SinkLoRA: Enhanced Efficiency and Chat Capabilities for Long-Context Large Language Models
Abstract
Extending the functionality of the Transformer model to accommodate longer sequence lengths has become a critical challenge. This extension is crucial not only for improving tasks such as language translation and long-context processing but also for enabling novel applications like chatbots, code generation, and multimedia content creation. The primary obstacle is the self-attention mechanism, which scales quadratically with sequence length in terms of computation time and memory requirements. LongLoRA proposed shifted sparse attention (S2-Attn), effectively enabling context extension and leading to non-trivial computation savings with similar performance to fine-tuning with vanilla attention. However, LongLoRA is still not as efficient as vanilla attention, reaching only 39% of the perplexity improvement compared to full attention. This inefficiency is due to the cyclic shift applied within different attention head patterns, causing either chaos in the attention head structure or unnecessary information exchange between token groups. To address these issues, We propose SinkLoRA, which features better work partitioning. Specifically, (1) we developed SF-Attn with a segmentation and reassembly algorithm to proportionally return cyclically shifted groups of attention heads to their un-shifted state together with global attention of "sink attention tokens", achieving 92% of the perplexity improvement compared to full attention after fine tuning, and (2) applied a SOTA KV cache compression algorithm H2O to accelerate inference. Furthermore, We conducted supervised fine-tuning with SinkLoRA using a self collected LongAlpaca-plus dataset. All our code, models, datasets, and demos are available at https://github.com/Dexter-GT-86/SinkLoRA.



1 Introduction
Enhancing the functionality of Transformer models to handle longer sequence lengths has become crucial for numerous applications, including language translation, long-context processing, chatbots, code generation, and multimedia content creation. The primary challenge lies in the self-attention mechanism, which scales quadratically with sequence length, leading to substantial computational time and memory requirements 4, 41, 21. To address this challenge, several approaches have been proposed. Longformer and BigBird utilize combinations of local, global, and sparse attention mechanisms to manage long contexts, reducing complexity to O(n) 4, 41. Reformer introduces locality-sensitive hashing (LSH) to approximate attention by hashing similar tokens into the same buckets, thereby reducing computational complexity 21. LSG Attention combines local, sparse, and global attention to effectively handle long contexts while minimizing computational overhead 9.
Despite these advancements, managing long-context interactions in practical applications remains a significant challenge. Recent work, such as LongLoRA, extends the context window of LLaMA2 from 4096 to 32768 tokens using Position Interpolation without substantial GPU or TPU resources 6. However, LongLoRA’s efficiency is limited, achieving only 39% of the perplexity improvement compared to full attention due to chaotic attention head structures and unnecessary information exchange between token groups.
To address these issues, we propose SinkLoRA, which offers better work partitioning. This includes the development of Sink Fixed Attention (SF-Attn), a segmentation and reassembly algorithm that, along with the global attention of “sink attention tokens,” achieves 92% of the perplexity improvement of full attention after fine-tuning. Additionally, we apply a state-of-the-art KV cache compression algorithm, Heavy Hitter Oracle (H2O), to accelerate inference 43, 16, 25.
We further enhanced SinkLoRA through supervised fine-tuning using our self-collected LongAlpaca-Plus dataset, comprising 28,000 entries from various sources, including Natural Questions, RedPajama 8, Book Summarization, and LongQA 6, ensuring a diverse and comprehensive collection for long instruction tuning.
In summary, the contributions of our work are as follows:
-
•
We present SinkLoRA, a memory-efficient and effective method to extend the context length of LLaMA2 and LLaMA3, representing a complete update of LongLoRA. This method improves fine-tuning efficiency and offers a flexible deployment inference strategy.
-
•
We introduce SF-Attn, a fine-tuning method that combines a segmentation & reassembly algorithm and global attention. This method is easy to implement, accurate, and memory-efficient, without increasing computational complexity. By directly modifying the attention pattern, SF-Attn effectively redistributes attention scores, reducing the undue emphasis on initial tokens across different token groups.
-
•
We achieve efficient deployment of computationally intensive large language models (LLMs) in production environments by using the Heavy Hitter Oracle (H2O) KV caching method. This method stores the key-value states of previously generated tokens, significantly reducing the need for repetitive computations and thus lowering latency in autoregressive generation. This enhancement allows for a more flexible and efficient inference strategy, reducing computational overhead while maintaining model performance.
-
•
Our SinkLoRA performs favorably against state-of-the-art methods. We evaluate its performance on the PG19, Proof-pile, and LongBench datasets, demonstrating its effectiveness. Specifically, for LLaMA2 7B, SinkLoRA outperforms LongLoRA and is competitive with LongChat-13B.
1.1 Motivation for the Research
Motivation 1: Elevating Attention Scores for Initial Tokens
Prior studies have demonstrated the Attention Sink phenomenon, where certain tokens, typically the initial tokens in a sequence, receive disproportionately high attention scores during the model’s computation 39. This often occurs because these tokens are visible to all subsequent tokens, leading to significant attention even when they lack semantic importance, particularly in autoregressive language models 33.
The Sparse Shifted Attention mechanism implemented in LongLoRA 6 attempts to address this by shifting the high attention scores from these initial tokens to other tokens that previously received lower attention. This shift reduces the overemphasis on initial tokens. To further improve this, we need to develop a method that directly modifies the attention pattern. By applying this technique, we can effectively redistribute attention scores, thereby reducing the undue emphasis on initial tokens across different token groups.
Motivation 2: Maintaining Initial Tokens During Fine-Tuning
The concept of attention sinks is also utilized in Streaming LLM 39 to improve the model’s handling of long texts. By retaining the Key-Value (KV) pairs of a few initial tokens (attention sinks) along with the most recent tokens, the model ensures stable attention scores and performance even for extended sequences. Inspired by this approach, we aim to carry this mindset from training into inference. Our research aims to modify the fine-tuning process so that initial tokens attend to all other tokens, thereby accumulating more attention scores and enhancing the model’s capacity to handle long sequences.
Motivation 3: Flexible Deployment of Inference Strategy
Efficient deployment of computationally intensive large language models (LLMs) in production environments often relies on Key-Value (KV) caching 16. KV caching stores the key-value states of previously generated tokens, significantly reducing the need for repetitive computations and thus lowering latency in autoregressive generation. However, LongLoRA 6 retains only the original standard self-attention mechanism during inference. To address this limitation, it is necessary to apply an optional KV cache function. This enhancement allows for a more flexible and efficient inference strategy, reducing computational overhead while maintaining model performance.
2 Related Work
2.1 Long-context Transformers
The primary obstacle in scaling Transformer models to handle longer sequence lengths lies in the self-attention mechanism, which scales quadratically with sequence length in terms of computation time and memory requirements. This quadratic computational burden has prompted significant research efforts focused on developing more efficient sparse Transformer models. Notable examples include Longformer 4 and BigBird 41, which utilize a combination of local, global, and sparse attention mechanisms to manage long contexts, thereby reducing the complexity to O(n). These models achieve a balance between maintaining sufficient context for understanding while managing computational load. For achieving complexity of O(n log n), several approaches have been proposed. Fixed Window Attention 7 employs a fixed-size window for attention, which confines the attention computation to a limited context window. Reformer 21 introduces locality-sensitive hashing (LSH) to approximate attention by hashing similar tokens into the same buckets, thus reducing the computational complexity. LSG Attention 9, adapted from BigBird, combines local, sparse, and global attention to effectively handle long contexts while minimizing computational overhead. Equipping Transformer 40 proposes a novel reading strategy termed random access, which enables Transformers to efficiently process long documents without needing to examine every token. This method shows promising results across pretraining, fine-tuning, and inference phases, demonstrating its efficacy in handling extended contexts. Despite these advancements, the ability of these methods to manage long-context conversations, such as those required in chat applications, remains limited. This highlights an ongoing challenge in enhancing the context-handling capabilities of Transformer models for interactive and real-time applications.
2.2 Long-context LLMs
Recent advancements in Large Language Models (LLMs) have significantly extended their capabilities, including handling long-context inputs. Math Word Problems (MWPs) have demonstrated notable performance in solving mathematical questions using LLMs 34. Moreover, leveraging LLMs for SQL querying has shown promise in optimizing resource allocation, though it remains less efficient than traditional relational databases 42. LongLoRA 6, employing Position Interpolation 5, has successfully extended the context window of Llama 2 from 4096 to 32768 tokens without requiring substantial GPU or TPU resources. Meta’s Llama 3, featuring up to 70 billion parameters, represents a significant advancement in open-source LLMs, offering enhancements in computational efficiency, trust and safety tools, and collaborations with major platforms 38. Open-source models such as BLOOM 22, OPT 18, and Falcon 28 continue to challenge proprietary models, although models like Vicuna 29 and Alpaca 1 still lag behind their closed-source counterparts in certain aspects. Despite these advancements, effectively managing long-context interactions remains a significant challenge, necessitating ongoing research and development to address the complexities in long-context LLM applications.
2.3 KV-Cache Compression
Compressing the size of KV cache is more difficult than reducing the size of weights because they are more sensitive and dependent on model inputs. A cost-effective method for KV cache compression is token dropping 25, 43, 16, which establishes an importance policy to retain significant KVs and remove insignificant ones. Jiang et al. 20 and Xiao et al. 39 suggest preserving tokens that are local to the current sequence position, as these are crucial for generation. For example, H2O 43 and FastGen 16 proposed reducing KV cache size by dropping tokens based on their attention scores. Similarly, SparQ 32 drops tokens according to attention score sparsity and also considers the error in the pruned value cache.
These pruning methods are generally effective for summarization tasks and zero-shot inference. Zhang et al. 43 and Liu et al. 25 recommend identifying a small set of influential tokens, termed heavy-hitters, to better maintain generation quality. Ge et al. 16 have empirically demonstrated that different attention heads prioritize different tokens and have developed an adaptive importance policy for evicting KVs. However, these approaches can cause significant issues since the context contained in the evicted KVs is entirely discarded.
| Setting | Training | Target Context Length | ||
|---|---|---|---|---|
| 4096 | 6144 | 8192 | ||
| Full Attention | Long | 8.59 | 8.16 | 7.8 |
| Sparse Shifted Attention | Short & Shift | 9.09 | 8.82 | 8.6 |
| Sink Fixed Attention | Short & Global | 8.60 | 8.17 | 7.85 |
3 Our Method: SinkLoRA
3.1 Background
LongLoRA. LongLoRA, introduced by Chen et al. (2023) 6, is an innovative fine-tuning methodology aimed at extending the context window sizes of large language models (LLMs) efficiently. Leveraging Position Interpolation 5, LongLoRA builds upon the low-rank adaptations introduced by LoRA 17 and incorporates Shifted Sparse Attention (S2-Attn) 6. Inspired by the Swin Transformer 24, S2-Attn manages extended contexts by partitioning the total context into multiple groups and performing attention computations independently within each group. To ensure continuity, it shifts half of the attention heads by half the group size. This method effectively simulates long-context operations using short attention spans during training, allowing for the handling of significantly larger contexts without a substantial increase in computational overhead. Furthermore, LongLoRA is designed to be compatible with existing LLM optimization techniques and infrastructures, such as Flash-Attention2 11, 10, thereby enhancing its usability without requiring major system modifications. The approach also emphasizes efficient parameter utilization, necessitating minimal adjustments to the learnable embedding and normalization layers, which represent a small portion of the overall model parameters. This efficiency is crucial for scaling up to larger models while maintaining the practicality of LongLoRA for enhancing performance in tasks that demand deep contextual understanding.
Attention Sink. In autoregressive large language models (LLMs), an intriguing phenomenon known as the “attention sink” 39 is observed, where initial tokens receive a disproportionate amount of attention scores, regardless of their semantic relevance to the task. These initial tokens, although lacking significant semantic importance, tend to accumulate high attention scores. This phenomenon arises due to the nature of the Softmax function used in the attention mechanism, which ensures that attention scores across all tokens sum to one. In situations where few tokens are strongly related to the current query, the model redistributes attention to available tokens, often defaulting to the initial ones. Given the autoregressive nature of LLMs, where each token predicts the next in sequence, initial tokens are consistently visible to nearly all subsequent tokens, inherently training them to become preferred targets for attention, thus acting as “attention sinks.” This insight highlights a fundamental challenge in the attention mechanism of autoregressive models and suggests areas for improving attention distribution strategies in language modeling.
Heavy-Hitter Oracle. The Heavy-Hitter Oracle (H2O) 43 is a SOTA method that addresses the challenge of reducing the memory footprint of the KV cache in language models. This method is based on the observation that a small subset of tokens, termed “Heavy Hitters” (H2), significantly contribute to the overall attention scores in language models. Analysis shows that these H2 tokens frequently co-occur within the text, making their presence a natural outcome of the text’s structure. Experiments indicate that removing these tokens can significantly impair model performance, underscoring their importance. The H2O approach combines this understanding with a dynamic cache eviction policy that optimally balances the retention of recent tokens and crucial H2 tokens. This strategy ensures efficient memory use while maintaining the computational dynamics essential for robust model performance.
3.2 APPLYING Sink Fixed Attention to Improve Fine Tune Progress
3.2.1 Pilot study
To confirm our approach, we conducted a pilot study to evaluate the effectiveness of different attention mechanisms under various context lengths.
In Table 1, we establish a standard baseline by training and testing with full attention and fine-tuning, which consistently delivers good quality across various context lengths. Our first trial involved training with short attention(Sparse Shifted Attention), represented by the pattern in Figure 2(a).
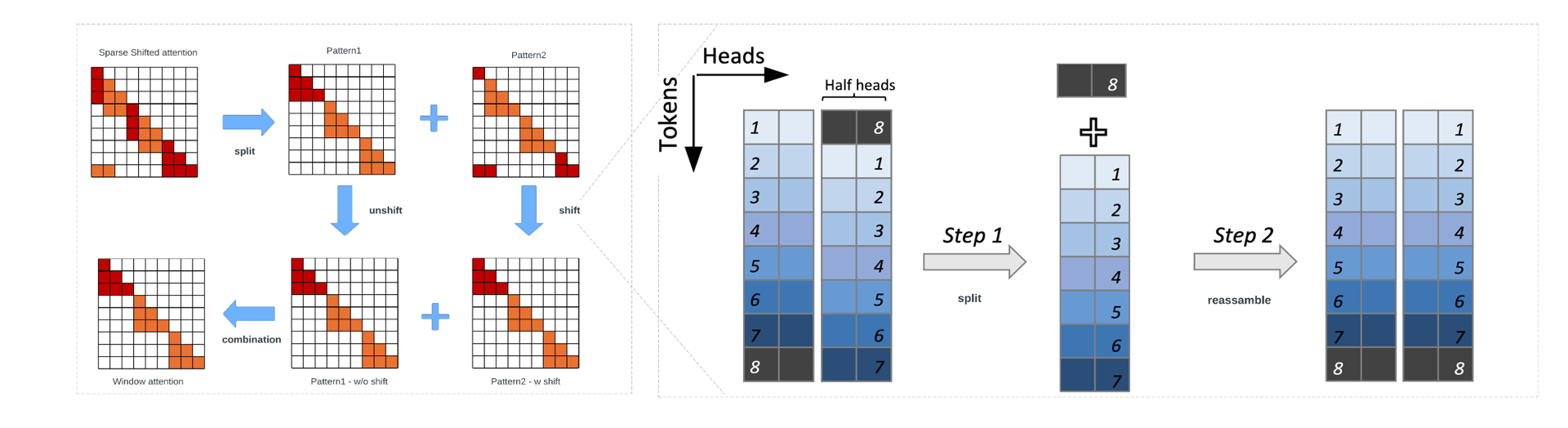
In this trial, given the high computational cost associated with self-attention modules for long contexts, to address this issue, we introduced Sink Fixed Attention (SF-Attn) reassembly into group window attention, as shown in Figure 2 (b). This stage ensures better continuity and interaction between tokens by reassembling the attention pattern, depicted in Figure 2 (c). This method enhances the attention mechanism by making initial tokens attend to all tokens, thus providing global attention. As a result, SF-Attn demonstrates significant improvements over Sparse Shifted Attention, reducing perplexity notably across all target context lengths, especially at 8192 tokens.
The findings from this pilot study indicate that SF-Attn, through reassembly and global attention adjustments, effectively balances performance and computational efficiency. This makes it a promising solution for extending the context length of large language models in practical applications. there is no information exchange between different groups.
The detail of SF-Attn will be show in Section 3.2.2
3.2.2 Sink Fixed Attention
Sink Fixed Attention includes two main parts: Segmentation & Reassembly Algorithm, Global Attention.
Segmentation & Reassembly Algorithm
As shown in 4, the input tensor is divided into two halves. The second half is split into two parts: one part stays in place while the other part is shifted and wrapped around. These parts are then combined back together in a new order. This reassembled tensor is processed through the standard self-attention mechanism. Finally, the output tensor undergoes a similar splitting, shifting, and recombining process before passing through a feed forward operation to produce the final output. This approach simplifies the attention calculation and improves the model’s performance by focusing on key areas of the input. This makes the sparse shifted attention similar to the fixed window attention. We provide a PyTorch-style code in Algorithm 1.
Global Attention
We choose the first four initial tokens as "sink attention tokens". When training Llama-2-7B and Llama-3-8B models, this setting follows the structure of StreamingLLM 39. Using the global attention strategy from Longformer and BigBird 4, 41, we make the sink attention tokens attend to all tokens across the sequence, and all tokens in the sequence attend to the sink attention tokens. Specifically, after the Segmentation & Reassembly Algorithm, we obtain the attention scores map of all the tokens in the currently fixed window as a shifted back version.
Add new tokens (sink attention tokens) to the current sequence. Correspondingly, construct a new adjacency matrix . For and , it holds that and .
By doing this, we keep the sink attention tokens attending in attention score calculation before going inside hidden layers. Since the number of such tokens is small relative to and independent of , the complexity of the combined local and global attention is still .
3.3 Applying KV Cache Algorithm to Accelerate Inference Process
In this section, we apply the H2O algorithm to LongLoRA. The LongLoRA codebase6 only provides a full attention solution for the inference stage. We incorporate the H2O eviction system 43 by creating a new class to manage the KV cache values in memory, thus optimizing the inference process. This integration is illustrated in Figure 3.
| Setting | Training | Attention | Target Context Length | ||
|---|---|---|---|---|---|
| 4096 | 6144 | 8192 | |||
| 7B-Llama2 | Full-Attn | 8.59 | 8.16 | 7.83 | |
| 8192 | S2-Attn | 9.10 | 8.82 | 8.6 | |
| SF-Attn | 8.60 | 8.17 | 7.85 | ||
| 8B-Llama3 | Full-Attn | 5.10 | 4.85 | 4.65 | |
| 8192 | S2-Attn | 5.40 | 5.24 | 5.13 | |
| SF-Attn | 5.11 | 4.86 | 4.66 | ||
| Model | Training Context Length | Evaluation Context Length | ||||
|---|---|---|---|---|---|---|
| 2048 | 4096 | 8192 | 12288 | 16384 | ||
| 7B-Llama-2 | 16384 | 8.73 | 8.55 | 8.30 | 8.13 | 8.05 |
| 8B-Llama-3 | 16384 | 5.11 | 5.02 | 4.89 | 4.77 | 4.72 |
| Evaluation Context | 3k | 6k | 10k | 13k | 16k |
|---|---|---|---|---|---|
| ChatGLM2-6B 13 | 0.88 | 0.46 | 0.02 | 0.02 | 0.02 |
| MPT-30B-chat 35 | 0.96 | 1.00 | 0.76 | - | - |
| MPT-7B-storywriter 36 | 0.46 | 0.46 | 0.28 | 0.34 | 0.36 |
| LongChat-13B 23 | 1.00 | 1.00 | 1.00 | 0.98 | 0.90 |
| LongLoRA-13B 6 | 1.00 | 0.98 | 0.98 | 0.98 | 0.94 |
| Ours-8B | 1.00 | 1.00 | 1.00 | 0.98 | 0.96 |
4 Experiment
4.1 Experimental Settings
4.1.1 ENVIRONMENTS
All our experiments were conducted on a machine equipped with 2× A100 GPUs. We utilize PyTorch 27 as the primary framework for training all models, integrating DeepSpeed 31 and Flash-Attention2 10 to optimize performance. By default, DeepSpeed was employed in stage 2, while stage 3 was reserved for experiments involving the maximum context length. Gradient checkpointing, a standard technique in the Peft codebase 12, was used to manage memory efficiently. It is worth noting that while our experiments predominantly utilized 2× A100 GPUs, the use of RTX 4090 GPUs is also feasible for certain tasks, such as fine-tuning 7B models to an 8192 context size.
4.1.2 Models
4.1.3 Training Procedure
To train the model, we use the Llama-2 and llama-3 model with bf16 precision enabled and a maximum sequence length base on requirement. Flash attention 10is utilized for efficient computation. Low-rank training is enabled, and the model undergoes three epochs of training with a batch size of 1 for training and 2 for evaluation per device. Gradient accumulation is set to 1 step. The evaluation strategy is disabled, while the model is saved every 512 steps with a total limit of 2 saved checkpoints. The learning rate is set to 2e-5 with no weight decay, and a warmup phase of 20 steps is included. The learning rate follows a constant schedule with warmup. Logs are recorded every step, and the training process is optimized using DeepSpeed configuration (stage2.json)31 with tf32 precision enabled.
4.1.4 Datasets
The “LongAlpaca-Plus” dataset, containing 28,000 entries, is structured with a significant focus on different sources which is a update version of LongAlpaca 6. Natural Questions make up 44% of the dataset, totaling 12,320 entries, sourced from a subset of Natural Questions data. RedPajama contributes 27% of the dataset with 7,560 entries, also derived from its specific subset. Book Summarization comprises 18% of the dataset with 5,040 entries, and LongQA represents the smallest portion at 11%, with 3,080 entries. This distribution ensures a diverse and comprehensive dataset for long instruction tuning tasks. The Overview of LongAlpaca-Plus dataset is provided in Section B.
4.1.5 Metrics
Perplexity Perplexity, a crucial metric in natural language processing (NLP), quantifies a language model’s predictive uncertainty, being inversely related to the probability assigned to the actual sequence of words. Originating from information theory, perplexity measures the efficiency of a communication system, and in NLP, it reflects how well a language model understands language patterns 19. Mathematically, it is defined as
| (1) |
where p(x) is the probability distribution over all possible sequences x. Employed extensively in evaluating language models, from early n-gram approaches to advanced neural architectures, perplexity aids in comparing model performances, tuning during development, and enhancing tasks like machine translation and text generation 19, 14. As a quantitative measure, it offers insights into model improvements and the effectiveness of different configurations, making it an indispensable tool in language model evaluation 15.
Passkey Retrieval We using the similar of format provide in LongLoRA6 for passkey retrieval. The document adheres to this structure:
Within a large amount of extraneous text, crucial information is concealed. Identify and remember this key information, as you will be tested on it.
Here is an example document structure:
———————————————————————————————————————–
The flowers are blooming. The trees are tall. The river flows. Just keep going. Onward and upward. (repeated M times)
Critical Note: The passkey is 84729. Remember this number. 84729 is the passkey.
The flowers are blooming. The trees are tall. The river flows. Just keep going. Onward and upward. (repeated N times)
What is the passkey? The passkey is… ———————————————————————————————————————– The length of the document varies based on the values of M and N. The passkey number, such as 84729, is randomly generated and changes with each test.
LongBench LongBench 3 is a bilingual, multitask benchmark designed to evaluate the long context understanding capabilities of large language models (LLMs). It focuses on assessing the models’ performance in handling extended text inputs in both English and Chinese. The benchmark includes 21 datasets covering six task categories: single-document QA, multi-document QA, summarization, few-shot learning, synthetic tasks, and code completion.


| Static Sparsity | KV Cache Budget (%) | ||
|---|---|---|---|
| 50 | 75 | 100 | |
| Full | 9.2 | 6.9 | 4.7 |
| H2O | 6.2 | 5.8 | 4.4 |
| Model | Avg | Single-Doc QA | Multi-Doc QA | Summarization | Few-shot Learning | Code | Synthetic |
|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo | 44.0 | 39.8 | 38.7 | 26.5 | 67.1 | 54.1 | 37.8 |
| Llama2-7B-chat | 31.0 | 24.9 | 22.6 | 24.7 | 60.0 | 48.1 | 5.9 |
| LongChat-v1.5-7B | 34.3 | 28.7 | 20.6 | 26.7 | 60.0 | 54.1 | 15.8 |
| Vicuna-v1.5-7B | 31.9 | 28.0 | 18.6 | 26.0 | 66.2 | 47.3 | 5.5 |
| LongLoRA-7B | 36.8 | 28.7 | 28.1 | 27.8 | 63.7 | 56.0 | 16.7 |
| Ours-7B | 38.8 | 35.9 | 32.7 | 31.1 | 65.4 | 59.2 | 22.3 |
4.2 Main Results
Perplexity Result.
Table 2 presents the perplexity evaluation on the proof-pile test split using three attention mechanisms: Full-Attn, S2-Attn, and SF-Attn for 7B and 8B model sizes. The 7B-Llama2 model, with a training context length of 8192, shows that the SF-Attn mechanism consistently outperforms the other attention mechanisms across all target context lengths (4096, 6144, and 8192). Specifically, the perplexity values for SF-Attn are 8.60, 8.17, and 7.85, respectively, indicating more efficient performance.
Similarly, the 8B-Llama3 model, trained with the same context length, exhibits lower perplexity scores when using the SF-Attn mechanism: 5.11, 4.86, and 4.66 for target context lengths of 4096, 6144, and 8192, respectively. This demonstrates that the SF-Attn mechanism provides a notable improvement in perplexity over both Full-Attn and S2-Attn.
Table 3 summarizes the maximum context length we can fine-tune for various model sizes using a single 2x A100 machine. Both Llama2 and Llama3 models were evaluated using the same training settings. The 7B-Llama2 model shows perplexity results of 8.73, 8.55, 8.30, 8.13, and 8.05 for evaluation context lengths of 2048, 4096, 8192, 12288, and 16384, respectively. The 8B-Llama3 model achieves perplexity values of 5.11, 5.02, 4.89, 4.77, and 4.72 for the same evaluation context lengths.
These results indicate that the SF-Attn mechanism outperforms both Full-Attn and S2-Attn mechanisms in terms of perplexity, especially for larger context lengths. This validates the efficiency and effectiveness of the H2O algorithm within the LongLoRA framework.
Passkey Retrieval Result.
Table 4 presents the topic retrieval evaluation with LongChat. This task involves retrieving target topics from very long conversations with context lengths of 3k, 6k, 10k, 13k, and 16k. Our model, fine-tuned on Llama3 8B, achieves comparable performance to the state-of-the-art LongChat-13B with a lower fine-tuning cost. Specifically, our model maintains an accuracy of 1.00 for context lengths up to 10k and shows a slight decrease to 0.98 and 0.96 for 13k and 16k context lengths, respectively. This demonstrates our model’s robustness and efficiency in handling long-context retrieval tasks.
Figure 5 compares the passkey retrieval accuracy between Llama2 7B, LongLoRA 7B, and our 7B model fine-tuned on a context length of 32,768. Our model shows no retrieval accuracy degradation up to 33k or 36k, surpassing the context length limits of LongLoRA, which are 30k and 34k. This indicates that our model can handle longer context lengths with higher accuracy compared to existing models.
LongBench Result.
Analyzing the data from Table 6, we observe that GPT-3.5-Turbo consistently outperforms other models across various tasks, achieving the highest average score (44.0). This indicates its superior overall performance. Notably, our model, Ours-7B, secures the second highest average score (38.8), demonstrating competitive performance. Specifically, Ours-7B excels in the Code task with a leading score of 59.2, surpassing GPT-3.5-Turbo (54.1).
Despite these strengths, there are areas for improvement, particularly in the Synthetic task where Ours-7B scores 22.3, significantly lower than GPT-3.5-Turbo’s 37.8. This highlights the need to enhance our model’s capabilities in synthetic tasks to further boost its overall performance. Overall, while GPT-3.5-Turbo remains the top performer, our model shows promising results and potential for optimization.
H2O Inference Result
In this analysis, we examine the performance and efficiency of various KV cache methods for the LLaMA-3-8B model, as depicted in Figure 5 and Table 6.
Figure 5 presents a comparative analysis between the baseline model utilizing a full cache, the H2O method, and the “Local” strategy, which employs the most recent KV embeddings. The evaluation was conducted on the OpenBookQA dataset. Notably, the Heavy-Hitter Oracle (H2O) method sustains high accuracy levels even with a reduced KV cache budget, demonstrating its effectiveness in preserving model performance. Conversely, the Local method exhibits a marked decline in accuracy as the KV cache budget diminishes.
Table 6 details the inference hours required for LLaMA-3-8B under different KV cache budgets. The H2O method substantially reduces inference time compared to the Full method across all cache budgets. For instance, at a 100% KV cache budget, the H2O method decreases inference time from 4.7 hours (Full) to 4.4 hours. This reduction is even more significant at lower KV cache budgets, underscoring the efficiency of the H2O method in environments with limited resources.
In conclusion, the H2O method provides an optimal balance between maintaining high accuracy and reducing inference time, thereby representing a valuable strategy for optimizing large language models such as LLaMA-3-8B. This method’s ability to offer substantial computational savings while preserving performance highlights its potential for broader applications in resource-constrained settings.
| Training Method | Perplexity |
|---|---|
| SF-Attn | 8.64 |
| S2-Attn + Global Attention | 8.91 |
| S2-Attn + S&R Algorithm | 8.86 |
| S2-Attn | 9.09 |
| Training Method | Perplexity |
|---|---|
| S2Attn | 9.09 |
| Just shift up | 9.35 |
| Just shift back | 9.60 |
| S2-Attn + S&R Algorithm | 8.86 |
| Setting | Traing | Attention | Target Context Length | ||
|---|---|---|---|---|---|
| 4096 | 6144 | 8192 | |||
| 7B-Llama2 | Full-Attn | 8.59 | 8.16 | 7.83 | |
| -Attn | 9.09 | 8.82 | 8.64 | ||
| 8192 | Sparse Fixed Attention | 8.85 | 8.50 | 8.24 | |
| Stride Attention | 8.81 | 8.47 | 8.22 | ||
| Random Attention | 8.78 | 8.44 | 8.20 | ||
| SF-Attn | 8.60 | 8.17 | 7.85 | ||
4.3 Ablation Study
Ablation on SF-Attn training steps
To evaluate the effectiveness of different components in our SF-Attn training methodology, we conducted a series of ablation studies. Table 7 presents the perplexity results for various training methods using the validation split of the PG-19 dataset. The SF-Attn method alone yields a perplexity of 8.64, establishing a baseline for comparison. Introducing global attention to S2-Attn results in a perplexity of 8.91, indicating that global attention alone does not significantly improve performance. Combining S2-Attn with the Segmentation and Reassembly (S&R) Algorithm results in a perplexity of 8.86, showing a moderate improvement over S2-Attn alone. The baseline S2-Attn method alone has a higher perplexity of 9.09 compared to the SF-Attn baseline, demonstrating the need for additional enhancements to achieve better performance. These results indicate that while the SF-Attn method alone is effective, combining it with additional techniques like the S&R Algorithm can yield improvements in perplexity.
Further ablation studies were conducted to analyze the impact of individual components of the Segmentation and Reassembly (S&R) Algorithm. Table 8 provides perplexity results for these experiments. The baseline S2-Attn method has a perplexity of 9.09. When the model only applies the "shift up" step, the perplexity increases to 9.35, indicating that this step alone is not sufficient for improving performance. Applying only the "shift back" step results in a perplexity of 9.60345459, showing that this step alone is also insufficient. The complete Segmentation and Reassembly Algorithm achieves a perplexity of 8.86, demonstrating the effectiveness of combining both shifting steps. These ablation studies highlight the importance of the Segmentation and Reassembly Algorithm in enhancing the performance of the SF-Attn training method. By integrating both the "shift up" and "shift back" steps, the S&R Algorithm effectively reduces perplexity and improves model performance.
Ablation on SF-Attn Varation
specifically focusing on the Sparse Fixed Attention (SF-Attn) and its variations. Figure 7 illustrates the different attention patterns: Sparse Fixed Attention, Stride Attention, and Random Attention. These variations represent different strategies for distributing attention across the token sequence. Sparse Fixed Attention uses a fixed sparse pattern, Stride Attention distributes attention in a stride pattern, and Random Attention allocates attention randomly.
Table 9 presents the results of fine-tuning a Llama2 7B model on sequences with varying target context lengths (4096, 6144, and 8192) and evaluating on the PG19 validation set. The performance is measured across different settings of the attention mechanism. Key observations include that Full Attention (Full-Attn) shows consistent performance but is computationally expensive. S²-Attention (S²-Attn) performs slightly better than Full Attention, particularly at longer context lengths. Sparse Fixed Attention maintains competitive performance and is more efficient. Stride and Random Attention also perform well but slightly lower than Sparse Fixed Attention. The SF-Attention method, combining elements of these strategies, achieves the best balance with the lowest perplexity scores, indicating it is the most efficient and effective attention mechanism for handling long sequences.
5 Discussion
5.1 The Failure of Shift Operation
The shift operation of Sparse Shift Attention 6 is inspired by the Swin Transformer 24. It aims to facilitate more information exchange between different groups of tokens. However, this approach also leads to an information leaking problem.
The information leaking issue likely arises because the shift operation allows tokens from different segments to share information too freely. While the intention is to enhance the model’s ability to integrate information from various parts of the sequence, it inadvertently causes tokens to access information that they should not be aware of at that particular stage of processing. This premature exposure to information can disrupt the model’s learning process, leading to overfitting or incorrect associations.
Moreover, the shift operation might blur the distinct boundaries between token groups, causing the model to lose track of the specific context within each group. This can result in a degradation of performance, as the model might struggle to maintain a coherent understanding of the local context, which is essential for accurately interpreting and generating long sequences.
In summary, while the shift operation aims to improve information exchange, it inadvertently causes information leakage by allowing tokens to prematurely access and integrate information from different segments. This undermines the model’s ability to maintain distinct contextual boundaries and can negatively impact its performance on tasks requiring precise contextual understanding.
5.2 The Success of Making Sink Attention Tokens Globally Operative
The method described in the following section details the successful implementation of globally operative sink attention tokens, enhancing the model’s ability to handle long sequences efficiently.
The successful results observed from implementing sink attention tokens can be attributed to several key factors. First, by designating specific tokens as sink attention tokens that attend to all other tokens in the sequence, the model can effectively capture and integrate information from across the entire sequence. This global attention mechanism ensures that critical information is not lost, even in very long sequences.
Furthermore, by ensuring that all tokens in the sequence also attend to the sink attention tokens, the model can maintain a coherent understanding of the sequence context. This bidirectional attention flow allows the model to reinforce important information at multiple stages, enhancing the overall comprehension and retention of context.
The efficient complexity of O(n log n) achieved through this method, due to the relatively small number of sink attention tokens, ensures that this enhanced capability does not come at the cost of significantly increased computational overhead. This balance between maintaining comprehensive attention and computational efficiency is likely a key factor in the improved performance observed in models utilizing this technique.
In summary, the implementation of globally operative sink attention tokens allows the model to maintain a robust and coherent understanding of long sequences, ensuring critical information is attended to throughout the processing stages, thus leading to improved performance on tasks requiring extensive context comprehension.
5.3 The Convenience of Applying KV Cache Compression Function
As the results shown in the H2O inference test indicate, the H2O method can maintain accuracy even when the KV cache budget is reduced by half. However, the time savings achieved with this method are significant, reducing inference time by a factor of 1.5. This capability allows for flexible deployment of inference methods based on the available computing resources. The ability to adjust the KV cache budget without compromising accuracy ensures that large language models can be efficiently and effectively utilized in resource-constrained environments, optimizing both performance and computational efficiency.
5.4 The Good Result of Chatbot
As shown in the example of chat ability comparison in Section C, we observe the responses from two versions of the LongLoRA model to a story-related question.
The user input describes a narrative involving an old fisherman named Tom, who ventures farther out to sea to a place known as the “Blue Deep” in hopes of finding fish after several unsuccessful weeks. The question asks why Tom decided to venture farther out to sea than he ever had before.
The LongLoRA-7B model’s response focuses on Tom’s desperation and worry about not catching any fish, emphasizing his repeated return with an empty net and his determination to support his family. This response accurately captures the key elements of Tom’s motivation as described in the narrative.
On the other hand, the SinkLoRA-7B model provides a more detailed explanation, highlighting the prolonged disappearance of fish and Tom’s resultant decision to take the risk of venturing to the “Blue Deep.” It also mentions Tom’s hope to find fish there, providing a more comprehensive understanding of his motivations.
The reason for the differing levels of detail and context in the responses can be attributed to the training and fine-tuning differences between the two models. The SinkLoRA-7B model might have been trained on a more diverse dataset or undergone additional fine-tuning to better understand and generate contextually rich responses. This additional training could enable it to provide more nuanced and detailed answers, capturing the subtleties of the narrative more effectively.
In conclusion, both models successfully identify Tom’s primary motivation, but the SinkLoRA-7B model offers a more thorough and contextually rich explanation. This comparison underscores the effectiveness of the chat capabilities in understanding and accurately responding to narrative-based questions. The observed differences highlight the importance of extensive training and fine-tuning in enhancing model performance and response quality.
6 Conclusion and Future Work
In this study, we introduced SinkLoRA, a significant enhancement over the original LongLoRA, designed to improve the efficiency and performance of large language models (LLMs) in handling long-context sequences. SinkLoRA addresses the limitations of the previous model by implementing Sink Fixed Attention (SF-Attn) and utilizing advanced KV cache compression techniques like the Heavy-Hitter Oracle (H2O). Our proposed SF-Attn method effectively redistributes attention scores, reducing the overemphasis on initial tokens and improving overall model accuracy. This approach, combined with the segmentation and reassembly algorithm, allows for better handling of extended contexts without increasing computational complexity. The integration of the H2O KV cache compression further accelerates inference, making SinkLoRA a highly efficient solution for deploying LLMs in resource-constrained environments.
Future work will focus on further optimizing the attention mechanisms and exploring the compatibility of SinkLoRA with other types of LLMs and position encodings. We also plan to investigate more advanced KV cache management techniques to enhance the flexibility and efficiency of inference processes. The goal is to continue improving the performance and scalability of LLMs, enabling their application in a broader range of tasks and environments. In summary, SinkLoRA represents a substantial step forward in the development of efficient long-context processing techniques for large language models, offering promising avenues for future research and application.
References
- [1] Pascal Severin Andermatt and Tobias Fankhauser. Uzh_pandas at simpletext@ clef-2023: Alpaca lora 7b and lens model selection for scientific literature simplification. arXiv preprint arXiv:2004.05150, 2023.
- [2] Zhangir Azerbayev, Edward Ayers, and Bartosz Piotrowski. Proof-pile, 2022. URL https://github. com/zhangir-azerbayev/proof-pile, 2022.
- [3] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
- [4] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- [5] Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023.
- [6] Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. Longlora: Efficient fine-tuning of long-context large language models. arXiv preprint arXiv:2309.12307, 2023.
- [7] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
- [8] Together Computer. Redpajama: An open source recipe to reproduce llama training dataset, 2023.
- [9] Charles Condevaux and Sébastien Harispe. Lsg attention: Extrapolation of pretrained transformers to long sequences. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pages 443–454. Springer, 2023.
- [10] Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- [11] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- [12] Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5(3):220–235, 2023.
- [13] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. arXiv preprint arXiv:2103.10360, 2021.
- [14] KD Finkelstein. Chess upgrade 1995: Improved radiation shielding. Review of Scientific Instruments, 67(9):3378–3378, 1996.
- [15] John S Garofolo, Ellen M Voorhees, Cedric GP Auzanne, and Vincent M Stanford. Spoken document retrieval: 1998 evaluation and investigation of new metrics. In ESCA Tutorial and Research Workshop (ETRW) on Accessing Information in Spoken Audio, 1999.
- [16] Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms. arXiv preprint arXiv:2310.01801, 2023.
- [17] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [18] Srinivasan Iyer. Xi victoria lin, ramakanth pasunuru, todor mihaylov, dániel simig, ping yu, kurt shuster, tianlu wang, qing liu, punit singh koura, et al. 2022. opt-iml: Scaling language model instruction meta learning through the lens of generalization. arXiv preprint arXiv:2212.12017, 2022.
- [19] Fred Jelinek, Robert L Mercer, Lalit R Bahl, and James K Baker. Perplexity—a measure of the difficulty of speech recognition tasks. The Journal of the Acoustical Society of America, 62(S1):S63–S63, 1977.
- [20] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- [21] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020.
- [22] Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. Bloom: A 176b-parameter open-access multilingual language model. Advances in neural information processing systems, 2023.
- [23] Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. How long can context length of open-source llms truly promise? In NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023.
- [24] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021.
- [25] Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36, 2024.
- [26] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018.
- [27] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. Advances in Neural Information Processing Systems, 2017.
- [28] Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The refinedweb dataset for falcon llm: outperforming curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116, 2023.
- [29] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- [30] Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507, 2019.
- [31] Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506, 2020.
- [32] Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, and Douglas Orr. Sparq attention: Bandwidth-efficient llm inference. arXiv preprint arXiv:2312.04985, 2023.
- [33] Selim Sandal and Ismail Akturk. Zero-shot rtl code generation with attention sink augmented large language models. arXiv preprint arXiv:2401.08683, 2024.
- [34] Ankit Satpute, Noah Gießing, Andre Greiner-Petter, Moritz Schubotz, Olaf Teschke, Akiko Aizawa, and Bela Gipp. Can llms master math? investigating large language models on math stack exchange. arXiv preprint arXiv:2404.00344, 2024.
- [35] MosaicML NLP Team et al. Introducing mpt-30a: Raising the bar for open-source foundation models, 2023.
- [36] MosaicML NLP Team et al. Introducing mpt-30b: Raising the bar for open-source foundation models, 2023.
- [37] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [38] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Introducing meta llama 3: The most capable openly available llm to date, 2024. Accessed: 2024-05-04.
- [39] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023.
- [40] Chenghao Yang, Zi Yang, and Nan Hua. Equipping transformer with random-access reading for long-context understanding. arXiv preprint arXiv:2405.13216, 2024.
- [41] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283–17297, 2020.
- [42] Xiang Zhang, Khatoon Khedri, and Reza Rawassizadeh. Can llms substitute sql? comparing resource utilization of querying llms versus traditional relational databases. arXiv preprint arXiv:2404.08727, 2024.
- [43] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36, 2024.
Appendix
We organize our supplementary material as follows.
Appendix A Varation of SF-Attn

We provide Varation of SF-Attn in Figure 7.
Appendix B Dataset Overview
We provide Overview of Dataset in Figure 8.

Appendix C Example of Chat
We provide a example of dialogue in Figure 9.
