Single-Subject Deep-Learning Image Reconstruction with a Neural Optimization Transfer Algorithm for PET-enabled Dual-Energy CT Imaging
Abstract
Combining dual-energy computed tomography (DECT) with positron emission tomography (PET) offers many potential clinical applications but typically requires expensive hardware upgrades or increases radiation doses on PET/CT scanners due to an extra X-ray CT scan. The recent PET-enabled DECT method allows DECT imaging on PET/CT without requiring a second X-ray CT scan. It combines the already existing X-ray CT image with a 511 keV -ray CT (gCT) image reconstructed from time-of-flight PET emission data. A kernelized framework has been developed for reconstructing gCT image but this method has not fully exploited the potential of prior knowledge. Use of deep neural networks may explore the power of deep learning in this application. However, common approaches require a large database for training, which is impractical for a new imaging method like PET-enabled DECT. Here, we propose a single-subject method by using neural-network representation as a deep coefficient prior to improving gCT image reconstruction without population-based pre-training. The resulting optimization problem becomes the tomographic estimation of nonlinear neural-network parameters from gCT projection data. This complicated problem can be efficiently solved by utilizing the optimization transfer strategy with quadratic surrogates. Each iteration of the proposed neural optimization transfer algorithm includes: PET activity image update; gCT image update; and least-square neural-network learning in the gCT image domain. This algorithm is guaranteed to monotonically increase the data likelihood. Results from computer simulation, real phantom data and real patient data have demonstrated that the proposed method can significantly improve gCT image quality and consequent multi-material decomposition as compared to other methods.
Index Terms:
PET-enabled dual-energy CT, PET/CT, image reconstruction, kernel methods, convolutional neural-networkI Introduction
Conventionally, standard dual-energy computed tomography (DECT) uses two different X-ray energies to obtain energy-dependent tissue attenuation information to allow quantitative material decomposition [1]. Integration of DECT with positron emission tomography (PET) offers more accurate attenuation correction for PET [2, 3], enables multi-modality characterization of disease states in cancer and other diseases [4] and would open up novel clinical applications. However, it is not trivial to combine DECT with PET because it either requires costly CT hardware upgrade on existing PET/CT or significantly increases CT radiation dose due to the need for the second X-ray CT scan.
A PET-enabled DECT method has been proposed to enable DECT imaging on clinical time-of-flight PET/CT scanners without a change of scanner hardware or adding additional radiation dose or scan time [5]. In PET-enabled DECT imaging, a high-energy “-ray CT (gCT)” image at 511 keV is reconstructed from a standard time-of-flight PET emission scan and combined with the already-existing low-energy X-ray CT (usually 140 keV) to produce a pair of DECT images for multi-material decomposition.
The gCT image can be reconstructed from PET emission data using the maximum-likelihood attenuation and activity (MLAA) method [6, 7]. However, standard MLAA reconstruction can be very noisy due to the limited counting statistics of PET data. Regularization-based MLAA methods [7, 8, 9] can suppress noise, but generally require a more complex optimization algorithm, involve one or more hard-to-tune penalty parameters, and need to run for many iterations for a convergent solution. The kernel MLAA method, or KAA in short in this paper, has been developed by integrating the X-ray CT image prior into the forward model of MLAA attenuation image reconstruction through a kernel framework [5]. KAA has demonstrated substantial improvements over the MLAA for PET-enabled DECT imaging. Nonetheless the estimated kernel coefficient image may still suffer from noise and result in artifacts in material decomposition, such as in low-count scan cases. The aim of this paper is to improve gCT image reconstruction algorithm by exploring the power of deep neural networks.
For general CT image reconstruction, common ways to explore deep learning include direct end-to-end mapping or unrolled model-based deep-learning reconstruction [10, 11]. However, all these approaches require pre-training using a large population-based database, which is not applicable for a new imaging method like the PET-enabled DECT because no existing database of 511 keV gCT images is available yet. An alternative way is the single-subject learning approach that explores neural network representation, for example, in a way similar to the deep image prior (DIP) framework [12]. Such methods [13, 14, 16, 15, 17, 18] do not require population-based pre-training but is based on the data of single subjects. Direct application of DIP reconstruction to standard MLAA, however, would result in oversmoothing and subsequently induce artifacts in material decomposition, as will be demonstrated later in the evaluation studies.
In this paper, we integrate deep image prior with the KAA framework to develop a neural KAA approach for gCT image reconstruction. This leads to the tomographic estimation of nonlinear neural network parameters from projection data. Different from a possible DIP reconstruction method that would be directly using neural networks for gCT image representation, our method employs the DIP model to represent the kernel coefficient image within the KAA framework, enforcing an implicit regularization on gCT image reconstruction to suppress high noise while preserve image contrast at the same time.
For all DIP-type CT reconstructions, including the proposed neural KAA for gCT, the optimization problem becomes more challenging due to the coupling of unknown neural-network parameters in the projection domain. One solution involves employing a class of gradient descent algorithms (e.g., [19, 17]) by violently computing the derivatives of the projection-based likelihood function with respect to neural-network parameters. However, the computational efficiency is low due to the forward and backward processes containing a large-size system matrix. It is also challenging to select an appropriate step size for algorithm convergence due to the high computational cost. Alternatively the alternating direction method of multipliers (ADMM) algorithm can be used [13, 20, 21] and may decouple the neural network learning step from the tomographic reconstruction step. However, ADMM often involves one or more hyper-parameters that are known difficult to tune [22, 23].
To overcome these issues, we propose an iterative algorithm for the proposed neural KAA reconstruction problem using the theory of optimization transfer with quadratic surrogates [24]. The resulting neural optimization transfer algorithm can decouple the non-linear neural-network learning from the tomographic reconstruction step without introducing hyper-parameters as compared to ADMM. The proposed algorithm is easy and efficient to implement in practice by using existing deep learning libraries. Specifically, it essentially deals with a -ray CT transmission reconstruction problem, resulting in the derivation of a quadratic surrogate function for optimization transfer and consequently a unique least-square formulation for neural network learning (see Fig. 2 and Eq. (42)). The proposed neural optimization transfer algorithm is expected to solve different DIP-type reconstruction problems for X-ray CT [17, 20], magnetic resonance imaging [25, 21], and other imaging modalities [26, 27] that employ a least-square reconstruction formula. Thus the algorithmic contribution from this work may have a broad impact in single-subject deep-learning reconstruction for tomographic imaging.
Part of this work was presented at the 2021 SPIE medical imaging conference [28]. Here we gave the detailed derivation of the proposed neural optimization transfer algorithm and theoretically proved its convergence. Besides, we tested the proposed method on more rigorous computer simulation study and implemented PET-enabled DECT imaging on uEXPLORER PET/CT scanner using a real phantom scan and a patient scan. The remaining of this paper is organized as follows. Section II introduces the background materials regarding PET-enabled dual-energy CT. Section III describes the proposed neural KAA method for gCT image reconstruction from time-of-flight PET data. The proposed neural optimization transfer algorithm is elaborated in Section IV. We then present a computer simulation study in Section V, a real phantom study in Section VI and a real patient study in Section VII to demonstrate the improvement of the proposed method. Finally, discussions and conclusions are drawn in Sections VIII and IX, respectively.

II PET-Enabled Dual-Energy CT
The PET-enabled DECT method merges the high-energy (511 keV) gCT image, reconstructed from time-of-flight PET emission data, with a low-energy X-ray CT image for dual-energy imaging [5], as illustrated in Fig. 1. The gCT image is not acquired using an external radiation source but the internal -rays generated by annihilation radiation of PET radiotracer decays in a subject. In this work, we aim to propose a single-subject deep learning framework to improve gCT image reconstruction without the need of population-based pre-training. The unique advantage is that the proposed framework is more adaptive for this new imaging modality that is difficult for collecting a large training dataset.
II-A Statistical Model of PET Emission Data
Commonly the PET measurement is well modeled as independent Poisson random variables which follows the log-likelihood function:
| (1) |
where denotes the index of PET detector pair and is the total number of detector pairs. denotes the th time-of-flight bin and is the number of time-of-flight bins. The expectation of the PET projection data is related to the radiotracer activity image and object attenuation image at 511 keV via
| (2) |
where is the PET detection probability matrix for time-of-flight bin . accounts for the expectation of random and scattered events. is the normalization factor with the th element being
| (3) |
where represents the multiplicative factor excluding the attenuation correction factor and is the system matrix for transmission imaging.
II-B Standard MLAA Reconstruction
The MLAA reconstruction algorithm [6] simultaneously estimates the attenuation image and the activity image from the PET projection data by maximizing the Poisson log-likelihood,
| (4) |
An iterative interleaved updating strategy is commonly used to seek the solution. At each iteration of the algorithm, is first obtained based on the attenuation image from the previous iteration :
| (5) |
which can be updated by the maximum-likelihood expectation maximization (MLEM) algorithm [29] with one subiteration,
| (6) |
where denotes the updated sensitivity image from the iteration ,
is then updated with the estimated following the maximum-likelihood transmission reconstruction formulation,
| (7) | |||||
where
| (8) |
with and
| (9) |
The sub-optimization problem Eq. (7) can be solved using the separable paraboloidal surrogate algorithm [30].
Note that conventional applications of MLAA mainly focused on improving PET attenuation correction (e.g., [31, 32, 8, 33, 34, 35, 36]). A new application of MLAA demonstrated the potential of gCT reconstruction for improving the estimation of proton stopping-power in proton therapy [37]. Differently in our PET-enabled DECT method, the gCT image is combined with X-ray CT image to form a DECT image pair for multi-material decomposition [5].
II-C Kernel MLAA (KAA) for gCT Reconstruction
The gCT image estimate by the MLAA method [6] is commonly noisy due to the limited counting statistics of PET emission data. To suppress noise, the kernel MLAA or KAA integrates the X-ray CT prior image into the PET forward model by describing the gCT image intensity at pixel using a kernel representation [5, 38],
| (10) |
where is the kernel function (e.g., radial Gaussian) with and denoting the feature vectors of pixel and that are extracted from the X-ray CT image . defines the neighborhood of pixel , for example, selected by a k-nearest neighbor algorithm. denotes the corresponding kernel coefficient of each neighboring pixel in .
The equivalent matrix-vector form for the gCT image representation is
| (11) |
where is the kernel matrix and is the corresponding kernel coefficient image. Substituting Eq. (11) into the MLAA formulation in Eq. (4) gives the following KAA optimization formulation,
| (12) |
Once is determined, the gCT image is obtained as . Note that the conventional MLAA can be considered as a special case of the KAA with equal to an identity matrix.
The KAA problem is also solved using an interleaving optimization strategy between the activity image update and the kernel coefficient image update [5]. In each iteration of KAA, is first obtained using the MLEM updating formula Eq. (6) and then is obtained using the following kernelized transmission reconstruction (KTR) optimization,
| (13) |
as illustrated in Fig. 2a.
II-D Material Decomposition Using PET-enabled DECT
For each image pixel , the gCT attenuation value and X-ray CT attenuation value jointly form a pair of dual-energy measurements , which can be modeled by a set of material bases, such as air (A), soft tissue (S) or equivalently water, and bone (B):
| (14) |
subject to The coefficients with are the fraction of each basis material in pixel . The material basis matrix consists of the linear attenuation coefficients of each basis material measured at the low and high energies. Finally, is estimated using the following least-square optimization for each image pixel,
| (15) |
III Proposed Neural KAA for gCT Reconstruction
III-A Kernel Model with Deep Coefficient Prior for gCT
While demonstrating a substantially better performance than MLAA (e.g., in [5]), KAA may still suffer from noise or artifacts in low-count cases. In this work, we exploit neural networks as a conditional deep coefficient prior for improving KAA for gCT image reconstruction.
The kernel coefficient image for in Eq. (11) is described as a function of the conditional neural networks,
| (16) |
where is the available image prior from the corresponding X-ray CT in this work and denotes the neural network mapping from the known input image to the image with the parameters of the neural network.
The gCT image is then modeled using the following kernel representation with the conditional deep coefficient prior,
| (17) |
Fig. 3 shows a graphical illustration of the proposed model for representing a gCT image, of which the last layer is a linear kernel representation with pre-determined weights that are also calculated from .
By substituting the gCT representation Eq. (17) into the forward model in Eq. 2, we have the following forward projection model that is parameterized by the neural network parameters :
| (18) |
The model is equivalent to the standard KAA image model in Eq. (2) if the neural network is an identity mapping. It is also equal to a conditional DIP (CDIP) model directly in the gCT image domain if the kernel matrix is an identity matrix, which leads to .



III-B Optimization Formulation
By combining the forward projection model with the MLAA formulation Eq. (4), we have the proposed neural KAA optimization formulation,
| (19) |
Similar to the optimization approach for MLAA and KAA, an interleaving updating strategy can be used here to estimate and iteratively,
| (20) |
| (21) |
Once is estimated, the gCT image is obtained by
| (22) |
Compared to the previous KAA approach, the neural KAA approach combines the kernel representation with a neural network-based deep coefficient prior, which introduces an implicit regularization for KAA to improve the gCT image estimate through Eq. (21).
III-C The Optimization Challenge
In each iteration of the neural KAA, the estimation step in Eq. (20) can be directly implemented by using the MLEM algorithm Eq. (6). The -estimation step Eq. (21) follows a KTR formulation but with using neural networks as a conditional deep coefficient prior. For simplicity, we rewrite this neural KTR problem in Eq. (21) as
| (23) |
where is the transmission likelihood function at iteration ,
| (24) | |||||
with defined in Eq. (8) but the line integral following a kernelized neural-network model,
| (25) |
The optimization problem Eq. (23) is challenging to solve because the unknown neural network parameters is nonlinearly involved in the projection domain for transmission imaging due to Eq. (25), resulting in a complex optimization problem.
One commonly used solution would be a type of gradient descent algorithm that uses the chain rule to calculate the gradient of with respect to [19, 17, 18, 25],
| (26) |
which is then fed into an existing deep learning package to estimate the network parameters from the PET projection data . However, such an approach ties each calculation of , which relates to the neural network component, with a calculation of , which relates to the PET tomographic reconstruction. While the former operation is usually efficient by using a deep learning library, the latter operation requires both forward and back projections of PET data and is computationally intensive due to the large size of the transmission system matrix . As a result, the whole algorithm can be slow due to the natural need for many iterations for training a neural network.
Another solution would be the ADMM algorithm as used for the DIP reconstruction [13, 20, 21]. This type of algorithms may separate the neural network learning step (that uses ) from the tomographic reconstruction step (that uses ). However, a major weakness of ADMM is that it is difficult to tune the induced hyper-parameters in practice as demonstrated by many studies [22, 23].
In this work, we develop an approach to decoupling the reconstruction step and neural network learning step without adding extra hyper-parameters towards a more practical and efficient implementation.

IV A Neural Optimization Transfer Algorithm for gCT
IV-A Optimization Transfer with Quadratic Surrogates
The neural network reconstruction problem shares the same complication as the tomographic reconstruction of nonlinear kinetic parameters in dynamic PET [40] which, however, can be solved by a quadratic surrogate-based optimization transfer algorithm [39]. Thus we apply the principle of optimization transfer [24] to convert the original difficult problem for into a quadratic surrogate optimization problem, as illustrated in Fig. 4. The quadratic surrogate function minorizes the transmission likelihood function ,
| (27) |
| (28) |
Then the maximization of is transferred into maximizing the surrogate function,
| (29) |
The quadratic surrogate is designed to be easy to solve. The new update is guaranteed to monotonically increase the original likelihood , i.e.,
| (30) |
as also demonstrated by Fig. 4.
Note that the concept of optimization transfer has been also applied for the KAA reconstruction in which the gCT projection is linear with respect to the unknown attenuation image [5]. However, in the neural KAA, the unknown becomes the neural network parameters which is non-linearly involved in the gCT projection domain. Our derivations will show how the quadratic surrogate functions are built to decouple the linear tomographic reconstruction step and the nonlinear neural network learning step from each other, as also shown in Fig. 2.
IV-B Paraboloidal Surrogates in the Projection Domain
One difficulty with dealing the objective function directly is the Poisson log-likelihood function follows a non-quadratic form. Following a derivation similar to [41, 30], a paraboloidal surrogate function can be constructed for ,
| (31) | ||||
where is calculated with and . is chosen by design as the optimal curvature of the Poisson log-likelihood [41],
| (32) |
where and are the first and second derivatives of , respectively [41].
With several algebraic operations similar to the way in [39], we then can derive the following equivalent quadratic form for in Eq. (31),
| (33) |
where is the remainder that is independent of the unknown parameter . is an intermediate gCT projection data [5],
| (34) |
and is an intermediate weight also in the projection domain,
| (35) |
Based on this quadratic surrogate , the maximization of for the neural KTR is transferred to an equivalent weighted least-square reconstruction problem,
| (36) |
This quadratic form is simpler than the original non-quadratic likelihood function . However, the nonlinear neural network model is still coupled in the projection domain.
IV-C Separable Quadratic Surrogates in the Image Domain
By considering as a single matrix and using the convexity of Eq. (33) to build a separable quadratic surrogate [42], we can construct the following surrogate for ,
| (37) | ||||
where . is the gradient of with respect to at iteration ,
| (38) |
and is an intermediate weight image,
| (39) |
where is the all-one vector. Note that is also equal to the gradient of with respect to at iteration .
After matching a quadratic function, we can have the following equivalent form for ,
| (40) |
where is an intermediate kernel coefficient image calculated from
| (41) |
with . denotes the corresponding remainder term that is independent of . Note that is equivalent to one iteration of the KTR reconstruction algorithm in [5].
Thus, the weighted least-square reconstruction problem Eq. (36) defined in the projection domain is transferred to the following neural-network learning problem that is fully defined in the image domain,
| (42) |
In particular, the cost function here follows a weighted -norm loss that can be easily used with an existing deep learning package (e.g., PyTorch).
It is straightforward to prove that the surrogate function minorizes the original likelihood function ,
| (43) |
| (44) |
Note that the optimization transfer algorithm in [5] for standard KAA (Fig. 2a) is only a special case of the derived algorithm for the neural KAA (Fig. 2b) here without having the least-square neural network learning step. Therefore we call the new algorithm the neural optimization transfer algorithm to highlight its estimation of the neural network model parameters. The associated least-square form in Eq. (42) for network training is not arbitrarily defined but analytically derived from the theory of optimization transfer for a non-linear model. Furthermore, no any new hyper-parameters are introduced from the optimization transfer process, which represents an important advantage as compared to a possible ADMM algorithm.
| Algorithm 1 The neural optimization transfer algorithm for gCT reconstruction | |
|---|---|
| 1: | Input parameters: Maximum iteration number MaxIt, initial , and initial to provide . |
| 2: | for to MaxIt do |
| 3: | Obtain the activity image update using Eq. (6); |
| 4: | Get the intermediate kernel coefficient image : |
| , | |
| where and are calculated based on and in Eq. (38) and Eq. (39); | |
| 5: | Perform the least-square neural-network learning in Eq. (42) to update and : |
| ; | |
| 6: | end for |
| 7: | return |




IV-D Summary of the Algorithm
A pseudo-code of the proposed neural optimization transfer algorithm for gCT reconstruction is summarized in Algorithm 1. The algorithm consists of three separate steps in each iteration:
-
1.
PET activity image reconstruction: Obtain the PET activity image update using one iteration of MLEM algorithm in Eq. (6).
-
2.
Kernelized gCT image reconstruction: Obtain an intermediate kernel coefficient image update using one iteration of the KTR algorithm in Eq. (41);
-
3.
Least-square neural-network learning for gCT image approximation: Update the network model parameters using Eq. (42) to approximate ;
Step 1 and step 2 are updated analytically. The tomographic reconstruction of projection data are only involved in these two steps. Step 3 can be implemented efficiently using existing deep learning packages without involving any projection data directly. Thus, the neural network learning step is decoupled from the image reconstruction steps and is easy to implement in practice. The initialized weights of the neural network learning at the reconstruction iteration are inherited from the previous iteration rather than a random initialization. Note that random initialization was also tested but demonstrated a less stable performance. The algorithm is guaranteed to increase the likelihood function monotonically due to the nature of optimization transfer [24].
Note that many other imaging modalities such as X-ray CT [17, 20], MRI [25, 21], and optical tomography [26, 27] may often use the same weighted least-square reconstruction formula in Eq. (36) (but with constant and ). Thus the neural optimization transfer algorithm in Algorithm 1 may be also applicable to these reconstruction problems, though without the need for Step 1 which is specific for the neural KAA for gCT reconstruction.
IV-E Neural Network Structure and Settings
Any neural-network model that is suitable for image representation would be compatible with the proposed algorithm. As an example, here we use a popular residual U-Net architecture to represent the kernel coefficient image, as illustrated in Fig. 5, following its previous successful use for PET activity image reconstruction [13, 43]. The model comprises the following key components: (1) A convolution layer (kernel size: 3) + batch normalization (BN) + leaky rectified linear unit (LReLU) for feature extraction; (2) The strided convolution layer (strided size: 2, kernel size: 3) for down-sampling; (3) Bilinear/trilinear interpolation for up-sampling; (4) The additive operation used for skip connection between encoder and decoder paths; (5) A ReLU operation prior to the output layer used for generating the non-negative kernel coefficient image. The number of feature maps for each layer is also included in Fig. 5.
In this work, the input image of the neural network was set to an X-ray CT image, that can be explained as the conditional deep image prior (CDIP) [44]. We used the Adam algorithm with a learning rate of and 150 sub-iterations for the least-square neural network learning, which were the same setting as previous work [43]. The neural-network learning step was implemented with PyTorch on a PC with an Intel i9-9920X CPU with 64GB RAM and a NVIDIA GeForce RTX 2080Ti GPU.































V Computer Simulation Studies
V-A Simulation Setup
We first conducted a two-dimensional computer simulation study following the GE Discovery 690 PET/CT scanner geometry. This PET scanner has a time-of-flight (TOF) timing resolution of approximately 550 ps. The simulation was conducted using one chest slice of the XCAT phantom [45]. Fig. 6a and Fig. 6b show the simulated ground truth of PET activity image and 511 keV gCT attenuation image, respectively. The low-energy X-ray CT image was simulated from XCAT at 80 keV and is shown in Fig. 6c. The activity and gCT images were first forward projected to generate noise-free emission sinograms with the size of 281 (radial bins) 288 (angular bins) 11 (TOF bins). A 40% uniform background was included to simulate random and scattered events. Poisson noise was then generated using 5 million expected events. The projection data was reconstructed into PET activity and gCT images of 180180 with a pixel size of 3.93.9 mm2. Ten noisy realizations were simulated and reconstructed for comparing reconstruction methods.
V-B Compared Methods and Implementation Details
In this work, four types of reconstruction methods were compared, including (1) the standard MLAA [6], (2) existing KAA [5], (3) a CDIP reconstruction method, which is equal to the proposed neural KAA with , and (4) proposed neural KAA that uses the neural optimization transfer algorithm.
For constructing kernels, the feature vector was chosen as the pixel intensities of X-ray CT image in a image patch centered at pixel . The radial Gaussian kernel function, , was used to build the kernel matrix using and NN search with , in the same way as [5].
The initial estimate of the PET activity image was set to a uniform image. Following [5], we used the X-ray CT-converted 511 keV attenuation map as the initial estimate of gCT image for accelerated convergence. All reconstructions were run for 3000 iterations for investigating the convergence behaviors of different algorithms.
V-C Evaluation Metrics
As the focus of this work is on gCT for DECT, the evlauation of PET activity image quality is not concerned. Different reconstruction algorithms were first compared for gCT image quality using the mean squared error (MSE),
| (45) |
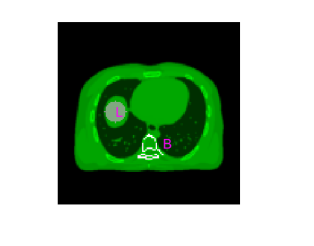
where represents the reconstructed gCT image by each method and denotes the ground truth. The error image, defined as , was used for highlighting the differences in key parts. The ensemble bias and standard deviation (SD) of the mean intensity in a regions of interest (ROI) were also calculated to evaluate ROI quantification in a liver region and a bone region (Fig. 6(d)),
| (46) |
where is the true average intensity in a ROI and denotes the mean of realizations ().
Different reconstruction algorithms were further compared for DECT multi-material decomposition. Similarly, the image MSE, error image, and ROI-based bias and SD were calculated for each of the material basis fractional images.
V-D Neural Optimization Transfer versus Gradient descent
Fig. 7 shows the plots of Poisson log-likelihood as a function of iteration number for one simulated data for the proposed neural optimization transfer and gradient descent algorithms. Here the implementation of gradient descent algorithm followed [17] with an optimized step size using grid search. While the gradient descent algorithm not surprisingly demonstrates an oscillating behavior because of the non-convex nature of the original likelihood function (Eq. 23), the proposed neural optimization transfer algorithm shows a monotonic increase in the likelihood function as the iteration increases, which is guaranteed by the theory of optimization transfer.
V-E Comparison for gCT Image Quality
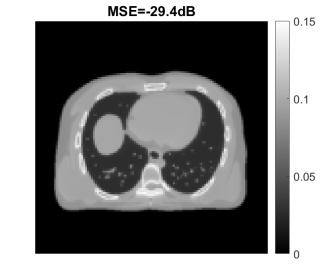
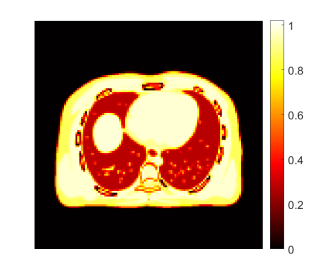
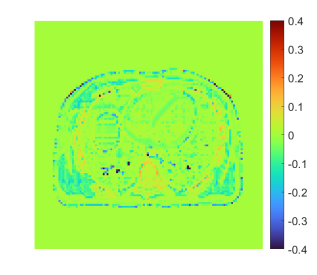
Fig. 24 shows the true and reconstructed 511-keV gCT images using different algorithms with 400 iterations, as well as corresponding error images. The image MSE results were included for quantitative comparison. The selection of 400 iterations was a balance for different methods (KAA, CDIP and the proposed method) to show good image quality according to the MSE performance. The MLAA reconstruction was noisy. The KAA method substantially improved the gCT image quality, but with a lower contrast in the bone region as compared to the ground truth (as evidenced in its error image). The CDIP method had a slightly better MSE than KAA, but it induced artifacts, which was in turn propagated into the material decomposition results as shown later in Fig. 25. In comparison, the proposed neural KAA demonstrated the least level of noise with good visual quality, and achieved the lowest MSE among different algorithms.
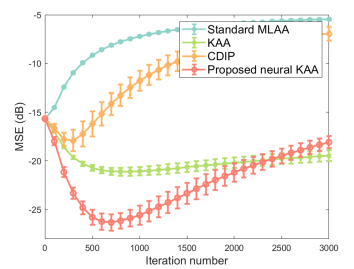
Fig. 9a shows the MSE plots as a function of iteration number for different algorithms. The iteration number varied from 0 to 3000 with a step of 100 iterations and error bars were calculated over the 10 noisy realizations. Compared to KAA, the proposed neural KAA showed a lower MSE among different methods. The curve also shows that similar to other algorithms, early stopping of the iterations is beneficial for the neural KAA to obtain good image quality while keep computational efficiency.
Fig. 9b and Fig. 9c further show the comparison of ensemble bias versus SD for gCT quantification in a liver region and a bone region. The curves were obtained by varying the iteration number from 300 to 3000 iterations with an interval of 100 iterations. As iteration number increases, the bias of ROI quantification is reduced while the SD increases. At a comparable bias level, the proposed neural KAA had a lower noise SD than the other three methods.



V-F Comparison for Material Decomposition
We also conducted a comparison of different reconstruction methods for multi-material decomposition (MMD). Fig. 25 shows the fractional basis images of bone and soft tissue obtained from MMD of the PET-enabled DECT images with 400 iterations, as well as their corresponding error images. The ground truth of the soft tissue and bone bases was generated using the noise-free pair of low-energy X-ray CT image ( in Eq. (14)) and the 511 keV gCT image. The conventional KAA method outperformed MLAA but were still with noise artifacts, as pointed by arrows. Interestingly, even though the CDIP reconstruction had a better MSE for gCT images than KAA, the benefit did not propagate into the MMD basis images. The proposed neural KAA achieved less noise and artifacts than KAA thanks to the CDIP-based regularization on the kernel coefficient image .
Fig. 11 further shows image MSE as a function of iteration number for each basis fractional image. Again, the proposed neural KAA demonstrated the lower minimum MSE result in each basis image among different reconstruction methods.
Fig. 12 shows the quantitative comparisons of ensemble bias versus SD for ROI quantification on the soft tissue (a) and bone (b) fractional images by varying the reconstruction iteration number. Similar to the results of gCT ROI quantification, the neural KAA achieved the lowest noise level at a comparable bias level. It is noticeable that for the bone ROI quantification, both the standard KAA and neural KAA showed a bias when compared to MLAA. The bias was propagated from the gCT reconstruction (as shown in Fig. 9c).

V-G Investigation of Neural Network Learning Settings
Our experiments indicated that neural network learning is stable when the learning rate in the Adam optimizer ranges from to . A larger rate may make the learning difficult to converge, while a smaller rate may reduce the convergence rate. The sub-iteration number used in the least-square neural network learning may also have influenced the results. Fig. 13 shows the effect of this sub-iteration number of neural network learning and total outer-iteration number of the neural KAA on the gCT image MSE. The results suggest the algorithm becomes relatively stable after 150 sub-iterations under different total outer-iterations of the neural KAA.







VI Evaluation on Real Phantom Data
VI-A Phantom Data Acquisition
We have further evaluated different reconstruction methods using a real three-dimensional (3D) phantom scan on the uEXPLORER PET/CT scanner [46] at UC Davis. This phantom [47] was filled with water in the background and four inserts were filled with (1) lung tissue equivalent material, (2) water, and (3&4) salt water, as shown in Fig. 14. Other attenuation materials composed of fat tissue-equivalent materials and bovine rib bones were wrapped around the phantom. A 18F-FDG solution was uniformly filled in all five compartments. Two X-ray CT scans, one at 80 kVp and the other at 140 kVp, were acquired to provide the reference for MMD analysis. In this study, the reconstructions were performed on a truncated dataset of 2-min scan duration and 7 cm axial length to reduce computational time. The projection data were acquired with 27 TOF bins for a TOF resolution of 505ps [46]. The 3D sinogram for each TOF bin was of 533 radial bins, 420 angular bins, and 576 direct and oblique detector planes. The reconstructed gCT image size was with a voxel size of mm3. For MMD using a PET-enabled DECT image pair, the X-ray CT image was downsampled to match with the gCT voxel size using linear interpolation.
VI-B Reconstruction Methods
We used the 80 kVp CT image as the image prior to generate the kernel matrix and the input of the neural network. The settings of the neural network in the CDIP method and proposed neural KAA were the same as in the simulation study except using a 3D version of U-Net to match with the data. All reconstructions were implemented using the CASToR package [48] as described in [47] and run for 400 iterations. The 80 kVp X-ray CT-converted attenuation map was used as the initial for gCT.
VI-C Results
Fig. 15 shows the gCT images reconstructed using different algorithms with 400 iterations. Similar to the results shown in the simulation, the MLAA was extremely noisy. Both the standard KAA and CDIP methods reduced noise significantly but still contained significant artifacts. In contrast, the proposed neural KAA demonstrated the best visual quality.
Fig. 16 shows the bone fractional images from MMD and corresponding error images using different approaches. Compared to the reference from X-ray DECT, the image by MLAA demonstrated heavy noise. Both the KAA and CDIP methods suppressed the noise, but not without additional noise or artifacts. In comparison, the proposed neural KAA demonstrated the least artifacts and noise in the uniform regions and achieved the most similar bone fraction pattern with the reference image, as pointed by the arrows.
Fig. 17 further shows a quantitative comparison for ROI quantification of bone fraction. Here the ROI quantification is plotted versus the background noise SD measured in the water region by varying the iteration number from 40 to 400 with an interval of 20 iterations. As the iteration number increases, the estimated bone fraction becomes lower while the SD increases. Compared to the other three methods, the proposed neural KAA was the closest to the X-ray DECT reference (dashed line) and also achieved the lowest background noise level.
VII Evaluation on Real Patient Data
We have also evaluated different reconstruction methods for PET-enabled DECT imaging using a cancer patient scan on the uEXPLORER scanner. The injection dose of 18F-FDG was around 10 mCi. Similar to the phantom study, we extracted the last 2-min emission scan data for gCT reconstruction. All the other settings were the same with the real phantom experiment.
Fig. 18 shows the reconstructed gCT images of the patient data using different algorithms with 400 iterations. Again, the MLAA was extremely noisy. Both the standard KAA and CDIP methods yielded the similar noise behavior to the phantom results in Fig. 15. By contrast, the proposed neural KAA largely overcame the issues and demonstrated a better visual quality, though no ground truth was available.
Fig. 19 further shows a plot of contrast recovery coefficient (CRC) versus background noise SD for a bone ROI quantification in the gCT image. The CRC was calculated by , where is the mean intensity in the bone ROI and is the ROI mean of the muscle background. The plot was generated by varying the iteration number from 40 to 400 with an interval of 20 iterations. Compared to other three methods, the proposed neural KAA achieved the best trade-off of CRC versus background noise.
Finally, Fig. 20 shows the bone fractional images of MMD from PET-enabled DECT using different approaches. Even though there was no available X-ray DECT imaging as the reference, observations were similar to the physical phantom results. The bone fractional image derived from MLAA demonstrated heavy noise. Both KAA and CDIP results showed noticeable noise or artifacts, as pointed by the arrows. In comparison, the proposed neural KAA achieved a good visual quality with reduced noise and artifacts.
VIII Discussion
This work has developed a single-subject deep-learning framework to improve gCT reconstruction in PET-enabled DECT imaging. The proposed neural KAA approach estimates neural network parameters from PET projection data for gCT image reconstruction and results in a challenging optimization problem. The often used gradient descent algorithm for DIP reconstruction was slow and not able to provide stable results (Fig. 7). While ADMM is another possible option, our comparisons (results not shown) have indicated ADMM was also unstable and it was difficult to tune the hyper-parameters. We have solved the optimization problem by developing a neural optimization transfer algorithm, which decouples the optimization problem into modular steps that can be easily implemented using existing libraries for image-based neural network learning and projection-based tomographic reconstruction, respectively. Particularly, the network learning step follows a least-square form (Eq. (42)) in the image domain that is widely used in deep learning, which is not empirically assigned in this work but theoretically derived from the theory of optimization transfer with quadratic surrogates. This least-square type of optimization transfer can be also applied to other imaging modalities that employ the least-square reconstruction with neural networks (e.g., X-ray CT [17, 20], MRI [25, 21], and optical tomography [26, 27]).
Both the standard KAA [5] and CDIP demonstrated an improvement as compared to MLAA for gCT image reconstruction. However, the former still suffered from noise and the latter resulted in over-smoothing which in turn impacted materiel decomposition (Fig. 25). By combining them together, the proposed neural KAA achieved a much better performance by inheriting the advantages of each method to balance noise suppression and oversmoothing.
There are other applications of deep neural networks for 511 keV attenuation image enhancement [49, 50, 51, 52], which typically target post-reconstruction image processing for a attenuation correction purpose. Another promising direction is the unrolled model-based deep-learning reconstruction that considers PET physical process [1, 2, 3]. For example, it is possible to extend the idea of [3], which is designed for PET activity image reconstruction, to develop an unrolled forward-backward splitting transmission-reconstruction (FBSTR-Net) algorithm for gCT imaging, as shown in the Supplemental Material. However, all these methods require a population-based training database of patient scans, which has not been available for the development of the novel PET-enabled DECT imaging method. Here as an alternative, we used simulated data to compare our proposed single-subject learning method with the FBSTR-Net. The results are provided in the supplemental Fig. 24 and Fig. 25. The FBSTR-Net was better than CDIP, comparable to KAA, but not as good as the neural KAA, indicating the benefit of the deep coefficient prior that is more adaptive to individual patients. Furthermore, the proposed neural KAA does not require pre-training and is directly applicable to single subjects, which is critical for PET-enabled DECT as a new imaging method for which no prior database is available, even though online learning is needed with an increased computational cost. The use of deep neural networks in single-subject deep learning may be also achieved by another way that uses convolutional neural network to improve the kernel construction [38]. This direction is complementary to, not competing with, the neural KAA in this paper because the former improves while the latter improves in the kernel model . Our future work will combine them together.
Similar to many other deep learning approaches, the neural network learning module of the proposed algorithm involves parameter tuning, such as the sub-iteration number and learning rate. However, these parameters were all set to be the same as we used in our other works [43]. The stable performance that we have observed indicates the robustness of the neural optimization transfer algorithm, despite the different tomographic reconstruction tasks. Future studies may continue the evaluation of the stability using more datasets.
The current implementation of the algorithm may need hundreds of iterations (e.g., 400) for gCT image reconstruction. However, ordered subsets can be used to accelerate the algorithm [56]. If 20 subsets are used, the needed number of iterations would be approximately 20, which is computationally feasible for clinical practice. While the neural KAA requires a neural network training in each reconstruction iteration, each training only took 10 seconds for the 3D real patient data without any code optimization. To further accelerate the online training, it may be possible to apply transfer learning by fixing the first few layers (for common feature extraction) but fine-tuning the later layers for adaption [57]. In this way, the benefits of population-based deep learning and single-subject learning may be also jointly explored to improve the performance of deep reconstruction.
There are limitations in this work. We observed a marginally increased bias in bone region quantification compared to the standard MLAA method, meanwhile the intensity inside the spine was overestimated as compared to the ground truth in the simulation study. This might be due to suboptimal spatial correlations embedded in the kernel matrix, causing oversmoothing. Further improvement of the kernel matrix could be achieved by using trained kernels following the deep kernel concept [58], which will be investigated in future work. In addition, patient movement and physiological motion between a PET scan and an X-ray CT scan would affect the kernel construction and gCT image reconstruction. This effect may be mitigated by registering the X-ray CT image with the non-attenuation-corrected PET image and will be explored in our future work. While the current PET-enabled DECT imaging is implemented with the PET resolution, we are also developing a super-resolution reconstruction approach to improve the gCT resolution to the X-ray CT resolution [59].
IX Conclusion
In this paper, we have developed a neural KAA approach that combines the existing KAA with a neural network-based deep coefficient prior to improve gCT image reconstruction for PET-enabled DECT imaging. A neural optimization transfer algorithm has been further developed to address the optimization challenge for the tomographic estimation of neural network parameters. This leads to an efficient modular implementation that decouples the tomographic reconstruction steps from the neural network learning step with the latter following a unique least squares form in Eq. (42). Computer simulation, real phantom and patient results for gCT image reconstruction and multi-material decomposition have demonstrated the feasibility of the algorithm and shown noticeable improvements over the existing methods for PET-enabled DECT imaging.
References
- [1] C. H. McCollough, S. Leng, L. Yu, and J. G. Fletcher, “Dual-and multi-energy CT: principles, technical approaches, and clinical applications,” Radiology, vol. 276, pp. 637-653, Mar. 2015.
- [2] P. E. Kinahan and A. M. Alessio, and J. A. Fessler, “Dual energy CT attenuation correction methods for quantitative assessment of response to cancer therapy with PET/CT imaging,” Technology in Cancer Research and Treatment, vol. 5, no. 4, pp. 319-327, Aug. 2006.
- [3] T. Xia, A. M. Alessio, P. E. Kinahan, “ Dual energy CT for attenuation correction with PET/CT,” Med Phys. vol. 41, no. 1, pp. 012501, Jan. 2014.
- [4] H. Wu, Y. Fang, Y. Yang, H. Huang, X. Wu and J. Huo, “Clinical utility of dual-energy CT used as an add-on to 18F FDG PET/CT in the preoperative staging of resectable NSCLC with suspected single osteolytic metastases,” Lung Cancer, vol. 140, pp. 80-86, Nov. 2020.
- [5] G.B. Wang, “PET-enabled dual-energy CT: image reconstruction and a proof-of-concept computer simulation study,” Phys. Med. Biol., vol. 65, p. 245028, Nov. 2020.
- [6] A. Rezaei, T. B. Terzopoulos, and H. Zaidi, “Simultaneous reconstruction of activity and attenuation in time-of-flight PET,” IEEE Trans. Med. Imag., vol. 31, no. 12, pp. 2224-2233, Dec. 2012
- [7] J. Nuyts, P. Dupont, S. Stroobants, et al., “Simultaneous maximum a posteriori reconstruction of attenuation and activity distributions from emission sinograms,” IEEE Trans. Med. Imag., vol. 18, no. 5, pp. 393-403, 1999.
- [8] A. Mehranian and H. Zaidi, “Joint estimation of activity and attenuation in whole-Body TOF PET/MRI using constrained Gaussian mixture models,” IEEE Trans. Med. Imaging, vol. 34, pp. 1808–1821, 2015.
- [9] A. Mehranian, H. Zaidi, and A. J. Reader, “MR-guided joint reconstruction of activity and attenuation in brain PET-MR,” Neuroimage, vol. 162, pp. 276–288, Nov. 2017.
- [10] C. M. McLeavy et al., “The future of CT: deep learning reconstruction,” Clinical Radiology, vol. 76, no. 6, pp. 407-415, Jun. 202.
- [11] G. Wang, J. C. Ye, and B. De Man, “Deep learning for tomographic image reconstruction,” Nature Machine Intelligence, vol. 2, no. 12, pp. 737-748, Dec. 2020.
- [12] D. Ulyanov, A. Vedaldi, and V. Lempitsky, “Deep image prior,” Int. J. Comput. Vis., vol. 128, no. 7, pp. 1867-1888, 2020.
- [13] K. Gong, C. Catana, J. Y. Qi, and Q. Z. Li, “PET image reconstruction using deep image prior,” IEEE Trans. Med. Imag., vol. 38, no. 7, pp. 1655-1665, Jul. 2019.
- [14] K. Gong et al., “Iterative PET image reconstruction using convolutional neural network representation,” IEEE Trans. Med. Imag., vol. 38, no. 3, pp. 675-685, Mar. 2019.
- [15] Z. Xie et al., “Generative adversarial network based regularized image reconstruction for PET,” Phys. Med. Biol., vol. 65, no. 12, pp. 125016, 2020.
- [16] K. Ote, F. Hashimoto, Y. Onishi, T. Isobe and Y. Ouchi, ”List-mode PET image reconstruction using deep image prior,” IEEE Trans. Med. Imag., vol. 42, no. 6, pp. 1822-1834, June 2023.
- [17] D. O. Baguer, J. Leuschner, and M. Schmidt, “Computed tomography reconstruction using deep image prior and learned reconstruction methods,” Inverse Problems, vol. 36, no. 9, p. 094004, Sep. 2020.
- [18] Z. Shu and A. Entezari, “Sparse-view and limited-angle CT reconstruction with untrained networks and deep image prior,” Computer Methods and Programs in Biomedicine, vol. 226, pp. 107167–107167, Nov. 2022.
- [19] M. Akçakaya, B. Yaman, H. Chung, and J. C. Ye, “Unsupervised deep learning methods for biological image reconstruction and enhancement: An overview from a signal processing perspective,” IEEE Signal Processing Magazine, vol. 39, no. 2, pp. 28-44, Mar. 2022.
- [20] S. Barutcu, S. Aslan, A. K. Katsaggelos, and D. Gürsoy, “Limited-angle computed tomography with deep image and physics priors,” Scientific Reports, vol. 11, no. 1, p. 17740, Sep. 2021.
- [21] D. Zhao, Y. Huang, Y. Gan, and J. Q. Zheng, “J-LOUCR: Joint learned optimized undersampling and constrained reconstruction for accelerated MRI by reference-driven deep image prior,” Biomedical Signal Processing and Control, vol. 87, pp. 105513–105513, Jan. 2024.
- [22] H. Zhang and B. Dong, “A review on deep learning in medical image reconstruction,” Journal of the Operations Research Society of China, vol. 8, no. 2, pp. 311-340, Jan. 2020.
- [23] B. Yedder, B. Cardoen, and G. Hamarneh,“Deep learning for biomedical image reconstruction: a survey,” Artificial Intelligence Review, vol. 54, no. 1, pp. 215-251, Aug. 2020.
- [24] K. Lange, D. R. Hunter, and I. Yang, “Optimization transfer using surrogate objective functions,” J. Comput. Graphical Stat., vol. 9, no. 1, pp. 1-20, 2000.
- [25] J. Yoo, K. H. Jin, H. Gupta, J. Yerly, M. Stuber and M. Unser, “Time-dependent deep image prior for dynamic MRI,” IEEE Trans. Med. Imag., vol. 40, no. 12, pp. 3337-3348, Dec. 2021.
- [26] K. Z. Zhou and R. Horstmeyer, “Diffraction tomography with a deep image prior,” Optics Express, vol. 28, no. 9, pp. 12872–12872, Apr. 2020.
- [27] T. Vu et al., “Deep image prior for undersampling high-speed photoacoustic microscopy,” Photoacoustics, vol. 22, pp. 100266–100266, Jun. 2021.
- [28] S. Li and G.B. Wang, “Neural MLAA for PET-enabled dual-energy CT imaging,” SPIE Medical Imaging: Physics of Medical Imaging, 115951G, 2021.
- [29] L. A. Shepp and Y. Vardi, “Maximum likelihood reconstruction for emission tomography,” IEEE Trans. Med. Imag., vol. MI-1, no. 2, pp. 113-122, Oct. 1982.
- [30] H. Erdogan and J. A. Fessler, “Monotonic algorithms for transmission tomography,” IEEE Trans. Med. Imag., vol. 18, no. 8, pp. 801-814, Aug. 1999.
- [31] V. Y. Panin, M. Aykac, and M. E. Casey, “Simultaneous reconstruction of emission activity and attenuation coefficient distribution from TOF data, acquired with external transmission source,” Phys. Med. Biol., vol. 58, pp. 3649-3669, 2013.
- [32] A. Bousse et al., “Maximum-likelihood joint image reconstruction/motion estimation in attenuation-corrected respiratory gated PET/CT using a single attenuation map,” IEEE Trans. Med. Imag., vol. 35, pp. 217-228, Jan. 2016.
- [33] S. Ahn et al., “Joint estimation of activity and attenuation for PET using pragmatic MR-based prior: application to clinical TOF PET/MR whole-body data for FDG and non-FDG tracers,” Phys. Med. Biol., vol. 63, p. 045006, 2018.
- [34] M. Defrise, A. Rezaei, and J. Nuyts, “Transmission-less attenuation correction in time-of-flight PET: analysis of a discrete iterative algorithm,” Phys. Med. Biol., vol. 59, pp. 1073–1095, 2014.
- [35] Y. Berker and Y. S. Li, “Attenuation correction in emission tomography using the emission data a review,” Med. Phys., vol. 43, pp. 807–832, 2016.
- [36] T. Heußer, C. M. Rank, Y. Berker, M. T. Freitag, and M. Kachelrieß, “MLAA-based attenuation correction of flexible hardware components in hybrid PET/MR imaging,” EJNMMI Physics, vol. 4, no. 1, Mar. 2017.
- [37] C. Bäumer et al., “Can a ToF-PET photon attenuation reconstruction test stopping power estimations in proton therapy? a phantom study,” Phys. Med. Biol., vol. 66, no. 21, pp. 215010–215010, Oct. 2021.
- [38] S. Li and G.B. Wang, “Modified kernel MLAA using autoencoder for PET-enabled dual-energy CT,” Philos. Trans. Royal Soc. A, vol. 379, no. 2204, 2021.
- [39] G.B. Wang and J. Qi, “Generalized algorithms for direct reconstruction of parametric images from dynamic PET data,” IEEE Trans. on Med. Imag., vol. 28, no. 11, pp. 1717-1726, Nov. 2009.
- [40] G.B. Wang and J. Qi, “Direct estimation of kinetic parametric images for dynamic PET,” Theranostics, vol. 3, no. 10, pp. 802-815, 2013.
- [41] J. A. Fessler and H. Erdogan, “A paraboloidal surrogates algorithm for convergent penalized-likelihood emission image reconstruction,” in 1998 IEEE Nucl. Sci. Syp. Med. Imag. Conf., vol. 2, pp. 1132–5, 1998.
- [42] H. Erdogan, and J. A. Fessler, “Ordered subsets algorithms for transmission tomography,” Phys. Med. Biol., vol. 44, no. 11, pp. 2835-51, 1999.
- [43] S. Li, K. Gong, R. D. Badawi, E. J. Kim, J. Qi and G.B. Wang, “Neural KEM: A kernel method with deep coefficient prior for PET image reconstruction,” IEEE Trans. Med. Imag., vol. 42, no. 3, pp. 785-796, March 2023.
- [44] J. Cui, K. Gong, N. Guo, K. Kim, H. Liu, and Q. Li, “Unsupervised PET Logan parametric image estimation using conditional deep image prior,” Medical Image Analysis, vol. 80, p. 102519, 2022.
- [45] W. P. Segars, M. Mahesh, T. J. Beck, E. C. Frey, and B. M. Tsui, “ Realistic CT simulation using the 4D XCAT phantom,” Med. Phys. vol. 35, no. 8, pp. 3800-8, 2008.
- [46] B. Spencer et al., “Performance evaluation of the uEXPLORER total-body PET/CT scanner based on NEMA NU 2-2018 with additional tests to characterize PET scanners with a long axial field of view,” J. Nucl. Med., vol. 62, no.6, pp. 861-870, 2021.
- [47] Y. Zhu et al., “Feasibility of PET-enabled dual-energy CT imaging: First physical phantom and patient results,” https://arxiv.org/abs/2402.02091, 2024.
- [48] T. Merlin et al., “CASToR: a generic data organization and processing code framework for multi-modal and multi-dimensional tomographic reconstruction,” Phys. Med. Biol., vol. 63, no. 18, p. 185005, 2018.
- [49] D. Hwang et al., “Improving the accuracy of simultaneously reconstructed activity and attenuation maps using deep learning,” J. Nucl. Med., vol. 59, pp. 1624–1629, Oct. 2018.
- [50] D. Hwang et al., “Generation of PET attenuation map for whole-body time-of-flight 18F-FDG PET/MRI using a deep neural network trained with simultaneously reconstructed activity and attenuation maps,” J. Nucl. Med., vol. 60, pp. 1183-1189, 2019.
- [51] T. Toyonaga et al., “Deep learning–based attenuation correction for whole-body PET — a multi-tracer study with 18F-FDG, 68 Ga-DOTATATE, and 18F-Fluciclovine,” European Journal of Nuclear Medicine and Molecular Imaging, vol. 49, no. 9, pp. 3086–3097, Mar. 2022.
- [52] L. Shi, J. Zhang, T. Toyonaga, D. Shao, J. A. Onofrey, and Y. Lu, “Deep learning-based attenuation map generation with simultaneously reconstructed PET activity and attenuation and low-dose application,” Phys. Med. Biol., vol. 68, no. 3, pp. 035014–035014, Jan. 2023.
- [53] G. Corda-D’Incan, J. A. Schnabel and A. J. Reader, “Memory-efficient training for fully unrolled deep learned PET image reconstruction With iteration-dependent targets,” IEEE Trans. Radiat. Plasma Med. Sci., vol. 6, no. 5, pp. 552-563, May 2022.
- [54] H. Lim, I. Y. Chun, Y. K. Dewaraja and J. A. Fessler, “Improved low-count quantitative PET reconstruction with an iterative neural network,” IEEE Trans. Med. Imag., vol. 39, no. 11, pp. 3512-3522, Nov. 2020
- [55] A. Mehranian and A. J. Reader, “Model-based deep learning PET image reconstruction using forward–backward splitting expectation–maximization,” IEEE Trans. Radiat. Plasma Med. Sci., vol. 5, no. 1, pp. 54-64, Jan. 2021.
- [56] L. Presotto, V. Bettinardi, L. Gianolli and D. Perani, “Alternating strategies and ordered subset acceleration schemes for maximum likelihood activity and attenuation reconstruction in time-of-flight PET,” IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), pp. 1-4, 2015.
- [57] K. Gong, J. Guan, C. C. Liu and J. Qi, “PET image denoising using a deep neural network through fine tuning,” IEEE Trans. Radiat. Plasma Med. Sci., vol. 3, no. 2, pp. 153-161, March 2019.
- [58] S. Li and G.B. Wang, “Deep kernel representation for image reconstruction in PET,” IEEE Trans. Med. Imag., vol. 41, no. 11, pp. 3029-3038, Nov. 2022.
- [59] Y. Zhu, et al., “Super-resolution reconstruction of -ray CT images for PET-enabled dual-energy CT imaging,” Proc SPIE Int Soc Opt Eng. Feb. 2024.
Supplemental Material:
Comparison With Model-Based Deep Reconstruction Method
Model-based deep-learning methods (e.g., [1, 2, 3]) have been developed for PET but are mainly used for reconstruction of activity images. Here, we applied the Forward-Backward Splitting (FBS) idea of [3] to develop an unrolled model for gCT image reconstruction and compare it to our proposed single-subject deep-learning reconstruction method. As for a new imaging modality for which no prior training database of patient scans is available, this comparison was performed on 2D simulation data in this preliminary study.
IX-A Unrolled FBS Model for gCT Reconstruction
Based on the maximum-a-posteriori (MAP) reconstruction of PET emission data, we can update the attenuation image following
| (47) |
where is a regularization term that imposes prior information on , controlled by the regularization parameter . By using the FBS algorithm as the same as used in [3], the optimization of Eq. (47) is performed in the following steps
| (48) |
| (49) |
where Eq. (48) is a gradient descent step of with the step size of , which can be solved by a deep-learning model, e.g., U-Net. Eq. (49) is an optimization problem regarding the log-likelihood function with as the regularization hyperparameter. Different from [3] for PET activity image reconstruction, here our focus is for gCT image reconstruction and the separable paraboloidal surrogate (SPS) algorithm is thus used
| (50) |
where is updated by
| (51) |
where and are the gradient image and intermediate weight image respectively as given by same formulas to Eq. (38) and Eq. (39) with an identity matrix and an identity mapping .
Finally, by setting the derivative of Eq. (50) to zero, we get a closed-form solution
| (52) |
We call this new algorithm a transmission-reconstruction or FBSTR to emphasize its nature for gCT attenuation image reconstruction.
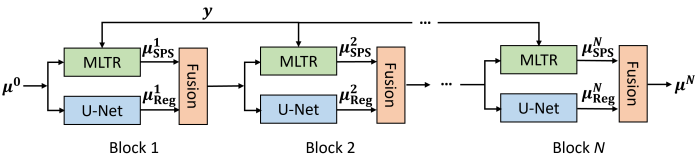



































IX-B FBSTR-Net Training
The unrolled FBSTR algorithm can be represented as a deep iterative neural network, FBSTR-Net , with blocks, as illustrated in Fig. 21. For each block, we have three steps: (1) the regularization update based on the previous gCT image estimate using a U-Net model; (2) MLTR from projection domain using the SPS (Eq. (51)); (3) pixel-by-pixel image fusion by Eq. (52). The trainable parameters of U-Net model are shared across all blocks. We formulate the training process between the output of FBSTR-Net () and the reference image () using a mean-squared-error (MSE) loss function
| (53) |
with . is the number of training data. includes the trainable parameters in the U-Net model and the hyperparameter . is the projection data and is the initial estimate.
IX-C Experiment Design and Implementation Details
Following the same simulation setting as described in Section V.A, we established a training dataset using ten other chest slices of the XCAT phantom, following a similar strategy as used in [2]. The examples of gCT images for training are shown in Fig. 22. For each case, we simulated ten noisy realizations so that total 100 training samples were included in our experiment. The ratio of the training set to the validation set is 2 to 8 [3]. The simulated data in Section V.A was considered as the testing data for method comparison. The same U-Net structure used for the neural KAA and CDIP was used in the FBSTR-Net instead of the residual learning unit used in [3] because of the U-Net’s better performance. The block number and learning rate was selected as 50 and 0.01 respectively according to the performance of validation set. The initialization, , was also the X-ray CT image-converted 511 keV attenuation map.
IX-D Comparison for gCT Image Reconstruction
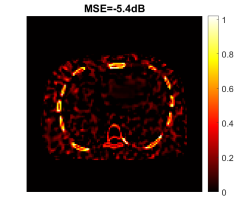
Fig. 24 shows the true and reconstructed 511-keV gCT images using different algorithms as well as the corresponding error images. Here, we mainly focus on the FBSTR-Net results. The image MSE value was also included for quantitative comparison. It can be seen that the gCT image derived from FBSTR-Net had a slightly worse MSE than KAA. Its error image demonstrated relatively larger bias around bone regions. The ensemble bias and SD for gCT quantification in a liver region and a bone region using different reconstruction methods are presented in Table I. In addition to FBSTR-Net, the quantification results of 400 iterations of other methods were also included for comparison. A larger bone bias was observed in the FBSTR-Net result, which can be reflected from the error image in Fig. 24.
| ROI (%) | MLAA | FBSTR-Net | KAA | CDIP | Nerual KAA |
|---|---|---|---|---|---|
| Liver Bias | 1.52 | 1.1 | 1.09 | 1.43 | 0.82 |
| Liver SD | 0.75 | 0.62 | 0.53 | 0.63 | 0.23 |
| Bone Bias | 9.94 | 16.4 | 11.22 | 8.95 | 7.84 |
| Bone SD | 0.39 | 0.33 | 0.23 | 0.43 | 0.21 |
IX-E Comparison for Material Decomposition
Fig. 25 shows the fractional basis images of bone and soft tissue obtained from MMD of the PET-enabled DECT images. The corresponding error images are also shown. The FBSTR-Net demonstrated a superior performance than CDIP and was comparable to KAA. While the CDIP had a better MSE than FBSTR-Net for gCT image comparison in Fig. 24, in the case of fractional images in Fig. 25, the inferior MSE results of CDIP were attributable to significant artifacts in the uniform regions. In comparison, the proposed neural KAA achieved the best result with the lowest MSE. Compared to KAA and FBSTR-Net, the improvement is due to the additional use of neural network as the deep coefficient prior (). Similar to the Table I, the quantitative comparisons of ensemble bias and SD for ROI quantification on the soft tissue and bone fractional images are presented in Table II. While FBSTR-Net exhibited a bias in the soft tissue region comparable to that of KAA, it demonstrated a more pronounced bias in the bone region, which was propagated from the gCT reconstruction.
| ROI (%) | MLAA | FBSTR-Net | KAA | CDIP | Nerual KAA |
|---|---|---|---|---|---|
| Soft-tissue Bias | 14.53 | 6.39 | 6.12 | 7.83 | 3.92 |
| Soft-tissue SD | 2.09 | 2.41 | 2.26 | 2.46 | 1.13 |
| Bone Bias | 15.53 | 19.88 | 17.32 | 14.12 | 12.23 |
| Bone SD | 0.7 | 0.64 | 0.48 | 0.8 | 0.49 |
IX-F Discussion
By and large, the FBSTR-Net, an example of model-based deep reconstruction methods, suggested a promising direction for gCT image reconstruction. Once trained, it can be applied directly to other data. However, it is challenging to apply the method to patient scans directly given no training database has been built. In comparison, the single-subject deep learning reconstruction method is directly applicable to a patient scan. In the future, we will apply the population-based deep learning approach for the real data when a training dataset of PET-enabled DECT imaging becomes available and investigate its generalization performance on unseen PET emission data.
The architecture of neural networks is crucial for training a model-based deep reconstruction method. In this preliminary study, we only compared the U-Net architecture and a general residual learning unit (no downsampling) [3]. A better performance may be achieved by using a more advanced neural-network architecture. When applying such model-based methods, it will be important to also elaborately investigate the model hyperparameters (e.g., block number, learning rate, optimizer) and training strategies. A comprehensive investigation of these aspects for FBSTR-Net is beyond the scope of this paper but would be worth exploring in the future.
References
- [1] G. Corda-D’Incan, J. A. Schnabel and A. J. Reader, “Memory-efficient training for fully unrolled deep learned PET image reconstruction With iteration-dependent targets,” IEEE Trans. Radiat. Plasma Med. Sci., vol. 6, no. 5, pp. 552-563, May 2022.
- [2] H. Lim, I. Y. Chun, Y. K. Dewaraja and J. A. Fessler, “Improved low-count quantitative PET reconstruction with an iterative neural network,” IEEE Trans. Med. Imag., vol. 39, no. 11, pp. 3512-3522, Nov. 2020
- [3] A. Mehranian and A. J. Reader, “Model-based deep learning PET image reconstruction using forward–backward splitting expectation–maximization,” IEEE Trans. Radiat. Plasma Med. Sci., vol. 5, no. 1, pp. 54-64, Jan. 2021.