SIRD: A Sender-Informed, Receiver-Driven Datacenter Transport Protocol
Abstract.
Datacenter congestion management protocols must navigate the throughput-latency-buffering trade-off in the presence of growing constraints due to switching hardware trends, oversubscribed topologies, and varying network configurability and features. In this context, receiver-driven protocols, which schedule packet transmissions instead of reacting to congestion, have shown great promise and work exceptionally well when the bottleneck lies at the ToR-to-receiver link. However, independent receiver schedules may collide if a shared link is the bottleneck instead.
We present SIRD, a receiver-driven congestion control protocol designed around the simple insight that single-owner links should be scheduled while shared links should be managed through traditional congestion control algorithms. The approach achieves the best of both worlds by allowing precise control of the most common bottleneck and robust bandwidth sharing for shared bottlenecks. SIRD is implemented by end hosts and does not depend on Ethernet priorities or extensive network configuration.
We compare SIRD to state-of-the-art receiver-driven protocols (Homa, dcPIM, and ExpressPass) and production-grade reactive protocols (Swift and DCTCP) and show that SIRD is the only one that can consistently maximize link utilization, minimize queuing, and obtain near-optimal latency across a wide set of workloads and traffic patterns. SIRD causes less peak buffering than Homa and achieves competitive latency and utilization without requiring Ethernet priorities. Unlike dcPIM, SIRD operates without latency-inducing message exchange rounds and outperforms it in utilization, buffering, and tail latency by 9%, 43%, and 46% respectively. Finally, SIRD achieves lower tail latency and % higher utilization than ExpressPass.
1. Introduction
Emerging datacenter workloads like ML training (Rajasekaran et al., 2023; Gebara et al., 2021) and disaggregated resource management (Gao et al., 2016) increasingly demand high-throughput and low-latency networking. At the same time, datacenter networking hardware continues to offer higher link speeds, but switch packet buffer capacity is failing to keep up, and SRAM density trends show that this is unlikely to change (Chang et al., 2022; David Schor, 2022). The combination imposes a challenge for congestion control that generally relies on buffering to deliver high throughput. The challenge is compounded by other important concerns such as multi-tenancy, hardware heterogeneity, and cost of operations (Greenberg et al., 2009). In industry, the Ultra Ethernet Consortium is in the process of drafting modern congestion control mechanisms (Consortium, 2023).
The most established approach to managing congestion is by reactively slowing down sender transmission rates after detecting a problem. This is the approach of sender-driven (SD) protocols (Li et al., 2019; Alizadeh et al., 2010; Kumar et al., 2020; Addanki et al., 2022; Zhu et al., 2015; Mittal et al., 2015; Alizadeh et al., 2012; Liu et al., 2021; Arslan et al., 2023; Wang et al., 2023; Zhou et al., 2021) like DCTCP (Alizadeh et al., 2010) and Swift (Kumar et al., 2020) in which senders make decisions based on network feedback. The protocol family has seen decades of evolution in terms of congestion algorithm and signal quality, contributed both by industry and academia. However, the reactive nature of SD protocols often requires several round-trips to address congestion; a limitation for workloads dominated by small flows (Montazeri et al., 2018; Cai et al., 2022; Ghabashneh et al., 2022). Further, the flow-oriented basis of these schemes makes it difficult to reduce latency through message-centric scheduling (Alizadeh et al., 2013; Bai et al., 2015).
To address these limitations, a recent line of work (Hu et al., 2020; Montazeri et al., 2018; Cho et al., 2017; Handley et al., 2017; Cai et al., 2022; Perry et al., 2014; Gao et al., 2015) proactively schedules packet transmissions instead of reacting to congestion buildup. Scheduling is usually handled by receivers that precisely allocate bandwidth by controlling the arrival rate of credit packets to senders. This enables tight control over ToR-to-Host ports which are the most congested (Singh et al., 2015; Zhang et al., 2017; Ghabashneh et al., 2022). The receiver-driven (RD) approach enables high throughput with limited buffering in dcPIM (Cai et al., 2022) and near-optimal latency in Homa (Montazeri et al., 2018).
The fundamental tension in the design of receiver-driven schemes is how to schedule packets over shared links. Each receiver has exclusive control of its downlink but must share the network core and sender uplinks with other receivers. In a distributed protocol, this creates scheduling conflicts if receivers do not coordinate in some manner. Proposed solutions for this problem include explicit pre-matching of senders and receivers (dcPIM (Cai et al., 2022)), in-network credit throttling (Expresspass (Cho et al., 2017)), and the overcommitment of receiver downlinks (Homa (Montazeri et al., 2018)). Despite impressive results, each of these approaches makes a major sacrifice either in message latency, protocol complexity or packet buffer utilization.
We propose SIRD, a receiver-driven design based on the following simple insight: exclusive links (receiver downlinks) should be managed proactively, and shared links (sender uplinks and switch-to-switch links) should be managed reactively. We implement this principle through receiver-driven scheduling that reacts to congestion feedback from shared links using end-host signals to detect congestion on sender uplinks and ECN (Ramakrishnan et al., 2001) to signal congestion in the network. Our approach maintains explicit control over the most common bottleneck (ToR-host links) and simultaneously inherits the robustness, generality, and simplicity of reactive designs. We show that SIRD matches or exceeds the best result of any existing proposal without suffering any of the drawbacks. Beyond quantifiable performance metrics, SIRD’s end-to-end design does not require the use of in-network priority queues, typically reserved to offer isolation among services (Arslan et al., 2023), nor extensive switch configuration.
SIRD receivers coordinate to share core and sender links through a reactive control loop similar to SD schemes. Congestion information flows to receivers within data packets. Receivers run two independent control loops to converge to a bandwidth allocation that does not cause congestion: one to detect congested end-host senders, and one to control congestion in the core network. As network queuing is kept at a minimum, and because senders can initiate data transfers without waiting for matching roundtrips, SIRD delivers messages with low latency.
We compare SIRD to three state-of-the-art proactive protocols (Homa (Montazeri et al., 2018), dcPIM (Cai et al., 2022), and ExpressPass (Cho et al., 2017)) and two production-grade reactive protocols (DCTCP (Alizadeh et al., 2010) and Swift (Kumar et al., 2020)) using large-scale simulations across nine combinations of workloads and traffic patterns. Our evaluation shows that SIRD is the only protocol that can simultaneously maximize link utilization, minimize the use of switch buffers, and obtain near-optimal latency. Specifically: (1) SIRD causes less peak top-of-rack (ToR) buffering than Homa, yet achieves competitive latency and utilization in all scenarios without requiring Ethernet priorities. (2) Unlike dcPIM, SIRD does not rely on latency-inducing message exchange rounds and outperforms it in link utilization, peak ToR buffering, and tail latency by 9%, 43%, and 46% respectively while delivering more predictable performance. (3) SIRD achieves lower tail latency and % higher utilization than ExpressPass. (4) SIRD outperforms DCTCP and Swift across the board, especially in incast-heavy scenarios.
We further show through a prototype DPDK implementation that SIRD can be implemented at line rate on commodity hardware.
All artifacts will be open-sourced prior to publication.
2. Background
The main goals of congestion control (CC) are enabling efficient sharing of network resources and achieving high network utilization while preventing packet loss. There are also other, at times conflicting, CC goals, e.g., fairness, flow completion time, flow deadlines, and multi-tenancy.
Existing datacenter CC schemes for Ethernet networks can be broadly split into two categories: reactive and proactive. In reactive (also sender-driven (SD)) schemes (Alizadeh et al., 2010, 2012, 2013; Liu et al., 2021; Kumar et al., 2020; Li et al., 2019; Mittal et al., 2015; Zhu et al., 2015), senders control congestion by participating in a distributed coordination process to determine the appropriate transmission rates. Senders obtain congestion information through congestion signals like ECN (Ramakrishnan et al., 2001; Alizadeh et al., 2010), delay (Mittal et al., 2015; Kumar et al., 2020), and in-network telemetry (Li et al., 2019; Wang et al., 2023).
In proactive schemes (Montazeri et al., 2018; Gao et al., 2015; Bai et al., 2015; Handley et al., 2017; Cho et al., 2017; Cai et al., 2022; Perry et al., 2014; Le et al., 2021) bandwidth is allocated explicitly, either globally or per-receiver. Global approaches (Perry et al., 2014; Le et al., 2021) use a centralized arbiter that controls all transmissions and hence face scalability challenges. In Receiver-driven (RD) protocols, each receiver explicitly schedules its downlink by transmitting special-purpose packets such as credits (Cho et al., 2017), grants (Montazeri et al., 2018), or pulls (Handley et al., 2017) to senders. The credit rate can be explicitly controlled by a pacer (Cho et al., 2017; Handley et al., 2017) or be self-clocked (Montazeri et al., 2018; Gao et al., 2015; Cai et al., 2022).
2.1. Exclusive and shared links
Congestion can occur in Host-to-ToR uplinks and the network core, which are shared among receivers, and ToR-to-host downlinks, which are exclusive to a single receiver.
Exclusive links: In the context of RD protocols, ToR-to-Host links (downlinks) can be seen as exclusively controlled by a single entity, the receiver. By controlling the rate of credit transmission, a receiver can explicitly control the rate of data arrival - assuming the bottleneck is the downlink. In fact, downlinks are the most common point of congestion in datacenter networks (Singh et al., 2015; Zhang et al., 2017; Kumar et al., 2020; Ghabashneh et al., 2022). Congestion at the ToR downlink is the result of incast traffic from multiple senders to one receiver. In turn, incast is the result of the fan-out/fan-in patterns of datacenter applications (Dean and Barroso, 2013).
RD schemes excel in managing incast traffic because each receiver explicitly controls the arrival rate of data (Montazeri et al., 2018; Gao et al., 2015; Bai et al., 2015; Handley et al., 2017; Cho et al., 2017; Cai et al., 2022). This level of control also allows RD schemes to precisely dictate which message should be prioritized in downlinks, and can even factor-in a server’s application requirements (Ousterhout et al., 2019). Recent work has delivered significant message latency gains by scheduling messages based on their remaining size (SRPT policy) (Hu et al., 2020; Montazeri et al., 2018; Gao et al., 2015). In contrast, SD schemes (Alizadeh et al., 2010, 2012, 2013; Liu et al., 2021; Kumar et al., 2020; Li et al., 2019; Mittal et al., 2015) treat downlinks as any other link. Senders must first detect downlink congestion and then independently adjust their rates/windows such that the level of congestion falls below an acceptable target.
Shared links: Unlike exclusive downlinks, core and sender-to-ToR link bottlenecks pose a challenge for RD schemes. Shared link bottlenecks can appear when multiple receivers concurrently send credit packets through the same link to pull data in the reverse direction. Before discussing existing approaches to deal with this key challenge, we delve deeper into the specifics of shared-link congestion.
When core congestion occurs, multiple flows with unrelated senders and receivers compete for bandwidth at the network core. Note that the core may have multiple tiers or be configured differently but is fundamentally shared infrastructure. Congestion at the core of a fabric is less common than at downlinks (Montazeri et al., 2018; Singh et al., 2015; Ghabashneh et al., 2022) but can still occur due to core network oversubscription. Oversubscription can be permanent to reduce cost (Singh et al., 2015) or transient due to component failures. Congestion at the core can also occur as a consequence of static ECMP IP routing decisions that cause multiple flows to saturate one core switch and one core-to-Tor downlink, while other core switches have idle capacity (Greenberg et al., 2009; Alizadeh et al., 2014).
Uplink congestion occurs due to fan-out of multiple flows to different receivers or due to bandwidth mismatch between the sender uplink and the receiver downlink. Because the resulting packet buffering is in hosts and not in the fabric, sender congestion is generally a less severe problem. For RD schemes, uplink congestion is known as the unresponsive sender problem and leads to degraded throughput as independent scheduling decisions of receivers may conflict, wasting downlink bandwidth. Whereas the term unresponsive has been used in the context of SRPT scheduling, where messages are transmitted to completion, we will use congested sender as a general description of uplink congestion.
RD protocols have proposed various mechanisms for overcoming the tension between independent receiver scheduling and the fact that some links are shared. One of the earliest designs, pHost (Gao et al., 2015), employs a timeout mechanism at receivers to detect unresponsive senders and direct credit to other senders. NDP (Handley et al., 2017) employs custom very shallow buffer switches and eagerly drops packets, using header trimming to recover quickly. NDP receivers handle uplink sharing by only crediting senders as long as they transmit data packets - whether dropped or not. pHost and NDP do not explicitly deal with core congestion and, further, the analysis by Montazeri et al. (Montazeri et al., 2018) showed that neither of the two achieves high overall link utilization. Homa (Montazeri et al., 2018) introduced controlled overcommitment in which each receiver can send credit to up to senders at a time. Homa achieves high utilization as it is statistically likely that at least one of the k senders will respond. However, it trades queuing for throughput by meaningfully increasing the amount of expected inbound traffic to each receiver. To let small messages bypass long network queues, Homa relies on Ethernet priorities which are normally used for application-level QoS guarantees (Arslan et al., 2023; Kumar et al., 2020; Hoefler et al., 2023). dcPIM (Cai et al., 2022) employs a semi-synchronous round-based matching algorithm where senders and receivers exchange messages to achieve a bipartite matching. This coordinates the sharing of sender uplinks but congestion at the core is only implicitly addressed by the protocol’s overall low link contention. The downside of this link-sharing approach is message latency. dcPIM delivers small messages quickly by excluding them from the matching process. However, messages larger than the bandwidth-delay-product (BDP) of the network must wait for several RTTs before starting transmission. ExpressPass (Cho et al., 2017) manages all links, exclusive and shared, via a hop-by-hop approach which configures switches to drop excess credit packets, which in turn rate limits data packets in the opposite direction. To reduce credit drops, ExpressPass uses recent credit drop rates as feedback to adjust the future sending rate, and in this way also improves utilization and fairness across multiple bottlenecks. Out of the designs discussed so far, ExpressPass is the only one that explicitly manages core congestion and can operate with highly oversubscribed topologies. ExpressPass’s hop-by-hop design helps it achieve near-zero queuing (Cho et al., 2017), but is more complex to deploy and maintain due to its switch configuration and path symmetry requirements, and suffers under small-flow-dominated workloads (see §5.3).
2.2. The impact of ASIC trends on buffering

Congestion control protocols generally depend on buffering to offset coordination and control loop delays and, as a result, face a throughput-buffering trade-off. Maximum bandwidth utilization can trivially be achieved with high levels of in-network buffering, but at the cost of queuing-induced latency and expensive dropped packet retransmissions. Conversely, low buffering can lead to throughput loss for protocols that are slow in capturing newly available bandwidth.
High-speed packet buffering is handled by low latency and relatively small SRAM buffers in switch ASICs. Figure 1 shows that the size of these buffers is not increasing in size as fast as the bisection bandwidth of switch ASICs. For example, nVidia’s top-end Spectrum 4 ASIC (rightmost point in Figure 1) has a MB buffer, which corresponds to MB per Tbps of bisection bandwidth (Nvidia, 2022). The previous Tbps and Tbps top-end Spectrum ASICs were equipped with MB and MB per Tbps respectively (Mellanox, 2020, 2017). Unfortunately, future scaling of SRAM densities appears unlikely given CMOS process limitations (Chang et al., 2022; David Schor, 2022). In parallel, datacenter round-trip times (RTT) are not falling as they are dominated by host software processing, PCIe latency, and ASIC serialization latencies. Consequently, CC protocols must handle higher BDPs with less switch buffer space at their disposal.
To better absorb instantaneous bursts of traffic, switch packet buffers are generally shared among egress ports. Some ASICs advertise fully-shareable buffers while others implement separate pools or statically apportion some of the space to each port (Ghabashneh et al., 2022). On top of the physical implementation, various buffer-sharing algorithms dynamically limit each port’s maximum allocation to avoid unfairness (Alizadeh et al., 2010). However, if a large part of the overall buffer is occupied, the per-port cap becomes more equitable, limiting burst absorbability (Ghabashneh et al., 2022).
Figure 2 provides some insight into whether existing congestion control schemes are future-proof given these hardware trends by measuring Homa’s buffer occupancy distribution as a function of load for the Websearch workload (Alizadeh et al., 2013). Hosts generate flows following the Poisson distribution but traffic patterns are often more bursty (Zhang et al., 2017) and thus challenging (full methodology in §5.1). To achieve best-in-class message latency and link utilization Homa uses Ethernet priorities and overcommitment of downlinks, the latter drastically increasing queuing in the fabric. Figure 2 compares the buffer occupancy distribution (assuming infinite buffers in the experiment) with the actual resources of two leading ASICs, adjusted to the port radix of the simulation. The simulated ToR switches have Gbps downlinks to servers (Alizadeh et al., 2013) and uplinks for a total bisection bandwidth of Tbps. Using the Spectrum 4 buffer-bandwidth ratio of MB per Tbps corresponds to MB of buffer per port (Figure 2 left) and a MB total ToR buffer (right). In practice, the buffer is neither partitioned nor fully shared; however, between the two extremes, Homa operates with more than the per-port buffer and is close to overflowing a fully shared buffer. In the latter case, the presence of persistent queuing also limits the flexibility of the buffer-sharing algorithm.


3. SIRD Design Pillars
SIRD is an end-to-end receiver-driven scheme that manages exclusive links proactively and shared links reactively. In practice, this means that receivers perform precise credit-based scheduling when the bottleneck is their downlinks and use well-established congestion signals and algorithms to coordinate over shared links. SIRD does not face the limitations discussed in §2 as it:
-
•
is end-to-end, with all decision-making happening at end hosts, and does not rely on advanced switch features or configuration.
-
•
achieves high throughput by using sender and core link congestion feedback to allow receivers to direct credit to links with spare capacity.
-
•
causes minimal buffering in the network by largely eliminating the need to overcommit downlinks.
-
•
does not need Ethernet priorities to deliver messages with low latency, thanks to minimal buffering.
-
•
can start message transmission immediately without a prior matching stage.
-
•
explicitly tackles core congestion through its shared link management approach.
Efficient credit allocation: SIRD’s objective is to allow receivers to send the appropriate amount of credit depending on the real time availability of the bottleneck link. For downlinks the task is trivial as all the link’s capacity is managed by one receiver. However, when the bottleneck is shared (sender uplink or core link), SIRD receivers detect competition for bandwidth and adjust the amount of issued credit dynamically. For example, if a sender is the bottleneck because it transmits continuously to two receivers, each of them should converge to allocating half a BDP worth of credit. This approach makes the distribution of credit efficient because it is allocated to senders that can promptly use it rather than being accumulated by congested senders.
SIRD implements efficient credit allocation through informed overcommitment. Each receiver is allotted a limited amount of available credit , and the objective is to distribute it to senders that can use it. The minimum valid value of is as this is the amount of credit required to pull an equal amount of inbound traffic and fully utilize the downlink. Higher values of lead to downlink overcommitment. Unlike Homa’s controlled overcommitment that is statically configured and credits the senders sending the shortest messages, SIRD aggressively reduces overcommitment because it redirects credit to senders that can use it, based on feedback from senders and the network.

Figure 3 showcases the benefit of efficient credit allocation in SIRD by comparing the throughput-buffering trade-off across equivalent overcommitment levels for Homa () and SIRD () under high network load, when CC is essential. SIRD’s informed overcommitment matches Homa’s goodput with less overcommitment and less queuing.
SIRD implements informed overcommitment through a control loop at each receiver, which dynamically adjusts credit allocation across senders based on sender and network feedback. When a sender is concurrently credited by multiple receivers, the sender receives credit faster than it can consume it, causing it to accumulate. This is undesirable as receivers have a limited amount of credit to distribute. Equivalently, limiting accumulation makes credit available to the senders that can use it. SIRD’s control loop achieves this by setting an accumulated credit threshold, , that is similar in spirit to DCTCP’s marking threshold (Alizadeh et al., 2010), Swift’s target delay(Kumar et al., 2020), or HPCC’s (Li et al., 2019). At each sender, when the amount of accumulated credit across all receivers exceeds , a bit is set in all outgoing data packets. Based on arriving bit values, each receiver executes DCTCP’s well established AIMD algorithm and reduces the amount of credit allocated to the congested sender. SIRD can also use other algorithms or signals such as end-to-end delay on infrastructures with precise timestamping support (Kumar et al., 2020), In-Band Telemetry (Li et al., 2019; Wang et al., 2023) if available.
SIRD applies the same approach to handle core congestion using ECN as its signal, similar to DCTCP. Receivers observe whether the CE bit of data packets is set and execute the DCTCP algorithm to adjust per-sender credit limits. Similar to Swift (Kumar et al., 2020), each receiver runs two AIMD algorithms in parallel, one for senders and one for the core, and then enforces the decision of the most congested one. This separation allows the differentiation of the signal or the algorithm given the particular constraints or capabilities of hosts and network switches. In this paper, we use the same proven and simple combination for both and leave the exploration of more complex algorithms and signals to future work.
Starting at line rate: Prior work (Montazeri et al., 2018; Gao et al., 2015; Hu et al., 2020; Handley et al., 2017) has demonstrated the latency benefits of starting transmission at line rate, without a gradual ramp-up or preceding control handshakes that take at least one RTT. SIRD’s credit allocation mechanism operates while transmission progress is made, and thus, senders immediately start at line rate, sending the first BDP bytes unscheduled (without waiting for credit).
We further optimize the design based on the following simple observation: small messages benefit the most from unscheduled transmission since their latency is primarily determined by the RTT while throughput-dominated messages see minimal gain. For example, in the absence of queuing, delaying transmission by one RTT increases the end-to-end latency of a message sized at by 9% compared to 200% for a single-packet message. Therefore, to reduce unnecessary bursty traffic and queuing, SIRD senders do not start transmitting messages larger than a configurable threshold (UnschT) before explicitly receiving credits from the receiver. For messages smaller than UnschT, senders send the first bytes without waiting for credit. For example, if and , the first is unscheduled and the other is scheduled.
Ethernet priorities are not required: Homa’s main contribution is to leverage Ethernet priorities to solve for latency in a system that aggressively overcommits without sender state information. By efficiently allocating credit, SIRD maximizes utilization with minimal buffering, thereby largely eliminating its impact on latency, and removing the requirement for priorities. If available, SIRD can optionally use one separate priority lane to slightly lower the RTT of control packets and to deliver small messages even faster (see §5.5 for analysis on priority sensitivity).
4. SIRD Design
At a high level, SIRD is an RPC-oriented protocol, similar to other recently proposed datacenter transports (Montazeri et al., 2018; Gao et al., 2015; Cai et al., 2022). SIRD may be used to implement one-way messages or remote procedure calls (Montazeri et al., 2018; Kalia et al., 2019; Kogias et al., 2019). SIRD assumes that the length of each message is known or that data streams will be chunked into messages. SIRD further assumes that ECN is configured in all network switches; the ECN threshold is to be set according to DCTCP best practices (Alizadeh et al., 2010). SIRD is designed to be layered on top of UDP/IP for compatibility with all network deployments. The UDP source port is randomly selected for each packet for fine-grain load balancing, allowing an ECMP network to behave as efficaciously as random packet spraying (Dixit et al., 2013). We make no assumption of lossless delivery, network priorities, or smart NICs and switches.
In the rest of this section we present SIRD focusing on the mechanisms that enable informed overcommitment.
4.1. Base Sender-Receiver Interaction
SIRD defines three main packet types:
-
(1)
DATA: a packet that contains part of a message payload. There are two types of DATA packets: scheduled, that are sent after receiving credit, and unscheduled.
-
(2)
CREDITREQ: a control packet sent by a sender to a receiver to indicate that the former wants to send scheduled data, either an entire message if , or else just the scheduled portion of a message smaller than .
-
(3)
CREDIT: a control packet sent by the receiver to the sender to schedule the transmission of one DATA packet.
Generally, the flow of packets consists of credit flowing from receivers to senders and data flowing in the opposite direction. Credit leaves the receiver in a CREDIT packet, is used by the sender, and returns in a scheduled DATA packet.
4.2. Credit Management
Each SIRD receiver maintains two types of credit buckets that limit the amount of credit it can distribute: a global credit bucket and per-sender credit buckets.
The global credit bucket controls overcommitment by capping the total number of outstanding credits that a receiver can issue. Configuring is necessary to ensure maximum throughput. Further, bounds the queuing length from scheduled messages to bytes at the ToR’s downlink. Our experiments show that a value of as low as is sufficient to ensure high link utilization in challenging workloads.
Each receiver also maintains a credit bucket per sender machine it communicates with. The per-sender credit bucket caps the number of outstanding credits the receiver can issue to a sender. Informed overcommitment is implemented by adjusting the size of the per-sender credit bucket according to the level of congestion at the core and the sender (max ). Reducing the bucket size means that less of the receiver’s total credit can be allocated to a congested source or path, and thus, more is available for other senders.
Unlike protocols that manage congestion on a per-flow basis, SIRD does so per sender. In SIRD, all flows will face the same level of congestion since it performs packet spraying. Thus, SIRD receivers aggregate congestion signals from all flows and can react faster. From an implementation perspective, receivers need to keep less state, which is beneficial especially for a hardware implementation.
4.3. Informed Overcommitment
The informed overcommitment control loop uses two input signals that communicate the extent of congestion in the network and at senders. The signals are carried in DATA packets and are the ECN bit in the IP header set by the network and a bit in the SIRD header set by the sender. Each receiver runs two separate AIMD (additive-increase, multiplicative decrease) control loops and uses the most conservative of the two (similar to Swift (Kumar et al., 2020)) to adjust per-sender credit bucket sizes. Each control loop is configured with its own marking threshold ( and ). should be set according to DCTCP best practices (Alizadeh et al., 2010) to limit queuing in the network core. Note that is much higher than the allowed persistent queueing at ToR switches as controlled by . Thus, ToR switches never have to mark ECN.
should be set to limit the amount of credit a sender can accumulate, thus allowing receivers to efficiently distribute their limited aggregate credit. Intuitively, determines the level of accumulated credit the control loop is targeting when a sender is congested, i.e., receiving credit faster than it can use it. Setting it too high means each sender can accumulate substantial amounts of credit, and consequently, B would need to be configured higher to increase aggregate credit availability. Conversely, a very low value of SThr does not allow the control loop any slack when converging to a stable state and can cause throughput loss.
To understand the relationship between and , we analytically examine the congested-sender scenario from the perspective of a receiver R to find: how much total credit (B) R needs when receiving from congested senders to still have enough available to be able to saturate its downlink. Assuming each congested sender sends to receivers in total, the available uplink bandwidth for R is . Assuming uniform link speeds, we are interested in the case where senders are the bottleneck and cannot saturate R, or:
| (1) |
In this case, each of the senders accumulates up to credit in stable state, or from each receiver assuming an equal split (see §4.5). Therefore, R’s B must be large enough to allow of credit to be in flight (for any new senders) despite accumulation at congested senders, or:
| (2) |
If is the number of congested senders that maximizes the sum term, then (denominator) and the maximum value of the term is:
| (3) |
It follows that, in steady state, R can account for any number of congested senders as long as . Under dynamic traffic patterns (see §5.5) higher values of B can help increase overall utilization. Further, policies other than fair sharing can loosen this property. For example, if senders prioritize some receivers, then, in the worst case where R is de-prioritized by all k senders, Equation 2 loses from the denominator and B depends on the number of worst-case congested senders.
| UnschT | Messages that exceed UnschT in size ask for credit before transmitting. |
|---|---|
| B | Per-receiver global credit bucket size. Caps credited-but-not-received bytes. |
| NThr | ECN threshold, configured as for DCTCP. |
| SThr | Sender marking threshold (). |
-
•
: consumed credit from global receiver bucket of size B,
-
•
: consumed credit from the bucket of sender i,
-
•
: Sender and network credit bucket size,
-
•
: Requested but not granted credit for sender i.
4.4. Congestion Control Algorithm
Algorithm 1 describes the actions of a SIRD receiver. Assuming credit is available in the global bucket, the receiver tries to allocate it to an active sender (ln. 9). It first, selects one of the senders with available credit in the per-sender bucket (ln.10) based on policy (ln.11). The receiver sends a CREDIT packet (ln. 13) and reduces the available credit both in the global bucket, the per-sender bucket, and the remaining required credit for that message (ln. 14). Whenever a DATA packet arrives (ln. 2), if it is scheduled, the receiver replenishes credit in the global bucket (ln. 4) and the per-sender bucket (ln. 5). Then it executes the two independent AIMD control loops to adapt to a congested sender (ln. 6) and a congested core network (ln. 7), respectively. The receiver sets the size of the per-sender bucket as the minimum of the two values determined by the control loops (ln. 10).
Algorithm 2 describes the implementation of the sender-side algorithm for scheduled DATA packets. A host can send data to a receiver as long as it has available credit for said receiver. Congested senders mark the congested sender notification (sird.csn) bit if the total amount of accumulated credit exceeds (ln. 8). The sender can send unscheduled DATA packets at any point in time. SIRD senders naturally handle scenarios where a meaningful portion of uplink bandwidth is consumed by unscheduled packets because they limit credit accumulation and thus adapt the transmission rate of scheduled packets to the leftover bandwidth.
4.5. Packet Pacing and Scheduling
SIRD can be configured to schedule for fairness e.g., by crediting messages in a round-robin manner, or for latency minimization, e.g., by crediting smaller messages first (SRPT), or to accommodate different tenant classes. SIRD implements policies at the receiver (ln .11), which is the primary enforcer, and at the sender (ln. 7). By minimizing queuing in the fabric, SIRD does not need to enforce policies there, simplifying the design. Regardless of which policy is configured at senders, SIRD allocates part of the uplink bandwidth fairly across active receivers, as to ensure a regular flow of congestion information between sender-receiver pairs.
SIRD receivers pace credit transmission to match the downlink’s capacity for data packets. Pacing helps further reduce downlink queuing but is not needed for correctness.
4.6. Ethernet Priorities and Packet Loss
Whenever possible in the datacenter, CREDITREQ and CREDIT packets are sent at a higher network priority to further reduce RTT jitter. The unscheduled prefixes of messages also use it. Using one higher priority level for control and prefix packets has minimal impact on the overall traffic and should not affect other operations. SIRD does not require priorities to deliver high performance (§5.5).
Packet loss in SIRD will be very rare by design, but the protocol must nevertheless operate correctly in its presence. Ethernet packets may be dropped for reasons other than congestion, e.g., CRC errors or packet drops due to host, switch, or link-level restarts. SIRD employs Homa’s (Montazeri et al., 2018) retransmission design which uses timeouts at the receiver and the sender to detect packet loss.
5. Protocol Evaluation
We use network simulation to evaluate SIRD in complex scenarios. We seek to answer questions in four areas: (1) How well does SIRD navigate the throughput-buffering-latency trade-off (§5.2)? (2) Is SIRD’s congestion response robust against high load pressure and adverse traffic patterns? Does it effectively deal with core congestion (§5.3)? (3) Can SIRD deliver messages with low and predictable latency (§5.4)? (4) How important is SIRD’s sender-informed design in maximizing utilization while minimizing buffering? How sensitive is SIRD to its configuration parameters (§5.5)?
5.1. Methodology
Protocols: We compare SIRD to 5 baselines: DCTCP (Alizadeh et al., 2010), a widely deployed sender-driven scheme (Ghabashneh et al., 2022), Swift (Kumar et al., 2020), a state-of-the-art production sender-driven scheme, Homa (Montazeri et al., 2018), because of its near-optimal latency and its use of overcommitment, ExpressPass (Cho et al., 2017), as it employs a hop-by-hop approach to managing credit, and dcPIM (Cai et al., 2022), as a recent and unique point in the design space as it explicitly matches senders and receivers. We do not extend Homa with Aeolus (Hu et al., 2020) for the reasons discussed in (John K. Ousterhout, 2022a). Note that the Homa and dcPIM papers already include favorable comparisons to NDP (Handley et al., 2017), Aeolus (Hu et al., 2020), PIAS (Bai et al., 2015), pHost (Gao et al., 2015), and HPCC (Li et al., 2019), thus we did not include them in our evaluation.
We implement SIRD on ns-2 (Altman and Jimenez, 2012), reuse the original ns-2 DCTCP implementation (using the same parameters as (Alizadeh et al., 2013), scaled to 100Gbps) and the original ns-2 ExpressPass implementation (Cho et al., 2018), and port the published Homa simulator (Montazeri, 2019) to ns-2 using the same parameters as in (Montazeri et al., 2018) scaled to 100Gbps. The published Homa simulator does not implement the incast optimization (Montazeri et al., 2018), which further relies on two-way messages. We use a Swift simulator, kindly made public (Abdous et al., 2021), and configure its delay parameters to achieve similar throughput to DCTCP, respecting the guidelines (Kumar et al., 2020). Finally, we use the published dcPIM simulator (Cai, 2023).
| Prot. | Parameters |
|---|---|
| all | RTT(MSS): 5.5s intra-rack, 7.5s inter-rack |
| ; link@100Gbps | |
| SIRD | , |
| , | |
| DCTCP | Initial window: , g= |
| Marking ECN Threshold: | |
| Swift | Initial window: |
| base_target: , fs_range: | |
| , fs_max: , fs_min: | |
| XPass | |
| Homa | Same as (Montazeri et al., 2018) at 100Gbps (incl. priority split) |
| dcPIM | Same as (Cai et al., 2022) |
Table 2 lists protocol parameter values. DCTCP and Swift use pools of pre-established connections (40 for each host pair). SIRD approximates SRPT scheduling like Homa and dcPIM. SIRD, Homa, and dcPIM use packet spraying, DCTCP and Swift use ECMP. Homa uses 8 network priority levels, dcPIM 3, and SIRD 2 (§4.6). SIRD does not require priorities to operate well; we explore this in §5.5. The initial window of DCTCP and Swift is configured at like in (Alizadeh et al., 2013).
Topology: We simulate the two-tier leaf-spine topology used in previous work (Montazeri et al., 2018; Alizadeh et al., 2010, 2013; Gao et al., 2015; Cai et al., 2022) with 144 hosts, connected to 9 top-of-rack switches (16 hosts each) via 4 spine switches, with link speeds of 100Gbps to hosts and 400Gbps to spines; i.e., each switch has 3.2Tbps of bisection bandwidth. We simulate switches with infinite buffers, i.e., without packet drops (1) to avoid making methodologically complex assumptions as drop rates and thus latency and throughput are very sensitive to switch buffer sizes, organization, and configuration (Ghabashneh et al., 2022; John K. Ousterhout, 2022a) (see §2.2); and (2) to study intended mode of operation of the protocols that leverage buffering to achieve high link utilization and operate best without drops. SIRD never uses more than a small fraction of the theoretical capacity and does not benefit from this setup.
Workload: As in prior work, each host operates as a client and a server, with one-way messages generated according to an open-loop Poisson distribution to uniformly random receivers (all-to-all). We simulate 3 workloads: (1) WKa: an aggregate of RPC sizes at a Google datacenter (Felderman, 2018); (2) WKb: a Hadoop workload at Facebook (Roy et al., 2015); (3) WKc: a web search application (Alizadeh et al., 2013). We select them to test over a wide range of mean message sizes of 3KB, 125KB, and 2.5MB respectively.
We simulate these 3 workloads on 3 traffic configurations, for a total of 9 points of comparison. The configurations are: (1) Balanced: The default configuration described above. We vary the applied load, which does not include protocol-dependent header overheads, from 25% to 95% of link capacity. (2) Core: Same as (1) but ToR-Spine links are 200Gbps (2-to-1 oversubscription). Due to uniform message target selection, of messages travel via spines, turning the core into the bottleneck. We consequently reduce the load applied by hosts by to reflect the network’s reduced capacity. This is not meant to reflect a permanent load distribution, but we hypothesize that it is possible transiently. (3) Incast: We use the methodology of (Li et al., 2019; Cai et al., 2022) and combine background traffic with overlay incast traffic: 30 random senders periodically send a 500KB message to a random receiver. Incast traffic represents 7% of the total load.
We report the goodput (rate of received application payload), total buffering in switches, and message slowdown, defined as the ratio between the measured and the minimum possible latency for each message. In the incast configuration, we exclude incast messages from slowdown results.



5.2. Performance Overview
Figure 4 shows how protocols navigate the trade-offs between throughput, buffering, and latency by plotting their relative performance across all 9 workload-configuration combinations. The best-performing protocol on each of the 9 scenarios gets a score of (per metric) and the others are normalized to it, so that goodput is always whereas queuing and slowdown are always . We report the highest achieved goodput and the highest peak queuing over all the levels of applied load. We report slowdown at 50% applied load which is a level most protocols can deliver in all scenarios. The following figures and calculations do not include cases where a protocol cannot satisfy a specific load level, or cannot stop network buffers from growing infinitely.
Overall, SIRD is the only protocol that consistently achieves near-ideal scores across all metrics. Specifically, SIRD causes less peak network queuing than Homa and achieves similar latency and goodput performance. SIRD outperforms dcPIM in message slowdown, and peak goodput and queuing by , , and respectively. ExpressPass causes practically zero queuing thanks to its hop-by-hop design, and 88% less than SIRD, but SIRD delivers lower message slowdown and more goodput. SIRD never causes more than 0.8MB and 2.3MB in ToR queuing on receiver- and core-bottleneck scenarios respectively, which maps to 8% and 23% of the packet buffer size assuming 3.13 MB/Tbps (§2.2).
5.3. Congestion Response
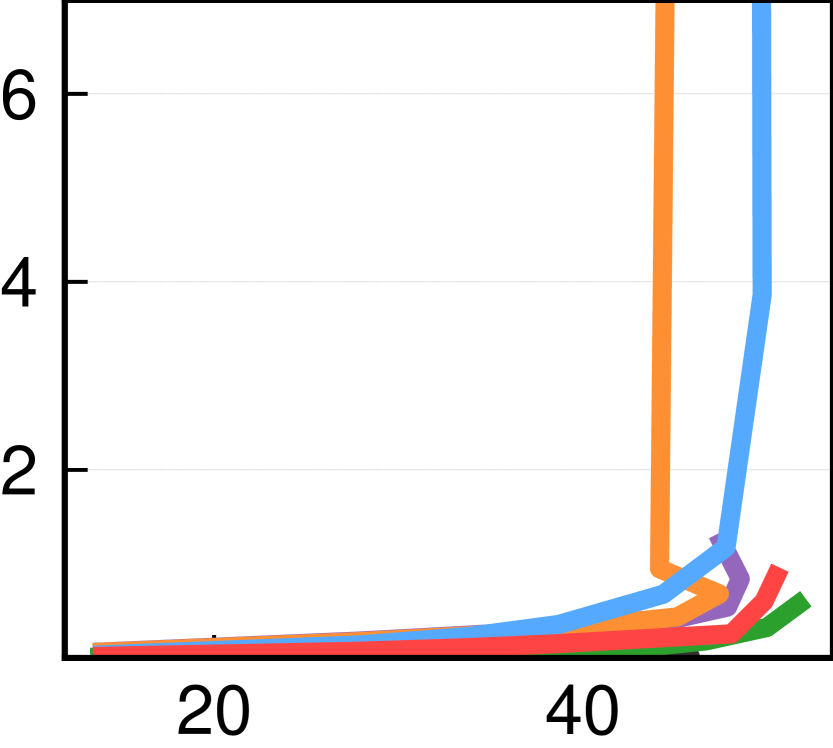
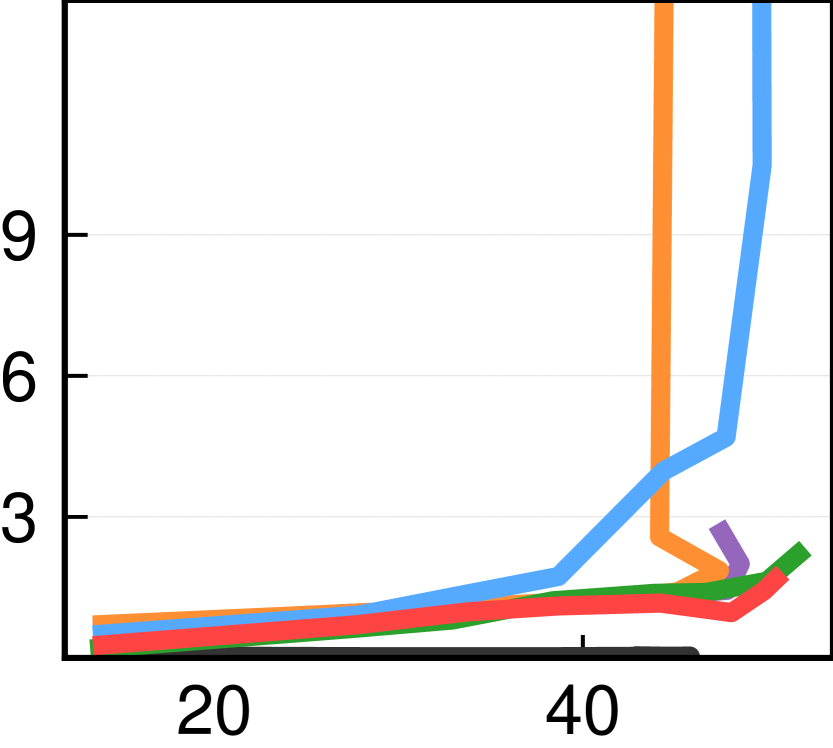
We now zoom in on how each protocol manages congestion across different levels of applied stress. Figure 5 plots maximum buffering across ToR switches as a function of achieved goodput for balanced (top), core (middle), and incast (bottom) configurations. The reported goodput is the mean across all 144 hosts and reflects the rate of message delivery to applications. ToR queuing covers both downlinks and links to aggregation switches (core).
Overall, SIRD consistently achieves high goodput while causing minimal buffering across load levels, even under high levels of stress. Through informed overcommitment, SIRD makes effective use of a limited amount of credit and achieves high goodput while reducing the need for packet buffer space by up to compared to Homa’s controlled overcommitment. Further, SIRD displays a more predictable congestion response compared to dcPIM and ExpressPass. As expected, based on 4(a), DCTCP and Swift cause meaningful buffering without achieving exceptional goodput. Mean queuing is qualitatively similar (appendix Figure 12).
dcPIM and ExpressPass sometimes compare favorably to SIRD but only when the workload mean message size is not small. They both struggle in terms of achieved goodput and buffering in WKa for all three configurations (left column). In WKa, of messages are smaller than and are responsible for of the traffic. ExpressPass’s behavior is known and discussed in (Cho et al., 2017): more credit than needed may be sent for a small message which may then compete for bandwidth with productive credit of a large message. For dcPIM, the likely reason as discussed in (John K. Ousterhout, 2022b) is that to send a small message, a sender has to preempt the transmission of a larger message which can cause the receiver of the latter to remain partially idle. SIRD’s behavior is consistent across workload message sizes thanks to slight downlink overcommitment which absorbs small discontinuities in large message transmission.
In the core configuration (Figure 5 - middle row), where the core is the bottleneck, we observe that SIRD’s reactive congestion management, despite sharing the same ECN-based mechanism as DCTCP, achieves steadier behavior because it limits the number of bytes in the network. Homa grows ToR uplink queues aggressively as it does not explicitly manage core queuing which is only limited by the aggregate overcommitment level of receivers. The same applies to dcPIM but because it does not overcommit, queuing is much lower.
Last, the incast configuration (bottom row) illustrates the relative advantage of RD schemes over DCTCP and Swift.









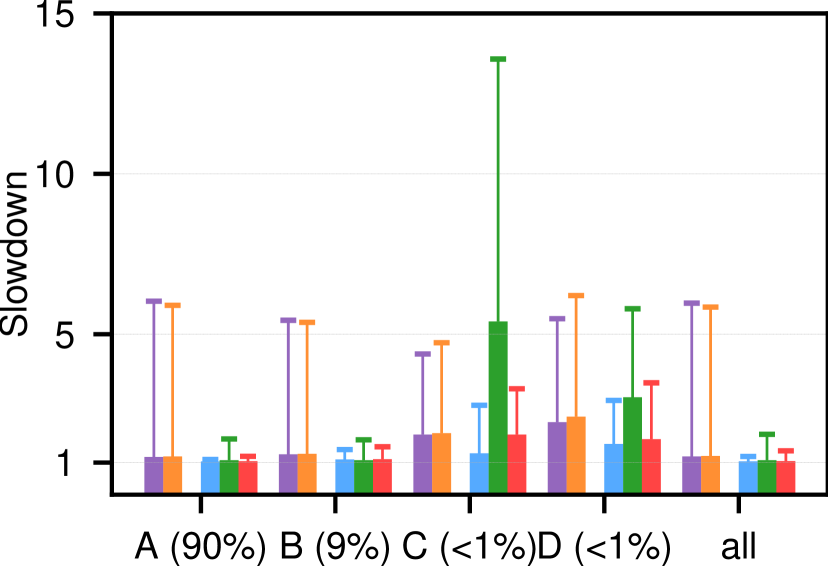
5.4. Message Latency
Figure 6 shows the median and percentile latency slowdown for different message size ranges across configurations at 50% applied load (except WKb results which fall between the other two and can be found in appendix Figure 11). Across each workload as a whole (rightmost bar cluster ”all”), SIRD is generally on par with Homa, and often outperforms dcPIM in terms of tail latency. For small, latency-sensitive messages (100KB - groups A and B), SIRD, dcPIM, and Homa offer close to hardware latency. Both in aggregate and for small messages, DCTCP and Swift perform an order of magnitude worse at the tail because they cause meaningful buffering without having a bypass mechanism like Homa.




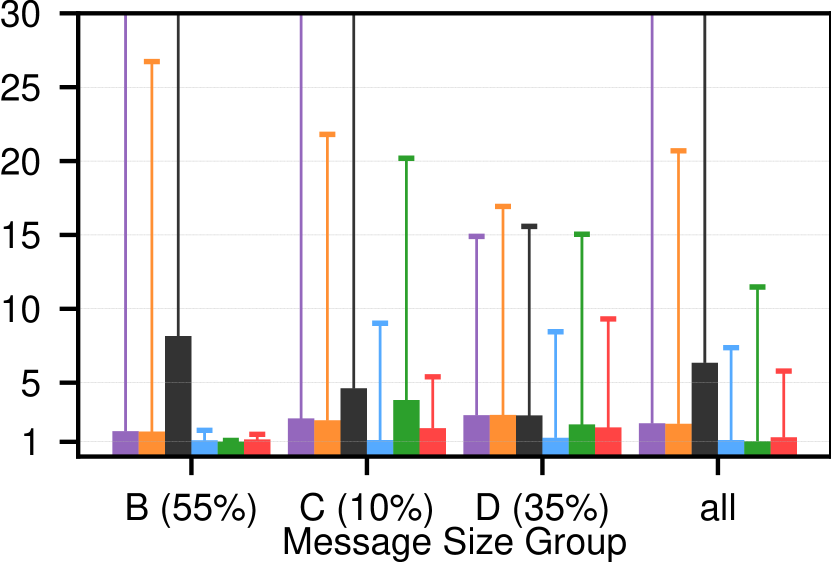
For messages larger than (groups C and D), SIRD comes closest to near-optimal Homa and strongly outperforms the other protocols. SIRD achieves up to lower latency than dcPIM in this size range because it does not wait for multi-RTT handshakes before sending a message as discussed in §3. Note that 6(b) is comparable to Figure 3d in (Cai et al., 2022). Similarly, SIRD outperforms ExpressPass on latency because it does not take multiple RTTs to capture the full link bandwidth and it implements SRPT.
The differences in latency for protocols other than dcPIM and ExpressPass, which wait before ramping up transmission, can be explained through their effective scheduling policies. That is, assuming that a protocol manages to deliver enough messages to achieve 50% goodput, lowering latency is a matter of appropriately ordering message transmission (when there are no conflicting application concerns). For example, perhaps surprisingly, DCTCP achieves equivalent or better latency than Swift in all but the incast scenarios. We argue that this is because Swift is better at fairly sharing bandwidth between messages thanks to its tighter control loop which converges faster. Latency-wise, fair sharing is inferior to FIFO or SRPT since it delays the completion of individual messages in favor of equitable progress. Along the same lines, SIRD cannot always match the latency of Homa because it approximates SRPT less faithfully as: (1) unlike Homa, a portion of the sender uplink is fair-shared (50% in this case). Note that Homa’s Linux implementation does the same to avoid starvation (Ousterhout, 2021). (2) To avoid credit accumulation in congested senders, informed overcommitment adjusts per-sender credit bucket sizes equitably.
In summary, SIRD delivers messages with low latency, outperforms dcPIM, ExpressPass, DCTCP, and Swift, and, without relying on Ethernet priorities, is competitive with Homa, which nearly optimally approximates SRPT (Montazeri et al., 2018).
5.5. Sensitivity Analysis
In this section, we explore SIRD’s sensitivity to its key parameters: , , and , as well as to the availability of Ethernet priorities. SIRD’s sensitivity to NThr is the same as DCTCP’s to (Alizadeh et al., 2010).
Informed overcommitment: Equation 2 introduced the key relationship —for a simple analytical scenario— between and , the two key parameters of informed overcommitment. Figure 7 shows the relationship in practice for Balanced WKc in terms of achieved goodput.
We observe that the presence of informed overcommitment increases goodput by , confirming that the introduced sender-informed mechanism is necessary to achieve high throughput with a limited amount of credit, and thus low queuing. When the mechanism is disabled (), there is stranded and unused credit at congested senders, which prevents receivers from achieving the full rate. With the mechanism enabled, the curves asymptotically converge to the same maximum goodput of 90Gbps. Reaching the plateau with a lower value of also demands lowering to reduce credit stranded at senders (Equation 2). Queuing increases with B similar to Figure 3 and remains stable when varying SThr. Finally, we observed that the median and percentile workload slowdown for range within and respectively, positively correlated to B. We selected rather than for our experiments because it halves expected buffering from to (). We do not configure lower than as we deem it unrealistic to implement in a real system because it may cause unwanted marking due to batch credit arrivals or processing loop variability.

Unscheduled transmissions: SIRD allows the unscheduled transmission of the prefix of messages . Figure 8 (left) explores the sensitivity to this parameter. Setting meaningfully increases median and tail latency for small messages while higher values offer no appreciable net benefit. The experiments indicated that increasing has little impact on max and mean ToR queuing, which range within KB and KB respectively.
The default value of is a satisfying compromise as large values do not yield latency benefits, yet can unnecessarily expose the fabric to coordinated traffic bursts (e.g., incast). We confirm this by running the same workload under the incast configuration which has a high concentration of message bursts. We observe the following performance degradation when comparing to : Overall percentile slowdown increases by 34% while maximum and mean ToR queuing increases by and respectively. These results justify our decision to introduce a size threshold above which messages are entirely scheduled.
Use of Ethernet priorities: SIRD may use a second 802.1p priority for control packets and/or unscheduled prefixes. Figure 8 (right) shows how the use of priorities impacts latency in terms of (i) possible degradation when no Ethernet priorities are available, and (ii) the benefit of prioritizing unscheduled prefixes. We observe that the slowdown of the workload as a whole is unaffected by priorities for control packets and benefits slightly by using high priority for unscheduled prefixes. Across message size groups, median latency is also largely unaffected, even for small messages, thanks to the absence of persistent queuing. Only the tail slowdown of small messages benefits from a high-priority data lane. We also observed that priority transmission of control packets increases goodput by as credit is delivered more predictably. Overall, the latency and utilization profiles of SIRD are not materially sensitive to the availability of Ethernet priorities. This differentiates SIRD from Homa, which fundamentally relies on priorities to bypass long queues,and dcPIM, which strongly benefits from tight control packet delivery due to its semi-synchronous nature.


6. System Implementation
We implemented SIRD as a user-level networking service on top of DPDK in 2660 lines of code and evaluated it in a real testbed. While the maturity of our testbed —10GbE NICs and a single ToR— limits the scope of the experiments, we focus on system-specific aspects and validate that (1) SIRD can have an implementation that is both simple and efficient, (2) SIRD behaves as expected under incast, provided that credits are appropriately paced (see §4.5), and (3) informed overcommitment is practical and successfully redistributes credit from congested to available senders. We do not use Ethernet priorities in the following experiments.
Incast: Given our server availability, we construct a 6-to-1 incast experiment in which 6 senders send 1MB messages to a single receiver in a closed-loop manner. The receiver responds with an 8-byte reply. A 7th sender measures queuing at the receiver’s downlink by sending 8-byte packets, waiting for the reply, and measuring the round-trip latency.
Figure 9 plots the latency CDF of the 8-byte packet, and compares it with the CDF of a purely unloaded experiment. We compare the behavior of SIRD with a variant that eagerly sends credits without pacing. SIRD (with pacing enabled) adds only 5s latency at the percentile, which implies that at most 4 packets are queued in the switch 99% of the time. Disabling pacing increases latency as the receiver sends credit faster than it can receive data, causing queuing.
Congested sender: We evaluate informed overcommitment by designing an experiment with a congested sender. The sender starts by sending large messages to each of the four receivers. Because it can only saturate 25% of each receiver downlink, it constitutes the experiment’s bottleneck. Later, four otherwise idle hosts each send one large message to one of the four receivers (one-to-one).
Figure 10 shows the aggregate throughput at the four receiver downlinks which is at best . When informed overcommitment is disabled (), each receiver, not knowing the state of the bottlenecked sender, gives it credit worth out of the it has available. This leaves each receiver with just of credit to allocate to the other sender, which only yields . Combined, the four receivers get . When SThr is properly configured (), the four 10Gbps links are fully utilized because the congested sender only receives the amount of credit it can use.

7. Related Work
The topic of datacenter congestion control has been extensively explored due to the increasing IO speeds, the s-scale latencies, emerging programmable hardware, RPC workloads, and host-centric concerns (Alizadeh et al., 2010, 2012, 2013; Liu et al., 2021; Kumar et al., 2020; Li et al., 2019; Mittal et al., 2015; Perry et al., 2014; Le et al., 2021; Montazeri et al., 2018; Gao et al., 2015; Bai et al., 2015; Handley et al., 2017; Cho et al., 2017; Marty et al., 2019; Kalia et al., 2019; Kogias et al., 2019; Zhu et al., 2015; Addanki et al., 2022; Sun et al., 2019; Vamanan et al., 2012; Agarwal et al., 2023; Cho et al., 2020; Noormohammadpour and Raghavendra, 2018; Hong et al., 2012; Wilson et al., 2011; Lim et al., 2021; Zats et al., 2015; Cheng et al., 2014; Wang et al., 2023; Le et al., 2023; Arslan et al., 2023; Goyal et al., 2022).
SD schemes like DCQCN (Zhu et al., 2015), Timely (Mittal et al., 2015), HPCC (Li et al., 2019), Bolt (Arslan et al., 2023), etc. use network signals in the form of ECN (Alizadeh et al., 2010; Zhu et al., 2015; Vamanan et al., 2012), delay (Mittal et al., 2015; Kumar et al., 2020), telemetry (Li et al., 2019; Wang et al., 2023; Zhou et al., 2021), and packet drops (Alizadeh et al., 2013) to adjust sending windows (Alizadeh et al., 2010; Kumar et al., 2020; Sun et al., 2019; Li et al., 2019) or rates (Mittal et al., 2015; Hong et al., 2012; Wilson et al., 2011). Some operate end-to-end with no or trivial switch support (Mittal et al., 2015; Kumar et al., 2020; Alizadeh et al., 2010) while others leverage novel but non-universal switch features to improve feedback quality (Li et al., 2019; Wang et al., 2023; Zhou et al., 2021) or to tighten reaction times (Arslan et al., 2023; Zats et al., 2015; Cheng et al., 2014). SIRD targets existing datacenter networks, built out of commodity switches.
RD protocols attempt to avoid congestion altogether by proactively scheduling packet transmissions (Hu et al., 2020; Handley et al., 2017; Le et al., 2021; Montazeri et al., 2018; Cai et al., 2022; Cho et al., 2017; Perry et al., 2014; Gao et al., 2015; Lim et al., 2023) have already been discussed in detail. Orthogonally to the concerns of this paper, FlexPass (Lim et al., 2023) enables fair bandwidth sharing between proactive and reactive protocols. EQDS (Olteanu et al., 2022) enables the coexistence of traditional protocols like DCTCP and RDMA by moving all queuing interactions to end-hosts and using an RD approach to admit packets into the network fabric.

Previous work has followed different approaches regarding the desired flow/message scheduling policy. The traditional approach is to aim for fair bandwidth allocation at the flow level (Alizadeh et al., 2010; Kumar et al., 2020; Mittal et al., 2015; Zhu et al., 2015). Alternatively, D2TCP, D3, and Karuna (Chen et al., 2016) prioritize flows based on deadlines communicated by higher-level services. A recent line of work (Montazeri et al., 2018; Gao et al., 2015; Alizadeh et al., 2013; Bai et al., 2015; Hu et al., 2020), which includes both proactive and reactive protocols, attempts to approximate SRPT or SJF (shorted job first) scheduling in the fabric which minimizes average latency (Alizadeh et al., 2013; Bar-Noy et al., 2000). SIRD can approximate a variety of policies at receivers and senders and avoids the need to enforce fabric policies as it keeps in-network queuing minimal. We use SRPT for our evaluation because it minimizes latency in the absence of service-level information.
8. Conclusion
SIRD is a novel congestion control protocol that tackles the fundamental tension of receiver-driven designs which is the management of shared links. SIRD applies proactive scheduling to exclusive receiver downlinks, which are statistically the most congested and reactively allocates the bandwidth of shared links. SIRD achieves high link utilization with hardly any buffering and is the only protocol, among the six evaluated, that robustly and simultaneously delivers high throughput with minimal queuing and low latency. SIRD does not depend on advanced switch ASIC features nor Ethernet priorities, which makes it pragmatically deployable on existing and heterogeneous datacenter networks.
References
- (1)
- Abdous et al. (2021) Sepehr Abdous, Erfan Sharafzadeh, and Soudeh Ghorbani. 2021. Burst-tolerant datacenter networks with Vertigo.. In Proceedings of the 2021 ACM Conference on Emerging Networking Experiments and Technology (CoNEXT). 1–15.
- Addanki et al. (2022) Vamsi Addanki, Oliver Michel, and Stefan Schmid. 2022. PowerTCP: Pushing the Performance Limits of Datacenter Networks.. In Proceedings of the 19th Symposium on Networked Systems Design and Implementation (NSDI). 51–70.
- Agarwal et al. (2023) Saksham Agarwal, Arvind Krishnamurthy, and Rachit Agarwal. 2023. Host Congestion Control.. In Proceedings of the ACM SIGCOMM 2023 Conference. 275–287.
- Alizadeh et al. (2014) Mohammad Alizadeh, Tom Edsall, Sarang Dharmapurikar, Ramanan Vaidyanathan, Kevin Chu, Andy Fingerhut, Vinh The Lam, Francis Matus, Rong Pan, Navindra Yadav, and George Varghese. 2014. CONGA: distributed congestion-aware load balancing for datacenters.. In Proceedings of the ACM SIGCOMM 2014 Conference. 503–514.
- Alizadeh et al. (2010) Mohammad Alizadeh, Albert G. Greenberg, David A. Maltz, Jitendra Padhye, Parveen Patel, Balaji Prabhakar, Sudipta Sengupta, and Murari Sridharan. 2010. Data center TCP (DCTCP).. In Proceedings of the ACM SIGCOMM 2010 Conference. 63–74.
- Alizadeh et al. (2012) Mohammad Alizadeh, Abdul Kabbani, Tom Edsall, Balaji Prabhakar, Amin Vahdat, and Masato Yasuda. 2012. Less Is More: Trading a Little Bandwidth for Ultra-Low Latency in the Data Center.. In Proceedings of the 9th Symposium on Networked Systems Design and Implementation (NSDI). 253–266.
- Alizadeh et al. (2013) Mohammad Alizadeh, Shuang Yang, Milad Sharif, Sachin Katti, Nick McKeown, Balaji Prabhakar, and Scott Shenker. 2013. pFabric: minimal near-optimal datacenter transport.. In Proceedings of the ACM SIGCOMM 2013 Conference. 435–446.
- Altman and Jimenez (2012) Eitan Altman and Tania Jimenez. 2012. NS Simulator for beginners. Synthesis Lectures on Communication Networks 5, 1 (2012), 1–184.
- Arslan et al. (2023) Serhat Arslan, Yuliang Li, Gautam Kumar, and Nandita Dukkipati. 2023. Bolt: Sub-RTT Congestion Control for Ultra-Low Latency.. In Proceedings of the 20th Symposium on Networked Systems Design and Implementation (NSDI). 219–236.
- Bai et al. (2015) Wei Bai, Kai Chen, Hao Wang, Li Chen, Dongsu Han, and Chen Tian. 2015. Information-Agnostic Flow Scheduling for Commodity Data Centers.. In Proceedings of the 12th Symposium on Networked Systems Design and Implementation (NSDI). 455–468.
- Bar-Noy et al. (2000) Amotz Bar-Noy, Magnús M. Halldórsson, Guy Kortsarz, Ravit Salman, and Hadas Shachnai. 2000. Sum Multicoloring of Graphs. J. Algorithms 37, 2 (2000), 422–450.
- Cai (2023) Qizhe Cai. 2023. dcPIM Simulation Repository. https://github.com/Terabit-Ethernet/dcPIM/tree/master/simulator. (2023).
- Cai et al. (2022) Qizhe Cai, Mina Tahmasbi Arashloo, and Rachit Agarwal. 2022. dcPIM: near-optimal proactive datacenter transport.. In Proceedings of the ACM SIGCOMM 2022 Conference. 53–65.
- Chang et al. (2022) Chih-Hao Chang, VS Chang, KH Pan, KT Lai, JH Lu, JA Ng, CY Chen, BF Wu, CJ Lin, CS Liang, et al. 2022. Critical Process Features Enabling Aggressive Contacted Gate Pitch Scaling for 3nm CMOS Technology and Beyond. In 2022 International Electron Devices Meeting (IEDM). IEEE, 27–1.
- Chen et al. (2016) Li Chen, Kai Chen, Wei Bai, and Mohammad Alizadeh. 2016. Scheduling Mix-flows in Commodity Datacenters with Karuna.. In Proceedings of the ACM SIGCOMM 2016 Conference. 174–187.
- Cheng et al. (2014) Peng Cheng, Fengyuan Ren, Ran Shu, and Chuang Lin. 2014. Catch the Whole Lot in an Action: Rapid Precise Packet Loss Notification in Data Center.. In Proceedings of the 11th Symposium on Networked Systems Design and Implementation (NSDI). 17–28.
- Cho et al. (2017) Inho Cho, Keon Jang, and Dongsu Han. 2017. Credit-Scheduled Delay-Bounded Congestion Control for Datacenters.. In Proceedings of the ACM SIGCOMM 2017 Conference. 239–252.
- Cho et al. (2018) Inho Cho, Keon Jang, and Dongsu Han. 2018. ExpressPass Simulation Repository. https://github.com/kaist-ina/ns2-xpass. (2018).
- Cho et al. (2020) Inho Cho, Ahmed Saeed, Joshua Fried, Seo Jin Park, Mohammad Alizadeh, and Adam Belay. 2020. Overload Control for s-scale RPCs with Breakwater.. In Proceedings of the 14th Symposium on Operating System Design and Implementation (OSDI). 299–314.
- Consortium (2023) Ultra Ethernet Consortium. 2023. Overview of and Motivation for the Forthcoming Ultra Ethernet Consortium Specification. https://ultraethernet.org/wp-content/uploads/sites/20/2023/10/23.07.12-UEC-1.0-Overview-FINAL-WITH-LOGO.pdf. (2023).
- David Schor (2022) David Schor. 2022. IEDM 2022: Did We Just Witness The Death Of SRAM? https://fuse.wikichip.org/news/7343/iedm-2022-did-we-just-witness-the-death-of-sram/. (2022).
- Dean and Barroso (2013) Jeffrey Dean and Luiz André Barroso. 2013. The tail at scale. Commun. ACM 56, 2 (2013), 74–80.
- Dixit et al. (2013) Advait Abhay Dixit, Pawan Prakash, Y. Charlie Hu, and Ramana Rao Kompella. 2013. On the impact of packet spraying in data center networks.. In Proceedings of the 2013 IEEE Conference on Computer Communications (INFOCOM). 2130–2138.
- Felderman (2018) Bob Felderman. 2018. Personal communication to the authors of (Montazeri et al., 2018). (2018).
- Gao et al. (2016) Peter Xiang Gao, Akshay Narayan, Sagar Karandikar, João Carreira, Sangjin Han, Rachit Agarwal, Sylvia Ratnasamy, and Scott Shenker. 2016. Network Requirements for Resource Disaggregation.. In Proceedings of the 12th Symposium on Operating System Design and Implementation (OSDI). 249–264.
- Gao et al. (2015) Peter Xiang Gao, Akshay Narayan, Gautam Kumar, Rachit Agarwal, Sylvia Ratnasamy, and Scott Shenker. 2015. pHost: distributed near-optimal datacenter transport over commodity network fabric.. In Proceedings of the 2015 ACM Conference on Emerging Networking Experiments and Technology (CoNEXT). 1:1–1:12.
- Gebara et al. (2021) Nadeen Gebara, Manya Ghobadi, and Paolo Costa. 2021. In-network Aggregation for Shared Machine Learning Clusters.. In Proceedings of the 4th Conference on Machine Learning and Systems (MLSys).
- Ghabashneh et al. (2022) Ehab Ghabashneh, Yimeng Zhao, Cristian Lumezanu, Neil Spring, Srikanth Sundaresan, and Sanjay G. Rao. 2022. A microscopic view of bursts, buffer contention, and loss in data centers.. In Proceedings of the 22nd ACM SIGCOMM Workshop on Internet Measurement (IMC). 567–580.
- Goyal et al. (2022) Prateesh Goyal, Preey Shah, Kevin Zhao, Georgios Nikolaidis, Mohammad Alizadeh, and Thomas E. Anderson. 2022. Backpressure Flow Control.. In Proceedings of the 19th Symposium on Networked Systems Design and Implementation (NSDI). 779–805.
- Greenberg et al. (2009) Albert G. Greenberg, James R. Hamilton, Navendu Jain, Srikanth Kandula, Changhoon Kim, Parantap Lahiri, David A. Maltz, Parveen Patel, and Sudipta Sengupta. 2009. VL2: a scalable and flexible data center network.. In Proceedings of the ACM SIGCOMM 2009 Conference. 51–62.
- Handley et al. (2017) Mark Handley, Costin Raiciu, Alexandru Agache, Andrei Voinescu, Andrew W. Moore, Gianni Antichi, and Marcin Wójcik. 2017. Re-architecting datacenter networks and stacks for low latency and high performance.. In Proceedings of the ACM SIGCOMM 2017 Conference. 29–42.
- Hoefler et al. (2023) Torsten Hoefler, Duncan Roweth, Keith D. Underwood, Robert Alverson, Mark Griswold, Vahid Tabatabaee, Mohan Kalkunte, Surendra Anubolu, Siyuan Shen, Moray McLaren, Abdul Kabbani, and Steve Scott. 2023. Data Center Ethernet and Remote Direct Memory Access: Issues at Hyperscale. Computer 56, 7 (2023), 67–77.
- Hong et al. (2012) Chi-Yao Hong, Matthew Caesar, and Brighten Godfrey. 2012. Finishing flows quickly with preemptive scheduling.. In Proceedings of the ACM SIGCOMM 2012 Conference. 127–138.
- Hu et al. (2020) Shuihai Hu, Wei Bai, Gaoxiong Zeng, Zilong Wang, Baochen Qiao, Kai Chen, Kun Tan, and Yi Wang. 2020. Aeolus: A Building Block for Proactive Transport in Datacenters.. In Proceedings of the ACM SIGCOMM 2020 Conference. 422–434.
- John K. Ousterhout (2022a) John K. Ousterhout. 2022a. Homa Wiki on Aeolus. https://homa-transport.atlassian.net/wiki/spaces/HOMA/pages/262185/A+Critique+of+Aeolus+A+Building+Block+for+Proactive+Transports+in+Datacenters. (2022).
- John K. Ousterhout (2022b) John K. Ousterhout. 2022b. Homa Wiki on dcPIM. https://homa-transport.atlassian.net/wiki/spaces/HOMA/pages/1507461/A+Critique+of+dcPIM+Near-Optimal+Proactive+Datacenter+Transport. (2022).
- Kalia et al. (2019) Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2019. Datacenter RPCs can be General and Fast.. In Proceedings of the 16th Symposium on Networked Systems Design and Implementation (NSDI). 1–16.
- Kogias et al. (2019) Marios Kogias, George Prekas, Adrien Ghosn, Jonas Fietz, and Edouard Bugnion. 2019. R2P2: Making RPCs first-class datacenter citizens.. In Proceedings of the 2019 USENIX Annual Technical Conference (ATC). 863–880.
- Kumar et al. (2020) Gautam Kumar, Nandita Dukkipati, Keon Jang, Hassan M. G. Wassel, Xian Wu, Behnam Montazeri, Yaogong Wang, Kevin Springborn, Christopher Alfeld, Michael Ryan, David Wetherall, and Amin Vahdat. 2020. Swift: Delay is Simple and Effective for Congestion Control in the Datacenter.. In Proceedings of the ACM SIGCOMM 2020 Conference. 514–528.
- Le et al. (2023) Yanfang Le, Jeongkeun Lee, Jeremias Blendin, Jiayi Chen, Georgios Nikolaidis, Rong Pan, Robert Soulé, Aditya Akella, Pedro Yebenes Segura, Arjun Singhvi, Yuliang Li, Qingkai Meng, Changhoon Kim, and Serhat Arslan. 2023. SFC: Near-Source Congestion Signaling and Flow Control. CoRR abs/2305.00538 (2023).
- Le et al. (2021) Yanfang Le, Radhika Niranjan Mysore, Lalith Suresh, Gerd Zellweger, Sujata Banerjee, Aditya Akella, and Michael M. Swift. 2021. PL2: Towards Predictable Low Latency in Rack-Scale Networks. CoRR abs/2101.06537 (2021).
- Li et al. (2019) Yuliang Li, Rui Miao, Hongqiang Harry Liu, Yan Zhuang, Fei Feng, Lingbo Tang, Zheng Cao, Ming Zhang, Frank Kelly, Mohammad Alizadeh, and Minlan Yu. 2019. HPCC: high precision congestion control.. In Proceedings of the ACM SIGCOMM 2019 Conference. 44–58.
- Lim et al. (2021) Hwijoon Lim, Wei Bai, Yibo Zhu, Youngmok Jung, and Dongsu Han. 2021. Towards timeout-less transport in commodity datacenter networks.. In Proceedings of the 2021 EuroSys Conference. 33–48.
- Lim et al. (2023) Hwijoon Lim, Jaehong Kim, Inho Cho, Keon Jang, Wei Bai, and Dongsu Han. 2023. FlexPass: A Case for Flexible Credit-based Transport for Datacenter Networks.. In Proceedings of the 2023 EuroSys Conference. 606–622.
- Liu et al. (2021) Shiyu Liu, Ahmad Ghalayini, Mohammad Alizadeh, Balaji Prabhakar, Mendel Rosenblum, and Anirudh Sivaraman. 2021. Breaking the Transience-Equilibrium Nexus: A New Approach to Datacenter Packet Transport.. In Proceedings of the 18th Symposium on Networked Systems Design and Implementation (NSDI). 47–63.
- Marty et al. (2019) Michael Marty, Marc de Kruijf, Jacob Adriaens, Christopher Alfeld, Sean Bauer, Carlo Contavalli, Michael Dalton, Nandita Dukkipati, William C. Evans, Steve D. Gribble, Nicholas Kidd, Roman Kononov, Gautam Kumar, Carl Mauer, Emily Musick, Lena E. Olson, Erik Rubow, Michael Ryan, Kevin Springborn, Paul Turner, Valas Valancius, Xi Wang, and Amin Vahdat. 2019. Snap: a microkernel approach to host networking.. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP). 399–413.
- Mellanox (2017) Mellanox. 2017. Spectrum 2 datasheet. https://nvdam.widen.net/s/gbk7knpsfd/sn3000-series. (2017).
- Mellanox (2020) Mellanox. 2020. Spectrum 3 datasheet. https://nvdam.widen.net/s/6269c25wv8/nv-spectrum-sn4000-product-brief. (2020).
- Mittal et al. (2015) Radhika Mittal, Vinh The Lam, Nandita Dukkipati, Emily R. Blem, Hassan M. G. Wassel, Monia Ghobadi, Amin Vahdat, Yaogong Wang, David Wetherall, and David Zats. 2015. TIMELY: RTT-based Congestion Control for the Datacenter.. In Proceedings of the ACM SIGCOMM 2015 Conference. 537–550.
- Montazeri (2019) Behnam Montazeri. 2019. Homa Simulation Repository. https://github.com/PlatformLab/HomaSimulation. (2019).
- Montazeri et al. (2018) Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John K. Ousterhout. 2018. Homa: a receiver-driven low-latency transport protocol using network priorities.. In Proceedings of the ACM SIGCOMM 2018 Conference. 221–235.
- Noormohammadpour and Raghavendra (2018) Mohammad Noormohammadpour and Cauligi S. Raghavendra. 2018. Datacenter Traffic Control: Understanding Techniques and Tradeoffs. IEEE Commun. Surv. Tutorials 20, 2 (2018), 1492–1525.
- Nvidia (2022) Nvidia. 2022. Spectrum 4 datasheet. https://nvdam.widen.net/s/mmvbnpk8qk/networking-ethernet-switches-sn5000-datasheet-us. (2022).
- Olteanu et al. (2022) Vladimir Andrei Olteanu, Haggai Eran, Dragos Dumitrescu, Adrian Popa, Cristi Baciu, Mark Silberstein, Georgios Nikolaidis, Mark Handley, and Costin Raiciu. 2022. An edge-queued datagram service for all datacenter traffic.. In Proceedings of the 19th Symposium on Networked Systems Design and Implementation (NSDI). 761–777.
- Ousterhout et al. (2019) Amy Ousterhout, Adam Belay, and Irene Zhang. 2019. Just In Time Delivery: Leveraging Operating Systems Knowledge for Better Datacenter Congestion Control.. In Proceedings of the 11th workshop on Hot topics in Cloud Computing (HotCloud).
- Ousterhout (2021) John K. Ousterhout. 2021. A Linux Kernel Implementation of the Homa Transport Protocol.. In Proceedings of the 2021 USENIX Annual Technical Conference (ATC). 99–115.
- Perry et al. (2014) Jonathan Perry, Amy Ousterhout, Hari Balakrishnan, Devavrat Shah, and Hans Fugal. 2014. Fastpass: a centralized ”zero-queue” datacenter network.. In Proceedings of the ACM SIGCOMM 2014 Conference. 307–318.
- Rajasekaran et al. (2023) Sudarsanan Rajasekaran, Manya Ghobadi, and Aditya Akella. 2023. CASSINI: Network-Aware Job Scheduling in Machine Learning Clusters. CoRR abs/2308.00852 (2023).
- Ramakrishnan et al. (2001) K. Ramakrishnan, S. Floyd, and D. Black. 2001. The Addition of Explicit Congestion Notification (ECN) to IP. RFC 3168 (Proposed Standard). (Sept. 2001). http://www.ietf.org/rfc/rfc3168.txt Updated by RFCs 4301, 6040.
- Roy et al. (2015) Arjun Roy, Hongyi Zeng, Jasmeet Bagga, George Porter, and Alex C. Snoeren. 2015. Inside the Social Network’s (Datacenter) Network.. In Proceedings of the ACM SIGCOMM 2015 Conference. 123–137.
- Singh et al. (2015) Arjun Singh, Joon Ong, Amit Agarwal, Glen Anderson, Ashby Armistead, Roy Bannon, Seb Boving, Gaurav Desai, Bob Felderman, Paulie Germano, Anand Kanagala, Jeff Provost, Jason Simmons, Eiichi Tanda, Jim Wanderer, Urs Hölzle, Stephen Stuart, and Amin Vahdat. 2015. Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network.. In Proceedings of the ACM SIGCOMM 2015 Conference. 183–197.
- Sun et al. (2019) Le Sun, Hai Dong, Omar Khadeer Hussain, Farookh Khadeer Hussain, and Alex X. Liu. 2019. A framework of cloud service selection with criteria interactions. Future Gener. Comput. Syst. 94 (2019), 749–764.
- Vamanan et al. (2012) Balajee Vamanan, Jahangir Hasan, and T. N. Vijaykumar. 2012. Deadline-aware datacenter tcp (D2TCP).. In Proceedings of the ACM SIGCOMM 2012 Conference. 115–126.
- Wang et al. (2023) Weitao Wang, Masoud Moshref, Yuliang Li, Gautam Kumar, T. S. Eugene Ng, Neal Cardwell, and Nandita Dukkipati. 2023. Poseidon: Efficient, Robust, and Practical Datacenter CC via Deployable INT.. In Proceedings of the 20th Symposium on Networked Systems Design and Implementation (NSDI). 255–274.
- Wilson et al. (2011) Christo Wilson, Hitesh Ballani, Thomas Karagiannis, and Antony I. T. Rowstron. 2011. Better never than late: meeting deadlines in datacenter networks.. In Proceedings of the ACM SIGCOMM 2011 Conference. 50–61.
- Zats et al. (2015) David Zats, Anand Padmanabha Iyer, Ganesh Ananthanarayanan, Rachit Agarwal, Randy H. Katz, Ion Stoica, and Amin Vahdat. 2015. FastLane: making short flows shorter with agile drop notification.. In Proceedings of the 2015 ACM Symposium on Cloud Computing (SOCC). 84–96.
- Zhang et al. (2017) Qiao Zhang, Vincent Liu, Hongyi Zeng, and Arvind Krishnamurthy. 2017. High-resolution measurement of data center microbursts.. In Proceedings of the 17th ACM SIGCOMM Workshop on Internet Measurement (IMC). 78–85.
- Zhou et al. (2021) Renjie Zhou, Dezun Dong, Shan Huang, and Yang Bai. 2021. FastTune: Timely and Precise Congestion Control in Data Center Network.. In Proceedings of the 2021 IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA). 238–245.
- Zhu et al. (2015) Yibo Zhu, Haggai Eran, Daniel Firestone, Chuanxiong Guo, Marina Lipshteyn, Yehonatan Liron, Jitendra Padhye, Shachar Raindel, Mohamad Haj Yahia, and Ming Zhang. 2015. Congestion Control for Large-Scale RDMA Deployments.. In Proceedings of the ACM SIGCOMM 2015 Conference. 523–536.
Appendix A Appendix
| ASIC/Model | BW | Buffer | |
| Broadcom | Trident+ | 0.64 | 9 |
| Trident2 | 1.28 | 12 | |
| Trident2+ | 1.28 | 16 | |
| Trident3-X4 | 1.7 | 32 | |
| Trident3-X5 | 2 | 32 | |
| Tomahawk | 3.2 | 16 | |
| Trident3-X7 | 3.2 | 32 | |
| Tomahawk 2 | 6.4 | 42 | |
| Tomahawk 3 BCM56983 | 6.4 | 32 | |
| Tomahawk 3 BCM56984 | 6.4 | 64 | |
| Tomahawk 3 BCM56982 | 8 | 64 | |
| Tomahawk 3 | 12.8 | 64 | |
| Trident4 BCM56880 | 12.8 | 132 | |
| Tomahawk 4 | 25.6 | 113 | |
| nVidia | Spectrum SN2100 | 1.6 | 16 |
| Spectrum SN2410 | 2 | 16 | |
| Spectrum SN2700 | 3.2 | 16 | |
| Spectrum SN3420 | 2.4 | 42 | |
| Spectrum SN3700 | 6.4 | 42 | |
| Spectrum SN3700C | 3.2 | 42 | |
| Spectrum SN4600C | 6.4 | 64 | |
| Spectrum SN4410 | 8 | 64 | |
| Spectrum SN4600 | 12.8 | 64 | |
| Spectrum SN4700 | 12.8 | 64 | |
| Spectrum SN5400 | 25.6 | 160 | |
| Spectrum SN5600 | 51.2 | 160 |




| Config | Default | Core | Incast | mean | range | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Wload | WKa | WKb | WKc | WKa | WKb | WKc | WKa | WKb | WKc | ||
| DCTCP | 7.69 | 3.19 | 1.91 | 5.02 | 3.18 | 2.58 | unstable | 18.88 | 5.54 | 6.0 | 16.97 |
| Swift | 6.68 | 2.98 | 2.92 | 4.92 | 3.16 | 3.53 | 53.5 | 10.23 | 3.57 | 10.17 | 50.58 |
| ExpressPass | unstable | 14.94 | 8.09 | unstable | 15.9 | 11.37 | unstable | 12.61 | 8.2 | 11.85 | 7.81 |
| Homa | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.42 | 1.27 | 1.08 | 0.42 |
| dcPIM | 1.67 | 2.98 | 1.84 | 1.58 | 3.45 | 2.68 | 1.66 | 2.05 | 1.98 | 2.21 | 1.87 |
| SIRD | 1.32 | 1.43 | 1.1 | 1.15 | 1.27 | 1.18 | 1.3 | 1.0 | 1.0 | 1.19 | 0.43 |
| Normalized 99th percentile slowdown of all messages at 50% load. | |||||||||||
| DCTCP | 0.9 | 0.98 | 0.98 | 0.9 | 0.94 | 0.94 | 0.81 | 0.83 | 0.96 | 0.92 | 0.17 |
| Swift | 0.89 | 0.92 | 0.91 | 0.87 | 0.92 | 0.89 | 0.92 | 1.0 | 0.92 | 0.92 | 0.13 |
| ExpressPass | 0.46 | 0.93 | 0.93 | 0.45 | 0.89 | 0.88 | 0.48 | 0.94 | 0.95 | 0.77 | 0.5 |
| Homa | 1.0 | 1.0 | 0.97 | 0.99 | 0.96 | 0.99 | 1.0 | 0.99 | 0.98 | 0.99 | 0.04 |
| dcPIM | 0.71 | 0.92 | 1.0 | 0.74 | 1.0 | 1.0 | 0.71 | 0.92 | 1.0 | 0.89 | 0.29 |
| SIRD | 0.96 | 0.97 | 0.98 | 1.0 | 0.98 | 0.96 | 0.96 | 0.96 | 1.0 | 0.97 | 0.04 |
| Normalized maximum goodput across applied load levels. | |||||||||||
| DCTCP | unstable | 85.81 | 9.71 | 3.68 | 62.13 | 7.94 | unstable | unstable | 260.51 | 71.63 | 256.83 |
| Swift | unstable | unstable | 8.41 | unstable | unstable | 10.12 | unstable | unstable | 125.77 | 48.1 | 117.36 |
| ExpressPass | 1.0 | 1.0 | 1.0 | unstable | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 |
| Homa | 137.45 | 115.99 | 30.18 | 7.06 | 434.71 | 79.62 | 143.38 | 150.57 | 145.29 | 138.25 | 427.65 |
| dcPIM | 52.07 | 7.76 | 3.1 | 1.04 | 51.24 | 13.09 | 34.25 | 7.18 | 7.41 | 19.68 | 51.03 |
| SIRD | 12.05 | 9.91 | 2.68 | 1.0 | 38.9 | 7.53 | 9.37 | 10.03 | 10.27 | 11.3 | 37.9 |
| Normalized maximum ToR queuing across applied load levels. | |||||||||||
| Config | Default | Core | Incast | mean | range | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Wload | WKa | WKb | WKc | WKa | WKb | WKc | WKa | WKb | WKc | ||
| DCTCP | 9.92 | 7.9 | 6.91 | 5.97 | 5.71 | 5.54 | unstable | 71.06 | 32.06 | 18.13 | 65.52 |
| Swift | 8.61 | 7.37 | 10.56 | 5.85 | 5.68 | 7.58 | 68.21 | 38.51 | 20.69 | 19.23 | 62.53 |
| ExpressPass | unstable | 36.94 | 29.26 | unstable | 28.56 | 24.42 | unstable | 47.45 | 47.45 | 35.68 | 23.03 |
| Homa | 1.29 | 2.47 | 3.62 | 1.19 | 1.8 | 2.15 | 1.27 | 5.36 | 7.37 | 2.95 | 6.18 |
| dcPIM | 2.16 | 7.37 | 6.66 | 1.88 | 6.2 | 5.76 | 2.11 | 7.7 | 11.48 | 5.7 | 9.6 |
| SIRD | 1.7 | 3.53 | 3.99 | 1.37 | 2.28 | 2.54 | 1.65 | 3.76 | 5.79 | 2.96 | 4.42 |
| 99th percentile slowdown of all messages at 50% load. | |||||||||||
| DCTCP | 74.65 | 83.85 | 83.95 | 43.63 | 48.54 | 47.42 | 67.8 | 70.53 | 80.74 | 66.79 | 40.32 |
| Swift | 74.52 | 78.16 | 78.69 | 42.16 | 47.41 | 45.15 | 76.8 | 85.46 | 77.57 | 67.32 | 43.3 |
| ExpressPass | 38.04 | 79.68 | 80.42 | 21.78 | 45.83 | 44.42 | 40.26 | 80.1 | 80.1 | 56.74 | 58.64 |
| Homa | 83.39 | 85.23 | 83.55 | 47.73 | 49.73 | 50.02 | 83.39 | 84.87 | 82.79 | 72.3 | 37.5 |
| dcPIM | 58.94 | 78.42 | 86.03 | 35.91 | 51.68 | 50.59 | 59.61 | 79.02 | 84.26 | 64.94 | 50.12 |
| SIRD | 79.74 | 82.27 | 84.71 | 48.27 | 50.47 | 48.75 | 79.7 | 81.98 | 84.13 | 71.11 | 36.44 |
| Maximum goodput across applied load levels (Gbps). | |||||||||||
| DCTCP | unstable | 7.0 | 2.7 | 8.3 | 2.67 | 1.46 | unstable | unstable | 21.06 | 7.2 | 19.6 |
| Swift | unstable | unstable | 2.33 | unstable | unstable | 1.87 | unstable | unstable | 10.17 | 4.79 | 8.3 |
| ExpressPass | 0.06 | 0.08 | 0.28 | unstable | 0.04 | 0.18 | 0.08 | 0.08 | 0.08 | 0.11 | 0.24 |
| Homa | 8.63 | 9.46 | 8.37 | 15.91 | 18.68 | 14.68 | 12.17 | 12.17 | 11.75 | 12.42 | 10.31 |
| dcPIM | 3.27 | 0.63 | 0.86 | 2.34 | 2.2 | 2.41 | 2.91 | 0.58 | 0.6 | 1.76 | 2.69 |
| SIRD | 0.76 | 0.81 | 0.75 | 2.26 | 1.67 | 1.39 | 0.79 | 0.81 | 0.83 | 1.12 | 1.51 |
| Maximum ToR queuing across applied load levels (MB). | |||||||||||