistent rule. All of those three hotels exhibit CoNF and thus including them would only strengthen our empirical findings. Subsequently, we made the same query and collected 88 additional hotels (August 6, 2024). A hotel’s page on Tripadvisor displays the average numerical rating of all reviews, as well as details of the first 10 reviews. More reviews can be shown if the user clicks for the next page of reviews. Each review has a rating (an integer between and ), the date the review was written, information on the user who wrote the review, as well as the text of the review.
We validate our theoretical findings using this dataset. Recall that Theorem 3.3 states that the average number of positive reviews from the first reviews is smaller under compared to . We corroborate this result by computing the empirical distributions for each hotel (similar to Figure 2). Since the hotel’s page on Tripadvisor shows 10 reviews by default, we use .
For each hotel, we compute two empirical distributions, which we call and . Let and be the dates of when the earliest and the latest review was written (among the reviews retrieved for this hotel). For each date between and , we compute what the 10 newest reviews were on that date and compute their average rating; this becomes a sample in our empirical distribution . The number of samples is thus simply the number of days between and , which, on average, corresponds to years. The empirical distribution is computed by randomly sampling 10 reviews out of the all the reviews retrieved from the particular hotel and computing their average rating, where the number of samples is equal to that of .
Results.
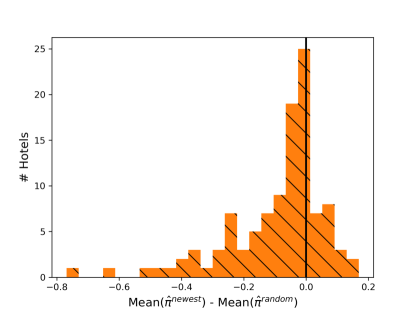
To validate our theoretical findings, we consider a null hypothesis positing that the probability of having higher mean than is exactly . In our data, we observe that, for 79 out of 109, the mean of is strictly smaller than that of which implies a p-value of (and thus rejects the null hypothesis). On average, the mean of is smaller than that of by , or 0.092 points out of 5 in absolute terms. Figure 3 plots a histogram of the difference between these means for the 109 hotels.
Next, in Figure 4, we plot the full distributions of and for four hotels (in Appendix F, we present the remaining 105 hotels); this is analogous to Figure 2. We observe that consistently has heavier left tails, while has heavier right tails. This observation matches the theoretical implication of our model (Proposition 3.4).

7 Conclusions
In this paper, we model the idea that customers read only a small number of reviews before making purchase decisions. This model gives rise to the Cost of Newest First, the idea that, when reviews are ordered by newest first, negative reviews will persist as the newest review longer than positive reviews. This phenomenon does not arise in models from the existing literature, since prior works assume that customers incorporate either all reviews or a summary statistic of all reviews into their beliefs. We show that incorporating randomness into the review ordering or using dynamic pricing can alleviate the negative impact of the Cost of Newest First.
Our work opens up a number of intriguing avenues for future research. First, existing literature on social learning studies the self-selection bias (which we do not consider in our model) – how does this self-selection bias interact with the Cost of Newest First? Second, in terms of operational decisions, a platform contains multiple products — should it take the state of reviews into consideration when making display or ranking decisions? Third, given this bounded rationality behavior, are there alternative methods of of disseminating relevant information from reviews? For example, one could succinctly summarize information from all reviews (via, e.g, generative AI) to be the most helpful for each customer. Fourth, we assume that the true quality does not change over time (which enables us to characterize the closed-form expression of the corresponding steady state). Given that changes in the product quality are one of the reasons behind the ubiquitous use of Newest First, it would be interesting to revisit the Cost of Newest First in such dynamic environments. Lastly, on the theoretical side, our analysis fully characterizes the steady state of a stochastic process whose state remains unchanged with some state-dependent probability (Lemma C.3 which is the crux in the analysis of Lemma 3.1). It would be interesting to apply this result to other settings that exhibit a similar structure.
Acknowledgements.
We thank the anonymous reviewers from the 25th ACM Conference on Economics and Computation (EC 2024) for their thorough feedback that greatly improved the presentation of the paper. We are also grateful to the Simons Institute for the Theory of Computing as this work started during the Fall’22 semester-long program on Data Driven Decision Processes.
References
- [AGI11] Nikolay Archak, Anindya Ghose, and Panagiotis G Ipeirotis. Deriving the pricing power of product features by mining consumer reviews. Management science, 57(8):1485–1509, 2011.
- [AMMO22] Daron Acemoglu, Ali Makhdoumi, Azarakhsh Malekian, and Asuman Ozdaglar. Learning from reviews: The selection effect and the speed of learning. Econometrica, 90(6):2857–2899, 2022.
- [Ban92] Abhijit V Banerjee. A simple model of herd behavior. The quarterly journal of economics, 107(3):797–817, 1992.
- [BHW92] Sushil Bikhchandani, David Hirshleifer, and Ivo Welch. A theory of fads, fashion, custom, and cultural change as informational cascades. Journal of political Economy, 100(5):992–1026, 1992.
- [BMZ12] John W Byers, Michael Mitzenmacher, and Georgios Zervas. The groupon effect on yelp ratings: a root cause analysis. In Proceedings of the 13th ACM conference on electronic commerce, pages 248–265, 2012.
- [Bon23] Tommaso Bondi. Alone, together: A model of social (mis)learning from consumer reviews. In Kevin Leyton-Brown, Jason D. Hartline, and Larry Samuelson, editors, Proceedings of the 24th ACM Conference on Economics and Computation, EC 2023, London, United Kingdom, July 9-12, 2023, page 296. ACM, 2023.
- [BPS18] Kostas Bimpikis, Yiangos Papanastasiou, and Nicos Savva. Crowdsourcing exploration. Management Science, 64(4):1477–1973, 2018.
- [BPS22] Etienne Boursier, Vianney Perchet, and Marco Scarsini. Social learning in non-stationary environments. In International Conference on Algorithmic Learning Theory, pages 128–129. PMLR, 2022.
- [BS18] Omar Besbes and Marco Scarsini. On information distortions in online ratings. Operations Research, 66(3):597–610, 2018.
- [CDO22] Ishita Chakraborty, Joyee Deb, and Aniko Oery. When do consumers talk? Available at SSRN 4155523, 2022.
- [CIMS17] Davide Crapis, Bar Ifrach, Costis Maglaras, and Marco Scarsini. Monopoly pricing in the presence of social learning. Management Science, 63(11):3586–3608, 2017.
- [CLT21] Ningyuan Chen, Anran Li, and Kalyan Talluri. Reviews and self-selection bias with operational implications. Management Science, 67(12):7472–7492, 2021.
- [CM06] Judith A Chevalier and Dina Mayzlin. The effect of word of mouth on sales: Online book reviews. Journal of marketing research, 43(3):345–354, 2006.
- [CSS24] Christoph Carnehl, André Stenzel, and Peter Schmidt. Pricing for the stars: Dynamic pricing in the presence of rating systems. Management Science, 70(3):1755–1772, 2024.
- [DLT21] Gregory DeCroix, Xiaoyang Long, and Jordan Tong. How service quality variability hurts revenue when customers learn: Implications for dynamic personalized pricing. Operations Research, 69(3):683–708, 2021.
- [FKKK14] Peter Frazier, David Kempe, Jon Kleinberg, and Robert Kleinberg. Incentivizing exploration. In Proceedings of the fifteenth ACM conference on Economics and computation, pages 5–22, 2014.
- [Gal97] Robert G Gallager. Discrete stochastic processes. Journal of the Operational Research Society, 48(1):103–103, 1997.
- [GHKV23] Wenshuo Guo, Nika Haghtalab, Kirthevasan Kandasamy, and Ellen Vitercik. Leveraging reviews: Learning to price with buyer and seller uncertainty. In Kevin Leyton-Brown, Jason D. Hartline, and Larry Samuelson, editors, Proceedings of the 24th ACM Conference on Economics and Computation, EC 2023, London, United Kingdom, July 9-12, 2023, page 816. ACM, 2023.
- [GI10] Anindya Ghose and Panagiotis G Ipeirotis. Estimating the helpfulness and economic impact of product reviews: Mining text and reviewer characteristics. IEEE transactions on knowledge and data engineering, 23(10):1498–1512, 2010.
- [GPR06] Jacob K Goeree, Thomas R Palfrey, and Brian W Rogers. Social learning with private and common values. Economic theory, 28:245–264, 2006.
- [HC24] Michael Hamilton and Titing Cui. Fresh rating systems: Structure, incentives, and fees. Incentives, and Fees (June 24, 2024), 2024.
- [HPZ17] Nan Hu, Paul A Pavlou, and Jie Zhang. On self-selection biases in online product reviews. MIS quarterly, 41(2):449–475, 2017.
- [IMSZ19] Bar Ifrach, Costis Maglaras, Marco Scarsini, and Anna Zseleva. Bayesian social learning from consumer reviews. Operations Research, 67(5):1209–1221, 2019.
- [Kav21] M Kavanagh. The impact of customer reviews on purchase decisions. Bizrate Insights, available at: https://bizrateinsights.com/resources/the-impact-of-customer-reviews-on-purchase-decisions/ (accessed 4 Feb 2024), 2021.
- [KKM+17] Sampath Kannan, Michael Kearns, Jamie Morgenstern, Mallesh Pai, Aaron Roth, Rakesh Vohra, and Zhiwei Steven Wu. Fairness incentives for myopic agents. In Proceedings of the 2017 ACM Conference on Economics and Computation, pages 369–386, 2017.
- [KMP14] Ilan Kremer, Yishay Mansour, and Motty Perry. Implementing the “wisdom of the crowd”. Journal of Political Economy, 122(5):988–1012, 2014.
- [LDRF+13] Stephan Ludwig, Ko De Ruyter, Mike Friedman, Elisabeth C Brüggen, Martin Wetzels, and Gerard Pfann. More than words: The influence of affective content and linguistic style matches in online reviews on conversion rates. Journal of marketing, 77(1):87–103, 2013.
- [LKAK18] Gaël Le Mens, Balázs Kovács, Judith Avrahami, and Yaakov Kareev. How endogenous crowd formation undermines the wisdom of the crowd in online ratings. Psychological science, 29(9):1475–1490, 2018.
- [LLS19] Xiao Liu, Dokyun Lee, and Kannan Srinivasan. Large-scale cross-category analysis of consumer review content on sales conversion leveraging deep learning. Journal of Marketing Research, 56(6):918–943, 2019.
- [LS16] Ilan Lobel and Evan Sadler. Preferences, homophily, and social learning. Operations Research, 64(3):564–584, 2016.
- [Luc16] Michael Luca. Reviews, reputation, and revenue: The case of yelp. com. Com (March 15, 2016). Harvard Business School NOM Unit Working Paper, (12-016), 2016.
- [LYMZ22] Zhanfei Lei, Dezhi Yin, Sabyasachi Mitra, and Han Zhang. Swayed by the reviews: Disentangling the effects of average ratings and individual reviews in online word-of-mouth. Production and Operations Management, 31(6):2393–2411, 2022.
- [MSS20] Yishay Mansour, Aleksandrs Slivkins, and Vasilis Syrgkanis. Bayesian incentive-compatible bandit exploration. Operations Research, 68(4):1132–1161, 2020.
- [MSSV23] Costis Maglaras, Marco Scarsini, Dongwook Shin, and Stefano Vaccari. Product ranking in the presence of social learning. Operations Research, 71(4):1136–1153, 2023.
- [Mur19] Rosie Murphy. Local consumer review survey 2019. Technical report, National Bureau of Economic Research, 2019.
- [PSX21] Sungsik Park, Woochoel Shin, and Jinhong Xie. The fateful first consumer review. Marketing Science, 40(3):481–507, 2021.
- [RHP23] Hang Ren, Tingliang Huang, and Georgia Perakis. Impact of social learning on consumer subsidies and supplier capacity for green technology adoption. Available at SSRN 4335284, 2023.
- [Say18] Amin Sayedi. Pricing in a duopoly with observational learning. Available at SSRN 3131561, 2018.
- [SR18] Sven Schmit and Carlos Riquelme. Human interaction with recommendation systems. In International Conference on Artificial Intelligence and Statistics, pages 862–870. PMLR, 2018.
- [SS00] Lones Smith and Peter Sørensen. Pathological outcomes of observational learning. Econometrica, 68(2):371–398, 2000.
- [ZZ10] Feng Zhu and Xiaoquan Zhang. Impact of online consumer reviews on sales: The moderating role of product and consumer characteristics. Journal of marketing, 74(2):133–148, 2010.
Appendix A Formal definition of the random ordering policy (Section 2.2)
We now show that the policy can be defined as the limit of as . For a vector of review ratings , we denote . Proposition A.1 implies that as , the draws from across different rounds are independent and the distribution approaches the distribution of .
Proposition A.1.
For any review rating vectors and rounds , the distribution of reviews by approaches the one of as , i.e.,
We first show that as goes to infinity, the reviews selected by at each round come from the infinite pool of reviews with high probability. Let be the largest integer such that and let be large enough so that . We define as the event that for every the reviews selected by come from the set . Lemma A.1 shows that happens with high probability.
Lemma A.1.
. Furthermore, .
Given that selects from the infinite negative pool of reviews with high probability (if holds), we now derive a concentration bound for the reviews in this pool. Recall that for . We partition those reviews into groups each containing reviews. Let be the event that, for each group, the average review rating concentrates around the group’s mean, i.e.
Our next lemma shows that the concentration event happens with high probability.
Lemma A.2.
. Furthermore, .
In order to decompose the left-hand-side of Proposition A.1 into a product of probabilities, we show the following independence lemma.
Lemma A.3.
Let . Then conditioned on and , the events for are independent.
Having shown independence across rounds, we prove that, for any round , is close to . Let be the set of review rating sequences for which event holds i.e.
Our next lemma shows that if the events and hold, then for any round , the distribution of is close to the distribution of . To ease notation, we let and .
Lemma A.4.
There exists some function satisfying such that assuming that and hold, for any and :
Proof of Proposition A.1.
By Lemma A.1 and Lemma A.2, we can upper bound the probability that neither of nor holds by
| (5) |
We thus assume that and holds which means we focus on sequences . By the law of total probability and the independence of across rounds (i.e. Lemma A.3):
| (6) | ||||
By Lemma A.4, we can upper and lower bound this decomposition by
| (7) |
Recall that consists of all sequences that satisfy the event . Summing across those sequences and using the independence between the choice of (which determines ) and the values of (which determine ), we obtain
| (8) |
We conclude the proof by combining (5), (6), (7), (8) and using the fact that . ∎
A.1 High probability bound on (Proof of Lemma A.1)
Proof of Lemma A.1.
Fix a particular round . Note that since , the most recent reviews that considers contain . The probability that all reviews come from that set is . For each round in , the subset of reviews is independently drawn by . Thus, . Next notice that and therefore, showing the second part. ∎
A.2 Concentration for infinite pool (Proof of Lemma A.2)
Proof of Lemma A.2.
For a fixed , by Chernoff bound, it holds that
By union bound on the groups, the event has probability at least . Note that , which yields the second part. ∎
A.3 Independence of across rounds (Proof of Lemma A.3)
Proof of Lemma A.3.
By definition, samples a -sized subset of reviews independently at every round. Thus, conditioning on the subset being sampled from , i.e. , and also conditioning on the exact values of these ratings, i.e. , the draws of are independent for . ∎
A.4 Single round approximation (Proof of Lemma A.4)
Let be the review ratings chosen from the most recent reviews. Recall that when holds, selects reviews from and that . Let for be a partition of all reviews into groups of reviews each. We first show that the reviews drawn by come from different groups with high probability. Let be the event that no two indices are such that and belong to the same group for some . Our next lemma lower bounds the probability of .
Lemma A.5.
Assume that and hold. The probability of any two selected indices being of different groups is: and thus .
Proof.
Let be the event that . Notice that is exactly the event that none of the hold. Further, note that implies that since we output an ordered set of reviews by recency. There are thus ways to choose to be in the same group . Hence the probability of is at most
as there are at most ways to choose and at most ways to choose . Using the inequalities , we obtain that
since . Thus, via union bound over and , i.e., events, the probability of is lower bounded as follows
∎
When the event holds then the reviews for come from different groups . We show that when this happens the values of the reviews are independent. Let be the event that review comes from group for . The next lemma shows that conditioned on the event , the values of are independent.161616This is not the case without conditioning on . As an example, consider two ordered reviews drawn uniformly from the three ordered review ratings . Conditioned on then deterministically while conditioned on then . As a results and are correlated. Recall that implies that .
Lemma A.6.
Let be group indices with . Conditioned on , , and , for any vector of review ratings , the events for are independent. Furthermore,
Proof.
For any specific review ratings , applying Bayes rule
There are choices for the set of ratings so that for and total number of choices. Hence holds with probability . Given that there is exactly one choice for the reviews which satisfies :
| (9) |
Since this holds for any we obtain independence of for . By summing (9) over , for any particular , we have . Therefore, the probability that has a particular value is equal to the fraction of which have value i.e.
∎
We next show that conditioned on the events ,, and the distribution of is close to the distribution of . Given that the latter consists of i.i.d. , for vector of review ratings . Recall that . Using the independence acorss different groups (Lemma A.6), the following lemma shows that has a similar decomposition as .
Lemma A.7.
Conditioned on , , and , for any vector of review ratings , is lower bounded by and upper bounded by
Proof.
Using Lemma A.6:
As , we have that for all . Applying these inequalities for each yeilds
for any . As is the union of events for all indices , this implies
∎
Proof of Lemma A.4.
The law of total probability yields the following decomposition
By this decomposition and Lemma A.7, we can lower bound by
and upper bound the same probability by
Therefore,
where
Recall that . Since (Lemma A.5) and , we obtain that for any because
As a result, satisfies the desired property and concludes the proof. ∎
Appendix B Generalizing beyond Beta-Bernoulli distributions (Remark 2.1)
We consider a generalization of the customer behavior model in Section 2. We only point to the modeling assumptions that change; everything else remains as in Section 2:
-
1.
With respect to the customer valuation, the product’s unobservable part is drawn from an arbitrary distribution with mean and finite support where and . That is, is no longer restricted to be Bernoulli with and in . This can capture a system where is the number of stars () which is common in online platforms such as Tripadvisor, Airbnb, and Amazon.
-
2.
With respect to the customer purchase behavior, when presented with a vector of reviews , the customer maps them to an estimated valuation , where is an arbitrary fixed mapping. The model of Section 2.1 is a special case where the estimate is created via a two-stage process: the customer initially creates a posterior belief and maps this posterior to an estimate via a mapping . Unlike this special case (where the estimate can only depend on the number of positive reviews in the displayed reviews), our generalization here allows an arbitrary mapping from that can also take the order of reviews into consideration.
-
3.
With respect to the customer review generation, the review in the event of a purchase and otherwise. The difference to Section 2 is that is not restricted to be Bernoulli.
-
4.
We assume that the estimator is strictly increasing in each coordinate of the review ratings . This extends Assumption 2.1 in a way that can capture the order of the reviews.
-
5.
We assume that the customer’s smallest estimated valuation where has nonzero mass on non-negative numbers, i.e, . This extends Assumption 2.2 and ensures that there exist non-negative prices inducing positive purchase probability.
The main driver behind all results in Sections 3 and 4 is the characterization of the stationary distribution of the Markov chain of the newest reviews.
-
•
Estimator generalizes the customer’s purchase behavior. The purchase probability at a state with review ratings is where is the pricing policy.
-
•
The review generation process changes the transition dynamics of upon a purchase, i.e., a new review takes one of the values (as opposed to in the original model).
-
•
Letting be the probability mass function of , the stationary distribution of is
- •
Using this stationary distribution and similar steps as in the proofs of Proposition 3.3 and Proposition 4.2 the revenue of in the generalized model becomes:
The revenue of (which shows i.i.d. reviews from ) directly follows by adapting the purchase probability in Proposition 3.2 and Theorem 4.3:
Theorem 3.1 and 4.2 then extend to our generalized model by analogously adapting their proofs. With respect to the negative results (Theorem 3.2 and Theorem 4.1), given that the model in the main body is a special case of the generalized model, they also directly extend. With respect to Section 5, similar extensions can be derived under appropriate assumptions; given that those results are about a specific time-discounting model, we do not focus on this extension.
Remark B.1.
The generalized model allows for customers who are fully Bayesian in estimating the fixed valuation given the ordering policy and use an estimator mapping . Such customers could be reactive to and account for the effect of CoNF; the extension of the CoNF result may thus seem surprising. The reason why this occurs is that CoNF evaluates the customers assuming that they follow the same behavioral model under and under (and does not consider the setting where customers are reactive to the ordering policy).
Appendix C Supplementary material for Section 3
C.1 Absorbing prices cause newest first to get “stuck” (Proposition 3.1)
Proposition 3.1 posits that for absorbing prices . Let denote the vector of the most recent reviews at round . As argued in Section 3.2, is a time-homogeneous Markov Chain with a finite state space . We say that a state of this Markov Chain is absorbing if . Given that is absorbing, an absorbing state will always exist. Once enters an absorbing state, no purchase is made thereafter and it stays at the absorbing state forever. Let be the first round that enters an absorbing state; after this round no purchase is ever made.
To simplify analysis, we define a fictitious Markov chain on the same state space that makes transitions with probability if and , where is the smallest number of positive reviews that induce a positive purchase probability. If is at state , then with probability , there is no purchase and it remains at the same state. With probability , there is a purchase (and a review); the review is positive with probability (and the state transitions to ) and the review is negative with probability (and the state transitions to ). Notice that has the same transitions as with the only difference being that the purchase probability is always . Let be the first time that enters the state . Our proof relies on the following lemmas.
Lemma C.1.
For , enters an absorbing state before enters : .
Proof.
Consider the following coupling of and . Let where be an infinite sequence of i.i.d. reviews. We will couple the processes and by setting and where we will update the indices and as described below. Initially, . Let be the purchase probability at time of the process . To ensure a purchase occurs in only if it also occurs in as long as is not at an absorbing state, we draw a random number and use the following coupling:
-
•
Case 1: (both processes get a purchase). and .
-
•
Case 2: (only gets a purchase). and .
-
•
Case 3: . and .
If is at an absorbing state then we only update (i.e. with probability and otherwise ). This coupling ensures that as long as is not at an absorbing state. Since the state is absorbing, it cannot be the case that enters an absorbing state before enters . Thus which yields the result after taking expectations. ∎
Lemma C.2.
For , enters after finitely many rounds, i.e., .
Proof.
Consider the process for . For any , the probability of obtaining consecutive purchases with negative review is:
| (10) |
Let . By (10), is stochastically dominated by a Geometric random variable with success probability , implying . Since only keeps track of every -th value of , and thus . ∎
C.2 Stationary Distribution under Newest First (Lemma 3.1)
We first state a general property characterizing how the stationary distribution of a Markov chain changes if we modify it so that in every state, the process remains there with some probability.
Lemma C.3.
Let be a Markov chain on a finite state space () with a transition probability matrix and a stationary distribution . For any function , we define a new Markov chain on the same state space . At state , transitions according to the matrix with probability and remains in with probability . Then is a stationary distribution of where is a normalizing constant
Proof of Lemma C.3.
For any state , the probability of a self-transition under is since there are two ways to transition from back to itself: (1) the transition followed by a transition back to via and (2) the transition that does not alter the current state. For all states , since the only way for to transition from to is to take a transition at and follow the transitions of to get to .
The distribution is a probability distribution by the definition of the normalizing constant . Using the transitions of , it holds that:
Hence, is a stationary distribution of as for all states . ∎
Proof of Lemma 3.1 .
We will show that the stationary distribution of the newest reviews is
where is the normalizing constant. In the language of Lemma C.3, corresponds to , the state space to , and is a function that expresses the purchase probability at a given state, i.e., . Note that with probability , remains at the same state (as there is no purchase).
To apply Lemma C.3, we need to show that whenever there is purchase, transitions according to a Markov chain with stationary distribution . Consider the Markov chain which always replaces the -th last review with a new review. This process has stationary distribution equal to the above numerator and transitions according to upon a purchase, i.e., with probability . As a result, by Lemma C.3, is a stationary distribution for . As is irreducible and aperiodic, this is the unique stationary distribution. ∎
C.3 Closed-form expression for Cost of Newest First (Lemma 3.2)
C.4 Monotonicity of CoNF under monotone hazard rate (Remark 3.1)
Definition C.1.
A continuous distribution with probability and cumulative density functions and has Monotone Hazard Rate (MHR) if the hazard rate function is non-decreasing in .
To complement Theorem 3.2, we also show a structural result for the behavior of as a function of when has MHR.
Proposition C.1.
Suppose that is a continuous distribution with support and has MHR. Then is non-decreasing for .171717The same proof also extends to cases when and/or .
Proof.
By Lemma 3.2, the CoNF is given by
Letting be the cumulative density function of and be the survival function:
We denote the ratio of the purchase probability with and positive reviews by . For , this ratio is because due to the monotonicity of (Assumption 2.1). Given that is continuous, is differentiable for any such that . Furthermore for , for all , and thus is differentiable at .
We now show that is non-decreasing in . Letting be the probability density function of and taking the derivative of with respect to :
Observe that since and the strict monotonicity of . By the MHR property of : , implying that , and thus is non-decreasing in .
To finish the proof of the theorem, we rewrite as a function of as
Note that the function is non-decreasing for . Since is non-decreasing in , then is monotonically increasing in for every . Thus, is non-decreasing in . ∎
C.5 Structure of CoNF for and uniform distributions (Remark 3.1)
To study how depends on the price we consider a set of instances where a single review is shown () and be the uniform distribution on . The set of non-degenerate and non-absorbing prices is . First, we provide a closed form expression for the CoNF.
Proposition C.2.
Let and . For , the CoNF is given by
Proof.
We next quantify how fast the CoNF increases as : we show that a price of results in a CoNF of . In particular, for we define a target price and show the following corollary.
Corollary C.1.
Let and . For and , the CoNF is lower bounded by
Proof.
We first verify that is a solution to the equation
| (12) |
which is equivalent to
| (13) |
If , the solution of is and in order for to hold we need which can be rewritten as . As a result, and hence satisfies (13).
If , the solution is and in order for to hold we need which can be rewritten as . As a result, and hence satisfies (13).
As the first fraction in Proposition C.2 corresponds to (12), we obtain that . Since has MHR, is non-decreasing in (Proposition C.1) which finishes the proof of the corollary. ∎
C.6 Upper bounding CoNF by the effect of reviews on purchase (Remark 3.2)
Recall that quantifies how much the review ratings affect the purchase probability. It is expected that when the review ratings have a small effect on the purchase probability then the CoNF is also small (i.e. small would imply a small ). We formalize this below.
Proposition C.3.
For all non-absorbing prices , the CoNF is upper bounded by .
Proof.
The monotonicity of , implies that for all :
Taking expectation over the number of positive reviews , the first inequality implies
| (14) |
Similarly, taking expectation of the the reciprocal of the second inequality (which is well-defined as is non-absorbing) implies that
| (15) |
Expressing as the ratio of the expressions in Propositions 3.2 and 3.3 and using (14) and (15):
which concludes the proof. ∎
C.7 Average rating under is smaller than under (Theorem 3.3)
Theorem 3.3 states that the average review rating of the reviews displayed by is strictly smaller than the average rating of the reviews displayed by . To prove the theorem we first compare the behavior of and based on (i.e., the largest number of positive review ratings where the purchase probability is at most the average purchase rate ).
Lemma C.4.
For non-degenerate and non-absorbing price , if and if .
Proof of Lemma C.4.
By Lemma 3.1, it holds that . By the definition of and the monotonicity of , if , and thus . The other case is analogous. ∎
Lemma C.5.
For any non-degenerate and non-absorbing price , the probability of showing at most positive review ratings is strictly larger under than under . Formally, .
Proof of Lemma C.5.
By Lemma C.4, for . To show the claim it is enough to show that there is some such that . We show that the purchase probability when all reviews are negative is strictly greater under than under i.e. . By the monotonicity of , for all . Since is non-degenerate, the inequality is strict when . Taking the reciprocal and expectation of the last inequality yields the result. ∎
Proof of Theorem 3.3.
Appendix D Supplementary material for Section 4
D.1 CoNF still exists under optimal dynamic pricing (Proposition 4.1)
Proof of Proposition 4.1.
For any , we provide an instance with . The instance consists of a single review , true quality , estimate mappings , , and customer-specific valuation where .
First, for any and any price the revenue of selling to a customer with valuation where is given by if . Thus, the revenue maximizing price is yielding an optimal revenue of
| (16) |
Theorems 4.3 and 4.5 imply that . Using (16) with , we obtain
| (17) |
where because for and thus
Using (17) , the CoNF can be expressed as:
where (1) follows by the expression for the optimal revenue (17), (2) follows by which follows by the definition of , (3) follows by , and (4) follows by because and .
Thus, . The second term is as , and thus as . Therefore, for any there is some sufficiently small such that . ∎
D.2 is no worse than under optimal dynamic pricing (Remark 4.1)
Theorem 3.1 established that for any fixed non-degenerate and non-absorbing price . Here we show that if the platform optimizes over dynamic prices we have i.e. has no smaller revenue that under optimal dynamic prices. Recall that . We show the following result.
Theorem D.1.
For any problem instance, .
Proof.
By definition of , it is sufficient to show that
| (18) |
Letting and , Theorem 4.4 yields that the pricing policy given by is optimal under and is thus the maximizer of the left-hand side of (18). To prove (18) it is sufficient to show that offering prices under yields the same revenue as offering prices under i.e. .
As shows i.i.d. reviews, the revenue of any pricing policy is given by
| (19) |
For any reviews the purchase probability under equals
| (20) |
and is independent of . As , the number of positive review ratings is distributed as ; the expected price of is thus
| (21) |
where the last equality uses the definition of . Combining (19), (20),and (21), we obtain . The last expression is exactly equal to by Theorem 4.5 which concludes the proof. ∎
Another way to prove Theorem D.1 stems from using the convexity of , defined in the beginning of Section 4.2. This is shown in the lemma below.
Lemma D.1.
is a convex function in .
Alternative proof of Theorem D.1.
By Theorem 4.3 and Theorem 4.5, we know that
and
By Lemma D.1 is convex. Thus by Jensen’s inequality the theorem follows as
∎
Proof of Lemma D.1.
Let . To show that is convex, it suffices to prove that
Let be an optimal price for selling to a customer with valuation . We define two prices and . The probability that a customer with valuation purchases under equals the probability that a customer with valuation purchases under and thus
Similarly, a customer with valuation purchases under equals the probability that a customer with valuation purchases under and thus
Therefore, rearranging and using that we obtain
Upper bounding the left-hand side, the proof of the lemma concludes as
∎
D.3 Stronger CoNF upper bound under further assumptions on (Remark 4.2)
Theorem D.2.
For any instance with for all :
Proof.
Similar to the proof of Theorem 4.2, we define and let for convenience. We refine the analysis of Lemma 4.5, to show that for any , . We consider two cases:
-
•
If , then and thus
since as . If , then
-
•
If , then
The first inequality uses as the optimal price . The second inequality uses as .
By Lemma 4.4, the expected price ratio is upper bounded as . Combining this with the aforementioned bound on the demand ratio the proof follows. ∎
D.4 Characterization of optimal revenue under Newest First (Theorem 4.5)
Proof of Theorem 4.5.
Letting , Theorem 4.4 establishes that the optimal dynamic pricing policy is review-offsetting with offset . Using the expression for the revenue of review-offsetting policies with offset in Lemma 4.2:
∎
D.5 All optimal dynamic policies under Newest First (Remark 4.3)
Theorem D.3.
Suppose that the platform uses as the review ordering policy. Let be any revenue-maximizing price for . A dynamic pricing policy is optimal if and only if it has the form
For an arbitrary dynamic pricing policy , letting , the optimality condition of the theorem can be rewritten as 181818If the customer-specific distribution is strictly regular, there is a unique optimal dynamic pricing policy.
| (22) |
Recall that by Theorem 4.5, the optimal dynamic pricing revenue under is equal to the optimal revenue of selling to a customer with valuation , i.e., . Lemma 4.1 establishes that the revenue of is upper bounded by the revenue of one of the policies and that equality is achieved if and only if each of have the same revenue. To characterize all optimal dynamic pricing policies, we show that is optimal if and only if is a revenue maximizing price when selling to a customer with valuation (Lemma D.2).
Lemma D.2.
The policy is optimal if and only if is a revenue maximizing price when selling to a customer with valuation i.e. .
Proof.
Given that is a review-offsetting policy with offset , Lemma 4.2 implies
By adding and subtracting from each side the purchase probability can be rewritten as
Thus, the revenue of is equal to the revenue of offering a price of to a customer with valuation , which is maximized if and only . ∎
Proof of Theorem D.3.
D.6 Uniqueness of optimal dynamic pricing for Newest and Random (Remark 4.3)
We show that the optimal dynamic pricing policies under and are unique assuming mild regularity conditions on the customer-specific value distribution . For a continuous random variable with bounded support, let be its survival function. As has a continuous distribution, the inverse survival function is well-defined for , i.e., for any quantile , is the unique price which induces a purchase probability . Let be the revenue as a function of the quantile . We require a notion of strict regularity.
Definition D.1 (Strict Regularity).
A random variable has a strictly regular distribution if the revenue function is strictly concave in the quantile .
In order to show uniqueness of the optimal dynamic pricing policies, we extend the strict regularity assumption by imposing a few mild further conditions.
Definition D.2 (Well-behavedness).
A random variable is well-behaved if: (1) is continuous with bounded support; (2) is strictly regular; (3) .
Condition (3) implies that we can achieve a strictly positive revenue by selling to a customer with a well-behaved valuation .
Lemma D.3.
For any and well-behaved random variable , is also well-behaved.
Proof of Lemma D.3.
To prove that is well-behaved we establish all three conditions of Definition D.2. First, the continuity and boundedness of imply that also has these properties. Second, is strictly concave and is linear in ; thus is strictly concave. Third, as , adding a non-negative scalar yields . ∎
Lemma D.4.
For a well-behaved random variable , the revenue-maximizing price is unique.
Proof of Lemma D.4.
Letting the support of be implies that for all , , and . Thus,
By the third condition of well-behavedness, which implies that and thus there exists some quantile such that . In particular, for , as . Since , , and is strictly concave on , it holds that either (a) has a unique maximizer at or (b) is strictly increasing for . We consider these two cases separately below.
For case (a), the optimal price has a quantile such that for all . The strict concavity of implies
| (23) |
We show that is the unique revenue-maximizing price. It suffices to show that this price provides strictly higher revenue than any other price , i.e., . Let be the quantile associated with the price .
-
•
If the continuity of implies that and thus the revenue of is strictly larger than the revenue of by the assumption of case (a) that for all .
-
•
If , then which combined with yields that the revenue of is strictly larger than the revenue of .
-
•
Lastly, if , then by (23).
For case (b), is strictly increasing for . Let . Since , , and we obtain that . To show that is the unique revenue-maximizing price, it suffices to prove that for any .
-
•
If the continuity of implies that and thus the revenue of is strictly larger than the revenue of by the assumption of case (b) that is increasing on .
-
•
If then and thus which is strictly smaller than .
-
•
Lastly if , then .
As a result, in both cases, we established that there exists a unique revenue-maximizing . ∎
Proposition D.1.
For a well-behaved customer-specific valuation , the optimal dynamic pricing policies under and are unique.
Proof.
The valuation of a customer at a state with review ratings is . By Theorem 4.3, any optimal dynamic pricing policy under outputs, at each state of review ratings , a revenue-maximizing price for a customer with valuation . Combining Lemma D.3 with and Lemma D.4, this price is unique for every state of review ratings .
By Theorem D.3, any optimal dynamic pricing policy under outputs, at each state of review ratings , a price of where is a revenue-maximizing price for a customer with valuation . Combining Lemma D.3 with and Lemma D.4, the price is unique for every state of review ratings . ∎
D.7 Dynamic pricing revenue of Newest First (Proposition 4.2)
As an analogue of Lemma 3.1, let denote the process of the newest reviews. We note that is a time-homogenous Markov chain on a finite state space .
If is at state it stays at that state if there is no purchase (with probability ). If there is a purchase with a positive review, it transitions to (with probability ). If there is a purchase with a negative review, it transitions to (with probability ). If and is non-absorbing, is a single-recurrence-class Markov chain with no transient states. Thus, admits a unique stationary distribution characterized in the following lemma.
Lemma D.5.
The stationary distribution of under any non-absorbing policy is 191919Recall that for a state of reviews , denotes the number of positive review ratings.
where is a normalizing constant.
Proof of Lemma D.5.
Similar to the proof of Lemma 3.1, we invoke Lemma C.3. In the language of Lemma C.3, corresponds to , the state space to , and is a function that expresses the purchase probability at a given state, i.e., . Note that with probability , remains at the same state (as there is no purchase).
To apply Lemma C.3, we need to show that whenever there is purchase, transitions according to a Markov chain with stationary distribution . Consider the Markov chain which always replaces the -th last review with a new review. This process has stationary distribution equal to the above numerator and transitions according to upon a purchase, i.e., with probability . As a result, by Lemma C.3, is a stationary distribution for . As is irreducible and aperiodic, this is the unique stationary distribution. ∎
Proof of Proposition 4.2.
D.8 Ratio of averages is bounded by maximum ratio (Lemma 4.3)
Proof of Lemma 4.3.
We show the inequality by contradiction and assume that for all . Given that the denominators are positive, this implies that for any
Summing over we obtain the following which is a contradiction:
As a result . With respect to equality, let . Thus,
| (24) |
Multiplying by the denominators and rearranging the above can be rewritten as
| (25) |
Since , for all , and for all , (25) holds only if for all . For the “if” direction, suppose that for all . In particular this holds, when is a maximizing index and is an arbitrary index. This implies that (25) holds for any and therefore so does (24), which concludes the proof. ∎
D.9 Comparing optimal dynamic pricing for Newest and Random (Remark 4.4)
We compare the optimal dynamic pricing policies under and assuming that the customer-specific valuation is well-behaved (Definition D.2). Recall that Proposition D.1 implies that when is well-behaved, the optimal dynamic pricing policies under and are unique. Let and be those pricing policies.
Proposition D.2.
Let . For any well-behaved customer-specific valuation , the unique dynamic pricing policies and satisfy:
-
•
for review states with
-
•
for review states with
-
•
review states with .
Intuitively, Proposition D.2 suggests charges higher prices in review states with “high” ratings and lower prices in review states with “low” ratings compared to in order to induce the same purchase probability in every review state.
To prove Proposition D.2, we introduce the revenue maximizing price of selling to a customer with valuation for a non-negative scalar i.e. .
We also introduce the function which intuitively captures the smallest idiosyncratic valuation a customer needs to have to purchase the product and is also a proxy for the purchase probability of a customer with valuation (since ).
Lemma D.6.
For any well-behaved customer-specific value distribution , is weakly decreasing for .
Proof of Proposition D.2.
Theorem 4.3 implies that the optimal dynamic pricing policy under is for . Theorem 4.4 implies that the optimal dynamic pricing policy under is . As a result:
By Lemma D.6, is monotonically decreasing which implies the result of the proposition. ∎
To prove Lemma D.6, we use an auxiliary lemma which shows that for large enough , the revenue-maximizing price is equal to (and thus induces a purchase probability of one). Given that is well-behaved, we let its support be .
Lemma D.7.
For any well-behaved customer-specific value distribution and , there exists some threshold such that for and for .
Proof of Lemma D.7.
First observe that since setting a price below is never optimal. Indeed, prices induce a purchase probability of one. Setting a price of for a small enough still induces a purchase probability of one and achieves a strictly higher revenue.
Second, observe that any price induces a purchase probability of zero and thus zero revenue. As is well-behaved, then so is (Lemma D.3). This implies that and thus the optimal revenue is strictly positive (as one can find a price such that ). Thus, for all .
Finally, let be the set of increments such that the revenue-maximizing price of selling to a customer with valuation is equal to . Observe that setting a price of induces a purchase probability of one and thus a revenue of . Thus, if and only if the optimal revenue of selling to a customer with valuation is . Given that , to conclude the proof it is sufficient to show that there exists some such that . To prove this, it suffices to show that satisfies two properties: (a) If then for all ; (b) If is a decreasing sequence with and , then .
For an increment and price , let be the revenue of offering a price to a customer with valuation . For property (a), let and . To show that , it is sufficient to show for all prices . Expanding we have
where the last inequality uses since and .
For property (b), let be a decreasing sequence with and such that . We show that . The continuity of implies that revenue function is continuous in for any fixed price . Combining this with the fact that for all , we obtain
∎
Proof of Lemma D.6.
Lemma D.7 shows that for and for for some threshold . Thus, for and for . It thus suffices to show that is monotonically decreasing for . The continuity of implies that the function is differentiable for and thus the first-order conditions must be satisfied at . Denoting the survival and density functions of by and respectively, this yields
for . Rearranging the last equation yields
| (26) |
for any . The strict regularity of implies that the function is strictly increasing. Thus, the left-hand side of (26) is increasing in while the right-hand side is strictly decreasing in . Hence, is decreasing for concluding the proof. ∎
D.10 Platforms unaware of state-depending behavior (Theorem 4.6)
Proof of Theorem 4.6.
Suppose that has support on . Then Theorem 4.1 gives
| (27) |
Since is non-negative, Theorem 4.2 gives
| (28) |
Combining (27) and (28) with the fact that ,
For any there exist such that when , . ∎
Appendix E Supplementary material for Section 5
E.1 Limiting behavior of for discounting customers (Section 5.1)
Theorem E.1.
For any discount factor , .
To prove the theorem, for the -th most recent review we denote by its information where is the review rating and is the number of rounds elapsed since posting the review. For a vector of the most recent reviews and their information, let be the random variable of the information from the review chosen by i.e. uniformly at random without replacement from . Given reviews with their information , the purchase probability of the customer is
For any round , let denote the most recent reviews comprising the -th most recent review rating and number of rounds elapsed since posting the review. Notice that if is at state , the ex-ante purchase probability is equal to where the expectation is over the uniform randomly chosen -sized subset , selected by , which determines the random variable . The next lemma shows that, for any state of the most recent reviews , the ex-ante purchase probability at concentrates around the purchase probability of , which we denote by .
Lemma E.1.
For any discount factor and any , there exists some threshold such that for any window size and state of reviews , it holds that
Proof of Theorem E.1.
By the law of total expectation, the revenue of is given by (1):
By Lemma E.1 for , summing for , and taking the outer expectation yields:
Taking a limit infinum and applying the above bounds we get:
Given that , . Taking , establishes that , which is equal to as the reviews shown by do not affect the customer’s posterior belief. ∎
Proof of Lemma E.1.
As , for any review information vector the contribution in the customer’s belief from the -th review goes to as . Therefore the customer’s posterior beliefs converge to the prior as . The continuity of the customer-specific value distribution implies that the purchase probability is continuous in . Together with the continuity of in this implies that for any review ratings , the purchase probability for any set of reviews shown converges the purchase probability under , i.e.,
as . Thus, for any , there exists a threshold , such that for any reviews with information if it holds that .
Let where . We define the event that all of the selected reviews indices in chosen by are greater the threshold , i.e., . When this event holds, the time elapsed since the review’s posting will be greater than as and . As a result, for the chosen and for realizations such that holds we have:
| (29) |
Using the law of total expectation
where as there are ways to choose distinct indices from but exactly satisfy that for all . The proof follows by taking the lower (resp. upper) bounds on and . ∎
E.2 Instances inducing review-benefiting prices (Discussion on Definition 5.1)
In this section we consider a class of instances where the platform shows a single review , the customer-specific distribution is uniform, i.e., , and the estimator mapping is increasing in the mean of the distribution. We say that the instance is review-monotonic if for any with
Lemma E.2.
For any review-monotonic problem instance in the class , and any price , is review-benefiting for .
Proof of Lemma E.2.
To show that is review-benefiting, expanding Definition 5.1 (for ), it suffices that for any with ,
| (30) |
Let . Since the instance is in , is increasing in the mean and , it holds that and thus for any estimate . As the support of is , the purchase probability of selling to a customer with valuation is given by . Substituting this expression for in (30) and cancelling the common terms on both sides of the equation, we obtain the following inequality,
which holds as the problem instance is review-monotonic. ∎
Let be the subclass of instances in where customers are a) pessimistic in estimating the fixed valuation, i.e., is the -quantile of for and b) have a correct =prior mean, i.e., and .
Proposition E.1.
For any instance in the class and any price , is review-benefiting for .
Recalling that for any instance in , is the -quantile of , the following lemma shows a closed form expression for and .
Lemma E.3.
For any quantile and weight , the -quantiles of and are given by and .
Proof.
For any , the density of is , and its -quantile is thus given by solving the equation
Similarly, the density of is and its -quantile is thus given by solving the equation
∎
Proof of Proposition E.1.
To prove the proposition, by Lemma E.2 it suffices to show that any instance in the class is review-monotonic. The rest of the proof focuses on that.
Using the closed form for the -quantiles of and given by Lemma E.3 and the customer’s correct prior mean (i.e. and ) the instance is review-monotonic if and only if for any :
As , to show the above it suffices to prove that for any , the function is strictly decreasing for , or equivalently its derivative for . The derivative of is given by
Since , to show that it suffices to prove that for all . Given that the right-hand side is increasing in for , it suffices to prove the above holds for . Letting this holds when for . The derivative is decreasing for and thus is concave for . The concavity of , combined with and yields that for all as desired. ∎
Let be the subclass of where a) are risk-neutral in estimating the fixed valuation, i.e., and b) have a negatively biased prior mean, i.e., .
Proposition E.2.
For any instance in the class and any price , is review-benefiting for .
Proof of Proposition E.2.
By Lemma E.2 it suffices to show that any instance in the class is review-monotonic. Given that customers are risk-neutral, for . As a result, to prove that the instance is review-monotonic it suffices to show for all with :
The last condition () holds as the customer’s prior mean is negatively biased, concluding the proof. ∎
E.3 Newest First maximizes revenue with extreme discounting (Theorem 5.1)
Definition E.1.
Let be the information of the -th review shown by the platform, where is the review rating and is the number of rounds elapsed since posting. A price is strongly non-absorbing if for any information vector and any discount factor , the purchase probability lies in , i.e.,
When , only the review from the last round counts and thus the expression simplifies to where .
For a fixed window and any round , let denote the information of the most recent reviews comprising the -th most recent review rating and number of rounds elapsed since posting the review. We define the random process to capture the state of reviews. If the newest review came from the previous round (), then if (positive review) and if (negative review). If no review was posted in the previous round (), then the customer does not take reviews into account and thus . In the latter case, the reviews shown by do not contain a review from the previous round and hence the purchase probability is
When the purchase probability can be different from if the newest review is among the reviews that were selected. This happens with probability as there are ways to choose reviews from the most recent but only of them contain the newest review. Letting and , when , the purchase probability when is thus
The next lemma characterizes the stationary distribution of the Markov chain .
Lemma E.4.
The process is a time-homogenous Markov chain with stationary distribution:
Proof of Lemma E.4.
We describe the transition dynamics of the process . If , then a purchase occurs with probability . If a purchase occurs, a new review is posted and the state transitions to if the review is positive (with probability ) and to if the review is negative (with probability ). If no purchase occurs the state remains the same (). If a purchase occurs with probability . If a purchase occurs, a new review is posted and the state transitions to if the review is positive (with probability ) and to if the review is negative (with probability ). If no purchase occurs the state remains the same (). As is obtained from through transition dynamics which are independent of the time , is a time-homogeneous Markov chain. Given that is strongly non-absorbing and , every state of can be reached from every other with positive probability. Hence, is a single-recurrence class Markov chain with no transient states and therefore it has a unique stationary distribution.
We now describe the steady-state equations for the process and solve for the stationary distribution . The stationary distribution at must satisfy the equation as there are three ways to end up in state : the process was in a state and no purchase was made (with probability ). The stationary distribution at state must satisfy the equation as there are three ways to end up in . The process was in some state , a purchase was made, and the corresponding review was positive () with probability this negative and with probability . Thus, the steady-state equations of the Markov chain are given by
The stationary distribution stated in the lemma follows by solving this system of equations. ∎
Proof of Theorem 5.1.
As the ex-ante expected revenue in state is equal to , using the closed form for the stationary distribution in Lemma E.4 and the Ergodic theorem yields:
Substituting the expressions for , , transforms the second term in the denominator:
Diff is independent of and, as is review-benefiting, . Together with the fact that is strictly decreasing in this implies that is strictly increasing in and thus is strictly decreasing in . ∎
E.4 Random maximizes revenue with no discounting (Theorem 5.2)
To prove Theorem 5.2, we start with a more general class of review ordering policies. Let denote the family of all -sized subsets of . We denote by the review ordering policy that selects reviews from the most recent according to a fixed probability distribution ; when is the uniform distribution over , .
The next lemma shows that maximizes the revenue over all distributions over , which suggests for any fixed window , more randomness in the ordering implies more revenue.
Lemma E.5.
For any non-degenerate and non-absorbing price the uniform distribution maximizes the revenue over , i.e., .
We also define the distribution which ignores the -th most recent review and places equal probability on every -sized subset of . The next lemma shows that is strictly sub-optimal.
Lemma E.6.
For any non-degenerate and non-absorbing price , the revenue of is strictly suboptimal, i.e., .
Proof of Theorem 5.2.
To prove Lemma E.5, we first characterize the stationary distribution of the reviews generated by in way analogous to Lemma 3.1. In particular for any state of the most recent review ratings , the purchase probability is .
A useful quantity is the inverse purchase rate conditioned on positive reviews, i.e.,
Intuitively, is the average number of rounds the process of the most recent reviews spends at a review state with positive reviews. The following lemma shows that the uniform distribution minimizes this purchase rate for any and characterizes the equality conditions. The proof is provided at the end of this section.
Lemma E.7.
For any and any probability distribution , the inverse purchase rate under is at least the inverse purchase rate under , i.e., . Equality is achieved if and only if for all states with .
Denoting the most recent reviews at round by , we show that is a time-homogenous Markov chain on . If is at state , a purchase occurs with probability . If a purchase occurs, a new review is left and the state transitions to if the review is positive (with probability ) and to if the review is negative (with probability ). If there is no purchase, the state remains the same . Given that is a non-absorbing price, for every state of reviews , the purchase probability is positive and the probability of any new review is strictly positive (since ). Then can reach every state from every other state with positive probability (i.e. it is a single-recurrence-class Markov chain with no transient states), and hence has a unique stationary distribution denoted by . Our next lemma characterizes the form of this stationary distribution. For convenience, let be the number of positive review ratings among a vector of review ratings .
Lemma E.8.
For any non-absorbing price and any distribution , the stationary distribution of the Markov chain under the review ordering policy is given by
Proof of Lemma E.8.
Similar to the proof of Lemma 3.1, we invoke Lemma C.3. Recall that Lemma C.3 starts with a Markov chain with state space , transition matrix , and stationary distribution . For any function on , it then transforms into a new Markov chain which remains at every state with probability and transitions according to otherwise. The lemma establishes that the stationary distribution of is given by where .
In the language of Lemma C.3, corresponds to , the state space to , and is a function that expresses the purchase probability at a given state, i.e., . Note that with probability , remains at the same state (as there is no purchase).
To apply Lemma C.3, we need to show that whenever there is a purchase, transitions according to a Markov chain with stationary distribution . Consider the Markov chain which always replaces the -th last review with a new review. This process has stationary distribution equal to the above numerator and transitions according to upon a purchase, i.e., with probability . Hence, by Lemma C.3, a stationary distribution for is
This is the unique stationary distribution as is irreducible and aperiodic. Expanding over the number of positive reviews , the lemma follows as the expectation in the denominator of can be expressed as
∎
Having established the stationary distribution of we give an expression for the revenue of (similar to Proposition 3.3).
Lemma E.9.
For any non-absorbing price and any distribution , the revenue of is given by
Proof of Lemma E.9.
Using Eq. (1) and the Ergodic theorem, the revenue of is
The second equality uses that the ex-ante purchase probability for review state is and the law of iterated expectation. The third equality expresses the revenue of the stationary distribution via the Ergodic theorem. Expanding by Lemma E.8, the term cancels out:
The proof is concluded by noting that the term in the square brackets equals 1, since it is the sum over all probabilities of . ∎
Proof of Lemma E.5.
Proof of Lemma E.6.
By Lemma E.9, the revenue of can be expressed as:
By Lemma E.7, it is thus sufficient to show that there is some number of positive ratings such that . For the sake of contradiction assume this is not the case, i.e., for all . The equality condition of Lemma E.7 applied for each implies that
| (31) |
Letting denote the purchase probability given positive reviews, we show below (by induction on ) that (31) implies for any number of positive review ratings , which contradicts the fact that the price is non-degenerate.
For the base case of the induction (), consider two settings with one positive review: in the first one the positive review is the -th most recent review, while in the second one the positive review is the -th most recent review. Formally, we apply Eq. 31 for and . As places zero mass on any subset containing the last review implies that, the purchase probability at is . The purchase probability at equals when the -th review is chosen and otherwise implying . Observing that and solving the equality implies .
For the induction step (), suppose that for all . We apply Eq. 31 for ( zeros followed by ones) and ( zeros, followed by ones, followed by one). If the state of the reviews is , as never selects the -th most recent review, any reviews selected by contain at most positive review ratings and the induction hypothesis implies that the purchase probability is thus equal to regardless of the choice of the reviews. Thus, . Suppose the state of the review is . If the selected set of the selected reviews contains all the reviews at indices , the number of positive reviews is and the purchase probability . Otherwise, the selected reviews contain at most positive review ratings and by the induction hypothesis the purchase probability is . Thus, . Observing that and solving the equality implies , which finishes the induction step and the proof. ∎
We complete this subsection by proving Lemma E.7. An important quantity towards that proof is the inverse purchase rate for positive review ratings under the uniform distribution, i.e., , which we characterize in the following lemma. To ease notation, let be the purchase probability given positive reviews.
Lemma E.10.
For any number of positive review ratings , the inverse purchase rate for under the uniform distribution on is given by .
Proof of Lemma E.10.
Recall that places a probability of on every subset of . Thus, by counting the number of occurrences of each term , the purchase probability at any state with can be expressed as:
| (32) |
The second equality uses that for any number of positive reviews there are ways to choose with : ways to choose the indices from the indices where , and ways to choose the remaining indices from the indices where . The third equality uses the binomial coefficient identity
Given that the right-hand side of Eq. 32 does not depend on the review ratings ,
which completes the proof. ∎
Proof of Lemma E.7.
By Jensen’s inequality applied to the convex function ,
| (33) |
To show the lemma, it suffices to prove that for any probability distribution , the lower bound term on the left-hand side is independent of and equal to . We start by analyzing the sum in the denominator . Letting be the purchase probability given positive reviews, recalling that , and rearranging, we express the sum of interest as:
By counting the number of occurrences of each term , the inner sum can be expressed as:
| (34) |
since for any number of positive reviews there are ways to choose sequences with such that : there are ways to choose the subsequence such that and ways to choose the complementary subsequence such that .
Observing that the right-hand side of (34) is independent of , using the fact that (as is a probability distribution) as well as inequality Eq. 33 and Lemma E.10, we obtain:
This completes the proof of the inequality statement of the lemma. With respect to the equality statement, for any , the equality conditions of Jensen’s inequality imply that Eq. 33 holds with equality if and only if for any with . ∎
E.5 When customer discount slightly a finite is the best (Theorem 5.3)
The proof of Theorem 5.3 uses the following two lemmas that characterize the behavior of the revenue of as a function of the window and the discount factor . The proofs of those lemmas are provided in Appendices E.6 and E.7 respectively.
Lemma E.11.
For any non-degenerate and non-absorbing price and any -time-discounting customers, the revenue of converges to the revenue of as the window size goes to , i.e., .
Lemma E.12.
For any window and any non-degenerate and strongly non-absorbing price , the revenue is a continuous function of the discount factor .
Proof of Theorem 5.3.
For any review-benefiting price , by Proposition 3.2 and Eq. (4):
By Lemma E.11, . Since is strictly increasing in (Theorem 5.2), there exists a window with
Given that , again invoking Theorem 5.2 the above implies that
By Lemma E.12, and . As a result there exists some such that for all discount factors ,
which completes the proof. ∎
E.6 Limiting behavior of under no discounting (Lemma E.11)
We next provide the proof of Lemma E.11. Given that can be expressed as a function of a i.i.d. trials (Lemma E.9), we first show that with trials and success probability is well-concentrated around its mean. Formally, the event occurs with high probability.
Lemma E.13.
For any , and thus .
Proof.
By Chernoff bound, . Taking the limit as yields the result. ∎
Recall that is the inverse purchase rate conditioned on positive review ratings and denotes the purchase probability given positive reviews. The following lemma connects the inverse purchase rate of (assuming that the above concentration holds) with the revenue of .
Lemma E.14.
There exists a threshold such that for any window , it holds that
Proof of Lemma E.14.
Let be large enough so that for , and , which implies that and for . By Lemma E.10 for and , it holds that
One of the terms in the denominator is the binomial coefficient ratio . Letting and , we show below
| (35) |
which implies that is lower and upper bounded respectively by
Given that (as ), and , these lower and upper bounds converge to as which is equal to (by Proposition 3.2) and yields the result. We conclude the proof by showing Eq. (35). We expand the binomial coefficient ratio in the denominator of Eq. (35) as:
Observing that for , for , and for , we can bound the binomial coefficient
Given that (as ), the above proves (35). ∎
Proof of Lemma E.11.
Lemma E.9 connects the revenue of to . By the law ot total expectation, the latter term can be expanded to:
We now show that , which combined with Lemma E.13 implies that the second term goes to 0 as . As is increasing, for all number of positive review ratings and thus for all review rating states . Hence,
The proof is concluded by invoking Lemma E.9 and bounding the limit as for the expansion of (using Lemmas E.13 and E.14 as well as the boundedness of ):
∎
E.7 Continuity of revenue in the discount factor (Lemma E.12)
To prove Lemma E.12 we analyze the process of the most recent reviews under . Let be the information of the -th most recent review where is the review rating and is the staleness of the review (i.e., the number of rounds elapsed since posting the review). For a vector of the most recent reviews and their information, let be the random variable of the information from the reviews chosen by , i.e., uniformly at random without replacement from . We also denote the staleness of a state by the staleness of its oldest review, i.e., . Given reviews with their information , the purchase probability of the customer is
| (36) |
For any round , let denote the most recent reviews where the -th most recent review has rating and staleness . For any state let be the first round that reaches conditioned on starting in . The following lemma shows that the long-range transition probability of between two states decay geometrically with the staleness of the destination state. Formally, for two review states , in the next lemma shows that if starts in the probability that it ends up in after exactly rounds decays geometrically with the staleness . Further, the lemma shows that the first round enters the state , i.e., has geometrically decaying tails (its proof is provided in Section E.8).
Lemma E.15.
For any problem instance and bounded price , there exist two constants such that for any discount factor and any two review states , a) and b) .
Equipped with this lemma, we decompose the revenue of into the contribution from states with different staleness . For a state of the most recent reviews, let be the ex-ante purchase probability, where the randomness in the expectation is taken over the reviews chosen by from the most recent reviews.
Lemma E.16.
The process is a time-homogeneous Markov chain. Letting be its stationary distribution, the revenue of can be expressed as where is the contribution from states with staleness .
Proof of Lemma E.16.
The proof has three components: (1) is a time-homogeneous Markov chain; (2) is irreducible, i.e., any state can be reached from any other state with positive probability; (3) is positive-recurrent, i.e., for any state . Theorem 3 in [Gal97] then implies that has a stationary distribution and the Ergodic theorem thus yields
The last step expands and regroups over states with staleness . The remainder of the proof shows the aforementioned three components.
(1) We first argue that is a time-homogeneous Markov chain. If is at state where for , the ex-ante purchase probability is equal to . If a purchase occurs, a review with staleness of 1 is left and the next state is where with probability (positive review) , and with probability (negative review). If a purchase does not occur, the review ratings of the most recent reviews remain the same while the staleness of each review increases by one, i.e., the next state is . Thus, is time-homogeneous Markov chain.
(2) We second show that is irreducible. By part a) of Lemma E.15, for any two states implying the irreducibility of .
(3) We finally show that is positive-recurrent. The expected return time for any state is
The second inequality uses b) of Lemma E.15. The last equality uses . ∎
We next show that for any staleness , the contribution (from Lemma E.16) is bounded.
Lemma E.17.
For any strongly non-absorbing price , there exists some constant such that the contribution from states with staleness is bounded by .
Proof of Lemma E.17.
The proof has three components: (1) there exists some such that for any state , (2) the ex-ante purchase probability is for any state ; (3) has at most summands. Using (1), (2), and (3) the proof is concluded as
The remainder of the proof shows the aforementioned three components.
(1) We first show that is aperiodic at any state . The lower bound in part a) of Lemma E.15 implies that . Invoking the lower bound in part a) of Lemma E.15 again and the time-homogeneity of , for any state ,
Given that the greatest common divisor of and is 1, is aperiodic at the state .
Let be any state of review information. For any number of rounds , expressing over the possible states the Markov chain at round , using the time-homogeneity of , and the upper bound of part a) of Lemma E.15 we obtain
As is aperiodic at , Theorem 1 in [Gal97] yields .
(2) Given that is the ex-ante purchase probability, it is at most .
(3) It remains to show that has at most summands, or equivalently . For any staleness there are at most review states whose oldest review has staleness as and for all and there are thus at most possibilities for each information for . ∎
To show continuity of it remains to show continuity of each term as well as their sum. This is done in the following lemmas (proofs in Section E.8)
Lemma E.18.
For any strongly non-absorbing price , the contribution from states with staleness , , is continuous in the discount factor .
Lemma E.19.
Let be a sequence of continuous functions . Suppose that . Then is continuous in .
Proof of Lemma E.12.
To prove that is continuous in , we express it as sum over the contribution of different staleness levels (Lemma E.16):
By Lemma E.17, each summand is upper bounded by , which implies that for any . By Lemma E.18 each summand is also continuous; Lemma E.19 then implies that is continuous in . ∎
E.8 Auxillary lemmas for the proof of Lemma E.12 (Lemmas E.15, E.18, E.19)
Proof of Lemma E.15.
Lemma E.15 states that the long-range transition probabilities between any two states decay geometrically with the staleness of the destination state, i.e., there are constants such that for any states : a) and b) . Let and where and are the smallest and largest (over review states and discount factor) purchase probabilities:
For any state of review information , the ex-ante purchase probability is thus , and the non-zero transition probabilities exiting are equal to (purchase and positive review), (purchase and negative review) or (no purchase). As a result, each of these one-round, non-zero transitions probabilities is at least and at most . Given that is strongly non-absorbing, is continuous, and is continuous in , then , and thus .
Having established that the one-round, non-zero transition probabilities lie in , we now show the -round transition probabilities from to lie in , where is the staleness of the oldest review in the state . We first argue that conditioning on and , the information states are fixed. Let if there was a purchase and a review at round , and otherwise. Letting where the -the most recent review has rating and staleness , the event implies that review rating was left at round , i.e., , and no purchase was made in any other round, i.e. for . Therefore, the values are deterministically fixed. Together with the fact that , this implies that the states are also deterministically fixed and thus the -transition probability can be decomposed into a product of one-round transitions from to where . As each of those transition probabilities is in the interval , then is in the interval , yielding part a).
To prove b), let for denote the process of every -th state of . Using the time-homogeneity of and the lower bound from part a), for any state ,
| (37) |
Letting , Eq. 37 implies that is stochastically dominated by a random variable and . The definition of implies that where . Hence
where the second inequality uses that the event implies that (as is an integer). This concludes the proof. ∎
Proof of Lemma E.18.
Recall that . To prove the lemma, we show the following three components: (1) For any , is continuous in ; (2) For any , is continuous in ; (3) the number of summands in is at most . Those components imply that is continuous in . We now prove the three components.
(1) We first show that is continuous in . For any state of reviews , the ex-ante purchase probability is , where
The continuity of the customer-specific valuation and the function imply that is continuous in for any , and thus the same holds for .
(2) We next show that for any state , the stationary distribution is continuous in . Given that is positive recurrent (see proof of Lemma E.16), Theorem 3 in [Gal97] yields that its stationary distribution at any state of review information is given by . Thus, it suffices to show the continuity of .
Let be the set of states which can be reached from within one round. Notice that any is obtained from after either a purchase (with positive or negative review), or no purchase. The respective probabilities are , , and . As is continuous in , each of the one-round transition probabilities are continuous in . The tail probability can be expanded as
There are three events at state (purchase with a positive/negative review, or no purchase) yielding . Given that each of the one-round transition probabilities is continuous in and , sums over at most continuous terms and is thus also continuous. Using part b) in Lemma E.15, we bound the tail probability as
where the first inequality uses that , the second inequality part b) in Lemma E.15, and the last inequality that and . Given that the right-hand side does not depend on , . Further, as
Lemma E.19 implies is continuous in , and thus so is .
(3) It remains to show that the number of terms that sums over is at most , or equivalently . For any staleness there are at most review states whose oldest review has staleness as and for all and there are thus possibilities for each information for . ∎
Proof Lemma E.19.
Let . Since there exists some such that . Thus, for every ,
Thus, for any , triangle inequality implies
By the continuity of for each , there exists some s.t. whenever , and thus . ∎
E.9 Non-monotononicity in the discount factor (Theorem 5.4)
We first show that under a more general class of instances, for any discount factor there exists a non-absorbing price for which the existence of CoNF results in smaller revenue under with discounting customers as opposed to non-discounting ones. Let be the class of instances where a single review is shown , is a continuous distribution with support on , and the fixed quality estimator is strictly increasing in the mean of .
Note that generalizes the class because the customer-specific valuation allows for continuous distributions other than uniform and the fixed quality estimator allows for a richer class of mappings other than the -quantile for .
Lemma E.20.
For any problem instance in and discount factor , there exists such that for any , the price is non-absorbing and induces higher revenue when compared to non-discounting, i.e., .
Proof of Theorem 5.4.
Consider the interval . Given that for any and , the interval is non-empty. Proposition E.1 implies that any price is review-benefiting for any instance in the class . Given that is non-empty, there exists for all , any price is review-benefiting for any instance . By Lemma E.20, there exists such that for all , any price is also non-absorbing and . Taking concludes the proof. ∎
To prove Lemma E.20, consider the process where the most recent review has rating and staleness . We argue that is a time-homogeneous Markov chain. Let be the purchase probability given for price , review rating , and staleness of the review , i.e.,
If is at state , a purchase occurs with probability . If a purchase occurs a review with staleness of 1 is left and the next state is where with probability (positive review) and with probability (negative review). If a purchase does not occur, the most recent review remains the same while its staleness increases by one, i.e., the next state is . Thus, is a time-homogeneous Markov chain. The next lemma characterizes the stationary distribution of . For review rating , let be the probability that after obtaining a review rating of , this review remains as the most recent one for at least the next rounds. Given that probability of no purchase at state is , then . For review rating , let be the expected number of rounds the most recent review remains .
Lemma E.21.
For any non-absorbing price , the stationary distribution of at rating and staleness is given by
Proof.
By Theorem 3 in [Gal97], it suffices to show that satisfies the stationary state equations of . We now describe those equations. Consider a state with rating and staleness . If the staleness is , the only way to reach is to first obtain state and obtain no purchase decisions. Therefore, the stationary equation for is:
| (38) |
If the staleness is , then can be reached from any after a purchase and a review rating of . Therefore, the stationary equation at is
| (39) |
First, in the lemma statement satisfies Eq. 39 as:
Second, to see that in the lemma statement satisfies Eq. 39, we substitute in the right-hand side and expand
The last equality holds as and the term inside the parenthesis is equal to . The latter holds as corresponds to the probability that, when starting from a state with review rating , we receive a new review after rounds; given that the price is non-absorbing, we eventually receive a new review and thus for any .
Finally, it remains to show that is a valid probability distribution, which follows as
∎
Lemma E.22.
For any discount factor , the revenue of is given by
Proof.
By the Ergodic thoerem and substituting the stationary distribution (Lemma E.21):
The last equality holds as for any (see proof of Lemma E.21). ∎
Proof of Lemma E.20.
We first show that, when , any non-absorbing price induces revenue that is lower bounded by a positive quantity. For such a price, the purchase probability for a negative review is increasing in the staleness, i.e., . This holds as is increasing in and enables us to upper bound the expected time needed to escape a negative-rating state. In particular, using that for any ,
This bound on enables us to show a lower bound on the revenue of . In particular, the monotonicity of implies that the purchase probability under positive review is larger than under negative review, i.e., and thus . Combining this with Lemma E.22:
The price is absorbing (as the purchase probability is zero when the review is negative) and thus by Proposition 3.1. The remainder of the proof establishes that there exits a positive quantity such that for non-absorbing prices close to , , which then concludes the lemma.
First observe that the price is non-absorbing for any ; this holds by the continuity of as the purchase probability for any review is at least . For this price the purchase probability given a negative review with staleness two is,
| (40) |
where is the difference in the fixed value estimate given negative review between non-discounting and discounting. The strict monotonicity of implies that , and therefore . Combining with the continuity of and the fact that , Eq. 40 implies that there exists some such that for any , and , yielding . As a result, the revenue under is lower bounded by :
Second, for a non-discounting customer, the continuity of implies that is continuous in the price . Combined with and (the price is absorbing), there exists such that for ,
Letting , any price where satisfies the claim of the lemma. ∎
Appendix F Supplementary material for Section 6
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a8be9092-aed7-4cc0-b181-29e3011c5ef5/x4.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a8be9092-aed7-4cc0-b181-29e3011c5ef5/x5.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a8be9092-aed7-4cc0-b181-29e3011c5ef5/x6.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a8be9092-aed7-4cc0-b181-29e3011c5ef5/x7.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a8be9092-aed7-4cc0-b181-29e3011c5ef5/x8.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a8be9092-aed7-4cc0-b181-29e3011c5ef5/x9.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a8be9092-aed7-4cc0-b181-29e3011c5ef5/x10.png)