Jing Wang \Email[email protected]
\NameAnna Choromanska \Email[email protected]
\addrDepartment of Electrical and Computer Engineering, New York University
SGB: Stochastic Gradient Bound Method for Optimizing
Partition Functions
Abstract
This paper addresses the problem of optimizing partition functions in a stochastic learning setting. We propose a stochastic variant of the bound majorization algorithm from [Jebara and Choromanska(2012)] that relies on upper-bounding the partition function with a quadratic surrogate. The update of the proposed method, that we refer to as Stochastic Partition Function Bound (SPFB), resembles scaled stochastic gradient descent where the scaling factor relies on a second order term that is however different from the Hessian. Similarly to quasi-Newton schemes, this term is constructed using the stochastic approximation of the value of the function and its gradient. We prove sub-linear convergence rate of the proposed method and show the construction of its low-rank variant (LSPFB). Experiments on logistic regression demonstrate that the proposed schemes significantly outperform SGD. We also discuss how to use quadratic partition function bound for efficient training of deep learning models and in non-convex optimization.
1 Introduction
The problem of estimating the probability density function over a set of random variables underlies majority of learning frameworks and heavily depends on the partition function. Partition function is a normalizer of a density function and ensures that it integrates to . This function needs to be minimized when learning proper data distribution. Optimizing the partition function however is a hard and often intractable problem [Goodfellow et al.(2016)Goodfellow, Bengio, and Courville]. It has been addressed in a number of ways in the literature. Below we review strategies that directly confront the partition function (we skip pseudo-likelihood strategies [Huang and Ogata(2002)] and score matching [Hyvärinen(2005)] and ratio matching [Hyvarinen(2007)] techniques, which avoid direct partition function computations).
There exists a variety of Markov chain Monte Carlo methods for approximately maximizing the likelihood of models with partition functions such as i) contrastive divergence [Hinton(2002), Carreira-Perpiñán and Hinton(2005)] and persistent contrastive divergence [Tieleman(2008)], which perform Gibbs sampling and are used inside a gradient descent procedure to compute model parameter update, and ii) fast persistent contrastive divergence [Tieleman and Hinton(2009)], which relies on re-parametrizing the model and introducing the parameters that are trained with much larger learning rate such that the Markov chain is forced to mix rapidly. The above mentioned techniques are Gibbs sampling strategies that focus on estimating the gradient of the log-partition function. Another technique called noise-contrastive estimation [Gutmann and Hyvärinen(2012)] treats partition function like an additional model parameter whose estimate can be learned via nonlinear logistic regression discriminating between the observed data and some artificially generated noise. Methods that directly estimate the partiton function rely on importance sampling. More conretely they estimate the ratio of the partition functions of two models, where one of the partition function is known. The extensions of this technique, annealed importance sampling [Neal(2001), Jarzynski(1997)] and bridge sampling [Bennett(1976)], cope with the setting where two considered distributions are far from each other.
Finally, bound majorization constitutes yet another strategy for performing density estimation. Bound majorization methods iteratively construct and optimize variational bound on the original optimization problem. Among these techniques we have iterative scaling schemes [Darroch and Ratcliff(1972), Berger(1997)], EM algorithm [Balakrishnan et al.(2017)Balakrishnan, Wainwright, and Yu, Dempster et al.(1977)Dempster, Laird, and Rubin], non-negative matrix factorization method [Lee and Seung()], convex-concave procedure [Yuille and Rangarajan(2002)], minimization by incremental surrogate optimization [Mairal(2015)], and technique based on constructing quadratic partition function bound [Jebara and Choromanska(2012)] (early predecessors of these techniques include [Böhning and Lindsay(1988), Lafferty et al.(2001)Lafferty, McCallum, and Pereira]). The latter technique uses tighter bound compared to the aforementioned methods, and exhibits faster convergence compared to generic first- [Malouf(2002), Wallach(2002), Sha and Pereira(2003)] and second-order [Zhu et al.(1997)Zhu, Byrd, Lu, and Nocedal, Benson and More(2001), Andrew and Gao(2007)] techniques in the batch optimization setting for both convex and non-convex learning problems. In this paper we revisit the quadratic bound majorization technique and propose its stochastic variant that we analyze both theoretically and empirically. We prove its convergence rate and show that it is performing favorably compared to SGD [Robbins and Monro(1951), Bottou(2010)]. Finally, we propose future research directions that can utilize quadratic partition function bound in non-convex optimization, including deep learning setting. With a pressing need to develop landscape-driven deep learning optimization strategies [Feng and Tu(2020), Chaudhari et al.(2017)Chaudhari, A. Choromanska, Soatto, LeCun, Baldassi, Borgs, Chayes, Sagun, and Zecchina, Chaudhari et al.(2019)Chaudhari, A. Choromanska, Soatto, LeCun, Baldassi, Borgs, Chayes, Sagun, and Zecchina, Hochreiter and Schmidhuber(1997), Jastrzebski et al.(2018)Jastrzebski, Kenton, Arpit, Ballas, Fischer, Bengio, and Storkey, Wen et al.(2018)Wen, Wang, Yan, Xu, Chen, and Li, Keskar et al.(2017)Keskar, Mudigere, Nocedal, Smelyanskiy, and Tang, Sagun et al.(2018)Sagun, Evci, Güney, Dauphin, and Bottou, Simsekli et al.(2019)Simsekli, Sagun, and Gürbüzbalaban, Jiang et al.(2019)Jiang, Neyshabur, Mobahi, Krishnan, and Bengio, Chaudhari et al.(2017)Chaudhari, A. Choromanska, Soatto, LeCun, Baldassi, Borgs, Chayes, Sagun, and Zecchina, Baldassi et al.(2015)Baldassi, Ingrosso, Lucibello, Saglietti, and Zecchina, Baldassi et al.(2016a)Baldassi, Borgs, Chayes, Ingrosso, Lucibello, Saglietti, and Zecchina, Baldassi et al.(2016b)Baldassi, Gerace, Lucibello, Saglietti, and Zecchina], we foresee the resurgence of interest in bound majorization techniques and its applicability to non-convex learning problems.
2 Method
boxruled \IncMargin1em {algorithm2e}[H] \LinesNumbered
, observation , . \KwOutBound parameters: , ,
Init , ,
boxruled \IncMargin1em {algorithm2e}[H] \LinesNumbered\KwIninitial parameters , training data set , features , learning rates , regularization coefficient \KwOutModel parameters
Consider the log-linear model given by a density function of the form
| (2.1) |
where is the observation-label pair (), represents a feature map, is a model parameter vector, and is the partition function. Maximum likelihood framework estimates from a training data set by maximizing the objective function of the form
| (2.2) |
where the second term is a regularization ( is a regularization coefficient). This framework and its various extensions underlie logistic regression, conditional random fields, maximum entropy estimation, latent likelihood, deep belief networks, and other density estimation approaches. Equation 2.2 requires minimizing the partition function . This can be done by optimizing the variational quadratic bound on the partition function instead. The bound is shown in Theorem 1.
2.1 Stochastic Partition Function Bound (SPFB)
The partition function bound of Algorithm 2 can be used to optimize the objective in Equation 2.2. The maximum likelihood parameter update given by the bound takes the form:
| (2.4) |
where s and s are computed from Algorithm 2. In contrast to the above full-batch update, Stochastic Partition Function Bound (SPFB) method that we propose in Algorithm 2 updates parameters after seeing each training data point, rather than the entire data set, according to the formula:
| (2.5) |
where is the learning rate. Denote to be an unbiased estimation of objective function , where . The above formula (2.5) can be rewritten as
| (2.6) |
The next theorem shows the convergence rate of SPFB.
Theorem 2
is the sequence of parameters generated by Algorithm 2. There exists , such that for all iterations ,
| (2.7) |
and there exists a constant , such that for all , . Define the learning rate in iteration as , where . Then for all ,
| (2.8) |
where .
Theorem 2 guarantees sub-linear convergence rate for SPFB when the step size is diminishing. However, the time complexity of SPFB is , due to the computation and inversion of matrix , which is less appealing than the complexity of SGD. This is next addressed.
2.2 Low-rank bound
In this section, we provide a low-rank construction of the bound that applies to both batch and stochastic setting. We decompose matrix into , where (orthnormal matrix), , and (diagonal matrix) and apply Woodbury formula to compute the inverse: (clearly, the inverse only requires time and does not affect the total time complexity when rank ). Note that Algorithm 2 performs rank-one update to matrix of the form: , where ). This update can be “projected” onto matrices , and . The concrete updates of matrices , and are shown in Algorithm 2.2. The next theorem, Theorem 3, guarantees that the low-rank bound is indeed an upper-bound on the partition function 111We simultaneously repair the low-rank bound construction of [Jebara and Choromanska(2012)], which breaks this property..
Theorem 3
Let . In each iteration of the -loop in Algorithm 2.2 finds such that
| (2.9) |
for any for any .
Low-rank variant of Algorithm 2 is presented in Algorithm 2.2. Note that all proofs supporting this section are deferred to the Supplement.
boxruled \IncMargin2em {algorithm2e}[H] Low-rank Partition Function Bound \LinesNumbered\KwIn, observation , , rank \KwOutLow-rank bound parameters: , , , , , , , ,
\For(\tcp*[h]-loop)each sample in batch Init ,
\Foreach label ; ;
; ; ,
; ; ;
,
\uIf
; ; \uElse ;
,
boxruled \IncMargin1em {algorithm2e}[H] MLE via Low-rank Stochastic Partition Function Bound (LSPFB) \LinesNumbered\KwIninitial parameters , training data set , features , learning rates , regularization coefficient \KwOutModel parameters
Set
\Whilenot converged randomly select a training point
Get , , , from , , via Algorithm 2.2 (input batch is a single data point )
;
3 Experiments
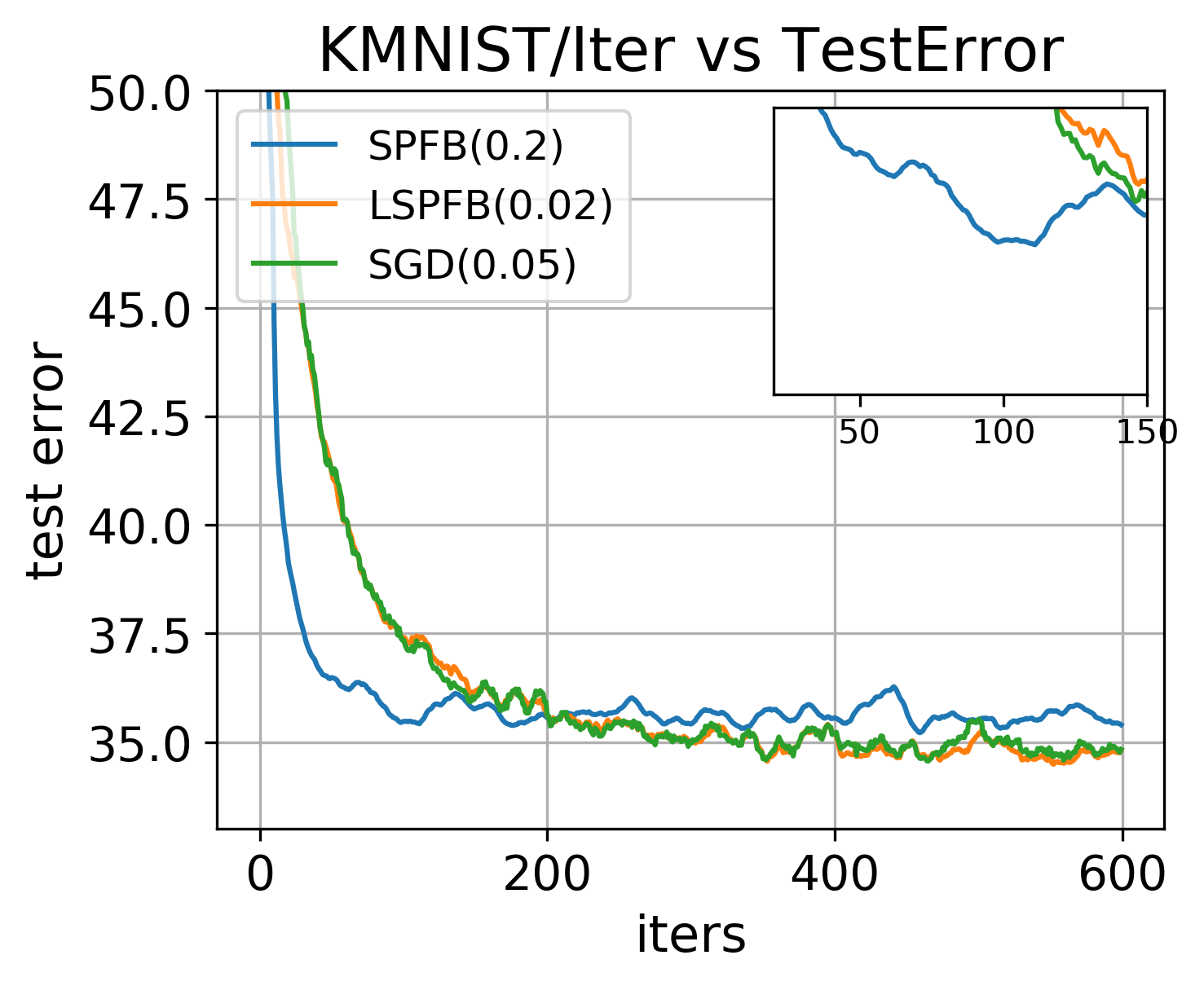
Experiments were performed on adult111http://archive.ics.uci.edu/ml/datasets/Adult (, , ), KMNIST222https://pytorch.org/docs/stable/torchvision/datasets.html (, , ), and Fashion-MNIST2 (, , ) data sets. All algorithms were run with mini-batch size equal to . For low-rank methods, we explored the following settings of the rank : . Hyperparameters for all methods were chosen to achieve the best test performance. We compare SPFB and LSPFB with SGD for -regularized logistic regression on the adult, KMNIST, and Fashion-MNIST data sets. Both SPFB and LSPFB show clear advantage over SGD in terms of convergence speed.
fig
\subfigure
 \subfigure
\subfigure
 \subfigure
\subfigure
 \subfigure
\subfigure

\subfigure
 \subfigure
\subfigure
 \subfigure
\subfigure
 \subfigure
\subfigure

\subfigure
 \subfigure
\subfigure
 \subfigure
\subfigure
 \subfigure
\subfigure
4 Discussion
Here we briefly discuss the future extensions of this work. First, we will analyze whether the batch bound method of Algorithm 2 admits super-linear convergence rate and thus match the convergence rate of quasi-Newton techniques (the existing convergence analysis in the original paper shows linear rate only). On the empirical side, we will investigate applying the bound techniques discussed in this paper to optimize each layer of the network during backpropagation. Per-layer bounds, when combined together, may potentially lead to a universal quadratic bound on the original highly complex deep learning loss function. This approach would open up new possibilities for training deep learning models as it reduces the deep learning non-convex optimization problem to a convex one. We will also investigate applying the developed technique to backpropagation-free [Choromanska et al.(2019)Choromanska, Cowen, Kumaravel, Luss, Rigotti, Rish, Diachille, Gurev, Kingsbury, Tejwani, and Bouneffouf] setting and large-batch [You et al.(2017)You, Gitman, and Ginsburg] training of deep learning models. Finally, we will explore the applicability of the bound techniques in the context of biasing the gradient to explore wide valleys in the non-convex optimization landscape [Chaudhari et al.(2017)Chaudhari, A. Choromanska, Soatto, LeCun, Baldassi, Borgs, Chayes, Sagun, and Zecchina]. In this case enforcing the width of the bound to be sufficiently large should provide a simple mechanism for finding solutions that lie in the flat regions of the landscape.
References
- [Andrew and Gao(2007)] Galen Andrew and Jianfeng Gao. Scalable training of l 1-regularized log-linear models. In Proceedings of the 24th international conference on Machine learning, pages 33–40, 2007.
- [Balakrishnan et al.(2017)Balakrishnan, Wainwright, and Yu] S. Balakrishnan, M. J. Wainwright, and B. Yu. Statistical guarantees for the em algorithm: From population to sample-based analysis. Ann. Statist., 45(1):77–120, 2017.
- [Baldassi et al.(2015)Baldassi, Ingrosso, Lucibello, Saglietti, and Zecchina] C. Baldassi, A. Ingrosso, C. Lucibello, L. Saglietti, and R. Zecchina. Subdominant dense clusters allow for simple learning and high computational performance in neural networks with discrete synapses. Physical review letters, 115(12):128101, 2015.
- [Baldassi et al.(2016a)Baldassi, Borgs, Chayes, Ingrosso, Lucibello, Saglietti, and Zecchina] C. Baldassi, C. Borgs, J. T. Chayes, A. Ingrosso, C. Lucibello, L. Saglietti, and R. Zecchina. Unreasonable effectiveness of learning neural networks: From accessible states and robust ensembles to basic algorithmic schemes. In PNAS, 2016a.
- [Baldassi et al.(2016b)Baldassi, Gerace, Lucibello, Saglietti, and Zecchina] C. Baldassi, F. Gerace, C. Lucibello, L. Saglietti, and R. Zecchina. Learning may need only a few bits of synaptic precision. Physical Review E, 93(5):052313, 2016b.
- [Bennett(1976)] C. H. Bennett. Efficient Estimation of Free Energy Differences from Monte Carlo Data. Journal of Computational Physics, 22(2):245–268, October 1976. 10.1016/0021-9991(76)90078-4.
- [Benson and More(2001)] Steven J Benson and Jorge J More. A limited memory variable metric method in subspaces and bound constrained optimization problems. In in Subspaces and Bound Constrained Optimization Problems. Citeseer, 2001.
- [Berger(1997)] Adam Berger. The improved iterative scaling algorithm: A gentle introduction, 1997.
- [Böhning and Lindsay(1988)] Dankmar Böhning and Bruce G Lindsay. Monotonicity of quadratic-approximation algorithms. Annals of the Institute of Statistical Mathematics, 40(4):641–663, 1988.
- [Bottou(2010)] Léon Bottou. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010, pages 177–186. Springer, 2010.
- [Broyden et al.(1973)Broyden, Dennis Jr, and Moré] Charles George Broyden, John E Dennis Jr, and Jorge J Moré. On the local and superlinear convergence of quasi-newton methods. IMA Journal of Applied Mathematics, 12(3):223–245, 1973.
- [Byrd et al.(2016)Byrd, Hansen, Nocedal, and Singer] Richard H Byrd, Samantha L Hansen, Jorge Nocedal, and Yoram Singer. A stochastic quasi-newton method for large-scale optimization. SIAM Journal on Optimization, 26(2):1008–1031, 2016.
- [Carreira-Perpiñán and Hinton(2005)] Miguel Á. Carreira-Perpiñán and Geoffrey E. Hinton. On contrastive divergence learning. In AISTATS, 2005.
- [Chaudhari et al.(2017)Chaudhari, A. Choromanska, Soatto, LeCun, Baldassi, Borgs, Chayes, Sagun, and Zecchina] P. Chaudhari, A. Choromanska, S. Soatto, Y. LeCun, C. Baldassi, C. Borgs, J. Chayes, L. Sagun, and R. Zecchina. Entropy-sgd: Biasing gradient descent into wide valleys. In ICLR, 2017.
- [Chaudhari et al.(2019)Chaudhari, A. Choromanska, Soatto, LeCun, Baldassi, Borgs, Chayes, Sagun, and Zecchina] P. Chaudhari, A. Choromanska, S. Soatto, Y. LeCun, C. Baldassi, C. Borgs, J. Chayes, L. Sagun, and R. Zecchina. Entropy-sgd: Biasing gradient descent into wide valleys (journal version). Journal of Statistical Mechanics: Theory and Experiment, 2019(12):124018, 2019.
- [Choromanska et al.(2019)Choromanska, Cowen, Kumaravel, Luss, Rigotti, Rish, Diachille, Gurev, Kingsbury, Tejwani, and Bouneffouf] Anna Choromanska, Benjamin Cowen, Sadhana Kumaravel, Ronny Luss, Mattia Rigotti, Irina Rish, Paolo Diachille, Viatcheslav Gurev, Brian Kingsbury, Ravi Tejwani, and Djallel Bouneffouf. Beyond backprop: Online alternating minimization with auxiliary variables. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 1193–1202. PMLR, 2019. URL http://proceedings.mlr.press/v97/choromanska19a.html.
- [Darroch and Ratcliff(1972)] John N Darroch and Douglas Ratcliff. Generalized iterative scaling for log-linear models. The annals of mathematical statistics, pages 1470–1480, 1972.
- [Dempster et al.(1977)Dempster, Laird, and Rubin] A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the em algorithm. JOURNAL OF THE ROYAL STATISTICAL SOCIETY, SERIES B, 39(1):1–38, 1977.
- [Feng and Tu(2020)] Y. Feng and Y. Tu. How neural networks find generalizable solutions: Self-tuned annealing in deep learning. CoRR, abs/2001.01678, 2020.
- [Goodfellow et al.(2016)Goodfellow, Bengio, and Courville] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
- [Gutmann and Hyvärinen(2012)] Michael U. Gutmann and Aapo Hyvärinen. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics. J. Mach. Learn. Res., 13(null):307–361, February 2012. ISSN 1532-4435.
- [Hinton(2002)] Geoffrey E Hinton. Training products of experts by minimizing contrastive divergence. Neural Computation, 14(8):1771–1800, 2002. URL http://www.ncbi.nlm.nih.gov/pubmed/12180402.
- [Hochreiter and Schmidhuber(1997)] S. Hochreiter and J. Schmidhuber. Flat minima. Neural Computation, 9(1):1–42, 1997.
- [Huang and Ogata(2002)] Fuchun Huang and Yosihiko Ogata. Generalized pseudo-likelihood estimates for markov random fields on lattice. Annals of the Institute of Statistical Mathematics, 54:1–18, 02 2002. 10.1023/A:1016170102988.
- [Hyvärinen(2005)] Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching. J. Mach. Learn. Res., 6:695–709, December 2005. ISSN 1532-4435.
- [Hyvarinen(2007)] Aapo Hyvarinen. Some extensions of score matching. Computational Statistics & Data Analysis, 51(5):2499–2512, 2007. URL https://EconPapers.repec.org/RePEc:eee:csdana:v:51:y:2007:i:5:p:2499-2512.
- [Jarzynski(1997)] C. Jarzynski. Nonequilibrium equality for free energy differences. Phys. Rev. Lett., 78:2690–2693, Apr 1997. 10.1103/PhysRevLett.78.2690. URL https://link.aps.org/doi/10.1103/PhysRevLett.78.2690.
- [Jastrzebski et al.(2018)Jastrzebski, Kenton, Arpit, Ballas, Fischer, Bengio, and Storkey] S. Jastrzebski, Z. Kenton, D. Arpit, N. Ballas, A. Fischer, Y. Bengio, and A. Storkey. Finding flatter minima with sgd. In ICLR Workshop Track, 2018.
- [Jebara and Choromanska(2012)] Tony Jebara and Anna Choromanska. Majorization for crfs and latent likelihoods. In Advances in Neural Information Processing Systems, pages 557–565, 2012.
- [Jiang et al.(2019)Jiang, Neyshabur, Mobahi, Krishnan, and Bengio] Y. Jiang, B. Neyshabur, H. Mobahi, D. Krishnan, and S. Bengio. Fantastic generalization measures and where to find them. CoRR, abs/1912.02178, 2019.
- [Keskar et al.(2017)Keskar, Mudigere, Nocedal, Smelyanskiy, and Tang] N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima. In ICLR, 2017. URL http://arxiv.org/abs/1609.04836.
- [Krizhevsky et al.()Krizhevsky, Nair, and Hinton] Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar-100 (canadian institute for advanced research).
- [Lafferty et al.(2001)Lafferty, McCallum, and Pereira] John Lafferty, Andrew McCallum, and Fernando CN Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. 2001.
- [Lee and Seung()] Daniel D. Lee and H. Sebastian Seung. Learning the parts of objects by nonnegative matrix factorization. Nature, 401:788–791, 1999.
- [Mairal(2015)] Julien Mairal. Incremental majorization-minimization optimization with application to large-scale machine learning. SIAM J. on Optimization, 25(2):829–855, April 2015. ISSN 1052-6234. 10.1137/140957639. URL https://doi.org/10.1137/140957639.
- [Malouf(2002)] Robert Malouf. A comparison of algorithms for maximum entropy parameter estimation. In COLING-02: The 6th Conference on Natural Language Learning 2002 (CoNLL-2002), 2002.
- [Neal(2001)] R.M. Neal. Annealed importance sampling. Statistics and Computing, 11, 01 2001.
- [Robbins and Monro(1951)] Herbert Robbins and Sutton Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400–407, 1951.
- [Sagun et al.(2018)Sagun, Evci, Güney, Dauphin, and Bottou] L. Sagun, U. Evci, V. Ugur Güney, Y. Dauphin, and L. Bottou. Empirical analysis of the hessian of over-parametrized neural networks. In ICLR Workshop, 2018.
- [Sha and Pereira(2003)] Fei Sha and Fernando Pereira. Shallow parsing with conditional random fields. In Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, pages 213–220, 2003.
- [Simsekli et al.(2019)Simsekli, Sagun, and Gürbüzbalaban] U. Simsekli, L. Sagun, and M. Gürbüzbalaban. A tail-index analysis of stochastic gradient noise in deep neural networks. CoRR, abs/1901.06053, 2019.
- [Tieleman(2008)] Tijmen Tieleman. Training restricted boltzmann machines using approximations to the likelihood gradient. In Proceedings of the 25th International Conference on Machine Learning, ICML ’08, page 1064–1071, New York, NY, USA, 2008. Association for Computing Machinery. ISBN 9781605582054. 10.1145/1390156.1390290. URL https://doi.org/10.1145/1390156.1390290.
- [Tieleman and Hinton(2009)] Tijmen Tieleman and Geoffrey Hinton. Using fast weights to improve persistent contrastive divergence. In Proceedings of the 26th Annual International Conference on Machine Learning, page 1033–1040, 2009.
- [Wallach(2002)] Hanna Wallach. Efficient training of conditional random fields. PhD thesis, Citeseer, 2002.
- [Wen et al.(2018)Wen, Wang, Yan, Xu, Chen, and Li] W. Wen, Y. Wang, F. Yan, C. Xu, Y. Chen, and H. Li. Smoothout: Smoothing out sharp minima for generalization in large-batch deep learning. CoRR, abs/1805.07898, 2018.
- [You et al.(2017)You, Gitman, and Ginsburg] Y. You, I. Gitman, and B. Ginsburg. Scaling SGD batch size to 32k for imagenet training. CoRR, abs/1708.03888, 2017.
- [Yuille and Rangarajan(2002)] Alan L Yuille and Anand Rangarajan. The concave-convex procedure (cccp). In T. G. Dietterich, S. Becker, and Z. Ghahramani, editors, Advances in Neural Information Processing Systems 14, pages 1033–1040. MIT Press, 2002. URL http://papers.nips.cc/paper/2125-the-concave-convex-procedure-cccp.pdf.
- [Zhu et al.(1997)Zhu, Byrd, Lu, and Nocedal] Ciyou Zhu, Richard H Byrd, Peihuang Lu, and Jorge Nocedal. Algorithm 778: L-bfgs-b: Fortran subroutines for large-scale bound-constrained optimization. ACM Transactions on Mathematical Software (TOMS), 23(4):550–560, 1997.
Supplementary material
Appendix A Proof for Theorem 2: sub-linear convergence rate
The proof in this section inspires by [Broyden et al.(1973)Broyden, Dennis Jr, and Moré, Byrd et al.(2016)Byrd, Hansen, Nocedal, and Singer]. We analysis the convergence rate of Stochastic version of Bound Majorization Method. It is easy to know that the objective function
is strongly convex and and twice continuously differentiable, where . Therfore, we can make the following assumption
Assumption 1
Assume that
-
(1)
The objective function is twice continuous differentiable.
-
(2)
There exists such that for all ,
(A.1)
For stochastic partition function bound (SPFB) method, define to be the learning rate, to be the Hessian approximation and to be the unbiased estimation of objective function in each iteration, then the update for parameter is
| (A.2) |
In order to analysis the convergence for SPFB, we add a condition that the variance of estimation is bounded then construct the following assumption:
Assumption 2
Assume that
-
(1)
The objective function is twice continuous differentiable.
-
(2)
There exists such that for all ,
(A.3) -
(3)
There exists a constant , such that for all ,
(A.4)
Lemma 1
For matrices compute in Algorithm 2, there exists such that for all
| (A.5) |
Proof A.1.
For easy notation, we omit the subscripts and demote as . From Algorithm2, the formulation for is
| (A.6) |
where is the initialization of in algorithm 2. Define , we can compute the upper bound of
| (A.7) |
we can also conclude that there exits such that , which imply
Since , where is the current observation, we have
| (A.8) |
Therefore,
| (A.9) |
Based on previous proof, the upperbound for matrix is
| (A.10) |
When , .
Denote as the set of all observations. Define ,
,
Theorem 2
is the sequence of parameters generated by Algorithm 2. There exists , such that for all iterations ,
| (A.11) |
and there exists a constant , such that for all ,
| (A.12) |
Define the learning rate in iteration as
Then for all ,
| (A.13) |
where .
Proof A.2.
| (A.14) |
Taking the expectation, we have
| (A.15) |
Now, we want to correlate with . For all , by condition (2) in Assumption 2,
| (A.16) |
the second inequality comes from computing the minimum of quadratic function . Setting yields
| (A.17) |
which together with formula (A.15) yields
| (A.18) |
Define , , when , holds. We finish the proof by induction. Assume ,
| (A.19) |
Appendix B Proof for Thm 3: Low-rank Bound
The lower-bound in [Jebara and Choromanska(2012)] is not correct since is not sufficient for . We loose and fix the bound in this section. We use some proof steps in [Jebara and Choromanska(2012)].
Lemma 2
, , we have
Proof B.1.
By Jensen’s inequality, if convex, satisfies , then
Set ,,
Lemma 3
If non-zero, then .
Proof B.2.
Lemma 4
Let non-zero, matrix . If and , then A has exactly 2 opposite eigenvalues .
Proof B.3.
Because (By Lemma 3),
-
(a)
, there is only one non-zero eigenvalue .
Therefore, all eigenvalues of matrix are 0 and , which contradicts the condition .
-
(b)
, assume are 2 non-zero eigenvalues of .
(B.1) Without loss of generality, assume , then the characteristic polynomial of matrix is
and matrix satisfies
(B.2) Because
We can conclude that
(B.3) From formula , and we can conclude that the eigenvalues and .
Proof B.4.
Define , then the partition function is represented as , where n is the number of labels. From proof of Thm 1 (details included in [Jebara and Choromanska(2012)]), we already find a sequence of matrix , vector and constant such that:
| (B.5) |
where the terminate terms , , are the output of algorithm 2. If we could find sequences of (orthnormal), and (diagonal) upper-bounds matrices as
| (B.6) |
the upper-bound B.5 of partition function over only labels can be renewed as
| (B.7) |
When , denote , the formula B.7 is equivalent to B.4 and we finish the proof. We successfully decompose into lower-rank while keep the upper-bound at the same time. In the following part, we are going to show how to construct the matrix sequence , and satisfies the condition B.6. The proof is based on mathematical induction.
-
•
From proof of Thm 1 in [Jebara and Choromanska(2012)], , . Define , and , it is obvious that holds for all .
-
•
Assume , and satisfies condition (B.6), we are going to find , and satisfies this condition as well. From line 5 in algorithm 2, , where . Define the subspace constructed by row vectors of as Map the vector onto subspace and denote the residual orthogonal to subspace as
(B.8) substitute (• ‣ B.4) into , we have
(B.9) By Lemma 4, the maximum eigenvalue of matrix is . Define , we have
(B.12) Define
(B.13) by (B.11) and (B.12), it is easy to know,
(B.14) We have already prove is larger than , then all we need is the upper-bound of . Perform SVD decomposition on and denote the result as
define , then (• ‣ B.4) can be simplified as
(B.15) It is easy to know that and is a -svd decomposition. In order to keep the construction of , we have no choice but to remove the smallest eigenvalue and corresponding eigenvector from matrix .
-
case 1)
, remove eigenvalue and corresponding eigenvector .
(B.16) where ,. In this case , .
-
case 2)
, remove (absolute value smallest) eigenvalue in and corresponding eigenvalue .
(B.17) where ,. In this case,
In both cases
(B.18) (B.19) where orthnormal, and are diagonal, and . Therefore, for all we have
(B.20) is not sufficient for the condition , we would like to relax it by constructing such that , which is equivalent to
(B.21) Set , by Lemma 2 we have
(B.22) Combine (• ‣ B.4) and (• ‣ B.4), is what we want. Let , together with and defined in former case 1) and case 2), we have
-
case 1)