Situation-aware Autonomous Driving Decision Making
with Cooperative Perception on Demand
Abstract
This paper investigates the impact of cooperative perception on autonomous driving decision making on urban roads. The extended perception range contributed by the cooperative perception can be properly leveraged to address the implicit dependencies within the vehicles, thereby the vehicle decision making performance can be improved. Meanwhile, we acknowledge the inherent limitation of wireless communication and propose a Cooperative Perception on Demand (CPoD) strategy, where the cooperative perception will only be activated when the extended perception range is necessary for proper situation-awareness. The situation-aware decision making with CPoD is modeled as a Partially Observable Markov Decision Process (POMDP) and solved in an online manner. The evaluation results demonstrate that the proposed approach can function safely and efficiently for autonomous driving on urban roads.
I Introduction
As autonomous vehicles being navigating on the urban road, the proper decision making requires the comprehensive awareness of the surrounding environment, which includes both the road context and the other vehicles’ motion intention. The knowledge of the road context can help to narrow down the reasoning scope of the other traffic participants’ behaviors [1]. Similarly, to understand the semantic meaning of the other vehicles’ behaviors, i.e., motion intention, can contribute a more robust prediction of their future motion, which in turn can be employed for a more accurate risk evaluation[2].
The difficulty of situation awareness, however, is always aggravated by the limited autonomous vehicle perception ability, which has to experience the difficulties introduced by the inevitable sensor noise and sensing occlusion. The resulting sensing limitation can dramatically weaken the autonomous vehicle’s ability of perceiving the obstacles’ states and blind the implicit behavior dependencies within the vehicles. As a preeminent candidate to extend perception range without substantial additional costs, cooperative perception is the exchange of local sensing information with other vehicles or infrastructures via wireless communications [3]. The perception range thereby can be considerably extended up to the boundary to the connected vehicle, which thereby can be useful for better situation awareness.
While the benefits of cooperative perception has been well recognized, there always come with some challenges of the cooperative perception applications on autonomous driving [4]. Firstly, the challenge can arise from the balance of information quantity and quality. There still lacks the comprehensive strategy and general rules to efficiently and robustly process and represent the information shared by the different participants. Secondly, the perception uncertainties might increase dramatically according to the growth of the extended sensing range due to the perception processing error, which hints that the perception failures need to be explicitly considered. Last but not least, the applicability of cooperative perception can be always obstructed by the inherent communication constraints, such as the limited bandwidth.
In this paper, we investigate the impact of cooperative perception on situation-aware decision making for autonomous driving on urban roads. Extending upon our previous work in [5], we explicitly consider a sensing occlusion problem and aim at employing cooperative perception to address this issue. Given the fact that the communication between vehicles is always constrained, we propose a Cooperative Perception on Demand (CPoD) strategy, which means that the cooperative perception will be activated only when the on-board sensing is not informative enough for proper situation awareness. To properly feature CPoD inside the situation-aware decision making module, the Partially Observable Markov Decision Making Process (POMDP) is utilized for its innate ability to balance the exploration and exploitation. The evaluation results show that the proposed algorithm is efficient and safe enough to handle some common urban driving scenarios.
Compared to the previous work, the contributions of this study are obvious as follows:
-
•
We investigate the impact of cooperative perception on autonomous vehicle decision making module.
-
•
The proposal of CPoD can actively alleviate the constraints on vehicle communication.
The remainder of this paper is organized as follows. Section II introduces some related works and Section III provides the preliminaries on both cooperative perception and POMDP. The problem statement is discussed in Section IV. Thereafter, the detailed discussion of the situation-aware decision making with CPoD is presented in Section V. The evaluations of the proposed algorithm are elaborated in Section VI and this paper is concluded in Section VII.
II Related Work
Three folds of literature directly related to our study will be identified. Firstly, the application of cooperative perception on autonomous driving will be briefly discussed. The second one is the multi-agent active sensing using decision-theoretic techniques, and the last one is how the POMDP has been employed for autonomous driving decision making.
Given the obvious benefits of cooperative perception, the extension of cooperative perception to autonomous driving has attracted dramatic research interests recently. Given the extended perception range, the motion planning horizon can be extended to the boundary of the connected vehicles, which thereby can contribute to an earlier hidden obstacle avoidance [6]. Similarly, the situation awareness can be improved as well, because each vehicle’s behavior is correlated to others, which hints that the expanded sensing information through cooperative perception can be useful for better reasoning of the vehicles’ behaviors [7].
The multi-agent active sensing using decision-theoretic techniques aims at properly coordinating the sensors or mobile platforms to achieve a wider sensing coverage or to reduce the uncertainties of object characteristics identification [8, 9]. While great achievements have been made, the communication constraint, however, is occasionally overlooked [10]. Moreover, while these approaches can properly handle the planning for perception issue, but not vice versa. In a sense, the investigation on how the enhanced perception can contribute to the planning is not comprehensive.
Regarding the autonomous driving decision making, the most common approach is to manually tailor the specific action sets for different situations using a Finite State Machine or similar frameworks like behavior trees [11]. These approaches, however, lack the comprehensive understanding of the environment. The absence of full situational awareness can make the driving decisions become danger-prone, which has been evidenced by an incident of DUC [12]. As an principle approach of balancing exploration and exploitation, POMDP has been widely adopted for autonomous driving decision making recently [13, 14, 15]. The POMDP applications around the literature can vary from designing some specific driving behaviors, such as lane changing and merging[13], to a more general traffic negotiation [5].
As reviewed above, a general situation-aware decision making approach to integrate the above three components is still an interesting and challenging problem.
III Preliminaries
III-A Cooperative Perception
In contrast to cooperative driving, where the vehicles are centrally controlled or share their motion intention directly, cooperative perception targets at sharing local sensing information only, which is more applicable to different traffic participants in typical urban traffic situations.
In the context of autonomous vehicle perception, the sensing information is typically projected into a local frame, which can be processed as a local observation that consists of a set of perceived obstacles or features representing the environment. Let depict a local sensing map of the vehicle , and let be a string that defines the neighbors of a vehicle , where denotes the size of the following and leading neighbors respectively. Then cooperative perception is formulated as,
| (1) |
where denotes the relative pose of vehicle w.r.t. vehicle , which consists of the translation and rotation . Given the relative pose, the operator computes the pose transformation. The operation thereby is called map merging and the resulting denotes the extended sensing map of vehicle using cooperative perception. Since the agents participated in the cooperative perception are designed to work in a decentralized manner, we adhere to the following rules in this study:
-
•
There is no central entity required for the operation.
-
•
There is no common communication facility, which means only local point-to-point communication between neighbors is considered.
-
•
There is no communication delay being considered.
III-B Partially Observable Markov Decision Process
A POMDP is formally a tuple , where is the state space, is a set of actions and denotes the observation space. The transition function models the probability of transiting to state when the agent takes an action at state . The observation function , similarly, gives the probability of observing when action is applied and the resulting state is . The reward function is the reward obtained by performing action in state , and is a discount factor.
The solution to the POMDP thereby is an optimal policy that maximizes the expected accumulated reward , where and denote the agent’s state and action at time , respectively. The true state, however, is not fully observable to the agent, thus the agent maintains a belief state , i.e. a probability distribution over , instead. The policy therefore maps a prescribed action from a belief .
IV Problem Statement
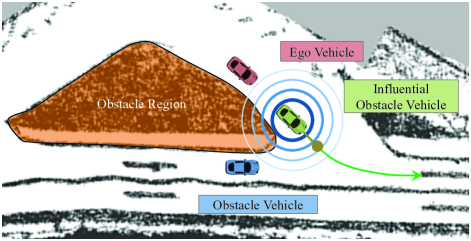
Onwards, we name the autonomous vehicle as an ego vehicle and consider all the other vehicles as obstacle vehicles. Also, we define the Influential Obstacle Vehicle (IOV) as the obstacle vehicle that imposes the most significant impact on the ego vehicle’s driving decisions, such as the leading vehicle on the single-lane road, or the vehicles to be negotiated at the intersection.
In sight of the influence of IOV, the perception sharing between ego vehicle and IOV becomes more essential, where a more conscious decision can be made if an ego vehicle can see what IOV see. Taking Fig. 1 for instance, the ego vehicle is following the leading vehicle to conduct lane merging. Since the ego vehicle’s driving decision is heavily affected by the leading vehicle (identified as IOV), the inference over the leading vehicle’s motion intention becomes essential. Without cooperative perception, another coming obstacle vehicle (blue) is blind to the ego vehicle. Given the on-board observation that the IOV is driven in a normal speed, the ego vehicle might draw a confident but danger-prone conclusion that the IOV will merge into the lane directly. On the other hand, if the IOV shares what it sees with the ego vehicle, the ego vehicle can then properly acknowledge the dependencies between the IOV and the coming obstacle vehicle, such that a more reasonable inference can be made as: the IOV may have a fairly high chance to commit a deceleration.
Obviously, the perception sharing can contribute to a greatly extended perception range, and more importantly a comprehensive understanding of the situation evolution, but it does bring itself with some limitations, especially the communication constraints. Therefore, to properly identify the situation in which perception sharing should be activated can be quite helpful in sense. The difficulty of situation identification, however, can always be aggravated by the fact that the situation, including the obstacle vehicle behavior and environment context, is not fully observable. In sight of this, this paper proposes a Cooperative Perception on Demand (CPoD) strategy and seeks to feature the CPoD inside the decision making module. In a sense, perception sharing will only be activated when the situation awareness becomes difficult, such as the IOV’s motion intention is ambiguous or the collision risk is critical.
Formally speaking, let and denotes the sensing map of ego vehicle and IOV respectively, both of which consist of a set of environment features. As a function of the CPoD decision , the ego vehicle’s extended sensing map is modeled as,
| (2) |
As such, once the CPoD is activated, the ego vehicle’s perception range can be extended to as far as IOV can reach. Thereafter, this study seeks to solve a decision making problem to minimize the cost expectation as,
| (3) |
where and depict the situation state and state space respectively. The situation state is usually associated with certain uncertainties, which can include, to name a few, the road context, the obstacle vehicle’s moving intention, etc. The inference over the situation state, thereby, is driven by the sensing information . Moreover, represents the ego vehicle’s action, which consists of both the CPoD decision and the acceleration command , and denotes the corresponding action space. The cost function targets to encourage the driving efficiency and penalize both the colliding risk and the vehicle communication, which thereby can properly balance the driving safety and information gaining.
Worth mentioning that the sensing fusion and perception uncertainty modeling problems are out of the scope of this paper, the reader can refer to [4] and [16] for a more detailed discussion. In this context, we assume that a well-processed perception, especially the uncertainty modeling, is alway available.
V Situation-aware Decision Making with CPoD
V-A Overview
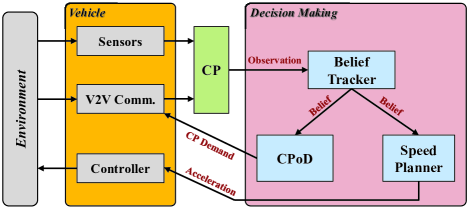
The overall framework of the autonomous driving decision making with CPoD is depicted in Fig. 2. The autonomous vehicle is featured with the on-board sensors and the V2V communication ability, where the V2V communication will only be enabled when CPoD has been activated. Once the V2V communication is enabled, the cooperative perception module will start to process the sensing data provided by both the on-board sensors and the IOV, otherwise only the on-board sensing data will be processed.
Given the augmented sensing information provided by cooperative perception, the decision making module will come into act. The decision making module is in change of making two sub-decisions: 1) decision about the CPoD and 2) decision about the ego vehicle’s acceleration. Both of these decisions are made upon the situation state belief provided by the belief tracker.
V-B POMDP Modeling
Hereafter, the POMDP model for situation-aware decision making with CPoD will be discussed. Generally speaking, the ego vehicle will receive the IOV’s sensing information once the CPoD is activated, thereafter the acceleration command will be chosen, which drives the ego vehicle’s state transition. Regarding the obstacle vehicles, their state transitions are driven by the inferred motion intention, the road context, and the implicit dependencies within the vehicles.
V-B1 Ego Vehicle State Transition Model
The ego vehicle state consists of the vehicle pose and velocity . Given our previous discussion, the ego vehicle action space is discretized as,
| (4) |
which has been verified to be qualified for an ego vehicle to achieve most tactical maneuvers, such as traffic negotiation at intersections, maintaining the safe distance with other obstacle vehicles, etc.[5]. The vehicle steering control, on the other hand, is accomplished by following a pre-specified reference route using a close-loop path tracking algorithm. Given the acceleration command and steering angle, the ego vehicle system can be forwarded for a fixed time duration using the kinematic car model in [17].
V-B2 Obstacle Vehicle State Transition Model
Due to the on-board sensing limitation, some obstacle vehicles cannot be visible to the ego vehicle, thus we define as the set of obstacle vehicles that are within the range of the extended sensing map . Each obstacle vehicle is associated with an unique identification number, and the state of obstacle vehicle is modeled as , where denotes the motion intention and represents the motion intention space. Compared to the ego vehicle state, the inclusion of motion intention here is to provide a semantic meaning of the obstacle vehicle behavior and to properly model the obstacle vehicle’s state transition.
Rather than addressing the motion intention as hidden goals [15, 2, 14], the reaction based motion intention is employed in this study [5], which is abstracted from human driving behaviors by generalizing a bunch of vehicle behavior training data [18]. More specifically, given the vehicle behavior training data, the road context can be learned first to represent the traffic rules and the typical vehicle motion pattern, thereafter the reaction is modeled as the deviation of the observed vehicle behavior from the generalized road context. Given the observed reaction, the motion intention space is defined as , where their specific meanings are illustrated in Table I.
| Motion Intention | Description |
|---|---|
| Stopping | Obstacle vehicle will commit a full stop for giving way or parking |
| Hesitating | Obstacle vehicle will either decelerate or accelerate to adjust its driving behavior |
| Normal | Obstacle vehicle’s behavior will comply with the generalized road context |
| Aggressive | Obstacle vehicle’s behavior will be aggressive without any sense to negotiate |
Provided the generalized road context and the inferred motion intention , the state transition of obstacle vehicle is modeled as,
| (5) |
where is defined as the vehicle metric state for notation clarity, and denotes the road context information corresponding to vehicle state at time . In detail, the road context features the possible driving directions according to the traffic rules and the typical (or reference) vehicle speed as well. As such, the obstacle vehicle state transition is driven by the inferred motion intention and constrained by the road context.
While Eqn. (5) can provide an reasonable modeling of the obstacle vehicle’s state transition, the dependencies within the vehicle behaviors are not considered. Therefore, we seek to reformulate the state transition and make it conditional on a joint metric state as,
| (6) |
where the joint metric state is assumed to be conditional independent on the vehicle ’s state and the corresponding road context. The inclusion of into the state transition enables us to model the implicit vehicle dependencies as each vehicle has to avoid the potential collision with any other vehicles. Due to the sensing occlusion, the vehicle dependencies can only considered for the obstacle vehicles that are not blind to the ego vehicle. In a sense, the size of the joint metric state is a function of the sensing range. Therefore, the larger sensing range can be extended for ego vehicle, the more comprehensive vehicle behavior dependency can be considered. This is where cooperative perception can come into effect and contribute.
Referring to Eqn. (6), we can always marginalize the transition function over an implicit obstacle vehicle action , including speed and steering angle , to explicitly model the obstacle vehicle state transition as,
| (7) |
where can follow the same transition model as that of ego vehicle given the inferred obstacle vehicle action , and the motion intention remains constant within the transition process .
Regarding the inference of the obstacle vehicle action , the obstacle vehicle speed can be properly modeled using the inferred motion intention and the implicit vehicle dependencies. The steering angle, however, is not featured by the motion intention, thus we aim at using the road context to enable the steering angle prediction. As such, the obstacle vehicle action inference can be reformulated as,
| (8) |
In short, the speed inference is accomplished by mapping the acceleration command to the inferred motion intention according to Table I, meanwhile the obstacle vehicle can still have certain chance to commit a deceleration if the collision risk with any other vehicles is high. The inference over the steering control is more straightforward, which is sampled from the possible driving directions according to the traffic rules featured by the road context . The reader can refer to [5] for a more detailed discussion.
V-B3 Observation Modeling
Thanks to the recent research advances in vehicle detection and tracking, the vehicle metric state can be properly observed with Gaussian noise imposed, thereby we can simply generate the observations with an one-on-one mapping directly from the corresponding metric states. As such, the observation of any vehicle is modeled as an vector consisting of the values of vehicle pose and velocity. The joint observation thereby is defined as . In a sense, only the vehicles that are falling inside the extended sensing map are observed.
V-B4 Belief Tracking
Since the obstacle vehicle motion intention can only be partially observable, the motion intention needs to be maintained as a belief state. Given the augmented observation, the belief tracker is dedicated for inferring and tracking the obstacle vehicle motion intentions using Bayes rules. The inference of obstacle vehicle ’s motion intention thereby can be formulated as,
| (9) |
where is the normalization factor, and the motion intention remains constant within the transition process.
Regarding the observation function , we model it as a Gaussian with mean and covariance , where the operator calculates the deviation of the observed vehicle state from the corresponding road context . Recall our earlier discussion, we aim at using this deviation as an interesting hint to infer the motion intention. More specifically, the speed deviation is employed in this study, where the observed vehicle speed is given as , and the road context provides the reference speed that is generalized from the vehicle behavior training data using Gaussian Process[18]. Thereafter, the mean value can be reformulated as and defined in Table II, which is proposed according to the motion intention definition in Table I. Moreover, the covariance function is defined as , where the scaling factor is to adjust the belief confidence.
V-B5 Reward Function
The main objective of the ego vehicle is to arrive the destination as quickly as possible, meanwhile avoid collision with any other obstacle vehicles. Within this process, the communication within the vehicles needs to be actively requested if the situation becomes tricky. Two sub-decisions have to be made by an ego vehicle, thus the reward function is decoupled as,
| (10) |
For acceleration-based reward function , we want the vehicle move safely, efficiently and smoothly, thus it is defined as . The reward function provides a reward when the vehicle reach the destination, and outputs a high penalty if the ego vehicle is in collision. The action reward targets to smooth the vehicle velocity by proving a small penalty if . The speed reward is to encourage high speed travel and improve the driving efficiency, where is the ego vehicle’s maximum speed and is a scaling factor.
Regarding CPoD based reward function , we want to emphasize the cost of communication by introducing a constant penalty every time cooperative perception is activated. Once the situation awareness becomes tricky or the collision risk is high, the cooperative perception should be activated to gain more sensing information for proper decision making. As such, we introduce the to reward cooperative perception if the IOV’s motion intention , in which case IOV’s behavior becomes harder to predict. Moreover, another reward will be imposed once the Time-To-Collision between ego vehicle and IOV is lower than the designed threshold. In summary, the -driven reward function is formulated as .
Worth mentioning that we design the reward function w.r.t. the vehicle state rather than the belief state, the purpose is to ensure that the POMDP value function stays piece-wise linear and convex, although the usage of belief state or entropy to evaluate information gain is more reasonable in some cases.
V-C POMDP Solver
Given the designed POMDP model, the online POMDP solver DESPOT is employed for its efficiency of handling the large observation space [19]. As an online POMDP solver, DESPOT only searches the belief space that is achievable from the current belief state and interleaves the planning and executing phases, Moreover, rather than searching the whole belief tree, DESPOT only samples a scenario set with constant size . As a consequence, the belief tree of height contains only nodes. The belief state is represented by the random particles within DESPOT, and for each particle the obstacle vehicles’ motion intentions are randomly sampled for belief state representation.
VI Evaluation
In this section, the proposed algorithm will be evaluated to validate its functionality.
VI-A Settings
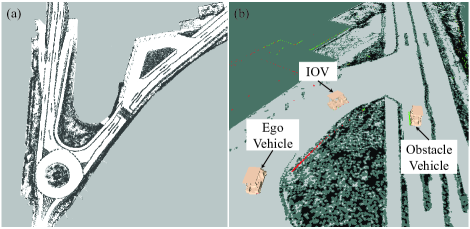
Given the environment and the corresponding road context as Fig. 3(a), the Stage simulator is employed for simulation evaluation, where Gaussian noise is purposely imposed on the vehicle pose and velocity measurement.
Implementation-wise, each vehicle is running an independent navigation system in ROS [20], where the vehicle communication is accomplished by sharing an unique ROS core. The proposed algorithm is running with 2 Hz for both CPoD and vehicle acceleration control, and the Pure-Pursuit tracking algorithm is employed for the vehicle steering control [21].

VI-B Results
The proposed algorithm has been successfully applied for several urban road driving scenarios within the evaluation stage. Here, we want to highlight the ability of our algorithm to address the autonomous driving decision making at the T-junction (see Fig. 3(b)), where the evaluating scenario is same as what is discussed in Section IV.
As illustrated in Fig. 4(a), the ego vehicle is following the leading vehicle (identified as IOV) to approach the T-junction for lane merging. Meanwhile, there comes another obstacle vehicle that is blind to the ego vehicle, which means its motion intention is quite ambiguous because no observation is available. Before the IOV and the obstacle vehicle getting interacted, the ego vehicle reasonably maintains a smooth speed to follow the IOV while deactivating the CPoD to save the ”expensive” communication. This balance breaks down when the IOV commits a deceleration in order to give way to the obstacle vehicle. Right after the IOV’s motion intention is updated, the ego vehicle actively enables the CPoD to extend the sensing range and start to infer the obstacle vehicle’s motion intention as Fig. 4(b). Given the inferred situation evolution, especially the behavior correlation between IOV and obstacle vehicle, the ego vehicle decides to decelerate far before the obstacle clearance become critical, this is thanks to the cooperative perception which makes the vehicle behavior dependency analysis become achievable. After the obstacle vehicle becoming clear, the IOV starts to move forward for lane merging, the ego vehicle also decides to speed up while keeping the CPoD being deactivated (see Fig. 4(c)).
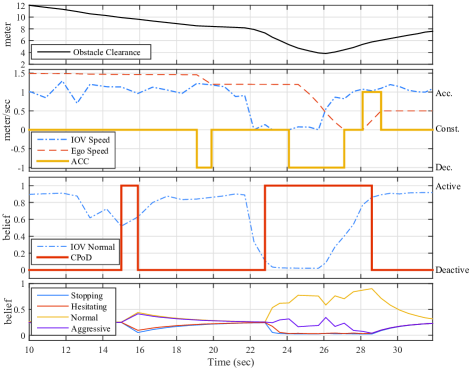
The detailed illustration of the situation evolution can be found in Fig. 5, where Fig. 5(a) depicts the obstacle clearance. The acceleration decision, along with the speed of both ego vehicle and IOV, are shown in Fig. 5(b), from which we can find that acceleration decision is quite responsive to the obstacle clearance and the driving efficiency. Moreover, the CPoD decision and the IOV’s motion intention is shown in Fig. 5(c), where only the Normal belief is plotted because it is directly related to the CPoD decision. An interesting observation is that the CPoD decision is highly depends on the IOV’s motion intention, which is exactly our expected behavior. In order to demonstrate the CPoD’s impact on the obstacle vehicle, we also plot the obstacle vehicle’s motion intention in Fig. 5(d), where the motion intention belief can be quickly updated when the CPoD is activated, otherwise the motion intention will stay ambiguous.
Acknowledging that the proposed approach is probabilistic in nature, we extensively conducted 100 evaluation trials for this T-junction scenario. For the sake of investigating the impact of cooperative perception on decision making, we also implemented an algorithm with the CPoD being deactivated constantly and we name it as CPWO. Moreover, in order to address the concern that the introduction of the CPoD might make the decision sub-optimal compared to the case where cooperative perception is always activated, another algorithm, CPW, with CPoD being activated all the time is implemented as well.
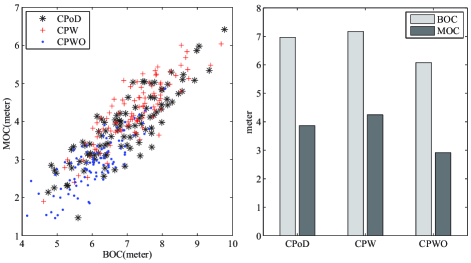
In order to compare the decision making performance, two evaluating metrics are proposed, which includes the Braking Obstacle Clearance (BOC) and Minimal Obstacle Clearance (MOC). More specifically, when the IOV is stopping for the coming obstacle vehicle, the BOC represents the distance between the ego vehicle and IOV when the ego vehicle decides to decelerate. Moreover, MOC measures the minimal distance between the ego vehicle and the IOV during the whole navigation process. The results are depicted in Fig. 6, where the BOC and MOC are plotted in two separate dimensions in Fig. 6(a) and the corresponding mean values are represented in Fig. 6(b). By comparing the navigation performance of CPoD and CPWO, we can safely conclude that the inclusion of cooperative perception can helpfully improve the driving safety, because the ego vehicle is able to react earlier and maintain a larger safety gap with the leading vehicle. Moreover, the CPoD can achieve almost the same performance as that of CPW, which hints that the modeling of CPoD inside POMDP can properly identify the situation where cooperative perception is necessary, whereas the communication constraints can be alleviated.

Given the promising result we achieved for lane-merging at T-junction, we extend the evaluation scenario to an single-lane road where the ego vehicle is following a leading vehicle that blocks its sight-view in Fig. 7(a). Similarly, the obstacle vehicle is not visible to the ego vehicle, such that the ego vehicle need to reasonably active the CPoD and choose the optimal acceleration command to drive safely and efficiently. The overall navigation result is demonstrated in Fig. 7, which shows similar performance as that of the T-junction scenario. (a) shows the evaluating scenario, where the most front obstacle vehicle is blind to the ego vehicle. The most front obstacle vehicle suddenly commits a stop and the leading vehicle starts to decelerate as well, the CPoD is then activated accordingly as in (b). Thereafter, the ego vehicle safely commit an deceleration while making the CPoD be enabled in (c).
VII Conclusion
In this paper, we introduced a problem of situation-aware autonomous driving decision making with cooperative perception. The extended perception range contributed by the cooperative perception is properly employed to address the implicit dependencies within the vehicles. Meanwhile, we acknowledge the limitation of wireless communication and propose a CPoD scheme. The situation-aware decision making problem, together with the CPoD, is unified as a POMDP model and solved in an online manner. The extensive evaluations show that the proposed algorithm can properly improve the driving functionality and the perception sharing. The future work can be contributed to improving the identification of IOV and extending the simulation evaluations to the real experiments as well.
References
- [1] S. Sivaraman, B. Morris, and M. Trivedi, “Observing on-road vehicle behavior: Issues, approaches, and perspectives,” in Intelligent Transportation Systems-(ITSC), 2013 16th International IEEE Conference on. IEEE, 2013, pp. 1772–1777.
- [2] T. Bandyopadhyay, C. Z. Jie, D. Hsu, M. H. Ang Jr, D. Rus, and E. Frazzoli, “Intention-aware pedestrian avoidance,” in Experimental Robotics. Springer International Publishing, 2013, pp. 963–977.
- [3] H. Li, “Cooperative perception: Application in the context of outdoor intelligent vehicle systems,” Ph.D. dissertation, Paris, ENMP, 2012.
- [4] S.-W. Kim, B. Qin, Z. J. Chong, X. Shen, W. Liu, M. Ang, E. Frazzoli, and D. Rus, “Multivehicle cooperative driving using cooperative perception: Design and experimental validation,” IEEE Transaction on Intelligent Transportation System, 2014.
- [5] W. Liu, S.-W. Kim, and M. H. Ang, “Situation-aware decision making for autonomous driving on urban road using online POMDP,” in Intelligent Vehicles (IV), 2015 IEEE Symposium on. IEEE, 2015.
- [6] W. Liu, S. Kim, Z. Chong, X. Shen, and M. Ang, “Motion planning using cooperative perception on urban road,” in Robotics, Automation and Mechatronics (RAM), 2013 6th IEEE Conference on. IEEE, 2013, pp. 130–137.
- [7] W. Liu, S.-W. Kim, K. Marczuk, and M. H. Ang, “Vehicle motion intention reasoning using cooperative perception on urban road,” in Intelligent Transportation Systems (ITSC), 2014 IEEE 17th International Conference on. IEEE, 2014, pp. 424–430.
- [8] M. T. Spaan and P. U. Lima, “A decision-theoretic approach to dynamic sensor selection in camera networks.” in ICAPS, 2009.
- [9] M. T. Spaan, “Cooperative active perception using POMDPs,” in AAAI 2008 workshop on advancements in POMDP solvers, 2008.
- [10] M. Otte and N. Correll, “Any-com multi-robot path-planning with dynamic teams: Multi-robot coordination under communication constraints,” in Experimental Robotics. Springer, 2014, pp. 743–757.
- [11] D. Ferguson, T. M. Howard, and M. Likhachev, “Motion planning in urban environments,” Journal of Field Robotics, vol. 25, no. 11-12, pp. 939–960, 2008.
- [12] L. Fletcher, S. Teller, E. Olson, D. Moore, Y. Kuwata, J. How, J. Leonard, I. Miller, M. Campbell, D. Huttenlocher, et al., “The mit–cornell collision and why it happened,” Journal of Field Robotics, vol. 25, no. 10, pp. 775–807, 2008.
- [13] S. Ulbrich and M. Maurer, “Probabilistic online POMDP decision making for lane changes in fully automated driving,” in Intelligent Transportation Systems, 2013, pp. 2063–2070.
- [14] H. Bai, S. Cai, N. Ye, D. Hsu, and W. S. Lee, “Intention-aware online POMDP planning for autonomous driving in a crowd,” in Robotics and Automation (ICRA), 2015 IEEE International Conference on. IEEE, 2015, pp. 454–460.
- [15] C. Shaojun, “Online POMDP planning for vehicle navigation in densely populated area,” 2014.
- [16] X. Shen, S. Pendleton, and M. H. Ang Jr., “Scalable cooperative localization with minimal sensor configuration,” in International Symposium on Distributed Autonomous Robotics System, 2014.
- [17] S. M. LaValle, Planning algorithms. Cambridge university press, 2006.
- [18] W. Liu, S.-W. Kim, and M. H. Ang, “Probabilistic road context inference for autonomous vehicles,” in Robotics and Automation (ICRA), 2015 IEEE International Conference on. IEEE, 2015.
- [19] A. Somani, N. Ye, D. Hsu, and W. S. Lee, “DESPOT: Online POMDP planning with regularization,” in Advances In Neural Information Processing Systems, 2013, pp. 1772–1780.
- [20] M. Quigley, K. Conley, B. P. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, and A. Y. Ng, “Ros: an open-source robot operating system,” in ICRA Workshop on Open Source Software, 2009.
- [21] Z. Chong, B. Qin, T. Bandyopadhyay, T. Wongpiromsarn, B. Rebsamen, P. Dai, E. Rankin, and M. H. Ang Jr, “Autonomy for mobility on demand,” Intelligent Autonomous Systems 12, pp. 671–682, 2013.