Simpler is More: Efficient Top-K Nearest Neighbors Search on Large Road Networks
Abstract.
Top- Nearest Neighbors (NN) problem on road network has numerous applications on location-based services. As direct search using the ’s algorithm results in a large search space, a plethora of complex-index-based approaches have been proposed to speedup the query processing. However, even with the current state-of-the-art approach, long query processing delays persist, along with significant space overhead and prohibitively long indexing time. In this paper, we depart from the complex index designs prevalent in existing literature and propose a simple index named -. With -, we can answer a NN query optimally and progressively with small and size-bounded index. To improve the index construction performance, we propose a bidirectional construction algorithm which can effectively share the common computation during the construction. Theoretical analysis and experimental results on real road networks demonstrate the superiority of - over the state-of-the-art approach in query processing performance, index size, and index construction efficiency.
1. Introduction
Top nearest neighbors (NN) search on road network is a fundamental operation in location-based services (Bhatia et al., 2010; Abbasifard et al., 2014; Nodarakis et al., 2017). Formally, given a road network , a set of candidate objects , and a query vertex , NN search identifies objects in with the shortest distance to . NN search finds many important real world applications. For example, in the accommodation booking platforms like Booking (Booking, [n.d.]), Airbnb (Airnb, [n.d.]) and Trip (Trip, [n.d.]), an important operation is to show several accommodations closest to the location provided by users. In restaurant-review services, such as Yelp (Yelp, [n.d.]), Dianping (Dianping, [n.d.]) and OpenRice (OpenRice, [n.d.]), platforms utilize NN search to present several nearby restaurants to the user. In ride-hailing services like Uber (Uber, [n.d.]) and Didi (DiDi, [n.d.]), several available vehicles near the pickup location are presented before users send the ride-hailing request.

Example 1.1.
Figure 1 shows a NN search example in location-based service. Assume that tourists in New York, such as ”John” and ”Jennie”, want to find Starbucks nearby to drink coffee, the location-based service providers like Google Map generally present several candidate stores based on the distance from their locations, which can be modeled as NN search problem. In Figure 1, there are Starbucks stores (marked with ), therefore, the candidate object set . For ”Jennie”, the NN search returns while the NN search for ”John” returns .
Motivation. Given a NN query for vertex , the query can be directly answered by exploring the vertices based on their distance to using ’s algorithm (Dijkstra, 1959). Nevertheless, this method is inefficient, especially when the road network is large and the candidate objects are far from . Therefore, researchers resort to indexing-based solutions to accelerate query processing (Papadias et al., 2003b; Demiryurek et al., 2009a; Lee et al., 2010; Zhong et al., 2015; Shen et al., 2017; Luo et al., 2018; He et al., 2019; Ouyang et al., 2020a).
Although existing index-based approaches have made strides in accelerating the query processing, they still suffer from the long query processing delay and their performance is far from optimal. Additionally, these solutions exhibit significant space overhead and prohibitively long indexing times, severely limiting their practical applicability. Take the state-of-the-art approach (Ouyang et al., 2020a) for NN queries on road networks as an example. The size of on the dataset with only 23.95 million vertices and 58.33 million edges (nearly 442.5 MB if an edge is stored by two 4 byte integers) exceeds GB, and it takes more than hours to construct the corresponding index. Motivated by these, this paper aims to propose a new index-based solution for NN query that can overcome the shortcomings of existing solutions in query processing performance, index size and index construction.
A Minimalist NN Index Design. Revisiting the existing solutions, they generally design a complex index to speedup the query processing. For example, consists of three different parts. Incredibly, as an index for NN query, one of the three parts is even a complete index structure for shortest distance query. The complex-index design leads to the drawbacks of as analyzed in Section 3. This drives us to ask: is this complex-index design thinking really suitable for NN query?
In this paper, we adopt a completely opposite design approach. Going back to the essence of NN search, it only needs to return the nearest neighbors for the query vertex. Moreover, the value of the NN search used in real applications is typically not large as users often have limited attention spans and prefer to quickly obtain relevant information to reduce cognitive load and facilitate decision-making (Tugend, y 27; Ph.D., er 1; Sthapit, 2018; Chernev et al., 2015; Schwartz, 2004; Luo et al., 2018). For example, Yelp App (Yelp, [n.d.]) provides customers with results every time when searching nearest specific place type, such as restaurant or gas station. A similar strategy is also adopted in other Apps like OpenRice (OpenRice, [n.d.]) and OpenTable (OpenTable, [n.d.]). Therefore, our proposed new index named - only simply records the nearest neighbors of each vertex. The benefits of this minimalist NN index design are twofold: regarding the query processing, the query can be answered progressively 111Progressive query processing outputs results gradually in a well-bounded delay, allowing users to obtain useful results even before query processing completes. It also provides a choice to early terminate the search when a user finds sufficient answers (Papadias et al., 2003a). in optimal time. Regarding the space-consumption of the index, only the essential information directly to NN query is stored in the index and the value of is small in practice, resulting in a well-bounded index space.
New Challenges. - successfully addresses the issues of long query delays and oversized indexes by directly storing the nearest neighbors for each vertex. However, this strategy leaves the trouble to the index construction as the index structure intuitively implies that we have to explore all the query space before constructing it. A straightforward approach is to compute the nearest neighbors for each vertex by ’s algorithm (Dijkstra, 1959). However, the time complexity of this approach is , where is the number of vertices and is the number of edges in the road network. Clearly, this approach is impractical to handle large road networks. Another possible approach is to use the existing index like to accelerate the computation of nearest neighbors for each vertex. Nevertheless, this approach unavoidably induces the drawbacks of existing approaches as discussed above. Overall, the efficiency of the index construction algorithm determines the applicability of our index while it is challenging to design such an efficient index construction algorithm that could outperform existing solutions.
Our Idea. The above discussed approaches compute the nearest neighbors for each vertex independently, which miss the potential opportunities to re-use the intermediate results during the construction. Therefore, we adopt a computation sharing strategy to achieve the efficient index construction. To effectively share the computation, we introduce the concept of bridge neighbor set for a vertex and reveal the hidden relationships between its bridge neighbor set and nearest neighbors. Following these findings, we design a bridge neighbor preserved graph (-) of the input road network with which the bridge neighbor set of a vertex can be easily obtained. Based on -, we first propose a bottom-up index construction algorithm in which the intermediate results during the construction can be largely shared and further improve the performance by introducing a bidirectional construction algorithm. Additionally, the given candidate objects may be updated in some cases (Ouyang et al., 2020a), we also design efficient algorithm to incrementally maintain the index for these updates.
Contributions. In this paper, we make the following contributions:
(1) A new attempt at an alternative NN index design paradigm with a simple yet effective NN index. Recognizing the complex index in the existing solutions leads to long query processing delay, oversized index and prohibitive indexing time, we embrace minimalism and design a simple NN index that has a well-bounded space and enables progressive and optimal query processing. To the best of our knowledge, this is the first work that systematically studies such simple yet effective index for NN query.
(2) Efficient index construction and maintenance algorithms. Following the designed index, we propose a novel index construction algorithm with which the shortest distance computation regarding a vertex and its top nearest neighbors can be effectively shared. We also propose index maintenance algorithms to handle object insertion and deletion. We provide time complexity analysis for all proposed algorithms.
(3) Extensive experiments on real-world road networks. We extensively evaluate our proposed algorithms on real road networks. Compared with the state-of-the-art approach -, experimental results demonstrate that our approach reduces the index space two order of magnitude, speeds up the query time up to two orders of magnitude, and achieves up to two orders of magnitude speedup in index construction.
2. Preliminaries
| Notations | Descriptions |
|---|---|
| nearest neighbor set of | |
| decreasing rank partial NN of | |
| bridge neighbor preserved graph of | |
| decreasing rank path subgraph of | |
| increasing rank path subgraph of | |
| neighbors of in | |
| neighbors of in with lower rank than | |
| neighbors of in with higher rank than | |
| length of decreasing rank shortest path between and |
Let be a connected and weighted graph to represent a real-world road network, where and is the set of vertices and edges in , respectively. We use (resp. ) to denote the number of vertices (resp. edges) in . For each vertex , the neighbours of , denoted by , is defined as . The degree of a vertex is the number of neighbors of , i.e., . The weight of an edge is denoted as . A path in is a sequence of vertices , such that for each . The length of , denoted by , is the sum for the weight of edges in , i.e., . Given two vertices and , the shortest path between and in is a path from to with smallest . The distance between u and v in G, denoted as , is the weight of the shortest path between them.
Regarding the given set of candidate objects , we assume all objects in are on vertices following the previous works (Shen et al., 2017; Luo et al., 2018; He et al., 2019; Ouyang et al., 2020a). In real-world road networks, each object may appear on any point of edges. For an object not on a vertex, we can see as a vertex object with an offset, and the distance between and a query vertex can be computed by mapping to an adjacent vertex with an offset following the previous works (Shen et al., 2017; Luo et al., 2018; He et al., 2019; Ouyang et al., 2020a) as well. Specifically, assume is on an edge with a distance to , is on an edge with a distance . The distance between and is represented as . We denote the NN result of a vertex as and define the problem of NN search as follows.
Problem Definition. Given a road network , a query vertex , an integer , and a set of candidate objects ), we aim to computes objects from , denoted by , such that .
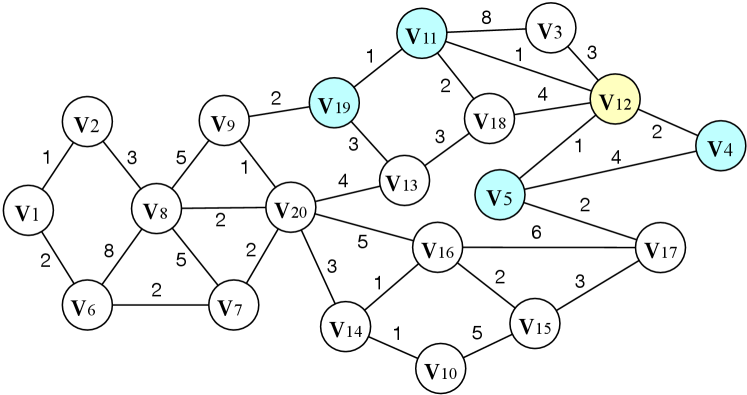
Example 2.1.
Consider the graph in Figure 2 and assume all vertices are in the candidate object set. For a given query vertex and , . The corresponding distances between and vertex in are and respectively.
3. The State-of-the-art Solution
(Ouyang et al., 2020a) is the state-of-the-art index-based approach for NN queries on road networks. designs an index based on tree decomposition (Robertson and Seymour, 1984; Xu et al., 2005) and - (Ouyang et al., 2018), which proves superiority over other existing approaches. Specifically,
Index Structure. decomposes the input road network into a tree-like structure by tree decomposition (Xu et al., 2005). Given the decomposed tree structure, each vertex has a child vertex set and an ancestor vertex set . Apart from the decomposed tree structure, contains the other two parts: TNN for each vertex which stores the top nearest neighbors of in and - (Ouyang et al., 2018) which is used to compute the shortest distance between and .
Query Processing. Given a query vertex , for each vertex in the NN of , there exists a vertex such that and in TNN of . Following this idea, answers the NN query in rounds. In each round (), it outputs the top -th result by iterating the vertices in and computing the corresponding shortest distance through -.
Index Construction. To construct the index, first decomposes the graph following (Xu et al., 2005). With the decomposed tree, and can be obtained accordingly. After that, builds the - based on (Ouyang et al., 2018). At last, the TNN for each vertex is constructed by querying the shortest distance of corresponding vertex pairs through -.
Drawbacks. Although accelerates the NN query processing on road network, the following drawbacks limit its applicability in practice:
-
•
Oversized Index. The size of is generally huge in practice. As verified in our experiments, the size of on (only vertices and edges) exceeds GB, in which - takes GB space.
-
•
Long Query Delay. To answer a NN query regarding vertex , has to iterate the vertices in and compute the corresponding shortest distance in rounds. Moreover, the shortest distance computation is not free, and needs heavy exploration on the -. These two factors lead to long query delay of -.
-
•
Prohibitive Indexing Time. As shown in the above, to construct the index, has to decompose the road network first, and then build the - and compute the TNN accordingly. Obviously, the time cost of these procedures are expensive, especially the - construction. For the dataset USA, takes s to construct the index, in which - consumes s.
4. Our Indexing Approach
According to the above analysis, although the use of - accelerates the query processing of -, heavily depending on the - directly leads to the drawbacks of -. This raises a natural question: why do we need an index for shortest distance such as - when addressing NN problem? Based on the logic of -, partial NN (namely TNN) is maintained for each vertex and - is used to refine the partial NN to obtain the final results when processing the query. This motivates us to further ask: Is it necessary to maintain the partial NN? How about maintaining the NN for each vertex directly as an index? In this way, the drawbacks regarding index size and query delay can be totally addressed. Following this idea, we propose the following index and query processing algorithm.
4.1. Index Structure and Query Processing
Our index just simply records the NN for each vertex in the graph, which is formally defined as follows:
Definition 4.1.
(-) Given a graph , an integer and a set of candidate objects , for each vertex , - records the top- nearest neighbors of in , namely , in the increasing order of their shortest distances from .
Example 4.2.
| - | - | ||
|---|---|---|---|
Query Processing. Based on our -, for a NN query regarding a vertex , we can answer the query directly by retrieving the corresponding items of in the -.
4.2. Theoretical Analysis
Following the index structure and query processing algorithm, we have the following theoretical results.
Optimal Query Processing. Since our query processing algorithm can answer the query directly by scanning the corresponding items of the query vertex in the -, the following theorem exists obviously:
Theorem 4.3.
Given a NN query, our algorithm takes time to process the query.
To answer a NN query, any algorithm needs to output the results at least, which takes time. On the other hand, Theorem 4.3 shows the time complexity of our query processing algorithm is . Therefore, the optimality holds.
Incremental Polynomial Query Processing. Consider an algorithm that returns several results. Let be the number of results in the output. An algorithm is said to have incremental polynomial if for all , the output time of the first results is bounded by a polynomial function of the input size and (Chang et al., 1994). Since the items for each vertex in the - are recorded in the increasing order of their distance from , we have:
Theorem 4.4.
Given a NN query regarding , for every , our algorithm outputs the top -th nearest neighbor in time.
Theorem 4.4 shows that our query processing algorithm is incremental polynomial, indicating that it progressively provides results for a query within a bounded delay. The capability of incremental polynomial query processing is considered as a significant technical contribution of (Ouyang et al., 2020a) and Theorem 4.4 confirms that our algorithm also possesses this desirable theoretical guarantee.
Bounded Index Space. Since - only stores the top- nearest neighbors of each vertex in the road network, we have:
Theorem 4.5.
Given a road network and an integer , the size of - is bounded by .
Remark. According to the above analysis, - processes a query in optimal time while takes time ( is the height of the tree decomposition), which means - surpasses at the query processing. For the index size, the size of - is while that of is . As introduced in Section 1, the value of NN search in real road network applications is not large, therefore, the index size of - is advantageous compared with in practice. Note that although (Ouyang et al., 2020a) claims TEN-Index is parameter-free index, both TEN-Index and KNN-Index constructs their index based on a specific , which means we needs to construct different indices for different values of . A compromise solution to address this problem for and our index is that we can construct the index based on a moderately large value, and the NN search with smaller values can be answered based on the constructed index directly.
5. Index Construction
Based on the structure of -, it can be constructed straightforwardly by computing the top nearest neighbors of each vertex through algorithm or -. However, these approaches are time-consuming and inefficient to handle large road network. In this section, we present our new approach to construct the -.
5.1. Key Properties of
The above discussed direct approaches using algorithm or compute the nearest neighbors for each vertex independently, which misses the potential opportunities to re-use the intermediate results during the index construction. In this section, we introduce two important properties regarding the distance computation, which lays the foundation for our computation-sharing index construction algorithms. We first define:
Definition 5.1.
(Bridge Neighbor Set) Given a vertex , the bridge neighbor set of , denoted by , is the set of neighbors such that the weight of the edge is equal to the distance between and in , i.e., .
Example 5.2.
Based on Definition 5.1, we have following property regarding the bridge neighbor set of and its nearest neighbors:
Property 1.
Given a vertex , .
Proof: We prove this property by contradiction. Assume that but . According to Definition 5.1, the shortest path between and must pass through one vertex such that for all , , we have . Therefore, . This implies that there are at least vertices whose distance to are smaller than the distance between and , which contradicts . The proof completes.
Following Property 1, we have:
Property 2.
Given a vertex , where .
Proof: According to Definition 5.1, for , each shortest path between and must pass through at least one vertex , so we have .
Based on Property 1, when a vertex , must be in . Moreover, when the bridge neighbor set of , the distance and ( accordingly where ) for all have been computed, we can compute for each efficiently following Property 2. Obviously, just selects vertices from with the smallest distance values. Therefore, if we process the vertices in in a certain order, and when processing each vertex , the vertices and have been computed, then and thereby - can be computed efficiently by sharing the computed results. The remaining problem is how to make this idea practically applicable. In next section, we present a bottom-up computation-sharing algorithm, which paves the way to our final index construction algorithm.
5.2. A Bottom-Up Computation-Sharing Algorithm
To compute the bridge neighbor set and share the computation effectively, we construct the index based on the bridge neighbor preserved graph of the road network , which is defined as:
Definition 5.3.
(BN-Graph) Given a road network , a graph is a bridge neighbor preserved graph (-) of if (1) ; (2) for each edge , ; (3) for any two vertices , .
Based on Definition 5.3, we propose Algorithm 1 to compute the - of an input road network and obtain the bridge neighbor set for each vertex accordingly. Intuitively, a - of with larger bridge neighbor set for each vertex has more potential possibility to share the computation following the analysis of Section 5.1. Meanwhile, the construction of - should not be costly. Following this idea, for a given road network and a total vertex order (the order used in our paper is discussed at the end of this section), our algorithm (Algorithm 1) contains two steps to construct -: (1) Edge insertion, it aims to add edges to connect vertices to enlarge the bridge neighbor set. (2) Edge deletion, it deletes edges to guarantee that the bridge neighbor set is enlarged correctly. Specifically,
Step 1. Edge Insertion: Given a graph and a rank over all vertices in , it initializes as , and iterates every vertex in the increasing order of (line 1-2). For every pair of vertices among the neighbors of in with higher ranks than , if , a new edge with weight is inserted into (line 5-7). Otherwise, if , it updates as (line 8-9).
Step 2. Edge Deletion: After the edge insertion step, it further iterates the vertex in the decreasing order of (line 10). For every pair of vertices among the neighbors of in with higher ranks than (line 11-12), if , it updates as and marks the updated edge as removed (line 13-15). At last, the marked edges in are removed (line 16), and for each vertex is set as (line 17-18).
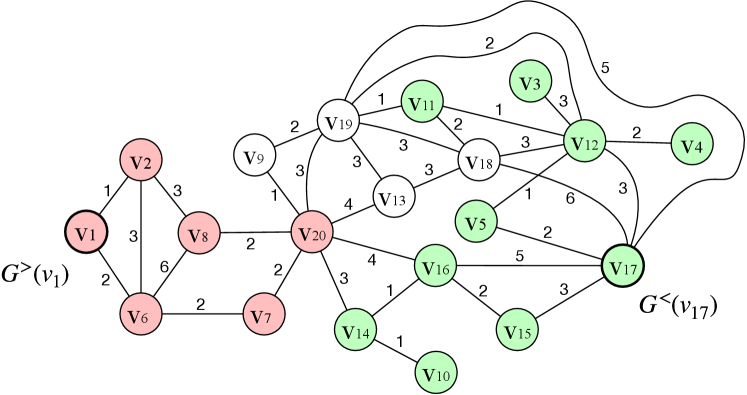
Example 5.4.
Consider the road network in Figure 2 and assume the vertex order , the - of is shown in Figure 4. To construct , we first conduct the edge insertion step. For , its is . There exists no edge in currently, then with is added into . The procedure continues until all vertices are processed. In the edge deletion step, vertices are processed in the reverse order of . Take as an example. When processing , its is . Since , is marked. When all the vertices are processed, the marked edges are removed, and Figure 4 shows the final .
Based on the procedure of Algorithm 1, we have:
Lemma 5.5.
The graph generated at the end of Algorithm 1 is a - of .
Proof: Based on Algorithm 1, it is direct that , meeting the condition (1) of -. For any two vertices , , where . Clearly, retains all edges with in and includes all inserted edges with in . Therefore, for any two vertices , , satisfying the condition (3) of -. Next, we prove that satisfies condition (2) via induction. Obviously, for , . Assume that for , for , . Now, we prove it for . Suppose connects to . From the insertion step, and form a clique. Thus, the shortest path from to either only contains and , or passes a vertex in , i.e, or . Since the includes and , we have for any two vertices . Thus, . As line 10-15 of Algorithm 1 can guarantee that , and satisfies condition (3) of -, i.e. , we have . Therefore, is a - of .
Following Lemma 5.5, it is clear that for each vertex , its NN in is the same as that in based on the condition (3) of Definition 5.3. Moreover, is the bridge neighbor set of in based on the condition (2) of Definition 5.3. The following problem is how to compute for each vertex via and . According to the discussion in Section 5.1, to fully utilize the intermediate computed results during the - construction, we define a special type of path based on the given total vertex order as follows:
Definition 5.6.
(Monotonic Rank Path) Given the - of a road network , for a vertex , a path in is a decreasing rank path of if , and it is an increasing rank path of if .
Definition 5.7.
(Monotonic Rank Path Subgraph) Given the - of a road network , for a vertex , the decreasing rank path subgraph of , denoted by , is the subgraph induced by all decreasing rank paths of in . The increasing rank path subgraph, denoted by , is the subgraph induced by all increasing rank paths of in .
Example 5.8.
Given the - in Figure 4, for vertex , increasing rank paths of contain or or , , , , . The increasing rank path subgraph of , i.e., , is the subgraph induced by these paths, which is shown in pink in Figure 4. The decreasing rank path subgraph of , i.e., , can be obtained similarly, which is shown in green in Figure 4.
Definition 5.9.
(Decreasing Rank Partial NN) Given a vertex and a set of candidate objects , the decreasing rank partial NN of , denoted by , is the NN of in .
Lemma 5.10.
Given a vertex in a road network , .
Proof: This lemma can be proved directly based on Property 1.
Therefore, if we can obtain for each vertex, we can obtain following Lemma 5.10. Moreover, we have:
Lemma 5.11.
Given a road network of and a set of candidate objects , let be the vertex with the lowest rank, we have .
Based on Lemma 5.11, the decreasing rank partial NN for the vertex with the lowest rank can be computed directly. Regarding the remaining vertices, we further divide into two parts: which contains the neighbors of in with lower rank than , i.e., and which contains the neighbors of in with higher rank than , i.e., . We have:
Lemma 5.12.
Given a vertex in a road network , .
Lemma 5.12 indicates the scope of for each vertex. To obtain , we only need to compute the distance between and , and retrieve the top objects. To avoid the expensive algorithm, we define:
Definition 5.13.
(Decreasing Rank Shortest Path) Given the - of a road network , for two vertices , the decreasing rank shortest path between and is the rank decreasing path from to with the smallest length in .
In - of , for any two vertices , one shortest path between and is a decreasing rank shortest path. We call the length of decreasing rank shortest path between and as decreasing rank distance and denote it as . We have:
Lemma 5.14.
Given the - of a road network , for a vertex , , where .
Proof: Based on Definition 5.7 and Definition 5.9, we have . According to Definition 5.13, for , there is one decreasing rank shortest path between and , which passes through one vertex . Therefore, .
Lemma 5.15.
Given the - of a road network , for a vertex , let , if , there is a shortest path between and in , which is also a decreasing rank shortest path.
Proof: According to Definition 5.7 and Definition 5.9, if , we know . Based on Definition 5.13, there is one decreasing rank shortest path between and . When , there is a shortest path between and in , which is also a decreasing shortest path.
Based on Lemma 5.11, Lemma 5.12, and Lemma 5.14, to obtain for each vertex, we can adopt a bottom-up strategy based on the increasing order of , and the computed distance for a lower rank vertex can be re-used to compute the distance for a higher rank vertex. However, only contains the vertices whose shortest paths to pass through , the vertices whose shortest paths to pass through does not considered. Unfortunately, these vertices cannot be obtained by only exploring the vertices in in the similar way as discussed above since this approach only explores the vertices whose ranks are not higher than . On the other hand, we have the following lemmas regarding the distance between and based on Lemma 5.10:
Lemma 5.16.
Given the - of a road network , for a vertex , let , .
Proof: This lemma can be proved by Lemma 5.5.
Lemma 5.17.
Given the - of a road network , for a vertex , , where .




Algorithm. By combing the above two cases together, our index construction algorithm is shown in Algorithm 2. It first generates the - using Algorithm 1 (line 1). Then, it adopts a bottom-up strategy to compute in the increasing order of (line 2-7). Specifically, for each vertex , it retrieves based on Lemma 5.12 (line 4) and computes based on Lemma 5.14 (line 5-6). Then, is the vertices in with the smallest (line 7). After that, it constructs by conducting search from on (line 9). And we compute the single source shortest distance from to each vertex in using the Dijkstra’s Algorithm (line 10-11). Then, following Lemma 5.10, it retrieves (line 12) and computes based on Lemma 5.17 (line 13-14). can be obtained from directly. can be computed (line 10-11) after the construction of (line ) following Lemma 5.16. At last, the vertices in with the smallest is returned as in line 15.
Example 5.18.
Following the - in Figure 4, Figure 5 takes as an example to show the procedure of Algorithm 2 to compute . According to Algorithm 2, we compute first. Based on , , which is shown in green in Figure 5 (a). Following Algorithm 2, when computing , we already have and , which is shown in Figure 5 (b). Consequently, following line 6 of Algorithm 2, we can achieve . Figure 5 (b) shows this set for constructing . After sorting distance, we have .
Figure 5 (c) shows the in purple with bold lines. Using Algorithm, we compute the distance from to each vertex in . And and . Following line 12 of Algorithm 2, when computing , we have and , which is shown in Figure 5 (d). Following line 14 of Algorithm 2, we achieve , which is shown in Figure 5 (c). Then, we select nearest objects from as the - of , namely, .
The correctness of Algorithm 2 is straightforward following the above discussion. For the efficiency of the algorithm, we have:
Theorem 5.19.
Proof: Algorithm 1 requires time (line 1 of Algorithm 2). Specifically, in the for loop (line 2-9 of Algorithm 1), for each vertex , line 4-9 of Algorithm 1 takes time and the for loop terminates at iterations. Therefore, the edge insertion step (line 2-9 of Algorithm 1) requires time. Similarly, the edge deletion step requires (line 10-16 of Algorithm 1). Scanning all vertices to achieve is bounded by (line 17-18 of Algorithm 1). Obviously, for , . Therefore, the time complexity of Algorithm 1 is . In the for loop from line 3 to line 7 of Algorithm 2, line 4 of Algorithm 2 takes , since each vertex is only explored by the vertex . At the same time with obtaining (line 4 of Algorithm 2), line 5-7 of Algorithm 2 could be done. Therefore, construction (line 3-7 of Algorithm 2) requires time. In the for loop (line 8-15 of Algorithm 2), constructing by conducting search requires time (line 9 of Algorithm 2). Computing for via algorithm (line 10-11 of Algorithm 2) consumes time. Obtaining and distance computation require (line 12-15 of Algorithm 2). Therefore, construction (line 8-15 of Algorithm 2) requires . In summary, the time complexity of Algorithm 2 is .
Remark. Based on Theorem 5.19, we prefer the generated - with smaller and . Thus, we use the following heuristic total order in this paper: (1) The vertex with the minimum degree in has the lowest rank (the vertex with a smallest has the lowest rank if more than one vertices have the minimum degree); (2) for two unprocessed vertices and in line 2 of Algorithm 1, if the number of unprocessed neighbors of is bigger than that of in . Note this order can be obtained incidentally in Algorithm 1, and does not affect the time complexity of Algorithm 1.
5.3. A Bidirectional Construction Algorithm
Algorithm 2 adopts a bottom-up strategy to construct the - with which the computation regarding is well shared. However, it still needs to invoke algorithm to compute the distance between and in line 11-12, which is costly. To address this problem, we propose a new algorithm to further improve the index construction efficiency. Instead of following the sole bottom-up direction which adopted in Algorithm 2, the new algorithm constructs the index in a bidirectional manner, which totally avoids the invocation of algorithm. Before introducing our algorithm, we have:
Lemma 5.20.
Given a road network , let be the vertex with the highest rank, .
Lemma 5.21.
Given the - of a road network , for a vertex , .
Proof: This lemma can be proved directly based on Property 1.
Lemma 5.20 and Lemma 5.21 imply that if we process the vertices in the decreasing order of their ranks when computing , it can re-use the computed information of vertices with higher ranks in the computation of the NN for vertices with lower ranks. Moreover, we have:
Lemma 5.22.
Given the - of a road network , for a vertex , , where .
Proof: For , there are two parts. The one part contains all whose shortest paths to pass through , this distance computation can be proved based on Property 2. The other part contains all whose shortest paths to pass through , can be directly obtained from based on Lemma 5.15.
Algorithm. Following Lemma 5.22, our new bidirectional construction algorithm is shown in Algorithm 3. It first generates the - of using Algorithm 1 (line 1) and computes in the same way as Algorithm 2 (line 2). After that, it processes the vertices in the decreasing order of their ranks (line 4-9). For each vertex , it retrieves based on Lemma 5.21 and stores them in (line 5). Then, the distance between and is computed following Lemma 5.22 (line 6-8). Since the index construction procedure follows the decreasing order of , for has been computed before computing . can be obtained from directly. And can be achieved from - directly. At last, the vertices in with the smallest is returned as in line 9.
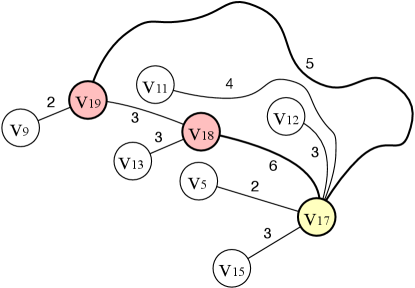

Example 5.23.
Figure 6 shows the construction procedure following Algorithm 3. Based on the - in Figure 4, for , , which is shown in pink in Figure 6 (a). can be constructed in the same way as shown in Example 5.18. Following line 5 of Algorithm 3, when computing , we already have , and , which is shown in Figure 6 (b). According to line 7-8 of Algorithm 3, we have . After sorting distance, the nearest neighbors for is selected from the set , namely, .
Theorem 5.24.
Proof: As proved in Theorem 5.19, Algorithm 1 requires time (line 1 of Algorithm 3) and construction requires (line 2 of Algorithm 3). In the for loop from line 4 to line 9 of Algorithm 3, obtaining and distance computation require (line 5-9 of Algorithm 3) and the loop terminates in iterations. Therefore, the for loop takes (line 4-9 of Algorithm 3). In summary, the bidirectional construction (Algorithm 3) requires .
6. Candidate Object Update
In some cases, the candidate objects may be updated by inserting new objects or deleting existing objects. Straightforwardly, we can reconstruct the index from scratch by Algorithm 3 to handle the update. However, this approach is inefficient as the update of a candidate object may not affect the NN results of all the vertices. In this section, we discuss how to maintain the - incrementally when the candidate objects are updated.
Obviously, when a candidate object is inserted or deleted, the update of will not affect the NN results of a vertex if and are far away from each other. Specifically, let be the vertex in with the largest distance to . If , then cannot be in , which means deleting or inserting will not affect . Moreover, we have the following lemma based on Property 1 and Property 2:
Lemma 6.1.
Given the - of the road network , for a vertex , when an object is inserted/deleted, could be affected if and only if there exists at least one vertex whose changes due to the update of .
Therefore, we can maintain the - starting from the vertex of the updated object . Based on the definition of NN, it is clear that will be changed. Following Lemma 6.1, the change of will possibly lead to the change of where . Then, we check whether needs to be updated based on and as discussed above. We continue to repeat the above procedure recursively, and it is obvious that the - is correctly maintained when no more vertices whose NN results change. Based on the above idea, our algorithms to handle the candidate object insertion and deletion are shown in Algorithm 4 and Algorithm 5, respectively.
Object Insertion. Algorithm 4 shows the algorithm for candidate object insertion. An array stores the distance between and other vertices, a set stores vertices whose NN results should be updated, and a queue stores the vertices whose bridge neighbor sets should be checked (line 1). Then, it initializes as and adds in and (line 1). After that, it pops a vertex from (line 4), and for each , it computes the distance between and , which can be obtained based on the fact (line 6). Note that instead of visting all , only the vertices whose changes due to the update of need to be explored following Lemma 6.1, which is captured by . If is not in and is smaller than the distance between and , where is the vertex with the largest distance to in which can be obtained directly based on -, it adds into and (line 7-8). The procedure terminates when becomes empty (line 3). At last, for each vertex , it removes from and inserts into (line 9-10). When inserting into , is the shortest distance between and , which can be guaranteed by Lemma 6.1.
Theorem 6.2.
Given the - and its corresponding - of a road network , Algorithm 4 maintains the - correctly when an object is inserted.
Proof: Algorithm 4 (line 5-6) can guarantee for is the distance between and before inserting to for (line 9-10). Even though when using (line 7), may not be the distance between and and returns , the final result can not be affected. Since , returning denotes that . Therefore, we have . Overall, Algorithm 4 maintains the - correctly when an object is inserted.
Theorem 6.3.
Given the - and its corresponding - of a road network , when an object is inserted, Algorithm 4 maintains the - in , where and .
Proof: The time complexity of (line 11-14) is . In the for loop (line 3-8), for each vertex , line 5-8 requires time and the loop terminates in at most iterations. Therefore, the for loop (line 3-8) requires time. In the for loop (line 9-10), removing from requires , inserting into in the correct position needs and the loop stops in iterations. Therefore, the for loop (line 9-10) requires time. In summary, the overall time complexity of Algorithm 4 is , since in real applications the parameter is not large and .
Object Deletion. Algorithm 5 shows the algorithm for candidate object deletion, which follows a similar framework as Algorithm 4. The main difference is in line 10. When the vertices whose need to be updated are determined, Algorithm 5 finds a new vertex to replace in by procedure and deletes from . For procedure , it is easy to know that must be the vertex in with the smallest distance to according to Property 1, thus it first retrieves such set of vertices, namely (line 16), and finds the vertex in with the smallest distance to (line 17, since the vertices are processed in decreasing order of , can be obtained in the similar way as line 7-8 of Algorithm 3 following the same idea). At last, it inserted into in line 18.
Theorem 6.4.
Given the - and its corresponding - of a road network , Algorithm 5 maintains the - correctly when an object is deleted.
Proof: Algorithm 5 (line 5-6) can guarantee for is the distance between and , before processing each (line 9-10). Even though when using (line 7), may not be the distance between and and returns , the final result can not be affected. Since , returning denotes that . Therefore, we have . Overall, Algorithm 5 maintains the - correctly when an object is deleted.
Theorem 6.5.
Given the - and its corresponding - of a road network , when an object is deleted, Algorithm 5 maintains the - in , where and .
Proof: The time complexity of (line 11-14) is . In the for loop (line 3-8), for each vertex , line 5-8 requires time and the loop terminates in at most iterations. Therefore, the for loop (line 3-8) requires time. For the procedure (line 15-18), retrieving from needs time (line 16). At the same time with retrieving , the vertex with the smallest distance from can be achieved (line 17). Line 18 requires time, since and should be inserted into the end of . Therefore, the time complexity of (line 15-18) is . In the for loop (line 9-10), deleting from requires , and the loop stops in iterations. Therefore, the for loop (line 9-10) requires time. In summary, the overall time complexity of Algorithm 4 is .
7. Experiments
In this section, we compare our algorithms with the state-of-the-art method. All experiments are conducted on a machine with an Intel Xeon CPU and 384 GB main memory running Linux.
| Dataset | Name | |||||
|---|---|---|---|---|---|---|
| New York City | 264,346 | 733,846 | 725 | 56 | 116 | |
| San Francisco Bay Area | 321,270 | 800,172 | 388 | 45 | 100 | |
| Colorado | 435,666 | 1,057,066 | 524 | 65 | 122 | |
| Florida | 1,070,376 | 2,712,798 | 556 | 49 | 85 | |
| Northwest USA | 1,207,945 | 2,840,208 | 619 | 49 | 119 | |
| Northeast USA | 1,524,453 | 3,897,636 | 1096 | 81 | 149 | |
| California and Nevada | 1,890,815 | 4,657,742 | 795 | 93 | 204 | |
| Great Lakes | 2,758,119 | 6,885,658 | 1674 | 124 | 327 | |
| Eastern USA | 3,598,623 | 8,778,114 | 1089 | 102 | 233 | |
| Western USA | 6,262,104 | 15,248,146 | 1356 | 128 | 276 | |
| Central USA | 14,081,816 | 34,292,496 | 2811 | 234 | 531 | |
| Full USA | 23,947,347 | 58,333,344 | 3315 | 257 | 587 |












Datasets. We use twelve publicly available real road networks from DIMACS 222http://users.diag.uniroma1.it/challenge9/download.shtml. In each road network, vertices represent intersections between roads, edges correspond to roads or road segments, the weight of an edge is the physical distance between two vertices. Table 2 provides the details about these datasets. Table 2 also shows the value of , and for each road network. Clearly, , and are small in practice.
Algorithms. We compare the following algorithms:
-
•
: The state-of-the-art algorithm for NN queries queries, which is introduced in Section 3.
-
•
-: Our proposed algorithms for NN queries. For the index construction algorithms, we further distinguish between (Algorithm 2) and (Algorithm 3) for comparison.
- •
-
•
: Using Dijkstra’s Algorithm to compute top- nearest neighbors for all vertices in a given graph to construct the - as discussed in Section 5.
-
•
: Using - to compute top- nearest neighbors for all vertices in a given graph to construct the - as discussed in Section 5.
All the algorithms are implemented in C++ and compiled in GCC with -O3. The time cost is measured as the amount of wall-clock time elapsed during the program’s execution. If an algorithm cannot finish in 6 hours, we denote the processing time as .
Parameter Settings. Following previous NN works (Ouyang et al., 2020a; He et al., 2019; Luo et al., 2018), we randomly select candidate objects in each dataset with a density . The candidate density and the query parameter settings are shown in Table 3, default values display in bold and italic font.
| Parameters | Values |
|---|---|
| 0.5, 0.1, 0.05, 0.01, 0.005, 0.001, 0.0005, 0.0001 | |
| 100, 80, 60, 40, 30, 20, 10 |
Exp-1: Query Processing Time when Varying . In this experiment, we evaluate the query processing time of our algorithms -, the SOTA solutions and by varying the parameter . We randomly generate queries and report average running time of each algorithm in Figure 7.
As shown in Figure 7, our algorithm is the most efficient one compared with and and the growth for query processing time of and is sharper than that of - with increase of . For example, on dataset, when increases from to , the query processing time of grows from us to us and raises from us to us. However, our - processing time grows from us to us. This is consistent with our analysis in Section 4.2. For , is out of memory, the query processing time for could
not be tested at this and following experiments.












Exp-2: Query Processing Time when Varying . We also compare our - with the SOTA solutions and by varying object (the density , therefore, we vary by changing ). We randomly generate queries for every dataset. We report the average processing time of each algorithm in Figure 8.
As shown in Figure 8, the query processing time of our algorithm is stable with the decrease of candidate object . However, the query processing time of and increases significantly with the decrease of candidate density . For example, when - achieves 2 orders of magnitude speedup compared with in all datasets, and - achieves 4 orders of magnitude speedup compared with . Moreover, the more sparsely the object set distributes, the larger speedup is. This is because our proposed algorithm is optimal regarding query processing as analyzed in Section 4.2.












Exp-3: Progressive Query Processing. In this experiment, we evaluate the progressive query processing strategy of -, and by outputing every outputs in all datasets with . As shown in Figure 9, the lines of and - are linear in all datasets, and the total time of - is always smaller than that of -. The reasons are similar as explained in Exp-1 and Exp-2. does not support incremental polynomial query processing, so it has the same the total time for different outputs.


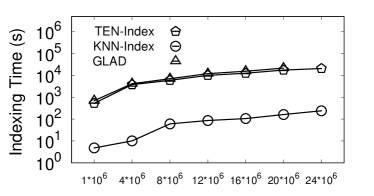
Exp-4: Indexing Time. In this experiment, we evaluate the indexing time for , -, --, , and -. Figure 10 shows that is the fastest in all datasets, and achieves up to 2 orders of magnitude speedup compared with and . For example, only takes s for while costs s. -- and takes the similar indexing time as -- depends on the -. They both rely on -. Also, the indexing time of and are similar, since constructs the additional grid index on the basis of -. As shown in Figure 10, cannot complete the index construction within hours for and . And for is out of memory. - cannot finish index construction within hours for , , , , and . Although index construction frameworks in and are similar, consumes much more time compared with . For example, for , only costs s, but costs s. This is because first uses BFS to construct for each vertex , and then uses Dijkstra’s Algorithm to compute for when constructing the index. However, adopts a bidirectional construction strategy to avoid the time-consuming BFS search and the computation of Dijkstra’s Algorithm during the index construction. The experimental results demonstrate the efficiency of our proposed algorithm regarding index construction.
Exp-5: Index Size. In this experiment, we evaluate the index size for -, and . The experimental results for the road networks are shown in Figure 11. Figure 11 shows the index size of - is much smaller than that of and . For example, for the dataset , the - size is only GB while size is GB, which is times smaller than that of -.
| USA | CTR | |||||||
|---|---|---|---|---|---|---|---|---|
| - | - | - | - | |||||
| Indexing Time (s) | Indexing Time (s) | Index Size (GB) | Index Size (GB) | Indexing Time (s) | Indexing Time (s) | Index Size (GB) | Index Size (GB) | |
| 19669.787 | 266.005 | 169.265 | 1.784 | 10877.527 | 169.578 | 98.021 | 1.049 | |
| 19670.198 | 283.850 | 169.277 | 3.568 | 10878.179 | 179.480 | 98.028 | 2.908 | |
| 19670.336 | 297.224 | 169.286 | 5.353 | 10881.515 | 186.859 | 98.034 | 3.148 | |
| 19671.470 | 321.845 | 169.293 | 7.1369 | 10882.434 | 201.225 | 98.039 | 4.197 | |
| 19672.287 | 345.169 | 169.305 | 10.705 | 10884.793 | 215.737 | 98.046 | 6.295 | |
| 19672.839 | 382.074 | 169.315 | 14.274 | 10885.981 | 238.944 | 98.053 | 8.393 | |
| 19710.726 | 418.251 | 169.324 | 17.842 | 10887.369 | 253.219 | 98.058 | 10.492 | |
Exp-6: Indexing Time and Index Space when Varying . We evaluate the performance of - and when varying on and with . The results on the other datasets are omitted due to similar trends. As shown in Table 4, the index size and the indexing time of and - both increases with the growth of slightly. For example, when increases from to , the indexing time for increases by s and the index size for increases by GB. This is consistent with our analysis in Section 4.2.

Exp-7: Scalability when Varying Graph Size. In this experiment, we evaluate the scalability of -, and . To test the scalability for indexing time and index size, we divide the map of the whole US into grids. We select a grid in the middle and generate an induced network by all vertices falling the grid. Using this method, we generate datasets. We report the indexing time and index size for these ten networks in Figure 13. The labels on -axis represent the number of vertices. For the largest datasets, is out of memory. As shown in Figure 13, when the dataset increases from to , the indexing time increases stably for all algorithms, which verifies our - has a good scalability. Moreover, our - always outperforms and . The reasons are similar as explained in Exp-4 and Exp-5.

Exp-8: Object Update. In this experiment, we evaluate the performance of our update algorithms. To generate updated objects, we randomly select an object with either insertion or deletion. We skip the update if for deletion and for insertion. For each dataset, we repeat this step until updates are generated. The average time for each update is reported in Figure 12. The update time of - is slower than that of and that of , since our update algorithm needs more time to compute the distance between each vertex and the updated objects. As analyzed in Section 3, contains -, - can compute the distance between any two vertices efficiently. Therefore, based on -, can finish insertion or deletion in the shorter time. Since only needs to update objects’ grid index, the update operation is easier and costs shorter time.
Exp-9: System Throughput. We evaluate the throughput of answering queries mixed by NN queries and object updates. Following (Ouyang et al., 2020b), the throughput is calculated based on two models, which are (1) Batch Update Arrival + Query First ( +) and (2) Random Update Arrival + First Come First Served ( +) (Luo et al., 2018). We report the throughput of each algorithm under different and for a representative dataset , which is also used in (Ouyang et al., 2020b). The results are shown in Figure 14. We can see that the throughput of - is larger for the + model as our query processing algorithm is very fast. However, in the + model, the throughput of - is smaller than that of and . This is because our update algorithm costs more time than the update algorithms for and . Also, the throughput of -, and all will go down with the decrease of . When the candidate density is relatively high, our update algorithms are faster. When decreases in Figure 14(c), our update algorithms cost more time. Even if our query processing time is not affected by , our throughput still decrease with the fall of . For and , the query processing time and updating time both will be longer with decrease of . Therefore, the throughput of and have a similar trend with that of -. In summary, - is good at handling the + workload while and are good at handling + workload, and -, and have their respective advantages regarding throughput.




Exp-10: Indexing Time of Different Vertex Total Orders. We evaluate index construction performance using different total orders. We adopt three total orders: (1) degree-based total order in which the vertex with the smallest degree is processed first; (2) id-based total order in which the vertex with the smallest id is processed first; (3) and our proposed total order. As shown in Figure 15, degree-based order can finish - construction for four small datasets, and id-based order only can construct - for 3 small datasets within hours. Our order can finish constructing - for all datasets, and the construction time in our order is 4 orders of magnitude faster than the other two orders. The experimental results are also consistent with our analysis in Section 5.2.

8. Related Work
The direct approach to answer a NN query is the ’s algorithm (Dijkstra, 1959). Nevertheless, this approach is inefficient obviously. Therefore, a plethora of index based -search enhanced solutions (Papadias et al., 2003b; Demiryurek et al., 2009a; Lee et al., 2010; Zhong et al., 2015; Shen et al., 2017; Luo et al., 2018) are proposed in the literature, which generally adopts the following search framework for a given query vertex : (1) Initialize the distance for vertices it connected as their edge weights and other vertices as . (2) Maintain two vertex sets and . contains vertices whose distance to is computed. contains vertices whose distance to is not computed yet, but have neighbors in . Initially, is inserted in and the neighbors of are inserted in . (3) Select one node with the smallest distance to from , and add it to . Then, the neighbors of are inserted into . Here, different indexing methods add different restrictions, pruning unnecessary vertices to be inserted in , to improve the query processing performance. (4) Repeat (3) until .
Specifically, (Papadias et al., 2003b) uses Euclidean distance as a pruning bound to acquire the NN results. (Papadias et al., 2003b) improves ’s Euclidean distance bound by expending searching space from the query location. (Demiryurek et al., 2009a) adapts a Euclidean restriction-based method to deal with continuous nearest neighbor problem. (Demiryurek et al., 2009a) divides the map into grids and records which vertices and edges belong to some grid. Given a query vertex, the fixed distance between grids is used to filter a proximate range. (Lee et al., 2010) separates the input graph into many subgraphs hierarchically and skips the subgraphs without candidate objects to speedup NN query processing. - (Zhong et al., 2015) adapts a binary tree division method to divide a graph into two disjoint subgraphs recursively until the number of vertices in a tree node is smaller than a predefined parameter. In each subgraph, - maintains a distance matrix which stores distance between borders and vertices, which is used to prune unnecessary vertex exploration during the search. - (Shen et al., 2017) constructs a similar structure as - but adds additional nearest objects for borders, which leads to a faster query processing than -. Based on the contraction hierarchy () (Geisberger et al., 2008), (Luo et al., 2018) constructs a DNN index recording the top- nearest neighbors for each vertex from objects whose ranks are lower than , where the rank is defined by the contraction hierarchy. To answer a NN query with vertex , performs search from following the and maintains a candidate result set . When visiting a vertex , if there is a vertex in the DNN of such that the distance of and is smaller than the -th distance to in , updates . The processing finishes when the search is far enough or all vertices are explored. Although the methods design different pruning algorithms to reduce the search space in step (3), the number of explored vertices cannot be well-bounded. In worst case, these methods degenerate into ’s algorithm, which leads to long query processing delay unavoidably. For , asit constructs DNN based on , which causes a relatively huge index size. Additionally, the vertex ranking method in employs ’s Algorithm, which incurs an expensive time cost regarding index construction. The experimental results of (Ouyang et al., 2020a) also verify above discussions.
Apart from the -search enhanced solutions, (Li et al., 2018) exploits the massive parallelism of GPU to accelerate the NN query processing. (He et al., 2019) partitions the road network into girds based on the geographical coordinate of each vertex. When answering a NN query, it starts the search from the grid containing the query vertex and updates the candidate result via probing vertices in neighbor grids iteratively. It avoids the exploration to the vertices in a grid if the minimum Euclidean distance between any vertex inside the grid and the query vertex is not less than the largest distance in the candidate result. As needs to use - to compute the exact shortest distance to select the final exact NN results, the query processing is long. Moreover, since depends on -, the index size of is huge and the indexing time of is long, which are similar to (Ouyang et al., 2020a). (Ouyang et al., 2020a) is the state-of-the-art approach to NN query in road network, which has been discussed in Section 3. (Li et al., 2023) extend (Ouyang et al., 2020a) and (He et al., 2019) onto time-dependent road networks. (Jiang et al., 2023) extends tree decomposition method (Ouyang et al., 2018) to deal with NN search on flow graph.
Besides, continuous NN query problem on road network is also studied in the literature (Shahabi et al., 2003; Kolahdouzan and Shahabi, 2005; Cho and Chung, 2005; Mouratidis et al., 2006; Demiryurek et al., 2009b; Cho et al., 2013; Zheng et al., 2016; Kolahdouzan and Shahabi, 2004; Jiang et al., 2023, 2021). Different from our setting, these studies generally assume that the query vertex is moving on the road network, and thus are orthogonal to ours. As a result, the proposed techniques in these studies cannot be used to address our problem.
9. Conclusion
Motivated by existing complex-index-based approaches for classical top nearest neighbors search in road networks suffers from the long query processing delay, oversized index space, and prohibitive indexing time, we embrace minimalism and design a simple index for NN query. The index has a well-bounded space and supports progressive and optimal query processing. Moreover, we further design efficient algorithms to support the index construction. Experimental results demonstrate the significant superiority of our index over the state-of-the-art approach.
References
- (1)
- Abbasifard et al. (2014) Mohammad Reza Abbasifard, Bijan Ghahremani, and Hassan Naderi. 2014. A survey on nearest neighbor search methods. International Journal of Computer Applications 95, 25 (2014).
- Airnb ([n.d.]) Airnb. [n.d.]. https://www.airbnb.com/.
- Bhatia et al. (2010) Nitin Bhatia et al. 2010. Survey of nearest neighbor techniques. arXiv preprint arXiv:1007.0085 (2010).
- Booking ([n.d.]) Booking. [n.d.]. https://www.booking.com/.
- Chang et al. (1994) Y. H. Chang, Jia-Shung Wang, and Richard C. T. Lee. 1994. Generating All Maximal Independent Sets on Trees in Lexicographic Order. Inf. Sci. 76, 3-4 (1994), 279–296.
- Chernev et al. (2015) Alexander Chernev, Ulf Böckenholt, and Joseph Goodman. 2015. Choice overload: A conceptual review and meta-analysis. Journal of Consumer Psychology 25, 2 (2015), 333–358.
- Cho et al. (2013) Hyung-Ju Cho, Se Jin Kwon, and Tae-Sun Chung. 2013. A safe exit algorithm for continuous nearest neighbor monitoring in road networks. Mob. Inf. Syst. 9, 1 (2013), 37–53.
- Cho and Chung (2005) Hyung-Ju Cho and Chin-Wan Chung. 2005. An efficient and scalable approach to CNN queries in a road network. In Proceedings of VLDB, Vol. 2. International Conference on VLDB, 865–876.
- Demiryurek et al. (2009a) Ugur Demiryurek, Farnoush Banaei-Kashani, and Cyrus Shahabi. 2009a. Efficient continuous nearest neighbor query in spatial networks using euclidean restriction. In Proceedings of SSTD. Springer, 25–43.
- Demiryurek et al. (2009b) Ugur Demiryurek, Farnoush Banaei Kashani, and Cyrus Shahabi. 2009b. Efficient Continuous Nearest Neighbor Query in Spatial Networks Using Euclidean Restriction. In Proceedings of SSTD, Vol. 5644. 25–43.
- Dianping ([n.d.]) Dianping. [n.d.]. https://www.dianping.com/.
- DiDi ([n.d.]) DiDi. [n.d.]. https://www.didiglobal.com.
- Dijkstra (1959) Edsger W. Dijkstra. 1959. A note on two problems in connexion with graphs. Vol. 1. 269–271.
- Geisberger et al. (2008) Robert Geisberger, Peter Sanders, Dominik Schultes, and Daniel Delling. 2008. Contraction hierarchies: Faster and simpler hierarchical routing in road networks. In Proceedings of WEA. Springer, 319–333.
- He et al. (2019) Dan He, Sibo Wang, Xiaofang Zhou, and Reynold Cheng. 2019. An efficient framework for correctness-aware kNN queries on road networks. In Proceedings of ICDE. IEEE, 1298–1309.
- Jiang et al. (2023) Wei Jiang, Guanyu Li, Mei Bai, Bo Ning, Xite Wang, and Fangliang Wei. 2023. Graph-Indexed k NN Query Optimization on Road Network. Electronics 12, 21 (2023), 4536.
- Jiang et al. (2021) Wei Jiang, Fangliang Wei, Guanyu Li, Mei Bai, Yongqiang Ren, and Jingmin An. 2021. Tree index nearest neighbor search of moving objects along a road network. Wireless Communications and Mobile Computing 2021 (2021), 1–18.
- Kolahdouzan and Shahabi (2004) Mohammad R. Kolahdouzan and Cyrus Shahabi. 2004. Voronoi-Based K Nearest Neighbor Search for Spatial Network Databases. In Proceedings of VLDB. 840–851.
- Kolahdouzan and Shahabi (2005) Mohammad R. Kolahdouzan and Cyrus Shahabi. 2005. Alternative Solutions for Continuous K Nearest Neighbor Queries in Spatial Network Databases. GeoInformatica 9, 4 (2005), 321–341.
- Lee et al. (2010) Ken CK Lee, Wang-Chien Lee, Baihua Zheng, and Yuan Tian. 2010. ROAD: A new spatial object search framework for road networks. IEEE transactions on knowledge and data engineering 24, 3 (2010), 547–560.
- Li et al. (2018) Chuanwen Li, Yu Gu, Jianzhong Qi, Jiayuan He, Qingxu Deng, and Ge Yu. 2018. A GPU Accelerated Update Efficient Index for kNN Queries in Road Networks. In Proceedings of ICDE. 881–892.
- Li et al. (2023) Jiajia Li, Cancan Ni, Dan He, Lei Li, Xiufeng Xia, and Xiaofang Zhou. 2023. Efficient k NN query for moving objects on time-dependent road networks. The VLDB Journal 32, 3 (2023), 575–594.
- Luo et al. (2018) Siqiang Luo, Ben Kao, Guoliang Li, Jiafeng Hu, Reynold Cheng, and Yudian Zheng. 2018. Toain: a throughput optimizing adaptive index for answering dynamic k nn queries on road networks. Proceedings of VLDB 11, 5 (2018), 594–606.
- Mouratidis et al. (2006) Kyriakos Mouratidis, Man Lung Yiu, Dimitris Papadias, and Nikos Mamoulis. 2006. Continuous Nearest Neighbor Monitoring in Road Networks. In Proceedings of VLDB. 43–54.
- Nodarakis et al. (2017) Nikolaos Nodarakis, Angeliki Rapti, Spyros Sioutas, Athanasios K Tsakalidis, Dimitrios Tsolis, Giannis Tzimas, and Yannis Panagis. 2017. (A) kNN query processing on the cloud: a survey. In Algorithmic Aspects of Cloud Computing: Second International Workshop, ALGOCLOUD 2016, Aarhus, Denmark, August 22, 2016, Revised Selected Papers 2. Springer, 26–40.
- OpenRice ([n.d.]) OpenRice. [n.d.]. https://www.openrice.com/.
- OpenTable ([n.d.]) OpenTable. [n.d.]. https://www.opentable.com.au/.
- Ouyang et al. (2018) Dian Ouyang, Lu Qin, Lijun Chang, Xuemin Lin, Ying Zhang, and Qing Zhu. 2018. When hierarchy meets 2-hop-labeling: Efficient shortest distance queries on road networks. In Proceedings of SIGMOD. 709–724.
- Ouyang et al. (2020a) Dian Ouyang, Dong Wen, Lu Qin, Lijun Chang, Ying Zhang, and Xuemin Lin. 2020a. Progressive top-k nearest neighbors search in large road networks. In Proceedings of SIGMOD. 1781–1795.
- Ouyang et al. (2020b) Dian Ouyang, Long Yuan, Lu Qin, Lijun Chang, Ying Zhang, and Xuemin Lin. 2020b. Efficient shortest path index maintenance on dynamic road networks with theoretical guarantees. Proceedings of the VLDB Endowment 13, 5 (2020), 602–615.
- Papadias et al. (2003a) Dimitris Papadias, Yufei Tao, Greg Fu, and Bernhard Seeger. 2003a. An optimal and progressive algorithm for skyline queries. In Proceedings of the 2003 ACM SIGMOD international conference on Management of data. 467–478.
- Papadias et al. (2003b) Dimitris Papadias, Jun Zhang, Nikos Mamoulis, and Yufei Tao. 2003b. Query processing in spatial network databases. In Proceedings of VLDB. Elsevier, 802–813.
- Ph.D. (er 1) Frederick Muench Ph.D. 2010, November 1. The Burden of Choice. https://www.psychologytoday.com/ca/blog/more-tech-support/201011/the-burden-choice.
- Robertson and Seymour (1984) Neil Robertson and Paul D Seymour. 1984. Graph minors. III. Planar tree-width. Journal of Combinatorial Theory, Series B 36, 1 (1984), 49–64.
- Schwartz (2004) Barry Schwartz. 2004. The paradox of choice: Why more is less. New York (2004).
- Shahabi et al. (2003) Cyrus Shahabi, Mohammad R. Kolahdouzan, and Mehdi Sharifzadeh. 2003. A Road Network Embedding Technique for K-Nearest Neighbor Search in Moving Object Databases. GeoInformatica 7, 3 (2003), 255–273.
- Shen et al. (2017) Bilong Shen, Ying Zhao, Guoliang Li, Weimin Zheng, Yue Qin, Bo Yuan, and Yongming Rao. 2017. V-tree: Efficient knn search on moving objects with road-network constraints. In Proceedings of ICDE. IEEE, 609–620.
- Sthapit (2018) Erose Sthapit. 2018. The more the merrier: Souvenir shopping, the absence of choice overload and preferred attributes. Tourism management perspectives 26 (2018), 126–134.
- Trip ([n.d.]) Trip. [n.d.]. https://www.trip.com/.
- Tugend (y 27) Alina Tugend. 2010, February 27. Too many choices: A problem that can paralyze. https://www.nytimes.com/2010/02/27/your-money/27shortcuts.html?_r=1&.
- Uber ([n.d.]) Uber. [n.d.]. https://www.uber.com/.
- Xu et al. (2005) Jinbo Xu, Feng Jiao, and Bonnie Berger. 2005. A tree-decomposition approach to protein structure prediction. In 2005 IEEE Computational Systems Bioinformatics Conference (CSB’05). IEEE, 247–256.
- Yelp ([n.d.]) Yelp. [n.d.]. https://www.yelp.com/.
- Zheng et al. (2016) Bolong Zheng, Kai Zheng, Xiaokui Xiao, Han Su, Hongzhi Yin, Xiaofang Zhou, and GuoHui Li. 2016. Keyword-aware continuous kNN query on road networks. In Proceedings of ICDE. IEEE Computer Society, 871–882.
- Zhong et al. (2015) Ruicheng Zhong, Guoliang Li, Kian-Lee Tan, Lizhu Zhou, and Zhiguo Gong. 2015. G-tree: An efficient and scalable index for spatial search on road networks. IEEE Transactions on Knowledge and Data Engineering 27, 8 (2015), 2175–2189.