Shot in the Dark: Few-Shot Learning with No Base-Class Labels
Abstract
Few-shot learning aims to build classifiers for new classes from a small number of labeled examples and is commonly facilitated by access to examples from a distinct set of ‘base classes’. The difference in data distribution between the test set (novel classes) and the base classes used to learn an inductive bias often results in poor generalization on the novel classes. To alleviate problems caused by the distribution shift, previous research has explored the use of unlabeled examples from the novel classes, in addition to labeled examples of the base classes, which is known as the transductive setting. In this work, we show that, surprisingly, off-the-shelf self-supervised learning outperforms transductive few-shot methods by 3.9% for 5-shot accuracy on miniImageNet without using any base class labels. This motivates us to examine more carefully the role of features learned through self-supervision in few-shot learning. Comprehensive experiments are conducted to compare the transferability, robustness, efficiency, and the complementarity of supervised and self-supervised features.
1 Introduction
Deep architectures have achieved significant success in various vision tasks including image classification and object detection. Such success have relied heavily on massive numbers of annotated examples. However, in real-world scenarios, we are frequently unable to collect enough labeled examples. This has motivated the study of few-shot learning (FSL), which focuses on building classifiers for novel categories from one or very few labeled examples.
Previous approaches to FSL include meta-learning and metric learning. Meta-learning aims to learn task-agnostic knowledge that improves optimization. Metric learning focuses on learning representations on base categories that can generalize to novel categories. Most previous FSL methods attempt to borrow a strong inductive bias from the supervised learning of base classes. However, the challenge of FSL is that a helpful inductive bias, i.e., one that improves performance on novel classes, is hard to develop when there is a large difference between the base and novel classes.
To address this challenge, previous research explores using unlabeled examples from novel classes to improve the generalization on novel classes, which is referred to transductive few-shot learning. Typical transductive few-shot learning (TFSL) methods include exploiting unlabeled novel examples that have been classified (by an initial classifier) with high confidence in order to self-train the model [26, 23, 4] or fine-tuning the model on unlabeled novel examples with an auxiliary loss serving as a regularizer [8, 31, 24]. These methods still focus on improving the generalization of inductive bias borrowed from the supervised learning of base classes.
In comparison, our key motivation is that, unlabeled examples from novel classes not only can fine-tune or retrain a pre-trained model, but also can effectively train a new model from scratch. The advantage of doing so is that the model can generalize better on novel classes. In this paper, we demonstrate the effectiveness of an extremely simple baseline for transductive few-shot learning. Our baseline does not use any labels on the base classes. We conduct self-supervised learning on unlabeled data from both the base and the novel classes to learn a feature embedding. When doing few-shot classification, we directly learn a linear classifier on top of the feature embedding from the few given labeled examples and then classify the testing examples. Surprisingly, this baseline significantly outperforms state-of-the-art transductive few-shot learning methods, which have additional access to base-class labels.
The empirical performance of this baseline should not be “the final solution” for few-shot learning. We believe that meta-learning, metric learning, data augmentation, and transfer learning are also critical for effective few-shot learning. However, this baseline can help us interpret existing results and indicates that using self-supervised learning to learn a generalized representation could be another important tool in addressing few-shot learning.
To investigate the best possible way to use self-supervised learning in few-shot learning, it is necessary to examine more carefully the role of features learned through self-supervision in few-shot learning. For brevity, we refer to these features as ‘self-supervised features’. (1) In a non-transductive few-shot learning setting, we explore the complementarity and transferability of supervised and self-supervised features. By directly concatenating self-supervised and supervised features, we get a 2-3% performance boost and achieve new state-of-the-art results. We conduct cross-domain few-shot learning and show that supervised features have better transferability than self-supervised features. However, when more novel labeled examples are given, self-supervised features overtake supervised features. (2) In a transductive few-shot learning setting, we show that simple off-the-shelf self-supervised learning significantly outperforms other competitors who have additional access to base-class labels. We confirm the performance gain is not from a better representation but from a representation that better generalizes on the novel classes. The proof is that the self-supervised features achieve the top performance on the novel classes but not on other unseen classes. (3) For both non-transductive and transductive settings, we conduct comprehensive experiments to explore the effect of different backbone architectures and datasets. We report results using a shallow ResNet, a very deep ResNet, a very wide ResNet, and a specially designed shallow ResNet that is commonly used for few-shot learning. While deeper models generally have significantly better performance for the standard classification task on both large (e.g, ImageNet [7]) and small datasets (e.g., CIFAR-10) as shown in [18], the performance gain is relatively small for supervised features in few-shot learning. In comparison, self-supervised features show a much larger improvement when using a deeper network, especially in the transductive setting. We also conduct experiments on various datasets, including large datasets, small datasets, and datasets that have small or large domain differences between base and novel classes. We show the efficiency and robustness of self-supervised features on all kinds of datasets except for very small datasets.
2 Related Work
Few-shot Learning. Few-shot learning is a classic problem [27], which refers to learning from one or a few labeled examples for each novel class. Existing FSL methods can be broadly grouped into three categories: data augmentation, meta-learning, and metric learning. Data augmentation methods synthesize [43, 34, 6], hallucinate [16] or deform [5] images to generate additional examples to address the training data scarcity. Meta-learning [10, 32, 28, 21] attempts to learn a parameterized mapping from limited training examples to hidden parameters that accelerate or improve the optimization procedure. Metric learning [37, 1, 22] aims at learning a transferable metric space (or embedding). MatchingNet [40] and ProtoNet [35] adopt cosine and Euclidean distance to separate instances belonging to different classes. Recently, some works [6, 25, 39] showed that learning a classifier on top of supervised features can achieve surprisingly competitive performance.

Transductive Few-shot Learning. TFSL methods use the distribution support of unlabeled novel instances to help few-shot learning. Some TFSL methods [26, 23, 42] exploit unlabeled instances with high confidence to train the model. [4] propose a data augmentation method to directly mix base examples and selected novel examples in the image domain to learn generalized features. In addition, previous work[8, 31, 24] seek to take unlabeled testing instances to acquire an auxiliary loss serving as a regularizer to adapt the inductive bias. These methods borrow inductive bias from the supervised learning of the base classes and further utilize unlabeled novel examples to improve it. In comparison, we show that unlabeled novel examples in addition to labeled examples of the base classes can directly develop a very strong inductive bias.
Self-supervised Learning. Self-supervised learning aims to explore the internal data distribution and learns discriminative features without annotations. Some work takes predicting rotation [13], counting [30], predicting the relative position of patches [9], colorization [46, 20], and solving jigsaw puzzles [29] as self-supervised tasks to learn representations. Recently, instance discrimination [44, 2, 15, 38] has attracted much attention. [17] propose a momentum contrast to update models and shows superior performance to supervised learning. In this work, we explore the generalization ability of self-supervised features to new classes in the few-shot setting, i.e., in circumstances where few labeled examples of novel classes are given. Other works that have explored transductive techniques, e.g., [17], have used large training sets for new classes. Gidaris et al. [12] and Su et al. [36] take rotation prediction, solving jigsaw as auxilary tasks to learn better representation on base classes to help few-shot learning. Tian et al. [39] utilize contrastive learning to learn features for non-transductive few-shot learning. In comparison, while previous works only conduct self-supervised learning under the non-transductive, we confirm the effectiveness of self-supervised learning in a transductive few-shot setting. We claim this as our major contribution.
3 Methods
In Fig. 1, we illustrate our few-shot learning settings. We denote the base category set as and the novel category set as , in which . Correspondingly, we denote the labeled base dataset as , the labeled novel dataset as , the unlabeled base dataset as , and the unlabeled novel dataset as .
In a standard few-shot learning task, we are only given labeled examples from base classes so the training set is . For transductive few-shot learning (TFSL), we are given . For unlabeled-base-class few-shot learning (UBC-FSL), we have . For unlabeled-base-class transductive few-shot learning (UBC-TFSL), we denote the training set as . Note that UBC-TFSL has strictly less supervision than TFSL and this setting has not been explored before. We claim we are the first to explore this setting.
These four few-shot learning settings use the same evaluation protocol as in previous works [40]. At inference time, we are given a collection of N-way-m-shot classification tasks sampled from to evaluate our methods.

3.1 Self-supervised learning
Here we take instance discrimination as our self-supervision task due to its efficiency. We follow momentum contrast [17], where each training example is augmented twice into and . and are then fed into two encoders forming two embeddings , and . A standard log-softmax function is used to discriminate a positive pair (2 instances augmented from one image) from several negative pairs (2 instances augmented from 2 images):
| (1) |
where is a temperature hyper-parameter. Since our implementations are based on MoCo-v2 [3], please refer to it for further details. We also try other self-supervised methods in § 4.6.
3.2 Evaluation Protocols
Here we introduce our protocols for the four different few-shot learning settings. All protocols consist of a training phase and an evaluation phase. In the training phase, we learn a feature embedding on the training sets , , , and . In the evaluation phase, we evaluate the few-shot classification performance. For simplicity and efficiency, we learn a logistic regression classifier on top of the learned feature embedding of training examples and then classify the testing examples. Training and testing examples come from the given N-way-m-shot classification task. Such procedures are repeated times and we report the average few-shot classification accuracies with 95% confidence intervals. Now, we would like to introduce our methods.
Few-shot learning baseline. We learn our embedding network on using cross-entropy loss under a standard classification process. We use the logit layer as the feature embedding as it is slightly better than the pre-classification layer. This baseline is very simple and achieve the state-of-the-art performance.
Unlabeled-base-class few-shot learning. For UBC-FSL, we learn from self-supervised supervision on . We follow MoCo-v2 to do instance discrimination. The output of the final layer of the model is used as the feature embedding.
Unlabeled-base-class transductive few-shot learning. For UBC-TFSL, our method is similar to our UBC-FSL method. The difference is that we train on , which has additional access to unlabeled test instances.
Combination of FSL baseline and UBC-FSL. This method works under standard, non-transductive, few-shot learning setting. We explore the complementarity between supervised features (from the FSL baseline) and self-supervised features (from UBC-FSL). We directly concatenate normalized supervised features and normalized self-supervised features and then do normalization again. T his feature is used as the feature embedding and we refer this method as “Combined”.
| miniImageNet | tieredImageNet | |||||
| setting | method | backbone | 1-shot | 5-shot | 1-shot | 5-shot |
| Non-transductive | MetaOptNet | ResNet-12∗ | 62.60.6 | 78.60.4 | 65.90.7 | 81.50.5 |
| Distill | ResNet-12∗ | 64.80.6 | 82.10.4 | 71.50.6 | 86.00.4 | |
| Neg-Cosine | ResNet-12∗ | 63.80.8 | 81.50.5 | - | - | |
| Neg-Cosine | WRN-28-10 | 61.70.8 | 81.70.5 | - | - | |
| UBC-FSL (Ours) | ResNet-12∗ | 47.80.6 | 68.50.5 | 52.80.6 | 69.80.6 | |
| UBC-FSL (Ours) | ResNet-12 | 56.90.6 | 76.50.4 | 58.00.7 | 76.30.5 | |
| UBC-FSL (Ours) | ResNet-50 | 56.20.6 | 75.40.4 | 66.60.7 | 83.10.5 | |
| UBC-FSL (Ours) | ResNet-101 | 57.50.6 | 77.20.4 | 68.00.7 | 84.30.5 | |
| UBC-FSL (Ours) | WRN-28-10 | 57.10.6 | 76.50.4 | 67.50.7 | 83.90.5 | |
| FSL baseline | ResNet-12∗ | 61.70.7 | 79.40.5 | 69.60.7 | 84.20.6 | |
| FSL baseline | ResNet-12 | 61.10.6 | 76.10.6 | 66.40.7 | 81.30.5 | |
| FSL baseline | ResNet-50 | 61.30.6 | 76.00.4 | 69.40.7 | 83.30.5 | |
| FSL baseline | ResNet-101 | 62.70.7 | 77.60.5 | 70.50.7 | 83.80.5 | |
| FSL baseline | WRN-28-10 | 62.40.7 | 77.50.5 | 70.20.7 | 83.50.5 | |
| Combined (Ours) | ResNet-12∗ | 59.80.8 | 73.30.7 | 69.20.7 | 82.00.6 | |
| Combined (Ours) | ResNet-12 | 63.80.7 | 79.90.6 | 67.80.7 | 83.00.5 | |
| Combined (Ours) | ResNet-50 | 63.90.9 | 79.90.5 | 72.30.7 | 86.10.5 | |
| Combined (Ours) | ResNet-101 | 65.60.6 | 81.60.4 | 73.50.7 | 86.70.5 | |
| Combined (Ours) | WRN-28-10 | 65.20.6 | 81.20.4 | 73.10.7 | 86.40.5 | |
| Transductive | ICI | ResNet-12∗ | 66.81.1 | 79.10.7 | 80.7 1.1 | 87.90.6 |
| ICI | ResNet50 | 60.21.1 | 75.20.7 | 78.61.1 | 86.80.6 | |
| ICI | ResNet101 | 64.31.2 | 78.10.7 | 82.41.0 | 89.40.6 | |
| TAFSSL | DenseNet | 80.10.2 | 85.70.1 | 86.00.2 | 89.30.1 | |
| EPNet | WRN-28-10 | 79.20.9 | 88.00.5 | 83.60.9 | 89.30.5 | |
| EPNet (full) | WRN-28-10 | 80.20.8 | 88.90.5 | 84.80.8 | 89.90.6 | |
| UBC-TFSL (Ours) | ResNet-12∗ | 51.10.9 | 74.60.6 | 57.20.6 | 74.70.6 | |
| UBC-TFSL (Ours) | ResNet-12 | 70.30.6 | 86.90.3 | 65.70.7 | 81.40.5 | |
| UBC-TFSL (Ours) | ResNet-50 | 79.10.6 | 92.10.3 | 81.00.6 | 90.70.4 | |
| UBC-TFSL (Ours) | ResNet-101 | 80.40.6 | 92.80.2 | 87.00.6 | 93.60.3 | |
| UBC-TFSL (Ours) | WRN-28-10 | 80.30.6 | 92.40.2 | 85.70.6 | 93.00.3 | |
4 Experiments
We define two types of experiments based upon whether the base and novel classes come from the same dataset or not. We refer to the standard FSL paradigm in which the base and novel classes come from the same dataset (e.g., ImageNet) as single-domain FSL. We also perform experiments in which the novel classes are chosen from a separate dataset, which we call cross-domain FSL. In cross-domain FSL, the domain differences between the base and novel classes are much larger than the single-domain FSL. For both setting, we report 5-way-1-shot and 5-way-5-shot accuracies.
Datasets. For single-domain FSL, we run experiments on three datasets: miniImageNet [40], tieredImageNet [33], and Caltech-256 [14]. The miniImageNet contains 100 classes randomly selected from ImageNet [7] with 600 images per class. We follow [32] to split the categories into 64 base, 16 validation, and 20 novel classes. The tieredImageNet is another subset of ImageNet but has far more classes (608 classes). These classes are first divided into 34 groups and then further divided into 20 training groups (351 classes), 6 validation groups (97 classes), and 8 testing groups (160 classes), which ensure the distinction between training and testing sets. Caltech-256 (Caltech) has 30607 images from 256 classes. Following [6], we split it into 150, 56, and 50 classes for training, validation, and testing respectively.
For the cross-domain experiments, we construct a dataset that has high dissimilarity between base and novel classes by drawing the base classes from one dataset and the novel classes from another. We denote this dataset as ’miniImageNet&CUB’, which is a combination of miniImageNet and CUB-200-2011 (CUB) dataset [41]. CUB is a fine-grained image classification dataset including 200 bird classes and 11788 bird images. We follow [19] to split the categories into 100 base, 50 validation, and 50 novel classes. In miniImageNet&CUB, the training set (base classes) contains 64 classes from miniImageNet and the testing set (novel classes) contains 100 classes from CUB. Specifically, the 64 classes in the training set are the 64 base classes in miniImageNet and the 100 classes in the test set are the 100 base classes in CUB.
Competitors. We compare our methods with the top few-shot learning methods: MetaOptNet [21], Distill [39], and Neg-Cosine [25]. We also compare with three transductive few-shot learning methods: ICI [42], TAFSSL [24], and EPNet [31]. TFSL methods have 100 unlabeled images per novel class by default. EPNet (full) and our UBC-TFSL uses all of the images of novel classes as unlabeled training samples.
Implementation details. Most of our settings are the same as [3]. We use a mini-batch size of 256 with 8 GPUs. We set the learning rate as 0.03 and use cosine annealing to decrese the learning rate. The feature dimension for contrastive loss is 128. The momentum for memory update is 0.5 and the temperature is set as 0.07. For miniImageNet, miniImageNet&CUB, and Caltech-256, we sample 2048 negative pairs in our contrastive loss and train 1000 epochs. For tieredImageNet, we sample 20480 negative pairs and train 800 epochs.
Architecture. We use ResNet-12∗, ResNet-12, ResNet-50, ResNet-101, and WRN-28-10 as our backbone architecture. ResNet-12∗ is a modified version of ResNet-12 and will be introduced in Sec.§ 4.2. WRN-28-10 [45] is a very wide version of ResNet-10 and have 36.5M parameters whereas ResNet-50 and ResNet-101 have 25.6M and 44.4M parameters respectively.
4.1 Self-supervised learning can develop a strong inductive bias with no base-class labels


[36] shed light on improving few-shot learning with self-supervision and claim that “Self-supervision alone is not enough” for FSL. We agree there is still a gap between unlabeled-base-class few-shot learning and few-shot learning. However, in the transductive few-shot classification setting, we present the surprising result that state-of-the-art performance can be obtained without using any labeled examples from the base classes at all.
The results on miniImageNet and tieredImageNet are shown in Table 1. A better visualization is shown in Fig. 2. Results on Caltech-256 and miniImageNet&CUB are provided in supplementary material. We notice that (1) UBC-FSL shows some potential. Even without any base-class labels, it only underperforms the state-of-the-art few-shot methods by in 1-shot and 5-shot accuracy on miniImageNet and tieredImageNet. (2) There is great complementarity among supervised features and self-supervised features. Combining supervised and self-supervised features (“Combined”) beats the FSL baseline on all four datasets for all backbone networks. Specifically, it gives 4% and 2.9% improvements in 5-shot accuracy on miniImageNet and tieredImageNet when using ResNet-101. Also, it beats all other FSL competitors on tieredImageNet. (3) For the transductive few-shot classification setting, state-of-the-art can be obtained without actually using any labeled examples at all. Even without any base-class labels, UBC-TFSL significantly surpasses all other methods. In Table 1, it outperforms all other TFSL methods by and for 5-shot accuracy on miniImageNet and tieredImageNet respectively. (4) The FSL baseline struggles to learn a strong inductive bias with high dissimilarity between base and novel classes (cross-domain) whereas such dissimilarity has a relatively minor effect on UBC-TFSL. In miniImageNet&CUB (please refer to supplementary), UBC-TFSL outperforms the FSL baseline by and for 1-shot and 5-shot accuracy respectively.
4.2 A deeper network is better
While deeper models generally have better performance for the standard classification task on both large (e.g, ImageNet [7]) and small dataset(e.g., CIFAR-10) as shown in [18], most previous few-shot methods [39, 21] report the best results with a modified version (ResNet-12∗) of ResNet-12[18]. ResNet-12∗ employs several modifications, including making it wider, changing the input size from to , using Leaky ReLU’s instead of ReLU’s, adding additional Dropblock layers [11], and removing the global pooling layer after the last residual block. We feel that the effect of different backbone architecture is not very clear in few-shot learning literature. We want to know if using a very deep network (e.g., ResNet-101) can bring significant improvement in few-shot classification as in the standard classification task. More importantly, we want to explore the differences between supervised and self-supervised features when using various backbone architectures in few-shot learning.
As shown in Table 1, we report results using ResNet-12∗, ResNet-12, ResNet-50, ResNet-101, and WRN-28-10. To better compare the effect of depth of backbone architecture, we visualize the performance in Fig. 3. We notice that (1) ResNet-101 have the best performance and all our baselines benefit from deeper network in most cases. (2) The commonly used ResNet-12∗ work well for FSL baseline but do not suit for self-supervised learning based baselines. (3) The wide network WRN-28-10 has very good performance on all our baselines, only slightly underperform ResNet-101. We confirm that few-shot learning can actually benefit from a deeper or wider backbone architecture. The performance gain is small for supervised features (FSL baseline) and large for self-supervised features (UBC-FSL), especially in a transductive setting (UBC-TFSL).

4.3 Supervised vs. self-supervised features in cross-domain FSL
Another interesting question is whether models learned in a single domain can perform well in a new domain (with highly dissimilar classes). To study this, we conduct cross-domain FSL, in which we learn models on miniImageNet or tieredImageNet and evaluate our models on Caltech-256 and CUB. Specifically, the FSL baseline and UBC-FSL are trained on base classes of the source dataset, and UBC-TFSL are trained on both base and novel classes of the source dataset. Then, we evaluate our methods on the testing set of target datasets (Caltech-256 and CUB).
Notice that the way we are applying the UBC-TFSL model, it does not qualify as a true transductive setting, since the model does not have access to unlabeled data from the testing set. Instead, we are testing whether this model can improve its performance on cross-domain classes with unlabeled data from additional classes in the source data set.
Previous work [17] compares supervised and self-supervised features when transferring to a new domain for classification, object detection, and instance segmentation. It shows that self-supervised features have better transferability for these tasks. However, the conclusion is based on when large numbers of labeled examples are used to learn the final linear classifier. In few-shot setting, we show that supervised features do better than self-supervised features.
In the first row of Fig. 4, we compare UBC-FSL, FSL baseline, UBC-TFSL, and Combined in cross-domain FSL. The x-axis and y-axis denote the 1-shot testing accuracy on the source and target dataset respectively. Surprisingly, supervised features (FSL baseline, Combined) significantly outperform self-supervised features (UBC-FSL, UBC-TFSL) on the target dataset even if they have lower accuracy on the source dataset. In the second row of Fig. 4, we visualize the performance of our methods on base and novel classes in single-domain FSL. The x-axis and y-axis denote the 1-shot accuracy on base and novel classes respectively. As you can see, UBC-TFSL (gray points) outperforms FSL baseline (orange) on novel classes but underperforms on base classes. These experiments show that UBC-TFSL has mediocre performance when it does not have access to unlabeled data from the test classes, but performs extremely well when it does. In other words, it is not simply access to additional unlabeled data that helps, but rather, data from the test classes themselves.
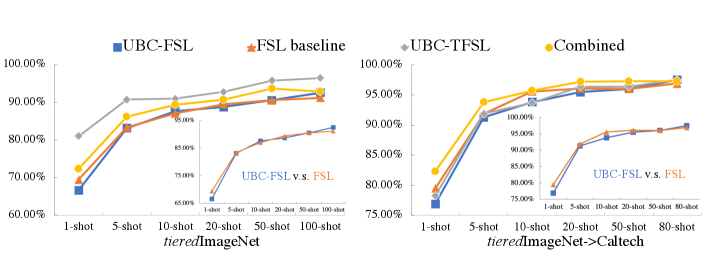
4.4 Supervised vs. self-supervised features with larger shots
In Fig. 5, we compare UBC-FSL, the FSL baseline, UBC-TFSL and Combined with larger shots using ResNet-50 on tieredImageNet and tieredImageNet-Caltech (cross-domain FSL). For 1-shot learning, there is a large gap around 5% between UBC-FSL and the FSL baseline. However, as the shots become larger, this gap gradually diminishes. For 100-shot on tieredImageNet and 80-shot on Caltech, UBC-FSL even outperforms the FSL baseline by 1.3% and 0.6% respectively.
We suggest that supervised features may contain higher-level semantic concepts that are easier to digest with a few training instances while self-supervised features have better transferability with abundant training data. This statement is compatible with previous work [17], which use abundant labeled data to learn the final classification layer and claims that self-supervised features have better transferability.
4.5 Supervised vs. self-supervised features and dataset size
In this section, we compare supervised and self-supervised features under various dataset sizes. We conduct experiments on Caltech, miniImageNet, and tieredImageNet, which have 30607, 60000, and 779165 images respectively. We also randomly select subsets of miniImageNet (20%, 40%, 60%, 80%, and 100%) and report the 1-shot accuracy. An equal portion of examples from each class are randomly selected. As shown in Fig. 6, self-supervised features (UBC-TFSL) significantly outperform other methods with a big dataset. However, when the dataset is small (e.g., Caltech-256 and 20% of miniImageNet), it is overtaken by the FSL baseline. This result suggests that supervised features are more robust to dataset size.
4.6 Comparing different self-supervised methods
| miniImageNet | ||||
|---|---|---|---|---|
| method | backbone | 1-shot | 5-shot | |
| UBC-FSL (MoCo-v2) | ResNet-101 | 57.50.6 | 77.20.4 | |
| UBC-FSL (CMC) | ResNet-101 | 56.90.6 | 76.90.5 | |
| UBC-FSL (SimCLR) | ResNet-101 | 57.60.7 | 76.70.6 | |
| UBC-TFSL (MoCo-v2) | ResNet-101 | 80.40.6 | 92.80.2 | |
| UBC-TFSL (CMC) | ResNet-101 | 79.70.6 | 92.10.3 | |
| UBC-TFSL (SimCLR) | ResNet-101 | 79.50.7 | 92.20.3 | |
As shown in Table 2, we compare three different instance discrimination methods to learn the feature embedding. Here we compare MoCo-v2 [3], CMC [38], and SimCLR [2]. From the results, we can see that all these self-supervised methods can learn a powerful inductive bias, especially in the transductive setting, suggesting that most self-supervised methods can be generalized to learn a good embedding for few-shot learning.
5 Conclusion
Most previous FSL methods borrow a strong inductive bias from the supervised learning of base classes. In this paper, we show that no base class labels are needed to develop such an inductive bias and that self-supervised learning can provide a powerful inductive bias for few-shot learning. We examine the role of features learned through self-supervision in few-shot learning through comprehensive experiments.
References
- [1] Peyman Bateni, Raghav Goyal, Vaden Masrani, Frank Wood, and Leonid Sigal. Improved few-shot visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [2] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
- [3] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
- [4] Zitian Chen, Yanwei Fu, Kaiyu Chen, and Yu-Gang Jiang. Image block augmentation for one-shot learning. In Association for the Advancement of Artificial Intelligence (AAAI), volume 33, pages 3379–3386, 2019.
- [5] Zitian Chen, Yanwei Fu, Yu-Xiong Wang, Lin Ma, Wei Liu, and Martial Hebert. Image deformation meta-networks for one-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8680–8689, 2019.
- [6] Zitian Chen, Yanwei Fu, Yinda Zhang, Yu-Gang Jiang, Xiangyang Xue, and Leonid Sigal. Multi-level semantic feature augmentation for one-shot learning. IEEE Transactions on Image Processing, 28(9):4594–4605, 2019.
- [7] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255, 2009.
- [8] Guneet Singh Dhillon, Pratik Chaudhari, Avinash Ravichandran, and Stefano Soatto. A baseline for few-shot image classification. In Proceedings of the International Conference on Learning Representations (ICLR), 2019.
- [9] Carl Doersch, Abhinav Gupta, and Alexei A Efros. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1422–1430, 2015.
- [10] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning (ICML), pages 1126–1135, 2017.
- [11] Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. Dropblock: A regularization method for convolutional networks. In Advances in Neural Information Processing Systems (NeurIps), 2018.
- [12] Spyros Gidaris, Andrei Bursuc, Nikos Komodakis, Patrick Pérez, and Matthieu Cord. Boosting few-shot visual learning with self-supervision. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 8059–8068, 2019.
- [13] Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations (ICLR), 2018.
- [14] Gregory Griffin, Alex Holub, and Pietro Perona. Caltech-256 object category dataset. 2007.
- [15] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprint arXiv:2006.07733, 2020.
- [16] Bharath Hariharan and Ross Girshick. Low-shot visual recognition by shrinking and hallucinating features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 3018–3027, 2017.
- [17] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 9729–9738, 2020.
- [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2015.
- [19] Nathan Hilliard, Lawrence Phillips, Scott Howland, Artëm Yankov, Courtney D Corley, and Nathan O Hodas. Few-shot learning with metric-agnostic conditional embeddings. arXiv preprint arXiv:1802.04376, 2018.
- [20] Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Colorization as a proxy task for visual understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6874–6883, 2017.
- [21] Kwonjoon Lee, Subhransu Maji, Avinash Ravichandran, and Stefano Soatto. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 10657–10665, 2019.
- [22] Aoxue Li, Weiran Huang, Xu Lan, Jiashi Feng, Zhenguo Li, and Liwei Wang. Boosting few-shot learning with adaptive margin loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 12576–12584, 2020.
- [23] Xinzhe Li, Qianru Sun, Yaoyao Liu, Qin Zhou, Shibao Zheng, Tat-Seng Chua, and Bernt Schiele. Learning to self-train for semi-supervised few-shot classification. In Advances in Neural Information Processing Systems (NeurIps), 2019.
- [24] Moshe Lichtenstein, Prasanna Sattigeri, Rogerio Feris, Raja Giryes, and Leonid Karlinsky. Tafssl: Task-adaptive feature sub-space learning for few-shot classification. Proceedings of the European Conference on Computer Vision (ECCV), pages 522–539, 2020.
- [25] Bin Liu, Yue Cao, Yutong Lin, Qi Li, Zheng Zhang, Mingsheng Long, and Han Hu. Negative margin matters: Understanding margin in few-shot classification. In Proceedings of the European Conference on Computer Vision (ECCV), pages 438–455, 2020.
- [26] Yanbin Liu, Juho Lee, Minseop Park, Saehoon Kim, Eunho Yang, Sung Ju Hwang, and Yi Yang. Learning to propagate labels: Transductive propagation network for few-shot learning. In Proceedings of the International Conference on Learning Representations (ICLR), 2018.
- [27] Erik G. Miller, Nicholas E. Matsakis, and Paul A. Viola. Learning from one example through shared densities on transforms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, pages 464–471, 2000.
- [28] Tsendsuren Munkhdalai and Hong Yu. Meta networks. In Proceedings of the International Conference on Machine Learning (ICML), pages 2554–2563, 2017.
- [29] Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. In Proceedings of the European Conference on Computer Vision (ECCV), pages 69–84, 2016.
- [30] Mehdi Noroozi, Hamed Pirsiavash, and Paolo Favaro. Representation learning by learning to count. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), pages 5898–5906, 2017.
- [31] Rodríguez Pau, Laradji Issam, Drouin Alexandre, and Lacoste Alexandre. Embedding propagation: Smoother manifold for few-shot classification. Proceedings of the European Conference on Computer Vision (ECCV), pages 121–138, 2020.
- [32] Sachin Ravi and Hugo Larochelle. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations (ICLR), 2017.
- [33] Mengye Ren, Eleni Triantafillou, Sachin Ravi, Jake Snell, Kevin Swersky, Joshua B Tenenbaum, Hugo Larochelle, and Richard S Zemel. Meta-learning for semi-supervised few-shot classification. In Proceedings of the International Conference on Learning Representations (ICLR), 2018.
- [34] Eli Schwartz, Leonid Karlinsky, Joseph Shtok, Sivan Harary, Mattias Marder, Abhishek Kumar, Rogerio Feris, Raja Giryes, and Alex Bronstein. Delta-encoder: An effective sample synthesis method for few-shot object recognition. In Advances in Neural Information Processing Systems (NeurIPS), 2018.
- [35] Jake Snell, Kevin Swersky, and Richard S. Zemeln. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems Advances in Neural Information Processing Systems (NeurIPS), 2017.
- [36] Jong-Chyi Su, Subhransu Maji, and Bharath Hariharan. When does self-supervision improve few-shot learning? Proceedings of the European Conference on Computer Vision (ECCV), pages 645–666, 2020.
- [37] Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip H.S. Torr, and Timothy M. Hospedales. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1199–1208, 2018.
- [38] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. Proceedings of the European Conference on Computer Vision (ECCV), 2020.
- [39] Yonglong Tian, Yue Wang, Dilip Krishnan, Joshua B Tenenbaum, and Phillip Isola. Rethinking few-shot image classification: a good embedding is all you need? arXiv preprint arXiv:2003.11539, 2020.
- [40] Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. Matching networks for one shot learning. In Advances in Neural Information Processing Systems Advances in Neural Information Processing Systems (NeurIPS), 2016.
- [41] Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011.
- [42] Yikai Wang, Chengming Xu, Chen Liu, Li Zhang, and Yanwei Fu. Instance credibility inference for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 12836–12845, 2020.
- [43] Yu-Xiong Wang, Ross Girshick, Martial Hebert, and Bharath Hariharan. Low-shot learning from imaginary data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7278–7286, 2018.
- [44] Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3733–3742, 2018.
- [45] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. In Proceedings of the British Machine Vision Conference (BMVC), 2016.
- [46] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. In Proceedings of the European Conference on Computer Vision (ECCV), pages 649–666, 2016.
Appendix
A1 Compare to TFSL using the same backbone network
To further make a fair comparison with TFSL methods, we implement EPNet111We use public code available at https://github.com/ElementAI/embedding-propagation. and use ResNet-12, ResNet-50, ResNet-101 as its backbone. All experiments setting are the same and we have 600 unlabeled images per novel class. As shown in Table A1, we report results on miniImageNet.
| miniImageNet | ||||
|---|---|---|---|---|
| method | backbone | 1-shot | 5-shot | |
| EPNet | ResNet-12 | 75.91.0 | 84.80.6 | |
| EPNet | ResNet-50 | 75.41.1 | 84.30.7 | |
| EPNet | ResNet-101 | 76.10.8 | 86.00.7 | |
| UBC-TFSL | ResNet-12 | 70.30.6 | 86.90.3 | |
| UBC-TFSL | ResNet-50 | 79.10.6 | 92.10.3 | |
| UBC-TFSL | ResNet-101 | 80.40.6 | 92.80.2 | |
| Caltech | miniImageNet&CUB | |||||
| setting | method | backbone | 1-shot | 5-shot | 1-shot | 5-shot |
| Non-transductive | UBC-FSL (Ours) | ResNet-12∗ | 48.70.6 | 68.90.6 | 36.00.5 | 54.30.5 |
| UBC-FSL (Ours) | ResNet-12 | 54.00.6 | 74.60.5 | 39.10.6 | 57.60.5 | |
| UBC-FSL (Ours) | ResNet-50 | 49.60.7 | 69.00.5 | 39.40.6 | 57.70.5 | |
| UBC-FSL (Ours) | ResNet-101 | 50.10.6 | 69.90.5 | 40.70.6 | 59.40.6 | |
| FSL baseline | ResNet-12∗ | 65.70.6 | 81.50.5 | 42.80.5 | 60.90.6 | |
| FSL baseline | ResNet-12 | 64.10.6 | 80.50.6 | 42.60.6 | 60.60.5 | |
| FSL baseline | ResNet-50 | 65.70.7 | 81.90.3 | 43.60.6 | 62.10.5 | |
| FSL baseline | ResNet-101 | 66.40.6 | 82.50.4 | 43.90.6 | 62.40.6 | |
| Combined (Ours) | ResNet-12∗ | 65.40.6 | 82.70.5 | 42.90.5 | 61.70.7 | |
| Combined (Ours) | ResNet-12 | 64.70.6 | 82.40.4 | 43.40.6 | 63.20.5 | |
| Combined (Ours) | ResNet-50 | 65.60.6 | 82.80.4 | 44.10.6 | 64.40.5 | |
| Combined (Ours) | ResNet-101 | 66.50.5 | 83.20.4 | 45.10.6 | 65.60.5 | |
| Transductive | UBC-TFSL (Ours) | ResNet-12∗ | 56.40.6 | 74.80.6 | 39.70.4 | 58.90.5 |
| UBC-TFSL (Ours) | ResNet-12 | 60.70.7 | 80.00.5 | 44.90.6 | 65.00.6 | |
| UBC-TFSL (Ours) | ResNet-50 | 61.80.6 | 81.40.5 | 59.10.8 | 76.20.6 | |
| UBC-TFSL (Ours) | ResNet-101 | 61.40.6 | 80.30.5 | 59.00.8 | 75.50.6 | |
A2 Results on Caltech-256 and miniImageNet&CUB
We report our results on Caltech-256 and miniImageNet&CUB in Table A2.
A3 Results for cross-domain FSL
| miniImageNetCaltech | miniImageNetCUB | ||||
|---|---|---|---|---|---|
| method | backbone | 1-shot | 5-shot | 1-shot | 5-shot |
| UBC-FSL (Ours) | ResNet-12 | 41.30.5 | 59.10.6 | 60.20.7 | 80.10.4 |
| UBC-FSL (Ours) | ResNet-50 | 41.40.6 | 58.50.6 | 58.80.6 | 79.00.5 |
| UBC-FSL (Ours) | ResNet-101 | 42.30.5 | 59.90.6 | 60.80.6 | 80.70.4 |
| FSL baseline | ResNet-12 | 46.00.6 | 63.70.5 | 62.40.6 | 79.10.4 |
| FSL baseline | ResNet-50 | 46.30.6 | 64.90.5 | 63.20.8 | 79.90.5 |
| FSL baseline | ResNet-101 | 47.30.6 | 65.60.5 | 64.60.7 | 81.10.5 |
| Combined (Ours) | ResNet-12 | 46.40.6 | 65.10.5 | 65.50.6 | 83.00.4 |
| Combined (Ours) | ResNet-50 | 47.00.4 | 66.30.5 | 65.70.8 | 83.20.4 |
| Combined (Ours) | ResNet-101 | 47.60.6 | 67.30.5 | 67.40.5 | 84.50.4 |
| UBC-TFSL (Ours) | ResNet-12 | 41.50.5 | 59.20.6 | 61.10.6 | 81.10.5 |
| UBC-TFSL (Ours) | ResNet-50 | 43.10.5 | 61.00.7 | 62.30.6 | 82.80.4 |
| UBC-TFSL (Ours) | ResNet-101 | 44.00.6 | 61.70.6 | 63.00.6 | 83.30.4 |
| tieredImageNetCaltech | tieredImageNetCUB | ||||
|---|---|---|---|---|---|
| method | backbone | 1-shot | 5-shot | 1-shot | 5-shot |
| UBC-FSL (Ours) | ResNet-12 | 46.30.5 | 64.30.6 | 65.20.7 | 84.10.5 |
| UBC-FSL (Ours) | ResNet-50 | 58.10.7 | 76.30.6 | 76.90.5 | 91.30.4 |
| UBC-FSL (Ours) | ResNet-101 | 57.00.7 | 75.40.6 | 78.90.8 | 92.50.4 |
| FSL baseline | ResNet-12 | 63.60.7 | 82.40.5 | 75.20.7 | 90.00.4 |
| FSL baseline | ResNet-50 | 70.00.5 | 85.50.5 | 79.50.7 | 91.90.5 |
| FSL baseline | ResNet-101 | 72.90.7 | 87.20.5 | 80.70.7 | 92.60.3 |
| Combined (Ours) | ResNet-12 | 58.8 0.8 | 79.20.6 | 75.60.6 | 90.60.3 |
| Combined (Ours) | ResNet-50 | 69.00.7 | 86.20.4 | 82.30.6 | 93.80.4 |
| Combined (Ours) | ResNet-101 | 70.60.7 | 87.30.3 | 83.80.5 | 94.60.3 |
| UBC-TFSL (Ours) | ResNet-12 | 44.80.6 | 62.70.7 | 66.00.7 | 84.60.7 |
| UBC-TFSL (Ours) | ResNet-50 | 56.50.6 | 74.50.6 | 78.30.6 | 91.90.4 |
| UBC-TFSL (Ours) | ResNet-101 | 59.40.7 | 76.30.7 | 81.10.7 | 93.30.5 |