Simultaneous Reduction of Number of Spots and Energy Layers in Intensity Modulated Proton Therapy for Rapid Spot Scanning Delivery
Abstract
Background: Reducing proton treatment time improves patient comfort and decreases the risk of error from intra-fractional motion, but must be balanced against clinical goals and treatment plan quality.
Purpose: To improve the delivery efficiency of spot scanning proton therapy by simultaneously reducing the number of spots and energy layers using the reweighted regularization method.
Methods: We formulated the proton treatment planning problem as a convex optimization problem with a cost function consisting of a dosimetric plan quality term plus a weighted regularization term. We iteratively solved this problem and adaptively updated the regularization weights to promote the sparsity of both the spots and energy layers. The proposed algorithm was tested on four head-and-neck cancer patients, and its performance, in terms of reducing the number of spots and energy layers, was compared with existing standard and group regularization methods. We also compared the effectiveness of the three methods (, group , and reweighted ) at improving plan delivery efficiency without compromising dosimetric plan quality by constructing each of their Pareto surfaces charting the trade-off between plan delivery and plan quality.
Results: The reweighted regularization method reduced the number of spots and energy layers by an average over all patients of and , respectively, with an insignificant cost to dosimetric plan quality. From the Pareto surfaces, it is clear that reweighted provided a better trade-off between plan delivery efficiency and dosimetric plan quality than standard or group regularization, requiring the lowest cost to quality to achieve any given level of delivery efficiency.
Conclusions: Reweighted regularization is a powerful method for simultaneously promoting the sparsity of spots and energy layers at a small cost to dosimetric plan quality. This sparsity reduces the time required for spot scanning and energy layer switching, thereby improving the delivery efficiency of proton plans.
1 Introduction
Intensity modulated proton therapy (IMPT) is typically delivered via the pencil beam scanning technique. The patient is irradiated by a sequence of proton spots, arranged laterally to cover the treatment volume, where the depth of penetration of each spot is determined by its energy layer. During IMPT, protons are transmitted spot-by-spot within every energy layer, and layer-by-layer within every beam over a set of fixed-angle beams. The total plan delivery time is roughly equal to the total switching time between beams (gantry rotation plus beam setup time), switching time between energy layers, travel time between spots, and dose delivery time at each spot [GCM+20, ZSL+22].
In this study, we seek to reduce IMPT delivery time by reducing the number of proton spots and energy layers. A shorter treatment time is desirable because it improves patient comfort, increases patient throughput (hence lowering treatment costs), and decreases the risk of error due to intra-fractional motion [LZZ15, SPS+16, MCN+20]. Simultaneously, we want to ensure clinical goals are met and the quality of the treatment plan remains uncompromised. This trade-off between delivery time and plan quality has been the subject of abundant research.
One thread of research focuses on greedy algorithms for energy layer assignment. These algorithms combine a variety of techniques for control point sampling, energy layer distribution, energy layer filtration, and spot optimization [DLZ+16]. The goal is to reduce energy layer switching time by pruning the number of energy layers and sequencing them so layer switches only occur from low-to-high energy level [LLZ+20, EBW+22].
Another strand of research takes a structured optimization-based approach. For example, Müller and Wilkens (2016) [MW16] directly minimize the sum of spot intensities as part of a prioritized optimization routine. Other authors formulate the proton treatment delivery problem as a mixed-integer program (MIP), where each energy layer [CLL+14] or path between layers [WSGJ+22, WZSG+22] is associated with a binary indicator variable. Their objective is to minimize the dose fidelity (e.g., over/underdose to the target) plus some penalty or constraints on the energy layers, which promote a lower switching time. Although mathematically elegant, these MIPs are computationally difficult to solve, as they scale poorly with the number of energy layers due to the combinatorial nature of the problem.
To avoid this issue, researchers turned their attention to continuous optimization models. A proton treatment planning problem in this category only contains continuous variables, like spot intensities and doses. Typically, the objective includes a regularization function that is selected to encourage sparsity (i.e., more zero elements) in the spots and energy layers. The regularizer applies a penalty to the total spot intensity within each layer group. A variety of options have been proposed for this penalty function: logarithm [vdWKHH15, vdWBA+20], norm [GRL+20], and norm [JHP+18, LCL+19, GCM+20, WSGJ+22]. The last of these is of particular interest because it is convex and widely used in statistics for promoting group sparsity; the associated regularizer is known as the group lasso [YL06, MvdGB08, LH15, IPR16].
The standard lasso (i.e., norm penalty) promotes sparsity of the spot intensities, but does not directly penalize the energy layers. The group lasso (i.e., group norm penalty) promotes sparsity of the energy layers, but actually increases the number of nonzero spots. Since IMPT delivery time depends on both the number of spots and energy layers [GCM+20], neither of these regularizers is ideal. In this paper, we propose a new regularization method that simultaneously reduces the number of nonzero spots and energy layers, while upholding treatment plan quality. Our reweighted method combines the penalty from standard lasso with a weighting mechanism that differentiates between the spots of different energy layers, similar to the group lasso. We test the proposed method on four head-and-neck cancer patients and demonstrate its ability to 1) reduce the number of spots and energy layers simultaneously, and 2) provide a better trade-off between dosimetric plan quality and plan delivery efficiency than existing regularization methods (i.e., standard and group lasso).
2 Methods and materials
2.1 Problem formulation
We discretize the patient’s body into voxels and the proton beams into spots. For each spot , we calculate the radiation dose delivered by a unit intensity of that spot to voxel and call this value . The dose influence matrix is then , where its rows correspond to the voxels and its columns to the spots. Let be the prescription vector, i.e., equals the physician-prescribed dose if is a target voxel and zero otherwise. We concatenate the spot intensities of all beams and all energy layers within each beam, denoting this collective as the vector . The typical treatment planning problem seeks a vector of spot intensities that minimizes the deviation of the delivered dose, , from the prescription . This deviation can be decomposed into a penalty on the overdose, , and the underdose, , which we combine to form the cost function
| (1) |
where are penalty parameters that determine the relative importance of the over/underdose to the treatment plan. (Note the underdose is ignored for non-target voxels because ).
Dose constraints are defined for each anatomical structure. For a given structure , let be the row slice of containing only the rows of the voxels in . A maximum dose constraint takes the form of , where is an upper bound. Similarly, a mean dose constraint is of the form . By stacking the constraint matrices/vectors for all structures, we can represent the set of dose constraints as a single linear inequality , where and . Then, our treatment planning problem is
| (2) |
with variables , and . Since the objective function is monotonically increasing in and over the nonnegative reals, we can write this problem equivalently as
| (3) |
(The derivation is provided in appendix A). Problem 3 is a convex quadratic program (QP), hence can be solved using standard convex methods, e.g., the alternating direction method of multipliers (ADMM) [BPC+11, FTZ23] or interior-point methods [Wri97, Gor22]. The reader is referred to S. Boyd and L. Vandenberghe (2004) [BV04] and J. Nocedal and S. J. Wright (2006) [NW06] for a thorough discussion of convex optimization.
2.2 Common regularizers
The cost function defined in 1 focuses solely on the difference of the delivered dose from the prescription, i.e., the dosimetric plan quality. However, in our treatment scenario, we are also interested in reducing the dose delivery time, i.e., increasing the plan delivery efficiency. The delivery time is positively correlated with the number of nonzero spots (spot scanning rate) and nonzero energy layers (energy switching time) [GCM+20, PEL+18]. Thus, we want to augment the objective of problem 3 with a regularization function , which penalizes the spot vector in a way that reduces the number of nonzero spots/layers, while maintaining high plan quality. The regularized treatment planning problem is
| (4) |
with respect to , and . Here we have introduced a regularization weight to balance the trade-off between dosimetric plan quality, represented by the cost , and plan delivery efficiency, as captured by the regularization term . A larger value of places more importance on efficiency.
In the following subsections, we review a few regularization functions that have been suggested in the literature. Let and be a set of subsets of , where each has exactly elements. Specifically in our setting, represents a partition of spots into energy layers with containing the indices of the spots in layer .
2.2.1 regularizer
One method of reducing the delivery time is to directly penalize the number of nonzero spots. This can be accomplished via the regularizer
| (5) |
which we have defined as the number of nonzero elements in . (Here denotes the cardinality of set ). Unfortunately, the regularization function is computationally expensive to implement. To solve problem 4 with , we would need to solve a series of large mixed-integer programs in order to determine the optimal subset of nonzero spots out of all possible combinations from [BKM16]. As the number of spots is typically very large (on the order of to ), this quickly becomes computationally intractable.
Another option is to apply the regularizer to the energy layers:
| (6) |
In this case, returns the number of nonzero energy layers, where a layer is zero if and only if all its spots are zero, i.e., . The associated combinatorial problem or MIP simplifies to finding the optimal subset of nonzero layers, which is more manageable since is typically on the order of . Cao et al. (2014) [CLL+14] developed an iterative method to solve an approximation of this MIP and were able to reduce the number of proton energies in their IMPT plan, while satisfying certain dosimetric criteria. Nevertheless, as combinatorial optimization is still expensive, we turn our attention to a different regularization function.
2.2.2 regularizer
A common approximation of the regularizer is the norm. Define the regularization function to be
| (7) |
This function is closed, convex, and continuous. When used as a regularizer in problem 4, it produces a convex optimization problem – a form of the lasso problem – that promotes sparsity in the solution vector [Tib96]. The lasso problem is well-studied in the literature [VBL13, HTW15], and various methods have been developed to solve it quickly and efficiently [PH07, SFR07, WL08, SYOS10].
One downside of the regularizer is that it does not differentiate between energy layers and thus is insensitive to the number of layers: since the spot vector is nonnegative, the absolute value of its elements , and any sum over energy layers decouples into the sum over all spots . As energy layer switching time is typically longer than spot delivery or travel time, regularization is not the most effective method for improving plan delivery efficiency.
2.2.3 Group regularizer
The group regularizer, also known as the group lasso, provides an alternative method for efficiently implementing group penalties. This regularization function is defined as
| (8) |
It is the sum of the norm of the vector corresponding to each group (i.e., energy layer), weighted by the reciprocal of the square root of the total number of group elements [YL06]. (The weights may differ across applications; see N. Simon and R. Tibshirani (2012) [ST12] for alternatives). Group lasso has been widely researched in the context of statistical analysis and regression [MvdGB08, JOV09, LH15, IPR16, MSH07], and many algorithms exist for solving the associated optimization problem effectively [Rak11, QSG13, YZ15]. Jensen et al. (2018) [JHP+18] employed a version of the group lasso to perform adaptive IMPT energy layer optimization.
In our proton treatment delivery scenario, the group lasso is capable of differentiating between energy layers, and thus is a good regularizer for reducing the number of nonzero layers. However, it also tends to increase the number of nonzero spots within the active layers, as the quadratic penalty term in equation 8 mostly ignores small spot intensities (square of a small is near zero). This failure to generate sparsity in the spot vector due to the characteristics of the norm make it an inadequate regularizer for our purposes.
2.3 Reweighted method
As we have discussed, the regularization function promotes sparsity of the spots, but not the energy layers. The group regularization function promotes sparsity of the layers, but not the spots – indeed, it tends to produce dense spot vectors due to the norm. In this section, we introduce the reweighted regularization method, which promotes sparsity in both the spots and the energy layers.
The reweighted method assigns a weight to every spot based on its intensity and energy layer. The weights are chosen to counteract the intensity of each layer, so that all spots, regardless of intensity, contribute roughly equally to the total regularization penalty. This is done to imitate the “ideal” group regularizer (equation 6), which counts every nonzero layer as one unit (due to ) regardless of intensity.
Formally, we define the weighted group regularizer
| (9) |
with weight parameters for . An intuitive way to set is to make it inversely proportional to the optimal total intensity of energy layer , i.e.,
where is an optimal spot vector. However, we do not know beforehand. We will approximate this weighting scheme iteratively using the reweighted method.
The reweighted method is a type of majorization-minimization (MM) algorithm, which solves an optimization problem by iteratively minimizing a surrogate function that majorizes the actual objective function. MM algorithms have a rich history in the literature [FBDN07, SSW10, Mai15, SBP17], and reweighted in particular has been used to solve problems in portfolio optimization [LFB07], matrix rank minimization [Faz02, FHB03], and sparse signal recovery [CWB08]. Research has shown that it is fast and robust, outperforming standard regularization in a variety of settings.
We now describe the reweighted method in our treatment planning setting. Let the initial weights . At each iteration ,
-
1.
Set to a solution of
(10) -
2.
Compute the total intensity of each energy layer .
-
3.
Lower threshold the solution
where for some small .
-
4.
Update the weights. First, compute the standardized reciprocals
(11) Then, calculate the scaling term
(12) The new weights are .
-
5.
Terminate on convergence of the objective, or when reaches a user-defined maximum number of iterations .
Step 3 was introduced to ensure stability of the algorithm, so that a zero energy layer estimate would not preclude the subsequent estimate from being nonzero. In our computational experiments, we found that a threshold fraction of produced good results. Step 4 was added to ensure the regularization term () and the reweighted term () contribute a similar amount to the objective. To this end, the reweighted term is scaled by so that .
The reweighted method has a number of advantages over the other regularizers we have reviewed here. It encourages sparsity in energy layers by properly grouping the penalty. It spreads this penalty evenly across all energy layers using its weighting scheme, rather than prioritizing those spots with large magnitudes. Finally, it is easy to implement: each iteration of the algorithm only requires that we solve a simple convex problem with regularization, which can be done efficiently using many off-the-shelf solvers. Moreover, the number of reweighting iterations needed in practice is typically very low, with most of the improvement coming from the first two to three iterations, so its computational cost is overall low. As we will see in the next section, reweighted outperforms regular and group penalties in sparsifying spots/layers.
2.4 Patient population and computational framework
We compared the reweighted method with standard and group regularization on four head-and-neck cancer patient cases from The Cancer Imaging Archive (TCIA) [CVS+13, BdOCM]. For each patient, we created the dose influence matrix using the proton pencil beam calculation engine in the open-source package MatRad [WCW+17, WWG+18], assuming a relative biological effectiveness (RBE) of . The proton spots were situated on a rectangular grid with a spot spacing of mm, and the grid covered the entire PTV plus mm out from its perimeter. The voxel resolution and dose grid resolution were both mm mm mm. Every patient plan was generated using two co-planar beams with beam angles selected using a Bayesian optimization algorithm [THS+20]. Table 1 provides more details.
| Patient | ||||
| 1 | 2 | 3 | 4 | |
| Beam configuration | ||||
| PTV volume (cm3) | 162.7 | 169.7 | 129.9 | 12.4 |
| Number of voxels () | 87012 | 117907 | 110869 | 50728 |
| Number of spots () | 6378 | 7011 | 5257 | 713 |
| Number of energy layers () | 56 | 70 | 62 | 38 |
Each patient had a single planning target volume (PTV) that was prescribed a dose of Gy delivered in fractions of Gy per fraction. The mean/max dose bounds for important structures are given in Table 2. We manually adjusted the weights in cost function 1, without exhaustive search, to obtain reasonable treatment plans. In the majority of cases, for PTV voxels and for all other voxels provided the best results.
| Dose Bound (Gy) | ||
| PTV | 84 | N/A |
| Left Parotid | 73.5 | 26 |
| Right Parotid | 73.5 | 26 |
| Mandible | 70 | N/A |
| Spinal Cord | 45 | N/A |
| Constrictors | N/A | 40 |
| Brainstem | 54 | N/A |
We implemented the standard , group , and reweighted based treatment planning methods in Python using CVXPY [DB16, AVDB18, DAM+22] and solved the associated optimization problems with MOSEK [ApS22]. All computational processes were executed on a -bit PC with an AMD Ryzen 9 3900X CPU @ GHz/ cores and GB RAM. For reweighted , we ran the algorithm for iterations due to the diminishing benefits of more iterations.
To facilitate comparisons, we scaled the group regularizer so it lay in the same range as the standard regularizer. First, we solved problem 4 with the standard regularizer (equation 7) and . Let us call this solution . Then, we computed a scaling term such that . When we ran the group method, we used the scaled regularization function as the regularizer in problem 4. This allowed us to obtain better spot/energy layer comparison plots between the standard and group methods. As pointed out earlier, the reweighted method is similarly scaled via step 4 of the algorithm.
After each method finished, we trimmed the optimal spot vector further to increase sparsity. First, we zeroed out all elements that fell below a fraction of the maximum spot intensity, i.e., we set if . We then zeroed out all energy layers of the resulting that fell below the same fraction of the maximum layer intensity: for each , we set for all if . A choice of provided a reasonable trade-off between sparsity and dose coverage in our computational experiments.
3 Results
3.1 Simultaneous reduction of spots and energy layers
We first compared the results of the regularization methods on a single patient. Figure 1 depicts optimal spot intensities of the unregularized model and the , group , and reweighted regularized models for patient . For all three regularizers, a regularization weight of was used; this choice accentuated the difference between their spot vectors. Without regularization, about one third of the total spots are nonzero, with individual spot intensities ranging between and . Under regularization, that fraction is reduced to only , or nonzero spots, as the penalty encourages further sparsity. By contrast, with group regularization, the number of active spots increases significantly to or , while the average intensity drops to a little over . Reweighted regularization produced a spot vector with the lowest number of nonzero elements: just or of the spots are nonzero. For patient , these active spots tend to reside in the first beam, and their maximum intensity exceeds that of the other methods.
Figure 2 shows the optimal intensity of the energy layers for patient , using the three regularization models, all with . Over of the total energy layers are nonzero under the unregularized model. These active layers are divided fairly evenly into two clusters, which coincide with the two beams delineated by the vertical red line. The total intensity of each energy layer averages between and . With regularization, the fraction of nonzero energy layers drops to a modest , where most of that reduction comes from deactivated layers at the edges of the clusters. Group regularization results in a steeper drop in the fraction of active energy layers, down to with additional sparsity in the middle of both beam clusters. However, the reweighted method performs better than both of these methods, cutting the number of nonzero energy layers down to only – a reduction of over – with a commensurate increase in the intensity of the active layers.
A summary of the results from the different regularization methods is given in Figure 3. For a fixed , it is clear that reweighted achieves the lowest number of nonzero spots and nonzero energy layers out of all the methods.



3.2 Trade-off between delivery efficiency and PTV coverage
The regularization weight in the previous section was chosen to highlight the distinctions between the optimal intensity plots. However, must be carefully selected to balance the trade-off between the total delivery time (highly correlated with the sparsity of the spots/energy layers) and the quality of the resulting treatment plan. Figure 4 examines this trade-off for reweighted regularization on patient using two measures of plan quality: D and D for the PTV. For different values of , we solved problem 4 using the reweighted method, counted up the number of nonzero spots/energy layers, and calculated the optimal dose vector and PTV dose percentiles. We then plotted a point corresponding to this result in each of the subfigures of Figure 4 with the sparsity metric on the vertical axis and the plan quality metric on the horizontal axis (e.g., the unregularized point is marked by a triangle ). By connecting the points in each subfigure, we obtained a set of Pareto optimal curves, which show the trade-off between plan delivery efficiency and plan quality.
The top left subfigure depicts the number of nonzero spots versus D to the PTV for ranging from zero to (marked by the square). As increases, the number of active spots decreases, but so does D. A choice of (marked by the star) achieves the lowest number of nonzero spots , while still maintaining D above of the prescription, indicated by the vertical gray dotted line at Gy. A similar plot can be seen in the bottom left subfigure, which shows the number of nonzero energy layers versus D to the PTV; the same choice of yields active layers. On the righthand side, the subfigures display the number of nonzero spots (top) and energy layers (bottom) versus D to the PTV. As the regularization weight increases, D also increases, but never exceeds of the prescription (as indicated by the dotted line at Gy) for any . Thus, out of all the weights, yields a good trade-off between sparsity and PTV coverage: it achieves a reduction of and in the number of spots and energy layers, respectively, while still fulfilling all target dose constraints.

3.3 Trade-off between delivery efficiency and overall plan quality
This section studies the Pareto optimal trade-off curves between spot/energy layer sparsity and treatment plan quality using different regularizers to determine which regularization method provides the best trade-off, i.e., the largest increase in sparsity for the least decrease in plan quality. Rather than plotting multiple dose-volume metrics, we focus on a single consolidated quality measure: the plan cost function (equation 1), which includes dose fidelity terms for the PTV and all organs-at-risk (OARs). A lower value of at the optimum implies a higher quality treatment plan.
To facilitate comparison, we also focus on the relative change in sparsity (number of nonzero spots/energy layers) and plan cost with respect to the unregularized solution. Let be the optimal spots resulting from the unregularized problem 3, and be the optimal spots resulting from a particular regularization method. We evaluate the plan cost function given in equation 1 on (with and ) to obtain , and similarly on to obtain . Then, the relative percentage change in plan cost for the regularizer is . The relative change in the number of nonzero spots () and number of nonzero energy layers () is defined in a similar fashion as and , respectively. Thus, to construct the trade-off curve, we solve the regularized problem for various values of and plot the relative change in sparsity versus the relative change in plan cost at each solution point.
For every patient, Figure 5 depicts the relative percentage change in the number of nonzero spots versus the relative percentage change in plan cost for the , group , and reweighted regularization methods. The origin corresponds to the unregularized plan (). Both the and reweighted trade-off curves drop sharply from the origin, attaining on average a to decrease in nonzero spots for a less than increase in plan cost, with reweighted slightly outperforming by on average percentage points over all four patients. By contrast, the number of nonzero spots rises with group regularization, increasing up to within the first to increase in plan cost for all except patient . This is consistent with our spot intensity plot for patient (Figure 1), which shows the spot distribution is denser under group than without regularization.
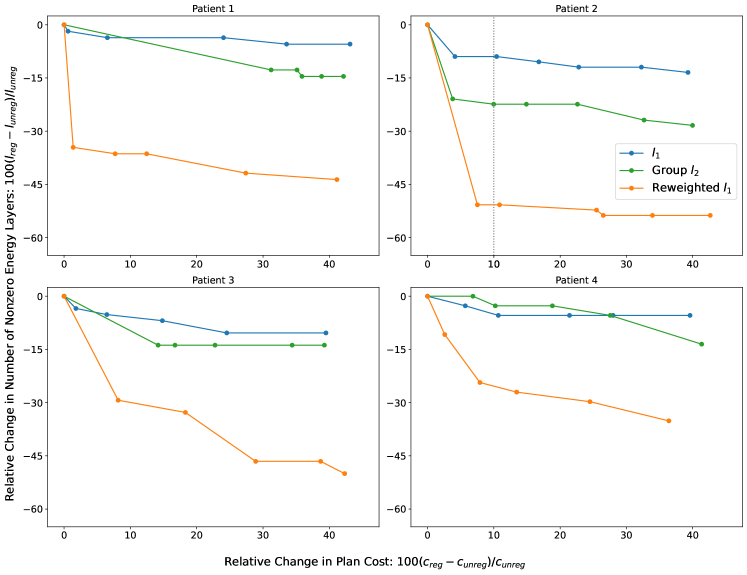
Figure 6 depicts the relative percentage change in the number of nonzero energy layers versus the relative percentage change in plan cost for the three regularization methods. Both and group trade-off curves decrease moderately from the origin, with group averaging about lower number of nonzero layers for a given percentage increase in cost. This matches our observations in Figures 2 and 3 that the group function is more effective at penalizing energy layers than the norm.
However, the reweighted method significantly outperforms both these regularizers. For patient , it achieves an over decrease in the number of nonzero energy layers for a less than increase in plan cost. For the other patients, it provides a to reduction in active energy layers with a less than increment in plan cost. The average reduction in the number of nonzero layers from reweighted exceeds the best reduction from group by percentage points, and the majority of this reduction is realized with only about cost to treatment plan quality, relative to the unregularized plan.
The vertical dotted lines in Figures 5 and 6 for patient correspond to a increase in the plan cost. The intersection of these lines with the Pareto curves of different regularization methods demonstrates the reduction in the number of nonzero spots and energy layers obtained using different regularizers. Figure 7 (top right) depicts the dose-volume histogram (DVH) curves of the unregularized plan, the regularized plan, and the reweighted regularized plan at the same relative change in plan cost. (We chose not to show the DVHs of group regularized plans because they overlap considerably with the DVHs of corresponding regularized plans, and as we saw earlier, group results in far worse delivery efficiency than or reweighted regularization). Compared to no regularization, the reweighted method reduces the number of active spots and energy layers by more than , while providing relatively similar DVH curves with different trade-offs (compromised left parotid and PTV coverage/homogeneity, and improved right parotid and mandible). One can re-adjust the PTV/OAR weights in the plan cost function of the reweighted problem to achieve more uniform trade-offs. In the same vein, compared to standard regularization, reweighted reduces the number of active spots and energy layers by about and , respectively, while producing almost identical DVH curves. The Pareto curves and DVHs of the other patients, also plotted at roughly relative change in plan cost, tell a similar story.


3.4 Relative improvement in delivery time
The total plan delivery time is dependent on a multitude of machine-specific factors. In this section, we provide an estimate of how regularization directly impacts the delivery time, assuming a specific set of machine parameters. The total delivery time () can be approximated by
| (13) |
where is the number of nonzero beams, is the number of nonzero energy layers, is the number of nonzero spots in energy layer , is the beam switching time (gantry rotation plus beam setup time), is the energy layer switching time, is the spot travel time, and is the proton dose rate [GCM+20, ZSL+22]. Following van de Water et al. (2015) [vdWKHH15], we let seconds, seconds, seconds, and protons/second. We compute using the unregularized model and the , group , and reweighted regularized models, with regularization weight chosen such that each regularized plan achieves a cost to plan quality. Then, we plot the relative percentage change in delivery time of each regularized model with respect to the unregularized model (i.e., ).
The results for patient are shown in Figure 8. Standard reduces delivery time by a modest , while group actually raises delivery time by due to the increase in the number of nonzero spots, which increases the spot delivery and spot travel time. By contrast, reweighted achieves a reduction in delivery time through its simultaneous reduction of the number of nonzero spots and nonzero energy layers by and , respectively. This reduction comes at only a minor cost to the PTV and mandible – D to the PTV goes up by and maximum dose to the mandible goes up by . Results for the other patients reflect similar outcomes, with reweighted reducing total delivery time by between and ; see Table 3 and Figure 9 in appendix B for additional data and plots.

4 Discussion
This study proposed a method to improve the delivery efficiency of pencil beam scanning proton plans by simultaneously reducing the number of spots and energy layers using reweighted regularization. One can exactly model the spot/energy layer reduction problem using the regularizer, which in principle would improve plan delivery at the smallest possible cost to plan quality, but the -regularized optimization problem is nonconvex and computationally prohibitive to solve. In imaging science and statistics, researchers often employ the norm as a convex surrogate for the norm, and in some cases (e.g., compressed sensing), the norm has proven to be just as effective as the norm at promoting sparsity [CRT06]. The reweighted regularization method was proposed [CWB08] to bridge the gap between the regularizer and the regularizer by better approximating the norm, while retaining the convexity of the norm. In proton treatment planning, this property translates to improving the plan delivery efficiency at a lower cost to plan quality, which we have demonstrated in this work. Our limited computational experiments on four head-and-neck cancer patients show that, for the same cost to plan quality, the reweighted method reduced the number of nonzero spots by up to percentage points more than standard and the number of nonzero energy layers by to percentage points more than group regularization.
Promoting spot/energy layer sparsity to improve plan delivery in IMPT is analogous to promoting beam profile smoothness to improve plan delivery in IMRT. Prior research has shown that plan delivery efficiency in IMRT can be significantly improved at minimal cost to dosimetric plan quality due to the phenomenon of degeneracy [AMNR02, LASP04]. The structure of the treatment planning problem results in a multitude of feasible plans with near-equal objective value (i.e., quality). This same phenomenon has been observed in IMPT planning problems [vdWBA+20, vdWKHH15, GCM+20, LCL+19], although unlike IMRT, it currently lacks a rigorous mathematical analysis. Our computational experiments demonstrated that with the reweighted method, one can reduce the number of spots and energy layers by on average and , respectively, without significantly compromising the dosimetric plan quality.
In this study, we have adopted a constrained optimization framework, where the dosimetric plan quality is represented by a quadratic term in the objective, the sparsity promotion is carried out via a regularization penalty term, and the mean/max clinical dose criteria are enforced by hard constraints. However, the proposed reweighted method is agnostic to the optimization framework and can also be used in conjunction with an automation tool (e.g., hierarchical optimization [ZHZ+22, BSH09, THDZ20], multiple criteria optimization (MCO) [CB08, MKBT08], knowledge-based planning (KBP) [AMT+12, SNZ+20]). DVH constraints and plan robustness may be integrated into the optimization problem using existing techniques in the literature [FUXB19, ZST+13, MHDZ20, FTZ23, THDZ20]. To limit the scope of this paper, we have not incorporated robustness into our formulation of the treatment planning problem. A preliminary robustness analysis of range and setup uncertainty scenarios shows that the reweighted method generates plans with a similar level of robustness to the unregularized model’s plans. Moreover, even without accounting for these uncertainties in the optimization, the DVH curves and clinical metrics of the plans lie within an acceptable range across the majority of scenarios. Appendix B.1 provides details on our analysis and the resulting figures.
Finally, we mention that in this proof-of-concept work, we have not enforced the machine-specific minimum-monitor-unit (min-MU) constraint. One can enforce the min-MU constraint using a two-step optimization method as described in Lin et al. (2019) [LCL+19]: the first step identifies the active spots/energy layers (i.e., those with intensity greater than a pre-determined value), and the second step removes the inactive spots/energy layers and enforces the min-MU constraint on the remaining spots. Increasing the min-MU threshold also allows for a higher dose rate, which can accelerate the delivery of each spot. This is especially important because the intensities of the active spots usually increase with the overall sparsity of the spots/energy layers in the treatment plan. Gao et al. (2020) [GCM+20] suggested using different min-MU thresholds for each energy layer to further increase the dose rate and expedite spot delivery.
5 Conclusion
The reweighted regularization method is capable of simultaneously reducing the number of spots and energy layers in a proton treatment plan, while imposing minimal cost to dosimetric plan quality. Moreover, it achieves a better trade-off between delivery efficiency and plan quality than standard and group regularization. Thus, reweighted regularization is a powerful method for improving the delivery of proton therapy.
Acknowledgments
This work was partially supported by MSK Cancer Center Support Grant/Core Grant from the NIH (P30 CA008748).
References
- [AMNR02] M. Alber, G. Meedt, F. Nüsslin, and R. Reemtsen. On the degeneracy of the IMRT optimization problem. Med. Phys., 29(11):2584–2589, 2002.
- [AMT+12] L. M. Appenzoller, J. M. Michalski, W. L. Thorstad, S. Mutic, and K. L. Moore. Predicting dose-volume histograms for organs-at-risk in IMRT planning. Med. Phys., 39(12):7446–7461, 2012.
- [ApS22] MOSEK ApS. The MOSEK Optimizer API for Python, Version 10.0, 2022.
- [AVDB18] A. Agrawal, R. Verschueren, S. Diamond, and S. Boyd. A rewriting system for convex optimization problems. J. Control Decis., 5(1):42–60, 2018.
- [BdOCM] T. Bejarano, M. de Ornelas-Couto, and I. B. Mihaylov. Head-and-neck squamous cell carcinoma patients with CT taken during pre-treatment, mid-treatment, and post-treatment (HNSCC-3DCT-RT) [data set]. doi:10.7937/K9/TCIA.2018.13upr2xf.
- [BKM16] D. Bertsimas, A. King, and R. Mazumder. Best subset selection via a modern optimization lens. Ann. Stat., 44(2):813–852, 4 2016. doi:10.1214/15-AOS1388.
- [BPC+11] S. Boyd, N. Parikh, E. Chu, B. Peleato, , and J. Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn., 3(1):1–122, 2011.
- [BSH09] S. Breedveld, P. Storchi, and B. Heijmen. The equivalence of multi-criteria methods for radiotherapy plan optimization. Phys. Med. Biol., 54(23):7199–7209, 2009.
- [BV04] S. Boyd and L. Vandenberghe. Convex Optimization. Cambridge University Press, 2004.
- [CB08] D. Craft and T. Bortfeld. How many plans are needed in an IMRT multi-objective plan database? Phys. Med. Biol., 53(11):2785–2796, 2008.
- [CLL+14] W. Cao, G. Lim, L. Liao, Y. Li, S. Jiang, X. Li, H. Li, K. Suzuki, X. R. Zhu, D. Gomez, and X. Zhang. Proton energy optimization and reduction for intensity-modulated proton therapy. Phys. Med. Biol., 59(21):6341–6354, 2014. doi:10.1088/0031-9155/59/21/6341.
- [CRT06] E. J. Candes, J. K. Romberg, and T. Tao. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math., 59(8):1207–1223, 2006.
- [CVS+13] K. Clark, B. Vendt, K. Smith, J. Freymann, J. Kirby, P. Koppel, S. Moore, S. Phillips, D. Maffitt, M. Pringle, L. Tarbox, and F. Prior. The cancer imaging archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging, 26(6):1045–1057, 2013.
- [CWB08] E. J. Candés, M. B. Wakin, and S. P. Boyd. Enhancing sparsity by reweighted minimization. J. Fourier Anal. Appl., 14(1):877–905, 2008. doi:10.1007/s00041-008-9045-x.
- [DAM+22] S. Diamond, A. Agrawal, R. Murray, B. Stellato, and S. Boyd. CVXPY: Disciplined Convex Programming in Python, Version 1.3, 2022.
- [DB16] S. Diamond and S. Boyd. CVXPY: A Python-embedded modeling language for convex optimization. J. Mach. Learn. Res., 17(83):1–5, 2016.
- [DLZ+16] X. Ding, X. Li, M. Zhang, P. Kabolizadeh, C. Stevens, and D. Yan. Spot-scanning proton arc (SPArc) therapy: The first robust and delivery-efficient spot-scanning proton arc therapy. Int. J. Radiat. Oncol. Biol. Phys., 96(5):1107–1116, 12 2016. doi:10.1016/j.ijrobp.2016.08.049.
- [EBW+22] E. Engwall, C. Battinelli, V. Wase, O. Marthin, L. Glimelius, R. Bokrantz, B. Andersson, and A. Fredriksson. Fast robust optimization of proton PBS arc therapy plans using early energy layer selection and spot assignment. Phys. Med. Biol., 67(6):065010, 3 2022. doi:10.1088/1361-6560/ac55a6.
- [Faz02] M. Fazel. Matrix Rank Minimization with Applications. PhD thesis, Stanford University, 2002. https://faculty.washington.edu/mfazel/thesis-final.pdf.
- [FBDN07] M. Figueiredo, J. Bioucas-Dias, and R. D. Nowak. Majorization–minimization algorithms for wavelet-based image restoration. IEEE Trans. Image Process., 16(12):2980–2991, 12 2007. doi:10.1109/TIP.2007.909318.
- [FHB03] M. Fazel, H. Hindi, and S. Boyd. Log-det heuristic for matrix rank minimization with applications to hankel and euclidean distance matrices. In Proceedings of the American Control Conference (ACM), pages 2156–2162, Denver, CO, 6 2003. doi:10.1109/ACC.2003.1243393.
- [FTZ23] A. Fu, V. T. Taasti, and M. Zarepisheh. Distributed and scalable optimization for robust proton treatment planning. Med. Phys., 50(1):633–642, 1 2023. doi:10.1002/mp.15897.
- [FUXB19] A. Fu, B. Ungun, L. Xing, and S. Boyd. A convex optimization approach to radiation treatment planning with dose constraints. Optim. Eng., 20:277–300, 2019.
- [GCM+20] H. Gao, B. Clasie, M. McDonald, K. M. Langen, T. Liu, and Y. Lin. Technical note: Plan-delivery-time constrained inverse optimization method with minimum-MU-per-energy-layer (MMPEL) for efficient pencil beam scanning proton therapy. Med. Phys., 47(9):3892–3897, 9 2020.
- [Gor22] B. L. Gorissen. Interior point methods can exploit structure of convex piecewise linear functions with application in radiation therapy. SIAM J. Optim., 32(1):256–275, 2022. doi:10.1137/21M1402364.
- [GRL+20] W. Gu, D. Ruan, Q. Lyu, W. Zou, L. Dong, and K. Sheng. A novel energy layer optimization framework for spot-scanning proton arc therapy. Med. Phys., 47(5):2072–2084, 2 2020. doi:10.1002/mp.14083.
- [HTW15] T. Hastie, R. Tibshirani, and M. Wainwright. Statistical Learning with Sparsity: The Lasso and Generalizations. Monographs on Statistics and Applied Probability. Taylor and Francis, 2015.
- [IPR16] S. Ivanoff, F. Picard, and V. Rivoirard. Adaptive lasso and group-lasso for functional Poisson regression. J. Mach. Learn. Res., 17(1):1903–1948, 2016.
- [JHP+18] M. F. Jensen, L. Hoffmann, J. B. B. Petersen, D. S. Møller, and M. Alber. Energy layer optimization strategies for intensity-modulated proton therapy of lung cancer patients. Med. Phys., 45(10):4355–4363, 10 2018. doi:10.1002/mp.13139.
- [JOV09] L. Jacob, G. Obozinski, and J.-P. Vert. Group lasso with overlap and graph lasso. In Proceedings of the International Conference on Machine Learning (ICML), pages 433–440, Montreal, Canada, 6 2009. doi:10.1145/1553374.1553431.
- [LASP04] J. Llacer, N. Agazaryan, T. D. Solberg, and C. Promberger. Degeneracy, frequency response and filtering in IMRT optimization. Phys. Med. Biol., 49(13):2853–2880, 2004.
- [LCL+19] Y. Lin, B. Clasie, T. Liu, M. McDonald, K. M. Langen, and H. Gao. Minimum-MU and sparse-energy-layer (MMSEL) constrained inverse optimization method for efficiently deliverable PBS, plans. Phys. Med. Biol., 64(20):205001, 2019. doi:10.1088/1361-6560/ab4529.
- [LFB07] M. S. Lobo, M. Fazel, and S. Boyd. Portfolio optimization with linear and fixed transaction costs. Ann. Oper. Res, 152(1):341–365, 2007. doi:10.1007/s10479-006-0145-1.
- [LH15] M. Lim and T. Hastie. Learning interactions via hierarchical group-lasso regularization. J. Comput. Graph. Stat., 24(3):627–654, 2015. doi:10.1080/10618600.2014.938812.
- [LLZ+20] G. Liu, X. Li, L. Zhao, W. Zheng, A. Qin, S. Z hang, C. Stevens, D. Yan, P. Kabolizadeh, and X. Ding. A novel energy sequence optimization algorithm for efficient spot-scanning proton arc (SPArc) treatment delivery. Acta Oncol., 59(10):1178–1185, 2020. doi:10.1080/0284186X.2020.1765415.
- [LZZ15] H. Li, X. R. Zhu, and X. Zhang. Reducing dose uncertainty for spot-scanning proton beam therapy of moving tumors by optimizing the spot delivery sequence. Int. J. Radiat. Oncol. Biol. Phys., 93(3):547–556, 2015. doi:10.1016/j.ijrobp.2015.06.019.
- [Mai15] J. Mairal. Incremental majorization-minimization optimization with application to large-scale machine learning. SIAM J. Optim., 25(2):829–855, 2015. doi:10.1137/140957639.
- [MCN+20] D. Mah, C. C. Chen, A. O. Nawaz, G. Galbreath, R. Shmulenson, N. Lee, and B. Chon. Retrospective analysis of reduced energy switching and room switching times on throughput efficiency of a multi-room proton therapy center. Brit. J. Radiol., 93(1107):20190820, 3 2020. doi:10.1259/bjr.20190820.
- [MHDZ20] S. Mukherjee, L. Hong, J. O. Deasy, and M. Zarepisheh. Integrating soft and hard dose-volume constraints into hierarchical constrained IMRT optimization. Med. Phys., 47(2):414–421, 2020.
- [MKBT08] M. Monz, K.-H. Küfer, T. Bortfeld, and C. Thieke. Pareto navigation—algorithmic foundation of interactive multi-criteria IMRT planning. Phys. Med. Biol., 53(4):985–998, 2008.
- [MSH07] S. Ma, X. Song, and J. Huang. Supervised group lasso with applications to microarray data analysis. BMC Bioinform., 8(60):1–17, 2 2007. doi:10.1186/1471-2105-8-60.
- [MvdGB08] L. Meier, S. van de Geer, and P. Bühlmann. The group lasso for logistic regression. J. R. Stat. Soc., B: Stat. Methodol., 70(1):53–71, 2 2008. doi:10.1111/j.1467-9868.2007.00627.x.
- [MW16] B. S. Müller and J. J. Wilkens. Prioritized efficiency optimization for intensity modulated proton therapy. Phys. Med. Biol., 61(23):8249–8265, 2016. doi:10.1088/0031-9155/61/23/8249.
- [NW06] J. Nocedal and S. J. Wright. Numerical Optimization. Springer-Verlag, 2006.
- [Pag12] H. Paganetti. Range uncertainties in proton therapy and the role of Monte Carlo simulations. Phys. Med. Biol., 57(11):R99–R117, 2012.
- [PEL+18] P. R. Poulsen, J. Eley, U. Langner, II C. B. Simone, and K. Langen. Efficient interplay effect mitigation for proton pencil beam scanning by spot-adapted layered repainting evenly spread out over the full breathing cycle. Int. J. Radiat. Oncol. Biol. Phys., 100(1):226–234, 1 2018.
- [PH07] M. Y. Park and T. Hastie. -regularization path algorithm for generalized linear models. J. R. Stat. Soc., B: Stat. Methodol., 69(4):659–677, 9 2007. doi:10.1111/j.1467-9868.2007.00607.x.
- [PSL17] D. Petrova, S. Smickovska, and E. Lazarevska. Conformity index and homogeneity index of the postoperative whole breast radiotherapy. Open Access Maced. J. Med. Sci., 5(6):736–739, 2017.
- [QSG13] Z. Qin, K. Scheinberg, and D. Goldfarb. Efficient block-coordinate descent algorithms for the group lasso. Math. Program. Comput., 5(2):143–169, 6 2013. doi:10.1007/s12532-013-0051-x.
- [Rak11] A. Rakotomamonjy. Surveying and comparing simultaneous sparse approximation (or group-lasso) algorithms. Signal Process., 91(7):1505–1526, 7 2011. doi:10.1016/j.sigpro.2011.01.012.
- [SBP17] Y. Sun, P. Babu, and D. P. Palomar. Majorization-minimization algorithms in signal processing, communications, and machine learning. IEEE Trans. Signal Process., 65(3):794–816, 2 2017.
- [SFR07] M. Schmidt, G. Fung, and R. Rosales. Fast optimization methods for regularization: A comparative study and two new approaches. In European Conference on Machine Learning (ECML), pages 286–297, Warsaw, Poland, 9 2007.
- [SNZ+20] C. Shen, D. Nguyen, Z. Zhou, S. B. Jiang, B. Dong, and X. Jia. An introduction to deep learning in medical physics: Advantages, potential, and challenges. Phys. Med. Biol., 65(5):05TR01, 2020.
- [SPS+16] K. Suzuki, M. B. Palmer, N. Sahoo, X. Zhang, F. Poenisch, D. S. Mackin, A. Y. Liu, R. Wu, X. R. Zhu, S. J. Frank, M. T. Gillin, and A. K. Lee. Quantitative analysis of treatment process time and throughput capacity for spot scanning proton therapy. Med. Phys., 43(7):3975–3986, 7 2016.
- [SSW10] E. D. Schifano, R. L. Strawderman, and M. T. Wells. Majorization-minimization algorithms for nonsmoothly penalized objective functions. Electron. J. Stat., 4(1):1258–1299, 2010. doi:10.1214/10-EJS582.
- [ST12] N. Simon and R. Tibshirani. Standardization and the group lasso. Stat. Sin., 22(3):983–1001, 7 2012. doi:10.5705/ss.2011.075.
- [SYOS10] J. Shi, W. Yin, S. Osher, and P. Sajda. A fast hybrid algorithm for large-scale -regularized logistic regression. J. Mach. Learn. Res., 11(23):713–741, 2010.
- [TBD+18] V. T. Taasti, C. Bäumer, C. V. Dahlgren, A. J. Deisher, M. Ellerbrock, J. Free, J. Gora, A. Kozera, A. J. Lomax, L. De Marzi, S. Molinelli, B.-K. K. Teo, P. Wohlfahrt, J. B. B. Petersen, L. P. Muren, D. C. Hansen, and C. Richter. Inter-centre variability of CT-based stopping-power prediction in particle therapy: Survey-based evaluation. Phys. Imaging Radiat., 6(1):25–30, 2018.
- [THDZ20] V. T. Taasti, L. Hong, J. O. Deasy, and M. Zarepisheh. Automated proton treatment planning with robust optimization using constrained hierarchical optimization. Med. Phys., 47(7):2779–2790, 2020.
- [THS+20] V. T. Taasti, L. Hong, J. S. Shim, J. O. Deasy, and M. Zarepisheh. Automating proton treatment planning with beam angle selection using bayesian optimization. Med. Phys., 47(8):3286–3296, 8 2020. doi:10.1002/mp.14215.
- [Tib96] R. Tibshirani. Regression shrinkage and selection via the lasso. J. R. Stat. Soc., B: Stat. Methodol., 58(1):267–288, 1996.
- [VBL13] D. Vidaurre, C. Bielza, and P. Larrañaga. A survey of regression. Int. Stat. Rev., 81(3):361–381, 12 2013.
- [vdWBA+20] S. van de Water, M. F. Belosi, F. Albertini, C. Winterhalter, D. C. Weber, and A. J. Lomax. Shortening delivery times for intensity-modulated proton therapy by reducing the number of proton spots: An experimental verification. Phys. Med. Biol., 65(9):095008, 5 2020. doi:10.1088/1361-6560/ab7e7c.
- [vdWKHH15] S. van de Water, H. M. Kooy, B. J. M. Heijmen, and M. S. Hoogeman. Shortening delivery times of intensity modulated proton therapy by reducing proton energy layers during treatment plan optimization. Int. J. Radiat. Oncol. Biol. Phys., 92(2):460–468, 2015. doi:10.1016/j.ijrobp.2015.01.031.
- [WCW+17] H.-P. Wieser, E. Cisternas, N. Wahl, S. Ulrich, A. Stadler, H. Mescher, L.-R. Müller, T. Klinge, H. Gabrys, L. Burigo, A. Mairani, S. Ecker, B. Ackermann, M. Ellerbrock, K. Parodi, O. Jäkel, and M. Bangert. Development of the open-source dose calculation and optimization toolkit matRad. Med. Phys., 44(6):2556–2568, 2017.
- [WL08] T. T. Wu and K. Lange. Coordinate descent algorithms for lasso penalized regression. Ann. Appl. Stat., 2(1):224–244, 2008. doi:10.1214/07-AOAS147.
- [Wri97] S. J. Wright. Primal-Dual Interior Point Methods. Society for Industrial and Applied Mathematics, 1997.
- [WSGJ+22] S. Wuyckens, M. Saint-Guillain, G. Janssens, L. Zhao, X. Li, X. Ding, E. Sterpin, J. A. Lee, and K. Souris. Treatment planning in arc proton therapy: Comparison of several optimization problem statements and their corresponding solvers. Comput. Biol. Med., 148(1):105609, 9 2022. doi:10.1016/j.compbiomed.2022.105609.
- [WWG+18] H.P. Wieser, N. Wahl, H.S. Gabryś, L.R. Müller, G. Pezzano, J. Winter, S. Ulrich, L. Burigo, O. Jäkel, and M. Bangert. MatRad – an open-source treatment planning toolkit for educational purposes. Med. Phys. Int., 6(1):119–127, 2018.
- [WZSG+22] S. Wuyckens, L. Zhao, M. Saint-Guillain, G. Janssens, E. Sterpin, K. Souris, X. Ding, and J. A. Lee. Bi-criteria Pareto optimization to balance irradiation time and dosimetric objectives in proton arc therapy. Phys. Med. Biol., 67(1):245017, 12 2022. doi:10.1088/1361-6560/aca5e9.
- [YL06] M. Yuan and Y. Lin. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc., B: Stat. Methodol., 68(1):49–67, 2 2006. doi:10.1111/j.1467-9868.2005.00532.x.
- [YZ15] Y. Yang and H. Zou. A fast unified algorithm for solving group-lasso penalized learning problems. Stat. Comput., 25(1):1129–1141, 2015. doi:10.1007/s11222-014-9498-5.
- [ZHZ+22] M. Zarepisheh, L. Hong, Y. Zhou, Q. Huang, J. Yang, G. Jhanwar, H. D. Pham, P. Dursun, P. Zhang, M. A. Hunt, G. S. Mageras, J. T. Yang, Y. Yamada, and J. O. Deasy. Automated and clinically optimal treatment planning for cancer radiotherapy. INFORMS J. Appl. Anal., 52(1):69–89, 2022.
- [ZSL+22] G. Zhang, H. Shen, Y. Lin, R. C. Chen, Y. Long, and H. Gao. Energy layer optimization via energy matrix regularization for proton spot-scanning arc therapy. Med. Phys., 49(9):5752–5762, 9 2022. doi:10.1002/mp.15836.
- [ZST+13] M. Zarepisheh, M. Shakourifar, G. Trigila, P. S. Ghomi, S. Couzens, A. Abebe, L. Noreña, W. Shang, S. B. Jiang, and Y. Zinchenko. A moment-based approach for DVH-guided radiotherapy treatment plan optimization. Phys. Med. Biol., 58(6):1869–1887, 2013.
Appendix A Derivation of problem 3
Problem 2 in the main text is a nonconvex optimization problem because the equality constraints and are nonlinear. We will show that it is equivalent to the convex optimization problem 3, which replaces the nonlinear equality constraints with the linear equality constraint . Since the objective functions are identical, it is sufficient to prove that any solution of problem 2 is a feasible point for problem 3 and vice versa.
Let be a solution of problem 2. Then,
because any real function can be written as the sum of its nonnegative and nonpositive parts. Thus, is feasible for problem 3, and since the two problems have the same objective function, is a solution of problem 3.
Now let us show the converse. First, we will relax the equality constraints in problem 2 to get
| (14) |
This relaxed problem is equivalent to problem 2 because the relaxed constraints, and , are tight at the optimum, since the objective function 1 is monotonically increasing over the nonnegative reals. Any feasible point of problem 14 that does not satisfy and cannot be optimal, as we can perturb it to obtain another feasible point with a strictly lower objective value.
For example, suppose for a voxel , then we can decrease by some small quantity to get that still satisfies the inequality constraint. (Here is the indicator vector of index , which equals 1 at and 0 elsewhere). The new point is feasible for problem 14, but attains a lower objective because the quadratic term by our choice of , assuming . If , the underdose to voxel has no impact on the objective and can be removed entirely from the optimization problem.
Appendix B Delivery efficiency and plan quality metrics
In this section, we present further results on the delivery time and other clinical metrics. Figure 9 is an extension of Figure 8 in the main text, depicting the relative percentage change in total delivery time, number of nonzero spots/energy layers, and several dosimetric quantities at cost to plan quality for patients , , and . Table 3 provides the absolute values for the metrics plotted in the two figures. Together, they show that reweighted regularization outperforms and group regularization in all patients.

| Unregularized | Group | Reweighted | |||
| Patient 1 | Num. Nonzero Spots | 1796 | 1102 | 4264 | 1061 |
| Num. Nonzero Layers | 55 | 53 | 48 | 35 | |
| Delivery Time (s) | 155.41 | 144.49 | 166.16 | 108.26 | |
| PTV: D2% (Gy) | 71.90 | 73.10 | 73.18 | 72.70 | |
| PTV: D98% (Gy) | 68.17 | 68.46 | 68.29 | 68.34 | |
| PTV: CI | 1.40 | 1.37 | 1.38 | 1.40 | |
| Mandible: Dmax (Gy) | 67.49 | 68.50 | 67.62 | 68.77 | |
| Parotids: Dmean (Gy) | 11.50 | 8.96 | 11.53 | 7.95 | |
| Patient 2 | Num. Nonzero Spots | 2295 | 1182 | 5719 | 976 |
| Num. Nonzero Layers | 67 | 61 | 52 | 33 | |
| Delivery Time (s) | 184.28 | 161.21 | 188.67 | 103.43 | |
| PTV: D2% (Gy) | 70.37 | 73.49 | 73.61 | 73.30 | |
| PTV: D98% (Gy) | 68.21 | 67.62 | 67.73 | 67.93 | |
| PTV: CI | 1.49 | 1.44 | 1.45 | 1.48 | |
| Mandible: Dmax (Gy) | 64.86 | 63.84 | 67.36 | 66.13 | |
| Parotids: Dmean (Gy) | 2.04 | 1.29 | 3.63 | 1.49 | |
| Patient 3 | Num. Nonzero Spots | 1751 | 1247 | 3738 | 1172 |
| Num. Nonzero Layers | 58 | 55 | 50 | 41 | |
| Delivery Time (s) | 160.93 | 149.92 | 164.88 | 121.31 | |
| PTV: D2% (Gy) | 70.54 | 72.44 | 71.95 | 72.12 | |
| PTV: D98% (Gy) | 67.70 | 66.97 | 67.06 | 67.14 | |
| PTV: CI | 1.84 | 1.78 | 1.78 | 1.83 | |
| Mandible: Dmax (Gy) | 67.06 | 67.53 | 65.91 | 67.11 | |
| Parotids: Dmean (Gy) | 13.41 | 13.54 | 13.37 | 13.51 | |
| Patient 4 | Num. Nonzero Spots | 259 | 195 | 480 | 169 |
| Num. Nonzero Layers | 37 | 35 | 36 | 27 | |
| Delivery Time (s) | 104.22 | 99.60 | 104.44 | 83.42 | |
| PTV: D2% (Gy) | 71.27 | 72.47 | 71.77 | 71.88 | |
| PTV: D98% (Gy) | 68.28 | 67.71 | 67.95 | 67.88 | |
| PTV: CI | 1.59 | 1.48 | 1.54 | 1.56 | |
| Mandible: Dmax (Gy) | 64.03 | 62.29 | 63.32 | 64.55 | |
| Parotids: Dmean (Gy) | 7.01 | 5.83 | 6.79 | 6.14 |
B.1 Robustness analysis
To analyze the robustness of the proton plans, we generated uncertainty scenarios (including the nominal scenario) by rescaling the stopping power ratio (SPR) image to simulate range over/undershoot errors [TBD+18, Pag12] and shifting the isocenter mm in the , , and directions to simulate setup errors. For each scenario , we computed the dose influence matrix . We solved the unregularized treatment planning problem 3 using only the dose influence matrix of the nominal scenario to get the optimal nominal spot vector and calculated the dose in each scenario to be . We repeated this process, again using only the nominal dose influence matrix in the optimization, with the reweighted regularization method to obtain doses . (As before, was chosen such that the reweighted plan results in a cost to plan quality relative to the unregularized plan). In the end, for each patient, we had two sets of dose vectors representing the potential scenario outcomes if we were to treat using the unregularized plan and the reweighted regularized plan: and .
Figures 10–13 depict the DVH bands resulting from these sets of doses for each patient. Every band delineates the range of DVH curves for a particular structure, taken across all uncertainty scenarios. The corresponding solid line is the DVH curve in the nominal scenario. Generally, the DVH bands of the reweighted regularized plan are similar to those of the unregularized plan. For patients and , the reweighted plan results in a slightly narrower PTV band (smaller range of uncertainty), while the opposite is true for patients and . In the case of OARs, the most noticeable difference is the reweighted plan exhibits thinner bands for the mandible in patient , but wider bands for the left parotid in patient . All other structures have comparable DVH bands between the unregularized and the reweighted regularized plans. We also provide the median and range of several clinical metrics in Table 4. These values support our conclusion that the reweighted method produces a treatment plan with similar robustness to the plan generated by the unregularized model, and its resulting dose satisfies clinical constraints in the majority of our uncertainty scenarios.




| Unregularized | Reweighted | ||||
| Median | Range | Median | Range | ||
| Patient 1 | PTV: D2% (Gy) | 72.73 | 4.84 | 73.36 | 4.42 |
| PTV: D98% (Gy) | 64.06 | 12.69 | 62.96 | 13.60 | |
| Mandible: Dmax (Gy) | 69.58 | 4.55 | 70.91 | 1.80 | |
| Left Parotid: Dmean (Gy) | 25.70 | 9.42 | 17.76 | 8.14 | |
| Patient 2 | PTV: D2% (Gy) | 71.03 | 2.48 | 73.58 | 3.97 |
| PTV: D98% (Gy) | 64.89 | 9.07 | 64.18 | 9.89 | |
| Mandible: Dmax (Gy) | 65.80 | 19.66 | 67.26 | 18.00 | |
| Left Parotid: Dmean (Gy) | 1.15 | 1.16 | 2.32 | 2.08 | |
| Right Parotid: Dmean (Gy) | 2.71 | 3.22 | 0.87 | 1.55 | |
| Patient 3 | PTV: D2% (Gy) | 71.66 | 4.08 | 72.73 | 5.33 |
| PTV: D98% (Gy) | 64.30 | 11.23 | 62.54 | 12.01 | |
| Mandible: Dmax (Gy) | 67.33 | 5.63 | 67.12 | 3.31 | |
| Left Parotid: Dmean (Gy) | 25.61 | 6.28 | 25.80 | 9.45 | |
| Spinal Cord: Dmax (Gy) | 26.79 | 35.76 | 23.50 | 34.56 | |
| Patient 4 | PTV: D2% (Gy) | 71.29 | 7.97 | 71.85 | 7.62 |
| PTV: D98% (Gy) | 64.21 | 12.14 | 63.16 | 11.83 | |
| Mandible: Dmax (Gy) | 69.70 | 4.94 | 70.22 | 3.69 | |
| Right Parotid: Dmean (Gy) | 10.92 | 8.98 | 9.65 | 8.27 | |
| Constrictors: Dmean (Gy) | 4.58 | 5.70 | 4.55 | 5.72 | |